
model_id
stringlengths 7
105
| model_card
stringlengths 1
130k
| model_labels
listlengths 2
80k
|
|---|---|---|
gashiari/vit-base-oxford-iiit-pets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2250
- Accuracy: 0.9256
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3596 | 1.0 | 370 | 0.3148 | 0.9120 |
| 0.2113 | 2.0 | 740 | 0.2509 | 0.9256 |
| 0.1735 | 3.0 | 1110 | 0.2327 | 0.9323 |
| 0.1412 | 4.0 | 1480 | 0.2244 | 0.9432 |
| 0.1192 | 5.0 | 1850 | 0.2232 | 0.9378 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu118
- Datasets 3.5.0
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
Juju-234/swin-tiny-patch4-window7-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0949
- Accuracy: 0.9705
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3684 | 1.0 | 77 | 0.3369 | 0.8967 |
| 0.1458 | 2.0 | 154 | 0.1216 | 0.9705 |
| 0.0691 | 3.0 | 231 | 0.0949 | 0.9705 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
LastTransformer/results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/mobilenet_v2_1.0_224](https://huggingface.co/google/mobilenet_v2_1.0_224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0019
- Accuracy: 0.7151
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00023769336048631227
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.2354 | 1.0 | 1563 | 1.0944 | 0.7300 |
| 0.8403 | 2.0 | 3126 | 1.0387 | 0.7400 |
| 0.5246 | 3.0 | 4689 | 0.9588 | 0.7400 |
| 0.3101 | 4.0 | 6252 | 0.9053 | 0.7300 |
| 0.1642 | 5.0 | 7815 | 0.9296 | 0.7300 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
[
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7",
"label_8",
"label_9",
"label_10",
"label_11",
"label_12",
"label_13",
"label_14",
"label_15",
"label_16",
"label_17",
"label_18",
"label_19",
"label_20",
"label_21",
"label_22",
"label_23",
"label_24",
"label_25",
"label_26",
"label_27",
"label_28",
"label_29",
"label_30",
"label_31",
"label_32",
"label_33",
"label_34",
"label_35",
"label_36",
"label_37",
"label_38",
"label_39",
"label_40",
"label_41",
"label_42",
"label_43",
"label_44",
"label_45",
"label_46",
"label_47",
"label_48",
"label_49",
"label_50",
"label_51",
"label_52",
"label_53",
"label_54",
"label_55",
"label_56",
"label_57",
"label_58",
"label_59",
"label_60",
"label_61",
"label_62",
"label_63",
"label_64",
"label_65",
"label_66",
"label_67",
"label_68",
"label_69",
"label_70",
"label_71",
"label_72",
"label_73",
"label_74",
"label_75",
"label_76",
"label_77",
"label_78",
"label_79",
"label_80",
"label_81",
"label_82",
"label_83",
"label_84",
"label_85",
"label_86",
"label_87",
"label_88",
"label_89",
"label_90",
"label_91",
"label_92",
"label_93",
"label_94",
"label_95",
"label_96",
"label_97",
"label_98",
"label_99"
] |
Juju-234/vit-base-patch16-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-finetuned-eurosat
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1555
- Accuracy: 0.9742
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.5979 | 1.0 | 20 | 0.5092 | 0.8118 |
| 0.242 | 2.0 | 40 | 0.2310 | 0.9520 |
| 0.2236 | 2.8831 | 57 | 0.1555 | 0.9742 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
hoangtrung1801/nsfw-vit-model
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"drawings",
"hentai",
"neutral",
"porn",
"sexy"
] |
VinayHajare/EfficientNetB0-finetuned-Marathi-Sign-Language
|
# EfficientNetB0-finetuned-Marathi-Sign-Language
A EfficientNetB0 finetune to identify Marathi-Sign-Language gesture and return its equivalent Devnagari Character.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Vinay Arjun Hajare
- **Model type:** Image-Classification
- **Language(s) (NLP):** Marathi (mr)
- **License:** MIT
- **Finetuned from model:** google/efficientnet-b0
### Direct Use
```python
import gradio as gr
from transformers import EfficientNetImageProcessor, EfficientNetForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "VinayHajare/EfficientNetB0-finetuned-Marathi-Sign-Language"
model = EfficientNetForImageClassification.from_pretrained(model_name)
processor = EfficientNetImageProcessor.from_pretrained.from_pretrained(model_name)
# Marathi label mapping
id2label = {
"0": "अ", "1": "आ", "2": "इ", "3": "ई", "4": "उ", "5": "ऊ",
"6": "ए", "7": "ऐ", "8": "ओ", "9": "औ", "10": "क", "11": "क्ष",
"12": "ख", "13": "ग", "14": "घ", "15": "च", "16": "छ", "17": "ज",
"18": "ज्ञ", "19": "झ", "20": "ट", "21": "ठ", "22": "ड", "23": "ढ",
"24": "ण", "25": "त", "26": "थ", "27": "द", "28": "ध", "29": "न",
"30": "प", "31": "फ", "32": "ब", "33": "भ", "34": "म", "35": "य",
"36": "र", "37": "ल", "38": "ळ", "39": "व", "40": "श", "41": "स", "42": "ह"
}
def classify_marathi_sign(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_marathi_sign,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=5, label="Marathi Sign Classification"),
title="Marathi-Sign-Language-Detection",
description="Upload an image of a Marathi sign language hand gesture to identify the corresponding character."
)
if __name__ == "__main__":
iface.launch()
```
|
[
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7",
"label_8",
"label_9",
"label_10",
"label_11",
"label_12",
"label_13",
"label_14",
"label_15",
"label_16",
"label_17",
"label_18",
"label_19",
"label_20",
"label_21",
"label_22",
"label_23",
"label_24",
"label_25",
"label_26",
"label_27",
"label_28",
"label_29",
"label_30",
"label_31",
"label_32",
"label_33",
"label_34",
"label_35",
"label_36",
"label_37",
"label_38",
"label_39",
"label_40",
"label_41",
"label_42"
] |
DaniilPechersky/dog-cats-model
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dog-cats-model
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.3298
- eval_accuracy: 0.9175
- eval_runtime: 11.3655
- eval_samples_per_second: 65.021
- eval_steps_per_second: 8.183
- epoch: 1.0
- step: 370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
u1tracore/cats123
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cats123
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2925
- eval_accuracy: 0.9283
- eval_runtime: 10.7283
- eval_samples_per_second: 68.883
- eval_steps_per_second: 8.669
- epoch: 1.0
- step: 370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
thundergrove/finetune-cats
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetune-cats
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2082
- eval_model_preparation_time: 0.0244
- eval_accuracy: 0.9513
- eval_runtime: 10.5309
- eval_samples_per_second: 70.174
- eval_steps_per_second: 8.831
- epoch: 2.0
- step: 740
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
abbeleve/myclass
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# myclass
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
suzzit/skin-cancer-classificationv8
|
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# suzzit/skin-cancer-classificationv8
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0345
- Train Accuracy: 0.9917
- Validation Loss: 1.1785
- Validation Accuracy: 0.6304
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 27740, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': np.float32(0.9), 'beta_2': np.float32(0.999), 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.0712 | 0.9827 | 1.0406 | 0.6456 | 0 |
| 0.0554 | 0.9859 | 1.0842 | 0.6430 | 1 |
| 0.0510 | 0.9859 | 1.1185 | 0.6278 | 2 |
| 0.0401 | 0.9917 | 1.1199 | 0.6557 | 3 |
| 0.0345 | 0.9917 | 1.1785 | 0.6304 | 4 |
### Framework versions
- Transformers 4.51.3
- TensorFlow 2.18.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"0",
"1",
"2"
] |
VinayHajare/siglip2-finetuned-marathi-sign-language
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# siglip2-finetuned-marathi-sign-language
This model is a fine-tuned version of [google/siglip2-base-patch16-224](https://huggingface.co/google/siglip2-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0006
- Model Preparation Time: 0.0057
- Accuracy: 0.9997
## Model description
Marathi-Sign-Language-Detection is a vision-language model fine-tuned from google/siglip2-base-patch16-224 for multi-class image classification. It is trained to recognize Marathi sign language hand gestures and map them to corresponding Devanagari characters using the SiglipForImageClassification architecture.
## Training and evaluation data
```java
Classification Report:
precision recall f1-score support
अ 1.0000 1.0000 1.0000 404
आ 1.0000 1.0000 1.0000 409
इ 1.0000 1.0000 1.0000 440
ई 0.9866 1.0000 0.9932 441
उ 1.0000 1.0000 1.0000 479
ऊ 1.0000 1.0000 1.0000 428
ए 1.0000 1.0000 1.0000 457
ऐ 1.0000 1.0000 1.0000 436
ओ 1.0000 1.0000 1.0000 430
औ 1.0000 1.0000 1.0000 408
क 1.0000 1.0000 1.0000 433
क्ष 1.0000 1.0000 1.0000 480
ख 1.0000 1.0000 1.0000 456
ग 1.0000 1.0000 1.0000 444
घ 1.0000 1.0000 1.0000 480
च 1.0000 1.0000 1.0000 463
छ 1.0000 1.0000 1.0000 468
ज 1.0000 1.0000 1.0000 480
ज्ञ 1.0000 1.0000 1.0000 480
झ 1.0000 1.0000 1.0000 480
ट 1.0000 1.0000 1.0000 480
ठ 1.0000 1.0000 1.0000 480
ड 1.0000 1.0000 1.0000 480
ढ 1.0000 1.0000 1.0000 480
ण 1.0000 1.0000 1.0000 480
त 1.0000 1.0000 1.0000 480
थ 1.0000 1.0000 1.0000 480
द 1.0000 0.9875 0.9937 480
ध 1.0000 1.0000 1.0000 480
न 1.0000 1.0000 1.0000 480
प 1.0000 1.0000 1.0000 480
फ 1.0000 1.0000 1.0000 480
ब 1.0000 1.0000 1.0000 480
भ 1.0000 1.0000 1.0000 480
म 1.0000 1.0000 1.0000 480
य 1.0000 1.0000 1.0000 480
र 1.0000 1.0000 1.0000 484
ल 1.0000 1.0000 1.0000 480
ळ 1.0000 1.0000 1.0000 480
व 1.0000 1.0000 1.0000 480
श 1.0000 1.0000 1.0000 480
स 1.0000 1.0000 1.0000 480
ह 1.0000 1.0000 1.0000 480
accuracy 0.9997 20040
macro avg 0.9997 0.9997 0.9997 20040
weighted avg 0.9997 0.9997 0.9997 20040
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "VinayHajare/siglip2-finetuned-marathi-sign-language"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Marathi label mapping
id2label = {
"0": "अ", "1": "आ", "2": "इ", "3": "ई", "4": "उ", "5": "ऊ",
"6": "ए", "7": "ऐ", "8": "ओ", "9": "औ", "10": "क", "11": "क्ष",
"12": "ख", "13": "ग", "14": "घ", "15": "च", "16": "छ", "17": "ज",
"18": "ज्ञ", "19": "झ", "20": "ट", "21": "ठ", "22": "ड", "23": "ढ",
"24": "ण", "25": "त", "26": "थ", "27": "द", "28": "ध", "29": "न",
"30": "प", "31": "फ", "32": "ब", "33": "भ", "34": "म", "35": "य",
"36": "र", "37": "ल", "38": "ळ", "39": "व", "40": "श", "41": "स", "42": "ह"
}
def classify_marathi_sign(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_marathi_sign,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=5, label="Marathi Sign Classification"),
title="Marathi-Sign-Language-Detection",
description="Upload an image of a Marathi sign language hand gesture to identify the corresponding character."
)
if __name__ == "__main__":
iface.launch()
```
---
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Model Preparation Time | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:----------------------:|:--------:|
| 1.4439 | 1.0 | 940 | 0.0090 | 0.0057 | 0.9980 |
| 0.0052 | 2.0 | 1880 | 0.0035 | 0.0057 | 0.9993 |
| 0.0031 | 3.0 | 2820 | 0.0016 | 0.0057 | 0.9997 |
| 0.001 | 4.0 | 3760 | 0.0010 | 0.0057 | 0.9997 |
| 0.0007 | 5.0 | 4700 | 0.0013 | 0.0057 | 0.9997 |
| 0.0005 | 6.0 | 5640 | 0.0006 | 0.0057 | 0.9997 |
### Framework versions
- Transformers 4.52.0.dev0
- Pytorch 2.6.0+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
[
"अ",
"आ",
"क",
"क्ष",
"ख",
"ग",
"घ",
"च",
"छ",
"ज",
"ज्ञ",
"झ",
"इ",
"ट",
"ठ",
"ड",
"ढ",
"ण",
"त",
"थ",
"द",
"ध",
"न",
"ई",
"प",
"फ",
"ब",
"भ",
"म",
"य",
"र",
"ल",
"ळ",
"व",
"उ",
"श",
"स",
"ह",
"ऊ",
"ए",
"ऐ",
"ओ",
"औ"
] |
ikram98ai/compliance_verification_ViT
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans-demo-v5
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the ikram98ai/compliance_verification dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5769
- Accuracy: 0.6585
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 128
- eval_batch_size: 256
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.5984 | 0.2459 | 30 | 0.5906 | 0.6400 |
| 0.6018 | 0.4918 | 60 | 0.5841 | 0.6579 |
| 0.5816 | 0.7377 | 90 | 0.5819 | 0.6433 |
| 0.594 | 0.9836 | 120 | 0.5769 | 0.6585 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
[
"compliant",
"non-compliant"
] |
prithivMLmods/GiD-Land-Cover-Classification
|

# **GiD-Land-Cover-Classification**
> **GiD-Land-Cover-Classification** is a multi-class image classification model based on `google/siglip2-base-patch16-224`, trained to detect **land cover types** in geographical or environmental imagery. This model can be used for **urban planning**, **agriculture monitoring**, and **environmental analysis**.
```py
Classification Report:
precision recall f1-score support
arbor woodland 0.8868 0.9130 0.8997 2000
artificial grassland 0.9173 0.9425 0.9297 2000
dry cropland 0.9320 0.9395 0.9358 2000
garden plot 0.8639 0.8380 0.8508 2000
industrial land 0.8967 0.8940 0.8953 2000
irrigated land 0.8817 0.7865 0.8314 2000
lake 0.7597 0.8045 0.7814 2000
natural grassland 0.9770 0.9750 0.9760 2000
paddy field 0.9305 0.9580 0.9441 2000
pond 0.7646 0.7405 0.7523 2000
river 0.8124 0.7945 0.8033 2000
rural residential 0.8875 0.8325 0.8591 2000
shrub land 0.8936 0.9195 0.9064 2000
traffic land 0.9577 0.9510 0.9543 2000
urban residential 0.7821 0.8470 0.8133 2000
accuracy 0.8757 30000
macro avg 0.8762 0.8757 0.8755 30000
weighted avg 0.8762 0.8757 0.8755 30000
```

