
script
stringlengths 113
767k
|
|---|
# # Offline Predictions with AutoML models for Bengali Handwritten graphemes
# We have seen how to import data and train models in Google AutoML and export the models into the `saved_model` format of Tensorflow - among others (see [this Notebook](https://www.kaggle.com/wardenga/bengali-handwritten-graphemes-with-automl). In this Notebook we are going to import the `saved_model.pb` produced by AutoMl and make predictions.
import tensorflow.compat.v1 as tf # modyficatin for tensorflow 2.1 might follow soon
tf.disable_v2_behavior()
import pandas as pd
import numpy as np
import io
from matplotlib.image import imsave
import csv
import os
import time
# Load the model with `tf.saved_model.loader.load()` inside a `tf.Session`. Then we transform the data to an image (as in [this Notebook](https://www.kaggle.com/wardenga/bengali-handwritten-graphemes-with-automl)) since images are what we fed AutoML with.
# Note that the path fed to the loader has to be to the DIRECTORY that the `saved_model.pb` is contained in, not the file.
def make_predict_batch(img, export_path):
"""
INPUT
-`img` list of bytes representing the images to be classified
OUTPUT
-dataframe containing the probabilities of the labels and the la
els as columnames
"""
with tf.Session(graph=tf.Graph()) as sess:
tf.saved_model.loader.load(sess, ["serve"], export_path)
graph = tf.get_default_graph()
feed_dict = {"Placeholder:0": img}
y_pred = sess.run(["Softmax:0", "Tile:0"], feed_dict=feed_dict)
labels = [label.decode() for label in y_pred[1][0]]
return pd.DataFrame(data=y_pred[0], columns=labels)
# The actual prediction is made in the following Part of the above function (inside the `tf.Session`.
# `
# feed_dict={'Placeholder:0':[imageBytearray.getvalue()]}
# y_pred=sess.run(['Softmax:0','Tile:0'],feed_dict=feed_dict)
# `
# To understand How to adopt this for your pre-trained model we have to dive a bit into the structure of the model (see [this Blogpost](https://heartbeat.fritz.ai/automl-vision-edge-exporting-and-loading-tensorflow-saved-models-with-python-f4e8ce1b943a)). In fact we have to identify the input (here: 'Placeholder:0') and output nodes of the graph. Some trial and error can be involved here, especially since the last nodes in this example are not giving the actual prediction but the order of the labels, while the 'Softmax'-node actually gives the probabilities (You can look at the structure of the graph with the webapp [Netron](https://lutzroeder.github.io/netron/)). Lets look at an example prediction
i = 0
name = f"test_image_data_{i}.parquet"
test_img = pd.read_parquet("../input/bengaliai-cv19/" + name)
test_img.head()
height = 137
width = 236
# we need the directory of the saved model
dir_path = "../input/trained-models/Trained_Models/tf_saved_model-Bengaliai_vowel-2020-01-27T205839579Z"
images = test_img.iloc[:, 1:].values.reshape(-1, height, width)
image_id = test_img.image_id
imagebytes = []
for i in range(test_img.shape[0]):
imageBytearray = io.BytesIO()
imsave(imageBytearray, images[i], format="png")
imagebytes.append(imageBytearray.getvalue())
res = make_predict_batch(imagebytes, dir_path)
res["image_id"] = image_id
res.head()
np.argmax(make_predict(test_img.iloc[0], dir_path)["Test_0"][0])
# You can see here the argmax in the first array has index 8, but in this case it doesn't mean the label is 8. The label is encoded in the second array corresponding to the key of the dictionary.
# The following Function takes this into account and also formats a submission file following the requirements of the Bengali.Ai competition.
# walk the working directory to find the names of the directories
import os
inputFolder = "../input/"
for root, directories, filenames in os.walk(inputFolder):
for filename in filenames:
print(os.path.join(root, filename))
def make_submit(img, height=137, width=236):
""" """
consonant_path = "../input/trained-models/Trained_Models/tf_saved_model-Bengaliai_consonant-2020-01-27T205840376Z"
root_path = "../input/trained-models/Trained_Models/tf_saved_model-Bengaliai_root-2020-01-27T205838805Z"
vowel_path = "../input/trained-models/Trained_Models/tf_saved_model-Bengaliai_vowel-2020-01-27T205839579Z"
# transform the images from a dataframe to a list of images and then bytes
images = img.iloc[:, 1:].values.reshape(-1, height, width)
image_id = img.image_id
imagebytes = []
for i in range(img.shape[0]):
imageBytearray = io.BytesIO()
imsave(imageBytearray, images[i], format="png")
imagebytes.append(imageBytearray.getvalue())
# get the predictions from the three models - passing the bytes_list
start_pred = time.time()
prediction_root = make_predict_batch(imagebytes, export_path=root_path)
prediction_consonant = make_predict_batch(imagebytes, export_path=consonant_path)
prediction_vowel = make_predict_batch(imagebytes, export_path=vowel_path)
end_pred = time.time()
print("Prediction took {} seconds.".format(end_pred - start_pred))
start_sub = time.time()
p0 = prediction_root.idxmax(axis=1)
p1 = prediction_vowel.idxmax(axis=1)
p2 = prediction_consonant.idxmax(axis=1)
row_id = []
target = []
for i in range(len(image_id)):
row_id += [
image_id.iloc[i] + "_grapheme_root",
image_id.iloc[i] + "_vowel_diacritic",
image_id.iloc[i] + "_consonant_diacritic",
]
target += [p0[i], p1[i], p2[i]]
submission_df = pd.DataFrame({"row_id": row_id, "target": target})
# submission_df.to_csv(name, index=False)
end_sub = time.time()
print("Writing the submission_df took {} seconds".format(end_sub - start_sub))
return submission_df
# Finally we can make the submission
import gc
start = time.time()
for i in range(4):
start1 = time.time()
name = f"test_image_data_{i}.parquet"
print("start with " + name + "...")
test_img = pd.read_parquet("../input/bengaliai-cv19/" + name)
print("starting prediction")
start1 = time.time()
if i == 0:
df = make_submit(test_img)
df.to_csv("submission.csv", mode="w", index=False)
else:
df = make_submit(test_img)
df.to_csv("submission.csv", mode="a", header=False, index=False)
end1 = time.time()
print(end1 - start1)
gc.collect() # make place on disk (maybe)
end = time.time()
print(end - start)
df.head()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import math
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
from sklearn import metrics
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import RandomForestClassifier
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# Read both train and test datasets as a DataFrame
train = pd.read_csv("../input/house-prices-advanced-regression-techniques/train.csv")
test = pd.read_csv("../input/house-prices-advanced-regression-techniques/test.csv")
numerical_train = train.select_dtypes(include=["int", "float"])
numerical_train.drop(
["Id", "YearBuilt", "YearRemodAdd", "GarageYrBlt", "MoSold", "YrSold"],
axis=1,
inplace=True,
)
# **Exploratory Analysis**
# The aim is to get a good understanding of the data set and have ideas for data cleaning and feature engineering.
# 1. Start by analysing the data to get a feel for what we have.
# * Look at the features, their data type, the target variable.
# * Check for missing data and the scale of the data.
# * Make sure to understand the dataset.
#
# 2. Plot Numerical Distributions.
# * Use histogram or scatter plots.
# * Check if anything looks out of place.
#
#
# 3. Plot Categorical Distributions.
# * Use bar plots.
# * Check for sparse classes, these can lead to overfitting.
#
#
# 4. Plot Segmentations.
# * Use box plots.
# * Check the relationship between categorical and numeric features.
#
#
# 5. Study Correlations.
# * Use heat maps.
# * Correlation is a value between -1 and 1.
# * Close to -1 or 1 means strong negative or positive correlation.
# * 0 means no correlation.
# * Check which features are strongly correlated with the target.
train.head()
sns.distplot(train["SalePrice"])
# Statistics about the data
train.describe()
train.info()
# Seperate out the numerical data
numerical_train = train.select_dtypes(include=["int", "float"])
numerical_train.head()
# Plot the distributions of all numerical data.
i = 1
fig = plt.figure(figsize=(40, 50))
for item in numerical_train:
axes = fig.add_subplot(8, 5, i)
axes = numerical_train[item].plot.hist(rot=0, subplots=True)
plt.xticks(rotation=45)
i += 1
# Seperate out the categorical data
categorical_train = train.select_dtypes(include=["object"])
categorical_train.head()
# Plot the counts of all categorical data.
i = 1
fig = plt.figure(figsize=(40, 50))
for item in categorical_train:
axes = fig.add_subplot(9, 5, i)
axes = categorical_train[item].value_counts().plot.bar(rot=0, subplots=True)
plt.xticks(rotation=45)
i += 1
# Boxplot all categorical data with SalePrice
i = 1
fig = plt.figure(figsize=(40, 50))
for item in categorical_train:
data = pd.concat([train["SalePrice"], categorical_train[item]], axis=1)
axes = fig.add_subplot(9, 5, i)
axes = sns.boxplot(x=item, y="SalePrice", data=data)
plt.xticks(rotation=45)
i += 1
# Correlation matrix
corrmat = train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=0.8, square=True)
# Correlation matrix with strong correlations with SalePrice
sorted_corrs = train.corr()["SalePrice"].abs().sort_values()
strong_corrs = sorted_corrs[sorted_corrs > 0.5]
cols = strong_corrs.index
corrmat = train[strong_corrs.index].corr()
sns.heatmap(
corrmat,
cbar=True,
annot=True,
square=True,
fmt=".2f",
annot_kws={"size": 10},
yticklabels=cols.values,
xticklabels=cols.values,
)
# The histogram on the diagonal is the distribution of a single variable
# The scatter plots represent the relationships between two variables
sns.set()
cols = strong_corrs.index
sns.pairplot(numerical_train[cols], height=2.5)
plt.show()
# **Data Cleaning**
# The aim is to leave a clean data set that will avoid errors later on.
# 1. Remove Unwanted Observations.
# * Remove duplicated data.
# * Remove any data that is irrelevant for the task.
# 2. Fix Structural Errors.
# * Check for typos, inconsistent capitalisation and mislabeled classes.
# 3. Filter Unwanted Outliers.
# * Remove any data that is obviously wrong.
# 4. Handle Missing Data.
# * Dropping the data - sub-optimal because you lose all the information associated.
# * Imputing the data e.g. using the mean - sub-optimal because your reinforcing patterns from other features.
# * Flag observation with indicator that observation is missing and label numerical data as 0
# * label categorical data as 'missing'.
#
df = train
def transform_features(df):
# Count number of missing values in each numerical column
num_missing = df.isnull().sum()
# Drop the columns where at least 5% of the values are missing
drop_missing_cols = num_missing[(num_missing > len(df) / 20)].sort_values()
df = df.drop(drop_missing_cols.index, axis=1)
# Count number of missing values in each categorical column
text_mv_counts = (
df.select_dtypes(include=["object"]).isnull().sum().sort_values(ascending=False)
)
# Drop the columns where at least 1 missing value
drop_missing_cols_2 = text_mv_counts[text_mv_counts > 0]
df = df.drop(drop_missing_cols_2.index, axis=1)
# For numerical columns with missing values calcualate number of missing values
num_missing = df.select_dtypes(include=["int", "float"]).isnull().sum()
fixable_numeric_cols = num_missing[
(num_missing <= len(df) / 20) & (num_missing > 0)
].sort_values()
# Calcualte the most common value for each column
replacement_values_dict = (
df[fixable_numeric_cols.index].mode().to_dict(orient="records")[0]
)
# For numerial columns with missing values fill with most common value in that column
df = df.fillna(replacement_values_dict)
# Compute two new columns by combining other columns which could be useful
years_sold = df["YrSold"] - df["YearBuilt"]
years_since_remod = df["YrSold"] - df["YearRemodAdd"]
df["YearsBeforeSale"] = years_sold
df["YearsSinceRemod"] = years_since_remod
# Drop the no longer needed original year columns
df = df.drop(["YearBuilt", "YearRemodAdd"], axis=1)
# Remove irrelevant data
df = df.drop(["Id"], axis=1)
return df
transform_features(df)
# **Feature Engineering**
# The aim is to transform the data into a analytical base table.
# 1. Combine Numerical Features.
# * Sum/multiply/subtract features to create a new feature that could be more useful.
# 2. Combine Sparse Categorical Classes.
# 3. Add Knowledge.
# * Create my own features indicate other useful information from my own knowledge.
# 4. Add Dummy Variables.
# 5. Remove Unused or RedundantFeatures.
def select_features(df, uniq_threshold):
# Create list of all column names that are supposed to be categorical
nominal_features = [
"Id",
"MSSubClass",
"MSZoning",
"Street",
"Alley",
"LandContour",
"LotConfig",
"Neighborhood",
"Condition1",
"Condition2",
"BldgType",
"HouseStyle",
"RoofStyle",
"RoofMatl",
"Exterior1st",
"Exterior2nd",
"MasVnrType",
"Foundation",
"Heating",
"CentralAir",
"GarageType",
"MiscFeature",
"SaleType",
"SaleCondition",
]
# Check which categorical columns we have carried with us
transform_cat_cols = []
for col in nominal_features:
if col in df.columns:
transform_cat_cols.append(col)
# Check how many unique values in each categorical column
uniqueness_counts = (
df[transform_cat_cols].apply(lambda col: len(col.value_counts())).sort_values()
)
# For each item that has more than the defined unique threshold values, create category 'Other'
for item in uniqueness_counts.iteritems():
if item[1] >= uniq_threshold:
# Count unique values in the column
unique_val = df[item[0]].value_counts()
# Select the 10th least common index and the rest lower than that
other_index = unique_val.loc[
unique_val < unique_val.iloc[uniq_threshold - 2]
].index
df.loc[df[item[0]].isin(list(other_index)), item[0]] = "Other"
# Select the text columns and convert to categorical
text_cols = df.select_dtypes(include=["object"])
for col in text_cols:
df[col] = df[col].astype("category")
# Create dummy columns
df = pd.concat(
[df, pd.get_dummies(df.select_dtypes(include=["category"]))], axis=1
).drop(text_cols, axis=1)
return df
def drop_features(df, coeff_threshold):
# Select numerical columns
numerical_df = df.select_dtypes(include=["int", "float"])
# print(numerical_df)
# Compute the absolute correlation between the numerical columns and SalePrice
abs_corr_coeffs = numerical_df.corr()["SalePrice"].abs().sort_values()
# print(abs_corr_coeffs)
# Drop the columns that have a coefficient lower than than the defined threshold
df = df.drop(abs_corr_coeffs[abs_corr_coeffs < coeff_threshold].index, axis=1)
return df
# **Algorithm Selection**
# We will use Regression.
# **Model Training**
# 1. Tune and Fit Hyperparameters.
# * Gradient descent algorithm
# * k-fold cross validation
#
#
# 2. Check error with performance metrics such as MSE.
# 3. Select Winning Model.
# split the data to train the model
# y = train.SalePrice
# X_train,X_test,y_train,y_test = train_test_split(train_df.drop(['SalePrice'], axis=1) ,y ,test_size=0.2 , random_state=0)
# Scale the data
# scaler = StandardScaler().fit(train_df[features])
# rescaled_train_df = scaler.transform(train_df[features])
# rescaled_test_df = scaler.transform(test_df[features])
# model = linear_model.LinearRegression()
# model.fit(train_df[features], train["SalePrice"])
# predictions = model.predict(test_df[features])
transform_train_df = transform_features(train)
transform_test_df = transform_features(test)
train_df = select_features(transform_train_df, uniq_threshold=100)
test_df = select_features(transform_test_df, uniq_threshold=100)
train_features = drop_features(train_df, coeff_threshold=0.01)
test_features = test_df.columns
features = pd.Series(list(set(train_features) & set(test_features)))
X_train = train_df[features]
y_train = train["SalePrice"]
X_test = test_df[features]
X_train
# rfgs_parameters = {
# 'n_estimators': [50],
# 'max_depth' : [n for n in range(2, 16)],
# 'max_features': [n for n in range(2, 16)],
# "min_samples_split": [n for n in range(2, 8)],
# "min_samples_leaf": [n for n in range(2, 8)],
# "bootstrap": [True,False]
# }
# rfr_cv = GridSearchCV(RandomForestRegressor(), rfgs_parameters, cv=8, scoring='neg_mean_squared_log_error')
# rfr_cv.fit(X_train, y_train)
# predictions = rfr_cv.predict(X_test)
model_rf = RandomForestClassifier(n_estimators=1000, oob_score=True, random_state=42)
model_rf.fit(X_train, y_train)
predictions = model_rf.predict(X_test)
# Output the predictions into a csv
submission = pd.DataFrame(test.Id)
predictions = pd.DataFrame({"SalePrice": predictions})
output = pd.concat([submission, predictions], axis=1)
output.to_csv("submission.csv", index=False)
|
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import cv2
import glob
# ### Importing data
train_path = "../input/asl-alphabet/asl_alphabet_train/asl_alphabet_train/"
test_path = "../input/asl-alphabet/asl_alphabet_test/asl_alphabet_test/"
# Finding all the existing categories in training data
categories = np.array([])
for dirs in glob.glob(train_path + "/*"):
categories = np.append(categories, dirs.split("/")[-1])
print("Classes in the data: ", categories)
# ### Exploring the data
# Finding the training set size wrt labels/categories
num_imgs = np.array([])
for i in categories:
num_imgs = np.append(num_imgs, len(glob.glob(train_path + i + "/*")))
num_imgs = (
pd.DataFrame([categories, num_imgs], index=["label", "no. of images"])
.T.set_index("label")
.T
)
num_imgs
# Plotting some sample pictures for a given label
def plot_samples(label, num_samples=3):
plt.figure(figsize=(20, 6))
print("Showing sample images of label:", label)
for i in range(num_samples):
plt.subplot(1, num_samples, i + 1)
plt.imshow(
cv2.imread(
glob.glob(train_path + label + "/*")[
np.random.randint(0, num_imgs[label][0])
]
)
)
plt.tight_layout()
plot_samples("I", 5)
print("Shape of input images:", cv2.imread(glob.glob(train_path + "A/*")[0]).shape)
# Since I, J are similar when rotated, rotation range is limited in datagenerator
plot_samples("J", 5)
# ### Data Augmentation
datagen = ImageDataGenerator(
samplewise_center=True,
samplewise_std_normalization=True,
validation_split=0.1,
rotation_range=5,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
fill_mode="nearest",
)
train_gen = datagen.flow_from_directory(
train_path, target_size=(64, 64), batch_size=32, shuffle=True, subset="training"
)
val_gen = datagen.flow_from_directory(
train_path, target_size=(64, 64), batch_size=32, shuffle=True, subset="validation"
)
# Plotting some transformed images
plt.figure(figsize=(20, 6))
for i in range(5):
plt.subplot(1, 5, i + 1)
plt.imshow(train_gen.next()[0][0])
plt.tight_layout()
# ### Making a CNN model
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
model = Sequential()
model.add(
Conv2D(
32,
(4, 4),
strides=1,
activation="relu",
padding="same",
input_shape=(64, 64, 3),
)
)
model.add(Conv2D(32, (3, 3), strides=2, activation="relu", padding="valid"))
model.add(Dropout(0.2))
model.add(Conv2D(64, (3, 3), strides=1, activation="relu", padding="same"))
model.add(Conv2D(64, (3, 3), strides=2, activation="relu", padding="valid"))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), strides=1, activation="relu", padding="same"))
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(512, activation="relu"))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.2))
model.add(Dense(29, activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
# ### Training the CNN model
# Fitting the data to the model by using data generator
history = model.fit_generator(train_gen, epochs=30, validation_data=val_gen)
plt.plot(history.history["accuracy"], label="train")
plt.plot(history.history["val_accuracy"], label="validation")
plt.ylabel("Accuracy")
plt.xlabel("Epochs")
plt.legend()
# ### Error Analysis
# Finding the prediction data on validation set to plot confusion matrix - helps to analyse errors
validation_gen = datagen.flow_from_directory(
train_path, target_size=(64, 64), batch_size=1, shuffle=False, subset="validation"
)
y_pred = np.argmax(model.predict_generator(validation_gen), axis=1)
y_true = validation_gen.classes
import seaborn as sns
from sklearn.metrics import confusion_matrix
plt.figure(figsize=(15, 10))
# Here 0 to 28 labels are mapped to their original categories
ax = sns.heatmap(
confusion_matrix(y_true, y_pred),
annot=True,
xticklabels=np.sort(categories),
yticklabels=np.sort(categories),
cmap="GnBu",
)
ax.set_xlabel("Predicted values")
ax.set_ylabel("True values")
ax.set_title("Confusion matrix")
# * There seems to be confusion b/w (M,N),(X,S),(U,R),(I,E),(V,K),(Y,T),(V,W),(X,T)
# * Model can be improved by including/augementing more data of confused labels
# ### Save the weights
# Saving the model weights to load later
model.save_weights("als_hand_sign_model.h5")
|
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# ### Importing the Dataset
data = pd.read_csv(
"/kaggle/input/website-traffic/website-traffic.csv", parse_dates=["Date"]
).dropna()
data
data["traffic"].plot()
plt.ylabel("Number of Visitors Per Day")
plt.xlabel("Days")
plt.title("Plotting the Website Traffic")
# # **Seasonal Decompose**
# By decomposing a time series into these four components, it is easier to analyze the data and identify the underlying patterns and trends.
#
from statsmodels.tsa.seasonal import seasonal_decompose
s = seasonal_decompose(data["traffic"], period=7)
s.plot()
size = int(len(data) * 0.80)
training_data = data[:size]
testing_data = data[size:]
plt.grid(True)
plt.xlabel("Days")
plt.ylabel("Number of Visitors Per Day")
plt.plot(training_data["traffic"], "green", label="Train Data")
plt.plot(testing_data["traffic"], "blue", label="Test Data")
plt.legend()
# **When a time series is stationary, it means that the statistical properties of the data do not change over time**
# # CHECKING FOR STATIONARITY
# There are several methods to determine stationarity in time series data, some of which are:
# **1.Visual inspection:** Plotting the time series and examining it visually for any trend or seasonal patterns can provide an initial indication of stationarity.
# **2. Using Statistical Plots :** Plots such as ACF and PACF can be implemented to analyze and visualize time series data.
# **3.Augmented Dickey-Fuller (ADF) test:** The ADF test is a statistical test that checks whether a time series is stationary or not. The test computes a test statistic and compares it to critical values to determine whether the null hypothesis of non-stationarity can be rejected.
# # **1.Visual inspection:**
# By plotting the Traffic Column in dataset we can clearly note that the time series is not at all Stationary as the mean is not zero and also mean, variance change over time
# # **2.Using Statistical Plots**
# The **Autocorrelation Function (ACF)** and **Partial Autocorrelation Function (PACF)** are important tools in time series analysis for understanding the properties of the data and determining the appropriate models to use for forecasting.
# **1. Autocorrelation Function (ACF)**
# The ACF measures the correlation between a time series and its lagged values. It helps to identify the presence of any repeating patterns or cycles in the data.
# A strong positive correlation at a specific lag indicates that the data is highly correlated with its past values at that lag, while a strong negative correlation indicates that the data is negatively correlated with its past values at that lag. The ACF can help to determine the order of an Autoregressive (AR) model.
# **2. Partial Autocorrelation Function (PACF)**
# The PACF, on the other hand, measures the correlation between a time series and its lagged values after removing the effect of the intervening lags. It helps to identify the presence of any direct or immediate relationships between the data and its past values.
# A strong positive correlation at a specific lag indicates that the data is highly correlated with its past values at that lag after removing the effect of the intervening lags, while a strong negative correlation indicates that the data is negatively correlated with its past values at that lag after removing the effect of the intervening lags. The PACF can help to determine the order of a Moving Average (MA) model.
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(data["traffic"])
plot_pacf(data["traffic"])
# These plots clearly denotes non - stationary in data
# In general, a non-stationary time series will have an ACF plot that does not decay to zero, indicating the presence of autocorrelation at all lags. Similarly, the PACF plot will not exhibit a clear cutoff, indicating the presence of multiple significant lags. These patterns can make it difficult to determine the appropriate lag order for an AR or MA model.
# It is important to note that ACF and PACF plots alone are not sufficient to determine the stationarity of a time series. Other methods such as the **Augmented Dickey-Fuller (ADF) test** test should also be used to confirm the stationarity of the series.
# # **3.Augmented Dickey-Fuller (ADF) test:**
# The Augmented Dickey-Fuller (ADF) test is a statistical test used to determine whether a time series is stationary or not. The test is based on the null hypothesis that the time series has a unit root, which indicates that the series is non-stationary.
# The ADF test computes a test statistic based on the coefficients of the regression equation, and compares it to critical values to determine whether the null hypothesis of non-stationarity can be rejected. If the test statistic is less than the critical value, the null hypothesis is rejected, and the time series is considered stationary.
# In the ADF (Augmented Dickey-Fuller) test, the **p-value is the probability of obtaining a test statistic at least as extreme as the observed value, assuming that the null hypothesis of non-stationarity is true.**The p-value is used to determine the statistical significance of the test and whether the null hypothesis can be rejected.
# If the** p-value** is less than a predetermined **level of significance (e.g., 0.05)**, the null hypothesis of **non-stationarity is rejected,** and the time series is considered stationary. Conversely, if the p-value is greater than the level of significance, the null hypothesis cannot be rejected, and the time series is considered non-stationary.
from statsmodels.tsa.stattools import adfuller
adf_test = adfuller(data["traffic"])
adf_test
print("P-value for Checking Stationarity :", adf_test[1])
# # HENCE FROM ABOVE RESULTS THE TIME SERIES IS NOT STATIONARY
# # To Make it Stationary we need to perform Differencing and have to feed it into Time Series Model
data_diff = data["traffic"].diff().dropna()
data_diff.plot()
data["traffic"]
data_diff
plot_acf(data_diff)
plot_pacf(data_diff)
adf_test_diff = adfuller(data_diff)
adf_test_diff
# # Henceforth the model becomes Stationary
# Auto_arima is an **automated version of the ARIMA **(Autoregressive Integrated Moving Average) model selection process. It is a popular method for selecting the optimal order of the ARIMA model for a given time series dataset. Some advantages of using auto_arima include:
# 1. **Automated model selection:** Auto_arima automates the process of selecting the **best ARIMA model by analyzing the time series data and selecting the optimal values of p, d, and q parameters**. This eliminates the need for manual selection, which can be time-consuming and error-prone.
# 2. The `pmdarima.auto_arima` function takes as input the time series data and a range of values for `p`, `d`, and `q` parameters, and returns an optimized ARIMA model. It uses a combination of iterative and seasonal algorithms to search for the best model.
# 3. **Improved accuracy:** Auto_arima can select a more accurate model than a manual selection, as it searches over a wider range of possible models and selects the one with the lowest AIC (Akaike Information Criterion) value.
# 4. **Flexible:** Auto_arima can handle both seasonal and non-seasonal time series data, making it a versatile model selection tool.
# ## Determining the p q d parameters uding autoarima
import pmdarima as pm
auto_arima = pm.auto_arima(training_data["traffic"], seasonal=False, stepwise=False)
auto_arima
auto_arima.summary()
# ARIMA(4,1,0) is a type of time series model that stands for AutoRegressive Integrated Moving Average. It is characterized by the following parameters:
# **p=4:** The number of autoregressive (AR) terms. This means that the model uses the values of the series from the previous four time periods to predict the current value.
# **d=1**: The degree of differencing. This means that the model uses the first difference of the series (i.e., the difference between consecutive observations) to make it stationary.
# q=0: The number of moving average (MA) terms. This means that the model does not use the moving average terms to predict the current value.
arima_fit = auto_arima.fit(training_data["traffic"])
# # **ARIMA(4,1,0)**
from statsmodels.tsa.arima.model import ARIMA
arima = ARIMA(training_data["traffic"], order=(4, 1, 0))
arima_fit = arima.fit()
print(arima_fit.summary())
forecast_test = arima_fit.forecast(len(testing_data))
pred = pd.DataFrame(forecast_test)
pred
forecast_test_auto = auto_arima.predict(n_periods=len(testing_data))
data["forecast_auto"] = [None] * len(training_data) + list(forecast_test_auto)
data.plot()
|
# # TalkingData AdTracking Fraud Detection Challenge
# TalkingData is back with another competition: This time, our task is to predict where a click on some advertising is fraudlent given a few basic attributes about the device that made the click. What sets this competition apart is the sheer scale of the dataset: with 240 million rows it might be the biggest one I've seen on Kaggle so far.
# There are some similarities with the last competition TalkingData launched: https://www.kaggle.com/c/talkingdata-mobile-user-demographics - that competition was about predicting the demographics of a user given their activity, and you can view this as a similar problem (predicting whether a user is real or not given their activity). However, that competition was plagued by a [leak](https://www.kaggle.com/wiki/Leakage) where the dataset wasn't sorted properly and certain portions of the dataset had different demographic distribtions. This meant that by adding the row ID as a feature you could get a huge boost in performance. Let's hope TalkingData have learnt their lesson this time around. 😉
# Looking at the evaluation page, we can see that the evaluation metric used is** ROC-AUC** (the area under a curve on a Receiver Operator Characteristic graph).
# In english, this means a few important things:
# * This competition is a **binary classification** problem - i.e. our target variable is a binary attribute (Is the user making the click fraudlent or not?) and our goal is to classify users into "fraudlent" or "not fraudlent" as well as possible
# * Unlike metrics such as [LogLoss](http://www.exegetic.biz/blog/2015/12/making-sense-logarithmic-loss/), the AUC score only depends on **how well you well you can separate the two classes**. In practice, this means that only the order of your predictions matter,
# * As a result of this, any rescaling done to your model's output probabilities will have no effect on your score. In some other competitions, adding a constant or multiplier to your predictions to rescale it to the distribution can help but that doesn't apply here.
#
# If you want a more intuitive explanation of how AUC works, I recommend [this post](https://stats.stackexchange.com/questions/132777/what-does-auc-stand-for-and-what-is-it).
# Let's dive right in by looking at the data we're given:
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import mlcrate as mlc
import os
import gc
import matplotlib.pyplot as plt
import seaborn as sns
pal = sns.color_palette()
print("# File sizes")
for f in os.listdir("../input"):
if "zip" not in f:
print(
f.ljust(30)
+ str(round(os.path.getsize("../input/" + f) / 1000000, 2))
+ "MB"
)
# Wow, that is some really big data. Unfortunately we don't have enough kernel memory to load the full dataset into memory; however we can get a glimpse at some of the statistics:
import subprocess
print("# Line count:")
for file in ["train.csv", "test.csv", "train_sample.csv"]:
lines = subprocess.run(
["wc", "-l", "../input/{}".format(file)], stdout=subprocess.PIPE
).stdout.decode("utf-8")
print(lines, end="", flush=True)
# That makes **185 million rows** in the training set and ** 19 million** in the test set. Handily the organisers have provided a `train_sample.csv` which contains 100K rows in case you don't want to download the full data
# For this analysis, I'm going to use the first 1M rows of the training and test datasets.
# ## Data overview
df_train = pd.read_csv("../input/train.csv", nrows=1000000)
df_test = pd.read_csv("../input/test.csv", nrows=1000000)
print("Training set:")
df_train.head()
print("Test set:")
df_test.head()
# ### Looking at the columns
# According to the data page, our data contains:
# * `ip`: ip address of click
# * `app`: app id for marketing
# * `device`: device type id of user mobile phone (e.g., iphone 6 plus, iphone 7, huawei mate 7, etc.)
# * `os`: os version id of user mobile phone
# * `channel`: channel id of mobile ad publisher
# * `click_time`: timestamp of click (UTC)
# * `attributed_time`: if user download the app for after clicking an ad, this is the time of the app download
# * `is_attributed`: the target that is to be predicted, indicating the app was downloaded
# **A few things of note:**
# * If you look at the data samples above, you'll notice that all these variables are encoded - meaning we don't know what the actual value corresponds to - each value has instead been assigned an ID which we're given. This has likely been done because data such as IP addresses are sensitive, although it does unfortunately reduce the amount of feature engineering we can do on these.
# * The `attributed_time` variable is only available in the training set - it's not immediately useful for classification but it could be used for some interesting analysis (for example, one could fill in the variable in the test set by building a model to predict it).
# For each of our encoded values, let's look at the number of unique values:
plt.figure(figsize=(15, 8))
cols = ["ip", "app", "device", "os", "channel"]
uniques = [len(df_train[col].unique()) for col in cols]
sns.set(font_scale=1.2)
ax = sns.barplot(cols, uniques, palette=pal, log=True)
ax.set(
xlabel="Feature",
ylabel="log(unique count)",
title="Number of unique values per feature",
)
for p, uniq in zip(ax.patches, uniques):
height = p.get_height()
ax.text(p.get_x() + p.get_width() / 2.0, height + 10, uniq, ha="center")
# for col, uniq in zip(cols, uniques):
# ax.text(col, uniq, uniq, color='black', ha="center")
# ## Encoded variables statistics
# Although the actual values of these variables aren't helpful for us, it can still be useful to know what their distributions are. Note these statistics are computed on 1M samples, and so will be higher for the full dataset.
for col, uniq in zip(cols, uniques):
counts = df_train[col].value_counts()
sorted_counts = np.sort(counts.values)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
(line,) = ax.plot(sorted_counts, color="red")
ax.set_yscale("log")
plt.title("Distribution of value counts for {}".format(col))
plt.ylabel("log(Occurence count)")
plt.xlabel("Index")
plt.show()
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
plt.hist(sorted_counts, bins=50)
ax.set_yscale("log", nonposy="clip")
plt.title("Histogram of value counts for {}".format(col))
plt.ylabel("Number of IDs")
plt.xlabel("Occurences of value for ID")
plt.show()
max_count = np.max(counts)
min_count = np.min(counts)
gt = [10, 100, 1000]
prop_gt = []
for value in gt:
prop_gt.append(round((counts > value).mean() * 100, 2))
print(
"Variable '{}': | Unique values: {} | Count of most common: {} | Count of least common: {} | count>10: {}% | count>100: {}% | count>1000: {}%".format(
col, uniq, max_count, min_count, *prop_gt
)
)
# ## What we're trying to predict
plt.figure(figsize=(8, 8))
sns.set(font_scale=1.2)
mean = (df_train.is_attributed.values == 1).mean()
ax = sns.barplot(["Fraudulent (1)", "Not Fradulent (0)"], [mean, 1 - mean], palette=pal)
ax.set(xlabel="Target Value", ylabel="Probability", title="Target value distribution")
for p, uniq in zip(ax.patches, [mean, 1 - mean]):
height = p.get_height()
ax.text(
p.get_x() + p.get_width() / 2.0,
height + 0.01,
"{}%".format(round(uniq * 100, 2)),
ha="center",
)
|
# ## Θεωρητικό Μέρος
# α) Σύμφωνα με το paper, η διαδικασία παραγωγής της Γκαουσιανής πυραμίδας ισοδυναμεί με την συνέλιξη της αρχικής εικονάς με ένα σετ ισοδύναμων συναρτήσεων βαρών h. Η συνάρτηση αυτή h μοιάζει όλο και περισσότερο με την συνάρτηση της Γκαουσιανής κατανομής όσο το α γίνεται μικρότερο της μονάδας αλλά καθώς η παράμετρος α προσεγγίζει την μονάδα, το σχήμα της συνάρτησης βαρών h παίρνει πιο τριγωνικές μορφές. Επιπλέον η παράμετρος α καθορίζει το κατά πόσο θα μειωθούν η διακύμανση και η εντροπία των ιστογραμμάτων των εικόνων του κάθε επιπέδου της πυραμίδας.
# b) Η εντροπία είναι ο ελάχιστος αριθμός από bits ανά pixel, που χρειαζόμαστε για να κωδικοποιήσουμε μία εικόνα. Επειδή χρησιμοποιούμε 8 bits για την αναπαράσταση του κάθε pixel σε μία grayscale εικόνα, άρα έχουμε 2^8=256 δυνατά αποτελέσματα, η μέγιστη εντροπία θα είναι:
# $ -\sum \limits _{n=0}^ {255}P(n)\log(P(n)) = -\sum \limits _{n=0}^{255}2^{(-8)}\log(2^{(-8)}) = -\log(2^{(-8)}) = 8 $
# c)
# d)
# ## Εργαστηριακό Μέρος
# ### Α. Υλοποίηση Αλγορίθμου
import numpy as np
def GKernel(a=0.0):
w_n = np.array(
[(0.25 - a / 2), 0.25, a, 0.25, (0.25 - a / 2)]
) # initializing row vector w(n) with given constraints
w_m = w_n.reshape((5, 1)) # initializing column vector w(m)
w = np.outer(w_m, w_n) # getting the 5x5 kernel
return w
def GReduce(I, h):
window = 5
offset = window // 2
row, col = I.shape
if row % 2 == 0:
height = row - offset
else:
height = row - offset - 1
if col % 2 == 0:
width = row - offset
else:
width = row - offset - 1
nextLevel = np.zeros((width // 2 - 1, height // 2 - 1))
for i in range(2, width):
for j in range(2, height):
if j % 2 == 0 and i % 2 == 0:
patch = I[i - offset : i + offset + 1, j - offset : j + offset + 1]
psum = np.dot(patch, h).sum()
nextLevel[(i // 2) - 1, (j // 2) - 1] = psum
return nextLevel
import matplotlib.pyplot as plt
from skimage import io
from skimage.transform import resize
from skimage import color
img = io.imread("/kaggle/input/lenapng/lena.png")
gray_img = color.rgb2gray(img)
plt.imshow(gray_img, cmap=plt.get_cmap("gray"))
plt.show()
print(gray_img.shape)
I_out = GReduce(img, GKernel(0.5))
plt.imshow(I_out, cmap=plt.get_cmap("gray"))
plt.show()
|
# # Investigate SMOTE for a simple classifier for Fraud Detection
# ### This kernel is higly inspired from [Khyati Mahendru post on Medium](https://medium.com/analytics-vidhya/balance-your-data-using-smote-98e4d79fcddb)
# **Fraud Detection** is a dataset higly imbalanced as the vast majority of samples refer to non-fraud transactions.
# # SMOTE
# **S**ynthetic **M**inority **O**versampling **TE**chnique
# >This technique generates synthetic data for the minority class.
# SMOTE proceeds by joining the points of the minority class with line segments and then places artificial points on these lines.
#
# The SMOTE algorithm works in 4 simple steps:
# 1. Choose a minority class input vector
# 2. Find its k nearest neighbors (k_neighbors is specified as an argument in the SMOTE() function)
# 3. Choose one of these neighbors and place a synthetic point anywhere on the line joining the point under consideration and its chosen neighbor
# 4. Repeat the steps until data is balanced
# SMOTE is implemented in Python using the [imblearn](https://imbalanced-learn.readthedocs.io/en/stable/install.html) library
# (to install use: `pip install -U imbalanced-learn`).
# Additional resources on SMOTE and related tasks:
# [SMOTE oversampling](https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/)
# [SMOTE docs & examples](https://imbalanced-learn.readthedocs.io/en/stable/auto_examples/index.html)
# [Tips for advanced feature engineering](https://towardsdatascience.com/4-tips-for-advanced-feature-engineering-and-preprocessing-ec11575c09ea)
#
# import required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
# import logistic regression model and accuracy_score metric
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
accuracy_score,
balanced_accuracy_score,
f1_score,
cohen_kappa_score,
)
from imblearn.over_sampling import SMOTE, SVMSMOTE
# Helper functions to compute and print metrics for classifier
def confusion_mat(y_true, y_pred, label="Confusion Matrix - Training Dataset"):
print(label)
cm = pd.crosstab(
y_true, y_pred, rownames=["True"], colnames=["Predicted"], margins=True
)
print(
pd.crosstab(
y_true, y_pred, rownames=["True"], colnames=["Predicted"], margins=True
)
)
return cm
def metrics_clf(y_pred, y_true, print_metrics=True):
acc = accuracy_score(y_true, y_pred)
bal_acc = balanced_accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
kappa = cohen_kappa_score(y_true, y_pred)
if print_metrics:
print(f"Accuracy score = {acc:.3f}\n")
print(f"Balanced Accuracy score = {bal_acc:.3f}\n")
print(f"F1 Accuracy score = {f1:.3f}\n")
print(f"Cohen Kappa score = {kappa:.3f}\n")
return (acc, bal_acc, f1, kappa)
# # Load data
# Show full output in cell
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# Load data
data = pd.read_csv("../input/creditcardfraud/creditcard.csv")
# Show five sampled records
data.sample(5)
# Show proportion of Classes
# 1 means Fraud, 0 Normal
_ = data["Class"].value_counts().plot.bar()
data["Class"].value_counts()
print("Proportion of the classes in the data:\n")
print(data["Class"].value_counts() / len(data))
# Remove Time from data
data = data.drop(["Time"], axis=1)
# create X and y array for model split
X = np.array(data[data.columns.difference(["Class"])])
y = np.array(data["Class"]).reshape(-1, 1)
X
y
# ## Scale data
# standardize the data
scaler = StandardScaler()
scaler.fit(X)
X = scaler.transform(X)
# > Split data into Training and Test using stratify = Class return arrays with the same proportion of classes
# although these are highly imbalanced (0.998 for "0" class and 0.002 for "1" class)!!
# split into training and testing datasets using stratify, i.e. same proportion class labels (0/1) in training and test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=2, shuffle=True, stratify=y
)
print("Proportion of the classes in training data:\n")
unique, counts = np.unique(y_train, return_counts=True)
print(f'"{unique[0]}": {counts[0]/len(y_train):.3f}')
print(f'"{unique[1]}": {counts[1]/len(y_train):.3f}')
print("Proportion of the classes in test data:\n")
unique, counts = np.unique(y_test, return_counts=True)
print(f'"{unique[0]}": {counts[0]/len(y_test):.3f}')
print(f'"{unique[1]}": {counts[1]/len(y_test):.3f}')
# ## Logistic regression model
# Fit a simple Logistic regression model
model_LR = LogisticRegression(solver="lbfgs")
# ## Model without SMOTE
# fit the model
model_LR.fit(X_train, y_train.ravel())
# prediction for training dataset
train_pred = model_LR.predict(X_train)
# prediction for testing dataset
test_pred = model_LR.predict(X_test)
# ## Metrics on Training
(acc_train, b_acc_train, f1_train, k_train) = metrics_clf(y_train, train_pred)
cm_train = confusion_mat(
y_train.ravel(), train_pred, "Confusion Matrix - Train Dataset (NO SMOTE)"
)
# ## Metrics on Test
(acc_test_sm, b_acc_test_sm, f1_test_sm, k_test_sm) = metrics_clf(y_test, test_pred)
cm_test = confusion_mat(
y_test.ravel(), test_pred, "Confusion Matrix - Test Dataset (NO SMOTE)"
)
# # Metrics analysis
# This simple classifier show very high accuracy but this is not due to correct classification.
# The model has predicted the majority class for almost all the examples (see confusion matrix),and being the majority class ("0" i.e. not fraud transaction) about 99.8% of total samples this leads to such high accuracy scores.
# More significative metrics for imbalanced dataset are:
# 1. F1 score
# 2. Cohen Kappa
# 3. Balanced accuracy
# For a detailed article/discussion to this metrics refer to [Which Evaluation Metric Should You Choose](https://neptune.ai/blog/f1-score-accuracy-roc-auc-pr-auc)
# ## Model with SMOTE (Synthetic Minority Oversampling Technique)
# [SMOTE parameters](https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SMOTE.html#imblearn.over_sampling.SMOTE)
# sm = SMOTE(random_state = 42, n_jobs=-1)
sm = SVMSMOTE(random_state=42, k_neighbors=20, n_jobs=-1)
# generate balanced training data
# test data is left untouched
X_train_new, y_train_new = sm.fit_sample(X_train, y_train.ravel())
# observe that data has been balanced
ax = (
pd.Series(y_train_new)
.value_counts()
.plot.bar(title="Class distribution", y="Count")
)
_ = ax.set_ylabel("Count")
# fit the model on balanced training data
_ = model_LR.fit(X_train_new, y_train_new)
# prediction for Training data
train_pred_sm = model_LR.predict(X_train_new)
# prediction for Testing data
test_pred_sm = model_LR.predict(
X_test,
)
# ## Metrics on Training (SMOTE)
# > **NOTE how Accuracy is now almost equal to balanced accuracy F1 and Cohen Kappa improved**
(acc_test_sm, b_acc_test_sm, f1_test_sm, k_test_sm) = metrics_clf(
y_train_new, train_pred_sm
)
cm_test = confusion_mat(
y_train_new.ravel(), train_pred_sm, "Confusion Matrix - Train Dataset (SMOTE)"
)
# * ## Metrics on Test (SMOTE)
(acc_test_sm, b_acc_test_sm, f1_test_sm, k_test_sm) = metrics_clf(y_test, test_pred_sm)
f1_score(y_true=y_test, y_pred=test_pred_sm)
cm_test_sm = confusion_mat(
y_test.ravel(), test_pred_sm, "Confusion Matrix - Test Dataset"
)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (
Input,
Conv2D,
BatchNormalization,
Flatten,
Dense,
LeakyReLU,
Activation,
)
from tensorflow.keras.optimizers import Adam
import os
for dirname, _, filenames in os.walk("../input/"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
df_train = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
df_test = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
df_submission = pd.read_csv("/kaggle/input/digit-recognizer/sample_submission.csv")
df_train.head(5)
df_test.head()
df_submission.head()
plt.imshow(df_train.iloc[3].values[1:].reshape(28, 28), cmap="gray")
model = Sequential(
[
Input(shape=(28, 28, 1)),
Conv2D(filters=32, kernel_size=(3, 3), strides=(2, 2), padding="same"),
BatchNormalization(),
Activation("relu"),
Conv2D(filters=32, kernel_size=(3, 3), padding="same"),
BatchNormalization(),
Activation("relu"),
Conv2D(filters=64, kernel_size=(3, 3), strides=(2, 2), padding="same"),
BatchNormalization(),
Activation("relu"),
Conv2D(filters=64, kernel_size=(3, 3), strides=(2, 2), padding="same"),
BatchNormalization(),
Activation("relu"),
Flatten(),
Dense(units=10),
Activation("softmax"),
]
)
model.compile(loss="categorical_crossentropy", optimizer=Adam(), metrics=["accuracy"])
model.summary()
X_train = df_train.iloc[:, 1:].values.reshape(-1, 28, 28, 1)
y_train = df_train.iloc[:, 0].values.reshape(-1, 1)
X_test = df_test.values.reshape(-1, 28, 28, 1)
print(
"Number of samples: {} - after reshape: {}".format(len(df_train), X_train.shape[0])
)
print(X_train[0].min(), X_train[0].max())
X_train = X_train / 255.0
X_test = X_test / 255.0
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train, num_classes=10)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25)
model.fit(
X_train,
y_train,
validation_data=(X_val, y_val),
batch_size=32,
epochs=25,
verbose=1,
)
out_test = model.predict_classes(X_test)
df_submission.head()
df_submiss = np.hstack(
(np.arange(1, out_test.shape[0] + 1, 1).reshape(-1, 1), out_test.reshape(-1, 1))
)
df_submiss
data = pd.DataFrame(data=df_submiss, columns=["ImageId", "Label"])
data
data.to_csv("submission.csv", index=False)
|
# # G20C0846 - Machine Learning Assignment 4 Task 4
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import fashion_mnist
class_names = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
print(f"X_train's shape is {X_train.shape}")
print(f"y_train's shape is {y_train.shape}")
print(f"y_train has {np.max(y_train) + 1} classes")
# We want to add channels to our X data, so that they
# are compatible with the Convolutional Layers
# The idea here is that we are working in greyscale
# So the image has 1 channel
# The image data is of shape (N, im_height, im_width, channels)
X_train = X_train.reshape(X_train.shape + (1,))
X_test = X_test.reshape(X_test.shape + (1,))
print(X_train.shape)
print(X_test.shape)
print(
f"The maximum value of X_train is {np.max(X_train)}. We don't want this, because it'll make training longer"
)
# normalize each value for each pixel for the entire vector for each input
X_train = X_train / 255
X_test = X_test / 255
print(
f"Now the maximum value of X_train is {np.max(X_train)}. We have now scaled our training data."
)
# Let's take a look at some of these images
fig, ax = plt.subplots(2, 5)
for i in range(2):
for j in range(5):
ind = (i * 5) + j
ds_ex = np.where(y_train == ind)[0][0]
ax[i, j].imshow(X_train[ds_ex, ...])
ax[i, j].set_title(class_names[ind])
plt.show()
def to_one_hot(y):
"""
Input: y of shape (n_samples)
Output: y of shape (n_samples, n_classes)
"""
onehot = np.zeros((y.shape[0], len(class_names)))
onehot[np.arange(y.shape[0]), y] = 1
# for i in range(len(y)):
# onehot[i, y[i]] = 1
return onehot
y_train = to_one_hot(y_train)
y_test = to_one_hot(y_test)
# ## Creating a Convolutional Neural Network (CNN)
# Over to you. Create a CNN to classify this
from keras.layers.core import (
Dense,
Dropout,
Activation,
) # Types of layers to be used in our cnnmodel
# import CNN tools
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Conv2D, MaxPooling2D, Flatten, BatchNormalization
# create instance
from keras.models import Sequential
cnnmodel = Sequential()
# Convolution Layer 1 (28 by 28 pixel images grayscale hence input shape)
cnnmodel.add(
Conv2D(32, (3, 3), input_shape=(28, 28, 1))
) # 32 different 3x3 kernels -- so 32 feature maps (different characteristics of an image)
cnnmodel.add(
BatchNormalization(axis=-1)
) # normalize each feature map before activation (scales and centres)
cnnmodel.add(Activation("relu")) # relu activation
cnnmodel.add(
Dropout(0.2)
) # 20% dropout of randomly selected nodes (Helped prevent overfitting and increased accuracy)
# Convolution Layer 2
cnnmodel.add(
Conv2D(32, (3, 3))
) # 32 different 3x3 kernels -- so 32 feature maps (different characteristics of an image)
cnnmodel.add(
BatchNormalization(axis=-1)
) # normalize each feature map before activation (scales and centres)
cnnmodel.add(Activation("relu")) # relu activation
cnnmodel.add(
MaxPooling2D(pool_size=(2, 2))
) # Pool the max values over a 2x2 kernel (non-highlighted elements are discarded per feature map, while keeping features of interest)
cnnmodel.add(
Dropout(0.2)
) # 20% dropout of randomly selected nodes (Helped prevent overfitting and increased accuracy)
# Convolution Layer 3
cnnmodel.add(
Conv2D(64, (3, 3))
) # 64 different 3x3 kernels -- so 64 feature maps (different characteristics of an image)
cnnmodel.add(
BatchNormalization(axis=-1)
) # normalize each feature map before activation (scales and centres)
cnnmodel.add(Activation("relu")) # relu activation
cnnmodel.add(
Dropout(0.2)
) # 20% dropout of randomly selected nodes (Helped prevent overfitting and increased accuracy)
# Convolution Layer 4
cnnmodel.add(
Conv2D(64, (3, 3))
) # 64 different 3x3 kernels -- so 64 feature maps (different characteristics of an image)
cnnmodel.add(
BatchNormalization(axis=-1)
) # normalize each feature map before activation (scales and centres)
cnnmodel.add(Activation("relu")) # relu activation
cnnmodel.add(
MaxPooling2D(pool_size=(2, 2))
) # Pool the max values over a 2x2 kernel (non-highlighted elements are discarded per feature map, while keeping features of interest)
cnnmodel.add(Flatten()) # Flatten final 4x4x64 output matrix into a 1024-length vector
cnnmodel.add(
Dropout(0.2)
) # 20% dropout of randomly selected nodes (Helped prevent overfitting and increased accuracy)
# Fully Connected Layer 5
cnnmodel.add(Dense(512)) # 512 FCN nodes
cnnmodel.add(BatchNormalization()) # normalization
cnnmodel.add(Activation("relu")) # relu activation
cnnmodel.add(
Dropout(0.2)
) # 20% dropout of randomly selected nodes (Helped prevent overfitting and increased accuracy)
# Fully Connected Layer 6
cnnmodel.add(Dense(10)) # final 10 FCN nodes (10 classes of target)
cnnmodel.add(Activation("softmax")) # softmax activation
cnnmodel.summary() # summary of the cnnmodel
# ## Compile and train the model
# compile the cnnmodel (categorical and not binary crossentropy as we have multiple classes/categories)
cnnmodel.compile(
loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]
)
cnnmodel.fit(
X_train, y_train, batch_size=32, epochs=10, verbose=1
) # out of (32,64,128,256,512) they were extremely close but 32 was the batch size that seemed to give the best results
# ## Evaluate the model's predictions
# predict with the cnnmodel
score = cnnmodel.evaluate(X_test, y_test)
print("Loss:", score[0])
print("Test accuracy:", score[1])
# The GPU really helped speed things up, super cool
|
print(
" This group project aims to show an analytical way in which various variables from Leauge of Legends are useful in guiding a player to get good\n",
"As such, we will be gathering data from a dataset on kaggle that contains over 50,000 ranked matches.\n",
"These matches all have various variables that we can use to glean an understanding into how players can and do get better at playing some popular games",
)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import xgboost as xgb
from sklearn import preprocessing
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.metrics import (
accuracy_score,
precision_score,
recall_score,
f1_score,
mean_absolute_error,
mean_squared_error,
r2_score,
)
df = pd.read_csv("/kaggle/input/league-of-legends/games.csv")
df.info()
plt.figure(figsize=(60, 60))
sns.heatmap(df.corr(method="pearson"), annot=True)
print("\nPlotting a heatmap of our true data to see what comes to mind")
for i in df.columns:
sns.displot(df, x=i, kde=True)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# Kaliforniya Kooperatif Okyanus Balıkçılık Araştırmaları (CalCOFI), Kaliforniya Balık ve Yaban Hayatı Bölümü, NOAA Balıkçılık Servisi ve Scripps Oşinografi Enstitüsü'nün eşsiz bir ortaklığıdır. Organizasyon 1949'da Kaliforniya'daki sardalya nüfusunun çöküşünün ekolojik yönlerini incelemek için kuruldu. Bugün odak noktamız Kaliforniya sahillerindeki deniz çevresi, yaşam kaynaklarının yönetimi ve El Nino ve iklim değişikliği göstergelerinin izlenmesine yönelmiştir. CalCOFI, güney ve orta Kaliforniya'da üç ayda bir geziler düzenleyerek istasyon ve devam etmekte olan bir dizi hidrografik ve biyolojik veri toplar. 500 m'ye kadar derinliklerde toplanan veriler şunları içerir: sıcaklık, tuzluluk, oksijen, fosfat, silikat, nitrat ve nitrit, klorofil, transmissometre, PAR, C14 birincil üretkenliği, fitoplankton biyolojik çeşitliliği, zooplankton biyokütlesi ve zooplankton biyolojik çeşitliliği.
# Su tuzluluğu ile su sıcaklığı arasında bir ilişki var mı? Tuzluluk derecesine göre su sıcaklığını tahmin edebilir misiniz?
# bottle datasini okuyoruz
data = pd.read_csv("/kaggle/input/calcofi/bottle.csv")
data = pd.DataFrame(data)
data.head()
# tuzluluk ve sicaklik iliskisi inceleneceginden bu iki veriyi ayri bir degiskene atiyoruz
salt_degree = data[["Salnty", "T_degC"]]
salt_degree.head()
# iki ozellik arasindaki bagintiyi gozlemlemek icin scatter grafige dokuyoruz
from matplotlib import pyplot as plt
import seaborn as sns
plt.figure(figsize=(13, 9))
plt.scatter(salt_degree["Salnty"], salt_degree["T_degC"], s=65)
plt.xlabel("Slnty", fontsize=25)
plt.ylabel("Temp", fontsize=25)
plt.title("slnty-Temp", fontsize=25)
plt.show()
# datayi incelemeyi hizlandirmak ve daha anlamli halde gorebilmek icin 750 veriyi aliyoruz
new_salt_degree = salt_degree[:][:750]
len(new_salt_degree)
# datamiz icindeki Nan degerleri tespit edip temizliyoruz
new_salt_degree["Salnty"].isna().value_counts()
new_salt_degree["T_degC"].isna().value_counts()
new_salt_degree = new_salt_degree.dropna(axis=0, how="any")
# datamiz icindeki tekrar eden degerleri siliyoruz
new_salt_degree = new_salt_degree.drop_duplicates(subset=["Salnty", "T_degC"])
len(new_salt_degree)
# 717 veriyi tekrar scatter ile gozlemliyoruz
plt.figure(figsize=(12, 12))
plt.scatter(new_salt_degree["Salnty"], new_salt_degree["T_degC"], s=65)
plt.xlabel("Slnty", fontsize=25)
plt.ylabel("Temp", fontsize=25)
plt.title("Slnty-Temp", fontsize=25)
plt.show()
# #########################################
# 1. Lineer regrasyon modeli uygulamasi
# #############################################
from sklearn.linear_model import LinearRegression
# Tmp ve Slt adli iki degiskende kolon degerlerini tutuyoruz
Slt = new_salt_degree.iloc[:, 0:1].values
Tmp = new_salt_degree.iloc[:, -1].values
# regresyon modelimizde girilen tuz degerine gore sicaklik degeri aliyoruz
lin_reg = LinearRegression()
lin_reg.fit(Slt, Tmp)
# scatter grafiginde lineer degisimi gosteriyoruz
sns.set(font_scale=2)
plt.figure(figsize=(15, 15))
plt.scatter(Slt, Tmp, s=65)
plt.plot(Slt, lin_reg.predict(Slt), color="red", linewidth="6")
plt.xlabel("Slt", fontsize=25)
plt.ylabel("Tmp", fontsize=25)
plt.title("salt degerlerine gore temp tahmin gosterimi", fontsize=25)
plt.show()
# tuz degerine gore tahmini hava sicakligi tahmini yaptiriyoruz
degree_lin = lin_reg.predict([[33]])
degree_lin
# r_square ile tahminlerimizin dogruluk degerini tespit ediyoruz
from sklearn.metrics import mean_squared_error, r2_score
Tmp_head_lin = lin_reg.predict(Slt)
print("Linear Regression R_Square Score: ", r2_score(Tmp, Tmp_head_lin))
degerlendirme = {}
degerlendirme["Linear Regression R_Square Score:"] = r2_score(Tmp, Tmp_head_lin)
# ########################################
# 2. Multiple Linear Regression modeli uygulamasi
# ############################################
m_lin_reg = LinearRegression()
m_lin_reg = m_lin_reg.fit(Slt, Tmp)
m_lin_reg.intercept_ # constant b0
m_lin_reg.coef_
# tuz degerine gore tahmini hava sicakligi tahmini yaptiriyoruz
degree_m_lin = m_lin_reg.predict([[33]])
degree_m_lin
# r_square ile tahminlerimizin dogruluk degerini tespit ediyoruz
Tmp_head_m_lin = m_lin_reg.predict(Slt)
print("Multiple Linear Regression R_Square Score: ", r2_score(Tmp, Tmp_head_m_lin))
degerlendirme["Multiple Linear Regression R_Square Score:"] = r2_score(
Tmp, Tmp_head_m_lin
)
# scatter grafiginde m-lineer degisimi gosteriyoruz
import operator
plt.scatter(Slt, Tmp, s=65)
sort_axis = operator.itemgetter(0)
sorted_zip = sorted(zip(Slt, Tmp), key=sort_axis)
X_test, y_pred = zip(*sorted_zip)
plt.plot(Slt, Tmp, color="g")
plt.show()
# #################################
# 3. Polynomial Regression modeli uygulamasi
# ##################################
from sklearn.preprocessing import PolynomialFeatures
pol = PolynomialFeatures(degree=3)
Slt_pol = pol.fit_transform(Slt)
pol.fit(Slt_pol, Tmp)
lin_reg2 = LinearRegression()
lin_reg2.fit(Slt_pol, Tmp)
# tuz degerine gore hava sicakligi tahmini yaptiriyoruz
Predict_Tmp_pol = lin_reg2.predict(pol.fit_transform([[33]]))
Predict_Tmp_pol
##r_square ile tahminlerimizin dogruluk degerini tespit ediyoruz
Tmp_head_pol = lin_reg2.predict(Slt_pol)
print("Polynomial Regression R_Square Score: ", r2_score(Tmp, Tmp_head_pol))
degerlendirme["Polynomial Regression R_Square Score:"] = r2_score(Tmp, Tmp_head_pol)
sns.set(font_scale=1.6)
plt.figure(figsize=(13, 9))
x_grid = np.arange(min(Slt), max(Slt), 0.1)
x_grid = x_grid.reshape(-1, 1)
plt.scatter(Slt, Tmp, s=65)
plt.plot(
x_grid, lin_reg2.predict(pol.fit_transform(x_grid)), color="red", linewidth="6"
)
plt.xlabel("Slt", fontsize=25)
plt.ylabel("Temp", fontsize=25)
plt.title("salt degerlerine gore temp tahmin gosterimi", fontsize=25)
plt.show()
# ########################
# 4.Decision Tree modeli uygulamasi
# #######################
from sklearn.tree import DecisionTreeRegressor
Slt_ = new_salt_degree.iloc[:, 0].values.reshape(-1, 1)
Tmp_ = new_salt_degree.iloc[:, 1].values.reshape(-1, 1)
dt_reg = DecisionTreeRegressor()
dt_reg.fit(Slt_, Tmp_)
dt_reg.predict([[33]])
Tmp_head = dt_reg.predict(Slt_)
plt.scatter(Slt_, Tmp_, color="red")
plt.plot(Slt_, Tmp_head, color="green")
plt.xlabel("Slnty")
plt.ylabel("Tmp")
plt.title("Decision Tree Model")
plt.show()
##r_square ile tahminlerimizin dogruluk degerini tespit ediyoruz
Tmp_head_dt = dt_reg.predict(Slt_)
print("Decision Tree Regression R_Square Score: ", r2_score(Tmp, Tmp_head_dt))
degerlendirme["Decision Tree Regression R_Square Score:"] = r2_score(Tmp, Tmp_head_dt)
# ############################################
# 5-Random Forest modeli uygulamasi
# ########################################
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor(n_estimators=100, random_state=42)
rf_reg.fit(Slt_, Tmp_)
rf_reg.predict([[33]])
Tmp_head = rf_reg.predict(Slt_)
plt.scatter(Slt_, Tmp_, color="red")
plt.plot(Slt_, Tmp_head, color="green")
plt.xlabel("Slnty")
plt.ylabel("Tmp")
plt.title("Random Forest Model")
plt.show()
##r_square ile tahminlerimizin dogruluk degerini tespit ediyoruz
Tmp_head_rf = rf_reg.predict(Slt_)
print("Random Forest Regression R_Square Score: ", r2_score(Tmp, Tmp_head_rf))
degerlendirme["Random Forest Regression R_Square Score:"] = r2_score(Tmp, Tmp_head_rf)
# ##################################
degerlendirme
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import shutil
from PIL import Image
import matplotlib.pyplot as plt
import zipfile
# 데이터셋 압축 해제
with zipfile.ZipFile(
"/kaggle/input/oxford-102-flower-pytorch/flower_data.zip", "r"
) as zip_ref:
zip_ref.extractall("/kaggle/working/")
# 이미지 전처리
transform = transforms.Compose(
[
transforms.Resize((224, 224)), # 이미지 사이즈 조정
transforms.RandomHorizontalFlip(), # 좌우 반전
transforms.RandomRotation(10), # 무작위 회전
transforms.ToTensor(), # 텐서 형태로 변환
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
) # 이미지 정규화
# 데이터셋 불러오기
trainset = torchvision.datasets.ImageFolder(
root="flower_data/train", transform=transform
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=128, shuffle=True, num_workers=2
)
testset = torchvision.datasets.ImageFolder(
root="flower_data/valid", transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=128, shuffle=False, num_workers=2
)
# train 폴더 경로
train_folder = "flower_data/train/4"
# train 폴더 내 첫 번째 이미지 경로
img_path = os.path.join(train_folder, os.listdir(train_folder)[1])
# 이미지 로드
img = Image.open(img_path)
# 이미지 출력
plt.imshow(img)
plt.show()
# CNN 모델 정의
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(128 * 28 * 28, 512)
self.fc2 = nn.Linear(512, 102)
self.dropout = nn.Dropout(0.2)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.pool(self.relu(self.conv2(x)))
x = self.pool(self.relu(self.conv3(x)))
x = x.view(-1, 128 * 28 * 28)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
# 모델 선언 및 최적화 기준 정의
model = CNNModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 모델 학습
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
# 모델 출력(batch_size=512)에서 batch_size를 재조정(batch_size=128)
outputs = outputs.view(inputs.shape[0], -1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print("[%d, %5d] loss: %.3f" % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print("Finished Training")
# 모델 검증
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
# 모델 출력(batch_size=512)에서 batch_size를 재조정(batch_size=128)
outputs = outputs.view(images.shape[0], -1)
_, predicted = torch.max(outputs.data, 1)
# predicted 텐서를 labels와 크기를 맞춰줌
predicted = predicted.view(-1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(
"Accuracy of the network on the %d test images: %d %%"
% (total, 100 * correct / total)
)
|
# # 2. Model Train
# ## Model Xception
# ### Import libraries
import os
import timeit
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from sklearn.metrics import (
accuracy_score,
balanced_accuracy_score,
classification_report,
confusion_matrix,
)
from sklearn.utils.class_weight import compute_class_weight
np.random.seed(12049)
def get_plot_loss_acc(model, model_name):
fig = plt.figure()
plt.subplot(2, 1, 1)
plt.plot(model.history.history["loss"])
plt.plot(model.history.history["val_loss"])
plt.title(f"{model_name} \n\n model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "valid"], loc="upper right")
plt.subplot(2, 1, 2)
plt.plot(model.history.history["accuracy"])
plt.plot(model.history.history["val_accuracy"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train", "valid"], loc="lower right")
plt.tight_layout()
def compute_confusion_matrix(ytrue, ypred, class_names, model_name):
cm = confusion_matrix(
y_true=ytrue.labels,
y_pred=np.argmax(ypred, axis=1),
)
cmn = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis]
plt.subplots(figsize=(6, 5))
sns.heatmap(
cmn,
annot=True,
fmt=".2f",
cmap="Purples",
xticklabels=class_names,
yticklabels=class_names,
)
plt.title(f"Confusion Matrix - {model_name}")
plt.ylabel("Actual")
plt.xlabel("Predicted")
plt.show(block=False)
def get_evaluate(data, name, model):
score_model = model.evaluate(data, verbose=1)
print(f"{name} loss: {score_model[0]:.2f}")
print(f"{name} accuracy: {score_model[1]:.2f}")
def get_predict(data, model):
predict_model = model.predict(data)
return predict_model
def get_metrics(y_test, y_pred, model_name):
acc = accuracy_score(y_test, y_pred)
bal_acc = balanced_accuracy_score(y_test, y_pred)
print(f"Accuracy Score - {model_name}: {acc:.2f}")
print(f"Balanced Accuracy Score - {model_name}: {bal_acc:.2f}")
print("\n")
print(classification_report(y_test, y_pred))
# ### Load data
base_dir = "/kaggle/input/knee-osteoarthritis-dataset-with-severity/"
train_path = os.path.join(base_dir, "train")
valid_path = os.path.join(base_dir, "val")
test_path = os.path.join(base_dir, "test")
# ### Definitions
model_name = "Xception"
class_names = ["Healthy", "Doubtful", "Minimal", "Moderate", "Severe"]
target_size = (224, 224)
epochs = 100
batch_size = 256
img_shape = (224, 224, 3)
# Save model
save_model_ft = os.path.join("/kaggle/working/", f"model_{model_name}_ft.hdf5")
# ### Image data generator
aug_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
preprocessing_function=tf.keras.applications.xception.preprocess_input,
horizontal_flip=True,
brightness_range=[0.3, 0.8],
width_shift_range=[-50, 0, 50, 30, -30],
zoom_range=0.1,
fill_mode="nearest",
)
noaug_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
preprocessing_function=tf.keras.applications.xception.preprocess_input,
)
train_generator = aug_datagen.flow_from_directory(
train_path, class_mode="categorical", target_size=target_size, shuffle=True
)
valid_generator = noaug_datagen.flow_from_directory(
valid_path,
class_mode="categorical",
target_size=target_size,
shuffle=False,
)
y_train = train_generator.labels
y_val = valid_generator.labels
# ### Weight data
unique, counts = np.unique(y_train, return_counts=True)
print("Train: ", dict(zip(unique, counts)))
class_weights = compute_class_weight(
class_weight="balanced", classes=np.unique(y_train), y=y_train
)
train_class_weights = dict(enumerate(class_weights))
print(train_class_weights)
# ### Train data
classes = np.unique(y_train)
# Callbacks
early = tf.keras.callbacks.EarlyStopping(
monitor="val_loss", min_delta=0.01, patience=8, restore_best_weights=True
)
plateau = tf.keras.callbacks.ReduceLROnPlateau(
monitor="loss", factor=0.1, min_delta=0.01, min_lr=1e-10, patience=4, mode="auto"
)
model = tf.keras.applications.xception.Xception(
input_shape=(img_shape),
include_top=False,
weights="imagenet",
)
# ### Fine-tuning
for layer in model.layers:
layer.trainable = True
model_ft = tf.keras.models.Sequential(
[
model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(5, activation="softmax"),
]
)
model_ft.summary()
model_ft.compile(
optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"]
)
start_ft = timeit.default_timer()
history = model_ft.fit(
train_generator,
epochs=epochs,
batch_size=batch_size,
callbacks=[early, plateau],
validation_data=valid_generator,
class_weight=train_class_weights,
verbose=1,
)
stop_ft = timeit.default_timer()
execution_time_ft = (stop_ft - start_ft) / 60
print(f"Model {model_name} fine tuning executed in {execution_time_ft:.2f} minutes")
model_ft.save(save_model_ft)
get_plot_loss_acc(model_ft, f"{model_name} Fine Tuning")
get_evaluate(valid_generator, "Valid", model_ft)
predict_model_ft = get_predict(valid_generator, model_ft)
get_metrics(
valid_generator.labels,
y_pred=np.argmax(predict_model_ft, axis=1),
model_name=model_name,
)
compute_confusion_matrix(
valid_generator, predict_model_ft, class_names, f"{model_name} Fine Tuning"
)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import numpy as np
import pandas as pd
train = pd.read_csv("../input/titanic/train.csv")
test = pd.read_csv("../input/titanic/test.csv")
gender_submission = pd.read_csv("../input/titanic/gender_submission.csv")
train.head(10)
test.head(10)
gender_submission.head(10)
test_shape = test.shape
train_shape = train.shape
print(test_shape)
print(train_shape)
test.describe()
train.describe()
|
# # LesionFinder: Bounding Box Regression for Chest CT (Evaluation)
# Here, we evaluate the previously trained LesionFinder model for lesion bounding box regression. The training notebook can be found [here](https://www.kaggle.com/code/benjaminahlbrecht/lesionfinder-bounding-box-regression-for-chest-ct).
# ## Preamble
# ---------------------------------------------------------------------------- #
import os
import torch
from torch.utils.data import DataLoader
import lightning.pytorch as pl
from lesionfinder_utilities import DeepLesionDataset, ResizeWithBoundingBox, ResnetYolo
MODEL_FNAME = "/kaggle/input/lesionfinder-bounding-box-regression-for-chest-ct/models/model_epoch=12_val_loss=0.43.ckpt"
DATA_DIR = "/kaggle/input/nih-deeplesion-tensor-slices/tensors"
DATA_DIR_TRAIN = os.path.join(DATA_DIR, "train")
DATA_DIR_VAL = os.path.join(DATA_DIR, "validation")
DATA_DIR_TEST = os.path.join(DATA_DIR, "test")
if torch.cuda.is_available():
DEVICE = "cuda"
else:
DEVICE = "cpu"
# Feed data in by mini-batches using gradient accumulation
MINIBATCH_SIZE = 12
N_MINIBATCHES = 6
# Height and width to resize images
HEIGHT = 500
WIDTH = 500
# Device information for PyTorch Lightning (Align with Hardware)
ACCELERATOR = "gpu"
N_DEVICES = 1
augmentations = ResizeWithBoundingBox((HEIGHT, WIDTH))
dataset_test = DeepLesionDataset(DATA_DIR_TEST, augmentations=augmentations)
dataloader_test = DataLoader(dataset_test, batch_size=MINIBATCH_SIZE)
# Retrieve the best model
model = ResnetYolo.load_from_checkpoint(MODEL_FNAME)
# ## Model Evaluation
# Redefine our trainer to contain our evaluation metrics
trainer = pl.Trainer(
devices=N_DEVICES,
accelerator=ACCELERATOR,
accumulate_grad_batches=N_MINIBATCHES,
)
results = trainer.test(model, dataloaders=dataloader_test)
|
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import logging
import nltk
import string
import collections
from collections import Counter
import wordcloud
from wordcloud import WordCloud
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
pd.set_option("display.max_colwidth", 200)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s :: %(name)s :: %(levelname)s :: %(message)s",
datefmt="%d-%b-%y %H:%M:%S",
)
logger = logging.getLogger(__name__)
logger.info("Logger initialised...")
train_df = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
# ## EDA
train_df.shape
train_df["target"].value_counts()
sns.countplot(train_df["target"])
logger.info("% of samples where keyword column is 0")
len(train_df[train_df["keyword"].isna()]) * 100 / len(train_df)
logger.info("% of samples where location column is 0")
len(train_df[train_df["location"].isna()]) * 100 / len(train_df)
sns.barplot(
train_df["keyword"].value_counts()[:20].values,
train_df["keyword"].value_counts()[:20].index,
orient="H",
)
## Keyword chart when target is 1
sns.barplot(
train_df[train_df["target"] == 1]["keyword"].value_counts()[:20].values,
train_df[train_df["target"] == 1]["keyword"].value_counts()[:20].index,
orient="H",
)
sns.barplot(
train_df["location"].value_counts()[:20].values,
train_df["location"].value_counts()[:20].index,
orient="H",
)
## Location chart when target is 1
sns.barplot(
train_df[train_df["target"] == 1]["location"].value_counts()[:20].values,
train_df[train_df["target"] == 1]["location"].value_counts()[:20].index,
orient="H",
)
# ## Data Preprocessing
# ### Cleaning text
# * Converting Text Lowercase
# * Tokenization
# * Removing Punctuatons
# * Stop Words removal
# * Stemmning
# * Lemmatization
# * POS Tagging
# #### 1. Make text lowercase
def to_lowercases(x):
return x.lower()
train_df["text_lower"] = train_df["text"].apply(to_lowercases)
train_df.head(1)
# #### 2. Tokenization
def get_tokens(x):
tokens = nltk.word_tokenize(x)
return tokens
train_df["tokens"] = train_df["text_lower"].apply(get_tokens)
train_df.head(1)
# #### 3. Removal of punctuations
print("Punctuation: ", string.punctuation)
def remove_punct(x):
text_without_puct = [t for t in x if t not in string.punctuation]
return text_without_puct
train_df["token_without_punct"] = train_df["tokens"].apply(remove_punct)
train_df.head(1)
# #### 4. Removal of Stop Words
stop_words = nltk.corpus.stopwords.words("english")
def remove_stop_words(x):
text_without_stopwords = [t for t in x if t not in stop_words]
return text_without_stopwords
train_df["remove_stop_words"] = train_df["token_without_punct"].apply(remove_stop_words)
train_df.head(1)
# #### 5. Stemming
from nltk.stem import PorterStemmer
porter = PorterStemmer()
def stemming_text(x):
stem = np.vectorize(porter.stem)
stemming = stem(x)
return stemming
train_df["stemming"] = train_df["remove_stop_words"].apply(stemming_text)
train_df.head(1)
# #### 6. Lemmatization
from nltk.stem import WordNetLemmatizer
lemma = WordNetLemmatizer()
def lemmatization(x):
lemmatized = np.vectorize(lemma.lemmatize)(x)
return lemmatized
train_df["lemmatized"] = train_df["stemming"].apply(lemmatization)
train_df.head(1)
# #### 7. POS Tagging
def get_post(x):
pos_tagging = nltk.pos_tag(x)
return pos_tagging
train_df["pos_tagging"] = train_df["lemmatized"].apply(get_post)
train_df.head(1)
# ### Text Analysis
# #### frequency distribution
from nltk import FreqDist
fdist = FreqDist()
def freq_dist(x):
for word in x:
fdist[word] += 1
return fdist
train_df["lemmatized"].apply(freq_dist)[1]
fdist = FreqDist()
def freq_dist(x):
for word in x:
fdist[word] += 1
return fdist
most_common = Counter(train_df["lemmatized"].apply(freq_dist)[1]).most_common(50)
l = []
for k, v in most_common:
l.append(k.replace("'", ""))
wordcloud = WordCloud(
background_color="white", max_words=200, max_font_size=40, scale=3, random_state=1
).generate(str(l))
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud)
# #### Bigrams and Trigrams
fdist = nltk.FreqDist()
def bigrams(x):
y = list(nltk.bigrams(x))
for word in y:
fdist[word] += 1
return fdist
bigrams = train_df["lemmatized"].apply(bigrams)
Counter(fdist).most_common(20)
fdist = nltk.FreqDist()
def trigrams(x):
y = list(nltk.trigrams(x))
for word in y:
fdist[word] += 1
return fdist
trigrams = train_df["lemmatized"].apply(trigrams)
Counter(fdist).most_common(20)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# ## Import Module
import numpy as np
import statsmodels.api as sm
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml # for link openml data
from patsy.contrasts import Treatment # for dummy encoding
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
pd.set_option("display.max_column", None)
# ## Reading Data from openml: 41214; 41215
# You can read data in your environment by following code:
# #### Fetch the French Motor Third-Party Liability Claims dataset
# def load_mtpl2(n_samples=None):
# """Fetch the French Motor Third-Party Liability Claims dataset.
# Parameters
# ----------
# n_samples: int, default=None
# number of samples to select (for faster run time). Full dataset has
# 678013 samples.
# """
# # freMTPL2freq dataset from https://www.openml.org/d/41214
# df_freq = fetch_openml(data_id=41214, as_frame=True, parser="auto").data
# df_freq["IDpol"] = df_freq["IDpol"].astype(int)
# df_freq.set_index("IDpol", inplace=True)
# # freMTPL2sev dataset from https://www.openml.org/d/41215
# df_sev = fetch_openml(data_id=41215, as_frame=True, parser="auto").data
# # sum ClaimAmount over identical IDs
# df_sev = df_sev.groupby("IDpol").sum()
# df = df_freq.join(df_sev, how="left")
# df["ClaimAmount"].fillna(0, inplace=True)
# # unquote string fields
# for column_name in df.columns[df.dtypes.values == object]:
# df[column_name] = df[column_name].str.strip("'")
# return df.iloc[:n_samples]
# #### loading data
# df = load_mtpl2()
# #### Note: filter out claims with zero amount, as the severity model
# #### requires strictly positive target values.
# df.loc[(df["ClaimAmount"] == 0) & (df["ClaimNb"] >= 1), "ClaimNb"] = 0
# #### Correct for unreasonable observations (that might be data error)
# #### and a few exceptionally large claim amounts
# df["ClaimNb"] = df["ClaimNb"].clip(upper=4)
# df["Exposure"] = df["Exposure"].clip(upper=1)
# df["ClaimAmount"] = df["ClaimAmount"].clip(upper=200000)
# #### Insurances companies are interested in modeling the Pure Premium, that is
# #### the expected total claim amount per unit of exposure for each policyholder
# #### in their portfolio:
# df["PurePremium"] = df["ClaimAmount"] / df["Exposure"]
# #### This can be indirectly approximated by a 2-step modeling: the product of the
# #### Frequency times the average claim amount per claim:
# df["Frequency"] = df["ClaimNb"] / df["Exposure"]
# df["AvgClaimAmount"] = df["ClaimAmount"] / np.fmax(df["ClaimNb"], 1)
# loading data
df = pd.read_csv("/kaggle/input/french-motor-insurance/GLM_example.csv")
df.head(5)
# ## Feature Encoding
# Categorical Variables: Area; VehBrand; VehGas; Region.
# Numerical Variables: VehPower; VehAge; DrivAge; BonusMalus.
# Weight for PurePremium: Exposure
# Dependence: PurePremium
Cat_formula = "Area + VehBrand + VehGas + Region"
Num_formula = "VehPower + VehAge + DrivAge + BonusMalus"
# Categories: Dummy Encoding
# Number: Raw
from patsy import dmatrix
df_encoding = dmatrix(Cat_formula + "+" + Num_formula, df, return_type="dataframe")
df = pd.concat([df, df_encoding], axis=1) # concatinate them
print(df.shape)
df.head(10)
# ## Modeling a Purepremium GLMs model by StatsModels Module
import statsmodels.formula.api as smf
# formula = 'PurePremium ~ ' + '+' + df_encoding
glm_pp_model = sm.GLM(
df.PurePremium,
df_encoding,
family=sm.families.Tweedie(sm.families.links.Log(), var_power=1.9),
freq_weights=np.asarray(df["Exposure"]),
).fit(
scale="X2", tol=1e-4, use_t=True
) # Design Matrix must includes the intercept if you want it
# The default scale for Binomial, Poisson and Negative Binomial families is 1. The default for the other families is Pearson’s Chi-Square estimate.
# scale can be ‘X2’, ‘dev’, or a float The default value is None, which uses X2 for Gamma, Gaussian, and Inverse Gaussian. X2 is Pearson’s chi-square divided by df_resid. The default is 1 for the Binomial and Poisson families. dev is the deviance divided by df_resid
print(glm_pp_model.summary())
# print estimators
Statsm_est = pd.DataFrame(glm_pp_model.params, columns=["Statsm_est"])
Statsm_est
# return prediction
df["Statsm_predictor"] = glm_pp_model.predict(df_encoding)
df["Statsm_Epredictor"] = df["Statsm_predictor"] * df["Exposure"]
df.head(5)
# ## Modeling a Purepremium GLMs model by Sklearn TweedieRegressor
# ***Note: the default vertion of sklearn in Kaggle is v1.02, which TweedieRegresor is without argument solver and only can use the optimizer "lbfgs". The ibfgs is suitable for small lines of observations. However, our case has more than 600 thounds policies.***
# In your PC environment, if it has recent sklearn version that surport "newton-cholesky" optimizer,please use the following code for more efficient.
# ############################
# %%time
# #power = 1.9; alpha = 0.05; weight = 'Exposure'; X = df_encoding; y = df.Purepremium
# glm_pure_premium = TweedieRegressor(power=1.9,
# alpha=0,
# solver="newton-cholesky",
# link='log',
# tol=1e-8,
# verbose=0)
# glm_pure_premium.fit(
# df_encoding.iloc[:,1:], df["PurePremium"], sample_weight=df["Exposure"]
# )
# #Do not include the intercept, because TweedieRegressor will auto add it
# ############################
from sklearn.linear_model import TweedieRegressor
# power = 1.9; alpha = 0.05; weight = 'Exposure'; X = df_encoding; y = df.Purepremium
glm_pure_premium = TweedieRegressor(
power=1.9,
warm_start=True,
alpha=0,
# solver="newton-cholesky",
link="log",
tol=1e-8,
max_iter=5000,
verbose=0,
)
glm_pure_premium.fit(
df_encoding.iloc[:, 1:], df["PurePremium"], sample_weight=df["Exposure"]
) # Do not include the intercept, because TweedieRegressor will auto add it
# print estimators
dict_paras = dict(
zip(
df_encoding.columns,
np.append(glm_pure_premium.intercept_, glm_pure_premium.coef_),
)
)
TweedieReg_est = pd.DataFrame(dict_paras, index=["TweedieReg_est"]).transpose()
TweedieReg_est
# get predict
df["TewdieeRegressor_predictor"] = glm_pure_premium.predict(df_encoding.iloc[:, 1:])
df["TewdieeRegressor_Epredictor"] = df["TewdieeRegressor_predictor"] * df["Exposure"]
df.head(10)
# ## Comparison¶
est_para = pd.concat([Statsm_est, TweedieReg_est], axis=1)
est_para["est_diff"] = est_para["Statsm_est"] - est_para["TweedieReg_est"]
est_para
df["predictor_diff"] = df["Statsm_Epredictor"] - df["TewdieeRegressor_Epredictor"]
# print abs_sum
df["predictor_diff"].abs().sum()
from sklearn.metrics import auc
def lorenz_curve(y_true, y_pred, exposure):
y_true, y_pred = np.asarray(y_true), np.asarray(y_pred)
exposure = np.asarray(exposure)
# order samples by increasing predicted risk:
ranking = np.argsort(y_pred)
ranked_exposure = exposure[ranking]
ranked_pure_premium = y_true[ranking]
cumulated_claim_amount = np.cumsum(ranked_pure_premium * ranked_exposure)
cumulated_claim_amount /= cumulated_claim_amount[-1]
cumulated_samples = np.linspace(0, 1, len(cumulated_claim_amount))
return cumulated_samples, cumulated_claim_amount
fig, ax = plt.subplots(figsize=(8, 8))
for label, y_pred in [
("Statsmodel", df.Statsm_Epredictor),
("TweedieRegressor", df.TewdieeRegressor_Epredictor),
]:
ordered_samples, cum_claims = lorenz_curve(
df["PurePremium"], y_pred, df["Exposure"]
)
gini = 1 - 2 * auc(ordered_samples, cum_claims)
label += " (Gini index: {:.3f})".format(gini)
ax.plot(ordered_samples, cum_claims, linestyle="-", label=label)
# Oracle model: y_pred == y_test
ordered_samples, cum_claims = lorenz_curve(
df["PurePremium"], df["PurePremium"], df["Exposure"]
)
gini = 1 - 2 * auc(ordered_samples, cum_claims)
label = "Oracle (Gini index: {:.3f})".format(gini)
ax.plot(ordered_samples, cum_claims, linestyle="-.", color="gray", label=label)
# Random baseline
ax.plot([0, 1], [0, 1], linestyle="--", color="black", label="Random baseline")
ax.set(
title="Lorenz Curves",
xlabel="Fraction of policyholders\n(ordered by model from safest to riskiest)",
ylabel="Fraction of total claim amount",
)
ax.legend(loc="upper left")
plt.plot()
|
# Lo scopo dell'elaborato è individuare una serie di attributi presenti nel dataset che influenzano la Life Expectancy, quindi la target variable è Life Expectancy.
# - Data Cleaning, to detect and remove null values
# - Data Exploration and Feature Engineering
# We want to improve life expectancy, take it as a response variable and try predict that, put the focus on this, try to exctract information.
# # LOAD DATASET
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import math
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import scale, MinMaxScaler, StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.tree import DecisionTreeRegressor
import warnings
warnings.filterwarnings("ignore")
sns.set_style("whitegrid")
# Load data
le = pd.read_csv("/kaggle/input/life-expectancy-who/Life Expectancy Data.csv", sep=",")
le.dataframeName = "Life Expectancy Data.csv"
le.head()
# # DATA CLEANING
# Replacing original names with other format names
orig_cols = list(le.columns)
new_cols = []
for col in orig_cols:
new_cols.append(col.strip().replace(" ", " ").replace(" ", "_").lower())
le.columns = new_cols
le.describe() # only numerical columns
# Counting all rows with NULL values
le.isnull().sum()
# Delete all rows with NULL values
le.dropna(inplace=True)
le.isnull().sum()
# Change status from Developing/Developed to 0/1
status = pd.get_dummies(le.status)
le = pd.concat([le, status], axis=1)
le = le.drop(["status"], axis=1)
le.rename(columns={"developing": 0, "developed": 1})
# # DATA EXPLORATION
# Create a dictionary of columns.
col_dict = {
"life_expectancy": 1,
"adult_mortality": 2,
"infant_deaths": 3,
"alcohol": 4,
"percentage_expenditure": 5,
"hepatitis_b": 6,
"measles": 7,
"bmi": 8,
"under-five_deaths": 9,
"polio": 10,
"total_expenditure": 11,
"diphtheria": 12,
"hiv/aids": 13,
"gdp": 14,
"population": 15,
"thinness_1-19_years": 16,
"thinness_5-9_years": 17,
"income_composition_of_resources": 18,
"schooling": 19,
}
# Detect outliers in each variable using box plots.
plt.figure(figsize=(18, 30))
for variable, i in col_dict.items():
plt.subplot(5, 4, i)
plt.boxplot(le[variable], whis=1.5)
plt.title(variable)
plt.show()
# Our data set is ready for investigation and regression process!
# The first thing is to check correlations between variables.
# Data Exploration
le.columns
# Heatmap to see correlations
plt.figure(figsize=(14, 12))
sns.heatmap(le.corr(), annot=True)
plt.title("Correlation between different features")
# As we see above, ‘Schooling’, ‘Income_composition_of_resources’, ‘BMI’, and ‘Adult_Mortality’ have a high correlation between Life Expectancy.
# ‘HIV/AIDS’, ‘Diphtheria’, ‘thinness_1_19_years’, ‘thinness_5_9_years’, ‘Polio’, ‘GDP’, ‘percentage_expenditure’ and ‘Alcohol’ have medium correlation between Life Expectancy.
# And the rest of our columns; ’hepatitis_B’, ‘Total_Expenditure’, ‘under_five_deaths’, ‘infant_deaths’, 'population' and ‘Measles’ have low correlation between Life Expectancy.
