
repo_id
stringlengths 15
89
| file_path
stringlengths 27
180
| content
stringlengths 1
2.23M
| __index_level_0__
int64 0
0
|
|---|---|---|---|
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/audio_classification.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 오디오 분류[[audio_classification]]
[[open-in-colab]]
<Youtube id="KWwzcmG98Ds"/>
오디오 분류는 텍스트와 마찬가지로 입력 데이터에 클래스 레이블 출력을 할당합니다. 유일한 차이점은 텍스트 입력 대신 원시 오디오 파형이 있다는 것입니다. 오디오 분류의 실제 적용 분야에는 화자의 의도 파악, 언어 분류, 소리로 동물 종을 식별하는 것 등이 있습니다.
이 문서에서 방법을 알아보겠습니다:
1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트를 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)로 미세 조정하여 화자의 의도를 분류합니다.
2. 추론에 미세 조정된 모델을 사용하세요.
<Tip>
이 튜토리얼에서 설명하는 작업은 아래의 모델 아키텍처에서 지원됩니다:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Audio Spectrogram Transformer](../model_doc/audio-spectrogram-transformer), [Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm), [Whisper](../model_doc/whisper)
<!--End of the generated tip-->
</Tip>
시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
```bash
pip install transformers datasets evaluate
```
모델을 업로드하고 커뮤니티와 공유할 수 있도록 허깅페이스 계정에 로그인하는 것이 좋습니다. 메시지가 표시되면 토큰을 입력하여 로그인합니다:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## MInDS-14 데이터셋 불러오기[[load_minds_14_dataset]]
먼저 🤗 Datasets 라이브러리에서 MinDS-14 데이터 세트를 가져옵니다:
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
데이터 세트의 `train` 분할을 [`~datasets.Dataset.train_test_split`] 메소드를 사용하여 더 작은 훈련 및 테스트 집합으로 분할합니다. 이렇게 하면 전체 데이터 세트에 더 많은 시간을 소비하기 전에 모든 것이 작동하는지 실험하고 확인할 수 있습니다.
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
이제 데이터 집합을 살펴볼게요:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 450
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 113
})
})
```
데이터 세트에는 `lang_id` 및 `english_transcription`과 같은 유용한 정보가 많이 포함되어 있지만 이 가이드에서는 `audio` 및 `intent_class`에 중점을 둘 것입니다. 다른 열은 [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 제거합니다:
```py
>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
```
예시를 살펴보겠습니다:
```py
>>> minds["train"][0]
{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
-0.00024414, -0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 8000},
'intent_class': 2}
```
두 개의 필드가 있습니다:
- `audio`: 오디오 파일을 가져오고 리샘플링하기 위해 호출해야 하는 음성 신호의 1차원 `배열`입니다.
- `intent_class`: 화자의 의도에 대한 클래스 ID를 나타냅니다.
모델이 레이블 ID에서 레이블 이름을 쉽게 가져올 수 있도록 레이블 이름을 정수로 매핑하는 사전을 만들거나 그 반대로 매핑하는 사전을 만듭니다:
```py
>>> labels = minds["train"].features["intent_class"].names
>>> label2id, id2label = dict(), dict()
>>> for i, label in enumerate(labels):
... label2id[label] = str(i)
... id2label[str(i)] = label
```
이제 레이블 ID를 레이블 이름으로 변환할 수 있습니다:
```py
>>> id2label[str(2)]
'app_error'
```
## 전처리[[preprocess]]
다음 단계는 오디오 신호를 처리하기 위해 Wav2Vec2 특징 추출기를 가져오는 것입니다:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
MinDS-14 데이터 세트의 샘플링 속도는 8000khz이므로(이 정보는 [데이터세트 카드](https://huggingface.co/datasets/PolyAI/minds14)에서 확인할 수 있습니다), 사전 훈련된 Wav2Vec2 모델을 사용하려면 데이터 세트를 16000kHz로 리샘플링해야 합니다:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
-2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 16000},
'intent_class': 2}
```
이제 전처리 함수를 만듭니다:
1. 가져올 `오디오` 열을 호출하고 필요한 경우 오디오 파일을 리샘플링합니다.
2. 오디오 파일의 샘플링 속도가 모델에 사전 훈련된 오디오 데이터의 샘플링 속도와 일치하는지 확인합니다. 이 정보는 Wav2Vec2 [모델 카드](https://huggingface.co/facebook/wav2vec2-base)에서 확인할 수 있습니다.
3. 긴 입력이 잘리지 않고 일괄 처리되도록 최대 입력 길이를 설정합니다.
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
... )
... return inputs
```
전체 데이터 세트에 전처리 기능을 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용합니다. `batched=True`를 설정하여 데이터 집합의 여러 요소를 한 번에 처리하면 `map`의 속도를 높일 수 있습니다. 필요하지 않은 열을 제거하고 `intent_class`의 이름을 모델이 예상하는 이름인 `label`로 변경합니다:
```py
>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
```
## 평가하기[[evaluate]]
훈련 중에 메트릭을 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는 [accuracy(정확도)](https://huggingface.co/spaces/evaluate-metric/accuracy) 메트릭을 가져옵니다(메트릭을 가져오고 계산하는 방법에 대한 자세한 내용은 🤗 Evalutate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour) 참조하세요):
```py
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
```
그런 다음 예측과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 정확도를 계산하는 함수를 만듭니다:
```py
>>> import numpy as np
>>> def compute_metrics(eval_pred):
... predictions = np.argmax(eval_pred.predictions, axis=1)
... return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
```
이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 트레이닝을 설정할 때 이 함수를 사용합니다.
## 훈련[[train]]
<frameworkcontent>
<pt>
<Tip>
[`Trainer`]로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-with-pytorch-trainer)을 살펴보세요!
</Tip>
이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForAudioClassification`]을 이용해서 Wav2Vec2를 불러옵니다. 예상되는 레이블 수와 레이블 매핑을 지정합니다:
```py
>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
>>> num_labels = len(id2label)
>>> model = AutoModelForAudioClassification.from_pretrained(
... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
... )
```
이제 세 단계만 남았습니다:
1. 훈련 하이퍼파라미터를 [`TrainingArguments`]에 정의합니다. 유일한 필수 매개변수는 모델을 저장할 위치를 지정하는 `output_dir`입니다. `push_to_hub = True`를 설정하여 이 모델을 허브로 푸시합니다(모델을 업로드하려면 허깅 페이스에 로그인해야 합니다). 각 에폭이 끝날 때마다 [`Trainer`]가 정확도를 평가하고 훈련 체크포인트를 저장합니다.
2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 훈련 인자를 [`Trainer`]에 전달합니다.
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정합니다.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_mind_model",
... evaluation_strategy="epoch",
... save_strategy="epoch",
... learning_rate=3e-5,
... per_device_train_batch_size=32,
... gradient_accumulation_steps=4,
... per_device_eval_batch_size=32,
... num_train_epochs=10,
... warmup_ratio=0.1,
... logging_steps=10,
... load_best_model_at_end=True,
... metric_for_best_model="accuracy",
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=feature_extractor,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
훈련이 완료되면 모든 사람이 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유하세요:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for audio classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
</Tip>
## 추론[[inference]]
이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
추론을 실행할 오디오 파일을 가져옵니다. 필요한 경우 오디오 파일의 샘플링 속도를 모델의 샘플링 속도와 일치하도록 리샘플링하는 것을 잊지 마세요!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
추론을 위해 미세 조정한 모델을 시험해 보는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다. 모델을 사용하여 오디오 분류를 위한 `pipeline`을 인스턴스화하고 오디오 파일을 전달합니다:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
>>> classifier(audio_file)
[
{'score': 0.09766869246959686, 'label': 'cash_deposit'},
{'score': 0.07998877018690109, 'label': 'app_error'},
{'score': 0.0781070664525032, 'label': 'joint_account'},
{'score': 0.07667109370231628, 'label': 'pay_bill'},
{'score': 0.0755252093076706, 'label': 'balance'}
]
```
원하는 경우 `pipeline`의 결과를 수동으로 복제할 수도 있습니다:
<frameworkcontent>
<pt>
특징 추출기를 가져와서 오디오 파일을 전처리하고 `입력`을 PyTorch 텐서로 반환합니다:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
모델에 입력을 전달하고 로짓을 반환합니다:
```py
>>> from transformers import AutoModelForAudioClassification
>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
확률이 가장 높은 클래스를 가져온 다음 모델의 `id2label` 매핑을 사용하여 이를 레이블로 변환합니다:
```py
>>> import torch
>>> predicted_class_ids = torch.argmax(logits).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'cash_deposit'
```
</pt>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/token_classification.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 토큰 분류[[token-classification]]
[[open-in-colab]]
<Youtube id="wVHdVlPScxA"/>
토큰 분류는 문장의 개별 토큰에 레이블을 할당합니다. 가장 일반적인 토큰 분류 작업 중 하나는 개체명 인식(Named Entity Recognition, NER)입니다. 개체명 인식은 문장에서 사람, 위치 또는 조직과 같은 각 개체의 레이블을 찾으려고 시도합니다.
이 가이드에서 학습할 내용은:
1. [WNUT 17](https://huggingface.co/datasets/wnut_17) 데이터 세트에서 [DistilBERT](https://huggingface.co/distilbert-base-uncased)를 파인 튜닝하여 새로운 개체를 탐지합니다.
2. 추론을 위해 파인 튜닝 모델을 사용합니다.
<Tip>
이 튜토리얼에서 설명하는 작업은 다음 모델 아키텍처에 의해 지원됩니다:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [BioGpt](../model_doc/biogpt), [BLOOM](../model_doc/bloom), [CamemBERT](../model_doc/camembert), [CANINE](../model_doc/canine), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ErnieM](../model_doc/ernie_m), [ESM](../model_doc/esm), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [GPT-Sw3](../model_doc/gpt-sw3), [OpenAI GPT-2](../model_doc/gpt2), [GPTBigCode](../model_doc/gpt_bigcode), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [LayoutLMv2](../model_doc/layoutlmv2), [LayoutLMv3](../model_doc/layoutlmv3), [LiLT](../model_doc/lilt), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [MarkupLM](../model_doc/markuplm), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [QDQBert](../model_doc/qdqbert), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [XLNet](../model_doc/xlnet), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
시작하기 전에, 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
```bash
pip install transformers datasets evaluate seqeval
```
Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에 공유하는 것을 권장합니다. 메시지가 표시되면, 토큰을 입력하여 로그인하세요:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## WNUT 17 데이터 세트 가져오기[[load-wnut-17-dataset]]
먼저 🤗 Datasets 라이브러리에서 WNUT 17 데이터 세트를 가져옵니다:
```py
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17")
```
다음 예제를 살펴보세요:
```py
>>> wnut["train"][0]
{'id': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
}
```
`ner_tags`의 각 숫자는 개체를 나타냅니다. 숫자를 레이블 이름으로 변환하여 개체가 무엇인지 확인합니다:
```py
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> label_list
[
"O",
"B-corporation",
"I-corporation",
"B-creative-work",
"I-creative-work",
"B-group",
"I-group",
"B-location",
"I-location",
"B-person",
"I-person",
"B-product",
"I-product",
]
```
각 `ner_tag`의 앞에 붙은 문자는 개체의 토큰 위치를 나타냅니다:
- `B-`는 개체의 시작을 나타냅니다.
- `I-`는 토큰이 동일한 개체 내부에 포함되어 있음을 나타냅니다(예를 들어 `State` 토큰은 `Empire State Building`와 같은 개체의 일부입니다).
- `0`는 토큰이 어떤 개체에도 해당하지 않음을 나타냅니다.
## 전처리[[preprocess]]
<Youtube id="iY2AZYdZAr0"/>
다음으로 `tokens` 필드를 전처리하기 위해 DistilBERT 토크나이저를 가져옵니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
위의 예제 `tokens` 필드를 보면 입력이 이미 토큰화된 것처럼 보입니다. 그러나 실제로 입력은 아직 토큰화되지 않았으므로 단어를 하위 단어로 토큰화하기 위해 `is_split_into_words=True`를 설정해야 합니다. 예제로 확인합니다:
```py
>>> example = wnut["train"][0]
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
>>> tokens
['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
```
그러나 이로 인해 `[CLS]`과 `[SEP]`라는 특수 토큰이 추가되고, 하위 단어 토큰화로 인해 입력과 레이블 간에 불일치가 발생합니다. 하나의 레이블에 해당하는 단일 단어는 이제 두 개의 하위 단어로 분할될 수 있습니다. 토큰과 레이블을 다음과 같이 재정렬해야 합니다:
1. [`word_ids`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.BatchEncoding.word_ids) 메소드로 모든 토큰을 해당 단어에 매핑합니다.
2. 특수 토큰 `[CLS]`와 `[SEP]`에 `-100` 레이블을 할당하여, PyTorch 손실 함수가 해당 토큰을 무시하도록 합니다.
3. 주어진 단어의 첫 번째 토큰에만 레이블을 지정합니다. 같은 단어의 다른 하위 토큰에 `-100`을 할당합니다.
다음은 토큰과 레이블을 재정렬하고 DistilBERT의 최대 입력 길이보다 길지 않도록 시퀀스를 잘라내는 함수를 만드는 방법입니다:
```py
>>> def tokenize_and_align_labels(examples):
... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
... labels = []
... for i, label in enumerate(examples[f"ner_tags"]):
... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
... previous_word_idx = None
... label_ids = []
... for word_idx in word_ids: # Set the special tokens to -100.
... if word_idx is None:
... label_ids.append(-100)
... elif word_idx != previous_word_idx: # Only label the first token of a given word.
... label_ids.append(label[word_idx])
... else:
... label_ids.append(-100)
... previous_word_idx = word_idx
... labels.append(label_ids)
... tokenized_inputs["labels"] = labels
... return tokenized_inputs
```
전체 데이터 세트에 전처리 함수를 적용하려면, 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `batched=True`로 설정하여 데이터 세트의 여러 요소를 한 번에 처리하면 `map` 함수의 속도를 높일 수 있습니다:
```py
>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
```
이제 [`DataCollatorWithPadding`]를 사용하여 예제 배치를 만들어봅시다. 데이터 세트 전체를 최대 길이로 패딩하는 대신, *동적 패딩*을 사용하여 배치에서 가장 긴 길이에 맞게 문장을 패딩하는 것이 효율적입니다.
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
```
</tf>
</frameworkcontent>
## 평가[[evaluation]]
훈련 중 모델의 성능을 평가하기 위해 평가 지표를 포함하는 것이 유용합니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 빠르게 평가 방법을 가져올 수 있습니다. 이 작업에서는 [seqeval](https://huggingface.co/spaces/evaluate-metric/seqeval) 평가 지표를 가져옵니다. (평가 지표를 가져오고 계산하는 방법에 대해서는 🤗 Evaluate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요). Seqeval은 실제로 정밀도, 재현률, F1 및 정확도와 같은 여러 점수를 산출합니다.
```py
>>> import evaluate
>>> seqeval = evaluate.load("seqeval")
```
먼저 NER 레이블을 가져온 다음, [`~evaluate.EvaluationModule.compute`]에 실제 예측과 실제 레이블을 전달하여 점수를 계산하는 함수를 만듭니다:
```py
>>> import numpy as np
>>> labels = [label_list[i] for i in example[f"ner_tags"]]
>>> def compute_metrics(p):
... predictions, labels = p
... predictions = np.argmax(predictions, axis=2)
... true_predictions = [
... [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... true_labels = [
... [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... results = seqeval.compute(predictions=true_predictions, references=true_labels)
... return {
... "precision": results["overall_precision"],
... "recall": results["overall_recall"],
... "f1": results["overall_f1"],
... "accuracy": results["overall_accuracy"],
... }
```
이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정하면 이 함수로 되돌아올 것입니다.
## 훈련[[train]]
모델을 훈련하기 전에, `id2label`와 `label2id`를 사용하여 예상되는 id와 레이블의 맵을 생성하세요:
```py
>>> id2label = {
... 0: "O",
... 1: "B-corporation",
... 2: "I-corporation",
... 3: "B-creative-work",
... 4: "I-creative-work",
... 5: "B-group",
... 6: "I-group",
... 7: "B-location",
... 8: "I-location",
... 9: "B-person",
... 10: "I-person",
... 11: "B-product",
... 12: "I-product",
... }
>>> label2id = {
... "O": 0,
... "B-corporation": 1,
... "I-corporation": 2,
... "B-creative-work": 3,
... "I-creative-work": 4,
... "B-group": 5,
... "I-group": 6,
... "B-location": 7,
... "I-location": 8,
... "B-person": 9,
... "I-person": 10,
... "B-product": 11,
... "I-product": 12,
... }
```
<frameworkcontent>
<pt>
<Tip>
[`Trainer`]를 사용하여 모델을 파인 튜닝하는 방법에 익숙하지 않은 경우, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인하세요!
</Tip>
이제 모델을 훈련시킬 준비가 되었습니다! [`AutoModelForSequenceClassification`]로 DistilBERT를 가져오고 예상되는 레이블 수와 레이블 매핑을 지정하세요:
```py
>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
>>> model = AutoModelForTokenClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )
```
이제 세 단계만 거치면 끝입니다:
1. [`TrainingArguments`]에서 하이퍼파라미터를 정의하세요. `output_dir`는 모델을 저장할 위치를 지정하는 유일한 매개변수입니다. 이 모델을 허브에 업로드하기 위해 `push_to_hub=True`를 설정합니다(모델을 업로드하기 위해 Hugging Face에 로그인해야합니다.) 각 에폭이 끝날 때마다, [`Trainer`]는 seqeval 점수를 평가하고 훈련 체크포인트를 저장합니다.
2. [`Trainer`]에 훈련 인수와 모델, 데이터 세트, 토크나이저, 데이터 콜레이터 및 `compute_metrics` 함수를 전달하세요.
3. [`~Trainer.train`]를 호출하여 모델을 파인 튜닝하세요.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_wnut_model",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=2,
... weight_decay=0.01,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
훈련이 완료되면, [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유할 수 있습니다.
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
Keras를 사용하여 모델을 파인 튜닝하는 방법에 익숙하지 않은 경우, [여기](../training#train-a-tensorflow-model-with-keras)의 기본 튜토리얼을 확인하세요!
</Tip>
TensorFlow에서 모델을 파인 튜닝하려면, 먼저 옵티마이저 함수와 학습률 스케쥴, 그리고 일부 훈련 하이퍼파라미터를 설정해야 합니다:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 3
>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=2e-5,
... num_train_steps=num_train_steps,
... weight_decay_rate=0.01,
... num_warmup_steps=0,
... )
```
그런 다음 [`TFAutoModelForSequenceClassification`]을 사용하여 DistilBERT를 가져오고, 예상되는 레이블 수와 레이블 매핑을 지정합니다:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )
```
[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용하여 데이터 세트를 `tf.data.Dataset` 형식으로 변환합니다:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_wnut["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_wnut["validation"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)를 사용하여 훈련할 모델을 구성합니다:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
훈련을 시작하기 전에 설정해야할 마지막 두 가지는 예측에서 seqeval 점수를 계산하고, 모델을 허브에 업로드할 방법을 제공하는 것입니다. 모두 [Keras callbacks](../main_classes/keras_callbacks)를 사용하여 수행됩니다.
[`~transformers.KerasMetricCallback`]에 `compute_metrics` 함수를 전달하세요:
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
[`~transformers.PushToHubCallback`]에서 모델과 토크나이저를 업로드할 위치를 지정합니다:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_wnut_model",
... tokenizer=tokenizer,
... )
```
그런 다음 콜백을 함께 묶습니다:
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
드디어, 모델 훈련을 시작할 준비가 되었습니다! [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)에 훈련 데이터 세트, 검증 데이터 세트, 에폭의 수 및 콜백을 전달하여 파인 튜닝합니다:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
```
훈련이 완료되면, 모델이 자동으로 허브에 업로드되어 누구나 사용할 수 있습니다!
</tf>
</frameworkcontent>
<Tip>
토큰 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)를 참조하세요.
</Tip>
## 추론[[inference]]
좋아요, 이제 모델을 파인 튜닝했으니 추론에 사용할 수 있습니다!
추론을 수행하고자 하는 텍스트를 가져와봅시다:
```py
>>> text = "The Golden State Warriors are an American professional basketball team based in San Francisco."
```
파인 튜닝된 모델로 추론을 시도하는 가장 간단한 방법은 [`pipeline`]를 사용하는 것입니다. 모델로 NER의 `pipeline`을 인스턴스화하고, 텍스트를 전달해보세요:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("ner", model="stevhliu/my_awesome_wnut_model")
>>> classifier(text)
[{'entity': 'B-location',
'score': 0.42658573,
'index': 2,
'word': 'golden',
'start': 4,
'end': 10},
{'entity': 'I-location',
'score': 0.35856336,
'index': 3,
'word': 'state',
'start': 11,
'end': 16},
{'entity': 'B-group',
'score': 0.3064001,
'index': 4,
'word': 'warriors',
'start': 17,
'end': 25},
{'entity': 'B-location',
'score': 0.65523505,
'index': 13,
'word': 'san',
'start': 80,
'end': 83},
{'entity': 'B-location',
'score': 0.4668663,
'index': 14,
'word': 'francisco',
'start': 84,
'end': 93}]
```
원한다면, `pipeline`의 결과를 수동으로 복제할 수도 있습니다:
<frameworkcontent>
<pt>
텍스트를 토큰화하고 PyTorch 텐서를 반환합니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="pt")
```
입력을 모델에 전달하고 `logits`을 반환합니다:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
가장 높은 확률을 가진 클래스를 모델의 `id2label` 매핑을 사용하여 텍스트 레이블로 변환합니다:
```py
>>> predictions = torch.argmax(logits, dim=2)
>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
```
</pt>
<tf>
텍스트를 토큰화하고 TensorFlow 텐서를 반환합니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="tf")
```
입력값을 모델에 전달하고 `logits`을 반환합니다:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> logits = model(**inputs).logits
```
가장 높은 확률을 가진 클래스를 모델의 `id2label` 매핑을 사용하여 텍스트 레이블로 변환합니다:
```py
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
```
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/asr.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 자동 음성 인식[[automatic-speech-recognition]]
[[open-in-colab]]
<Youtube id="TksaY_FDgnk"/>
자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
Siri와 Alexa와 같은 가상 어시스턴트는 ASR 모델을 사용하여 일상적으로 사용자를 돕고 있으며, 회의 중 라이브 캡션 및 메모 작성과 같은 유용한 사용자 친화적 응용 프로그램도 많이 있습니다.
이 가이드에서 소개할 내용은 아래와 같습니다:
1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트에서 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)를 미세 조정하여 오디오를 텍스트로 변환합니다.
2. 미세 조정한 모델을 추론에 사용합니다.
<Tip>
이 튜토리얼에서 설명하는 작업은 다음 모델 아키텍처에 의해 지원됩니다:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
<!--End of the generated tip-->
</Tip>
시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
```bash
pip install transformers datasets evaluate jiwer
```
Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에 공유할 수 있습니다. 토큰을 입력하여 로그인하세요.
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## MInDS-14 데이터 세트 가져오기[[load-minds-14-dataset]]
먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
이렇게 하면 전체 데이터 세트에 대한 훈련에 시간을 들이기 전에 모든 것이 작동하는지 실험하고 검증할 수 있습니다.
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
[`~Dataset.train_test_split`] 메소드를 사용하여 데이터 세트의 `train`을 훈련 세트와 테스트 세트로 나누세요:
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
그리고 데이터 세트를 확인하세요:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
데이터 세트에는 `lang_id`와 `english_transcription`과 같은 유용한 정보가 많이 포함되어 있지만, 이 가이드에서는 `audio`와 `transcription`에 초점을 맞출 것입니다. 다른 열은 [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 제거하세요:
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
예시를 다시 한번 확인해보세요:
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
두 개의 필드가 있습니다:
- `audio`: 오디오 파일을 가져오고 리샘플링하기 위해 호출해야 하는 음성 신호의 1차원 `array(배열)`
- `transcription`: 목표 텍스트
## 전처리[[preprocess]]
다음으로 오디오 신호를 처리하기 위한 Wav2Vec2 프로세서를 가져옵니다:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터 세트 카드](https://huggingface.co/datasets/PolyAI/minds14)에서 확인), 사전 훈련된 Wav2Vec2 모델을 사용하려면 데이터 세트를 16000kHz로 리샘플링해야 합니다:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
위의 'transcription'에서 볼 수 있듯이 텍스트는 대문자와 소문자가 섞여 있습니다. Wav2Vec2 토크나이저는 대문자 문자에 대해서만 훈련되어 있으므로 텍스트가 토크나이저의 어휘와 일치하는지 확인해야 합니다:
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
이제 다음 작업을 수행할 전처리 함수를 만들어보겠습니다:
1. `audio` 열을 호출하여 오디오 파일을 가져오고 리샘플링합니다.
2. 오디오 파일에서 `input_values`를 추출하고 프로세서로 `transcription` 열을 토큰화합니다.
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
전체 데이터 세트에 전처리 함수를 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `num_proc` 매개변수를 사용하여 프로세스 수를 늘리면 `map`의 속도를 높일 수 있습니다. [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 필요하지 않은 열을 제거하세요:
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers에는 자동 음성 인식용 데이터 콜레이터가 없으므로 예제 배치를 생성하려면 [`DataCollatorWithPadding`]을 조정해야 합니다. 이렇게 하면 데이터 콜레이터는 텍스트와 레이블을 배치에서 가장 긴 요소의 길이에 동적으로 패딩하여 길이를 균일하게 합니다. `tokenizer` 함수에서 `padding=True`를 설정하여 텍스트를 패딩할 수 있지만, 동적 패딩이 더 효율적입니다.
다른 데이터 콜레이터와 달리 이 특정 데이터 콜레이터는 `input_values`와 `labels`에 대해 다른 패딩 방법을 적용해야 합니다.
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # 입력과 레이블을 분할합니다
... # 길이가 다르고, 각각 다른 패딩 방법을 사용해야 하기 때문입니다
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # 패딩에 대해 손실을 적용하지 않도록 -100으로 대체합니다
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
이제 `DataCollatorForCTCWithPadding`을 인스턴스화합니다:
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## 평가하기[[evaluate]]
훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
이 작업에서는 [단어 오류율(Word Error Rate, WER)](https://huggingface.co/spaces/evaluate-metric/wer) 평가 지표를 가져옵니다.
(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
그런 다음 예측값과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 WER을 계산하는 함수를 만듭니다:
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정할 때 이 함수로 되돌아올 것입니다.
## 훈련하기[[train]]
<frameworkcontent>
<pt>
<Tip>
[`Trainer`]로 모델을 미세 조정하는 것이 익숙하지 않다면, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인해보세요!
</Tip>
이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForCTC`]로 Wav2Vec2를 가져오세요. `ctc_loss_reduction` 매개변수로 CTC 손실에 적용할 축소(reduction) 방법을 지정하세요. 기본값인 합계 대신 평균을 사용하는 것이 더 좋은 경우가 많습니다:
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
이제 세 단계만 남았습니다:
1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. `output_dir`은 모델을 저장할 경로를 지정하는 유일한 필수 매개변수입니다. `push_to_hub=True`를 설정하여 모델을 Hub에 업로드 할 수 있습니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다). [`Trainer`]는 각 에폭마다 WER을 평가하고 훈련 체크포인트를 저장합니다.
2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 [`Trainer`]에 훈련 인수를 전달하세요.