---
## **Label Classes**
The model distinguishes between the following land cover types:
```
0: arbor woodland
1: artificial grassland
2: dry cropland
3: garden plot
4: industrial land
5: irrigated land
6: lake
7: natural grassland
8: paddy field
9: pond
10: river
11: rural residential
12: shrub land
13: traffic land
14: urban residential
```
---
## **Installation**
```bash
pip install transformers torch pillow gradio
```
---
## **Example Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/GiD-Land-Cover-Classification"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to label mapping
id2label = {
"0": "arbor woodland",
"1": "artificial grassland",
"2": "dry cropland",
"3": "garden plot",
"4": "industrial land",
"5": "irrigated land",
"6": "lake",
"7": "natural grassland",
"8": "paddy field",
"9": "pond",
"10": "river",
"11": "rural residential",
"12": "shrub land",
"13": "traffic land",
"14": "urban residential"
}
def detect_land_cover(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=detect_land_cover,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=5, label="Land Cover Type"),
title="GiD-Land-Cover-Classification",
description="Upload an image to classify its land cover type: arbor woodland, dry cropland, lake, river, traffic land, etc."
)
if __name__ == "__main__":
iface.launch()
```
---
## **Applications**
* **Urban Development Planning**
* **Agricultural Monitoring**
* **Land Use and Land Cover (LULC) Mapping**
* **Disaster Management and Flood Risk Analysis**
|
[
"arbor woodland",
"artificial grassland",
"dry cropland",
"garden plot",
"industrial land",
"irrigated land",
"lake",
"natural grassland",
"paddy field",
"pond",
"river",
"rural residential",
"shrub land",
"traffic land",
"urban residential"
] |
StevenCole01/my_awesome_food_model
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3394
- Accuracy: 0.827
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.4977 | 0.992 | 31 | 3.2405 | 0.749 |
| 2.6548 | 1.984 | 62 | 2.5386 | 0.822 |
| 2.3421 | 2.976 | 93 | 2.3394 | 0.827 |
### Framework versions
- Transformers 4.45.1
- Pytorch 2.4.0
- Datasets 3.0.1
- Tokenizers 0.20.0
|
[
"apple_pie",
"baby_back_ribs",
"bruschetta",
"waffles",
"caesar_salad",
"cannoli",
"caprese_salad",
"carrot_cake",
"ceviche",
"cheesecake",
"cheese_plate",
"chicken_curry",
"chicken_quesadilla",
"baklava",
"chicken_wings",
"chocolate_cake",
"chocolate_mousse",
"churros",
"clam_chowder",
"club_sandwich",
"crab_cakes",
"creme_brulee",
"croque_madame",
"cup_cakes",
"beef_carpaccio",
"deviled_eggs",
"donuts",
"dumplings",
"edamame",
"eggs_benedict",
"escargots",
"falafel",
"filet_mignon",
"fish_and_chips",
"foie_gras",
"beef_tartare",
"french_fries",
"french_onion_soup",
"french_toast",
"fried_calamari",
"fried_rice",
"frozen_yogurt",
"garlic_bread",
"gnocchi",
"greek_salad",
"grilled_cheese_sandwich",
"beet_salad",
"grilled_salmon",
"guacamole",
"gyoza",
"hamburger",
"hot_and_sour_soup",
"hot_dog",
"huevos_rancheros",
"hummus",
"ice_cream",
"lasagna",
"beignets",
"lobster_bisque",
"lobster_roll_sandwich",
"macaroni_and_cheese",
"macarons",
"miso_soup",
"mussels",
"nachos",
"omelette",
"onion_rings",
"oysters",
"bibimbap",
"pad_thai",
"paella",
"pancakes",
"panna_cotta",
"peking_duck",
"pho",
"pizza",
"pork_chop",
"poutine",
"prime_rib",
"bread_pudding",
"pulled_pork_sandwich",
"ramen",
"ravioli",
"red_velvet_cake",
"risotto",
"samosa",
"sashimi",
"scallops",
"seaweed_salad",
"shrimp_and_grits",
"breakfast_burrito",
"spaghetti_bolognese",
"spaghetti_carbonara",
"spring_rolls",
"steak",
"strawberry_shortcake",
"sushi",
"tacos",
"takoyaki",
"tiramisu",
"tuna_tartare"
] |
Sagittarius0712/swin-tiny-patch4-window7-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1562
- Accuracy: 0.9557
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.4933 | 1.0 | 20 | 0.4633 | 0.8376 |
| 0.1845 | 2.0 | 40 | 0.2697 | 0.9483 |
| 0.1549 | 2.8831 | 57 | 0.1562 | 0.9557 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
Juju-234/swin-small-patch4-window7-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-small-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-small-patch4-window7-224](https://huggingface.co/microsoft/swin-small-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2162
- Accuracy: 0.9446
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5887 | 1.0 | 77 | 0.5121 | 0.8487 |
| 0.3032 | 2.0 | 154 | 0.2563 | 0.9373 |
| 0.2768 | 3.0 | 231 | 0.2162 | 0.9446 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
Sagittarius0712/swin-small-patch4-window7-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-small-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-small-patch4-window7-224](https://huggingface.co/microsoft/swin-small-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1298
- Accuracy: 0.9631
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1372 | 1.0 | 77 | 0.1271 | 0.9631 |
| 0.183 | 2.0 | 154 | 0.1332 | 0.9594 |
| 0.1602 | 3.0 | 231 | 0.1384 | 0.9594 |
| 0.1693 | 4.0 | 308 | 0.1307 | 0.9594 |
| 0.2016 | 5.0 | 385 | 0.1266 | 0.9631 |
| 0.1148 | 6.0 | 462 | 0.1298 | 0.9631 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
suzzit/skin-cancer-classificationv9
|
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# suzzit/skin-cancer-classificationv9
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0443
- Train Accuracy: 0.9892
- Validation Loss: 1.1616
- Validation Accuracy: 0.7089
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 1e-05, 'decay_steps': 27740, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': np.float32(0.9), 'beta_2': np.float32(0.999), 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.0840 | 0.9744 | 1.0091 | 0.7013 | 0 |
| 0.0629 | 0.9845 | 1.0412 | 0.7063 | 1 |
| 0.0524 | 0.9856 | 1.1035 | 0.7038 | 2 |
| 0.0457 | 0.9892 | 1.1231 | 0.7013 | 3 |
| 0.0443 | 0.9892 | 1.1616 | 0.7089 | 4 |
### Framework versions
- Transformers 4.51.3
- TensorFlow 2.19.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"0",
"1",
"2"
] |
panda992/fish_disease_datasets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fish_disease_datasets
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the fish_disease_datasets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0866
- Accuracy: 0.9728
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.3865 | 0.7634 | 100 | 0.4161 | 0.8913 |
| 0.1206 | 1.5267 | 200 | 0.2170 | 0.9457 |
| 0.1132 | 2.2901 | 300 | 0.1317 | 0.9674 |
| 0.0547 | 3.0534 | 400 | 0.0879 | 0.9810 |
| 0.0209 | 3.8168 | 500 | 0.0866 | 0.9728 |
### Framework versions
- Transformers 4.52.3
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"bacterial red disease",
"bacterial diseases - aeromoniasis",
"bacterial gill disease",
"fungal diseases saprolegniasis",
"healthy fish",
"parasitic diseases",
"viral diseases white tail disease"
] |
pmaheshai/train_dir
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# train_dir
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
This Model fine tunes the google Vit transformer model with the fake and real face images . This model can cen be utilzied
for vlaidating a given face image is a Fake or real face image
It achieves the following results on the evaluation set:
- Loss: 0.0852
- Accuracy: 0.975
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.325 | 1.0 | 438 | 0.2307 | 0.9083 |
| 0.198 | 2.0 | 876 | 0.2022 | 0.925 |
| 0.1401 | 3.0 | 1314 | 0.1086 | 0.9657 |
| 0.1044 | 4.0 | 1752 | 0.0859 | 0.975 |
| 0.0098 | 5.0 | 2190 | 0.0852 | 0.975 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"fake",
"real"
] |
huserluk/vit-base-oxford-iiit-pets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2219
- Accuracy: 0.9310
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3959 | 1.0 | 370 | 0.2880 | 0.9296 |
| 0.2157 | 2.0 | 740 | 0.2222 | 0.9350 |
| 0.1806 | 3.0 | 1110 | 0.1989 | 0.9418 |
| 0.1638 | 4.0 | 1480 | 0.1905 | 0.9405 |
| 0.1242 | 5.0 | 1850 | 0.1885 | 0.9418 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
shrestha1/vit-Facial-Expression-Recognition
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-Facial-Expression-Recognition
This model is a fine-tuned version of [motheecreator/vit-Facial-Expression-Recognition](https://huggingface.co/motheecreator/vit-Facial-Expression-Recognition) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2561
- Accuracy: 0.9135
- F1: 0.9137
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|
| 0.5281 | 0.8909 | 100 | 0.2554 | 0.9131 | 0.9118 |
| 0.5278 | 1.7751 | 200 | 0.2535 | 0.9136 | 0.9127 |
| 0.4992 | 2.6592 | 300 | 0.2602 | 0.9107 | 0.9085 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angry",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
Granitagushi/vit-base-fashion
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-fashion
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the zalando-datasets/fashion_mnist dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2513
- Accuracy: 0.9102
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.2888 | 1.0 | 3000 | 0.2934 | 0.8917 |
| 0.3066 | 2.0 | 6000 | 0.2694 | 0.9013 |
| 0.2722 | 3.0 | 9000 | 0.2589 | 0.9042 |
| 0.2593 | 4.0 | 12000 | 0.2576 | 0.9048 |
| 0.2422 | 5.0 | 15000 | 0.2540 | 0.9078 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
[
"9",
"0",
"3",
"2",
"7",
"5",
"1",
"6",
"4",
"8"
] |
TalentoTechIA/Hamilton_08_05_25
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Hamilton_08_05_25
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0303
- Accuracy: 0.9850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.1287 | 3.8462 | 500 | 0.0303 | 0.9850 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
TalentoTechIA/ManuelQuiceno
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ManuelQuiceno
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1054
- Accuracy: 0.9699
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.0619 | 3.8462 | 500 | 0.1054 | 0.9699 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
TalentoTechIA/David_08_05_25
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# David_08_05_25
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0737
- Accuracy: 0.9774
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.0524 | 3.8462 | 500 | 0.0737 | 0.9774 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
TalentoTechIA/andfelipe
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# andfelipe
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0765
- Accuracy: 0.9774
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.1509 | 3.8462 | 500 | 0.0765 | 0.9774 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
TalentoTechIA/Mariapaula
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Mariapaula
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0314
- Accuracy: 0.9774
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.125 | 3.8462 | 500 | 0.0314 | 0.9774 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
eduardojuazpue/TalentoTechIA
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# TalentoTechIA
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0285
- Accuracy: 0.9850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.1358 | 3.8462 | 500 | 0.0285 | 0.9850 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
tapasco/Tapasco
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tapasco
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0237
- Accuracy: 0.9925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.1395 | 3.8462 | 500 | 0.0237 | 0.9925 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
TalentoTechIA/davincii
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# davincii
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1066
- Accuracy: 0.9699
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.1214 | 3.8462 | 500 | 0.1066 | 0.9699 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"angular_leaf_spot",
"bean_rust",
"healthy"
] |
prithivMLmods/Alzheimer-Stage-Classifier
|

# **Alzheimer-Stage-Classifier**
> **Alzheimer-Stage-Classifier** is a multi-class image classification model based on `google/siglip2-base-patch16-224`, designed to identify stages of Alzheimer’s disease from medical imaging data. This tool can assist in **clinical decision support**, **early diagnosis**, and **disease progression tracking**.
```py
Classification Report:
precision recall f1-score support
MildDemented 0.9634 0.9860 0.9746 8960
ModerateDemented 1.0000 1.0000 1.0000 6464
NonDemented 0.8920 0.8910 0.8915 9600
VeryMildDemented 0.8904 0.8704 0.8803 8960
accuracy 0.9314 33984
macro avg 0.9364 0.9369 0.9366 33984
weighted avg 0.9309 0.9314 0.9311 33984
```

---
## **Label Classes**
The model classifies input images into the following stages of Alzheimer’s disease:
```
0: MildDemented
1: ModerateDemented
2: NonDemented
3: VeryMildDemented
```
---
## **Installation**
```bash
pip install transformers torch pillow gradio
```
---
## **Example Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Alzheimer-Stage-Classifier"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to label mapping
id2label = {
"0": "MildDemented",
"1": "ModerateDemented",
"2": "NonDemented",
"3": "VeryMildDemented"
}
def classify_alzheimer_stage(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_alzheimer_stage,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=4, label="Alzheimer Stage"),
title="Alzheimer-Stage-Classifier",
description="Upload a brain scan image to classify the stage of Alzheimer's: NonDemented, VeryMildDemented, MildDemented, or ModerateDemented."
)
if __name__ == "__main__":
iface.launch()
```
---
## **Applications**
* **Early Alzheimer’s Screening**
* **Clinical Diagnosis Support**
* **Longitudinal Study & Disease Monitoring**
* **Research on Cognitive Decline**
|
[
"milddemented",
"moderatedemented",
"nondemented",
"verymilddemented"
] |
prithivMLmods/Face-Mask-Detection
|

# **Face-Mask-Detection**
> **Face-Mask-Detection** is a binary image classification model based on `google/siglip2-base-patch16-224`, trained to detect whether a person is **wearing a face mask** or **not**. This model can be used in **public health monitoring**, **access control systems**, and **workplace compliance enforcement**.
```py
Classification Report:
precision recall f1-score support
Face_Mask Found 0.9662 0.9561 0.9611 5883
Face_Mask Not_Found 0.9568 0.9667 0.9617 5909
accuracy 0.9614 11792
macro avg 0.9615 0.9614 0.9614 11792
weighted avg 0.9615 0.9614 0.9614 11792
```

---
## **Label Classes**
The model distinguishes between the following face mask statuses:
```
0: Face_Mask Found
1: Face_Mask Not_Found
```
---
## **Installation**
```bash
pip install transformers torch pillow gradio
```
---
## **Example Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Face-Mask-Detection"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to label mapping
id2label = {
"0": "Face_Mask Found",
"1": "Face_Mask Not_Found"
}
def detect_face_mask(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=detect_face_mask,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="Mask Status"),
title="Face-Mask-Detection",
description="Upload an image to check if a person is wearing a face mask or not."
)
if __name__ == "__main__":
iface.launch()
```
---
## **Applications**
* **COVID-19 Compliance Monitoring**
* **Security and Access Control**
* **Automated Surveillance Systems**
* **Health Safety Enforcement in Public Spaces**
|
[
"face_mask found",
"face_mask not_found"
] |
prithivMLmods/Document-Type-Detection
|

# **Document-Type-Detection**
> **Document-Type-Detection** is a multi-class image classification model based on `google/siglip2-base-patch16-224`, trained to detect and classify **types of documents** from scanned or photographed images. This model is helpful for **automated document sorting**, **OCR pipelines**, and **digital archiving systems**.
```py
Classification Report:
precision recall f1-score support
Advertisement-Doc 0.8940 0.8940 0.8940 2000
Hand-Written-Doc 0.9168 0.9310 0.9238 2000
Invoice-Doc 0.9026 0.8940 0.8983 2000
Letter-Doc 0.8380 0.8820 0.8594 2000
News-Article-Doc 0.9258 0.8800 0.9023 2000
Resume-Doc 0.9425 0.9340 0.9382 2000
accuracy 0.9025 12000
macro avg 0.9033 0.9025 0.9027 12000
weighted avg 0.9033 0.9025 0.9027 12000
```

---
## **Label Classes**
The model classifies images into the following document types:
```
0: Advertisement-Doc
1: Hand-Written-Doc
2: Invoice-Doc
3: Letter-Doc
4: News-Article-Doc
5: Resume-Doc
```
---
## **Installation**
```bash
pip install transformers torch pillow gradio
```
---
## **Example Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Document-Type-Detection"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to label mapping
id2label = {
"0": "Advertisement-Doc",
"1": "Hand-Written-Doc",
"2": "Invoice-Doc",
"3": "Letter-Doc",
"4": "News-Article-Doc",
"5": "Resume-Doc"
}
def detect_doc_type(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=detect_doc_type,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=6, label="Document Type"),
title="Document-Type-Detection",
description="Upload a document image to classify it as one of: Advertisement, Hand-Written, Invoice, Letter, News Article, or Resume."
)
if __name__ == "__main__":
iface.launch()
```
---
## **Applications**
* **Automated Document Sorting**
* **Digital Libraries and Archives**
* **OCR Preprocessing**
* **Enterprise Document Management**
|
[
"advertisement-doc",
"hand-written-doc",
"invoice-doc",
"letter-doc",
"news-article-doc",
"resume-doc"
] |
BurakKaynakcioglu/finetuned-animal
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-animal
This model is a fine-tuned version of [microsoft/swin-base-patch4-window7-224](https://huggingface.co/microsoft/swin-base-patch4-window7-224) on the animal_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1517
- Accuracy: 0.9665
- Precision: 0.9706
- Recall: 0.9665
- F1: 0.9664
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.6969 | 1.0 | 254 | 0.2613 | 0.9232 | 0.9372 | 0.9232 | 0.9182 |
| 0.4414 | 2.0 | 508 | 0.1796 | 0.9497 | 0.9520 | 0.9497 | 0.9472 |
| 0.3728 | 3.0 | 762 | 0.1895 | 0.9427 | 0.9556 | 0.9427 | 0.9417 |
| 0.3379 | 4.0 | 1016 | 0.1334 | 0.9651 | 0.9698 | 0.9651 | 0.9651 |
| 0.2953 | 5.0 | 1270 | 0.1837 | 0.9511 | 0.9626 | 0.9511 | 0.9494 |
| 0.2896 | 6.0 | 1524 | 0.1450 | 0.9609 | 0.9674 | 0.9609 | 0.9604 |
| 0.2567 | 7.0 | 1778 | 0.1517 | 0.9665 | 0.9706 | 0.9665 | 0.9664 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
[
"antelope",
"badger",
"caterpillar",
"chimpanzee",
"cockroach",
"cow",
"coyote",
"crab",
"crow",
"deer",
"dog",
"dolphin",
"bat",
"donkey",
"dragonfly",
"duck",
"eagle",
"elephant",
"flamingo",
"fly",
"fox",
"goat",
"goldfish",
"bear",
"goose",
"gorilla",
"grasshopper",
"hamster",
"hare",
"hedgehog",
"hippopotamus",
"hornbill",
"horse",
"hummingbird",
"bee",
"hyena",
"jellyfish",
"kangaroo",
"koala",
"ladybugs",
"leopard",
"lion",
"lizard",
"lobster",
"mosquito",
"beetle",
"moth",
"mouse",
"octopus",
"okapi",
"orangutan",
"otter",
"owl",
"ox",
"oyster",
"panda",
"bison",
"parrot",
"pelecaniformes",
"penguin",
"pig",
"pigeon",
"porcupine",
"possum",
"raccoon",
"rat",
"reindeer",
"boar",
"rhinoceros",
"sandpiper",
"seahorse",
"seal",
"shark",
"sheep",
"snake",
"sparrow",
"squid",
"squirrel",
"butterfly",
"starfish",
"swan",
"tiger",
"turkey",
"turtle",
"whale",
"wolf",
"wombat",
"woodpecker",
"zebra",
"cat"
] |
juju5u5yp/swin-large-patch4-window7-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-large-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-large-patch4-window7-224](https://huggingface.co/microsoft/swin-large-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5298
- Accuracy: 0.2177
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.5735 | 1.0 | 77 | 1.5865 | 0.2103 |
| 1.5082 | 2.0 | 154 | 1.5431 | 0.2103 |
| 1.5095 | 3.0 | 231 | 1.5298 | 0.2177 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
prithivMLmods/Bone-Fracture-Detection
|

# **Bone-Fracture-Detection**
> **Bone-Fracture-Detection** is a binary image classification model based on `google/siglip2-base-patch16-224`, trained to detect **fractures in bone X-ray images**. It is designed for use in **medical diagnostics**, **clinical triage**, and **radiology assistance systems**.
```py
Classification Report:
precision recall f1-score support
Fractured 0.8633 0.7893 0.8246 4480
Not Fractured 0.8020 0.8722 0.8356 4383
accuracy 0.8303 8863
macro avg 0.8326 0.8308 0.8301 8863
weighted avg 0.8330 0.8303 0.8301 8863
```