# As we can see with follows plots:
# All columns (in correlation with life expectancy).
all_col = [
"adult_mortality",
"infant_deaths",
"alcohol",
"percentage_expenditure",
"hepatitis_b",
"measles",
"bmi",
"under-five_deaths",
"polio",
"total_expenditure",
"diphtheria",
"hiv/aids",
"gdp",
"population",
"thinness_1-19_years",
"thinness_5-9_years",
"income_composition_of_resources",
"schooling",
]
plt.figure(figsize=(15, 25))
for i in range(len(all_col)):
plt.subplot(6, 3, i + 1)
plt.scatter(le[all_col[i]], le["life_expectancy"])
plt.xlabel(all_col[i])
plt.ylabel("Life Expectancy")
plt.show()
# # FEATURES EXTRACTION
# - **PCA**
# The categorical columns, 'year' and 'country' will be
# dropped as they don't have significant differences among
# life expectancy.
pca_le = le.copy()
pca_drop = pca_le.drop(columns=["country", "year"], axis=1)
cols = pca_drop.columns.tolist()
cols
# We drop also same correlated variables
pca_drop = pca_drop.drop(
columns=[
"infant_deaths",
"percentage_expenditure",
"polio",
"thinness_1-19_years",
"schooling",
"Developing",
],
axis=1,
)
# And very low correlated variables
pca_drop = pca_drop.drop(columns=["population", "measles"], axis=1)
plt.figure(figsize=(14, 12))
sns.heatmap(pca_drop.corr(), annot=True)
plt.title("Correlation between different features")
# PCA is an unsupervised technique so the target variable
# is not needed and can be dropped.
pca_drop = pca_drop.drop(columns=["life_expectancy"], axis=1)
X = pca_drop.iloc[:, 0:12].values
y = pca_drop.iloc[:, 0].values
np.shape(X)
# **COVARIANCE MATRIX**
# Standardization
X_std = StandardScaler().fit_transform(X)
mean_vec = np.mean(X_std, axis=0)
cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0] - 1)
print("Covariance matrix \n%s" % cov_mat)
# **Eigen decomposition of the covariance matrix**
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print("Eigenvectors \n%s" % eig_vecs)
print("\nEigenvalues \n%s" % eig_vals)
# **Selecting Principal Components**
# Make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:, i]) for i in range(len(eig_vals))]
# Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs.sort(key=lambda x: x[0], reverse=True)
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
print("Eigenvalues in descending order:")
for i in eig_pairs:
print(i[0])
# **What principal components are we going to choose?**
tot = sum(eig_vals)
var_exp = [(i / tot) * 100 for i in sorted(eig_vals, reverse=True)]
var_exp
# Stampiamo i valori degli eigenvalues
plt.figure(figsize=(8, 4))
plt.bar(range(12), var_exp, alpha=0.7, align="center", label="individual variance")
plt.ylabel("Explained variance ratio")
plt.xlabel("Principal components")
plt.legend(loc="best")
plt.tight_layout()
# The plot above clearly shows that maximum variance (somewhere around 32%) can be explained by the first principal component alone. The second and third also are important (around 12% and 11%). Fourth and fifth principal component give less informations then first three but more than other principal components. Sixth, seventh and eighth principal component share almost equal amount of information as compared to the rest of the Principal components, but we cannot ignore that since they both contribute almost 19% of the data. But we can drop the last component as it has less than 10% of the variance
pca = PCA().fit(X_std)
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlim(0, 12, 1)
plt.xlabel("Number of components")
plt.ylabel("Cumulative explained variance")
# The above plot shows almost 90% variance by the first 8 components. Those features are as follows:
# 1. Income Composition Of Resources
# 2. Adult Mortality
# 3. HIV/AIDS
# 4. BMI
# 5. Thinness 5-9 Years
# 6. GDP
# 7. Developed
# 8. Alcohol
# # DATA ANALYSIS
# **- Linear Regression**
lr_le = le.groupby(["country"]).mean()
lr_le = lr_le.drop(["year"], axis=1)
lr_le
le_labels = lr_le["life_expectancy"]
le_features = lr_le.drop("life_expectancy", axis=1)
min_max_scaler = MinMaxScaler()
le_features = min_max_scaler.fit_transform(le_features)
le_features_train, le_features_test, le_labels_train, le_labels_test = train_test_split(
le_features, le_labels, train_size=0.7, test_size=0.3
)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
df = pd.read_csv("../input/real-and-fake-news-dataset/news.csv")
print(df.shape)
print(df.head())
X = df["text"]
y = df["label"]
print("Num of FAKE:", y[y == "FAKE"].shape[0])
print("Num of REAL:", y[y == "REAL"].shape[0])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=123
)
tfidf = TfidfVectorizer(stop_words="english", max_df=0.6)
tfidf_train = tfidf.fit_transform(X_train)
tfidf_test = tfidf.transform(X_test)
pac = PassiveAggressiveClassifier(max_iter=50)
pac.fit(tfidf_train, y_train)
y_pred = pac.predict(tfidf_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Matrix:", confusion_matrix(y_test, y_pred, labels=["FAKE", "REAL"]))
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import re
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")
df.head(5)
# **Preparing the Data**
df["release_year"] = pd.to_datetime(df["release_year"], format="%Y")
df["date_added"] = pd.to_datetime(df["date_added"])
indeks = df[np.isnan(df["date_added"])].index
df.loc[indeks, "date_added"] = df.loc[indeks, "release_year"]
df["release_year"] = df["release_year"].dt.year
# **Exploratory Data Analysis**
# * Content type on Netflix
plt.figure(figsize=(6, 8))
total = df["type"].value_counts()
sns.barplot(x=total.index, y=total.values)
plt.box(on=None)
# * Number of programmes released by year
release = df["release_year"].value_counts()
release = release.sort_index(ascending=True)
plt.figure(figsize=(8, 6))
plt.plot(release[-11:-1])
plt.scatter(
release[-11:-1].index,
release[-11:-1].values,
s=0.5 * release[-11:-1].values,
c="orange",
)
plt.box(on=None)
plt.xticks(release[-11:-1].index)
plt.title("Number of Programmes Released by Year", color="red", fontsize=15)
# * Number of programmes by Rating
rating = df["rating"].value_counts()
# rating = rating.sort_values()
plt.figure(figsize=(8, 6))
plt.title("Number of Programmes by Rating", color="red", fontsize=15)
# plt.barh(rating.index, rating.values, align='center');
sns.barplot(x=rating.values, y=rating.index, palette="gnuplot")
plt.box(on=None)
plt.xlabel("Number of Programmes")
# * Most Popular Programmes by Country & Rating
country_rating = (
df.groupby(["country", "rating"]).count().sort_values("show_id", ascending=False)
)
plt.figure(figsize=(8, 6))
sns.barplot(
y=country_rating.index[:10], x=country_rating["show_id"][:10], palette="gnuplot2"
)
plt.box(on=None)
plt.title("Most Popular Programmes by Country & Rating", fontsize=15, color="red")
plt.xlabel("Number of Programmes")
# Analysis on Movie Programmes
# * Movies by Rating
movie = df.copy()
movie = movie[movie["type"] == "Movie"]
movie["minute"] = [int(re.findall("\d{1,3}", w)[0]) for w in movie.duration.ravel()]
duration_rating = movie.groupby(["rating"]).mean().sort_values("minute")
plt.figure(figsize=(8, 6))
sns.barplot(
x=duration_rating.index, y=duration_rating.minute.values, palette="gnuplot_r"
)
plt.box(on=None)
plt.title("Number of Movies by Rating", fontsize=15, color="red")
plt.xlabel("Movie Rating")
# * Movie's Duration Trends
duration_year = movie.groupby(["release_year"]).mean().sort_values("minute")
duration_year = duration_year.sort_index()
plt.figure(figsize=(15, 6))
sns.lineplot(x=duration_year.index, y=duration_year.minute.values)
plt.box(on=None)
plt.ylabel("Movie duration in minutes")
plt.xlabel("Year of released")
plt.title("YoY Trends of Movie's Duration", fontsize=15, color="red")
# The average movie's duration released during 1960 era was the longest
# * The Most Productive Director by number of movies produced
plt.figure(figsize=(8, 8))
sns.barplot(
y=movie.director.value_counts()[:10].sort_values().index,
x=movie.director.value_counts()[:10].sort_values().values,
)
plt.title("Most Productive Movie Director", color="red", fontsize=15)
plt.box(on=None)
plt.xticks(movie.director.value_counts()[:10].sort_values().values)
plt.xlabel("Number of Movies Released")
# Paul and Ramos produced 18 Movies so far. They have been the most productive director.
# * Director's Productivity by Total Minutes of Movies Produced
director_minute = movie.groupby("director").sum().sort_values("minute", ascending=False)
plt.figure(figsize=(8, 8))
sns.barplot(y=director_minute.index[:10], x=director_minute.minute[:10])
plt.title("Most Productive Movie Director in Video Length", color="red", fontsize=15)
plt.box(on=None)
plt.xlabel("Length of Movies Released")
|
import numpy as np
import pandas as pd
data = pd.read_csv("/kaggle/input/car-price-prediction/CarPrice_Assignment.csv")
data.info()
data.head()
data.corr()
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
data[
[
"CarName",
"fueltype",
"aspiration",
"doornumber",
"carbody",
"drivewheel",
"enginelocation",
"enginetype",
"cylindernumber",
"fuelsystem",
]
] = ordinal_encoder.fit_transform(
data[
[
"CarName",
"fueltype",
"aspiration",
"doornumber",
"carbody",
"drivewheel",
"enginelocation",
"enginetype",
"cylindernumber",
"fuelsystem",
]
]
)
data.info()
data.head()
X = data.drop(["price"], axis=1)
Y = data["price"]
X_train, Y_train, X_test, Y_test = X[:150], Y[:150], X[150:], Y[150:]
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, Y_train)
Y_pred = lin_reg.predict(X_test)
lin_reg.intercept_, lin_reg.coef_
from sklearn.metrics import mean_squared_error
lin_rmse = mean_squared_error(Y_test, Y_pred, squared=False)
lin_rmse
from sklearn.metrics import r2_score
print(r2_score(Y_test, Y_pred))
X = np.array(X_train)
Y = np.array(Y_train)
coeffs = np.linalg.inv(X.T @ X) @ X.T @ Y
coeffs
Y_pred = X_test @ coeffs
print(r2_score(Y_test, Y_pred))
|
import numpy as np
import pandas as pd
import os
filename = os.listdir(
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k"
)[0]
import librosa
import panns_inference
from panns_inference import AudioTagging, SoundEventDetection, labels
# Download PANN model
audio_path = (
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k/" + filename
)
(audio, _) = librosa.core.load(audio_path, sr=16000, mono=True)
audio = audio[None, :] # (batch_size, segment_samples)
print("------ Audio tagging ------")
at = AudioTagging(checkpoint_path="/root/panns_data/Cnn14_mAP=0.431.pth", device="cuda")
(clipwise_output, embedding) = at.inference(audio)
print(embedding)
print(embedding.shape)
# audio_dir = '/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k/'
# audio_list = [librosa.core.load(audio_dir + filename, sr=16000, mono=True)[0] for filename in os.listdir(audio_dir)[:10]]
# audio = np.stack(audio_list, axis=0)
# print(audio.shape)
# print(audio[0].shape)
# print('------ Audio tagging ------')
# at = AudioTagging(checkpoint_path='/root/panns_data/Cnn14_mAP=0.431.pth', device='cuda')
# (clipwise_output, embedding) = at.inference(audio)
# print(embedding.shape)
import spacy # for tokenizer
import torch
from torch.nn.utils.rnn import pad_sequence # pad batch
from torch.utils.data import DataLoader, Dataset
spacy_eng = spacy.load("en_core_web_sm")
class Vocabulary:
def __init__(self, freq_threshold):
self.itos = {0: "<PAD>", 1: "<SOS>", 2: "<EOS>", 3: "<UNK>"}
self.stoi = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "<UNK>": 3}
self.freq_threshold = freq_threshold
def __len__(self):
return len(self.itos)
@staticmethod
def tokenizer_eng(text):
return [tok.text.lower() for tok in spacy_eng.tokenizer(text)]
def build_vocabulary(self, sentence_list):
frequencies = {}
idx = 4
for sentence in sentence_list:
for word in self.tokenizer_eng(sentence):
if word not in frequencies:
frequencies[word] = 1
else:
frequencies[word] += 1
if frequencies[word] == self.freq_threshold:
self.stoi[word] = idx
self.itos[idx] = word
idx += 1
def numericalize(self, text):
tokenized_text = self.tokenizer_eng(text)
return [
self.stoi[token] if token in self.stoi else self.stoi["<UNK>"]
for token in tokenized_text
]
class MusicCapsDataset(Dataset):
def __init__(self, data_dir, df, freq_threshold=5):
self.data_dir = data_dir
self.df = df.reset_index(drop=True)
# Initialize vocabulary and build vocab
self.vocab = Vocabulary(freq_threshold)
self.vocab.build_vocabulary(self.df["caption"].values.tolist())
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
ytid = self.df.loc[idx, "ytid"]
audio_file = os.path.join(self.data_dir, f"{ytid}.wav")
waveform, sample_rate = librosa.load(audio_file, sr=16000)
caption = self.df.loc[idx]["caption"]
numericalized_caption = [self.vocab.stoi["<SOS>"]]
numericalized_caption += self.vocab.numericalize(caption)
numericalized_caption.append(self.vocab.stoi["<EOS>"])
return torch.tensor(waveform), torch.tensor(numericalized_caption)
class MyCollate:
def __init__(self, pad_idx):
self.pad_idx = pad_idx
def __call__(self, batch):
audio_clips = torch.stack([item[0] for item in batch], dim=0)
targets = [item[1] for item in batch]
targets = pad_sequence(targets, batch_first=False, padding_value=self.pad_idx)
return audio_clips, targets
def get_loader(df, batch_size=4, num_workers=1, shuffle=True):
dataset = MusicCapsDataset(
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k", df
)
pad_idx = dataset.vocab.stoi["<PAD>"]
loader = DataLoader(
dataset=dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=shuffle,
collate_fn=MyCollate(pad_idx=pad_idx),
)
return loader, dataset
from sklearn.model_selection import train_test_split
# Load data
df = pd.read_csv("/kaggle/input/musiccaps-split-captions/split_captions.csv")
# Split the dataset into training and testing sets
train_df, test_df = train_test_split(df, test_size=0.2, random_state=42)
train_loader, dataset = get_loader(train_df)
test_loader, test_dataset = get_loader(test_df)
for idx, (audio, captions) in enumerate(train_loader):
print(type(audio))
print(audio.shape)
print(captions.shape)
print(captions)
if idx == 0:
break
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, embed_size):
super(Encoder, self).__init__()
self.at = AudioTagging(
checkpoint_path="/root/panns_data/Cnn14_mAP=0.431.pth", device="cuda"
)
self.fc = nn.Linear(2048, embed_size)
def forward(self, x):
_, embedding = self.at.inference(x)
embedding = torch.tensor(embedding).to("cuda")
return self.fc(embedding)
encoder = Encoder(256).to("cuda")
for idx, (audio, captions) in enumerate(train_loader):
print(type(audio))
print(audio.shape)
print(captions.shape)
out = encoder.forward(audio)
print(out)
print(out.shape)
if idx == 0:
break
# Using LSTMCell
# class DecoderRNN(nn.Module):
# def __init__(self, embed_size, hidden_size, vocab_size, num_layers=1):
# super(DecoderRNN, self).__init__()
# # define the properties
# self.embed_size = embed_size
# self.hidden_size = hidden_size
# self.vocab_size = vocab_size
# self.lstm_cell = nn.LSTMCell(input_size=embed_size, hidden_size=hidden_size)
# self.fc_out = nn.Linear(in_features=hidden_size, out_features=vocab_size)
# self.embed = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_size)
# self.softmax = nn.Softmax(dim=1)
# def forward(self, features, captions, teacher_force_ratio=0.5):
# # Features & Captions to CUDA
# features = features.to('cuda') # (batch_size, 256)
# captions = captions.permute(1, 0).to('cuda') # (batch_size, caption_length)
# # batch size
# batch_size = captions.size(0)
# target_length = captions.size(1)
# # init the hidden and cell states
# hidden = self.init_hidden(features)
# # define the output tensor placeholder
# outputs = torch.zeros(batch_size, target_length, self.vocab_size).to('cuda')
# # first token
# inp = captions[:, 0]
# # pass the caption word by word
# for t in range(1, target_length):
# # Apply word embedding
# embedded = self.embed(inp)
# # Perform LSTM forward pass
# hidden = self.lstm_cell(embedded, hidden)
# # Compute output probabilities
# output = self.fc_out(hidden[0]) # (batch_size, vocab_size)
# outputs[:, t] = output
# use_teacher_forcing = torch.rand(1).item() < teacher_force_ratio
# if use_teacher_forcing:
# inp = captions[:, t]
# else:
# inp = output.argmax(dim=1)
# return outputs
# def init_hidden(self, encoder_feats):
# initial_hidden = encoder_feats.to('cuda')
# initial_cell = torch.zeros(encoder_feats.size(0), self.hidden_size).to('cuda')
# return (initial_hidden, initial_cell)
# def generate_caption(self, encoder_features, max_length):
# self.eval()
# batch_size = encoder_features.size(0)
# # Prepare the initial hidden state from the encoder features
# hidden = self.init_hidden(encoder_features)
# # Initialize the input tensor with the <start> token
# inp = torch.tensor([dataset.vocab.stoi['<SOS>']], device='cuda')
# # Initialize the generated caption
# caption = []
# for _ in range(max_length):
# # Apply embedding to the input
# embedded = self.embed(inp)
# # Perform LSTM cell forward pass
# hidden = self.lstm_cell(embedded, hidden)
# # Compute output probabilities
# output = self.fc_out(hidden[0])
# # Get the index of the highest probability token
# top_token = output.argmax(dim=1)
# # Add the token to the caption
# caption.append(top_token.item())
# # Update the input for the next iteration
# inp = top_token
# # If the <end> token is generated, break the loop
# if top_token.item() == dataset.vocab.stoi['<EOS>']:
# break
# self.train()
# return caption
# # Using PyTorch LSTM
# class DecoderRNN(nn.Module):
# def __init__(self, embed_size, hidden_size, vocab_size, num_layers=1):
# super(DecoderRNN, self).__init__()
# # define the properties
# self.embed_size = embed_size
# self.hidden_size = hidden_size
# self.vocab_size = vocab_size
# self.num_layers = num_layers
# self.lstm = nn.LSTM(input_size=embed_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
# self.fc_out = nn.Linear(in_features=hidden_size, out_features=vocab_size)
# self.embed = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_size)
# def forward(self, features, captions, teacher_force_ratio=0.5):
# # Features & Captions to CUDA
# features = features.to('cuda') # (batch_size, 256)
# captions = captions.permute(1, 0).to('cuda') # (batch_size, caption_length)
# # batch size
# batch_size = captions.size(0)
# target_length = captions.size(1)
# # init the hidden and cell states
# hidden = self.init_hidden(features)
# # right-shift captions
# right_shifted_captions = captions[:, :-1]
# # Embed the right-shifted captions
# embedded = self.embedding(right_shifted_captions)
# # Pass the embedded captions and the initial hidden state through the LSTM
# lstm_out, _ = self.lstm(embedded, hidden)
# # Compute the output probabilities
# output = self.out(lstm_out)
# return outputs
# def init_hidden(self, encoder_feats):
# initial_hidden = encoder_feats.to('cuda')
# initial_cell = torch.zeros(encoder_feats.size(0), self.hidden_size).to('cuda')
# return (initial_hidden, initial_cell)
# def generate_caption(self, encoder_features, max_length):
# self.eval()
# batch_size = encoder_features.size(0)
# # Prepare the initial hidden state from the encoder features
# hidden = self.init_hidden(encoder_features)
# # Initialize the input tensor with the <start> token
# inp = torch.tensor([dataset.vocab.stoi['<SOS>']], device='cuda')
# # Initialize the generated caption
# caption = []
# for _ in range(max_length):
# # Apply embedding to the input
# embedded = self.embed(inp)
# # Perform LSTM cell forward pass
# hidden = self.lstm_cell(embedded, hidden)
# # Compute output probabilities
# output = self.fc_out(hidden[0])
# # Get the index of the highest probability token
# top_token = output.argmax(dim=1)
# # Add the token to the caption
# caption.append(top_token.item())
# # Update the input for the next iteration
# inp = top_token
# # If the <end> token is generated, break the loop
# if top_token.item() == dataset.vocab.stoi['<EOS>']:
# break
# self.train()
# return caption
# class EncoderDecoder(nn.Module):
# def __init__(self, encoder, decoder):
# super(EncoderDecoder, self).__init__()
# self.encoder = encoder
# self.decoder = decoder
# def forward(self, audios, target_captions, teacher_forcing_ratio=0.5):
# # Pass the images through the encoder to get the feature vector
# encoder_features = self.encoder(audios)
# # Pass the feature vector and target captions through the decoder
# outputs = self.decoder(encoder_features, target_captions, teacher_forcing_ratio)
# return outputs
# def generate_caption(self, audio_input, max_length=50):
# self.encoder.eval()
# encoder_features = self.encoder(audio_input)
# self.encoder.train()
# caption = self.decoder.generate_caption(encoder_features, max_length)
# return ' '.join([dataset.vocab.itos[idx] for idx in caption])
# encoder = Encoder(256).to('cuda')
# decoder = DecoderRNN(256, 256, len(dataset.vocab), 1).to('cuda')
# model = EncoderDecoder(encoder, decoder)
# for idx, (audio, captions) in enumerate(train_loader):
# for clip in audio:
# out = model.generate_caption(clip.unsqueeze(0), 50)
# print(out)
# if idx == 2:
# break
# import torch.optim as optim
# # Set device
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# # Define model
# encoder = Encoder(256).to('cuda')
# decoder = DecoderRNN(256, 256, len(dataset.vocab), 1).to('cuda')
# model = EncoderDecoder(encoder, decoder)
# model.to(device)
# # Loss function and optimizer
# criterion = nn.CrossEntropyLoss()
# optimizer = optim.Adam(model.parameters(), lr=0.001)
# # Number of epochs
# num_epochs = 3
# # Training loop
# for epoch in range(num_epochs):
# for idx, (audios, target_captions) in enumerate(train_loader):
# audios = audios.to(device)
# target_captions = target_captions.to(device)
# # Zero the gradients
# optimizer.zero_grad()
# # Forward pass
# outputs = model(audios, target_captions)
# # Calculate loss
# loss = criterion(outputs.view(-1, len(dataset.vocab)), target_captions.view(-1))
# # Backward pass
# loss.backward()
# # Update weights
# optimizer.step()
# # Print training progress
# if idx % 100 == 0:
# print(f'Epoch [{epoch + 1}/{num_epochs}], Step [{idx}/{len(train_loader)}], Loss: {loss.item()}')
# print_examples(model, device, dataset)
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
super(DecoderRNN, self).__init__()
self.embed_size = embed_size
self.hidden_size = hidden_size
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(0.5)
def forward(self, features, captions):
# Features: [batch_size, feature_size] (note: feature_size == word_embed_size)
# Captions: [caption_length, batch_size]
embeddings = self.embed(captions)
# print(embeddings.shape) # [caption_length, batch_size, embed_size]
# print(features.unsqueeze(0).shape) # [1, batch_size, feature_size]
hiddens = self.init_hidden(features)
# print(embeddings.shape) # [caption_length + 1, batch_size, embed_size]
hiddens, _ = self.lstm(embeddings, hiddens)
outputs = self.linear(hiddens)
return outputs
def init_hidden(self, encoder_features):
initial_hidden = encoder_features.to("cuda")
initial_cell = torch.zeros(encoder_features.size(0), self.hidden_size).to(
"cuda"
)
return (initial_hidden.unsqueeze(0), initial_cell.unsqueeze(0))
decoder = DecoderRNN(256, 256, len(dataset.vocab), 1).to("cuda")
for idx, (audio, captions) in enumerate(train_loader):
print(type(audio))
print(audio.shape)
print(captions.shape)
features = encoder(audio)
print()
out = decoder(features.to("cuda"), captions.to("cuda"))
print(out.shape)
print(out)
if idx == 0:
break
class CNNtoRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
super(CNNtoRNN, self).__init__()
self.encoder = Encoder(embed_size)
self.decoderRNN = DecoderRNN(embed_size, hidden_size, vocab_size, num_layers)
def forward(self, audios, captions):
features = self.encoder(audios)
outputs = self.decoderRNN(features, captions)
return outputs
def caption_audio(self, audios, vocab, max_length=35):
# Set the model to evaluation mode
self.eval()
# Obtain the features from the encoder
encoder_features = self.encoder(audios)
# Initialize the hidden state
hidden = self.decoderRNN.init_hidden(encoder_features)
# Initialize the input with the <start> token for each sample in the batch
batch_size = audios.size(0)
inp = torch.tensor([vocab.stoi["<SOS>"]] * batch_size, device="cuda")
# Prepare the output tensor
captions = torch.zeros(batch_size, max_length, device="cuda").long()
with torch.no_grad():
for t in range(max_length):
# Embed the input
embedded = self.decoderRNN.embed(inp).unsqueeze(0)
# Pass the embedded input and the hidden state through the LSTM
lstm_out, hidden = self.decoderRNN.lstm(embedded, hidden)
# Compute the output probabilities
output = self.decoderRNN.linear(lstm_out.squeeze(0))
# Get the highest probability token for the next input
top_token = output.argmax(dim=1)
# Save the top token to the captions tensor
captions[:, t] = top_token.item()
# Update the input for the next iteration
inp = top_token
return [vocab.itos[idx] for idx in captions]
# class CNNtoRNN(nn.Module):
# def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
# super(CNNtoRNN, self).__init__()
# self.encoder = Encoder(embed_size)
# self.decoderRNN = DecoderRNN(embed_size, hidden_size, vocab_size, num_layers)
# def forward(self, audios, captions):
# features = self.encoder(audios)
# outputs = self.decoderRNN(features, captions)
# return outputs
# def caption_audio(self, audio, vocabulary):
# with torch.no_grad():
# x = self.encoder(audio).unsqueeze(0)
# output = self.decoderRNN(x, )
# for _ in range(max_length):
# hiddens, states = self.decoderRNN.lstm_cell(x, states)
# output = self.decoderRNN.linear(hiddens.squeeze(0))
# predicted = output.argmax(0)
# result_caption.append(predicted.item())
# x = self.decoderRNN.embed(predicted).unsqueeze(0)
# if vocabulary.itos[predicted.item()] == "<EOS>":
# break
# return [vocabulary.itos[idx] for idx in result_caption]
def print_examples(model, device, dataset):
model.eval()
y, sr = librosa.load(
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k/BqIZipifARo.wav",
sr=44100,
)
example = torch.from_numpy(y).unsqueeze(0)
print(
"Example 1 CORRECT: The song is an instrumental. The tempo is medium with an electric guitar playing a dreamy solo with a keyboard accompaniment , string section harmony and rhythmic percussion rhythm. The song is passionate and emotional. The song is a rock guitar instrumental."
)
print(
"Example 1 OUTPUT: "
+ " ".join(model.caption_audio(example.to(device), dataset.vocab))
# + " ".join(model.generate_caption(example.to(device)))
)
y, sr = librosa.load(
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k/cS2gRhH6it4.wav",
sr=44100,
)
example = torch.from_numpy(y).unsqueeze(0)
print(
"Example 2 CORRECT: This is a Hindu music piece. There is a female vocalist singing at a medium-to-high pitch in a devotional manner. A sitar provides a melodic background. The tabla is being played in the rhythmic background. The atmosphere is spiritual. This piece could be played at religious events and online content related to Hindu religion."
)
print(
"Example 2 OUTPUT: "
+ " ".join(model.caption_audio(example.to(device), dataset.vocab))
# + " ".join(model.generate_caption(example.to(device)))
)
y, sr = librosa.load(
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k/GopccU3Am1w.wav",
sr=44100,
)
example = torch.from_numpy(y).unsqueeze(0)
print(
"Example 3 CORRECT: The low quality recording features a live performance of a spooky glass melody. The recording is very noisy, as there are crowd chattering noises in the background."
)
print(
"Example 3 OUTPUT: "
+ " ".join(model.caption_audio(example.to(device), dataset.vocab))
# + " ".join(model.generate_caption(example.to(device)))
)
y, sr = librosa.load(
"/kaggle/input/musiccaps-dataset-16k/musiccaps-audio-trimmed-16k/6HQqly6duac.wav",
sr=44100,
)
example = torch.from_numpy(y).unsqueeze(0)
print(
"Example 4 CORRECT: The low quality recording features a live performance of guitar percussion. It sounds shimmering and groovy. The recording is noisy and in mono."
)
print(
"Example 4 OUTPUT: "
+ " ".join(model.caption_audio(example.to(device), dataset.vocab))
# + " ".join(model.generate_caption(example.to(device)))
)
model.train()
print(len(dataset.vocab))
# # Model Training
import torch.optim as optim
from tqdm import tqdm
torch.backends.cudnn.benchmark = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Hyperparameters
embed_size = 256
hidden_size = 256
vocab_size = len(dataset.vocab)
num_layers = 1
learning_rate = 3e-3
num_epochs = 5
# initialize model, loss etc
model = CNNtoRNN(embed_size, hidden_size, vocab_size, num_layers).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=dataset.vocab.stoi["<PAD>"])
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(num_epochs):
# Uncomment the line below to see a couple of test cases
print(f"EPOCH: {epoch}")
# print_examples(model, device, dataset)
# if save_model:
# checkpoint = {
# "state_dict": model.state_dict(),
# "optimizer": optimizer.state_dict(),
# "step": step,
# }
# save_checkpoint(checkpoint)
for idx, (audios, captions) in tqdm(
enumerate(train_loader), total=len(train_loader), leave=False
):
audios = audios.to(device)
captions = captions.to(device)
outputs = model(audios, captions[:-1])
# print(outputs.shape) # (sequence, batch, vocab)
# print(captions.shape) # (sequence, batch)
# print(outputs.reshape(-1, outputs.shape[2]).shape)
# print(captions.reshape(-1).shape)
loss = criterion(
outputs.reshape(-1, len(dataset.vocab)), captions[1:].reshape(-1)
)
optimizer.zero_grad()
loss.backward(loss)
optimizer.step()
|
import torchvision.models as models
import numpy as np
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from torchsummary import summary
import torch
from torch.utils.data import TensorDataset, DataLoader, Dataset
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
from torch.optim import lr_scheduler
import time
import tqdm
from sklearn.metrics import classification_report
import itertools
from tqdm import tqdm
from PIL import Image
train_on_gpu = True
from torch.utils.data.sampler import SubsetRandomSampler
from torch.optim.lr_scheduler import StepLR, ReduceLROnPlateau, CosineAnnealingLR
import pretrainedmodels
from sklearn.model_selection import train_test_split
import albumentations
from albumentations import pytorch as AT
batch_size = 64
batch_size_test = 64
num_workers = 4
target_names = ["class 0", "class 1"]
class MyDataset(Dataset):
def __init__(
self,
datatype="train",
df=None,
transform=None,
augument_=True,
dataloc="../input/histopathologic-cancer-detection/train/",
):
# self.datafolder = datafolder
self.datatype = datatype
self.df = df
self.augument = augument_
self.transform = transform
self.dataloc = dataloc
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
label = self.df[idx][1]
img_name = self.df[idx][0] + ".tif"
img_dir = os.path.join(self.dataloc, img_name)
img = cv2.imread(img_dir)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# img = Image.open(img_dir).convert("RGB")
img = self.transform(image=img)
return img["image"], label
data_transforms = albumentations.Compose(
[
albumentations.Resize(96, 96),
albumentations.RandomRotate90(p=0.5),
albumentations.Transpose(p=0.5),
albumentations.Flip(p=0.5),
albumentations.OneOf(
[
albumentations.CLAHE(clip_limit=2),
albumentations.IAASharpen(),
albumentations.IAAEmboss(),
albumentations.RandomBrightness(),
albumentations.RandomContrast(),
albumentations.JpegCompression(),
albumentations.Blur(),
albumentations.GaussNoise(),
],
p=0.5,
),
albumentations.HueSaturationValue(p=0.5),
albumentations.ShiftScaleRotate(
shift_limit=0.15, scale_limit=0.15, rotate_limit=45, p=0.5
),
albumentations.Normalize(),
AT.ToTensor(),
]
)
data_transforms_test = albumentations.Compose(
[albumentations.Resize(96, 96), albumentations.Normalize(), AT.ToTensor()]
)
class Densenet169(nn.Module):
def __init__(self, pretrained=True):
super(Densenet169, self).__init__()
self.model = models.densenet169(num_classes=1000, pretrained=pretrained)
self.linear = nn.Linear(1000 + 2, 16)
self.bn = nn.BatchNorm1d(16)
self.dropout = nn.Dropout(0.2)
self.elu = nn.ELU()
self.out = nn.Linear(16, 1)
self.sig = nn.Sigmoid()
def forward(self, x):
out = self.model(x)
batch = out.shape[0]
max_pool, _ = torch.max(out, 1, keepdim=True)
avg_pool = torch.mean(out, 1, keepdim=True)
out = out.view(batch, -1)
conc = torch.cat((out, max_pool, avg_pool), 1)
conc = self.linear(conc)
conc = self.elu(conc)
conc = self.bn(conc)
conc = self.dropout(conc)
res = self.out(conc)
res = self.sig(res)
return res
model_conv = Densenet169(pretrained=False)
model_conv.cuda()
model_conv.load_state_dict(torch.load("../input/des-model1/model (4).pt"))
test = pd.read_csv("../input/histopathologic-cancer-detection/sample_submission.csv")
test_dataset = MyDataset(
datatype="test",
df=test.values,
transform=data_transforms_test,
augument_=False,
dataloc="../input/histopathologic-cancer-detection/test/",
)
test_loader = DataLoader(
test_dataset,
batch_size=128,
num_workers=num_workers,
pin_memory=True,
shuffle=False,
)
Sig = nn.Sigmoid()
model_conv.eval()
preds = []
with torch.no_grad():
for batch_i, (data, target) in tqdm(enumerate(test_loader), total=len(test_loader)):
data, target = data.cuda(), target.cuda()
output = model_conv(data)
# output = Sig(output)
pr = output.detach().cpu().numpy()
for i in pr:
preds.append(i[0])
a = np.array(preds)
sub = pd.read_csv("../input/histopathologic-cancer-detection/sample_submission.csv")
test_preds = pd.DataFrame({"imgs": test["id"].values.tolist(), "preds": a})
test_preds["imgs"] = test_preds["imgs"].apply(lambda x: x.split(".")[0])
sub = pd.merge(sub, test_preds, left_on="id", right_on="imgs")
sub
sub = sub[["id", "preds"]]
sub.columns = ["id", "label"]
sub.to_csv("sub.csv", index=False)
sub.head()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# Step 2 : Data import
import pickle
# Import visualization modules
import matplotlib.pyplot as plt
import seaborn as sns
# Use pandas to read in csv file
train = pd.read_csv("/kaggle/input/glass/glass.csv")
train.head(5)
train.describe()
# Step 3: Clean up data
# Use the .isnull() method to locate missing data
missing_values = train.isnull()
missing_values.tail
# create new column for "Type" to "g_type" form 0 or 1.
train["g_type"] = train.Type.map({1: 0, 2: 0, 3: 0, 5: 1, 6: 1, 7: 1})
train.head()
# split dataset in features and target variable
feature_cols = ["RI", "Na", "Mg", "Al", "Si", "K", "Ca", "Ba", "Fe", "g_type"]
f, ax = plt.subplots(figsize=(16, 12))
plt.title("Glass Correlation Matrix", fontsize=25)
sns.heatmap(
train[feature_cols].corr(),
linewidths=0.25,
vmax=0.7,
square=True,
cmap="BuGn",
# "BuGn_r" to reverse
linecolor="b",
annot=True,
annot_kws={"size": 8},
mask=None,
cbar_kws={"shrink": 0.9},
)
X = train.loc[:, ["Ca", "Al", "Ba"]]
y = train.g_type # Target variable
train.Type.value_counts().sort_index # Features
from sklearn.model_selection import train_test_split
# Split data set into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=0
)
from sklearn.linear_model import LogisticRegression
# instantiate the model (using the default parameters)
logreg = LogisticRegression()
# fit the model with data
logreg.fit(X_train, y_train)
#
y_pred = logreg.predict(X_test)
pkl_filename = "pickle_model.pkl"
with open(pkl_filename, "wb") as file:
pickle.dump(logreg, file)
# Load from file
with open(pkl_filename, "rb") as file:
pickle_model = pickle.load(file)
# Calculate the accuracy score and predict target values
score = pickle_model.score(X_test, y_test)
print("Test score: {0:.2f} %".format(100 * score))
Ypredict = pickle_model.predict(X_test)
# import the metrics class
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
cnf_matrix
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
import matplotlib.pyplot as plt
# import the metrics class
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
cnf_matrix
class_names = [0, 1] # name of classes
fig, ax = plt.subplots()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
# create heatmap
sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu", fmt="g")
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title("Confusion matrix", y=1.1)
plt.ylabel("Actual label")
plt.xlabel("Predicted label")
|
import pandas as pd
from pandas import datetime
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
df = pd.read_csv(
"../input/rossmann-store-sales/train.csv", parse_dates=["Date"], low_memory=False
)
df.head()
df["Date"] = pd.to_datetime(df["Date"], format="%Y-%m-%d")
df["Hour"] = df["Date"].dt.hour
df["Day_of_Month"] = df["Date"].dt.day
df["Day_of_Week"] = df["Date"].dt.dayofweek
df["Month"] = df["Date"].dt.month
print(df["Date"].min())
print(df["Date"].max())
test = pd.read_csv(
"../input/rossmann-store-sales/test.csv", parse_dates=True, low_memory=False
)
test.head()
test["Date"] = pd.to_datetime(test["Date"], format="%Y-%m-%d")
test["Hour"] = test["Date"].dt.hour
test["Day_of_Month"] = test["Date"].dt.day
test["Day_of_Week"] = test["Date"].dt.dayofweek
test["Month"] = test["Date"].dt.month
print(test["Date"].min())
print(test["Date"].max())
sns.pointplot(x="Month", y="Sales", data=df)
sns.pointplot(x="Day_of_Week", y="Sales", data=df)
sns.countplot(x="Day_of_Week", hue="Open", data=df)
plt.title("Store Daily Open Countplot")
sns.pointplot(x="Day_of_Month", y="Sales", data=df)
df["SalesPerCustomer"] = df["Sales"] / df["Customers"]
df["SalesPerCustomer"].describe()
df.Open.value_counts()
np.sum([df["Sales"] == 0])
# drop closed stores and stores with zero sales
df = df[(df["Open"] != 0) & (df["Sales"] != 0)]
store = pd.read_csv("../input/rossmann-store-sales/store.csv")
store.head(30)
store.isnull().sum()
store["CompetitionDistance"] = store["CompetitionDistance"].fillna(
store["CompetitionDistance"].max()
)
store["CompetitionOpenSinceMonth"] = store["CompetitionOpenSinceMonth"].fillna(
store["CompetitionOpenSinceMonth"].mode().iloc[0]
) # try 0
store["CompetitionOpenSinceYear"] = store["CompetitionOpenSinceYear"].fillna(
store["CompetitionOpenSinceYear"].mode().iloc[0]
) # try 0
store["Promo2SinceWeek"] = store["Promo2SinceWeek"].fillna(0) # try 0
store["Promo2SinceYear"] = store["Promo2SinceYear"].fillna(
store["Promo2SinceYear"].mode().iloc[0]
) # try 0
store["PromoInterval"] = store["PromoInterval"].fillna(
store["PromoInterval"].mode().iloc[0]
) # try 0
store.head()
df_store = pd.merge(df, store, how="left", on="Store")
df_store.head()
df_store.groupby("StoreType")["Sales"].describe()
df_store.groupby("StoreType")["Customers", "Sales"].sum()
# sales trends
sns.catplot(
data=df_store,
x="Month",
y="Sales",
col="StoreType", # per store type in cols
palette="plasma",
hue="StoreType",
row="Promo", # per promo in the store in rows
color="c",
)
# customer trends
sns.catplot(
data=df_store,
x="Month",
y="Customers",
col="StoreType", # per store type in cols
palette="plasma",
hue="StoreType",
row="Promo", # per promo in the store in rows
color="c",
)
# sales per customer
sns.catplot(
data=df_store,
x="Month",
y="SalesPerCustomer",
col="StoreType", # per store type in cols
palette="plasma",
hue="StoreType",
row="Promo", # per promo in the store in rows
color="c",
)
sns.catplot(
data=df_store,
x="Month",
y="Sales",
col="DayOfWeek", # per store type in cols
palette="plasma",
hue="StoreType",
row="StoreType", # per store type in rows
color="c",
)
# stores open on sunday
df_store[(df_store.Open == 1) & (df_store.DayOfWeek == 7)]["Store"].unique()
sns.catplot(
data=df_store,
x="DayOfWeek",
y="Sales",
col="Promo",
row="Promo2",
hue="Promo2",
palette="RdPu",
)
df_store["StateHoliday"] = df_store["StateHoliday"].map(
{"0": 0, 0: 0, "a": 1, "b": 2, "c": 3}
)
df_store["StateHoliday"] = df_store["StateHoliday"].astype(int)
df_store["StoreType"] = df_store["StoreType"].map({"a": 1, "b": 2, "c": 3, "d": 4})
df_store["StoreType"] = df_store["StoreType"].astype(int)
df_store.isnull().sum()
df_store["Assortment"] = df_store["Assortment"].map({"a": 1, "b": 2, "c": 3})
df_store["Assortment"] = df_store["Assortment"].astype(int)
df_store["PromoInterval"] = df_store["PromoInterval"].map(
{"Jan,Apr,Jul,Oct": 1, "Feb,May,Aug,Nov": 2, "Mar,Jun,Sept,Dec": 3}
)
df_store["PromoInterval"] = df_store["PromoInterval"].astype(int)
df_store.to_csv("df_merged.csv", index=False)
df_store.isnull().sum()
len(df_store)
test = pd.merge(test, store, how="left", on="Store")
test.head()
test.isnull().sum()
test.fillna(method="ffill", inplace=True)
test["StateHoliday"] = test["StateHoliday"].map({"0": 0, 0: 0, "a": 1, "b": 2, "c": 3})
test["StateHoliday"] = test["StateHoliday"].astype(int)
test["StoreType"] = test["StoreType"].map({"a": 1, "b": 2, "c": 3, "d": 4})
test["StoreType"] = test["StoreType"].astype(int)
test["Assortment"] = test["Assortment"].map({"a": 1, "b": 2, "c": 3})
test["Assortment"] = test["Assortment"].astype(int)
test["PromoInterval"] = test["PromoInterval"].map(
{"Jan,Apr,Jul,Oct": 1, "Feb,May,Aug,Nov": 2, "Mar,Jun,Sept,Dec": 3}
)
test["PromoInterval"] = test["PromoInterval"].astype(int)
test.to_csv("test_merged.csv", index=False)
test = test.drop(["Id", "Date"], axis=1)
test.head()
# Machine Learning
X = df_store.drop(["Date", "Sales", "Customers", "SalesPerCustomer"], 1)
# Transform Target Variable
y = np.log1p(df_store["Sales"])
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.30, random_state=1)
X_train.shape, X_val.shape, y_train.shape, y_val.shape
# Machine Learning
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=12, n_estimators=200, random_state=42)
gbrt.fit(X_train, y_train)
print(gbrt.score(X_train, y_train))
y_pred = gbrt.predict(X_val)
from sklearn.metrics import r2_score, mean_squared_error
print(r2_score(y_val, y_pred))
print(np.sqrt(mean_squared_error(y_val, y_pred)))
plt.plot(y_val, y_pred, color="red", linewidth=2)
df1 = pd.DataFrame({"Actual": y_test, "Predicted": y_pred})
df1.head(25)
test["Predictions"] = y_pred.values
test["Sales"].plot(figsize=(16, 5), legend=True)
test["Predictions"].plot(legend=True)
y_pred = gbrt.predict(X_train)
print(r2_score(y_val, y_pred))
print(np.sqrt(mean_squared_error(y_val, y_pred)))
# Make Prediction CSV File
test_pred = gbrt.predict(test[X.columns])
test_pred_inv = np.exp(test_pred) - 1
test_pred_inv
# make submission df
prediction = pd.DataFrame(test_pred_inv)
submission = pd.read_csv("../input/rossmann-store-sales/sample_submission.csv")
prediction_df = pd.concat([submission["Id"], prediction], axis=1)
prediction_df.columns = ["Id", "Sales"]
prediction_df.to_csv("Sample_Submission.csv", index=False)
prediction_df.head()
|
# # Install kaggle-environments
# 1. Enable Internet in the Kernel (Settings side pane)
# 2. Curl cache may need purged if v0.1.6 cannot be found (uncomment if needed).
# !curl -X PURGE https://pypi.org/simple/kaggle-environments
# ConnectX environment was defined in v0.1.6
# # Create ConnectX Environment
from kaggle_environments import evaluate, make, utils
env = make("connectx", debug=True)
env.render()
# # Create an Agent
# To create the submission, an agent function should be fully encapsulated (no external dependencies).
# When your agent is being evaluated against others, it will not have access to the Kaggle docker image. Only the following can be imported: Python Standard Library Modules, gym, numpy, scipy, pytorch (1.3.1, cpu only), and more may be added later.
#
def my_agent(observation, configuration):
PLAYER = observation.mark
OPPONENT = 3 - PLAYER
def make_move(board, move, player):
for i in range(5, -1, -1):
new_piece = move + 7 * i
if board[new_piece] == 0:
board[new_piece] = player
return board, new_piece
return None, None # Illegal move
def check_win(board, move, player):
if board[move] != 0: # Full Column
return False
_, new_piece = make_move(board, move, player)
# check horizontal spaces
for j in range(4):
if new_piece + j > 41:
break
if (new_piece + j) % 7 < 3:
continue
if (
board[new_piece + j] == player
and board[new_piece + j - 1] == player
and board[new_piece + j - 2] == player
and board[new_piece + j - 3] == player
):
return True
# check vertical spaces
for j in range(4):
if new_piece + j * 7 > 41:
break
if new_piece + j * 7 < 21:
continue
if (
board[new_piece + j * 7] == player
and board[new_piece + j * 7 - 7] == player
and board[new_piece + j * 7 - 14] == player
and board[new_piece + j * 7 - 21] == player
):
return True
# check diagonal descending spaces
for j in range(4):
if new_piece + j * 8 > 41:
break
if new_piece + j * 8 < 24:
continue
if (
board[new_piece + j * 8] == player
and board[new_piece + j * 8 - 8] == player
and board[new_piece + j * 8 - 16] == player
and board[new_piece + j * 8 - 24] == player
):
return True
# check diagonal ascending spaces
for j in range(4):
if new_piece + j * 6 > 41:
break
if (new_piece + j * 6) % 7 > 3 or new_piece + j * 6 < 21:
continue
if (
board[new_piece + j * 6] == player
and board[new_piece + j * 6 - 6] == player
and board[new_piece + j * 6 - 12] == player
and board[new_piece + j * 6 - 18] == player
):
return True
return False
move_order = [3, 2, 4, 1, 5, 0, 6]
for i in range(configuration.columns):
if check_win(observation.board.copy(), i, PLAYER):
return i
else:
for j in range(configuration.columns):
new_board, _ = make_move(observation.board.copy(), i, PLAYER)
if (
new_board is not None
and i in move_order
and check_win(new_board.copy(), j, OPPONENT)
):
move_order.remove(i)
for i in range(configuration.columns):
if check_win(observation.board.copy(), i, OPPONENT):
return i
assert move_order is not None
for i in move_order:
if observation.board[i] == 0:
return i
# dead end
from random import choice
return choice(
[c for c in range(configuration.columns) if observation.board[c] == 0]
)
# # Test your Agent
env.reset()
# Play as the first agent against default "random" agent.
env.run([my_agent, "random"])
env.render(mode="ipython", width=500, height=450)
# # Debug/Train your Agent
# Play as first position against random agent.
trainer = env.train([None, "random"])
observation = trainer.reset()
while not env.done:
my_action = my_agent(observation, env.configuration)
print("My Action", my_action)
observation, reward, done, info = trainer.step(my_action)
print(observation, reward)
# env.render(mode="ipython", width=100, height=90, header=False, controls=False)
env.render()
# # Evaluate your Agent
def mean_reward(rewards):
return sum(r[0] for r in rewards) / sum(r[0] + r[1] for r in rewards)
# Run multiple episodes to estimate its performance.
print(
"My Agent vs Random Agent:",
mean_reward(evaluate("connectx", [my_agent, "random"], num_episodes=1000)),
)
print(
"My Agent vs Negamax Agent:",
mean_reward(evaluate("connectx", [my_agent, "negamax"], num_episodes=1)),
)
# # Play your Agent
# Click on any column to place a checker there ("manually select action").
# "None" represents which agent you'll manually play as (first or second player).
env.play([None, my_agent], width=500, height=450)
# # Write Submission File
#
import inspect
import os
def write_agent_to_file(function, file):
with open(file, "a" if os.path.exists(file) else "w") as f:
f.write(inspect.getsource(function))
print(function, "written to", file)
write_agent_to_file(my_agent, "submission.py")
# # Validate Submission
# Play your submission against itself. This is the first episode the competition will run to weed out erroneous agents.
# Why validate? This roughly verifies that your submission is fully encapsulated and can be run remotely.
# Note: Stdout replacement is a temporary workaround.
import sys
out = sys.stdout
submission = utils.read_file("/kaggle/working/submission.py")
agent = utils.get_last_callable(submission)
sys.stdout = out
env = make("connectx", debug=True)
env.run([agent, agent])
print(
"Success!" if env.state[0].status == env.state[1].status == "DONE" else "Failed..."
)
|
# ### Bitte denken Sie vor der Abgabe des Links daran, Ihr Notebook mit Klick auf den Button "Save Version" (oben rechts) zu speichern.
# Bearbeitungshinweis: Sie sind frei in der Art und Weise, wie Sie die Aufgaben lösen. Sie können z.B. auch weitere Code-Blöcke einfügen. Wenn Sie nicht weiterkommen, fragen Sie im Forum oder konsultieren Sie die üblichen Quellen (Google, Stackoverflow, ChatGPT)
import pandas as pd
# Importieren des zu bereinigenden Datensatzes. Er enthält Informationen zu Büchern der Nationalbibliothek des Vereinigten Königreichs ("British Library").
df = pd.read_csv(
"https://raw.githubusercontent.com/realpython/python-data-cleaning/master/Datasets/BL-Flickr-Images-Book.csv"
)
# Zeigen Sie, wie viele Beobachtungen und wie viele Variablen der Datensatz enthält.
# Anzahl der Beobachtungen (Zeilen) im Datensatz
anzahl_beobachtungen = df.shape[0]
# Anzahl der Variablen (Spalten) im Datensatz
anzahl_variablen = df.shape[1]
# Gib die Ergebnisse aus
print("Anzahl der Beobachtungen: ", anzahl_beobachtungen)
print("Anzahl der Variablen: ", anzahl_variablen)
# Löschen Sie alle Variablen, für die für mehr als 50% der Beobachtungen keine Informationen vorliegen.
# Berechne den Prozentsatz fehlender Werte pro Variable
fehlende_werte_prozent = df.isnull().mean() * 100
# Wähle die Variablen aus, für die mehr als 50% der Beobachtungen fehlen
variablen_mit_zu_vielen_fehlenden_werten = fehlende_werte_prozent[
fehlende_werte_prozent > 50
].index
# Lösche die Variablen aus dem DataFrame
df.drop(variablen_mit_zu_vielen_fehlenden_werten, axis=1, inplace=True)
# Gib eine Bestätigung aus
print("Folgende Variablen wurden gelöscht, da mehr als 50% der Beobachtungen fehlen:")
print(variablen_mit_zu_vielen_fehlenden_werten)
# Optional: Speichere das bereinigte DataFrame in eine neue Datei
df.to_csv(
"dein_bereinigter_datensatz.csv", index=False
) # Ersetze 'dein_bereinigter_datensatz.csv' mit dem gewünschten Dateinamen
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
train = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
train.shape
train.head()
test = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
test.shape
Y_train = train["label"]
X_train = train.drop(labels=["label"], axis=1)
plt.figure(figsize=(16, 8))
sns.countplot(Y_train, palette="icefire")
plt.title("Number of digit classes")
img = X_train.iloc[5].as_matrix()
img = img.reshape((28, 28))
plt.imshow(img, cmap="gray")
plt.title(train.iloc[0, 0])
plt.axis("off")
plt.show()
# Normalize
X_train = X_train / 255.0
test = test / 255.0
X_train.shape, test.shape
# Reshape
X_train = X_train.values.reshape(-1, 28, 28, 1)
test = test.values.reshape(-1, 28, 28, 1)
X_train.shape, test.shape
# Label encoding
from keras.utils.np_utils import to_categorical
Y_train = to_categorical(Y_train, num_classes=10)
from sklearn.model_selection import train_test_split
X_train, X_val, Y_train, Y_val = train_test_split(
X_train, Y_train, test_size=0.1, random_state=2
)
from sklearn.metrics import confusion_matrix
import itertools
from keras.utils.np_utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from keras.optimizers import RMSprop, Adam
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ReduceLROnPlateau
model = Sequential()
model.add(
Conv2D(
filters=16,
kernel_size=(5, 5),
padding="Same",
activation="relu",
input_shape=(28, 28, 1),
)
)
model.add(Conv2D(filters=16, kernel_size=(3, 3), padding="Same", activation="relu"))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="Same", activation="relu"))
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="Same", activation="relu"))
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="Same", activation="relu"))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="Same", activation="relu"))
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.20))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(10, activation="softmax"))
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999)
model.compile(
optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"]
)
epochs = 1
batch_size = 50
# data augmentation
datagen = ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=0.2,
zoom_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=False,
vertical_flip=False,
)
datagen.fit(X_train)
# Fit the model
history = model.fit_generator(
datagen.flow(X_train, Y_train, batch_size=batch_size),
epochs=epochs,
validation_data=(X_val, Y_val),
steps_per_epoch=X_train.shape[0] // batch_size,
)
# Plot the loss and accuracy curves for training and validation
plt.plot(history.history["val_loss"], color="b", label="validation loss")
plt.title("Test Loss")
plt.xlabel("Number of Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
|
# # Latest Corona Virus Data Visulization
# 
# ## Introduction
# The 2019-nCoV is a contagious coronavirus that hailed from Wuhan, China. This new strain of virus has striked fear in many countries as cities are quarantined and hospitals are overcrowded. This dataset will help us understand how 2019-nCoV is spread aroud the world.
# ## Data Loading
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # Data Visulizations
import seaborn as sns
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
file = pd.read_csv(
"/kaggle/input/2019-coronavirus-dataset-01212020-01262020/2019_nC0v_20200121_20200126_cleaned.csv"
)
file = file.drop(["Unnamed: 0"], axis=1)
file.info()
# - **Province/State ** - City of virus suspected cases.
# - **Country** - Country of virus suspected cases.
# - **Date last updated ** - Date of update of patient infected
# - **Confirmed** - Confirmation by doctors that this patient is infected with deadly virus
# - **Suspected** - Number of cases registered
# - **Recovered** - Recovery of the patient
# - **Deaths** - Death of the patient due to corna virus.
# Some Staticals calculations on dataset
round(file.describe())
# first few record of the dataset
file.head(10)
# Ok, now that we have a glimpse of the data, let's explore them.
# ## Data Explorations & Visulizations
# ### Relationship Between Confirmend,Suspected,Recovered and Death by Contry and States
plt.figure(figsize=(20, 6))
sns.pairplot(file, size=3.5)
plt.figure(figsize=(20, 6))
sns.pairplot(file, hue="Country", size=3.5)
plt.figure(figsize=(20, 6))
sns.pairplot(file, hue="Province/State", size=3.5)
# ### Country and State wise Explorations
data = pd.DataFrame(
file.groupby(["Country"])["Confirmed", "Suspected", "Recovered", "Deaths"].agg(
"sum"
)
).reset_index()
data.head(19)
data = pd.DataFrame(
file.groupby(["Country"])["Confirmed", "Suspected", "Recovered", "Deaths"].agg(
"sum"
)
).reset_index()
data.sort_values(by=["Confirmed"], inplace=True, ascending=False)
plt.figure(figsize=(12, 6))
# title
plt.title("Number of Patients Confirmed Infected by Corona Virus, by Country")
# Bar chart showing Number of Patients Confirmed Infected by Corona Virus, by Country
sns.barplot(y=data["Country"], x=data["Confirmed"], orient="h")
# Add label for vertical axis
plt.ylabel("Number of Confirmed Patients")
data.sort_values(by=["Suspected"], inplace=True, ascending=False)
plt.figure(figsize=(12, 6))
# title
plt.title("Number of Patients Suspected Infected by Corona Virus, by Country")
# Bar chart showing Number of Patients Confirmed Infected by Corona Virus, by Country
sns.barplot(y=data["Country"], x=data["Suspected"], orient="h")
# Add label for vertical axis
plt.ylabel("Number of Suspected Patients")
data.sort_values(by=["Recovered"], inplace=True, ascending=False)
plt.figure(figsize=(12, 6))
# title
plt.title("Number of Patients Recovered from by Corona Virus, by Country")
# Bar chart showing Number of Patients Confirmed Infected by Corona Virus, by Country
sns.barplot(y=data["Country"], x=data["Recovered"], orient="h")
# Add label for vertical axis
plt.ylabel("Number of Recovered Patients")
data.sort_values(by=["Deaths"], inplace=True, ascending=False)
plt.figure(figsize=(12, 6))
# title
plt.title("Number of Patients Died by Corona Virus, by Country")
# Bar chart showing Number of Patients Confirmed Infected by Corona Virus, by Country
sns.barplot(y=data["Country"], x=data["Deaths"], orient="h")
# Add label for vertical axis
plt.ylabel("Number of Deaths")
# As we got the insight that china and some other countries near by china have many cases.
# ## Sates of China
china = file[file["Country"] == "Mainland China"]
china_data = pd.DataFrame(
china.groupby(["Province/State"])[
"Confirmed", "Suspected", "Recovered", "Deaths"
].agg("sum")
).reset_index()
china_data.head(35)
china_data.sort_values(by=["Confirmed"], inplace=True, ascending=False)
plt.figure(figsize=(25, 10))
# title
plt.title("Number of Patients Confirmed Infected by Corona Virus, by States")
# Bar chart showing Number of Patients Confirmed Infected by Corona Virus, by Country
sns.barplot(x=china_data["Province/State"], y=china_data["Confirmed"], orient="v")
# Add label for vertical axis
plt.ylabel("Number of Confirmed Patients")
china_data.sort_values(by=["Deaths"], inplace=True, ascending=False)
plt.figure(figsize=(25, 10))
# title
plt.title("Number of Patients Died by Corona Virus, by States")
# Bar chart showing Number of Patients Confirmed Infected by Corona Virus, by Country
sns.barplot(x=china_data["Province/State"], y=china_data["Deaths"], orient="v")
# Add label for vertical axis
plt.ylabel("Number of Deaths")
|
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
print("success")
# # Load train and validation data from Facebook HMD dataset
df_train = pd.read_json(
"/kaggle/input/facebook-hateful-meme-dataset/data/train.jsonl", lines=True
)
df_dev = pd.read_json(
"/kaggle/input/facebook-hateful-meme-dataset/data/dev.jsonl", lines=True
)
print(df_train.tail())
# # check distribution of data in train and validation dataset
# distribution of movies based on certificate
df_train["label"].value_counts().plot(
kind="bar", figsize=(6, 6), width=0.2, title="Training data"
)
print("Distribution of training dataset\n", df_train.label.value_counts(), "\n")
print("Distribution of validation dataset\n", df_dev.label.value_counts())
# # Check null values
print(df_train.isna().sum())
print("\n\n", df_dev.isna().sum())
# # load pretrained word embedding model from gensim library
from gensim.models.word2vec import Word2Vec, KeyedVectors
trained = (
"/kaggle/input/nlpword2vecembeddingspretrained/GoogleNews-vectors-negative300.bin"
)
wv = KeyedVectors.load_word2vec_format(trained, binary=True)
# # word to vector conversion using gensim 'word2vec-google-news-300' model
w = wv["good"]
print(w)
print("\n\nlength of word vector", len(w))
print("\n\n type of word vector model ", type(wv))
print("\n\n word vector type", type(w))
# # Import spacy library for text preprocessing
import spacy
data = df_train
data.head()
# # use sapcy 'en_core_web_lg" model fpr preporocessing
import spacy
nlp = spacy.load("en_core_web_lg")
# # tokenize each word in a sentence and apply lemmatization on it, remove punctuation, space, brackets if any
def preprocess(text):
doc = nlp(text)
filtered_token = []
for token in doc:
if token.is_punct or token.is_space or token.is_bracket:
continue
token = token.lemma_
filtered_token.append(token.text)
return filtered_token
# # example showing text preprocessing
tokens = preprocess(
"My best friend Anu, (who is three months older than me) is coming to my house tonight!!!."
)
tokens
# # Apply preprocessing on the text column of training dataset
data["processed_text"] = data["text"].apply(lambda x: preprocess(x))
data
# # use gensim pretrained model to vectorize each token in the preprocessed text and take the average of vectors to keep the dimension same
import numpy as np
def gensim_vector(token):
vec_size = wv.vector_size
wv_final = np.zeros(vec_size) # take a vector consisting '0s' having size of wv
count = 1
for t in token:
if t in wv:
count += 1
wv_final += wv[t] # vectorize word and add to previous value
return wv_final / count # take the average
# # Apply the vectorization process on processed text column of the training dataset
data["text_vector"] = data["processed_text"].apply(gensim_vector)
data.head()
len(data.text_vector.iloc[0])
|
# Import libraries
import numpy as np # linear algebra
import re
import pandas as pd
import os
import re
import seaborn as sns
from statistics import median
from sklearn.model_selection import train_test_split, KFold, cross_val_score
from sklearn.linear_model import LogisticRegression
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# ## Cleaning the Data
# I'll start by reading in and previewing the dataset to get a sense of how it's structured.
train = pd.read_csv("/kaggle/input/forest-frenzy/train.csv")
train.head(20)
train.describe()
train.info()
# #### Some intial thoughts upon previewing the data:
# * With each individual soil and wilderness type in a separate binary field, this makes for very high dimensionality in the data.
# * Looking at the output from the describe function, there doesn't look to be any notable outliers.
# To reduce the dimensionality, I will transform each soil type into a catagorical field where each value corresponds to the soil type number. I will do the same for wilderness type.
def soil_type(df):
# Get list of all soil type binary columns
soil_cols = [col for col in df if col.startswith("soil")]
for a in soil_cols:
# Get soil type number contained in the column name
soil_num = re.findall("[-+]?[.]?[\d]+(?:,\d\d\d)*[\.]?\d*(?:[eE][-+]?\d+)?", a)
# Replace values of "1" with number of soil type
df[a] = df[a].replace(1, int(soil_num[0]))
# Create new field combining all soil type numbers
df["soil_type"] = df[soil_cols].sum(1)
# Drop old soil type variables from data frame
df = df.drop(soil_cols, axis=1, inplace=True)
soil_type(train)
train.head()
def wilderness_area(df):
# Get list of all wilderness area designation binary columns
wilderness_cols = [col for col in df if col.startswith("wilderness")]
# Iterate through columns and replace values of "1" with the wilderness area designation
for a in wilderness_cols:
wilderness_num = re.findall(
"[-+]?[.]?[\d]+(?:,\d\d\d)*[\.]?\d*(?:[eE][-+]?\d+)?", a
)
df[a] = df[a].replace(1, int(wilderness_num[0]))
# Create new field combining all wilderness area designations
df["wilderness_area"] = df[wilderness_cols].sum(1)
# Drop old wilderness area columns from data frame
df = df.drop(wilderness_cols, axis=1, inplace=True)
wilderness_area(train)
# Re order data frame columns
train = train[
[
"elevation",
"aspect",
"slope",
"horizontal_distance_to_hydrology",
"vertical_distance_to_hydrology",
"horizontal_distance_to_roadways",
"hillshade_9am",
"hillshade_noon",
"hillshade_3pm",
"horizontal_distance_to_fire_points",
"soil_type",
"wilderness_area",
"cover_type",
]
]
train.head()
# # Exploring the Data and Variable Selection
# Now that I've done a bit of data clean up, I'll do some exploratory analysis before choosing my variables. I'd like to get a sense of how the outcome variable, 'cover_type', is distributed. Let's view it in a bar chart.
location_plot = sns.countplot(x=train["cover_type"])
location_plot.set_xticklabels(location_plot.get_xticklabels(), rotation=40, ha="right")
# The overwhelming majority of the records have a cover type of 1 or 2. This may pose an accuracy challenge when I fit my models using K-folds. With far fewer observations for the other cover types, there will be less of a sample in each of the folds, making them potentially difficult to predict.
#
# Let's take a look at the variable correlation:
# Create correlation matrix
corr = train.corr()
sns.heatmap(
corr,
xticklabels=corr.columns,
yticklabels=corr.columns,
annot=True,
annot_kws={"fontsize": 8},
cmap=sns.diverging_palette(220, 20, as_cmap=True),
)
# My observations from the correlation matrix:
# * **hillshade_3pm** has a significant negative correlation with **hillshade_9am** and moderate positive correlation with **hillshade_noon**.
# * **aspect** has a moderate negative correlation with **hillshade_9am** and moderate positive correlation with **hillshade_3pm**.
# * **elevation** has a moderate positive correlation with **soil**
# Before finalizing my predictors, let's view a scatterplot matrix:
# Given these findings, I will omit **hillshade_3pm**, **aspect**, and **elevation** from my predictors.
#
# Create scatterplot matrix
sns.set_theme(style="ticks")
sns.pairplot(train, diag_kind="kde")
# * With the exception of **hillshade_3pm** all variables have some sort of skewed distribution, which violates a few of the assumptions of the model's I'll be testing.
# * Looking at the scatter plots, there may be some potential collinearity between some of the variables. However, any potential collinearity doesnt look to be too strong, so I won't address this for now.
# # Variable selection and k-folds parameters
# Given the from my EDA findings, I will omit **hillshade_3pm**, **aspect**, and **elevation** from my predictors. Let's create the dataframe for the training set:
# Create data frame for classification models
x_train = train[
[
"elevation",
"slope",
"horizontal_distance_to_hydrology",
"vertical_distance_to_hydrology",
"horizontal_distance_to_roadways",
"hillshade_9am",
"hillshade_noon",
"horizontal_distance_to_fire_points",
"soil_type",
"wilderness_area",
]
]
y_train = train[["cover_type"]]
y_train = y_train.values.ravel()
# I've decided to use 10 folds for my k-folds cross validation. The data set seems large enough to benefit from 10 folds vs just using 5. I'll write a function that computes the macro f score and validates the models using 10 folds:
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.metrics import f1_score
# Run k-folds cross validation with 10 folds
# Return macro F1 Score
def macro_f1(model):
# Perform 10-fold cross validation and make predictions for each fold
y_pred = cross_val_predict(model, x_train, y_train, cv=10)
# Get macro F1 Score
return f1_score(y_train, y_pred, average="macro")
# # Logistic Regression
from sklearn.linear_model import LogisticRegression
# Create a logistic regression model
MLRmodel = LogisticRegression(multi_class="multinomial", solver="saga")
macro_f1(MLRmodel)
# # Linear Discriminant Analysis
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
LDAmodel = LinearDiscriminantAnalysis()
macro_f1(LDAmodel)
# # Quadratic Discriminant Analysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis as qda
QDA_model = qda()
macro_f1(QDA_model)
# # Naive Bayes
from sklearn.naive_bayes import GaussianNB
NB_model = GaussianNB()
macro_f1(NB_model)
# # K-Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
KNN_model = KNeighborsClassifier(n_neighbors=4)
macro_f1(KNN_model)
# # Model Comparison Discussion
# Let's compare the macro f1 scores for all of the models and discuss:
# View macro f1 scores of each model from lowest to highest
score_compare = {
"model": [
"Logistic Regression",
"Linear Discriminant Analysis",
"Quadratic Discriminant Analysis",
"Naive Bayes",
"K-Nearest Neighbors",
],
"Macro F1 Score": [
0.31479793153367874,
0.4435040757853047,
0.001330914178786138,
0.45683416522775644,
0.8779698848458111,
],
}
df = pd.DataFrame(data=score_compare)
df.sort_values(by=["Macro F1 Score"])
#
# **K-Nearest Neighbors** : My theory is that KNN performed the best since it doesn't make any assumtions about the decision boundary, making it a much more flexible model option. I think that the data having a big spatial context also majorly helped KNN perform well since it's "nearest neighbors" in the real world are likely to have similar attributes, making the classification method more accurate.
# **Naive Bayes** : Naive bayes performed the second best, but still did not get a great score. NB expects predictors to be independent from each other, and We can not confidently assume that. Though I tried to account for this when evaluating the correlation matrix, this assumption may be the reason for it's poor performance.
# **Linear Discriminant Analysis** : Since LDA assumes that the predictors are normally distributed for each class, common variance in each class and assumes a linear decision boundary, it makes sense why it did not perform well. The data are too complex to make those assumptions.
# **Logistic Regression** : Logistic regression seems too simple of models for the complexity of the dataset, as it has a linear decision boundary. The decision boundaries of the data likely non-linear, so it's not suprising that the model underfits.
# **Quadratic Discriminant Analysis** : I expected QDA to perform much better than it did, considering QDA is usually performs well with larger datasets and allows for more variance between classes. However, the data are more skewed towards cover types 1 and 2, and there are much fewer observations for the other cover type classes. QDA doesn't assume a linear decision boundary, but with the lack of observations for the other cover type classes and the complexity of the data, it makes sense that it did not perform as well as KNN. Still, not sure why it resulted in the lowest score of all models.
# # Cleaning and running model on test set
# I will run the same data cleaning tasks for the test set as I did for the training set. Then I will fit a new KNN model to all of the training set, then use this model to predict on the test set.
test = pd.read_csv("/kaggle/input/forest-frenzy/test.csv")
# Create single column for soil type catagory
soil_type(test)
# Create single column for wilderness area type catagory
wilderness_area(test)
x_test = test[
[
"elevation",
"slope",
"horizontal_distance_to_hydrology",
"vertical_distance_to_hydrology",
"horizontal_distance_to_roadways",
"hillshade_9am",
"hillshade_noon",
"horizontal_distance_to_fire_points",
"soil_type",
"wilderness_area",
]
]
# Fit k-nearest neighbors to all of training data
KNN_model = KNeighborsClassifier(n_neighbors=4)
KNN_model.fit(x_train, y_train)
# Run k-nearest neighbors model on test set
test_predictions = KNN_model.predict(x_test)
# Create submission data frame and preview
submission = pd.DataFrame({"id": test["id"], "cover_type": test_predictions})
submission.head()
# Create submission file
submission.to_csv("submission.csv", index=False)
|
# 
# # Quake Forecast by Air Voltage Signals
# ### Dyson Lin, Founder & CEO of Taiwan Quake Forecast Institute
# ### 2020-02-12 05:59 UTC+8
# I measure air voltage signals to predict quakes.
# I also interpret IRIS signals to predict quakes.
# I have 30+ quake forecast stations around the world.
# I accurately predicted a lot of big quakes around the world.
# Recently, I accurately predicted two big quakes in Turkey.
# That made me famous in Turkey within a few days.
# I will develop some AI models to predict quakes automatically.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
|
# # Start with Kaggle comps: Future sales
# The aim of this notebook is to predict monthly sales of a series of products from the C1 company. This includes working with time-series and managing considerably large datasets, and we will need some advanced techniques to deal with them.
# Main workflow of the algorithm:
# 1. Step 1. Load data
# 2. Step 2. Data exploration (EDA)
# 3. Step 3. Missings cleaning
# 4. Step 4. Feature engineering
# 5. Step 5. Mean encoding and generation of lag
# 6. Step 6. Data preparation and prediction (LGBoost)
# Let's start by importing the libraries:
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
import seaborn as sns
import lightgbm as lgb
from xgboost import XGBRegressor
from sklearn.model_selection import cross_val_score
from xgboost import plot_importance
import time
import datetime
import re
from itertools import product
from math import isnan
import scipy.stats as stats
import gc
import pickle
import os
print(os.listdir("../input"))
# DISCLAIMER: Some procedures and ideas (in particular feature couples to extract lag and duplicated russian shop_names) in this kernel have been influenced by the following two kernels:
# https://www.kaggle.com/kyakovlev/1st-place-solution-part-1-hands-on-data
# https://www.kaggle.com/dlarionov/feature-engineering-xgboost
# ## Step1. Load data
# This step consists on several procedures, not just data loading as usually:
# * Read all data files provided by Kaggle competition
# * Display load data
# * Join train/test data and fill some values as the month of the test data
# * Define a function to downgrade data types (to deal with massive arrays) for future use
# * Fill some missings with 0s
# * Generate support flag features (in_test, is_new_item)
# Load input files
sales_train = pd.read_csv(
"../input/competitive-data-science-predict-future-sales/sales_train.csv",
parse_dates=["date"],
infer_datetime_format=False,
dayfirst=True,
)
test = pd.read_csv("../input/competitive-data-science-predict-future-sales/test.csv")
item_categories = pd.read_csv(
"../input/competitive-data-science-predict-future-sales/item_categories.csv"
)
items = pd.read_csv("../input/competitive-data-science-predict-future-sales/items.csv")
shops = pd.read_csv("../input/competitive-data-science-predict-future-sales/shops.csv")
# Take a brief look on the content
print("Sales_train")
display(sales_train.head(10))
print("Test")
display(test.head(10))
print("Item_categories")
display(item_categories.head(10))
print("Items")
display(items.head(10))
print("Shops")
display(shops.head(1))
# Auxiliar function to reduce data storage
def downcast_dtypes(df):
# Columns to downcast
float_cols = [c for c in df if df[c].dtype == "float64"]
int_cols = [c for c in df if df[c].dtype == "int64"]
# Downcast
df[float_cols] = df[float_cols].astype(np.float16)
df[int_cols] = df[int_cols].astype(np.int16)
return df
# Prepare the test set to merge it with sales_train
test["date_block_num"] = 34
test["date"] = datetime.datetime(2015, 11, 1, 0, 0, 0)
# Join train and test sets. Fill date_block_num = 34 for test rows
all_data = pd.concat([sales_train, test], axis=0, sort=False)
all_data["date_block_num"].fillna(34, inplace=True)
# Create flag (in_test) for month=34
all_data["in_test"] = 0
all_data.loc[all_data.date_block_num == 34, "in_test"] = 1
# Create a flag (is_new_item) for elements in test not in sales_train
new_items = set(test["item_id"].unique()) - set(sales_train["item_id"].unique())
all_data.loc[all_data["item_id"].isin(new_items), "is_new_item"] = 1
# Fill missings with 0
all_data.fillna(0, inplace=True)
all_data = downcast_dtypes(all_data)
all_data = all_data.reset_index()
display(all_data.head(10))
print("Train set size: ", len(sales_train))
print("Test set size: ", len(test))
print("Item categories set size: ", len(item_categories))
print("Items set size: ", len(items))
print("Shops set size: ", len(shops))
print("All data size: ", len(all_data))
print("Duplicates in train dataset: ", len(sales_train[sales_train.duplicated()]))
# ## Step 2. Data exploration (EDA)
# In the previous step, we had the opportunity to see how data is structured and which types of data are we dealing with. However, we haven't analysed the existance of outliers, abnormal values (either extremely high or low), duplicate categorical values, etc. That's what we will study in the following code blocks.
# A brief summary of our EDA:
# * Analyze extreme values in item_price and item_cnt_day
# * Deal with the outliers (extremely large values and negative counts)
# * Find and deal with duplicates in shop_name
# * Fix negative item_prices
# * Create an enriched dataset for further exploration (optional but recommended). Includes some feature engineering
# * Analyze sells by price categories
# * Analyze monthly sales
# * Create a correlation matrix
# Describe merged data to look for inusual values
display(all_data.describe())
print("Item_price outlier: ")
print(all_data.loc[all_data["item_price"].idxmax()])
print("\nItem_cnt_day maximum: ")
print(all_data.loc[all_data["item_cnt_day"].idxmax()])
f1, axes = plt.subplots(1, 2, figsize=(15, 5))
f1.subplots_adjust(hspace=0.4, wspace=0.2)
sns.boxplot(x=all_data["item_price"], ax=axes[0])
sns.boxplot(x=all_data["item_cnt_day"], ax=axes[1])
print(shops["shop_name"].unique())
# Conclusions by now:
# 1. There are negative prices and counts (errors, returns?)
# 2. Item_id = 6066 has an abnormal large price (item_price = 307980), and is only sold one time
# 3. 2 items have very large item_cnt_day when compared with the other products
# 4. Shop_name contains the shops' city names (Москва, Moscow). An additional feature can be obtained
# 5. Якутск city is expressed as Якутск and !Якутск. This could be fixed
# 6. Shop_id = 0 & 1 are the same than 57 & 58 but for фран (Google translator => fran, maybe franchise). Shop_id = 10 & 11 are the same
# Let's tackle these outliers, duplicates and negative numbers.
# Drop outliers and negative counts (see graphs below)
all_data = all_data.drop(all_data[all_data["item_price"] > 100000].index)
all_data = all_data.drop(all_data[all_data["item_cnt_day"] > 1100].index)
sales_train = sales_train.drop(sales_train[sales_train["item_price"] > 100000].index)
sales_train = sales_train.drop(sales_train[sales_train["item_cnt_day"] > 1100].index)
# There are shops with same address and almost same name in russian.
# Unify duplicated shops (see https://www.kaggle.com/dlarionov/feature-engineering-xgboost)
all_data.loc[all_data["shop_id"] == 11, "shop_id"] = 10
all_data.loc[all_data["shop_id"] == 57, "shop_id"] = 0
all_data.loc[all_data["shop_id"] == 58, "shop_id"] = 1
sales_train.loc[sales_train["shop_id"] == 11, "shop_id"] = 10
sales_train.loc[sales_train["shop_id"] == 57, "shop_id"] = 0
sales_train.loc[sales_train["shop_id"] == 58, "shop_id"] = 1
test.loc[test["shop_id"] == 11, "shop_id"] = 10
test.loc[test["shop_id"] == 57, "shop_id"] = 0
test.loc[test["shop_id"] == 58, "shop_id"] = 1
# Instead of deleting negative price items, replace them with the median value for the impacted group:
all_data.loc[all_data["item_price"] < 0, "item_price"] = all_data[
(all_data["shop_id"] == 32)
& (all_data["item_id"] == 2973)
& (all_data["date_block_num"] == 4)
& (all_data["item_price"] > 0)
].item_price.median()
print("Raw data length: ", len(sales_train), ", post-outliers length: ", len(all_data))
# Now, an enriched matrix with additional features will be created just for data exploration purposes. This may proof useful later on to think about how to structure our data and have a general view of our datasets.
# **Disclaimer**: This is completely optional and techniques used to enrich data should be considered as feature engineering. However, while developping this kernel I found it useful to figure out which way to deal with time-series data.
ts = time.time()
# Enrich data with additional features and aggregates for data exploration purposes
def enrich_data(all_data, items, shops, item_categories):
# Aggregate at month level. Calculate item_cnt_month and item_price (median)
count_data = (
all_data.groupby(
["shop_id", "item_id", "date_block_num", "in_test", "is_new_item"]
)["item_cnt_day"]
.sum()
.rename("item_cnt_month")
.reset_index()
)
price_data = (
all_data.groupby(
["shop_id", "item_id", "date_block_num", "in_test", "is_new_item"]
)["item_price"]
.median()
.rename("item_price_median")
.reset_index()
)
all_data = pd.merge(
count_data,
price_data,
on=["shop_id", "item_id", "in_test", "date_block_num", "is_new_item"],
how="left",
)
# Extract day, month, year
# all_data['day'] = all_data['date'].dt.day
# all_data['month'] = all_data['date'].dt.month
# all_data['year'] = all_data['date'].dt.year
# Add item, shop and item_category details
all_data = all_data.join(items, on="item_id", rsuffix="_item")
all_data = all_data.join(shops, on="shop_id", rsuffix="_shop")
all_data = all_data.join(
item_categories, on="item_category_id", rsuffix="_item_category"
)
all_data = all_data.drop(
columns=[
"item_id_item",
"shop_id_shop",
"item_category_id_item_category",
"item_name",
]
)
# Extract main category and subcategory from category name
categories_split = all_data["item_category_name"].str.split("-")
all_data["main_category"] = categories_split.map(lambda row: row[0].strip())
all_data["secondary_category"] = categories_split.map(
lambda row: row[1].strip() if (len(row) > 1) else "N/A"
)
# Extract cities information from shop_name. Replace !Якутск by Якутск since it's the same city
all_data["city"] = all_data["shop_name"].str.split(" ").map(lambda row: row[0])
all_data.loc[all_data.city == "!Якутск", "city"] = "Якутск"
# Encode cities and categories
encoder = sklearn.preprocessing.LabelEncoder()
all_data["city_label"] = encoder.fit_transform(all_data["city"])
all_data["main_category_label"] = encoder.fit_transform(all_data["main_category"])
all_data["secondary_category_label"] = encoder.fit_transform(
all_data["secondary_category"]
)
all_data = all_data.drop(
[
"city",
"shop_name",
"item_category_name",
"main_category",
"secondary_category",
],
axis=1,
)
# Create price categories (0-5, 5-10, 10,20, 20,30, 30-50, 50-100, >100)
def price_category(row):
if row.item_price_median < 5.0:
val = 1
elif row.item_price_median < 10.0:
val = 2
elif row.item_price_median < 100.0:
val = 3
elif row.item_price_median < 200.0:
val = 4
elif row.item_price_median < 300.0:
val = 5
elif row.item_price_median < 500.0:
val = 6
elif row.item_price_median < 1000.0:
val = 7
elif row.item_price_median > 1000.0:
val = 8
else:
val = 0
return val
all_data["price_cat"] = all_data.apply(price_category, axis=1)
# Downgrade numeric data types
all_data = downcast_dtypes(all_data)
# Performance test dropping month_cnt
# all_data.drop('item_cnt_month', axis=1, inplace=True)
return all_data
all_data2 = enrich_data(all_data, items, shops, item_categories)
items_prices = all_data2[
["item_id", "shop_id", "date_block_num", "item_price_median", "price_cat"]
]
time.time() - ts
all_data2.head()
# Alright, now we have an advanced view of the kind of data we are dealing with. This will help us to define how to wotk with time-series in the following steps. But first, let's finish our exploratory analysis by:
# * Study monthly sales by month
# * Study monthly sales by price category
# * Look at the correlation matrix of our enriched data.
# Analyze monthly sells for all shops
all_data2["item_cnt_month"] = all_data2["item_cnt_month"].astype(np.float64)
count_monthly_sales = all_data2.groupby("date_block_num").item_cnt_month.sum(axis=0)
f = plt.figure()
ax = f.add_subplot(111)
plt.plot(count_monthly_sales)
plt.axvline(x=12, color="grey", linestyle="--") # Vertical grey line for December month
plt.axvline(x=24, color="grey", linestyle="--")
plt.xlabel("date_block_num")
plt.title("Monthly total sells")
plt.show()
# Analyze monthly sells for each price category
count_price_cat_sales = all_data2.groupby("price_cat").item_cnt_month.sum(axis=0)
f = plt.figure()
ax = f.add_subplot(111)
plt.plot(count_price_cat_sales)
plt.xticks(
[0, 1, 2, 3, 4, 5, 6, 7, 8],
[
"others",
"0<p<5₽",
"5<p<10₽",
"10<p<100₽",
"100<p<200₽",
"200<p<300₽",
"300<p<500₽",
"500<p<1000₽",
">1000₽",
],
rotation="45",
)
plt.title("Price category sells")
plt.show()
# Looks like C1 company has a decreasing tendency on sales. There are some reasons for this behavior (depreciation of the ruble), but we don't need to tackle this explicitly for our prediction purposes since the algorithm will detect the tendency automatically from data.
# Additionally, we see there's an increasing sales count on items with higher prices, but this could be due to our bin size. Just take it into account.
# Correlation matrix for monthly sales
all_data2 = all_data2[all_data2["date_block_num"] < 34]
# all_data2 = all_data2.drop(columns=['in_test', 'is_new_item'], inplace=True)
# Correlation matrix
f = plt.figure(figsize=(9, 5))
plt.matshow(all_data2.corr(), fignum=f.number)
plt.xticks(range(all_data2.shape[1]), all_data2.columns, fontsize=10, rotation=90)
plt.yticks(range(all_data2.shape[1]), all_data2.columns, fontsize=10)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
# Not surprising correlations, but a good look-up result in case we find something interesting later on.
# # Step 3. Missings cleaning
# Since we filled missing values with 0s, we expect little or no missings in this section. However, it's always a good practice to check out before feature engineering and detection.
# Missings count. There are no missings (remind that we filled all missings on the beginning of this kernel with 0s)
missings_count = {col: all_data[col].isnull().sum() for col in all_data.columns}
missings = pd.DataFrame.from_dict(missings_count, orient="index")
print(missings.nlargest(30, 0))
# # Step 4. Feature engineering
# Steps 4 and 5 are those in which we will need to be more incisive. Since data is strongly dependent on time, it's important to define how to work with it.
# Here we have two options:
# * Do we create a row for each item/shop pair and then create a column for each month?
# * Or it could be better to generate one different row for each item/shop/date_block_num sale
# You can try the first option to obtain some decent results (you can see the results here https://www.kaggle.com/saga21/start-with-kaggle-comps-future-sales-v0), but we can make a step further and decide to structure data by item/shop/date_month. With this, we will have a row for each monthly sale, which will help the algorithm to predict future data (and not just predict an additional column for the new month).
# What we will do:
# * Generate all combinations of existent item/shop/date_block_num (cartesian product) from the training set
# * Revenue. New feature from item_price * item_cnt_day
# * Item_cnt_month. New feature from grouping item/shops by month and summing the item_cnt_day
# * Join test data
# * Join item, shop and item category details (see additional files provided by the competition)
# * Month. Numeric month value from 1 to 12
# * Days. Number of days in each month (no leap years)
# * Main_category. From item categories, extract the principal type
# * Secondary_category. From item categories, extract the secondary type
# * City. Extract the city from shop_name
# * Shop_type. Extract the type from shop_name
# * Encode categorical columns: main_category, secondary_category, city and shop_type
ts = time.time()
# Extend all_data for all item/shop pairs.
def add_all_pairs(sales_train, test, items, shops, item_categories, items_prices):
tmp = []
for month in range(34):
sales = sales_train[sales_train.date_block_num == month]
tmp.append(
np.array(
list(product([month], sales.shop_id.unique(), sales.item_id.unique())),
dtype="int16",
)
)
tmp = pd.DataFrame(np.vstack(tmp), columns=["date_block_num", "shop_id", "item_id"])
tmp["date_block_num"] = tmp["date_block_num"].astype(np.int8)
tmp["shop_id"] = tmp["shop_id"].astype(np.int8)
tmp["item_id"] = tmp["item_id"].astype(np.int16)
tmp.sort_values(["date_block_num", "shop_id", "item_id"], inplace=True)
sales_train["revenue"] = sales_train["item_price"] * sales_train["item_cnt_day"]
group = sales_train.groupby(["date_block_num", "shop_id", "item_id"]).agg(
{"item_cnt_day": ["sum"]}
)
group.columns = ["item_cnt_month"]
group.reset_index(inplace=True)
tmp = pd.merge(tmp, group, on=["date_block_num", "shop_id", "item_id"], how="left")
tmp["item_cnt_month"] = (
tmp["item_cnt_month"].fillna(0).clip(0, 20).astype(np.float16)
)
tmp = pd.concat(
[tmp, test],
ignore_index=True,
sort=False,
keys=["date_block_num", "shop_id", "item_id"],
)
# price_data = tmp.groupby(['shop_id', 'item_id', 'date_block_num', 'in_test', 'is_new_item'])['item_price'].median().rename('item_price_median').reset_index()
# tmp = tmp.join(price_data, on=[[]])
# Add item, shop and item_category details
tmp = tmp.join(items, on="item_id", rsuffix="_item")
tmp = tmp.join(shops, on="shop_id", rsuffix="_shop")
tmp = tmp.join(item_categories, on="item_category_id", rsuffix="_item_category")
tmp = pd.merge(
tmp, items_prices, on=["date_block_num", "shop_id", "item_id"], how="left"
)
tmp = tmp.drop(
columns=[
"item_id_item",
"shop_id_shop",
"item_category_id_item_category",
"item_name",
]
)
# Extract month, year & nºdays in each month
tmp["month"] = tmp["date_block_num"] % 12
tmp["days"] = tmp["month"].map(
pd.Series([31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31])
)
# Extract main category and subcategory from category name
categories_split = tmp["item_category_name"].str.split("-")
tmp["main_category"] = categories_split.map(lambda row: row[0].strip())
tmp["secondary_category"] = categories_split.map(
lambda row: row[1].strip() if (len(row) > 1) else "N/A"
)
# Extract cities information from shop_name. Replace !Якутск by Якутск since it's the same city.
tmp["city"] = tmp["shop_name"].str.split(" ").map(lambda row: row[0])
tmp.loc[tmp.city == "!Якутск", "city"] = "Якутск"
tmp["shop_type"] = tmp["shop_name"].apply(
lambda x: "мтрц"
if "мтрц" in x
else "трц"
if "трц" in x
else "трк"
if "трк" in x
else "тц"
if "тц" in x
else "тк"
if "тк" in x
else "NO_DATA"
)
# Encode cities and categories
encoder = sklearn.preprocessing.LabelEncoder()
tmp["city_label"] = encoder.fit_transform(tmp["city"])
tmp["shop_type_label"] = encoder.fit_transform(tmp["shop_type"])
tmp["main_category_label"] = encoder.fit_transform(tmp["main_category"])
tmp["secondary_category_label"] = encoder.fit_transform(tmp["secondary_category"])
tmp = tmp.drop(
[
"ID",
"city",
"date",
"shop_name",
"item_category_name",
"main_category",
"secondary_category",
],
axis=1,
)
# Downgrade numeric data types
tmp = downcast_dtypes(tmp)
tmp.fillna(0, inplace=True)
return tmp
all_pairs = add_all_pairs(
sales_train, test, items, shops, item_categories, items_prices
)
time.time() - ts
# Fine, so we have extracted some nice additional features and now our sales have one row for each item/shop/date_block_num. It looks promising.