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=processor.feature_extractor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
훈련이 완료되면 모두가 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 Hub에 공유하세요:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
자동 음성 인식을 위해 모델을 미세 조정하는 더 자세한 예제는 영어 자동 음성 인식을 위한 [블로그 포스트](https://huggingface.co/blog/fine-tune-wav2vec2-english)와 다국어 자동 음성 인식을 위한 [포스트](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)를 참조하세요.
</Tip>
## 추론하기[[inference]]
좋아요, 이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
추론에 사용할 오디오 파일을 가져오세요. 필요한 경우 오디오 파일의 샘플링 비율을 모델의 샘플링 레이트에 맞게 리샘플링하는 것을 잊지 마세요!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
추론을 위해 미세 조정된 모델을 시험해보는 가장 간단한 방법은 [`pipeline`]을 사용하는 것입니다. 모델을 사용하여 자동 음성 인식을 위한 `pipeline`을 인스턴스화하고 오디오 파일을 전달하세요:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
텍스트로 변환된 결과가 꽤 괜찮지만 더 좋을 수도 있습니다! 더 나은 결과를 얻으려면 더 많은 예제로 모델을 미세 조정하세요!
</Tip>
`pipeline`의 결과를 수동으로 재현할 수도 있습니다:
<frameworkcontent>
<pt>
오디오 파일과 텍스트를 전처리하고 PyTorch 텐서로 `input`을 반환할 프로세서를 가져오세요:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
입력을 모델에 전달하고 로짓을 반환하세요:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
가장 높은 확률의 `input_ids`를 예측하고, 프로세서를 사용하여 예측된 `input_ids`를 다시 텍스트로 디코딩하세요:
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/zero_shot_object_detection.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 제로샷(zero-shot) 객체 탐지[[zeroshot-object-detection]]
[[open-in-colab]]
일반적으로 [객체 탐지](object_detection)에 사용되는 모델을 학습하기 위해서는 레이블이 지정된 이미지 데이터 세트가 필요합니다.
그리고 학습 데이터에 존재하는 클래스(레이블)만 탐지할 수 있다는 한계점이 있습니다.
다른 방식을 사용하는 [OWL-ViT](../model_doc/owlvit) 모델로 제로샷 객체 탐지가 가능합니다.
OWL-ViT는 개방형 어휘(open-vocabulary) 객체 탐지기입니다.
즉, 레이블이 지정된 데이터 세트에 미세 조정하지 않고 자유 텍스트 쿼리를 기반으로 이미지에서 객체를 탐지할 수 있습니다.
OWL-ViT 모델은 멀티 모달 표현을 활용해 개방형 어휘 탐지(open-vocabulary detection)를 수행합니다.
[CLIP](../model_doc/clip) 모델에 경량화(lightweight)된 객체 분류와 지역화(localization) 헤드를 결합합니다.
개방형 어휘 탐지는 CLIP의 텍스트 인코더로 free-text 쿼리를 임베딩하고, 객체 분류와 지역화 헤드의 입력으로 사용합니다.
이미지와 해당 텍스트 설명을 연결하면 ViT가 이미지 패치(image patches)를 입력으로 처리합니다.
OWL-ViT 모델의 저자들은 CLIP 모델을 처음부터 학습(scratch learning)한 후에, bipartite matching loss를 사용하여 표준 객체 인식 데이터셋으로 OWL-ViT 모델을 미세 조정했습니다.
이 접근 방식을 사용하면 모델은 레이블이 지정된 데이터 세트에 대한 사전 학습 없이도 텍스트 설명을 기반으로 객체를 탐지할 수 있습니다.
이번 가이드에서는 OWL-ViT 모델의 사용법을 다룰 것입니다:
- 텍스트 프롬프트 기반 객체 탐지
- 일괄 객체 탐지
- 이미지 가이드 객체 탐지
시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
```bash
pip install -q transformers
```
## 제로샷(zero-shot) 객체 탐지 파이프라인[[zeroshot-object-detection-pipeline]]
[`pipeline`]을 활용하면 가장 간단하게 OWL-ViT 모델을 추론해볼 수 있습니다.
[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 제로샷(zero-shot) 객체 탐지용 파이프라인을 인스턴스화합니다:
```python
>>> from transformers import pipeline
>>> checkpoint = "google/owlvit-base-patch32"
>>> detector = pipeline(model=checkpoint, task="zero-shot-object-detection")
```
다음으로, 객체를 탐지하고 싶은 이미지를 선택하세요.
여기서는 [NASA](https://www.nasa.gov/multimedia/imagegallery/index.html) Great Images 데이터 세트의 일부인 우주비행사 에일린 콜린스(Eileen Collins) 사진을 사용하겠습니다.
```py
>>> import skimage
>>> import numpy as np
>>> from PIL import Image
>>> image = skimage.data.astronaut()
>>> image = Image.fromarray(np.uint8(image)).convert("RGB")
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_1.png" alt="Astronaut Eileen Collins"/>
</div>
이미지와 해당 이미지의 후보 레이블을 파이프라인으로 전달합니다.
여기서는 이미지를 직접 전달하지만, 컴퓨터에 저장된 이미지의 경로나 url로 전달할 수도 있습니다.
candidate_labels는 이 예시처럼 간단한 단어일 수도 있고 좀 더 설명적인 단어일 수도 있습니다.
또한, 이미지를 검색(query)하려는 모든 항목에 대한 텍스트 설명도 전달합니다.
```py
>>> predictions = detector(
... image,
... candidate_labels=["human face", "rocket", "nasa badge", "star-spangled banner"],
... )
>>> predictions
[{'score': 0.3571370542049408,
'label': 'human face',
'box': {'xmin': 180, 'ymin': 71, 'xmax': 271, 'ymax': 178}},
{'score': 0.28099656105041504,
'label': 'nasa badge',
'box': {'xmin': 129, 'ymin': 348, 'xmax': 206, 'ymax': 427}},
{'score': 0.2110239565372467,
'label': 'rocket',
'box': {'xmin': 350, 'ymin': -1, 'xmax': 468, 'ymax': 288}},
{'score': 0.13790413737297058,
'label': 'star-spangled banner',
'box': {'xmin': 1, 'ymin': 1, 'xmax': 105, 'ymax': 509}},
{'score': 0.11950037628412247,
'label': 'nasa badge',
'box': {'xmin': 277, 'ymin': 338, 'xmax': 327, 'ymax': 380}},
{'score': 0.10649408400058746,
'label': 'rocket',
'box': {'xmin': 358, 'ymin': 64, 'xmax': 424, 'ymax': 280}}]
```
이제 예측값을 시각화해봅시다:
```py
>>> from PIL import ImageDraw
>>> draw = ImageDraw.Draw(image)
>>> for prediction in predictions:
... box = prediction["box"]
... label = prediction["label"]
... score = prediction["score"]
... xmin, ymin, xmax, ymax = box.values()
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{label}: {round(score,2)}", fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_2.png" alt="Visualized predictions on NASA image"/>
</div>
## 텍스트 프롬프트 기반 객체 탐지[[textprompted-zeroshot-object-detection-by-hand]]
제로샷 객체 탐지 파이프라인 사용법에 대해 살펴보았으니, 이제 동일한 결과를 복제해보겠습니다.
[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?other=owlvit)에서 관련 모델과 프로세서를 가져오는 것으로 시작합니다.
여기서는 이전과 동일한 체크포인트를 사용하겠습니다:
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
다른 이미지를 사용해 보겠습니다:
```py
>>> import requests
>>> url = "https://unsplash.com/photos/oj0zeY2Ltk4/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTR8fHBpY25pY3xlbnwwfHx8fDE2Nzc0OTE1NDk&force=true&w=640"
>>> im = Image.open(requests.get(url, stream=True).raw)
>>> im
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_3.png" alt="Beach photo"/>
</div>
프로세서를 사용해 모델의 입력을 준비합니다.
프로세서는 모델의 입력으로 사용하기 위해 이미지 크기를 변환하고 정규화하는 이미지 프로세서와 텍스트 입력을 처리하는 [`CLIPTokenizer`]로 구성됩니다.
```py
>>> text_queries = ["hat", "book", "sunglasses", "camera"]
>>> inputs = processor(text=text_queries, images=im, return_tensors="pt")
```
모델에 입력을 전달하고 결과를 후처리 및 시각화합니다.
이미지 프로세서가 모델에 이미지를 입력하기 전에 이미지 크기를 조정했기 때문에, [`~OwlViTImageProcessor.post_process_object_detection`] 메소드를 사용해
예측값의 바운딩 박스(bounding box)가 원본 이미지의 좌표와 상대적으로 동일한지 확인해야 합니다.
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
... target_sizes = torch.tensor([im.size[::-1]])
... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(im)
>>> scores = results["scores"].tolist()
>>> labels = results["labels"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{text_queries[label]}: {round(score,2)}", fill="white")
>>> im
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_4.png" alt="Beach photo with detected objects"/>
</div>
## 일괄 처리[[batch-processing]]
여러 이미지와 텍스트 쿼리를 전달하여 여러 이미지에서 서로 다른(또는 동일한) 객체를 검색할 수 있습니다.
일괄 처리를 위해서 텍스트 쿼리는 이중 리스트로, 이미지는 PIL 이미지, PyTorch 텐서, 또는 NumPy 배열로 이루어진 리스트로 프로세서에 전달해야 합니다.
```py
>>> images = [image, im]
>>> text_queries = [
... ["human face", "rocket", "nasa badge", "star-spangled banner"],
... ["hat", "book", "sunglasses", "camera"],
... ]
>>> inputs = processor(text=text_queries, images=images, return_tensors="pt")
```
이전에는 후처리를 위해 단일 이미지의 크기를 텐서로 전달했지만, 튜플을 전달할 수 있고, 여러 이미지를 처리하는 경우에는 튜플로 이루어진 리스트를 전달할 수도 있습니다.
아래 두 예제에 대한 예측을 생성하고, 두 번째 이미지(`image_idx = 1`)를 시각화해 보겠습니다.
```py
>>> with torch.no_grad():
... outputs = model(**inputs)
... target_sizes = [x.size[::-1] for x in images]
... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)
>>> image_idx = 1
>>> draw = ImageDraw.Draw(images[image_idx])
>>> scores = results[image_idx]["scores"].tolist()
>>> labels = results[image_idx]["labels"].tolist()
>>> boxes = results[image_idx]["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{text_queries[image_idx][label]}: {round(score,2)}", fill="white")
>>> images[image_idx]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_4.png" alt="Beach photo with detected objects"/>
</div>
## 이미지 가이드 객체 탐지[[imageguided-object-detection]]
텍스트 쿼리를 이용한 제로샷 객체 탐지 외에도 OWL-ViT 모델은 이미지 가이드 객체 탐지 기능을 제공합니다.
이미지를 쿼리로 사용해 대상 이미지에서 유사한 객체를 찾을 수 있다는 의미입니다.
텍스트 쿼리와 달리 하나의 예제 이미지에서만 가능합니다.
소파에 고양이 두 마리가 있는 이미지를 대상 이미지(target image)로, 고양이 한 마리가 있는 이미지를 쿼리로 사용해보겠습니다:
```py
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image_target = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000524280.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
```
다음 이미지를 살펴보겠습니다:
```py
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(1, 2)
>>> ax[0].imshow(image_target)
>>> ax[1].imshow(query_image)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_5.png" alt="Cats"/>
</div>
전처리 단계에서 텍스트 쿼리 대신에 `query_images`를 사용합니다:
```py
>>> inputs = processor(images=image_target, query_images=query_image, return_tensors="pt")
```
예측의 경우, 모델에 입력을 전달하는 대신 [`~OwlViTForObjectDetection.image_guided_detection`]에 전달합니다.
레이블이 없다는 점을 제외하면 이전과 동일합니다.
이전과 동일하게 이미지를 시각화합니다.
```py
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
... target_sizes = torch.tensor([image_target.size[::-1]])
... results = processor.post_process_image_guided_detection(outputs=outputs, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(image_target)
>>> scores = results["scores"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="white", width=4)
>>> image_target
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_6.png" alt="Cats with bounding boxes"/>
</div>
OWL-ViT 모델을 추론하고 싶다면 아래 데모를 확인하세요:
<iframe
src="https://adirik-owl-vit.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
| 0 |
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/zero_shot_image_classification.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 제로샷(zero-shot) 이미지 분류[[zeroshot-image-classification]]
[[open-in-colab]]
제로샷(zero-shot) 이미지 분류는 특정 카테고리의 예시가 포함된 데이터를 학습되지 않은 모델을 사용해 이미지 분류를 수행하는 작업입니다.
일반적으로 이미지 분류를 위해서는 레이블이 달린 특정 이미지 데이터로 모델 학습이 필요하며, 이 모델은 특정 이미지의 특징을 레이블에 "매핑"하는 방법을 학습합니다.
새로운 레이블이 있는 분류 작업에 이러한 모델을 사용해야 하는 경우에는, 모델을 "재보정"하기 위해 미세 조정이 필요합니다.
이와 대조적으로, 제로샷 또는 개방형 어휘(open vocabulary) 이미지 분류 모델은 일반적으로 대규모 이미지 데이터와 해당 설명에 대해 학습된 멀티모달(multimodal) 모델입니다.
이러한 모델은 제로샷 이미지 분류를 포함한 많은 다운스트림 작업에 사용할 수 있는 정렬된(aligned) 비전 언어 표현을 학습합니다.
이는 이미지 분류에 대한 보다 유연한 접근 방식으로, 추가 학습 데이터 없이 새로운 레이블이나 학습하지 못한 카테고리에 대해 모델을 일반화할 수 있습니다.
또한, 사용자가 대상 개체에 대한 자유 형식의 텍스트 설명으로 이미지를 검색할 수 있습니다.
이번 가이드에서 배울 내용은 다음과 같습니다:
* 제로샷 이미지 분류 파이프라인 만들기
* 직접 제로샷 이미지 분류 모델 추론 실행하기
시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
```bash
pip install -q transformers
```
## 제로샷(zero-shot) 이미지 분류 파이프라인[[zeroshot-image-classification-pipeline]]
[`pipeline`]을 활용하면 가장 간단하게 제로샷 이미지 분류를 지원하는 모델로 추론해볼 수 있습니다.
[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 파이프라인을 인스턴스화합니다.
```python
>>> from transformers import pipeline
>>> checkpoint = "openai/clip-vit-large-patch14"
>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
```
다음으로, 분류하고 싶은 이미지를 선택하세요.
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/owl.jpg" alt="Photo of an owl"/>
</div>
이미지와 해당 이미지의 후보 레이블인 `candidate_labels`를 파이프라인으로 전달합니다.
여기서는 이미지를 직접 전달하지만, 컴퓨터에 저장된 이미지의 경로나 url로 전달할 수도 있습니다.
`candidate_labels`는 이 예시처럼 간단한 단어일 수도 있고 좀 더 설명적인 단어일 수도 있습니다.
```py
>>> predictions = classifier(image, candidate_labels=["fox", "bear", "seagull", "owl"])
>>> predictions
[{'score': 0.9996670484542847, 'label': 'owl'},
{'score': 0.000199399160919711, 'label': 'seagull'},
{'score': 7.392891711788252e-05, 'label': 'fox'},
{'score': 5.96074532950297e-05, 'label': 'bear'}]
```
## 직접 제로샷(zero-shot) 이미지 분류하기[[zeroshot-image-classification-by-hand]]
이제 제로샷 이미지 분류 파이프라인 사용 방법을 살펴보았으니, 실행하는 방법을 살펴보겠습니다.
[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 모델과 프로세서를 가져오는 것으로 시작합니다.
여기서는 이전과 동일한 체크포인트를 사용하겠습니다:
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
다른 이미지를 사용해 보겠습니다.
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg" alt="Photo of a car"/>
</div>
프로세서를 사용해 모델의 입력을 준비합니다.
프로세서는 모델의 입력으로 사용하기 위해 이미지 크기를 변환하고 정규화하는 이미지 프로세서와 텍스트 입력을 처리하는 토크나이저로 구성됩니다.
```py
>>> candidate_labels = ["tree", "car", "bike", "cat"]
>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
```
모델에 입력을 전달하고, 결과를 후처리합니다:
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits = outputs.logits_per_image[0]
>>> probs = logits.softmax(dim=-1).numpy()
>>> scores = probs.tolist()
>>> result = [
... {"score": score, "label": candidate_label}
... for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
... ]
>>> result
[{'score': 0.998572, 'label': 'car'},
{'score': 0.0010570387, 'label': 'bike'},
{'score': 0.0003393686, 'label': 'tree'},
{'score': 3.1572064e-05, 'label': 'cat'}]
```
| 0 |
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/masked_language_modeling.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 마스킹된 언어 모델링(Masked language modeling)[[masked-language-modeling]]
[[open-in-colab]]
<Youtube id="mqElG5QJWUg"/>
마스킹된 언어 모델링은 시퀀스에서 마스킹된 토큰을 예측하며, 모델은 양방향으로 토큰에 액세스할 수 있습니다.
즉, 모델은 토큰의 왼쪽과 오른쪽 양쪽에서 접근할 수 있습니다.
마스킹된 언어 모델링은 전체 시퀀스에 대한 문맥적 이해가 필요한 작업에 적합하며, BERT가 그 예에 해당합니다.
이번 가이드에서 다룰 내용은 다음과 같습니다:
1. [ELI5](https://huggingface.co/datasets/eli5) 데이터 세트에서 [r/askscience](https://www.reddit.com/r/askscience/) 부분을 사용해 [DistilRoBERTa](https://huggingface.co/distilroberta-base) 모델을 미세 조정합니다.
2. 추론 시에 직접 미세 조정한 모델을 사용합니다.
<Tip>
이번 가이드에서처럼 다른 아키텍처를 미세 조정해 마스킹된 언어 모델링을 할 수 있습니다.
다음 아키텍쳐 중 하나를 선택하세요:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[ALBERT](../model_doc/albert), [BART](../model_doc/bart), [BERT](../model_doc/bert), [BigBird](../model_doc/big_bird), [CamemBERT](../model_doc/camembert), [ConvBERT](../model_doc/convbert), [Data2VecText](../model_doc/data2vec-text), [DeBERTa](../model_doc/deberta), [DeBERTa-v2](../model_doc/deberta-v2), [DistilBERT](../model_doc/distilbert), [ELECTRA](../model_doc/electra), [ERNIE](../model_doc/ernie), [ESM](../model_doc/esm), [FlauBERT](../model_doc/flaubert), [FNet](../model_doc/fnet), [Funnel Transformer](../model_doc/funnel), [I-BERT](../model_doc/ibert), [LayoutLM](../model_doc/layoutlm), [Longformer](../model_doc/longformer), [LUKE](../model_doc/luke), [mBART](../model_doc/mbart), [MEGA](../model_doc/mega), [Megatron-BERT](../model_doc/megatron-bert), [MobileBERT](../model_doc/mobilebert), [MPNet](../model_doc/mpnet), [MVP](../model_doc/mvp), [Nezha](../model_doc/nezha), [Nyströmformer](../model_doc/nystromformer), [Perceiver](../model_doc/perceiver), [QDQBert](../model_doc/qdqbert), [Reformer](../model_doc/reformer), [RemBERT](../model_doc/rembert), [RoBERTa](../model_doc/roberta), [RoBERTa-PreLayerNorm](../model_doc/roberta-prelayernorm), [RoCBert](../model_doc/roc_bert), [RoFormer](../model_doc/roformer), [SqueezeBERT](../model_doc/squeezebert), [TAPAS](../model_doc/tapas), [Wav2Vec2](../model_doc/wav2vec2), [XLM](../model_doc/xlm), [XLM-RoBERTa](../model_doc/xlm-roberta), [XLM-RoBERTa-XL](../model_doc/xlm-roberta-xl), [X-MOD](../model_doc/xmod), [YOSO](../model_doc/yoso)
<!--End of the generated tip-->
</Tip>
시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
```bash
pip install transformers datasets evaluate
```
Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티와의 공유를 권장합니다. 메시지가 표시되면(When prompted) 토큰을 입력하여 로그인합니다:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## ELI5 데이터 세트 가져오기[[load-eli5-dataset]]
먼저 🤗 Datasets 라이브러리에서 ELI5 데이터 세트의 r/askscience 중 일부만 가져옵니다.
이렇게 하면 전체 데이터 세트 학습에 더 많은 시간을 할애하기 전에 모든 것이 작동하는지 실험하고 확인할 수 있습니다.
```py
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
```
데이터 세트의 `train_asks`를 [`~datasets.Dataset.train_test_split`] 메소드를 사용해 훈련 데이터와 테스트 데이터로 분할합니다:
```py
>>> eli5 = eli5.train_test_split(test_size=0.2)
```
그리고 아래 예시를 살펴보세요:
```py
>>> eli5["train"][0]
{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
'score': [6, 3],
'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
'answers_urls': {'url': []},
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls': {'url': []}}
```
많아 보일 수 있지만 실제로는 `text` 필드에만 집중하면 됩나다.
언어 모델링 작업의 멋진 점은 (비지도 학습으로) *다음 단어가 레이블*이기 때문에 레이블이 따로 필요하지 않습니다.
## 전처리[[preprocess]]
<Youtube id="8PmhEIXhBvI"/>
마스킹된 언어 모델링을 위해, 다음 단계로 DistilRoBERTa 토크나이저를 가져와서 `text` 하위 필드를 처리합니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilroberta-base")
```
위의 예제에서와 마찬가지로, `text` 필드는 `answers` 안에 중첩되어 있습니다.
따라서 중첩된 구조에서 [`flatten`](https://huggingface.co/docs/datasets/process#flatten) 메소드를 사용하여 `text` 하위 필드를 추출합니다:
```py
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'answers.a_id': ['c3d1aib', 'c3d4lya'],
'answers.score': [6, 3],
'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
"Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
'answers_urls.url': [],
'document': '',
'q_id': 'nyxfp',
'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
'subreddit': 'askscience',
'title': 'Few questions about this space walk photograph.',
'title_urls.url': []}
```
이제 각 하위 필드는 `answers` 접두사(prefix)로 표시된 대로 별도의 열이 되고, `text` 필드는 이제 리스트가 되었습니다.
각 문장을 개별적으로 토큰화하는 대신 리스트를 문자열로 변환하여 한번에 토큰화할 수 있습니다.
다음은 각 예제에 대해 문자열로 이루어진 리스트를 `join`하고 결과를 토큰화하는 첫 번째 전처리 함수입니다:
```py
>>> def preprocess_function(examples):
... return tokenizer([" ".join(x) for x in examples["answers.text"]])
```
이 전처리 함수를 전체 데이터 세트에 적용하기 위해 🤗 Datasets [`~datasets.Dataset.map`] 메소드를 사용합니다.
데이터 세트의 여러 요소를 한 번에 처리하도록 `batched=True`를 설정하고 `num_proc`로 처리 횟수를 늘리면 `map` 함수의 속도를 높일 수 있습니다.
필요하지 않은 열은 제거합니다:
```py
>>> tokenized_eli5 = eli5.map(
... preprocess_function,
... batched=True,
... num_proc=4,
... remove_columns=eli5["train"].column_names,
... )
```
이 데이터 세트에는 토큰 시퀀스가 포함되어 있지만 이 중 일부는 모델의 최대 입력 길이보다 깁니다.
이제 두 번째 전처리 함수를 사용해
- 모든 시퀀스를 연결하고
- 연결된 시퀀스를 정의한 `block_size` 보다 더 짧은 덩어리로 분할하는데, 이 덩어리는 모델의 최대 입력 길이보다 짧고 GPU RAM이 수용할 수 있는 길이여야 합니다.
```py
>>> block_size = 128
>>> def group_texts(examples):
... # Concatenate all texts.
... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
... total_length = len(concatenated_examples[list(examples.keys())[0]])
... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
... # customize this part to your needs.
... if total_length >= block_size:
... total_length = (total_length // block_size) * block_size
... # Split by chunks of block_size.
... result = {
... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
... for k, t in concatenated_examples.items()
... }
... result["labels"] = result["input_ids"].copy()
... return result
```
전체 데이터 세트에 `group_texts` 함수를 적용합니다:
```py
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
```
이제 [`DataCollatorForLanguageModeling`]을 사용하여 데이터 예제의 배치를 생성합니다.
데이터 세트 전체를 최대 길이로 패딩하는 것보다 collation 단계에서 매 배치안에서의 최대 길이로 문장을 *동적으로 패딩*하는 것이 더 효율적입니다.
<frameworkcontent>
<pt>
시퀀스 끝 토큰을 패딩 토큰으로 사용하고 데이터를 반복할 때마다 토큰을 무작위로 마스킹하도록 `mlm_-probability`를 지정합니다:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
```
</pt>
<tf>
시퀀스 끝 토큰을 패딩 토큰으로 사용하고 데이터를 반복할 때마다 토큰을 무작위로 마스킹하도록 `mlm_-probability`를 지정합니다:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15, return_tensors="tf")
```
</tf>
</frameworkcontent>
## 훈련[[train]]
<frameworkcontent>
<pt>
<Tip>
[`Trainer`]로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-with-pytorch-trainer)를 살펴보세요!
</Tip>
이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForMaskedLM`]를 사용해 DistilRoBERTa 모델을 가져옵니다:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("distilroberta-base")
```
이제 세 단계가 남았습니다:
1. [`TrainingArguments`]의 훈련 하이퍼파라미터를 정의합니다. 모델 저장 위치를 지정하는 `output_dir`은 유일한 필수 파라미터입니다. `push_to_hub=True`를 설정하여 이 모델을 Hub에 업로드합니다 (모델을 업로드하려면 Hugging Face에 로그인해야 합니다).
2. 모델, 데이터 세트 및 데이터 콜레이터(collator)와 함께 훈련 인수를 [`Trainer`]에 전달합니다.
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정합니다.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_eli5_mlm_model",
... evaluation_strategy="epoch",
... learning_rate=2e-5,
... num_train_epochs=3,
... weight_decay=0.01,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=lm_dataset["train"],
... eval_dataset=lm_dataset["test"],
... data_collator=data_collator,
... )
>>> trainer.train()
```
훈련이 완료되면 [`~transformers.Trainer.evaluate`] 메소드를 사용하여 펄플렉서티(perplexity)를 계산하고 모델을 평가합니다:
```py
>>> import math
>>> eval_results = trainer.evaluate()
>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 8.76
```
그리고 [`~transformers.Trainer.push_to_hub`] 메소드를 사용해 다른 사람들이 사용할 수 있도록, Hub로 모델을 업로드합니다.
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
Keras로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-a-tensorflow-model-with-keras)를 살펴보세요!
</Tip>
TensorFlow로 모델을 미세 조정하기 위해서는 옵티마이저(optimizer) 함수 설정, 학습률(learning rate) 스케쥴링, 훈련 하이퍼파라미터 설정부터 시작하세요:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
다음으로 [`TFAutoModelForMaskedLM`]를 사용해 DistilRoBERTa 모델을 가져옵니다:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("distilroberta-base")
```
[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] 메소드를 사용해 데이터 세트를 `tf.data.Dataset` 형식으로 변환하세요:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... lm_dataset["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = model.prepare_tf_dataset(
... lm_dataset["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 메소드를 통해 모델 훈련을 구성합니다:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer)
```
이는 업로드할 모델과 토크나이저의 위치를 [`~transformers.PushToHubCallback`]에 지정하여 수행할 수 있습니다:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
... output_dir="my_awesome_eli5_mlm_model",
... tokenizer=tokenizer,
... )
```
드디어 모델을 훈련할 준비가 되었습니다!
모델을 미세 조정할 때 훈련 및 검증 데이터 세트, 에포크 수, 콜백이 포함된 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)을 호출합니다:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
```
훈련이 완료되면, 자동으로 Hub로 업로드되어 누구나 사용할 수 있습니다!