---
## **Label Classes**
The model distinguishes between the following bone conditions:
```
0: Fractured
1: Not Fractured
```
---
## **Installation**
```bash
pip install transformers torch pillow gradio
```
---
## **Example Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Bone-Fracture-Detection"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to label mapping
id2label = {
"0": "Fractured",
"1": "Not Fractured"
}
def detect_fracture(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=detect_fracture,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="Fracture Detection"),
title="Bone-Fracture-Detection",
description="Upload a bone X-ray image to detect if there is a fracture."
)
if __name__ == "__main__":
iface.launch()
```
---
## **Applications**
* **Orthopedic Diagnostic Support**
* **Emergency Room Triage**
* **Automated Radiology Review**
* **Clinical Research in Bone Health**
|
[
"fractured",
"not fractured"
] |
prithivMLmods/Realistic-Gender-Classification
|

# **Realistic-Gender-Classification**
> **Realistic-Gender-Classification** is a binary image classification model based on `google/siglip2-base-patch16-224`, designed to classify **gender** from realistic human portrait images. It can be used in **demographic analysis**, **personalization systems**, and **automated tagging** in large-scale image datasets.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
```py
Classification Report:
precision recall f1-score support
female portrait 0.9754 0.9656 0.9705 1600
male portrait 0.9660 0.9756 0.9708 1600
accuracy 0.9706 3200
macro avg 0.9707 0.9706 0.9706 3200
weighted avg 0.9707 0.9706 0.9706 3200
```

---
## **Label Classes**
The model distinguishes between the following portrait gender categories:
```
0: female portrait
1: male portrait
```
---
## **Installation**
```bash
pip install transformers torch pillow gradio
```
---
## **Example Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Realistic-Gender-Classification"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# ID to label mapping
id2label = {
"0": "female portrait",
"1": "male portrait"
}
def classify_gender(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_gender,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="Gender Classification"),
title="Realistic-Gender-Classification",
description="Upload a realistic portrait image to classify it as 'female portrait' or 'male portrait'."
)
if __name__ == "__main__":
iface.launch()
```
---
## Demo Inference
> [!note]
female portrait


> [!note]
male portrait


## **Applications**
* **Demographic Insights in Visual Data**
* **Dataset Curation & Tagging**
* **Media Analytics**
* **Audience Profiling for Marketing**
|
[
"female portrait",
"male portrait"
] |
gutkia01/vit-base-oxford-iiit-pets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1844
- Accuracy: 0.9418
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.146 | 1.0 | 370 | 0.1661 | 0.9472 |
| 0.1211 | 2.0 | 740 | 0.1510 | 0.9567 |
| 0.1083 | 3.0 | 1110 | 0.1489 | 0.9567 |
| 0.1038 | 4.0 | 1480 | 0.1463 | 0.9594 |
| 0.0911 | 5.0 | 1850 | 0.1447 | 0.9608 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
Dc-4nderson/confidence-image-vit
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"not confident",
"confident",
"kinda confident"
] |
AirasInnovations/Satyadrishti-V1-SMALL
|

## 🔭 Model Overview
**Satyadrishti-V1** is India’s First Open-Source Deepfake Detection engine by [AIRAS INC](https://www.airas.ai). It is designed to detect image authenticity by classifying images as either "Real" or "Fake". This model is part of the Satyadrishti series and leverages Google's `siglip2-base-patch16-224` vision-language architecture.
This specific variant, **Satyadrishti-V1 Small**, has been fine-tuned for lightweight deployment while maintaining high accuracy.
---
## 📦 General Information
| Metadata | Value |
|---------|-------|
| **Model Name** | Satyadrishti-V1 Small |
| **Model ID** | AirasInnovations/Satyadrishti-V1-SMALL |
| **License** | Apache-2.0 |
| **Language** | English |
| **Library** | Transformers |
| **Base Model** | google/siglip2-base-patch16-224 |
| **Pipeline Tag** | image-classification |
| **Tags** | deepfakedetection, image-authenticity |
---
## 🧠 Model Architecture
- **Architecture**: Fine-tuned SigLIP Vision Transformer
- **Task**: Binary Image Classification (Real vs Fake)
- **Classes**:
- `Class 0`: Fake (Deepfake / AI-generated / Manipulated)
- `Class 1`: Real (Authentic)
---
## 📈 Training Details
### Dataset
- **Primary Dataset**: [prithivMLmods/Deepfake-vs-Real-v2](https://huggingface.co/datasets/prithivMLmods/Deepfake-vs-Real-v2)
- **Image Count**: ~5.47k
- **Image Size**: Up to 194px width
- **Includes**: Real photos and synthetic images including outputs from DALL-E 3, Imagen, etc.
- **Data Augmentation**: Horizontal flips, rotations, color jittering
### Hyperparameters
| Parameter | Value |
|---------|-------|
| **Base Model** | google/siglip2-base-patch16-224 (~375M params) |
| **Fine-Tuned Model Size** | ~92 million parameters |
| **Optimizer** | AdamW |
| **Learning Rate** | 5e-5 |
| **Loss Function** | Cross-Entropy Loss |
| **Epochs** | 10 |
| **Hardware** | 2x NVIDIA T4 GPUs |
| **Training Time** | ~4 hours |
---
## ✅ Evaluation Metrics
| Metric | Score |
|--------|-------|
| **Accuracy** | 96% |
| **Precision** | 98% |
| **Recall** | 98% |
| **F1-Score** | 97% |
> ⚠️ Note: These metrics were computed on a dedicated validation set. Performance may vary depending on real-world input distribution and image quality.
---
## 📌 Intended Use
The model is intended for detecting whether an image is **real (authentic)** or **fake (manipulated or AI-generated)**. It can be applied in various domains:
- **Social Media Moderation**
- **Digital Forensics**
- **Journalism & Fact-Checking**
- **Authentication Systems**
- **Research & Development**
---
## 🛠️ How to Use
### Requirements
```bash
pip install transformers torch pillow gradio
```
### Code Example
```python
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
model_name = "AirasInnovations/Satyadrishti-V1-SMALL"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
def detect_authenticity(image):
image = image.convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
labels = model.config.id2label
return {labels[i]: round(probs[i], 3) for i in range(len(probs))}
```
You can also use it directly via Gradio interface as shown in the example script.
---
## 🆚 Comparison with Vatsav Deepfake Detection
| Feature | Vatsav Deepfake Detection | Satyadrishti-V1 Small |
|--------|----------------------------|------------------------|
| **Training Data Age** | 3 years old | Jan–April 2025 |
| **Evaluation Data** | Kaggle dataset | prithivMLmods Deepfake-vs-Real-v2 |
| **Open Source?** | ❌ No | ✅ Yes |
| **Accuracy** | 75% | 96% |
| **Precision** | 75% | 98% |
| **Recall** | 100% | 98% |
| **F1-Score** | ~86% | 97% |
---
## 📚 Citation & Acknowledgments
We thank [Google Research](https://ai.googleblog.com/) for open-sourcing the SigLIP architecture and [Prithiv MLMods](https://huggingface.co/prithivMLmods) for providing updated datasets for training.
If you use this model in your work, please cite:
```
@misc{airas-satyadrishti,
author = {AIRAS INC},
title = {Satyadrishti: India's First Open-Source Deepfake Detection Engine},
year = {2025},
publisher = {Hugging Face},
journal = {Model Card},
howpublished = {\url{https://huggingface.co/AirasInnovations/Satyadrishti-V1-SMALL}}
}
```
---
## 📬 Contact
For support, feedback, or collaboration opportunities, please visit [AIRAS INC Website](https://www.airas.ai) or reach out to us at [email protected].
|
[
"fake",
"real"
] |
HBH1520/finetuned-animal
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-animal
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2938
- Accuracy: 0.9539
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 3.1203 | 0.3937 | 100 | 2.9482 | 0.8645 |
| 1.9251 | 0.7874 | 200 | 1.8309 | 0.9008 |
| 1.1303 | 1.1811 | 300 | 1.0964 | 0.9316 |
| 0.9344 | 1.5748 | 400 | 0.7386 | 0.9358 |
| 0.6817 | 1.9685 | 500 | 0.5442 | 0.9469 |
| 0.4973 | 2.3622 | 600 | 0.4395 | 0.9330 |
| 0.3576 | 2.7559 | 700 | 0.3812 | 0.9413 |
| 0.366 | 3.1496 | 800 | 0.3367 | 0.9469 |
| 0.2382 | 3.5433 | 900 | 0.3032 | 0.9525 |
| 0.3751 | 3.9370 | 1000 | 0.2938 | 0.9539 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"antelope",
"badger",
"caterpillar",
"chimpanzee",
"cockroach",
"cow",
"coyote",
"crab",
"crow",
"deer",
"dog",
"dolphin",
"bat",
"donkey",
"dragonfly",
"duck",
"eagle",
"elephant",
"flamingo",
"fly",
"fox",
"goat",
"goldfish",
"bear",
"goose",
"gorilla",
"grasshopper",
"hamster",
"hare",
"hedgehog",
"hippopotamus",
"hornbill",
"horse",
"hummingbird",
"bee",
"hyena",
"jellyfish",
"kangaroo",
"koala",
"ladybugs",
"leopard",
"lion",
"lizard",
"lobster",
"mosquito",
"beetle",
"moth",
"mouse",
"octopus",
"okapi",
"orangutan",
"otter",
"owl",
"ox",
"oyster",
"panda",
"bison",
"parrot",
"pelecaniformes",
"penguin",
"pig",
"pigeon",
"porcupine",
"possum",
"raccoon",
"rat",
"reindeer",
"boar",
"rhinoceros",
"sandpiper",
"seahorse",
"seal",
"shark",
"sheep",
"snake",
"sparrow",
"squid",
"squirrel",
"butterfly",
"starfish",
"swan",
"tiger",
"turkey",
"turtle",
"whale",
"wolf",
"wombat",
"woodpecker",
"zebra",
"cat"
] |
Juju-234/swin-large-patch4-window7-224-finetuned-eurosat
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-large-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-large-patch4-window7-224](https://huggingface.co/microsoft/swin-large-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4098
- Accuracy: 0.4539
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-------:|:----:|:---------------:|:--------:|
| 1.5265 | 1.0 | 20 | 1.6373 | 0.2214 |
| 1.455 | 2.0 | 40 | 1.5808 | 0.2546 |
| 1.41 | 3.0 | 60 | 1.5281 | 0.2620 |
| 1.3791 | 4.0 | 80 | 1.4928 | 0.3026 |
| 1.3496 | 5.0 | 100 | 1.4662 | 0.3395 |
| 1.3218 | 6.0 | 120 | 1.4461 | 0.3985 |
| 1.3146 | 7.0 | 140 | 1.4331 | 0.4207 |
| 1.298 | 8.0 | 160 | 1.4245 | 0.4391 |
| 1.2922 | 9.0 | 180 | 1.4168 | 0.4502 |
| 1.3002 | 10.0 | 200 | 1.4121 | 0.4502 |
| 1.279 | 11.0 | 220 | 1.4101 | 0.4502 |
| 1.279 | 11.4156 | 228 | 1.4098 | 0.4539 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"unlabeled",
"cyst",
"normal",
"stone",
"tumor"
] |
nokyn/vit-base-oxford-iiit-pets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2029
- Accuracy: 0.9323
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3839 | 1.0 | 370 | 0.3148 | 0.9147 |
| 0.1747 | 2.0 | 740 | 0.2455 | 0.9283 |
| 0.1691 | 3.0 | 1110 | 0.2289 | 0.9242 |
| 0.1638 | 4.0 | 1480 | 0.2189 | 0.9323 |
| 0.1214 | 5.0 | 1850 | 0.2188 | 0.9269 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
n1kooo/vit-cifar100
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-cifar100
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the n1kooo/vit-cifar100 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5073
- Accuracy: 0.8628
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.5825 | 1.0 | 2500 | 0.5352 | 0.851 |
| 0.4471 | 2.0 | 5000 | 0.4986 | 0.8542 |
| 0.3538 | 3.0 | 7500 | 0.4779 | 0.8624 |
| 0.3358 | 4.0 | 10000 | 0.4731 | 0.8602 |
| 0.2974 | 5.0 | 12500 | 0.4710 | 0.8624 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"19",
"29",
"0",
"11",
"1",
"86",
"90",
"28",
"23",
"31",
"39",
"96",
"82",
"17",
"71",
"8",
"97",
"80",
"74",
"59",
"70",
"87",
"84",
"64",
"52",
"42",
"47",
"65",
"21",
"22",
"81",
"24",
"78",
"45",
"49",
"56",
"76",
"89",
"73",
"14",
"9",
"6",
"20",
"98",
"36",
"55",
"72",
"43",
"51",
"35",
"83",
"33",
"27",
"53",
"92",
"50",
"15",
"18",
"46",
"75",
"38",
"66",
"77",
"69",
"95",
"99",
"93",
"4",
"61",
"94",
"68",
"34",
"32",
"88",
"67",
"30",
"62",
"63",
"40",
"26",
"48",
"79",
"85",
"54",
"44",
"7",
"12",
"2",
"41",
"37",
"13",
"25",
"10",
"57",
"5",
"60",
"91",
"3",
"58",
"16"
] |
Sarthak003/finetuned-indian-96cls-balanced
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-indian-96cls-balanced
This model is a fine-tuned version of [Sarthak003/finetuned-indian-96cls-balanced](https://huggingface.co/Sarthak003/finetuned-indian-96cls-balanced) on the indian_food_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9211
- Accuracy: 0.7823
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.9087 | 0.4167 | 100 | 1.3922 | 0.6625 |
| 0.7702 | 0.8333 | 200 | 1.2053 | 0.7052 |
| 0.5377 | 1.25 | 300 | 1.2581 | 0.6781 |
| 0.5526 | 1.6667 | 400 | 1.1839 | 0.6937 |
| 0.4904 | 2.0833 | 500 | 1.1946 | 0.6865 |
| 0.4365 | 2.5 | 600 | 1.1218 | 0.7104 |
| 0.3538 | 2.9167 | 700 | 1.1562 | 0.6958 |
| 0.407 | 3.3333 | 800 | 1.1106 | 0.7094 |
| 0.4028 | 3.75 | 900 | 1.1087 | 0.7104 |
| 0.1751 | 4.1667 | 1000 | 1.1438 | 0.7177 |
| 0.3216 | 4.5833 | 1100 | 1.1052 | 0.7271 |
| 0.3618 | 5.0 | 1200 | 1.0883 | 0.7146 |
| 0.2827 | 5.4167 | 1300 | 1.0367 | 0.7312 |
| 0.2351 | 5.8333 | 1400 | 1.0086 | 0.7406 |
| 0.3047 | 6.25 | 1500 | 1.0453 | 0.75 |
| 0.1383 | 6.6667 | 1600 | 0.9886 | 0.75 |
| 0.2271 | 7.0833 | 1700 | 0.9542 | 0.7667 |
| 0.3034 | 7.5 | 1800 | 0.9683 | 0.7635 |
| 0.3133 | 7.9167 | 1900 | 0.9404 | 0.7625 |
| 0.1997 | 8.3333 | 2000 | 0.9467 | 0.7615 |
| 0.1457 | 8.75 | 2100 | 0.9716 | 0.7594 |
| 0.1462 | 9.1667 | 2200 | 0.9388 | 0.7667 |
| 0.2873 | 9.5833 | 2300 | 0.9265 | 0.7844 |
| 0.2293 | 10.0 | 2400 | 0.9211 | 0.7823 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"adhirasam",
"aloo_gobi",
"aloo_matar",
"aloo_methi",
"aloo_shimla_mirch",
"aloo_tikki",
"anarsa",
"ariselu",
"bandar_laddu",
"basundi",
"bhatura",
"bhindi_masala",
"biryani",
"boondi",
"burger",
"butter_chicken",
"butter_naan",
"chai",
"chak_hao_kheer",
"cham_cham",
"chana_masala",
"chapati",
"chhena_kheeri",
"chicken_razala",
"chicken_tikka",
"chicken_tikka_masala",
"chikki",
"chole_bhature",
"daal_baati_churma",
"daal_puri",
"dal_makhani",
"dal_tadka",
"dharwad_pedha",
"dhokla",
"doodhpak",
"double_ka_meetha",
"dum_aloo",
"fried_rice",
"gajar_ka_halwa",
"gavvalu",
"ghevar",
"gulab_jamun",
"idli",
"imarti",
"jalebi",
"kaathi_rolls",
"kachori",
"kadai_paneer",
"kadhi_pakoda",
"kajjikaya",
"kakinada_khaja",
"kalakand",
"karela_bharta",
"kofta",
"kulfi",
"kuzhi_paniyaram",
"lassi",
"ledikeni",
"litti_chokha",
"lyangcha",
"maach_jhol",
"makki_di_roti_sarson_da_saag",
"malapua",
"masala_dosa",
"misi_roti",
"misti_doi",
"modak",
"momos",
"mysore_pak",
"naan",
"navrattan_korma",
"paani_puri",
"pakode",
"palak_paneer",
"paneer_butter_masala",
"pav_bhaji",
"phirni",
"pithe",
"pizza",
"poha",
"poornalu",
"pootharekulu",
"qubani_ka_meetha",
"rabri",
"ras_malai",
"rasgulla",
"samosa",
"sandesh",
"shankarpali",
"sheer_korma",
"sheera",
"shrikhand",
"sohan_halwa",
"sohan_papdi",
"sutar_feni",
"unni_appam"
] |
Haaaaaaaaaax/dinov2-Base-finetuned-chest_xray
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dinov2-Base-finetuned-chest_xray
This model is a fine-tuned version of [facebook/dinov2-base](https://huggingface.co/facebook/dinov2-base) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1155
- Accuracy: 0.978
- F1: 0.9780
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.6168 | 1.0 | 500 | 0.3097 | 0.881 | 0.8804 |
| 0.4064 | 2.0 | 1000 | 0.2299 | 0.931 | 0.9309 |
| 0.2011 | 3.0 | 1500 | 0.1904 | 0.943 | 0.9430 |
| 0.148 | 4.0 | 2000 | 0.2213 | 0.94 | 0.9399 |
| 0.2495 | 5.0 | 2500 | 0.2518 | 0.933 | 0.9328 |
| 0.1926 | 6.0 | 3000 | 0.1155 | 0.966 | 0.9660 |
| 0.1565 | 7.0 | 3500 | 0.1711 | 0.959 | 0.9590 |
| 0.1881 | 8.0 | 4000 | 0.1235 | 0.967 | 0.9670 |
| 0.139 | 9.0 | 4500 | 0.1285 | 0.97 | 0.9700 |
| 0.1317 | 10.0 | 5000 | 0.1155 | 0.978 | 0.9780 |
### Framework versions
- Transformers 4.51.1
- Pytorch 2.5.1+cu124
- Datasets 3.5.0
- Tokenizers 0.21.0
|
[
"normal",
"pneumonia"
] |
qwe123432534/my_food_recognizer
|
Supervised Fine Tuned version of `timm/vit_base_patch16_224.augreg2_in21k_ft_in1k` on the `ethz/food101` dataset.
Artefeacts:
1. [Hugging Face Space on Food Classification using this model](https://huggingface.co/spaces/ariG23498/food-classification)
2. [Training code for the model](https://github.com/ariG23498/timm-wrapper-examples/blob/main/%2304_sft.ipynb)
|
[
"apple_pie",
"baby_back_ribs",
"baklava",
"beef_carpaccio",
"beef_tartare",
"beet_salad",
"beignets",
"bibimbap",
"bread_pudding",
"breakfast_burrito",
"bruschetta",
"caesar_salad",
"cannoli",
"caprese_salad",
"carrot_cake",
"ceviche",
"cheesecake",
"cheese_plate",
"chicken_curry",
"chicken_quesadilla",
"chicken_wings",
"chocolate_cake",
"chocolate_mousse",
"churros",
"clam_chowder",
"club_sandwich",
"crab_cakes",
"creme_brulee",
"croque_madame",
"cup_cakes",
"deviled_eggs",
"donuts",
"dumplings",
"edamame",
"eggs_benedict",
"escargots",
"falafel",
"filet_mignon",
"fish_and_chips",
"foie_gras",
"french_fries",
"french_onion_soup",
"french_toast",
"fried_calamari",
"fried_rice",
"frozen_yogurt",
"garlic_bread",
"gnocchi",
"greek_salad",
"grilled_cheese_sandwich",
"grilled_salmon",
"guacamole",
"gyoza",
"hamburger",
"hot_and_sour_soup",
"hot_dog",
"huevos_rancheros",
"hummus",
"ice_cream",
"lasagna",
"lobster_bisque",
"lobster_roll_sandwich",
"macaroni_and_cheese",
"macarons",
"miso_soup",
"mussels",
"nachos",
"omelette",
"onion_rings",
"oysters",
"pad_thai",
"paella",
"pancakes",
"panna_cotta",
"peking_duck",
"pho",
"pizza",
"pork_chop",
"poutine",
"prime_rib",
"pulled_pork_sandwich",
"ramen",
"ravioli",
"red_velvet_cake",
"risotto",
"samosa",
"sashimi",
"scallops",
"seaweed_salad",
"shrimp_and_grits",
"spaghetti_bolognese",
"spaghetti_carbonara",
"spring_rolls",
"steak",
"strawberry_shortcake",
"sushi",
"tacos",
"takoyaki",
"tiramisu",
"tuna_tartare",
"waffles"
] |
djbp/swinv2-tiny-patch4-window8-256-finetuned-validshop-car-1
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swinv2-tiny-patch4-window8-256-finetuned-validshop-car-1
This model is a fine-tuned version of [microsoft/swinv2-tiny-patch4-window8-256](https://huggingface.co/microsoft/swinv2-tiny-patch4-window8-256) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2577
- Accuracy: 0.8915
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.9275 | 1.0 | 37 | 0.2632 | 0.8605 |
| 0.7211 | 2.0 | 74 | 0.2196 | 0.9070 |
| 0.5262 | 3.0 | 111 | 0.2471 | 0.9070 |
| 0.4001 | 4.0 | 148 | 0.2224 | 0.9147 |
| 0.5917 | 5.0 | 185 | 0.1857 | 0.9225 |
| 0.3629 | 5.8493 | 216 | 0.2577 | 0.8915 |
### Framework versions
- Transformers 4.48.0.dev0
- Pytorch 2.4.0+cu121
- Datasets 3.6.0
- Tokenizers 0.21.0
|
[
"invalidshop",
"validshop"
] |
prithivMLmods/IMAGENETTE
|

