|
|
--- |
|
|
datasets: |
|
|
- ai4bharat/IndicQuestionGeneration |
|
|
- ai4bharat/IndicSentiment |
|
|
- ai4bharat/IndicParaphrase |
|
|
- smallstepai/marathi-instruction-tuning-alpaca |
|
|
|
|
|
language: |
|
|
- mr |
|
|
metrics: |
|
|
- accuracy |
|
|
tags: |
|
|
- marathi |
|
|
- sentiment analysis |
|
|
- reading comprehension |
|
|
- paraphrasing |
|
|
- translation |
|
|
library_name: transformers |
|
|
pipeline_tag: text-generation |
|
|
license: llama2 |
|
|
--- |
|
|
|
|
|
# Misal-7B-instruct-v0.1 |
|
|
|
|
|
[smallstep.ai](https://www.linkedin.com/company/smallstepai/about/) |
|
|
|
|
|
## What have we built? |
|
|
|
|
|
Misal 7B, a pretrained and instruction tuned large language model based on Meta’s Llama 7B architecture exclusively for Marathi. |
|
|
|
|
|
## How we built it? |
|
|
|
|
|
Detailed blog [here](https://smallstep.ai/making-misal). |
|
|
|
|
|
## Benchmarking : |
|
|
|
|
|
We did a manual round of evaluations using internet data (we have released the evaluation data here). This is a fairly small dataset with 100 questions taken from the internet. We understand that a better evaluation method is needed to benchmark our model, this being the first iteration we decided to proceed with manual evaluation. |
|
|
|
|
|
Our main aim was to see if the model understands basic instructions, if so how well is it able to understand it, hence we have limited our evaluation to Reading comprehension, Translation, Sentiment Analysis, Paraphrasing like tasks. |
|
|
|
|
|
[Manual Evaluation Set ](https://huggingface.co/datasets/smallstepai/Misal-Evaluation-v0.1) |
|
|
|
|
|
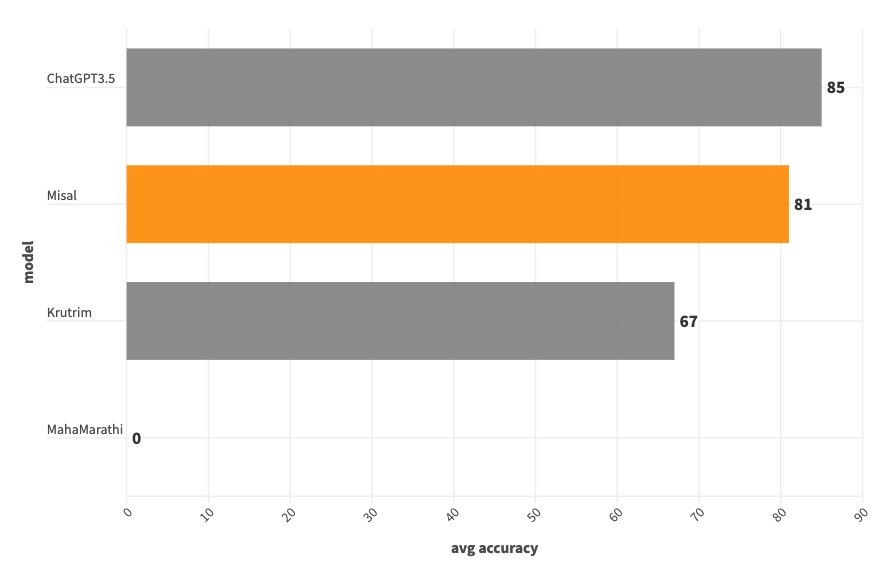
| | Misal | ChatGPT3.5 | Krutrim | MahaMarathi | |
|
|
| --------------------- | ----- | ---------- | ------- | ----------- | |
|
|
| reading comprehension | 88 | 68 | 40 | 0 | |
|
|
| sentiment analysis | 68 | 76 | 60 | 0 | |
|
|
| paraphrase | 92 | 100 | 88 | 0 | |
|
|
| translation | 76 | 96 | 80 | 0 | |
|
|
| average | 81 | 85 | 67 | 0 | |
|
|
|
|
|
## Summary : |
|
|
|
|
|
Our model beats ChatGPT 3.5 at reading comprehension. |
|
|
|
|
|
While we are not able to beat ChatGPT 3.5 on remaining tasks like sentiment analysis, paraphrasing, translation, our model beats Ola Krutrim at all the tasks except translation. |
|
|
|
|
|
 |
|
|
|
|
|
## License |
|
|
|
|
|
The model inherits the license from meta-llama/Llama-2-7b. |
|
|
|
|
|
## Usage |
|
|
|
|
|
### Installation |
|
|
|
|
|
```bash |
|
|
pip install transformers accelerate |
|
|
``` |
|
|
|
|
|
### Prompt |
|
|
|
|
|
```python |
|
|
आपण एक मदतगार, आदरणीय आणि प्रामाणिक सहाय्यक आहात.नेहमी शक्य तितकी उपयुक्त उत्तर द्या. तुमची उत्तरे हानिकारक, अनैतिक, वर्णद्वेषी, लैंगिकतावादी, हानिकारक, धोकादायक किंवा बेकायदेशीर नसावीत. कृपया खात्री करा की तुमची उत्तरे सामाजिक दृष्टिकोनाने निष्पक्ष आणि सकारात्मक स्वरूपाची आहेत. जर एखाद्या प्रश्नाला काही अर्थ नसेल किंवा वस्तुस्थितीशी सुसंगती नसेल, तर उत्तर देण्याऐवजी काहीतरी बरोबर का नाही हे स्पष्ट करा. तुम्हाला एखाद्या प्रश्नाचे उत्तर माहित नसल्यास, कृपया चुकीची माहिती देऊ नये. |
|
|
|
|
|
### Instruction: |
|
|
|
|
|
<instruction> |
|
|
|
|
|
### Input: |
|
|
|
|
|
<input data> |
|
|
|
|
|
### Response: |
|
|
``` |
|
|
|
|
|
### PyTorch |
|
|
|
|
|
```python |
|
|
from transformers import AutoModelForCausalLM, AutoTokenizer |
|
|
device = "cuda" |
|
|
model = AutoModelForCausalLM.from_pretrained("smallstepai/Misal-7B-instruct-v0.1", torch_dtype=torch.bfloat16, device_map='auto') |
|
|
tokenizer = AutoTokenizer.from_pretrained("smallstepai/Misal-7B-instruct-v0.1") |
|
|
|
|
|
def ask_misal(model, tokenizer, instruction, inputs='', system_prompt='', max_new_tokens=200, device='cuda'): |
|
|
|
|
|
ip = dict(system_prompt=system_prompt, instruction=instruction, inputs=inputs) |
|
|
model_inputs = tokenizer.apply_chat_template(ip, return_tensors='pt') |
|
|
outputs = model.generate(model_inputs.to(device), max_new_tokens=max_new_tokens) |
|
|
response = tokenizer.decode(outputs[0]).split('### Response:')[1].strip() |
|
|
return response |
|
|
|
|
|
instruction="सादरीकरण कसे करावे?" |
|
|
resp = ask_misal(model, tokenizer, instruction=instruction, max_new_tokens=1024) |
|
|
print(resp) |
|
|
``` |
|
|
|
|
|
### Team |
|
|
|
|
|
Sagar Sarkale, Abhijeet Katte, Prasad Mane, Shravani Chavan |