</tf>
</frameworkcontent>
<Tip>
마스킹된 언어 모델링을 위해 모델을 미세 조정하는 방법에 대한 보다 심층적인 예제는
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)을 참조하세요.
</Tip>
## 추론[[inference]]
지금까지 모델 미세 조정을 잘 했으니, 추론에 사용할 수 있습니다!
모델이 빈칸을 채울 텍스트를 스페셜 토큰(special token)인 `<mask>` 토큰으로 표시합니다:
```py
>>> text = "The Milky Way is a <mask> galaxy."
```
추론을 위해 미세 조정한 모델을 테스트하는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다.
`fill-mask`태스크로 `pipeline`을 인스턴스화하고 텍스트를 전달합니다.
`top_k` 매개변수를 사용하여 반환하는 예측의 수를 지정할 수 있습니다:
```py
>>> from transformers import pipeline
>>> mask_filler = pipeline("fill-mask", "stevhliu/my_awesome_eli5_mlm_model")
>>> mask_filler(text, top_k=3)
[{'score': 0.5150994658470154,
'token': 21300,
'token_str': ' spiral',
'sequence': 'The Milky Way is a spiral galaxy.'},
{'score': 0.07087188959121704,
'token': 2232,
'token_str': ' massive',
'sequence': 'The Milky Way is a massive galaxy.'},
{'score': 0.06434620916843414,
'token': 650,
'token_str': ' small',
'sequence': 'The Milky Way is a small galaxy.'}]
```
<frameworkcontent>
<pt>
텍스트를 토큰화하고 `input_ids`를 PyTorch 텐서 형태로 반환합니다.
또한, `<mask>` 토큰의 위치를 지정해야 합니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="pt")
>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
```
모델에 `inputs`를 입력하고, 마스킹된 토큰의 `logits`를 반환합니다:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
```
그런 다음 가장 높은 확률은 가진 마스크 토큰 3개를 반환하고, 출력합니다:
```py
>>> top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
>>> for token in top_3_tokens:
... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
```
</pt>
<tf>
텍스트를 토큰화하고 `input_ids`를 TensorFlow 텐서 형태로 반환합니다.
또한, `<mask>` 토큰의 위치를 지정해야 합니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="tf")
>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
```
모델에 `inputs`를 입력하고, 마스킹된 토큰의 `logits`를 반환합니다:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
```
그런 다음 가장 높은 확률은 가진 마스크 토큰 3개를 반환하고, 출력합니다:
```py
>>> top_3_tokens = tf.math.top_k(mask_token_logits, 3).indices.numpy()
>>> for token in top_3_tokens:
... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
```
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source/ko
|
hf_public_repos/transformers/docs/source/ko/tasks/visual_question_answering.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 시각적 질의응답 (Visual Question Answering)
[[open-in-colab]]
시각적 질의응답(VQA)은 이미지를 기반으로 개방형 질문에 대응하는 작업입니다. 이 작업을 지원하는 모델의 입력은 대부분 이미지와 질문의 조합이며, 출력은 자연어로 된 답변입니다.
VQA의 주요 사용 사례는 다음과 같습니다:
* 시각 장애인을 위한 접근성 애플리케이션을 구축할 수 있습니다.
* 교육: 강의나 교과서에 나온 시각 자료에 대한 질문에 답할 수 있습니다. 또한 체험형 전시와 유적 등에서도 VQA를 활용할 수 있습니다.
* 고객 서비스 및 전자상거래: VQA는 사용자가 제품에 대해 질문할 수 있게 함으로써 사용자 경험을 향상시킬 수 있습니다.
* 이미지 검색: VQA 모델을 사용하여 원하는 특성을 가진 이미지를 검색할 수 있습니다. 예를 들어 사용자는 "강아지가 있어?"라고 물어봐서 주어진 이미지 묶음에서 강아지가 있는 모든 이미지를 받아볼 수 있습니다.
이 가이드에서 학습할 내용은 다음과 같습니다:
- VQA 모델 중 하나인 [ViLT](../../en/model_doc/vilt)를 [`Graphcore/vqa` 데이터셋](https://huggingface.co/datasets/Graphcore/vqa) 에서 미세조정하는 방법
- 미세조정된 ViLT 모델로 추론하는 방법
- BLIP-2 같은 생성 모델로 제로샷 VQA 추론을 실행하는 방법
## ViLT 미세 조정 [[finetuning-vilt]]
ViLT는 Vision Transformer (ViT) 내에 텍스트 임베딩을 포함하여 비전/자연어 사전훈련(VLP; Vision-and-Language Pretraining)을 위한 기본 디자인을 제공합니다.
ViLT 모델은 비전 트랜스포머(ViT)에 텍스트 임베딩을 넣어 비전/언어 사전훈련(VLP; Vision-and-Language Pre-training)을 위한 기본적인 디자인을 갖췄습니다. 이 모델은 여러 다운스트림 작업에 사용할 수 있습니다. VQA 태스크에서는 (`[CLS]` 토큰의 최종 은닉 상태 위에 선형 레이어인) 분류 헤더가 있으며 무작위로 초기화됩니다.
따라서 여기에서 시각적 질의응답은 **분류 문제**로 취급됩니다.
최근의 BLIP, BLIP-2, InstructBLIP와 같은 모델들은 VQA를 생성형 작업으로 간주합니다. 가이드의 후반부에서는 이런 모델들을 사용하여 제로샷 VQA 추론을 하는 방법에 대해 설명하겠습니다.
시작하기 전 필요한 모든 라이브러리를 설치했는지 확인하세요.
```bash
pip install -q transformers datasets
```
커뮤니티에 모델을 공유하는 것을 권장 드립니다. Hugging Face 계정에 로그인하여 🤗 Hub에 업로드할 수 있습니다.
메시지가 나타나면 로그인할 토큰을 입력하세요:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
모델 체크포인트를 전역 변수로 선언하세요.
```py
>>> model_checkpoint = "dandelin/vilt-b32-mlm"
```
## 데이터 가져오기 [[load-the-data]]
이 가이드에서는 `Graphcore/vqa` 데이터세트의 작은 샘플을 사용합니다. 전체 데이터세트는 [🤗 Hub](https://huggingface.co/datasets/Graphcore/vqa) 에서 확인할 수 있습니다.
[`Graphcore/vqa` 데이터세트](https://huggingface.co/datasets/Graphcore/vqa) 의 대안으로 공식 [VQA 데이터세트 페이지](https://visualqa.org/download.html) 에서 동일한 데이터를 수동으로 다운로드할 수 있습니다. 직접 공수한 데이터로 튜토리얼을 따르고 싶다면 [이미지 데이터세트 만들기](https://huggingface.co/docs/datasets/image_dataset#loading-script) 라는
🤗 Datasets 문서를 참조하세요.
검증 데이터의 첫 200개 항목을 불러와 데이터세트의 특성을 확인해 보겠습니다:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("Graphcore/vqa", split="validation[:200]")
>>> dataset
Dataset({
features: ['question', 'question_type', 'question_id', 'image_id', 'answer_type', 'label'],
num_rows: 200
})
```
예제를 하나 뽑아 데이터세트의 특성을 이해해 보겠습니다.
```py
>>> dataset[0]
{'question': 'Where is he looking?',
'question_type': 'none of the above',
'question_id': 262148000,
'image_id': '/root/.cache/huggingface/datasets/downloads/extracted/ca733e0e000fb2d7a09fbcc94dbfe7b5a30750681d0e965f8e0a23b1c2f98c75/val2014/COCO_val2014_000000262148.jpg',
'answer_type': 'other',
'label': {'ids': ['at table', 'down', 'skateboard', 'table'],
'weights': [0.30000001192092896,
1.0,
0.30000001192092896,
0.30000001192092896]}}
```
데이터세트에는 다음과 같은 특성이 포함되어 있습니다:
* `question`: 이미지에 대한 질문
* `image_id`: 질문과 관련된 이미지의 경로
* `label`: 데이터의 레이블 (annotations)
나머지 특성들은 필요하지 않기 때문에 삭제해도 됩니다:
```py
>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
```
보시다시피 `label` 특성은 같은 질문마다 답변이 여러 개 있을 수 있습니다. 모두 다른 데이터 라벨러들로부터 수집되었기 때문인데요. 질문의 답변은 주관적일 수 있습니다. 이 경우 질문은 "그는 어디를 보고 있나요?" 였지만, 어떤 사람들은 "아래"로 레이블을 달았고, 다른 사람들은 "테이블" 또는 "스케이트보드" 등으로 주석을 달았습니다.
아래의 이미지를 보고 어떤 답변을 선택할 것인지 생각해 보세요:
```python
>>> from PIL import Image
>>> image = Image.open(dataset[0]['image_id'])
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/vqa-example.png" alt="VQA Image Example"/>
</div>
질문과 답변의 모호성으로 인해 이러한 데이터세트는 여러 개의 답변이 가능하므로 다중 레이블 분류 문제로 처리됩니다. 게다가, 원핫(one-hot) 인코딩 벡터를 생성하기보다는 레이블에서 특정 답변이 나타나는 횟수를 기반으로 소프트 인코딩을 생성합니다.
위의 예시에서 "아래"라는 답변이 다른 답변보다 훨씬 더 자주 선택되었기 때문에 데이터세트에서 `weight`라고 불리는 점수로 1.0을 가지며, 나머지 답변들은 1.0 미만의 점수를 가집니다.
적절한 분류 헤더로 모델을 나중에 인스턴스화하기 위해 레이블을 정수로 매핑한 딕셔너리 하나, 반대로 정수를 레이블로 매핑한 딕셔너리 하나 총 2개의 딕셔너리를 생성하세요:
```py
>>> import itertools
>>> labels = [item['ids'] for item in dataset['label']]
>>> flattened_labels = list(itertools.chain(*labels))
>>> unique_labels = list(set(flattened_labels))
>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
>>> id2label = {idx: label for label, idx in label2id.items()}
```
이제 매핑이 완료되었으므로 문자열 답변을 해당 id로 교체하고, 데이터세트의 더 편리한 후처리를 위해 편평화 할 수 있습니다.
```python
>>> def replace_ids(inputs):
... inputs["label"]["ids"] = [label2id[x] for x in inputs["label"]["ids"]]
... return inputs
>>> dataset = dataset.map(replace_ids)
>>> flat_dataset = dataset.flatten()
>>> flat_dataset.features
{'question': Value(dtype='string', id=None),
'image_id': Value(dtype='string', id=None),
'label.ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None),
'label.weights': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None)}
```
## 데이터 전처리 [[preprocessing-data]]
다음 단계는 모델을 위해 이미지와 텍스트 데이터를 준비하기 위해 ViLT 프로세서를 가져오는 것입니다.
[`ViltProcessor`]는 BERT 토크나이저와 ViLT 이미지 프로세서를 편리하게 하나의 프로세서로 묶습니다:
```py
>>> from transformers import ViltProcessor
>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
```
데이터를 전처리하려면 이미지와 질문을 [`ViltProcessor`]로 인코딩해야 합니다. 프로세서는 [`BertTokenizerFast`]로 텍스트를 토크나이즈하고 텍스트 데이터를 위해 `input_ids`, `attention_mask` 및 `token_type_ids`를 생성합니다.
이미지는 [`ViltImageProcessor`]로 이미지를 크기 조정하고 정규화하며, `pixel_values`와 `pixel_mask`를 생성합니다.
이런 전처리 단계는 모두 내부에서 이루어지므로, `processor`를 호출하기만 하면 됩니다. 하지만 아직 타겟 레이블이 완성되지 않았습니다. 타겟의 표현에서 각 요소는 가능한 답변(레이블)에 해당합니다. 정확한 답변의 요소는 해당 점수(weight)를 유지시키고 나머지 요소는 0으로 설정해야 합니다.
아래 함수가 위에서 설명한대로 이미지와 질문에 `processor`를 적용하고 레이블을 형식에 맞춥니다:
```py
>>> import torch
>>> def preprocess_data(examples):
... image_paths = examples['image_id']
... images = [Image.open(image_path) for image_path in image_paths]
... texts = examples['question']
... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
... for k, v in encoding.items():
... encoding[k] = v.squeeze()
... targets = []
... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
... target = torch.zeros(len(id2label))
... for label, score in zip(labels, scores):
... target[label] = score
... targets.append(target)
... encoding["labels"] = targets
... return encoding
```
전체 데이터세트에 전처리 함수를 적용하려면 🤗 Datasets의 [`~datasets.map`] 함수를 사용하십시오. `batched=True`를 설정하여 데이터세트의 여러 요소를 한 번에 처리함으로써 `map`을 더 빠르게 할 수 있습니다. 이 시점에서 필요하지 않은 열은 제거하세요.
```py
>>> processed_dataset = flat_dataset.map(preprocess_data, batched=True, remove_columns=['question','question_type', 'question_id', 'image_id', 'answer_type', 'label.ids', 'label.weights'])
>>> processed_dataset
Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'pixel_values', 'pixel_mask', 'labels'],
num_rows: 200
})
```
마지막 단계로, [`DefaultDataCollator`]를 사용하여 예제로 쓸 배치를 생성하세요:
```py
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator()
```
## 모델 훈련 [[train-the-model]]
이제 모델을 훈련하기 위해 준비되었습니다! [`ViltForQuestionAnswering`]으로 ViLT를 가져올 차례입니다. 레이블의 수와 레이블 매핑을 지정하세요:
```py
>>> from transformers import ViltForQuestionAnswering
>>> model = ViltForQuestionAnswering.from_pretrained(model_checkpoint, num_labels=len(id2label), id2label=id2label, label2id=label2id)
```
이 시점에서는 다음 세 단계만 남았습니다:
1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요:
```py
>>> from transformers import TrainingArguments
>>> repo_id = "MariaK/vilt_finetuned_200"
>>> training_args = TrainingArguments(
... output_dir=repo_id,
... per_device_train_batch_size=4,
... num_train_epochs=20,
... save_steps=200,
... logging_steps=50,
... learning_rate=5e-5,
... save_total_limit=2,
... remove_unused_columns=False,
... push_to_hub=True,
... )
```
2. 모델, 데이터세트, 프로세서, 데이터 콜레이터와 함께 훈련 인수를 [`Trainer`]에 전달하세요:
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... data_collator=data_collator,
... train_dataset=processed_dataset,
... tokenizer=processor,
... )
```
3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요:
```py
>>> trainer.train()
```
훈련이 완료되면, [`~Trainer.push_to_hub`] 메소드를 사용하여 🤗 Hub에 모델을 공유하세요:
```py
>>> trainer.push_to_hub()
```
## 추론 [[inference]]
ViLT 모델을 미세 조정하고 🤗 Hub에 업로드했다면 추론에 사용할 수 있습니다. 미세 조정된 모델을 추론에 사용해보는 가장 간단한 방법은 [`Pipeline`]에서 사용하는 것입니다.
```py
>>> from transformers import pipeline
>>> pipe = pipeline("visual-question-answering", model="MariaK/vilt_finetuned_200")
```
이 가이드의 모델은 200개의 예제에서만 훈련되었으므로 그다지 많은 것을 기대할 수는 없습니다. 데이터세트의 첫 번째 예제를 사용하여 추론 결과를 설명해보겠습니다:
```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
>>> print(question)
>>> pipe(image, question, top_k=1)
"Where is he looking?"
[{'score': 0.5498199462890625, 'answer': 'down'}]
```
비록 확신은 별로 없지만, 모델은 실제로 무언가를 배웠습니다. 더 많은 예제와 더 긴 훈련 기간이 주어진다면 분명 더 나은 결과를 얻을 수 있을 것입니다!
원한다면 파이프라인의 결과를 수동으로 복제할 수도 있습니다:
1. 이미지와 질문을 가져와서 프로세서를 사용하여 모델에 준비합니다.
2. 전처리된 결과를 모델에 전달합니다.
3. 로짓에서 가장 가능성 있는 답변의 id를 가져와서 `id2label`에서 실제 답변을 찾습니다.
```py
>>> processor = ViltProcessor.from_pretrained("MariaK/vilt_finetuned_200")
>>> image = Image.open(example['image_id'])
>>> question = example['question']
>>> # prepare inputs
>>> inputs = processor(image, question, return_tensors="pt")
>>> model = ViltForQuestionAnswering.from_pretrained("MariaK/vilt_finetuned_200")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits = outputs.logits
>>> idx = logits.argmax(-1).item()
>>> print("Predicted answer:", model.config.id2label[idx])
Predicted answer: down
```
## 제로샷 VQA [[zeroshot-vqa]]
이전 모델은 VQA를 분류 문제로 처리했습니다. BLIP, BLIP-2 및 InstructBLIP와 같은 최근의 모델은 VQA를 생성 작업으로 접근합니다. [BLIP-2](../../en/model_doc/blip-2)를 예로 들어 보겠습니다. 이 모델은 사전훈련된 비전 인코더와 LLM의 모든 조합을 사용할 수 있는 새로운 비전-자연어 사전 학습 패러다임을 도입했습니다. ([BLIP-2 블로그 포스트](https://huggingface.co/blog/blip-2)를 통해 더 자세히 알아볼 수 있어요)
이를 통해 시각적 질의응답을 포함한 여러 비전-자연어 작업에서 SOTA를 달성할 수 있었습니다.
이 모델을 어떻게 VQA에 사용할 수 있는지 설명해 보겠습니다. 먼저 모델을 가져와 보겠습니다. 여기서 GPU가 사용 가능한 경우 모델을 명시적으로 GPU로 전송할 것입니다. 이전에는 훈련할 때 쓰지 않은 이유는 [`Trainer`]가 이 부분을 자동으로 처리하기 때문입니다:
```py
>>> from transformers import AutoProcessor, Blip2ForConditionalGeneration
>>> import torch
>>> processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
>>> model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device)
```
모델은 이미지와 텍스트를 입력으로 받으므로, VQA 데이터세트의 첫 번째 예제에서와 동일한 이미지/질문 쌍을 사용해 보겠습니다:
```py
>>> example = dataset[0]
>>> image = Image.open(example['image_id'])
>>> question = example['question']
```
BLIP-2를 시각적 질의응답 작업에 사용하려면 텍스트 프롬프트가 `Question: {} Answer:` 형식을 따라야 합니다.
```py
>>> prompt = f"Question: {question} Answer:"
```
이제 모델의 프로세서로 이미지/프롬프트를 전처리하고, 처리된 입력을 모델을 통해 전달하고, 출력을 디코드해야 합니다:
```py
>>> inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
>>> print(generated_text)
"He is looking at the crowd"
```
보시다시피 모델은 군중을 인식하고, 얼굴의 방향(아래쪽을 보고 있음)을 인식했지만, 군중이 스케이터 뒤에 있다는 사실을 놓쳤습니다. 그러나 사람이 직접 라벨링한 데이터셋을 얻을 수 없는 경우에, 이 접근법은 빠르게 유용한 결과를 생성할 수 있습니다.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/tr/index.md
|
<!--Telif Hakkı 2020 The HuggingFace Ekibi. Tüm hakları saklıdır.
Apache Lisansı, Sürüm 2.0 (Lisans); bu dosyayı yürürlükteki yasalara uygun bir şekilde kullanabilirsiniz. Lisansın bir kopyasını aşağıdaki adresten alabilirsiniz.
http://www.apache.org/licenses/LICENSE-2.0
Lisansa tabi olmayan durumlarda veya yazılı anlaşma olmadıkça, Lisans kapsamında dağıtılan yazılım, herhangi bir türde (açık veya zımni) garanti veya koşul olmaksızın, "OLDUĞU GİBİ" ESASINA GÖRE dağıtılır. Lisans hükümleri, özel belirli dil kullanımı, yetkileri ve kısıtlamaları belirler.
⚠️ Bu dosya Markdown biçimindedir, ancak belge oluşturucumuz için özgü sözdizimleri içerir (MDX gibi) ve muhtemelen Markdown görüntüleyicinizde düzgün bir şekilde görüntülenmeyebilir.
-->
# 🤗 Transformers
[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) ve [JAX](https://jax.readthedocs.io/en/latest/) için son teknoloji makine öğrenimi.
🤗 Transformers, güncel önceden eğitilmiş (pretrained) modelleri indirmenizi ve eğitmenizi kolaylaştıran API'ler ve araçlar sunar. Önceden eğitilmiş modeller kullanarak, hesaplama maliyetlerinizi ve karbon ayak izinizi azaltabilir, ve sıfırdan bir modeli eğitmek için gereken zaman ve kaynaklardan tasarruf edebilirsiniz. Bu modeller farklı modalitelerde ortak görevleri destekler. Örneğin:
📝 **Doğal Dil İşleme**: metin sınıflandırma, adlandırılmış varlık tanıma, soru cevaplama, dil modelleme, özetleme, çeviri, çoktan seçmeli ve metin oluşturma.<br>
🖼️ **Bilgisayarlı Görü**: görüntü sınıflandırma, nesne tespiti ve bölümleme (segmentation).<br>
🗣️ **Ses**: otomatik konuşma tanıma ve ses sınıflandırma.<br>
🐙 **Çoklu Model**: tablo soru cevaplama, optik karakter tanıma, taranmış belgelerden bilgi çıkarma, video sınıflandırma ve görsel soru cevaplama.
🤗 Transformers, PyTorch, TensorFlow ve JAX arasında çerçeve (framework) uyumluluğu sağlar. Bu, bir modelin yaşam döngüsünün her aşamasında farklı bir çerçeve kullanma esnekliği sunar; bir çerçevede üç satır kodla bir modeli eğitebilir ve başka bir çerçevede tahminleme için kullanabilirsiniz. Modeller ayrıca üretim ortamlarında kullanılmak üzere ONNX ve TorchScript gibi bir formata aktarılabilir.
Büyüyen topluluğa [Hub](https://huggingface.co/models), [Forum](https://discuss.huggingface.co/) veya [Discord](https://discord.com/invite/JfAtkvEtRb) üzerinden katılabilirsiniz!
## Hugging Face ekibinden özel destek arıyorsanız
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Uzman Hızlandırma Programı" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## İçindekiler
Dokümantasyon, beş bölüme ayrılmıştır:
- **BAŞLARKEN**, kütüphanenin hızlı bir turunu ve çalışmaya başlamak için kurulum talimatlarını sağlar.
- **ÖĞRETİCİLER**, başlangıç yapmak için harika bir yerdir. Bu bölüm, kütüphane kullanmaya başlamak için ihtiyacınız olan temel becerileri kazanmanıza yardımcı olacaktır.
- **NASIL YAPILIR KILAVUZLARI**, önceden eğitilmiş bir modele dil modellemesi için ince ayar (fine-tuning) yapmak veya özel bir model yazmak, ve paylaşmak gibi belirli bir hedefe nasıl ulaşılacağını gösterir.
- **KAVRAMSAL REHBERLER**, modellerin, görevlerin ve 🤗 Transformers tasarım felsefesinin temel kavramları ve fikirleri hakkında daha fazla tartışma ve açıklama sunar.
- **API** tüm sınıfları (class) ve fonksiyonları (functions) açıklar:
- **ANA SINIFLAR**, yapılandırma, model, tokenizer ve pipeline gibi en önemli sınıfları (classes) ayrıntılandırır.
- **MODELLER**, kütüphanede kullanılan her modelle ilgili sınıfları ve fonksiyonları detaylı olarak inceler.
- **DAHİLİ YARDIMCILAR**, kullanılan yardımcı sınıfları ve fonksiyonları detaylı olarak inceler.
## Desteklenen Modeller ve Çerçeveler
Aşağıdaki tablo, her bir model için kütüphanede yer alan mevcut desteği temsil etmektedir. Her bir model için bir Python tokenizer'ına ("slow" olarak adlandırılır) sahip olup olmadıkları, 🤗 Tokenizers kütüphanesi tarafından desteklenen hızlı bir tokenizer'a sahip olup olmadıkları, Jax (Flax aracılığıyla), PyTorch ve/veya TensorFlow'da destek olup olmadıklarını göstermektedir.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | PyTorch support | TensorFlow support | Flax Support |
|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
| [LED](model_doc/led) | ✅ | ✅ | ❌ |
| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/tr/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
title: Get started
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/index.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
Apprentissage automatique de pointe pour [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), et [JAX](https://jax.readthedocs.io/en/latest/).
🤗 Transformers fournit des API et des outils pour télécharger et entraîner facilement des modèles pré-entraînés de pointe. L'utilisation de modèles pré-entraînés peut réduire vos coûts de calcul, votre empreinte carbone, et vous faire économiser le temps et les ressources nécessaires pour entraîner un modèle à partir de zéro. Ces modèles prennent en charge des tâches courantes dans différentes modalités, telles que :
📝 **Traitement automatique des langues**: classification de texte, reconnaissance d'entités, système de question-réponse, modèle de langage, génération de résumé, traduction, question à choix multiples et génération de texte.<br>
🖼️ **Vision par ordinateur**: classification d'image, détection d'objet et segmentation.<br>
🗣️ **Audio**: reconnaissance automatique de la parole et classification audio.<br>
🐙 **Multimodalité**: système de question-réponse avec des tableaux ou images, reconnaissance optique de caractères, extraction d'information depuis des documents scannés et classification de vidéo.
🤗 Transformers prend en charge l'interopérabilité entre PyTorch, TensorFlow et JAX. Cela permet d'utiliser un framework différent à chaque étape de la vie d'un modèle, par exemple entraîner un modèle en trois lignes de code avec un framework, et le charger pour l'inférence avec un autre. Les modèles peuvent également être exportés dans un format comme ONNX et TorchScript pour être déployés dans des environnements de production.
Rejoignez la communauté grandissante sur le [Hub](https://huggingface.co/models), le [forum](https://discuss.huggingface.co/) ou [Discord](https://discord.com/invite/JfAtkvEtRb) dès aujourd'hui !
## Si vous cherchez un support personnalisé de l'équipe Hugging Face
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## Contents
La documentation est organisée en 5 parties:
- **DEMARRER** propose une visite rapide de la bibliothèque et des instructions d'installation pour être opérationnel.
- **TUTORIELS** excellent point de départ pour les débutants. Cette section vous aidera à acquérir les compétences de base dont vous avez besoin pour commencer à utiliser la bibliothèque.
- **GUIDES D'UTILISATION** pour différentes tâches comme par exemple le finetuning d'un modèle pré-entraîné pour la classification de texte ou comment créer et partager votre propre modèle.
- **GUIDES CONCEPTUELS** pour plus de discussions et d'explications sur les concepts et les idées sous-jacentes aux modèles, aux tâches et à la philosophie de conception de 🤗 Transformers.
- **API** décrit toutes les classes et fonctions :
- **CLASSES PRINCIPALES** détaille les classes les plus importantes comme la configuration, le modèle, le tokenizer et le pipeline..
- **MODELES** détaille les classes et les fonctions propres à chaque modèle de la bibliothèque.
- **UTILITAIRES INTERNES** détaille les classes et fonctions utilitaires utilisées en interne.
### Modèles supportés
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) and a German version of DistilBERT.
1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
1. **[FastSpeech2Conformer](model_doc/fastspeech2_conformer)** (from ESPnet) released with the paper [Recent Developments On Espnet Toolkit Boosted By Conformer](https://arxiv.org/abs/2010.13956) by Pengcheng Guo, Florian Boyer, Xuankai Chang, Tomoki Hayashi, Yosuke Higuchi, Hirofumi Inaguma, Naoyuki Kamo, Chenda Li, Daniel Garcia-Romero, Jiatong Shi, Jing Shi, Shinji Watanabe, Kun Wei, Wangyou Zhang, and Yuekai Zhang.