# # Step 5. Mean encoding
# LGB algorithm read rows to extract information from them and predict the target value. We need to provide the algorithm with the historical information for each item, and this is obtained through lags. Lags are essentially columns with information from the past. For example, a lag of 1 month from item_cnt_month would inform about the last month sales for this item.
# What we will add:
# * **Downgrade** (again) data to deal with large arrays
# * **Support functions**. Create some support functions for lag generation; calculate_lag, prepare_lag_columns and prepare_lag_columns_price. This allows to calculate automatic lags for several columns in a readable code-friendly style. As a rule of thumb: if you need to calculate the same non-trivial computation more than once, creater a function instead
# * **Compute lags**. Lags of monthly sales grouped by several column combinations (how many past sales by shop and category, or by secondary category, etc)
# * **Price_trend**. Track item_prices changes to account for price fluctuations (discounts)
# * **Drop columns**. Some features were generated in order to compute another one. Drop those that are not useful any more or may introduce data leaking (for example, item_price is strongly correlated to sales, since items that were never sell have no price informed).
ts = time.time()
# First downgrade some columns (still more) to fasten the mean encoding
all_pairs["date_block_num"] = all_pairs["date_block_num"].astype(np.int8)
all_pairs["city_label"] = all_pairs["city_label"].astype(np.int8)
all_pairs["item_cnt_month"] = all_pairs["item_cnt_month"].astype(np.int8)
all_pairs["item_category_id"] = all_pairs["item_category_id"].astype(np.int8)
all_pairs["main_category_label"] = all_pairs["main_category_label"].astype(np.int8)
all_pairs["secondary_category_label"] = all_pairs["secondary_category_label"].astype(
np.int8
)
# Function to calculate lag over different columns. Lag gives information about a variable from different past times
def calculate_lag(df, lag, column):
ancilla = df[["date_block_num", "shop_id", "item_id", column]]
for l in lag:
shift_ancilla = ancilla.copy()
shift_ancilla.columns = [
"date_block_num",
"shop_id",
"item_id",
column + "_lag_" + str(l),
]
shift_ancilla["date_block_num"] += l
df = pd.merge(
df, shift_ancilla, on=["date_block_num", "shop_id", "item_id"], how="left"
)
return df
# Function to specify lag columns,compute item_cnt aggregate (mean) and call calculate_lag
def prepare_lag_columns(df, lag, column_list, name):
ancilla = df.groupby(column_list).agg({"item_cnt_month": ["mean"]})
ancilla.columns = [name]
ancilla.reset_index(inplace=True)
df = pd.merge(df, ancilla, on=column_list, how="left")
df[name] = df[name].astype(np.float16)
df = calculate_lag(df, lag, name)
df.drop([name], axis=1, inplace=True)
return df
# Auxiliar function to compute item_price groups (for trends). Lags will be calculated post-preparation
def prepare_lag_columns_price(df, column_list, name):
ancilla = sales_train.groupby(column_list).agg({"item_price": ["mean"]})
ancilla.columns = [name]
ancilla.reset_index(inplace=True)
df = pd.merge(df, ancilla, on=column_list, how="left")
df[name] = df[name].astype(np.float16)
return df
# Let's compute all lags for sells. Arguments of the function are :(df, lag_list, column_list, name of the column)
all_pairs = calculate_lag(all_pairs, [1, 2, 3, 4, 5, 6, 12], "item_cnt_month")
all_pairs = prepare_lag_columns(
all_pairs, [1], ["date_block_num", "item_id"], "total_avg_month_cnt"
)
all_pairs = prepare_lag_columns(
all_pairs, [1, 2, 3, 4, 5, 6, 12], ["date_block_num"], "item_avg_month_cnt"
)
all_pairs = prepare_lag_columns(
all_pairs,
[1, 2, 3, 4, 5, 6, 12],
["date_block_num", "shop_id"],
"shop_avg_month_cnt",
)
all_pairs = prepare_lag_columns(
all_pairs, [1], ["date_block_num", "city_label"], "city_avg_month_cnt"
)
all_pairs = prepare_lag_columns(
all_pairs,
[1],
["date_block_num", "item_id", "city_label"],
"item_city_avg_month_cnt",
)
all_pairs = prepare_lag_columns(
all_pairs, [1], ["date_block_num", "item_category_id"], "category_id_avg_month_cnt"
)
all_pairs = prepare_lag_columns(
all_pairs,
[1],
["date_block_num", "main_category_label"],
"main_category_avg_month_cnt",
)
all_pairs = prepare_lag_columns(
all_pairs,
[1],
["date_block_num", "secondary_category_label"],
"secondary_category_avg_month_cnt",
)
all_pairs = prepare_lag_columns(
all_pairs,
[1],
["date_block_num", "shop_id", "item_category_id"],
"shop_category_id_avg_month_cnt",
)
all_pairs = prepare_lag_columns(
all_pairs,
[1],
["date_block_num", "shop_id", "main_category_label"],
"shop_main_category_avg_month_cnt",
)
all_pairs = prepare_lag_columns(
all_pairs,
[1],
["date_block_num", "shop_id", "secondary_category_label"],
"shop_secondary_category_avg_month_cnt",
)
# For item_price the procedure is more tricky. Compute both item price and monthly price in order to compute the trend.
all_pairs = prepare_lag_columns_price(all_pairs, ["item_id"], "item_avg_price")
all_pairs = prepare_lag_columns_price(
all_pairs, ["date_block_num", "item_id"], "item_avg_price_month"
)
all_pairs = calculate_lag(all_pairs, [1, 2, 3, 4, 5, 6], "item_avg_price_month")
for lag in [1, 2, 3, 4, 5, 6]:
all_pairs["trend_price_lag_" + str(lag)] = (
all_pairs["item_avg_price_month_lag_" + str(lag)] - all_pairs["item_avg_price"]
) / all_pairs["item_avg_price"]
def clean_trend_price_lag(row):
for l in [1, 2, 3, 4, 5, 6]:
if row["trend_price_lag_" + str(l)]:
return row["trend_price_lag_" + str(l)]
return 0
# For some reason my kernel expodes when using df.apply() for all rows, so I had to segment it
dummy_1, dummy_2, dummy_3, dummy_4 = [], [], [], []
dummy_1 = pd.DataFrame(dummy_1)
dummy_2 = pd.DataFrame(dummy_2)
dummy_3 = pd.DataFrame(dummy_3)
dummy_4 = pd.DataFrame(dummy_4)
dummy_1 = all_pairs[:3000000].apply(clean_trend_price_lag, axis=1)
dummy_2 = all_pairs[3000000:6000000].apply(clean_trend_price_lag, axis=1)
dummy_3 = all_pairs[6000000:9000000].apply(clean_trend_price_lag, axis=1)
dummy_4 = all_pairs[9000000:].apply(clean_trend_price_lag, axis=1)
all_pairs["trend_price_lag"] = pd.concat([dummy_1, dummy_2, dummy_3, dummy_4])
all_pairs["trend_price_lag"] = all_pairs["trend_price_lag"].astype(np.float16)
all_pairs["trend_price_lag"].fillna(0, inplace=True)
# all_pairs.drop(['item_avg_price','item_avg_price_month'], axis=1, inplace=True)
for i in [1, 2, 3, 4, 5, 6]:
all_pairs.drop(
["item_avg_price_month_lag_" + str(i), "trend_price_lag_" + str(i)],
axis=1,
inplace=True,
)
all_pairs.drop("shop_type", axis=1, inplace=True)
time.time() - ts
# Ok, that's been a while. We are working with huge datasets and the computations of additional features are computationally costly, but it will prove to be advantageous.
# To finish up, we will compute some additional values:
# * **Shop_avg_revenue**. All sales for a certain shop, in order to track very profitable shops or poor selling ones. Since we are only interested in the last month, we will drop all additional columns but the lag
# * **Item_shop_first_sale**. Months since the first sell of a certain shop was made
# * **Item_first_sale**. Months since the first sell of a certain item
ts = time.time()
group = sales_train.groupby(["date_block_num", "shop_id"]).agg({"revenue": ["sum"]})
group.columns = ["date_shop_revenue"]
group.reset_index(inplace=True)
all_pairs = pd.merge(all_pairs, group, on=["date_block_num", "shop_id"], how="left")
all_pairs["date_shop_revenue"] = all_pairs["date_shop_revenue"].astype(np.float32)
group = group.groupby(["shop_id"]).agg({"date_shop_revenue": ["mean"]})
group.columns = ["shop_avg_revenue"]
group.reset_index(inplace=True)
all_pairs = pd.merge(all_pairs, group, on=["shop_id"], how="left")
all_pairs["shop_avg_revenue"] = all_pairs["shop_avg_revenue"].astype(np.float32)
all_pairs["delta_revenue"] = (
all_pairs["date_shop_revenue"] - all_pairs["shop_avg_revenue"]
) / all_pairs["shop_avg_revenue"]
all_pairs["delta_revenue"] = all_pairs["delta_revenue"].astype(np.float16)
all_pairs = calculate_lag(all_pairs, [1], "delta_revenue")
all_pairs.drop(
["date_shop_revenue", "shop_avg_revenue", "delta_revenue"], axis=1, inplace=True
)
# First sale extraction
all_pairs["item_shop_first_sale"] = all_pairs["date_block_num"] - all_pairs.groupby(
["item_id", "shop_id"]
)["date_block_num"].transform("min")
all_pairs["item_first_sale"] = all_pairs["date_block_num"] - all_pairs.groupby(
"item_id"
)["date_block_num"].transform("min")
time.time() - ts
# A final correlation matrix and we are done...
# Correlation matrix for monthly sales
all_pairs2 = all_pairs[all_pairs["date_block_num"] < 34]
# all_data2 = all_data2.drop(columns=['in_test', 'is_new_item'], inplace=True)
# Correlation matrix
f = plt.figure(figsize=(9, 5))
plt.matshow(all_pairs2.corr(), fignum=f.number)
plt.xticks(range(all_pairs2.shape[1]), all_pairs2.columns, fontsize=7, rotation=90)
plt.yticks(range(all_pairs2.shape[1]), all_pairs2.columns, fontsize=7)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
# # Step 6. Data preparation and prediction (LGB)
# This is our last step. We need to carefully prepare data, proceed with our splits and apply the LGB algorithm
# In this section we will proceed with:
# * **Drop first 11 months**. Since some of our lags cover the previous 12 months, the first 11 months have no complete lag information. Hence, to be coherent, we will drop this data (yep, that hurts)
# * **Fill lag missings**. When needed.
# * **Drop columns**. Some of them introduce data leaking (item_price_median), and others provide not enough information and generate noise in the algorithm (this is tested manually through the LGB)
# * **Split data**. The filtering condition is just date_block_num. Train from 11 to 32, validation with 33 and test with 34.
# * **Run LGB**. This might require some fine tuning and parameter optimization. Feel free to perform some grid search through cross-validation.
# * **Submit results**. Finally! Let's grab some coffe.
ts = time.time()
all_pairs = all_pairs[all_pairs.date_block_num > 11]
time.time() - ts
ts = time.time()
def fill_na(df):
for col in df.columns:
if ("_lag_" in col) & (df[col].isnull().any()):
if "item_cnt" in col:
df[col].fillna(0, inplace=True)
return df
all_pairs = fill_na(all_pairs)
all_pairs.fillna(0, inplace=True)
time.time() - ts
all_pairs.columns
all_pairs.drop(
[
"item_price_median",
"price_cat",
"item_avg_price",
"item_avg_price_month",
"main_category_avg_month_cnt_lag_1",
"secondary_category_avg_month_cnt_lag_1",
"shop_main_category_avg_month_cnt_lag_1",
"shop_secondary_category_avg_month_cnt_lag_1",
],
inplace=True,
axis=1,
)
all_pairs.to_pickle("data.pkl")
data = pd.read_pickle("data.pkl")
X_train = data[data.date_block_num < 33].drop(["item_cnt_month"], axis=1)
Y_train = data[data.date_block_num < 33]["item_cnt_month"]
X_valid = data[data.date_block_num == 33].drop(["item_cnt_month"], axis=1)
Y_valid = data[data.date_block_num == 33]["item_cnt_month"]
X_test = data[data.date_block_num == 34].drop(["item_cnt_month"], axis=1)
gc.collect()
model = lgb.LGBMRegressor(
n_estimators=10000,
learning_rate=0.3,
min_child_weight=300,
# num_leaves=32,
colsample_bytree=0.8,
subsample=0.8,
max_depth=8,
# reg_alpha=0.04,
# reg_lambda=0.073,
# min_split_gain=0.0222415,
verbose=1,
seed=21,
)
model.fit(
X_train,
Y_train,
eval_metric="rmse",
eval_set=[(X_train, Y_train), (X_valid, Y_valid)],
verbose=1,
early_stopping_rounds=10,
)
# Cross validation accuracy for 3 folds
# scores = cross_val_score(model, X_train, Y_train, cv=3)
# print(scores)
Y_pred = model.predict(X_valid).clip(0, 20)
Y_test = model.predict(X_test).clip(0, 20)
submission = pd.DataFrame({"ID": test.index, "item_cnt_month": Y_test})
submission.to_csv("submission.csv", index=False)
# save predictions for an ensemble
pickle.dump(Y_pred, open("xgb_train.pickle", "wb"))
pickle.dump(Y_test, open("xgb_test.pickle", "wb"))
submission
"""
ALTERNATIVE OPTION WITH XGB. TIME CONSUMING, BUT ALLOWS TO STUDY FEATURE IMPORTANCE
ts = time.time()
model = XGBRegressor(
max_depth=8,
n_estimators=1000,
min_child_weight=300,
colsample_bytree=0.8,
subsample=0.8,
eta=0.3,
seed=21)
model.fit(
X_train,
Y_train,
eval_metric="rmse",
eval_set=[(X_train, Y_train), (X_valid, Y_valid)],
verbose=True,
early_stopping_rounds = 10)
time.time() - ts
def plot_features(booster, figsize):
fig, ax = plt.subplots(1,1,figsize=figsize)
return plot_importance(booster=booster, ax=ax)
plot_features(model, (10,14))
"""
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from matplotlib import pyplot as plt
import seaborn as sns
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
data = pd.read_csv("../input/birds-bones-and-living-habits/bird.csv", index_col="id")
display(data)
data.info()
data.describe()
data.dropna(inplace=True)
plt.figure(figsize=(15, 15))
sns.heatmap(
np.cov(data.drop(["type"], axis=1).T),
annot=True,
cbar=False,
fmt="0.2f",
cmap="YlGnBu",
xticklabels=df.columns,
yticklabels=df.columns,
)
plt.title("Covariance matrix")
plt.figure(figsize=(15, 15))
sns.heatmap(
data.corr(),
annot=True,
cbar=False,
fmt="0.2f",
cmap="YlGnBu",
xticklabels=df.columns,
yticklabels=df.columns,
)
plt.title("Correlation matrix")
df_special = data.drop(["tarw", "tibw", "femw", "ulnaw", "humw"], axis=1)
df_special
sns.pairplot(df_special, hue="type", corner=True)
for feature in df_special.columns[:-1]:
sns.boxplot(x="type", y=feature, data=df_special)
sns.swarmplot(x="type", y=feature, data=df_special, color="0.3")
plt.show()
for feature in df_special.columns[:-1]:
for typ in data["type"].unique():
df = df_special[df_special["type"] == typ]
sns.distplot(a=df[feature], label=typ, hist=False)
plt.title(feature)
plt.show()
# # NOMOR 2
from sklearn.preprocessing import MinMaxScaler, StandardScaler, normalize
def normalisasi(data, scaler):
data_norm = scaler.fit_transform(data)
return data_norm
df = data.drop(["type"], axis=1)
# # MINMAX
min_max_scale = MinMaxScaler()
min_max = normalisasi(df, min_max_scale)
min_max = pd.DataFrame(min_max, columns=data.columns[:-1])
min_max["type"] = data["type"]
min_max
min_max.describe()
# ## STANDARD
standard_scale = StandardScaler()
standard = normalisasi(df, standard_scale)
standard = pd.DataFrame(standard, columns=data.columns[:-1])
standard["type"] = data["type"]
standard
standard.describe()
# # NOMOR 3
eig_values, eig_vectors = np.linalg.eig(cov_matrix)
print("Eigen Values of dataset: ", eig_values)
print()
print("Eigen vector of dataset: ", eig_vectors)
eig_sum = np.sum(eig_values)
data_eig = [(i / eig_sum) * 100 for i in sorted(eig_values, reverse=True)]
data_fr = np.cumsum(data_eig)
data_fr
sns.lineplot(
y=data_fr,
x=range(len(data_fr)),
)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# トレーニングデータのファイル名一覧を取得
filenames = os.listdir("/kaggle/input/dogs-vs-cats/train/train")
categories = [] # 正解ラベルを格納するリスト
# 取得したファイル名の数だけ処理を繰り返す
for filename in filenames:
# ファイル名から文字列を切り取る
category = filename.split(".")[0]
# 切り取った文字列にdogが含まれていれば'1'
# そうでなければ'0'をcategoriesに格納
whichCategories = "1" if category == "dog" else "0"
categories.append(whichCategories)
# 教師データのDataFrameを作成
df = pd.DataFrame({"filename": filenames, "category": categories})
print(len(os.listdir("/kaggle/input/dogs-vs-cats/train/train")))
print(len(os.listdir("/kaggle/input/dogs-vs-cats/test/test")))
df.head()
import matplotlib.pyplot as plt
import random
import time
from keras import layers
from keras.layers import Dense, Dropout, GlobalMaxPooling2D, Flatten
from keras.preprocessing.image import load_img
from keras.applications import VGG16
from keras.models import Model, Sequential
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint, EarlyStopping
from sklearn.model_selection import train_test_split
plt.figure(figsize=(12, 12))
TRAIN_DATA = "/kaggle/input/dogs-vs-cats/train/train"
# 9枚の画像を表示してみる
for i in range(9):
plt.subplot(3, 3, i + 1)
# データからランダムに画像を読み込む
image = load_img(TRAIN_DATA + "/" + random.choice(df.filename))
plt.imshow(image)
plt.tight_layout()
plt.show()
image_size = 224
input_shape = (image_size, image_size, 3)
epochs = 7 # エポック数
batch_size = 16 # バッチサイズ
VGG16model = VGG16(input_shape=input_shape, include_top=False, weights="imagenet")
for layer in VGG16model.layers[:15]:
layer.trainable = False
last_layer = VGG16model.get_layer("block5_pool")
last_output = last_layer.output
# 512ノードのプーリング層を追加
new_last_layers = GlobalMaxPooling2D()(last_output)
# 512ノードの全結合層を追加、活性化関数はReLU
new_last_layers = Dense(512, activation="relu")(new_last_layers)
# 過学習防止のためドロップアウトを追加、レートは0.5
new_last_layers = Dropout(0.5)(new_last_layers)
# 最後に犬猫を示す2ノードの出力層を追加、活性化関数はシグモイド関数
new_last_layers = layers.Dense(2, activation="sigmoid")(new_last_layers)
# VGG16に定義したblockAの部分を組み込む
model = Model(VGG16model.input, new_last_layers)
# モデルのコンパイル
model.compile(
loss="categorical_crossentropy",
optimizer=SGD(lr=1e-4, momentum=0.9),
metrics=["accuracy"],
)
# サマリーの表示
# 最後の出力層が2ノードになっていることを確認
model.summary()
train_df, validate_df = train_test_split(df, test_size=0.1)
train_df = train_df.reset_index()
validate_df = validate_df.reset_index()
total_train = train_df.shape[0]
total_validate = validate_df.shape[0]
# 画像加工による画像の水増し定義
train_datagen = ImageDataGenerator(
# ここでは回転や拡大、反転等、画像加工に係る
# 各種パラメータを設定している
rotation_range=15,
rescale=1.0 / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest",
width_shift_range=0.1,
height_shift_range=0.1,
)
# 学習データのジェネレータを作成
train_generator = train_datagen.flow_from_dataframe(
train_df,
TRAIN_DATA,
x_col="filename",
y_col="category",
class_mode="categorical",
target_size=(image_size, image_size),
batch_size=batch_size,
)
# 検証データのジェネレータ作成
validation_datagen = ImageDataGenerator(rescale=1.0 / 255)
validation_generator = validation_datagen.flow_from_dataframe(
validate_df,
TRAIN_DATA,
x_col="filename",
y_col="category",
class_mode="categorical",
target_size=(image_size, image_size),
batch_size=batch_size,
)
history = model.fit_generator(
train_generator, # 学習データのジェネレータ
epochs=epochs, # エポック数
# 検証データのジェネレータ
validation_data=validation_generator,
validation_steps=total_validate // batch_size,
steps_per_epoch=total_train // batch_size,
)
TEST_DATA = "/kaggle/input/dogs-vs-cats/test/test"
filenames = os.listdir(TEST_DATA)
sample = random.choice(filenames)
img = load_img(TEST_DATA + "/" + sample, target_size=(224, 224))
plt.imshow(img)
img = np.asarray(img)
img = np.expand_dims(img, axis=0)
predict = model.predict(img) # 犬か猫か分類
dog_vs_cat = np.argmax(predict, axis=1)
print("dog") if dog_vs_cat == 1 else print("cat")
test_filenames = os.listdir(TEST_DATA)
test_df = pd.DataFrame({"filename": test_filenames})
nb_samples = test_df.shape[0]
# テストデータのジェネレータを作成
test_gen = ImageDataGenerator(rescale=1.0 / 255)
test_generator = test_gen.flow_from_dataframe(
test_df,
TEST_DATA,
x_col="filename",
y_col=None,
class_mode=None,
batch_size=batch_size,
target_size=(image_size, image_size),
shuffle=False,
)
predict = model.predict_generator(
test_generator, steps=np.ceil(nb_samples / batch_size)
)
dog_vs_cat = np.argmax(predict, axis=1)
submission_df = test_df.copy()
submission_df["id"] = submission_df["filename"].str.split(".").str[0]
submission_df["label"] = dog_vs_cat
submission_df.drop(["filename"], axis=1, inplace=True)
# ファイルに出力
submission_df.to_csv("submission.csv", index=False)
f = open("submission.csv")
print(f.read())
f.close()
img = load_img(TEST_DATA + "/5713.jpg")
plt.imshow(img)
|
# #Task 1
# Our dataset was provided by Adam Bittlingmayer from Kaggle covering appoximately 3,600,000 customer reviews from Amazon. There are 2 categories of label to classify the review as eitherpositive or negative based on the number of stars given by the writer. To initialize the processes required in task 1, each review with more than 100 terms was imported and tokenized.Afterward, all of the tokens that were punctuations, label, stopword, or not an English word (emoji, special character, foreign language) were removed. The remaining tokens would undergothe process of lemmatizing to reduce from plural term to regular term, and stemming using Snowball algorithm to accquire primal forms before appending into a clean list. Finally, thenewly clean list was exported into a text file.
#
import bz2
from nltk.corpus import stopwords, words
from nltk.tokenize import word_tokenize
from nltk.stem import SnowballStemmer
from nltk.stem import WordNetLemmatizer
filename = bz2.open("../input/amazonreviews/test.ft.txt.bz2", "rt", encoding="utf-8")
corpusfile = "corpus_text.txt"
stop_words = set(stopwords.words("english"))
punctuation = [
".",
",",
"!",
"?",
":",
";",
"`",
"~",
"@",
"#",
"%",
"&",
"*",
"(",
")",
"[",
"]",
"{",
"}",
"-",
"_",
]
labels = ["__label__1", "__label__2"]
English_words = set(words.words())
stemmer = SnowballStemmer("english")
lemmatizer = WordNetLemmatizer()
# corpus = []
# with bz2.open(filename, 'r') as infile:
for line in filename:
with open(corpusfile, "a") as outfile:
if len(line) > 100:
word_tokens = word_tokenize(line)
filter_sent = []
for w in word_tokens:
if (
w.lower() not in stop_words
and w.lower() not in punctuation
and w.lower() not in labels
and w.lower() in English_words
):
filter_sent.append(stemmer.stem(lemmatizer.lemmatize(w.lower())))
for w in filter_sent:
outfile.write(str(w) + " ")
outfile.write("\n")
outfile.close()
filename.close()
# #Task 2 and 3
# After finishing data-filtering process, we selected our query containing 10 terms. Each term is evaluated for it term frequency and inverted-document-frequency using the following equation:
# Then we plotted frequency of each term and their respective inverted-document-frequency using bar charts
# #Task 4 and 5
# . The next step is to calulated the score for each document-query pair using TF-IDF score. There are approximatly 40,000 documents, so we decided to plot the results using a histogram graph. Most of the documents' scores are around 0 bins, which we would expect for the outcome
import math
import numpy as np
from nltk.tokenize import word_tokenize
from nltk.stem import SnowballStemmer
from nltk.stem import WordNetLemmatizer
import matplotlib.pyplot as plt
query = "game love music book fun good bad product money waste"
stemmer = SnowballStemmer("english")
lemmatizer = WordNetLemmatizer()
query_term = word_tokenize(query)
term_doc_frequency = []
term_frequency = []
doc_frequency = []
tfidf_term_doc_score = []
filename = "../input/output/corpus_text.txt"
i = 0
for term in query_term:
doc_count = 0
total_doc = 0
single_term_doc_frequency = []
with open(filename, "r") as infile:
for line in infile:
term_count = 0
term_count += line.count(stemmer.stem(lemmatizer.lemmatize(term.lower())))
single_term_doc_frequency.append(term_count)
if (stemmer.stem(lemmatizer.lemmatize(term.lower()))) in line:
doc_count += 1
total_doc += 1
term_doc_frequency.append(single_term_doc_frequency)
doc_frequency.append(math.log10(total_doc / doc_count))
term_frequency = [sum(arr) for arr in term_doc_frequency]
for i in range(0, len(term_doc_frequency)):
tf_score = []
for j in term_doc_frequency[i]:
if j != 0:
tf_score.append((1 + math.log10(j)) * doc_frequency[i])
else:
tf_score.append(0)
tfidf_term_doc_score.append(tf_score)
tfidf_doc_score = [sum(x) for x in zip(*tfidf_term_doc_score)]
y_pos = np.arange(len(query_term))
plt.barh(y_pos, term_frequency, align="center", alpha=0.5)
plt.yticks(y_pos, query_term)
plt.xlabel("tf score")
plt.title("Term Frequency of Query")
plt.show()
plt.barh(y_pos, doc_frequency, align="center", alpha=0.5)
plt.yticks(y_pos, query_term)
plt.xlabel("idf score")
plt.title("Inverted Document Frequency Score of Query")
plt.show()
hist, bins = np.histogram(tfidf_doc_score, bins=50)
center = (bins[:-1] + bins[1:]) / 2
plt.bar(center, hist, align="center")
plt.show()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
house_price_train = pd.read_csv(
"/kaggle/input/house-prices-advanced-regression-techniques/train.csv"
)
house_price_test = pd.read_csv(
"/kaggle/input/house-prices-advanced-regression-techniques/test.csv"
)
print(house_price_train.shape)
house_price_train.head()
house_price_train.describe()
house_price_train.describe(exclude="number")
# 欠損値ありリスト
a = house_price_train.isnull().sum()
a[a != 0]
# 相関ヒートマップ(色薄いところが相関高い ※数値項目のみ対象)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(20, 10))
sns.heatmap(
house_price_train.select_dtypes(include="number").corr(),
vmax=1,
vmin=-1,
center=0,
annot=False,
)
# 相関係数値ソート
ret = np.empty(2)
sp = pd.Series(house_price_train["SalePrice"])
for i in house_price_train.select_dtypes(include="number").columns:
ret = np.vstack((ret, [i, sp.corr(pd.Series(house_price_train[i]))]))
ret[np.argsort(ret[:, 1])[::-1]]
# とりあえず相関>0.5のメンバー
features = [
"OverallQual",
"GrLivArea",
"GarageCars",
"GarageArea",
"TotalBsmtSF",
"1stFlrSF",
"FullBath",
"TotRmsAbvGrd",
"YearBuilt",
"YearRemodAdd",
]
house_price_train[features].describe()
house_price_train[features].dtypes
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
house_price_train[features], house_price_train["SalePrice"], test_size=0.2
)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_log_error
model_rf = RandomForestRegressor()
model_rf.fit(x_train, y_train)
preds = model_rf.predict(x_test)
print(np.sqrt(mean_squared_log_error(y_test, preds)))
house_price_test[features].describe()
# testの方にだけ若干欠損値あり
house_price_test[features].dtypes
house_price_test = house_price_test.fillna(
{"GarageCars": 0, "GarageArea": 0, "TotalBsmtSF": 0}
)
for i in features:
house_price_test = house_price_test.fillna({i: 0})
# 提出
preds = model_rf.predict(house_price_test[features])
output = pd.DataFrame({"Id": house_price_test.Id, "SalePrice": preds})
output.to_csv("my_submission.csv", index=False)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import pandas as pd
iris_df = pd.read_csv("../input/iris/Iris.csv")
iris_df
# there are no entries with NaN
iris_df.isna().sum()
from sklearn.preprocessing import MinMaxScaler
minmax_scaler = MinMaxScaler(feature_range=(0, 1))
iris_df["SepalLengthCm"] = minmax_scaler.fit_transform(iris_df[["SepalLengthCm"]])
iris_df["SepalWidthCm"] = minmax_scaler.fit_transform(iris_df[["SepalWidthCm"]])
iris_df["PetalLengthCm"] = minmax_scaler.fit_transform(iris_df[["PetalLengthCm"]])
iris_df["PetalWidthCm"] = minmax_scaler.fit_transform(iris_df[["PetalWidthCm"]])
iris_df
iris_input = iris_df
iris_output = iris_df["Species"]
iris_input = iris_input.drop(["Species"], axis=1)
iris_input = iris_input.drop(["Id"], axis=1)
print(iris_input)
print(iris_output)
remember_iris_output = iris_output
iris_output.shape
from sklearn import preprocessing
my_label_encoder = preprocessing.LabelEncoder()
my_label_encoder.fit(iris_output)
iris_output = my_label_encoder.transform(iris_output)
from keras.utils import to_categorical
iris_output = to_categorical(iris_output)
print(iris_output)
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(
iris_input, iris_output, test_size=0.2, random_state=1
)
X_train, X_val, Y_train, Y_val = train_test_split(
X_train, Y_train, test_size=0.1, random_state=1
)
print("X_train.shape: ", X_train.shape)
print("Y_train.shape: ", Y_train.shape)
print("X_test.shape: ", X_test.shape)
print("Y_test.shape: ", Y_test.shape)
print("X_val.shape: ", X_val.shape)
print("Y_val.shape: ", Y_val.shape)
print(Y_test)
# my MLP with regularization
from keras import regularizers
from keras.models import Sequential
from keras.layers.core import Dense # MLP
model = Sequential()
model.add(
Dense(
10,
kernel_regularizer=regularizers.l2(0.001),
activity_regularizer=regularizers.l2(0.001),
activation="tanh",
input_shape=(4,),
)
)
model.add(
Dense(
8,
kernel_regularizer=regularizers.l2(0.001),
activity_regularizer=regularizers.l2(0.001),
activation="tanh",
)
)
model.add(
Dense(
6,
kernel_regularizer=regularizers.l2(0.001),
activity_regularizer=regularizers.l2(0.001),
activation="tanh",
)
)
model.add(Dense(3, activation="softmax")) # !
# optimizer 'adam' produces the best results
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["acc"])
# Keras needs a numpy array as input and not a pandas dataframe
print(X_train)
print(Y_train)
history = model.fit(
X_train,
Y_train,
shuffle=True,
batch_size=64,
epochs=1000,
verbose=2,
validation_data=(X_val, Y_val),
)
import matplotlib.pyplot as plt
# Plot training & validation accuracy values
plt.plot(history.history["acc"])
plt.plot(history.history["val_acc"])
plt.title("Model accuracy")
plt.ylabel("Accuracy")
plt.xlabel("Epoch")
plt.legend(["Train", "Validation"], loc="upper left")
plt.show()
# Plot training & validation loss values
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("Model loss")
plt.ylabel("Loss")
plt.xlabel("Epoch")
plt.legend(["Train", "Validation"], loc="upper left")
plt.show()
# have a look at my results
eval_train = model.evaluate(X_train, Y_train)
print(eval_train)
eval_val = model.evaluate(X_val, Y_val)
print(eval_val)
eval_test = model.evaluate(X_test, Y_test)
print(eval_test)
# my prediction
print(X_test)
results = model.predict(X_test)
results = (results > 0.5).astype(int)
results
# results.shape
text_pred = list(my_label_encoder.inverse_transform(results.argmax(1)))
print(text_pred)
print(len(text_pred))
Y_pred = results
print(Y_test)
print(Y_pred)
# Accuracy of the predicted values
from sklearn.metrics import classification_report
iris_names = [
"1-0-0 = iris setosa",
"0-1-0 = iris versicolor",
"0-0-1 = iris virginica",
]
print(classification_report(Y_test, Y_pred, target_names=iris_names))
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import pandas as pd
deliveries = pd.read_csv("../input/ipldata/deliveries.csv")
matches = pd.read_csv("../input/ipldata/matches.csv")
matches["city"][0:3]
import pandas as pd
StudentData = pd.read_csv("../input/studentdata/StudentData.csv")
StudentData.head(10)
import matplotlib.pyplot as plt
plt.hist(StudentData["marks(out of 100)"], color="g")
plt.xlabel("marks out of 100")
plt.ylabel("Number of Students")
matches.isnull().any()
y = matches["winner"]
X = matches.drop(["winner"], axis=1)
import seaborn as sns
matches.boxplot()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
soccer = pd.read_csv(
"/kaggle/input/us-major-league-soccer-salaries/mls-salaries-2017.csv"
)
soccer.head(10)
len(soccer.index) # count of column
soccer["base_salary"]
average = soccer["base_salary"].mean()
print(average)
soccer["base_salary"].max() # max base salary
soccer["guaranteed_compensation"].max()
player = soccer[
soccer["guaranteed_compensation"] == soccer["guaranteed_compensation"].max()
]
player
player["last_name"].iloc[0]
player2 = soccer[soccer["last_name"] == "Gonzalez Pirez"]
player2["position"].iloc[0]
soccer.groupby("position").mean()
soccer["position"].nunique() # how many position we have
soccer["position"].value_counts()
soccer["club"].value_counts()
def find_word(last_name):
if "hi" in last_name.lower():
return True
return False
soccer[soccer["last_name"].apply(find_word)]
import matplotlib.pyplot as plt
clubCount = soccer["club"].value_counts()
print(clubCount)
plt.hist(clubCount, facecolor="blue", edgecolor="white", normed=True, bins=30)
plt.ylabel("clubCount")
plt.show()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
#
# # Understanding March Madness and what is this competition all about 🤔
# # Part 1
# 
# March brings one of the most awaited events for sports fans in the US — The **NCAA Women’s and Men’s Division 1 Tournament** aka **March madness**. This brings the sport of basketball into the spotlight and many basketball fanatics get into the work of predicting the winners and rooting for their favorites. Basketball is a fairly popular game in the US and is [ranked second to](https://en.wikipedia.org/wiki/Basketball_in_the_United_States) American football. However, for a person like me, who is born in India, my familiarity with March madness is on a lower side. Things would have been different if this were a competition for predicting [**IPL**](https://www.iplt20.com/) winners. The **Indian Premier League** (**IPL**) is a professional [**Twenty20 cricket**](https://en.wikipedia.org/wiki/Twenty20_cricket "Twenty20 cricket") league in [India](https://en.wikipedia.org/wiki/India "India") contested during March or April and May of every year by eight teams representing eight different cities in India. So, before exploring the dataset, I shall first explain the whole concept of NCAA March Madness and how the format is designed. Hopefully, this will help the people to actually understand a large amount of dataset and not be daunted by it.
# # **NCAA Division I Basketball Tournament**
#
# 
# This tournament is a knockout tournament where the loser is immediately eliminated from the tournament. Since it is mostly played in march, hence it has been accorded the title of **March Madness**. The first edition took place in 1939 and has been regularly held since then. the Women’s Championship was inaugurated in the 1981–82 season.
# # Format
# The male edition tournament comprises of **68** teams that compete in **7** rounds for the National Championship Title. However, the number of Teams in the Women’s edition is **64**.
# 
# ---
# # Selection
# The selection procedure takes place by two methods:
# 
# ## 1. Automatic
# 32 Teams get selected in this way.
# - Men’s Division 1 Team comprises of **353** Teams.
# 
# - Each one of those teams belongs to **32** [conferences](https://en.wikipedia.org/wiki/List_of_NCAA_conferences).
# 
# - Each of those conferences conducts a tournament and if a time wins the tournament, they get selected for the NCAA.
#
# ## 2. At Large
# The second selection process is called ‘At Large’ where The NCAA selection committee convenes at the final days of the regular season and decides which 36 teams which are not the Automatic qualifiers can be sent to the playoffs. This selection is based on multiple stats and rankings.
# ---
# ## Selection Sunday
# These “at-large” teams are announced in a nationally televised event on the Sunday preceding the [“First Four” play-in games](https://en.wikipedia.org/wiki/NCAA_Men%27s_Division_I_Basketball_Opening_Round_game "NCAA Men's Division I Basketball Opening Round game"). This Sunday is called ‘Selection Sunday and is on March 15.
# ## Seeding
# After all the 68(64 in case of Women), have been decided, the selection committee ranks them in a process called seeding where each team gets a ranking from 1 to 68. Then **First Four** play-in games are contested between teams holding the four lowest-seeded automatic bids and the four lowest-seeded at-large bids.
# The Teams are then split into 4 regions of 16 Teams each. Each team is now ranked from 1 to 16 in each region. After the [First Four](https://en.wikipedia.org/wiki/First_Four "First Four"), the tournament occurs during the course of three weekends, at pre-selected neutral sites across the United States. Here, the first round matches are determined by pitting the top team in the region with the lowest-seeded team in that region and so on. This ranking is the team’s seed.
# # March Madness Begins
# 
# ## First Round
# The First round consisting of 64 teams playing in 32 games over the course of a week. From here 32 teams emerge as winners and go on to the second round.
# ## Sweet Sixteen
# Next, the sweet sixteen round takes place, which sees the elimination of 16 teams. Rest of the 16 teams move forward.
# ## Elite Eight
# The next fight is for the Elite Eight as only 8 teams remain in the competition.
# ## Final Four
# 
# The penultimate round of the tournament where the 4 teams contest to reserve a place in the finals. Four teams, one from each region (East, South, Midwest, and West), compete in a preselected location for the national championship.
#
# ---
# # Who are Cinderellas?
# Upsets do happen in the tournament and sometimes the underdogs, who are seeded low, deliver an unexpected. They are called Cinderellas.
# So, this was a background behind the NCAA Baskerball tournament. Now let's have a look at the datasets provided.I shall be analysing the NCAA Division I Women's Basketball Tournament data. I assume the Men's tournament data should also be on the same lines.
# ---
# # Part 2
# ### Analysing NCAA Division I Women's Basketball Tournament Data
# Our goal is to use the historical data to understand "*what dictates the ability of a team to “stay in the game” and increase their chance to win late in the contest*?"
# Importing the libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import display
# The data that has been provided has been grouped under different sections. This is useful due to the large amount of data.The various groups are:
# * Basics
# * Team Box Scores
# * Geography
# * Public Rankings
# * Play by Play
# * Other Supplementary data
# It'll be prudent to go over every section to understand the nature of the data provided. In the coming days, I shall be doing exactly this and analysing which factors contribute towards better performance.
# ## Data Section 1- The Basics
# This includes the details about the Team, Seasons, Seeds Information,Game Results.
# ### 1. The Team
Wteams = pd.read_csv(
"../input/march-madness-analytics-2020/2020DataFiles/2020-Womens-Data/WDataFiles_Stage1/WTeams.csv"
)
Wteams.head()
# No of Teams
Wteams["TeamID"].nunique()
# > Team ID referes to the unique ID which identifies every team. There are 365 participating Women 's Teams.
# ### 2. Seasons
# The year in which the tournament was played.The current season counts as 2020.
Wseason = pd.read_csv(
"../input/march-madness-analytics-2020/2020DataFiles/2020-Womens-Data/WDataFiles_Stage1/WSeasons.csv"
)
Wseason.tail()
# Total held seasons including the current
Wseason["Season"].count()
# > There are 4 regions in the final tournament- X, W,X,Y and Z.
# ### 3. Seed Data
# This file identifies the seeds for all teams in each NCAA® tournament, for all seasons of historical data
Wseeds = pd.read_csv(
"../input/march-madness-analytics-2020/2020DataFiles/2020-Womens-Data/WDataFiles_Stage1/WNCAATourneySeeds.csv"
)
Wseeds.head()
# The Seed value consists of a 3 character Identifier. The first character denotes the region and the last two denote the seed in that region. Let's merge the Team's name from the Wteams file.
Wseeds = pd.merge(Wseeds, Wteams, on="TeamID")
Wseeds.head()
# Separating the regions from the Seeds
Wseeds["Region"] = Wseeds["Seed"].apply(lambda x: x[0][:1])
Wseeds["Seed"] = Wseeds["Seed"].apply(lambda x: int(x[1:3]))
print(Wseeds.head())
print(Wseeds.shape)
# Teams with maximum top seeds
colors = ["dodgerblue", "plum", "#F0A30A", "#8c564b", "orange", "green", "yellow"]
Wseeds[Wseeds["Seed"] == 1]["TeamName"].value_counts()[:10].plot(
kind="bar", color=colors, linewidth=2, edgecolor="black"
)
plt.xlabel("Number of times in Top seeded positions")
# Connecticut/UConn has been the top seeded team for the maximum no of times
# Teams with maximum lowest seeds
Wseeds[Wseeds["Seed"] == 16]["TeamName"].value_counts()[:10].plot(
kind="bar", color=colors, edgecolor="black", linewidth=1
)
plt.xlabel("Number of times in bottom seeded positions")
# Does being Top/ Lower seeding affect the tournament results? This is a question to be looked upon.
# ### 4. Regular Season Compact results
# This file identifies the game-by-game results for many seasons of historical data, starting with the 1998 season. There are 0 to 132 day numbers for selection of 64 teams.
#
rg_season_compact_results = pd.read_csv(
"../input/march-madness-analytics-2020/2020DataFiles/2020-Womens-Data/WDataFiles_Stage1/WRegularSeasonCompactResults.csv"
)
rg_season_compact_results.head()
# where
# * WScore - the numberof points scored by the winning team.
# * WTeamID - the id number of the team that won the game
# * LTeamID - the id number of the team that lost the game.
# * LScore - the number of points scored by the losing team.
#
# Winning and Losing score Average over the years
x = rg_season_compact_results.groupby("Season")[["WScore", "LScore"]].mean()
fig = plt.gcf()
fig.set_size_inches(14, 6)
plt.plot(
x.index,
x["WScore"],
marker="o",
markerfacecolor="green",
markersize=12,
color="green",
linewidth=4,
)
plt.plot(
x.index,
x["LScore"],
marker=7,
markerfacecolor="red",
markersize=12,
color="red",
linewidth=4,
)
plt.legend()
# ### 5.Tourney Compact Results
# This file identifies the game-by-game tournament results for all seasons of historical data.
tourney_compact_results = pd.read_csv(
"../input/march-madness-analytics-2020/2020DataFiles/2020-Womens-Data/WDataFiles_Stage1/WNCAATourneyCompactResults.csv"
)
tourney_compact_results.tail()
# This file is pretty similar to the previous file except that there are 63 games listed in all the seasons.Whereas for the regular season, it displays all the games played.
#
games_played = (
tourney_compact_results.groupby("Season")["DayNum"]
.count()
.to_frame()
.merge(
rg_season_compact_results.groupby("Season")["DayNum"].count().to_frame(),
on="Season",
)
)
games_played.rename(
columns={"DayNum_x": "Tournament Games", "DayNum_y": "Regular season games"}
)
# ### Is there a home team advantage?
ax = sns.countplot(x=tourney_compact_results["WLoc"])
ax.set_title("Win Locations")
ax.set_xlabel("Location")
ax.set_ylabel("Frequency")
# # Data Section 2- Team Box Scores
# This section provides game-by-game stats at a team level (free throws attempted, defensive rebounds, turnovers, etc.) for all regular season, conference tournament, and NCAA® tournament games since the 2009-10 season.
# ### 1.WNCAA Tourney Detailed Results.
# This file provides team-level box scores for many NCAA® tournaments, starting with the 2010 season
tourney_detailed_results = pd.read_csv(
"../input/march-madness-analytics-2020/2020DataFiles/2020-Womens-Data/WDataFiles_Stage1/WNCAATourneyDetailedResults.csv"
)
tourney_detailed_results.head()
tourney_detailed_results.columns
# Again let's checkput if there is a home team advantage in the tournaments?
ax = sns.countplot(x=tourney_detailed_results["WLoc"])
ax.set_title("Win Locations")
ax.set_xlabel("Location")
ax.set_ylabel("Frequency")
games_stats = []
for row in tourney_detailed_results.to_dict("records"):
game = {}
game["Season"] = row["Season"]
game["DayNum"] = row["DayNum"]
game["TeamID"] = row["WTeamID"]
game["OpponentID"] = row["LTeamID"]
game["Loc"] = row["WLoc"]
game["Won"] = 1
game["Score"] = row["WScore"]
game["FGA"] = row["WFGA"]
game["FGM3"] = row["WFGM3"]
game["FGA3"] = row["WFGA3"]
game["FTM"] = row["WFTM"]
game["FTA"] = row["WFTA"]
game["OR"] = row["WOR"]
game["DR"] = row["WDR"]
game["AST"] = row["WAst"]
game["TO"] = row["WTO"]
game["STL"] = row["WStl"]
game["BLK"] = row["WBlk"]
game["PF"] = row["WPF"]
games_stats.append(game)
game = {}
game["Season"] = row["Season"]
game["DayNum"] = row["DayNum"]
game["TeamID"] = row["LTeamID"]
game["OpponentID"] = row["WTeamID"]
game["Loc"] = row["WLoc"]
game["Won"] = 0
game["Score"] = row["LScore"]
game["FGA"] = row["LFGA"]
game["FGM3"] = row["LFGM3"]
game["FGA3"] = row["LFGA3"]
game["FTM"] = row["LFTM"]
game["FTA"] = row["LFTA"]
game["OR"] = row["LOR"]
game["DR"] = row["LDR"]
game["AST"] = row["LAst"]
game["TO"] = row["LTO"]
game["STL"] = row["LStl"]
game["BLK"] = row["LBlk"]
game["PF"] = row["LPF"]
games_stats.append(game)
# Separating winners from losers for clarity
tournament = pd.DataFrame(games_stats)
tournament.head()
tournament = tournament.set_index(["Season", "TeamID", "OpponentID"])["Won"].to_frame()
tournament
|
# # Introduction
# This notebook shows how to use the [Google's Translation API](https://cloud.google.com/translate) to translate review texts from a popular dataset from English to German. To do so, we're
# - Using a user-defined secret to store a service account credential within Kaggle (and provide it to the API from within Kernels). If you're forking this Kernel, you have to provide your own
# - Install the necessary packages
# - Initialize the API client and wrap the call in a function
# - Read the input CSV
# - Row by row, call the Translation API and populate a new column to our data
# - Write down the results data
# (this naively calls the Translation API row by row. For better performance, use it in [batch mode](https://cloud.google.com/translate/docs/advanced/batch-translation))
#
# Install packages
# Handle credentials
import json
from google.oauth2 import service_account
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value = user_secrets.get_secret("translation-playground")
service_account_info = json.loads(secret_value)
credentials = service_account.Credentials.from_service_account_info(
service_account_info
)
# Setup client & translation function
from google.cloud import translate_v2 as translate
translate_client = translate.Client(credentials=credentials)
def translate(text, target_lang, source_lang="en"):
try:
result = translate_client.translate(
text, target_language=target_lang, source_language=source_lang
)
return result["translatedText"]
except:
return ""
# Test it
print(translate("This is a very nice text to translate", "de"))
import pandas as pd
data = pd.read_csv(
"../input/womens-ecommerce-clothing-reviews/Womens Clothing E-Commerce Reviews.csv"
)
data.head()
# data = data[:10]
data["Review Text DE"] = data.apply(
lambda row: translate(row["Review Text"], "de"), axis=1
)
data.head()
data.to_csv("/kaggle/working/Reviews_DE.csv")
|
# # Introduction
# *The dataset is about amusement park roller coasters around the world. The data contains information about roller coasters like location, manufacturer, speed, height, length, and duration of the ride.*
# > **Index**
# **Data Wrangling:**
# In the initial data wrangling steps, the dataset was loaded into a pandas dataframe. The dataframe was explored for missing values, duplicates and data types. The data was then cleaned and transformed by changing data types, renaming columns, dropping duplicates and replacing values.
# **Exploratory Data Analysis:**
# Several data visualization techniques were used to explore the data. Histogram, KDE plot and scatter plot were used to understand the distribution of data. Bar plots and heat maps were used to visualize the relationship between variables.
# **Conclusion:**
# In conclusion, the analysis of the roller coaster dataset provides insights into the characteristics of the rides around the world. The analysis can be used to understand the trends in roller coaster design, identify the best rides, and provide recommendations for improving the amusement park experience.
# # Data Wrangling
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import seaborn as sns
pd.set_option("max_columns", 200)
# * This code imports several useful libraries for data analysis and visualization in Python.
# * numpy (imported as np) is a popular library for numerical computing in Python. pandas (imported as pd) is a library for data manipulation and analysis. matplotlib.pylab (imported as plt) is a plotting library for creating visualizations in Python. seaborn is a library built on top of matplotlib that provides additional functionality for creating more advanced and aesthetically pleasing visualizations.
# * The last line of code (pd.set_option('max_columns', 200)) sets the maximum number of columns displayed when printing a pandas DataFrame to 200. This is a useful setting when working with large datasets with many columns, as it allows you to see more of the data without truncation.
filePath = "/kaggle/input/rollercoaster-database/coaster_db.csv"
# Load the dataset
df = pd.read_csv(filePath)
df.head()
# * This code reads in a CSV file located at the specified file path (/kaggle/input/rollercoaster-database/coaster_db.csv) using pandas library's read_csv() function and assigns it to a DataFrame object called df.
# * Overall, this code is useful for reading in and exploring data stored in a CSV file using pandas library in Python.
df.shape
df.columns
# Drop unnecessary columns
df = df[
[
"coaster_name",
#'Length', 'Speed',
"Location",
"Status",
#'Opening date', 'Type',
"Manufacturer",
#'Height restriction', 'Model', 'Height',
#'Inversions', 'Lift/launch system', 'Cost', 'Trains', 'Park section',
#'Duration', 'Capacity', 'G-force', 'Designer', 'Max vertical angle',
#'Drop', 'Soft opening date', 'Fast Lane available', 'Replaced',
#'Track layout', 'Fastrack available', 'Soft opening date.1',
#'Closing date', 'Opened', 'Replaced by', 'Website',
#'Flash Pass Available', 'Must transfer from wheelchair', 'Theme',
#'Single rider line available', 'Restraint Style',
#'Flash Pass available', 'Acceleration', 'Restraints', 'Name',
"year_introduced",
"latitude",
"longitude",
"Type_Main",
"opening_date_clean",
#'speed1', 'speed2', 'speed1_value', 'speed1_unit',
"speed_mph",
#'height_value', 'height_unit',
"height_ft",
"Inversions_clean",
"Gforce_clean",
]
].copy()
# * This code is using pandas library in Python to manipulate a DataFrame object called df.
# * The code selects a subset of columns from df using a list of column names and assigns the resulting DataFrame to df.
# * All other columns from the original df are commented out and not selected.
# * The copy() method is called on the resulting DataFrame to create a new copy of the DataFrame with only the selected columns. This is done to prevent changes made to the new DataFrame from affecting the original df.
# * Overall, this code is useful for selecting specific columns from a DataFrame object in Python using pandas library and creating a new copy of the resulting DataFrame.
df.head()
df.shape
# Impute missing values
df.isna().sum()
# * Calling df.isna().sum() is useful to quickly identify the number of missing values in each column of a DataFrame. This can be important for performing data cleaning and preprocessing tasks, such as imputing missing values or removing rows with missing values.
# * Overall, this code is useful for checking the presence of missing values in a DataFrame object in Python using pandas library.
# Drop null values
df.dropna(subset=["Status"], inplace=True)
mask = df["Manufacturer"].isna()
# Fill null values
df.loc[mask, "Manufacturer"] = "Other"
df[mask]
df.info()
df.Status.unique()
# Clean the data
df["Status"].replace(
[
"Removed",
"Closed",
#'Operating',
"Not Currently Operating",
#'In Production',
"Discontinued",
"closed for maintenance as of july 30 no reopening date known",
"Closed in 2021",
"SBNO December 2019",
#'Under construction',
"Temporarily Closed",
"SBNO (Standing But Not Operating)",
"Temporarily closed",
"Chapter 7 bankruptcy; rides dismantled and sold; property sold",
#'Under Maintenance'
],
"Not Operating",
inplace=True,
)
# * This code replaces multiple values in the 'Status' column of the DataFrame object df using the replace() method. The first argument to replace() is a list of the values to be replaced, and the second argument is the value to replace them with.
# * Replacing values in a column is a common data preprocessing step in data analysis and modeling. It can be used to consolidate categories, correct misspellings, or otherwise clean and standardize data before analysis.
# * Overall, this code is useful for replacing multiple values in a column of a DataFrame object in Python using pandas library.
df["Status"].unique()
df.Status.replace(
[ #'Not Operating', 'Operating',
"In Production",
"Under construction",
"Under Maintenance",
],
"Under Production/Maintenance",
inplace=True,
)
# Change to proper data type
df["Status"] = df["Status"].astype("category")
# * This code changes the data type of the 'Status' column in the DataFrame object df to a categorical data type using the astype() method. The argument passed to astype() is the string 'category', which specifies that the 'Status' column should be converted to a categorical data type.
# * Categorical data types are useful for working with columns that have a small number of unique values, such as the 'Status' column in this DataFrame. Categorical data types can make certain operations, such as grouping and aggregating data, faster and more memory-efficient. They can also be useful for preserving the order of categories and reducing the memory footprint of a DataFrame.
# * Overall, this code is useful for changing the data type of a column to a categorical data type in a DataFrame object in Python using the astype() method from the pandas library.
df["opening_date_clean"] = pd.to_datetime(df["opening_date_clean"])
# * This code converts the 'opening_date_clean' column in the DataFrame object df from a string data type to a datetime data type using the to_datetime() method from the pandas library. The result is that each value in the 'opening_date_clean' column is now a datetime object, which allows for easier manipulation and analysis of the data.
# * Datetime objects in Python represent dates and times as values that can be manipulated mathematically, and have many useful methods and properties for working with dates and times. By converting the 'opening_date_clean' column to a datetime data type, we can use these methods and properties to perform tasks such as filtering by dates, calculating time differences, and extracting date components (e.g. year, month, day) for analysis.
# * Overall, this code is useful for converting a column of dates in string format to a datetime format in a DataFrame object in Python using the to_datetime() method from the pandas library.
df.info()
df.columns
# Rename columns
df.rename(
columns={
"coaster_name": "Coaster_Name",
"year_introduced": "Year_Introduced",
"latitude": "Latitude",
"longitude": "Longitude",
"opening_date_clean": "Opening_Date",
"speed_mph": "Speed_mph",
"height_ft": "Height_ft",
"Inversions_clean": "Inversions",
"Gforce_clean": "Gforce",
},
inplace=True,
)
# * By convention, renaming columns is done to have a more readable and standardized format for column names, and the new names reflect the content of the corresponding columns more accurately.
df.head()
# Check for duplicate data
df.loc[df.duplicated()]
df.loc[df["Coaster_Name"].duplicated()]
df.query('Coaster_Name == "Crystal Beach Cyclone"')
df.columns
# Remove duplicated data
df = df.loc[
~df.duplicated(
subset=[
"Coaster_Name",
"Location",
"Status",
"Manufacturer",
"Opening_Date",
"Type_Main",
]
)
].reset_index(drop=True)
# * This code drops duplicate rows in the df dataframe based on a subset of columns, namely 'Coaster_Name', 'Location', 'Status', 'Manufacturer', 'Opening_Date', and 'Type_Main'. The ~ symbol in front of the df.duplicated() function returns a boolean array indicating which rows are not duplicates, so the loc function filters out the duplicated rows and a new dataframe without duplicates is created using the reset_index() method. The drop=True parameter ensures that the original index is dropped and a new one is created.
df.info()
# # Exploratory Data Analysis
# Explore the data with visualization
# Top 10 years coasters introduced
ax = (
df["Year_Introduced"]
.value_counts()
.head(10)
.sort_index()
.plot(kind="bar", title="Top 10 Years Coasters Introduced")
)
ax.set_xlabel("Year Introduced")
ax.set_ylabel("Count")
plt.show()
# * This code will produce a horizontal bar chart with the top 10 years on the y-axis and the count of coasters on the x-axis. The sort_index() method is used to sort the years in ascending order.
# Coaster speed
ax = df["Speed_mph"].plot(kind="hist", bins=20, title="Coaster Speed (mph)")
ax.set_xlabel("Speed (mph)")
plt.show()
# * This histogram shows the distribution of coaster speed in miles per hour.
ax = df["Speed_mph"].plot(kind="kde", title="Coaster Speed (mph)")
ax.set_xlabel("Speed (mph)")
plt.show()
# Coaster speed vs height
df.plot(kind="scatter", x="Speed_mph", y="Height_ft", title="Coaster Speed vs Height")
plt.show()
# * The scatter plot shows a weak positive correlation between coaster speed and height, with some outliers having high speeds and low heights, and vice versa. However, there are a lot of points clustered at the lower end of both variables, indicating that most coasters tend to have relatively modest speeds and heights.
sns.scatterplot(x="Speed_mph", y="Height_ft", hue="Year_Introduced", data=df)
plt.show()
# Pairplot
sns.pairplot(
data=df,
vars=["Year_Introduced", "Speed_mph", "Height_ft", "Inversions", "Gforce"],
hue="Type_Main",
)
plt.show()
# *The pairplot gives us an idea of the relationship between different variables in the dataset. From the plot, we can see the following:*
# * Coasters with high speed usually have high heights and more inversions.
# * Most of the coasters in the dataset have less than 5 inversions.
# * Most of the coasters in the dataset have less than 6 g-forces.
# * Steel coasters tend to have higher speeds, heights, and inversions compared to wooden coasters.
# * Overall, the plot shows that there are some variables that have a strong relationship with each other, while others have little to no relationship.
# Heatmap correlation
df_corr = (
df[["Year_Introduced", "Speed_mph", "Height_ft", "Inversions", "Gforce"]]
.dropna()
.corr()
)
sns.heatmap(df_corr, annot=True)
plt.show()
# * The heatmap shows that there is a positive correlation between coaster speed and height, and a negative correlation between coaster speed and year introduced, which makes sense. Also, there is a positive correlation between coaster height and year introduced, which could mean that as technology and construction techniques improve, coasters are able to reach greater heights.
# # Conclusion
# Average coaster speed by location
ax = (
df.query('Location != "Other"')
.groupby("Location")["Speed_mph"]
.agg(["mean", "count"])
.query("count >= 10")
.sort_values("mean")["mean"]
.plot(kind="barh", figsize=(12, 5), title="Average Coaster Speed by Location")
)
ax.set_xlabel("Average Coaster Speed")
plt.show()
|
# **This kernel uses fgcnn model from deepctr package**
# **fgcnn :** [fgcnn using deepctr](https://deepctr-doc.readthedocs.io/en/v0.7.0/deepctr.models.fgcnn.html)
# code forked from https://www.kaggle.com/siavrez/deepfm-model
from deepctr.inputs import SparseFeat, DenseFeat, get_feature_names
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.optimizers import Adam, RMSprop
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras import backend as K
from tensorflow.keras import callbacks
from tensorflow.keras import utils
from deepctr.models import *
from deepctr.models.fgcnn import FGCNN
from deepctr.models.nffm import NFFM
import tensorflow.keras as keras
import tensorflow as tf
import pandas as pd
import numpy as np
import warnings
warnings.simplefilter("ignore")
train = pd.read_csv("../input/cat-in-the-dat-ii/train.csv")
test = pd.read_csv("../input/cat-in-the-dat-ii/test.csv")
test["target"] = -1
data = pd.concat([train, test]).reset_index(drop=True)
data["null"] = data.isna().sum(axis=1)
sparse_features = [feat for feat in train.columns if feat not in ["id", "target"]]
data[sparse_features] = data[sparse_features].fillna(
"-1",
)
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat].fillna("-1").astype(str).values)
train = data[data.target != -1].reset_index(drop=True)
test = data[data.target == -1].reset_index(drop=True)
fixlen_feature_columns = [
SparseFeat(feat, data[feat].nunique()) for feat in sparse_features
]
dnn_feature_columns = fixlen_feature_columns
linear_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
def auc(y_true, y_pred):
def fallback_auc(y_true, y_pred):
try:
return roc_auc_score(y_true, y_pred)
except:
return 0.5
return tf.py_function(fallback_auc, (y_true, y_pred), tf.double)
class CyclicLR(keras.callbacks.Callback):
def __init__(
self,
base_lr=0.001,
max_lr=0.006,
step_size=2000.0,
mode="triangular",
gamma=1.0,
scale_fn=None,
scale_mode="cycle",
):
super(CyclicLR, self).__init__()
self.base_lr = base_lr
self.max_lr = max_lr
self.step_size = step_size
self.mode = mode
self.gamma = gamma
if scale_fn == None:
if self.mode == "triangular":
self.scale_fn = lambda x: 1.0
self.scale_mode = "cycle"
elif self.mode == "triangular2":
self.scale_fn = lambda x: 1 / (2.0 ** (x - 1))
self.scale_mode = "cycle"
elif self.mode == "exp_range":
self.scale_fn = lambda x: gamma ** (x)
self.scale_mode = "iterations"
else:
self.scale_fn = scale_fn
self.scale_mode = scale_mode
self.clr_iterations = 0.0
self.trn_iterations = 0.0
self.history = {}
self._reset()
def _reset(self, new_base_lr=None, new_max_lr=None, new_step_size=None):
"""Resets cycle iterations.
Optional boundary/step size adjustment.
"""
if new_base_lr != None:
self.base_lr = new_base_lr
if new_max_lr != None:
self.max_lr = new_max_lr
if new_step_size != None:
self.step_size = new_step_size
self.clr_iterations = 0.0
def clr(self):
cycle = np.floor(1 + self.clr_iterations / (2 * self.step_size))
x = np.abs(self.clr_iterations / self.step_size - 2 * cycle + 1)
if self.scale_mode == "cycle":
return self.base_lr + (self.max_lr - self.base_lr) * np.maximum(
0, (1 - x)
) * self.scale_fn(cycle)
else:
return self.base_lr + (self.max_lr - self.base_lr) * np.maximum(
0, (1 - x)
) * self.scale_fn(self.clr_iterations)
def on_train_begin(self, logs={}):
logs = logs or {}
if self.clr_iterations == 0:
K.set_value(self.model.optimizer.lr, self.base_lr)
else:
K.set_value(self.model.optimizer.lr, self.clr())
def on_batch_end(self, epoch, logs=None):
logs = logs or {}
self.trn_iterations += 1
self.clr_iterations += 1
K.set_value(self.model.optimizer.lr, self.clr())
target = ["target"]
N_Splits = 20
Epochs = 10
SEED = 2020
oof_pred_deepfm = np.zeros((len(train),))
y_pred_deepfm = np.zeros((len(test),))
skf = StratifiedKFold(n_splits=N_Splits, shuffle=True, random_state=SEED)
for fold, (tr_ind, val_ind) in enumerate(skf.split(train, train[target])):
X_train, X_val = (
train[sparse_features].iloc[tr_ind],
train[sparse_features].iloc[val_ind],
)
y_train, y_val = train[target].iloc[tr_ind], train[target].iloc[val_ind]
train_model_input = {name: X_train[name] for name in feature_names}
val_model_input = {name: X_val[name] for name in feature_names}
test_model_input = {name: test[name] for name in feature_names}
model = NFFM(linear_feature_columns, dnn_feature_columns)
model.compile(
"adam",
"binary_crossentropy",
metrics=[auc],
)
es = callbacks.EarlyStopping(
monitor="val_auc",
min_delta=0.0001,
patience=2,
verbose=1,
mode="max",
baseline=None,
restore_best_weights=True,
)
sb = callbacks.ModelCheckpoint(
"./nn_model.w8", save_weights_only=True, save_best_only=True, verbose=0
)
clr = CyclicLR(
base_lr=0.00001 / 100,
max_lr=0.0001,
step_size=int(1.0 * (test.shape[0]) / 1024),
mode="exp_range",
gamma=1.0,
scale_fn=None,
scale_mode="cycle",
)
history = model.fit(
train_model_input,
y_train,
validation_data=(val_model_input, y_val),
batch_size=512,
epochs=Epochs,
verbose=1,
callbacks=[es, sb, clr],
)
model.load_weights("./nn_model.w8")
val_pred = model.predict(val_model_input, batch_size=512)
print(f"validation AUC fold {fold+1} : {round(roc_auc_score(y_val, val_pred), 5)}")
oof_pred_deepfm[val_ind] = val_pred.ravel()
y_pred_deepfm += model.predict(test_model_input, batch_size=512).ravel() / (
N_Splits
)
K.clear_session()
print(f"OOF AUC : {round(roc_auc_score(train.target.values, oof_pred_deepfm), 5)}")
test_idx = test.id.values
submission = pd.DataFrame.from_dict({"id": test_idx, "target": y_pred_deepfm})
submission.to_csv("submission.csv", index=False)
print("Submission file saved!")
np.save("oof_pred_deepfm.npy", oof_pred_deepfm)
np.save("y_pred_deepfm.npy", y_pred_deepfm)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)+
import matplotlib.pyplot as plt
import re
import re
from sklearn.ensemble import RandomForestClassifier
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
women = train_data.loc[train_data.Sex == "female"]["Survived"]
rate_women = sum(women) / len(women)
print("% of women who survived:", rate_women)
men = train_data.loc[train_data.Sex == "male"]["Survived"]
rate_men = sum(men) / len(men)
print("% of men who survived:", rate_men)
train_data.drop("PassengerId", axis=1, inplace=True)
train_data.describe()
fig = plt.figure(figsize=(10, 4))
fig.add_subplot(121)
train_data.Survived[train_data["Sex"] == "male"].value_counts().plot(kind="pie")
fig.add_subplot(122)
train_data.Survived[train_data["Sex"] == "female"].value_counts().plot(kind="pie")
from sklearn.preprocessing import LabelEncoder
train_data["Sex"] = LabelEncoder().fit_transform(train_data["Sex"])
train_data["Name"] = train_data["Name"].map(
lambda x: x.split(",")[1].split(".")[0].strip()
)
titles = train_data["Name"].unique()
titles
train_data["Age"].fillna(-1, inplace=True)
medians = dict()
for title in titles:
median = train_data.Age[
(train_data["Age"] != -1) & (train_data["Name"] == title)
].median()
medians[title] = median
for index, row in train_data.iterrows():
if row["Age"] == -1:
train_data.loc[index, "Age"] = medians[row["Name"]]
train_data.head()
replacement = {
"Don": 0,
"Rev": 0,
"Jonkheer": 0,
"Capt": 0,
"Mr": 1,
"Dr": 2,
"Col": 3,
"Major": 3,
"Master": 4,
"Miss": 5,
"Mrs": 6,
"Mme": 7,
"Ms": 7,
"Mlle": 7,
"Sir": 7,
"Lady": 7,
"the Countess": 7,
}
train_data["Name"] = train_data["Name"].apply(lambda x: replacement.get(x))
from sklearn.preprocessing import StandardScaler
train_data["Name"] = StandardScaler().fit_transform(
train_data["Name"].values.reshape(-1, 1)
)
train_data.head()
train_data["Age"] = StandardScaler().fit_transform(
train_data["Age"].values.reshape(-1, 1)
)
train_data["Fare"].fillna(-1, inplace=True)
medians = dict()
for pclass in train_data["Pclass"].unique():
median = train_data.Fare[
(train_data["Fare"] != -1) & (train_data["Pclass"] == pclass)
].median()
medians[pclass] = median
for index, row in train_data.iterrows():
if row["Fare"] == -1:
train_data.loc[index, "Fare"] = medians[row["Pclass"]]
train_data["Fare"] = StandardScaler().fit_transform(
train_data["Fare"].values.reshape(-1, 1)
)
train_data["Pclass"] = StandardScaler().fit_transform(
train_data["Pclass"].values.reshape(-1, 1)
)
replacement = {6: 0, 4: 0, 5: 1, 0: 2, 2: 3, 1: 4, 3: 5}
train_data["Parch"] = train_data["Parch"].apply(lambda x: replacement.get(x))
train_data["Parch"] = StandardScaler().fit_transform(
train_data["Parch"].values.reshape(-1, 1)
)
train_data.drop("Ticket", axis=1, inplace=True)
train_data.head()
train_data["Embarked"].value_counts()
train_data["Embarked"].fillna("S", inplace=True)
train_data.head()
replacement = {"S": 0, "Q": 1, "C": 2}
train_data["Embarked"] = train_data["Embarked"].apply(lambda x: replacement.get(x))
train_data["Embarked"] = StandardScaler().fit_transform(
train_data["Embarked"].values.reshape(-1, 1)
)
train_data.head()["Embarked"]
train_data["SibSp"].unique()
replacement = {5: 0, 8: 0, 4: 1, 3: 2, 0: 3, 2: 4, 1: 5}
train_data["SibSp"] = train_data["SibSp"].apply(lambda x: replacement.get(x))
train_data["SibSp"] = StandardScaler().fit_transform(
train_data["SibSp"].values.reshape(-1, 1)
)
train_data.head()["SibSp"]
train_data["Cabin"].fillna("U", inplace=True)
train_data["Cabin"] = train_data["Cabin"].apply(lambda x: x[0])
train_data["Cabin"].unique()
replacement = {"T": 0, "U": 1, "A": 2, "G": 3, "C": 4, "F": 5, "B": 6, "E": 7, "D": 8}
train_data["Cabin"] = train_data["Cabin"].apply(lambda x: replacement.get(x))
train_data["Cabin"] = StandardScaler().fit_transform(
train_data["Cabin"].values.reshape(-1, 1)
)
train_data.head()["Cabin"]
train_data.head()
from sklearn.model_selection import train_test_split
train_data.head()
# survived = train_data['Survived']
# train_data.drop('Survived', axis=1, inplace=True)
# X_train, X_test, y_train, y_test = train_test_split(train_data, survived, test_size=0.2, random_state=42)
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
models = [
RandomForestClassifier(n_estimators=100),
MLPClassifier(),
]
for model in models:
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print(score)
|
# # US Accidents Exploratory Data Analysis
import pandas as pd
import numpy as np
import seaborn as sns
# # Data Preparation and Cleaning
# 1. Load the file
# 2. Look at the information about data
# 3. Fix any missing or incorrect values
df = pd.read_csv("/kaggle/input/us-accidents/US_Accidents_Dec21_updated.csv")
df
df.info()
df.describe()
# Looking for missing values
missing_percentages = df.isna().sum().sort_values(ascending=False) / len(df)
missing_percentages
type(missing_percentages)
missing_percentages[missing_percentages != 0]
# Here we will select only those columns which have missing values
missing_percentages[missing_percentages != 0].plot(kind="barh")
# # Exploratory Analysis and Visualization
# We will analyze following columns
# 1. City
# 2. Start Time
# ### City
df.columns
df.City
unique_cities = df.City.unique()
len(unique_cities)
cities_by_accidents = df.City.value_counts()
cities_by_accidents
cities_by_accidents[:20]
"New York" in df.City
"New York" in df.State
"ny" in df.State
sns.set_style("darkgrid")
# So, we can see there is no data related to new york city or new york state in dataset
cities_by_accidents[:20].plot(kind="barh")
sns.histplot(cities_by_accidents, log_scale=True)
cities_by_accidents[cities_by_accidents == 1]
# 1110 cities reported only 1 accident, this less data is of no use
high_accident_cities = cities_by_accidents[cities_by_accidents >= 1000]
low_accident_cities = cities_by_accidents[cities_by_accidents < 1000]
len(high_accident_cities) / len(unique_cities)
# Around 4% of all cities have more than 1000 accidents in dataset
sns.distplot(high_accident_cities)
sns.distplot(low_accident_cities)
# ### Start Time
df.Start_Time
df.Start_Time = pd.to_datetime(df.Start_Time)
df.Start_Time
sns.distplot(df.Start_Time.dt.hour, bins=24, kde=False, norm_hist=True)
# Mostly accidents are happening between 2pm and 7pm
sns.distplot(df.Start_Time.dt.dayofweek, bins=7, kde=False, norm_hist=True)
# Mostly accidents are happening on working days
# Now let's see accidents on Sundays
sundays_start_time = df.Start_Time[df.Start_Time.dt.dayofweek == 6]
sns.distplot(sundays_start_time.dt.hour, bins=24, kde=False, norm_hist=True)
# To see accidents distribution by month
sns.distplot(df.Start_Time.dt.month, bins=12, kde=False, norm_hist=True)
|
import pandas as pd
import numpy as np # linear algebra
import seaborn as sns
import matplotlib.pyplot as plt
# Comment this if the data visualisations doesn't work on your side
plt.style.use("bmh")
dsall = pd.read_csv(
"../input/from-sas-01/Houses5_CategsAsCols_MissingMedianReplaced.csv"
)
dstr = dsall.loc[dsall["scenario_train"] == 1]
dste = dsall.loc[dsall["scenario_test"] == 0]
non_features = ["Id", "SalePrice", "scenario_train", "scenario_train"]
xkeys = [key for key in dstr.keys() if key not in non_features]
print(f"we have {len(xkeys)} features. wow")
# prepare the data for training
from sklearn.model_selection import train_test_split
X = dstr[xkeys].values
dfy = (dstr[["SalePrice"]] * 10).astype(int)
print(dfy.describe())
y = dfy.values
print("y shape", y.shape)
print("y dtype", y.dtype)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.333, random_state=42
)
print("shapes", X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# crossvalidate the max depth for the random forest classifier
from sklearn import ensemble
mds = [None, 1, 2, 3, 10, 100, 200]
data = []
for md in mds:
scores = []
ns = range(100)
for n in ns:
clf = ensemble.RandomForestClassifier(max_depth=md, n_estimators=1)
clf.fit(X_train, y_train.ravel())
s = clf.score(X_test, y_test.ravel())
scores.append(s)
data.append(scores)
plt.boxplot(data, labels=["None", "1", "2", "3", "10", "100", "200"])
plt.title("'max_depth' crossvalidation")
plt.show()
ests = [1, 2, 3, 10, 20, 50]
data = []
for est in ests:
scores = []
ns = range(100)
for n in ns:
clf = ensemble.RandomForestClassifier(max_depth=1, n_estimators=est)
clf.fit(X_train, y_train.ravel())
s = clf.score(X_test, y_test.ravel())
scores.append(s)
data.append(scores)
plt.boxplot(data, labels=ests)
plt.title("'n_estimators' crossvalidation")
plt.show()
# create the submission
import math
clf = ensemble.RandomForestClassifier(max_depth=1, n_estimators=1)
clf.fit(X, y.ravel())
y_pred = np.exp(clf.predict(dste[xkeys].values) / 10.0)
dspred = pd.DataFrame(y_pred)
print(dspred.describe())
print(dspred)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import torch
import torch.nn as nn
import torch.nn.functional as F
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# load in the 28x28 images
train = pd.read_csv("/kaggle/input/digit-recognizer/train.csv")
labels = train["label"]
train = train.drop(["label"], axis=1)
tensor = torch.Tensor(train.values)
tensor.shape
train_data = tensor.reshape(-1, 1, 28, 28)
# Define the classifier. will use a strided But 7x7 conv followed by two 3x3 convs to save on number of parameters
class CNNClassifier(nn.Module):
def __init__(self):
super().__init__()
self.c1 = nn.Conv2d(1, 4, kernel_size=7, stride=2)
self.c2 = nn.Conv2d(4, 8, kernel_size=3)
self.c3 = nn.Conv2d(8, 16, kernel_size=3)
self.lin = nn.Linear(16, 10)
self.b1 = nn.BatchNorm2d(4)
self.b2 = nn.BatchNorm2d(16)
self.b3 = nn.BatchNorm2d(10)
def forward(self, x):
# pass through the conv net
x = F.relu(self.b1(self.c1(x)))
x = F.relu(self.b2(self.c3(self.c2(x))))
# make a prediction
x = self.lin(x.mean(dim=[2, 3]))
# return torch.argmax(x, dim=1) // apparently CrossEntropyLoss takes care of the vector... totally forgot
return x
# Training loop
# init the model
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(device)
model = CNNClassifier().to(device)
data_loader = torch.utils.data.DataLoader(
[x for x in zip(train_data, labels)], batch_size=256
)
# some basic hyper parameters
e = 30
learning_rate = 1e-3
# define the loss and optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
loss = nn.CrossEntropyLoss()
global_step = 0
for epoch in range(e):
model.train()
for img, label in data_loader:
img, label = img.to(device), label.to(device)
res = model(img)
loss_val = loss(res, label)
optimizer.zero_grad()
loss_val.backward()
optimizer.step()
if global_step % 256 == 0:
print(loss_val)
global_step += 1
# evaluate the model
model.eval()
test = pd.read_csv("/kaggle/input/digit-recognizer/test.csv")
test.head()
test_tensor = torch.Tensor(test.values)
test_ = test_tensor.reshape(-1, 1, 28, 28)
test_data = torch.utils.data.DataLoader(test_, batch_size=1)
import matplotlib.pyplot as plt
predictions = []
image_id = []
i = 0
for image in test_data:
res = model(image.to(device))
predictions.append(torch.argmax(res).item())
img = image.reshape(28, 28)
# imgplot = plt.imshow(img.numpy(), cmap='gray')
# plt.show()
# print(predictions)
# need the image id for the submission format
i += 1
image_id.append(i)
df = pd.DataFrame({"ImageId": image_id, "Label": predictions})
df.to_csv("/kaggle/working/submission.csv", index=False)
|
from pathlib import Path
import os
data_path = Path("/kaggle/input/abstraction-and-reasoning-challenge/")
training_path = data_path / "training"
evaluation_path = data_path / "evaluation"
test_path = data_path / "test"
training_tasks = list(training_path.glob("*"))
evaluation_tasks = list(evaluation_path.glob("*"))
test_tasks = list(test_path.glob("*"))
# ### How many colors are there?
import numpy as np
def get_color_set(img):
return set(np.array(img).flatten())
def get_task_color_set(task):
s = set()
for problems in task.values():
for problem in problems:
try:
in_, out_ = problem.values()
s.update(get_color_set(in_))
s.update(get_color_set(out_))
except ValueError:
(in_,) = problem.values()
s.update(get_color_set(in_))
return s
import json
from tqdm import tqdm_notebook
task_files = training_tasks
color_set = set()
for task_files in [training_tasks, evaluation_tasks, test_tasks]:
for task_file in tqdm_notebook(task_files):
with open(task_file, "r") as f:
task = json.load(f)
color_set.update(get_task_color_set(task))
print(f"Total color labels used: {len(color_set)}.")
print(f"Color set: {color_set}")
# It seems there are only 10 colors overall. This means they can be potentially treated as classification targets.
# ### How frequently are the output colors not the same as input colors across tasks?
def has_color_difference(task):
s_in, s_out = set(), set()
for problems in task.values():
for problem in problems:
in_, out_ = problem.values()
s_in.update(get_color_set(in_))
s_out.update(get_color_set(out_))
if len(s_in.difference(s_out)) > 0:
return True
return False
diff_vector = []
for task_files in [training_tasks, evaluation_tasks]:
for task_file in tqdm_notebook(task_files):
with open(task_file, "r") as f:
task = json.load(f)
diff_vector.append(has_color_difference(task))
diff_vector = np.array(diff_vector)
print(
f"{diff_vector.mean() * 100} % of tasks have different colors in the output from the ones in the input."
)
# ### What is the distribution of the colors across all tasks?
def get_color_count(task):
s = get_task_color_set(task)
color_counts = np.zeros(10)
for c in s:
color_counts[c] += 1
return color_counts
count_vector = np.zeros(10)
for task_files in [training_tasks, evaluation_tasks, test_tasks]:
for task_file in tqdm_notebook(task_files):
with open(task_file, "r") as f:
task = json.load(f)
count_vector += get_color_count(task)
color_dist = count_vector / count_vector.sum()
import seaborn as sns
sns.barplot(np.arange(10), color_dist)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# Install libraries that are needed.
# This analysis will use data from the following study: https://www.cell.com/cell/fulltext/S0092-8674(15)01195-2/. It contains omics data from 705 breast cancer patients.
# Open the dataset
df = pd.read_csv("/kaggle/input/brca-multiomics-tcga/brca_data_w_subtypes.csv")
# Let's print the head of the dataframe and look at the contents of the matrix
print(df.head())
# Our MO data contains four types of omics, each columns' name starting with either:
# mu: Whether a sonamic mutation (i.e., a mutation that happened after conception) is present for a gene.
# cn: Copy number of a part of the genome (i.e., amount of amplification of a part of the genome, this changes between different cells and individuals).