# IMAGENETTE
> IMAGENETTE is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for multi-class image classification. It is trained to classify images into 10 categories from the popular Imagenette dataset using the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
> *ImageNet Large Scale Visual Recognition Challenge* https://arxiv.org/pdf/1409.0575
```py
Classification Report:
precision recall f1-score support
tench 0.9885 0.9834 0.9859 963
english springer 0.9843 0.9822 0.9832 955
cassette player 0.9544 0.9486 0.9515 993
chain saw 0.9257 0.8998 0.9125 858
church 0.9654 0.9798 0.9726 941
French horn 0.9757 0.9665 0.9711 956
garbage truck 0.8883 0.9761 0.9301 961
gas pump 0.9366 0.9044 0.9202 931
golf ball 0.9925 0.9716 0.9819 951
parachute 0.9821 0.9708 0.9764 960
accuracy 0.9590 9469
macro avg 0.9593 0.9583 0.9586 9469
weighted avg 0.9597 0.9590 0.9591 9469
```

---
## Label Space: 10 Classes
The model predicts one of the following image classes:
```
0: tench
1: english springer
2: cassette player
3: chain saw
4: church
5: French horn
6: garbage truck
7: gas pump
8: golf ball
9: parachute
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/IMAGENETTE"
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "tench",
"1": "english springer",
"2": "cassette player",
"3": "chain saw",
"4": "church",
"5": "French horn",
"6": "garbage truck",
"7": "gas pump",
"8": "golf ball",
"9": "parachute"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=3, label="Image Classification"),
title="IMAGENETTE - SigLIP2 Classifier",
description="Upload an image to classify it into one of 10 categories from the Imagenette dataset."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
IMAGENETTE is designed for:
* Educational purposes and model benchmarking.
* Demonstrating the performance of SigLIP2 on a small but diverse classification task.
* Fine-tuning workflows on vision-language models.
|
[
"tench",
"english springer",
"cassette player",
"chain saw",
"church",
"french horn",
"garbage truck",
"gas pump",
"golf ball",
"parachute"
] |
prithivMLmods/DOZE-GUARD-RLDD
|

# DOZE-GUARD-RLDD
> DOZE-GUARD-RLDD [Real-Time Distracted Driver Detection] is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether a person in the image is drowsy or non-drowsy using the SiglipForImageClassification architecture.
> [!note]
> DOZE GUARD RLDD detection works best with crisp and high-quality images. Noisy images are not recommended for validation.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
*Detection and Prediction of Driver Drowsiness for the Prevention of Road Accidents Using Deep Neural Networks Techniques* https://www.researchgate.net/publication/353397807_Detection_and_Prediction_of_Driver_Drowsiness_for_the_Prevention_of_Road_Accidents_Using_Deep_Neural_Networks_Techniques
```py
Classification Report:
precision recall f1-score support
Drowsy 0.9818 0.9952 0.9885 17868
Non Drowsy 0.9945 0.9788 0.9866 15566
accuracy 0.9876 33434
macro avg 0.9881 0.9870 0.9875 33434
weighted avg 0.9877 0.9876 0.9876 33434
```

---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Drowsy
Class 1: Non Drowsy
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/DOZE-GUARD-RLDD" # Replace with your model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Drowsy",
"1": "Non Drowsy"
}
def classify_drowsiness(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_drowsiness,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="Drowsiness Detection"),
title="DOZE-GUARD-RLDD",
description="Upload an image to classify whether the person is drowsy or non-drowsy."
)
if __name__ == "__main__":
iface.launch()
```
---
## Demo Inference



## Intended Use
**DOZE-GUARD-RLDD** is useful in scenarios such as:
* **Driver Monitoring** – Detect drowsiness in drivers to prevent accidents.
* **Workplace Safety** – Monitor employee alertness to improve safety in high-risk environments.
* **Healthcare** – Assist in diagnosing conditions related to sleep deprivation or drowsiness.
* **Surveillance** – Real-time monitoring of individuals for drowsiness detection in critical areas.
|
[
"drowsy",
"non drowsy"
] |
groebmic/vit-base-oxford-iiit-pets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4854
- Accuracy: 0.1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 5 | 3.3969 | 0.3 |
| No log | 2.0 | 10 | 3.2582 | 0.3 |
| No log | 3.0 | 15 | 3.1567 | 0.3 |
| No log | 4.0 | 20 | 3.0951 | 0.3 |
| No log | 5.0 | 25 | 3.0715 | 0.3 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
Ayca11/checkpoints
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# checkpoints
This model is a fine-tuned version of [motheecreator/vit-Facial-Expression-Recognition](https://huggingface.co/motheecreator/vit-Facial-Expression-Recognition) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3915
- Accuracy: 0.868
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 512
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.52.2
- Pytorch 2.6.0+cu124
- Datasets 2.14.5
- Tokenizers 0.21.1
|
[
"angry",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
mjpsm/specified-participation-image-classifier-updated
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"not paying attention",
"paying attention"
] |
truskovskiyk/axl-tif-images-v1
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# axl-tif-images-v1
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1686
- Accuracy: 0.9583
- F1: 0.9576
- Precision: 0.9608
- Recall: 0.9583
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.5574 | 1.0 | 24 | 0.3268 | 0.9583 | 0.9576 | 0.9608 | 0.9583 |
| 0.2038 | 2.0 | 48 | 0.1576 | 0.9583 | 0.9576 | 0.9608 | 0.9583 |
| 0.0568 | 3.0 | 72 | 0.3077 | 0.9167 | 0.9132 | 0.9259 | 0.9167 |
| 0.0661 | 4.0 | 96 | 0.1585 | 0.9583 | 0.9589 | 0.9630 | 0.9583 |
| 0.0648 | 5.0 | 120 | 0.0147 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0185 | 6.0 | 144 | 0.0130 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0113 | 7.0 | 168 | 0.0113 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0463 | 8.0 | 192 | 0.1764 | 0.9583 | 0.9589 | 0.9630 | 0.9583 |
| 0.1297 | 9.0 | 216 | 0.0098 | 1.0 | 1.0 | 1.0 | 1.0 |
| 0.0763 | 10.0 | 240 | 0.1686 | 0.9583 | 0.9576 | 0.9608 | 0.9583 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"good",
"bad"
] |
encku/compass-05-25
|
# Model Trained Using AutoTrain
- Problem type: Image Classification
## Validation Metrics
loss: 5.828354551340453e-05
f1_macro: 1.0
f1_micro: 1.0
f1_weighted: 1.0
precision_macro: 1.0
precision_micro: 1.0
precision_weighted: 1.0
recall_macro: 1.0
recall_micro: 1.0
recall_weighted: 1.0
accuracy: 1.0
|
[
"018200250002",
"018200250019",
"018200250101",
"018200261244",
"01823743",
"021136180596",
"021136180947",
"021136181364",
"021136181371",
"025000058011",
"03435515",
"049000003710",
"049000007909",
"049000019162",
"049000040869",
"049000071542",
"04904403",
"04904500",
"04976400",
"04997704",
"070847012474",
"070847811169",
"070847898245",
"071990095451",
"071990300654",
"080660956435",
"080660957210",
"083783110012",
"083783375534",
"083900005757",
"083900005771",
"085000027141",
"085000028728",
"085000029275",
"085000031377",
"087692832317",
"696859256493",
"786162200433",
"786162338006",
"796030250965",
"810628031474",
"816751021214",
"852304007878",
"853045008001",
"853045008964",
"855344007075",
"855352008064",
"857531005284",
"857531005857",
"858770002058",
"860003623305",
"860003623374"
] |
BramaSeta/emotion_classification
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7842
- Accuracy: 0.3312
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7"
] |
shingguy1/food-calorie-vit
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"pizza",
"hamburger",
"sushi",
"salad",
"pasta",
"ice_cream",
"fried_rice",
"tacos",
"steak",
"chocolate_cake"
] |
prithivMLmods/AIorNot-SigLIP2
|

# AIorNot-SigLIP2
> AIorNot-SigLIP2 is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether an image is generated by AI or is a real photograph using the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
```py
Classification Report:
precision recall f1-score support
Real 0.9215 0.8842 0.9025 8288
AI 0.9100 0.9396 0.9246 10330
accuracy 0.9149 18618
macro avg 0.9158 0.9119 0.9135 18618
weighted avg 0.9151 0.9149 0.9147 18618
```

---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Real
Class 1: AI
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/AIorNot-SigLIP2" # Replace with your model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Real",
"1": "AI"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="AI or Real Detection"),
title="AIorNot-SigLIP2",
description="Upload an image to classify whether it is AI-generated or Real."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
AIorNot-SigLIP2 is useful in scenarios such as:
* AI Content Detection – Identify AI-generated images for social platforms or media verification.
* Digital Media Forensics – Assist in distinguishing synthetic from real-world imagery.
* Dataset Filtering – Clean datasets by separating real photographs from AI-synthesized ones.
* Research & Development – Benchmark performance of image authenticity detectors.
|
[
"real",
"ai"
] |
prithivMLmods/OpenSDI-Flux.1-SigLIP2
|

# OpenSDI-Flux.1-SigLIP2
> OpenSDI-Flux.1-SigLIP2 is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether an image is a real photograph or generated using the Flux.1 generative model, based on the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
*OpenSDI: Spotting Diffusion-Generated Images in the Open World* https://arxiv.org/pdf/2503.19653, OpenSDI Flux.1 SigLIP2 works best with crisp and high-quality images. Noisy images are not recommended for validation.
> [!warning]
If the task is based on image content moderation or AI-generated image vs. real image classification, it is recommended to use this model.
```py
Classification Report:
precision recall f1-score support
Real_Image 0.9108 0.9238 0.9172 10000
Flux.1_Generated 0.9227 0.9095 0.9160 10000
accuracy 0.9166 20000
macro avg 0.9167 0.9166 0.9166 20000
weighted avg 0.9167 0.9166 0.9166 20000
```

