
MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings
Paper
•
2506.23115
•
Published
•
36
MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings. Haonan Chen, Hong Liu, Yuping Luo, Liang Wang, Nan Yang, Furu Wei, Zhicheng Dou, arXiv 2025
This repo presents the MoCa-Qwen25VL series of multimodal embedding models.
The model is trained based on Qwen2.5-3B-VL-Instruct.
🏠 Homepage | 💻 Code | 🤖 MoCa-Qwen25VL-7B | 🤖 MoCa-Qwen25VL-3B | 📚 Datasets | 📄 Paper
Highlights
Performances on MMEB and ViDoRe-v2 benchmarks.
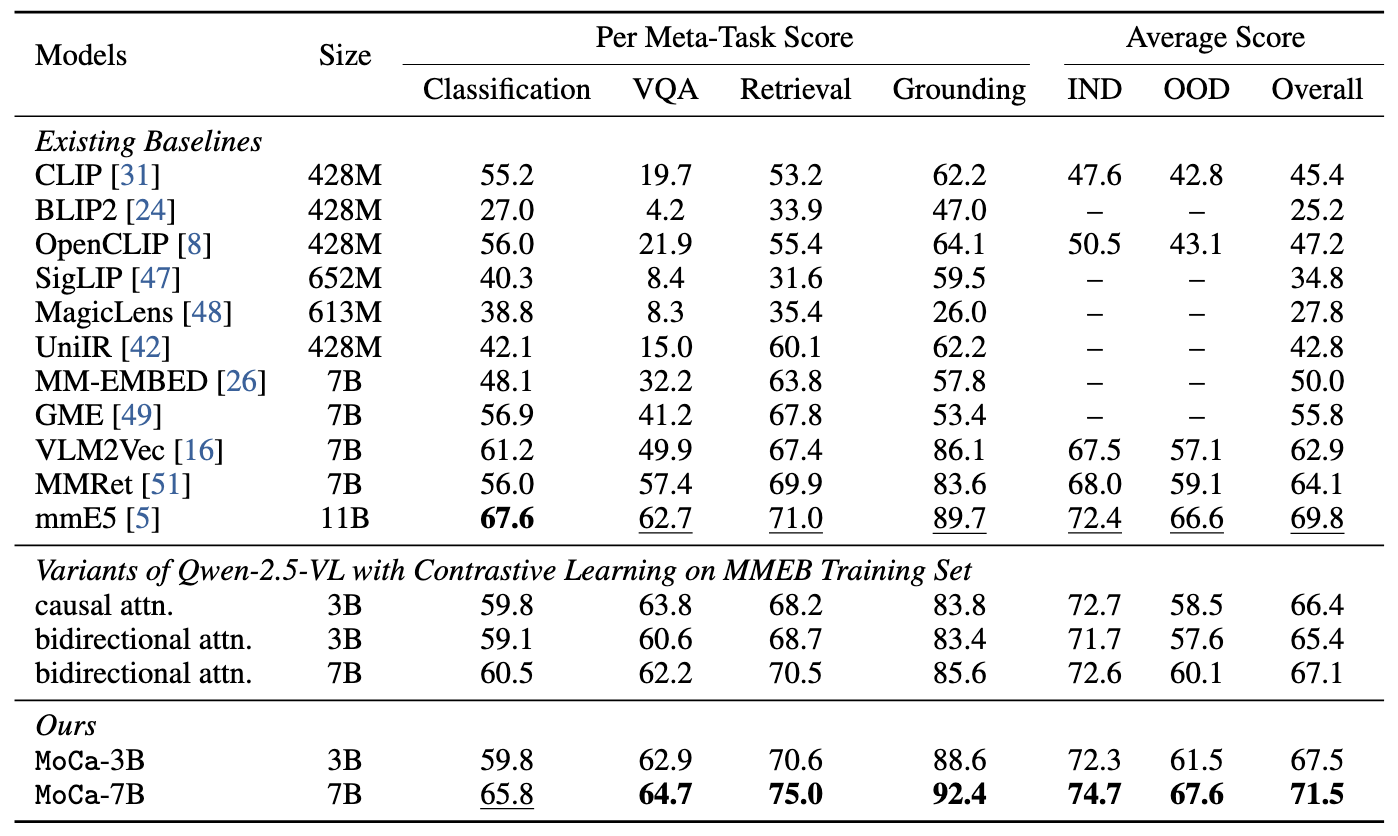
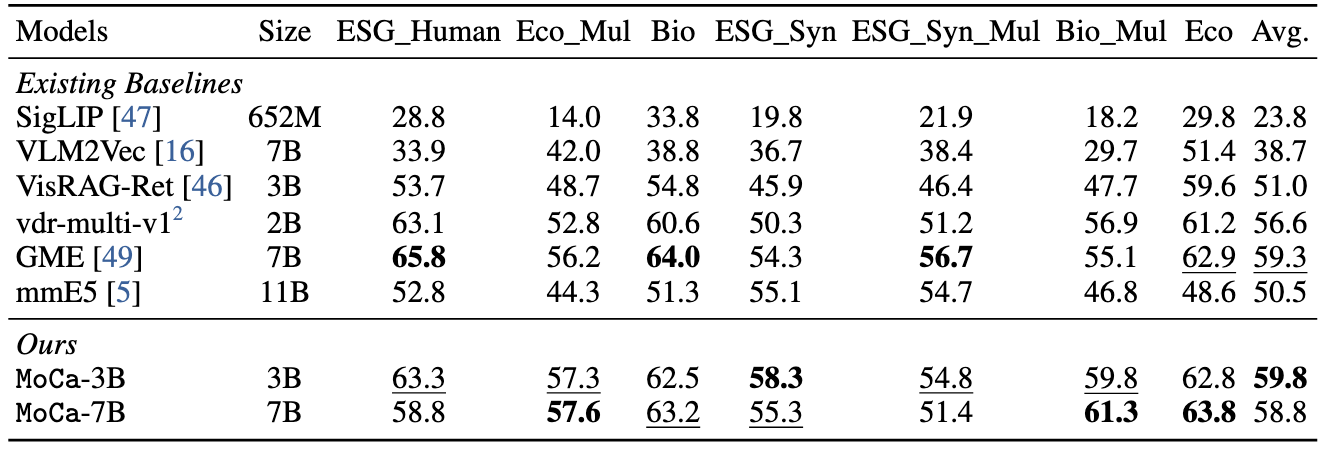
Below is an example we adapted from VLM2Vec.
git clone https://github.com/haon-chen/MoCa.git
cd MoCa
pip install -r requirements.txt
pip install flash-attn==2.5.8
from transformers import AutoProcessor, AutoConfig
from src.vlm_backbone.qwen2_5_vl_embed.qwen2_5_vl_embed import Qwen2_5ForEmbedding
import torch
from PIL import Image
import torch.nn.functional as F
def compute_similarity(q_reps, p_reps):
return torch.matmul(q_reps, p_reps.transpose(0, 1))
model_name = "moca-embed/MoCa-Qwen25VL-3B"
processor_name = "Qwen/Qwen2.5-VL-3B-Instruct"
# Load Processor and Model
processor = AutoProcessor.from_pretrained(processor_name)
config = AutoConfig.from_pretrained(model_name)
model = Qwen2_5ForEmbedding.from_pretrained(
model_name, config=config,
torch_dtype=torch.bfloat16,
attn_implementation='flash_attention_2',
bidirectional=True,
).to("cuda")
model.eval()
# Image + Text -> Text
inputs = processor(text='<|vision_start|><|image_pad|><|vision_end|>Represent the given image with the following question: What is in the image\n', images=[Image.open(