# rs: RNA-Seq.
# pp: Protein levels.
# Additionally, we have the type of information about the patient's survival and tumour type.
# Let's separate each omics into its own dataframe for more clarity.
outcomes = df[
["vital.status", "PR.Status", "ER.Status", "HER2.Final.Status", "histological.type"]
]
df_mu = df[[col for col in df if col.startswith("mu")]]
df_cn = df[[col for col in df if col.startswith("cn")]]
df_rs = df[[col for col in df if col.startswith("rs")]]
df_pp = df[[col for col in df if col.startswith("pp")]]
# Import libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Calculate Pearson's correlation coefficients between copy number and RNA-seq data
correlation_matrix = np.corrcoef(df_cn, df_rs, rowvar=False)[
: df_cn.shape[1], df_cn.shape[1] :
]
# Create a dataframe from the correlation matrix
correlation_df = pd.DataFrame(
correlation_matrix, index=df_cn.columns, columns=df_rs.columns
)
# Plot the heatmap
plt.figure(figsize=(20, 20))
sns.clustermap(correlation_df, cmap="coolwarm")
# Customize plot appearance
plt.title("Pairwise Pearson's Correlations between Copy Number and RNA-seq Data")
# Show the plot
plt.show()
# This is difficult to interpret, but we can already see that there are clusters of copy numbers highly correlated with gene expression.
from sklearn.decomposition import PCA
# Combine the dataframes
combined_data = pd.concat([df_cn, df_rs], axis=1)
# Standardize the combined data
standardized_data = (combined_data - combined_data.mean()) / combined_data.std()
# Apply PCA to reduce dimensionality
n_components = 2
pca = PCA(n_components=n_components)
reduced_data = pca.fit_transform(standardized_data)
# Plot the reduced data
plt.figure(figsize=(10, 10))
plt.scatter(reduced_data[:, 0], reduced_data[:, 1], s=50)
# Customize plot appearance
plt.title("PCA of Combined Copy Number and RNA-seq Data")
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
# Show the plot
plt.show()
from sklearn.cluster import KMeans
# Apply PCA to reduce dimensionality
n_components = 2
pca = PCA(n_components=n_components)
reduced_data = pca.fit_transform(standardized_data)
# Apply KMeans clustering
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
cluster_assignments = kmeans.fit_predict(standardized_data)
# Plot the reduced data with cluster colors
plt.figure(figsize=(10, 10))
for cluster in range(n_clusters):
cluster_points = reduced_data[cluster_assignments == cluster]
plt.scatter(
cluster_points[:, 0], cluster_points[:, 1], s=50, label=f"Cluster {cluster + 1}"
)
# Customize plot appearance
plt.title("PCA of Combined Copy Number and RNA-seq Data with KMeans Clustering")
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.legend()
# Show the plot
plt.show()
# Is there any relationship between these clusters and survival?
# Let's overlay survival rate on top of these clusters?
survived = (outcomes["vital.status"]).to_numpy()
# Define marker shapes for the survived array
marker_shapes = {0: ".", 1: "o"}
colors = ["blue", "red", "green", "pink"]
# Plot the reduced data with cluster colors and different shapes for survived values
plt.figure(figsize=(10, 10))
for cluster in range(n_clusters):
for survived_value, marker_shape in marker_shapes.items():
cluster_points = reduced_data[
(cluster_assignments == cluster) & (survived == survived_value)
]
plt.scatter(
cluster_points[:, 0],
cluster_points[:, 1],
s=50,
marker=marker_shape,
label=f"Cluster {cluster + 1}, Survived: {survived_value}",
color=colors[cluster],
)
# Customize plot appearance
plt.title("PCA of Combined Copy Number and RNA-seq Data with KMeans Clustering")
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.legend()
# Show the plot
plt.show()
# Proportions of survival in each cluster
cluster_survival = []
for cluster in [0, 1, 2, 3]:
cluster_survival.append(
np.sum((cluster_assignments == cluster) & (survived == 1))
/ np.sum(cluster_assignments == cluster)
)
labels = ["Cluster 1", "Cluster 2", "Cluster 3", "Cluster 4"]
# create a bar plot
plt.bar(labels, cluster_survival)
# add a title to the plot
plt.title("Proportion of survived members in each cluster")
# add labels to the x and y axes
plt.xlabel("X-axis label")
plt.ylabel("Y-axis label")
# display the plot
plt.show()
# Clearly being part of Cluster 2 is associated with survival. What about cancer type?
# Let's overlay cancer type on top of these clusters?
cancer_types_desc = ["infiltrating ductal carcinoma", "infiltrating lobular carcinoma"]
cancer = (outcomes["histological.type"]).to_numpy()
# Define marker shapes for the cancer array
marker_shapes = {
"infiltrating ductal carcinoma": ".",
"infiltrating lobular carcinoma": "o",
}
colors = ["blue", "red", "green", "pink"]
# Plot the reduced data with cluster colors and different shapes for cancer values
plt.figure(figsize=(10, 10))
for cluster in range(n_clusters):
for cancer_value, marker_shape in marker_shapes.items():
cluster_points = reduced_data[
(cluster_assignments == cluster) & (cancer == cancer_value)
]
plt.scatter(
cluster_points[:, 0],
cluster_points[:, 1],
s=50,
marker=marker_shape,
label=f"Cluster {cluster + 1}, Cancer Type: {cancer_value}",
color=colors[cluster],
)
# Customize plot appearance
plt.title("PCA of Combined Copy Number and RNA-seq Data with KMeans Clustering")
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.legend()
# Show the plot
plt.show()
# Proportions of infiltrating lobular carcinoma in each cluster
cluster_survival = []
for cluster in [0, 1, 2, 3]:
cluster_survival.append(
np.sum(
(cluster_assignments == cluster)
& (cancer == "infiltrating lobular carcinoma")
)
/ np.sum(cluster_assignments == cluster)
)
labels = ["Cluster 1", "Cluster 2", "Cluster 3", "Cluster 4"]
# create a bar plot
plt.bar(labels, cluster_survival)
# add a title to the plot
plt.title("Proportion of infiltrating lobular carcinoma in each cluster")
# add labels to the x and y axes
plt.xlabel("X-axis label")
plt.ylabel("Y-axis label")
# display the plot
plt.show()
|
#
#
import numpy as np
import pandas as pd
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, models, transforms
from torch.utils.data.sampler import SubsetRandomSampler
import matplotlib.pyplot as plt
import time
import copy
from random import shuffle
import tqdm.notebook as tqdm
import sklearn
from sklearn.metrics import accuracy_score, cohen_kappa_score
from sklearn.metrics import classification_report
from PIL import Image
import cv2
import os
import shutil
df = pd.read_csv("./covid-chestxray-dataset/metadata.csv")
selected_df = df[df.finding == "Pneumonia/Viral/COVID-19"]
selected_df = selected_df[(selected_df.view == "AP") | (selected_df.view == "PA")]
selected_df.head(2)
images = selected_df.filename.values.tolist()
os.makedirs("./COVID19-DATASET/train/covid19")
os.makedirs("./COVID19-DATASET/train/normal")
COVID_PATH = "./COVID19-DATASET/train/covid19"
NORMAL_PATH = "./COVID19-DATASET/train/normal"
for image in images:
shutil.copy(
os.path.join("./covid-chestxray-dataset/images", image),
os.path.join(COVID_PATH, image),
)
for image in os.listdir("../input/chest-xray-pneumonia/chest_xray/train/NORMAL")[:300]:
shutil.copy(
os.path.join("../input/chest-xray-pneumonia/chest_xray/train/NORMAL", image),
os.path.join(NORMAL_PATH, image),
)
DATA_PATH = "./COVID19-DATASET/train"
class_names = os.listdir(DATA_PATH)
image_count = {}
for i in class_names:
image_count[i] = len(os.listdir(os.path.join(DATA_PATH, i)))
# Plotting Distribution of Each Classes
fig1, ax1 = plt.subplots()
ax1.pie(
image_count.values(),
labels=image_count.keys(),
shadow=True,
autopct="%1.1f%%",
startangle=90,
)
plt.show()
fig = plt.figure(figsize=(16, 5))
fig.suptitle("COVID19 Positive", size=22)
img_paths = os.listdir(COVID_PATH)
shuffle(img_paths)
for i, image in enumerate(img_paths[:4]):
img = cv2.imread(os.path.join(COVID_PATH, image))
plt.subplot(1, 4, i + 1, frameon=False)
plt.imshow(img)
fig.show()
fig = plt.figure(figsize=(16, 5))
fig.suptitle("COVID19 Negative - Healthy", size=22)
img_paths = os.listdir(NORMAL_PATH)
shuffle(img_paths)
for i, image in enumerate(img_paths[:4]):
img = cv2.imread(os.path.join(NORMAL_PATH, image))
plt.subplot(1, 4, i + 1, frameon=False)
plt.imshow(img)
fig.show()
# Statistics Based on ImageNet Data for Normalisation
mean_nums = [0.485, 0.456, 0.406]
std_nums = [0.229, 0.224, 0.225]
data_transforms = {
"train": transforms.Compose(
[
transforms.Resize((150, 150)), # Resizes all images into same dimension
transforms.RandomRotation(10), # Rotates the images upto Max of 10 Degrees
transforms.RandomHorizontalFlip(
p=0.4
), # Performs Horizantal Flip over images
transforms.ToTensor(), # Coverts into Tensors
transforms.Normalize(mean=mean_nums, std=std_nums),
]
), # Normalizes
"val": transforms.Compose(
[
transforms.Resize((150, 150)),
transforms.CenterCrop(
150
), # Performs Crop at Center and resizes it to 150x150
transforms.ToTensor(),
transforms.Normalize(mean=mean_nums, std=std_nums),
]
),
}
# ## Train and Validation Data Split
def load_split_train_test(datadir, valid_size=0.3):
train_data = datasets.ImageFolder(
datadir, transform=data_transforms["train"]
) # Picks up Image Paths from its respective folders and label them
test_data = datasets.ImageFolder(datadir, transform=data_transforms["val"])
num_train = len(train_data)
indices = list(range(num_train))
split = int(np.floor(valid_size * num_train))
np.random.shuffle(indices)
train_idx, test_idx = indices[split:], indices[:split]
dataset_size = {"train": len(train_idx), "val": len(test_idx)}
train_sampler = SubsetRandomSampler(
train_idx
) # Sampler for splitting train and val images
test_sampler = SubsetRandomSampler(test_idx)
trainloader = torch.utils.data.DataLoader(
train_data, sampler=train_sampler, batch_size=8
) # DataLoader provides data from traininng and validation in batches
testloader = torch.utils.data.DataLoader(
test_data, sampler=test_sampler, batch_size=8
)
return trainloader, testloader, dataset_size
trainloader, valloader, dataset_size = load_split_train_test(DATA_PATH, 0.2)
dataloaders = {"train": trainloader, "val": valloader}
data_sizes = {x: len(dataloaders[x].sampler) for x in ["train", "val"]}
class_names = trainloader.dataset.classes
print(class_names)
def imshow(inp, size=(30, 30), title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = mean_nums
std = std_nums
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.figure(figsize=size)
plt.imshow(inp)
if title is not None:
plt.title(title, size=30)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders["train"]))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
if torch.cuda.is_available():
device = torch.device("cuda:0")
print("Training on GPU... Ready for HyperJump...")
else:
device = torch.device("cpu")
print("Training on CPU... May the force be with you...")
torch.cuda.empty_cache()
# ## Dense-net 121
def CNN_Model(pretrained=True):
model = models.densenet121(
pretrained=pretrained
) # Returns Defined Densenet model with weights trained on ImageNet
num_ftrs = (
model.classifier.in_features
) # Get the number of features output from CNN layer
model.classifier = nn.Linear(
num_ftrs, len(class_names)
) # Overwrites the Classifier layer with custom defined layer for transfer learning
model = model.to(device) # Transfer the Model to GPU if available
return model
model = CNN_Model(pretrained=True)
# specify loss function (categorical cross-entropy loss)
criterion = nn.CrossEntropyLoss()
# Specify optimizer which performs Gradient Descent
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = optim.lr_scheduler.StepLR(
optimizer, step_size=7, gamma=0.1
) # Learning Scheduler
pytorch_total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Number of trainable parameters: \n{}".format(pytorch_total_params))
# ### Training
def train_model(model, criterion, optimizer, scheduler, num_epochs=10):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = np.inf
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch + 1, num_epochs))
print("-" * 10)
# Each epoch has a training and validation phase
for phase in ["train", "val"]:
if phase == "train":
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
current_loss = 0.0
current_corrects = 0
current_kappa = 0
val_kappa = list()
for inputs, labels in tqdm.tqdm(
dataloaders[phase], desc=phase, leave=False
):
inputs = inputs.to(device)
labels = labels.to(device)
# We need to zero the gradients in the Cache.
optimizer.zero_grad()
# Time to carry out the forward training poss
# We only need to log the loss stats if we are in training phase
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == "train":
loss.backward()
optimizer.step()
if phase == "train":
scheduler.step()
# We want variables to hold the loss statistics
current_loss += loss.item() * inputs.size(0)
current_corrects += torch.sum(preds == labels.data)
val_kappa.append(
cohen_kappa_score(preds.cpu().numpy(), labels.data.cpu().numpy())
)
epoch_loss = current_loss / data_sizes[phase]
epoch_acc = current_corrects.double() / data_sizes[phase]
if phase == "val":
epoch_kappa = np.mean(val_kappa)
print(
"{} Loss: {:.4f} | {} Accuracy: {:.4f} | Kappa Score: {:.4f}".format(
phase, epoch_loss, phase, epoch_acc, epoch_kappa
)
)
else:
print(
"{} Loss: {:.4f} | {} Accuracy: {:.4f}".format(
phase, epoch_loss, phase, epoch_acc
)
)
# EARLY STOPPING
if phase == "val" and epoch_loss < best_loss:
print(
"Val loss Decreased from {:.4f} to {:.4f} \nSaving Weights... ".format(
best_loss, epoch_loss
)
)
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_since = time.time() - since
print(
"Training complete in {:.0f}m {:.0f}s".format(time_since // 60, time_since % 60)
)
print("Best val loss: {:.4f}".format(best_loss))
# Now we'll load in the best model weights and return it
model.load_state_dict(best_model_wts)
return model
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_handeled = 0
ax = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders["val"]):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_handeled += 1
ax = plt.subplot(num_images // 2, 2, images_handeled)
ax.axis("off")
ax.set_title(
"Actual: {} predicted: {}".format(
class_names[labels[j].item()], class_names[preds[j]]
)
)
imshow(inputs.cpu().data[j], (5, 5))
if images_handeled == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
base_model = train_model(model, criterion, optimizer, exp_lr_scheduler, num_epochs=10)
visualize_model(base_model)
plt.show()
|
# ### Librerias
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import pandas as pd
import seaborn as sns
import numpy as np
from matplotlib import pyplot as plt
import re
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import scipy.signal
from sklearn.model_selection import learning_curve
from sklearn.model_selection import KFold
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import SVR
import numpy as np
from sklearn.svm import SVC
from sklearn import svm
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.model_selection import cross_val_score, StratifiedKFold, GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
import warnings
warnings.filterwarnings("ignore")
# ### Carga el data set, elimina colunas y primera fila no utilizable. No hace PCA
df = pd.read_csv(
"/kaggle/input/raman-spectroscopy-of-diabetes/thumbNail.csv"
) # innerArm thumbNail earLobe vein
df.head(5)
has_DM2 = df.pop("has_DM2")
patientID = df.pop("patientID")
df.head()
# #### Crop Data to 800-1800 cm^-1
droped_columns = []
for col in df.columns:
# print("------------------------------>" + re.findall(r'\d+', col)[0])
if (
int(re.findall(r"\d+", col)[0]) <= 800
or int(re.findall(r"\d+", col)[0]) >= 1800
):
droped_columns.append(col)
df.drop(droped_columns, axis=1, inplace=True)
X, y = df.drop(0), has_DM2.drop(0)
# ### Aguala datos pacientes 1 y 0; 50% caso uno. Inicialmente son 19 registros, despues 22
from imblearn.over_sampling import SMOTE
from collections import Counter
# https://www.kaggle.com/vaishnavinath/before-and-after-smote/comments
sm = SMOTE(random_state=42)
print(
"EL dataset original antes del Resampled SMOTE tiene: ", X.shape, " filas, columnas"
)
X_resamp_tr, y_resamp_tr = sm.fit_resample(X, y)
print("Resampled dataset shape %s" % Counter(y_resamp_tr))
X = pd.DataFrame(X_resamp_tr)
y = pd.DataFrame({"target": y_resamp_tr})
print("EL dataset despues del Resampled SMOTE tiene: ", X.shape, " filas, columna")
print(" ")
# ### Selecciona sklearn.feature_selection import SelectFromModel
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
# Load the boston dataset.
# https://towardsdatascience.com/5-feature-selection-method-from-scikit-learn-you-should-know-ed4d116e4172
# https://programmerclick.com/article/51341441214/
print("EL dataset original tiene :", X.shape[1], "caracteristicas (columnas)")
C = 0.05
penalty = "l1"
lsvc = LinearSVC(C=C, penalty=penalty, dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X = model.transform(X)
print(
"El dataset despues del SelectFromModel: C= "
+ str(C)
+ " penalty= "
+ penalty
+ " tiene :",
X.shape[1],
" caracteristicas (columnas)",
)
print(" ")
# ### Standarizado de datos
# Standarizado de datos
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
# esto es necesario para que pueda recorrer los valores de X e y en el k-fold
X = np.array(X)
y = np.array(y)
# ### Funciones de algoritmos y graficas
C = [1, 0.1, 0.25, 0.5, 2, 0.75]
kernel = ["linear", "rbf"]
gamma = ["auto", 0.01, 0.001, 0.0001, 1]
decision_function_shape = ["ovo", "ovr"]
svm = SVC(random_state=1)
def svm_1(X_train, y_train):
svm = SVC(random_state=1)
grid_svm = GridSearchCV(
estimator=svm,
cv=5,
param_grid=dict(
kernel=kernel,
C=C,
gamma=gamma,
decision_function_shape=decision_function_shape,
),
)
grid_svm.fit(X_train, y_train)
print("best score: ", grid_svm.best_score_)
print("best param: ", grid_svm.best_params_)
svm_model = SVC(
C=2,
decision_function_shape="ovo",
gamma="auto",
kernel="linear",
random_state=1,
)
svm_model.fit(X_train, y_train)
print("train_accuracy:", svm_model.score(X_train, y_train))
print("test_accuracy: ", svm_model.score(X_test, y_test))
pred_test_svm = svm_model.predict(X_test) # predicción
svm_accuracy = accuracy_score(y_test, pred_test_svm) # predicción
print("predicción svm_accuracy :", svm_accuracy)
print(confusion_matrix(y_test, pred_test_svm))
matris(svm_model)
roc(y_test, pred_test_svm)
report("SVM 1", y_test, pred_test_svm)
# grafico_train_val(X_train, y_train, svm_model)
def matris(svm_model):
from yellowbrick.classifier import ConfusionMatrix
cm = ConfusionMatrix(svm_model, classes=[0, 1])
cm.fit(X_train, y_train)
cm.score(X_test, y_test)
cm.poof()
def roc(y_test, pred_test):
from sklearn.metrics import (
confusion_matrix,
classification_report,
roc_curve,
accuracy_score,
auc,
)
fpr, tpr, _ = roc_curve(y_test, pred_test)
# calculate AUC
roc_auc = auc(fpr, tpr)
print("ROC AUC: %0.2f" % roc_auc)
# plot of ROC curve for a specified class
plt.figure()
plt.plot(fpr, tpr, label="ROC curve(area= %2.f)" % roc_auc)
plt.plot([0, 1], [0, 1], "k--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False positive rate")
plt.ylabel("True positive rate")
plt.title("ROC curve")
plt.legend(loc="lower right")
plt.grid()
plt.show()
def report(titulo, y_test, pred_test):
print(
titulo,
"\n",
classification_report(
y_test, pred_test, target_names=["0 - healthy", "1 - diabet "]
),
)
# https://scikit-learn.org/stable/auto_examples/model_selection/plot_learning_curve.html
def grafico_train_val(X_train, y_train, classifier):
train_sizes, train_scores, test_scores = learning_curve(
estimator=classifier,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=8,
n_jobs=-1,
)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(
train_sizes,
train_mean,
color="r",
marker="o",
markersize=5,
label="entrenamiento",
)
plt.fill_between(
train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15,
color="r",
)
plt.plot(
train_sizes,
test_mean,
color="b",
linestyle="--",
marker="s",
markersize=5,
label="evaluacion",
)
plt.fill_between(
train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color="b"
)
plt.grid()
plt.title("Curva de aprendizaje")
plt.legend(loc="upper right")
plt.xlabel("Cant de ejemplos de entrenamiento")
plt.ylabel("Precision")
plt.show()
# ### StratifiedKFold
# https://insaid.medium.com/cross-validation-techniques-27d99becc7a0
from sklearn.svm import SVC
from xgboost import XGBClassifier
from sklearn.model_selection import cross_val_score, StratifiedKFold, GridSearchCV
skf = StratifiedKFold(n_splits=6, shuffle=True, random_state=1)
for train_index, test_index in skf.split(X, y):
print(
"--------------------------------------------------------------------------------------"
)
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print(
"--------------------------------------------------------------------------------------"
)
svm_1(X_train, y_train)
|
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
import catboost
import os
from sklearn import metrics
from sklearn.model_selection import train_test_split
from catboost.utils import get_roc_curve
from catboost.utils import get_fpr_curve
from catboost.utils import get_fnr_curve
from catboost.utils import select_threshold
from catboost import CatBoostClassifier, Pool, FeaturesData, cv, MetricVisualizer
cols = [
"Age",
"BusinessTravel",
"Department",
"DistanceFromHome",
"Lyon_EducationTemp",
"EducationField",
"Gender",
"JobRole",
"MaritalStatus",
"MonthlyIncome",
"NumCompaniesWorked",
"PercentSalaryHike",
"StandardHours",
"StockOptionLevel",
"TotalWorkingYears",
"TrainingTimesLastYear",
"YearsAtCompany",
"YearsSinceLastPromotion",
"YearsWithCurrManager",
"Attrition",
]
dtypes = {
"Age": np.float64,
"BusinessTravel": np.unicode_,
"Department": np.unicode_,
"DistanceFromHome": np.float32,
"Lyon_EducationTemp": np.float64,
"EducationField": np.unicode_,
"Gender": np.unicode_,
"JobRole": np.unicode,
"MaritalStatus": np.unicode,
"MonthlyIncome": np.float64,
"NumCompaniesWorked": np.float64,
"PercentSalaryHike": np.float64,
"StandardHours": np.float64,
"StockOptionLevel": np.float64,
"TotalWorkingYears": np.float64,
"TrainingTimesLastYear": np.float64,
"YearsAtCompany": np.float64,
"YearsSinceLastPromotion": np.float64,
"YearsWithCurrManager": np.float64,
"Attrition": np.int32,
}
train_df = pd.read_csv(
"../input/train-data/training_data-2.csv",
names=cols,
decimal=".",
sep=",",
skiprows=[0],
index_col=False,
dtype=dtypes,
)
total_experience = train_df["TotalWorkingYears"] + train_df["TrainingTimesLastYear"]
train_df = pd.concat([train_df, total_experience.rename("TotalExperience")], axis=1)
cols.remove("Attrition")
cols.append("Id")
dtypes.pop("Attrition", None)
dtypes["Id"] = np.int32
test_df = pd.read_csv(
"../input/test-data/test_data.csv",
names=cols,
decimal=".",
sep=",",
skiprows=[0],
index_col=False,
dtype=dtypes,
)
total_experience = test_df["TotalWorkingYears"] + test_df["TrainingTimesLastYear"]
test_df = pd.concat([test_df, total_experience.rename("TotalExperience")], axis=1)
train_df = train_df.drop("StandardHours", axis=1)
test_df = test_df.drop("StandardHours", axis=1)
y = train_df.Attrition
X = train_df.drop("Attrition", axis=1)
cat_features = list([1, 2, 5, 6, 7, 8])
dataset_dir = "./sber"
if not os.path.exists(dataset_dir):
os.makedirs(dataset_dir)
train_df.to_csv(
os.path.join(dataset_dir, "train.csv"), index=False, sep=",", header=True
)
test_df.to_csv(os.path.join(dataset_dir, "test.csv"), index=False, sep=",", header=True)
from catboost.utils import create_cd
feature_names = dict()
for column, name in enumerate(train_df):
feature_names[column] = name
create_cd(
label=None,
cat_features=cat_features,
feature_names=feature_names,
output_path=os.path.join(dataset_dir, "train.cd"),
)
pool1 = Pool(
data=pd.DataFrame(X),
label=pd.DataFrame(y),
cat_features=list([1, 2, 5, 6, 7, 8]),
has_header=True,
)
X_prepared = X.values.astype(str).astype(object)
print(pool1.shape)
print(pool1.get_feature_names())
X_train, X_validation, y_train, y_validation = train_test_split(
X, y, train_size=0.8, random_state=1234
)
model = CatBoostClassifier(
iterations=50, random_seed=63, learning_rate=0.5, custom_loss=["AUC", "Accuracy"]
)
model.fit(
X_train,
y_train,
cat_features=cat_features,
eval_set=(X_validation, y_validation),
verbose=False,
plot=True,
)
print("Model is fitted: " + str(model.is_fitted()))
print("Model params:")
print(model.get_params())
print("Tree count: " + str(model.tree_count_))
model1 = CatBoostClassifier(
learning_rate=0.7,
iterations=100,
random_seed=0,
custom_loss=["AUC", "Accuracy"],
train_dir="learing_rate_0.7",
)
model2 = CatBoostClassifier(
learning_rate=0.01,
iterations=100,
random_seed=0,
custom_loss=["AUC", "Accuracy"],
train_dir="learing_rate_0.01",
)
model1.fit(
X_train,
y_train,
eval_set=(X_validation, y_validation),
cat_features=cat_features,
verbose=False,
)
model2.fit(
X_train,
y_train,
eval_set=(X_validation, y_validation),
cat_features=cat_features,
verbose=False,
)
MetricVisualizer(["learing_rate_0.01", "learing_rate_0.7"]).start()
params = {}
params["loss_function"] = "Logloss"
params["iterations"] = 80
params["custom_loss"] = "AUC"
params["random_seed"] = 63
params["learning_rate"] = 0.5
cv_data = cv(
params=params,
pool=Pool(X, label=y, cat_features=cat_features),
fold_count=5,
shuffle=True,
partition_random_seed=0,
plot=True,
stratified=False,
verbose=False,
)
cv_data.head()
best_value = np.min(cv_data["test-Logloss-mean"])
best_iter = np.argmin(cv_data["test-Logloss-mean"])
print(
"Best validation Logloss score, not stratified: {:.4f}±{:.4f} on step {}".format(
best_value, cv_data["test-Logloss-std"][best_iter], best_iter
)
)
cv_data = cv(
params=params,
pool=Pool(X, label=y, cat_features=cat_features),
fold_count=5,
type="Classical",
shuffle=True,
partition_random_seed=0,
plot=True,
stratified=True,
verbose=False,
)
best_value = np.min(cv_data["test-Logloss-mean"])
best_iter = np.argmin(cv_data["test-Logloss-mean"])
print(
"Best validation Logloss score, stratified: {:.4f}±{:.4f} on step {}".format(
best_value, cv_data["test-Logloss-std"][best_iter], best_iter
)
)
model_with_early_stop = CatBoostClassifier(
iterations=200,
random_seed=63,
learning_rate=0.5,
early_stopping_rounds=20,
custom_loss=["AUC"],
)
model_with_early_stop.fit(
X_train,
y_train,
cat_features=cat_features,
eval_set=(X_validation, y_validation),
verbose=False,
plot=True,
)
print(model_with_early_stop.tree_count_)
model = CatBoostClassifier(
custom_loss=["AUC"],
random_seed=63,
iterations=200,
learning_rate=0.03,
)
model.fit(X_train, y_train, cat_features=cat_features, verbose=False, plot=True)
eval_pool = Pool(X_validation, y_validation, cat_features=cat_features)
curve = get_roc_curve(model, eval_pool)
(fpr, tpr, thresholds) = curve
roc_auc = sklearn.metrics.auc(fpr, tpr)
plt.figure(figsize=(16, 8))
lw = 2
plt.plot(
fpr,
tpr,
color="darkorange",
lw=lw,
label="ROC curve (area = %0.2f)" % roc_auc,
alpha=0.5,
)
plt.plot([0, 1], [0, 1], color="navy", lw=lw, linestyle="--", alpha=0.5)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid(True)
plt.xlabel("False Positive Rate", fontsize=16)
plt.ylabel("True Positive Rate", fontsize=16)
plt.title("Receiver operating characteristic", fontsize=20)
plt.legend(loc="lower right", fontsize=16)
plt.show()
(thresholds, fpr) = get_fpr_curve(curve=curve)
(thresholds, fnr) = get_fnr_curve(curve=curve)
plt.figure(figsize=(16, 8))
lw = 2
plt.plot(thresholds, fpr, color="blue", lw=lw, label="FPR", alpha=0.5)
plt.plot(thresholds, fnr, color="green", lw=lw, label="FNR", alpha=0.5)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid(True)
plt.xlabel("Threshold", fontsize=16)
plt.ylabel("Error Rate", fontsize=16)
plt.title("FPR-FNR curves", fontsize=20)
plt.legend(loc="lower left", fontsize=16)
plt.show()
print(select_threshold(model=model, data=eval_pool, FNR=0.01))
print(select_threshold(model=model, data=eval_pool, FPR=0.01))
print(model.predict_proba(data=X_validation))
print(model.predict(data=X_validation))
raw_pred = model.predict(data=X_validation, prediction_type="RawFormulaVal")
# print(raw_pred)
from numpy import exp
sigmoid = lambda x: 1 / (1 + exp(-x))
probabilities = sigmoid(raw_pred)
print(probabilities)
model.get_feature_importance(prettified=True)
shap_values = model.get_feature_importance(pool1, type="ShapValues")
expected_value = shap_values[0, -1]
shap_values = shap_values[:, :-1]
print(shap_values.shape)
import shap
shap.initjs()
shap.force_plot(expected_value, shap_values[3, :], X.iloc[3, :])
shap.summary_plot(shap_values, X)
X_small = X.iloc[0:200]
shap_small = shap_values[:200]
shap.force_plot(expected_value, shap_small, X_small)
# from catboost.eval.catboost_evaluation import *
# learn_params = {'iterations': 20, # 2000
# 'learning_rate': 0.5, # we set big learning_rate,
# # because we have small
# # #iterations
# 'random_seed': 0,
# 'verbose': False,
# 'loss_function' : 'Logloss',
# 'boosting_type': 'Plain'}
# evaluator = CatboostEvaluation('sber/train.tsv',
# fold_size=1300, # <= 50% of dataset
# fold_count=20,
# column_description='sber/train.cd',
# partition_random_seed=0,
# #working_dir=...
# )
# result = evaluator.eval_features(learn_config=learn_params,
# eval_metrics=['Logloss', 'Accuracy'],
# features_to_eval=[5, 6, 7])
# from catboost.eval.evaluation_result import *
# logloss_result = result.get_metric_results('Logloss')
# logloss_result.get_baseline_comparison(
# ScoreConfig(ScoreType.Rel, overfit_iterations_info=False)
# )
from catboost import CatBoost
fast_model = CatBoostClassifier(
random_seed=63,
iterations=150,
learning_rate=0.01,
boosting_type="Plain",
bootstrap_type="Bernoulli",
subsample=0.5,
one_hot_max_size=20,
rsm=0.5,
leaf_estimation_iterations=5,
max_ctr_complexity=1,
)
fast_model.fit(X_train, y_train, cat_features=cat_features, verbose=False, plot=True)
tunned_model = CatBoostClassifier(
random_seed=63,
iterations=1000,
learning_rate=0.03,
l2_leaf_reg=3,
bagging_temperature=1,
random_strength=1,
one_hot_max_size=2,
leaf_estimation_method="Newton",
)
tunned_model.fit(
X_train,
y_train,
cat_features=cat_features,
verbose=False,
eval_set=(X_validation, y_validation),
plot=True,
)
tunned_model.tree_count_
best_model = CatBoostClassifier(
custom_loss=["AUC", "Accuracy"],
random_seed=63,
iterations=int(tunned_model.tree_count_ * 1.2),
eval_metric="AUC",
)
best_model.fit(X, y, cat_features=cat_features, verbose=100, plot=True)
best_model.compare(model_with_early_stop, eval_pool, ["Logloss", "AUC"])
eval_metrics = best_model.eval_metrics(eval_pool, ["AUC"], plot=True)
params = {}
params["loss_function"] = "Logloss"
params["iterations"] = int(tunned_model.tree_count_ * 1.2)
params["custom_loss"] = "AUC"
params["random_seed"] = 63
cv_data = cv(
params=params,
pool=Pool(X, label=y, cat_features=cat_features),
fold_count=5,
shuffle=True,
partition_random_seed=0,
plot=True,
stratified=False,
verbose=False,
)
cv_data.head()
import hyperopt
def hyperopt_objective(params):
model = CatBoostClassifier(
l2_leaf_reg=int(params["l2_leaf_reg"]),
learning_rate=params["learning_rate"],
iterations=int(tunned_model.tree_count_ * 1.2),
eval_metric="AUC",
random_seed=42,
verbose=False,
loss_function="Logloss",
)
cv_data = cv(Pool(X, label=y, cat_features=cat_features), model.get_params())
best_logloss = np.min(cv_data["test-Logloss-mean"])
return best_logloss # as hyperopt minimises
cv_data.head()
best_logloss
from numpy.random import RandomState
params_space = {
"l2_leaf_reg": hyperopt.hp.qloguniform("l2_leaf_reg", 0, 2, 1),
"learning_rate": hyperopt.hp.uniform("learning_rate", 1e-3, 5e-1),
}
trials = hyperopt.Trials()
best = hyperopt.fmin(
hyperopt_objective,
space=params_space,
algo=hyperopt.tpe.suggest,
max_evals=50,
trials=trials,
rstate=RandomState(123),
)
print(best)
hyperopt_model = CatBoostClassifier(
custom_loss=["AUC", "Accuracy"],
learning_rate=0.10800296388715394,
l2_leaf_reg=6.0,
random_seed=63,
iterations=int(tunned_model.tree_count_ * 1.2),
eval_metric="AUC",
)
hyperopt_model.fit(X, y, cat_features=cat_features, verbose=100, plot=True)
best_model.compare(hyperopt_model, eval_pool, ["Logloss", "AUC"])
params = {}
params["loss_function"] = "Logloss"
params["iterations"] = int(tunned_model.tree_count_ * 1.2)
params["custom_loss"] = "AUC"
params["random_seed"] = 63
params["learning_rate"] = 0.10800296388715394
cv_data = cv(
params=params,
pool=Pool(X, label=y, cat_features=cat_features),
fold_count=5,
shuffle=True,
partition_random_seed=0,
plot=True,
stratified=False,
verbose=False,
)
X_test = test_df # .drop('id', axis=1)
test_pool = Pool(data=X_test, cat_features=cat_features)
contest_predictions = hyperopt_model.predict_proba(test_pool)
print("Predictoins:")
print(contest_predictions)
id_test_data = [num for num in range(1764)]
result_csv = pd.concat(
[pd.DataFrame(id_test_data), pd.DataFrame(contest_predictions)], axis=1
)
# result_csv = pd.concat([result_csv, pd.DataFrame(result)], axis=1)
result_csv.drop("0", axis=1)
result_csv.to_csv("out.csv", encoding="utf-8", index=False)
result_csv.describe(include="all")
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# DATA LOAD
import os
data_dir = "/kaggle/input/proy1segmentaciondeimagenesdermatoscopicas/"
imgs_files = [
os.path.join(data_dir, "Images/Images", f)
for f in sorted(os.listdir(os.path.join(data_dir, "Images/Images")))
if (
os.path.isfile(os.path.join(data_dir, "Images/Images", f))
and f.endswith(".jpg")
)
]
masks_files = [
os.path.join(data_dir, "Masks/Masks", f)
for f in sorted(os.listdir(os.path.join(data_dir, "Masks/Masks")))
if (os.path.isfile(os.path.join(data_dir, "Masks/Masks", f)) and f.endswith(".png"))
]
# Ordenamos para que cada imagen se corresponda con cada máscara
imgs_files.sort()
masks_files.sort()
print("Number of images", len(imgs_files))
print("Number of masks", len(masks_files))
# Convert files into skimages and visualize
import matplotlib.pyplot as plt
from skimage import io
images = io.ImageCollection(imgs_files)
masks = io.ImageCollection(masks_files)
index = 1
plt.figure(figsize=(15, 8))
for i in range(4):
plt.subplot(2, 4, index)
plt.imshow(images[i])
index += 1
plt.title("Image %i" % (i))
plt.subplot(2, 4, index)
plt.imshow(masks[i], cmap="gray")
index += 1
plt.title("Mask %i" % (i))
# PREPROCESSING
# Grayscale
from skimage.color import rgb2gray
gray_images = [rgb2gray(image) for image in images]
plt.imshow(gray_images[2], cmap="gray")
print(gray_images[2].shape)
print(masks[2].shape)
# Note that images and mask have the same size
# remove black borders:
from skimage.exposure import histogram
img = gray_images[2]
new_mask = np.where(img != img.min(), 255, img)
"""
def remove_black_borders (image, mask):
if (image.min()==0)
return cropped_image, cropped_mask
"""
# IMAGE SEGMENTATION
from skimage import filters
val = filters.threshold_otsu(gray_images[1])
my_mask = gray_images[1] < val
plt.subplot(1, 2, 1)
plt.imshow(gray_images[1], cmap="gray")
plt.title("Dermoscopy image")
plt.subplot(1, 2, 2)
plt.imshow(mask, cmap="gray")
plt.title("Automated mask")
import copy
from skimage import filters
automated_masks = copy.copy(masks)
for i, image in enumerate(gray_images):
val = filters.threshold_otsu(image)
my_mask = image < val
automated_masks[i] = my_mask
|
# # Categorical Feature Encoding Challenge II
# Binary classification, with every feature a categorical (and i
# a dataset that contains only categorical features, and includes:
# * binary features
# * low- and high-cardinality nominal features
# * low- and high-cardinality ordinal features
# * (potentially) cyclical features
# This challenge adds the additional complexity of feature interactions, as well as missing data.
# This Playground competition will give you the opportunity to try different encoding schemes for different algorithms to compare how they perform.
# Submissions are evaluated on area under the ROC curve between the predicted probability and the observed target.
# Final submission deadline: March 31, 2020
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import wandb
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
import scipy
import pandas as pd
from sklearn.linear_model import LogisticRegression
# Any results you write to the current directory are saved as output.
D0 = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/train.csv", index_col="id")
D_test = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/test.csv", index_col="id")
y_train = D0["target"]
D = D0.drop(columns="target")
test_ids = D_test.index
D_all = pd.concat([D, D_test])
num_train = len(D)
print(f"D_all.shape = {D_all.shape}")
# Map value in train xor test
for col in D.columns.difference(["id"]):
train_vals = set(D[col].dropna().unique())
test_vals = set(D_test[col].dropna().unique())
xor_cat_vals = train_vals ^ test_vals
if xor_cat_vals:
print(f"Replacing {len(xor_cat_vals)} values in {col}, {xor_cat_vals}")
D_all.loc[D_all[col].isin(xor_cat_vals), col] = "xor"
# Info for ordinal encoding
ord_maps = {
"ord_0": {val: i for i, val in enumerate([1, 2, 3])},
"ord_1": {
val: i
for i, val in enumerate(
["Novice", "Contributor", "Expert", "Master", "Grandmaster"]
)
},
"ord_2": {
val: i
for i, val in enumerate(
["Freezing", "Cold", "Warm", "Hot", "Boiling Hot", "Lava Hot"]
)
},
**{
col: {val: i for i, val in enumerate(sorted(D_all[col].dropna().unique()))}
for col in ["ord_3", "ord_4", "ord_5", "day", "month"]
},
}
# OneHot encoding
oh_cols = D_all.columns.difference(ord_maps.keys() - {"day", "month"})
print(f"OneHot encoding {len(oh_cols)} columns")
one_hot = pd.get_dummies(
D_all[oh_cols],
columns=oh_cols,
drop_first=True,
dummy_na=True,
sparse=True,
dtype="int8",
).sparse.to_coo()
# Ordinal encoding
ord_cols = pd.concat(
[
D_all[col].map(ord_map).fillna(max(ord_map.values()) // 2).astype("float32")
for col, ord_map in ord_maps.items()
],
axis=1,
)
ord_cols /= ord_cols.max() # for convergence
ord_cols_sqr = 4 * (ord_cols - 0.5) ** 2
# Combine data
X = scipy.sparse.hstack([one_hot, ord_cols, ord_cols_sqr]).tocsr()
print(f"X.shape = {X.shape}")
X_train = X[:num_train]
X_test = X[num_train:]
# Make submission
clf = LogisticRegression(C=0.05, solver="lbfgs", max_iter=5000)
clf.fit(X_train, y_train)
pred = clf.predict_proba(X_test)[:, 1]
pd.DataFrame({"id": test_ids, "target": pred}).to_csv("submission.csv", index=False)
|
# > # Hi Guys,
# ## This notebook is on classification algorithms that shows how well different algorithms perform on the same dataset. In this Notebook the classification algorithms I have used are mentioned below:
# ### 1. Neural Network
# ### 2. Logistic Regression
# ### 3. Random Forest
# ### 4. Gradient Boosting Classifier
# ## And the winner of this Competiton is Logisitc Regression as per confusion matrix, it gave a better accuracy rate at the time of cross_validation, and also when predicting the prediction data that is present in test.csv and gender_submission.csv has the actual labels that should be for test data.
# ## So you can predict the testing data and then cross_check it with the actual labels.
# Importing all the libraries we need
import os
import random
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_validate
from keras.layers import Dense, Dropout
from keras.models import Sequential
for dir in os.walk("/kaggle/input/"):
print(dir[2])
# Getting the training data
training_data = pd.read_csv("../input/train.csv")
# Printing first fice instances of training data
training_data.head(10)
# Printing last five instances of training data
training_data.tail(10)
# Getting a total number of data values we have
print(len(training_data))
# Checking for null values
training_data.isna().sum()
# Droping the columns that are not necessary
training_data = training_data.drop(columns=["Ticket", "Name", "Cabin", "PassengerId"])
training_data.isna().sum()
# Replacing Null values in dataset with mean values
mean_value = training_data["Age"].mean()
training_data["Age"] = training_data["Age"].fillna(mean_value)
training_data.isna().sum()
# Dropping the values that are null
training_data = training_data.dropna()
print(len(training_data))
training_data.head()
training_data.info()
training_data.describe()
# This will give us the count of unique values present in Survived column
training_data["Survived"].value_counts()
# Plotting a graph for visualization
training_data["Survived"].value_counts().plot.bar()
# Generating Testing data
testing_data = pd.read_csv("../input/test.csv")
# First 10 instances of testing_data
testing_data.head(10)
# Last 10 instances of testing_data
testing_data.tail(10)
# Getting the total number of instances in testing_data
print(len(testing_data))
# Getting count of Na values
testing_data.isna().sum()
# Droping columns that are not necessary
testing_data = testing_data.drop(columns=["PassengerId", "Cabin", "Name", "Ticket"])
# Filling the null values with mean values
mean_value = testing_data["Age"].mean()
testing_data["Age"] = testing_data["Age"].fillna(mean_value)
mean_value = testing_data["Fare"].mean()
testing_data["Fare"] = testing_data["Fare"].fillna(mean_value)
testing_data = testing_data.dropna()
testing_data.isna().sum()
print(len(testing_data))
# Reading the actual labels for test data
gender_submission = pd.read_csv("../input/gender_submission.csv")
gender_submission.head()
len(gender_submission)
gender_submission["Survived"].value_counts().plot.bar()
training_data.head()
# Encoding the values from column Sex and Embarked
enc = LabelEncoder()
training_data["Sex"] = enc.fit_transform(training_data["Sex"])
training_data["Embarked"] = enc.fit_transform(training_data["Embarked"])
training_data.head()
training_data["Sex"].value_counts().plot.bar()
training_data["Embarked"].value_counts().plot.bar()
sns.pairplot(training_data, hue="Survived")
# Generating trianing data
X_train = training_data.iloc[:, 1:]
Y_train = np.array(training_data["Survived"])
# Converting it into numpy array
X_train = np.array(X_train)
print(X_train.shape)
Y_train = np.array(Y_train)
print(Y_train.shape)
print(X_train[0, :])
print(X_train[0:5])
print(Y_train[0:5])
# Splitting training data into train and test, becuase we don't have test data here and the test data in test.csv is for prediction purpose so we will work on training data
X_t, x_test, Y_t, y_test = train_test_split(X_train, Y_train)
Y_t.shape
# > # 1. Neural Network
# Creating our Neural Network
model = Sequential()
# First Hidden layer with 256 neurons
model.add(Dense(256, activation="sigmoid", input_dim=(7)))
# Second Hideen layer with 256 neurons
model.add(Dense(256, activation="relu"))
# Third Hidden layer with 128 neurons
model.add(Dense(128, activation="sigmoid"))
# Fourth Hidden layer with 128 neurons
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(1, activation="sigmoid"))
# Defining rules for our Neural Netowrk
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
# Fitting data to our model
model.fit(X_t, Y_t, epochs=50, batch_size=32)
# Evaluating our model on test data
model.evaluate(x_test, y_test, batch_size=32)
# > # 2. Logistic Regression
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_t, Y_t)
# Evaluating on test data
classifier.score(x_test, y_test)
# > # 3. Random Forest Classifier
from sklearn.ensemble import RandomForestClassifier
classifier_2 = RandomForestClassifier()
classifier_2.fit(X_t, Y_t)
# Evaluating on test data
classifier_2.score(x_test, y_test)
# > # 4. Gradient Boosting Classifier
from sklearn.ensemble import GradientBoostingClassifier
classifier_3 = GradientBoostingClassifier()
classifier_3.fit(X_t, Y_t)
# Evaluating on test data
classifier_3.score(x_test, y_test)
# Cross validation on Logistic Regression
result = cross_validate(classifier, X_train, Y_train, cv=5)
print(result)
# Cross validation on Random Forest Classifier
result = cross_validate(classifier_2, X_train, Y_train, cv=5)
print(result)
# Cross validation on Gradient Boosting Classifier
result = cross_validate(classifier_3, X_train, Y_train, cv=5)
print(result)
print(type(testing_data))
print(len(testing_data))
print(testing_data[0:5])
# Encoding 'Sex' and 'Embarked' column of testing_data
testing_data["Sex"] = enc.fit_transform(testing_data["Sex"])
testing_data["Embarked"] = enc.fit_transform(testing_data["Embarked"])
# Forst five instances of testing_data
testing_data.head()
# X_pred is variable that stores values to be predicted
X_pred = np.array(testing_data)
print(X_pred[0:5])
X_pred.shape
# Predicting values, here Y_pred contains predicted values
Y_pred = model.predict(X_pred).round()
# Y_test contains the actual labels for our prediction data
Y_test = np.array(gender_submission)
Y_test = Y_test[:, 1]
print(Y_test)
print(Y_test.shape)
Y_pred = Y_pred.reshape(
418,
)
print(Y_pred)
print(Y_pred.shape)
# > ## Confusion Matrix for Neural Network
cm = confusion_matrix(Y_test, Y_pred)
plt.subplots(figsize=(10, 8))
sns.heatmap(cm, xticklabels=["Survived", "Dead"], yticklabels=["Survived", "Dead"])
Y_pred = classifier.predict(X_pred).round()
print(Y_pred)
# > ## Confusion Matrix for Logistic Regression
cm = confusion_matrix(Y_test, Y_pred)
plt.subplots(figsize=(10, 8))
sns.heatmap(cm, xticklabels=["Survived", "Dead"], yticklabels=["Survived", "Dead"])
Y_pred = classifier_2.predict(X_pred).round()
print(Y_pred)
# > ## Confusion Matrix for Random Forest
cm = confusion_matrix(Y_test, Y_pred)
plt.subplots(figsize=(10, 8))
sns.heatmap(cm, xticklabels=["Survived", "Dead"], yticklabels=["Survived", "Dead"])
Y_pred = classifier_3.predict(X_pred).round()
print(Y_pred)
# > ## Confustion Matrix for Gradient Boosting Classifier
cm = confusion_matrix(Y_test, Y_pred)
plt.subplots(figsize=(10, 8))
sns.heatmap(cm, xticklabels=["Survived", "Dead"], yticklabels=["Survived", "Dead"])
|
# # **Logistic Regression [Detailed Concept + Practical Implementation with Python]**
# * What is logistic regression?
# * What are the types of logistic regression?
# * Application of logistic regression.
# * Graphical representation of logistic regression.
# * Linear regression vs logistic regression.
# * Math behind the logistic regression.
# * Implementation of logistic regression in practical problems using real life datasets.
# **What is logistic regression?**
# Logistic regression is a statistical analysis method to predict a binary outcome, such as yes or no, based on prior observations of a data set. A logistic regression model predicts a dependent data variable by analyzing the relationship between one or more existing independent variables.
# **What are the types of logistic regression?**
# There are 3 main types of logistic regression:
# * **Binary logistic regression**: This is the most common type of logistic regression,
# used when the dependent variable is binary (i.e., has only two possible values).
# * **Multinomial logistic regression**: This type of logistic regression is used
# when the dependent variable has three or more unordered categories.
# * **Ordinal logistic regression**: This type of logistic regression is
# used when the dependent variable has three or more ordered categories.
# **Application of Logistic Regression**
# * **Binary classification:** Logistic regression can be used to predict whether an observation belongs to one of two classes (e.g. fraud or not fraud, spam or not spam).
# * **Customer churn prediction:** Logistic regression can be used to predict whether a customer is likely to churn or stay with a company based on their previous behavior, demographics, and other factors.
# * **Medical diagnosis:** Logistic regression can be used to predict the presence or absence of a medical condition based on symptoms, test results, and other factors.
# * **Credit risk assessment:** Logistic regression can be used to predict the likelihood of default for a borrower based on their credit history and other financial information.
# * **Image classification:** Logistic regression can be used in image classification tasks where we have to predict whether an image belongs to a certain class or not.
# **Graphical view of logistic regression.**
# **How logistic regression works?**
# The logistic function, also known as the** sigmoid function**, has an S-shaped curve that ranges from 0 to 1. It is defined as:
# **p = 1 / (1 + e^(-z))**
# where p is the probability of the dependent variable being in the positive category, e is the base of the natural logarithm, and z is the linear combination of the independent variables.
# To fit a logistic regression model, the maximum likelihood estimation method is commonly used. This method involves finding the parameters of the logistic function that maximize the likelihood of the observed data given the model.
# In practice, logistic regression involves the following steps:
# **Data preparation:** Collect and clean the data, and prepare the variables for analysis.
# **Model specification:** Select the independent variables that are hypothesized to be related to the dependent variable, and define the functional form of the logistic regression equation.
# **Model estimation:** Use maximum likelihood estimation or another suitable method to estimate the parameters of the logistic regression equation.
# **Model evaluation:** Evaluate the goodness of fit of the model, assess the statistical significance of the independent variables, and check for multicollinearity and other potential problems.
# **Prediction:** Use the fitted logistic regression model to make predictions about the probability of the dependent variable being in the positive category for new observations.
from IPython.display import Image
import os
Image("/kaggle/input/images/46-4.png")
Image("/kaggle/input/logistic-pictures/WhatsApp Image 2023-04-09 at 19.08.01.jpeg")
# **Sigmoid Function:**
Image("/kaggle/input/logistic-pictures/download.png")
Image("/kaggle/input/logistic-pictures/download (1).png")
Image("/kaggle/input/logistic-pictures/download (2).png")
# **Likelihood Function:**
Image("/kaggle/input/likelihood-fuction/download (3).png")
# **Maximum Likelihood Estimation by Newton Raphson Method:**
# [https://www.statlect.com/fundamentals-of-statistics/logistic-model-maximum-likelihood](http://)
Image("/kaggle/input/images/logistic-regression-in-machine-learning.png")
# **Linear Regression vs Logistic Regression.**
# * Linear regression provides a continuous output but Logistic regression provides discreet output.
# * Linear regression is used to model the relationship between a dependent variable that is continuous and one or more independent variables, while logistic regression is used to model the relationship between a binary (i.e., 0 or 1) dependent variable and one or more independent variables.
# * In linear regression, the performance is measured using metrics such as mean squared error (MSE) or root mean squared error (RMSE). In contrast, logistic regression performance is measured using metrics such as accuracy, precision, recall, F1 score, or area under the ROC curve (AUC).
# * In linear regression, the coefficients represent the change in the dependent variable associated with a unit change in the independent variable. In contrast, in logistic regression, the coefficients represent the change in the log odds of the dependent variable associated with a unit change in the independent variable.
Image("/kaggle/input/images/LogReg_1.png")
Image("/kaggle/input/wefvearb/linear-regression-vs-logistic-regression.png")
# **Math Behind the Logistic Regression.**
# # Application of Logistic Regression in Iris Dataset using Pyhton Raw Code.
import numpy as np
import pandas as pd
# Load the iris dataset
data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
header=None,
)
data = data.sample(frac=1).reset_index(drop=True) # Shuffle the data
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
y = np.where(
y == "Iris-setosa", 1, 0
) # Convert labels to binary (setosa vs non-setosa)
# Define the logistic function
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# Define the cost function
def cost(theta, X, y):
m = len(y)
h = sigmoid(np.dot(X, theta))
J = (-1 / m) * np.sum(y * np.log(h) + (1 - y) * np.log(1 - h))
return J
# Define the gradient function
def gradient(theta, X, y):
m = len(y)
h = sigmoid(np.dot(X, theta))
grad = (1 / m) * np.dot(X.T, (h - y))
return grad
# Define the function to perform logistic regression
def logistic_regression(X, y, alpha, num_iters):
m, n = X.shape
X = np.concatenate((np.ones((m, 1)), X), axis=1) # Add intercept term
theta = np.zeros(n + 1)
for i in range(num_iters):
grad = gradient(theta, X, y)
theta -= alpha * grad
if i % 100 == 0:
print(f"Cost after iteration {i}: {cost(theta, X, y)}")
return theta
# Perform logistic regression
alpha = 0.01
num_iters = 1000
theta = logistic_regression(X, y, alpha, num_iters)
# Print the coefficients of the logistic regression model
print("Coefficients:", theta)
# # Application of Logistic Regression in Iris Datset using Scikit Learn.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Importing iris data set for machine learning database.
iris = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data",
header=None,
)
iris.columns = ["sepal_length", "sepal_width", "petal_length", "petal_width", "class"]
iris.head()
iris.tail()
# Encoding categorical features
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le
iris.columns
iris["class"] = le.fit_transform(iris["class"])
iris.head()
np.unique(iris["class"], return_counts=True)
X = iris.iloc[:, 0:3]
Y = iris.iloc[:, 4]
# another source code
# X = iris.iloc[:, :-1]
# y = iris.iloc[:, -1]
X.head()
Y.head()
# Splitting X and Y
xtrain, xtest, ytrain, ytest = train_test_split(X, Y, test_size=0.2, random_state=2)
xtrain.head()
ytrain.head()
# fitting the logitic regression
model = LogisticRegression()
model.fit(xtrain, ytrain)
# Predicting model using xtest
ypred = model.predict(xtest)
score = accuracy_score(ytest, ypred)
score * 100
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
cm = confusion_matrix(ypred, ytest)
sns.heatmap(cm, annot=True, cmap="Blues")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()
precision = precision_score(ytest, ypred, average="weighted")
recall = recall_score(ytest, ypred, average="weighted")
f1score = f1_score(ytest, ypred, average="weighted")
print("Precision:", precision)
print("Recall:", recall)
print("F1Score:", f1score)
# **Hyperparameter Of Logistic Regression**
# Logistic regression has several hyperparameters that can be tuned to optimize its performance. Here are some commonly used hyperparameters in logistic regression:
# * penalty: Specifies the norm used in the penalization. Can be either "l1" or "l2".
# * C: Inverse of regularization strength. Smaller values specify stronger regularization.
# * fit_intercept: Specifies whether or not to fit an intercept term.
# * solver: Specifies the algorithm to use in the optimization problem. Common choices are "liblinear", "lbfgs", and "sag".
# * max_iter: Maximum number of iterations for the solver to converge.
# * multi_class: Specifies how to handle multi-class problems. Can be either "ovr" (one-vs-rest) or "multinomial".
# * dualbool, default=False Dual or primal formulation. Dual formulation is only implemented for l2 penalty with liblinear solver. Prefer dual=False when n_samples > n_features.
# These hyperparameters can be tuned using techniques such as grid search, random search, or Bayesian optimization to find the combination that results in the best performance on the given task.
# **Deriving the hyperparameters of logistic regression.**
# **"penalty"**
# The penalty parameter in logistic regression is a hyperparameter that specifies the type of regularization to be applied to the model. Regularization is a technique used to prevent overfitting by adding a penalty term to the cost function.
# There are two types of regularization that can be used in logistic regression:
# * L1 Regularization (penalty='l1'): Also known as Lasso regularization, it adds a penalty term to the cost function that is proportional to the absolute value of the weights. L1 regularization is useful for feature selection as it tends to set the weights of irrelevant features to zero.
# * L2 Regularization (penalty='l2'): Also known as Ridge regularization, it adds a penalty term to the cost function that is proportional to the square of the weights. L2 regularization is useful for dealing with multicollinearity as it tends to spread the weight values across all the features.
# By default, logistic regression uses L2 regularization (penalty='l2').
# You can specify L1 regularization by setting the penalty parameter to 'l1' when creating the logistic regression object. The value of the penalty parameter can also be optimized using hyperparameter tuning techniques such as grid search or random search to find the best value for the given task.
# **"C"**
# The C parameter in logistic regression is a hyperparameter that controls the strength of the regularization term. It is the inverse of the regularization strength, so smaller values of C correspond to stronger regularization.
# **"fit_intercept"**
# The fit_intercept parameter in logistic regression is a hyperparameter that controls whether or not to include an intercept term in the model. An intercept term is a constant value added to the linear equation that represents the logistic regression model.
# By default, fit_intercept is set to True, which means an intercept term will be included in the model. If fit_intercept is set to False, then the model will not include an intercept term.
# **"solver"**
# The solver parameter in logistic regression is a hyperparameter that specifies the algorithm to use for optimizing the parameters of the logistic regression model. Different solvers use different optimization techniques to find the parameters that minimize the cost function.
# The available options for solver depend on the implementation and library used. Some common solvers include:
# * **lbfgs: Limited-memory Broyden-Fletcher-Goldfarb-Shanno algorithm.** This solver uses an approximation to the Hessian matrix to perform a quasi-Newton optimization of the parameters. It is a good choice for small to medium-sized datasets.
# * **newton-cg: Newton's conjugate gradient algorithm.** This solver also uses the Hessian matrix to perform a Newton-Raphson optimization of the parameters. It is a good choice for small to medium-sized datasets and can be faster than lbfgs for some problems.
#
# * **liblinear: Library for Large Linear Classification.** This solver uses a coordinate descent algorithm to optimize the parameters. It is a good choice for large datasets and handles L1 and L2 regularization.
# * **sag: Stochastic Average Gradient descent algorithm.** This solver uses a stochastic gradient descent algorithm to optimize the parameters. It is a good choice for large datasets and can handle L2 regularization.
# * **saga: Stochastic Average Gradient descent algorithm** with an adaptive penalty. This solver is a variant of sag that can handle both L1 and L2 regularization.
# The choice of solver depends on the specific problem and dataset. Some solvers may perform better than others depending on the size of the dataset, the complexity of the model, and the type of regularization used. It's a good practice to try different solvers and compare their performance using cross-validation or other evaluation metrics.
# **"max_iter"**
# The max_iter parameter in logistic regression is a hyperparameter that controls the maximum number of iterations for the solver to converge to the optimal solution.
# The solver in logistic regression is an iterative optimization algorithm that updates the model parameters in each iteration to minimize the cost function. The convergence of the solver is reached when the change in the cost function or the parameters between iterations falls below a certain tolerance level.
# **"multiclass"**
# The multi_class parameter in logistic regression is a hyperparameter that specifies the strategy to use for handling multiclass classification problems.
# Logistic regression is originally designed for binary classification problems (i.e., predicting one of two classes). However, it can also be extended to handle multiclass problems, where the goal is to predict one of more than two classes. There are three strategies for handling multiclass problems in logistic regression:
# * **ovr (One-vs-Rest):** This strategy treats each class as a separate binary classification problem. For each class, a separate logistic regression model is trained to distinguish that class from all the other classes combined. During prediction, the model with the highest predicted probability is selected.
# * **multinomial:** This strategy trains a single logistic regression model to predict all the classes simultaneously. The model learns the relationships between the different classes and their corresponding features. During prediction, the class with the highest predicted probability is selected.
# * **auto:** This strategy automatically selects between ovr and multinomial based on the type of solver. If the solver supports multinomial loss, then multinomial is used. Otherwise, ovr is used.
# The choice of multi_class strategy depends on the specific problem and dataset. In general, multinomial is preferred when there are many classes and they are not highly imbalanced, as it can lead to more accurate predictions. However, ovr can be a good choice when there are few classes or the classes are highly imbalanced, as it can be more robust to class imbalance.
# **Notes for choosing hyperparameter:**
# * To choose a solver, you might want to consider the following aspects:
#
# * For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones;
#
# * For multiclass problems, only ‘newton-cg’, ‘sag’, ‘saga’ and ‘lbfgs’ handle multinomial loss;
#
# * ‘liblinear’ is limited to one-versus-rest schemes.
# * ‘newton-cholesky’ is a good choice for n_samples >> n_features, especially with one-hot encoded categorical features with rare categories. Note that it is limited to binary classification and the one-versus-rest reduction for multiclass classification. Be aware that the memory usage of this solver has a quadratic dependency on n_features because it explicitly computes the Hessian matrix.
# The choice of the algorithm depends on the penalty chosen. Supported penalties by solver:
# * ‘lbfgs’ - [‘l2’, None]
# * ‘liblinear’ - [‘l1’, ‘l2’]
# * ‘newton-cg’ - [‘l2’, None]
# * ‘newton-cholesky’ - [‘l2’, None]
# * ‘sag’ - [‘l2’, None]
# * ‘saga’ - [‘elasticnet’, ‘l1’, ‘l2’, None]
# **Hyperparameter tuning in Iris Dataset.**
from sklearn.model_selection import GridSearchCV
param_grid = {
"penalty": ["l1", "l2", "elasticnet", "none"],
"C": [0.001, 0.01, 0.1, 1, 10, 100],
"solver": ["newton-cg", "lbfgs", "liblinear", "sag", "saga"],
"max_iter": [100, 500, 1000, 5000],
}
# Define the grid search object
grid_search = GridSearchCV(model, param_grid=param_grid, cv=10, n_jobs=-1, verbose=1)
# Fit the grid search object to the training data
grid_search.fit(xtrain, ytrain)
# Print the best hyperparameters and the corresponding accuracy score
print("Best hyperparameters: ", grid_search.best_params_)
print("Accuracy score: ", grid_search.best_score_)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# import
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.cluster import KMeans
import sklearn.metrics.cluster as smc
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
train = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/train.csv")
test = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/test.csv")
# print(train.info())
# print(test.info())
train.head()
print(train.shape)
print(test.shape)
train["bin_3"] = train["bin_3"].apply(lambda x: 1 if x == "T" else 0)
train["bin_4"] = train["bin_4"].apply(lambda x: 1 if x == "Y" else 0)
test["bin_3"] = test["bin_3"].apply(lambda x: 1 if x == "T" else 0)
test["bin_4"] = test["bin_4"].apply(lambda x: 1 if x == "Y" else 0)
train.head()
# print(train['bin_0'].value_counts())
test_labels = train["target"]
train = train.drop(["target"], axis=1)
train.head()
# X_train_part = X_train[:4200]
# y_train_part = y_train[:4200]
# X_test_part = X_test[:1800]
# y_test_part = y_test[:1800]
# train_part = train[:6000]
# test_labels2 = test_labels[:6000]
from category_encoders.m_estimate import MEstimateEncoder
imputer1 = SimpleImputer(strategy="median")
imputer = SimpleImputer(strategy="most-frequent")
train_1 = train
def Preparation(train, test_set=False):
train_cat = train.drop(["id", "nom_5", "nom_6", "nom_9"], axis=1)
cat_pipeline = Pipeline(
[
("imputer2", SimpleImputer(strategy="most_frequent")),
("cat", OneHotEncoder(categories="auto")),
# ('cat',MEstimateEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown='value', handle_missing='value', random_state=None, randomized=False, sigma=0.05, m=1.0)),
]
)
train_cat_tr = cat_pipeline.fit_transform(train_cat)
categorical_features = list(train_cat)
full_pipeline = ColumnTransformer(
[
# ("num", num_pipeline, numerical_features),
("cat", cat_pipeline, categorical_features),
]
)
train_prepared = full_pipeline.fit_transform(train)
print(train_prepared.shape)
return train_prepared
train_1 = Preparation(train_1) # train_1
# print(train_1)
X_train, X_test, y_train, y_test = train_test_split(
train_1, test_labels, random_state=42, test_size=0.2
) # train_1,test_labels
# print(help(train_test_split))
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
from catboost import CatBoostClassifier
params = { # 30,2000,0.15,5
"bagging_temperature": 0.8,
"l2_leaf_reg": 30,
"iterations": 998,
"learning_rate": 0.15,
"depth": 5,
"random_strength": 0.8,
"loss_function": "Logloss",
"eval_metric": "AUC",
"verbose": False,
}
catb = CatBoostClassifier(**params, nan_mode="Min").fit(
X_train,
y_train,
verbose_eval=100,
early_stopping_rounds=50,
eval_set=(X_test, y_test),
use_best_model=False,
plot=True,
)
preds2 = catb.predict_proba(X_test)[:, 1]
print("ROC AUC score is %.4f" % (roc_auc_score(y_test, preds2)))
print("Catboost Model Performance Results:\n")
plot_roc_curve(catb, X_test, y_test)
plt.title("ROC Curve")
# submission
test_id = test.index
test_sub = Preparation(test)
test_pred = catb.predict_proba(test_sub)[:, 1]
submission = pd.read_csv("/kaggle/input/cat-in-the-dat-ii/sample_submission.csv")
submission.target = test_pred
submission.to_csv("submission.csv", index=False)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import re
import matplotlib.pyplot as plt
plt.style.use("ggplot")
import matplotlib.cm as cm
# ------------------------------------------------------------------
# Functions used in this exercise
# Note: There is probably much better way in separating the player name and country from player.
# Since the primary objective is to analyze the data, I'm compromising the elegancy
def get_player_name(player):
vals = re.findall(r"\((.*?)\)", player)
name = player
for v in vals:
to_rep = "(" + v + ")"
name = name.replace(to_rep, "")
return name
def get_country(player):
vals = re.findall(r"\((.*?)\)", player)
country = vals[-1]
if (
"ICC" in country and len(country.split("/")) == 2
): # If a player played for his country and ICC, then ignore ICC
country = country.replace("ICC", "").replace("/", "")
return country
# ------------------------------------------------------------------
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Read the data in
print("Reading the data...")
df = pd.read_csv(
"/kaggle/input/icc-test-cricket-runs/ICC Test Batting Figures.csv",
encoding="ISO-8859-1",
)
print("Done")
# preview the data
df.head()
# Drop the player profile column.. No use
df.drop("Player Profile", axis=1, inplace=True)
# Player contains the player name and country
# Create 2 new columns with just player name and country
df["Name"] = df["Player"].apply(get_player_name)
df["Country"] = df["Player"].apply(get_country)
# Look at the number of players by country
df.groupby("Country").count()
# hhmm there are some players played for multiple countries
# Lets add another column to store the number of countries
df["NumCountries"] = df["Country"].apply(lambda x: len(x.split("/")))
# Did someone play for more than 2 countries?
print("Number of Countries")
print(df.NumCountries.value_counts())
# Who played for more than 1 country?
print(df.loc[df["NumCountries"] > 1, ["Player", "Mat"]])
# I remember Kepler Wessels, Rankin and Traicos.. It happened in my lifetime !!!!
# Out of 3001 players, 15 played for multiple countries. That is 0.5% Small number.. Delete these players
df.drop(df[df["NumCountries"] > 1].index, inplace=True)
# Lets do some charting
# How many players per country?
players_by_country = df.groupby("Country")["Player"].count()
plt.xticks(rotation="vertical")
plt.bar(x=players_by_country.index, height=players_by_country.values)
plt.show()
# Ofcourse, Eng has more players as they played from early and they play a lot
# Look at the column types
df.dtypes
# Remove * in HS. This indicates the batsman was not-out..
df["HS"] = df["HS"].str.replace("*", "")
# Inn, NO, Runs, HS, Avg, 100, 50, 0 are object.. Convert them to numeric... Some players have not scored any runs or does not
# have avergage.. Convert them to NaN using 'coerce'
for col in ["Inn", "NO", "Runs", "Avg", "HS", "100", "50", "0"]:
df[col] = pd.to_numeric(df[col], errors="coerce")
# Now look at the types
df.dtypes
df
# Span contains the range of the year in which the player played
# Create new columns From/To store the debut year and retired/finally dropped from the team year
df = pd.concat(
[
df,
df["Span"].apply(
lambda x: pd.Series(
{"From": int(x.split("-")[0]), "To": int(x.split("-")[1])}
)
),
],
axis=1,
)
df.head()
# Create a column to store the number of years the player was active
df["SpanYears"] = df["To"] - df["From"]
df.head()
# Which player had longest career
print("Player with longest career")
# Using this approach instead of idxmax so we can identify if there are more than 1 player with long career
df[["Player", "Span"]][df["SpanYears"] == df["SpanYears"].max()]
# Who had more number of ducks (0)
print("Player with most ducks")
df[["Player", "Inn", "Runs", "0"]][df["0"] == df["0"].max()]
# No surprise who that player is.. But he is a great bowler and gentleman though
# Who coverts 50s to 100s more often
# For this create a new data frame which has players who scored more than 1000 runs
# to avoid cases where tail enders or players who have not played many matches scoring 1 or 2 100s by luck
gp = df.drop(df[df["Runs"] < 1000].index)
gp["100To50"] = gp["100"] / gp["50"]
print("Player who converts more 50s to 100s")
gp[["Player", "Inn", "Runs", "100", "50", "100To50"]][
gp["100To50"] == gp["100To50"].max()
].sort_values("Runs", ascending=True)
|
import pandas as pd
from sklearn.model_selection import train_test_split
import math
import time
from sklearn.naive_bayes import GaussianNB
import numpy as np
from sklearn import metrics
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
data_test = pd.read_csv("/kaggle/input/titanic/test.csv")
data_train = pd.read_csv("/kaggle/input/titanic/train.csv")
def removeQuestionMark(outCol, inpCol):
for i in inpCol:
repl = X[i].value_counts().keys().tolist()[0]
X[i] = X[i].replace(to_replace=" ?", value=repl)
rep = y[outCol[0]].value_counts().keys().tolist()[0]
y[outCol[0]] = y[outCol[0]].replace(to_replace=" ?", value=rep)
def CategTraining(X_train, y_train, outCol):
trainCount = y_train[outCol[0]].value_counts().to_dict()
col1 = list(X_train.columns)
outputList = y_train[outCol[0]].value_counts().keys().tolist()
trainDict = dict([(key, []) for key in col1])
for i in range(0, len(col1)):
inputList = X_train[col1[i]].value_counts().keys().tolist()
proxy = dict(
[(key, dict([(keys, []) for keys in outputList])) for key in inputList]
)
trainDict[col1[i]] = proxy
for i in trainDict.keys():
for j in trainDict[i].keys():
for k in trainDict[i][j].keys():
num = (
X_train.loc[(X_train[i] == j) & (y_train[outCol[0]] == k)]
).shape[0]
den = trainCount[k]
prob = num / den
trainDict[i][j][k] = prob
return trainDict
def CategTesting(outCol, trainDict, y_train, X_test):
trainProb = (y_train[outCol[0]].value_counts() / y_train.shape[0]).to_dict()
outputList = y_train[outCol[0]].value_counts().keys().tolist()
testDict1 = dict(
[(key, dict([(keys, []) for keys in outputList])) for key in X_test.index]
)
for i in testDict1.keys():
for j in testDict1[i].keys():
prob = 1
l = 0
for k in trainDict.keys():
prob = trainDict[k][X_test.loc[i][l]][j] * prob
l = l + 1
testDict1[i][j] = prob * trainProb[j]
return testDict1
def Probop(y_test, posOp):
Probop = dict([(key, []) for key in posOp])
for i in Probop.keys():
Probop[i] = (y_test["Salaray"].value_counts()[i]) / y_test.shape[0]
return Probop
def Predict(testDict, prediction, ProbOp):
testInd = y_test.index
FinalPrediction = dict([(keys, []) for keys in testInd])
for i in FinalPrediction.keys():
maxi = 0
pr = ""
p = 0
for j in posOp:
p = prediction[i][j] * testDict[i][j]
if p > maxi:
maxi = p
pr = j
FinalPrediction[i] = pr
return FinalPrediction
data_train["Age"].fillna(data_train["Age"].mean(), inplace=True)
data_train["Fare"].fillna(data_train["Fare"].mean(), inplace=True)
data_test["Age"].fillna(data_test["Age"].mean(), inplace=True)
data_test["Fare"].fillna(data_test["Fare"].mean(), inplace=True)
data_train["Pclass"].fillna(data_train["Pclass"].mode().tolist()[0], inplace=True)
data_train["Sex"].fillna(data_train["Sex"].mode().tolist()[0], inplace=True)
data_train["Parch"].fillna(data_train["Parch"].mode().tolist()[0], inplace=True)
data_train["SibSp"].fillna(data_train["SibSp"].mode().tolist()[0], inplace=True)
data_train["Cabin"].fillna(data_train["Cabin"].mode().tolist()[0], inplace=True)
data_train["Embarked"].fillna(data_train["Embarked"].mode().tolist()[0], inplace=True)
data_test["Pclass"].fillna(data_test["Pclass"].mode().tolist()[0], inplace=True)
data_test["Sex"].fillna(data_test["Sex"].mode().tolist()[0], inplace=True)
data_test["Parch"].fillna(data_test["Parch"].mode().tolist()[0], inplace=True)
data_test["SibSp"].fillna(data_test["SibSp"].mode().tolist()[0], inplace=True)
data_test["Cabin"].fillna(data_test["Cabin"].mode().tolist()[0], inplace=True)
data_test["Embarked"].fillna(data_test["Embarked"].mode().tolist()[0], inplace=True)
X_train = data_train[
["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Cabin", "Embarked"]
]
y_train = data_train[["Survived"]]
X_test = data_test[
["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Cabin", "Embarked"]
]
inpCol = list(X_train.columns)
outCol = list(y_train.columns)
categ_X_train_data = X_train[["Sex", "Cabin", "Embarked"]]
trainDict = CategTraining(categ_X_train_data, y_train, outCol)
testDict = CategTesting(outCol, trainDict, y_train, X_test)
cont_X_Train_data = X_train[["Pclass", "Age", "SibSp", "Parch", "Fare"]]
X_test = x_test[["Pclass", "Age", "SibSp", "Parch", "Fare"]]
posOp = y_train["Survived"].value_counts().keys().tolist()
size = y_train.shape[0]
ProbOp = Probop(y_test, posOp)
clf = GaussianNB()
clf.fit(cont_X_train_data, y_train)
s = clf.predict_proba(X_test)
outputList = y_train[outCol[0]].value_counts().keys().tolist()
prediction = dict(
[(key, dict([(keys, []) for keys in outputList])) for key in X_test.index]
)
r = 0
c = 0
for i in prediction.keys():
c = 0
for j in prediction[i].keys():
prediction[i][j] = s[r][c]
c = c + 1
r = r + 1
Predictions = Predict(testDict, prediction, ProbOp)
|
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style("dark")
plt.style.use("fivethirtyeight")
titanic = pd.read_csv(
"../input/titanic/train.csv", sep=",", index_col="PassengerId", parse_dates=True
)
titanic.head(10)
titanic.shape
# #### Grouping the datset by sex and getting each columns mean value
group_by_sex = titanic.groupby("Sex").mean()
group_by_sex
# ### The next three figures shows the distribution between the survival chance based on Age and Sex
plt.figure(figsize=(10, 8))
plt.title("Survival rate ")
sns.countplot("Survived", data=titanic, hue="Survived")
plt.show()
plt.figure(figsize=(10, 8))
plt.title("Survival rate based on sex ")
sns.barplot(x="Sex", y="Survived", data=titanic, hue="Sex")
plt.show()
plt.figure(figsize=(10, 8))
plt.title("Gender Age Distribution")
sns.barplot(x="Survived", y="Age", data=titanic, hue="Survived")
# ## New dataset for males that survived, taking into account only Age and Pclass
# locate the male passengers and find all who survived
male_percent_survived = titanic.loc[(titanic.Sex == "male") & (titanic.Survived > 0)]
male_percent_survived
# Which passenger class had the most survivals
male_percent_survived.Pclass.value_counts()
plt.figure(figsize=(8, 6))
plt.title("Ranking of male that survived based on their passengerclass")
sns.countplot(
x=male_percent_survived.Pclass, data=male_percent_survived, hue="Survived"
)
# Which Age had the most survivals
male_percent_survived.Age.value_counts()
# taking passengers from ages 1 and above
male_age_above_092 = male_percent_survived.loc[male_percent_survived.Age > 0.92]
male_age_above_092
plt.figure(figsize=(30, 15))
plt.title("Ranking of male that survived based on their ages")
sns.countplot(
x=male_age_above_092.Age.astype(int), data=male_percent_survived, hue="Survived"
)
|
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
train = pd.read_csv(
"/kaggle/input/house-prices-advanced-regression-techniques/train.csv"
)
train.isnull().sum()
train.head()
x = train[
[
"Id",
"MSSubClass",
"LotArea",
"OverallQual",
"OverallCond",
"YearBuilt",
"YearRemodAdd",
"PoolArea",
"MiscVal",
"MoSold",
"YrSold",
]
]
y = train["SalePrice"]
xtrain, xval, ytrain, yval = train_test_split(x, y, test_size=0.2, random_state=42)
y.isnull().sum()
x.isnull().sum()
np.isnan(x).sum()
model = RandomForestClassifier()
model.fit(xtrain, ytrain)
test = pd.read_csv("/kaggle/input/house-prices-advanced-regression-techniques/test.csv")
test1 = test[
[
"Id",
"MSSubClass",
"LotArea",
"OverallQual",
"OverallCond",
"YearBuilt",
"YearRemodAdd",
"PoolArea",
"MiscVal",
"MoSold",
"YrSold",
]
]
predicted = model.predict(test1)
submission = pd.DataFrame({"Id": test1["Id"], "SalePrice": predicted})
submission.to_csv("submission.csv", index=False)
|
# Import librairies
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
plt.style.use("seaborn")
# # Load the data
# The input file has string columns with and without double quotes, so the quotes are not taken into account, and a comma in a string is considered as a delimiter.
# So I had to tinker with this file!!!
# Columns are
# * Year
# * Type (of ads)
# * Product
# * Title
# * Notes (description of the spot TV)
# Load the data without delimiter (line by line)
temp = pd.read_csv(
"../input/superbowlads/superbowl-ads.csv", delimiter="^", quotechar='"'
)
# Line 561 , the 'Year' is missing
temp.iloc[561] = "2020," + temp.iloc[561]
# Split the data
new = temp.iloc[:, 0].str.split(",", n=3, expand=True)
new[3] = new[3].str.replace('"', "")
new[1] = new[1].str.replace('"', "")
new[2] = new[2].str.strip('"')
new2 = new[2].str.split('""', n=1, expand=True)
new = pd.concat([new.iloc[:, [0, 1]], new2, new.iloc[:, 3]], axis=1).values
# Build the final dataframe
df = pd.DataFrame(new, columns=["Year", "Type", "Product", "Title", "Notes"])
del temp, new, new2
df.head()
df.info()
# # Count the type of ads by year
df_counts = pd.crosstab(df["Type"], df["Year"])
df_counts.head()
# # Number of ads by year
ads_by_year = df_counts.sum(axis=0)
ads_by_year.plot(figsize=(16, 9), title="Number of ads over year")
plt.show()
# # Most frequent type (more than 10 times from 1969 to 2020)
df_counts["Total"] = df_counts.sum(axis=1)
df_counts.sort_values(by="Total", ascending=False, inplace=True)
top = df_counts.loc[df_counts["Total"] > 10].drop("Total", 1)
filter = list(top.index)
print(50 * "#" + "\n# Most frequent type (descending order)\n" + 50 * "#")
print(filter)
top.head(10)
# # Evolution over year of the overall most frequent type
# What we can see :
# * The categories Film / Food / Beer are a constant over time
# * There is a peak for advertisements regarding websites in 2000 !
# * 'TV series' and 'Wireless' appeared since 2016
labels = filter
fig, ax = plt.subplots(figsize=(18, 10), dpi=100)
ax.stackplot(top.columns, top.values, labels=labels)
ax.legend(loc="upper left")
plt.show()
# # Top 10 year by year
# > Another way to see the evaluation
col = df_counts.columns
result = []
for i in range(0, col.shape[0]):
list_temp = list(
df_counts.loc[df_counts[col[i]] > 0, col[i]]
.sort_values(ascending=False)[:10]
.index
)
for j in range(len(list_temp), 10):
list_temp.append("-")
result.append(list_temp)
result = np.vstack(result).transpose()
result = pd.DataFrame(data=result, columns=col)
result.iloc[:, :18].head(10)
result.iloc[:, 18:].head(10)
# # Do you have periods to type ads ?
# > by trying to check this by doing a hierarchical clustering of the years
# > Not really convincing
from scipy.spatial.distance import pdist, squareform
from scipy.cluster.hierarchy import linkage, dendrogram
from matplotlib.colors import rgb2hex, colorConverter
from scipy.cluster.hierarchy import set_link_color_palette
df_counts.head()
clustdf = df_counts.transpose()
c_dist = pdist(clustdf) # computing the distance
c_link = linkage(
clustdf, metric="correlation", method="complete"
) # computing the linkage
fig, axes = plt.subplots(1, 1, figsize=(14, 14))
dendro = dendrogram(
c_link,
labels=list(df_counts.columns),
orientation="right",
ax=axes,
color_threshold=0.5,
)
plt.show()
|
# ****AI Factory – Assignment for candidates****
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from fastai import *
from fastai.vision import *
from fastai.callbacks import *
from sklearn.model_selection import train_test_split
import seaborn as sns
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# delete pictures in folder
# shutil.rmtree('./data/composites/')
train = pd.read_json("../input/sar-iceberg/train.json")
test = pd.read_json("../input/sar-iceberg/test.json")
train.head()
# We can see we have to convert the data to an image then use a model to classify it , resnet34 with 2 blank matrices at the end.
# **Distribution of target variable:**
sns.countplot(train.is_iceberg).set_title("Target variable distribution")
# Data is balanced
# get more info on dataset
train.info(), test.info()
# will check to repositioning picture according to angle of satellite.
train.inc_angle = train.inc_angle.replace("na", 0, inplace=True)
train.inc_angle.describe()
# let's see an image
img1 = train.loc[5, ["band_1", "band_2"]]
img1 = np.stack([img1["band_1"], img1["band_2"]], -1).reshape(75, 75, 2)
plt.imshow(img1[:, :, 0])
plt.imshow(img1[:, :, 1])
# **Image creation (to Jpgs)**
# shape of dataset
train.shape
# this will help us to have more images and allowing us to see more charactersitics in image
def color_composite(data):
rgb_arrays = []
for i, row in data.iterrows():
band_1 = np.array(row["band_1"]).reshape(75, 75)
band_2 = np.array(row["band_2"]).reshape(75, 75)
band_3 = band_1 / band_2
r = (band_1 + abs(band_1.min())) / np.max((band_1 + abs(band_1.min())))
g = (band_2 + abs(band_2.min())) / np.max((band_2 + abs(band_2.min())))
b = (band_3 + abs(band_3.min())) / np.max((band_3 + abs(band_3.min())))
rgb = np.dstack((r, g, b))
rgb_arrays.append(rgb)
return np.array(rgb_arrays)
rgb_train = color_composite(train)
rgb_test = color_composite(test)
print("The train shape {}".format(rgb_train.shape))
print("The test shape {}".format(rgb_test.shape))
# look at some ships
ships = np.random.choice(np.where(train.is_iceberg == 0)[0], 9)
fig = plt.figure(1, figsize=(12, 12))
for i in range(9):
ax = fig.add_subplot(3, 3, i + 1)
arr = rgb_train[ships[i], :, :]
ax.imshow(arr)
plt.show()
# look at some iceberg
iceberg = np.random.choice(np.where(train.is_iceberg == 1)[0], 9)
fig = plt.figure(1, figsize=(12, 12))
for i in range(9):
ax = fig.add_subplot(3, 3, i + 1)
arr = rgb_train[iceberg[i], :, :]
ax.imshow(arr)
plt.show()
# for creating labels and folders
# we have to label if iceberg or ship therefore I will create 2 folders - one ship, one iceberg in train set.
iceberg = train[train.is_iceberg == 1]
ship = train[train.is_iceberg == 0]
# save images to disk
os.makedirs("./data/composites", exist_ok=True)
os.makedirs("./data/composites/train/ship", exist_ok=True)
os.makedirs("./data/composites/train/iceberg", exist_ok=True)
os.makedirs("./data/composites/test", exist_ok=True)
# save train iceberg images
for idx in iceberg.index:
img = rgb_train[idx]
plt.imsave("./data/composites/train/iceberg_" + str(idx) + ".png", img)
# save train ship images
for idx in ship.index:
img = rgb_train[idx]
plt.imsave("./data/composites/train/ship_" + str(idx) + ".png", img)
# save test images
for idx in range(len(test)):
img = rgb_test[idx]
plt.imsave("./data/composites/test/" + str(idx) + ".png", img)
# GPU required
torch.cuda.is_available()
torch.backends.cudnn.enabled
# copy model to kernel resnet 34
# Fix to enable Resnet to live on Kaggle - creates a writable location for the models
cache_dir = os.path.expanduser(os.path.join("~", ".torch"))
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
# print("directory created :" .cache_dir)
models_dir = os.path.join(cache_dir, "models")
if not os.path.exists(models_dir):
os.makedirs(models_dir)
# print("directory created :" . cache_dir)
# get pictures/files directory
path = "../working/data/composites/"
path_img = "../working/data/composites/train/"
fnames = get_image_files(path_img)
fnames[:5]
np.random.seed(2)
pat = r"/([^/]+)_\d+.png$"
tfms = get_transforms(do_flip=True, flip_vert=True, max_lighting=0.3, max_warp=0.2)
data = ImageDataBunch.from_name_re(
path_img,
fnames,
pat,
valid_pct=0.3,
ds_tfms=tfms,
size=128,
bs=256,
resize_method=ResizeMethod.CROP,
padding_mode="reflection",
).normalize(
imagenet_stats
) # imagenet stats
# convert image to grayscale
for itemList in ["train_dl", "valid_dl", "fix_dl", "test_dl"]:
itemList = getattr(data, itemList)
if itemList:
itemList.x.convert_mode = "L"
data.classes
# **added imagenet weights**
# let's check image + label
data.show_batch(rows=3, figsize=(7, 8))
# create a learner
learn = cnn_learner(
data, models.resnet34, metrics=[error_rate, accuracy], model_dir="/tmp/models/"
)
learn.summary()
learn.fit_one_cycle(4)
learn.save("stage-1")
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_top_losses(9, figsize=(9, 9))
interp.plot_confusion_matrix()
learn.lr_find()
learn.recorder.plot(suggestion=True)
lr = 1e-01
learn.fit_one_cycle(5, 1e-02)
learn.save("stage-2")
# The learner has a built in method for plotting the training and validation loss.
learn.recorder.plot_losses()
# Initiating refit and checking LR
learn.unfreeze
learn.lr_find()
learn.recorder.plot(suggestion=True)
# access the corresponding learning rate
# min_grad_lr = learn.recorder.min_grad_lr
# min_grad_lr
learn.fit_one_cycle(10, slice(1e-02, 1e-01))
learn.save("stage-3")
learn.recorder.plot_losses()
# create a new learner
# learn = cnn_learner(data, models.resnet34, metrics=[error_rate,accuracy] ,callback_fns=[partial(SaveModelCallback)],
# wd=0.1,ps=[0.9, 0.6, 0.4])
# learn = learn.load('stage-3')
# it becomes to be alike...
unfrozen_validation = learn.validate()
print("Final model validation loss: {0}".format(unfrozen_validation[0]))
# Explring the result
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(2, 2))
test = pd.read_json("../input/sar-iceberg/test.json")
Xtest = get_images(test)
test_predictions = model.predict_proba(Xtest)
submission = pd.DataFrame({"id": test["id"], "is_iceberg": test_predictions[:, 1]})
submission.to_csv("sub_submission.csv", index=False)
|
# # **Vectorizers** - #1 micro challenge
# # Rules
# I have an idea of an alternative challenge format for a while. I want to test it.
# In short, it's a short challenge with specific measurable goals to be achieved.
# In this challenge, you are given a fixed pipeline and only can change the vectorization process. The vectorization method interface is fixed, the rest is up to you.