---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Real_Image
Class 1: Flux.1_Generated
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/OpenSDI-Flux.1-SigLIP2" # Update if needed
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Real_Image",
"1": "Flux.1_Generated"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="Flux.1 Image Detection"),
title="OpenSDI-Flux.1-SigLIP2",
description="Upload an image to determine whether it is a real photograph or generated by Flux.1."
)
if __name__ == "__main__":
iface.launch()
```
---
## Demo Inference
> [!warning]
Flux.1 Generated
| Image 1 | Image 2 |
|-----|--------|
|  |  |
> [!warning]
Real Image
| Image 1 | Image 2 |
|-----|-----|
| 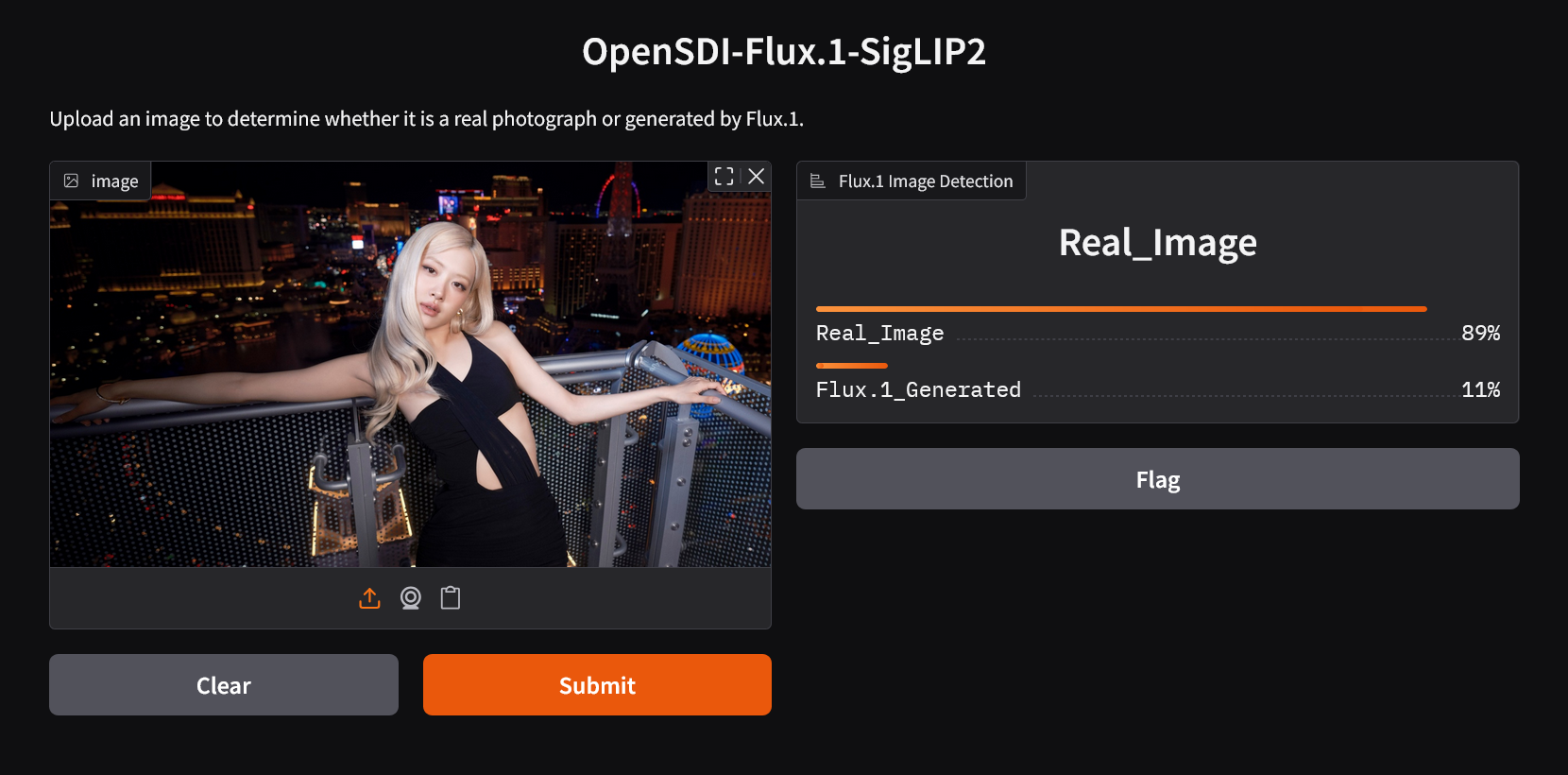 |  |
---
## Intended Use
OpenSDI-Flux.1-SigLIP2 is designed for tasks such as:
* Generative Model Evaluation – Distinguish Flux.1-generated images from real photos for benchmarking and validation.
* Dataset Auditing – Detect synthetic images in real-world datasets to maintain integrity.
* Misinformation Detection – Identify AI-generated visuals in online or news content.
* Media Authentication – Verify whether visual content originates from human-captured or model-generated sources.
|
[
"real_image",
"flux.1_generated"
] |
java0325/jas-resnet-18
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"tench, tinca tinca",
"goldfish, carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, carcharodon carcharias",
"tiger shark, galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, struthio camelus",
"brambling, fringilla montifringilla",
"goldfinch, carduelis carduelis",
"house finch, linnet, carpodacus mexicanus",
"junco, snowbird",
"indigo bunting, indigo finch, indigo bird, passerina cyanea",
"robin, american robin, turdus migratorius",
"bulbul",
"jay",
"magpie",
"chickadee",
"water ouzel, dipper",
"kite",
"bald eagle, american eagle, haliaeetus leucocephalus",
"vulture",
"great grey owl, great gray owl, strix nebulosa",
"european fire salamander, salamandra salamandra",
"common newt, triturus vulgaris",
"eft",
"spotted salamander, ambystoma maculatum",
"axolotl, mud puppy, ambystoma mexicanum",
"bullfrog, rana catesbeiana",
"tree frog, tree-frog",
"tailed frog, bell toad, ribbed toad, tailed toad, ascaphus trui",
"loggerhead, loggerhead turtle, caretta caretta",
"leatherback turtle, leatherback, leathery turtle, dermochelys coriacea",
"mud turtle",
"terrapin",
"box turtle, box tortoise",
"banded gecko",
"common iguana, iguana, iguana iguana",
"american chameleon, anole, anolis carolinensis",
"whiptail, whiptail lizard",
"agama",
"frilled lizard, chlamydosaurus kingi",
"alligator lizard",
"gila monster, heloderma suspectum",
"green lizard, lacerta viridis",
"african chameleon, chamaeleo chamaeleon",
"komodo dragon, komodo lizard, dragon lizard, giant lizard, varanus komodoensis",
"african crocodile, nile crocodile, crocodylus niloticus",
"american alligator, alligator mississipiensis",
"triceratops",
"thunder snake, worm snake, carphophis amoenus",
"ringneck snake, ring-necked snake, ring snake",
"hognose snake, puff adder, sand viper",
"green snake, grass snake",
"king snake, kingsnake",
"garter snake, grass snake",
"water snake",
"vine snake",
"night snake, hypsiglena torquata",
"boa constrictor, constrictor constrictor",
"rock python, rock snake, python sebae",
"indian cobra, naja naja",
"green mamba",
"sea snake",
"horned viper, cerastes, sand viper, horned asp, cerastes cornutus",
"diamondback, diamondback rattlesnake, crotalus adamanteus",
"sidewinder, horned rattlesnake, crotalus cerastes",
"trilobite",
"harvestman, daddy longlegs, phalangium opilio",
"scorpion",
"black and gold garden spider, argiope aurantia",
"barn spider, araneus cavaticus",
"garden spider, aranea diademata",
"black widow, latrodectus mactans",
"tarantula",
"wolf spider, hunting spider",
"tick",
"centipede",
"black grouse",
"ptarmigan",
"ruffed grouse, partridge, bonasa umbellus",
"prairie chicken, prairie grouse, prairie fowl",
"peacock",
"quail",
"partridge",
"african grey, african gray, psittacus erithacus",
"macaw",
"sulphur-crested cockatoo, kakatoe galerita, cacatua galerita",
"lorikeet",
"coucal",
"bee eater",
"hornbill",
"hummingbird",
"jacamar",
"toucan",
"drake",
"red-breasted merganser, mergus serrator",
"goose",
"black swan, cygnus atratus",
"tusker",
"echidna, spiny anteater, anteater",
"platypus, duckbill, duckbilled platypus, duck-billed platypus, ornithorhynchus anatinus",
"wallaby, brush kangaroo",
"koala, koala bear, kangaroo bear, native bear, phascolarctos cinereus",
"wombat",
"jellyfish",
"sea anemone, anemone",
"brain coral",
"flatworm, platyhelminth",
"nematode, nematode worm, roundworm",
"conch",
"snail",
"slug",
"sea slug, nudibranch",
"chiton, coat-of-mail shell, sea cradle, polyplacophore",
"chambered nautilus, pearly nautilus, nautilus",
"dungeness crab, cancer magister",
"rock crab, cancer irroratus",
"fiddler crab",
"king crab, alaska crab, alaskan king crab, alaska king crab, paralithodes camtschatica",
"american lobster, northern lobster, maine lobster, homarus americanus",
"spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish",
"crayfish, crawfish, crawdad, crawdaddy",
"hermit crab",
"isopod",
"white stork, ciconia ciconia",
"black stork, ciconia nigra",
"spoonbill",
"flamingo",
"little blue heron, egretta caerulea",
"american egret, great white heron, egretta albus",
"bittern",
"crane",
"limpkin, aramus pictus",
"european gallinule, porphyrio porphyrio",
"american coot, marsh hen, mud hen, water hen, fulica americana",
"bustard",
"ruddy turnstone, arenaria interpres",
"red-backed sandpiper, dunlin, erolia alpina",
"redshank, tringa totanus",
"dowitcher",
"oystercatcher, oyster catcher",
"pelican",
"king penguin, aptenodytes patagonica",
"albatross, mollymawk",
"grey whale, gray whale, devilfish, eschrichtius gibbosus, eschrichtius robustus",
"killer whale, killer, orca, grampus, sea wolf, orcinus orca",
"dugong, dugong dugon",
"sea lion",
"chihuahua",
"japanese spaniel",
"maltese dog, maltese terrier, maltese",
"pekinese, pekingese, peke",
"shih-tzu",
"blenheim spaniel",
"papillon",
"toy terrier",
"rhodesian ridgeback",
"afghan hound, afghan",
"basset, basset hound",
"beagle",
"bloodhound, sleuthhound",
"bluetick",
"black-and-tan coonhound",
"walker hound, walker foxhound",
"english foxhound",
"redbone",
"borzoi, russian wolfhound",
"irish wolfhound",
"italian greyhound",
"whippet",
"ibizan hound, ibizan podenco",
"norwegian elkhound, elkhound",
"otterhound, otter hound",
"saluki, gazelle hound",
"scottish deerhound, deerhound",
"weimaraner",
"staffordshire bullterrier, staffordshire bull terrier",
"american staffordshire terrier, staffordshire terrier, american pit bull terrier, pit bull terrier",
"bedlington terrier",
"border terrier",
"kerry blue terrier",
"irish terrier",
"norfolk terrier",
"norwich terrier",
"yorkshire terrier",
"wire-haired fox terrier",
"lakeland terrier",
"sealyham terrier, sealyham",
"airedale, airedale terrier",
"cairn, cairn terrier",
"australian terrier",
"dandie dinmont, dandie dinmont terrier",
"boston bull, boston terrier",
"miniature schnauzer",
"giant schnauzer",
"standard schnauzer",
"scotch terrier, scottish terrier, scottie",
"tibetan terrier, chrysanthemum dog",
"silky terrier, sydney silky",
"soft-coated wheaten terrier",
"west highland white terrier",
"lhasa, lhasa apso",
"flat-coated retriever",
"curly-coated retriever",
"golden retriever",
"labrador retriever",
"chesapeake bay retriever",
"german short-haired pointer",
"vizsla, hungarian pointer",
"english setter",
"irish setter, red setter",
"gordon setter",
"brittany spaniel",
"clumber, clumber spaniel",
"english springer, english springer spaniel",
"welsh springer spaniel",
"cocker spaniel, english cocker spaniel, cocker",
"sussex spaniel",
"irish water spaniel",
"kuvasz",
"schipperke",
"groenendael",
"malinois",
"briard",
"kelpie",
"komondor",
"old english sheepdog, bobtail",
"shetland sheepdog, shetland sheep dog, shetland",
"collie",
"border collie",
"bouvier des flandres, bouviers des flandres",
"rottweiler",
"german shepherd, german shepherd dog, german police dog, alsatian",
"doberman, doberman pinscher",
"miniature pinscher",
"greater swiss mountain dog",
"bernese mountain dog",
"appenzeller",
"entlebucher",
"boxer",
"bull mastiff",
"tibetan mastiff",
"french bulldog",
"great dane",
"saint bernard, st bernard",
"eskimo dog, husky",
"malamute, malemute, alaskan malamute",
"siberian husky",
"dalmatian, coach dog, carriage dog",
"affenpinscher, monkey pinscher, monkey dog",
"basenji",
"pug, pug-dog",
"leonberg",
"newfoundland, newfoundland dog",
"great pyrenees",
"samoyed, samoyede",
"pomeranian",
"chow, chow chow",
"keeshond",
"brabancon griffon",
"pembroke, pembroke welsh corgi",
"cardigan, cardigan welsh corgi",
"toy poodle",
"miniature poodle",
"standard poodle",
"mexican hairless",
"timber wolf, grey wolf, gray wolf, canis lupus",
"white wolf, arctic wolf, canis lupus tundrarum",
"red wolf, maned wolf, canis rufus, canis niger",
"coyote, prairie wolf, brush wolf, canis latrans",
"dingo, warrigal, warragal, canis dingo",
"dhole, cuon alpinus",
"african hunting dog, hyena dog, cape hunting dog, lycaon pictus",
"hyena, hyaena",
"red fox, vulpes vulpes",
"kit fox, vulpes macrotis",
"arctic fox, white fox, alopex lagopus",
"grey fox, gray fox, urocyon cinereoargenteus",
"tabby, tabby cat",
"tiger cat",
"persian cat",
"siamese cat, siamese",
"egyptian cat",
"cougar, puma, catamount, mountain lion, painter, panther, felis concolor",
"lynx, catamount",
"leopard, panthera pardus",
"snow leopard, ounce, panthera uncia",
"jaguar, panther, panthera onca, felis onca",
"lion, king of beasts, panthera leo",
"tiger, panthera tigris",
"cheetah, chetah, acinonyx jubatus",
"brown bear, bruin, ursus arctos",
"american black bear, black bear, ursus americanus, euarctos americanus",
"ice bear, polar bear, ursus maritimus, thalarctos maritimus",
"sloth bear, melursus ursinus, ursus ursinus",
"mongoose",
"meerkat, mierkat",
"tiger beetle",
"ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle",
"ground beetle, carabid beetle",
"long-horned beetle, longicorn, longicorn beetle",
"leaf beetle, chrysomelid",
"dung beetle",
"rhinoceros beetle",
"weevil",
"fly",
"bee",
"ant, emmet, pismire",
"grasshopper, hopper",
"cricket",
"walking stick, walkingstick, stick insect",
"cockroach, roach",
"mantis, mantid",
"cicada, cicala",
"leafhopper",
"lacewing, lacewing fly",
"dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk",
"damselfly",
"admiral",
"ringlet, ringlet butterfly",
"monarch, monarch butterfly, milkweed butterfly, danaus plexippus",
"cabbage butterfly",
"sulphur butterfly, sulfur butterfly",
"lycaenid, lycaenid butterfly",
"starfish, sea star",
"sea urchin",
"sea cucumber, holothurian",
"wood rabbit, cottontail, cottontail rabbit",
"hare",
"angora, angora rabbit",
"hamster",
"porcupine, hedgehog",
"fox squirrel, eastern fox squirrel, sciurus niger",
"marmot",
"beaver",
"guinea pig, cavia cobaya",
"sorrel",
"zebra",
"hog, pig, grunter, squealer, sus scrofa",
"wild boar, boar, sus scrofa",
"warthog",
"hippopotamus, hippo, river horse, hippopotamus amphibius",
"ox",
"water buffalo, water ox, asiatic buffalo, bubalus bubalis",
"bison",
"ram, tup",
"bighorn, bighorn sheep, cimarron, rocky mountain bighorn, rocky mountain sheep, ovis canadensis",
"ibex, capra ibex",
"hartebeest",
"impala, aepyceros melampus",
"gazelle",
"arabian camel, dromedary, camelus dromedarius",
"llama",
"weasel",
"mink",
"polecat, fitch, foulmart, foumart, mustela putorius",
"black-footed ferret, ferret, mustela nigripes",
"otter",
"skunk, polecat, wood pussy",
"badger",
"armadillo",
"three-toed sloth, ai, bradypus tridactylus",
"orangutan, orang, orangutang, pongo pygmaeus",
"gorilla, gorilla gorilla",
"chimpanzee, chimp, pan troglodytes",
"gibbon, hylobates lar",
"siamang, hylobates syndactylus, symphalangus syndactylus",
"guenon, guenon monkey",
"patas, hussar monkey, erythrocebus patas",
"baboon",
"macaque",
"langur",
"colobus, colobus monkey",
"proboscis monkey, nasalis larvatus",
"marmoset",
"capuchin, ringtail, cebus capucinus",
"howler monkey, howler",
"titi, titi monkey",
"spider monkey, ateles geoffroyi",
"squirrel monkey, saimiri sciureus",
"madagascar cat, ring-tailed lemur, lemur catta",
"indri, indris, indri indri, indri brevicaudatus",
"indian elephant, elephas maximus",
"african elephant, loxodonta africana",
"lesser panda, red panda, panda, bear cat, cat bear, ailurus fulgens",
"giant panda, panda, panda bear, coon bear, ailuropoda melanoleuca",
"barracouta, snoek",
"eel",
"coho, cohoe, coho salmon, blue jack, silver salmon, oncorhynchus kisutch",
"rock beauty, holocanthus tricolor",
"anemone fish",
"sturgeon",
"gar, garfish, garpike, billfish, lepisosteus osseus",
"lionfish",
"puffer, pufferfish, blowfish, globefish",
"abacus",
"abaya",
"academic gown, academic robe, judge's robe",
"accordion, piano accordion, squeeze box",
"acoustic guitar",
"aircraft carrier, carrier, flattop, attack aircraft carrier",
"airliner",
"airship, dirigible",
"altar",
"ambulance",
"amphibian, amphibious vehicle",
"analog clock",
"apiary, bee house",
"apron",
"ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin",
"assault rifle, assault gun",
"backpack, back pack, knapsack, packsack, rucksack, haversack",
"bakery, bakeshop, bakehouse",
"balance beam, beam",
"balloon",
"ballpoint, ballpoint pen, ballpen, biro",
"band aid",
"banjo",
"bannister, banister, balustrade, balusters, handrail",
"barbell",
"barber chair",
"barbershop",
"barn",
"barometer",
"barrel, cask",
"barrow, garden cart, lawn cart, wheelbarrow",
"baseball",
"basketball",
"bassinet",
"bassoon",
"bathing cap, swimming cap",
"bath towel",
"bathtub, bathing tub, bath, tub",
"beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon",
"beacon, lighthouse, beacon light, pharos",
"beaker",
"bearskin, busby, shako",
"beer bottle",
"beer glass",
"bell cote, bell cot",
"bib",
"bicycle-built-for-two, tandem bicycle, tandem",
"bikini, two-piece",
"binder, ring-binder",
"binoculars, field glasses, opera glasses",
"birdhouse",
"boathouse",
"bobsled, bobsleigh, bob",
"bolo tie, bolo, bola tie, bola",
"bonnet, poke bonnet",
"bookcase",
"bookshop, bookstore, bookstall",
"bottlecap",
"bow",
"bow tie, bow-tie, bowtie",
"brass, memorial tablet, plaque",
"brassiere, bra, bandeau",
"breakwater, groin, groyne, mole, bulwark, seawall, jetty",
"breastplate, aegis, egis",
"broom",
"bucket, pail",
"buckle",
"bulletproof vest",
"bullet train, bullet",
"butcher shop, meat market",
"cab, hack, taxi, taxicab",
"caldron, cauldron",
"candle, taper, wax light",
"cannon",
"canoe",
"can opener, tin opener",
"cardigan",
"car mirror",
"carousel, carrousel, merry-go-round, roundabout, whirligig",
"carpenter's kit, tool kit",