'figures/example.jpg')], return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = 'A cat and a dog'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**text_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.4824]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**text_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.3613]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a dog.\n', return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = '<|vision_start|><|image_pad|><|vision_end|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**tgt_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|vision_start|><|image_pad|><|vision_end|>Represent the given image. = tensor([[0.3945]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a tiger.\n', return_tensors="pt").to("cuda")
qry_output = F.normalize(model(**inputs, return_dict=True, output_hidden_states=True), dim=-1)
string = '<|vision_start|><|image_pad|><|vision_end|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[Image.open('figures/example.jpg')], return_tensors="pt").to("cuda")
tgt_output = F.normalize(model(**tgt_inputs, return_dict=True, output_hidden_states=True), dim=-1)
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|vision_start|><|image_pad|><|vision_end|>Represent the given image. = tensor([[0.3184]], device='cuda:0', dtype=torch.bfloat16)
If you use this model in your research, please cite the associated paper.
@article{chen2025moca,
title={MoCa: Modality-aware Continual Pre-training Makes Better Bidirectional Multimodal Embeddings},
author={Chen, Haonan and Liu, Hong and Luo, Yuping and Wang, Liang and Yang, Nan and Wei, Furu and Dou, Zhicheng},
journal={arXiv preprint arXiv:2506.23115},
year={2025}
}
Totally Free + Zero Barriers + No Login Required