# You need to **fork [original notebook](https://www.kaggle.com/dremovd/micro-challenge-vectorizers)**
# In order to compete, you also need to **make your Kaggle notebook public**.
# # Challenge [data](https://www.kaggle.com/c/nlp-getting-started/data)
# Data is the same as for the official competition, you can read description here https://www.kaggle.com/c/nlp-getting-started/data
# # Goals
# - 🥉 Bronze. F1-score >= **0.80** at **public** leaderboard
# - 🥈 Silver. F1-score >= **0.81** at **public** leaderboard
# - 🥇 Gold. F1-score >= **0.81** at **public** leaderboard + runtime is below **1 minute**
# # [Submit](https://forms.gle/H8MPo4xpu4NDVsX49)
# You can submit your **public** Kaggle notebook via this [link](https://forms.gle/H8MPo4xpu4NDVsX49)
# # [Leaderboard](http://bit.ly/36pSp3S)
# The final leaderboard is sorted by a medal type and then by submission time. The earlier you achieved the goal is better. You can see current leaderboard by this [link](http://bit.ly/36pSp3S)
# # Fixed pipeline
# In order to participate, the part below need to be unchanged
import pandas as pd
import numpy as np
from joblib import Parallel, delayed
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression, RidgeClassifier
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.metrics import f1_score
import scipy
def simple_pipeline():
print("Load data")
train, test = load_data()
data = pd.concat([train, test], axis=0, ignore_index=True)
print("Vectorization")
X = vectorization(data.drop("target", axis=1))
if type(X) == scipy.sparse.coo_matrix:
X = X.tocsr()
test_mask = data.is_test.values
X_train = X[~test_mask]
y_train = data["target"][~test_mask]
X_test = X[test_mask]
if scipy.sparse.issparse(X):
X_train.sort_indices()
X_test.sort_indices()
model = build_model(X_train, y_train)
print("Prediction with model")
p = model.predict(X_test)
print("Generate submission")
make_submission(data[test_mask], p)
def load_data():
train = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
train["is_test"] = False
test = pd.read_csv("/kaggle/input/nlp-getting-started/test.csv")
test["target"] = -1
test["is_test"] = True
return train, test
def calculate_validation_metric(model, X, y, metric):
folds = StratifiedKFold(n_splits=4, shuffle=True, random_state=0)
score = cross_val_score(model, X, y, scoring=metric, cv=folds, n_jobs=4)
return np.mean(score), model
def select_model(X, y):
models = [
LinearSVC(C=30),
LinearSVC(C=10),
LinearSVC(C=3),
LinearSVC(C=1),
LinearSVC(C=0.3),
LinearSVC(C=0.1),
LinearSVC(C=0.03),
RidgeClassifier(alpha=30),
RidgeClassifier(alpha=10),
RidgeClassifier(alpha=3),
RidgeClassifier(alpha=1),
RidgeClassifier(alpha=0.3),
RidgeClassifier(alpha=0.1),
RidgeClassifier(alpha=0.03),
LogisticRegression(C=30),
LogisticRegression(C=10),
LogisticRegression(C=3),
LogisticRegression(C=1),
LogisticRegression(C=0.3),
LogisticRegression(C=0.1),
LogisticRegression(C=0.03),
]
results = [
calculate_validation_metric(
model,
X,
y,
"f1_macro",
)
for model in models
]
best_result, best_model = max(results, key=lambda x: x[0])
print("Best model validation result: {:.4f}".format(best_result))
print("Best model: {}".format(best_model))
return best_model
def build_model(X, y):
print("Selecting best model")
best_model = select_model(X, y)
print("Refit model to full dataset")
best_model.fit(X, y)
return best_model
def make_submission(data, p):
submission = data[["id"]].copy()
submission["target"] = p
submission.to_csv("submission.csv", index=False)
# # Your part
# ## In *vectorization* method you can change everything and use any dependencies
from sklearn.feature_extraction.text import (
TfidfVectorizer,
CountVectorizer,
HashingVectorizer,
)
from scipy.sparse import hstack
def vectorization(data):
"""
data is concatenated train and test datasets with target excluded
Result value "vectors" expected to have some number of rows as data
"""
tfidf_chars = TfidfVectorizer(
analyzer="char", strip_accents="ascii", ngram_range=(3, 6), min_df=0.0015
)
tfidf_words = TfidfVectorizer(
analyzer="word",
strip_accents="ascii",
)
text = data["text"].fillna("").str.lower()
keyword = data["keyword"].fillna("").str.lower()
vectors_word = tfidf_words.fit_transform(text + " " + keyword)
vectors_char = tfidf_chars.fit_transform(text)
return hstack((vectors_word, vectors_char))
simple_pipeline()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook
from IPython.core.display import HTML
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import (
StratifiedKFold,
KFold,
TimeSeriesSplit,
train_test_split,
)
from sklearn.metrics import roc_auc_score
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
import lightgbm as lgb
import warnings
from tqdm.notebook import tqdm
import data_science_utils.feature_extraction_util as fe
from data_science_utils.plot_util import *
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import GridSearchCV
from missingpy import MissForest
# # Load Data
test_identity = pd.read_csv("/kaggle/input/ieee-fraud-detection/test_identity.csv")
test_identity.columns = test_identity.columns.str.replace("-", "_")
train_identity = pd.read_csv("/kaggle/input/ieee-fraud-detection/train_identity.csv")
test_transaction = pd.read_csv(
"/kaggle/input/ieee-fraud-detection/test_transaction.csv"
)
train_transaction = pd.read_csv(
"/kaggle/input/ieee-fraud-detection/train_transaction.csv"
)
train = pd.merge(train_identity, train_transaction, on="TransactionID", how="right")
test = pd.merge(test_identity, test_transaction, on="TransactionID", how="right")
# Clear unused data to free up some memory
test_identity, train_identity, test_transaction, train_transaction = [None] * 4
# # Fill missing data
numerical_columns = ["id_0" + str(i) for i in range(1, 10)] + ["id_10", "id_11"]
# ## Categorical Data with -999
test.loc[:, ~test.columns.isin(numerical_columns)] = test.loc[
:, ~test.columns.isin(numerical_columns)
].fillna(-999)
train.loc[:, ~train.columns.isin(numerical_columns)] = train.loc[
:, ~train.columns.isin(numerical_columns)
].fillna(-999)
# ## Fill numerical with imputation (missForest)
imputer = MissForest()
test.loc[:, test.columns.isin(numerical_columns)] = imputer.fit_transform(
test.loc[:, test.columns.isin(numerical_columns)]
)
train.loc[:, train.columns.isin(numerical_columns)] = imputer.fit_transform(
train.loc[:, train.columns.isin(numerical_columns)]
)
# # Fix covariate shift
params = {
"objective": "binary",
"boosting_type": "gbdt",
"subsample": 1,
"bagging_seed": 11,
"metric": "auc",
"num_boost_round": 100,
"verbose": -1,
}
train, test = fe.correct_features_with_covariate_shift(
train,
test,
params,
train.columns.drop(["isFraud", "TransactionID", "TransactionDT"]),
)
# # Add more features
train["TransactionAmt_decimal"] = (
(train["TransactionAmt"] - train["TransactionAmt"].astype(int)) * 1000
).astype(int)
test["TransactionAmt_decimal"] = (
(test["TransactionAmt"] - test["TransactionAmt"].astype(int)) * 1000
).astype(int)
# Count encoding for card1 feature.
# Explained in this kernel: https://www.kaggle.com/nroman/eda-for-cis-fraud-detection
train["card1_count_full"] = train["card1"].map(
pd.concat([train["card1"], test["card1"]], ignore_index=True).value_counts(
dropna=False
)
)
test["card1_count_full"] = test["card1"].map(
pd.concat([train["card1"], test["card1"]], ignore_index=True).value_counts(
dropna=False
)
)
# https://www.kaggle.com/fchmiel/day-and-time-powerful-predictive-feature
train["Transaction_day_of_week"] = np.floor(
(train["TransactionDT"] / (3600 * 24) - 1) % 7
)
test["Transaction_day_of_week"] = np.floor(
(test["TransactionDT"] / (3600 * 24) - 1) % 7
)
train["Transaction_hour"] = np.floor(train["TransactionDT"] / 3600) % 24
test["Transaction_hour"] = np.floor(test["TransactionDT"] / 3600) % 24
# Some arbitrary features interaction
for feature in [
"id_02__id_20",
"id_02__D8",
"D11__DeviceInfo",
"DeviceInfo__P_emaildomain",
"P_emaildomain__C2",
"card2__dist1",
"card1__card5",
"card2__id_20",
"card5__P_emaildomain",
"addr1__card1",
]:
f1, f2 = feature.split("__")
train[feature] = train[f1].astype(str) + "_" + train[f2].astype(str)
test[feature] = test[f1].astype(str) + "_" + test[f2].astype(str)
le = LabelEncoder()
le.fit(
list(train[feature].astype(str).values) + list(test[feature].astype(str).values)
)
train[feature] = le.transform(list(train[feature].astype(str).values))
test[feature] = le.transform(list(test[feature].astype(str).values))
for feature in ["id_34", "id_36"]:
if feature in useful_features:
# Count encoded for both train and test
train[feature + "_count_full"] = train[feature].map(
pd.concat([train[feature], test[feature]], ignore_index=True).value_counts(
dropna=False
)
)
test[feature + "_count_full"] = test[feature].map(
pd.concat([train[feature], test[feature]], ignore_index=True).value_counts(
dropna=False
)
)
for feature in ["id_01", "id_31", "id_33", "id_35", "id_36"]:
if feature in useful_features:
# Count encoded separately for train and test
train[feature + "_count_dist"] = train[feature].map(
train[feature].value_counts(dropna=False)
)
test[feature + "_count_dist"] = test[feature].map(
test[feature].value_counts(dropna=False)
)
# # Train lightgbm
params = {
"num_leaves": 491,
"min_child_weight": 0.03454472573214212,
"feature_fraction": 0.3797454081646243,
"bagging_fraction": 0.4181193142567742,
"min_data_in_leaf": 106,
"objective": "binary",
"max_depth": -1,
"learning_rate": 0.0066,
"n_estimators": 1000,
"boosting_type": "gbdt",
"bagging_seed": 11,
"metric": "auc",
"verbosity": -1,
"reg_alpha": 0.3899927210061127,
"reg_lambda": 0.6485237330340494,
"random_state": 47,
}
X_train, X_test, y_train, y_test = train_test_split(
train.drop(columns=["isFraud", "TransactionID", "TransactionDT"]),
train["isFraud"],
test_size=0.33,
)
clf = lgb.LGBMClassifier(**params)
clf.fit(X_train, y_train)
cols_to_drop = ["TransactionID", "TransactionDT"]
sub = pd.read_csv("/kaggle/input/ieee-fraud-detection/sample_submission.csv")
sub["isFraud"] = clf.predict_proba(test.drop(columns=cols_to_drop))[:, 1]
sub["TransactionID"] = test.TransactionID
sub.to_csv("submission.csv", index=False)
|
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# ----
# # Imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import string
from matplotlib.colors import is_color_like
import nltk
from nltk.corpus import stopwords
nltk.download("stopwords")
nltk.download("punkt")
stop_words = stopwords.words("english")
print(stop_words)
from nltk.stem import PorterStemmer
porter = PorterStemmer()
from sklearn.feature_extraction.text import (
TfidfTransformer,
TfidfVectorizer,
CountVectorizer,
)
from sklearn.cluster import KMeans
from gensim.summarization import summarize # pip3 install gensim==3.6.0
from gensim.summarization import keywords
from joblib import dump, load
# ----
CSV_DIRECTORY = "../input/data-combined/data.csv"
df = pd.read_csv(CSV_DIRECTORY, index_col=0).reset_index()
df.head()
# ## More Answer Types
def more_separation(input_question, answer):
question = input_question.split()
# filter_question = filter(lambda w: not w in stopwords, split_question.split())
if answer.lower() == "yes" or answer.lower() == "no":
return "yes/no"
elif answer.translate(str.maketrans("", "", string.punctuation)).isnumeric():
return "number"
###
elif (len(answer) > 1 and is_color_like(answer)) or answer == "clear":
return "colour"
elif question[0] == "Where":
return "location"
elif question[0] == "What" and question[1] == "is":
return "identify"
else:
return "other"
df["answer_type"] = df.apply(
lambda x: more_separation(x["question"], x["answer"]), axis=1
)
# ## Kmeans for Question Labels
def remove_stopwords_punctuation_from_tokens(question_tokens):
new_list = []
for token in eval(question_tokens):
if token not in stop_words and token not in string.punctuation:
# print(token)
new_list.append(token)
return new_list
def stem_tokens(question_tokens):
return [porter.stem(token) for token in question_tokens]
def normalize_tokens(tokens):
return [token.lower() for token in tokens]
df["question_tokens"] = (
df["question_tokens"]
.apply(remove_stopwords_punctuation_from_tokens)
.apply(normalize_tokens)
)
df = df[~df["question_tokens"].apply(lambda x: isinstance(x, (list)) and len(x) == 0)]
df.head()
# Convert the preprocessed tokens to strings
df["question_text"] = df["question_tokens"].apply(lambda x: " ".join(x))
df.head()
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(df["question_text"])
# Print the shape of the tfidf matrix
print(tfidf_matrix.shape)
tfidf_matrix.todense()
# Initialize the KMeans model
kmeans = KMeans()
kmeans.fit(tfidf_matrix)
MAX_N_CLUSTERS = 30
# Calculate the within-cluster sum of squares (WCSS) for different numbers of clusters
wcss = []
for i in range(1, MAX_N_CLUSTERS + 1):
kmeans = KMeans(
n_clusters=i, init="k-means++", max_iter=300, n_init=10, random_state=0
)
kmeans.fit(tfidf_matrix)
wcss.append(kmeans.inertia_)
# Plot the elbow curve
plt.plot(range(1, MAX_N_CLUSTERS + 1), wcss)
plt.title("Elbow Method")
plt.xlabel("Number of clusters")
plt.ylabel("WCSS")
plt.show()
N_CLUSTERS = 30
# Initialize the KMeans model with the optimal number of clusters
kmeans = KMeans(
n_clusters=N_CLUSTERS, init="k-means++", max_iter=300, n_init=10, random_state=0
)
kmeans.fit(tfidf_matrix)
# Add the cluster labels to the dataframe
df["cluster_label"] = kmeans.labels_
dump(kmeans, "./kmeans_model.joblib")
# Print the number of questions in each cluster
df["cluster_label"].value_counts()
NO_SUMMARY_WORDS = 1
NO_SUMMARY_SAMPLE_SIZE = 900
cluster_labels = {}
for idx in range(N_CLUSTERS):
subset = df[df["cluster_label"] == idx].sample(
n=min(NO_SUMMARY_SAMPLE_SIZE, len(df)), random_state=42
)
text = ". ".join(subset["question_text"].tolist())
sentences = nltk.sent_tokenize(text)
summary = summarize(" ".join(sentences))
summary_keywords = keywords(summary, words=NO_SUMMARY_WORDS, lemmatize=True)
cluster_labels[f"{idx}"] = summary_keywords
print(cluster_labels)
def assign_named_label(label):
return cluster_labels[f"{label}"]
df["cluster_name"] = df["cluster_label"].apply(assign_named_label)
df[500:550]
|
# # Task: Predict Malignant and Benign Skin Moles
# I'm starting on FastAI's online course and chose this Task for my first round of practice. If you've been through FastAI's course before this might seem firmiliar, if not take a look at some of the basics from week one.
# Because this is a balenced dataset today I'm simply going look at accuracy as the evaluation metric. This project is for educational purposes and considering that I cobbled together with some spare time on my weekend, I'm pretty happy with this. I'm not a doctor (I don't even play one on TV).
# Thanks to:
# * Cluadio Fanconi https://www.kaggle.com/fanconic for the Task, and also for creating a submission to compete against (His model produced an accuracy of about 92% so thats what I'm shoot for)
# * The International Skin Imaging Collaboration https://www.isic-archive.com/ for the dataset. All the images are well centered and are size 224 so they made the bar for entry very reasonable.
import numpy as np
import pandas as pd
import os
import sys
from fastai import *
from fastai.vision import *
PATH = Path("/kaggle/input/skin-cancer-malignant-vs-benign/")
data = ImageDataBunch.from_folder(
PATH,
train="train/",
# valid="train/",
# test="test/",
valid_pct=0.3,
ds_tfms=get_transforms(),
size=224,
bs=32,
).normalize(imagenet_stats)
print(f"Classes: \n {data.classes}")
learn = cnn_learner(data, models.resnet50, metrics=error_rate)
learn.summary()
learn.fit_one_cycle(4)
interp = ClassificationInterpretation.from_learner(learn)
losses, idxs = interp.top_losses()
len(data.valid_ds) == len(losses) == len(idxs)
interp.plot_confusion_matrix(figsize=(4, 4))
Model_Path = Path("/kaggle/working/")
learn.model_dir = Model_Path
learn.save(
"stage-1"
) # checkpointing the model incase the next couple of tasks backfire
learn.unfreeze()
learn.fit_one_cycle(2)
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(3, max_lr=slice(1e-6, 1e-4))
interp = ClassificationInterpretation.from_learner(learn)
losses, idxs = interp.top_losses()
len(data.valid_ds) == len(losses) == len(idxs)
interp.plot_confusion_matrix(figsize=(4, 4))
# # Final thoughts:
# Initially this would appear to have an accuracy of 93%(at least on the validation set). Each week I challenge myself to complete one Kaggle Task and this week I didn't have enough time to do this project justice. While my results look good, I did not manage to test for overfitting (which is a serious asterisk to append to this). Later I will revisit this notebook when I'm able to retest the model against the test data instead of just a validation set.
# If you have any constructive feedback feel free to message me or leave a comment. If you liked the notebook I'd appriciate the upvote. And if you would like to collaborate with me on a future Kaggle task send me a message here or on LinkedIn.
learn.save("Final")
|
# # Linear Regression with Scikit Learn - Machine Learning with Python
# This is a part of [Zero to Data Science Bootcamp by Jovian](https://zerotodatascience.com) and [Machine Learning with Python: Zero to GBMs](https://jovian.ai/learn/machine-learning-with-python-zero-to-gbms)
# 
# The following topics are covered in this tutorial:
# - A typical problem statement for machine learning
# - Downloading and exploring a dataset for machine learning
# - Linear regression with one variable using Scikit-learn
# - Linear regression with multiple variables
# - Using categorical features for machine learning
# - Regression coefficients and feature importance
# - Other models and techniques for regression using Scikit-learn
# - Applying linear regression to other datasets
# ## Problem Statement
# This tutorial takes a practical and coding-focused approach. We'll define the terms _machine learning_ and _linear regression_ in the context of a problem, and later generalize their definitions. We'll work through a typical machine learning problem step-by-step:
# > **QUESTION**: ACME Insurance Inc. offers affordable health insurance to thousands of customer all over the United States. As the lead data scientist at ACME, **you're tasked with creating an automated system to estimate the annual medical expenditure for new customers**, using information such as their age, sex, BMI, children, smoking habits and region of residence.
# >
# > Estimates from your system will be used to determine the annual insurance premium (amount paid every month) offered to the customer. Due to regulatory requirements, you must be able to explain why your system outputs a certain prediction.
# >
# > You're given a [CSV file](https://raw.githubusercontent.com/JovianML/opendatasets/master/data/medical-charges.csv) containing verified historical data, consisting of the aforementioned information and the actual medical charges incurred by over 1300 customers.
# >
# >
# > Dataset source: https://github.com/stedy/Machine-Learning-with-R-datasets
# ## Downloading the Data
# To begin, let's import the data using pandas
import pandas as pd
medical_df = pd.read_csv("/kaggle/input/insurance/insurance.csv")
medical_df
# The dataset contains 1338 rows and 7 columns. Each row of the dataset contains information about one customer.
# Our objective is to find a way to estimate the value in the "charges" column using the values in the other columns. If we can do so for the historical data, then we should able to estimate charges for new customers too, simply by asking for information like their age, sex, BMI, no. of children, smoking habits and region.
# ## Overlooking the data.
# **Let's check the data type for each column.**
medical_df.info()
# Looks like "age", "children", "bmi" ([body mass index](https://en.wikipedia.org/wiki/Body_mass_index)) and "charges" are numbers, whereas "sex", "smoker" and "region" are strings (possibly categories). None of the columns contain any missing values, which saves us a fair bit of work!
# **Here are some statistics for the numerical columns:**
medical_df.describe()
# The ranges of values in the numerical columns seem reasonable too (no negative ages!), so we may not have to do much data cleaning or correction. The "charges" column seems to be significantly skewed however, as the median (50 percentile) is much lower than the maximum value.
# ## Exploratory Analysis and Visualization
# Let's explore the data by visualizing the distribution of values in some columns of the dataset, and the relationships between "charges" and other columns.
# We'll use libraries Matplotlib, Seaborn and Plotly for visualization. Follow these tutorials to learn how to use these libraries:
# - https://jovian.ai/aakashns/python-matplotlib-data-visualization
# - https://jovian.ai/aakashns/interactive-visualization-plotly
# - https://jovian.ai/aakashns/dataviz-cheatsheet
import plotly.express as px
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
# The following settings will improve the default style and font sizes for our charts. This Also helps to save the Plotly plots for offline use.
sns.set_style("darkgrid")
matplotlib.rcParams["font.size"] = 14
matplotlib.rcParams["figure.figsize"] = (16, 9)
matplotlib.rcParams["figure.facecolor"] = "#00000000"
# ### Age
# Age is a numeric column. The minimum age in the dataset is 18 and the maximum age is 64. Thus, we can visualize the distribution of age using a histogram with 47 bins (one for each year) and a box plot. We'll use plotly to make the chart interactive, but you can create similar charts using Seaborn.
# > When "**marginal='box'**" is used, a box plot is added on either the x-axis or y-axis of the histogram, depending on the orientation of the histogram. The box plot displays the summary statistics of the data distribution, such as the median, quartiles, and outliers, providing additional insights into the distribution of the data.
# > This can be useful for gaining a deeper understanding of the shape, spread, and central tendency of the data in the histogram, and for identifying potential outliers or skewness in the distribution. It can also help in comparing the distribution of data across different categories or groups, if applicable.
fig = px.histogram(
medical_df, x="age", marginal="box", nbins=47, title="Distribution of Age"
)
fig.update_layout(bargap=0.1)
fig.show()
# The distribution of ages in the dataset is almost uniform, with 20-30 customers at every age, except for the ages 18 and 19, which seem to have over twice as many customers as other ages. ***This might due to the fact that there might be some discounts for early bird joiners or people might be aware that insurances is a must. But these are just my assumptions. Also we have enough data or information to confirm it is true or not.*** The uniform distribution might arise from the fact that there isn't a big variation in the [number of people of any given age](https://www.statista.com/statistics/241488/population-of-the-us-by-sex-and-age/) (between 18 & 64) in the USA.
# ### Body Mass Index
# Let's look at the distribution of BMI (Body Mass Index) of customers, using a histogram and box plot.
fig = px.histogram(
medical_df,
x="bmi",
marginal="box",
color_discrete_sequence=["red"],
title="Distribution of BMI (Body Mass Index)",
)
fig.update_layout(bargap=0.1)
fig.show()
# The measurements of body mass index seem to form a [Gaussian distribution](https://en.wikipedia.org/wiki/Normal_distribution) centered around the value 30, with a few outliers towards the right. Here's how BMI values can be interpreted ([source](https://study.com/academy/lesson/what-is-bmi-definition-formula-calculation.html)):
# 
# *The distribution of ages in a sample of the U.S population may form a uniform distribution because the age distribution is relatively the same across all age groups. This means that there are roughly equal numbers of individuals in each age group, resulting in a uniform distribution.*
# *On the other hand, the distribution of BMIs (Body Mass Index) may form a Gaussian or normal distribution because BMI tends to follow a bell-shaped curve in a large population. A Gaussian distribution implies that most people in the dataset tend to have BMIs around a particular value, which is the peak of the distribution, with fewer individuals having higher or lower BMIs on the left and right tails of the curve.*
# ### Charges
# Let's visualize the distribution of "charges" i.e. the annual medical charges for customers. This is the column we're trying to predict. Let's also use the categorical column "smoker" to distinguish the charges for smokers and non-smokers.
fig = px.histogram(
medical_df,
x="charges",
marginal="box",
color="smoker",
color_discrete_sequence=["green", "grey"],
title="Annual Medical Charges vs Smoking",
)
fig.update_layout(bargap=0.1)
fig.show()
# We can make the following observations from the above graph:
# * For most customers, the annual medical charges are under \\$10,000. Only a small fraction of customer have higher medical expenses, possibly due to accidents, major illnesses and genetic diseases. The distribution follows a "power law"
# * There is a significant difference in medical expenses between smokers and non-smokers. While the median for non-smokers is \\$7300, the median for smokers is close to \\$35,000.
# Visualizing the distribution of medical charges in connection with other factors like "sex" and "region".
fig = px.histogram(
medical_df,
x="charges",
marginal="box",
color="sex",
color_discrete_sequence=["green", "grey"],
title="Annual Medical Charges vs Gender",
)
fig.update_layout(bargap=0.1)
fig.show()
fig = px.histogram(
medical_df,
x="charges",
marginal="box",
color="region",
title="Annual Medical Charges vs Region",
)
fig.update_layout(bargap=0.1)
fig.show()
# ### Smoker
# Let's visualize the distribution of the "smoker" column (containing values "yes" and "no") using a histogram.
medical_df.smoker.value_counts()
px.histogram(medical_df, x="smoker", color="sex", title="Smoker")
# It appears that 20% of customers have reported that they smoke. The national average seems to around 14% for male and 11% for female. we have a pretty similar values here like 11% for male and 8.5% for female. so our data seems good to overall U.S average
# Lets visualize the distributions of the "sex", "region" and "children" columns and report our observations.
px.histogram(medical_df, x="sex", title="Gender Distribution")
px.histogram(medical_df, x="region", title="Region Distribution")
px.histogram(medical_df, x="children", title="Childrens Distributions")
# The "Region and Gender" columns have equally distributed in our dataset while the "Children" column have a "power law" distribution. which is basically having a huge amount of count on a paricular value in a column while having very less counts on other values.
# Having looked at individual columns, we can now visualize the relationship between "charges" (the value we wish to predict) and other columns.
# ### Age and Charges
# Let's visualize the relationship between "age" and "charges" using a scatter plot. Each point in the scatter plot represents one customer. We'll also use values in the "smoker" column to color the points.
fig = px.scatter(
medical_df,
x="age",
y="charges",
color="smoker",
opacity=0.8,
hover_data=["sex"],
title="Age vs. Charges",
)
fig.update_traces(marker_size=5)
fig.show()
# We can make the following observations from the above chart:
# * The general trend seems to be that medical charges increase with age, as we might expect. However, there is significant variation at every age, and it's clear that age alone cannot be used to accurately determine medical charges.
# * We can see three "clusters" of points, each of which seems to form a line with an increasing slope:
# 1. The first and the largest cluster consists primary of presumably "healthy non-smokers" who have relatively low medical charges compared to others
#
# 2. The second cluster contains a mix of smokers and non-smokers. It's possible that these are actually two distinct but overlapping clusters: "non-smokers with medical issues" and "smokers without major medical issues".
#
# 3. The final cluster consists exclusively of smokers, presumably smokers with major medical issues that are possibly related to or worsened by smoking.
# 4. Among the 3 clusters I can see that the uppermost cluster have a average BMI hovering around in the thirties while the middle and lower cluster has BMI averaging in the twenties.
# ### BMI and Charges
# Let's visualize the relationship between BMI (body mass index) and charges using another scatter plot. Once again, we'll use the values from the "smoker" column to color the points.
fig = px.scatter(
medical_df,
x="bmi",
y="charges",
color="smoker",
opacity=0.8,
hover_data=["sex"],
title="BMI vs. Charges",
)
fig.update_traces(marker_size=5)
fig.show()
# It appears that for non-smokers, an increase in BMI doesn't seem to be related to an increase in medical charges. However, medical charges seem to be significantly higher for smokers with a BMI greater than 30.
# Creating some more graphs to visualize how the "charges" column is related to other columns ("children", "sex", "region" and "smoker")
fig, ax = plt.subplots(figsize=(8, 6))
sns.barplot(x="children", y="charges", hue="smoker", data=medical_df, ax=ax)
ax.set_ylabel("Charges")
ax.set_title("Charges by Children with Smoker")
plt.show()
fig, ax = plt.subplots(figsize=(8, 6))
sns.barplot(x="sex", y="charges", hue="smoker", data=medical_df, ax=ax)
ax.set_ylabel("Charges")
ax.set_title("Charges by Sex with Smoker")
plt.show()
fig, ax = plt.subplots(figsize=(8, 6))
sns.barplot(x="region", y="charges", hue="smoker", data=medical_df, ax=ax)
ax.set_ylabel("Charges")
ax.set_title("Charges by Region with Smoker")
plt.show()
# ### Correlation
# As you can tell from the analysis, the values in some columns are more closely related to the values in "charges" compared to other columns. E.g. "age" and "charges" seem to grow together, whereas "bmi" and "charges" don't.
# This relationship is often expressed numerically using a measure called the _correlation coefficient_, which can be computed using the `.corr` method of a Pandas series.
medical_df.charges.corr(medical_df.age)
medical_df.charges.corr(medical_df.bmi)
# To compute the correlation for categorical columns, they must first be converted into numeric columns.
smoker_values = {"no": 0, "yes": 1}
smoker_numeric = medical_df.smoker.map(smoker_values)
medical_df.charges.corr(smoker_numeric)
#
# Here's how correlation coefficients can be interpreted ([source](https://statisticsbyjim.com/basics/correlations)):
# * **Strength**: The greater the absolute value of the correlation coefficient, the stronger the relationship.
# * The extreme values of -1 and 1 indicate a perfectly linear relationship where a change in one variable is accompanied by a perfectly consistent change in the other. For these relationships, all of the data points fall on a line. In practice, you won’t see either type of perfect relationship.
# * A coefficient of zero represents no linear relationship. As one variable increases, there is no tendency in the other variable to either increase or decrease.
#
# * When the value is in-between 0 and +1/-1, there is a relationship, but the points don’t all fall on a line. As r approaches -1 or 1, the strength of the relationship increases and the data points tend to fall closer to a line.
# * **Direction**: The sign of the correlation coefficient represents the direction of the relationship.
# * Positive coefficients indicate that when the value of one variable increases, the value of the other variable also tends to increase. Positive relationships produce an upward slope on a scatterplot.
#
# * Negative coefficients represent cases when the value of one variable increases, the value of the other variable tends to decrease. Negative relationships produce a downward slope.
# Here's the same relationship expressed visually ([source](https://www.cuemath.com/data/how-to-calculate-correlation-coefficient/)):
# The correlation coefficient has the following formula:
# You can learn more about the mathematical definition and geometric interpretation of correlation here: https://www.youtube.com/watch?v=xZ_z8KWkhXE
# Pandas dataframes also provide a `.corr` method to compute the correlation coefficients between all pairs of numeric columns.
medical_df.corr()
# The result of `.corr` is called a correlation matrix and is often visualized using a heatmap.
sns.heatmap(medical_df.corr(), cmap="Reds", annot=True)
plt.title("Correlation Matrix")
# **Correlation vs causation fallacy:** Note that a high correlation cannot be used to interpret a cause-effect relationship between features. Two features $X$ and $Y$ can be correlated if $X$ causes $Y$ or if $Y$ causes $X$, or if both are caused independently by some other factor $Z$, and the correlation will no longer hold true if one of the cause-effect relationships is broken. It's also possible that $X$ are $Y$ simply appear to be correlated because the sample is too small.
# While this may seem obvious, computers can't differentiate between correlation and causation, and decisions based on automated system can often have major consequences on society, so it's important to study why automated systems lead to a given result. Determining cause-effect relationships requires human insight.
# ## Linear Regression using a Single Feature
# We now know that the "smoker" and "age" columns have the strongest correlation with "charges". Let's try to find a way of estimating the value of "charges" using the value of "age" for non-smokers. First, let's create a data frame containing just the data for non-smokers.
# ***NOTE: Some of the code below are just to slice the Linear Regression Model to understand the intution behind it. Just follow the explanation and not the code. A Linear model will be build at the end of the notebook. I'll hide the code just to avoid confusion***
# Next, let's visualize the relationship between "age" and "charges"
plt.title("Age vs. Charges")
sns.scatterplot(data=medical_df, x="age", y="charges", hue="smoker", alpha=0.7, s=15)
# We'll try and "fit" a line using this points, and use the line to predict charges for a given age. A line on the X&Y coordinates has the following formula:
# $y = wx + b$
# The line is characterized two numbers: $w$ (called "slope") and $b$ (called "intercept").
# ### Model
# In the above case, the x axis shows "age" and the y axis shows "charges". Thus, we're assuming the following relationship between the two:
# $charges = w \times age + b$
# We'll try determine $w$ and $b$ for the line that best fits the data.
# * This technique is called _linear regression_, and we call the above equation a _linear regression model_, because it models the relationship between "age" and "charges" as a straight line.
# * The numbers $w$ and $b$ are called the _parameters_ or _weights_ of the model.
# * The values in the "age" column of the dataset are called the _inputs_ to the model and the values in the charges column are called "targets".
# Let define a helper function `estimate_charges`, to compute $charges$, given $age$, $w$ and $b$.
#
def estimate_charges(age, w, b):
return w * age + b
# The `estimate_charges` function is our very first _model_.
# Let's _test_ the values for a given $age$,$w$ and $b$ and use them to estimate the value for charges.
age = 32
w = 50
b = 100
print("The predicted charge for the given values is:", estimate_charges(age, w, b))
# This is a very basic single point $y$ we predicted manually using some pre assumed values. lets try to do for an list of _ages_ and see what happends
# we create a pandas series by taking first 10 age values from our dataset
ages = medical_df.age.head(10)
ages
# Our fuction can take the pandas series of values and create estimated charges for each age.
# The resultant is also a pandas dataframe.
estimated_charges = estimate_charges(ages, w, b)
estimated_charges
# We can plot the estimated charges using a line graph.
plt.plot(ages, estimated_charges, "r-o")
plt.xlabel("Age")
plt.ylabel("Estimated Charges")
# As expected, the points lie on a straight line. This happened because of the fact that we used manual values for the $w$ and $b$
# Now we input all the ages in our data and we can overlay this line on the actual data, so see how well our _model_ fits the _data_.
# Repeating the same steps as above but for all the age values
ages = medical_df.age
target = medical_df.charges
estimated_charges = estimate_charges(ages, w, b)
plt.plot(ages, estimated_charges, "r", alpha=0.9)
plt.scatter(ages, target, s=8, alpha=0.8)
plt.xlabel("Age")
plt.ylabel("Charges")
plt.legend(["Estimate", "Actual"])
# Clearly, the our estimates are quite poor and the line does not "fit" the data. However, we can try different values of $w$ and $b$ to move the line around. Let's define a helper function `try_parameters` which takes `w` and `b` as inputs and creates the above plot.
def try_parameters(w, b):
ages = medical_df.age
target = medical_df.charges
def estimate_charges(age, w, b):
return w * age + b
estimated_charges = estimate_charges(ages, w, b)
plt.plot(ages, estimated_charges, "r", alpha=0.9)
plt.scatter(ages, target, s=8, alpha=0.8)
plt.xlabel("Age")
plt.ylabel("Charges")
plt.legend(["Estimate", "Actual"])
# This function is similar to the previous one _estimate_charges_ but in that the $w$ and $b$ is fixed. Here we are using an option to change the $w$ and $b$ values as inputs and the program create '_y_=$w$x + $b$' then plots it against our 'medical_df' data. Now we'll try to experiment with different $w$ and $b$ values.
try_parameters(60, 200)
try_parameters(400, 5000)
try_parameters(550, -5000)
# As we change the values, of $w$ and $b$ manually, trying to move the line visually closer to the points, we are _learning_ the approximate relationship between "age" and "charges".
# Wouldn't it be nice if a computer could try several different values of `w` and `b` and _learn_ the relationship between "age" and "charges"? To do this, we need to solve a couple of problems:
# 1. We need a way to measure numerically how well the line fits the points.
# 2. Once the "measure of fit" has been computed, we need a way to modify `w` and `b` to improve the the fit.
# If we can solve the above problems, it should be possible for a computer to determine `w` and `b` for the best fit line, starting from a random guess.
# ### Calculating Loss
# We can compare our model's predictions with the actual targets using the following method:
# * Calculate the difference between the targets and predictions (the differenced is called the "residual")
# * Square all elements of the difference matrix to remove negative values.
# * Calculate the average of the elements in the resulting matrix.
# * Take the square root of the result
# The result is a single number, known as the **root mean squared error** (RMSE). The above description can be stated mathematically as follows:
# Geometrically, the residuals can be visualized as follows:
# Let's define a function to compute the RMSE.
import numpy as np
def rmse(targets, predictions):
return np.sqrt(np.mean(np.square(targets - predictions)))
# Let's compute the RMSE for our model with a sample set of weights
try_parameters(50, 100)
targets = medical_df["charges"]
predicted = estimate_charges(medical_df.age, w, b)
rmse(targets, predicted)
# Here's how we can interpret the above number: *On average, each element in the prediction differs from the actual target by \\$16359*.
# The result is called the *loss* because it indicates how bad the model is at predicting the target variables. It represents information loss in the model: the lower the loss, the better the model.
# ### Optimizer
# Next, we need a strategy to modify weights `w` and `b` to reduce the loss and improve the "fit" of the line to the data.
# * Ordinary Least Squares: https://www.youtube.com/watch?v=szXbuO3bVRk (better for smaller datasets)
# * Stochastic gradient descent: https://www.youtube.com/watch?v=sDv4f4s2SB8 (better for larger datasets)
# Both of these have the same objective: to minimize the loss, however, while ordinary least squares directly computes the best values for `w` and `b` using matrix operations, while gradient descent uses a iterative approach, starting with a random values of `w` and `b` and slowly improving them using derivatives.
# Here's a visualization of how gradient descent works:
# 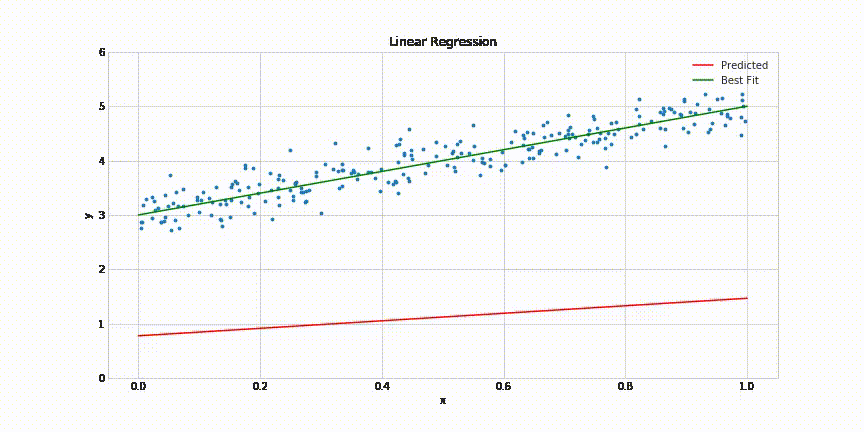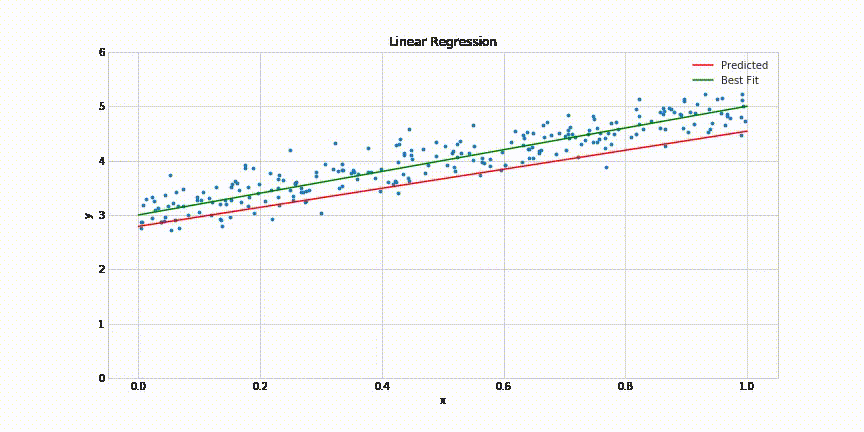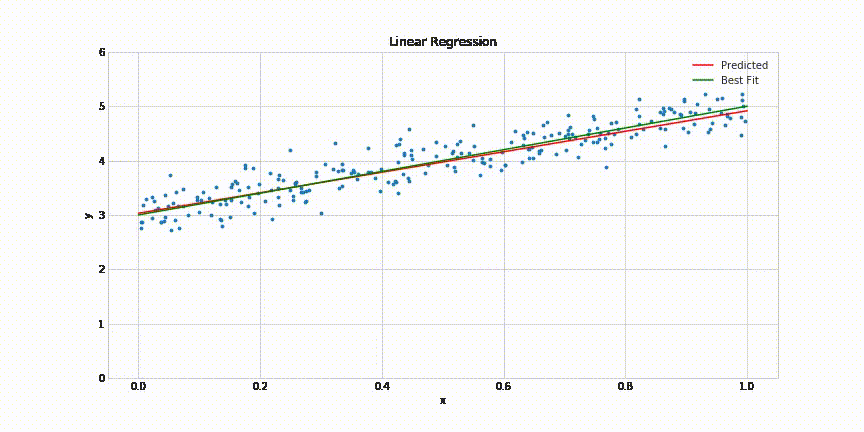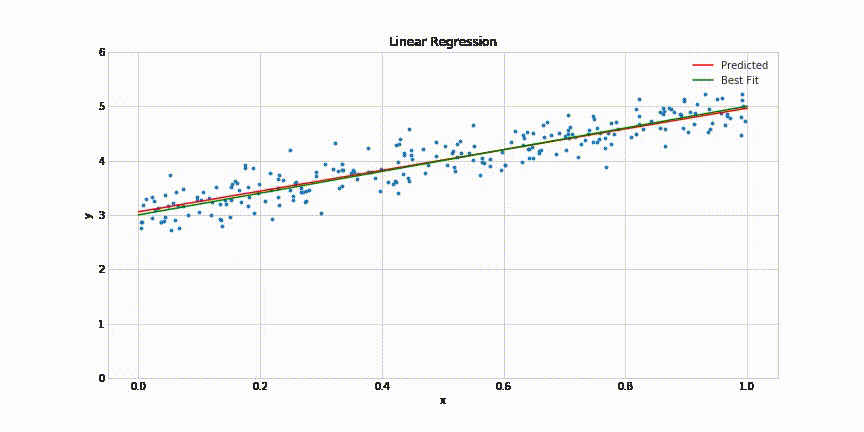
# Doesn't it look similar to our own strategy of gradually moving the line closer to the points?
# ### Linear Regression using Scikit-learn
# **In practice, you'll never need to implement either of the above methods yourself**. You can use a library like `scikit-learn` to do this for you.
# Let's use the `LinearRegression` class from `scikit-learn` to find the best fit line for "age" vs. "charges" using the ordinary least squares optimization technique.
from sklearn.linear_model import LinearRegression
# First, we create a new model object.
model = LinearRegression()
# Next, we can use the `fit` method of the model to find the best fit line for the inputs and targets.
help(model.fit) # to Understand how the function Linear Regression works.
# Not that the input `X` must be a 2-d array, so we'll need to pass a dataframe, instead of a single column.
inputs = medical_df[["age"]]
targets = medical_df.charges
print("inputs.shape :", inputs.shape)
print("targes.shape :", targets.shape)
# Let's fit the model to the data.
model.fit(inputs, targets)
# We can now make predictions using the model. Let's try predicting the charges for the ages 23, 37 and 61
model.predict(np.array([[23], [37], [61]]))
# Do these values seem reasonable? Compare them with the scatter plot above.
# Let compute the predictions for the entire set of inputs
predictions = model.predict(inputs)
predictions
# Let's compute the RMSE loss to evaluate the model.
rmse(targets, predictions)
# Seems like our prediction is off by $11551 on average, which is not too bad considering the fact that there are several outliers.
# The parameters of the model are stored in the `coef_` and `intercept_` properties.
# w
model.coef_
# b
model.intercept_
# Are these parameters close to your best guesses?
# Let's visualize the line created by the above parameters.
try_parameters(model.coef_, model.intercept_)
# Indeed the line is quite close to the points. It is slightly above the cluster of points, because it's also trying to account for the outliers.
# we can use the [`SGDRegressor`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDRegressor.html) class from `scikit-learn` to train a model using the stochastic gradient descent technique. Make predictions and compute the loss.
# ### Machine Learning
# Congratulations, you've just trained your first _machine learning model!_ Machine learning is simply the process of computing the best parameters to model the relationship between some feature and targets.
# Every machine learning problem has three components:
# 1. **Model**
# 2. **Cost Function**
# 3. **Optimizer**
# We'll look at several examples of each of the above in future tutorials. Here's how the relationship between these three components can be visualized:
# As we've seen above, it takes just a few lines of code to train a machine learning model using `scikit-learn`.
# Below is the complied version of how the linear regression is impliemented using `scikitlearn` in python
# Create inputs and targets
inputs, targets = medical_df[["age"]], medical_df["charges"]
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# ## Linear Regression using Multiple Features
# So far, we've used on the "age" feature to estimate "charges". Adding another feature like "bmi" is fairly straightforward. We simply assume the following relationship:
# $charges = w_1 \times age + w_2 \times bmi + b$
# We need to change just one line of code to include the BMI.
# Create inputs and targets
inputs, targets = medical_df[["age", "bmi"]], medical_df["charges"]
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# As you can see, adding the BMI doesn't seem to reduce the loss by much, as the BMI has a very weak correlation with charges, especially for non smokers.
medical_df.charges.corr(medical_df.bmi)
fig = px.scatter(medical_df, x="bmi", y="charges", title="BMI vs. Charges")
fig.update_traces(marker_size=5)
fig.show()
# We can also visualize the relationship between all 3 variables "age", "bmi" and "charges" using a 3D scatter plot.
fig = px.scatter_3d(medical_df, x="age", y="bmi", z="charges")
fig.update_traces(marker_size=3, marker_opacity=0.5)
fig.show()
# You can see that it's harder to interpret a 3D scatter plot compared to a 2D scatter plot. As we add more features, it becomes impossible to visualize all feature at once, which is why we use measures like correlation and loss.
# Let's also check the parameters of the model.
model.coef_, model.intercept_
# One thing important thing to keep in mind: ***you can't find a relationship that doesn't exist, no matter what machine learning technique or optimization algorithm you apply***.
# Let's go one step further, and add the final numeric column: "children", which seems to have some correlation with "charges".
# $charges = w_1 \times age + w_2 \times bmi + w_3 \times children + b$
medical_df.charges.corr(medical_df.children)
fig = px.strip(medical_df, x="children", y="charges", title="Children vs. Charges")
fig.update_traces(marker_size=4, marker_opacity=0.7)
fig.show()
# Create inputs and targets
inputs, targets = medical_df[["age", "bmi", "children"]], medical_df["charges"]
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# Once again, we don't see a big reduction in the loss, even though it's greater than in the case of BMI.
# ## Using Categorical Features for Machine Learning
# So far we've been using only numeric columns, since we can only perform computations with numbers. If we could use categorical columns like "smoker", we can train a single model for the entire dataset.
# To use the categorical columns, we simply need to convert them to numbers. There are three common techniques for doing this:
# 1. If a categorical column has just two categories (it's called a binary category), then we can replace their values with 0 and 1.
# 2. If a categorical column has more than 2 categories, we can perform one-hot encoding i.e. create a new column for each category with 1s and 0s.
# 3. If the categories have a natural order (e.g. cold, neutral, warm, hot), then they can be converted to numbers (e.g. 1, 2, 3, 4) preserving the order. These are called ordinals
# ## Binary Categories
# we have $3$ categorical columns in the dataset. let's try to address them one by one.
# #### Column 1
# The "smoker" category has just two values "yes" and "no". Let's create a new column "smoker_code" containing 0 for "no" and 1 for "yes".
#
sns.barplot(data=medical_df, x="smoker", y="charges")
smoker_codes = {"no": 0, "yes": 1}
medical_df["smoker_code"] = medical_df.smoker.map(
smoker_codes
) # creating a new column `smoker_code` ,
# instead of overwriting `smoker` column
medical_df.charges.corr(medical_df.smoker_code)
medical_df
# We can now use the `smoker_df` column for linear regression.
# $charges = w_1 \times age + w_2 \times bmi + w_3 \times children + w_4 \times smoker + b$
# Create inputs and targets
inputs, targets = (
medical_df[["age", "bmi", "children", "smoker_code"]],
medical_df["charges"],
)
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# The loss reduces from `11355` to `6056`, almost by 50%! This is an important lesson: never ignore categorical data.
# #### Column 2
# Let's try adding the "sex" column as well.
# $charges = w_1 \times age + w_2 \times bmi + w_3 \times children + w_4 \times smoker + w_5 \times sex + b$
sns.barplot(data=medical_df, x="sex", y="charges")
sex_codes = {"female": 0, "male": 1}
medical_df["sex_code"] = medical_df.sex.map(
sex_codes
) # maping numbers inplace as we did in `smoker` column
medical_df.charges.corr(medical_df.sex_code) # still weak coorelation
# Create inputs and targets
inputs, targets = (
medical_df[["age", "bmi", "children", "smoker_code", "sex_code"]],
medical_df["charges"],
)
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# As you might expect, this does have a significant impact on the loss.
# ### One-hot Encoding
# #### Column 3
# The "region" column contains 4 values, so we'll need to use hot encoding and create a new column for each region.
# 
#
sns.barplot(data=medical_df, x="region", y="charges")
# `ONEHOTENCODING` can be done in $2$ ways one using `OneHotEncoder` from *sklearn* or using `get_dummies` from *pandas*. Both will yeild similar results but the only differene is than the $OneHotEncoder$ will not overide the origonal dataset instead it will give array as output which we can then merge. While, $get_dummies$ directly merges the result onto the original datset when used. **I used $OneHotEncoder$ for this tutorial as we are doing *ONEHOTENCODING* first then *Scaling* more on this i'll explain it below.**
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit(medical_df[["region"]])
enc.categories_
one_hot = enc.transform(medical_df[["region"]]).toarray()
one_hot
medical_df[["northeast", "northwest", "southeast", "southwest"]] = one_hot
medical_df
# Let's include the region columns into our linear regression model.
# $charges = w_1 \times age + w_2 \times bmi + w_3 \times children + w_4 \times smoker + w_5 \times sex + w_6 \times region + b$
# Create inputs and targets
input_cols = [
"age",
"bmi",
"children",
"smoker_code",
"sex_code",
"northeast",
"northwest",
"southeast",
"southwest",
]
inputs, targets = medical_df[input_cols], medical_df["charges"]
# Since we have the original columns as well the encoded columns i'll select the encoded columns alone
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# ## Model Improvements
# Let's discuss and apply some more improvements to our model.
# ### Feature Scaling
# Recall that due to regulatory requirements, we also need to explain the rationale behind the predictions our model.
# $charges = w_1 \times age + w_2 \times bmi + w_3 \times children + w_4 \times smoker + w_5 \times sex + w_6 \times region + b$
# To compare the importance of each feature in the model, our first instinct might be to compare their weights.
# w
model.coef_
# b
model.intercept_
weights_df = pd.DataFrame(
{
"feature": np.append(input_cols, 1),
"weight": np.append(model.coef_, model.intercept_),
}
)
weights_df
# While it seems like BMI and the "northeast" have a higher weight than age, keep in mind that the range of values for BMI is limited (15 to 40) and the "northeast" column only takes the values 0 and 1.
# Because different columns have different ranges, we run into two issues:
# 1. We can't compare the weights of different column to identify which features are important
# 2. A column with a larger range of inputs may disproportionately affect the loss and dominate the optimization process.
# For this reason, it's common practice to scale (or standardize) the values in numeric column by subtracting the mean and dividing by the standard deviation.
# 
# Feature scaling is performed on datasets to normalize or standardize the numerical features, bringing them to a similar scale or range. This is done to ensure that all features contribute equally to the model's predictions and to prevent any unintended bias or dominance of certain features due to differences in scale.
# Performing scaling on datasets can have several benefits:
# * Prevents numerical features with different magnitudes or units of measurement from dominating or biasing the model's predictions. Scaling brings features to a similar scale, which helps in fair and balanced contribution of all features to the model's decision-making process.
# * Enhances the convergence and performance of machine learning algorithms that are sensitive to the scale of input features. Algorithms such as gradient descent or SVM can converge faster and perform better with scaled features, as differences in scale can impact their optimization or decision boundary.
# * Improves the interpretability of model results. Scaling makes it easier to compare the relative importance or contribution of different features to the model's predictions, as they are on a similar scale.
# Common scaling techniques include min-max scaling (also known as normalization), where features are scaled to a specific range (e.g., [0, 1]), and z-score scaling (also known as standardization), where features are scaled to have zero mean and unit variance. Scaling is typically performed after splitting the data into training and testing sets to prevent data leakage and ensure that the scaling is done independently for each set.
# In summary, performing scaling on datasets means normalizing or standardizing the numerical features to a similar scale or range, which can prevent bias, enhance model performance, and improve interpretability of results.
# We can apply scaling using the StandardScaler class from `scikit-learn`.
medical_df
from sklearn.preprocessing import StandardScaler
numeric_cols = [
"age",
"bmi",
"children",
] # Scaling can be done only on numerical columns
scaler = (
StandardScaler()
) # This should not include converted catrgorical columns. More on this below.
scaler.fit(medical_df[numeric_cols])
scaler.mean_ # this is the mean predicted for these columns induvidually
scaler.var_ # this is the variance predicted for these columns induvidually
# We can now scale data as follows:
scaled_inputs = scaler.transform(medical_df[numeric_cols])
scaled_inputs
# since the scaler only gives output in arrays we have to merge them back to the original columns. But i'm taking the categorical columns from the original dataset then using them directly in the linear regression model. J**ust try to understand how scaling works i'll attached a complied code of how to implement linear regression code in python at the end**. Let's continue, after scaling these can now we combined with the categorical data
cat_cols = [
"smoker_code",
"sex_code",
"northeast",
"northwest",
"southeast",
"southwest",
]
categorical_data = medical_df[cat_cols].values
inputs = np.concatenate((scaled_inputs, categorical_data), axis=1)
targets = medical_df.charges
# Create and train the model
model = LinearRegression().fit(inputs, targets)
# Generate predictions
predictions = model.predict(inputs)
# Compute loss to evalute the model
loss = rmse(targets, predictions)
print("Loss:", loss)
# We can now compare the weights in the formula:
# $charges = w_1 \times age + w_2 \times bmi + w_3 \times children + w_4 \times smoker + w_5 \times sex + w_6 \times region + b$
weights_df = pd.DataFrame(
{
"feature": np.append(numeric_cols + cat_cols, 1),
"weight": np.append(model.coef_, model.intercept_),
}
)
weights_df.sort_values("weight", ascending=False)
# As you can see now, The weights are distributed accoding to the importance of the features correctlyt. the most important feature are:
# 1. Smoker
# 2. Age
# 3. BMI
# ## (SCALING AFTER ENCODING) vs (ENCODING AFTER SCALING)
# In general, it is recommended to perform feature scaling before encoding categorical variables in a dataset that contains both categorical and numerical columns. The reason is that most feature scaling techniques operate on numerical values and are intended to bring numerical features to a similar scale or range, which can improve the performance of machine learning algorithms.
# Here are some reasons why it is usually better to perform feature scaling before encoding categorical variables:
# * Scaling numerical features can help in mitigating the impact of differences in magnitude or units of measurement among numerical features. Many machine learning algorithms are sensitive to the scale of input features, and features with larger magnitudes may dominate or bias the model's predictions. Scaling numerical features can bring them to a similar scale, helping to prevent this issue.
# * Feature scaling can also help in improving the convergence and performance of certain machine learning algorithms that are based on distance or similarity measures, such as k-nearest neighbors or support vector machines. These algorithms can be affected by differences in scale among numerical features, and scaling can help in making the algorithm more robust and accurate.
# * Categorical variables, on the other hand, do not typically require scaling because they are represented as discrete values or labels, and their values do not have a magnitude or units of measurement that can be scaled. Encoding categorical variables, such as one-hot encoding or label encoding, is usually done to convert them into numerical representations that can be understood by machine learning algorithms.
# By performing feature scaling before encoding categorical variables, you ensure that the numerical features in your dataset are on a similar scale and can be effectively processed by machine learning algorithms. Additionally, it helps to prevent any unintended bias or dominance of certain features due to differences in scale. Once the numerical features are scaled, you can then proceed with encoding the categorical variables to prepare the data for further analysis or modeling.
# **Thus it is always best practise to first scale numerical values then encoding.**
# ### Creating a Test Set
# Models like the one we've created in this tutorial are designed to be used in the real world. It's common practice to set aside a small fraction of the data (e.g. 10%) just for testing and reporting the results of the model. ***This is a very basic demo of test train split, there is more common and straight forward way which i will be explaining the below with a fresh linear regression example.***
from sklearn.model_selection import train_test_split
inputs_train, inputs_test, targets_train, targets_test = train_test_split(
inputs, targets, test_size=0.1
)
# here the inputs is nothing but the numerical columns + categorical columns
# Create and train the model
model = LinearRegression().fit(inputs_train, targets_train)
# Generate predictions
predictions_test = model.predict(inputs_test)
# Compute loss to evalute the model
loss = rmse(targets_test, predictions_test)
print("Test Loss:", loss)
# Let's compare this with the training loss.
# Generate predictions
predictions_train = model.predict(inputs_train)
# Compute loss to evalute the model
loss = rmse(targets_train, predictions_train)
print("Training Loss:", loss)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import warnings
warnings.filterwarnings("ignore")
from tqdm import tqdm_notebook
import re
from bs4 import BeautifulSoup
import os
import re
import gc
import sys
import time
import json
import random
import unicodedata
import multiprocessing
from functools import partial, lru_cache
import emoji
import numpy as np
import pandas as pd
from sklearn.externals import joblib
from tqdm import tqdm, tqdm_notebook
from sklearn.preprocessing import MinMaxScaler
from nltk import TweetTokenizer
from nltk.stem import PorterStemmer, SnowballStemmer
from nltk.stem.lancaster import LancasterStemmer
import html
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import numpy as np
from sklearn.model_selection import GroupKFold
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook as tqdm
import tensorflow as tf
import tensorflow.keras.backend as K
import os
from scipy.stats import spearmanr
from math import floor, ceil
from transformers import *
np.set_printoptions(suppress=True)
print(tf.__version__)
GOOGLE_PATH = "../input/google-quest-challenge/"
STACK_PATH = "../input/stackexchange123/StackexchangeExtract/"
train = pd.read_csv(GOOGLE_PATH + "train.csv")
test = pd.read_csv(GOOGLE_PATH + "test.csv")
sample_submission = pd.read_csv(GOOGLE_PATH + "sample_submission.csv")
train.shape, test.shape
target_columns = sample_submission.columns[1:].values
target_columns.shape
def url_id_ex(url):
try:
ids = int(url.split("/")[-2])
except:
ids = int(url.split("/")[-1])
return ids
# category_type
train["category_type"] = train["url"].apply(lambda x: x.split(".")[0].split("/")[-1])
test["category_type"] = test["url"].apply(lambda x: x.split(".")[0].split("/")[-1])
train["quser_id"] = train["question_user_page"].apply(lambda x: int(x.split("/")[-1]))
train["auser_id"] = train["answer_user_page"].apply(lambda x: int(x.split("/")[-1]))
train["url_id"] = train["url"].apply(url_id_ex)
test["quser_id"] = test["question_user_page"].apply(lambda x: int(x.split("/")[-1]))
test["auser_id"] = test["answer_user_page"].apply(lambda x: int(x.split("/")[-1]))
test["url_id"] = test["url"].apply(url_id_ex)
train.category_type.replace("programmers", "softwareengineering", inplace=True)
test.category_type.replace("programmers", "softwareengineering", inplace=True)
def final_dataframe(files_path, df):
listofdir = list(os.listdir(files_path))
listofdir.remove("dataset-metadata.json")
final_list = []
posts_columns = None
q_users_columns = None
a_users_columns = None
for file in tqdm_notebook(listofdir):
temp_df = df[df.category_type == file]
temp_users = pd.read_csv(STACK_PATH + file + "/user_df.csv")
temp_posts = pd.read_csv(STACK_PATH + file + "/posts_df.csv")
temp_users_columns = temp_users.columns.values
posts_columns = temp_posts.columns.values
temp_df = pd.merge(
temp_df, temp_posts, left_on="url_id", right_on="Id", how="left"
)
del temp_posts
temp_users = temp_users.add_prefix("q_")
q_users_columns = temp_users.columns.values
temp_df = pd.merge(
temp_df, temp_users, left_on="quser_id", right_on="q_Id", how="left"
)
temp_users.columns = temp_users_columns
temp_users = temp_users.add_prefix("a_")
a_users_columns = temp_users.columns.values
temp_df = pd.merge(
temp_df, temp_users, left_on="auser_id", right_on="a_Id", how="left"
)
del temp_users
temp_df = temp_df.to_dict("records")
final_list.extend(temp_df)
del temp_df
total_columns_dic = {
"posts_columns": posts_columns,
"q_users_columns": q_users_columns,
"a_users_columns": a_users_columns,
}
final_df = pd.DataFrame(final_list)
del final_list
return final_df, total_columns_dic
files_path = STACK_PATH
train_final, total_columns_dic = final_dataframe(files_path, train)
test_final, total_columns_dic = final_dataframe(files_path, test)
train_final.shape, test_final.shape
stackof_train = train[train.category == "STACKOVERFLOW"].copy()
stackof_test = test[test.category == "STACKOVERFLOW"].copy()
stackof_train.shape, stackof_test.shape
train_final = train_final.append(stackof_train)
test_final = test_final.append(stackof_test)
train_final.shape, test_final.shape
test_columns = test.columns.values.tolist()
train_columns = train.columns.values.tolist()
train_final = pd.merge(
train, train_final, left_on=train_columns, right_on=train_columns, how="left"
)
test_final = pd.merge(
test, test_final, left_on=test_columns, right_on=test_columns, how="left"
)
train_final.shape, test_final.shape
from pandas.api.types import is_datetime64_any_dtype as is_datetime
from pandas.api.types import is_categorical_dtype
def reduce_mem_usage(df, use_float16=False):
"""
Iterate through all the columns of a dataframe and modify the data type to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024**2
print("Memory usage of dataframe is {:.2f} MB".format(start_mem))
for col in df.columns:
if is_datetime(df[col]) or is_categorical_dtype(df[col]):
continue
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
use_float16
and c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float16)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
# df[col] = df[col].astype("category")
pass
end_mem = df.memory_usage().sum() / 1024**2
print("Memory usage after optimization is: {:.2f} MB".format(end_mem))
print("Decreased by {:.1f}%".format(100 * (start_mem - end_mem) / start_mem))
return df
from bs4 import BeautifulSoup
def removing_html_tags(raw_html):
cleantext = BeautifulSoup(raw_html, "lxml").text
return cleantext
def replace_urls(text):
text = re.sub(r"^https?:\/\/.*[\r\n]*", " web ", text, flags=re.MULTILINE)
return text
def clean_AboutMe(text):
text = removing_html_tags(text)
text = replace_urls(text)
return text
def clean_Name(text):
text = str(text)
text = re.sub(r" ", "_", text, flags=re.MULTILINE)
text = re.sub(r",", " ", text, flags=re.MULTILINE)
return text
def clean_Class(text):
text = str(text)
text = re.sub(r",", " ", text, flags=re.MULTILINE)
return text
def log_transform_apply(value):
if value == 0:
return value
elif value < 1:
value = np.log1p(abs(value))
return -value
else:
return np.log1p(value)
train_final_targets = train_final[target_columns].copy()
train_final_targets["qa_id"] = train_final["qa_id"]
train_final.drop(columns=target_columns, inplace=True)
train_final = reduce_mem_usage(train_final)
test_final = reduce_mem_usage(test_final)
# User AboutMe
train_final["q_AboutMe_nan"] = train_final["q_AboutMe"].isnull().astype(int)
train_final["a_AboutMe_nan"] = train_final["a_AboutMe"].isnull().astype(int)
test_final["q_AboutMe_nan"] = test_final["q_AboutMe"].isnull().astype(int)
test_final["a_AboutMe_nan"] = test_final["a_AboutMe"].isnull().astype(int)
train_final["q_AboutMe"].fillna("nane", inplace=True)
train_final["a_AboutMe"].fillna("nane", inplace=True)
test_final["q_AboutMe"].fillna("nane", inplace=True)
test_final["a_AboutMe"].fillna("nane", inplace=True)
train_final["q_AboutMe"] = train_final["q_AboutMe"].apply(clean_AboutMe)
train_final["a_AboutMe"] = train_final["a_AboutMe"].apply(clean_AboutMe)
test_final["q_AboutMe"] = test_final["q_AboutMe"].apply(clean_AboutMe)
test_final["a_AboutMe"] = test_final["a_AboutMe"].apply(clean_AboutMe)
# User TagBased
train_final["q_TagBased_nan"] = train_final["q_TagBased"].isnull().astype(int)
train_final["a_TagBased_nan"] = train_final["a_TagBased"].isnull().astype(int)
test_final["q_TagBased_nan"] = test_final["q_TagBased"].isnull().astype(int)
test_final["a_TagBased_nan"] = test_final["a_TagBased"].isnull().astype(int)
train_final["q_TagBased"].fillna("nane", inplace=True)
train_final["a_TagBased"].fillna("nane", inplace=True)
test_final["q_TagBased"].fillna("nane", inplace=True)
test_final["a_TagBased"].fillna("nane", inplace=True)
train_final["q_TagBased"] = train_final["q_TagBased"].apply(clean_Class)
train_final["a_TagBased"] = train_final["a_TagBased"].apply(clean_Class)
test_final["q_TagBased"] = test_final["q_TagBased"].apply(clean_Class)
test_final["a_TagBased"] = test_final["a_TagBased"].apply(clean_Class)
# User Name
train_final["q_Name_nan"] = train_final["q_Name"].isnull().astype(int)
train_final["a_Name_nan"] = train_final["a_Name"].isnull().astype(int)
test_final["q_Name_nan"] = test_final["q_Name"].isnull().astype(int)
test_final["a_Name_nan"] = test_final["a_Name"].isnull().astype(int)
train_final["q_Name"].fillna("nane", inplace=True)
train_final["a_Name"].fillna("nane", inplace=True)
test_final["q_Name"].fillna("nane", inplace=True)
test_final["a_Name"].fillna("nane", inplace=True)
train_final["q_Name"] = train_final["q_Name"].apply(clean_Name)
train_final["a_Name"] = train_final["a_Name"].apply(clean_Name)
test_final["q_Name"] = test_final["q_Name"].apply(clean_Name)
test_final["a_Name"] = test_final["a_Name"].apply(clean_Name)
# User Class
train_final["q_Class"].fillna("0", inplace=True)
train_final["a_Class"].fillna("0", inplace=True)
test_final["q_Class"].fillna("0", inplace=True)
test_final["a_Class"].fillna("0", inplace=True)
train_final["q_Class"] = train_final["q_Class"].apply(clean_Class)
train_final["a_Class"] = train_final["a_Class"].apply(clean_Class)
test_final["q_Class"] = test_final["q_Class"].apply(clean_Class)
test_final["a_Class"] = test_final["a_Class"].apply(clean_Class)
# User Views
train_final["q_Views_nan"] = train_final["q_Views"].isnull().astype(int)
train_final["a_Views_nan"] = train_final["a_Views"].isnull().astype(int)
test_final["q_Views_nan"] = test_final["q_Views"].isnull().astype(int)
test_final["a_Views_nan"] = test_final["a_Views"].isnull().astype(int)
train_final["q_Views"].fillna(0, inplace=True)
train_final["a_Views"].fillna(0, inplace=True)
test_final["q_Views"].fillna(0, inplace=True)
test_final["a_Views"].fillna(0, inplace=True)
# User UpVotes
# train_final["q_Views_nan"] = train_final["q_Views"].isnull().astype(int)
# train_final["a_Views_nan"] = train_final["a_Views"].isnull().astype(int)
# test_final["q_Views_nan"] = test_final["q_Views"].isnull().astype(int)
# test_final["a_Views_nan"] = test_final["a_Views"].isnull().astype(int)
# User UpVotes
train_final["q_UpVotes_nan"] = train_final["q_UpVotes"].isnull().astype(int)
train_final["a_UpVotes_nan"] = train_final["a_UpVotes"].isnull().astype(int)
test_final["q_UpVotes_nan"] = test_final["q_UpVotes"].isnull().astype(int)
test_final["a_UpVotes_nan"] = test_final["a_UpVotes"].isnull().astype(int)
train_final["q_UpVotes"].fillna(0, inplace=True)
train_final["a_UpVotes"].fillna(0, inplace=True)
test_final["q_UpVotes"].fillna(0, inplace=True)
test_final["a_UpVotes"].fillna(0, inplace=True)
# User DownVotes
train_final["q_DownVotes_nan"] = train_final["q_DownVotes"].isnull().astype(int)
train_final["a_DownVotes_nan"] = train_final["a_DownVotes"].isnull().astype(int)
test_final["q_DownVotes_nan"] = test_final["q_DownVotes"].isnull().astype(int)
test_final["a_DownVotes_nan"] = test_final["a_DownVotes"].isnull().astype(int)
train_final["q_DownVotes"].fillna(0, inplace=True)
train_final["a_DownVotes"].fillna(0, inplace=True)
test_final["q_DownVotes"].fillna(0, inplace=True)
test_final["a_DownVotes"].fillna(0, inplace=True)
user_drop_cols = [
"q_Id",
"q_DisplayName",
"q_UserId",
"a_Id",
"a_DisplayName",
"a_UserId",
]
def clean_Tags(text):
text = str(text)
text = re.sub(r"><", "> <", text, flags=re.MULTILINE)
text = re.sub(r">", "", text, flags=re.MULTILINE)
text = re.sub(r"<", "", text, flags=re.MULTILINE)
text = "".join([i for i in text if not i.isdigit()])
return text
# Posts PostTypeId
train_final["PostTypeId_nan"] = train_final["PostTypeId"].isnull().astype(int)
test_final["PostTypeId_nan"] = test_final["PostTypeId"].isnull().astype(int)
train_final["PostTypeId"].fillna(1.0, inplace=True)
test_final["PostTypeId"].fillna(1.0, inplace=True)
# Posts Score
train_final["Score_nan"] = train_final["Score"].isnull().astype(int)
test_final["Score_nan"] = test_final["Score"].isnull().astype(int)
train_final["Score"].fillna(0, inplace=True)
test_final["Score"].fillna(0, inplace=True)
train_final["Score"] = train_final["Score"].apply(log_transform_apply)
test_final["Score"] = test_final["Score"].apply(log_transform_apply)
# Posts ViewCount
train_final["ViewCount_nan"] = train_final["ViewCount"].isnull().astype(int)
test_final["ViewCount_nan"] = test_final["ViewCount"].isnull().astype(int)
train_final["ViewCount"].fillna(0, inplace=True)
test_final["ViewCount"].fillna(0, inplace=True)
train_final["ViewCount"] = np.log1p(abs(train_final["ViewCount"]))
test_final["ViewCount"] = np.log1p(abs(test_final["ViewCount"]))
# Posts Tags
train_final["Tags_nan"] = train_final["Tags"].isnull().astype(int)
test_final["Tags_nan"] = test_final["Tags"].isnull().astype(int)
train_final["Tags"].fillna("<nanetag>", inplace=True)
test_final["Tags"].fillna("<nanetag>", inplace=True)
train_final["Tags"] = train_final["Tags"].apply(clean_Tags)
test_final["Tags"] = test_final["Tags"].apply(clean_Tags)
# Posts AnswerCount
train_final["AnswerCount_nan"] = train_final["AnswerCount"].isnull().astype(int)
test_final["AnswerCount_nan"] = test_final["AnswerCount"].isnull().astype(int)
train_final["AnswerCount"].fillna(1, inplace=True)
test_final["AnswerCount"].fillna(1, inplace=True)
# Posts CommentCount
train_final["CommentCount_nan"] = train_final["CommentCount"].isnull().astype(int)
test_final["CommentCount_nan"] = test_final["CommentCount"].isnull().astype(int)
train_final["CommentCount"].fillna(0, inplace=True)
test_final["CommentCount"].fillna(0, inplace=True)
# Posts FavoriteCount
train_final["FavoriteCount_nan"] = train_final["FavoriteCount"].isnull().astype(int)
test_final["FavoriteCount_nan"] = test_final["FavoriteCount"].isnull().astype(int)
train_final["FavoriteCount"].fillna(0, inplace=True)
test_final["FavoriteCount"].fillna(0, inplace=True)
train_final["FavoriteCount"] = train_final["FavoriteCount"].apply(log_transform_apply)
test_final["FavoriteCount"] = test_final["FavoriteCount"].apply(log_transform_apply)
posts_drop_cols = [
"Id",
"AcceptedAnswerId",
"OwnerUserId",
"LastActivityDate",
"ParentId",
"ClosedDate",
"LastEditorDisplayName",
"OwnerDisplayName",
"CommunityOwnedDate",
]
def get_code_html(text, body):
if text == np.nan:
body = str(body)
code_list = []
codes_list1 = re.findall(":\n\n.*?\n\n\n", body, flags=re.DOTALL)
codes_list2 = re.findall(".\n\n(.*?)\n\n\n", body, flags=re.DOTALL)
codes_list3 = re.findall("{(.*?)}", body, flags=re.DOTALL)
code_list.extend(codes_list1)
code_list.extend(codes_list2)
code_list.extend(codes_list3)
if len(codes_list) > 0:
code = "<#next#>".join(map(str, codes_list))
return code
else:
return "NONE"
else:
text = str(text)
codes_list = re.findall("<code>(.*?)</code>", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = "<#next#>".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code_replace(text, code):
text = str(text)
code = str(code)
if code != "NONE":
codes_list = code.split("<#next#>")
codes_list = sorted(codes_list, key=len, reverse=True)
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text, flags=re.DOTALL)
return text
else:
return text
def get_blockquote_html(text):
text = str(text)
codes_list = re.findall("<blockquote>(.*?)</blockquote>", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_slsldolel(text):
text = str(text)
codes_list = re.findall("\\\\\$(.*?)\\\\\$", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_slsldolel_replace(text):
text = str(text)
codes_list = re.findall("\\\\\$.*?\\\\\$", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [FORMULA] ", text)
return text
else:
return text
def get_doldol(text):
text = str(text)
codes_list = re.findall("\$\$(.*?)\$\$", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_doldol_replace(text):
text = str(text)
codes_list = re.findall("\$\$.*?\$\$", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [FORMULA] ", text)
return text
else:
return text
def get_spdol(text):
text = str(text)
codes_list = re.findall(" \$(.*?) \$", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_spdol_replace(text):
text = str(text)
codes_list = re.findall(" \$.*? \$", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [FORMULA] ", text)
return text
else:
return text
def get_dol(text):
text = str(text)
codes_list = re.findall("\$(.*?)\$", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_dol_replace(text):
text = str(text)
codes_list = re.findall("\$.*?\$", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [FORMULA] ", text)
return text
else:
return text
def get_code1(text):
text = str(text)
codes_list = re.findall(":\n\n(.*?)\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " . ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code1_replace(text):
text = str(text)
codes_list = re.findall(":\n\n.*?\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text)
return text
else:
return text
def get_code2(text):
text = str(text)
codes_list = re.findall(".\n\n(.*?)\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " . ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code2_replace(text):
text = str(text)
codes_list = re.findall(".\n\n.*?\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
if i.count("\n") > 4:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text)
else:
pass
return text
else:
return text
def get_code3(text):
text = str(text)
codes_list = re.findall("{(.*?)}", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " . ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code3_replace(text):
text = str(text)
codes_list = re.findall("{.*?}", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
if len(i) > 10:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text)
else:
pass
return text
else:
return text
# question_body_code
train_final["question_body_code"] = train_final.apply(
lambda x: get_code_html(x["Body"], x["question_body"]), axis=1
)
train_final["question_body_clean"] = train_final.apply(
lambda x: get_code_replace(x["question_body"], x["question_body_code"]), axis=1
)
test_final["question_body_code"] = test_final.apply(
lambda x: get_code_html(x["Body"], x["question_body"]), axis=1
)
test_final["question_body_clean"] = test_final.apply(
lambda x: get_code_replace(x["question_body"], x["question_body_code"]), axis=1
)
# question_body_slsldolel
train_final["question_body_slsldolel"] = train_final["question_body"].apply(
get_slsldolel
)
train_final["question_body_clean"] = train_final["question_body_clean"].apply(
get_slsldolel_replace
)
test_final["question_body_slsldolel"] = test_final["question_body"].apply(get_slsldolel)
test_final["question_body_clean"] = test_final["question_body_clean"].apply(
get_slsldolel_replace
)
# question_body_doldol
train_final["question_body_doldol"] = train_final["question_body"].apply(get_doldol)
train_final["question_body_clean"] = train_final["question_body_clean"].apply(
get_doldol_replace
)
test_final["question_body_doldol"] = test_final["question_body"].apply(get_doldol)
test_final["question_body_clean"] = test_final["question_body_clean"].apply(
get_doldol_replace
)
# question_body_spdol
train_final["question_body_spdol"] = train_final["question_body"].apply(get_spdol)
train_final["question_body_clean"] = train_final["question_body_clean"].apply(
get_spdol_replace
)
test_final["question_body_spdol"] = test_final["question_body"].apply(get_spdol)
test_final["question_body_clean"] = test_final["question_body_clean"].apply(
get_spdol_replace
)
# question_body_dol
train_final["question_body_dol"] = train_final["question_body"].apply(get_dol)
train_final["question_body_clean"] = train_final["question_body_clean"].apply(
get_dol_replace
)
test_final["question_body_dol"] = test_final["question_body"].apply(get_dol)
test_final["question_body_clean"] = test_final["question_body_clean"].apply(
get_dol_replace
)
train_final["question_body_all"] = list(
map(
lambda a, b, c, d, e: str(a)
+ " "
+ str(b)
+ " "
+ str(c)
+ " "
+ str(d)
+ " "
+ str(e),
train_final["question_body_code"],
train_final["question_body_slsldolel"],
train_final["question_body_doldol"],
train_final["question_body_spdol"],
train_final["question_body_dol"],
)
)
test_final["question_body_all"] = list(
map(
lambda a, b, c, d, e: str(a)
+ " "
+ str(b)
+ " "
+ str(c)
+ " "
+ str(d)
+ " "
+ str(e),
test_final["question_body_code"],
test_final["question_body_slsldolel"],
test_final["question_body_doldol"],
test_final["question_body_spdol"],
test_final["question_body_dol"],
)
)
def get_code1(text):
text = str(text)
codes_list = re.findall(":\n\n(.*?)\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " . ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code1_replace(text):
text = str(text)
codes_list = re.findall(":\n\n.*?\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text)
return text
else:
return text
def get_code2(text):
text = str(text)
codes_list = re.findall(".\n\n(.*?)\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " . ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code2_replace(text):
text = str(text)
codes_list = re.findall(".\n\n.*?\n\n\n", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
if i.count("\n") > 4:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text)
else:
pass
return text
else:
return text
def get_code3(text):
text = str(text)
codes_list = re.findall("{(.*?)}", text, flags=re.DOTALL)
if len(codes_list) > 0:
code = " . ".join(map(str, codes_list))
return code
else:
return "NONE"
def get_code3_replace(text):
text = str(text)
codes_list = re.findall("{.*?}", text, flags=re.DOTALL)
if len(codes_list) > 0:
# code = ' '.join(map(str, codes_list))
for i in codes_list:
if len(i) > 10:
i = re.escape(i)
text = re.sub(f"{i}", " [CODE] ", text)
else:
pass
return text
else:
return text
# answer_code1
train_final["answer_code1"] = train_final["answer"].apply(get_code1)
train_final["answer_clean"] = train_final["answer"].apply(get_code1_replace)
test_final["answer_code1"] = test_final["answer"].apply(get_code1)
test_final["answer_clean"] = test_final["answer"].apply(get_code1_replace)
# answer_code2
train_final["answer_code2"] = train_final["answer"].apply(get_code2)
train_final["answer_clean"] = train_final["answer_clean"].apply(get_code2_replace)
test_final["answer_code2"] = test_final["answer"].apply(get_code2)
test_final["answer_clean"] = test_final["answer_clean"].apply(get_code2_replace)
# answer_code3
train_final["answer_code3"] = train_final["answer"].apply(get_code3)
train_final["answer_clean"] = train_final["answer_clean"].apply(get_code3_replace)
test_final["answer_code3"] = test_final["answer"].apply(get_code3)
test_final["answer_clean"] = test_final["answer_clean"].apply(get_code3_replace)
train_final["answer_code"] = list(
map(
lambda a, b, c: str(a) + " " + str(b) + " " + str(c),
train_final["answer_code1"],
train_final["answer_code2"],
train_final["answer_code3"],
)
)
test_final["answer_code"] = list(
map(
lambda a, b, c: str(a) + " " + str(b) + " " + str(c),
test_final["answer_code1"],
test_final["answer_code2"],
test_final["answer_code3"],
)
)
# question_body_slsldolel
train_final["answer_slsldolel"] = train_final["answer"].apply(get_slsldolel)
train_final["answer_clean"] = train_final["answer_clean"].apply(get_slsldolel_replace)
test_final["answer_slsldolel"] = test_final["answer"].apply(get_slsldolel)
test_final["answer_clean"] = test_final["answer_clean"].apply(get_slsldolel_replace)
# question_body_doldol
train_final["answer_doldol"] = train_final["answer"].apply(get_doldol)
train_final["answer_clean"] = train_final["answer_clean"].apply(get_doldol_replace)
test_final["answer_doldol"] = test_final["answer"].apply(get_doldol)
test_final["answer_clean"] = test_final["answer_clean"].apply(get_doldol_replace)
# question_body_spdol
train_final["answer_spdol"] = train_final["answer"].apply(get_spdol)
train_final["answer_clean"] = train_final["answer_clean"].apply(get_spdol_replace)
test_final["answer_spdol"] = test_final["answer"].apply(get_spdol)
test_final["answer_clean"] = test_final["answer_clean"].apply(get_spdol_replace)
# question_body_dol
train_final["answer_dol"] = train_final["answer"].apply(get_dol)
train_final["answer_clean"] = train_final["answer_clean"].apply(get_dol_replace)
test_final["answer_dol"] = test_final["answer"].apply(get_dol)
test_final["answer_clean"] = test_final["answer_clean"].apply(get_dol_replace)
train_final["answer_all"] = list(
map(
lambda a, b, c, d, e: str(a)
+ " "
+ str(b)
+ " "
+ str(c)
+ " "
+ str(d)
+ " "
+ str(e),
train_final["answer_code"],
train_final["answer_slsldolel"],
train_final["answer_doldol"],
train_final["answer_spdol"],
train_final["answer_dol"],
)
)
test_final["answer_all"] = list(
map(
lambda a, b, c, d, e: str(a)
+ " "
+ str(b)
+ " "
+ str(c)
+ " "
+ str(d)
+ " "
+ str(e),
test_final["answer_code"],
test_final["answer_slsldolel"],
test_final["answer_doldol"],
test_final["answer_spdol"],
test_final["answer_dol"],
)
)
droped_columns = []
droped_columns.extend(user_drop_cols)
droped_columns.extend(posts_drop_cols)
print(len(droped_columns))
train_final.drop(columns=droped_columns, inplace=True)
test_final.drop(columns=droped_columns, inplace=True)
train_final.shape, test_final.shape, train_final_targets.shape
# ## Text cleaning
def url_replace(text):
text = re.sub(
"(?:(?:https?|ftp):\/\/)?[\w/\-?=%.]+\.[\w/\-?=%.]+",
"[URL]",
text,
flags=re.DOTALL,
)
return text
def url_count(text):
count = len(re.findall("(?:(?:https?|ftp):\/\/)?[\w/\-?=%.]+\.[\w/\-?=%.]+", text))
return count
CUSTOM_TABLE = str.maketrans(
{
"\xad": None,
"\x7f": None,
"\ufeff": None,
"\u200b": None,
"\u200e": None,
"\u202a": None,
"\u202c": None,
"‘": "'",
"’": "'",
"`": "'",
"“": '"',
"”": '"',
"«": '"',
"»": '"',
"ɢ": "G",
"ɪ": "I",
"ɴ": "N",
"ʀ": "R",
"ʏ": "Y",
"ʙ": "B",
"ʜ": "H",
"ʟ": "L",
"ғ": "F",
"ᴀ": "A",
"ᴄ": "C",
"ᴅ": "D",
"ᴇ": "E",
"ᴊ": "J",
"ᴋ": "K",
"ᴍ": "M",
"Μ": "M",
"ᴏ": "O",
"ᴘ": "P",
"ᴛ": "T",
"ᴜ": "U",
"ᴡ": "W",
"ᴠ": "V",
"ĸ": "K",
"в": "B",
"м": "M",
"н": "H",
"т": "T",
"ѕ": "S",
"—": "-",
"–": "-",
}
)
WORDS_REPLACER = [
("sh*t", "shit"),
("s**t", "shit"),
("f*ck", "fuck"),
("fu*k", "fuck"),
("f**k", "fuck"),
("f*****g", "fucking"),
("f***ing", "fucking"),
("f**king", "fucking"),
("p*ssy", "pussy"),
("p***y", "pussy"),
("pu**y", "pussy"),
("p*ss", "piss"),
("b*tch", "bitch"),
("bit*h", "bitch"),
("h*ll", "hell"),
("h**l", "hell"),
("cr*p", "crap"),
("d*mn", "damn"),
("stu*pid", "stupid"),
("st*pid", "stupid"),
("n*gger", "nigger"),
("n***ga", "nigger"),
("f*ggot", "faggot"),
("scr*w", "screw"),
("pr*ck", "prick"),
("g*d", "god"),
("s*x", "sex"),
("a*s", "ass"),
("a**hole", "asshole"),
("a***ole", "asshole"),
("a**", "ass"),
]
WORDS_REPLACER_2 = [
("ain't", "is not"),
("aren't", "are not"),
("can't", "cannot"),
("'cause", "because"),
("could've", "could have"),
("couldn't", "could not"),
("didn't", "did not"),
("doesn't", "does not"),
("don't", "do not"),
("hadn't", "had not"),
("hasn't", "has not"),
("haven't", "have not"),
("he'd", "he would"),
("he'll", "he will"),
("he's", "he is"),
("how'd", "how did"),
("how'd'y", "how do you"),
("how'll", "how will"),
("how's", "how is"),
("i'd", "i would"),
("i'd've", "i would have"),
("i'll", "i will"),
("i'll've", "i will have"),
("i'm", "i am"),
("i've", "i have"),
("i'd", "i would"),
("i'd've", "i would have"),
("i'll", "i will"),
("i'll've", "i will have"),
("i'm", "i am"),
("i've", "i have"),
("isn't", "is not"),
("it'd", "it would"),
("it'd've", "it would have"),
("it'll", "it will"),
("it'll've", "it will have"),
("it's", "it is"),
("let's", "let us"),
("ma'am", "madam"),
("mayn't", "may not"),
("might've", "might have"),
("mightn't", "might not"),
("mightn't've", "might not have"),
("must've", "must have"),
("mustn't", "must not"),
("mustn't've", "must not have"),
("needn't", "need not"),
("needn't've", "need not have"),
("o'clock", "of the clock"),
("oughtn't", "ought not"),
("oughtn't've", "ought not have"),
("shan't", "shall not"),
("sha'n't", "shall not"),
("shan't've", "shall not have"),
("she'd", "she would"),
("she'd've", "she would have"),
("she'll", "she will"),
("she'll've", "she will have"),
("she's", "she is"),
("should've", "should have"),
("shouldn't", "should not"),
("shouldn't've", "should not have"),
("so've", "so have"),
("so's", "so as"),
("this's", "this is"),
("that'd", "that would"),
("that'd've", "that would have"),
("that's", "that is"),
("there'd", "there would"),
("there'd've", "there would have"),
("there's", "there is"),
("here's", "here is"),
("they'd", "they would"),
("they'd've", "they would have"),
("they'll", "they will"),
("they'll've", "they will have"),
("they're", "they are"),
("they've", "they have"),
("to've", "to have"),
("wasn't", "was not"),
("we'd", "we would"),
("we'd've", "we would have"),
("we'll", "we will"),
("we'll've", "we will have"),
("we're", "we are"),
("we've", "we have"),
("weren't", "were not"),
("what'll", "what will"),
("what'll've", "what will have"),
("what're", "what are"),
("what's", "what is"),
("what've", "what have"),
("when's", "when is"),
("when've", "when have"),
("where'd", "where did"),
("where's", "where is"),
("where've", "where have"),
("who'll", "who will"),
("who'll've", "who will have"),
("who's", "who is"),
("who've", "who have"),
("why's", "why is"),
("why've", "why have"),
("will've", "will have"),
("won't", "will not"),
("won't've", "will not have"),
("would've", "would have"),
("wouldn't", "would not"),
("wouldn't've", "would not have"),
("y'all", "you all"),
("y'all'd", "you all would"),
("y'all'd've", "you all would have"),
("y'all're", "you all are"),
("y'all've", "you all have"),
("you'd", "you would"),
("you'd've", "you would have"),
("you'll", "you will"),
("you'll've", "you will have"),
("you're", "you are"),
("you've", "you have"),
("what”s", "what is"),
('what"s', "what is"),
("its", "it is"),
("what's", "what is"),
("'ll", "will"),
("n't", "not"),
("'re", "are"),
("ain't", "is not"),
("aren't", "are not"),
("can't", "cannot"),
("'cause", "because"),
("could've", "could have"),
("couldn't", "could not"),
("didn't", "did not"),
("doesn't", "does not"),
("don't", "do not"),
("hadn't", "had not"),
("hasn't", "has not"),
("haven't", "have not"),
("he'd", "he would"),
("he'll", "he will"),
("he's", "he is"),
("how'd", "how did"),
("how'd'y", "how do you"),
("how'll", "how will"),
("how's", "how is"),
("i'd", "i would"),
("i'd've", "i would have"),
("i'll", "i will"),
("i'll've", "i will have"),
("i'm", "i am"),
("i've", "i have"),
("i'd", "i would"),
("i'd've", "i would have"),
("i'll", "i will"),
("i'll've", "i will have"),
("i'm", "i am"),
("i've", "i have"),
("isn't", "is not"),
("it'd", "it would"),
("it'd've", "it would have"),
("it'll", "it will"),
("it'll've", "it will have"),
("it's", "it is"),
("let's", "let us"),
("ma'am", "madam"),
("mayn't", "may not"),
("might've", "might have"),
("mightn't", "might not"),
("mightn't've", "might not have"),
("must've", "must have"),
("mustn't", "must not"),
("mustn't've", "must not have"),
("needn't", "need not"),
("needn't've", "need not have"),
("o'clock", "of the clock"),
("oughtn't", "ought not"),
("oughtn't've", "ought not have"),
("shan't", "shall not"),
("sha'n't", "shall not"),
("shan't've", "shall not have"),
("she'd", "she would"),
("she'd've", "she would have"),
("she'll", "she will"),
("she'll've", "she will have"),
("she's", "she is"),
("should've", "should have"),
("shouldn't", "should not"),
("shouldn't've", "should not have"),
("so've", "so have"),
("so's", "so as"),
("this's", "this is"),
("that'd", "that would"),
("that'd've", "that would have"),
("that's", "that is"),
("there'd", "there would"),
("there'd've", "there would have"),
("there's", "there is"),
("here's", "here is"),
("they'd", "they would"),
("they'd've", "they would have"),
("'they're", "they are"),
("they'll", "they will"),
("they'll've", "they will have"),
("they're", "they are"),
("they've", "they have"),
("to've", "to have"),
("wasn't", "was not"),
("we'd", "we would"),
("we'd've", "we would have"),
("we'll", "we will"),
("we'll've", "we will have"),
("we're", "we are"),
("we've", "we have"),
("weren't", "were not"),
("what'll", "what will"),
("what'll've", "what will have"),
("what're", "what are"),
("what's", "what is"),
("what've", "what have"),
("when's", "when is"),
("when've", "when have"),
("where'd", "where did"),
("where's", "where is"),
("where've", "where have"),
("who'll", "who will"),
("who'll've", "who will have"),
("who's", "who is"),
("who've", "who have"),
("why's", "why is"),
("why've", "why have"),
("will've", "will have"),
("won't", "will not"),
("won't've", "will not have"),
("would've", "would have"),
("wouldn't", "would not"),
("wouldn't've", "would not have"),
("y'all", "you all"),
("y'all'd", "you all would"),
("y'all'd've", "you all would have"),
("y'all're", "you all are"),
("y'all've", "you all have"),
("you'd", "you would"),
("you'd've", "you would have"),
("you'll", "you will"),
("you'll've", "you will have"),
("you're", "you are"),
("you've", "you have"),
]
mispell_dict = {
"aren't": "are not",
"can't": "cannot",
"couldn't": "could not",
"couldnt": "could not",
"didn't": "did not",
"doesn't": "does not",
"doesnt": "does not",
"don't": "do not",
"hadn't": "had not",
"hasn't": "has not",
"haven't": "have not",
"havent": "have not",
"he'd": "he would",
"he'll": "he will",
"he's": "he is",
"i'd": "I would",
"i'd": "I had",
"i'll": "I will",
"i'm": "I am",
"isn't": "is not",
"it's": "it is",
"it'll": "it will",
"i've": "I have",
"let's": "let us",
"mightn't": "might not",
"mustn't": "must not",
"shan't": "shall not",
"she'd": "she would",
"she'll": "she will",
"she's": "she is",
"shouldn't": "should not",
"shouldnt": "should not",
"that's": "that is",
"thats": "that is",
"there's": "there is",
"theres": "there is",
"they'd": "they would",
"they'll": "they will",
"they're": "they are",
"theyre": "they are",
"they've": "they have",
"we'd": "we would",
"we're": "we are",
"weren't": "were not",
"we've": "we have",
"what'll": "what will",
"what're": "what are",
"what's": "what is",
"what've": "what have",
"where's": "where is",
"who'd": "who would",
"who'll": "who will",
"who're": "who are",
"who's": "who is",
"who've": "who have",
"won't": "will not",
"wouldn't": "would not",
"you'd": "you would",
"you'll": "you will",
"you're": "you are",
"you've": "you have",
"'re": " are",
"wasn't": "was not",
"we'll": " will",
"didn't": "did not",
"tryin'": "trying",
"‘": "'",
"₹": "e",
"´": "'",
"°": "",
"€": "e",
"™": "tm",
"√": " sqrt ",
"×": "x",
"²": "2",
"—": "-",
"–": "-",
"’": "'",
"_": "-",
"`": "'",
"“": '"',
"”": '"',
"“": '"',
"£": "e",
"∞": "infinity",
"θ": "theta",
"÷": "/",
"α": "alpha",
"•": ".",
"à": "a",
"−": "-",
"β": "beta",
"∅": "",
"³": "3",
"π": "pi",
"\u200b": " ",
"…": " ... ",
"\ufeff": "",
"करना": "",
"है": "",
}
WORDS_REPLACER_3 = [(k, v) for k, v in mispell_dict.items()]
WORDS_REPLACER_4 = [
("automattic", "automatic"),
("sweetpotato", "sweet potato"),
("statuscode", "status code"),
("applylayer", "apply layer"),
("aligator", "alligator"),
("downloands", "download"),
("dowloand", "download"),
("thougths", "thoughts"),
("helecopter", "helicopter"),
("telugul", "telugu"),
("unconditionaly", "unconditionally"),
("coompanies", "companies"),
("lndigenous", "indigenous"),
("evluate", "evaluate"),
("suggstion", "suggestion"),
("thinkning", "thinking"),
("concatinate", "concatenate"),
("constitutionals", "constitutional"),
("moneyback", "money back"),
("civilazation", "civilization"),
("paranoria", "paranoia"),
("rightside", "right side"),
("methamatics", "mathematics"),
("natual", "natural"),
("brodcast", "broadcast"),
("pleasesuggest", "please suggest"),
("intitution", "institution"),
("experinces", "experiences"),
("reallyreally", "really"),
("testostreone", "testosterone"),
("musceles", "muscle"),
("bacause", "because"),
("peradox", "paradox"),
("probabity", "probability"),
("collges", "college"),
("diciplined", "disciplined"),
("completeted", "completed"),
("lunchshould", "lunch should"),
("battlenet", "battle net"),
("dissapoint", "disappoint"),
("resultsnew", "results new"),
("indcidents", "incidents"),
("figuire", "figure"),
("protonneutron", "proton neutron"),
("tecnical", "technical"),
("patern", "pattern"),
("unenroll", "un enroll"),
("proceedures", "procedures"),
("srategy", "strategy"),
("mordern", "modern"),
("prepartion", "preparation"),
("throuhout", "throught"),
("academey", "academic"),
("instituitions", "institutions"),
("abadon", "abandon"),
("compitetive", "competitive"),
("hypercondriac", "hypochondriac"),
("spiliting", "splitting"),
("physchic", "psychic"),
("flippingly", "flipping"),
("likelyhood", "likelihood"),
("armsindustry", "arms industry"),
(" turorials", "tutorials"),
("photostats", "photostat"),
("sunconcious", "subconscious"),
("chemistryphysics", "chemistry physics"),
("secondlife", "second life"),
("histrorical", "historical"),
("disordes", "disorders"),
("differenturl", "differential"),
("councilling", " counselling"),
("sugarmill", "sugar mill"),
("relatiosnhip", "relationship"),
("fanpages", "fan pages"),
("agregator", "aggregator"),
("switc", "switch"),
("smatphones", "smartphones"),
("headsize", "head size"),
("pendrives", "pen drives"),
("biotecnology", "biotechnology"),
("borderlink", "border link"),
("furnance", "furnace"),
("competetion", "competition"),
("distibution", "distribution"),
("ananlysis", " analysis"),
("textile?", "textile"),
("howww", "how"),
("strategybusiness", "strategy business"),
("spectrun", "spectrum"),
("propasal", "proposal"),
("appilcable", "applicable"),
("accountwhat", " account what"),
("algorithems", " algorithms"),
("protuguese", " Portuguese"),
("exatly", "exactly"),
("disturbence", "disturbance"),
("govrnment", "government"),
("requiremnt", "requirement"),
("vargin", "virgin"),
("lonleley", "lonely"),
("unmateralistic", "materialistic"),
("dveloper", "developer"),
("dcuments", "documents"),
("techonologies", "technologies"),
("morining", "morning"),
("samsing", "Samsung"),
("engeeniring", "engineering"),
("racetrac", "racetrack"),
("physian", "physician"),
("theretell", "there tell"),
("tryto", "try to"),
("teamfight", "team fight"),
("recomend", "recommend"),
("spectables", "spectacles"),
("emtional", "emotional"),
("engeenerring", "engineering"),
("optionsgood", "options good"),
("primarykey", "primary key"),
("foreignkey", "foreign key"),
("concieved", "conceived"),
("leastexpensive", "least expensive"),
("foodtech", "food tech"),
("electronegetivity", "electronegativity"),
("polticians", "politicians"),
("distruptive", "disruptive"),
("currrent", "current"),
("hidraulogy", "hydrology"),
("californa", "California"),
("electrrical", "electrical"),
("navigationally", "navigation"),
("whwhat", "what"),
("bcos", "because"),
("vaccancies", "vacancies"),
("articels", "articles"),
("boilng", "boiling"),
("hyperintensity", "hyper intensity"),
("rascism", "racism"),
("messenging", "messaging"),
("cleaniness", "cleanliness"),
("vetenary", "veterinary"),
("investorswhat", "investors what"),
("chrestianity", "Christianity"),
("apporval", "approval"),
("repaire", "repair"),
("biggerchance", "bigger chance"),
("manufacturering", "manufacturing"),
("buildertrend", "builder trend"),
("allocatively", "allocative"),
("subliminals", "subliminal"),
("mechnically", "mechanically"),
("binaurial", "binaural"),
("naaked", "naked"),
("aantidepressant", "antidepressant"),
("geunine", "genuine"),
("quantitaive", "quantitative"),
("paticipated", "participated"),
("repliedjesus", "replied Jesus"),
("baised", "biased"),
("worldreport", "world report"),
("eecutives", "executives"),
("paitents", "patients"),
("telgu", "Telugu"),
("nomeniculature", "nomenclature"),
("crimimaly", "criminally"),
("resourse", "resource"),
("procurenent", "procurement"),
("improvemet", "improvement"),
("metamers", "metamer"),
("tautomers", "tautomer"),
("knowwhen", "know when"),
("whatdoes", "what does"),
("pletelets", "platelets"),
("pssesive", "possessive"),
("oxigen", "oxygen"),
("ethniticy", "ethnicity"),
("situatiation", "situation"),
("ecoplanet", "eco planet"),
("situatio", "situation"),
("dateing", "dating"),
("hostress", "hostess"),
("initialisation", "initialization"),
("hydrabd", "Hyderabad"),
("deppresed", "depressed"),
("dwnloadng", "downloading"),
("expirey", "expiry"),
("engeenering", "engineering"),
("hyderebad", "Hyderabad"),
("automatabl", "automatable"),
("architetureocasions", "architectureoccasions"),
("restaraunts", "restaurants"),
("recommedations", "recommendations"),
("intergrity", "integrity"),
("reletively", "relatively"),
("priceworthy", "price worthy"),
("princples", "principles"),
("reconigze", "recognize"),
("paticular", "particular"),
("musictheory", "music theory"),
("requied", "required"),
("netural", "natural"),
("fluoresent", "fluorescent"),
("girlfiend", "girlfriend"),
("develpment", "development"),
("eridicate", "eradicate"),
("techologys", "technologies"),
("hybridyzation", "hybridization"),
("ideaa", "ideas"),
("tchnology", "technology"),
("appropiate", "appropriate"),
("respone", "response"),
("celebreties", "celebrities"),
("exterion", "exterior"),
("uservoice", "user voice"),
("effeciently", "efficiently"),
("torquise", "turquoise "),
("governmentand", "government and"),
("eletricity", "electricity"),
("coulums", "columns"),
("nolonger", "no longer"),
("wheras", "whereas"),
("infnite", "infinite"),
("decolourised", "no color"),
("onepiece", "one piece"),
("assignements", "assignments"),
("celebarted", "celebrated"),
("pharmacistical", "pharmaceutical"),
("jainsingle", "Jain single"),
("asssistance", "assistance"),
("glases", "glasses"),
("polymorpism", "polymorphism"),
("amerians", "Americans"),
("masquitos", "mosquitoes"),
("interseted", "interested"),
("thehighest", "the highest"),
("etnicity", "ethnicity"),
("anopportunity", "anopportunity"),
("multidiscipline", "multi discipline"),
("smartchange", "smart change"),
("collegefest", "college fest"),
("disdvantages", "disadvantages"),
("successfcators", "success factors"),
("sustitute", "substitute"),
("caoching", "coaching"),
("bullyed", "bullied"),
("comunicate", "communicate"),
("prisioner", "prisoner"),
("tamilnaadu", "Tamil Nadu"),
("methodologyies", "methodologies"),
("tranfers", "transfers"),
("truenorth", "true north"),
("backdonation", "back donation"),
("oreals", "ordeals"),
("browsec", "browser"),
("solarwinds", "solar winds"),
("susten", "sustain"),
("carnegi", "Carnegie"),
("doesent", "doesn't"),
("automtotive", "automotive"),
("nimuselide", "nimesulide"),
("subsciption", "subscription"),
("quatrone", "Quattrone"),
("qatalyst", "catalyst"),
("vardamana", "Vardaman"),
("suplements", "supplements"),
("repore", "report"),
("pikettys", "Piketty"),
("paramilltary", "paramilitary"),
("aboutlastnight", "about last night"),
("vidyapeth", "Vidyapeeth"),
("extraterrestial", "extraterrestrial"),
("powerloom", "power loom"),
("zonbie", "zombie"),
("cococola", "Coca Cola"),
("hameorrhage", "hemorrhage"),
("abhayanand", "Abhay Anand"),
("romedynow", "remedy now"),
("couster", "counter"),
("encouaged", "encouraged"),
("toprepare", "to prepare"),
("eveteasing", "eve teasing"),
("roulete", "roulette"),
("sorkar", "Sarkar"),
("waveboard", "wave board"),
("acclerate", "accelerate"),
("togrow", "to grow"),
("felatio", "fellatio"),
("baherain", "Bahrain"),
("teatment", "treatment"),
("iwitness", "eye witness"),
("autoplaying", "autoplay"),
("twise", "twice"),
("timeskip", "time skip"),
("disphosphorus", "diphosphorus"),
("implemnt", "implement"),
("proview", "preview"),
("pinshoppr", "pin shoppe"),
("protestng", "protesting"),
("chromatographymass", "chromatography mass"),
("ncache", "cache"),
("dowloands", "downloads"),
("biospecifics", "bio specifics"),
("conforim", "conform"),
("dreft", "draft"),
("sinhaleseand", "Sinhalese"),
("swivl", "swivel"),
("officerjms", "officers"),
("refrigrant", "refrigerant"),
("kendras", "Kendra"),
("alchoholism", "alcoholism"),
("dollor", "dollar"),
("jeyalalitha", "Jayalalitha"),
("bettner", "better"),
("itemstream", "timestream"),
("notetaking", "note taking"),
("cringworthy", "cringeworthy"),
("easyday", "easy day"),
("scenessex", "scenes sex"),
("vivavideo", "via video"),
("washboth", "wash both"),
("textout", "text out"),
("createwindow", "create window"),
("calsium", "calcium"),
("biofibre", "bio fibre"),
("emailbesides", "email besides"),
("kathhi", "Kathi"),
("cenre", "center"),
("polyarmory", "polyamory"),
("superforecasters", "super forecasters"),
("blogers", "bloggers"),
("medicalwhich", "medical which"),
("iiving", "living"),
("pronouciation", "pronunciation"),
("youor", "you or"),
("thuderbird", "Thunderbird"),
("oneside", "one side"),
("spearow", "Spearow"),
("aanythign", "anything"),
("inmaking", "in making"),
("datamining", "data mining"),
("greybus", "grey bus"),
("onmeter", "on meter"),
("biling", "billing"),
("fidlago", "Fidalgo"),
("edfice", "edifice"),
("microsolutions", "micro solutions"),
("easly", "easily"),
("eukarotic", "eukaryotic"),
("accedental", "accidental"),
("intercasts", "interests"),
("oppresive", "oppressive"),
("generalizably", "generalizable"),
("tacometer", "tachometer"),
("loking", "looking"),
("scrypt", "script"),
("usafter", "us after"),
("everyweek", "every week"),
("hopesthe", "hopes the"),
("openflow", "OpenFlow"),
("checkride", "check ride"),
("springdrive", "spring drive"),
("emobile", "mobile"),
("dermotology", "dermatology"),
("somatrophin", "somatropin"),
("saywe", "say we"),
("multistores", "multistory"),
("bolognaise", "Bolognese"),
("hardisk", "harddisk"),
("penisula", "peninsula"),
("refferring", "referring"),
("freshere", "fresher"),
("pokemkon", "Pokemon"),
("nuero", "neuro"),
("whosampled", "who sampled"),
("researchkit", "research kit"),
("speach", "speech"),
("acept", "accept"),
("indiashoppe", "Indian shoppe"),
("todescribe", "to describe"),
("hollywod", "Hollywood"),
("whastup", "whassup"),
("kjedahls", "Kjeldahl"),
("lancher", "launcher"),
("stalkees", "stalkers"),
("baclinks", "backlinks"),
("instutional", "institutional"),
("wassap", "Wassup"),
("methylethyl", "methyl ethyl"),
("fundbox", "fund box"),
("keypoints", "key points"),
("particually", "particularly"),
("loseit", "lose it"),
("gowipe", "go wipe"),
("autority", "authority"),
("prinicple", "principle"),
("complaince", "compliance"),
("itnormal", "it normal"),
("forpeople", "for people"),
("chaces", "chances"),
("yearhow", "year how"),
("fastcomet", "fast comet"),
("withadd", "with add"),
("omnicient", "omniscient"),
("tofeel", "to feel"),
("becauseof", "because of"),
("laungauage", "language"),
("combodia", "Cambodia"),
("bhuvneshwer", "Bhubaneshwar"),
("cognito", "Cognito"),
("thaelsemia", "thalassemia"),
("meritstore", "merit store"),
("masterbuate", "masturbate"),
("planethere", "planet here"),
("mostof", "most of"),
("shallowin", "shallow in"),
("wordwhen", "word when"),
("biodesalination", "desalination"),
("tendulkars", "Tendulkar"),
("kerja", "Kerja"),
("sertifikat", "certificate"),
("indegenous", "indigenous"),
("lowpage", "low page"),
("asend", "ascend"),
("leadreship", "leadership"),
("openlab", "open lab"),
("foldinghome", "folding home"),
("sachins", "Sachin"),
("pleatue", "plateau"),
("passwor", "password"),
("manisfestation", "manifestation"),
("valryian", "valerian"),
("chemotaxic", "chemotaxis"),
("condesending", "condescending"),
("spiltzvilla", "splitsville"),
("mammaliaforme", "mammaliaform"),
("instituteagra", "institute agra"),
("learningand", "learning and"),
("ramamurthynagar", "Ramamurthy Nagar"),
("glucoses", "glucose"),
("imitaion", "imitation"),
("awited", "awaited"),
("realvision", "real vision"),
("simslot", "sim slot"),
("yourr", "your"),
("pacjage", "package"),
("branchth", "branch"),
("magzin", "magazine"),
("frozon", "frozen"),
("codescomputational", "code computational"),
("tempratures", "temperatures"),
("neurophaphy", "neuropathy"),
("freezone", "free zone"),
("speices", "species"),
("compaitable", "compatible"),
("sensilization", "sensitization"),
("tuboscope", "tube scope"),
("gamechangers", "game changer"),
("windsheild", "windshield"),
("explorerie", "explorer"),
("cuccina", "Cucina"),
("earthstone", "hearthstone"),
("vocabs", "vocab"),
("previouse", "previous"),
("oneview", "one view"),
("relance", "reliance"),
("waterstop", "water stop"),
("imput", "input"),
("survivers", "survivors"),
("benedryl", "Benadryl"),
("requestparam", "request param"),
("typeadd", "type add"),
("autists", "artists"),
("forany", "for any"),
("inteview", "interview"),
("aphantasia", "Phantasia"),
("lisanna", "Lisanne"),
("civilengineering", "civil engineering"),
("austrailia", "Australia"),
("alchoholic", "alcoholic"),
("adaptersuch", "adapter such"),
("sphilosopher", "philosopher"),
("calenderisation", "calendarization"),
("smooking", "smoking"),
("pemdulum", "pendulum"),
("analsyis", "analysis"),
("psycholology", "psychology"),
("ubantu", "ubuntu"),
("emals", "emails"),
("questionth", "questions"),
("jawarlal", "Jawaharlal"),
("svaldbard", "Svalbard"),
("prabhudeva", "Prabhudeva"),
("robtics", "robotics"),
("umblock", "unblock"),
("professionaly", "professionally"),
("biovault", "bio vault"),
("bibal", "bible"),
("higherstudies", "higher studies"),
("lestoil", "less oil"),
("biteshow", "bike show"),
("humanslike", "humans like"),
("purpse", "purpose"),
("barazilian", "Brazilian"),
("gravitional", "gravitational"),
("cylinderical", "cylindrical"),
("peparing", "preparing"),
("healthequity", "health equity"),
("appcleaner", "app cleaner"),
("instantq", "instant"),
("abolisihed", "abolished"),
("kwench", "quench"),
("prisamatic", "prismatic"),
("bhubneshwar", "Bhubaneshwar"),
("liscense", "license"),
("cyberbase", "cyber base"),
("safezone", "safe zone"),
("deactivat", "deactivate"),
("salicyclic", "salicylic"),
("cocacola", "coca cola"),
("noice", "noise"),
("examinaton", "examination"),
("pharmavigilance", "pharmacovigilance"),
("sixthsense", "sixth sense"),
("musiclly", "musically"),
("khardushan", "Kardashian"),
("chandragupt", "Chandragupta"),
("bayesians", "bayesian"),
("engineeringbut", "engineering but"),
("caretrust", "care trust"),
("girlbut", "girl but"),
("aviations", "aviation"),
("joinee", "joiner"),
("tutior", "tutor"),
("tylenal", "Tylenol"),
("neccesity", "necessity"),
("kapsule", "capsule"),
("prayes", "prayers"),
("depositmobile", "deposit mobile"),
("settopbox", "set top box"),
("meotic", "meiotic"),
("accidentially", "accidentally"),
("offcloud", "off cloud"),
("keshavam", "Keshava"),
("domaincentral", "domain central"),
("onetaste", "one taste"),
("lumpsum", "lump sum"),
("medschool", "med school"),
("digicard", "Digi card"),
("abroadus", "abroad"),
("campusexcept", "campus except"),
("aptittude", "aptitude"),
("neutrions", "neutrinos"),
("onepaper", "one paper"),
("remidies", "remedies"),
("convinient", "convenient"),
("financaily", "financially"),
("postives", "positives"),
("nikefuel", "Nike fuel"),
("ingrediants", "ingredients"),
("aspireat", "aspirate"),
("firstand", "first"),
("mohammmad", "Mohammad"),
("mutliple", "multiple"),
("dimonatization", "demonization"),
("cente", "center"),
("marshmellow", "marshmallow"),
("citreon", "Citroen"),
("theirony", "the irony"),
("slienced", "silenced"),
("identifiy", "identify"),
("energ", "energy"),
("distribuiton", "distribution"),
("devoloping", "developing"),
("maharstra", "Maharastra"),
("siesmologist", "seismologist"),
("geckoos", "geckos"),
("placememnt", "placement"),
("introvercy", "introvert"),
("nuerosurgeon", "neurosurgeon"),
("realsense", "real sense"),
("congac", "cognac"),
("plaese", "please"),
("addicition", "addiction"),
("othet", "other"),
("howwill", "how will"),
("betablockers", "beta blockers"),
("phython", "Python"),
("concelling", "counseling"),
("einstine", "Einstein"),
("takinng", "taking"),
("birtday", "birthday"),
("prefessor", "professor"),
("dreamscreen", "dream screen"),
("satyabama", "Satyabhama"),
("faminism", "feminism"),
("noooooooooo", "no"),
("certifaction", "certification"),
("smalll", "small"),
("sterlization", "sterilization"),
("athelete", "athlete"),
("comppany", "company"),
("handlebreakup", "handle a breakup"),
("wellrounded", "well rounded"),
("breif", "brief"),
("engginering", "engineering"),
("genrally", "generally"),
("forgote", "forgot"),
("compuny", "the company"),
("wholeseller", "wholesaler"),
("conventioal", "conventional"),
("healther", "healthier"),
("realitic", "realistic"),
("israil", "Israel"),
("morghulis", "Margulis"),
("begineer", "beginner"),
("unwaiveringly", "unwavering"),
("writen", "written"),
("gastly", "ghastly"),
("obscurial", "obscure"),
("permanetly", "permanently"),
("bday", "birthday"),
("studing", "studying"),
("blackcore", "black core"),
("macbok", "MacBook"),
("realted", "related"),
("resoning", "reasoning"),
("servicenow", "service now"),
("medels", "medals"),
("hairloss", "hair loss"),
("messanger", "messenger"),
("masterbate", "masturbate"),
("oppurtunities", "opportunities"),
("newzealand", "new zealand"),
("offcampus", "off campus"),
("lonliness", "loneliness"),
("percentilers", "percentiles"),
("caccount", "account"),
("imrovement", "improvement"),
("cashbacks", "cashback"),
("inhand", "in hand"),
("baahubali", "bahubali"),
("diffrent", "different"),
("strategywho", "strategy who"),
("meetme", "meet me"),
("wealthfront", "wealth front"),
("masterbation", "masturbation"),
("successfull", "successful"),
("lenght", "length"),
("increse", "increase"),
("mastrubation", "masturbation"),
("intresting", "interesting"),
("quesitons", "questions"),
("fullstack", "full stack"),
("harambe", "Harambee"),
("criterias", "criteria"),
("rajyasabha", "Rajya Sabha"),
("techmahindra", "tech Mahindra"),
("messeges", "messages"),
("intership", "internship"),
("benifits", "benefits"),
("dowload", "download"),
("dellhi", "Delhi"),
("traval", "travel"),
("prepration", "preparation"),
("engineeringwhat", "engineering what"),
("habbit", "habit"),
("diference", "difference"),
("permantley", "permanently"),
("doesnot", "does not"),
("thebest", "the best"),
("addmision", "admission"),
("gramatically", "grammatically"),
("dayswhich", "days which"),
("intrest", "interest"),
("seperatists", "separatists"),
("plagarism", "plagiarism"),
("demonitize", "demonetize"),
("explaination", "explanation"),
("numericals", "numerical"),
("defination", "definition"),
("inmortal", "immortal"),
("elasticsearch", "elastic search"),
]
REGEX_REPLACER = [
(re.compile(pat.replace("*", "\*"), flags=re.IGNORECASE), repl)
for pat, repl in WORDS_REPLACER
]
REGEX_REPLACER_2 = [
(re.compile(pat.replace("*", "\*"), flags=re.IGNORECASE), repl)
for pat, repl in WORDS_REPLACER_2
]
REGEX_REPLACER_3 = [
(re.compile(pat.replace("*", "\*"), flags=re.IGNORECASE), repl)
for pat, repl in WORDS_REPLACER_3
]
REGEX_REPLACER_4 = [
(re.compile(pat.replace("*", "\*"), flags=re.IGNORECASE), repl)
for pat, repl in WORDS_REPLACER_4
]
"""
WORDS_REPLACER_5 = [('["code"]', '["CODE"]'),
('["formula"]', '["FORMULA"]')
]
REGEX_REPLACER_5 = [
(re.compile(pat.replace("*", "\*"), flags=re.IGNORECASE), repl)
for pat, repl in WORDS_REPLACER_5
]
"""
RE_SPACE = re.compile(r"\s")
RE_MULTI_SPACE = re.compile(r"\s+")
symbols_to_isolate = ".,?!-;*…:—()[]%#$&_/@\・ω+=^–>\\°<~•≠™ˈʊɒ∞§{}·τα❤☺ɡ|¢→̶`❥━┣┫┗O►★©―ɪ✔®\x96\x92●£♥➤´¹☕≈÷♡◐║▬′ɔː€۩۞†μ✒➥═☆ˌ◄½ʻπδηλσερνʃ✬SUPERIT☻±♍µº¾✓◾؟.⬅℅»Вав❣⋅¿¬♫CMβ█▓▒░⇒⭐›¡₂₃❧▰▔◞▀▂▃▄▅▆▇↙γ̄″☹➡«φ⅓„✋:¥̲̅́∙‛◇✏▷❓❗¶˚˙)сиʿ✨。ɑ\x80◕!%¯−flfi₁²ʌ¼⁴⁄₄⌠♭✘╪▶☭✭♪☔☠♂☃☎✈✌✰❆☙○‣⚓年∎ℒ▪▙☏⅛casǀ℮¸w‚∼‖ℳ❄←☼⋆ʒ⊂、⅔¨͡๏⚾⚽Φ×θ₩?(℃⏩☮⚠月✊❌⭕▸■⇌☐☑⚡☄ǫ╭∩╮,例>ʕɐ̣Δ₀✞┈╱╲▏▕┃╰▊▋╯┳┊≥☒↑☝ɹ✅☛♩☞AJB◔◡↓♀⬆̱ℏ\x91⠀ˤ╚↺⇤∏✾◦♬³の|/∵∴√Ω¤☜▲↳▫‿⬇✧ovm-208'‰≤∕ˆ⚜☁"
symbols_to_delete2 = "\"#$%'()*+-/:;<=>@[\\]^_`{|}~" + "“”’"
isolate_dict = {ord(c): f" {c} " for c in symbols_to_isolate}
remove_dict = {ord(c): f"" for c in symbols_to_delete}
remove_dict1 = {ord(c): f"" for c in symbols_to_delete2}
NMS_TABLE = dict.fromkeys(
i for i in range(sys.maxunicode + 1) if unicodedata.category(chr(i)) == "Mn"
)
HEBREW_TABLE = {i: "א" for i in range(0x0590, 0x05FF)}
ARABIC_TABLE = {i: "ا" for i in range(0x0600, 0x06FF)}
CHINESE_TABLE = {i: "是" for i in range(0x4E00, 0x9FFF)}
KANJI_TABLE = {i: "ッ" for i in range(0x2E80, 0x2FD5)}
HIRAGANA_TABLE = {i: "ッ" for i in range(0x3041, 0x3096)}
KATAKANA_TABLE = {i: "ッ" for i in range(0x30A0, 0x30FF)}
TABLE = dict()
TABLE.update(CUSTOM_TABLE)
TABLE.update(NMS_TABLE)
# Non-english languages
TABLE.update(CHINESE_TABLE)
TABLE.update(HEBREW_TABLE)
TABLE.update(ARABIC_TABLE)
TABLE.update(HIRAGANA_TABLE)
TABLE.update(KATAKANA_TABLE)
TABLE.update(KANJI_TABLE)
EMOJI_REGEXP = emoji.get_emoji_regexp()
UNICODE_EMOJI_MY = {
k: f" EMJ {v.strip(':').replace('_', ' ')} "
for k, v in emoji.UNICODE_EMOJI_ALIAS.items()
}
def my_demojize(string: str) -> str:
def replace(match):
return UNICODE_EMOJI_MY.get(match.group(0), match.group(0))
return re.sub("\ufe0f", "", EMOJI_REGEXP.sub(replace, string))
def normalize(text: str) -> str:
text = text.replace("[CODE]", " ACODEA ")
text = text.replace("[FORMULA]", " AFORMULAA ")
# text = text.replace("[]", " [URL] ")
text = html.unescape(text)
text = text.lower()
text = my_demojize(text)
# replacing urls with "url" string
text = re.sub("(?:(?:https?|ftp):\/\/)?[\w/\-?=%.]+\.[\w/\-?=%.]+", "[WEB]", text)
text = text.replace("[WEB]", " AWEBA ")
text = RE_SPACE.sub(" ", text)
text = unicodedata.normalize("NFKD", text)
text = text.translate(TABLE)
text = RE_MULTI_SPACE.sub(" ", text).strip()
# remove some unimportent symbles
text = text.translate(remove_dict)
# remove some unimportent symbles
text = text.translate(remove_dict1)
text = text.translate(isolate_dict)
# Replacing and mispell
for pattern, repl in REGEX_REPLACER:
text = pattern.sub(repl, text)
for pattern, repl in REGEX_REPLACER_2:
text = pattern.sub(repl, text)
for pattern, repl in REGEX_REPLACER_3:
text = pattern.sub(repl, text)
# isolated_characters
# text = text.translate(isolate_dict)
for pattern, repl in REGEX_REPLACER_4:
text = pattern.sub(repl, text)
"""
for pattern, repl in REGEX_REPLACER_5:
text = pattern.sub(repl, text)
"""
text = RE_MULTI_SPACE.sub(" ", text).strip()
text = text.replace(" acodea ", " [CODE] ")
text = text.replace(" aformulaa ", " [FORMULA] ")
text = text.replace(" AWEBA ", " [WEB] ")
text = RE_MULTI_SPACE.sub(" ", text).strip()
return text
train_final["question_body_clean1"] = train_final.question_body_clean.apply(normalize)
train_final["answer_clean1"] = train_final.answer_clean.apply(normalize)
train_final["question_title_clean1"] = train_final.question_title.apply(normalize)
test_final["question_body_clean1"] = test_final.question_body_clean.apply(normalize)
test_final["answer_clean1"] = test_final.answer_clean.apply(normalize)
test_final["question_title_clean1"] = test_final.question_title.apply(normalize)
train_final["question_body_clean1"].fillna("please see figure below", inplace=True)
test_final["question_body_clean1"].fillna("please see figure below", inplace=True)
train_final["answer_clean1"].fillna("please see figure below", inplace=True)
test_final["answer_clean1"].fillna("please see figure below", inplace=True)
train_final["question_title_clean1"].fillna("please see figure below", inplace=True)
test_final["question_title_clean1"].fillna("please see figure below", inplace=True)
def replace_specialtokens(text):
text = text.replace(" [CODE] ", " code ")
text = text.replace(" [FORMULA] ", " formula ")
text = text.replace(" [WEB] ", " web ")
return text
train_final["question_body_clean2"] = train_final.question_body_clean1.apply(
replace_specialtokens
)
train_final["answer_clean2"] = train_final.answer_clean1.apply(replace_specialtokens)
train_final["question_title_clean2"] = train_final.question_title_clean1.apply(
replace_specialtokens
)
test_final["question_body_clean2"] = test_final.question_body_clean1.apply(
replace_specialtokens
)
test_final["answer_clean2"] = test_final.answer_clean1.apply(replace_specialtokens)
test_final["question_title_clean2"] = test_final.question_title_clean1.apply(
replace_specialtokens
)
train_final["question_body_all_clean"] = train_final.question_body_all.apply(normalize)
train_final["answer_all_clean"] = train_final.answer_all.apply(normalize)
test_final["question_body_all_clean"] = test_final.question_body_all.apply(normalize)
test_final["answer_all_clean"] = test_final.answer_all.apply(normalize)
# ## META DATA
from sklearn.decomposition import PCA
from scipy.sparse import vstack
from sklearn.feature_extraction.text import CountVectorizer
def text_metadata(train, test):
a_AboutMe_text = train["a_AboutMe"].apply(normalize)
q_AboutMe_text = train["q_AboutMe"].apply(normalize)
all_text = pd.concat([a_AboutMe_text, q_AboutMe_text])
word_vectorizer = TfidfVectorizer(
sublinear_tf=True,
strip_accents="unicode",
analyzer="word",
token_pattern=r"\w{1,}",
stop_words="english",
ngram_range=(1, 1),
)
word_vectorizer.fit(all_text)
q_AboutMe_cols = [f"q_AboutMe_PCA_{i}" for i in range(1, 101)]
a_AboutMe_cols = [f"a_AboutMe_PCA_{i}" for i in range(1, 101)]
q_AboutMe_text = word_vectorizer.transform(q_AboutMe_text)
a_AboutMe_text = word_vectorizer.transform(a_AboutMe_text)
tq_AboutMe_text = word_vectorizer.transform(test["q_AboutMe"].apply(normalize))
ta_AboutMe_text = word_vectorizer.transform(test["a_AboutMe"].apply(normalize))
new = vstack([q_AboutMe_text, a_AboutMe_text])
pca = PCA(n_components=100)
pca.fit(new.toarray())
q_AboutMe_text = pca.transform(q_AboutMe_text.toarray())
a_AboutMe_text = pca.transform(a_AboutMe_text.toarray())
tq_AboutMe_text = pca.transform(tq_AboutMe_text.toarray())
ta_AboutMe_text = pca.transform(ta_AboutMe_text.toarray())
train[q_AboutMe_cols] = pd.DataFrame(
q_AboutMe_text, columns=q_AboutMe_cols, index=train.index
)
test[q_AboutMe_cols] = pd.DataFrame(
tq_AboutMe_text, columns=q_AboutMe_cols, index=test.index
)
train[a_AboutMe_cols] = pd.DataFrame(
a_AboutMe_text, columns=a_AboutMe_cols, index=train.index
)
test[a_AboutMe_cols] = pd.DataFrame(
ta_AboutMe_text, columns=a_AboutMe_cols, index=test.index
)
# Tages
tags_all_text = train["Tags"]
word_vectorizer = CountVectorizer()
word_vectorizer.fit(tags_all_text)
tags_cols = ["Tags_" + sub for sub in word_vectorizer.get_feature_names()]
train[tags_cols] = pd.DataFrame(
word_vectorizer.transform(train["Tags"]).toarray(),
columns=tags_cols,
index=train.index,
)
test[tags_cols] = pd.DataFrame(
word_vectorizer.transform(test["Tags"]).toarray(),
columns=tags_cols,
index=test.index,
)
return train, test, q_AboutMe_cols, a_AboutMe_cols, tags_cols
train_final, test_final, q_AboutMe_cols, a_AboutMe_cols, tags_cols = text_metadata(
train_final, test_final
)
train_final.shape, test_final.shape
def linear_based_models(train, test, cat_cols, num_cols):
# Column std MinMax Scalling
std = MinMaxScaler()
train[num_cols] = std.fit_transform(train[num_cols])
test[num_cols] = std.transform(test[num_cols])
# One Hot Encoder
train = pd.get_dummies(train, columns=cat_cols, prefix=cat_cols)
test = pd.get_dummies(test, columns=cat_cols, prefix=cat_cols)
rem = list(set(train.columns).intersection(set(test.columns)))
train = train[rem]
test = test[rem]
return train, test
num_cols = [
"AnswerCount",
"CommentCount",
"FavoriteCount",
"PostTypeId",
"Score",
"ViewCount",
"a_DownVotes",
"a_UpVotes",
"a_Views",
"q_DownVotes",
"q_UpVotes",
"q_Views",
]
cat_cols = ["category", "category_type"]
train_final, test_final = linear_based_models(
train_final, test_final, cat_cols, num_cols
)
train_final.shape, test_final.shape
train_final = pd.merge(
train_final, train_final_targets, left_on="qa_id", right_on="qa_id", how="left"
)
train_final.shape, test_final.shape
# # Model
train_df = train_final
test_df = test_final
target_columns = train_df.columns.values.tolist()[-30:]
category_features = [col for col in train_df.columns if col.startswith("category_")]
tags_cols = [col for col in train_df.columns if col.startswith("Tags_")]
a_AboutMe_cols = [col for col in train_df.columns if col.startswith("a_AboutMe_")]
q_AboutMe_cols = [col for col in train_df.columns if col.startswith("q_AboutMe_")]
num_cols = [
"AnswerCount",
"CommentCount",
"FavoriteCount",
"PostTypeId",
"Score",
"ViewCount",
"a_DownVotes",
"a_UpVotes",
"a_Views",
"q_DownVotes",
"q_UpVotes",
"q_Views",
"AnswerCount_nan",
"CommentCount_nan",
"FavoriteCount_nan",
"Score_nan",
"ViewCount_nan",
"a_DownVotes_nan",
"a_UpVotes_nan",
"a_Views_nan",
"q_DownVotes_nan",
"q_UpVotes_nan",
"q_Views_nan",
]
a_AboutMe_cols = [
"a_AboutMe_PCA_64",
"a_AboutMe_PCA_19",
"a_AboutMe_PCA_40",
"a_AboutMe_PCA_6",
"a_AboutMe_PCA_77",
"a_AboutMe_PCA_35",
"a_AboutMe_PCA_100",
"a_AboutMe_PCA_57",
"a_AboutMe_PCA_76",
"a_AboutMe_PCA_16",
"a_AboutMe_PCA_67",
"a_AboutMe_PCA_36",
"a_AboutMe_PCA_25",
"a_AboutMe_PCA_26",
"a_AboutMe_PCA_7",
"a_AboutMe_PCA_50",
"a_AboutMe_PCA_32",
"a_AboutMe_PCA_60",
"a_AboutMe_PCA_54",
"a_AboutMe_PCA_84",
"a_AboutMe_PCA_66",
"a_AboutMe_PCA_88",
"a_AboutMe_PCA_61",
"a_AboutMe_PCA_23",
"a_AboutMe_PCA_37",
"a_AboutMe_PCA_1",
"a_AboutMe_PCA_21",
"a_AboutMe_PCA_20",
"a_AboutMe_PCA_55",
"a_AboutMe_PCA_86",
"a_AboutMe_PCA_2",
"a_AboutMe_PCA_3",
"a_AboutMe_PCA_99",
"a_AboutMe_PCA_18",
"a_AboutMe_PCA_78",
"a_AboutMe_PCA_51",
"a_AboutMe_PCA_53",
"a_AboutMe_PCA_96",
"a_AboutMe_PCA_15",
"a_AboutMe_PCA_11",
"a_AboutMe_PCA_89",
"a_AboutMe_PCA_82",
"a_AboutMe_PCA_13",
"a_AboutMe_PCA_44",
"a_AboutMe_PCA_28",
"a_AboutMe_PCA_41",
"a_AboutMe_PCA_68",
"a_AboutMe_PCA_42",
"a_AboutMe_PCA_27",
"a_AboutMe_PCA_73",
"a_AboutMe_PCA_95",
"a_AboutMe_PCA_85",
"a_AboutMe_PCA_49",
"a_AboutMe_PCA_33",
"a_AboutMe_PCA_48",
"a_AboutMe_PCA_59",
"a_AboutMe_PCA_46",
"a_AboutMe_PCA_65",
"a_AboutMe_PCA_75",
"a_AboutMe_PCA_63",
"a_AboutMe_PCA_4",
"a_AboutMe_PCA_52",
"a_AboutMe_PCA_5",
"a_AboutMe_PCA_17",
"a_AboutMe_PCA_92",
"a_AboutMe_PCA_47",
"a_AboutMe_PCA_80",
"a_AboutMe_PCA_14",
"a_AboutMe_PCA_98",
"a_AboutMe_PCA_34",
"a_AboutMe_PCA_83",
"a_AboutMe_PCA_58",
"a_AboutMe_PCA_94",
"a_AboutMe_PCA_69",
"a_AboutMe_PCA_45",
"a_AboutMe_PCA_31",
"a_AboutMe_PCA_91",
"a_AboutMe_PCA_12",
"a_AboutMe_PCA_70",
"a_AboutMe_PCA_8",
"a_AboutMe_PCA_39",
"a_AboutMe_PCA_74",
"a_AboutMe_PCA_43",
"a_AboutMe_PCA_62",
"a_AboutMe_PCA_10",
"a_AboutMe_PCA_9",
"a_AboutMe_PCA_22",
"a_AboutMe_PCA_30",
"a_AboutMe_PCA_24",
"a_AboutMe_PCA_87",
"a_AboutMe_PCA_79",
"a_AboutMe_PCA_81",
"a_AboutMe_PCA_90",
"a_AboutMe_PCA_93",
"a_AboutMe_PCA_38",
"a_AboutMe_PCA_72",
"a_AboutMe_PCA_29",
"a_AboutMe_PCA_56",
"a_AboutMe_PCA_97",
"a_AboutMe_PCA_71",
]
q_AboutMe_cols = [
"q_AboutMe_PCA_93",
"q_AboutMe_PCA_50",
"q_AboutMe_PCA_70",
"q_AboutMe_PCA_65",
"q_AboutMe_PCA_85",
"q_AboutMe_PCA_71",
"q_AboutMe_PCA_18",
"q_AboutMe_PCA_69",
"q_AboutMe_PCA_51",
"q_AboutMe_PCA_79",
"q_AboutMe_PCA_31",
"q_AboutMe_PCA_99",
"q_AboutMe_PCA_40",
"q_AboutMe_PCA_92",
"q_AboutMe_PCA_86",
"q_AboutMe_PCA_34",
"q_AboutMe_PCA_2",
"q_AboutMe_PCA_64",
"q_AboutMe_PCA_1",
"q_AboutMe_PCA_72",
"q_AboutMe_PCA_32",
"q_AboutMe_PCA_29",
"q_AboutMe_PCA_5",
"q_AboutMe_PCA_7",
"q_AboutMe_PCA_67",
"q_AboutMe_PCA_96",
"q_AboutMe_PCA_82",
"q_AboutMe_PCA_35",
"q_AboutMe_PCA_55",
"q_AboutMe_PCA_39",
"q_AboutMe_PCA_27",
"q_AboutMe_PCA_4",
"q_AboutMe_PCA_66",
"q_AboutMe_PCA_57",
"q_AboutMe_PCA_38",
"q_AboutMe_PCA_12",
"q_AboutMe_PCA_76",
"q_AboutMe_PCA_20",
"q_AboutMe_PCA_89",
"q_AboutMe_PCA_28",
"q_AboutMe_PCA_30",
"q_AboutMe_PCA_98",
"q_AboutMe_PCA_100",
"q_AboutMe_PCA_61",
"q_AboutMe_PCA_3",
"q_AboutMe_PCA_37",
"q_AboutMe_PCA_81",
"q_AboutMe_PCA_97",
"q_AboutMe_PCA_49",
"q_AboutMe_PCA_91",
"q_AboutMe_PCA_43",
"q_AboutMe_PCA_90",
"q_AboutMe_PCA_94",
"q_AboutMe_PCA_58",
"q_AboutMe_PCA_36",
"q_AboutMe_PCA_8",
"q_AboutMe_PCA_46",
"q_AboutMe_PCA_25",
"q_AboutMe_PCA_13",
"q_AboutMe_PCA_10",
"q_AboutMe_PCA_87",
"q_AboutMe_PCA_21",
"q_AboutMe_PCA_62",
"q_AboutMe_PCA_11",
"q_AboutMe_PCA_42",
"q_AboutMe_PCA_33",
"q_AboutMe_PCA_74",
"q_AboutMe_PCA_26",
"q_AboutMe_PCA_6",
"q_AboutMe_PCA_68",
"q_AboutMe_PCA_54",
"q_AboutMe_PCA_73",
"q_AboutMe_PCA_17",
"q_AboutMe_PCA_44",
"q_AboutMe_PCA_52",
"q_AboutMe_PCA_47",
"q_AboutMe_PCA_56",
"q_AboutMe_PCA_15",
"q_AboutMe_PCA_59",
"q_AboutMe_PCA_88",
"q_AboutMe_PCA_22",
"q_AboutMe_PCA_77",
"q_AboutMe_PCA_84",
"q_AboutMe_PCA_75",
"q_AboutMe_PCA_63",
"q_AboutMe_PCA_60",
"q_AboutMe_PCA_41",
"q_AboutMe_PCA_53",
"q_AboutMe_PCA_45",
"q_AboutMe_PCA_14",
"q_AboutMe_PCA_16",
"q_AboutMe_PCA_24",
"q_AboutMe_PCA_19",
"q_AboutMe_PCA_83",
"q_AboutMe_PCA_9",
"q_AboutMe_PCA_48",
"q_AboutMe_PCA_23",
"q_AboutMe_PCA_78",
"q_AboutMe_PCA_95",
"q_AboutMe_PCA_80",
]
meta_cols = [*category_features, *num_cols]
len(meta_cols)
def _convert_to_transformer_inputs(
title, question, answer, tokenizer, max_sequence_lenght
):
"""Converts tokenized input to ids, masks and segments for transformer (including bert)"""
def return_id(str1, str2, lenght):
inputs = tokenizer.encode_plus(
str1,
str2,
add_special_tokens=True,
max_length=lenght,
pad_to_max_length=True,
return_token_type_ids=True,
return_attention_mask=True,
truncation_strategy="longest_first",
)
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
token_type_ids = inputs["token_type_ids"]
return [input_ids, attention_mask, token_type_ids]
input_ids_q, attention_mask_q, token_type_ids_q = return_id(
title, question, max_sequence_lenght
)
input_ids_a, attention_mask_a, token_type_ids_a = return_id(
answer, None, max_sequence_lenght
)
return [
input_ids_q,
attention_mask_q,
token_type_ids_q,
input_ids_a,
attention_mask_a,
token_type_ids_a,
]
def compute_input_arrays(
df,
columns,
meta_cols,
q_AboutMe_cols,
a_AboutMe_cols,
tokenizer,
max_sequence_length,
):
input_ids_q, attention_mask_q, token_type_ids_q = [], [], []
input_ids_a, attention_mask_a, token_type_ids_a = [], [], []
meta_features = []
q_AboutMe_features = []
a_AboutMe_features = []
total_cols = [*columns, *meta_cols, *q_AboutMe_cols, *a_AboutMe_cols]
# i = 0
for _, instance in tqdm(df[total_cols].iterrows()):
t, q, a, qc, ac = (
instance.question_title_clean2,
instance.question_body_clean2,
instance.answer_clean2,
instance.question_body_all_clean,
instance.answer_all_clean,
)
t = str(t)
q = str(q) + " [SEP] " + str(qc)
a = str(a) + " [SEP] " + str(ac)
(
ids_q,
masks_q,
segments_q,
ids_a,
masks_a,
segments_a,
) = _convert_to_transformer_inputs(t, q, a, tokenizer, max_sequence_length)
input_ids_q.append(ids_q)
attention_mask_q.append(masks_q)
token_type_ids_q.append(segments_q)
input_ids_a.append(ids_a)
attention_mask_a.append(masks_a)
token_type_ids_a.append(segments_a)
meta_data = instance[meta_cols].values.tolist()
q_AboutMe_data = instance[q_AboutMe_cols].values.tolist()
a_AboutMe_data = instance[a_AboutMe_cols].values.tolist()
meta_features.append(meta_data)
q_AboutMe_features.append(q_AboutMe_data)
a_AboutMe_features.append(a_AboutMe_data)
# i = i+1
# if i == 100:
# break
return [
np.asarray(input_ids_q, dtype=np.int32),
np.asarray(attention_mask_q, dtype=np.int32),
np.asarray(token_type_ids_q, dtype=np.int32),
np.asarray(input_ids_a, dtype=np.int32),
np.asarray(attention_mask_a, dtype=np.int32),
np.asarray(token_type_ids_a, dtype=np.int32),
np.asarray(meta_features, dtype=np.float32),
np.asarray(q_AboutMe_features, dtype=np.float32),
np.asarray(a_AboutMe_features, dtype=np.float32),
]
def compute_output_arrays(df, columns):
return np.asarray(df[columns])
def create_model_soft(BERT_PATH):
q_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
q_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
q_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
meta_features_layer = tf.keras.layers.Input((len(meta_cols),), dtype=tf.float32)
q_AboutMe_features_layer = tf.keras.layers.Input(
(len(q_AboutMe_cols),), dtype=tf.float32
)
a_AboutMe_features_layer = tf.keras.layers.Input(
(len(a_AboutMe_cols),), dtype=tf.float32
)
config = BertConfig() # print(config) to see settings
config.output_hidden_states = False # Set to True to obtain hidden states
# caution: when using e.g. XLNet, XLNetConfig() will automatically use xlnet-large config
# normally ".from_pretrained('bert-base-uncased')", but because of no internet, the
# pretrained model has been downloaded manually and uploaded to kaggle.
bert_model = TFBertModel.from_pretrained(
BERT_PATH + "bert-base-uncased-tf_model.h5", config=config
)
# if config.output_hidden_states = True, obtain hidden states via bert_model(...)[-1]
q_embedding = bert_model(q_id, attention_mask=q_mask, token_type_ids=q_atn)[0]
a_embedding = bert_model(a_id, attention_mask=a_mask, token_type_ids=a_atn)[0]
q = tf.keras.layers.GlobalAveragePooling1D()(q_embedding)
a = tf.keras.layers.GlobalAveragePooling1D()(a_embedding)
x = tf.keras.layers.Concatenate()(
[
q,
q_AboutMe_features_layer,
a,
a_AboutMe_features_layer,
meta_features_layer,
]
)
x = tf.keras.layers.Dropout(0.2)(x)
x = tf.keras.layers.Dense(21, activation="sigmoid")(x)
model = tf.keras.models.Model(
inputs=[
q_id,
q_mask,
q_atn,
a_id,
a_mask,
a_atn,
meta_features_layer,
q_AboutMe_features_layer,
a_AboutMe_features_layer,
],
outputs=x,
)
return model
def create_model_hard(BERT_PATH):
q_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_id = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
q_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_mask = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
q_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
a_atn = tf.keras.layers.Input((MAX_SEQUENCE_LENGTH,), dtype=tf.int32)
meta_features_layer = tf.keras.layers.Input((len(meta_cols),), dtype=tf.float32)
q_AboutMe_features_layer = tf.keras.layers.Input(
(len(q_AboutMe_cols),), dtype=tf.float32
)
a_AboutMe_features_layer = tf.keras.layers.Input(
(len(a_AboutMe_cols),), dtype=tf.float32
)
config = BertConfig() # print(config) to see settings
config.output_hidden_states = False # Set to True to obtain hidden states
# caution: when using e.g. XLNet, XLNetConfig() will automatically use xlnet-large config
# normally ".from_pretrained('bert-base-uncased')", but because of no internet, the
# pretrained model has been downloaded manually and uploaded to kaggle.
bert_model = TFBertModel.from_pretrained(
BERT_PATH + "bert-base-uncased-tf_model.h5", config=config
)
# if config.output_hidden_states = True, obtain hidden states via bert_model(...)[-1]
q_embedding = bert_model(q_id, attention_mask=q_mask, token_type_ids=q_atn)[0]
a_embedding = bert_model(a_id, attention_mask=a_mask, token_type_ids=a_atn)[0]
q = tf.keras.layers.GlobalAveragePooling1D()(q_embedding)
a = tf.keras.layers.GlobalAveragePooling1D()(a_embedding)
x = tf.keras.layers.Concatenate()(
[
q,
q_AboutMe_features_layer,
a,
a_AboutMe_features_layer,
meta_features_layer,
]
)
x = tf.keras.layers.Dropout(0.2)(x)
x = tf.keras.layers.Dense(8, activation="sigmoid")(x)
model = tf.keras.models.Model(
inputs=[
q_id,
q_mask,
q_atn,
a_id,
a_mask,
a_atn,
meta_features_layer,
q_AboutMe_features_layer,
a_AboutMe_features_layer,
],
outputs=x,
)
return model
input_categories = [
"question_title_clean2",
"question_body_clean2",
"answer_clean2",
"question_body_all_clean",
"answer_all_clean",
]
MAX_SEQUENCE_LENGTH = 512
BERT_PATH = "../input/bert-base-uncased-huggingface-transformer/"
tokenizer = BertTokenizer.from_pretrained(BERT_PATH + "bert-base-uncased-vocab.txt")
# outputs = compute_output_arrays(train_df, target_columns)
# inputs = compute_input_arrays(train_df, input_categories,meta_cols, q_AboutMe_cols, a_AboutMe_cols ,tokenizer, MAX_SEQUENCE_LENGTH)
test_inputs = compute_input_arrays(
test_df,
input_categories,
meta_cols,
q_AboutMe_cols,
a_AboutMe_cols,
tokenizer,
MAX_SEQUENCE_LENGTH,
)
model_weights_path = "../input/quest-bert-soft-hard-models/"
soft_target_columns = [
#'question_asker_intent_understanding',
"question_body_critical",
"question_conversational",
"question_expect_short_answer",
"question_fact_seeking",
"question_has_commonly_accepted_answer",
"question_interestingness_others",
"question_interestingness_self",
"question_multi_intent",
#'question_not_really_a_question',
"question_opinion_seeking",
"question_type_choice",
#'question_type_compare',
#'question_type_consequence',
"question_type_definition",
"question_type_entity",
"question_type_instructions",
"question_type_procedure",
"question_type_reason_explanation",
#'question_type_spelling',
"question_well_written",
#'answer_helpful',
"answer_level_of_information",
#'answer_plausible',
#'answer_relevance',
#'answer_satisfaction',
"answer_type_instructions",
"answer_type_procedure",
"answer_type_reason_explanation",
"answer_well_written",
]
soft_test_predictions = []
for i in range(5):
for j in range(1, 3):
model_path = f"{model_weights_path}bert-{i}-{j}.h5"
model1 = create_model_soft(BERT_PATH)
model1.load_weights(model_path)
soft_test_predictions.append(model1.predict(test_inputs, batch_size=2))
len(soft_test_predictions)
soft_test_predictions[0].shape
soft_test_predictions = np.mean(soft_test_predictions, axis=0)
soft_test_predictions.shape
hard_target_columns = [
"question_asker_intent_understanding",
# 'question_body_critical',
# 'question_conversational',
# 'question_expect_short_answer',
# 'question_fact_seeking',
# 'question_has_commonly_accepted_answer',
# 'question_interestingness_others',
# 'question_interestingness_self',
# 'question_multi_intent',
"question_not_really_a_question",
# 'question_opinion_seeking',
# 'question_type_choice',
"question_type_compare",
"question_type_consequence",
# 'question_type_definition',
# 'question_type_entity',
# 'question_type_instructions',
# 'question_type_procedure',
# 'question_type_reason_explanation',
# 'question_type_spelling',
# 'question_well_written',
"answer_helpful",
# 'answer_level_of_information',
"answer_plausible",
"answer_relevance",
"answer_satisfaction",
# 'answer_type_instructions',
# 'answer_type_procedure',
# 'answer_type_reason_explanation',
# 'answer_well_written'
]
hard_test_predictions = []
for i in range(1, 5):
print(i)
model_path = f"{model_weights_path}hard-bert-{i}.h5"
model1 = create_model_hard(BERT_PATH)
model1.load_weights(model_path)
hard_test_predictions.append(model1.predict(test_inputs, batch_size=2))
hard_test_predictions[0].shape
hard_test_predictions = np.mean(hard_test_predictions, axis=0)
hard_test_predictions.shape
sample_submission[soft_target_columns] = soft_test_predictions
sample_submission[hard_target_columns] = hard_test_predictions
def question_type_spelling_hard(test):
if test["category_type_english"] == 1 or test["category_type_ell"] == 1:
if test["Tags_pronunciation"] == 1:
return 0.666667
elif test["Tags_spelling"] == 1:
return 0.666667
else:
return 0.555555
else:
return 0.00000
sample_submission["question_type_spelling"] = test_df.apply(
question_type_spelling_hard, 1
)
def question_type_compare_hard(text):
if text == np.nan:
return 0.00000
else:
text = str(text)
ls = text.split(" ")
if "vs" in ls:
return 1.000000
elif ("between" or "difference") in ls:
return 0.666667
elif ("means" or "better") in ls:
return 0.333333
else:
return 0.000000
sample_submission["question_type_compare"] = test_df.question_title_clean2.apply(
question_type_compare_hard
)
sample_submission.nunique(axis=0)
sample_submission.isna().sum().sum()
sample_submission.fillna(0.5, inplace=True)
sample_submission.iloc[:, 1:].max().max()
sample_submission.iloc[:, 1:].min().min()
# sample_submission.to_csv('submission.csv', index=False)
sample_submission.head()
TARGET_COLUMNS = target_columns
TARGET_COLUMNS
from sklearn.preprocessing import MinMaxScaler
def postprocessing(oof_df):
scaler = MinMaxScaler()
# type 1 column [0, 0.333333, 0.5, 0.666667, 1]
# type 2 column [0, 0.333333, 0.666667]
# type 3 column [0.333333, 0.444444, 0.5, 0.555556, 0.666667, 0.777778, 0.8333333, 0.888889, 1]
# type 4 column [0.200000, 0.266667, 0.300000, 0.333333, 0.400000, \
# 0.466667, 0.5, 0.533333, 0.600000, 0.666667, 0.700000, \
# 0.733333, 0.800000, 0.866667, 0.900000, 0.933333, 1]
# comment some columns based on oof result
################################################# handle type 1 columns
type_one_column_list = [
"question_conversational",
"question_has_commonly_accepted_answer",
"question_not_really_a_question",
"question_type_choice",
"question_type_compare",
"question_type_consequence",
"question_type_definition",
"question_type_entity",
"question_type_instructions",
]
oof_df[type_one_column_list] = scaler.fit_transform(oof_df[type_one_column_list])
tmp = oof_df.copy(deep=True)
for column in type_one_column_list:
oof_df.loc[tmp[column] <= 0.16667, column] = 0
oof_df.loc[
(tmp[column] > 0.16667) & (tmp[column] <= 0.41667), column
] = 0.333333
oof_df.loc[
(tmp[column] > 0.41667) & (tmp[column] <= 0.58333), column
] = 0.500000
oof_df.loc[
(tmp[column] > 0.58333) & (tmp[column] <= 0.73333), column
] = 0.666667
oof_df.loc[(tmp[column] > 0.73333), column] = 1
################################################# handle type 2 columns
# type_two_column_list = [
# 'question_type_spelling'
# ]
# for column in type_two_column_list:
# if sum(tmp[column] > 0.15)>0:
# oof_df.loc[tmp[column] <= 0.15, column] = 0
# oof_df.loc[(tmp[column] > 0.15) & (tmp[column] <= 0.45), column] = 0.333333
# oof_df.loc[(tmp[column] > 0.45), column] = 0.666667
# else:
# t1 = max(int(len(tmp[column])*0.0013),2)
# t2 = max(int(len(tmp[column])*0.0008),1)
# thred1 = sorted(list(tmp[column]))[-t1]
# thred2 = sorted(list(tmp[column]))[-t2]
# oof_df.loc[tmp[column] <= thred1, column] = 0
# oof_df.loc[(tmp[column] > thred1) & (tmp[column] <= thred2), column] = 0.333333
# oof_df.loc[(tmp[column] > thred2), column] = 0.666667
################################################# handle type 3 columns
type_three_column_list = [
"question_interestingness_self",
]
scaler = MinMaxScaler(feature_range=(0, 1))
oof_df[type_three_column_list] = scaler.fit_transform(
oof_df[type_three_column_list]
)
tmp[type_three_column_list] = scaler.fit_transform(tmp[type_three_column_list])
for column in type_three_column_list:
oof_df.loc[tmp[column] <= 0.385, column] = 0.333333
oof_df.loc[(tmp[column] > 0.385) & (tmp[column] <= 0.47), column] = 0.444444
oof_df.loc[(tmp[column] > 0.47) & (tmp[column] <= 0.525), column] = 0.5
oof_df.loc[(tmp[column] > 0.525) & (tmp[column] <= 0.605), column] = 0.555556
oof_df.loc[(tmp[column] > 0.605) & (tmp[column] <= 0.715), column] = 0.666667
oof_df.loc[(tmp[column] > 0.715) & (tmp[column] <= 0.8), column] = 0.833333
oof_df.loc[(tmp[column] > 0.8) & (tmp[column] <= 0.94), column] = 0.888889
oof_df.loc[(tmp[column] > 0.94), column] = 1
################################################# handle type 4 columns
type_four_column_list = ["answer_satisfaction"]
scaler = MinMaxScaler(feature_range=(0.2, 1))
oof_df[type_four_column_list] = scaler.fit_transform(oof_df[type_four_column_list])
tmp[type_four_column_list] = scaler.fit_transform(tmp[type_four_column_list])
for column in type_four_column_list:
oof_df.loc[tmp[column] <= 0.233, column] = 0.200000
oof_df.loc[(tmp[column] > 0.233) & (tmp[column] <= 0.283), column] = 0.266667
oof_df.loc[(tmp[column] > 0.283) & (tmp[column] <= 0.315), column] = 0.300000
oof_df.loc[(tmp[column] > 0.315) & (tmp[column] <= 0.365), column] = 0.333333
oof_df.loc[(tmp[column] > 0.365) & (tmp[column] <= 0.433), column] = 0.400000
oof_df.loc[(tmp[column] > 0.433) & (tmp[column] <= 0.483), column] = 0.466667
oof_df.loc[(tmp[column] > 0.483) & (tmp[column] <= 0.517), column] = 0.500000
oof_df.loc[(tmp[column] > 0.517) & (tmp[column] <= 0.567), column] = 0.533333
oof_df.loc[(tmp[column] > 0.567) & (tmp[column] <= 0.633), column] = 0.600000
oof_df.loc[(tmp[column] > 0.633) & (tmp[column] <= 0.683), column] = 0.666667
oof_df.loc[(tmp[column] > 0.683) & (tmp[column] <= 0.715), column] = 0.700000
oof_df.loc[(tmp[column] > 0.715) & (tmp[column] <= 0.767), column] = 0.733333
oof_df.loc[(tmp[column] > 0.767) & (tmp[column] <= 0.833), column] = 0.800000
oof_df.loc[(tmp[column] > 0.883) & (tmp[column] <= 0.915), column] = 0.900000
oof_df.loc[(tmp[column] > 0.915) & (tmp[column] <= 0.967), column] = 0.933333
oof_df.loc[(tmp[column] > 0.967), column] = 1
################################################# round to i / 90 (i from 0 to 90)
oof_values = oof_df[TARGET_COLUMNS].values
DEGREE = len(oof_df) // 45 * 9
# if degree:
# DEGREE = degree
# DEGREE = 90
oof_values = np.around(oof_values * DEGREE) / DEGREE ### 90 To be changed
oof_df[TARGET_COLUMNS] = oof_values
return oof_df
sample_submission_post = postprocessing(sample_submission)
sample_submission_post.shape
for column in TARGET_COLUMNS:
print(sample_submission_post[column].value_counts())
sample_submission_post
sample_submission_post[sample_submission_post[TARGET_COLUMNS] > 1.0] = 1.0
sample_submission_post
sample_submission_post.to_csv("submission.csv", index=False)
|
# # Especialização em Ciência de Dados - Turma 2018.1 - Facens
# ## Aula1 | Exercício 1 (valendo nota)
# * **Data de entrega:** 02/jan/2020 23:59
# * **Professor:** Matheus Mota
# * **Aluno:** Almir Rogério de Macedo
# * **RA:** 191338
from mpl_toolkits.mplot3d import Axes3D
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt # plotting
import numpy as np # linear algebra
import os # accessing directory structure
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
df = pd.read_csv("/kaggle/input/BR_eleitorado_2016_municipio.csv", delimiter=",")
df.dataframeName = "eleitorado.csv"
df.head()
# ## Questão 1
# **Enunciado:** Este notebook está associado ao *Kaggle Dataset* chamado "Aula1 | Exercício1". Este *Kaggle Dataset* possui dois arquivos em formato CSV (anv.csv e BR_eleitorado_2016_municipio ). Escolha um dos datasets disponíveis e já conhecidos, a seu critério. Uma vez definido o csv, escolha no mínimo 7 e no máximo 12 variáveis (colunas) que você avalia como sendo relevantes. Para cada uma das suas variáveis escolhidas, forneça:
# ### Questão 1 - Item A - Classificação das variáveis
# Classifique todas as variáveis escolhidas, e construa um dataframe com sua resposta.
# Exemplo:
classification = [
["UF", "Qualitativa Nominal"],
["Município", "Qualitativa Nominal"],
["total_eleitores", "Quantitativa Discreta"],
["Feminino", "Quantitativa Discreta"],
["Masculino", "Quantitativa Discreta"],
]
classification = pd.DataFrame(classification, columns=["Variavel", "Classificação"])
classification
# ### Questão 1 - Item B - Tabela de frequência
# Construa uma tabela de frequência para cada uma das **variáveis qualitativas** que você escolheu (caso não tenha escolhido nenhuma, deixe esta questão em branco). Uma dica: a função *value_counts()* do Pandas pode ser muito útil. =)
#
uf = df["uf"].value_counts()
f_uf = df["uf"].value_counts(normalize=True)
freqr = pd.concat(
[uf, f_uf],
axis=1,
keys=["Frequência Absoluta", "Frequência Relativa %"],
sort=False,
)
freqr
# ### Questão 1 - Item C - Representação Gráfica
# Para cada uma das variáveis, produza um ou mais gráficos, usando matplotlib, que descreva seu comportamento / caracteristica. Lembre-se que estes gráficos precisam ser compatíveis com a classificação da variável.
data = df.groupby(["uf"])["total_eleitores"].sum()
data = data.sort_values()[data > 0]
labels = data.keys().tolist()
plt.rcdefaults()
fig, ax = plt.subplots()
plt.xticks(rotation="vertical")
ax.bar(labels, data, align="center", ecolor="black", color="#ff4422")
ax.set_title("Quantidade de Eleitores por Região")
plt.show()
|
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from keras.utils import to_categorical
from tensorflow.python.keras import layers, models
from tensorflow.python.keras.regularizers import l2
from tensorflow.python.keras.losses import categorical_crossentropy
train = pd.read_csv("../input/digit-recognizer/train.csv")
test = pd.read_csv("../input/digit-recognizer/test.csv")
y = to_categorical(train.label, 10)
x = train.drop("label", axis=1).values.reshape(train.shape[0], 28, 28, 1) / 255
x_test = test.values.reshape(test.shape[0], 28, 28, 1) / 255
model = models.Sequential()
model.add(
layers.Conv2D(
16,
kernel_size=(9, 9),
kernel_initializer="he_normal",
kernel_regularizer=l2(0.005),
input_shape=(28, 28, 1),
)
)
model.add(
layers.Conv2D(
32,
kernel_size=(7, 7),
strides=2,
kernel_initializer="he_normal",
kernel_regularizer=l2(0.005),
activation="relu",
)
)
model.add(layers.Dropout(0.25))
model.add(
layers.Conv2D(
128,
kernel_size=(4, 4),
kernel_initializer="he_normal",
kernel_regularizer=l2(0.0001),
activation="relu",
)
)
model.add(
layers.Conv2D(
128,
kernel_size=(4, 4),
kernel_initializer="he_normal",
kernel_regularizer=l2(0.0001),
activation="relu",
)
)
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dense(512, kernel_initializer="he_normal", activation="relu"))
model.add(layers.Dense(10, activation="softmax"))
model.compile(loss=categorical_crossentropy, optimizer="adam", metrics=["accuracy"])
hist = model.fit(
x,
y,
batch_size=64,
epochs=11,
steps_per_epoch=len(x) * 0.7 / 64,
validation_split=0.3,
)
print("Train set: ", ", ".join([str(acc) for acc in hist.history["accuracy"]]))
print("Validation set: ", ", ".join([str(acc) for acc in hist.history["val_accuracy"]]))
fig, ax = plt.subplots(1, 2, figsize=(20, 5))
ax[0].plot(hist.history["accuracy"])
ax[0].set_title("Train set", fontsize=12)
ax[0].set_ylabel("accuracy")
ax[0].set_xlabel("epoch")
ax[1].plot(hist.history["val_accuracy"])
ax[1].set_title("Validation set", fontsize=12)
ax[1].set_ylabel("accuracy")
ax[1].set_xlabel("epoch")
fig, ax = plt.subplots(1, 10, constrained_layout=True, figsize=(20, 20))
pred = np.argmax(model.predict(x_test), axis=1)
for i in range(10):
ax[i].imshow(x_test[i].reshape(28, 28))
ax[i].set_xlabel("predicted:" + str(pred[i]), fontsize=18)
result = pd.read_csv("../input/digit-recognizer/sample_submission.csv")
result["Label"] = pred
result.to_csv("submission.csv", index=False)
|
#
#
# ROV underwater species detection
# A short notebook introducing techniques and common challenges for underwater species detection
#
#
#
# Install necessary packages one by one
# Download data folder
# Unzip folder
#
#
# ### NOTE: Data folder should be at the same level as the notebooks provided.
#
#
# Imports
import matplotlib.pyplot as plt
import cv2
import numpy as np
#
# OpenCV is a highly-optimised open-source computer vision library. It is built in C/C++ with binders for Python
# **PLEASE NOTE: All the code blocks involving video have been commented out to speed up commits, so please use CTRL + A and then CTRL + / to uncomment them when inside a code block before running **
# Play a video
#
import cv2
from IPython.display import clear_output
from google.colab.patches import cv2_imshow
# video_file = "./Data/videos/TjarnoROV1-990813_3-1122.mov"
# video = cv2.VideoCapture(video_file)
# try:
# while True:
# (grabbed, frame) = video.read()
# if not grabbed:
# break
# # The important part - Correct BGR to RGB channel
# frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# axis('off')
# # Title of the window
# title("Input Stream")
# # Display the frame
# imshow(frame)
# show()
# # Display the frame until new frame is available
# clear_output(wait=True)
# cv2.destroyAllWindows()
# video.release()
# except KeyboardInterrupt: video.release()
#
# Detect a colour
#
# video_file = "./Data/videos/TjarnoROV1-990813_3-1122.mov"
# video = cv2.VideoCapture(video_file)
# try:
# while True:
# (grabbed, frame) = video.read()
# if not grabbed:
# break
# blur = cv2.GaussianBlur(frame, (21, 21), 0)
# hsv = cv2.cvtColor(blur, cv2.COLOR_BGR2HSV)
# lower = np.array([0,120,70])
# upper = np.array([180,255,255])
# lower = np.array(lower, dtype="uint8")
# upper = np.array(upper, dtype="uint8")
# mask = cv2.inRange(hsv, lower, upper)
# frame = cv2.bitwise_and(frame, hsv, mask=mask)
# frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# axis('off')
# # Title of the window
# title("Input Stream")
# # Display the frame
# imshow(frame)
# show()
# # Display the frame until new frame is available
# clear_output(wait=True)
# cv2.destroyAllWindows()
# video.release()
# except KeyboardInterrupt: video.release()
#
# Problem 1: Distortion of colour between foreground and background objects
#
def clearImage(image):
# Convert the image from BGR to gray
dark_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
channels = cv2.split(image)
# Get the maximum value of each channel
# and get the dark channel of each image
# record the maximum value of each channel
a_max_dst = [float("-inf")] * len(channels)
for idx in range(len(channels)):
a_max_dst[idx] = channels[idx].max()
dark_image = cv2.min(channels[0], cv2.min(channels[1], channels[2]))
# Gaussian filtering the dark channel
dark_image = cv2.GaussianBlur(dark_image, (25, 25), 0)
image_t = (255.0 - 0.95 * dark_image) / 255.0
image_t = cv2.max(image_t, 0.5)
# Calculate t(x) and get the clear image
for idx in range(len(channels)):
channels[idx] = (
cv2.max(
cv2.add(
cv2.subtract(channels[idx].astype(np.float32), int(a_max_dst[idx]))
/ image_t,
int(a_max_dst[idx]),
),
0.0,
)
/ int(a_max_dst[idx])
* 255
)
channels[idx] = channels[idx].astype(np.uint8)
return cv2.merge(channels)
#
# Let's see what that looks like now
#
# video_file = "./Data/videos/TjarnoROV1-990813_3-1122.mov"
# video = cv2.VideoCapture(video_file)
# try:
# while True:
# (grabbed, frame) = video.read()
# if not grabbed:
# break
# # The important part - Correct BGR to RGB channel
# frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# n_frame = clearImage(frame)
# axis('off')
# # Title of the window
# title("Input Stream")
# # Display the frame
# imshow(n_frame)
# show()
# # Display the frame until new frame is available
# clear_output(wait=True)
# cv2.destroyAllWindows()
# video.release()
# except KeyboardInterrupt: video.release()
#
# Problem 2: How do we draw contours that represent the objects we detect with a suitable mask?
#
# Reference in C++:
# https://answers.opencv.org/question/26280/background-color-similar-to-object-color-how-isolate-it/
# video_file = "./Data/videos/TjarnoROV1-990813_3-1122.mov"
# video_file = "./Data/videos/000114 TMBL-ROV 2000 Säckenrevet EJ numrerade band_1440.mp4"
# video = cv2.VideoCapture(video_file)
# blur_size = 20
# grid_size = 500
# try:
# while True:
# (grabbed, frame) = video.read()
# if frame is None: break
# # Reduce the size that we observe to reduce noise from corners of the frame
# origin = frame[100:500, 100:500]
# if not grabbed:
# break
# # Clean up our image
# new_img = clearImage(frame)
# new_img = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# new_img = cv2.split(frame)[2]
# # Cut to the most important segment
# new_img = new_img[100:500, 100:500]
# blur_size += (1 - blur_size % 2)
# blur = cv2.GaussianBlur(new_img, (blur_size, blur_size), 0)
# # equalise the histogram
# equal = cv2.createCLAHE(clipLimit=1.0, tileGridSize=(5,5)).apply(blur)
# grid_size += (1 - grid_size % 2)
# # create a binary mask using an adaptive thresholding technique
# binimage = cv2.adaptiveThreshold(equal, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\
# cv2.THRESH_BINARY, grid_size, -30)
# #cv2.imshow("bin", binimage)
# contours, _ = cv2.findContours(binimage.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# # Cycle through contours and add area to array
# areas = []
# for c in contours:
# areas.append(cv2.contourArea(c))
# # Sort array of areas by size
# try:
# largest = np.argmax(areas)
# except:
# largest = None
# if largest is not None:
# fishMask = np.zeros(new_img.shape, dtype = np.uint8)
# # Choose our largest contour to be the object we wish to detect
# fishContours = contours[largest]
# cv2.polylines(origin, [fishContours], True, (0, 0, 255), 2)
# # Draw these contours we detect
# cv2.drawContours(fishMask, contours, -1, 255, -1);
# #cv2.imshow("fish_mask", fishMask)
# origin = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
# axis('off')
# # Title of the window
# title("Input Stream")
# # Display the frame
# imshow(origin)
# show()
# # Display the frame until new frame is available
# clear_output(wait=True)
# cv2.destroyAllWindows()
# video.release()
# except KeyboardInterrupt: video.release()
#
# Problem 3: A binary mask is not sufficient if we want to detect multiple objects in a frame, so what can we do?
# 
# First convert all the video frames into images so we can label them
#
### Save frames as images
# import cv2
# import numpy as np
# import scipy.io as sio
# video_file = "./Data/videos/TjarnoROV1-990813_3-1122.mov"
# video = cv2.VideoCapture(video_file)
# total_frames = video.get(cv2.CAP_PROP_FRAME_COUNT)
# frame_id = 0
# i = 0
# while True:
# (grabbed, frame) = video.read()
# if not grabbed:
# break
# new_img = clearImage(frame)
# new_img = cv2.resize(new_img, (416, 416))
# assert(new_img.shape == (416, 416, 3))
# adict = {}
# adict['img'] = new_img
# frame_id += 1
# if frame_id % 100 == 0:
# print("Saved", frame_id)
# cv2.imwrite("./Data/img/odf_video_frames/{:s}".format(str(i)+'.jpg'), new_img)
# #sio.savemat("./img/POTSDAM/imgs/{:s}".format(str(i)+'.mat'), adict)
# i += 1
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# print('Saved images')
# cv2.destroyAllWindows()
# video.release()
#
# YOLO V3
# 
# Train test split
#
import glob, os
dataset_path = "./Data/img/odf_video_frames"
# Percentage of images to be used for the test set
percentage_test = 10
# Create and/or truncate train.txt and test.txt
file_train = open("./Data/img/train.txt", "w")
file_test = open("./Data/img/test.txt", "w")
# Populate train.txt and test.txt
counter = 1
index_test = int(percentage_test / 100 * len(os.listdir(dataset_path)))
for pathAndFilename in glob.iglob(os.path.join(dataset_path, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test + 1:
counter = 1
file_test.write(os.path.basename(title) + ".jpg" + "\n")
else:
file_train.write(os.path.basename(title) + ".jpg" + "\n")
counter = counter + 1
#
# Annotation!
# Note that annotation with Labelimg cannot be done in the Cloud. Please run this on your local machine if you need to annotate data.
#
# !labelImg ./Data/img/odf_video_frames/ ./Data/img/odf_classes.txt
#
# Now, to the cloud for training...
# [Google Colab Workbook](https://colab.research.google.com/drive/1lZmojs-vsarIiSoicY1QKcpB1Bp0Co3O)
# 
# Model Evaluation
#
lines = []
for line in open("./Data/logs/train_log_example.log"):
if "avg" in line:
lines.append(line)
iterations = []
avg_loss = []
print("Retrieving data and plotting training loss graph...")
for i in range(len(lines)):
lineParts = lines[i].split(",")
iterations.append(int(lineParts[0].split(":")[0]))
avg_loss.append(float(lineParts[1].split()[0]))
fig = plt.figure(figsize=(15, 10))
for i in range(0, len(lines)):
plt.plot(iterations[i : i + 2], avg_loss[i : i + 2], "r.-")
plt.xlabel("Batch Number")
plt.ylabel("Avg Loss")
fig.savefig("training_loss_plot.png", dpi=1000)
print("Done! Plot saved as training_loss_plot.png")
#
# Note: Visualising using OpenCV does not work in the cloud - instead you can open the output file once it has been saved
#
## Visualize predictions using OpenCV
import argparse
import sys
import numpy as np
import os.path
# Initialize the parameters
confThreshold = 0.1 # Confidence threshold
nmsThreshold = 0.4 # Non-maximum suppression threshold
inpWidth = 416 # 608 #Width of network's input image
inpHeight = 416 # 608 #Height of network's input image
# Load names of classes
classesFile = "./Data/models/sweden_yolo/odf_classes.names"
classes = None
with open(classesFile, "rt") as f:
classes = f.read().rstrip("\n").split("\n")
# Give the configuration and weight files for the model and load the network using them.
modelConfiguration = "./Data/models/sweden_yolo/sweden_yolo.cfg"
modelWeights = "./Data/models/sweden_yolo/sweden_yolo.backup"
net = cv2.dnn.readNetFromDarknet(modelConfiguration, modelWeights)
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
# Get the names of the output layers
def getOutputsNames(net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# Draw the predicted bounding box
def drawPred(classId, conf, left, top, right, bottom):
# Draw a bounding box.
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 3)
label = "%.2f" % conf
# Get the label for the class name and its confidence
if classes:
assert classId < len(classes)
label = "%s:%s" % (classes[classId], label)
# Display the label at the top of the bounding box
labelSize, baseLine = cv2.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv2.rectangle(
frame,
(left, top - round(1.5 * labelSize[1])),
(left + round(1.5 * labelSize[0]), top + baseLine),
(0, 0, 255),
cv2.FILLED,
)
cv2.putText(frame, label, (left, top), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 0), 2)
# Remove the bounding boxes with low confidence using non-maxima suppression
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
classIds = []
confidences = []
boxes = []
# Scan through all the bounding boxes output from the network and keep only the
# ones with high confidence scores. Assign the box's class label as the class with the highest score.
classIds = []
confidences = []
boxes = []
for out in outs:
print("out.shape : ", out.shape)
for detection in out:
# if detection[4]>0.001:
scores = detection[5:]
classId = np.argmax(scores)
# if scores[classId]>confThreshold:
confidence = scores[classId]
if detection[4] > confThreshold:
print(detection[4], " - ", scores[classId], " - th : ", confThreshold)
print(detection)
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = int(center_x - width / 2)
top = int(center_y - height / 2)
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
# Perform non maximum suppression to eliminate redundant overlapping boxes with
# lower confidences.
indices = cv2.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
# Process inputs
winName = "ODF - Sweden Demo"
cv2.namedWindow(winName, cv2.WINDOW_NORMAL)
outputFile = "./Data/models/sweden_yolo/yolo_out_py.avi"
video_path = "./Data/models/sweden_yolo/crabs.mov"
cap = cv2.VideoCapture(video_path)
vid_writer = cv2.VideoWriter(
outputFile,
cv2.VideoWriter_fourcc("M", "J", "P", "G"),
30,
(
round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)),
),
)
count = 0
while cv2.waitKey(1) < 0:
# get frame from the video
hasFrame, frame = cap.read()
if frame is None:
break
# frame = frame[100:516, 100:516]
frame = clearImage(frame)
frame = cv2.resize(frame, (inpWidth, inpHeight))
# Stop the program if reached end of video
if not hasFrame:
print("Done processing !!!")