1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
### Frameworks compatibles
Le tableau ci-dessous représente la prise en charge actuelle dans la bibliothèque pour chacun de ces modèles, qu'ils aient ou non un tokenizer Python (appelé "slow"). Un tokenizer rapide ("fast") soutenu par la bibliothèque 🤗 Tokenizers, qu'ils aient un support en Jax (via Flax), PyTorch, et/ou TensorFlow.
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Modèle | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| BLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
| BridgeTower | ❌ | ❌ | ✅ | ❌ | ❌ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
| DETA | ❌ | ❌ | ✅ | ❌ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| EfficientFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FastSpeech2Conformer | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Graphormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OneFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ✅ | ❌ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| SpeechT5 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/quicktour.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Visite rapide
[[open-in-colab]]
Soyez opérationnel avec 🤗 Transformers ! Que vous soyez un développeur ou un utilisateur lambda, cette visite rapide vous aidera à démarrer et vous montrera comment utiliser le [`pipeline`] pour l'inférence, charger un modèle pré-entraîné et un préprocesseur avec une [AutoClass](./model_doc/auto), et entraîner rapidement un modèle avec PyTorch ou TensorFlow. Si vous êtes un débutant, nous vous recommandons de consulter nos tutoriels ou notre [cours](https://huggingface.co/course/chapter1/1) suivant pour des explications plus approfondies des concepts présentés ici.
Avant de commencer, assurez-vous que vous avez installé toutes les bibliothèques nécessaires :
```bash
!pip install transformers datasets
```
Vous aurez aussi besoin d'installer votre bibliothèque d'apprentissage profond favorite :
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## Pipeline
<Youtube id="tiZFewofSLM"/>
Le [`pipeline`] est le moyen le plus simple d'utiliser un modèle pré-entraîné pour l'inférence. Vous pouvez utiliser le [`pipeline`] prêt à l'emploi pour de nombreuses tâches dans différentes modalités. Consultez le tableau ci-dessous pour connaître les tâches prises en charge :
| **Tâche** | **Description** | **Modalité** | **Identifiant du pipeline** |
|------------------------------|--------------------------------------------------------------------------------------------------------------|----------------------|-----------------------------------------------|
| Classification de texte | Attribue une catégorie à une séquence de texte donnée | Texte | pipeline(task="sentiment-analysis") |
| Génération de texte | Génère du texte à partir d'une consigne donnée | Texte | pipeline(task="text-generation") |
| Reconnaissance de token nommé | Attribue une catégorie à chaque token dans une séquence (personnes, organisation, localisation, etc.) | Texte | pipeline(task="ner") |
| Question réponse | Extrait une réponse du texte en fonction du contexte et d'une question | Texte | pipeline(task="question-answering") |
| Prédiction de token masqué | Prédit correctement le token masqué dans une séquence | Texte | pipeline(task="fill-mask") |
| Génération de résumé | Génère un résumé d'une séquence de texte donnée ou d'un document | Texte | pipeline(task="summarization") |
| Traduction | Traduit du texte d'un langage à un autre | Texte | pipeline(task="translation") |
| Classification d'image | Attribue une catégorie à une image | Image | pipeline(task="image-classification") |
| Segmentation d'image | Attribue une catégorie à chaque pixel d'une image (supporte la segmentation sémantique, panoptique et d'instance) | Image | pipeline(task="image-segmentation") |
| Détection d'objets | Prédit les délimitations et catégories d'objets dans une image | Image | pipeline(task="object-detection") |
| Classification d'audio | Attribue une catégorie à un fichier audio | Audio | pipeline(task="audio-classification") |
| Reconnaissance automatique de la parole | Extrait le discours d'un fichier audio en texte | Audio | pipeline(task="automatic-speech-recognition") |
| Question réponse visuels | Etant données une image et une question, répond correctement à une question sur l'image | Modalités multiples | pipeline(task="vqa") |
Commencez par créer une instance de [`pipeline`] et spécifiez la tâche pour laquelle vous souhaitez l'utiliser. Vous pouvez utiliser le [`pipeline`] pour n'importe laquelle des tâches mentionnées dans le tableau précédent. Pour obtenir une liste complète des tâches prises en charge, consultez la documentation de l'[API pipeline](./main_classes/pipelines). Dans ce guide, nous utiliserons le [`pipeline`] pour l'analyse des sentiments à titre d'exemple :
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
Le [`pipeline`] télécharge et stocke en cache un [modèle pré-entraîné](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) et un tokenizer par défaut pour l'analyse des sentiments. Vous pouvez maintenant utiliser le `classifier` sur le texte de votre choix :
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
Si vous voulez classifier plus qu'un texte, donnez une liste de textes au [`pipeline`] pour obtenir une liste de dictionnaires en retour :
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, avec le score de: {round(result['score'], 4)}")
label: POSITIVE, avec le score de: 0.9998
label: NEGATIVE, avec le score de: 0.5309
```
Le [`pipeline`] peut aussi itérer sur un jeu de données entier pour n'importe quelle tâche. Prenons par exemple la reconnaissance automatique de la parole :
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
Chargez un jeu de données audio (voir le 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart#audio) pour plus de détails) sur lequel vous souhaitez itérer. Pour cet exemple, nous chargeons le jeu de données [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) :
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
Vous devez vous assurer que le taux d'échantillonnage de l'ensemble de données correspond au taux d'échantillonnage sur lequel [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) a été entraîné :
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
Les fichiers audio sont automatiquement chargés et rééchantillonnés lors de l'appel de la colonne `"audio"`.
Extrayez les tableaux de formes d'ondes brutes des quatre premiers échantillons et passez-les comme une liste au pipeline :
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FODING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE AP SO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I THURN A JOIN A COUNT']
```
Pour les ensembles de données plus importants où les entrées sont volumineuses (comme dans les domaines de la parole ou de la vision), utilisez plutôt un générateur au lieu d'une liste pour charger toutes les entrées en mémoire. Pour plus d'informations, consultez la documentation de l'[API pipeline](./main_classes/pipelines).
### Utiliser une autre modèle et tokenizer dans le pipeline
Le [`pipeline`] peut être utilisé avec n'importe quel modèle du [Hub](https://huggingface.co/models), ce qui permet d'adapter facilement le [`pipeline`] à d'autres cas d'utilisation. Par exemple, si vous souhaitez un modèle capable de traiter du texte français, utilisez les filtres du Hub pour trouver un modèle approprié. Le premier résultat renvoie un [modèle BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) multilingue finetuné pour l'analyse des sentiments que vous pouvez utiliser pour le texte français :
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Utilisez [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] pour charger le modèle pré-entraîné et le tokenizer adapté (plus de détails sur une `AutoClass` dans la section suivante) :
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Utilisez [`TFAutoModelForSequenceClassification`] et [`AutoTokenizer`] pour charger le modèle pré-entraîné et le tokenizer adapté (plus de détails sur une `TFAutoClass` dans la section suivante) :
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Spécifiez le modèle et le tokenizer dans le [`pipeline`], et utilisez le `classifier` sur le texte en français :
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Si vous ne parvenez pas à trouver un modèle adapté à votre cas d'utilisation, vous devrez finetuner un modèle pré-entraîné sur vos données. Jetez un coup d'œil à notre [tutoriel sur le finetuning](./training) pour apprendre comment faire. Enfin, après avoir finetuné votre modèle pré-entraîné, pensez à [partager](./model_sharing) le modèle avec la communauté sur le Hub afin de démocratiser l'apprentissage automatique pour tous ! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Les classes [`AutoModelForSequenceClassification`] et [`AutoTokenizer`] fonctionnent ensemble pour créer un [`pipeline`] comme celui que vous avez utilisé ci-dessus. Une [AutoClass](./model_doc/auto) est un raccourci qui récupère automatiquement l'architecture d'un modèle pré-entraîné à partir de son nom ou de son emplacement. Il vous suffit de sélectionner l'`AutoClass` appropriée à votre tâche et la classe de prétraitement qui lui est associée.
Reprenons l'exemple de la section précédente et voyons comment vous pouvez utiliser l'`AutoClass` pour reproduire les résultats du [`pipeline`].
### AutoTokenizer
Un tokenizer est chargé de prétraiter le texte pour en faire un tableau de chiffres qui servira d'entrée à un modèle. De nombreuses règles régissent le processus de tokenisation, notamment la manière de diviser un mot et le niveau auquel les mots doivent être divisés (pour en savoir plus sur la tokenisation, consultez le [résumé](./tokenizer_summary)). La chose la plus importante à retenir est que vous devez instancier un tokenizer avec le même nom de modèle pour vous assurer que vous utilisez les mêmes règles de tokenisation que celles avec lesquelles un modèle a été pré-entraîné.
Chargez un tokenizer avec [`AutoTokenizer`] :
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Passez votre texte au tokenizer :
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Le tokenizer retourne un dictionnaire contenant :
* [input_ids](./glossary#input-ids): la représentation numérique des tokens.
* [attention_mask](.glossary#attention-mask): indique quels tokens doivent faire l'objet d'une attention particulière (plus particulièrement les tokens de remplissage).
Un tokenizer peut également accepter une liste de textes, et remplir et tronquer le texte pour retourner un échantillon de longueur uniforme :
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
Consultez le tutoriel [prétraitement](./preprocessing) pour plus de détails sur la tokenisation, et sur la manière d'utiliser un [`AutoImageProcessor`], un [`AutoFeatureExtractor`] et un [`AutoProcessor`] pour prétraiter les images, l'audio et les contenus multimodaux.
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fournit un moyen simple et unifié de charger des instances pré-entraînées. Cela signifie que vous pouvez charger un [`AutoModel`] comme vous chargeriez un [`AutoTokenizer`]. La seule différence est de sélectionner l'[`AutoModel`] approprié pour la tâche. Pour une classification de texte (ou de séquence de textes), vous devez charger [`AutoModelForSequenceClassification`] :
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Voir le [résumé de la tâche](./task_summary) pour vérifier si elle est prise en charge par une classe [`AutoModel`].
</Tip>
Maintenant, passez votre échantillon d'entrées prétraitées directement au modèle. Il vous suffit de décompresser le dictionnaire en ajoutant `**` :
```py
>>> pt_outputs = pt_model(**pt_batch)
```
Le modèle produit les activations finales dans l'attribut `logits`. Appliquez la fonction softmax aux `logits` pour récupérer les probabilités :
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fournit un moyen simple et unifié de charger des instances pré-entraînés. Cela signifie que vous pouvez charger un [`TFAutoModel`] comme vous chargeriez un [`AutoTokenizer`]. La seule différence est de sélectionner le [`TFAutoModel`] approprié pour la tâche. Pour une classification de texte (ou de séquence de textes), vous devez charger [`TFAutoModelForSequenceClassification`] :
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Voir le [résumé de la tâche](./task_summary) pour vérifier si elle est prise en charge par une classe [`AutoModel`].
</Tip>
Passez maintenant votre échantillon d'entrées prétraitées directement au modèle en passant les clés du dictionnaire directement aux tensors :
```py
>>> tf_outputs = tf_model(tf_batch)
```
Le modèle produit les activations finales dans l'attribut `logits`. Appliquez la fonction softmax aux `logits` pour récupérer les probabilités :
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Tous les modèles 🤗 Transformers (PyTorch ou TensorFlow) produisent les tensors *avant* la fonction d'activation finale (comme softmax) car la fonction d'activation finale est souvent fusionnée avec le calcul de la perte. Les structures produites par le modèle sont des classes de données spéciales, de sorte que leurs attributs sont autocomplétés dans un environnement de développement. Les structures produites par le modèle se comportent comme un tuple ou un dictionnaire (vous pouvez les indexer avec un entier, une tranche ou une chaîne), auquel cas les attributs qui sont None sont ignorés.
</Tip>
### Sauvegarder un modèle
<frameworkcontent>
<pt>
Une fois que votre modèle est finetuné, vous pouvez le sauvegarder avec son tokenizer en utilisant [`PreTrainedModel.save_pretrained`] :
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Lorsque vous voulez réutiliser le modèle, rechargez-le avec [`PreTrainedModel.from_pretrained`] :
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Une fois que votre modèle est finetuné, vous pouvez le sauvegarder avec son tokenizer en utilisant [`TFPreTrainedModel.save_pretrained`] :
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Lorsque vous voulez réutiliser le modèle, rechargez-le avec [`TFPreTrainedModel.from_pretrained`] :
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Une fonctionnalité particulièrement cool 🤗 Transformers est la possibilité d'enregistrer un modèle et de le recharger en tant que modèle PyTorch ou TensorFlow. Le paramètre `from_pt` ou `from_tf` permet de convertir le modèle d'un framework à l'autre :
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## Constructions de modèles personnalisés
Vous pouvez modifier la configuration du modèle pour changer la façon dont un modèle est construit. La configuration spécifie les attributs d'un modèle, tels que le nombre de couches ou de têtes d'attention. Vous partez de zéro lorsque vous initialisez un modèle à partir d'une configuration personnalisée. Les attributs du modèle sont initialisés de manière aléatoire et vous devrez entraîner le modèle avant de pouvoir l'utiliser pour obtenir des résultats significatifs.
Commencez par importer [`AutoConfig`], puis chargez le modèle pré-entraîné que vous voulez modifier. Dans [`AutoConfig.from_pretrained`], vous pouvez spécifier l'attribut que vous souhaitez modifier, tel que le nombre de têtes d'attention :
```py
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
Créez un modèle personnalisé à partir de votre configuration avec [`AutoModel.from_config`] :
```py
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
Créez un modèle personnalisé à partir de votre configuration avec [`TFAutoModel.from_config`] :
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
Consultez le guide [Créer une architecture personnalisée](./create_a_model) pour plus d'informations sur la création de configurations personnalisées.
## Trainer - une boucle d'entraînement optimisée par PyTorch
Tous les modèles sont des [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) standard, vous pouvez donc les utiliser dans n'importe quelle boucle d'entraînement typique. Bien que vous puissiez écrire votre propre boucle d'entraînement, 🤗 Transformers fournit une classe [`Trainer`] pour PyTorch, qui contient la boucle d'entraînement de base et ajoute des fonctionnalités supplémentaires comme l'entraînement distribué, la précision mixte, et plus encore.
En fonction de votre tâche, vous passerez généralement les paramètres suivants à [`Trainer`] :
1. Un [`PreTrainedModel`] ou un [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module):
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`] contient les hyperparamètres du modèle que vous pouvez changer comme le taux d'apprentissage, la taille de l'échantillon, et le nombre d'époques pour s'entraîner. Les valeurs par défaut sont utilisées si vous ne spécifiez pas d'hyperparamètres d'apprentissage :
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. Une classe de prétraitement comme un tokenizer, un processeur d'images ou un extracteur de caractéristiques :
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. Chargez un jeu de données :
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. Créez une fonction qui transforme le texte du jeu de données en token :
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
```
Puis appliquez-la à l'intégralité du jeu de données avec [`~datasets.Dataset.map`]:
```py
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. Un [`DataCollatorWithPadding`] pour créer un échantillon d'exemples à partir de votre jeu de données :
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
Maintenant, rassemblez tous ces éléments dans un [`Trainer`] :
```py
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
Une fois que vous êtes prêt, appelez la fonction [`~Trainer.train`] pour commencer l'entraînement :
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
Pour les tâches - comme la traduction ou la génération de résumé - qui utilisent un modèle séquence à séquence, utilisez plutôt les classes [`Seq2SeqTrainer`] et [`Seq2SeqTrainingArguments`].
</Tip>
Vous pouvez personnaliser le comportement de la boucle d'apprentissage en redéfinissant les méthodes à l'intérieur de [`Trainer`]. Cela vous permet de personnaliser des caractéristiques telles que la fonction de perte, l'optimiseur et le planificateur. Consultez la documentation de [`Trainer`] pour savoir quelles méthodes peuvent être redéfinies.
L'autre moyen de personnaliser la boucle d'apprentissage est d'utiliser les [Callbacks](./main_classes/callbacks). Vous pouvez utiliser les callbacks pour intégrer d'autres bibliothèques et inspecter la boucle d'apprentissage afin de suivre la progression ou d'arrêter l'apprentissage plus tôt. Les callbacks ne modifient rien dans la boucle d'apprentissage elle-même. Pour personnaliser quelque chose comme la fonction de perte, vous devez redéfinir le [`Trainer`] à la place.
## Entraînement avec TensorFlow
Tous les modèles sont des modèles standard [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) afin qu'ils puissent être entraînés avec TensorFlow avec l'API [Keras](https://keras.io/). 🤗 Transformers fournit la fonction [`~TFPreTrainedModel.prepare_tf_dataset`] pour charger facilement votre jeu de données comme un `tf.data.Dataset` afin que vous puissiez commencer l'entraînement immédiatement avec les fonctions [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) et [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) de Keras.
1. Vous commencez avec un modèle [`TFPreTrainedModel`] ou [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) :
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. Une classe de prétraitement comme un tokenizer, un processeur d'images ou un extracteur de caractéristiques :
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. Créez une fonction qui transforme le texte du jeu de données en token :
```py
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. Appliquez le tokenizer à l'ensemble du jeu de données avec [`~datasets.Dataset.map`] et passez ensuite le jeu de données et le tokenizer à [`~TFPreTrainedModel.prepare_tf_dataset`]. Vous pouvez également modifier la taille de l'échantillon et mélanger le jeu de données ici si vous le souhaitez :
```py
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset, batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. Une fois que vous êtes prêt, appelez les fonctions `compile` et `fit` pour commencer l'entraînement :
```py
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5))
>>> model.fit(dataset) # doctest: +SKIP
```
## Et après ?
Maintenant que vous avez terminé la visite rapide de 🤗 Transformers, consultez nos guides et apprenez à faire des choses plus spécifiques comme créer un modèle personnalisé, finetuner un modèle pour une tâche, et comment entraîner un modèle avec un script. Si vous souhaitez en savoir plus sur les concepts fondamentaux de 🤗 Transformers, jetez un œil à nos guides conceptuels !
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/installation.md
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Installation
Installez 🤗 Transformers pour n'importe quelle librairie d'apprentissage profond avec laquelle vous avez l'habitude de travaillez, configurez votre cache et configurez 🤗 Transformers pour un usage hors ligne (facultatif).
🤗 Transformers est testé avec Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+ et Flax.
Consulter les instructions d'installation ci-dessous pour la librairie d'apprentissage profond que vous utilisez:
* Instructions d'installation pour [PyTorch](https://pytorch.org/get-started/locally/).
* Instructions d'installation pour [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
* Instructions d'installation pour [Flax](https://flax.readthedocs.io/en/latest/).
## Installation avec pip
Vous devriez installer 🤗 Transformers dans un [environnement virtuel](https://docs.python.org/3/library/venv.html).
Si vous n'êtes pas à l'aise avec les environnements virtuels, consultez ce [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
Utiliser un environnement virtuel permet de facilement gérer différents projets et d'éviter des erreurs de compatibilité entre les différentes dépendances.
Commencez par créer un environnement virtuel dans l'espace de travail de votre projet :
```bash
python -m venv .env
```
Activez l'environnement virtuel. Sur Linux ou MacOs :
```bash
source .env/bin/activate
```
Activez l'environnement virtuel sur Windows :
```bash
.env/Scripts/activate
```
Maintenant, 🤗 Transformers peut être installé avec la commande suivante :
```bash
pip install transformers
```
Pour une utilisation avec CPU seulement, 🤗 Transformers et la librairie d'apprentissage profond de votre choix peuvent être installés en une seule ligne.
Par exemple, installez 🤗 Transformers et PyTorch avec la commande suivante :
```bash
pip install 'transformers[torch]'
```
🤗 Transformers et TensorFlow 2.0 :
```bash
pip install 'transformers[tf-cpu]'
```
<Tip warning={true}>
Pour les architectures mac M1 / ARM
Vous devez installer les outils suivants avant d'installer TensorFLow 2.0
```
brew install cmake
brew install pkg-config
```
</Tip>
🤗 Transformers et Flax :
```bash
pip install 'transformers[flax]'
```
Vérifiez que 🤗 Transformers a bien été installé avec la commande suivante. La commande va télécharger un modèle pré-entraîné :
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Le label et score sont ensuite affichés :
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Installation depuis le code source
Installez 🤗 Transformers depuis le code source avec la commande suivante :
```bash
pip install git+https://github.com/huggingface/transformers
```
Cette commande installe la version depuis la branche `main` au lieu de la dernière version stable. La version de la branche `main` est utile pour avoir les derniers développements. Par exemple, si un bug a été résolu depuis la dernière version stable mais n'a pas encore été publié officiellement. Cependant, cela veut aussi dire que la version de la branche `main` n'est pas toujours stable. Nous nous efforçons de maintenir la version de la branche `main` opérationnelle, et la plupart des problèmes sont généralement résolus en l'espace de quelques heures ou d'un jour. Si vous recontrez un problème, n'hésitez pas à créer une [Issue](https://github.com/huggingface/transformers/issues) pour que l'on puisse trouver une solution au plus vite !
Vérifiez que 🤗 Transformers a bien été installé avec la commande suivante :
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Installation modifiable
Vous aurez besoin d'une installation modifiable si vous le souhaitez :
* Utiliser la version de la branche `main` du code source.
* Contribuer à 🤗 Transformers et vouler tester vos modifications du code source.
Clonez le projet et installez 🤗 Transformers avec les commandes suivantes :
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Ces commandes créent des liens entre le dossier où le projet a été cloné et les chemins de vos librairies Python. Python regardera maintenant dans le dossier que vous avez cloné en plus des dossiers où sont installées vos autres librairies. Par exemple, si vos librairies Python sont installées dans `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python cherchera aussi dans le dossier où vous avez cloné : `~/transformers/`.
<Tip warning={true}>
Vous devez garder le dossier `transformers` si vous voulez continuer d'utiliser la librairie.
</Tip>
Maintenant, vous pouvez facilement mettre à jour votre clone avec la dernière version de 🤗 Transformers en utilisant la commande suivante :
```bash
cd ~/transformers/
git pull
```
Votre environnement Python utilisera la version de la branche `main` lors de la prochaine exécution.
## Installation avec conda
Installation via le canal `conda-forge` de conda :
```bash
conda install conda-forge::transformers
```
## Configuration du cache
Les modèles pré-entraînés sont téléchargés et mis en cache localement dans le dossier suivant : `~/.cache/huggingface/hub`. C'est le dossier par défaut donné par la variable d'environnement `TRANSFORMERS_CACHE`. Sur Windows, le dossier par défaut est `C:\Users\nom_utilisateur\.cache\huggingface\hub`. Vous pouvez modifier les variables d'environnement indiquées ci-dessous - par ordre de priorité - pour spécifier un dossier de cache différent :
1. Variable d'environnement (par défaut) : `HUGGINGFACE_HUB_CACHE` ou `TRANSFORMERS_CACHE`.
2. Variable d'environnement : `HF_HOME`.
3. Variable d'environnement : `XDG_CACHE_HOME` + `/huggingface`.
<Tip>
🤗 Transformers utilisera les variables d'environnement `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE` si vous utilisez une version précédente de cette librairie et avez défini ces variables d'environnement, sauf si vous spécifiez la variable d'environnement `TRANSFORMERS_CACHE`.
</Tip>
## Mode hors ligne
🤗 Transformers peut fonctionner dans un environnement cloisonné ou hors ligne en n'utilisant que des fichiers locaux. Définissez la variable d'environnement `TRANSFORMERS_OFFLINE=1` pour activer ce mode.
<Tip>
Ajoutez [🤗 Datasets](https://huggingface.co/docs/datasets/) à votre processus d'entraînement hors ligne en définissant la variable d'environnement `HF_DATASETS_OFFLINE=1`.
</Tip>
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Le script devrait maintenant s'exécuter sans rester en attente ou attendre une expiration, car il n'essaiera pas de télécharger des modèle sur le Hub.
Vous pouvez aussi éviter de télécharger un modèle à chaque appel de la fonction [~PreTrainedModel.from_pretrained] en utilisant le paramètre [local_files_only]. Seuls les fichiers locaux sont chargés lorsque ce paramètre est activé (c.-à-d. `local_files_only=True`) :
```py
from transformers import T5Model
model = T5Model.from_pretrained("./path/to/local/directory", local_files_only=True)
```
### Récupérer des modèles et des tokenizers pour une utilisation hors ligne
Une autre option pour utiliser 🤗 Transformers hors ligne est de télécharger les fichiers à l'avance, puis d'utiliser les chemins locaux lorsque vous en avez besoin en mode hors ligne. Il existe trois façons de faire cela :
* Téléchargez un fichier via l'interface utilisateur sur le [Model Hub](https://huggingface.co/models) en cliquant sur l'icône ↓.

* Utilisez les fonctions [`PreTrainedModel.from_pretrained`] et [`PreTrainedModel.save_pretrained`] :
1. Téléchargez vos fichiers à l'avance avec [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Sauvegardez les fichiers dans un dossier de votre choix avec [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. Maintenant, lorsque vous êtes hors ligne, rechargez vos fichiers avec [`PreTrainedModel.from_pretrained`] depuis le dossier où vous les avez sauvegardés :
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* Téléchargez des fichiers de manière automatique avec la librairie [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) :
1. Installez la librairie `huggingface_hub` dans votre environnement virtuel :
```bash
python -m pip install huggingface_hub
```
2. Utilisez la fonction [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) pour télécharger un fichier vers un chemin de votre choix. Par exemple, la commande suivante télécharge le fichier `config.json` du modèle [T0](https://huggingface.co/bigscience/T0_3B) vers le chemin de votre choix :
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
Une fois que votre fichier est téléchargé et caché localement, spécifiez son chemin local pour le charger et l'utiliser :
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
Consultez la section [How to download files from the Hub (Comment télécharger des fichiers depuis le Hub)](https://huggingface.co/docs/hub/how-to-downstream) pour plus de détails sur le téléchargement de fichiers stockés sur le Hub.
</Tip>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/in_translation.md
|
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Traduction en cours.
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/_config.py
|
# docstyle-ignore
INSTALL_CONTENT = """
# Installation de Transformers
! pip install transformers datasets
# Pour installer à partir du code source au lieu de la dernière version, commentez la commande ci-dessus et décommentez la suivante.
# ! pip install git+https://github.com/huggingface/transformers.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
black_avoid_patterns = {
"{processor_class}": "FakeProcessorClass",
"{model_class}": "FakeModelClass",
"{object_class}": "FakeObjectClass",
}
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/autoclass_tutorial.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Chargement d'instances pré-entraînées avec une AutoClass
Avec autant d'architectures Transformer différentes, il peut être difficile d'en créer une pour votre ensemble de poids (aussi appelés "weights" ou "checkpoint" en anglais). Dans l'idée de créer une librairie facile, simple et flexible à utiliser, 🤗 Transformers fournit une `AutoClass` qui infère et charge automatiquement l'architecture correcte à partir d'un ensemble de poids donné. La fonction `from_pretrained()` vous permet de charger rapidement un modèle pré-entraîné pour n'importe quelle architecture afin que vous n'ayez pas à consacrer du temps et des ressources à l'entraînement d'un modèle à partir de zéro. Produire un tel code indépendant d'un ensemble de poids signifie que si votre code fonctionne pour un ensemble de poids, il fonctionnera avec un autre ensemble - tant qu'il a été entraîné pour une tâche similaire - même si l'architecture est différente.
<Tip>
Rappel, l'architecture fait référence au squelette du modèle et l'ensemble de poids contient les poids pour une architecture donnée. Par exemple, [BERT](https://huggingface.co/bert-base-uncased) est une architecture, tandis que `bert-base-uncased` est un ensemble de poids. Le terme modèle est général et peut signifier soit architecture soit ensemble de poids.