"carton",
"car wheel",
"cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, atm",
"cassette",
"cassette player",
"castle",
"catamaran",
"cd player",
"cello, violoncello",
"cellular telephone, cellular phone, cellphone, cell, mobile phone",
"chain",
"chainlink fence",
"chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour",
"chain saw, chainsaw",
"chest",
"chiffonier, commode",
"chime, bell, gong",
"china cabinet, china closet",
"christmas stocking",
"church, church building",
"cinema, movie theater, movie theatre, movie house, picture palace",
"cleaver, meat cleaver, chopper",
"cliff dwelling",
"cloak",
"clog, geta, patten, sabot",
"cocktail shaker",
"coffee mug",
"coffeepot",
"coil, spiral, volute, whorl, helix",
"combination lock",
"computer keyboard, keypad",
"confectionery, confectionary, candy store",
"container ship, containership, container vessel",
"convertible",
"corkscrew, bottle screw",
"cornet, horn, trumpet, trump",
"cowboy boot",
"cowboy hat, ten-gallon hat",
"cradle",
"crane",
"crash helmet",
"crate",
"crib, cot",
"crock pot",
"croquet ball",
"crutch",
"cuirass",
"dam, dike, dyke",
"desk",
"desktop computer",
"dial telephone, dial phone",
"diaper, nappy, napkin",
"digital clock",
"digital watch",
"dining table, board",
"dishrag, dishcloth",
"dishwasher, dish washer, dishwashing machine",
"disk brake, disc brake",
"dock, dockage, docking facility",
"dogsled, dog sled, dog sleigh",
"dome",
"doormat, welcome mat",
"drilling platform, offshore rig",
"drum, membranophone, tympan",
"drumstick",
"dumbbell",
"dutch oven",
"electric fan, blower",
"electric guitar",
"electric locomotive",
"entertainment center",
"envelope",
"espresso maker",
"face powder",
"feather boa, boa",
"file, file cabinet, filing cabinet",
"fireboat",
"fire engine, fire truck",
"fire screen, fireguard",
"flagpole, flagstaff",
"flute, transverse flute",
"folding chair",
"football helmet",
"forklift",
"fountain",
"fountain pen",
"four-poster",
"freight car",
"french horn, horn",
"frying pan, frypan, skillet",
"fur coat",
"garbage truck, dustcart",
"gasmask, respirator, gas helmet",
"gas pump, gasoline pump, petrol pump, island dispenser",
"goblet",
"go-kart",
"golf ball",
"golfcart, golf cart",
"gondola",
"gong, tam-tam",
"gown",
"grand piano, grand",
"greenhouse, nursery, glasshouse",
"grille, radiator grille",
"grocery store, grocery, food market, market",
"guillotine",
"hair slide",
"hair spray",
"half track",
"hammer",
"hamper",
"hand blower, blow dryer, blow drier, hair dryer, hair drier",
"hand-held computer, hand-held microcomputer",
"handkerchief, hankie, hanky, hankey",
"hard disc, hard disk, fixed disk",
"harmonica, mouth organ, harp, mouth harp",
"harp",
"harvester, reaper",
"hatchet",
"holster",
"home theater, home theatre",
"honeycomb",
"hook, claw",
"hoopskirt, crinoline",
"horizontal bar, high bar",
"horse cart, horse-cart",
"hourglass",
"ipod",
"iron, smoothing iron",
"jack-o'-lantern",
"jean, blue jean, denim",
"jeep, landrover",
"jersey, t-shirt, tee shirt",
"jigsaw puzzle",
"jinrikisha, ricksha, rickshaw",
"joystick",
"kimono",
"knee pad",
"knot",
"lab coat, laboratory coat",
"ladle",
"lampshade, lamp shade",
"laptop, laptop computer",
"lawn mower, mower",
"lens cap, lens cover",
"letter opener, paper knife, paperknife",
"library",
"lifeboat",
"lighter, light, igniter, ignitor",
"limousine, limo",
"liner, ocean liner",
"lipstick, lip rouge",
"loafer",
"lotion",
"loudspeaker, speaker, speaker unit, loudspeaker system, speaker system",
"loupe, jeweler's loupe",
"lumbermill, sawmill",
"magnetic compass",
"mailbag, postbag",
"mailbox, letter box",
"maillot",
"maillot, tank suit",
"manhole cover",
"maraca",
"marimba, xylophone",
"mask",
"matchstick",
"maypole",
"maze, labyrinth",
"measuring cup",
"medicine chest, medicine cabinet",
"megalith, megalithic structure",
"microphone, mike",
"microwave, microwave oven",
"military uniform",
"milk can",
"minibus",
"miniskirt, mini",
"minivan",
"missile",
"mitten",
"mixing bowl",
"mobile home, manufactured home",
"model t",
"modem",
"monastery",
"monitor",
"moped",
"mortar",
"mortarboard",
"mosque",
"mosquito net",
"motor scooter, scooter",
"mountain bike, all-terrain bike, off-roader",
"mountain tent",
"mouse, computer mouse",
"mousetrap",
"moving van",
"muzzle",
"nail",
"neck brace",
"necklace",
"nipple",
"notebook, notebook computer",
"obelisk",
"oboe, hautboy, hautbois",
"ocarina, sweet potato",
"odometer, hodometer, mileometer, milometer",
"oil filter",
"organ, pipe organ",
"oscilloscope, scope, cathode-ray oscilloscope, cro",
"overskirt",
"oxcart",
"oxygen mask",
"packet",
"paddle, boat paddle",
"paddlewheel, paddle wheel",
"padlock",
"paintbrush",
"pajama, pyjama, pj's, jammies",
"palace",
"panpipe, pandean pipe, syrinx",
"paper towel",
"parachute, chute",
"parallel bars, bars",
"park bench",
"parking meter",
"passenger car, coach, carriage",
"patio, terrace",
"pay-phone, pay-station",
"pedestal, plinth, footstall",
"pencil box, pencil case",
"pencil sharpener",
"perfume, essence",
"petri dish",
"photocopier",
"pick, plectrum, plectron",
"pickelhaube",
"picket fence, paling",
"pickup, pickup truck",
"pier",
"piggy bank, penny bank",
"pill bottle",
"pillow",
"ping-pong ball",
"pinwheel",
"pirate, pirate ship",
"pitcher, ewer",
"plane, carpenter's plane, woodworking plane",
"planetarium",
"plastic bag",
"plate rack",
"plow, plough",
"plunger, plumber's helper",
"polaroid camera, polaroid land camera",
"pole",
"police van, police wagon, paddy wagon, patrol wagon, wagon, black maria",
"poncho",
"pool table, billiard table, snooker table",
"pop bottle, soda bottle",
"pot, flowerpot",
"potter's wheel",
"power drill",
"prayer rug, prayer mat",
"printer",
"prison, prison house",
"projectile, missile",
"projector",
"puck, hockey puck",
"punching bag, punch bag, punching ball, punchball",
"purse",
"quill, quill pen",
"quilt, comforter, comfort, puff",
"racer, race car, racing car",
"racket, racquet",
"radiator",
"radio, wireless",
"radio telescope, radio reflector",
"rain barrel",
"recreational vehicle, rv, r.v.",
"reel",
"reflex camera",
"refrigerator, icebox",
"remote control, remote",
"restaurant, eating house, eating place, eatery",
"revolver, six-gun, six-shooter",
"rifle",
"rocking chair, rocker",
"rotisserie",
"rubber eraser, rubber, pencil eraser",
"rugby ball",
"rule, ruler",
"running shoe",
"safe",
"safety pin",
"saltshaker, salt shaker",
"sandal",
"sarong",
"sax, saxophone",
"scabbard",
"scale, weighing machine",
"school bus",
"schooner",
"scoreboard",
"screen, crt screen",
"screw",
"screwdriver",
"seat belt, seatbelt",
"sewing machine",
"shield, buckler",
"shoe shop, shoe-shop, shoe store",
"shoji",
"shopping basket",
"shopping cart",
"shovel",
"shower cap",
"shower curtain",
"ski",
"ski mask",
"sleeping bag",
"slide rule, slipstick",
"sliding door",
"slot, one-armed bandit",
"snorkel",
"snowmobile",
"snowplow, snowplough",
"soap dispenser",
"soccer ball",
"sock",
"solar dish, solar collector, solar furnace",
"sombrero",
"soup bowl",
"space bar",
"space heater",
"space shuttle",
"spatula",
"speedboat",
"spider web, spider's web",
"spindle",
"sports car, sport car",
"spotlight, spot",
"stage",
"steam locomotive",
"steel arch bridge",
"steel drum",
"stethoscope",
"stole",
"stone wall",
"stopwatch, stop watch",
"stove",
"strainer",
"streetcar, tram, tramcar, trolley, trolley car",
"stretcher",
"studio couch, day bed",
"stupa, tope",
"submarine, pigboat, sub, u-boat",
"suit, suit of clothes",
"sundial",
"sunglass",
"sunglasses, dark glasses, shades",
"sunscreen, sunblock, sun blocker",
"suspension bridge",
"swab, swob, mop",
"sweatshirt",
"swimming trunks, bathing trunks",
"swing",
"switch, electric switch, electrical switch",
"syringe",
"table lamp",
"tank, army tank, armored combat vehicle, armoured combat vehicle",
"tape player",
"teapot",
"teddy, teddy bear",
"television, television system",
"tennis ball",
"thatch, thatched roof",
"theater curtain, theatre curtain",
"thimble",
"thresher, thrasher, threshing machine",
"throne",
"tile roof",
"toaster",
"tobacco shop, tobacconist shop, tobacconist",
"toilet seat",
"torch",
"totem pole",
"tow truck, tow car, wrecker",
"toyshop",
"tractor",
"trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi",
"tray",
"trench coat",
"tricycle, trike, velocipede",
"trimaran",
"tripod",
"triumphal arch",
"trolleybus, trolley coach, trackless trolley",
"trombone",
"tub, vat",
"turnstile",
"typewriter keyboard",
"umbrella",
"unicycle, monocycle",
"upright, upright piano",
"vacuum, vacuum cleaner",
"vase",
"vault",
"velvet",
"vending machine",
"vestment",
"viaduct",
"violin, fiddle",
"volleyball",
"waffle iron",
"wall clock",
"wallet, billfold, notecase, pocketbook",
"wardrobe, closet, press",
"warplane, military plane",
"washbasin, handbasin, washbowl, lavabo, wash-hand basin",
"washer, automatic washer, washing machine",
"water bottle",
"water jug",
"water tower",
"whiskey jug",
"whistle",
"wig",
"window screen",
"window shade",
"windsor tie",
"wine bottle",
"wing",
"wok",
"wooden spoon",
"wool, woolen, woollen",
"worm fence, snake fence, snake-rail fence, virginia fence",
"wreck",
"yawl",
"yurt",
"web site, website, internet site, site",
"comic book",
"crossword puzzle, crossword",
"street sign",
"traffic light, traffic signal, stoplight",
"book jacket, dust cover, dust jacket, dust wrapper",
"menu",
"plate",
"guacamole",
"consomme",
"hot pot, hotpot",
"trifle",
"ice cream, icecream",
"ice lolly, lolly, lollipop, popsicle",
"french loaf",
"bagel, beigel",
"pretzel",
"cheeseburger",
"hotdog, hot dog, red hot",
"mashed potato",
"head cabbage",
"broccoli",
"cauliflower",
"zucchini, courgette",
"spaghetti squash",
"acorn squash",
"butternut squash",
"cucumber, cuke",
"artichoke, globe artichoke",
"bell pepper",
"cardoon",
"mushroom",
"granny smith",
"strawberry",
"orange",
"lemon",
"fig",
"pineapple, ananas",
"banana",
"jackfruit, jak, jack",
"custard apple",
"pomegranate",
"hay",
"carbonara",
"chocolate sauce, chocolate syrup",
"dough",
"meat loaf, meatloaf",
"pizza, pizza pie",
"potpie",
"burrito",
"red wine",
"espresso",
"cup",
"eggnog",
"alp",
"bubble",
"cliff, drop, drop-off",
"coral reef",
"geyser",
"lakeside, lakeshore",
"promontory, headland, head, foreland",
"sandbar, sand bar",
"seashore, coast, seacoast, sea-coast",
"valley, vale",
"volcano",
"ballplayer, baseball player",
"groom, bridegroom",
"scuba diver",
"rapeseed",
"daisy",
"yellow lady's slipper, yellow lady-slipper, cypripedium calceolus, cypripedium parviflorum",
"corn",
"acorn",
"hip, rose hip, rosehip",
"buckeye, horse chestnut, conker",
"coral fungus",
"agaric",
"gyromitra",
"stinkhorn, carrion fungus",
"earthstar",
"hen-of-the-woods, hen of the woods, polyporus frondosus, grifola frondosa",
"bolete",
"ear, spike, capitulum",
"toilet tissue, toilet paper, bathroom tissue"
] |
prithivMLmods/OpenSDI-SD1.5-SigLIP2
|

# OpenSDI-SD1.5-SigLIP2
> OpenSDI-SD1.5-SigLIP2 is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether an image is a real photograph or generated using Stable Diffusion 1.5 (SD1.5), utilizing the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
*OpenSDI: Spotting Diffusion-Generated Images in the Open World* https://arxiv.org/pdf/2503.19653, OpenSDI SD1.5 SigLIP2 works best with crisp and high-quality images. Noisy images are not recommended for validation.
> [!warning]
If the task is based on image content moderation or AI-generated image vs. real image classification, it is recommended to use the OpenSDI-Flux.1-SigLIP2 model.
```py
Classification Report:
precision recall f1-score support
Real_Image 0.9036 0.9323 0.9177 10000
SD1.5_Generated 0.9301 0.9005 0.9150 10000
accuracy 0.9164 20000
macro avg 0.9168 0.9164 0.9164 20000
weighted avg 0.9168 0.9164 0.9164 20000
```

---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Real_Image
Class 1: SD1.5_Generated
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/OpenSDI-SD1.5-SigLIP2" # Replace with your model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Real_Image",
"1": "SD1.5_Generated"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="SD1.5 Image Detection"),
title="OpenSDI-SD1.5-SigLIP2",
description="Upload an image to determine whether it is a real photograph or generated by Stable Diffusion 1.5 (SD1.5)."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
OpenSDI-SD1.5-SigLIP2 is designed for the following use cases:
* Generative Model Evaluation – Detect SD1.5-generated images for analysis and benchmarking.
* Dataset Integrity – Filter out AI-generated images from real-world image datasets.
* Digital Media Forensics – Support visual content verification and source validation.
* Trust & Safety – Detect synthetic media used in deceptive or misleading contexts.
|
[
"real_image",
"sd1.5_generated"
] |
hualin321/vit-base-oxford-iiit-pets
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-oxford-iiit-pets
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the pcuenq/oxford-pets dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2025
- Accuracy: 0.9405
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3667 | 1.0 | 370 | 0.2762 | 0.9378 |
| 0.2139 | 2.0 | 740 | 0.2188 | 0.9432 |
| 0.1798 | 3.0 | 1110 | 0.1945 | 0.9432 |
| 0.1433 | 4.0 | 1480 | 0.1892 | 0.9459 |
| 0.1299 | 5.0 | 1850 | 0.1852 | 0.9486 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"siamese",
"birman",
"shiba inu",
"staffordshire bull terrier",
"basset hound",
"bombay",
"japanese chin",
"chihuahua",
"german shorthaired",
"pomeranian",
"beagle",
"english cocker spaniel",
"american pit bull terrier",
"ragdoll",
"persian",
"egyptian mau",
"miniature pinscher",
"sphynx",
"maine coon",
"keeshond",
"yorkshire terrier",
"havanese",
"leonberger",
"wheaten terrier",
"american bulldog",
"english setter",
"boxer",
"newfoundland",
"bengal",
"samoyed",
"british shorthair",
"great pyrenees",
"abyssinian",
"pug",
"saint bernard",
"russian blue",
"scottish terrier"
] |
ElioBaserga/fruits-and-vegetables-vit
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fruits-and-vegetables-vit
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the fruits-and-vegetables-classification dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2598
- Accuracy: 0.9164
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.6402 | 1.0 | 195 | 0.4357 | 0.9003 |
| 0.9837 | 2.0 | 390 | 0.3048 | 0.9174 |
| 0.8899 | 3.0 | 585 | 0.2703 | 0.9174 |
| 0.8108 | 4.0 | 780 | 0.2568 | 0.9174 |
| 0.7973 | 5.0 | 975 | 0.2520 | 0.9174 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
[
"apple",
"banana",
"beetroot",
"bell pepper",
"cabbage",
"capsicum",
"carrot",
"cauliflower",
"chilli pepper",
"corn",
"cucumber",
"eggplant",
"garlic",
"ginger",
"grapes",
"jalepeno",
"kiwi",
"lemon",
"lettuce",
"mango",
"onion",
"orange",
"paprika",
"pear",
"peas",
"pineapple",