print("Output file is stored as ", outputFile)
cv2.waitKey(3000)
break
# Create a 4D blob from a frame.
blob = cv2.dnn.blobFromImage(
frame, 1 / 255, (inpWidth, inpHeight), [0, 0, 0], 1, crop=False
)
# Sets the input to the network
net.setInput(blob)
# Runs the forward pass to get output of the output layers
outs = net.forward(getOutputsNames(net))
# Remove the bounding boxes with low confidence
postprocess(frame, outs)
# Put efficiency information. The function getPerfProfile returns the overall time for inference(t) and the timings for each of the layers(in layersTimes)
t, _ = net.getPerfProfile()
label = "Inference time: %.2f ms" % (t * 1000.0 / cv2.getTickFrequency())
vid_writer.write(frame.astype(np.uint8))
count += 30 # i.e. at 30 fps, this advances one second
cap.set(1, count)
# cv2.imshow(winName, frame)
|
import numpy as np
import pandas as pd
from sklearn.manifold import TSNE
train = pd.read_csv("../input/digit-recognizer/train.csv")
test = pd.read_csv("../input/digit-recognizer/test.csv")
train = train[test.columns].values
test = test[test.columns].values
train_test = np.vstack([train, test])
train_test.shape
tsne = TSNE(n_components=2)
train_test_2D = tsne.fit_transform(train_test)
train_2D = train_test_2D[: train.shape[0]]
test_2D = train_test_2D[train.shape[0] :]
np.save("train_2D", train_2D)
np.save("test_2D", test_2D)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import jieba
from collections import Counter
df_train = pd.read_csv("/kaggle/input/pkdata/pk/train.csv")
df_train.head()
print("total number of question pairs:{}".format(len(df_train)))
print("positive tag:{}%".format(round(df_train["label"].mean() * 100, 2)))
question_series = pd.Series(
df_train["question1"].tolist() + df_train["question2"].tolist()
)
print("question num:{}".format(len(question_series)))
print("unique question num:{}".format(len(np.unique(question_series))))
plt.figure(figsize=(12, 5))
plt.hist(question_series.value_counts(), bins=50)
plt.yscale("log", nonposy="clip")
plt.title("Log-Histogram of question apperance counts")
plt.xlabel("Number of occurence of question")
plt.ylabel("Number of questions")
train_qs = question_series.astype(str)
dist_train = train_qs.apply(len)
plt.figure(figsize=(15, 10))
plt.hist(dist_train, bins=30, normed=True, label="train")
plt.title("Normalised histogram of character count in questions", fontsize=15)
plt.legend()
plt.xlabel("Number of characters", fontsize=15)
plt.ylabel("Probability", fontsize=15)
print("mean train character length:{:.2f}".format(dist_train.mean()))
train_qs = question_series.apply(lambda x: " ".join(jieba.cut(x)).split())
dist_train = train_qs.apply(len)
plt.figure(figsize=(15, 10))
plt.hist(dist_train, bins=30, normed=True, label="train")
plt.title("Normalised histogram of word count in questions", fontsize=15)
plt.legend()
plt.xlabel("Number of words", fontsize=15)
plt.ylabel("Probability", fontsize=15)
print("mean train character length:{:.2f}".format(dist_train.mean()))
# from pylab import mpl
# mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
# mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
words = " ".join(jieba.cut(" ".join(train_qs.astype(str))))
cloud = WordCloud(
width=1440, height=1080, font_path="/kaggle/input/simhei/SimHei.ttf"
).generate(words)
plt.figure(figsize=(29, 15))
plt.imshow(cloud)
plt.axis("off")
qmarks = np.mean(train_qs.apply(lambda x: "?" in x or "吗" in x or "怎么" in x))
numbers = np.mean(train_qs.apply(lambda x: max([y.isdigit() for y in x])))
print("obvious question:{:.2f}%".format(qmarks * 100))
# print('Question with [math] tags:{:.2f}'.format(math))
print("Question with numbers:{:.2f}%".format(numbers * 100))
|
# # CNN on a 3 class problem on images
# ### Importing libs
import pathlib
import os
import numpy as np
import pandas as pb
import seaborn as sns
import tensorflow as tf
import keras
import IPython.display as display
from PIL import Image
import cv2
import matplotlib.pyplot as plt
# ### Loading data
# - Using keras.preprocessing
data_dir = pathlib.Path("../input/images_train")
image_count = len(list(data_dir.glob("*/*.jpg")))
image_count
CLASS_NAMES = np.array(
[item.name for item in data_dir.glob("*") if item.name != ".DS_Store"]
)
CLASS_NAMES
cat = list(data_dir.glob("cat/*"))
car = list(data_dir.glob("car/*"))
flower = list(data_dir.glob("flower/*"))
for image_path in cat[:1]:
img = cv2.imread(str(image_path))
plt.imshow(img)
# ## Initialisation variables
BATCH_TRAIN_SIZE = 64
IMG_HEIGHT = 224
IMG_WIDTH = 224
STEPS_PER_EPOCH = np.ceil(image_count / BATCH_TRAIN_SIZE)
EPOCHS = 12
# ## Dataset Generator
# Let's generate image to float32 in range [0,1].
# Moreover, as our dataset has images of different size, we will target size them as 448 px
# ### Using ImageDataGenerator from keras
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1.0 / 255)
train_data_gen = image_generator.flow_from_directory(
directory=str(data_dir),
batch_size=BATCH_TRAIN_SIZE,
shuffle=True,
target_size=(224, 224),
class_mode="sparse",
classes=list(CLASS_NAMES),
)
def show_batch(image_batch, label_batch):
plt.figure(figsize=(10, 10))
for n in range(25):
ax = plt.subplot(5, 5, n + 1)
plt.imshow(image_batch[n])
plt.axis("off")
image_batch, label_batch = next(train_data_gen)
show_batch(image_batch, label_batch)
image_batch[2].shape
# ### Using tf.data
# Usinf tf.data, with ability of .cache(), method is actually faster for big dataset.
AUTOTUNE = tf.data.experimental.AUTOTUNE
list_ds = tf.data.Dataset.list_files(str(data_dir / "*/*"))
for f in list_ds.take(5):
print(f.numpy())
def get_label(file_path):
# convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
return parts[-2] == CLASS_NAMES
def decode_img(img):
# convert the compressed string to a 3D uint8 tensor
img = tf.image.decode_jpeg(img, channels=3)
# Use `convert_image_dtype` to convert to floats in the [0,1] range.
img = tf.image.convert_image_dtype(img, tf.float32)
# resize the image to the desired size.
return tf.image.resize(img, [IMG_WIDTH, IMG_HEIGHT])
def process_path(file_path):
label = get_label(file_path)
# load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
labeled_ds = list_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in labeled_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
train_ds = labeled_ds.take(np.ceil(1596 * 0.7))
test_ds = labeled_ds.take(np.ceil(1596 * 0.7))
# To train a model with this dataset you will want the data:
# To be well shuffled.
# To be batched.
# Batches to be available as soon as possible.
def prepare_for_training(ds, cache=True, shuffle_buffer_size=300):
# This is a small dataset, only load it once, and keep it in memory.
# use `.cache(filename)` to cache preprocessing work for datasets that don't
# fit in memory.
if cache:
if isinstance(cache, str):
ds = ds.cache(cache)
else:
ds = ds.cache()
ds = ds.shuffle(buffer_size=shuffle_buffer_size)
# Repeat forever
ds = ds.repeat()
ds = ds.batch(BATCH_TRAIN_SIZE)
# `prefetch` lets the dataset fetch batches in the background while the model
# is training.
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_dsfinal = prepare_for_training(train_ds)
test_dsfinal = prepare_for_training(test_ds)
image_batch, label_batch = next(iter(train_dsfinal))
show_batch(image_batch.numpy(), label_batch.numpy())
label_batch.shape
# ### Building model
# CNN model
class CNNModel:
def __init__(self):
self.inputs = tf.keras.Input(shape=(224, 224, 3))
self.x1 = tf.keras.layers.Conv2D(32, 3, activation="relu")(self.inputs)
self.x1 = tf.keras.layers.Conv2D(64, 3, activation="relu")(self.x1)
self.x1 = tf.keras.layers.MaxPooling2D(2, 2)(self.x1)
self.x2 = tf.keras.layers.Conv2D(32, 3, activation="relu")(self.x1)
self.x2 = tf.keras.layers.Conv2D(64, 3, activation="relu")(self.x2)
self.x2 = tf.keras.layers.MaxPooling2D(3, 3)(self.x2)
self.x3 = tf.keras.layers.Conv2D(32, 3, activation="relu")(self.x2)
self.x3 = tf.keras.layers.MaxPooling2D(2, 2)(self.x3)
self.x = tf.keras.layers.Dropout(0.2)(self.x3)
self.output = tf.keras.layers.Flatten()(self.x)
self.output = tf.keras.layers.Dense(224, activation="relu")(self.output)
self.output = tf.keras.layers.Dense(3, activation="softmax")(self.output)
self.model = tf.keras.Model(self.inputs, self.output)
"""
X_input = Input((480, 480, 3))
X = Conv2D(6, (5, 5), kernel_initializer = glorot_uniform(seed=0))(X_input) #480 - 4 = 476
X = BatchNormalization(axis = 3)(X)
X = Activation('relu')(X)
X = MaxPooling2D((2, 2), strides=(2, 2))(X) # 476 / 2 = 238
X = Conv2D(16, (5, 5), kernel_initializer = glorot_uniform(seed=0))(X) #238 - 4 = 234
X = BatchNormalization(axis = 3)(X)
X = Activation('relu')(X)
X = MaxPooling2D((2, 2), strides=(2, 2))(X) # 234 / 2 = 117
X = Conv2D(32, (5, 5), kernel_initializer = glorot_uniform(seed=0))(X) #117 - 4 = 113
X = BatchNormalization(axis = 3)(X)
X = Activation('relu')(X)
X = MaxPooling2D((2, 2), strides=(2, 2))(X) # 113 / 2 = 56
X = Conv2D(16, (5, 5), kernel_initializer = glorot_uniform(seed=0))(X) #56 - 4 = 52
X = BatchNormalization(axis = 3)(X)
X = Activation('relu')(X)
X = MaxPooling2D((2, 2), strides=(2, 2))(X) # 52 / 2 = 26
X = Conv2D(5, (5, 5), kernel_initializer = glorot_uniform(seed=0))(X) #26 - 4 = 22
X = BatchNormalization(axis = 3)(X)
X = Activation('relu')(X)
X = MaxPooling2D((2, 2), strides=(2, 2))(X) # 22 / 2 = 11
model = Model(inputs = X_input, outputs = X, name='ResNet50')
"""
def compile_cnn(self):
self.model.summary()
self.model.compile(
loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.RMSprop(lr=0.001),
metrics=["accuracy"],
)
def fit(self, dataset, n_epochs):
self.model.fit(
dataset,
steps_per_epoch=STEPS_PER_EPOCH,
epochs=n_epochs,
validation_data=test_dsfinal,
validation_steps=200,
)
# Create an instance of the model
model = CNNModel()
model.compile_cnn()
history = model.fit(dataset=train_dsfinal, n_epochs=EPOCHS)
acc = model.model.history.history["accuracy"]
val_acc = model.model.history.history["val_accuracy"]
loss = model.model.history.history["loss"]
val_loss = model.model.history.history["val_loss"]
epochs_range = range(EPOCHS)
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc, label="Validation Accuracy")
plt.legend(loc="lower right")
plt.title("Training and Validation Accuracy")
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss, label="Validation Loss")
plt.legend(loc="upper right")
plt.title("Training and Validation Loss")
plt.show()
model.model.evaluate(test_dsfinal, verbose=2, steps=64)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.feature_extraction.text import CountVectorizer
import matplotlib.pyplot as plt
import re
from sklearn.metrics import accuracy_score
import nltk
from nltk.corpus import stopwords
from nltk import regexp_tokenize
from nltk.stem import WordNetLemmatizer
import spacy
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
train = pd.read_csv(r"/kaggle/input/nlp-getting-started/train.csv")
test = pd.read_csv(r"/kaggle/input/nlp-getting-started/test.csv")
train.head()
nlp = spacy.load("en_core_web_lg")
with nlp.disable_pipes():
train_vectors = np.array([nlp(text).vector for text in train.text])
test_vectors = np.array([nlp(text).vector for text in test.text])
print(train_vectors.shape, test_vectors.shape)
X_train = train_vectors
y_train = train.target.to_numpy()
train_x, test_x, train_y, test_y = train_test_split(X_train, y_train, test_size=0.2)
from sklearn.ensemble import (
RandomForestClassifier,
VotingClassifier,
GradientBoostingClassifier,
)
from sklearn.svm import SVC
svc = SVC(kernel="rbf", C=0.7, gamma="auto", probability=True)
rfc = RandomForestClassifier(n_estimators=100)
gbc = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1)
# class keras_model:
# def __call__():
# model = keras.models.Sequential()
# model.add(keras.layers.Dense(1024, activation='relu'))
# model.add(keras.layers.Dense(512, activation='relu'))
# model.add(keras.layers.BatchNormalization())
# model.add(keras.layers.Dense(512, activation='relu'))
# model.add(keras.layers.Dropout(0.2))
# model.add(keras.layers.Dense(128, activation='relu'))
# model.add(keras.layers.Dense(128, activation='relu'))
# model.add(keras.layers.Dense(1, activation='sigmoid'))
# model.compile(optimizer='adam',
# loss='binary_crossentropy',
# metrics=['accuracy'])
# return model
# from keras.wrappers.scikit_learn import KerasClassifier
# keras_clf = KerasClassifier(keras_model(), batch_size=100, epochs=20)
# model.fit(X_train, y_train, batch_size=100, epochs=40)
# preds = model.predict_classes(test_vectors)
vcf = VotingClassifier(
estimators=[
("svc", svc),
("rfc", rfc),
("gbc", gbc),
],
voting="soft",
)
vcf.fit(X_train, y_train)
preds = vcf.predict(test_vectors)
print(accuracy_score((vcf.predict(test_x)), test_y))
print(len(test["id"]), len(preds))
submission = pd.DataFrame(columns=["id", "target"])
submission["id"] = test["id"]
submission["target"] = preds
submission
submission.to_csv("submission.csv", index=False)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
#
# ## Advanced Regression - Assignment Solution
# The solution is divided into the following sections:
# - Data understanding and exploration
# - Data cleaning
# - Data preparation
# - Model building and evaluation
# ### 1. Data Understanding and Exploration
# Let's first have a look at the dataset and understand the size, attribute names etc.
# Importing all required libraries
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import linear_model
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
from sklearn.model_selection import GridSearchCV
# Scaling libraries
from sklearn.preprocessing import scale
import os
import datetime
# hide warnings
import warnings
warnings.filterwarnings("ignore")
# To display all columns and rows
pd.set_option("display.max_columns", None)
pd.set_option("display.max_rows", None)
# Reading the dataset
housing = pd.read_csv(
"/kaggle/input/house-prices-advanced-regression-techniques/train.csv"
)
housing.head()
# summary of the dataset
print(housing.info())
# # 1460 rows and 81 columns
# # Let us analyse the data through visualization techniques. Before we do that we need to handle the Year columns. As you can see from the dataset summary,following columns do not have data type as Date:
# ### 1) YearBuilt
# ### 2) YearRemodAdd
# ### 3) GarageYrBlt
# ### 4) YrSold: Year Sold (YYYY)
# # We would use the year columns to calculate the age . Following would be the approach:
# 1. Check for any missing/null data for these columns first
# 2. If any missing / null values, remove them
# 3. Then Use these columns to create Age columns
# 4. Use visualization techniques to see the prices for these columns and rest of them
# 5. EDA and data visualization would would follow for the rest of the columns as well
# Checking the percentage of missing values
round(100 * (housing.isnull().sum() / len(housing.index)), 2)
# #### All year columns are non-null, except for 'GarageYrBlt'
# Dropping null values for the column 'GarageYrBlt'
housing = housing.dropna(axis=0, subset=["GarageYrBlt"])
housing["GarageYrBlt"].isnull().sum()
# Converting GarageYrBlt from float to int and converting to datetime
housing["GarageYrBlt"] = housing["GarageYrBlt"].astype(int)
# Converting year columns to datetime
housing["GarageYrBlt"] = pd.to_datetime(housing["GarageYrBlt"].astype(str), format="%Y")
# housing['GarageYrBlt'] = pd.to_datetime(housing['GarageYrBlt'], unit='s')
housing["YearRemodAdd"] = pd.to_datetime(
housing["YearRemodAdd"].astype(str), format="%Y"
)
housing["YrSold"] = pd.to_datetime(housing["YrSold"].astype(str), format="%Y")
housing["YearBuilt"] = pd.to_datetime(housing["YearBuilt"].astype(str), format="%Y")
# Converting the Year columns from datetime to date
housing["GarageYrBlt"] = housing["GarageYrBlt"].dt.date
housing["YearRemodAdd"] = housing["YearRemodAdd"].dt.date
housing["YrSold"] = housing["YrSold"].dt.date
housing["YearBuilt"] = housing["YearBuilt"].dt.date
# Calcualting the age using the Year column and today's date
now = datetime.date.today()
housing["GarageYrBltAge_in_years"] = now - housing["GarageYrBlt"]
housing["YearRemodAddAge_in_years"] = (now - housing["YearRemodAdd"]) / 365
housing["YrSoldAge_in_years"] = (now - housing["YrSold"]) / 365
housing["YearBuiltAge_in_years"] = (now - housing["YearBuilt"]) / 365
# Convert age to int
housing["GarageYrBltAge_in_years"] = housing.apply(
lambda row: row.GarageYrBltAge_in_years.days, axis=1
)
housing["YearRemodAddAge_in_years"] = housing.apply(
lambda row: row.YearRemodAddAge_in_years.days, axis=1
)
housing["YrSoldAge_in_years"] = housing.apply(
lambda row: row.YrSoldAge_in_years.days, axis=1
)
housing["YearBuiltAge_in_years"] = housing.apply(
lambda row: row.YearBuiltAge_in_years.days, axis=1
)
# we can drop the original columns of years
# housing = housing.drop(['GarageYrBlt','YearRemodAdd','YrSold','YearBuilt'],1)
housing.info()
# plot per sale price and YearBuild
plt.scatter(housing["YearBuiltAge_in_years"], housing["SalePrice"])
plt.ylabel("Sale Price")
plt.xlabel("YearBuiltAge_in_years")
# ### As can be seen from the above plot, as the age increases the price of house decreases, except for few outliers.[[](http://)](http://)
# plot per sale price and YearBuild
plt.scatter(housing["YearRemodAddAge_in_years"], housing["SalePrice"])
plt.ylabel("Sale Price")
plt.xlabel("YearRemodAddAge_in_years")
# plot per sale price and YearBuild
plt.scatter(housing["OverallQual"], housing["SalePrice"])
plt.ylabel("Sale Price")
plt.xlabel("OverallQual")
# ## Price of house increases with increase in Overall Quality parameter
# ### Data Exploration
# #### To perform linear regression, the (numeric) target variable should be linearly related to at least one another numeric variable. We'll first subset the list of all (independent) numeric variables, and then make a pairwise plot
# all numeric (float and int) variables in the dataset
housing_numeric = housing.select_dtypes(include=["float64", "int64"])
housing_numeric.head()
# plotting pairplot with few numeric variables.
housing_numeric_plot = housing[
[
"SalePrice",
"GarageYrBltAge_in_years",
"YearRemodAddAge_in_years",
"OverallQual",
"YearBuiltAge_in_years",
"LotArea",
"GarageCars",
"YrSoldAge_in_years",
"MoSold",
]
]
# pairwise scatter plot
plt.figure(figsize=(20, 10))
sns.pairplot(housing_numeric_plot)
plt.show()
housing.head()
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
ddf = pd.read_csv(
"/kaggle/input/lists-of-earthquakes-deadliest-and-largest/Deadliest earthquakes by year.csv"
)
ddf = ddf.loc[~ddf.Date.str.contains("March 3–25")]
ddf = ddf.loc[~ddf.Date.str.contains("June 11 and July 28")]
ddf.head()
ldf = pd.read_csv(
"/kaggle/input/lists-of-earthquakes-deadliest-and-largest/Largest earthquakes by year.csv"
)
ldf.head()
def preprocess_inputs(df):
df = df.copy()
drop_cols = ["Unnamed: 0", "Year"]
df["Magnitude"] = df["Magnitude"].str.replace("7.5-7.7", "7.6", regex=False)
df["Magnitude"] = pd.to_numeric(df["Magnitude"])
df["Depth (km)"] = df["Depth (km)"].str.replace("17.9 10.0", "17.9", regex=False)
df["Depth (km)"] = pd.to_numeric(df["Depth (km)"])
# 17.9 10.0
df["Date"] = (df["Year"]).astype("str") + " " + df["Date"]
df["Date"] = pd.to_datetime(df["Date"])
df = df.drop(drop_cols, axis=1)
return df
Xddf = preprocess_inputs(ddf)
Xddf
Xddf["MMI"].unique()
# Xddf.info()
# Xddf.loc[Xddf['Depth (km)'].str.contains('17.9 10.0')]
# Xddf.loc[Xddf['Magnitude']==7.8]
sns.histplot(data=Xddf, x="Magnitude", bins=20, kde=True)
plt.show()
sns.histplot(data=Xddf, x="Depth (km)", bins=10, kde=True)
plt.show()
# sns.lineplot(x = 'Date', data = Xddf)
Xddf.Location.unique()
Xddf.groupby("Location").count()
|
# ![]()
# # Kannada MNIST
# 
# # 1. Import
# System
import sys
import os
import argparse
import itertools
# Time
import time
import datetime
# Numerical Data
import random
import numpy as np
import pandas as pd
# Tools
import shutil
from glob import glob
from tqdm import tqdm
import gc
# NLP
import re
# Preprocessing
from sklearn import preprocessing
from sklearn.utils import class_weight as cw
from sklearn.utils import shuffle
# Model Selection
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
# Machine Learning Models
from sklearn import svm
from sklearn.svm import LinearSVC, SVC
# Evaluation Metrics
from sklearn import metrics
from sklearn.metrics import (
f1_score,
accuracy_score,
precision_score,
recall_score,
confusion_matrix,
classification_report,
roc_auc_score,
)
# Deep Learning - Keras - Preprocessing
from keras.preprocessing.image import ImageDataGenerator
# Deep Learning - Keras - Model
import keras
from keras import models
from keras.models import Model
from keras.models import load_model
from keras.models import Sequential
# Deep Learning - Keras - Layers
from keras.layers import (
Convolution1D,
concatenate,
SpatialDropout1D,
GlobalMaxPool1D,
GlobalAvgPool1D,
Embedding,
Conv2D,
SeparableConv1D,
Add,
BatchNormalization,
Activation,
GlobalAveragePooling2D,
LeakyReLU,
Flatten,
)
from keras.layers import (
Dense,
Input,
Dropout,
MaxPool2D,
MaxPooling2D,
Concatenate,
GlobalMaxPooling2D,
GlobalAveragePooling2D,
Lambda,
Multiply,
LSTM,
Bidirectional,
PReLU,
MaxPooling1D,
)
from keras.layers.pooling import _GlobalPooling1D
from keras.regularizers import l2
# Deep Learning - Keras - Pretrained Models
from keras.applications.xception import Xception
from keras.applications.resnet50 import ResNet50
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_resnet_v2 import InceptionResNetV2
from keras.applications.densenet import DenseNet201
from keras.applications.nasnet import NASNetMobile, NASNetLarge
from keras.applications.nasnet import preprocess_input
# Deep Learning - Keras - Model Parameters and Evaluation Metrics
from keras import optimizers
from keras.optimizers import Adam, SGD, RMSprop
from keras.losses import mae, sparse_categorical_crossentropy, binary_crossentropy
# Deep Learning - Keras - Visualisation
from keras.callbacks import (
ModelCheckpoint,
EarlyStopping,
TensorBoard,
ReduceLROnPlateau,
LearningRateScheduler,
)
# from keras.wrappers.scikit_learn import KerasClassifier
from keras import backend as K
# Deep Learning - TensorFlow
import tensorflow as tf
# Graph/ Visualization
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import matplotlib.image as mpimg
import seaborn as sns
from mlxtend.plotting import plot_confusion_matrix
# Image
import cv2
from PIL import Image
from IPython.display import display
# np.random.seed(42)
# Input data
print(os.listdir("../input/"))
# # 2. Functions
def date_time(x):
if x == 1:
return "Timestamp: {:%Y-%m-%d %H:%M:%S}".format(datetime.datetime.now())
if x == 2:
return "Timestamp: {:%Y-%b-%d %H:%M:%S}".format(datetime.datetime.now())
if x == 3:
return "Date now: %s" % datetime.datetime.now()
if x == 4:
return "Date today: %s" % datetime.date.today()
# # 3. Input Configuration
input_directory = r"../input/Kannada-MNIST/"
output_directory = r"../output/"
training_dir = input_directory + "train_images"
testing_dir = input_directory + r"test_images"
if not os.path.exists(output_directory):
os.mkdir(output_directory)
figure_directory = "../output/figures"
if not os.path.exists(figure_directory):
os.mkdir(figure_directory)
# model_input_directory = "../input/models/"
# if not os.path.exists(model_input_directory):
# os.mkdir(model_input_directory)
model_output_directory = "../output/models/"
if not os.path.exists(model_output_directory):
os.mkdir(model_output_directory)
file_name_pred_batch = figure_directory + r"/result"
file_name_pred_sample = figure_directory + r"/sample"
train_df = pd.read_csv(input_directory + "train.csv")
train_df.rename(index=str, columns={"label": "target"}, inplace=True)
train_df.head()
test_df = pd.read_csv(input_directory + "test.csv")
test_df.rename(index=str, columns={"label": "target"}, inplace=True)
test_df.head()
# # 4. Visualization
ticksize = 18
titlesize = ticksize + 8
labelsize = ticksize + 5
figsize = (18, 5)
params = {
"figure.figsize": figsize,
"axes.labelsize": labelsize,
"axes.titlesize": titlesize,
"xtick.labelsize": ticksize,
"ytick.labelsize": ticksize,
}
plt.rcParams.update(params)
col = "target"
xlabel = "Label"
ylabel = "Count"
sns.countplot(x=train_df[col])
plt.title("Label Count")
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.show()
# # 5. Preprocess
def get_data(train_X=None, train_Y=None, test_X=None, batch_size=32):
print("Preprocessing and Generating Data Batches.......\n")
rescale = 1.0 / 255
train_batch_size = batch_size
validation_batch_size = batch_size * 5
test_batch_size = batch_size * 5
train_shuffle = True
val_shuffle = True
test_shuffle = False
train_datagen = ImageDataGenerator(
horizontal_flip=False,
vertical_flip=False,
rotation_range=10,
# shear_range=15,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
rescale=rescale,
validation_split=0.25,
)
train_generator = train_datagen.flow(
x=train_X,
y=train_Y,
batch_size=batch_size,
shuffle=True,
sample_weight=None,
seed=42,
save_to_dir=None,
save_prefix="",
save_format="png",
subset="training",
)
validation_generator = train_datagen.flow(
x=train_X,
y=train_Y,
batch_size=validation_batch_size,
shuffle=True,
sample_weight=None,
seed=42,
save_to_dir=None,
save_prefix="",
save_format="png",
subset="validation",
)
test_datagen = ImageDataGenerator(rescale=rescale)
test_generator = test_datagen.flow(
x=test_X,
y=None,
batch_size=test_batch_size,
shuffle=False,
sample_weight=None,
seed=42,
save_to_dir=None,
save_prefix="",
save_format="png",
)
class_weights = get_weight(np.argmax(train_Y, axis=1))
steps_per_epoch = len(train_generator)
validation_steps = len(validation_generator)
print("\nPreprocessing and Data Batch Generation Completed.\n")
return (
train_generator,
validation_generator,
test_generator,
class_weights,
steps_per_epoch,
validation_steps,
)
# Calculate Class Weights
def get_weight(y):
class_weight_current = cw.compute_class_weight("balanced", np.unique(y), y)
return class_weight_current
# # 5. Model Function
def get_model(
model_name,
input_shape=(96, 96, 3),
num_class=2,
weights="imagenet",
dense_units=1024,
internet=False,
):
inputs = Input(input_shape)
if model_name == "Xception":
base_model = Xception(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNet50":
base_model = ResNet50(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNet101":
base_model = keras.applications.resnet.ResNet101(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNet152":
base_model = keras.applications.resnet.ResNet152(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNet50V2":
base_model = resnet_v2.ResNet50V2(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNet101V2":
base_model = resnet_v2.ResNet101V2(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNet152V2":
base_model = resnet_v2.ResNet152V2(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNeXt50":
base_model = resnext.ResNeXt50(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "ResNeXt101":
base_model = resnext.ResNeXt101(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "InceptionV3":
base_model = InceptionV3(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "InceptionResNetV2":
base_model = InceptionResNetV2(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "DenseNet201":
base_model = DenseNet201(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "NASNetMobile":
base_model = NASNetMobile(
include_top=False, weights=weights, input_shape=input_shape
)
elif model_name == "NASNetLarge":
base_model = NASNetLarge(
include_top=False, weights=weights, input_shape=input_shape
)
# x = base_model(inputs)
# x = Dropout(0.5)(x)
# out1 = GlobalMaxPooling2D()(x)
# out2 = GlobalAveragePooling2D()(x)
# out3 = Flatten()(x)
# out = Concatenate(axis=-1)([out1, out2, out3])
# out = Dropout(0.6)(out)
# out = BatchNormalization()(out)
# out = Dropout(0.5)(out)
# if num_class>1:
# out = Dense(num_class, activation="softmax", name="3_")(out)
# else:
# out = Dense(1, activation="sigmoid", name="3_")(out)
# model = Model(inputs, out)
# model = Model(inputs=base_model.input, outputs=outputs)
x = base_model.output
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
x = GlobalAveragePooling2D()(x)
x = BatchNormalization()(x)
x = Dropout(0.5)(x)
x = Dense(dense_units)(x)
x = BatchNormalization()(x)
x = Activation(activation="relu")(x)
x = Dropout(0.5)(x)
if num_class > 1:
outputs = Dense(num_class, activation="softmax")(x)
else:
outputs = Dense(1, activation="sigmoid")(x)
model = Model(inputs=base_model.input, outputs=outputs)
model.summary()
return model
def get_conv_model(num_class=2, input_shape=None, dense_units=dense_units):
model = Sequential()
model.add(
Conv2D(
filters=32,
kernel_size=(5, 5),
padding="Same",
activation="relu",
input_shape=input_shape,
)
)
model.add(BatchNormalization())
model.add(
Conv2D(
filters=32,
kernel_size=(5, 5),
padding="Same",
activation="relu",
kernel_regularizer=l2(1e-4),
)
)
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(
Conv2D(
filters=64,
kernel_size=(3, 3),
padding="Same",
activation="relu",
kernel_regularizer=l2(1e-4),
)
)
model.add(BatchNormalization())
model.add(
Conv2D(
filters=64,
kernel_size=(3, 3),
padding="Same",
activation="relu",
kernel_regularizer=l2(1e-4),
)
)
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(dense_units, activation="relu"))
model.add(Dropout(0.5))
# model.add(Conv2D(32, (3, 3), padding='same', use_bias=False, kernel_regularizer=l2(1e-4), input_shape = input_shape))
# model.add(BatchNormalization())
# model.add(Activation('relu'))
# model.add(Conv2D(32, (3, 3), padding='same', use_bias=False, kernel_regularizer=l2(1e-4)))
# model.add(BatchNormalization())
# model.add(Activation('relu'))
# model.add(MaxPool2D())
# model.add(Dropout(0.5))
# model.add(Conv2D(64, (3, 3), padding='same', use_bias=False, kernel_regularizer=l2(1e-4)))
# model.add(BatchNormalization())
# model.add(Activation('relu'))
# model.add(Conv2D(64, (3, 3), padding='same', use_bias=False, kernel_regularizer=l2(1e-4)))
# model.add(BatchNormalization())
# model.add(Activation('relu'))
# model.add(MaxPool2D())
# model.add(Dropout(0.5))
# model.add(GlobalAveragePooling2D())
if num_class > 1:
model.add(Dense(num_class, activation="softmax"))
else:
model.add(Dense(num_class, activation="sigmoid"))
print(model.summary())
return model
# ## Visualization
def plot_performance(history=None, figure_directory=None):
xlabel = "Epoch"
legends = ["Training", "Validation"]
ylim_pad = [0.005, 0.005]
ylim_pad = [0, 0]
plt.figure(figsize=(20, 5))
# Plot training & validation Accuracy values
y1 = history.history["accuracy"]
y2 = history.history["val_accuracy"]
min_y = min(min(y1), min(y2)) - ylim_pad[0]
max_y = max(max(y1), max(y2)) + ylim_pad[0]
# min_y = .96
# max_y = 1
plt.subplot(121)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Accuracy\n" + date_time(1), fontsize=17)
plt.xlabel(xlabel, fontsize=15)
plt.ylabel("Accuracy", fontsize=15)
plt.ylim(min_y, max_y)
plt.legend(legends, loc="upper left")
plt.grid()
# Plot training & validation loss values
y1 = history.history["loss"]
y2 = history.history["val_loss"]
min_y = min(min(y1), min(y2)) - ylim_pad[1]
max_y = max(max(y1), max(y2)) + ylim_pad[1]
# min_y = .1
# max_y = 0
plt.subplot(122)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Loss\n" + date_time(1), fontsize=17)
plt.xlabel(xlabel, fontsize=15)
plt.ylabel("Loss", fontsize=15)
plt.ylim(min_y, max_y)
plt.legend(legends, loc="upper left")
plt.grid()
if figure_directory:
plt.savefig(figure_directory + "/history")
plt.show()
# # 6. Output Configuration
main_model_dir = output_directory + r"models_output/"
main_log_dir = output_directory + r"logs/"
try:
os.mkdir(main_model_dir)
except:
print("Could not create main model directory")
try:
os.mkdir(main_log_dir)
except:
print("Could not create main log directory")
model_dir = main_model_dir + time.strftime("%Y-%m-%d %H-%M-%S") + "/"
log_dir = main_log_dir + time.strftime("%Y-%m-%d %H-%M-%S")
try:
os.mkdir(model_dir)
except:
print("Could not create model directory")
try:
os.mkdir(log_dir)
except:
print("Could not create log directory")
model_file = (
model_dir + "{epoch:02d}-val_acc-{val_acc:.2f}-val_loss-{val_loss:.2f}.hdf5"
)
# ## 6.2 Call Back Configuration
print("Settting Callbacks")
def step_decay(epoch, lr):
# initial_lrate = 1.0 # no longer needed
lrate = lr
if epoch == 2:
lrate = 0.0001
# lrate = lr * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
checkpoint = ModelCheckpoint(model_file, monitor="val_acc", save_best_only=True)
early_stopping = EarlyStopping(
monitor="val_loss", patience=10, verbose=1, restore_best_weights=True
)
reduce_lr = ReduceLROnPlateau(
monitor="val_loss", factor=0.6, patience=2, min_lr=0.0000001, verbose=1
)
learning_rate_scheduler = LearningRateScheduler(step_decay, verbose=1)
# f1_metrics = Metrics()
callbacks = [reduce_lr, early_stopping]
# callbacks = [checkpoint, reduce_lr, early_stopping]
# callbacks = [reduce_lr, early_stopping, f1_metrics]
print("Set Callbacks at ", date_time(1))
# # 7. Model
print("Getting Base Model", date_time(1))
# model_name="InceptionV3"
# model_name="NASNetMobile"
dim = 28
input_shape = (dim, dim, 1)
num_class = len(set(train_df["target"].values))
weights = "imagenet"
dense_units = 256
internet = True
# model = get_model(model_name=model_name,
# input_shape=input_shape,
# num_class=num_class,
# weights=weights,
# dense_units=dense_units,
# internet=internet)
model = get_conv_model(
num_class=num_class, input_shape=input_shape, dense_units=dense_units
)
print("Loaded Base Model", date_time(1))
loss = "categorical_crossentropy"
# loss = 'binary_crossentropy'
metrics = ["accuracy"]
# metrics = [auroc]
# # 8. Data
# train_X = train_df.drop(columns=["target"]).values
# train_Y = train_df["target"].values
# clf = svm.SVC()
# cross_val_score(clf, train_X, train_Y, cv=10, n_jobs=-1, verbose=2)
train_X = train_df.drop(columns=["target"]).values
train_X = train_X.reshape(train_X.shape[0], dim, dim, 1)
train_Y = train_df["target"].values
train_Y = keras.utils.to_categorical(train_Y, 10)
test_X = test_df.drop(columns=["id"]).values
test_X = test_X.reshape(test_X.shape[0], dim, dim, 1)
batch_size = 128
# class_mode = "categorical"
# class_mode = "binary"
# target_size = (dim, dim)
(
train_generator,
validation_generator,
test_generator,
class_weights,
steps_per_epoch,
validation_steps,
) = get_data(train_X=train_X, train_Y=train_Y, test_X=test_X, batch_size=batch_size)
# # 9. Training
print("Starting Trainning ...\n")
start_time = time.time()
print(date_time(1))
# batch_size = 32
# train_generator, validation_generator, test_generator, class_weights, steps_per_epoch, validation_steps = get_data(batch_size=batch_size)
print("\n\nCompliling Model ...\n")
learning_rate = 0.001
optimizer = Adam(learning_rate)
# optimizer = Adam()
model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
steps_per_epoch = len(train_generator)
validation_steps = len(validation_generator)
verbose = 1
epochs = 100
print("Trainning Model ...\n")
history = model.fit_generator(
train_generator,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
verbose=verbose,
callbacks=callbacks,
validation_data=validation_generator,
validation_steps=validation_steps,
class_weight=class_weights,
)
elapsed_time = time.time() - start_time
elapsed_time = time.strftime("%H:%M:%S", time.gmtime(elapsed_time))
print("\nElapsed Time: " + elapsed_time)
print("Completed Model Trainning", date_time(1))
# # 10. Model Performance
# Model Performance Visualization over the Epochs
plot_performance(history=history)
ypreds = model.predict_generator(
generator=test_generator, steps=len(test_generator), verbose=1
)
# ypreds
# ypred = ypreds[:,1]#
ypred = np.argmax(ypreds, axis=1)
sample_df = pd.read_csv(input_directory + "sample_submission.csv")
sample_df.head()
test_gen_id = test_generator.index_array
sample_submission_id = sample_df["id"]
len(test_gen_id), len(sample_submission_id)
sample_list = list(sample_df.id)
pred_dict = dict(
(key, value) for (key, value) in zip(test_generator.index_array, ypred)
)
pred_list_new = [pred_dict[f] for f in sample_list]
test_df = pd.DataFrame({"id": sample_list, "label": pred_list_new})
test_df.to_csv("submission.csv", header=True, index=False)
test_df.head()
|
# House Prices Project - Part 1: Feature Engineering and Data Transformation
# In this notebook, I present my data preparation and my analysis of the House Prices Project dataset.
# Here you'll find feature engineering techniques and some visualizations that help us have a good idea of how this dataset is structured.
# I create additional variables keeping in mind that I don't have a pre-selected regression model that I intend to use. So some variables may be more or less useful depending on the regression model adopted in the future. The model and variable selection techniques I'll present in my next notebook on the House Prices Project.
# Loading libraries and datasets
import math
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
from scipy.stats import pearsonr
from scipy.stats import mode
sns.set(style="white", context="notebook", palette="deep")
plt.rcParams["figure.figsize"] = (15, 7) # plot size
train = pd.read_csv("../input/house-prices-advanced-regression-techniques/train.csv")
test = pd.read_csv("../input/house-prices-advanced-regression-techniques/test.csv")
# Checking the datasets
# First things first. Let's see the datasets dimensions.
print("Train shape: " + str(train.shape) + ".")
print("Test shape: " + str(test.shape) + ".")
# Since we already have more than 80 columns in the training set, I'll adjust the display to show up to 100 rows and columns. This can help us better visualize some data that will be generated.
pd.set_option("display.max_rows", 100)
pd.set_option("display.max_columns", 100)
# Let's check for missing values.
print("Missing values in the train set: " + str(train.isnull().sum().sum()) + ".")
print("Missing values in the test set: " + str(test.isnull().sum().sum()) + ".")
# It will be necessary to work on this missing values. Since there are several missing values in the train and test sets, is more efficient to join both datasets and work on the missing values than to do it separately.
train["dataset"] = "train" # identify this as the train dataset
test["dataset"] = "test" # identify this as the train dataset
dataset = train.append(test, sort=False, ignore_index=True) # merge both datasets
del train, test # free some memory.
dataset.shape
dataset.dataset.value_counts()
# Checking all the columns in the dataset and getting some statistics.
dataset.columns
stats = dataset.describe().T
for i in range(len(dataset.columns)):
(
stats.loc[dataset.columns[i], "mode"],
stats.loc[dataset.columns[i], "mode_count"],
) = mode(dataset[dataset.columns[i]])
stats.loc[dataset.columns[i], "unique_values"] = (
dataset[dataset.columns[i]].value_counts().size
)
stats.loc[dataset.columns[i], "NaN"] = dataset[dataset.columns[i]].isnull().sum()
if np.isnan(stats.loc[dataset.columns[i], "count"]):
stats.loc[dataset.columns[i], "count"] = (
dataset.shape[0] - stats.loc[dataset.columns[i], "NaN"]
)
stats = stats[
[
"count",
"NaN",
"unique_values",
"mode",
"mode_count",
"mean",
"std",
"min",
"25%",
"50%",
"75%",
"max",
]
]
stats.index.name = "variable"
stats.reset_index(inplace=True)
stats
# Feature Engineering
# Dealing with NaN Values
# Let's treat all these missing data. First of all, lets check how many observations in each variable are missing values.
variables = list(
stats[stats["NaN"] > 0].sort_values(by=["NaN"], ascending=False).variable
)
sns.barplot(x="variable", y="NaN", data=stats[stats["NaN"] > 0], order=variables)
plt.xticks(rotation=45)
stats[stats["NaN"] > 0].sort_values(by=["NaN"], ascending=False)[["variable", "NaN"]]
# Having detailed information about which variables have missing values and how many they are, we can treat these cases and replace the *NaN* values for other values that may be more adequate. Some things that I would like to highlight:
# - One thing to notice is that the SalePrice variable has 1459 *NaN* values (the same number of rows in the test set). This is so because these are the values that we have to predict in this competition, so we are not dealing with those missing values now, they are our final goal;
# - Checking the data_description.txt file we can see that most of these missing values actually indicates that the house doesn't have that feature. i.e. Missing values in the variable FireplaceQu indicates that the house doesn't have a fireplace. With this in mind I'll replace the missing values with a *NA* when in case of a categorical variable or I'll replace it with a *0* otherwise.
# Direct transformation of NaN values into NA or into 0
# For this reason, the following variables had their *NaN* values transformed:
# - Alley,
# - BsmtCond,
# - BsmtExposure,
# - BsmtFinSF1,
# - BsmtFinSF2,
# - BsmtFinType1,
# - BsmtFinType2,
# - BsmtFullBath,
# - BsmtHalfBath,
# - BsmtQual,
# - BsmtUnfSF
# - Fence,
# - FireplaceQu,
# - GarageCond,
# - GarageFinish,
# - GarageQual,
# - GarageType,
# - MiscFeature,
# - TotalBsmtSF.
dataset["MiscFeature"].fillna("NA", inplace=True)
dataset["Alley"].fillna("NA", inplace=True)
dataset["Fence"].fillna("NA", inplace=True)
dataset["FireplaceQu"].fillna("NA", inplace=True)
dataset["GarageFinish"].fillna("NA", inplace=True)
dataset["GarageQual"].fillna("NA", inplace=True)
dataset["GarageCond"].fillna("NA", inplace=True)
dataset["GarageType"].fillna("NA", inplace=True)
dataset["BsmtExposure"].fillna("NA", inplace=True)
dataset["BsmtCond"].fillna("NA", inplace=True)
dataset["BsmtQual"].fillna("NA", inplace=True)
dataset["BsmtFinType1"].fillna("NA", inplace=True)
dataset["BsmtFinType2"].fillna("NA", inplace=True)
dataset["BsmtFullBath"].fillna(0.0, inplace=True)
dataset["BsmtHalfBath"].fillna(0.0, inplace=True)
dataset["BsmtFinSF1"].fillna(0.0, inplace=True)
dataset["BsmtFinSF2"].fillna(0.0, inplace=True)
dataset["BsmtUnfSF"].fillna(0.0, inplace=True)
dataset["TotalBsmtSF"].fillna(0.0, inplace=True)
# The following variables required some kind of additional evaluation before I could transform the missing values.
# PoolQC
# We can see in the stats dataset that PoolQC has 2909 missing values, but PoolArea has only 2906 zero values. So the 3 observations mismatched are real missing values. I'll check how is the crosstabulation between these two variables before decide what to do.
dataset.PoolQC.value_counts()
pd.crosstab(dataset.PoolArea, dataset.PoolQC)
dataset[
(pd.isna(dataset["PoolQC"])) & (dataset["PoolArea"] > 0)
].PoolArea.value_counts()
# Checking the variables we can see that the range between each classification in PoolQC doesn't quite match the range of these missing values. Checking the description file we see that there is another category that is not present in this classification: 'TA' meaning 'Average/Typical'. We have no rule of thumb here. It seems reasonable to me to assume that the missing labes are 'TA' and for this reason I'm coding these three values as 'TA', but another acceptable approach would be to take the median of the PoolArea variable of each category in PoolQC and assign the missing observations to the category in PoolQC that is closer to its median value in PoolArea. In the end, the most important thing here is to don't mislabel these three cases as *NA*.
indexes = dataset[(pd.isna(dataset["PoolQC"])) & (dataset["PoolArea"] > 0)].index
dataset.loc[indexes, "PoolQC"] = "TA"
dataset["PoolQC"].fillna("NA", inplace=True)
# LotFrontage
# LotFrontage is going to need some manipulation since it is a numerical variable with several *NaN* values. Luckily it is related to other variables with characteristics of the lot. Let's check:
# - LotArea;
# - LotShape;
# - LotConfig.
# fig, (ax1, ax2, ax3) = plt.subplots(1, 3)
ax1 = plt.subplot(212)
ax2 = plt.subplot(221)
ax3 = plt.subplot(222)
# plt.subplots_adjust(hspace = 0.5)
sns.scatterplot(y="LotFrontage", x="LotArea", data=dataset, ax=ax1, palette="rainbow")
sns.boxplot(y="LotFrontage", x="LotShape", data=dataset, ax=ax2, palette="rainbow")
sns.boxplot(y="LotFrontage", x="LotConfig", data=dataset, ax=ax3, palette="rainbow")
# Looking at the variables we see that LotArea seems to be closer related to LotFrontage than the other variables. Yet, this relation doens't seem to be linear. I'll check it's correlation with this variable as it is, with its square root and with its fourth roth to see which of these transformations are more related to LotFrontage.
pearsonr(
dataset.LotFrontage.dropna(), dataset[pd.notna(dataset["LotFrontage"])].LotArea
)
pearsonr(
dataset.LotFrontage.dropna(),
np.power(dataset[pd.notna(dataset["LotFrontage"])].LotArea, 1 / 2),
)
pearsonr(
dataset.LotFrontage.dropna(),
np.power(dataset[pd.notna(dataset["LotFrontage"])].LotArea, 1 / 4),
)
# The fourth root of Lot Area is closer related to LotFrontage and for this reason I'll use it to fill in the missing values in LotFrontage.
# Below I present the distribution of the fourth root of LotArea:
ax = sns.distplot(np.power(dataset[pd.notna(dataset["LotFrontage"])].LotArea, 1 / 4))
ax.set(xlabel="Fourth root of LotArea")
# The missing values will be fit on the regression line presented next in the scatterplot:
ax = sns.regplot(
y=dataset.LotFrontage.dropna(),
x=np.power(dataset[pd.notna(dataset["LotFrontage"])].LotArea, 1 / 4),
)
ax.set(xlabel="Fourth root of LotArea")
# Ok. So I'll use a robust regression model to predict the values in the missing observations.
X = np.power(dataset[pd.notna(dataset["LotFrontage"])].LotArea, 1 / 4)
X = sm.add_constant(X)
model = sm.RLM(dataset.LotFrontage.dropna(), X)
results = model.fit()
index = dataset[pd.isna(dataset["LotFrontage"])].index
X_test = np.power(dataset.loc[index, "LotArea"], 1 / 4)
X_test = sm.add_constant(X_test)
dataset.loc[index, "LotFrontage"] = results.predict(X_test)
ax = sns.scatterplot(y=dataset.LotFrontage, x=np.power(dataset.LotArea, 1 / 4))
ax.set(xlabel="Fourth root of LotArea")
# That's it.
# GarageYrBlt
# Since this is a numeric variable, if I just fill in its *NaN* values with a *zero* I can end up inserting a serious bias in the variable. It seems more reasonable to find another variable that is correlated with GarageYrBlt and see how I can manipulate both so I can fill in these gaps without harming my future models. For this reason, I'm checking its correlation with the YearBuilt variable.
pearsonr(
dataset.GarageYrBlt.dropna(), dataset[pd.notna(dataset["GarageYrBlt"])].YearBuilt
)
# Since these variables have a strong correlation, lets plot them together:
sns.regplot(
y=dataset.GarageYrBlt.dropna(),
x=dataset[pd.notna(dataset["GarageYrBlt"])].YearBuilt,
)
# Great! We can visualize the strong relation in the data and yet we see that there is a mislabelled observation in GarageYrBlt (the one with GarageYrBlt > 2200). To avoid that the mislabelled observation in GarageYrBlt insert a bias in the model, I'm going to replace it with a *NaN* value and then I'm going to create a linear model to predict the values in all the *NaN* observations in the GarageYrBlt variable.
index = dataset[dataset["GarageYrBlt"] > 2200].index
dataset.loc[index, "GarageYrBlt"] = np.nan
# Fits the Regression Model.
X = dataset[pd.notna(dataset["GarageYrBlt"])]["YearBuilt"]
X = sm.add_constant(X)
model = sm.OLS(dataset.GarageYrBlt.dropna(), X)
results = model.fit()
# Fill in the NaN values.
index = dataset[pd.isna(dataset["GarageYrBlt"])].index
X_test = dataset.loc[index, "YearBuilt"]
X_test = sm.add_constant(X_test)
X_test
dataset.loc[index, "GarageYrBlt"] = round(results.predict(X_test), 0).astype(int)
# The regression line in the previous plot suggests that in the more recent years GarageYrBlt might have a smaller value than YearBuilt. I'll check it:
dataset[(dataset["GarageYrBlt"] < dataset["YearBuilt"])][["GarageYrBlt", "YearBuilt"]]
# Ok. Is easy to see when the model filled the missing values. These observations, in recent years, are the ones where GarageYrBlt is equal to YearBuilt minus 4. In these cases, I'll make GarageYrBlt equal to YearBuilt. I'm calling 'recent years' anything that came after 2000 (counting the year 2000).
dataset["GarageYrBlt"] = np.where(
(dataset["GarageYrBlt"] >= 2000)
& (dataset["GarageYrBlt"] == dataset["YearBuilt"] - 4),
dataset["YearBuilt"],
dataset["GarageYrBlt"],
)
# MasVnrType and MasVnrArea
# There is one more observation in the MasVnrType variable counting as *NaN* then there is in the MasVnrArea variable. So that observation is very likely to be mislabelled. To fix it, I'll check what are the means of the MasVnrArea variable when grouped by the categories in MasVnrType and I'll choose the category with the median in MasVnrArea closest to the value in the observation with mislabelled data.
dataset[(pd.notna(dataset["MasVnrArea"])) & (pd.isna(dataset["MasVnrType"]))][
["MasVnrArea", "MasVnrType"]
]
dataset.groupby("MasVnrType", as_index=False)["MasVnrArea"].median()
index = dataset[
(pd.notna(dataset["MasVnrArea"])) & (pd.isna(dataset["MasVnrType"]))
].index
dataset.loc[index, "MasVnrType"] = "Stone"
# Now that we have the same number of *NaN* in both variables, we can set them equal to *NA* and zero.
dataset["MasVnrType"].fillna("NA", inplace=True)
dataset["MasVnrArea"].fillna(0, inplace=True)
# MSZoning
# According to the description file, there should be no *NaN* in this variable. To fix this, I'll compare the values in this variable with the values in MSSubClass and in LotArea (since the lot area may be influenced by the zoning classification of the sale). I'll choose the MSZoning value according to the category in MSSubClass of the observations with *NaN* values in the variable MSZoning and according to the LotArea closer to the median of LotArea of the observations grouped by MSSubClass.
# LotArea and MSSubClass of the observations with NaN in the MSZoning variable.
dataset[pd.isna(dataset["MSZoning"])][["MSSubClass", "LotArea"]]
# median LotArea grouped by MSZoning and MSSubClass.
temp = dataset.groupby(["MSSubClass", "MSZoning"], as_index=False)["LotArea"].median()
temp[temp["MSSubClass"].isin([20, 30, 70])]
# Makes the substitutions.
indexes = dataset[(pd.isna(dataset["MSZoning"])) & (dataset["MSSubClass"] == 30)].index
dataset.loc[indexes, "MSZoning"] = "C (all)"
indexes = dataset[pd.isna(dataset["MSZoning"])].index
dataset.loc[indexes, "MSZoning"] = "RL"
dataset["MSZoning"].value_counts()
# Utilities
# Let's check the distribution of this variable.
dataset["Utilities"].value_counts()
# Ok. So it's no brainer in which category the missing values should be classified in.
dataset["Utilities"].fillna("AllPub", inplace=True)
# Functional
# Let's check the distribution of this variable.
dataset["Functional"].value_counts()
# Ok. I guess it's reasonable to classify the missing values as 'Typ'.
dataset["Functional"].fillna("Typ", inplace=True)
# GarageArea
# Let's check this variable.
dataset["GarageArea"].value_counts()
dataset[pd.isna(dataset["GarageArea"])]
dataset[dataset["GarageType"] == "Detchd"].GarageArea.describe()
# I'll set this *NaN* observation equal to the median value of the variable GarageArea when the GarageType is equal to 'Detchd'.
dataset["GarageArea"].fillna(399, inplace=True)
# GarageCars
dataset["GarageCars"].value_counts()
dataset[pd.isna(dataset["GarageCars"])]
temp = dataset.groupby(["GarageType", "GarageCars"], as_index=False)[
"GarageArea"
].median()
temp[temp["GarageType"] == "Detchd"]
# It seems reasonable to assume that the GarageArea is equal to 1 or 2. I'll be pragmatic here and choose the one with the median Area closer to 399.
dataset["GarageCars"].fillna(1, inplace=True)
# Exterior1st and Exterior2nd
dataset[pd.isna(dataset["Exterior2nd"])]
# Both missing values of both variables are in the same line. I'll check some crosstabulations:
pd.crosstab(dataset["Exterior1st"], dataset["ExterCond"])
pd.crosstab(dataset["Exterior2nd"], dataset["ExterCond"])
# The numbers don't change very much from one table to the other. This suggests that there must be many cases in which both variables have the same values. Let's see if this is true:
len(dataset[dataset["Exterior1st"] == dataset["Exterior2nd"]])
# Indeed, in most of the cases both variables have the same value. Since 'VinylSd' is the the most common value for both variables, I'm setting the missing value in both variables equal to 'VinylSd'.
dataset["Exterior1st"].fillna("VinylSd", inplace=True)
dataset["Exterior2nd"].fillna("VinylSd", inplace=True)
# KitchenQual
dataset[pd.isna(dataset["KitchenQual"])]
dataset[dataset["KitchenAbvGr"] == 1].KitchenQual.value_counts()
dataset["KitchenQual"].fillna("TA", inplace=True)
# Electrical
dataset["Electrical"].value_counts()
dataset["Electrical"].fillna("SBrkr", inplace=True)
# SaleType
dataset[pd.isna(dataset["SaleType"])]
dataset[dataset["SaleCondition"] == "Normal"].SaleType.value_counts()
dataset["SaleType"].fillna("WD", inplace=True)
# SalePrice - Variable Transformation
# This variable statistics in the stats table strongly suggest that this variable is skewed to the left. Being this the case, it is recommended to log-transform SalePrice so that its distribution become more like a normal distribution, helping our dependent variable meet some assumptions made in inferential statistics.
# Let's check SalePrice distribution as it is:
sns.distplot(dataset.SalePrice.dropna())
# Lets check its distribution after log transformation:
sns.distplot(np.log(dataset.SalePrice.dropna()), hist=True)
# Comparing both distributions we can see that the log transformed variable seems closer to a normal distribution than the original data and for this reason I'm going to work with the log transformed variable in my regression models.
index = dataset[pd.notna(dataset["SalePrice"])].index
dataset.loc[index, "SalePriceLog"] = np.log(dataset.loc[index, "SalePrice"])
# Data Transformations
# The distribution of some variables suggest us that some transformations may be adequate to the regression models, depending on the model we choose to work with. Whith this in mind I'll update the stats dataset and I'll use it to help me decide which variables should be transformed, or created.
stats = dataset.describe().T
for i in range(len(dataset.columns)):
(
stats.loc[dataset.columns[i], "mode"],
stats.loc[dataset.columns[i], "mode_count"],
) = mode(dataset[dataset.columns[i]])
stats.loc[dataset.columns[i], "unique_values"] = (
dataset[dataset.columns[i]].value_counts().size
)
stats.loc[dataset.columns[i], "NaN"] = dataset[dataset.columns[i]].isnull().sum()
if np.isnan(stats.loc[dataset.columns[i], "count"]):
stats.loc[dataset.columns[i], "count"] = (
dataset.shape[0] - stats.loc[dataset.columns[i], "NaN"]
)
stats = stats[
[
"count",
"NaN",
"unique_values",
"mode",
"mode_count",
"mean",
"std",
"min",
"25%",
"50%",
"75%",
"max",
]
]
stats.index.name = "variable"
stats.reset_index(inplace=True)
stats
# Some observations based on the table presented previously:
# - The variables *MoSold, MSSubClass, OverallCond* and *OverallQual* may work better in a regression model if coded as **categorical variables**. For this reason I'll change them to be treated as categorical;
# - Some variables with no values equal to zero could perform better in a regression model if **log transformed** since they are skewed and a transformation could help prevent problems of multicolinearity:
# - MSSubClass;
# - LotFrontage;
# - LotArea;
# - 1stFlrSF;
# - GrLivArea.
# - Some other variables can be used to generate new **dummy variables** indicating the presence/absence of certain features:
# - 2ndFlrSF;
# - 3SsnPorch;
# - Alley;
# - EnclosedPorch;
# - Fence;
# - FireplaceQu;
# - GarageQual;
# - LowQualFinSF;
# - MasVnrType;
# - MiscFeature;
# - MiscVal;
# - PoolQC;
# - OpenPorchSF;
# - ScreenPorch
# - TotalBsmtSF;
# - WoodDeckSF.
# First I'll convert the above mentioned variables into string types.
dataset["MoSold"] = dataset["MoSold"].astype(str)
dataset["MSSubClass"] = dataset["MSSubClass"].astype(str)
dataset["OverallCond"] = dataset["OverallCond"].astype(str)
dataset["OverallQual"] = dataset["OverallQual"].astype(str)
# Now I make the log transformation of the following variables: *LotFrontage, LotArea, 1stFlrSF* and *GrLivArea*.
dataset["LotFrontageLog"] = np.log(dataset["LotFrontage"])
dataset["LotAreaLog"] = np.log(dataset["LotArea"])
dataset["1stFlrSFLog"] = np.log(dataset["1stFlrSF"])
dataset["GrLivAreaLog"] = np.log(dataset["GrLivArea"])
ax1 = plt.subplot(221)
ax2 = plt.subplot(222)
ax3 = plt.subplot(223)
ax4 = plt.subplot(224)
sns.distplot(dataset["LotFrontageLog"], ax=ax1)
sns.distplot(dataset["LotAreaLog"], ax=ax2)
sns.distplot(dataset["1stFlrSFLog"], ax=ax3)
sns.distplot(dataset["GrLivAreaLog"], ax=ax4)
# Finally, I create dummy variables to indicate the presence/absence of some features in the houses.
dataset["2ndFlrDummy"] = np.where(dataset["2ndFlrSF"] > 0, 1, 0)
dataset["3SsnPorchDummy"] = np.where(dataset["3SsnPorch"] > 0, 1, 0)
dataset["AlleyDummy"] = np.where(dataset["Alley"] != "NA", 1, 0)
dataset["EnclosedPorchDummy"] = np.where(dataset["EnclosedPorch"] > 0, 1, 0)
dataset["FireplaceDummy"] = np.where(dataset["FireplaceQu"] != "NA", 1, 0)
dataset["LowQualFinDummy"] = np.where(dataset["LowQualFinSF"] > 0, 1, 0)
dataset["OpenPorchDummy"] = np.where(dataset["OpenPorchSF"] > 0, 1, 0)
dataset["PoolDummy"] = np.where(dataset["PoolQC"] != "NA", 1, 0)
dataset["ScreenPorchDummy"] = np.where(dataset["ScreenPorch"] > 0, 1, 0)
dataset["PorchDummy"] = np.where(
dataset["3SsnPorchDummy"]
+ dataset["EnclosedPorchDummy"]
+ dataset["OpenPorchDummy"]
+ dataset["ScreenPorchDummy"]
> 0,
1,
0,
)
dataset["BsmtDummy"] = np.where(dataset["TotalBsmtSF"] > 0, 1, 0)
dataset["DeckDummy"] = np.where(dataset["WoodDeckSF"] > 0, 1, 0)
# Final look at the data
# This is a final look at the dataset before implementing the regression models.
# Here I try to have an idea of how each variable interact with the dependent variable of my future models: SalePriceLog.
# Correlation Matrix
# I'll start by checking for some correlations to have an idea of which variables are more likely to contribute to a regression model and which aren't.
sns.heatmap(dataset.corr(), cmap="Blues", linewidths=0.2)
# Since there are many variables in the dataset, I think an easier way of checking for correlations with the dependent variable its to just check the column SalePriceLog in the correlation matrix.
dataset.corr()["SalePrice"].sort_values(ascending=False)
# Visualizations
# Some variables didn't appear in the previous correlation analysis because they are categorical.
# To have an ideia of how they interact with the dependent variable I'll plot scatterplots of the numerical variables and scatterplots of the categorical variables. The Y axis is always SalePriceLog (the same visualizations can be generated to SalePrice by only replacing SalePriceLog by it in the code below).
variables = list(dataset.columns)[1:80] + list(dataset.columns)[83:]
while len(variables) >= 8:
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6), (ax7, ax8, ax9)) = plt.subplots(3, 3)
plt.subplots_adjust(hspace=0.5)
ax = [ax1, ax2, ax3, ax4, ax5, ax6, ax7, ax8, ax9]
for i in range(9):
if type(dataset[variables[i]][0]) in [np.int64, np.float64]:
sns.scatterplot(y="SalePriceLog", x=variables[i], data=dataset, ax=ax[i])
else:
sns.boxplot(
y="SalePriceLog",
x=variables[i],
data=dataset,
palette="rainbow",
ax=ax[i],
)
variables = variables[9:]
fig, ((ax1, ax2, ax3), (ax4, ax5, _)) = plt.subplots(2, 3, figsize=(15, 4.5))
plt.subplots_adjust(hspace=0.5)
sns.boxplot(y="SalePriceLog", x=variables[0], data=dataset, ax=ax1, palette="rainbow")
sns.boxplot(y="SalePriceLog", x=variables[1], data=dataset, ax=ax2, palette="rainbow")
sns.boxplot(y="SalePriceLog", x=variables[2], data=dataset, ax=ax3, palette="rainbow")
sns.boxplot(y="SalePriceLog", x=variables[3], data=dataset, ax=ax4, palette="rainbow")
sns.boxplot(y="SalePriceLog", x=variables[4], data=dataset, ax=ax5, palette="rainbow")
# The previous correlations and visualizations suggests that some variables that would be interresting to have in a regression model are:
# - 1stFlrSFLog;
# - BsmtCond;
# - BsmtDummy;
# - BsmtExposure;
# - BsmtFinSF1;
# - BsmtQual;
# - CentralAir;
# - ExterQual;
# - Fireplaces;
# - FireplaceQu;
# - FullBath;
# - GarageArea;
# - GarageCars;
# - GarageFinish;
# - GarageQual;
# - GarageYrBlt;
# - GrLivAreaLog;
# - HeatingQC;
# - KitchenQual;
# - LotAreaLog;
# - LotFrontage;
# - MasVnrArea;
# - OpenPorchDummy;
# - OverallQual;
# - TotalBsmtSF;
# - TotRmsAbvGrd;
# - YearBuilt;
# - YearRemodAdd.
# Train and Test Set
# Since there is no more modifications that I would like to make to the dataset, it's time to separate it into train and test set again.
train = dataset[dataset["dataset"] == "train"].copy()
train["dataset"] = None
test = dataset[dataset["dataset"] == "test"].copy()
test["dataset"] = None
print("training set shape: " + str(train.shape))
print("test set shape: " + str(test.shape))
train.to_csv("train_mod.csv", index=False)
test.to_csv("test_mod.csv", index=False)
|
class myfistclass:
x = 5
y = 10
pl = myfistclass() # object
print(pl.x)
print(pl.y)
class person:
def __init__(self, name, age):
self.name = name
self.age = age
def my_fun(abc):
print("hello my name is", abc.name)
print("my age is", abc.age)
pl = person("Garima", 20)
# print(pl.name)
# print(pl.age)
pl.my_fun()
# Inheritance
class person:
def __init__(self, fname, Lname):
self.fname = fname
self.Lname = Lname
def printname(self):
print(self.fname, self.Lname)
x = person("Garima", "Sharma")
x.printname()
# child class
class children:
pass
x = children("john", "joey")
x.printname()
|
# # Kensho Derived Wikimedia Dataset - Wikipedia Introduction
# This notebook will introduce you to the Wikipedia Sample of the Kensho Derived Wikimedia Dataset (KDWD). We'll explore the files and make some basic "getting to know you" plots. Lets start off by importing some packages.
from collections import Counter
import csv
import gc
import json
import os
import string
import subprocess
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from tqdm import tqdm
sns.set()
sns.set_context("talk")
# Lets check the input directory to see what files we have access to.
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# All of the KDWD files have one "thing" per line. We'll hard code the number of lines in the files we're going to use so we can have nice progress bars when streaming through them.
NUM_KLAT_LINES = 5_343_564
NUM_PAGE_LINES = 5_362_174
kdwd_path = os.path.join("/kaggle/input", "kensho-derived-wikimedia-data")
# # Page Metadata
# Lets examine the Wikipedia sample starting with page metadata in `page.csv`. After this we'll move on to the `link_annotated_text.jsonl` file.
page_df = pd.read_csv(
os.path.join(kdwd_path, "page.csv"),
keep_default_na=False, # dont read the page title "NaN" as a null
)
page_df
# We store pages in ascending `page_id` order and we have metadata for 5,362,174 of them. The `page_id` is the primary Wikipedia identifier for a page and the `item_id` is the unique identifier for the associated Wikidata page. We can construct Wikipedia and Wikidata urls from the metadata if we like.
def wikipedia_url_from_title(title):
return "https://en.wikipedia.org/wiki/{}".format(title.replace(" ", "_"))
def wikipedia_url_from_page_id(page_id):
return "https://en.wikipedia.org/?curid={}".format(page_id)
def wikidata_url_from_item_id(item_id):
return "https://www.wikidata.org/entity/Q{}".format(item_id)
title = "Kurt Vonnegut"
page_row_df = page_df[page_df["title"] == title]
print(page_row_df)
page_id = page_row_df.iloc[0]["page_id"]
item_id = page_row_df.iloc[0]["item_id"]
print(wikipedia_url_from_title(title))
print(wikipedia_url_from_page_id(page_id))
print(wikidata_url_from_item_id(item_id))
# The `views` column represents page views for the month of December 2019. Lets see what the most viewed pages were.
page_df.sort_values("views", ascending=False).head(25)
# The main Wikipedia page (title=`Wikipedia`) is always near the top of the list, but `Simple Mail Transfer Protocol` being in the number one spot appears to be an anomaly for this particular month. Wikimedia provides a pageviews analysis tool that is very useful for these sorts of investigations ([Simple Mail Transfer Protocol - pageview analysis](https://tools.wmflabs.org/pageviews/?project=en.wikipedia.org&platform=all-access&agent=user&start=2018-01&end=2020-01&pages=Simple_Mail_Transfer_Protocol)). Lets see what the full distribution looks like.
page_df["log_views"] = np.log10(page_df["views"] + 1)
fig, axes = plt.subplots(1, 2, figsize=(18, 8), sharex=True, sharey=True)
ax = axes[0]
counts, bins, patches = ax.hist(page_df["log_views"], bins=40, density=True)
ii = np.argmax(counts)
xx = (bins[ii] + bins[ii + 1]) / 2
ax.axvline(xx, color="red", ls="--", alpha=0.7)
ax.axhline(0.5, color="red", ls="--", alpha=0.7)
ax.set_xlim(-0.3, 5)
ax.set_xlabel("log10 views")
ax.set_ylabel("fraction")
ax.set_title("probability distribution")
ax = axes[1]
counts, bins, patches = ax.hist(
page_df["log_views"], bins=40, density=True, cumulative=True
)
ax.axvline(xx, color="red", ls="--", alpha=0.7)
ax.axhline(0.5, color="red", ls="--", alpha=0.7)
ax.set_xlabel("log10 views")
ax.set_title("cumulative distribution")
fig.suptitle("Distribution of page views for {} pages".format(page_df.shape[0]))
# Above we show probability and cumulative distributions for page views. The probability distribution is peaked around $log_{10}(30)=1.5$ and that corresponds with roughly half of pages. There is a cutoff at $log_{10}(5) = 0.70$ due to the [raw source of pageviews](https://dumps.wikimedia.org/other/pagecounts-ez/merged/) not including counts below 5.
# # Link Annotated Text
# Lets start exploring the link annotated text. First we'll write a simple class to iterate over page lines and load them into dictionaries.
#
class KdwdLinkAnnotatedText:
def __init__(self, file_path, max_pages=1_000_000):
self.file_path = file_path
self.num_lines = NUM_KLAT_LINES
self.max_pages = max_pages
self.pages_to_parse = min(self.num_lines, self.max_pages)
def __iter__(self):
with open(self.file_path) as fp:
for ii_line, line in enumerate(fp):
if ii_line == self.pages_to_parse:
break
yield json.loads(line)
file_path = os.path.join(kdwd_path, "link_annotated_text.jsonl")
klat = KdwdLinkAnnotatedText(file_path)
# Next we will grab a single page from the iterator and examine its structure.
first_page = next(iter(klat))
print("page_id: ", first_page["page_id"])
section = first_page["sections"][0]
print("section name: ", section["name"])
print("section text: ", section["text"])
print("section link_offsets: ", section["link_offsets"])
print("section link_lengths: ", section["link_lengths"])
print("section target_page_ids: ", section["target_page_ids"])
# The link data can be used to examine link anchor texts and their target pages.
for offset, length, target_page_id in zip(
section["link_offsets"], section["link_lengths"], section["target_page_ids"]
):
anchor_text = section["text"][offset : offset + length]
target_title = page_df[page_df["page_id"] == target_page_id].iloc[0]["title"]
print("{} -> {}".format(anchor_text, wikipedia_url_from_title(target_title)))
# Now lets iterate through part of the corpus and examine the vocabulary used in `Introduction` sections of the first 1M pages. We'll create a quick tokenizer function that will split on whitespace, lowercase, and remove punctuation.
table = str.maketrans("", "", string.punctuation)
def tokenize(text):
tokens = [tok.lower().strip() for tok in text.split()]
tokens = [tok.translate(table) for tok in tokens]
return tokens
unigrams = Counter()
words_per_section = []
for page in tqdm(
klat, total=min(klat.num_lines, klat.max_pages), desc="iterating over page text"
):
for section in page["sections"]:
tokens = tokenize(section["text"])
unigrams.update(tokens)
words_per_section.append(len(tokens))
# stop after intro section
break
print("num tokens= {}".format(sum(unigrams.values())))
print("unique tokens= {}".format(len(unigrams)))
def filter_unigrams(unigrams, min_count):
"""remove tokens that dont occur at least `min_count` times"""
tokens_to_filter = [tok for tok, count in unigrams.items() if count < min_count]
for tok in tokens_to_filter:
del unigrams[tok]
return unigrams
min_count = 5
unigrams = filter_unigrams(unigrams, min_count)
print("num tokens= {}".format(sum(unigrams.values())))
print("unique tokens= {}".format(len(unigrams)))
unigrams_df = pd.DataFrame(unigrams.most_common(), columns=["token", "count"])
unigrams_df
# Lets create the classic Zipf style count vs rank plot for our unigrams.
num_rows = unigrams_df.shape[0]
ii_rows_logs = np.linspace(1, np.log10(num_rows - 1), 34)
ii_rows = [0, 1, 3, 7] + [int(el) for el in 10**ii_rows_logs]
rows = unigrams_df.iloc[ii_rows, :]
indexs = np.log10(rows.index.values + 1)
counts = np.log10(rows["count"].values + 1)
tokens = rows["token"]
fig, ax = plt.subplots(figsize=(14, 12))
ax.scatter(indexs, counts)
for token, index, count in zip(tokens, indexs, counts):
ax.text(index + 0.05, count + 0.05, token, fontsize=12)
ax.set_xlim(-0.2, 6.5)
ax.set_xlabel("log10 rank")
ax.set_ylabel("log10 count")
ax.set_title("Zipf style plot for unigrams")
# And finally lets examine the distribution of section lengths measured in words.
xx = np.log10(np.array(words_per_section) + 1)
fig, axes = plt.subplots(1, 2, figsize=(18, 8), sharex=True, sharey=True)
ax = axes[0]
counts, bins, patches = ax.hist(xx, bins=40, density=True)
ii = np.argmax(counts)
xx_max = (bins[ii] + bins[ii + 1]) / 2
ax.axvline(xx_max, color="red", ls="--", alpha=0.7)
ax.axhline(0.5, color="red", ls="--", alpha=0.7)
ax.set_xlabel("log10 tokens/section")
ax.set_ylabel("fraction")
ax.set_title("probability distribution")
ax.set_xlim(0.3, 3.8)
ax = axes[1]
counts, bins, patches = ax.hist(xx, bins=40, density=True, cumulative=True)
ax.axvline(xx_max, color="red", ls="--", alpha=0.7)
ax.axhline(0.5, color="red", ls="--", alpha=0.7)
ax.set_xlabel("log10 tokens/section")
ax.set_title("cumulative distribution")
fig.suptitle(
"Distribution of tokens/section for {} pages".format(len(words_per_section))
)
|
# This notebook estimates the causal effects of markdowns on store sales. The regression of sales on markdowns have omitted variables bias because variables that affect markdown decision might also affect store sales. I use two methods to control these none observable variables. One is to use store fixed effects, and the other is to use lagged store sales.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import datetime
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import StandardScaler
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
from linearmodels import PanelOLS
print(os.listdir("../input"))
data_a = pd.read_csv("../input/retaildataset/Features data set.csv")
data_b = pd.read_csv("../input/retaildataset/sales data-set.csv")
data_a.head()
data_b.head()
data_b.isnull().sum()
# Extract store sales data from data_b
store_sales = pd.DataFrame(data_b.groupby(["Store", "Date"])["Weekly_Sales"].sum())
store_sales.head()
store_sales.reset_index(inplace=True)
store_sales.head()
# store_sales=store_sales.set_index(['Store', 'Date'])
# store_sales.head()
store_sales[store_sales["Store"] == 1].count()
store_sales.shape
# store_sales is balanced!
# Merge the sales data with markdowns data
data = pd.merge(
store_sales,
data_a,
how="left",
left_on=["Store", "Date"],
right_on=["Store", "Date"],
)
data.isnull().sum()
data["Weekly_Sales"] = data["Weekly_Sales"] / data["CPI"]
data["MarkDown1"] = data["MarkDown1"] / data["CPI"]
data["MarkDown2"] = data["MarkDown2"] / data["CPI"]
data["MarkDown3"] = data["MarkDown3"] / data["CPI"]
data["MarkDown4"] = data["MarkDown4"] / data["CPI"]
data["MarkDown5"] = data["MarkDown5"] / data["CPI"]
data[data["Store"] == 1].count()
data.shape
data["Date"] = pd.to_datetime(data["Date"])
data.head()
df = data
df.sort_values(["Store", "Date"], inplace=True)
df.reset_index(inplace=True)
df.drop(["index"], axis=1, inplace=True)
df["month"] = pd.to_datetime(df["Date"]).dt.to_period("M")
df.head()
# df_dummy=pd.get_dummies(df['month'])
# df_dummy=df_dummy.rename(columns=lambda s:'mcode'+s)
# df=df.join(df_dummy)
# df.head()
df["IsHoliday_pre"] = df.groupby("Store")["IsHoliday"].shift(1)
df["IsHoliday_next"] = df.groupby("Store")["IsHoliday"].shift(-1)
df.head()
df["sales_lag"] = df.groupby("Store")["Weekly_Sales"].shift(1)
df.head()
df.isnull().sum()
df = df[df["Date"].isin(pd.date_range(start="20111111", end="20121026"))]
df.isnull().sum()
# correlation matrix
corrmat = df[["MarkDown1", "MarkDown2", "MarkDown3", "MarkDown4", "MarkDown5"]].corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=0.8, square=True)
df["FilledMarkdown1"] = df["MarkDown1"].fillna(method="pad")
df["FilledMarkdown2"] = df["MarkDown2"].fillna(method="pad")
df["FilledMarkdown3"] = df["MarkDown3"].fillna(method="pad")
df["FilledMarkdown4"] = df["MarkDown4"].fillna(method="pad")
df["FilledMarkdown5"] = df["MarkDown5"].fillna(method="pad")
df.isnull().sum()
# df['MarkDown1'].fillna(df.groupby('Store')['MarkDown1'].shift(-1),inplace=True)#fill nan with previous values
# df['MarkDown2'].fillna(df.groupby('Store')['MarkDown2'].shift(-1),inplace=True)
# df['MarkDown3'].fillna(df.groupby('Store')['MarkDown3'].shift(-1),inplace=True)
# df['MarkDown4'].fillna(df.groupby('Store')['MarkDown4'].shift(-1),inplace=True)
# df['MarkDown5'].fillna(df.groupby('Store')['MarkDown5'].shift(-1),inplace=True)
# df.isnull().sum()
df["LogMarkdown1"] = np.log(df["FilledMarkdown1"])
df["LogMarkdown2"] = np.log(df["FilledMarkdown2"])
df["LogMarkdown3"] = np.log(df["FilledMarkdown3"])
df["LogMarkdown4"] = np.log(df["FilledMarkdown4"])
df["LogMarkdown5"] = np.log(df["FilledMarkdown5"])
df["LogSales"] = np.log(df["Weekly_Sales"])
df["LogSales_lag"] = np.log(df["sales_lag"])
df["LogCPI"] = np.log(df["CPI"])
df[df["LogMarkdown2"].isnull()][["MarkDown2", "FilledMarkdown2"]]
df["IsHoliday"] = df["IsHoliday"].apply(lambda x: int(x == True))
df["IsHoliday_pre"] = df["IsHoliday_pre"].apply(lambda x: int(x == True))
df["IsHoliday_next"] = df["IsHoliday_next"].apply(lambda x: int(x == True))
df["IsHoliday"].head()
df_test = df.drop(
["MarkDown1", "MarkDown2", "MarkDown3", "MarkDown4", "MarkDown5"], axis=1
)
df_test.isnull().sum()
df["TMarkdown"] = (
df["FilledMarkdown1"]
+ df["FilledMarkdown2"]
+ df["FilledMarkdown3"]
+ df["FilledMarkdown4"]
+ df["FilledMarkdown5"]
)
df_pn = df.set_index(["Store", "Date"])
df_pn.head()
# X=[df_pn.LogCPI,df_pn.Unemployment,df_pn.IsHoliday,df_pn.IsHoliday_pre,df_pn.IsHoliday_next,df_pn.LogMarkdown1,df_pn.LogMarkdown2,df_pn.LogMarkdown3,df_pn.LogMarkdown4,df_pn.LogMarkdown5]
X = df_pn[
[
"Unemployment",
"FilledMarkdown1",
"FilledMarkdown2",
"FilledMarkdown3",
"FilledMarkdown4",
"FilledMarkdown5",
]
]
y = df_pn["Weekly_Sales"]
y1 = np.log(y)
X.isnull().sum()
y.rank()
mod = PanelOLS(y, X, entity_effects=True, time_effects=True)
res = mod.fit(cov_type="clustered", cluster_entity=True)
res
df_pn["month"] = df_pn["month"].astype("str")
df_pn[
[
"IsHoliday",
"IsHoliday_pre",
"IsHoliday_next",
"FilledMarkdown1",
"FilledMarkdown2",
"FilledMarkdown3",
"FilledMarkdown4",
"FilledMarkdown5",
]
].corr()
df_pn[
[
"IsHoliday",
"IsHoliday_pre",
"IsHoliday_next",
"MarkDown1",
"MarkDown2",
"MarkDown3",
"MarkDown4",
"MarkDown5",
]
].corr()
formula_reg = "y ~ 1 + Unemployment+FilledMarkdown1+FilledMarkdown2+FilledMarkdown3+FilledMarkdown4+FilledMarkdown5+FilledMarkdown1*IsHoliday +FilledMarkdown2*IsHoliday+FilledMarkdown3*IsHoliday+FilledMarkdown4*IsHoliday+FilledMarkdown5*IsHoliday+FilledMarkdown1*IsHoliday_pre +FilledMarkdown2*IsHoliday_pre+FilledMarkdown3*IsHoliday_pre+FilledMarkdown4*IsHoliday_pre+FilledMarkdown5*IsHoliday_pre+FilledMarkdown1*IsHoliday_next +FilledMarkdown2*IsHoliday_next+FilledMarkdown3*IsHoliday_next+FilledMarkdown4*IsHoliday_next+FilledMarkdown5*IsHoliday_next+C(month)+ EntityEffects"
formula_reg1 = "y ~ 1 + sales_lag+Unemployment+FilledMarkdown1+FilledMarkdown2+FilledMarkdown3+FilledMarkdown4+FilledMarkdown5+FilledMarkdown1*IsHoliday +FilledMarkdown2*IsHoliday+FilledMarkdown3*IsHoliday+FilledMarkdown4*IsHoliday+FilledMarkdown5*IsHoliday+FilledMarkdown1*IsHoliday_pre +FilledMarkdown2*IsHoliday_pre+FilledMarkdown3*IsHoliday_pre+FilledMarkdown4*IsHoliday_pre+FilledMarkdown5*IsHoliday_pre+FilledMarkdown1*IsHoliday_next +FilledMarkdown2*IsHoliday_next+FilledMarkdown3*IsHoliday_next+FilledMarkdown4*IsHoliday_next+FilledMarkdown5*IsHoliday_next+C(month)"
df_pn["IsHoliday"]
mod1 = PanelOLS.from_formula(formula_reg, df_pn)
res1 = mod1.fit(cov_type="clustered", cluster_entity=True)
res1
mod2 = PanelOLS.from_formula(formula_reg1, df_pn)
res2 = mod2.fit(cov_type="clustered", cluster_entity=True)
res2
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
transcriptions = {
filename: f"{dirname}{filename}"
for filename in filenames
for dirname, _, filenames in os.walk("/kaggle/input/explorationspeechresources/")
}
tedxCorpus = pd.read_csv(
transcriptions["TEDx_Spanish.transcription"],
names=["sentence", "path"],
sep="TEDX_",
)
tedxCorpus.loc[:, "path"] = tedxCorpus.path.apply(lambda p: f"TEDX_{p}.wav")
tedxCorpus["gender"] = tedxCorpus.path.apply(
lambda x: "male" if "_M_" in x else "female"
)
tedxCorpus["accent"] = "mexicano"
transcriptions["TEDx_Spanish.transcription"] = tedxCorpus
transcriptions["validated.tsv"] = pd.read_table(
transcriptions["validated.tsv"], header=0
)
def process_crowfund(path, gender, accent):
df = pd.read_table(path, header=None, names=["path", "sentence"])
df["gender"] = gender
df["accent"] = accent
df.loc[:, "path"] = df.path.apply(lambda p: p + ".wav")
return df
transcriptions["es_co_male.tsv"] = process_crowfund(
transcriptions["es_co_male.tsv"], "male", "andino"
)
transcriptions["es_co_female.tsv"] = process_crowfund(
transcriptions["es_co_female.tsv"], "female", "andino"
)
transcriptions["es_pe_male.tsv"] = process_crowfund(
transcriptions["es_pe_male.tsv"], "male", "andino"
)
transcriptions["es_pe_female.tsv"] = process_crowfund(
transcriptions["es_pe_female.tsv"], "female", "andino"
)
transcriptions["es_portoric_female.tsv"] = process_crowfund(
transcriptions["es_portoric_female.tsv"], "female", "caribe"
)
tmp = pd.read_json(transcriptions["female_mex.json"], orient="index")
transcriptions["female_mex.json"] = pd.DataFrame()
transcriptions["female_mex.json"]["path"] = tmp.index
transcriptions["female_mex.json"]["sentence"] = tmp.clean.values
transcriptions["female_mex.json"]["gender"] = "female"
transcriptions["female_mex.json"]["accent"] = "mexicano"
tmp = None
def mergeDataframes(**dataframes):
return pd.concat(list(dataframes.values()), axis=0).reset_index(drop=True)
mergedTranscriptions = mergeDataframes(**transcriptions)
def getFrequencyDistribution(df, column_name):
return df[pd.notnull(df[column_name])].groupby(df[column_name]).size()
getFrequencyDistribution(mergedTranscriptions, "accent").plot.bar()
getFrequencyDistribution(mergedTranscriptions, "age").plot.bar()
getFrequencyDistribution(mergedTranscriptions, "gender").plot.bar()
# Repeated Values?
len(mergedTranscriptions.path.unique()) != len(mergedTranscriptions)
# Empty values?
len(mergedTranscriptions[mergedTranscriptions.sentence.isnull()]) + len(
mergedTranscriptions[mergedTranscriptions.path.isnull()]
)
# Grouping a-like accents
from collections import defaultdict
phonetic_groups = defaultdict(
lambda: "other",
{
**dict.fromkeys(["mexicano", "andino", "americacentral"], "mexican_alike"),
**dict.fromkeys(["canario", "caribe", "rioplatense"], "southAmerican"),
**dict.fromkeys(
["centrosurpeninsular", "nortepeninsular", "surpeninsular"], "spaniards"
),
"chileno": "chileno",
},
)
mergedTranscriptions.loc[:, "accent"] = mergedTranscriptions.accent.apply(
lambda a: phonetic_groups[a]
)
getFrequencyDistribution(mergedTranscriptions, "accent").plot.bar()
import numpy as np
def apply_w2l_format(dataframe):
dataframe = dataframe.reset_index()
dataframe.drop("index", axis=1, inplace=True)
dataframe["unique_id"] = dataframe.index
dataframe["duration"] = np.zeros(len(dataframe))
dataframe = dataframe[["unique_id", "path", "duration", "sentence"]]
return dataframe
mergedTranscriptions = apply_w2l_format(mergedTranscriptions)
mergedTranscriptions.groupby(
mergedTranscriptions.sentence.apply(lambda s: len(s.split()))
).size().plot.bar()
mergedTranscriptions.to_csv("raw_dataset.lst", sep="\t", index=False, header=None)
import re
import string
import ftfy
co_SentenceLevel = {
# Separate simbols from words
"?": " ? ",
"¿": " ¿ ",
",": " , ",
"'": " ' ",
"\.{2,}": " ",
".": " . ",
":": " : ",
ftfy.fix_encoding("á"): ftfy.fix_encoding("A"),
ftfy.fix_encoding("é"): ftfy.fix_encoding("E"),
ftfy.fix_encoding("í"): ftfy.fix_encoding("I"),
ftfy.fix_encoding("ó"): ftfy.fix_encoding("O"),
ftfy.fix_encoding("ú"): ftfy.fix_encoding("U"),
# delete some useless simbols
"-": " ",
"(": " ",
")": " ",
# delete double space, and sequences of "-,*,^,."
"\?{2,}|\!{2,}": " ",
}
def escapePattern(pattern):
"""Helper function to build our regex"""
if len(pattern) == 1:
pattern = re.escape(pattern)
return pattern
def compileCleanerRegex(cleaningOptions):
"""Given a dictionary of rules this contruct the regular expresion to detect the patterns"""
return re.compile("(%s)" % "|".join(map(escapePattern, cleaningOptions.keys())))
delete = ftfy.fix_encoding("\"!¡#$%&()*+-/:<=>@[\\]^_`{|}'~")
replaceVocal = ftfy.fix_encoding("äëïöü")
clean_regex = compileCleanerRegex(co_SentenceLevel)
rmPunc = str.maketrans("", "", delete)
rPVocal = str.maketrans(replaceVocal, "aeiou")
norm_spaces = re.compile("\s{1,}")
def clean_text(
text, cleaningOptions, cleaningRegex, removePunct, replaceVocab, norm_spaces
):
"""Cleaning function for text
Given a text this function applies the cleaning rules defined
in a dictionary using a regex to detect the patterns.
Args:
text (str): The text we want to clean.
cleaningRegex(regex): Regular expression to detect
the patterns defined in the cleaning options
compiled using the compileCleanerRegex(cleaningOptions) function.
Returns:
The cleaned text applying the cleaning options.
"""
text = ftfy.fix_encoding(text).lower()
text = cleaningRegex.sub(
lambda mo: cleaningOptions.get(
mo.group(1),
),
text,
)
text = text.translate(removePunct)
text = text.translate(replaceVocab)
return " ".join(norm_spaces.split(text.strip()))
from functools import partial
clean = partial(
clean_text,
cleaningOptions=co_SentenceLevel,
cleaningRegex=clean_regex,
removePunct=rmPunc,
replaceVocab=rPVocal,
norm_spaces=norm_spaces,
)
ph = """\"Tal programa, ""Rog-O-Matic"",el pingüino fue desarrollado para jugar.... y ganar el juego.\" ángel , diego gómez , carlos o'connor reina , ma . """
clean(ph)
from multiprocessing import Pool
from tqdm.notebook import tqdm
with Pool(8) as p:
mergedTranscriptions.loc[:, "sentence"] = tqdm(
p.imap(clean, mergedTranscriptions.sentence.values),
total=len(mergedTranscriptions),
)
mergedTranscriptions["sentence"].sample(10).values
mergedTranscriptions.to_csv("punc_dataset.lst", sep="\t", index=False, header=None)
punclst = string.punctuation + "¿"
rmPunc = str.maketrans("", "", punclst)
def remPunct(text, rmPunc=rmPunc, norm_spaces=norm_spaces):
text = text.translate(rmPunc)
return " ".join(norm_spaces.split(text.strip()))
with Pool(8) as p:
mergedTranscriptions.loc[:, "sentence"] = tqdm(
p.imap(remPunct, mergedTranscriptions.sentence.values),
total=len(mergedTranscriptions),
)
mergedTranscriptions["sentence"].sample(10).values
mergedTranscriptions.to_csv(
"np_accents_dataset.lst", sep="\t", index=False, header=None
)
mergedTranscriptions.loc[:, "sentence"] = mergedTranscriptions.sentence.apply(
lambda s: s.lower()
)
mergedTranscriptions.to_csv("np_dataset.lst", sep="\t", index=False, header=None)
mergedTranscriptions["sentence"].sample(10).values
|
# Import Dependencies
import numpy as np
from numpy import nan
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras import Sequential
from tensorflow.keras.layers import LSTM, Dense
data = pd.read_csv(
"../input/power-consumption-of-house/power_consumption_of_house.txt",
sep=";",
parse_dates=True,
low_memory=False,
)
data["date_time"] = data["Date"].str.cat(data["Time"], sep=" ")
data.drop(["Date", "Time"], inplace=True, axis=1)
data.set_index(["date_time"], inplace=True)
data.replace("?", nan, inplace=True)
data = data.astype("float")
data.head()
# First check how many values are null
np.isnan(data).sum()
# fill the null value
def fill_missing(data):
one_day = 24 * 60
for row in range(data.shape[0]):
for col in range(data.shape[1]):
if np.isnan(data[row, col]):
data[row, col] = data[row - one_day, col]
fill_missing(data.values)
# Again check the data after filling the value
np.isnan(data).sum()
data.describe()
data.shape
data.head()
# Converting the index as date
data.index = pd.to_datetime(data.index)
data = data.resample("D").sum()
data.head()
fig, ax = plt.subplots(figsize=(18, 18))
for i in range(len(data.columns)):
plt.subplot(len(data.columns), 1, i + 1)
name = data.columns[i]
plt.plot(data[name])
plt.title(name, y=0, loc="right")
plt.yticks([])
plt.show()
fig.tight_layout()
# # Exploring Active power consumption for each year
years = ["2007", "2008", "2009", "2010"]
fig, ax = plt.subplots(figsize=(18, 18))
for i in range(len(years)):
plt.subplot(len(years), 1, i + 1)
year = years[i]
active_power_data = data[str(year)]
plt.plot(active_power_data["Global_active_power"])
plt.title(str(year), y=0, loc="left")
plt.show()
fig.tight_layout()
# # Power consumption distribution with histogram
fig, ax = plt.subplots(figsize=(18, 18))
for i in range(len(years)):
plt.subplot(len(years), 1, i + 1)
year = years[i]
active_power_data = data[str(year)]
active_power_data["Global_active_power"].hist(bins=200)
plt.title(str(year), y=0, loc="left")
plt.show()
fig.tight_layout()
# for full data
fig, ax = plt.subplots(figsize=(18, 18))
for i in range(len(data.columns)):
plt.subplot(len(data.columns), 1, i + 1)
name = data.columns[i]
data[name].hist(bins=200)
plt.title(name, y=0, loc="right")
plt.yticks([])
plt.show()
fig.tight_layout()
# ## What can we predict
# Forecast hourly consumption for the next day.
# Forecast daily consumption for the next week.
# Forecast daily consumption for the next month.
# Forecast monthly consumption for the next year.
# ## Modeling Methods
# There are many modeling methods and few of those are as follows
# Naive Methods -> Naive methods would include methods that make very simple, but often very effective assumptions.
# Classical Linear Methods -> Classical linear methods include techniques are very effective for univariate time series forecasting
# Machine Learning Methods -> Machine learning methods require that the problem be framed as a supervised learning problem.
# k-nearest neighbors.
# SVM
# Decision trees
# Random forest
# Gradient boosting machines
# Deep Learning Methods -> combinations of CNN LSTM and ConvLSTM, have proven effective on time series classification tasks
# CNN
# LSTM
# CNN - LSTM
data_train = data.loc[:"2009-12-31", :]["Global_active_power"]
data_train.head()
data_test = data["2010"]["Global_active_power"]
data_test.head()
data_train.shape
data_test.shape
# # Prepare Training data
data_train = np.array(data_train)
print(data_train)
X_train, y_train = [], []
for i in range(7, len(data_train) - 7):
X_train.append(data_train[i - 7 : i])
y_train.append(data_train[i : i + 7])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train.shape, y_train.shape
pd.DataFrame(X_train).head()
x_scaler = MinMaxScaler()
X_train = x_scaler.fit_transform(X_train)
y_scaler = MinMaxScaler()
y_train = y_scaler.fit_transform(y_train)
X_train = X_train.reshape(1098, 7, 1)
X_train.shape
# # Build LSTM Network
model = Sequential()
model.add(LSTM(units=200, activation="relu", input_shape=(7, 1)))
model.add(Dense(7))
model.compile(loss="mse", optimizer="adam")
model.summary()
model.fit(X_train, y_train, epochs=100)
# # Prepare test dataset and test LSTM model
data_test = np.array(data_test)
X_test, y_test = [], []
for i in range(7, len(data_test) - 7):
X_test.append(data_test[i - 7 : i])
y_test.append(data_test[i : i + 7])
X_test, y_test = np.array(X_test), np.array(y_test)
X_test = x_scaler.transform(X_test)
y_test = y_scaler.transform(y_test)
X_test = X_test.reshape(331, 7, 1)
X_test.shape
y_pred = model.predict(X_test)
y_pred = y_scaler.inverse_transform(y_pred)
y_pred
y_true = y_scaler.inverse_transform(y_test)
y_true
# # Evaluate the Model
def evaluate_model(y_true, y_predicted):
scores = []
# calculate scores for each day
for i in range(y_true.shape[1]):
mse = mean_squared_error(y_true[:, i], y_predicted[:, i])
rmse = np.sqrt(mse)
scores.append(rmse)
# calculate score for whole prediction
total_score = 0
for row in range(y_true.shape[0]):
for col in range(y_predicted.shape[1]):
total_score = total_score + (y_true[row, col] - y_predicted[row, col]) ** 2
total_score = np.sqrt(total_score / (y_true.shape[0] * y_predicted.shape[1]))
return total_score, scores
evaluate_model(y_true, y_pred)
|
# # Avocado price prediction
# * **Task type:** regression
# * **Models used:** linear, XGB regression
#
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, cross_val_score
df = pd.read_csv("/kaggle/input/avocado-prices/avocado.csv")
df
# # Data preprocessing
df = df.drop("Unnamed: 0", axis=1)
df
# **As there are two types of avocados, let's see the price distribution of each one.**
import plotly.express as px
# conventional = df[df['type'] == 'conventional']
# organic = df[df['type'] == 'organic']
fig = px.histogram(
df, x="AveragePrice", color="type", marginal="box", hover_data=df.columns
)
fig.show()
# **So, on average, organic avocados are more expensive (as expected).**
# **Let's also check whether geography influences the price.**
fig = px.box(df, x="region", y="AveragePrice")
fig.show()
# **Correlation matrix**
corr = df.corr()
corr
f, ax = plt.subplots(nrows=1, ncols=1, figsize=(12, 10))
ax.set_title("Correlation Matrix", fontsize=16)
sns.heatmap(corr, vmin=-1, vmax=1, cmap="viridis", annot=True)
# **Checking for missing & duplicated data.**
df.isnull().sum()
df.duplicated().any()
df
# # Modeling
df1 = df.copy()
# Introducing new feature = 'season'
df1["Date"] = pd.to_datetime(df1["Date"])
df1["month"] = df1["Date"].dt.month
conditions = [
(df1["month"].between(3, 5, inclusive=True)),
(df1["month"].between(6, 8, inclusive=True)),
(df1["month"].between(9, 11, inclusive=True)),
(df1["month"].between(12, 2, inclusive=True)),
]
values = [0, 1, 2, 3]
# spring = 0, summer = 1, fall = 2, winter = 3
df1["seasons"] = np.select(conditions, values)
# encoding labels for 'type'
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df1["type"] = le.fit_transform(df1["type"])
# and region (One Hot Encoding instead of labelizing)
ohe = pd.get_dummies(data=df1, columns=["region"])
X = ohe.drop(
[
"AveragePrice",
"Date",
"4046",
"4225",
"4770",
"Small Bags",
"Large Bags",
"XLarge Bags",
],
axis=1,
)
y = df1["AveragePrice"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=0
)
X_train
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
pipe0 = Pipeline([("scaler", StandardScaler()), ("lr", LinearRegression())])
pipe0.fit(X_train, y_train)
y_pred0 = pipe0.predict(X_test)
r2_score(y_test, y_pred0)
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
pipe = Pipeline([("scaler", StandardScaler()), ("rf", RandomForestRegressor())])
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
r2_score(y_test, y_pred)
from xgboost import XGBRegressor
pipe2 = Pipeline([("scaler", StandardScaler()), ("xgb", XGBRegressor())])
pipe2.fit(X_train, y_train)
y_pred2 = pipe2.predict(X_test)
r2_score(y_test, y_pred2)
# **Apparently, the best model is the one with boosting (XGB).**
pd.DataFrame(
pipe2["xgb"].feature_importances_,
index=X_train.columns,
columns=["Feature Importances"],
)
|
from __future__ import absolute_import
from __future__ import print_function
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
import pandas as pd
import numpy as np
from keras.utils import np_utils
from keras.utils.np_utils import to_categorical # convert to one-hot-encoding
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D, BatchNormalization
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from keras import optimizers
from keras import losses
from keras.models import load_model
from keras import regularizers
import time
from keras import initializers
# Load the training dataset ~87K states
all_train = pd.read_csv("../input/applied-ai-assignment-2/Assignment_2_train.csv")
all_train.loc[(all_train.state == 4), "state"] = 0
all_train.loc[(all_train.state == 5), "state"] = 1
len(all_train)
all_train[1:5]
# Create a train/validation split
data_to_use = 1
train = all_train[: int(len(all_train) * data_to_use)]
split = 0.9
Train = train[: int(len(train) * split)]
Valid = train[int(len(train) * split) :]
# Remove the first and last column from the data, as it is the board name and the label
X_train = Train.iloc[:, 1:-1].values
X_valid = Valid.iloc[:, 1:-1].values
# Remove everything except the last column from the data, as it is the label and put it in y
y_train = Train.iloc[:, -1:].values
y_valid = Valid.iloc[:, -1:].values
len(X_train)
X_train[20].reshape(6, 7)
print(X_train.shape)
print(X_valid.shape)
sample_train = X_train.reshape(-1, 6, 7)
X_train = sample_train.reshape(79062, 6, 7, 1)
sample_valid = X_valid.reshape(-1, 6, 7)
X_valid = sample_valid.reshape(8785, 6, 7, 1)
print(X_train.shape)
print(X_valid.shape)
# set input to the shape of one X value
dimof_input = X_train.shape[1]
# Set y categorical
dimof_output = int(np.max(y_train) + 1)
y_train = np_utils.to_categorical(y_train, dimof_output)
y_valid = np_utils.to_categorical(y_valid, dimof_output)
from keras.models import Sequential
from keras.layers import Dense, Conv2D, Flatten
# create model
model = Sequential()
model.add(Conv2D(64, kernel_size=4, activation="relu", input_shape=(6, 7, 1)))
model.add(Flatten())
model.add(Dense(2, activation="softmax"))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
model.summary()
es = EarlyStopping(
monitor="val_loss", # do not change
mode="min", # do not change
verbose=1, # allows you to see more info per epoch
patience=10,
) # **** patience is how many validations to wait with nothing learned (patience * validation_freq)
mc = ModelCheckpoint(
"best_model.h5", monitor="val_loss", mode="min", verbose=0, save_best_only=True
) # do not change
history = model.fit(
X_train,
y_train,
batch_size=32,
validation_data=(X_valid, y_valid),
callbacks=[es, mc],
epochs=1,
)
|
import numpy as np
import tensorflow as tf
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
from keras.layers import Dense, Activation, Flatten
from keras.models import Sequential
train_datagen = ImageDataGenerator(
# rescale=1./255,
# zoom_range=0.2,
horizontal_flip=False
)
train_generator = train_datagen.flow_from_directory(
directory="/kaggle/input/image-data-with-valid/Data_Loader_Dataset/Train",
target_size=(224, 224),
color_mode="rgb",
batch_size=64,
class_mode="binary",
shuffle=True,
seed=42,
)
valid_datagen = ImageDataGenerator(
# rescale=1./255,
# zoom_range=0.2,
horizontal_flip=False
)
valid_generator = valid_datagen.flow_from_directory(
directory="/kaggle/input/image-data-with-valid/Data_Loader_Dataset/Valid",
target_size=(224, 224),
color_mode="rgb",
batch_size=64,
class_mode="binary",
shuffle=True,
seed=42,
)
model = Sequential(
[
keras.applications.resnet.ResNet50(
include_top=False,
weights="imagenet",
input_tensor=None,
input_shape=(224, 224, 3),
pooling="max",
),
# Flatten(),
Dense(512),
Activation("relu"),
Dense(1),
Activation("sigmoid"),
]
)
model.summary()
model.compile(optimizer=Adam(lr=0.01), loss="binary_crossentropy", metrics=["accuracy"])
history = model.fit_generator(
train_generator, validation_data=valid_generator, epochs=5, verbose=1
)
def eval_metric(model, history, metric_name):
"""
Function to evaluate a trained model on a chosen metric.