</Tip>
Dans ce tutoriel, vous apprendrez à:
* Charger un tokenizer pré-entraîné.
* Charger un processeur d'image pré-entraîné.
* Charger un extracteur de caractéristiques pré-entraîné.
* Charger un processeur pré-entraîné.
* Charger un modèle pré-entraîné.
## AutoTokenizer
Quasiment toutes les tâches de traitement du langage (NLP) commencent avec un tokenizer. Un tokenizer convertit votre texte initial dans un format qui peut être traité par le modèle.
Chargez un tokenizer avec [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
Puis, transformez votre texte initial comme montré ci-dessous:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoImageProcessor
Pour les tâches de vision, un processeur d'image traite l'image pour la formater correctment.
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
## AutoFeatureExtractor
Pour les tâches audio, un extracteur de caractéristiques (aussi appelés "features" en anglais) traite le signal audio pour le formater correctement.
Chargez un extracteur de caractéristiques avec [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
Les tâches multimodales nécessitent un processeur qui combine deux types d'outils de prétraitement. Par exemple, le modèle [LayoutLMV2](model_doc/layoutlmv2) nécessite un processeur d'image pour traiter les images et un tokenizer pour traiter le texte ; un processeur combine les deux.
Chargez un processeur avec [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
Enfin, les classes `AutoModelFor` vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir [ici](model_doc/auto) pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
<Tip warning={true}>
Pour les modèles PyTorch, la fonction `from_pretrained()` utilise `torch.load()` qui utilise `pickle` en interne et est connu pour être non sécurisé. En général, ne chargez jamais un modèle qui pourrait provenir d'une source non fiable, ou qui pourrait avoir été altéré. Ce risque de sécurité est partiellement atténué pour les modèles hébergés publiquement sur le Hugging Face Hub, qui sont [scannés pour les logiciels malveillants](https://huggingface.co/docs/hub/security-malware) à chaque modification. Consultez la [documentation du Hub](https://huggingface.co/docs/hub/security) pour connaître les meilleures pratiques comme la [vérification des modifications signées](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg) avec GPG.
Les points de contrôle TensorFlow et Flax ne sont pas concernés, et peuvent être chargés dans des architectures PyTorch en utilisant les arguments `from_tf` et `from_flax` de la fonction `from_pretrained` pour contourner ce problème.
</Tip>
En général, nous recommandons d'utiliser les classes `AutoTokenizer` et `AutoModelFor` pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain [tutoriel](preprocessing), vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
</pt>
<tf>
Enfin, les classes `TFAutoModelFor` vous permettent de charger un modèle pré-entraîné pour une tâche donnée (voir [ici](model_doc/auto) pour une liste complète des tâches disponibles). Par exemple, chargez un modèle pour la classification de séquence avec [`TFAutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
Réutilisez facilement le même ensemble de poids pour charger une architecture pour une tâche différente :
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
En général, nous recommandons d'utiliser les classes `AutoTokenizer` et `TFAutoModelFor` pour charger des instances pré-entraînées de tokenizers et modèles respectivement. Cela vous permettra de charger la bonne architecture à chaque fois. Dans le prochain [tutoriel](preprocessing), vous apprenez à utiliser un tokenizer, processeur d'image, extracteur de caractéristiques et processeur pour pré-traiter un jeu de données pour le fine-tuning.
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/fr/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Visite rapide
- local: installation
title: Installation
title: Démarrer
- sections:
- local: in_translation
title: Pipelines pour l'inférence
- local: autoclass_tutorial
title: Chargement d'instances pré-entraînées avec une AutoClass
- local: in_translation
title: Préparation des données
- local: in_translation
title: Fine-tune un modèle pré-entraîné
- local: in_translation
title: Entraînement avec un script
- local: in_translation
title: Entraînement distribué avec 🤗 Accelerate
- local: in_translation
title: Chargement et entraînement des adaptateurs avec 🤗 PEFT
- local: in_translation
title: Partager un modèle
- local: in_translation
title: Agents
- local: in_translation
title: Génération avec LLMs
title: Tutoriels
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/testing.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Testing
🤗 Transformersモデルがどのようにテストされ、新しいテストを書いて既存のテストを改善できるかを見てみましょう。
このリポジトリには2つのテストスイートがあります:
1. `tests` -- 一般的なAPI用のテスト
2. `examples` -- APIの一部ではないさまざまなアプリケーション用のテスト
## How transformers are tested
1. PRが提出されると、9つのCircleCiジョブでテストされます。PRへの新しいコミットごとに再テストされます。これらのジョブは、[この設定ファイル](https://github.com/huggingface/transformers/tree/main/.circleci/config.yml)で定義されており、必要な場合は同じ環境を自分のマシンで再現できます。
これらのCIジョブは `@slow` テストを実行しません。
2. [GitHub Actions](https://github.com/huggingface/transformers/actions)によって実行される3つのジョブがあります:
- [torch hub integration](https://github.com/huggingface/transformers/tree/main/.github/workflows/github-torch-hub.yml): torch hubの統合が動作するかどうかを確認します。
- [self-hosted (push)](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-push.yml): `main` にコミットが行われた場合に、GPUで高速テストを実行します。このジョブは、`main` でのコミットが以下のフォルダーのコードを更新した場合にのみ実行されます:`src`、`tests`、`.github`(追加されたモデルカード、ノートブックなどの実行を防ぐため)。
- [self-hosted runner](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-scheduled.yml): GPUで `tests` と `examples` の通常のテストと遅いテストを実行します。
```bash
RUN_SLOW=1 pytest tests/
RUN_SLOW=1 pytest examples/
```
結果は[here](https://github.com/huggingface/transformers/actions)で観察できます。
## Running tests
### Choosing which tests to run
このドキュメントは、テストを実行する方法の多くの詳細について説明しています。すべてを読んだ後でも、さらに詳細が必要な場合は、[こちら](https://docs.pytest.org/en/latest/usage.html)で見つけることができます。
以下は、テストを実行するためのいくつかの最も便利な方法です。
すべて実行します:
```console
pytest
```
または:
```bash
make test
```
後者は次のように定義されることに注意してください。
```bash
python -m pytest -n auto --dist=loadfile -s -v ./tests/
```
以下は、pytestに渡す設定情報です。
- テストプロセスをCPUコアの数と同じだけ実行するように指示します。ただし、RAMが十分でない場合は注意が必要です。
- 同じファイルからのすべてのテストは、同じテストプロセスで実行されるようにします。
- 出力のキャプチャを行いません。
- 冗長モードで実行します。
### Getting the list of all tests
テストスイートのすべてのテスト:
```bash
pytest --collect-only -q
```
指定されたテスト ファイルのすべてのテスト:
```bash
pytest tests/test_optimization.py --collect-only -q
```
### Run a specific test module
個別のテスト モジュールを実行するには:
```bash
pytest tests/utils/test_logging.py
```
### Run specific tests
ほとんどのテストでunittestが使用されているため、特定のサブテストを実行するには、それらのテストを含むunittestクラスの名前を知っている必要があります。例えば、それは次のようになるかもしれません:
```bash
pytest tests/test_optimization.py::OptimizationTest::test_adam_w
```
テストの実行方法:
テストファイル: `tests/test_optimization.py`
クラス名: `OptimizationTest`
テスト関数の名前: `test_adam_w`
ファイルに複数のクラスが含まれている場合は、特定のクラスのテストのみを実行することを選択できます。例えば:
```bash
pytest tests/test_optimization.py::OptimizationTest
```
テストクラス内のすべてのテストを実行します。
前述の通り、`OptimizationTest` クラスに含まれるテストを実行するには、次のコマンドを実行できます:
```bash
pytest tests/test_optimization.py::OptimizationTest --collect-only -q
```
キーワード式を使用してテストを実行できます。
名前に `adam` が含まれるテストのみを実行するには:
```bash
pytest -k adam tests/test_optimization.py
```
`and`および`or`は、すべてのキーワードが一致するか、いずれかを示すために使用できます。`not`は否定するために使用できます。
`adam`という名前を含むテストを除いてすべてのテストを実行するには:
```bash
pytest -k "not adam" tests/test_optimization.py
```
以下は、提供されたテキストの日本語訳です。
```bash
pytest -k "ada and not adam" tests/test_optimization.py
```
たとえば、`test_adafactor`と`test_adam_w`の両方を実行するには、以下のコマンドを使用できます:
```bash
pytest -k "test_adam_w or test_adam_w" tests/test_optimization.py
```
注意: ここでは、`or` を使用しています。キーワードのいずれか一つが一致すれば、両方を含めるためです。
両方のパターンを含むテストのみを含めたい場合は、`and` を使用してください。
```bash
pytest -k "test and ada" tests/test_optimization.py
```
### Run `accelerate` tests
時々、モデルに対して `accelerate` テストを実行する必要があります。たとえば、`OPT` 実行に対してこれらのテストを実行したい場合、コマンドに `-m accelerate_tests` を追加するだけで済みます:
```bash
RUN_SLOW=1 pytest -m accelerate_tests tests/models/opt/test_modeling_opt.py
```
### Run documentation tests
ドキュメンテーションの例が正しいかどうかをテストするには、`doctests` が合格しているかを確認する必要があります。
例として、[`WhisperModel.forward` のドックストリング](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py#L1017-L1035)を使用しましょう。
```python
r"""
Returns:
Example:
```python
>>> import torch
>>> from transformers import WhisperModel, WhisperFeatureExtractor
>>> from datasets import load_dataset
>>> model = WhisperModel.from_pretrained("openai/whisper-base")
>>> feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-base")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
>>> input_features = inputs.input_features
>>> decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
>>> last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
>>> list(last_hidden_state.shape)
[1, 2, 512]
```"""
```
指定したファイル内のすべてのドックストリング例を自動的にテストするために、以下の行を実行してください:
```bash
pytest --doctest-modules <path_to_file_or_dir>
```
ファイルにマークダウン拡張子がある場合は、`--doctest-glob="*.md"`引数を追加する必要があります。
### Run only modified tests
[pytest-picked](https://github.com/anapaulagomes/pytest-picked)を使用すると、未ステージングのファイルまたは現在のブランチ(Gitに従って)に関連するテストを実行できます。これは、変更内容に関連するテストのみ実行されるため、変更が何も壊れていないことを迅速に確認する素晴らしい方法です。変更されていないファイルに関連するテストは実行されません。
```bash
pip install pytest-picked
```
```bash
pytest --picked
```
すべてのテストは、変更されたがまだコミットされていないファイルとフォルダから実行されます。
### Automatically rerun failed tests on source modification
[pytest-xdist](https://github.com/pytest-dev/pytest-xdist)は、非常に便利な機能を提供しており、すべての失敗したテストを検出し、ファイルを修正する間にそれらの失敗したテストを連続して再実行することができます。そのため、修正を行った後にpytestを再起動する必要がありません。すべてのテストが合格するまで繰り返され、その後再度フルランが実行されます。
```bash
pip install pytest-xdist
```
モードに入るには: `pytest -f`または`pytest --looponfail`
ファイルの変更は、`looponfailroots`ルートディレクトリとその内容全体(再帰的に)を見て検出されます。この値のデフォルトが機能しない場合、`setup.cfg`で設定オプションを変更してプロジェクト内で変更できます。
```ini
[tool:pytest]
looponfailroots = transformers tests
```
または `pytest.ini`/`tox.ini` ファイル:
```ini
[pytest]
looponfailroots = transformers tests
```
ファイルの変更を探すことは、iniファイルのディレクトリを基準にして指定されたディレクトリ内でのみ行われます。
[pytest-watch](https://github.com/joeyespo/pytest-watch) は、この機能の代替実装です。
### Skip a test module
特定のテストモジュールを除外してすべてのテストモジュールを実行したい場合、実行するテストの明示的なリストを指定することができます。例えば、`test_modeling_*.py` テストを除外してすべてを実行するには次のようにします:
```bash
pytest *ls -1 tests/*py | grep -v test_modeling*
```
### Clearing state
CIビルドおよび速度に対する隔離が重要な場合(キャッシュに対して)、キャッシュをクリアする必要があります:
```bash
pytest --cache-clear tests
```
### Running tests in parallel
前述のように、`make test` は `pytest-xdist` プラグインを介してテストを並列実行します(`-n X` 引数、例: `-n 2` で2つの並列ジョブを実行)。
`pytest-xdist` の `--dist=` オプションを使用すると、テストがどのようにグループ化されるかを制御できます。`--dist=loadfile` は同じファイルにあるテストを同じプロセスに配置します。
テストの実行順序が異なり予測不可能であるため、`pytest-xdist` を使用してテストスイートを実行すると失敗が発生する場合(つまり、いくつかの未検出の連動テストがある場合)、[pytest-replay](https://github.com/ESSS/pytest-replay) を使用してテストを同じ順序で再生し、その後、失敗するシーケンスを最小限にするのに役立ちます。
### Test order and repetition
潜在的な相互依存性や状態に関連するバグ(ティアダウン)を検出するために、テストを複数回、連続して、ランダムに、またはセットで繰り返すことは有用です。そして、単純な複数回の繰り返しは、DLのランダム性によって明らかになるいくつかの問題を検出するのに役立ちます。
#### Repeat tests
- [pytest-flakefinder](https://github.com/dropbox/pytest-flakefinder):
```bash
pip install pytest-flakefinder
```
そして、すべてのテストを複数回実行します (デフォルトでは 50 回)。
```bash
pytest --flake-finder --flake-runs=5 tests/test_failing_test.py
```
<Tip>
このプラグインは、`pytest-xdist` の `-n` フラグでは動作しません。
</Tip>
<Tip>
別のプラグイン `pytest-repeat` もありますが、これは `unittest` では動作しません。
</Tip>
#### Run tests in a random order
```bash
pip install pytest-random-order
```
重要: `pytest-random-order` が存在すると、テストは自動的にランダム化されます。設定の変更や変更は必要ありません。
コマンドラインオプションは必須です。
前に説明したように、これにより、結合されたテスト (1 つのテストの状態が別のテストの状態に影響を与える) の検出が可能になります。いつ
`pytest-random-order` がインストールされていると、そのセッションに使用されたランダム シードが出力されます。例:
```bash
pytest tests
[...]
Using --random-order-bucket=module
Using --random-order-seed=573663
```
そのため、指定された特定のシーケンスが失敗した場合、その正確なシードを追加することでそれを再現できます。例:
```bash
pytest --random-order-seed=573663
[...]
Using --random-order-bucket=module
Using --random-order-seed=573663
```
特定のテストのリストを使用しない場合、またはまったくリストを使用しない場合、同じテストの正確な順序を再現します。テストのリストを手動で絞り込み始めると、シードに依存せず、テストが失敗した正確な順序で手動でリストを指定する必要があります。これには、`--random-order-bucket=none` を使用してランダム化を無効にするようpytestに指示する必要があります。例えば、次のようにします:
```bash
pytest --random-order-bucket=none tests/test_a.py tests/test_c.py tests/test_b.py
```
すべてのテストのシャッフルを無効にするには:
```bash
pytest --random-order-bucket=none
```
デフォルトでは、`--random-order-bucket=module` が暗黙的に適用され、モジュールレベルでファイルをシャッフルします。また、`class`、`package`、`global`、および`none` レベルでシャッフルすることもできます。詳細については、その[ドキュメンテーション](https://github.com/jbasko/pytest-random-order)を参照してください。
別のランダム化の代替手段は、[`pytest-randomly`](https://github.com/pytest-dev/pytest-randomly) です。このモジュールは非常に似た機能/インターフェースを持っていますが、`pytest-random-order` で利用可能なバケットモードを持っていません。インストール後に自動的に有効になるという同じ問題があります。
### Look and feel variations
#### pytest-sugar
[pytest-sugar](https://github.com/Frozenball/pytest-sugar) は、外観と操作性を向上させ、プログレスバーを追加し、即座に失敗したテストとアサーションを表示するプラグインです。インストール後に自動的にアクティブ化されます。
```bash
pip install pytest-sugar
```
これを使用せずにテストを実行するには、次を実行します。
```bash
pytest -p no:sugar
```
またはアンインストールします。
#### Report each sub-test name and its progress
`pytest` による単一またはグループのテストの場合 (`pip install pytest-pspec` の後):
```bash
pytest --pspec tests/test_optimization.py
```
#### Instantly shows failed tests
[pytest-instafail](https://github.com/pytest-dev/pytest-instafail) では、失敗とエラーが即座に表示されます。
テストセッションが終了するまで待機します。
```bash
pip install pytest-instafail
```
```bash
pytest --instafail
```
### To GPU or not to GPU
GPU が有効な設定で、CPU のみモードでテストするには、`CUDA_VISIBLE_DEVICES=""`を追加します。
```bash
CUDA_VISIBLE_DEVICES="" pytest tests/utils/test_logging.py
```
または、複数の GPU がある場合は、`pytest` でどれを使用するかを指定できます。たとえば、
2 番目の GPU GPU `0` と `1` がある場合は、次を実行できます。
```bash
CUDA_VISIBLE_DEVICES="1" pytest tests/utils/test_logging.py
```
これは、異なるGPUで異なるタスクを実行したい場合に便利です。
一部のテストはCPUのみで実行する必要があり、他のテストはCPU、GPU、またはTPUで実行する必要があり、また別のテストは複数のGPUで実行する必要があります。次のスキップデコレーターは、テストのCPU/GPU/TPUに関する要件を設定するために使用されます:
- `require_torch` - このテストはtorchの下でのみ実行されます。
- `require_torch_gpu` - `require_torch` に加えて、少なくとも1つのGPUが必要です。
- `require_torch_multi_gpu` - `require_torch` に加えて、少なくとも2つのGPUが必要です。
- `require_torch_non_multi_gpu` - `require_torch` に加えて、0または1つのGPUが必要です。
- `require_torch_up_to_2_gpus` - `require_torch` に加えて、0、1、または2つのGPUが必要です。
- `require_torch_tpu` - `require_torch` に加えて、少なくとも1つのTPUが必要です。
以下の表にGPUの要件を示します:
| n gpus | decorator |
|--------+--------------------------------|
| `>= 0` | `@require_torch` |
| `>= 1` | `@require_torch_gpu` |
| `>= 2` | `@require_torch_multi_gpu` |
| `< 2` | `@require_torch_non_multi_gpu` |
| `< 3` | `@require_torch_up_to_2_gpus` |
たとえば、使用可能な GPU が 2 つ以上あり、pytorch がインストールされている場合にのみ実行する必要があるテストを次に示します。
```python no-style
@require_torch_multi_gpu
def test_example_with_multi_gpu():
```
テストに `tensorflow` が必要な場合は、`require_tf` デコレータを使用します。例えば:
```python no-style
@require_tf
def test_tf_thing_with_tensorflow():
```
これらのデコレータは積み重ねることができます。たとえば、テストが遅く、pytorch で少なくとも 1 つの GPU が必要な場合は、次のようになります。
設定方法:
```python no-style
@require_torch_gpu
@slow
def test_example_slow_on_gpu():
```
`@parametrized` のような一部のデコレータはテスト名を書き換えるため、`@require_*` スキップ デコレータをリストする必要があります。
最後にそれらが正しく動作するようにします。正しい使用例は次のとおりです
```python no-style
@parameterized.expand(...)
@require_torch_multi_gpu
def test_integration_foo():
```
この順序の問題は `@pytest.mark.parametrize` には存在しません。最初または最後に配置しても、それでも問題は解決されます。
仕事。ただし、それは非単体テストでのみ機能します。
内部テスト:
- 利用可能な GPU の数:
```python
from transformers.testing_utils import get_gpu_count
n_gpu = get_gpu_count() # works with torch and tf
```
### Testing with a specific PyTorch backend or device
特定のtorchデバイスでテストスイートを実行するには、`TRANSFORMERS_TEST_DEVICE="$device"` を追加します。ここで `$device` は対象のバックエンドです。例えば、CPUでテストするには以下のようにします:
```bash
TRANSFORMERS_TEST_DEVICE="cpu" pytest tests/utils/test_logging.py
```
この変数は、`mps`などのカスタムまたはあまり一般的ではない PyTorch バックエンドをテストするのに役立ちます。また、特定の GPU をターゲットにしたり、CPU 専用モードでテストしたりすることで、`CUDA_VISIBLE_DEVICES`と同じ効果を達成するために使用することもできます。
特定のデバイスでは、初めて「torch」をインポートした後、追加のインポートが必要になります。これは、環境変数 `TRANSFORMERS_TEST_BACKEND` を使用して指定できます。
```bash
TRANSFORMERS_TEST_BACKEND="torch_npu" pytest tests/utils/test_logging.py
```
### Distributed training
`pytest` は直接的に分散トレーニングを処理することはできません。試みると、サブプロセスは正しい処理を行わず、自分自身が `pytest` であると思い込んでテストスイートをループで実行し続けます。ただし、通常のプロセスを生成し、それから複数のワーカーを生成し、IOパイプを管理するプロセスを生成すれば機能します。
これを使用するいくつかのテストがあります:
- [test_trainer_distributed.py](https://github.com/huggingface/transformers/tree/main/tests/trainer/test_trainer_distributed.py)
- [test_deepspeed.py](https://github.com/huggingface/transformers/tree/main/tests/deepspeed/test_deepspeed.py)
実行ポイントにすぐに移動するには、これらのテスト内で `execute_subprocess_async` 呼び出しを検索してください。
これらのテストを実行するには、少なくとも2つのGPUが必要です:
```bash
CUDA_VISIBLE_DEVICES=0,1 RUN_SLOW=1 pytest -sv tests/test_trainer_distributed.py
```
### Output capture
テストの実行中に、`stdout` および `stderr` に送信された出力はキャプチャされます。テストまたはセットアップメソッドが失敗した場合、通常、それに対応するキャプチャされた出力が失敗のトレースバックと共に表示されます。
出力のキャプチャを無効にし、`stdout` と `stderr` を通常通りに取得するには、`-s` または `--capture=no` を使用してください:
これらのテストを実行するには少なくとも2つのGPUが必要です:
```bash
pytest -s tests/utils/test_logging.py
```
テスト結果を JUnit 形式の出力に送信するには:
```bash
py.test tests --junitxml=result.xml
```
### Color control
色を持たないようにする(例:黄色のテキストを白い背景に表示すると読みにくいです):
```bash
pytest --color=no tests/utils/test_logging.py
```
### Sending test report to online pastebin service
テスト失敗ごとに URL を作成します。
```bash
pytest --pastebin=failed tests/utils/test_logging.py
```
これにより、テスト実行情報がリモートのPasteサービスに送信され、各エラーに対してURLが提供されます。通常通りテストを選択するか、たとえば特定のエラーのみを送信したい場合は `-x` を追加で指定できます。
テストセッション全体のログに対するURLを作成する方法:
```bash
pytest --pastebin=all tests/utils/test_logging.py
```
## Writing tests
🤗 transformersのテストは `unittest` を基にしていますが、 `pytest` で実行されるため、ほとんどの場合、両方のシステムの機能を使用できます。
[こちら](https://docs.pytest.org/en/stable/unittest.html)でサポートされている機能を読むことができますが、重要なことは、ほとんどの `pytest` のフィクスチャが動作しないことです。パラメータ化も同様ですが、似たような方法で動作する `parameterized` モジュールを使用しています。
### Parametrization
同じテストを異なる引数で複数回実行する必要があることがよくあります。これはテスト内部から行うこともできますが、その場合、そのテストを単一の引数セットで実行する方法はありません。
```python
# test_this1.py
import unittest
from parameterized import parameterized
class TestMathUnitTest(unittest.TestCase):
@parameterized.expand(
[
("negative", -1.5, -2.0),
("integer", 1, 1.0),
("large fraction", 1.6, 1),
]
)
def test_floor(self, name, input, expected):
assert_equal(math.floor(input), expected)
```
デフォルトでは、このテストは3回実行され、それぞれの実行で `test_floor` の最後の3つの引数がパラメータリストの対応する引数に割り当てられます。
そして、`negative` と `integer` パラメータのセットのみを実行することもできます:
```bash
pytest -k "negative and integer" tests/test_mytest.py
```
または、`Negative`のサブテストを除くすべての場合、次のようになります。
```bash
pytest -k "not negative" tests/test_mytest.py
```
`-k` フィルターを使用することに加えて、各サブテストの正確な名前を調べ、その正確な名前を使用して任意のサブテストまたはすべてのサブテストを実行することができます。
```bash
pytest test_this1.py --collect-only -q
```
すると次のものがリストされます:
```bash
test_this1.py::TestMathUnitTest::test_floor_0_negative
test_this1.py::TestMathUnitTest::test_floor_1_integer
test_this1.py::TestMathUnitTest::test_floor_2_large_fraction
```
したがって、2 つの特定のサブテストのみを実行できるようになりました。
```bash
pytest test_this1.py::TestMathUnitTest::test_floor_0_negative test_this1.py::TestMathUnitTest::test_floor_1_integer
```
`transformers`の開発者依存関係にすでに含まれているモジュール[parameterized](https://pypi.org/project/parameterized/) は、`unittests` と `pytest` テストの両方で機能します。
ただし、テストが `unittest` でない場合、`pytest.mark.parametrize` を使用することができます(または既存のテストのいくつかで、主に `examples` の下で使用されているのを見ることができます)。
次に、同じ例を示しますが、今度は `pytest` の `parametrize` マーカーを使用しています:
```python
# test_this2.py
import pytest
@pytest.mark.parametrize(
"name, input, expected",
[
("negative", -1.5, -2.0),
("integer", 1, 1.0),
("large fraction", 1.6, 1),
],
)
def test_floor(name, input, expected):
assert_equal(math.floor(input), expected)
```
`parameterized` と同様に、`pytest.mark.parametrize` を使用すると、`-k` フィルタが役立たない場合でも、サブテストの実行を細かく制御できます。ただし、このパラメータ化関数はサブテストの名前をわずかに異なるものにします。以下にその例を示します:
```bash
pytest test_this2.py --collect-only -q
```
すると次のものがリストされます:
```bash
test_this2.py::test_floor[integer-1-1.0]
test_this2.py::test_floor[negative--1.5--2.0]
test_this2.py::test_floor[large fraction-1.6-1]
```
これで、特定のテストのみを実行できるようになりました。
```bash
pytest test_this2.py::test_floor[negative--1.5--2.0] test_this2.py::test_floor[integer-1-1.0]
```
前の例と同様に。
### Files and directories
テストの中で、現在のテストファイルからの相対位置を知る必要があることがよくあります。しかし、これは簡単なことではありません。なぜなら、テストは複数のディレクトリから呼び出されるか、異なる深さのサブディレクトリに存在することがあるからです。`transformers.test_utils.TestCasePlus` というヘルパークラスは、すべての基本パスを整理し、簡単にアクセスできるようにすることで、この問題を解決します。
- `pathlib` オブジェクト(すべて完全に解決されたもの):
- `test_file_path` - 現在のテストファイルのパス、つまり `__file__`
- `test_file_dir` - 現在のテストファイルを含むディレクトリ
- `tests_dir` - `tests` テストスイートのディレクトリ
- `examples_dir` - `examples` テストスイートのディレクトリ
- `repo_root_dir` - リポジトリのディレクトリ
- `src_dir` - `transformers` サブディレクトリが存在する場所
- パスの文字列表現――上記と同じですが、これらは `pathlib` オブジェクトではなく文字列としてパスを返します:
- `test_file_path_str`
- `test_file_dir_str`
- `tests_dir_str`
- `examples_dir_str`
- `repo_root_dir_str`
- `src_dir_str`
これらを使用し始めるには、テストが `transformers.test_utils.TestCasePlus` のサブクラスに存在することを確認するだけです。例:
```python
from transformers.testing_utils import TestCasePlus
class PathExampleTest(TestCasePlus):
def test_something_involving_local_locations(self):
data_dir = self.tests_dir / "fixtures/tests_samples/wmt_en_ro"
```
もし、`pathlib` を介してパスを操作する必要がない場合、または単に文字列としてパスが必要な場合は、`pathlib` オブジェクトに `str()` を呼び出すか、`_str` で終わるアクセサを使用できます。例:
```python
from transformers.testing_utils import TestCasePlus
class PathExampleTest(TestCasePlus):
def test_something_involving_stringified_locations(self):
examples_dir = self.examples_dir_str
```
### Temporary files and directories
一意の一時ファイルとディレクトリの使用は、並列テストの実行には欠かせません。これにより、テストがお互いのデータを上書きしないようにします。また、これらを作成した各テストの終了時に一時ファイルとディレクトリが削除されることを望みます。そのため、これらのニーズを満たすパッケージである `tempfile` のようなパッケージの使用は重要です。
しかし、テストのデバッグ時には、一時ファイルやディレクトリに何が格納されているかを確認できる必要があり、テストを再実行するたびにランダムに変更されないその正確なパスを知りたいと思います。
`transformers.test_utils.TestCasePlus` というヘルパークラスは、このような目的に最適です。これは `unittest.TestCase` のサブクラスであるため、テストモジュールで簡単に継承することができます。
以下はその使用例です:
```python
from transformers.testing_utils import TestCasePlus
class ExamplesTests(TestCasePlus):
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir()
```
このコードはユニークな一時ディレクトリを作成し、`tmp_dir` をその場所に設定します。
- ユニークな一時ディレクトリを作成します:
```python
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir()
```
`tmp_dir` には、作成された一時ディレクトリへのパスが含まれます。期間終了後は自動的に削除されます
テスト。
- 任意の一時ディレクトリを作成し、テストの開始前にそれが空であることを確認し、テスト後には空にしないでください。
```python
def test_whatever(self):
tmp_dir = self.get_auto_remove_tmp_dir("./xxx")
```
これは、特定のディレクトリを監視し、前のテストがそこにデータを残さないことを確認したい場合に、デバッグに役立ちます。
- `before` と `after` 引数を直接オーバーライドすることで、デフォルトの動作をオーバーライドできます。以下のいずれかの動作に導きます:
- `before=True`:テストの開始時に常に一時ディレクトリがクリアされます。
- `before=False`:一時ディレクトリが既に存在する場合、既存のファイルはそのままになります。
- `after=True`:テストの終了時に常に一時ディレクトリが削除されます。
- `after=False`:テストの終了時に常に一時ディレクトリはそのままになります。
<Tip>
`rm -r`の相当を安全に実行するために、明示的な `tmp_dir` が使用される場合、プロジェクトリポジトリのチェックアウトのサブディレクトリのみが許可されます。誤って `/tmp` などのファイルシステムの重要な部分が削除されないように、常に `./` から始まるパスを渡してください。
</Tip>
<Tip>
各テストは複数の一時ディレクトリを登録でき、要求がない限りすべて自動で削除されます。
</Tip>
### Temporary sys.path override
別のテストからインポートするために一時的に `sys.path` をオーバーライドする必要がある場合、`ExtendSysPath` コンテキストマネージャを使用できます。例:
```python
import os
from transformers.testing_utils import ExtendSysPath
bindir = os.path.abspath(os.path.dirname(__file__))
with ExtendSysPath(f"{bindir}/.."):
from test_trainer import TrainerIntegrationCommon # noqa
```
### Skipping tests
これは、バグが見つかり、新しいテストが作成された場合であっても、バグがまだ修正されていない場合に役立ちます。メインリポジトリにコミットできるようにするには、`make test` の実行中にそれをスキップする必要があります。
メソッド:
- **skip** は、テストが特定の条件が満たされた場合にのみパスすることを期待しており、それ以外の場合は pytest がテストの実行をスキップします。一般的な例は、Windows専用のテストを非Windowsプラットフォームでスキップする場合、または現在利用できない外部リソースに依存するテストをスキップする場合です(例: データベースが利用できない場合)。
- **xfail** は、何らかの理由でテストが失敗することを期待しています。一般的な例は、まだ実装されていない機能のテストや、まだ修正されていないバグのテストです。テストが予想される失敗にもかかわらずパスした場合(pytest.mark.xfailでマークされたテスト)、それはxpassとしてテストサマリーに報告されます。
これらの2つの間の重要な違いの1つは、`skip` はテストを実行しない点であり、`xfail` は実行します。したがって、バグのあるコードが他のテストに影響を与える場合は、`xfail` を使用しないでください。
#### Implementation
- テスト全体を無条件にスキップする方法は次のとおりです:
```python no-style
@unittest.skip("this bug needs to be fixed")
def test_feature_x():
```
または pytest 経由:
```python no-style
@pytest.mark.skip(reason="this bug needs to be fixed")
```
または `xfail` の方法:
```python no-style
@pytest.mark.xfail
def test_feature_x():
```
- テスト内の内部チェックに基づいてテストをスキップする方法は次のとおりです。
```python
def test_feature_x():
if not has_something():
pytest.skip("unsupported configuration")
```
またはモジュール全体:
```python
import pytest
if not pytest.config.getoption("--custom-flag"):
pytest.skip("--custom-flag is missing, skipping tests", allow_module_level=True)
```
または `xfail` の方法:
```python
def test_feature_x():
pytest.xfail("expected to fail until bug XYZ is fixed")
```
- 一部のインポートが欠落している場合にモジュール内のすべてのテストをスキップする方法は次のとおりです。
```python
docutils = pytest.importorskip("docutils", minversion="0.3")
```
- 条件に基づいてテストをスキップします。
```python no-style
@pytest.mark.skipif(sys.version_info < (3,6), reason="requires python3.6 or higher")
def test_feature_x():
```
または:
```python no-style
@unittest.skipIf(torch_device == "cpu", "Can't do half precision")
def test_feature_x():
```
またはモジュール全体をスキップします。
```python no-style
@pytest.mark.skipif(sys.platform == 'win32', reason="does not run on windows")
class TestClass():
def test_feature_x(self):
```
詳細、例、および方法についての詳細は[こちら](https://docs.pytest.org/en/latest/skipping.html)を参照してください。
### Slow tests
テストライブラリは着実に成長しており、テストの一部は数分かかります。そのため、CIでテストスイートの完了を待つのは1時間待つ余裕がないことがあります。したがって、いくつかの例外を除いて、遅いテストは以下の例のようにマークすべきです:
```python no-style
from transformers.testing_utils import slow
@slow
def test_integration_foo():
```
テストが`@slow`としてマークされたら、そのようなテストを実行するには、環境変数 `RUN_SLOW=1`を設定します。例:
```bash
RUN_SLOW=1 pytest tests
```
`@parameterized` のようなデコレータはテスト名を書き換えるため、`@slow` および他のスキップデコレータ `@require_*` は正しく動作するためには、最後にリストアップする必要があります。以下は正しい使用例の一例です:
```python no-style
@parameteriz ed.expand(...)