"pomegranate",
"potato",
"raddish",
"soy beans",
"spinach",
"sweetcorn",
"sweetpotato",
"tomato",
"turnip",
"watermelon"
] |
panjiallatief/results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2786
- Accuracy: 0.55
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 80 | 2.0304 | 0.2188 |
| 2.0496 | 2.0 | 160 | 1.8376 | 0.35 |
| 1.7855 | 3.0 | 240 | 1.6403 | 0.4375 |
| 1.4719 | 4.0 | 320 | 1.5324 | 0.525 |
| 1.2454 | 5.0 | 400 | 1.4388 | 0.5312 |
| 1.2454 | 6.0 | 480 | 1.3698 | 0.575 |
| 1.0235 | 7.0 | 560 | 1.3360 | 0.5563 |
| 0.8674 | 8.0 | 640 | 1.3001 | 0.5687 |
| 0.7613 | 9.0 | 720 | 1.2869 | 0.55 |
| 0.6857 | 10.0 | 800 | 1.2786 | 0.55 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
prithivMLmods/OpenSDI-SD2.1-SigLIP2
|

# OpenSDI-SD2.1-SigLIP2
> OpenSDI-SD2.1-SigLIP2 is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether an image is a real photograph or generated using Stable Diffusion 2.1 (SD2.1), using the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
*OpenSDI: Spotting Diffusion-Generated Images in the Open World* https://arxiv.org/pdf/2503.19653, OpenSDI SD2.1 SigLIP2 works best with crisp and high-quality images. Noisy images are not recommended for validation.
> [!warning]
If the task is based on image content moderation or AI-generated image vs. real image classification, it is recommended to use the OpenSDI-Flux.1-SigLIP2 model.
```py
Classification Report:
precision recall f1-score support
Real_Image 0.8551 0.8967 0.8754 10000
SD2.1_Generated 0.8914 0.8481 0.8692 10000
accuracy 0.8724 20000
macro avg 0.8733 0.8724 0.8723 20000
weighted avg 0.8733 0.8724 0.8723 20000
```

---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Real_Image
Class 1: SD2.1_Generated
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/OpenSDI-SD2.1-SigLIP2" # Replace with your model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Real_Image",
"1": "SD2.1_Generated"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="SD2.1 Image Detection"),
title="OpenSDI-SD2.1-SigLIP2",
description="Upload an image to determine whether it is a real photograph or generated by Stable Diffusion 2.1 (SD2.1)."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
OpenSDI-SD2.1-SigLIP2 is designed for the following applications:
* Generative Image Detection – Identify SD2.1-generated images for auditing or validation.
* Dataset Curation – Clean datasets by removing synthetic images.
* Visual Authenticity Verification – Distinguish real images from AI-generated ones.
* Digital Forensics – Assist in tracing the source of digital images in investigative workflows.
|
[
"real_image",
"sd2.1_generated"
] |
panjiallatief/vit-emotion-classifier
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-emotion-classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6218
- Accuracy: 0.8672
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6535 | 1.0 | 32 | 0.7740 | 0.7812 |
| 0.296 | 2.0 | 64 | 0.5949 | 0.8047 |
| 0.1542 | 3.0 | 96 | 0.6261 | 0.8047 |
| 0.0838 | 4.0 | 128 | 0.6315 | 0.8047 |
| 0.0189 | 5.0 | 160 | 0.8360 | 0.7656 |
| 0.0223 | 6.0 | 192 | 0.7264 | 0.8047 |
| 0.0114 | 7.0 | 224 | 0.8634 | 0.8047 |
| 0.0408 | 8.0 | 256 | 0.6393 | 0.8438 |
| 0.0075 | 9.0 | 288 | 0.7023 | 0.8438 |
| 0.006 | 10.0 | 320 | 0.6481 | 0.8516 |
| 0.0053 | 11.0 | 352 | 0.6247 | 0.8516 |
| 0.0047 | 12.0 | 384 | 0.6220 | 0.8594 |
| 0.0043 | 13.0 | 416 | 0.6186 | 0.8594 |
| 0.0041 | 14.0 | 448 | 0.6193 | 0.8594 |
| 0.0038 | 15.0 | 480 | 0.6205 | 0.8594 |
| 0.0036 | 16.0 | 512 | 0.6205 | 0.8594 |
| 0.0035 | 17.0 | 544 | 0.6218 | 0.8672 |
| 0.0034 | 18.0 | 576 | 0.6224 | 0.8672 |
| 0.0033 | 19.0 | 608 | 0.6229 | 0.8672 |
| 0.0033 | 20.0 | 640 | 0.6232 | 0.8672 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
prithivMLmods/OpenSDI-SD3-SigLIP2
|

# OpenSDI-SD3-SigLIP2
> OpenSDI-SD3-SigLIP2 is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether an image is a real photograph or generated using Stable Diffusion 3 (SD3), using the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
*OpenSDI: Spotting Diffusion-Generated Images in the Open World* https://arxiv.org/pdf/2503.19653, OpenSDI SD3 SigLIP2 works best with crisp and high-quality images. Noisy images are not recommended for validation.
> [!warning]
If the task is based on image content moderation or AI-generated image vs. real image classification, it is recommended to use the OpenSDI-Flux.1-SigLIP2 model.
```py
Classification Report:
precision recall f1-score support
Real_Image 0.8526 0.8916 0.8716 10000
SD3_Generated 0.8864 0.8458 0.8656 10000
accuracy 0.8687 20000
macro avg 0.8695 0.8687 0.8686 20000
weighted avg 0.8695 0.8687 0.8686 20000
```
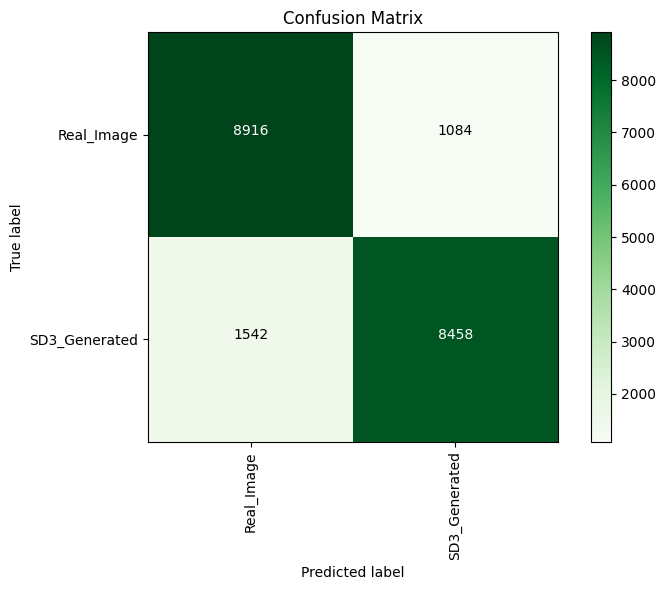
---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Real_Image
Class 1: SD3_Generated
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/OpenSDI-SD3-SigLIP2" # Update with the correct model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Real_Image",
"1": "SD3_Generated"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="SD3 Image Detection"),
title="OpenSDI-SD3-SigLIP2",
description="Upload an image to determine whether it is a real photograph or generated by Stable Diffusion 3 (SD3)."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
OpenSDI-SD3-SigLIP2 is designed for tasks such as:
* Generative Image Analysis – Identify SD3-generated images for benchmarking and quality inspection.
* Dataset Validation – Ensure training or evaluation datasets are free from unintended generative artifacts.
* Content Authenticity – Verify whether visual media originates from real-world photography or AI generation.
* Digital Forensics – Aid in determining the origin of visual content in investigative scenarios.
|
[
"real_image",
"sd3_generated"
] |
prithivMLmods/OpenSDI-SDXL-SigLIP2
|

# OpenSDI-SDXL-SigLIP2
> OpenSDI-SDXL-SigLIP2 is a vision-language encoder model fine-tuned from google/siglip2-base-patch16-224 for binary image classification. It is trained to detect whether an image is a real photograph or generated using Stable Diffusion XL (SDXL), utilizing the SiglipForImageClassification architecture.
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
> [!note]
*OpenSDI: Spotting Diffusion-Generated Images in the Open World* https://arxiv.org/pdf/2503.19653, OpenSDI SDXL SigLIP2 works best with crisp and high-quality images. Noisy images are not recommended for validation.
> [!warning]
If the task is based on image content moderation or AI-generated image vs. real image classification, it is recommended to use the OpenSDI-Flux.1-SigLIP2 model.
```py
Classification Report:
precision recall f1-score support
Real_Image 0.8632 0.8757 0.8694 10000
SDXL_Generated 0.8739 0.8612 0.8675 10000
accuracy 0.8685 20000
macro avg 0.8685 0.8684 0.8684 20000
weighted avg 0.8685 0.8685 0.8684 20000
```

---
## Label Space: 2 Classes
The model classifies an image as either:
```
Class 0: Real_Image
Class 1: SDXL_Generated
```
---
## Install Dependencies
```bash
pip install -q transformers torch pillow gradio hf_xet
```
---
## Inference Code
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/OpenSDI-SDXL-SigLIP2" # Replace with your model path
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "Real_Image",
"1": "SDXL_Generated"
}
def classify_image(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="SDXL Image Detection"),
title="OpenSDI-SDXL-SigLIP2",
description="Upload an image to determine whether it is a real photograph or generated by Stable Diffusion XL (SDXL)."
)
if __name__ == "__main__":
iface.launch()
```
---
## Intended Use
OpenSDI-SDXL-SigLIP2 is intended for the following scenarios:
* Generative Content Detection – Accurately identify images generated using SDXL.
* Dataset Integrity – Screen datasets to ensure they contain only authentic photographic content.
* Trust and Safety – Flag AI-generated media in user-generated content pipelines.
* Digital Media Forensics – Support authenticity verification in investigative workflows.
|
[
"real_image",
"sdxl_generated"
] |
Ratnasari/results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3361
- Accuracy: 0.5563
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
[
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7"
] |
ElioBaserga/less-augmentation-fruits-and-vegetables-vit
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# less-augmentation-fruits-and-vegetables-vit
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the less-augmentation-fruits-and-vegetables-vit dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2129
- Accuracy: 0.9304
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.809 | 1.0 | 195 | 0.2873 | 0.9145 |
| 0.5755 | 2.0 | 390 | 0.2350 | 0.9202 |
| 0.5052 | 3.0 | 585 | 0.2173 | 0.9145 |
| 0.4884 | 4.0 | 780 | 0.2104 | 0.9288 |
| 0.4518 | 5.0 | 975 | 0.2079 | 0.9288 |
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.1
|
[
"apple",
"banana",
"beetroot",
"bell pepper",
"cabbage",
"capsicum",
"carrot",
"cauliflower",
"chilli pepper",
"corn",
"cucumber",
"eggplant",
"garlic",
"ginger",
"grapes",
"jalepeno",
"kiwi",
"lemon",
"lettuce",
"mango",
"onion",
"orange",
"paprika",
"pear",
"peas",
"pineapple",
"pomegranate",
"potato",
"raddish",
"soy beans",
"spinach",
"sweetcorn",
"sweetpotato",
"tomato",
"turnip",
"watermelon"
] |
BeckerAnas/convnextv2-base-1k-224-finetuned-cifar10
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnextv2-base-1k-224-finetuned-cifar10
This model is a fine-tuned version of [facebook/convnextv2-base-1k-224](https://huggingface.co/facebook/convnextv2-base-1k-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0695
- Accuracy: 0.983
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.4043 | 1.0 | 352 | 0.1423 | 0.9716 |
| 0.2958 | 2.0 | 704 | 0.0955 | 0.9768 |
| 0.2352 | 2.9922 | 1053 | 0.0695 | 0.983 |
### Framework versions
- Transformers 4.49.0
- Pytorch 2.7.0+cpu
- Datasets 3.3.2
- Tokenizers 0.21.0
|
[
"airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"
] |
moemendhieb/swin-tiny-patch4-window7-224-finetuned-ecg-classification
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-ecg-classification
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.0319 | 0.9993 | 697 | 0.0000 | 1.0 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"f",
"m",
"n",
"q",
"s",
"v"
] |
gmanurung/results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5625
- Accuracy: 0.475
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4229 | 1.0 | 10 | 1.5451 | 0.5125 |
| 1.3878 | 2.0 | 20 | 1.5394 | 0.475 |
| 1.3487 | 3.0 | 30 | 1.4948 | 0.475 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7"
] |
Demeter123/vit-emotion-output
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-emotion-output
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6276
- Accuracy: 0.35
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.93 | 1.0 | 40 | 1.8458 | 0.2812 |
| 1.3766 | 2.0 | 80 | 1.6993 | 0.325 |
| 1.0995 | 3.0 | 120 | 1.6276 | 0.35 |
| 1.003 | 4.0 | 160 | 1.6134 | 0.35 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
MadanKhatri/finetuned-occupations
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-occupations
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the house_problem_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3327
- Accuracy: 0.9196
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.5893 | 0.9091 | 100 | 0.5142 | 0.8424 |
| 0.4248 | 1.8182 | 200 | 0.3701 | 0.8682 |
| 0.2474 | 2.7273 | 300 | 0.3613 | 0.8842 |
| 0.1783 | 3.6364 | 400 | 0.3638 | 0.8810 |
| 0.1297 | 4.5455 | 500 | 0.3828 | 0.8971 |
| 0.1512 | 5.4545 | 600 | 0.3935 | 0.9003 |
| 0.0856 | 6.3636 | 700 | 0.3825 | 0.9035 |
| 0.0619 | 7.2727 | 800 | 0.4082 | 0.9003 |
| 0.056 | 8.1818 | 900 | 0.3464 | 0.9003 |
| 0.0636 | 9.0909 | 1000 | 0.3327 | 0.9196 |
| 0.0519 | 10.0 | 1100 | 0.3202 | 0.9132 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"builder",
"electrician",
"others",
"plumber"
] |
jainrahul0807/finetuned-indian-food
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-indian-food
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the indian_food_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2850
- Accuracy: 0.9299
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 1.1125 | 0.3003 | 100 | 1.0195 | 0.8268 |
| 0.8802 | 0.6006 | 200 | 0.6498 | 0.8693 |
| 0.6563 | 0.9009 | 300 | 0.5065 | 0.8789 |
| 0.4343 | 1.2012 | 400 | 0.4502 | 0.9001 |
| 0.3887 | 1.5015 | 500 | 0.3969 | 0.8905 |
| 0.5071 | 1.8018 | 600 | 0.4055 | 0.9022 |
| 0.3226 | 2.1021 | 700 | 0.3429 | 0.9203 |
| 0.2538 | 2.4024 | 800 | 0.2985 | 0.9256 |
| 0.2855 | 2.7027 | 900 | 0.3444 | 0.9107 |
| 0.125 | 3.0030 | 1000 | 0.3459 | 0.9107 |
| 0.1862 | 3.3033 | 1100 | 0.2850 | 0.9299 |
| 0.2401 | 3.6036 | 1200 | 0.2923 | 0.9235 |
| 0.1122 | 3.9039 | 1300 | 0.2885 | 0.9277 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"burger",
"butter_naan",
"kaathi_rolls",
"kadai_paneer",
"kulfi",
"masala_dosa",
"momos",
"paani_puri",
"pakode",
"pav_bhaji",
"pizza",
"samosa",
"chai",
"chapati",
"chole_bhature",
"dal_makhani",
"dhokla",
"fried_rice",
"idli",
"jalebi"
] |
TulasiV/my_awesome_food_model
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6083
- Accuracy: 0.908
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7206 | 1.0 | 63 | 2.5057 | 0.837 |
| 1.8926 | 2.0 | 126 | 1.7650 | 0.888 |
| 1.6588 | 3.0 | 189 | 1.6083 | 0.908 |
### Framework versions
- Transformers 4.52.0.dev0
- Pytorch 2.7.0
- Datasets 3.5.1
- Tokenizers 0.21.1
|
[
"apple_pie",
"baby_back_ribs",
"bruschetta",
"waffles",
"caesar_salad",
"cannoli",
"caprese_salad",
"carrot_cake",
"ceviche",
"cheesecake",
"cheese_plate",
"chicken_curry",
"chicken_quesadilla",
"baklava",
"chicken_wings",
"chocolate_cake",
"chocolate_mousse",
"churros",
"clam_chowder",
"club_sandwich",
"crab_cakes",
"creme_brulee",
"croque_madame",
"cup_cakes",
"beef_carpaccio",
"deviled_eggs",
"donuts",
"dumplings",
"edamame",
"eggs_benedict",
"escargots",
"falafel",
"filet_mignon",
"fish_and_chips",
"foie_gras",
"beef_tartare",
"french_fries",
"french_onion_soup",
"french_toast",
"fried_calamari",
"fried_rice",
"frozen_yogurt",
"garlic_bread",
"gnocchi",
"greek_salad",
"grilled_cheese_sandwich",
"beet_salad",
"grilled_salmon",
"guacamole",
"gyoza",
"hamburger",
"hot_and_sour_soup",
"hot_dog",
"huevos_rancheros",
"hummus",
"ice_cream",
"lasagna",
"beignets",
"lobster_bisque",
"lobster_roll_sandwich",
"macaroni_and_cheese",
"macarons",
"miso_soup",
"mussels",
"nachos",
"omelette",
"onion_rings",
"oysters",
"bibimbap",
"pad_thai",
"paella",
"pancakes",
"panna_cotta",
"peking_duck",
"pho",
"pizza",
"pork_chop",
"poutine",
"prime_rib",
"bread_pudding",
"pulled_pork_sandwich",
"ramen",
"ravioli",
"red_velvet_cake",
"risotto",
"samosa",
"sashimi",
"scallops",
"seaweed_salad",
"shrimp_and_grits",
"breakfast_burrito",