Training and validation metric are plotted in a
line chart for each epoch.
Parameters:
history : model training history
metric_name : loss or accuracy
Output:
line chart with epochs of x-axis and metric on
y-axis
"""
metric = history.history[metric_name]
val_metric = history.history["val_" + metric_name]
e = range(1, 5 + 1)
plt.plot(e, metric, "bo", label="Train " + metric_name)
plt.plot(e, val_metric, "b", label="Validation " + metric_name)
plt.xlabel("Epoch number")
plt.ylabel(metric_name)
plt.title("Comparing training and validation " + metric_name)
plt.legend()
plt.show()
import matplotlib.pyplot as plt
eval_metric(model, history, "loss")
from keras.models import load_model
model.save("ResNet50_valid.h5")
import pickle
filename = "ResNet50_pickle.pkl"
model = pickle.dump(model, open(filename, "wb"))
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
df = pd.read_csv(
"/kaggle/input/key-indicators-of-heart-disease/heart_2022_Key_indicators.csv"
)
df.sample(3)
# ## Basic Preprocessing
df.info()
df.isnull().sum()
df.describe()
df.shape
# ## Data Processing
cat_df = df.select_dtypes(exclude=np.number)
num_df = df.select_dtypes(include=np.number)
cat_df.sample(2)
num_df.sample(2)
# ## ---> Categorical processing
# * One hot encoding
import matplotlib.pyplot as plt
import seaborn as sn
cat_cols = cat_df.columns
cat_cols
# ### ------> Unique values for each column
for col in cat_cols:
print(f"Unique {col}===============>", cat_df[col].unique())
value_cnts = {}
for col in cat_cols:
value_cnt = {}
for uv in cat_df[col].unique():
value_cnt[uv] = len(cat_df[cat_df[col] == uv])
value_cnts[col] = value_cnt
value_cnts
sn.barplot()
# ### ------> One hot encoding
cat_df_1hot = pd.get_dummies(cat_df)
cat_df_1hot.sample(4)
|
# ***
#
#
# Semantic Segementation + ⚡ PyTorch Lightning Training
#
#
#
# ⛈ Flood Imagery Segmentation </span
#
# If you liked the notebook, please leave an UPVOTE ⬆
# 1. Importing Libraries
#
# Importing Libraries
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
import PIL
from glob import glob
import tqdm
warnings.filterwarnings("ignore")
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models, datasets
from torch.utils.data import Dataset, DataLoader
import albumentations as A
from albumentations.pytorch import ToTensorV2
import cv2
from sklearn.model_selection import train_test_split, StratifiedKFold, KFold
import segmentation_models_pytorch as smp
import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
from pytorch_toolbelt.losses import JaccardLoss, BinaryFocalLoss
from iglovikov_helper_functions.dl.pytorch.lightning import find_average
import wandb
from pytorch_lightning.loggers import WandbLogger
from collections import OrderedDict
# 2. Configuration Variables
#
Config = dict(
input_path="/kaggle/input/flood-area-segmentation/",
BATCH=8,
wd=1e-6,
n_cpu=os.cpu_count(),
IMG_SIZE=224,
infra="Kaggle",
MODEL_PATH="",
EPOCH=8,
MODEL_NAME="mobilenet_v2",
_wandb_kernel="nikhil__xb",
encoders=["mit_b3", "resnet34", "timm-mobilenetv3_large_100"],
)
# 3. Weights & Biases Setup
#
wandb_logger = WandbLogger(
project="Flood_Segmentation",
group="vision",
anonymous="allow",
job_type="train",
config=Config,
)
# 4. Data Formatting
#
df = pd.read_csv("/kaggle/input/flood-area-segmentation/metadata.csv")
df.drop(0, axis=0, inplace=True)
df.set_axis(range(len(df)), inplace=True)
df.head()
# 5. Plot Color Distribution
#
def plot_hist(path, n_images, size=(8, 5), aug=None):
np.random.seed(42)
for i in range(n_images):
plt.figure(figsize=size)
id = np.random.randint(289)
img = plt.imread(path + "Image/" + df["Image"][id])
mask = plt.imread(path + "Mask/" + df["Mask"][id])
plt.subplot(1, 2, 1)
lum_img = img[:, :, 0]
plt.hist(lum_img.ravel(), bins=range(256), fc="k", ec="k")
plt.title("Histogram")
plt.subplot(1, 2, 2)
plt.imshow(img)
plt.title("Image")
plt.tight_layout()
plot_hist(Config["input_path"], n_images=5)
# 6. Plot Flood Images with Masks
#
def plot_image(path, n_images, size=(10, 6), aug=None):
np.random.seed(42)
for i in range(n_images):
plt.figure(figsize=size)
id = np.random.randint(290)
img = plt.imread(path + "Image/" + df["Image"][id])
mask = plt.imread(path + "Mask/" + df["Mask"][id])
if aug is not None:
_aug = aug(image=img, mask=mask)
img_tf = _aug["image"].numpy().transpose(1, 2, 0)
mask_tf = _aug["mask"].T
plt.subplot(1, 5, 1)
plt.imshow(img)
plt.title("Image")
plt.axis("off")
plt.subplot(1, 5, 2)
plt.imshow(mask, cmap="gray")
plt.title("Mask")
plt.axis("off")
plt.subplot(1, 5, 3)
plt.imshow(img, cmap="gray")
plt.imshow(mask, cmap="gray", alpha=0.5)
plt.title("Overlapping Mask")
plt.axis("off")
if aug is not None:
plt.subplot(1, 5, 4)
plt.imshow(img_tf)
plt.title("Augmented Image")
plt.axis("off")
plt.subplot(1, 5, 5)
plt.imshow(mask_tf)
plt.title(f"Augmented Mask")
plt.axis("off")
plt.tight_layout()
plt.show()
plot_image(Config["input_path"], n_images=5)
# 7. Augmentations
#
class Augments:
train = A.Compose(
[
A.Resize(
Config["IMG_SIZE"],
Config["IMG_SIZE"],
interpolation=cv2.INTER_NEAREST,
p=1,
),
A.RandomResizedCrop(
Config["IMG_SIZE"],
Config["IMG_SIZE"],
interpolation=cv2.INTER_NEAREST,
p=0.5,
),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.3),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), p=1),
ToTensorV2(),
]
)
valid = A.Compose(
[
A.Resize(
Config["IMG_SIZE"],
Config["IMG_SIZE"],
interpolation=cv2.INTER_NEAREST,
p=1,
),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), p=1),
ToTensorV2(),
]
)
# Plotting Image with Augmentations
plot_image(Config["input_path"], n_images=5, aug=Augments.train)
#
# ---
# ### Notes:-
# * The data contains two type of input values:-
# 1. Raw Image 2. Masked Image
# * Number of images = 290
# * Feature Selection can be done
# > SelectFromModel, RFE, SelectKBest, and SelectPercentile. You can also use the feature_importances_ or coef_ attributes of certain models to identify the most important features
# * Utilize Transfer Learning using freezing of weights and creating a custom header for it.
# * Create Minibatches, trained them in parallel and combined the results of the minibatches
# * Utilize Dropout, Learning Rate Scheduler, Optimizer= Adagrad
# * Early stopping to reduce risk of overfitting
# * Hyperparamter tuning
# * Cross Entropy Loss
# ---
# 8. PyTorch Dataset Class
#
class FloodDataset(Dataset):
def __init__(self, path, df, augments=None):
super().__init__()
self.path = path
self.df = df
self.augments = augments
self.data = df.values
def __getitem__(self, idx):
image_id, mask_id = self.data[idx]
im_path = self.path + "Image/" + image_id
mask_path = self.path + "Mask/" + mask_id
img = cv2.imread(im_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
mask = cv2.imread(mask_path)
mask = np.where(mask[:, :, 2] > 0, 1, 0)
# print(mask)
if self.augments is not None:
aug = self.augments(image=img, mask=mask)
img = aug["image"]
mask = aug["mask"]
mask = np.expand_dims(mask, 0)
return img, mask
def __len__(self):
return len(self.df)
#
# Helper Function
# ---
# Helper Function
def load_weights(checkpoint_dict):
new_state_dict = OrderedDict()
for k, v in checkpoint_dict.items():
name = k[12:]
new_state_dict[name] = v
return new_state_dict
def iou_pytorch(logits: torch.Tensor, targets: torch.Tensor, SMOOTH=1e-6):
output = (logits > 0.5).float()
if output.shape != targets.shape:
targets = torch.squeeze(targets, 1)
intersection = (targets * output).sum()
union = targets.sum() + output.sum() - intersection
result = (intersection + SMOOTH) / (union + SMOOTH)
return result
# 9. Model Class
#
class UnetModel(nn.Module):
def __init__(
self,
encoder_name=Config["encoders"],
in_channels=3,
classes=1,
pretrained=False,
index=0,
):
super().__init__()
self.i = index
self.model = smp.Unet(
encoder_name=encoder_name[self.i],
encoder_weights="imagenet",
classes=classes,
activation="sigmoid",
)
if pretrained:
checkpoint_dict = torch.load(
f"/kaggle/working/Fold={index}_Model=mobilenet_v2.ckpt"
)["state_dict"]
self.model.load_state_dict(load_weights(checkpoint_dict))
def forward(self, x):
x = self.model(x)
return x
model = UnetModel()
from torchsummary import summary
summary(model)
# 10. PyTorch Lightning Module Class
#
class SegmentFlood(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = UnetModel()
self.losses = [
("jaccard", 0.1, JaccardLoss(mode="binary", from_logits=True)),
("focal", 0.9, BinaryFocalLoss()),
]
def forward(self, batch):
return self.model(batch)
def training_step(self, batch, batch_idx):
image, mask = batch
logits = self.forward(image)
total_loss = 0
for loss_name, weight, loss in self.losses:
ls_mask = loss(logits, mask)
total_loss += weight * ls_mask
self.log("train_mask_{}".format(loss_name), ls_mask)
self.log("train_loss", total_loss)
lr = self._get_current_lr()
self.log("lr", lr)
return total_loss
def _get_current_lr(self):
lr = [x["lr"] for x in self.optimizer.param_groups]
return torch.Tensor([lr]).cuda()
def validation_step(self, batch, batch_idx):
image, mask = batch
logits = self.forward(image)
result = {}
for loss_name, _, loss in self.losses:
result[f"val_mask_{loss_name}"] = loss(logits, mask)
result["val_iou"] = iou_pytorch(logits, mask)
return result
def validation_epoch_end(self, outputs):
self.log("epoch", self.trainer.current_epoch)
avg_val_iou = find_average(outputs, "val_iou")
self.log("val_iou", avg_val_iou)
return {"val_iou": avg_val_iou}
def configure_optimizers(self):
params = [x for x in self.model.parameters() if x.requires_grad]
self.optimizer = torch.optim.AdamW(params, lr=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
self.optimizer, T_max=8, eta_min=0.6
)
dict_val = {"optimizer": self.optimizer, "lr_scheduler": scheduler}
return dict_val
train = df[: int(len(df) * 0.85)]
test = df[int(len(df) * 0.85) :]
# 11. Training by KFolds
#
kf = KFold(n_splits=3)
for fold_, (train_idx, valid_idx) in enumerate(kf.split(X=train)):
print(f"{'-'*20} Fold: {fold_} {'-'*20}")
train_df = df.loc[train_idx]
valid_df = df.loc[valid_idx]
train_tf = FloodDataset(Config["input_path"], train_df, Augments.train)
valid_tf = FloodDataset(Config["input_path"], valid_df, Augments.valid)
train_load = DataLoader(
train_tf,
batch_size=Config["BATCH"],
num_workers=Config["n_cpu"],
shuffle=True,
pin_memory=True,
)
valid_load = DataLoader(
valid_tf,
batch_size=Config["BATCH"],
num_workers=Config["n_cpu"],
shuffle=False,
pin_memory=True,
)
checkpoint = ModelCheckpoint(
monitor="val_iou",
dirpath="./",
filename=f"Fold={fold_}_Model={Config['encoders'][1]}",
save_top_k=1,
mode="max",
verbose=True,
)
FloodModel = SegmentFlood()
trainer = pl.Trainer(
max_epochs=Config["EPOCH"],
accelerator="gpu",
devices=1,
callbacks=[checkpoint],
logger=wandb_logger,
fast_dev_run=False,
)
trainer.fit(FloodModel, train_load, valid_load)
# 12. Checkpoint Values
#
checkpoint_keys1 = torch.load("/kaggle/working/Fold=0_Model=resnet50.ckpt")[
"callbacks"
] # VGG16 FIRST
checkpoint_keys1
checkpoint_keys2 = torch.load("/kaggle/working/Fold=1_Model=resnet50-v1.ckpt")[
"callbacks"
]
checkpoint_keys2
checkpoint_keys3 = torch.load("/kaggle/working/Fold=2_Model=resnet50.ckpt")["callbacks"]
checkpoint_keys3
# 13. Model Inference
#
model = SegmentFlood.load_from_checkpoint(
"/kaggle/working/Fold=1_Model=resnet50-v1.ckpt"
)
test_tf = FloodDataset(Config["input_path"], test, Augments.valid)
test_load = DataLoader(
test_tf,
batch_size=Config["BATCH"],
num_workers=Config["n_cpu"],
shuffle=False,
pin_memory=True,
)
validate_metrics = trainer.validate(model, dataloaders=test_load, verbose=False)
print(validate_metrics)
# 14. Plot Predictions
#
batch = next(iter(test_load))
with torch.no_grad():
model.eval()
logits = model(batch[0])
pr_masks = logits.sigmoid()
for image, gt_mask, pr_mask in zip(batch[0], batch[1], pr_masks):
plt.figure(figsize=(10, 5))
plt.subplot(1, 3, 1)
plt.imshow(image.numpy().transpose(1, 2, 0)) # convert CHW -> HWC
plt.title("Image")
plt.axis("off")
plt.subplot(1, 3, 2)
plt.imshow(
gt_mask.numpy().squeeze()
) # just squeeze classes dim, because we have only one class
plt.title("Ground truth")
plt.axis("off")
plt.subplot(1, 3, 3)
plt.imshow(
pr_mask.numpy().squeeze()
) # just squeeze classes dim, because we have only one class
plt.title("Prediction")
plt.axis("off")
plt.show()
|
# # 📲 **Imports.**
import io
import os
import cv2
import csv
import time
import copy
import math
import torch
import shutil
import logging
import argparse
import numpy as np
import torchvision
import numpy as np
import pandas as pd
import seaborn as sb
import torch.nn as nn
from PIL import Image
from tqdm import tqdm
import torch.optim as optim
from sklearn import datasets
import matplotlib.pyplot as plt
from tqdm.notebook import trange
from statistics import mean, stdev
from torchvision.utils import make_grid
import torch.utils.model_zoo as model_zoo
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets, models, transforms
from sklearn.model_selection import (
train_test_split,
StratifiedKFold,
StratifiedShuffleSplit,
KFold,
)
# # ✔ **Checking Pytorch and Torchvision Versions.**
print("PyTorch Version: ", torch.__version__)
print("Torchvision Version: ", torchvision.__version__)
# # ⌨ **Defining some parameters for the model.**
num_classes = 100
batch_size = 32
num_epochs = 20
# model_choice = "Resnet152"
# model_choice = "Resnet34"
model_choice = "ViT-L"
learning_rate = 0.01
SGD_momentum = 0.9
SGD_weight_decay = 1e-4
feature_extract = False
# # 🔧 **Transformation Configurations.**
transform_train = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(0.1),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.RandomAdjustSharpness(sharpness_factor=2, p=0.1),
transforms.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261)),
transforms.RandomErasing(p=0.75, scale=(0.02, 0.1), value=1.0, inplace=False),
]
)
transform_train_without_transformers = transforms.Compose([transforms.ToTensor()])
transform_test = transforms.Compose(
[
transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.247, 0.243, 0.261)),
]
)
# # 🖨 **Datasets and Dataloaders.**
""" Training Dataset & Dataloaders with Transformers
"""
train_set = torchvision.datasets.CIFAR100(
root="./data", train=True, download=True, transform=transform_train
)
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True, num_workers=1
)
""" Training Dataset & Dataloaders without Transformers
"""
train_set_without_transformers = torchvision.datasets.CIFAR100(
root="./data",
train=True,
download=True,
transform=transform_train_without_transformers,
)
train_loader_without_transformers = torch.utils.data.DataLoader(
train_set_without_transformers, batch_size=batch_size, shuffle=True, num_workers=0
)
""" Validation Dataset & Dataoaders
"""
validation_set = torchvision.datasets.CIFAR100(
root="./data", train=False, download=True, transform=transform_test
)
validation_loader = torch.utils.data.DataLoader(
validation_set, batch_size=batch_size, shuffle=False, num_workers=0
)
dataloaders_dict = {}
dataloaders_dict["Train"] = train_loader
dataloaders_dict["Validation"] = validation_loader
# # 📷 **Function for showing batch of the images.**
def show_batch(data):
for images, labels in data:
fig, ax = plt.subplots(figsize=(30, 30))
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(make_grid(images, nrow=16).permute(1, 2, 0))
break
# # 📸 **Showing Batch of The Images Before Applying Transformers.**
show_batch(train_loader_without_transformers)
# # 📸 **Showing Batch of The Images After After Applying Transformers.**
show_batch(train_loader)
# # 📜 **Function to get the learning rate to view it in every iteration.**
def Learning_Rate(optimizer):
for param_group in optimizer.param_groups:
return param_group["lr"]
# # 📝 **Training Loop (The *definition* of the function).**
def train_model(model, dataloaders, criterion, optimizer, scheduler, num_epochs=10):
since = time.time()
training_accuracy_history = []
training_loss_history = []
validation_accuracy_history = []
validation_loss_history = []
best_acc = 0.0
for epoch in trange(
num_epochs,
desc=f"Model: {model_choice}, Number of Epochs: {num_epochs}, Batch Size: {batch_size}, Learning Rate: {(Learning_Rate(optimizer)):.9f} ",
):
print("Epoch {}/{}".format(epoch + 1, num_epochs))
print("-" * 10)
# Each epoch has a training and validation phase
for phase in ["Train", "Validation"]:
if phase == "Train":
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == "Train"):
outputs = model_ft(inputs.to(device))
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == "Train":
loss.backward()
def closure():
outputs = model_ft(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
return loss
optimizer.step(closure)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print(
f"{phase} Loss: {epoch_loss:.9f}, Accuracy: {(epoch_acc * 100):.9f}%, Learning Rate: {(Learning_Rate(optimizer)):.9f}"
)
if phase == "Validation" and epoch_acc > best_acc:
best_acc = epoch_acc
# best_model_wts = copy.deepcopy(model.state_dict())
torch.save(model_ft.state_dict(), "./Best_Checkpoint.pth")
if phase == "Train":
training_accuracy_history.append(epoch_acc.item() * 100)
training_loss_history.append(epoch_loss)
if phase == "Validation":
validation_accuracy_history.append(epoch_acc.item() * 100)
validation_loss_history.append(epoch_loss)
torch.save(model_ft.state_dict(), "./Last_Checkpoint.pth")
scheduler.step()
print()
time_elapsed = time.time() - since
print(
"Training completed in {:.0f}h {:.0f}m {:.0f}s".format(
time_elapsed // 3600, (time_elapsed % 3600) // 60, time_elapsed % 60
)
)
print("Best Validation Accuracy: {:9f}".format(best_acc * 100))
model.load_state_dict(torch.load("./Best_Checkpoint.pth"))
return (
model,
validation_accuracy_history,
training_accuracy_history,
validation_loss_history,
training_loss_history,
)
# # 📝 **Choosing an Architecture (The *definition* of the function).**
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
model_ft = None
if model_name == "Resnet34":
"""Resnet34"""
model_ft = models.resnet34(models.ResNet34_Weights.DEFAULT)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Dropout(0.1), nn.Linear(num_ftrs, num_classes))
elif model_name == "Resnet18":
"""Resnet18"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
torch.nn.init.xavier_uniform_(model_ft.fc.weight)
model_ft.fc = nn.Sequential(nn.Dropout(0.1), nn.Linear(num_ftrs, num_classes))
elif model_name == "Resnet101":
"""Resnet101"""
model_ft = models.resnet101(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Dropout(0.1), nn.Linear(num_ftrs, num_classes))
elif model_name == "Resnext101":
"""Resnext101"""
model_ft = models.resnext101_32x8d(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Dropout(0.1), nn.Linear(num_ftrs, num_classes))
elif model_name == "Resnet152":
"""Resnet152"""
model_ft = models.resnet152(models.ResNet152_Weights.DEFAULT)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Dropout(0.1), nn.Linear(num_ftrs, num_classes))
elif model_name == "Alexnet":
"""Alexnet"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
elif model_name == "VGG11":
"""VGG11"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
elif model_name == "Squeezenet":
"""Squeezenet"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(
512, num_classes, kernel_size=(1, 1), stride=(1, 1)
)
model_ft.num_classes = num_classes
model_ft.classifier[1] = nn.Conv2d(
512, num_classes, kernel_size=(1, 1), stride=(1, 1)
)
elif model_name == "Densenet121":
"""Densenet121"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
elif model_name == "ViT-H":
"""Vision Transform - H"""
model_ft = torchvision.models.vit_h_14(weights="DEFAULT")
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.heads.head.in_features
model_ft.heads.head = nn.Linear(num_ftrs, num_classes)
elif model_name == "ViT-L":
"""Vision Transform - L"""
model_ft = torchvision.models.vit_l_16(weights="DEFAULT")
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.heads.head.in_features
model_ft.heads.head = nn.Linear(num_ftrs, num_classes)
else:
print("Invalid model name, exiting...")
exit()
return model_ft
# # 📜 **Function that changes *grad* value in the model.**
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
# # ⚙ **Choosing an Architecture (The *call* of the function).**
model_ft = initialize_model(
model_choice, num_classes, feature_extract, use_pretrained=True
)
# # 📠 **Checking if we want to extract the features or not.**
params_to_update = model_ft.parameters()
# print("Params to learn:")
if feature_extract:
params_to_update = []
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
pass
# print("\t",name)
else:
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
pass
# print("\t",name)
# # 🖥 **Transfaring the model to the GPU to make traning cycle faster and efficient.**
device = torch.device("cuda:0")
if torch.cuda.device_count() > 1:
print("Using", torch.cuda.device_count(), "GPUs")
model_ft = nn.DataParallel(model_ft)
model_ft.to(device)
# # ⌨ **Define the SAM optimizer class.**
class SAM(torch.optim.Optimizer):
def __init__(self, params, base_optimizer, rho=0.05, adaptive=False, **kwargs):
assert rho >= 0.0, f"Invalid rho, should be non-negative: {rho}"
defaults = dict(rho=rho, adaptive=adaptive, **kwargs)
super(SAM, self).__init__(params, defaults)
self.base_optimizer = base_optimizer(self.param_groups, **kwargs)
self.param_groups = self.base_optimizer.param_groups
self.defaults.update(self.base_optimizer.defaults)
@torch.no_grad()
def first_step(self, zero_grad=False):
grad_norm = self._grad_norm()
for group in self.param_groups:
scale = group["rho"] / (grad_norm + 1e-12)
for p in group["params"]:
if p.grad is None:
continue
self.state[p]["old_p"] = p.data.clone()
e_w = (
(torch.pow(p, 2) if group["adaptive"] else 1.0)
* p.grad
* scale.to(p)
)
p.add_(e_w) # climb to the local maximum "w + e(w)"
if zero_grad:
self.zero_grad()
@torch.no_grad()
def second_step(self, zero_grad=False):
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
p.data = self.state[p]["old_p"] # get back to "w" from "w + e(w)"
self.base_optimizer.step() # do the actual "sharpness-aware" update
if zero_grad:
self.zero_grad()
@torch.no_grad()
def step(self, closure=None):
assert (
closure is not None
), "Sharpness Aware Minimization requires closure, but it was not provided"
closure = torch.enable_grad()(
closure
) # the closure should do a full forward-backward pass
self.first_step(zero_grad=True)
closure()
self.second_step()
def _grad_norm(self):
shared_device = self.param_groups[0]["params"][
0
].device # put everything on the same device, in case of model parallelism
norm = torch.norm(
torch.stack(
[
((torch.abs(p) if group["adaptive"] else 1.0) * p.grad)
.norm(p=2)
.to(shared_device)
for group in self.param_groups
for p in group["params"]
if p.grad is not None
]
),
p=2,
)
return norm
def load_state_dict(self, state_dict):
super().load_state_dict(state_dict)
self.base_optimizer.param_groups = self.param_groups
# # ⌨ **Defining the *loss function*, *optimizer* and the *scheduler.***
criterion = nn.CrossEntropyLoss().to(device)
# optimizer = optim.SGD(params_to_update, lr = learning_rate, momentum = SGD_momentum, weight_decay = SGD_weight_decay)
base_optimizer = torch.optim.SGD
optimizer = SAM(
model_ft.parameters(),
base_optimizer,
lr=learning_rate,
momentum=SGD_momentum,
weight_decay=SGD_weight_decay,
)
# optimizer = optim.Adam(params_to_update, lr=1e-3)
# scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode = 'min', factor = 0.001, patience = 5, threshold = 0.0001, threshold_mode='abs')
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs)
# # ⚙ **Calling the training loop function.**
(
model_ft,
validation_accuracy_history,
training_accuracy_history,
validation_loss_history,
training_loss_history,
) = train_model(
model_ft, dataloaders_dict, criterion, optimizer, scheduler, num_epochs=num_epochs
)
# # 📈 **Plotting the Training and Validation Accuracies.**
plt.figure(figsize=[6, 4])
plt.plot(training_accuracy_history, "black", linewidth=2.0)
plt.plot(validation_accuracy_history, "blue", linewidth=2.0)
plt.legend(["Training Accuracy", "Validation Accuracy"], fontsize=14)
plt.xlabel("Epochs", fontsize=10)
plt.ylabel("Accuracy", fontsize=10)
plt.title("Accuracy Curves", fontsize=12)
# # 📉 **Plotting the Training and Validation Losses.**
plt.figure(figsize=[6, 4])
plt.plot(training_loss_history, "black", linewidth=2.0)
plt.plot(validation_loss_history, "green", linewidth=2.0)
plt.legend(["Training Loss", "Validation Loss"], fontsize=14)
plt.xlabel("Epochs", fontsize=10)
plt.ylabel("Loss", fontsize=10)
plt.title("Loss Curves", fontsize=12)
# # ➕➖ **Calculating the inference time for a single image.** ➗✖
# First Iteration
inference_data_loader = torch.utils.data.DataLoader(
validation_set, batch_size=1, shuffle=False, num_workers=2
)
images, labels = next(iter(inference_data_loader))
labels = labels.to(device)
images = images.to(device)
model_ft = model_ft.to(device)
start = time.time()
outputs = model_ft(images)
end = time.time()
infrence_time = end - start
print(f"The inference time is: {infrence_time}")
# Second Iteration
inference_data_loader = torch.utils.data.DataLoader(
validation_set, batch_size=1, shuffle=False, num_workers=2
)
images, labels = next(iter(inference_data_loader))
labels = labels.to(device)
images = images.to(device)
model_ft = model_ft.to(device)
start = time.time()
outputs = model_ft(images)
end = time.time()
infrence_time = end - start
print(f"The inference time is: {infrence_time}")
# # 📑 **Creating the prediction file.**
predictions = []
with torch.no_grad():
for data in validation_loader:
images, labels = data
outputs = model_ft(images)
_, predicted = torch.max(outputs.data, 1)
predictions.append(predicted)
predictions_transformed = [x.item() for x in torch.cat(predictions)]
with open("submission.csv", "w", encoding="utf-8", newline="") as out:
writer = csv.writer(out)
writer.writerow(["ID", "Label"])
for ID, Label in enumerate(predictions_transformed):
writer.writerow([ID, Label])
|
# # A transfer learning attempt
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
import pickle
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D, BatchNormalization
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import TensorBoard, EarlyStopping
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.applications.vgg16 import VGG16
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score
from mlxtend.plotting import plot_confusion_matrix
# ## First, we will load and pre-process the data
CATEGORIES = ["NORMAL", "PNEUMONIA"]
DIR_TRAINING = "/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/train/"
DIR_VALIDATION = "/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/val"
DIR_TEST = "/kaggle/input/chest-xray-pneumonia/chest_xray/chest_xray/test/"
NEW_SIZE = 100
X_train = []
y_train = []
X_validation = []
y_validation = []
X_test = []
y_test = []
for category in CATEGORIES:
label = CATEGORIES.index(category)
path_train = os.path.join(DIR_TRAINING, category)
path_val = os.path.join(DIR_VALIDATION, category)
path_test = os.path.join(DIR_TEST, category)
for img in os.listdir(path_train):
try:
img_train = cv2.imread(os.path.join(path_train, img), cv2.IMREAD_COLOR)
img_train = cv2.resize(img_train, (NEW_SIZE, NEW_SIZE))
X_train.append(img_train)
y_train.append(label)
except Exception as e:
pass
for img in os.listdir(path_val):
try:
img_val = cv2.imread(os.path.join(path_val, img), cv2.IMREAD_COLOR)
img_val = cv2.resize(img_val, (NEW_SIZE, NEW_SIZE))
X_validation.append(img_val)
y_validation.append(label)
except Exception as e:
pass
for img in os.listdir(path_test):
try:
img_test = cv2.imread(os.path.join(path_test, img), cv2.IMREAD_COLOR)
img_test = cv2.resize(img_test, (NEW_SIZE, NEW_SIZE))
X_test.append(img_test)
y_test.append(label)
except Exception as e:
pass
# ## Convert lists into arrays of appropiate size
X_train = np.array(X_train).reshape(-1, NEW_SIZE, NEW_SIZE, 3)
y_train = np.asarray(y_train)
X_validation = np.array(X_validation).reshape(-1, NEW_SIZE, NEW_SIZE, 3)
y_validation = np.asarray(y_validation)
X_test = np.array(X_test).reshape(-1, NEW_SIZE, NEW_SIZE, 3)
y_test = np.asarray(y_test)
# ## Let's have a look at the size of the dataset
hist_train, bins_train = np.histogram(y_train, bins=[0, 0.5, 1])
hist_validation, bins_validation = np.histogram(y_validation, bins=[0, 0.5, 1])
hist_test, bins_test = np.histogram(y_test, bins=[0, 0.5, 1])
x_labels = ["Train", "Val", "Test"]
x_hist = np.arange(len(x_labels))
normal = [hist_train[0], hist_validation[0], hist_test[0]]
pneumonia = [hist_train[1], hist_validation[1], hist_test[1]]
width = 0.35
fig, ax = plt.subplots()
rects1 = ax.bar(x_hist - width / 2, normal, width, label="Normal")
rects2 = ax.bar(x_hist + width / 2, pneumonia, width, label="Pneumonia")
ax.set_xticks(x_hist)
ax.set_xticklabels(x_labels)
ax.legend(["Normal", "Pneumonia"])
fig.tight_layout()
plt.show()
# ## We can see that it is a clearly unbalnace dataset
# ## Let's have a look at the images
fig = plt.figure(figsize=(16, 16))
for counter, img in enumerate(X_train[:5]):
ax = fig.add_subplot(1, 5, counter + 1)
ax.imshow(X_train[counter, :, :], cmap="gray")
plt.title("Normal")
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
for counter, img in enumerate(X_train[-5:]):
ax = fig.add_subplot(2, 5, counter + 1)
ax.imshow(X_train[-5 + counter, :, :], cmap="gray")
plt.title("Pneumonia")
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
plt.tight_layout()
plt.show()
# ## To evaluate these datasets we will use transfer learning
# ## Specifically, we will use the VGG16 model trained with the imagenet dataset (available in Keras), and then add a couple of dense layer and an output layer
base_model = VGG16(
include_top=False,
weights="imagenet",
input_shape=(NEW_SIZE, NEW_SIZE, 3),
pooling="avg",
)
model = Sequential()
model.add(base_model)
model.add(Dense(256))
model.add(Activation("relu"))
model.add(Dropout(0.2))
model.add(Dense(128))
model.add(Activation("relu"))
model.add(Dropout(0.2))
model.add(Dense(2, activation="softmax"))
# ## We comnpile the model
model.compile(
loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"]
)
model.summary()
# ## Validation dataset is pretty small, only 8 images for each label. Thus, I will go for splitting the train dataset into training and validation
(X_train2, X_val2, y_train2, y_val2) = train_test_split(
X_train, y_train, test_size=0.3, random_state=42
)
# ## Creation of generators for: augmentation of training data and for normalization of validation data
aug_train = ImageDataGenerator(
rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest",
)
generator_val = ImageDataGenerator()
aug_train.fit(X_train2)
generator_val.fit(X_val2)
# ## Fitting the data
base_model.trainable = False
earlystop = EarlyStopping(patience=10)
history = model.fit(
aug_train.flow(X_train2, y_train2, batch_size=32),
validation_data=generator_val.flow(X_val2, y_val2, batch_size=32),
epochs=100,
callbacks=[earlystop],
)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
break
# Any results you write to the current directory are saved as output.
# DATA LOAD
import os
data_dir = "/kaggle/input/proy1segmentaciondeimagenesdermatoscopicas/"
imgs_files = [
os.path.join(data_dir, "Images/Images", f)
for f in sorted(os.listdir(os.path.join(data_dir, "Images/Images")))
if (
os.path.isfile(os.path.join(data_dir, "Images/Images", f))
and f.endswith(".jpg")
)
]
masks_files = [
os.path.join(data_dir, "Masks/Masks", f)
for f in sorted(os.listdir(os.path.join(data_dir, "Masks/Masks")))
if (os.path.isfile(os.path.join(data_dir, "Masks/Masks", f)) and f.endswith(".png"))
]
# Ordenamos para que cada imagen se corresponda con cada máscara
imgs_files.sort()
masks_files.sort()
print("Number of images", len(imgs_files))
print("Number of masks", len(masks_files))
# Convert files into skimages and visualize
import matplotlib.pyplot as plt
from skimage import io
images = io.ImageCollection(imgs_files)
masks = io.ImageCollection(masks_files)
index = 1
plt.figure(figsize=(15, 8))
for i in range(4):
plt.subplot(2, 4, index)
plt.imshow(images[i])
index += 1
plt.title("Image %i" % (i))
plt.subplot(2, 4, index)
plt.imshow(masks[i], cmap="gray")
index += 1
plt.title("Mask %i" % (i))
# PREPROCESSING
# Grayscale
from skimage.color import rgb2gray
gray_images = [rgb2gray(image) for image in images]
plt.imshow(gray_images[2], cmap="gray")
print(gray_images[2].shape)
print(masks[2].shape)
# Note that images and mask have the same size
# **As we can see, there are black borders at the image, which must be removed while prepocessing.**
# **Another option is removing those borders from the mask when postprocessing.**
# IMAGE SEGMENTATION
import copy
from skimage import filters
automated_masks = []
for i, image in enumerate(gray_images):
val = filters.threshold_otsu(image)
my_mask = image < val
automated_masks.append(my_mask)
plt.figure(figsize=(20, 20))
plt.subplot(1, 3, 1)
plt.imshow(gray_images[1], cmap="gray")
plt.title("Dermoscopy image")
plt.subplot(1, 3, 2)
plt.imshow(masks[1], cmap="gray")
plt.title("True mask ")
plt.subplot(1, 3, 3)
plt.imshow(automated_masks[1], cmap="gray")
plt.title("Automated mask before postprocessing")
print(len(automated_masks))
type(automated_masks)
# POSTPORCESSING
# Fill holes within a mask
from scipy import ndimage
automated_masks_post = []
for i, auto_mask in enumerate(automated_masks):
fill_holes = ndimage.binary_fill_holes(auto_mask)
automated_masks_post.append(fill_holes)
print(len(automated_masks_post))
index = 1
for i in range(3):
plt.figure(figsize=(20, 60))
plt.subplot(3, 4, index)
plt.imshow(gray_images[i], cmap="gray")
plt.title("Dermoscopy image")
index += 1
plt.subplot(3, 4, index)
plt.imshow(masks[i], cmap="gray")
plt.title("True mask ")
index += 1
plt.subplot(3, 4, index)
plt.imshow(automated_masks[i], cmap="gray")
plt.title("Automated mask before postprocessing")
index += 1
plt.subplot(3, 4, index)
plt.imshow(automated_masks_post[i], cmap="gray")
plt.title("Automated mask after postprocessing")
index += 1
# **We can appreciate that at the last mask an inner hole was removed.
# Nevertheless all the masks should be smoothed to reach better results.
# Moreover, the black border must be eliminated.**
# EVALUATION
index = 1
# To visualize the performance of the algorithm
for i in range(3):
intersection = np.logical_and(masks[i], automated_masks_post[i])
union = np.logical_or(masks[i], automated_masks_post[i])
iou_score = np.sum(intersection) / np.sum(union)
plt.figure(figsize=(20, 60))
plt.subplot(3, 4, index)
plt.imshow(images[i])
plt.imshow(masks[i], cmap="RdYlGn", alpha=0.3)
plt.title("Ground truth")
index += 1
plt.subplot(3, 4, index)
plt.imshow(images[i])
plt.imshow(automated_masks_post[i], cmap="RdYlGn", alpha=0.3)
plt.title("Automated mask iou score %f" % (iou_score))
index += 1
plt.subplot(3, 4, index)
plt.imshow(images[i])
plt.imshow(intersection, cmap="RdYlGn", alpha=0.3)
plt.title("Intersection")
index += 1
plt.subplot(3, 4, index)
plt.imshow(images[i])
plt.imshow(union, cmap="RdYlGn", alpha=0.3)
plt.title("Union")
index += 1
from skimage.metrics import mean_squared_error
i = 1
MSE = mean_squared_error(masks[i], automated_masks_post[i])
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
df = pd.read_csv(
"/kaggle/input/key-indicators-of-heart-disease/heart_2022_Key_indicators.csv"
)
df.sample(3)
# ## Basic Preprocessing
df.info()
df.isnull().sum()
df.describe()
df.shape
# ## Data Processing
cat_df = df.select_dtypes(exclude=np.number)
target = cat_df["HeartDisease"]
cat_df.drop("HeartDisease", axis=1, inplace=True)
num_df = df.select_dtypes(include=np.number)
cat_df.sample(2)
num_df.sample(2)
# ## ---> Categorical processing
# * One hot encoding
# * Label Encoding
import matplotlib.pyplot as plt
import seaborn as sn
from sklearn.preprocessing import LabelEncoder
cat_cols = cat_df.columns
cat_cols
# ### ------> Unique values for each column
for col in cat_cols:
print(f"Unique {col}===============>", cat_df[col].unique())
value_cnts = {}
for col in cat_cols:
value_cnt = {}
for uv in cat_df[col].unique():
value_cnt[uv] = len(cat_df[cat_df[col] == uv])
value_cnts[col] = value_cnt
value_cnts
# ### ------> Unique values and their counts
plt.figure(figsize=(12, 8))
for i, col in enumerate(cat_cols[:6]):
plt.subplot(3, 2, i + 1)
sn.barplot(x=list(value_cnts[col].keys()), y=list(value_cnts[col].values()))
plt.title(col)
plt.show()
plt.figure(figsize=(12, 8))
temp = cat_cols[6:-4]
for i, col in enumerate(temp):
plt.subplot(2, 2, i + 1)
sn.barplot(x=list(value_cnts[col].keys()), y=list(value_cnts[col].values()))
plt.title(col)
plt.xticks(rotation=45)
plt.show()
plt.figure(figsize=(12, 8))
temp = cat_cols[10:]
for i, col in enumerate(temp):
plt.subplot(2, 2, i + 1)
sn.barplot(x=list(value_cnts[col].keys()), y=list(value_cnts[col].values()))
plt.title(col)
plt.xticks(rotation=45)
plt.show()
# ### ------> One hot encoding
cat_df_1hot = pd.get_dummies(cat_df)
cat_df_1hot.sample(4)
# ### ------> Label Encoding
encoder = LabelEncoder()
target = encoder.fit_transform(target)
target
# ## ---> Numerical Process
# >No need to process numerical data it is already in better format
num_df.sample(4)
# ## Training Model
df_final = pd.concat([num_df, cat_df_1hot], axis=1)
df_final.head(2)
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier, BaggingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
import warnings
warnings.filterwarnings("ignore")
X_train, X_test, y_train, y_test = train_test_split(df_final, target, test_size=0.3)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
model_rf = RandomForestClassifier()
model_rf.fit(X_train, y_train)
print("train score", model_rf.score(X_train, y_train))
print("test score", model_rf.score(X_test, y_test))
model_bg = BaggingClassifier()
model_bg.fit(X_train, y_train)
print("train score", model_bg.score(X_train, y_train))
print("test score", model_bg.score(X_test, y_test))
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)
print("train score", model_lr.score(X_train, y_train))
print("test score", model_lr.score(X_test, y_test))
model_dt = DecisionTreeClassifier()
model_dt.fit(X_train, y_train)
print("train score", model_dt.score(X_train, y_train))
print("test score", model_dt.score(X_test, y_test))
model_dt = DecisionTreeClassifier()
model_dt.fit(X_train, y_train)
print("train score", model_dt.score(X_train, y_train))
print("test score", model_dt.score(X_test, y_test))
|
# **Introduction**
# This is a very basic implementation of convolutional neural network (CNN) without using pretrained models. Fully implemented using keras. You can learn following things by reading this.
# 1. Keras implementation of a CNN.
# 2. StratidiedKFold evaluation.
# 3. Utility funcitons required when working with images.
# *Comment your improvements and be sure the upvote.*
# **Imports and Workspace setting**
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.utils import np_utils
from keras.utils import to_categorical
from keras.preprocessing.image import ImageDataGenerator, img_to_array, image, load_img
from keras import backend as K
from keras.optimizers import Adam, SGD
from keras.callbacks import ReduceLROnPlateau, EarlyStopping
from keras.models import load_model
import os
import numpy as np
import pandas as pd
import csv
from sklearn.model_selection import StratifiedKFold
from mpl_toolkits.axes_grid1 import ImageGrid
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [16, 10]
plt.rcParams["font.size"] = 16
# Variable defining
SAMPLE_PER_CATEGORY = 200
SEED = 1987
WIDTH = 64
HEIGHT = 64
DEPTH = 3
INPUT_SHAPE = (WIDTH, HEIGHT, DEPTH)
data_dir = "../input/plant-seedlings-classification/"
train_dir = os.path.join(data_dir, "train")
test_dir = os.path.join(data_dir, "test")
sample_submission = pd.read_csv(os.path.join(data_dir, "sample_submission.csv"))
# **Defining categories**
CATEGORIES = [
"Black-grass",
"Charlock",
"Cleavers",
"Common Chickweed",
"Common wheat",
"Fat Hen",
"Loose Silky-bent",
"Maize",
"Scentless Mayweed",
"Shepherds Purse",
"Small-flowered Cranesbill",
"Sugar beet",
]
NUM_CATEGORIES = len(CATEGORIES)
NUM_CATEGORIES
# **Training sample data set info**
for category in CATEGORIES:
print(
"{} {} images".format(
category, len(os.listdir(os.path.join(train_dir, category)))
)
)
def read_img(filepath, size):
img = image.load_img(
os.path.join(data_dir, filepath), target_size=size
) ## https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/image/load_img
img = image.img_to_array(img)
return img
train = []
for category_id, category in enumerate(CATEGORIES):
for file in os.listdir(os.path.join(train_dir, category)):
train.append(["train/{}/{}".format(category, file), category_id, category])
train = pd.DataFrame(train, columns=["file", "category_id", "category"])
train.shape
train.head(2)
# **Generating vector for training samples taking equal number of images from each category**
train = pd.concat(
[train[train["category"] == c][:SAMPLE_PER_CATEGORY] for c in CATEGORIES]
)
train = train.sample(frac=1)
train.index = np.arange(len(train))
train.shape
train
# **Understanding test-set**
test = []
for file in os.listdir(test_dir):
test.append(["test/{}".format(file), file])
test = pd.DataFrame(test, columns=["filepath", "file"])
test.shape
test.head(2)
# **Generating example images**
fig = plt.figure(1, figsize=(NUM_CATEGORIES, NUM_CATEGORIES))
grid = ImageGrid(fig, 111, nrows_ncols=(NUM_CATEGORIES, NUM_CATEGORIES), axes_pad=0.05)
i = 0
for category_id, category in enumerate(CATEGORIES):
for filepath in train[train["category"] == category]["file"].values[
:NUM_CATEGORIES
]:
ax = grid[i]
img = read_img(filepath, (WIDTH, HEIGHT))
ax.imshow(img / 255.0)
ax.axis("off")
if i % NUM_CATEGORIES == NUM_CATEGORIES - 1:
ax.text(250, 112, filepath.split("/")[1], verticalalignment="center")
i += 1
plt.show()
np.random.seed(seed=SEED)
# Used following articles and kernels for this work:
# > https://www.kaggle.com/chamathsajeewa/simple-convolution-neural-network
# > https://medium.com/@vijayabhaskar96/tutorial-on-keras-flow-from-dataframe-1fd4493d237c
# > https://www.kaggle.com/gaborfodor/seedlings-pretrained-keras-models
#
# create model from scratch
def createModel(number_of_hidden_layers, activation, optimizer, learning_rate, epochs):
print("Create Model")
model = Sequential()
model.add(Conv2D(WIDTH, (3, 3), padding="same", input_shape=INPUT_SHAPE))
model.add(Activation(activation))
model.add(Conv2D(WIDTH, (3, 3)))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(2 * WIDTH, (3, 3), padding="same"))
model.add(Activation(activation))
model.add(Conv2D(2 * WIDTH, (3, 3)))
model.add(Activation(activation))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
for i in range(0, number_of_hidden_layers):
model.add(Dense(512))
model.add(Activation(activation))
model.add(Dropout(0.3))
model.add(Dense(12, activation="softmax"))
if optimizer == "SGD":
opt = SGD(lr=learning_rate, decay=learning_rate / epochs)
elif optimizer == "Adam":
opt = Adam(lr=learning_rate, decay=learning_rate / epochs)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
return model
# **Print function for training history**
def printHistory(history, title, epochs):
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle(title, fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1, epochs + 1))
ax1.plot(epoch_list, history.history["accuracy"], label="Train Accuracy")
ax1.plot(epoch_list, history.history["val_accuracy"], label="Validation Accuracy")
ax1.set_xticks(np.arange(0, epochs + 1, 5))
ax1.set_ylabel("Accuracy Value")
ax1.set_xlabel("Epoch")
ax1.set_title("Accuracy")
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history["loss"], label="Train Loss")
ax2.plot(epoch_list, history.history["val_loss"], label="Validation Loss")
ax2.set_xticks(np.arange(0, epochs + 1, 5))
ax2.set_ylabel("Loss Value")
ax2.set_xlabel("Epoch")
ax2.set_title("Loss")
l2 = ax2.legend(loc="best")
# callbacks for keras modal
def get_callbacks(patience):
print("Get Callbacks")
lr_reduce = ReduceLROnPlateau(
monitor="val_acc", factor=0.1, min_delta=1e-5, patience=patience, verbose=1
)
# msave = ModelCheckpoint(filepath, save_best_only=True)
return [lr_reduce, EarlyStopping()]
def evaluateModelDFViaCrossValidation(
images,
epochs,
batch_size,
learning_rate,
cross_validation_folds,
activation,
number_of_hidden_layers,
optimizer,
):
print("Train Model")
datagen_train = ImageDataGenerator(rescale=1.0 / 255)
datagen_valid = ImageDataGenerator(rescale=1.0 / 255)
print("Cross validation")
kfold = StratifiedKFold(n_splits=cross_validation_folds, shuffle=True)
cvscores = []
iteration = 1
t = images.category_id
for train_index, test_index in kfold.split(np.zeros(len(t)), t):
print("======================================")
print("Iteration = ", iteration)
iteration = iteration + 1
train = images.loc[train_index]
test = images.loc[test_index]
print("======================================")
model = createModel(
number_of_hidden_layers, activation, optimizer, learning_rate, epochs
)
print("======================================")
train_generator = datagen_train.flow_from_dataframe(
dataframe=train,
directory="/kaggle/input/plant-seedlings-classification/",
x_col="file",
y_col="category",
batch_size=batch_size,
seed=SEED,
shuffle=True,
class_mode="categorical",
target_size=(HEIGHT, WIDTH),
)
valid_generator = datagen_valid.flow_from_dataframe(
dataframe=test,
directory="/kaggle/input/plant-seedlings-classification/",
x_col="file",
y_col="category",
batch_size=batch_size,
seed=SEED,
shuffle=False,
class_mode="categorical",
target_size=(HEIGHT, WIDTH),
)
STEP_SIZE_TRAIN = train_generator.n // train_generator.batch_size
STEP_SIZE_VALID = valid_generator.n // valid_generator.batch_size
# Trains the model on data generated batch-by-batch by a Python generator
history = model.fit_generator(
generator=train_generator,
validation_data=valid_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_steps=STEP_SIZE_VALID,
epochs=epochs,
verbose=1,
) # , \
# callbacks = get_callbacks(patience=2))
scores = model.evaluate_generator(
generator=valid_generator, steps=STEP_SIZE_VALID, pickle_safe=True
)
print("Accuarcy %s: %.2f%%" % (model.metrics_names[1], scores[1] * 100))
cvscores.append(scores[1] * 100)
printHistory(history, "Basic CNN performance", epochs)
accuracy = np.mean(cvscores)
std = np.std(cvscores)
print("Accuracy: %.2f%% (+/- %.2f%%)" % (accuracy, std))
return accuracy, std
# Use different combinations to find the best params.
# Also change the CreateModel function to change the network architecture
# evaluateModelDFViaCrossValidation(
# train,
# batch_size =32,
# cross_validation_folds = 5,
# learning_rate = 0.001,
# activation = 'relu',
# number_of_hidden_layers = 4,
# optimizer = 'Adam',
# epochs = 48
# )
# **Build the model with best params and save it**
def trainFinalModel(
images,
epochs,
batch_size,
learning_rate,
activation,
number_of_hidden_layers,
optimizer,
):
print("Train Model")
datagen_train = ImageDataGenerator(rescale=1.0 / 255)
print("======================================")
model = createModel(
number_of_hidden_layers, activation, optimizer, learning_rate, epochs
)
print("======================================")
train_generator = datagen_train.flow_from_dataframe(
dataframe=images,
directory="/kaggle/input/plant-seedlings-classification/",
x_col="file",
y_col="category",
batch_size=batch_size,
seed=SEED,
shuffle=True,
class_mode="categorical",
target_size=(HEIGHT, WIDTH),
)
STEP_SIZE_TRAIN = train_generator.n // train_generator.batch_size
# Trains the model on data generated batch-by-batch by a Python generator
model.fit_generator(
generator=train_generator,
steps_per_epoch=STEP_SIZE_TRAIN,
epochs=epochs,
verbose=1,
) # , \
# callbacks = get_callbacks(patience=2))
model.save("/kaggle/working/best_model")
# predict values
def predict_createSubmission():
print("Predicting......")
datagen_test = ImageDataGenerator(rescale=1.0 / 255)
test_generator = datagen_test.flow_from_dataframe(
dataframe=test,
directory="/kaggle/input/plant-seedlings-classification/test/",
x_col="file",
y_col=None,
batch_size=1,
seed=SEED,
shuffle=False,
class_mode=None,
target_size=(HEIGHT, WIDTH),
)
model = load_model("/kaggle/working/best_model")
filenames = test_generator.filenames
nb_samples = len(filenames)
predictions = model.predict_generator(
test_generator, steps=nb_samples
) # return prob of each class per image (softmax)
predicted_class_indices = np.argmax(predictions, axis=1)
predicted_labels = [CATEGORIES[k] for k in predicted_class_indices]
results = pd.DataFrame({"file": filenames, "species": predicted_labels})
print(results)
results.to_csv("submission.csv", index=False)
print("Prediction Completed")
# **Do predictions on given test images and submit predictions**
# Following model parameters were identified as best by evaluating various combinations above.
trainFinalModel(
train,
batch_size=32,
learning_rate=0.001,
activation="relu",
number_of_hidden_layers=2,
optimizer="Adam",
epochs=32,
)
predict_createSubmission()
|
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn import preprocessing
import matplotlib.pyplot as plt
SS = pd.read_csv("/kaggle/input/rsna-breast-cancer-detection/sample_submission.csv")
TE = pd.read_csv("/kaggle/input/rsna-breast-cancer-detection/test.csv")
TR = pd.read_csv("/kaggle/input/rsna-breast-cancer-detection/train.csv")
print(SS)
print(TE)
print(TR)
SS.head()
TE.head()
TR.head()
SS.shape
TE.shape
TR.shape
SS.dtypes
TE.dtypes
TR.dtypes
SS.isnull().sum()
TE.isnull().sum()
TR.isnull().sum()
SS.info()
TE.info()
TR.info()
SS.describe()
TE.describe()
TR.describe()
CS = SS.corr()
print(CS)
CE = TE.corr()
print(CE)
CR = TR.corr()
print(CR)
sns.heatmap(CS)
sns.heatmap(CE)
sns.heatmap(CR)
sns.heatmap(CS, annot=True)
sns.heatmap(CE, annot=True)
sns.heatmap(CR, annot=True)
sns.pairplot(SS)
sns.pairplot(TE)
SS.to_csv("submission.csv", index=False)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
tweets = pd.read_csv("/kaggle/input/trump-tweets/trumptweets.csv")
tweets.head(50)
tweets = tweets[["content"]]
tweets.head(5)
tweets.shape
def remove_punctuation(text):
"""a function for removing punctuation"""
import string
# replacing the punctuations with no space.
# which in effect deletes the punctuation marks.
translator = str.maketrans("", "", string.punctuation)
# return the text stripped of punctuation marks.
return text.translate(translator)
tweets["text"] = tweets["content"].apply(remove_punctuation)
tweets.head(10)
tweets = tweets["text"]
tweets.head(10)
from fastai.text import *
data = pd.read_csv("/kaggle/input/trump-tweets/trumptweets.csv", encoding="latin1")
data.head()
data = (
TextList.from_df(data, cols="content")
.split_by_rand_pct(0.1)
.label_for_lm()
.databunch(bs=48)
)
data.show_batch()
# Create deep learning model
learn = language_model_learner(data, AWD_LSTM, drop_mult=0.3, model_dir="/tmp/work")
# select the appropriate learning rate
learn.lr_find()
# we typically find the point where the slope is steepest
learn.recorder.plot(skip_end=15)
# Fit the model based on selected learning rate
learn.fit_one_cycle(1, 1e-2, moms=(0.8, 0.7))
# Predict Tweets starting from the given words
N_WORDS = 20
print(learn.predict("Clean energy will be", N_WORDS, temperature=0.75))
print(learn.predict("Russian hackers", N_WORDS, temperature=0.75))
print(learn.predict("Tesla", N_WORDS, temperature=0.75))
print(learn.predict("Clean energy will be", 2, temperature=0.75))
print(learn.predict("Clean energy will be", 10, temperature=0.75))
print(learn.predict("Global warming", 10, temperature=0.75))
print(learn.predict("Clean energy will be", 11, temperature=0.75))
print(learn.predict("Global warming", 11, temperature=0.75))
print(learn.predict("White house", 10, temperature=0.75))
print(learn.predict("I am", 10, temperature=0.75))
print(learn.predict("Deep fake", 10, temperature=0.75))
print(learn.predict("Calling", 10, temperature=0.75))
print(learn.predict("Putin", 10, temperature=0.75))
print(learn.predict("Russia", 10, temperature=0.75))
print(learn.predict("Nuclear war is", 10, temperature=0.75))
print(learn.predict("Iran is democratic", 10, temperature=0.75))
print(learn.predict("Global warming", 10, temperature=0.75))
|
# # Project 3
# We've built low-level models, and we've built high-level models. Now, our goal is two-fold:
# - Build low-level models into better high-level models, and vice-versa.
# - Ensemble our models to make them more reliable
# The process for performing hierarchical reconciliation is laid out well [here](https://nixtla.github.io/hierarchicalforecast/examples/tourismsmall.html). I'd recommend following along!
# Let's get going!
data_dir = "/kaggle/input/project-2-data/project_2_data"
preds_dir = "/kaggle/input/project-3-preds"
# ## Hierarchical Forecasting
# add imports
import pandas as pd
import numpy as np
# We're going to start by building a model at the store-deparment level. Our goal is to create a forecast at that level that coherently aggregates up to the state level.
data = (
pd.read_parquet(f"{data_dir}/sales_data.parquet")
.reset_index()
.rename(columns={"date": "ds", "sales": "y"})
.assign(store_dept_id=lambda df: df.store_id + "_" + df.dept_id)
.groupby(["ds", "store_dept_id", "store_id", "state_id"])
.y.sum()
.reset_index()
)
data.head()
# Now it's time to set up our hierarchical data. Use the `aggregate` method from `hierarchicalforecast` to hierarchically structure our data and get the proper summing dataframe.
from hierarchicalforecast.utils import aggregate
# this is the `spec` argument in the `aggregate` function
hierarchy_levels = [
["state_id"],
["state_id", "store_id"],
["state_id", "store_id", "store_dept_id"],
]
y_hier, S_df, tags = aggregate(df=data, spec=hierarchy_levels)
y_hier = y_hier.reset_index()
y_hier.head()
tags
from hierarchicalforecast.utils import HierarchicalPlot
hplots = HierarchicalPlot(S_df, tags)
hplots.plot_summing_matrix()
# I went ahead and split your data for you. Train a `StatsForecast` model (any algorithm works, I used AutoARIMA). Be sure to grab the fitted values (i.e. the predictions on the training set), since we'll need that later.
val = y_hier.groupby("unique_id").tail(28)
train = y_hier.drop(val.index)
from statsforecast import StatsForecast
from statsforecast.models import AutoETS
fcst = StatsForecast(models=[AutoETS(season_length=7)], freq="D")
models = fcst.fit(train)
y_fcst = fcst.forecast(h=28, fitted=True) # forecast on the validation period
y_fitted = (
fcst.forecast_fitted_values()
) # fitted values, i.e. forecast on the training data
# Use the `StatsForecast.plot` method to visualize your predictions. Try passing `plot_random=False` to see how the model performs at the top levels.
Y_df = y_hier.merge(
y_fcst.reset_index(), on=["ds", "unique_id"], how="outer"
).set_index("unique_id")
Yval_df = val.merge(
y_fcst.reset_index(), on=["ds", "unique_id"], how="outer"
).set_index("unique_id")
# Notebook too big, need to reduce the number of images
# hplots.plot_hierarchically_linked_series('TX/TX_3/TX_3_HOUSEHOLD_2', Y_df=Y_df, models=['y', 'AutoETS'])
# hplots.plot_hierarchically_linked_series('TX/TX_3/TX_3_HOUSEHOLD_2', Y_df=Yval_df)
# fcst.plot(y_hier.set_index('unique_id'), y_fcst, plot_random=True)
fcst.plot(val.set_index("unique_id"), y_fcst, plot_random=False)
# Now it's time to reconcile! Use the BottomUp, TopDown, and MinTrace reconciliation methods. For TopDown and MinTrace, try out the different methods provided by `hierarchicalforecast` to see which ones work best.
from hierarchicalforecast.core import HierarchicalReconciliation
from hierarchicalforecast.methods import (
BottomUp,
TopDown,
MiddleOut,
MinTrace,
OptimalCombination,
ERM,
)
reconcilers = [
BottomUp(),
MiddleOut(middle_level="state_id/store_id", top_down_method="forecast_proportions"),
MiddleOut(middle_level="state_id/store_id", top_down_method="average_proportions"),
MiddleOut(middle_level="state_id/store_id", top_down_method="proportion_averages"),
TopDown(method="forecast_proportions"),
TopDown(method="average_proportions"),
TopDown(method="proportion_averages"),
MinTrace(method="ols"),
MinTrace(method="wls_struct"),
MinTrace(method="wls_var"),
MinTrace(method="mint_shrink"),
MinTrace(method="mint_cov"),
OptimalCombination(method="ols"),
OptimalCombination(method="wls_struct"),
ERM(method="closed"),
ERM(method="reg"),
ERM(method="reg_bu"),
]
hrec = HierarchicalReconciliation(reconcilers=reconcilers)
y_rec = hrec.reconcile(Y_hat_df=y_fcst, Y_df=y_fitted, S=S_df, tags=tags)
y_rec.groupby("unique_id").head(2).head(10)
# Plot the results for your raw model predictions against the hierarchical predictions. How closely do the direct, non-hierarchical forecasts agree/disagree? What about the hierarchical forecasts?
# Hint: the below plot shows a sample, but the answer to this question lies with `plot_hierarchical_predictions_gap()`. Check out some of the other plotting methods, too!
Y_rec_df = val.merge(y_rec, on=["unique_id", "ds"]).set_index("unique_id")
Y_recs = [col for col in Y_rec_df.columns if col not in ["ds", "y"]]
len(Y_recs)
hplots = HierarchicalPlot(S_df, tags)
hplots.plot_hierarchically_linked_series(
bottom_series="TX/TX_3/TX_3_HOUSEHOLD_2",
Y_df=Y_rec_df[["ds", "y"] + Y_recs[0:9]],
)
hplots.plot_hierarchically_linked_series(
bottom_series="TX/TX_3/TX_3_HOUSEHOLD_2",
Y_df=Y_rec_df[["ds", "y"] + Y_recs[9:]],
)
hplots.plot_hierarchical_predictions_gap(
Y_df=Y_rec_df, models=["AutoETS/MinTrace_method-ols"]
)
hplots.plot_hierarchical_predictions_gap(Y_df=Y_rec_df, models=["AutoETS"])
# I can't put too many plots, but in these four we can see that the hierarchical models agree alot more then the non-hierarchical.
# Use the helper code below to calculate RMSSE for every method you tried, at every level of the hierarchy. This code is borrowed and modified from the `hierarchicalforecast` library, because their implementation of `msse` is different than our version. This formulation of RMSSE should line up with the formulation from Project 2.
from hierarchicalforecast.evaluation import HierarchicalEvaluation
def mse(y, y_hat, weights=None, axis=None):
delta_y = np.square(y - y_hat)
if weights is not None:
mse = np.average(delta_y, weights=weights, axis=axis)
else:
mse = np.nanmean(delta_y, axis=axis)
return mse
def rmsse(y, y_hat, y_insample, mask=None, insample_mask=None):
if mask is None:
mask = np.ones_like(y)
eps = np.finfo(float).eps
norm = mse(
y=y_insample[:, 1:], y_hat=y_insample[:, :-1], weights=insample_mask, axis=1
)
loss = mse(y=y, y_hat=y_hat, weights=mask, axis=1)
loss = np.sqrt(loss / (norm + eps))
return loss.mean()
HierarchicalEvaluation([rmsse]).evaluate(
Y_hat_df=y_rec, # your reconciled forecasts
Y_test_df=val.set_index(
"unique_id"
), # validation actuals DF, with unique_id as index
tags=tags, # tags from aggregate()
Y_df=train.set_index("unique_id"), # training actuals DF, with unique_id as index
)
# Answer the following questions:
# - What's more accurate, the direct forecast, or the hierarchical methods?
# - What's the most accurate method for top-level aggregation (i.e. the `state_id` level)?
# - What's the most accurate method for bottom-level aggregation (i.e. the `state_id`/`store_id`/`store_dept_id` level)?
# Using the MinTrace and OptmimalCombination methods of reconciliation seems to yield better RMSSE values Overall, and for `state_id`, and `state_id/store_id/store_dept_id` levels. ERM-reg showed a better performance on `state_id` and `state_id/store_id` level, ERM-closed was horrible though.
# I want to point out that Middle out despite getting 0.742 RMSSE for the state_id level, the `average_proportions` method yeilded many NaN values. I don't know if it was a error in set up, or it was expected given the data.
# ## Ensembling
# Now, let's try to ensemble predictions from multiple models.
# Below, fit two models -- one `mlforecast` model (could be the same one you used in Project 2), and one `statsforecast` model. You can fit the models at any level you want (just make sure both are fit at the same level), but I'd recommend trying out `item_id`. It's a little faster than at the `id` level, and it gives both models a good opportunity to show their diversity.
# Once you've fit both models, be sure to plot some sample predictions.
# Don't worry about tuning the performance much here. This is more about seeing ensembling in action than optimizing your individual models!
# [Optional, if you have extra time] You can also fit a `neuralforecast` model.
# read in a fresh copy of the data
data = (
pd.read_parquet(f"{data_dir}/sales_data.parquet")
.reset_index()
.groupby(["date", "item_id", "dept_id", "cat_id"])
.sales.sum()
.reset_index()
.assign(unique_id=lambda df: df.item_id.copy())
.rename(columns={"date": "ds", "sales": "y"})
)
data.head()
prices = (
pd.read_parquet(f"{data_dir}/prices.parquet")
.groupby(["date", "item_id"])
.sum()
.reset_index()
.assign(unique_id=lambda df: df.item_id.copy())
.rename(columns={"date": "ds"})
)
prices.head()
calendar = (
pd.read_parquet(f"{data_dir}/calendar.parquet")
.reset_index()
.rename(columns={"date": "ds"})
)
calendar.head()
data = (
data[["ds", "item_id", "dept_id", "cat_id", "unique_id", "y"]]
.merge(prices, how="left", on=["ds", "item_id", "unique_id"])
.merge(calendar, how="left", on=["ds"])
)
data = (
data.assign(
item_id=data.item_id.astype("category"),
dept_id=data.dept_id.astype("category"),
cat_id=data.cat_id.astype("category"),
event_name_1=data.event_name_1.astype("category"),
event_type_1=data.event_type_1.astype("category"),
event_name_2=data.event_name_2.astype("category"),
event_type_2=data.event_type_2.astype("category"),
)
.set_index(["unique_id", "ds"])
.sort_index()
)
data.head()
data
val_data = data.reset_index().groupby("unique_id").tail(28)
y = val_data.sort_values(["unique_id", "ds"]).y.values.reshape(-1, 28)
display(val_data)
train_data = data.reset_index().drop(val_data.index)
y_insample = train_data.sort_values(["unique_id", "ds"]).y.values.reshape(-1, 1210)
insample_mask = (y_insample.cumsum(axis=1) > 0).astype(int)[:, 1:]
display(train_data)
from statsforecast import StatsForecast
from mlforecast import MLForecast
from sklearn.preprocessing import OrdinalEncoder
from window_ops.rolling import (
rolling_mean,
seasonal_rolling_mean,
rolling_std,
rolling_max,
rolling_min,
)
from numba import njit
import lightgbm as lgb
import random
random.seed(415)
ml_skip = False # If True it would skip training and load previous saved forecast data.
if ml_skip:
preds_ml = pd.read_parquet(f"{preds_dir}/project_3_preds_ml_lgbm.parquet")
else:
val = val_data.copy(deep=True)
train = train_data.copy(deep=True)
# label encode categorical features
cat_feats = ["unique_id", "item_id", "snap_TX"]
enc_cat_feats = [f"{feat}_enc" for feat in cat_feats]
numeric_features = [
"sell_price",
"sell_price_rolling_max",
"sell_price_rolling_min",
]
train["sell_price_rolling_max"] = rolling_max(
train["sell_price"].to_numpy(), window_size=7
)
train["sell_price_rolling_min"] = rolling_min(
train["sell_price"].to_numpy(), window_size=7
)
val["sell_price_rolling_max"] = rolling_max(
val["sell_price"].to_numpy(), window_size=7
)
val["sell_price_rolling_min"] = rolling_min(
val["sell_price"].to_numpy(), window_size=7
)
encoder = OrdinalEncoder()
train[enc_cat_feats] = encoder.fit_transform(train[cat_feats])
val[enc_cat_feats] = encoder.transform(val[cat_feats])
reference_cols = ["unique_id", "ds", "y"]
# add features to this list if you want to use them
features = reference_cols + enc_cat_feats + numeric_features
train = train[features]
val = val[features]
@njit
def rolling_max_14(x):
return rolling_max(x, window_size=14)
@njit
def rolling_mean_28(x):
return rolling_mean(x, window_size=28)
@njit
def rolling_std_28(x):
return rolling_std(x, window_size=28)
@njit
def rolling_mean_7(x):
return rolling_mean(x, window_size=7)
@njit
def seasonal_rolling_mean_7(x):
return seasonal_rolling_mean(x, season_length=7, window_size=4, min_samples=1)
# feel free to tweak these parameters!
lgb_model_params = {
"verbose": -1,
"num_leaves": 512,
"n_estimators": 100,
"objective": "tweedie",
"tweedie_variance_power": 1.1,
"boosting": "dart",
"learning_rate": 0.1,
}
models = [lgb.LGBMRegressor(**lgb_model_params)]
fcst = MLForecast(
models=models,
freq="D",
# dictionary reads like this:
# {number of days to lag the feature: [list of functions to apply to the lagged data]}
# lags=[1, 2, 3, 7],
lag_transforms={
7: [rolling_mean_7, rolling_mean_28, seasonal_rolling_mean_7],
14: [rolling_mean_28],
21: [rolling_mean_28],
28: [rolling_mean_28],
},
date_features=["dayofweek", "dayofyear", "week"],
)
fcst.fit(
train,
id_col="unique_id",
time_col="ds",
target_col="y",
dropna=False,
static_features=["unique_id_enc", "item_id_enc"],
)
preds_ml = fcst.predict(28, dynamic_dfs=[val])
preds_ml.to_parquet("/kaggle/working/project_3_preds_ml_lgbm.parquet")
lgb.plot_importance(fcst.models_["LGBMRegressor"])
y_hat_ml = preds_ml.sort_values(["unique_id", "ds"]).LGBMRegressor.values.reshape(
-1, 28
)
print(
f"LightGBM Tweedie RMSSE: {rmsse(y, y_hat_ml, y_insample, insample_mask=insample_mask)}"
)
StatsForecast.plot(val_data[["unique_id", "ds", "y"]], preds_ml, level=[80, 90])
from ray import tune
from statsforecast import StatsForecast
from neuralforecast import NeuralForecast
from neuralforecast.auto import AutoNHITS, AutoTFT
from neuralforecast.losses.pytorch import DistributionLoss
from sklearn.preprocessing import OrdinalEncoder
from window_ops.rolling import (
rolling_mean,
seasonal_rolling_mean,
rolling_std,
rolling_max,
rolling_min,
)
from numba import njit
import random
random.seed(415)
nf_skip = True # If True it would skip training and load previous saved forecast data.
if nf_skip:
preds_nf = pd.read_parquet(f"{preds_dir}/project_3_preds_nf.parquet")
else:
val = val_data.copy(deep=True)
train = train_data.copy(deep=True)
# label encode categorical features
cat_feats = [
"unique_id",
"item_id",
"dept_id",
"cat_id",
"event_type_1",
"event_type_2",
]
enc_cat_feats = [f"{feat}_enc" for feat in cat_feats]
numeric_features = [
"sell_price",
"sell_price_rolling_max",
"sell_price_rolling_min",
]
train["sell_price_rolling_max"] = rolling_max(
train["sell_price"].to_numpy(), window_size=7
)
train["sell_price_rolling_min"] = rolling_min(
train["sell_price"].to_numpy(), window_size=7
)
val["sell_price_rolling_max"] = rolling_max(
val["sell_price"].to_numpy(), window_size=7
)
val["sell_price_rolling_min"] = rolling_min(
val["sell_price"].to_numpy(), window_size=7
)
encoder = OrdinalEncoder()
train[enc_cat_feats] = encoder.fit_transform(train[cat_feats])
val[enc_cat_feats] = encoder.transform(val[cat_feats])
reference_cols = ["unique_id", "ds", "y"]
# add features to this list if you want to use them
features = reference_cols + enc_cat_feats + numeric_features
train = train[features]
val = val[features]
config_nhits = {
"input_size": tune.choice(
[28, 28 * 2, 28 * 3, 28 * 5]
), # Length of input window
"n_blocks": 5 * [1], # Length of input window
"mlp_units": 5 * [[512, 512]], # Length of input window
"n_pool_kernel_size": tune.choice(
[5 * [1], 5 * [2], 5 * [4], [8, 4, 2, 1, 1]]
), # MaxPooling Kernel size
"n_freq_downsample": tune.choice(
[[8, 4, 2, 1, 1], [1, 1, 1, 1, 1]]
), # Interpolation expressivity ratios
"learning_rate": tune.loguniform(1e-4, 1e-2), # Initial Learning rate
"scaler_type": tune.choice([None]), # Scaler type
"max_steps": tune.choice([1000]), # Max number of training iterations
"batch_size": tune.choice([32, 64, 128, 256]), # Number of series in batch
"windows_batch_size": tune.choice(
[128, 256, 512, 1024]
), # Number of windows in batch
"random_seed": tune.randint(1, 20), # Random seed
# "stat_exog_list": ["unique_id_enc",
# "item_id_enc",
# "dept_id_enc",
# "cat_id_enc"], # Static exogenous columns.
# "futr_exog_list": ["sell_price",
# "sell_price_rolling_max",
# "sell_price_rolling_min"], # Future exogenous columns.
}
config_tft = {
"input_size": tune.choice([28, 28 * 2, 28 * 3]), # Length of input window
"hidden_size": tune.choice([64, 128, 256]), # Size of embeddings and encoders
"learning_rate": tune.loguniform(1e-4, 1e-2), # Initial learning rate
"scaler_type": tune.choice([None]), # Scaler type
"max_steps": tune.choice([500, 1000]), # Max number of training iterations
"batch_size": tune.choice([32, 64, 128, 256]), # Number of series in batch
"windows_batch_size": tune.choice(
[128, 256, 512, 1024]
), # Number of windows in batch
"random_seed": tune.randint(1, 20), # Random seed
# "stat_exog_list": ["unique_id_enc",
# "item_id_enc",
# "dept_id_enc",
# "cat_id_enc"], # Static exogenous columns.
# "futr_exog_list": ["sell_price",
# "sell_price_rolling_max",
# "sell_price_rolling_min"], # Future exogenous columns.
}
nf = NeuralForecast(
models=[
AutoNHITS(
h=28,
config=config_nhits,
loss=DistributionLoss(
distribution="Poisson", level=[80, 90], return_params=False
),
num_samples=10,
verbose=0,
),
AutoTFT(
h=28,
config=config_tft,
loss=DistributionLoss(
distribution="Poisson", level=[80, 90], return_params=False
),
num_samples=10,
verbose=0,
),
],
freq="D",
)
cv_df = nf.cross_validation(train, n_windows=3, step_size=28)
preds_nf = nf.predict(df=train, futr_df=val)
preds_nf.columns = preds_nf.columns.str.replace("-median", "")
preds_nf.to_parquet("/kaggle/working/project_3_preds_nf.parquet")
y_hat_nf1 = preds_nf.sort_values(["unique_id", "ds"]).AutoNHITS.values.reshape(-1, 28)
print(
f"AutoNHITS RMSSE: {rmsse(y, y_hat_nf1, y_insample, insample_mask=insample_mask)}"
)
y_hat_nf2 = preds_nf.sort_values(["unique_id", "ds"]).AutoTFT.values.reshape(-1, 28)
print(f"AutoTFT RMSSE: {rmsse(y, y_hat_nf2, y_insample, insample_mask=insample_mask)}")
StatsForecast.plot(val_data[["unique_id", "ds", "y"]], preds_nf, level=[80, 90])
preds_nf
# fit a statsforecast model (AutoETS takes FOREEEEVEEER, arrgh.)
from statsforecast.core import StatsForecast
from statsforecast.models import AutoETS
random.seed(415)
sf_skip = True # If True it would skip training and load previous saved forecast data.
if sf_skip:
preds_sf = pd.read_parquet(f"{preds_dir}/project_3_preds_sf_ets.parquet")
else:
val = val_data.copy()
train = train_data.copy()
reference_cols = ["unique_id", "ds", "y"]
# add features to this list if you want to use them
features = reference_cols
train = train[features]
al = val[features]
fcst = StatsForecast(models=[AutoETS(season_length=7)], freq="D")
fcst.fit(train)
preds_sf = fcst.forecast(h=28).reset_index()
preds_sf.to_parquet("/kaggle/working/project_3_preds_sf_ets.parquet")
y_hat_sf = preds_sf.sort_values(["unique_id", "ds"]).AutoETS.values.reshape(-1, 28)
print(f"AutoETS RMSSE: {rmsse(y, y_hat_sf, y_insample, insample_mask=insample_mask)}")
StatsForecast.plot(val_data[["unique_id", "ds", "y"]], preds_sf, level=[80, 90])
# Before starting to ensemble, let's check the RMSSE of our individual models. Our modified version of RMSSE takes predictions in a rectangular shape, with each row being one `unique_id` and each column being one of the 28 predictions for the validation set. That results in an array of shape `[n_unique_ids, 28]`. We need to do the same thing for the training data (`y_insample` here) to create the scale (the denominator). Finally, we create a mask to tell the RMSSE function not to calculate the scale value before each `unique_id` has its first sale, since we don't calculate the loss over those periods.
# This code assumes you stored your `mlforecast` predictions in `preds_ml` and your `statsforecast` predictions in `preds_sf`.
# Modify it to suit your needs!
print(
f"LightGBM Tweedie RMSSE: {rmsse(y, y_hat_ml, y_insample, insample_mask=insample_mask)}"
)
print(f"AutoETS RMSSE: {rmsse(y, y_hat_sf, y_insample, insample_mask=insample_mask)}")
print(
f"AutoNHITS RMSSE: {rmsse(y, y_hat_nf1, y_insample, insample_mask=insample_mask)}"
)
print(f"AutoTFT RMSSE: {rmsse(y, y_hat_nf2, y_insample, insample_mask=insample_mask)}")
# Create `y_hat`, which is a NumPy array of all of your model's predictions combined along a new axis. `y_hat` should be of shape `[n_models, n_unique_ids, 28]`. So, if you only fit one `mlforecast` model and one `statsforecast` model, it'd be of shape `[2, n_unique_ids, 28]`.
# The reason we're doing this is because we're going to have a single weight for each model, and that weight will be between 0 and 1. So, that means we can take a weighted average across the first dimension using those weights to calculate our ensemble. But, that after this!
# Hint: try running the following code:
# ```
# arr = np.array([
# [0, 1, 2],
# [3, 4, 5],
# [6, 7, 8],
# [9, 0, 1],
# ])
# print(arr.shape)
# print(arr[None, :].shape)
# ```
y_hat = np.concatenate(
[y_hat_ml[None, :], y_hat_sf[None, :], y_hat_nf1[None, :], y_hat_nf2[None, :]],
axis=0,
)
# Calculate `y_hat_avg` in `ensemble_metric`. `y_hat_avg` is a weighted average of `y_hat` along the first dimension, and is weighted according to `weights`, which is a list of floats of length `n_models`. There are some tests in there to help you out!
# Here's what you have to do:
# 1. Finish the definition for `init_guess`, which should be a list with length equal to the number of models you trained. Initialize it such that the weights for each model are between 0 and 1 and are equal for every model.
# 2. Run the code and make note of the RMSSE value. This is the RMSSE for a simple average of your predictions.
from functools import partial
def ensemble_metric(weights, y, y_hat, y_insample, insample_mask):
y_hat_avg = np.average(y_hat, axis=0, weights=weights)
assert (
y_hat_avg.ndim == 2
), "y_hat_avg has {y_hat_avg.ndim} dimensions, but it must be 2D. Did you calculate a weighted average over the first dimension?"
assert (
y_hat_avg.shape == y.shape
), "y_hat_avg and y must have the same shape. y_hat_avg has shape {y_hat_avg.shape}, but y has shape {y.shape}"
return rmsse(y, y_hat_avg, y_insample, insample_mask=insample_mask)
ensemble_metric = partial(
ensemble_metric,
y=y,
y_hat=y_hat,
y_insample=y_insample,
insample_mask=insample_mask,
)
# Our first guess is setting all weights equal to each other, such that they sum up to 1
init_guess = np.ones(y_hat.shape[0]) / y_hat.shape[0]
print(f"Inital Blend RMSSE: {ensemble_metric(init_guess):.6f}")
# On line 16, replace `oof_names` with a list of the names of your models in the order that you added them to `y_hat`.
from scipy.optimize import minimize
bnds = [(0, 1) for _ in range(y_hat.shape[0])] # Weights must be between 0 and 1
res_scipy = minimize(
fun=ensemble_metric,
x0=init_guess,
method="Powell",
bounds=bnds,
options=dict(maxiter=1_000_000),
tol=1e-8,
)
print(f"Optimised Blend RMSSE: {res_scipy.fun:.6f}")
print(f"Optimised Weights: {res_scipy.x}")
print("-" * 70)
oof_names = ["LGBMRegressor", "AutoETS", "AutoNHITS", "AutoTST"]
for n, key in enumerate(oof_names):
print(f"{key} Optimised Weights: {res_scipy.x[n]:.6f}")
ws = [res_scipy.x[i] for i in range(len(oof_names))]
# normalize the weights so they sum to 1
weights = ws / np.sum(ws)
print(f"Normalized weights:")
print(weights)
|
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
WINE_PATH = "../input/red-wine-quality-cortez-et-al-2009/winequality-red.csv"
wine = pd.read_csv(WINE_PATH)
# Look at the data
wine.shape
wine.info()
wine.describe()
import matplotlib.pyplot as plt
wine.hist(bins=50, figsize=(20, 15))
plt.show()
# Look at possible influential feature
corr_matrix = wine.corr()
corr_matrix["quality"].sort_values(ascending=False)
val = wine.values
len(val[1])
# Spliting the dataset and do stratified sampling on Alcohol
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(wine, test_size=0.2, random_state=42)
wine["alcohol_cat"] = pd.cut(
wine["alcohol"],
bins=[0, 9.3, 10, 10.7, 11.4, 12.1, np.inf],
labels=[1, 2, 3, 4, 5, 6],
)
wine["alcohol_cat"].hist()
from sklearn.model_selection import StratifiedShuffleSplit
alcohol_split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in alcohol_split.split(wine, wine["alcohol_cat"]):
strat_train_set = wine.loc[train_index]
strat_test_set = wine.loc[test_index]
wine = strat_train_set.copy()
from pandas.plotting import scatter_matrix
attributes = ["quality", "alcohol", "volatile acidity"]
scatter_matrix(wine[attributes], figsize=(15, 10))
wine = strat_train_set.drop(["quality"], axis=1)
wine_test = strat_test_set.drop(["quality"], axis=1)
wine_score_labels = strat_train_set["quality"].copy()
wine_test_score_labels = strat_test_set["quality"].copy()
# Check correlation again
# The data are all numerical and no null values, so it seems like only feature scaling is needed
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
num_pipeline = Pipeline(
[
("std_scaler", StandardScaler()),
]
)
wine_prepared = num_pipeline.fit_transform(wine)
wine_test_prepared = num_pipeline.transform(wine_test)
# start to train models (Linear Regression vs Decision Tree Regressor)
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
lin_reg = LinearRegression()
lin_reg.fit(wine_prepared, wine_score_labels)
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(wine_prepared, wine_score_labels)
strat_test_set
from sklearn.metrics import mean_absolute_error
print("Linear Model: {}".format(lin_reg.score(wine_prepared, wine_score_labels)))
print(
"Decision Tree Model: {}".format(tree_reg.score(wine_prepared, wine_score_labels))
)
from sklearn.metrics import mean_squared_error
wine_predictions = lin_reg.predict(wine_prepared)
lin_mse = mean_squared_error(wine_score_labels, wine_predictions)
line_rmse = np.sqrt(lin_mse)
line_rmse
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
from sklearn.model_selection import cross_val_score
scores = cross_val_score(
tree_reg, wine_prepared, wine_score_labels, scoring="neg_mean_squared_error", cv=30
)
test_scores = cross_val_score(
tree_reg,
wine_test_prepared,
wine_test_score_labels,
scoring="neg_mean_squared_error",
cv=30,
)
tree_rmse_test_scores = np.sqrt(-test_scores)
tree_rmse_scores = np.sqrt(-scores)
scores = cross_val_score(
lin_reg, wine_prepared, wine_score_labels, scoring="neg_mean_squared_error", cv=30
)
test_scores = cross_val_score(
lin_reg,
wine_test_prepared,
wine_test_score_labels,
scoring="neg_mean_squared_error",
cv=30,
)
lin_rmse_test_scores = np.sqrt(-test_scores)
lin_rmse_scores = np.sqrt(-scores)
print("Training:")
display_scores(tree_rmse_scores)
print("\nTesting:")
display_scores(tree_rmse_test_scores)
print("Training:")
display_scores(lin_rmse_scores)
print("\nTesting:")
display_scores(lin_rmse_test_scores)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.