@slow
def test_integration_foo():
```
このドキュメントの冒頭で説明したように、遅いテストは定期的なスケジュールに従って実行され、PRのCIチェックでは実行されません。そのため、一部の問題がPRの提出時に見落とされ、マージされる可能性があります。そのような問題は次回のスケジュールされたCIジョブで検出されます。しかし、それはまた、PRを提出する前に自分のマシンで遅いテストを実行する重要性を意味しています。
どのテストを遅いテストとしてマークすべきかを選択するための、おおまかな意思決定メカニズムが次に示されています:
- テストがライブラリの内部コンポーネントの1つに焦点を当てている場合(例: モデリングファイル、トークン化ファイル、パイプライン)、そのテストは遅いテストスイートで実行する必要があります。それがライブラリの他の側面、たとえばドキュメンテーションや例に焦点を当てている場合、それらのテストは遅いテストスイートで実行する必要があります。そして、このアプローチを洗練させるために例外を設ける必要があります。
- 重いウェイトセットや約50MB以上のデータセットをダウンロードする必要があるすべてのテスト(例: モデル統合テスト、トークナイザ統合テスト、パイプライン統合テスト)は遅いテストとして設定する必要があります。新しいモデルを追加する場合、統合テスト用にランダムなウェイトを持つ小さなバージョンを作成し、ハブにアップロードする必要があります。これについては以下の段落で詳しく説明します。
- 特に高速化されていないトレーニングを行う必要があるすべてのテストは遅いテストとして設定する必要があります。
- 一部の「遅い」であるべきでないテストが非常に遅い場合、およびそれらを `@slow` として設定する必要がある場合には例外を導入できます。大容量のファイルをディスクに保存および読み込みする自動モデリングテストは、`@slow` としてマークされたテストの良い例です。
- CIで1秒未満でテストが完了する場合(ダウンロードを含む)、それは通常のテストであるべきです。
すべての非遅いテストは、さまざまな内部要素を完全にカバーする必要がありますが、高速である必要があります。たとえば、特別に作成された小さなモデル(レイヤー数が最小限で、語彙サイズが小さいなど)を使用して、かなりのカバレッジを実現できます。その後、`@slow` テストでは大規模な遅いモデルを使用して質的なテストを実行できます。これらを使用するには、以下のように *tiny* モデルを探してください:
```bash
grep tiny tests examples
```
[スクリプトの例](https://github.com/huggingface/transformers/tree/main/scripts/fsmt/fsmt-make-tiny-model.py)があり、これにより tiny-wmt19-en-de のような小さなモデルが作成されます。特定のモデルのアーキテクチャに簡単に調整できます。
実行時間を誤って測定することが簡単です。たとえば、巨大なモデルのダウンロードに関するオーバーヘッドがある場合、ローカルでテストするとダウンロードされたファイルがキャッシュされ、ダウンロード時間が計測されなくなります。したがって、CIログの実行速度レポート(`pytest --durations=0 tests` の出力)を確認してください。
このレポートは、遅いテストとしてマークされていない遅い外れ値や、高速に書き直す必要があるテストを見つけるのにも役立ちます。テストスイートがCIで遅くなり始めた場合、このレポートのトップリストには最も遅いテストが表示されます。
### Testing the stdout/stderr output
`stdout` および/または `stderr` に書き込む関数をテストするために、テストは `pytest` の [capsys システム](https://docs.pytest.org/en/latest/capture.html) を使用してこれらのストリームにアクセスできます。以下はその方法です:
```python
import sys
def print_to_stdout(s):
print(s)
def print_to_stderr(s):
sys.stderr.write(s)
def test_result_and_stdout(capsys):
msg = "Hello"
print_to_stdout(msg)
print_to_stderr(msg)
out, err = capsys.readouterr() # consume the captured output streams
# optional: if you want to replay the consumed streams:
sys.stdout.write(out)
sys.stderr.write(err)
# test:
assert msg in out
assert msg in err
```
そしてもちろん、ほとんどの場合、`stderr`は例外の一部として提供されるため、そのような場合には try/excel を使用する必要があります。
ケース:
```python
def raise_exception(msg):
raise ValueError(msg)
def test_something_exception():
msg = "Not a good value"
error = ""
try:
raise_exception(msg)
except Exception as e:
error = str(e)
assert msg in error, f"{msg} is in the exception:\n{error}"
```
stdout をキャプチャするもう 1 つのアプローチは、`contextlib.redirect_stdout`を使用することです。
```python
from io import StringIO
from contextlib import redirect_stdout
def print_to_stdout(s):
print(s)
def test_result_and_stdout():
msg = "Hello"
buffer = StringIO()
with redirect_stdout(buffer):
print_to_stdout(msg)
out = buffer.getvalue()
# optional: if you want to replay the consumed streams:
sys.stdout.write(out)
# test:
assert msg in out
```
stdout をキャプチャする際の重要な潜在的な問題は、通常の `print` でこれまでに出力された内容をリセットする可能性がある `\r` 文字が含まれている可能性があることです。`pytest` 自体には問題はありませんが、`pytest -s` ではこれらの文字がバッファに含まれるため、`-s` ありとなしでテストを実行できるようにするには、`re.sub(r'~.*\r', '', buf, 0, re.M)` を使用してキャプチャされた出力に対して追加のクリーンアップを行う必要があります。
しかし、その後、`\r` が含まれているかどうかにかかわらず、すべての操作を自動的に処理するヘルパーコンテキストマネージャラッパーがあります。したがって、次のように簡単に行えます:
```python
from transformers.testing_utils import CaptureStdout
with CaptureStdout() as cs:
function_that_writes_to_stdout()
print(cs.out)
```
完全なテスト例は次のとおりです。
```python
from transformers.testing_utils import CaptureStdout
msg = "Secret message\r"
final = "Hello World"
with CaptureStdout() as cs:
print(msg + final)
assert cs.out == final + "\n", f"captured: {cs.out}, expecting {final}"
```
`stderr` をキャプチャしたい場合は、代わりに `CaptureStderr` クラスを使用してください。
```python
from transformers.testing_utils import CaptureStderr
with CaptureStderr() as cs:
function_that_writes_to_stderr()
print(cs.err)
```
両方のストリームを一度にキャプチャする必要がある場合は、親の `CaptureStd` クラスを使用します。
```python
from transformers.testing_utils import CaptureStd
with CaptureStd() as cs:
function_that_writes_to_stdout_and_stderr()
print(cs.err, cs.out)
```
また、テストの問題のデバッグを支援するために、デフォルトで、これらのコンテキスト マネージャーは終了時にキャプチャされたストリームを自動的に再生します。
文脈から。
### Capturing logger stream
ロガーの出力を検証する必要がある場合は、`CaptureLogger`を使用できます。
```python
from transformers import logging
from transformers.testing_utils import CaptureLogger
msg = "Testing 1, 2, 3"
logging.set_verbosity_info()
logger = logging.get_logger("transformers.models.bart.tokenization_bart")
with CaptureLogger(logger) as cl:
logger.info(msg)
assert cl.out, msg + "\n"
```
### Testing with environment variables
特定のテストで環境変数の影響をテストしたい場合は、ヘルパー デコレータを使用できます。
`transformers.testing_utils.mockenv`
```python
from transformers.testing_utils import mockenv
class HfArgumentParserTest(unittest.TestCase):
@mockenv(TRANSFORMERS_VERBOSITY="error")
def test_env_override(self):
env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None)
```
場合によっては、外部プログラムを呼び出す必要があるため、`os.environ` に`PYTHONPATH`を設定してインクルードする必要があります。
複数のローカル パス。ヘルパー クラス `transformers.test_utils.TestCasePlus` が役に立ちます。
```python
from transformers.testing_utils import TestCasePlus
class EnvExampleTest(TestCasePlus):
def test_external_prog(self):
env = self.get_env()
# now call the external program, passing `env` to it
```
テストファイルが `tests` テストスイートまたは `examples` のどちらにあるかに応じて
`env[PYTHONPATH]` を使用して、これら 2 つのディレクトリのいずれかを含めます。また、テストが確実に行われるようにするための `src` ディレクトリも含めます。
現在のリポジトリに対して実行され、最後に、テストが実行される前にすでに設定されていた `env[PYTHONPATH]` を使用して実行されます。
何かあれば呼ばれます。
このヘルパー メソッドは `os.environ` オブジェクトのコピーを作成するため、元のオブジェクトはそのまま残ります。
### Getting reproducible results
状況によっては、テストのランダム性を削除したい場合があります。同一の再現可能な結果セットを取得するには、
シードを修正する必要があります:
```python
seed = 42
# python RNG
import random
random.seed(seed)
# pytorch RNGs
import torch
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
# numpy RNG
import numpy as np
np.random.seed(seed)
# tf RNG
tf.random.set_seed(seed)
```
### Debugging tests
警告が発生した時点でデバッガーを開始するには、次の手順を実行します。
```bash
pytest tests/utils/test_logging.py -W error::UserWarning --pdb
```
## Working with github actions workflows
セルフプッシュのワークフローCIジョブをトリガーするには、以下の手順を実行する必要があります:
1. `transformers` のリモートリポジトリで新しいブランチを作成します(フォークではなく、元のリポジトリで行います)。
2. ブランチの名前は `ci_` または `ci-` で始まる必要があります(`main` もトリガーしますが、`main` ではPRを作成できません)。また、特定のパスでのみトリガーされます - このドキュメントが書かれた後に変更された場合に備えて、最新の定義は[こちら](https://github.com/huggingface/transformers/blob/main/.github/workflows/self-push.yml)の *push:* にあります。
3. このブランチからPRを作成します。
4. その後、このジョブが[ここ](https://github.com/huggingface/transformers/actions/workflows/self-push.yml)に表示されます。ジョブはバックログがある場合、すぐに実行されないことがあります。
## Testing Experimental CI Features
CI機能のテストは通常のCIの正常な動作に干渉する可能性があるため、新しいCI機能を追加する場合、以下の手順に従う必要があります。
1. テストが必要なものをテストするための新しい専用のジョブを作成します。
2. 新しいジョブは常に成功する必要があるため、常にグリーン ✓(詳細は以下参照)を表示する必要があります。
3. さまざまな種類のPR(ユーザーフォークブランチ、非フォークブランチ、github.com UIから直接ファイルを編集するブランチ、さまざまな強制プッシュなど)が実行されるまでいくつかの日間実行し、実験的なジョブのログを監視します(意図的に常にグリーンになるようになっている全体のジョブの緑ではなく)。
4. すべてが安定していることが明確になったら、新しい変更を既存のジョブに統合します。
このように、CI機能自体の実験が通常のワークフローに干渉しないようにできます。
では、新しいCI機能が開発中である間、ジョブを常に成功させるにはどうすればいいでしょうか?
TravisCIのような一部のCIは `ignore-step-failure` をサポートし、全体のジョブを成功として報告しますが、この文書が作成された時点ではCircleCIとGithub Actionsはそれをサポートしていません。
したがって、以下のワークアラウンドを使用できます:
1. bashスクリプト内で潜在的な失敗を抑制するために実行コマンドの冒頭に `set +euo pipefail` を記述します。
2. 最後のコマンドは成功する必要があります。たとえば `echo "done"` または単に `true` を使用できます。
以下は例です:
```yaml
- run:
name: run CI experiment
command: |
set +euo pipefail
echo "setting run-all-despite-any-errors-mode"
this_command_will_fail
echo "but bash continues to run"
# emulate another failure
false
# but the last command must be a success
echo "during experiment do not remove: reporting success to CI, even if there were failures"
```
単純なコマンドの場合は、次のようにすることもできます。
```bash
cmd_that_may_fail || true
```
もちろん、結果に満足したら、実験的なステップやジョブを通常のジョブと統合し、`set +euo pipefail` などの追加した要素を削除して、実験的なジョブが通常のCIの動作に干渉しないようにします。
このプロセス全体は、実験的なステップに対して `allow-failure` のようなものを設定し、PRの全体のステータスに影響を与えずに失敗させることができれば、はるかに簡単になったでしょう。しかし、前述の通り、現在はCircleCIとGithub Actionsはこの機能をサポートしていません。
この機能に関しての投票や、CIに特有のスレッドでその進捗状況を確認できます:
- [Github Actions:](https://github.com/actions/toolkit/issues/399)
- [CircleCI:](https://ideas.circleci.com/ideas/CCI-I-344)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/tokenizer_summary.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Summary of the tokenizers
[[open-in-colab]]
このページでは、トークナイゼーションについて詳しく見ていきます。
<Youtube id="VFp38yj8h3A"/>
[前処理のチュートリアル](preprocessing)で見たように、テキストをトークン化することは、それを単語またはサブワードに分割し、それらをルックアップテーブルを介してIDに変換することです。単語またはサブワードをIDに変換することは簡単ですので、この要約ではテキストを単語またはサブワードに分割する(つまり、テキストをトークナイズする)ことに焦点を当てます。具体的には、🤗 Transformersで使用される3つの主要なトークナイザ、[Byte-Pair Encoding(BPE)](#byte-pair-encoding)、[WordPiece](#wordpiece)、および[SentencePiece](#sentencepiece)を見て、どのモデルがどのトークナイザタイプを使用しているかの例を示します。
各モデルページでは、事前トレーニング済みモデルがどのトークナイザタイプを使用しているかを知るために、関連するトークナイザのドキュメントを確認できます。例えば、[`BertTokenizer`]を見ると、モデルが[WordPiece](#wordpiece)を使用していることがわかります。
## Introduction
テキストをより小さなチャンクに分割することは、見かけ以上に難しいタスクであり、複数の方法があります。例えば、次の文を考えてみましょう。「"Don't you love 🤗 Transformers? We sure do."」
<Youtube id="nhJxYji1aho"/>
このテキストをトークン化する簡単な方法は、スペースで分割することです。これにより、以下のようになります:
```
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
```
これは合理的な第一歩ですが、トークン "Transformers?" と "do." を見ると、句読点が単語 "Transformer" と "do" に結合されていることがわかり、これは最適ではありません。句読点を考慮に入れるべきで、モデルが単語とそれに続く可能性のあるすべての句読点記号の異なる表現を学ばなければならないことを避けるべきです。これにより、モデルが学ばなければならない表現の数が爆発的に増加します。句読点を考慮に入れた場合、例文のトークン化は次のようになります:
```
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
ただし、単語「"Don't"」をトークン化する方法に関しては、不利な側面があります。 「"Don't"」は「"do not"」を表しているため、「["Do", "n't"]」としてトークン化する方が適しています。ここから事柄が複雑になり、各モデルが独自のトークナイザータイプを持つ理由の一部でもあります。テキストをトークン化するために適用するルールに応じて、同じテキストに対して異なるトークナイズされた出力が生成されます。事前トレーニング済みモデルは、トレーニングデータをトークナイズするのに使用されたルールと同じルールでトークナイズされた入力を提供する場合にのみ正常に機能します。
[spaCy](https://spacy.io/)と[Moses](http://www.statmt.org/moses/?n=Development.GetStarted)は、2つの人気のあるルールベースのトークナイザーです。これらを私たちの例に適用すると、*spaCy*と*Moses*は次のような出力を生成します:
```
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
```
空白と句読点のトークン化、およびルールベースのトークン化が使用されていることがわかります。空白と句読点のトークン化、およびルールベースのトークン化は、文を単語に分割することをゆるやかに定義される単語トークン化の例です。テキストをより小さなチャンクに分割するための最も直感的な方法である一方、このトークン化方法は大規模なテキストコーパスに対して問題を引き起こすことがあります。この場合、空白と句読点のトークン化は通常、非常に大きな語彙(すべての一意な単語とトークンのセット)を生成します。例えば、[Transformer XL](model_doc/transformerxl)は空白と句読点のトークン化を使用しており、語彙サイズは267,735です!
このような大きな語彙サイズは、モデルに非常に大きな埋め込み行列を入力および出力レイヤーとして持たせることを強制し、メモリおよび時間の複雑さの増加を引き起こします。一般的に、トランスフォーマーモデルは、特に単一の言語で事前トレーニングされた場合、50,000を超える語彙サイズを持つことはほとんどありません。
したがって、シンプルな空白と句読点のトークン化が不十分な場合、なぜ単に文字単位でトークン化しないのかという疑問が生じますか?
<Youtube id="ssLq_EK2jLE"/>
文字単位のトークン化は非常にシンプルであり、メモリと時間の複雑さを大幅に削減できますが、モデルに意味のある入力表現を学習させることが非常に難しくなります。たとえば、文字「"t"」のための意味のあるコンテキスト独立の表現を学習することは、単語「"today"」のためのコンテキスト独立の表現を学習するよりもはるかに難しいです。そのため、文字単位のトークン化はしばしばパフォーマンスの低下を伴います。したがって、トランスフォーマーモデルは単語レベルと文字レベルのトークン化のハイブリッドである**サブワード**トークン化を使用して、両方の世界の利点を活かします。
## Subword tokenization
<Youtube id="zHvTiHr506c"/>
サブワードトークン化アルゴリズムは、頻繁に使用される単語をより小さなサブワードに分割すべきではないが、珍しい単語は意味のあるサブワードに分解されるという原則に依存しています。たとえば、「"annoyingly"」は珍しい単語と見なされ、その単語は「"annoying"」と「"ly"」に分解されるかもしれません。独立した「"annoying"」と「"ly"」はより頻繁に現れますが、「"annoyingly"」の意味は「"annoying"」と「"ly"」の合成的な意味によって保持されます。これは特にトルコ語などの結合言語で役立ちます。ここではサブワードを連結して(ほぼ)任意の長い複雑な単語を形成できます。
サブワードトークン化により、モデルは合理的な語彙サイズを持つことができ、意味のあるコンテキスト独立の表現を学習できます。さらに、サブワードトークン化により、モデルは以前に見たことのない単語を処理し、それらを既知のサブワードに分解することができます。例えば、[`~transformers.BertTokenizer`]は`"I have a new GPU!"`を以下のようにトークン化します:
```py
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> tokenizer.tokenize("I have a new GPU!")
["i", "have", "a", "new", "gp", "##u", "!"]