"spaghetti_bolognese",
"spaghetti_carbonara",
"spring_rolls",
"steak",
"strawberry_shortcake",
"sushi",
"tacos",
"takoyaki",
"tiramisu",
"tuna_tartare"
] |
bellowz/vision-fine
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"benign",
"malignant",
"normal"
] |
gmanurung/emotion_classification
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2712
- Accuracy: 0.5188
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.0443 | 1.0 | 20 | 1.9840 | 0.3 |
| 1.8461 | 2.0 | 40 | 1.7772 | 0.3187 |
| 1.6057 | 3.0 | 60 | 1.5779 | 0.4813 |
| 1.4538 | 4.0 | 80 | 1.4977 | 0.4188 |
| 1.3411 | 5.0 | 100 | 1.4193 | 0.4625 |
| 1.2416 | 6.0 | 120 | 1.4029 | 0.4938 |
| 1.1613 | 7.0 | 140 | 1.3528 | 0.525 |
| 1.0744 | 8.0 | 160 | 1.3925 | 0.475 |
| 1.0185 | 9.0 | 180 | 1.3326 | 0.4938 |
| 0.9413 | 10.0 | 200 | 1.3633 | 0.4688 |
| 0.857 | 11.0 | 220 | 1.3963 | 0.4562 |
| 0.8222 | 12.0 | 240 | 1.3978 | 0.4375 |
| 0.7635 | 13.0 | 260 | 1.2672 | 0.5062 |
| 0.7419 | 14.0 | 280 | 1.3466 | 0.4813 |
| 0.7053 | 15.0 | 300 | 1.2751 | 0.5375 |
| 0.6714 | 16.0 | 320 | 1.3368 | 0.5062 |
| 0.6291 | 17.0 | 340 | 1.2569 | 0.5125 |
| 0.6097 | 18.0 | 360 | 1.3321 | 0.475 |
| 0.5842 | 19.0 | 380 | 1.3639 | 0.4625 |
| 0.6013 | 20.0 | 400 | 1.3455 | 0.4813 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
rama-adiw/vit-emotion-results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-emotion-results
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3992
- Accuracy: 0.525
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.0003 | 1.0 | 40 | 1.9729 | 0.3063 |
| 1.7229 | 2.0 | 80 | 1.7334 | 0.3625 |
| 1.6051 | 3.0 | 120 | 1.5905 | 0.425 |
| 1.4902 | 4.0 | 160 | 1.5132 | 0.4313 |
| 1.3939 | 5.0 | 200 | 1.4877 | 0.4437 |
| 1.3373 | 6.0 | 240 | 1.4920 | 0.4125 |
| 1.238 | 7.0 | 280 | 1.3992 | 0.525 |
| 1.1901 | 8.0 | 320 | 1.3982 | 0.4875 |
| 1.0601 | 9.0 | 360 | 1.3512 | 0.5188 |
| 1.0272 | 10.0 | 400 | 1.3698 | 0.5125 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
AriqF/results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3316
- Accuracy: 0.5563
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 13
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.0192 | 1.0 | 40 | 1.9801 | 0.2687 |
| 1.7656 | 2.0 | 80 | 1.8060 | 0.4375 |
| 1.5519 | 3.0 | 120 | 1.6564 | 0.4625 |
| 1.3524 | 4.0 | 160 | 1.5762 | 0.475 |
| 1.1584 | 5.0 | 200 | 1.5078 | 0.5062 |
| 0.9827 | 6.0 | 240 | 1.4490 | 0.525 |
| 0.8292 | 7.0 | 280 | 1.4027 | 0.525 |
| 0.6822 | 8.0 | 320 | 1.3633 | 0.5312 |
| 0.5564 | 9.0 | 360 | 1.3588 | 0.5062 |
| 0.4856 | 10.0 | 400 | 1.3466 | 0.525 |
| 0.4572 | 11.0 | 440 | 1.3391 | 0.5437 |
| 0.4064 | 12.0 | 480 | 1.3316 | 0.5563 |
| 0.3951 | 13.0 | 520 | 1.3293 | 0.5563 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7"
] |
ccclllwww/smoker_detector_demo_test
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_food_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6881
- Accuracy: 0.6
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 2 | 0.7010 | 0.45 |
| No log | 1.8 | 3 | 0.7013 | 0.45 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"not_smoking",
"smoking"
] |
ccclllwww/my_custom_image_classifier
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_custom_image_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6592
- Accuracy: 0.65
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 2 | 0.6767 | 0.55 |
| No log | 1.8 | 3 | 0.6542 | 0.65 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"not_smoking",
"smoking"
] |
shingguy1/food-calorie-convnext
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
[
"pizza",
"hamburger",
"sushi",
"caesar_salad",
"spaghetti_bolognese",
"ice_cream",
"fried_rice",
"tacos",
"steak",
"chocolate_cake"
] |
tialdrine/vit-emotion-output
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-emotion-output
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5533
- Accuracy: 0.4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.8721 | 1.0 | 40 | 1.8115 | 0.3125 |
| 1.3538 | 2.0 | 80 | 1.6587 | 0.3312 |
| 1.1398 | 3.0 | 120 | 1.5723 | 0.3875 |
| 1.0086 | 4.0 | 160 | 1.5533 | 0.4 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
KiViDrag/beans_ViT
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beans_ViT
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2997
- Accuracy: 0.7969
- F1: 0.7991
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 17 | 0.8693 | 0.6090 | 0.5953 |
| No log | 2.0 | 34 | 0.9652 | 0.6015 | 0.5977 |
| No log | 3.0 | 51 | 0.7178 | 0.6992 | 0.6927 |
| No log | 4.0 | 68 | 0.7488 | 0.6992 | 0.6955 |
| No log | 5.0 | 85 | 0.6517 | 0.7068 | 0.7070 |
| No log | 6.0 | 102 | 0.7816 | 0.6842 | 0.6541 |
| No log | 7.0 | 119 | 0.5014 | 0.7744 | 0.7733 |
| No log | 8.0 | 136 | 0.5321 | 0.7669 | 0.7680 |
| No log | 9.0 | 153 | 0.5985 | 0.7444 | 0.7457 |
| No log | 10.0 | 170 | 0.4675 | 0.8271 | 0.8274 |
| No log | 11.0 | 187 | 0.5750 | 0.7744 | 0.7576 |
| No log | 12.0 | 204 | 0.6617 | 0.7293 | 0.7066 |
| No log | 13.0 | 221 | 0.6396 | 0.7594 | 0.7577 |
| No log | 14.0 | 238 | 0.4302 | 0.8346 | 0.8352 |
| No log | 15.0 | 255 | 0.4018 | 0.8421 | 0.8427 |
| No log | 16.0 | 272 | 0.5673 | 0.7895 | 0.7883 |
| No log | 17.0 | 289 | 0.5037 | 0.8120 | 0.8097 |
| No log | 18.0 | 306 | 0.5939 | 0.8496 | 0.8487 |
| No log | 19.0 | 323 | 0.6590 | 0.8120 | 0.8111 |
| No log | 20.0 | 340 | 0.6060 | 0.8571 | 0.8559 |
| No log | 21.0 | 357 | 0.5806 | 0.8421 | 0.8418 |
| No log | 22.0 | 374 | 0.6180 | 0.8421 | 0.8414 |
| No log | 23.0 | 391 | 0.7707 | 0.7669 | 0.7633 |
| No log | 24.0 | 408 | 0.5440 | 0.8421 | 0.8418 |
| No log | 25.0 | 425 | 0.6596 | 0.8496 | 0.8497 |
| No log | 26.0 | 442 | 0.5393 | 0.8346 | 0.8342 |
| No log | 27.0 | 459 | 0.6320 | 0.8797 | 0.8795 |
| No log | 28.0 | 476 | 0.5903 | 0.8496 | 0.8507 |
| No log | 29.0 | 493 | 0.6826 | 0.8647 | 0.8644 |
| 0.3346 | 30.0 | 510 | 0.6493 | 0.8571 | 0.8567 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
[
"label_0",
"label_1",
"label_2"
] |
KiViDrag/results
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4656
- Accuracy: 0.8125
- F1: 0.8141
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 17 | 0.8876 | 0.5865 | 0.5688 |
| No log | 2.0 | 34 | 0.8620 | 0.6090 | 0.6067 |
| No log | 3.0 | 51 | 0.7611 | 0.6842 | 0.6783 |
| No log | 4.0 | 68 | 0.6987 | 0.6842 | 0.6741 |
| No log | 5.0 | 85 | 0.6540 | 0.6917 | 0.6872 |
| No log | 6.0 | 102 | 0.7933 | 0.6767 | 0.6407 |
| No log | 7.0 | 119 | 0.4766 | 0.8195 | 0.8152 |
| No log | 8.0 | 136 | 0.4624 | 0.8271 | 0.8231 |
| No log | 9.0 | 153 | 0.4528 | 0.8271 | 0.8277 |
| No log | 10.0 | 170 | 0.4641 | 0.8120 | 0.8087 |
| No log | 11.0 | 187 | 0.6063 | 0.7368 | 0.7231 |
| No log | 12.0 | 204 | 0.4783 | 0.7594 | 0.7596 |
| No log | 13.0 | 221 | 0.4987 | 0.7970 | 0.7990 |
| No log | 14.0 | 238 | 0.6023 | 0.7669 | 0.7603 |
| No log | 15.0 | 255 | 0.4588 | 0.8271 | 0.8254 |
| No log | 16.0 | 272 | 0.4362 | 0.8120 | 0.8130 |
| No log | 17.0 | 289 | 0.5342 | 0.8271 | 0.8280 |
| No log | 18.0 | 306 | 0.5012 | 0.8120 | 0.8124 |
| No log | 19.0 | 323 | 0.4891 | 0.8496 | 0.8498 |
| No log | 20.0 | 340 | 0.8525 | 0.7744 | 0.7714 |
| No log | 21.0 | 357 | 0.5291 | 0.8195 | 0.8209 |
| No log | 22.0 | 374 | 0.5355 | 0.8271 | 0.8264 |
| No log | 23.0 | 391 | 0.6323 | 0.8045 | 0.8041 |
| No log | 24.0 | 408 | 0.6973 | 0.8346 | 0.8334 |
| No log | 25.0 | 425 | 0.6705 | 0.8571 | 0.8569 |
| No log | 26.0 | 442 | 0.6056 | 0.8571 | 0.8572 |
| No log | 27.0 | 459 | 0.7864 | 0.8421 | 0.8421 |
| No log | 28.0 | 476 | 0.7067 | 0.8346 | 0.8351 |
| No log | 29.0 | 493 | 0.6695 | 0.8571 | 0.8567 |
| 0.3504 | 30.0 | 510 | 0.6680 | 0.8647 | 0.8646 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
[
"label_0",
"label_1",
"label_2"
] |
ccclllwww/smoker_cls_base_V1
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smoker_cls_base_V1
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3286
- Accuracy: 0.8764
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5219 | 1.0 | 33 | 0.4787 | 0.8232 |
| 0.3797 | 2.0 | 66 | 0.3739 | 0.8422 |
| 0.3118 | 3.0 | 99 | 0.3507 | 0.8650 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"not_smoking",
"smoking"
] |
AriqF/emotion-classifier-vit
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion-classifier-vit
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2938
- Accuracy: 0.5437
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 13
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.9954 | 1.0 | 40 | 1.9657 | 0.3625 |
| 1.7379 | 2.0 | 80 | 1.7294 | 0.5 |
| 1.521 | 3.0 | 120 | 1.5916 | 0.5312 |
| 1.3358 | 4.0 | 160 | 1.5033 | 0.475 |
| 1.1573 | 5.0 | 200 | 1.4300 | 0.525 |
| 1.0019 | 6.0 | 240 | 1.3785 | 0.5312 |
| 0.8266 | 7.0 | 280 | 1.3402 | 0.5062 |
| 0.6911 | 8.0 | 320 | 1.2938 | 0.5437 |
| 0.5639 | 9.0 | 360 | 1.3023 | 0.5062 |
| 0.4955 | 10.0 | 400 | 1.2990 | 0.5125 |
| 0.4623 | 11.0 | 440 | 1.2864 | 0.5312 |
| 0.4193 | 12.0 | 480 | 1.2813 | 0.5188 |
| 0.4003 | 13.0 | 520 | 1.2815 | 0.5188 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"label_0",
"label_1",
"label_2",
"label_3",
"label_4",
"label_5",
"label_6",
"label_7"
] |
tukangsanted/emotion-vit
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion-vit
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4844
- Accuracy: 0.475
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.8841 | 1.0 | 40 | 1.8625 | 0.2625 |
| 1.5284 | 2.0 | 80 | 1.6332 | 0.35 |
| 1.3022 | 3.0 | 120 | 1.5466 | 0.4313 |
| 1.1572 | 4.0 | 160 | 1.4844 | 0.475 |
| 0.9867 | 5.0 | 200 | 1.4736 | 0.475 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"anger",
"contempt",
"disgust",
"fear",
"happy",
"neutral",
"sad",
"surprise"
] |
AlaaHussien/weather_classifier
|
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# AlaaHussien/weather_classifier
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1169
- Validation Loss: 0.2788
- Train Accuracy: 0.9206
- Train Precision: 0.9220
- Train Recall: 0.9206
- Train F1: 0.9208
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 3e-05, 'decay_steps': 27445, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Train Precision | Train Recall | Train F1 | Epoch |
|:----------:|:---------------:|:--------------:|:---------------:|:------------:|:--------:|:-----:|
| 0.1984 | 0.2676 | 0.9250 | 0.9266 | 0.9250 | 0.9244 | 0 |
| 0.1562 | 0.2494 | 0.9279 | 0.9293 | 0.9279 | 0.9280 | 1 |
| 0.1384 | 0.2656 | 0.9228 | 0.9238 | 0.9228 | 0.9227 | 2 |
| 0.1186 | 0.2668 | 0.9243 | 0.9248 | 0.9243 | 0.9238 | 3 |
| 0.1169 | 0.2788 | 0.9206 | 0.9220 | 0.9206 | 0.9208 | 4 |
### Framework versions
- Transformers 4.51.3
- TensorFlow 2.18.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"dew",
"fogsmog",
"frost",
"glaze",
"hail",
"lightning",
"rain",
"rainbow",
"rime",
"sandstorm",
"snow"
] |
Jesteban247/resnet-50-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet-50-finetuned-Brain_Cancer
This model is a fine-tuned version of [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3827
- Accuracy: 0.2699
- Precision: 0.2817
- F1 Score: 0.2215
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.1851 | 1.0 | 5 | 1.3858 | 0.2080 | 0.2294 | 0.1850 |
| 1.1803 | 2.0 | 10 | 1.3838 | 0.2611 | 0.2791 | 0.2149 |
| 1.385 | 2.4706 | 12 | 1.3827 | 0.2699 | 0.2817 | 0.2215 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Jesteban247/vit-base-patch16-224-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-finetuned-Brain_Cancer
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7629
- Accuracy: 0.7788
- Precision: 0.7859
- F1 Score: 0.7771
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.1069 | 1.0 | 5 | 1.0687 | 0.5044 | 0.5833 | 0.4533 |
| 0.7725 | 2.0 | 10 | 0.7898 | 0.7788 | 0.7859 | 0.7771 |
| 0.7676 | 2.4706 | 12 | 0.7629 | 0.7788 | 0.7859 | 0.7771 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Jesteban247/cvt-13-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cvt-13-finetuned-Brain_Cancer
This model is a fine-tuned version of [microsoft/cvt-13](https://huggingface.co/microsoft/cvt-13) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1826
- Accuracy: 0.5487
- Precision: 0.5218
- F1 Score: 0.4892
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.219 | 1.0 | 5 | 1.3278 | 0.3761 | 0.3350 | 0.3037 |
| 1.1102 | 2.0 | 10 | 1.1983 | 0.5221 | 0.5128 | 0.4701 |
| 1.2705 | 2.4706 | 12 | 1.1826 | 0.5487 | 0.5218 | 0.4892 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Jesteban247/swin-tiny-patch4-window7-224-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-Brain_Cancer
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6452
- Accuracy: 0.8142
- Precision: 0.8127
- F1 Score: 0.8090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.1158 | 1.0 | 5 | 0.9747 | 0.6903 | 0.7078 | 0.6291 |
| 0.7552 | 2.0 | 10 | 0.6770 | 0.8053 | 0.8065 | 0.7987 |
| 0.6982 | 2.4706 | 12 | 0.6452 | 0.8142 | 0.8127 | 0.8090 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Jesteban247/convnext-tiny-224-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-tiny-224-finetuned-Brain_Cancer
This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2496
- Accuracy: 0.5531
- Precision: 0.5890
- F1 Score: 0.5367
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.1963 | 1.0 | 5 | 1.3240 | 0.4336 | 0.4589 | 0.3947 |
| 1.1163 | 2.0 | 10 | 1.2571 | 0.5398 | 0.5698 | 0.5214 |
| 1.2711 | 2.4706 | 12 | 1.2496 | 0.5531 | 0.5890 | 0.5367 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Jesteban247/deit-base-patch16-224-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deit-base-patch16-224-finetuned-Brain_Cancer
This model is a fine-tuned version of [facebook/deit-base-patch16-224](https://huggingface.co/facebook/deit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5302
- Accuracy: 0.8451
- Precision: 0.8470
- F1 Score: 0.8453
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.0741 | 1.0 | 5 | 0.9123 | 0.7212 | 0.8389 | 0.7189 |
| 0.6529 | 2.0 | 10 | 0.5577 | 0.8451 | 0.8479 | 0.8453 |
| 0.5755 | 2.4706 | 12 | 0.5302 | 0.8451 | 0.8470 | 0.8453 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Jesteban247/beit-base-patch16-224-pt22k-ft22k-finetuned-Brain_Cancer
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-pt22k-ft22k-finetuned-Brain_Cancer
This model is a fine-tuned version of [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4982
- Accuracy: 0.8540
- Precision: 0.8565
- F1 Score: 0.8532
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | F1 Score |
|:-------------:|:------:|:----:|:---------------:|:--------:|:---------:|:--------:|
| 1.1401 | 1.0 | 5 | 0.9244 | 0.5885 | 0.7026 | 0.5746 |
| 0.6598 | 2.0 | 10 | 0.5261 | 0.8496 | 0.8513 | 0.8481 |
| 0.5349 | 2.4706 | 12 | 0.4982 | 0.8540 | 0.8565 | 0.8532 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
[
"glioma",
"meningioma",
"normal",
"pituitary"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.