```
「uncased」モデルを考慮しているため、まず文を小文字に変換しました。トークナイザの語彙に「["i", "have", "a", "new"]」という単語が存在することがわかりますが、「"gpu"」という単語は存在しません。したがって、トークナイザは「"gpu"」を既知のサブワード「["gp"、"##u"]」に分割します。ここで「"##"」は、トークンのデコードまたはトークナイゼーションの逆転のために、トークンの前の部分にスペースなしで接続する必要があることを意味します。
別の例として、[`~transformers.XLNetTokenizer`]は以下のように以前のサンプルテキストをトークン化します:
```py
>>> from transformers import XLNetTokenizer
>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet-base-cased")
>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
```
これらの「▁」の意味については、[SentencePiece](#sentencepiece)を見るときに詳しく説明します。ご覧の通り、「Transformers」という珍しい単語は、より頻繁に現れるサブワード「Transform」と「ers」に分割されています。
さて、異なるサブワードトークン化アルゴリズムがどのように動作するかを見てみましょう。これらのトークナイゼーションアルゴリズムはすべて、通常は対応するモデルがトレーニングされるコーパスで行われる形式のトレーニングに依存しています。
<a id='byte-pair-encoding'></a>
### Byte-Pair Encoding(BPE)
Byte-Pair Encoding(BPE)は、[Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., 2015)](https://arxiv.org/abs/1508.07909)で導入されました。BPEは、トレーニングデータを単語に分割するプリトークナイザに依存しています。プリトークナイゼーションは、空白のトークナイゼーションなど、非常に単純なものであることがあります。例えば、[GPT-2](model_doc/gpt2)、[RoBERTa](model_doc/roberta)です。より高度なプリトークナイゼーションには、ルールベースのトークナイゼーション([XLM](model_doc/xlm)、[FlauBERT](model_doc/flaubert)などが大部分の言語にMosesを使用)や、[GPT](model_doc/gpt)(Spacyとftfyを使用してトレーニングコーパス内の各単語の頻度を数える)などが含まれます。
プリトークナイゼーションの後、一意の単語セットが作成され、各単語がトレーニングデータで出現した頻度が決定されます。次に、BPEはベース語彙を作成し、ベース語彙の二つのシンボルから新しいシンボルを形成するためのマージルールを学習します。このプロセスは、語彙が所望の語彙サイズに達するまで続けられます。なお、所望の語彙サイズはトークナイザをトレーニングする前に定義するハイパーパラメータであることに注意してください。
例として、プリトークナイゼーションの後、次のセットの単語とその出現頻度が決定されたと仮定しましょう:
```
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
```
したがって、ベース語彙は「["b", "g", "h", "n", "p", "s", "u"]」です。すべての単語をベース語彙のシンボルに分割すると、次のようになります:
```
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
```
その後、BPEは可能なすべてのシンボルペアの頻度を数え、最も頻繁に発生するシンボルペアを選択します。上記の例では、`"h"`の後に`"u"`が15回(`"hug"`の10回、`"hugs"`の5回)出現します。しかし、最も頻繁なシンボルペアは、合計で20回(`"u"`の10回、`"g"`の5回、`"u"`の5回)出現する`"u"`の後に`"g"`が続くシンボルペアです。したがって、トークナイザが最初に学習するマージルールは、`"u"`の後に`"g"`が続くすべての`"u"`シンボルを一緒にグループ化することです。次に、`"ug"`が語彙に追加されます。単語のセットは次になります:
```
("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
```
次に、BPEは次に最も一般的なシンボルペアを識別します。それは「"u"」に続いて「"n"」で、16回出現します。したがって、「"u"」と「"n"」は「"un"」に結合され、語彙に追加されます。次に最も頻度の高いシンボルペアは、「"h"」に続いて「"ug"」で、15回出現します。再びペアが結合され、「hug」が語彙に追加できます。
この段階では、語彙は`["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]`であり、一意の単語のセットは以下のように表されます:
```
("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
```
前提として、Byte-Pair Encoding(BPE)のトレーニングがこの段階で停止すると、学習されたマージルールが新しい単語に適用されます(新しい単語にはベースボキャブラリに含まれていないシンボルが含まれていない限り)。 例えば、単語 "bug" は ["b", "ug"] としてトークン化されますが、"mug" はベースボキャブラリに "m" シンボルが含まれていないため、["<unk>", "ug"] としてトークン化されます。 一般的に、"m" のような単一の文字は、トレーニングデータには通常、各文字の少なくとも1つの出現が含まれているため、"<unk>" シンボルに置き換えられることはありませんが、絵文字のような非常に特殊な文字の場合には発生する可能性があります。
前述のように、ボキャブラリサイズ、すなわちベースボキャブラリサイズ + マージの回数は選択するハイパーパラメータです。 例えば、[GPT](model_doc/gpt) はベース文字が478文字で、40,000回のマージ後にトレーニングを停止したため、ボキャブラリサイズは40,478です。
#### Byte-level BPE
すべてのUnicode文字をベース文字と考えると、すべての可能なベース文字が含まれるかもしれないベースボキャブラリはかなり大きくなることがあります。 [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) は、ベースボキャブラリを256バイトにする賢いトリックとしてバイトをベースボキャブラリとして使用し、すべてのベース文字がボキャブラリに含まれるようにしています。 パンクチュエーションを扱うためのいくつかの追加ルールを備えたGPT2のトークナイザは、<unk> シンボルを必要とせずにすべてのテキストをトークン化できます。 [GPT-2](model_doc/gpt) は50,257のボキャブラリサイズを持っており、これは256バイトのベーストークン、特別なテキストの終了を示すトークン、および50,000回のマージで学習したシンボルに対応しています。
### WordPiece
WordPieceは、[BERT](model_doc/bert)、[DistilBERT](model_doc/distilbert)、および[Electra](model_doc/electra)で使用されるサブワードトークナイゼーションアルゴリズムです。 このアルゴリズムは、[Japanese and Korean Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) で概説されており、BPEに非常に似ています。 WordPieceは最も頻繁なシンボルペアを選択するのではなく、トレーニングデータに追加した場合にトレーニングデータの尤度を最大化するシンボルペアを選択します。
これは具体的にはどういう意味ですか?前の例を参照すると、トレーニングデータの尤度を最大化することは、そのシンボルペアの確率をその最初のシンボルに続く2番目のシンボルの確率で割ったものが、すべてのシンボルペアの中で最も大きい場合に該当するシンボルペアを見つけることに等しいです。 たとえば、"u" の後に "g" が続く場合、他のどのシンボルペアよりも "ug" の確率を "u"、"g" で割った確率が高ければ、それらのシンボルは結合されます。直感的に言えば、WordPieceは2つのシンボルを結合することによって失われるものを評価し、それがそれに値するかどうかを確認する点でBPEとはわずかに異なります。
### Unigram
Unigramは、[Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf) で導入されたサブワードトークナイゼーションアルゴリズムです。 BPEやWordPieceとは異なり、Unigramはベースボキャブラリを多数のシンボルで初期化し、各シンボルを削減してより小さなボキャブラリを取得します。 ベースボキャブラリは、事前にトークン化されたすべての単語と最も一般的な部分文字列に対応する可能性があります。 Unigramはtransformersのモデルの直接の使用には適していませんが、[SentencePiece](#sentencepiece)と組み合わせて使用されます。
各トレーニングステップで、Unigramアルゴリズムは現在のボキャブラリとユニグラム言語モデルを使用してトレーニングデータ上の損失(通常は対数尤度として定義)を定義します。その後、ボキャブラリ内の各シンボルについて、そのシンボルがボキャブラリから削除された場合に全体の損失がどれだけ増加するかを計算します。 Unigramは、損失の増加が最も低いp(通常は10%または20%)パーセントのシンボルを削除します。つまり、トレーニングデータ全体の損失に最も影響を与えない、最も損失の少ないシンボルを削除します。 このプロセスは、ボキャブラリが望ましいサイズに達するまで繰り返されます。 Unigramアルゴリズムは常にベース文字を保持するため、任意の単語をトークン化できます。
Unigramはマージルールに基づいていないため(BPEとWordPieceとは対照的に)、トレーニング後の新しいテキストのトークン化にはいくつかの方法があります。例として、トレーニングされたUnigramトークナイザが持つボキャブラリが次のような場合:
```
["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
```
`"hugs"`は、`["hug", "s"]`、`["h", "ug", "s"]`、または`["h", "u", "g", "s"]`のようにトークン化できます。では、どれを選択すべきでしょうか? Unigramは、トレーニングコーパス内の各トークンの確率を保存し、トレーニング後に各可能なトークン化の確率を計算できるようにします。このアルゴリズムは実際には最も可能性の高いトークン化を選択しますが、確率に従って可能なトークン化をサンプリングするオプションも提供します。
これらの確率は、トークナイザーがトレーニングに使用する損失によって定義されます。トレーニングデータが単語 \\(x_{1}, \dots, x_{N}\\) で構成され、単語 \\(x_{i}\\) のすべての可能なトークン化のセットが \\(S(x_{i})\\) と定義される場合、全体の損失は次のように定義されます。
$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
<a id='sentencepiece'></a>
### SentencePiece
これまでに説明したすべてのトークン化アルゴリズムには同じ問題があります。それは、入力テキストが単語を区切るためにスペースを使用していると仮定しているということです。しかし、すべての言語が単語を区切るためにスペースを使用しているわけではありません。この問題を一般的に解決するための1つの方法は、言語固有の前トークナイザーを使用することです(例:[XLM](model_doc/xlm)は特定の中国語、日本語、およびタイ語の前トークナイザーを使用しています)。より一般的にこの問題を解決するために、[SentencePiece:ニューラルテキスト処理のためのシンプルで言語非依存のサブワードトークナイザーおよびデトークナイザー(Kudo et al.、2018)](https://arxiv.org/pdf/1808.06226.pdf) は、入力を生の入力ストリームとして扱い、スペースを使用する文字のセットに含めます。それからBPEまたはunigramアルゴリズムを使用して適切な語彙を構築します。
たとえば、[`XLNetTokenizer`]はSentencePieceを使用しており、そのために前述の例で`"▁"`文字が語彙に含まれていました。SentencePieceを使用したデコードは非常に簡単で、すべてのトークンを単純に連結し、`"▁"`はスペースに置換されます。
ライブラリ内のすべてのtransformersモデルは、SentencePieceをunigramと組み合わせて使用します。SentencePieceを使用するモデルの例には、[ALBERT](model_doc/albert)、[XLNet](model_doc/xlnet)、[Marian](model_doc/marian)、および[T5](model_doc/t5)があります。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/task_summary.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# What 🤗 Transformers can do
🤗 Transformersは、自然言語処理(NLP)、コンピュータビジョン、音声処理などの最新の事前学習済みモデルのライブラリです。このライブラリには、Transformerモデルだけでなく、コンピュータビジョンタスク向けのモダンな畳み込みニューラルネットワークなど、Transformer以外のモデルも含まれています。現代のスマートフォン、アプリ、テレビなど、最も人気のある消費者製品の多くには、深層学習技術が使用されています。スマートフォンで撮影した写真から背景オブジェクトを削除したいですか?これはパノプティック・セグメンテーション(まだ何を意味するかわからなくても心配しないでください、以下のセクションで説明します!)のタスクの一例です。
このページでは、🤗 Transformersライブラリを使用して、たった3行のコードで解決できるさまざまな音声および音声、コンピュータビジョン、NLPタスクの概要を提供します!
## Audio
音声と音声処理のタスクは、他のモダリティとは少し異なります。なぜなら、入力としての生の音声波形は連続的な信号であるからです。テキストとは異なり、生の音声波形は文章を単語に分割できるようにきれいに分割できません。これを解決するために、通常、生の音声信号は定期的な間隔でサンプリングされます。間隔内でより多くのサンプルを取ると、サンプリングレートが高くなり、音声はより元の音声ソースに近づきます。
以前のアプローチでは、音声を前処理してそれから有用な特徴を抽出しました。しかし、現在では、生の音声波形を特徴エンコーダに直接フィードし、音声表現を抽出することから始めることが一般的です。これにより、前処理ステップが簡素化され、モデルは最も重要な特徴を学習できます。
### Audio classification
音声分類は、事前に定義されたクラスのセットから音声データにラベルを付けるタスクです。これは多くの具体的なアプリケーションを含む広範なカテゴリであり、いくつかの例は次のとおりです:
- 音響シーン分類:音声にシーンラベルを付ける(「オフィス」、「ビーチ」、「スタジアム」)
- 音響イベント検出:音声に音声イベントラベルを付ける(「車のクラクション」、「クジラの呼び声」、「ガラスの破裂」)
- タギング:複数の音を含む音声にラベルを付ける(鳥の鳴き声、会議でのスピーカー識別)
- 音楽分類:音楽にジャンルラベルを付ける(「メタル」、「ヒップホップ」、「カントリー」)
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
```
### Automatic speech recognition
自動音声認識(ASR)は音声をテキストに変換します。これは、人間のコミュニケーションの自然な形式である音声の一部として、部分的にそのような一般的なオーディオタスクの一つです。今日、ASRシステムはスピーカー、スマートフォン、自動車などの「スマート」テクノロジープロダクトに組み込まれています。私たちは仮想アシスタントに音楽を再生してもらったり、リマインダーを設定してもらったり、天気を教えてもらったりできます。
しかし、Transformerアーキテクチャが助けた主要な課題の一つは、低リソース言語におけるものです。大量の音声データで事前トレーニングし、低リソース言語でラベル付き音声データをわずか1時間だけでファインチューニングすることでも、以前のASRシステムと比較して高品質な結果を得ることができます。以前のASRシステムは100倍以上のラベル付きデータでトレーニングされていましたが、Transformerアーキテクチャはこの問題に貢献しました。
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
## Computer vision
最初で初めて成功したコンピュータビジョンのタスクの一つは、[畳み込みニューラルネットワーク(CNN)](glossary#convolution)を使用して郵便番号の画像を認識することでした。画像はピクセルから構成され、各ピクセルには数値があります。これにより、画像をピクセル値の行列として簡単に表現できます。特定のピクセル値の組み合わせは、画像の色を記述します。
コンピュータビジョンのタスクを解決する一般的な方法は次の2つです:
1. 畳み込みを使用して、低レベルの特徴から高レベルの抽象的な情報まで、画像の階層的な特徴を学習する。
2. 画像をパッチに分割し、各画像パッチが画像全体とどのように関連しているかを徐々に学習するためにTransformerを使用する。CNNが好むボトムアップアプローチとは異なり、これはぼんやりとした画像から始めて徐々に焦点を合わせるようなものです。
### Image classification
画像分類は、事前に定義されたクラスのセットから画像全体にラベルを付けます。多くの分類タスクと同様に、画像分類には多くの実用的な用途があり、その一部は次のとおりです:
* 医療:疾患の検出や患者の健康の監視に使用するために医療画像にラベルを付ける
* 環境:森林伐採の監視、野生地の管理情報、または山火事の検出に使用するために衛星画像にラベルを付ける
* 農業:作物の健康を監視するための作物の画像や、土地利用の監視のための衛星画像にラベルを付ける
* 生態学:野生動物の個体数を監視したり、絶滅危惧種を追跡するために動植物の種の画像にラベルを付ける
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
```
### Object detection
画像分類とは異なり、オブジェクト検出は画像内の複数のオブジェクトを識別し、オブジェクトの位置を画像内で定義する境界ボックスによって特定します。オブジェクト検出の例には次のような用途があります:
* 自動運転車:他の車両、歩行者、信号機などの日常の交通オブジェクトを検出
* リモートセンシング:災害モニタリング、都市計画、天候予測
* 欠陥検出:建物のクラックや構造上の損傷、製造上の欠陥を検出
```py
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
```
### Image segmentation
画像セグメンテーションは、画像内のすべてのピクセルをクラスに割り当てるピクセルレベルのタスクです。これはオブジェクト検出とは異なり、オブジェクトをラベル付けし、予測するために境界ボックスを使用する代わりに、セグメンテーションはより詳細になります。セグメンテーションはピクセルレベルでオブジェクトを検出できます。画像セグメンテーションにはいくつかのタイプがあります:
* インスタンスセグメンテーション:オブジェクトのクラスをラベル付けするだけでなく、オブジェクトの個別のインスタンス("犬-1"、"犬-2")もラベル付けします。
* パノプティックセグメンテーション:セマンティックセグメンテーションとインスタンスセグメンテーションの組み合わせ。セマンティッククラスごとに各ピクセルにラベルを付け、オブジェクトの個別のインスタンスもラベル付けします。
セグメンテーションタスクは、自動運転車にとって、周囲の世界のピクセルレベルのマップを作成し、歩行者や他の車両を安全に回避できるようにするのに役立ちます。また、医療画像では、タスクの細かい粒度が異常な細胞や臓器の特徴を識別するのに役立ちます。画像セグメンテーションは、eコマースで衣類を仮想的に試着したり、カメラを通じて実世界にオブジェクトを重ねて拡張現実の体験を作成したりするためにも使用できます。
```py
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
```
### Depth estimation
深度推定は、画像内の各ピクセルがカメラからの距離を予測します。このコンピュータビジョンタスクは、特にシーンの理解と再構築に重要です。たとえば、自動運転車では、歩行者、交通標識、他の車などの物体がどれだけ遠いかを理解し、障害物や衝突を回避するために必要です。深度情報はまた、2D画像から3D表現を構築し、生物学的構造や建物の高品質な3D表現を作成するのに役立ちます。
深度推定には次の2つのアプローチがあります:
* ステレオ:深度は、わずかに異なる角度からの同じ画像の2つの画像を比較して推定されます。
* モノキュラー:深度は単一の画像から推定されます。
```py
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
```
## Natural language processing
NLPタスクは、テキストが私たちにとって自然なコミュニケーション手段であるため、最も一般的なタスクの一つです。モデルが認識するための形式にテキストを変換するには、トークン化が必要です。これは、テキストのシーケンスを単語やサブワード(トークン)に分割し、それらのトークンを数字に変換することを意味します。その結果、テキストのシーケンスを数字のシーケンスとして表現し、一度数字のシーケンスがあれば、さまざまなNLPタスクを解決するためにモデルに入力できます!
### Text classification
どんなモダリティの分類タスクと同様に、テキスト分類は事前に定義されたクラスのセットからテキストのシーケンス(文レベル、段落、またはドキュメントであることがあります)にラベルを付けます。テキスト分類には多くの実用的な用途があり、その一部は次のとおりです:
* 感情分析:`positive`や`negative`のような極性に従ってテキストにラベルを付け、政治、金融、マーケティングなどの分野での意思決定をサポートします。
* コンテンツ分類:テキストをトピックに従ってラベル付けし、ニュースやソーシャルメディアのフィード内の情報を整理し、フィルタリングするのに役立ちます(`天気`、`スポーツ`、`金融`など)。
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
```
### Token classification
どんなNLPタスクでも、テキストはテキストのシーケンスを個々の単語やサブワードに分割して前処理されます。これらは[トークン](/glossary#token)として知られています。トークン分類は、事前に定義されたクラスのセットから各トークンにラベルを割り当てます。
トークン分類の一般的なタイプは次の2つです:
* 固有表現認識(NER):組織、人物、場所、日付などのエンティティのカテゴリに従ってトークンにラベルを付けます。NERは特にバイオメディカル環境で人気であり、遺伝子、タンパク質、薬物名などをラベル付けできます。
* 品詞タグ付け(POS):名詞、動詞、形容詞などの品詞に従ってトークンにラベルを付けます。POSは、翻訳システムが同じ単語が文法的にどのように異なるかを理解するのに役立ちます(名詞としての「銀行」と動詞としての「銀行」など)。
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
... {
... "entity": pred["entity"],
... "score": round(pred["score"], 4),
... "index": pred["index"],
... "word": pred["word"],
... "start": pred["start"],
... "end": pred["end"],
... }
... for pred in preds
... ]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
```
### Question answering
質問応答は、コンテキスト(オープンドメイン)を含む場合と含まない場合(クローズドドメイン)がある場合もある、別のトークンレベルのタスクで、質問に対する回答を返します。このタスクは、仮想アシスタントにレストランが営業しているかどうかのような質問をするときに発生します。また、顧客や技術サポートを提供し、検索エンジンがあなたが求めている関連情報を取得するのにも役立ちます。
質問応答の一般的なタイプは次の2つです:
* 抽出型:質問と一部のコンテキストが与えられた場合、モデルがコンテキストから抽出する必要のあるテキストのスパンが回答となります。
* 抽象的:質問と一部のコンテキストが与えられた場合、回答はコンテキストから生成されます。このアプローチは、[`QuestionAnsweringPipeline`]ではなく[`Text2TextGenerationPipeline`]で処理されます。
```py
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
... question="What is the name of the repository?",
... context="The name of the repository is huggingface/transformers",
... )
>>> print(
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
... )
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
```
### Summarization
要約は、長いテキストから短いバージョンを作成し、元の文書の意味の大部分を保ちながら試みるタスクです。要約はシーケンスからシーケンスへのタスクであり、入力よりも短いテキストシーケンスを出力します。要約を行うことで、読者が主要なポイントを迅速に理解できるようにするのに役立つ長文書がたくさんあります。法案、法的および財務文書、特許、科学論文など、読者の時間を節約し読書の支援となる文書の例があります。
質問応答と同様に、要約には2つのタイプがあります:
* 抽出的要約:元のテキストから最も重要な文を識別して抽出します。
* 抽象的要約:元のテキストからターゲットの要約(入力文書に含まれていない新しい単語を含むことがあります)を生成します。[`SummarizationPipeline`]は抽象的なアプローチを使用しています。
```py
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
... )
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
```
### Translation
翻訳は、ある言語のテキストシーケンスを別の言語に変換する作業です。これは異なるバックグラウンドを持つ人々がコミュニケーションをとるのに役立ち、広範な観客にコンテンツを翻訳して伝えるのに役立ち、新しい言語を学ぶのを支援する学習ツールにもなります。要約と共に、翻訳はシーケンス間のタスクであり、モデルは入力シーケンスを受け取り、ターゲットの出力シーケンスを返します。
初期の翻訳モデルは主に単一言語でしたが、最近では多言語モデルに対する関心が高まり、多くの言語対で翻訳できるような多言語モデルに注目が集まっています。
```py
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
```
### 言語モデリング
言語モデリングは、テキストのシーケンス内の単語を予測するタスクです。事前学習された言語モデルは、多くの他のダウンストリームタスクに対してファインチューニングできるため、非常に人気のあるNLPタスクとなっています。最近では、ゼロショットまたはフューショット学習を実証する大規模な言語モデル(LLM)に大きな関心が寄せられています。これは、モデルが明示的にトレーニングされていないタスクを解決できることを意味します!言語モデルは、流暢で説得力のあるテキストを生成するために使用できますが、テキストが常に正確であるわけではないため、注意が必要です。
言語モデリングには2つのタイプがあります:
* 因果的:モデルの目標は、シーケンス内の次のトークンを予測することであり、将来のトークンはマスクされます。
```py
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
```
* マスクされた:モデルの目的は、シーケンス内のトークン全体にアクセスしながら、シーケンス内のマスクされたトークンを予測することです。
```py
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
... {
... "score": round(pred["score"], 4),
... "token": pred["token"],
... "token_str": pred["token_str"],
... "sequence": pred["sequence"],
... }
... for pred in preds
... ]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
```
## Multimodal
マルチモーダルタスクは、特定の問題を解決するために複数のデータモダリティ(テキスト、画像、音声、ビデオ)を処理するためにモデルを必要とします。画像キャプショニングは、モデルが入力として画像を受け取り、画像を説明するテキストのシーケンスまたは画像のいくつかの特性を出力するマルチモーダルタスクの例です。
マルチモーダルモデルは異なるデータタイプまたはモダリティで作業しますが、内部的には前処理ステップがモデルにすべてのデータタイプを埋め込み(データに関する意味のある情報を保持するベクトルまたは数字のリスト)に変換するのを支援します。画像キャプショニングのようなタスクでは、モデルは画像の埋め込みとテキストの埋め込みの間の関係を学習します。
### Document question answering
ドキュメント質問応答は、ドキュメントからの自然言語の質問に答えるタスクです。テキストを入力とするトークンレベルの質問応答タスクとは異なり、ドキュメント質問応答はドキュメントの画像とそのドキュメントに関する質問を受け取り、答えを返します。ドキュメント質問応答は構造化されたドキュメントを解析し、それから重要な情報を抽出するために使用できます。以下の例では、レシートから合計金額とお釣りを抽出することができます。
```py
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/2/image/image.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
... question="What is the total amount?",
... image=image,
... )
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
```
このページが各モダリティのタスクの種類とそれぞれの重要性についての追加の背景情報を提供できたことを願っています。次の [セクション](tasks_explained) では、🤗 トランスフォーマーがこれらのタスクを解決するために **どのように** 動作するかを学びます。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/custom_tools.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Custom Tools and Prompts
<Tip>
トランスフォーマーのコンテキストでツールとエージェントが何であるかを知らない場合、
まず[Transformers Agents](transformers_agents)ページをお読みいただくことをお勧めします。
</Tip>
<Tip warning={true}>
Transformers Agentsは実験的なAPIであり、いつでも変更される可能性があります。
エージェントによって返される結果は、APIや基礎となるモデルが変更される可能性があるため、変化することがあります。
</Tip>
カスタムツールとプロンプトを作成し、使用することは、エージェントを強化し、新しいタスクを実行させるために非常に重要です。
このガイドでは、以下の内容を説明します:
- プロンプトのカスタマイズ方法
- カスタムツールの使用方法
- カスタムツールの作成方法
## Customizing the prompt
[Transformers Agents](transformers_agents)で説明されているように、エージェントは[`~Agent.run`]および[`~Agent.chat`]モードで実行できます。
`run`モードと`chat`モードの両方は同じロジックに基づいています。
エージェントを駆動する言語モデルは、長いプロンプトに基づいて条件付けられ、
次のトークンを生成して停止トークンに達するまでプロンプトを完了します。
両者の唯一の違いは、`chat`モードの間にプロンプトが前のユーザーの入力とモデルの生成と共に拡張されることです。
これにより、エージェントは過去の対話にアクセスでき、エージェントにあたかもメモリがあるかのように見えます。
### Structure of the prompt
プロンプトがどのように構築され、どのように最適化できるかを理解するために、プロンプトは大まかに4つの部分に分かれています。
1. イントロダクション:エージェントの振る舞い、ツールの概念の説明。
2. すべてのツールの説明。これはユーザーによって定義/選択されたツールでランタイム時に動的に置換される`<<all_tools>>`トークンによって定義されます。
3. タスクとその解決策の一連の例。
4. 現在の例と解決策の要求。
各部分をよりよく理解するために、`run`プロンプトがどのように見えるかの簡略版を見てみましょう:
````text
タスクを実行するために、Pythonのシンプルなコマンドのシリーズを考えてくることがあるでしょう。
[...]
意味がある場合は、中間結果を表示することができます。
ツール:
- document_qa:これはドキュメント(pdf)に関する質問に答えるツールです。情報を含むドキュメントである `document` と、ドキュメントに関する質問である `question` を受け取り、質問に対する回答を含むテキストを返します。
- image_captioner:これは画像の説明を生成するツールです。キャプションにする画像である `image` と、説明を含む英語のテキストを返すテキストを受け取ります。
[...]
タスク: "変数 `question` に関する質問に答えるための画像について回答してください。質問はフランス語です。"
次のツールを使用します:質問を英語に翻訳するための `translator`、そして入力画像に関する質問に答えるための `image_qa`。
回答:
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(image=image, question=translated_question)
print(f"The answer is {answer}")
```
タスク:「`document`内で最年長の人物を特定し、その結果をバナーとして表示する。」
以下のツールを使用します:`document_qa`を使用してドキュメント内で最年長の人物を見つけ、その回答に従って`image_generator`を使用して画像を生成します。
回答:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
```
[...]
タスク: "川と湖の絵を描いてください"
以下のものを使用します
````
導入部分("Tools:"の前のテキスト)は、モデルの振る舞いと実行すべきタスクを正確に説明しています。
この部分はおそらくエージェントが常に同じ方法で振る舞う必要があるため、カスタマイズする必要はありません。
2番目の部分("Tools"の下の箇条書き)は、`run`または`chat`を呼び出すたびに動的に追加されます。
`agent.toolbox`内のツールの数と同じ数の箇条書きがあり、それぞれの箇条書きにはツールの名前と説明が含まれています。
```text
- <tool.name>: <tool.description>
```
もうすぐ確認しましょう。 `document_qa` ツールを読み込んで名前と説明を出力します。
```py
from transformers import load_tool
document_qa = load_tool("document-question-answering")
print(f"- {document_qa.name}: {document_qa.description}")
```
which gives:
```text
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
```
ツール説明:
このツールは、2つのパートから成り立っています。最初のパートでは、ツールが何を行うかを説明し、2番目のパートでは入力引数と戻り値がどのように期待されるかを述べています。
良いツール名とツールの説明は、エージェントが正しく使用するために非常に重要です。エージェントがツールについて持っている唯一の情報は、その名前と説明です。したがって、ツール名と説明の両方が正確に記述され、ツールボックス内の既存のツールのスタイルに合致することを確認する必要があります。特に、説明にはコードスタイルで名前で期待されるすべての引数が言及され、期待される型とそれらが何であるかの説明も含めるべきです。
<Tip>
キュレートされたTransformersツールの命名と説明を確認して、ツールがどのような名前と説明を持つべきかを理解するのに役立ちます。
すべてのツールは[`Agent.toolbox`]プロパティで確認できます。
</Tip>
カスタマイズされた例:
ツールの使い方をエージェントに正確に示す一連の例が含まれています。これらの例は、エージェントが実際に正確で実行可能なコードを生成する可能性を最大化するように書かれているため、非常に重要です。大規模な言語モデルは、プロンプト内のパターンを認識し、新しいデータを使用してそのパターンを繰り返すことに非常に優れています。したがって、実践で正しい実行可能なコードを生成するエージェントの可能性を最大化するように、これらの例は書かれている必要があります。
以下は、一つの例です:
````text
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
```
````
パターン:モデルが繰り返しを行うように指示されるパターンには、3つの部分があります。
タスクの声明、エージェントの意図した動作の説明、そして最後に生成されるコードです。
プロンプトの一部であるすべての例には、この正確なパターンがあり、エージェントが新しいトークンを生成する際にも
同じパターンを再現することを確認しています。
プロンプトの例はTransformersチームによって厳選され、一連の問題ステートメントで厳密に評価されます。
これにより、エージェントのプロンプトがエージェントの実際の使用ケースを解決するためにできるだけ優れたものになります。
プロンプトの最後の部分に対応しています:
[こちら](https://github.com/huggingface/transformers/blob/main/src/transformers/tools/evaluate_agent.py)の問題ステートメントで厳密に評価される、エージェントのプロンプトができるだけ優れたものになるように
慎重に選定されたプロンプト例を提供しています。
```text
Task: "Draw me a picture of rivers and lakes"
I will use the following
```
これがエージェントに完成させるための最終的で未完成の例です。未完成の例は、実際のユーザー入力に基づいて動的に作成されます。上記の例では、ユーザーが次のように実行しました:
```py
agent.run("Draw me a picture of rivers and lakes")
```
ユーザーの入力 - つまり、タスク:"川と湖の絵を描いてください"は、以下のようなプロンプトテンプレートに変換されます:"タスク:<task> \n\n 次に私は以下を使用します"。
この文は、エージェントが条件付けられたプロンプトの最終行を構成し、したがってエージェントに対して前の例とまったく同じ方法で例を終了するよう強く影響します。
詳細には立ち入りませんが、チャットテンプレートは同じプロンプト構造を持ち、例はわずかに異なるスタイルを持っています。例:
````text
[...]
=====
Human: Answer the question in the variable `question` about the image stored in the variable `image`.
Assistant: I will use the tool `image_qa` to answer the question on the input image.
```py
answer = image_qa(text=question, image=image)
print(f"The answer is {answer}")
```
Human: I tried this code, it worked but didn't give me a good result. The question is in French
Assistant: In this case, the question needs to be translated first. I will use the tool `translator` to do this.
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(text=translated_question, image=image)
print(f"The answer is {answer}")
```
=====
[...]
````
*Human:* `run`プロンプトの例とは対照的に、各`chat`プロンプトの例には*Human*と*Assistant*の間で1つ以上のやりとりがあります。各やりとりは、`run`プロンプトの例と同様の構造になっています。ユーザーの入力は*Human:*の後ろに追加され、エージェントにはコードを生成する前に何を行う必要があるかを最初に生成するように指示されます。やりとりは以前のやりとりに基づいて行われることがあり、ユーザーが「I tried **this** code」と入力したように、以前に生成されたエージェントのコードを参照できます。
*Assistant:* `.chat`を実行すると、ユーザーの入力または*タスク*が未完了の形式に変換されます:
```text
Human: <user-input>\n\nAssistant:
```
以下のエージェントが完了するコマンドについて説明します。 `run` コマンドとは対照的に、`chat` コマンドは完了した例をプロンプトに追加します。そのため、次の `chat` ターンのためにエージェントにより多くの文脈を提供します。
さて、プロンプトの構造がわかったところで、どのようにカスタマイズできるかを見てみましょう!
### Writing good user inputs
大規模な言語モデルはユーザーの意図を理解する能力がますます向上していますが、エージェントが正しいタスクを選択するのを助けるために、できるだけ正確に記述することが非常に役立ちます。できるだけ正確であるとは何を意味するのでしょうか?
エージェントは、プロンプトでツール名とその説明のリストを見ています。ツールが追加されるほど、エージェントが正しいツールを選択するのが難しくなり、正しいツールの連続を選択するのはさらに難しくなります。共通の失敗例を見てみましょう。ここではコードのみを返すことにします。
```py
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.run("Show me a tree", return_code=True)
```
gives:
```text
==Explanation from the agent==
I will use the following tool: `image_segmenter` to create a segmentation mask for the image.
==Code generated by the agent==
mask = image_segmenter(image, prompt="tree")
```
これはおそらく私たちが望んでいたものではないでしょう。代わりに、木の画像が生成されることがより可能性が高いです。
特定のツールを使用するようエージェントを誘導するために、ツールの名前や説明に含まれている重要なキーワードを使用することは非常に役立ちます。さて、詳しく見てみましょう。
```py
agent.toolbox["image_generator"].description
```
```text
'This is a tool that creates an image according to a prompt, which is a text description. It takes an input named `prompt` which contains the image description and outputs an image.
```
名前と説明文には、キーワード「画像」、「プロンプト」、「作成」、および「生成」が使用されています。これらの言葉を使用することで、ここでの動作がより効果的になる可能性が高いです。プロンプトを少し詳細に調整しましょう。
```py
agent.run("Create an image of a tree", return_code=True)
```
gives:
```text
==Explanation from the agent==
I will use the following tool `image_generator` to generate an image of a tree.
==Code generated by the agent==
image = image_generator(prompt="tree")
```
簡単に言うと、エージェントがタスクを正確に適切なツールにマッピングできない場合は、ツールの名前や説明の最も関連性のあるキーワードを調べて、タスクリクエストをそれに合わせて洗練させてみてください。
### Customizing the tool descriptions
以前にも見たように、エージェントは各ツールの名前と説明にアクセスできます。ベースのツールは非常に正確な名前と説明を持っているはずですが、特定のユースケースに合わせてツールの説明や名前を変更することが役立つかもしれません。これは、非常に類似した複数のツールを追加した場合や、特定のドメイン(たとえば、画像生成や変換など)でエージェントを使用する場合に特に重要になるかもしれません。
よくある問題は、エージェントが画像生成タスクに頻繁に使用される場合、画像生成と画像変換/修正を混同することです。
例:
```py
agent.run("Make an image of a house and a car", return_code=True)
```
returns
```text
==Explanation from the agent==
I will use the following tools `image_generator` to generate an image of a house and `image_transformer` to transform the image of a car into the image of a house.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
house_car_image = image_transformer(image=car_image, prompt="A house")
```
これはおそらく私たちがここで望んでいる正確なものではないようです。エージェントは「image_generator」と「image_transformer」の違いを理解するのが難しいようで、しばしば両方を一緒に使用します。
ここでエージェントをサポートするために、"image_transformer"のツール名と説明を変更して、少し"image"や"prompt"から切り離してみましょう。代わりにそれを「modifier」と呼びましょう:
```py
agent.toolbox["modifier"] = agent.toolbox.pop("image_transformer")
agent.toolbox["modifier"].description = agent.toolbox["modifier"].description.replace(
"transforms an image according to a prompt", "modifies an image"
)
```
「変更」は、上記のプロンプトに新しい画像プロセッサを使用する強力な手がかりです。それでは、もう一度実行してみましょう。
```py
agent.run("Make an image of a house and a car", return_code=True)
```
Now we're getting:
```text
==Explanation from the agent==
I will use the following tools: `image_generator` to generate an image of a house, then `image_generator` to generate an image of a car.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
```
これは、私たちが考えていたものに確実に近づいています!ただし、家と車を同じ画像に含めたいと考えています。タスクを単一の画像生成に向けることで、より適切な方向に進めるはずです:
```py
agent.run("Create image: 'A house and car'", return_code=True)
```
```text
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="A house and car")
```
<Tip warning={true}>
エージェントは、特に複数のオブジェクトの画像を生成するなど、やや複雑なユースケースに関しては、まだ多くのユースケースに対して脆弱です。
エージェント自体とその基礎となるプロンプトは、今後数ヶ月でさらに改善され、さまざまなユーザーの入力に対してエージェントがより頑健になるようになります。
</Tip>
### Customizing the whole project
ユーザーに最大限の柔軟性を提供するために、[上記](#structure-of-the-prompt)で説明されたプロンプトテンプレート全体をユーザーが上書きできます。この場合、カスタムプロンプトには導入セクション、ツールセクション、例セクション、未完了の例セクションが含まれていることを確認してください。`run` プロンプトテンプレートを上書きしたい場合、以下のように行うことができます:
```py
template = """ [...] """
agent = HfAgent(your_endpoint, run_prompt_template=template)
```
<Tip warning={true}>
`<<all_tools>>` 文字列と `<<prompt>>` は、エージェントが使用できるツールを認識し、ユーザーのプロンプトを正しく挿入できるように、`template` のどこかに定義されていることを確認してください。
</Tip>
同様に、`chat` プロンプトテンプレートを上書きすることもできます。なお、`chat` モードでは常に以下の形式で交換が行われます:
上記のテキストの上に日本語の翻訳を提供してください。Markdownコードとして書いてください。
```text
Human: <<task>>
Assistant:
```
したがって、カスタム`chat`プロンプトテンプレートの例もこのフォーマットを使用することが重要です。以下のように、インスタンス化時に`chat`テンプレートを上書きできます。
```
template = """ [...] """
agent = HfAgent(url_endpoint=your_endpoint, chat_prompt_template=template)
```
<Tip warning={true}>
`<<all_tools>>` という文字列が `template` 内で定義されていることを確認してください。これにより、エージェントは使用可能なツールを把握できます。
</Tip>
両方の場合、プロンプトテンプレートの代わりに、コミュニティの誰かがホストしたテンプレートを使用したい場合は、リポジトリIDを渡すことができます。デフォルトのプロンプトは、[このリポジトリ](https://huggingface.co/datasets/huggingface-tools/default-prompts) にありますので、参考になります。
カスタムプロンプトをHubのリポジトリにアップロードしてコミュニティと共有する場合は、次のことを確認してください:
- データセットリポジトリを使用すること
- `run` コマンド用のプロンプトテンプレートを `run_prompt_template.txt` という名前のファイルに配置すること
- `chat` コマンド用のプロンプトテンプレートを `chat_prompt_template.txt` という名前のファイルに配置すること
## Using custom tools
このセクションでは、画像生成に特化した2つの既存のカスタムツールを利用します:
- [huggingface-tools/image-transformation](https://huggingface.co/spaces/huggingface-tools/image-transformation) をより多くの画像変更を可能にするために [diffusers/controlnet-canny-tool](https://huggingface.co/spaces/diffusers/controlnet-canny-tool) に置き換えます。
- 画像のアップスケーリング用の新しいツールをデフォルトのツールボックスに追加します:[diffusers/latent-upscaler-tool](https://huggingface.co/spaces/diffusers/latent-upscaler-tool) は既存の画像変換ツールを置き換えます。
便利な [`load_tool`] 関数を使用してカスタムツールをロードします:
```py
from transformers import load_tool
controlnet_transformer = load_tool("diffusers/controlnet-canny-tool")
upscaler = load_tool("diffusers/latent-upscaler-tool")
```
エージェントにカスタムツールを追加すると、ツールの説明と名前がエージェントのプロンプトに自動的に含まれます。したがって、エージェントがカスタムツールの使用方法を理解できるように、カスタムツールには適切に記述された説明と名前が必要です。
`controlnet_transformer`の説明と名前を見てみましょう。
最初に、便利な[`load_tool`]関数を使用してカスタムツールをロードします。
```py
print(f"Description: '{controlnet_transformer.description}'")
print(f"Name: '{controlnet_transformer.name}'")
```
gives
```text
Description: 'This is a tool that transforms an image with ControlNet according to a prompt.
It takes two inputs: `image`, which should be the image to transform, and `prompt`, which should be the prompt to use to change it. It returns the modified image.'
Name: 'image_transformer'
```
名前と説明は正確であり、[厳選されたツール](./transformers_agents#a-curated-set-of-tools)のスタイルに合っています。
次に、`controlnet_transformer`と`upscaler`を使ってエージェントをインスタンス化します。
```py
tools = [controlnet_transformer, upscaler]
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=tools)
```
以下のコマンドは、以下の情報を提供します:
```text
image_transformer has been replaced by <transformers_modules.diffusers.controlnet-canny-tool.bd76182c7777eba9612fc03c0
8718a60c0aa6312.image_transformation.ControlNetTransformationTool object at 0x7f1d3bfa3a00> as provided in `additional_tools`
```
一連の厳選されたツールにはすでに `image_transformer` ツールがあり、これをカスタムツールで置き換えます。
<Tip>
既存のツールを上書きすることは、特定のタスクに既存のツールをまったく同じ目的で使用したい場合に有益であることがあります。
なぜなら、エージェントはその特定のタスクの使用方法に精通しているからです。この場合、カスタムツールは既存のツールとまったく同じAPIに従うか、そのツールを使用するすべての例が更新されるようにプロンプトテンプレートを適応させる必要があります。
</Tip>
アップスケーラーツールには `image_upscaler` という名前が付けられ、これはデフォルトのツールボックスにはまだ存在しないため、単にツールのリストに追加されます。
エージェントが現在使用可能なツールボックスを確認するには、`agent.toolbox` 属性を使用できます。
```py
print("\n".join([f"- {a}" for a in agent.toolbox.keys()]))
```
```text
- document_qa
- image_captioner
- image_qa
- image_segmenter
- transcriber
- summarizer
- text_classifier
- text_qa
- text_reader
- translator
- image_transformer
- text_downloader
- image_generator
- video_generator
- image_upscaler
```
注意: `image_upscaler` がエージェントのツールボックスの一部となったことに注目してください。
それでは、新しいツールを試してみましょう で生成した画像を再利用します。
```py
from diffusers.utils import load_image
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png"
)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
美しい冬の風景にこの画像を変身させましょう:
```py
image = agent.run("Transform the image: 'A frozen lake and snowy forest'", image=image)
```
```text
==Explanation from the agent==
I will use the following tool: `image_transformer` to transform the image.
==Code generated by the agent==
image = image_transformer(image, prompt="A frozen lake and snowy forest")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_winter.png" width=200>
新しい画像処理ツールは、非常に強力な画像の変更を行うことができるControlNetに基づいています。
デフォルトでは、画像処理ツールはサイズが512x512ピクセルの画像を返します。それを拡大できるか見てみましょう。
```py
image = agent.run("Upscale the image", image)
```
```text
==Explanation from the agent==
I will use the following tool: `image_upscaler` to upscale the image.
==Code generated by the agent==
upscaled_image = image_upscaler(image)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_winter_upscale.png" width=400>
エージェントは、プロンプト「画像の拡大」を、その説明とツールの名前だけを基に、新たに追加されたアップスケーリングツールに自動的にマッピングし、正しく実行できました。
次に、新しいカスタムツールを作成する方法を見てみましょう。
### Adding new tools
このセクションでは、エージェントに追加できる新しいツールの作成方法を示します。
#### Creating a new tool
まず、ツールの作成から始めましょう。次のコードで、特定のタスクに関してHugging Face Hubで最もダウンロードされたモデルを取得する、あまり役立たないけれども楽しいタスクを追加します。
以下のコードでそれを行うことができます:
```python
from huggingface_hub import list_models
task = "text-classification"
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
print(model.id)
```
タスク `text-classification` の場合、これは `'facebook/bart-large-mnli'` を返します。`translation` の場合、`'t5-base'` を返します。
これをエージェントが利用できるツールに変換する方法は何でしょうか?すべてのツールは、主要な属性を保持するスーパークラス `Tool` に依存しています。私たちは、それを継承したクラスを作成します:
```python
from transformers import Tool
class HFModelDownloadsTool(Tool):
pass
```
このクラスにはいくつかの必要な要素があります:
- `name` 属性:これはツール自体の名前に対応し、他のツールと調和するために `model_download_counter` と名付けます。
- `description` 属性:これはエージェントのプロンプトを埋めるために使用されます。
- `inputs` と `outputs` 属性:これらを定義することで、Python インタープリターが型に関する賢明な選択を行うのに役立ち、ツールをHubにプッシュする際にgradio-demoを生成できるようになります。これらは、予想される値のリストであり、`text`、`image`、または`audio`になることがあります。
- `__call__` メソッド:これには推論コードが含まれています。これは上記で試したコードです!
こちらが現在のクラスの外観です:
```python
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = (
"This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub. "
"It takes the name of the category (such as text-classification, depth-estimation, etc), and "
"returns the name of the checkpoint."
)
inputs = ["text"]
outputs = ["text"]
def __call__(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
```
さて、今度はツールが使えるようになりました。このツールをファイルに保存し、メインスクリプトからインポートしましょう。このファイルを `model_downloads.py` という名前にし、結果のインポートコードは次のようになります:
以下は、現在のクラスの外観です:
```python
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
```
他の人々に利益をもたらし、より簡単な初期化のために、それをHubにあなたの名前空間でプッシュすることをお勧めします。これを行うには、`tool` 変数で `push_to_hub` を呼び出すだけです:
```python
tool.push_to_hub("hf-model-downloads")
```
エージェントがツールを使用する方法について、最終ステップを見てみましょう。
#### Having the agent use the tool
Hubにあるツールがあります。これは次のようにインスタンス化できます(ユーザー名をツールに合わせて変更してください):
```python
from transformers import load_tool
tool = load_tool("lysandre/hf-model-downloads")
```
エージェントで使用するためには、エージェントの初期化メソッドの `additional_tools` パラメータにそれを渡すだけです:
```python
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run(
"Can you read out loud the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?"
)
```
which outputs the following:
```text
==Code generated by the agent==
model = model_download_counter(task="text-to-video")
print(f"The model with the most downloads is {model}.")
audio_model = text_reader(model)
==Result==
The model with the most downloads is damo-vilab/text-to-video-ms-1.7b.
```
以下のテキストは、次のオーディオを生成します。
**Audio** |
|------------------------------------------------------------------------------------------------------------------------------------------------------|
| <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/damo.wav" type="audio/wav"/> |
<Tip>
特定のLLMに依存することがあり、うまく機能させるためには非常に正確なプロンプトが必要なものもあります。ツールの名前と説明を明確に定義することは、エージェントによって活用されるために非常に重要です。
</Tip>
### Replacing existing tools
既存のツールを置き換えるには、新しいアイテムをエージェントのツールボックスに割り当てるだけで行うことができます。以下はその方法です:
```python
from transformers import HfAgent, load_tool
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.toolbox["image-transformation"] = load_tool("diffusers/controlnet-canny-tool")
```
<Tip>
他のツールでツールを置き換える際には注意が必要です!これにより、エージェントのプロンプトも調整されます。これは、タスクに適したより良いプロンプトを持っている場合には良いことですが、他のツールが選択される確率が高くなり、定義したツールの代わりに他のツールが選択されることもあるかもしれません。
</Tip>
## Leveraging gradio-tools
[gradio-tools](https://github.com/freddyaboulton/gradio-tools)は、Hugging Face Spacesをツールとして使用することを可能にする強力なライブラリです。既存の多くのSpacesおよびカスタムSpacesを設計することもサポートしています。
我々は、`gradio_tools`を使用して`StableDiffusionPromptGeneratorTool`ツールを活用したいと考えています。このツールは`gradio-tools`ツールキットで提供されており、プロンプトを改善し、より良い画像を生成するために使用します。
まず、`gradio_tools`からツールをインポートし、それをインスタンス化します:
```python
from gradio_tools import StableDiffusionPromptGeneratorTool
gradio_tool = StableDiffusionPromptGeneratorTool()
```
そのインスタンスを `Tool.from_gradio` メソッドに渡します:
```python
from transformers import Tool
tool = Tool.from_gradio(gradio_tool)
```
これからは、通常のカスタムツールと同じようにそれを管理できます。私たちはプロンプトを改善するためにそれを活用します。
` a rabbit wearing a space suit`:
```python
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run("Generate an image of the `prompt` after improving it.", prompt="A rabbit wearing a space suit")
```
The model adequately leverages the tool:
```text
==Explanation from the agent==
I will use the following tools: `StableDiffusionPromptGenerator` to improve the prompt, then `image_generator` to generate an image according to the improved prompt.
==Code generated by the agent==
improved_prompt = StableDiffusionPromptGenerator(prompt)
print(f"The improved prompt is {improved_prompt}.")
image = image_generator(improved_prompt)
```
最終的に画像を生成する前に:

<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit.png">
<Tip warning={true}>
gradio-toolsは、さまざまなモダリティを使用する場合でも、*テキスト*の入力と出力が必要です。この実装は画像と音声オブジェクトと連携します。現時点では、これら2つは互換性がありませんが、サポートを向上させるために取り組んでおり、迅速に互換性が向上するでしょう。
</Tip>
## Future compatibility with Langchain
私たちはLangchainを愛しており、非常に魅力的なツールのスイートを持っていると考えています。これらのツールを扱うために、Langchainはさまざまなモダリティで作業する場合でも、*テキスト*の入出力が必要です。これは、オブジェクトのシリアル化バージョン(つまり、ディスクに保存されたバージョン)であることが多いです。
この違いにより、transformers-agentsとlangchain間ではマルチモダリティが処理されていません。
この制限は将来のバージョンで解決されることを目指しており、熱心なlangchainユーザーからの任意の支援を歓迎します。
私たちはより良いサポートを提供したいと考えています。お手伝いいただける場合は、ぜひ[問題を開いて](https://github.com/huggingface/transformers/issues/new)、お考えのことを共有してください。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/peft.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Load adapters with 🤗 PEFT
[[open-in-colab]]
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) メソッドは、事前学習済みモデルのパラメータをファインチューニング中に凍結し、その上にわずかな訓練可能なパラメータ(アダプター)を追加するアプローチです。アダプターは、タスク固有の情報を学習するために訓練されます。このアプローチは、メモリ使用量が少なく、完全にファインチューニングされたモデルと比較して計算リソースを低く抑えつつ、同等の結果を生成することが示されています。
PEFTで訓練されたアダプターは通常、完全なモデルのサイズよりも1桁小さく、共有、保存、読み込むのが便利です。
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">Hubに格納されているOPTForCausalLMモデルのアダプター重みは、モデルの全体サイズの約6MBで、モデル重みの全サイズは約700MBです。</figcaption>
</div>
🤗 PEFTライブラリについて詳しく知りたい場合は、[ドキュメンテーション](https://huggingface.co/docs/peft/index)をご覧ください。
## Setup
🤗 PEFTをインストールして始めましょう:
```bash
pip install peft
```
新機能を試してみたい場合、ソースからライブラリをインストールすることに興味があるかもしれません:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## Supported PEFT models
🤗 Transformersは、いくつかのPEFT(Parameter Efficient Fine-Tuning)メソッドをネイティブにサポートしており、ローカルまたはHubに格納されたアダプターウェイトを簡単に読み込んで実行またはトレーニングできます。以下のメソッドがサポートされています:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
他のPEFTメソッドを使用したい場合、プロンプト学習やプロンプト調整などについて詳しく知りたい場合、または🤗 PEFTライブラリ全般については、[ドキュメンテーション](https://huggingface.co/docs/peft/index)を参照してください。
## Load a PEFT adapter
🤗 TransformersからPEFTアダプターモデルを読み込んで使用するには、Hubリポジトリまたはローカルディレクトリに `adapter_config.json` ファイルとアダプターウェイトが含まれていることを確認してください。次に、`AutoModelFor` クラスを使用してPEFTアダプターモデルを読み込むことができます。たとえば、因果言語モデリング用のPEFTアダプターモデルを読み込むには:
1. PEFTモデルのIDを指定します。
2. それを[`AutoModelForCausalLM`] クラスに渡します。
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
PEFTアダプターを`AutoModelFor`クラスまたは基本モデルクラス(`OPTForCausalLM`または`LlamaForCausalLM`など)で読み込むことができます。
</Tip>
また、`load_adapter`メソッドを呼び出すことで、PEFTアダプターを読み込むこともできます:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
## Load in 8bit or 4bit
`bitsandbytes` 統合は、8ビットおよび4ビットの精度データ型をサポートしており、大規模なモデルを読み込む際にメモリを節約するのに役立ちます(詳細については `bitsandbytes` 統合の[ガイド](./quantization#bitsandbytes-integration)を参照してください)。[`~PreTrainedModel.from_pretrained`] に `load_in_8bit` または `load_in_4bit` パラメータを追加し、`device_map="auto"` を設定してモデルを効果的にハードウェアに分散配置できます:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)
```
## Add a new adapter
既存のアダプターを持つモデルに新しいアダプターを追加するために [`~peft.PeftModel.add_adapter`] を使用できます。ただし、新しいアダプターは現在のアダプターと同じタイプである限り、これを行うことができます。たとえば、モデルに既存の LoRA アダプターがアタッチされている場合:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
新しいアダプタを追加するには:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
[`~peft.PeftModel.set_adapter`] を使用して、どのアダプターを使用するかを設定できます:
```py
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## Enable and disable adapters
モデルにアダプターを追加したら、アダプターモジュールを有効または無効にすることができます。アダプターモジュールを有効にするには、次の手順を実行します:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
アダプターモジュールを無効にするには:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## Train a PEFT adapter
PEFTアダプターは[`Trainer`]クラスでサポートされており、特定のユースケースに対してアダプターをトレーニングすることができます。数行のコードを追加するだけで済みます。たとえば、LoRAアダプターをトレーニングする場合:
<Tip>
[`Trainer`]を使用したモデルの微調整に慣れていない場合は、[事前トレーニング済みモデルの微調整](training)チュートリアルをご覧ください。
</Tip>
1. タスクタイプとハイパーパラメータに対するアダプターの構成を定義します(ハイパーパラメータの詳細については[`~peft.LoraConfig`]を参照してください)。
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
```
2. モデルにアダプターを追加する。
```py
model.add_adapter(peft_config)
```
3. これで、モデルを [`Trainer`] に渡すことができます!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
保存するトレーニング済みアダプタとそれを読み込むための手順:
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/fast_tokenizers.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Use tokenizers from 🤗 Tokenizers
[`PreTrainedTokenizerFast`]は[🤗 Tokenizers](https://huggingface.co/docs/tokenizers)ライブラリに依存しています。🤗 Tokenizersライブラリから取得したトークナイザーは、非常に簡単に🤗 Transformersにロードできます。
具体的な内容に入る前に、まずはいくつかの行でダミーのトークナイザーを作成することから始めましょう:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
私たちは今、定義したファイルにトレーニングされたトークナイザーを持っています。これをランタイムで引き続き使用するか、
将来の再利用のためにJSONファイルに保存することができます。
## Loading directly from the tokenizer object
🤗 Transformersライブラリでこのトークナイザーオブジェクトをどのように活用できるかを見てみましょう。[`PreTrainedTokenizerFast`]クラスは、
*tokenizer*オブジェクトを引数として受け入れ、簡単にインスタンス化できるようにします。
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
このオブジェクトは、🤗 Transformers トークナイザーが共有するすべてのメソッドと一緒に使用できます!詳細については、[トークナイザーページ](main_classes/tokenizer)をご覧ください。
## Loading from a JSON file
JSONファイルからトークナイザーを読み込むには、まずトークナイザーを保存することから始めましょう:
```python
>>> tokenizer.save("tokenizer.json")
```
このファイルを保存したパスは、`PreTrainedTokenizerFast` の初期化メソッドに `tokenizer_file` パラメータを使用して渡すことができます:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
このオブジェクトは、🤗 Transformers トークナイザーが共有するすべてのメソッドと一緒に使用できるようになりました!詳細については、[トークナイザーページ](main_classes/tokenizer)をご覧ください。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/benchmarks.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdownですが、Hugging Faceのdoc-builder(MDXに類似)向けの特定の構文を含んでいるため、
Markdownビューアでは正しく表示されないことに注意してください。
-->
# Benchmarks
<Tip warning={true}>
Hugging Faceのベンチマークツールは非推奨であり、Transformerモデルの速度とメモリの複雑さを測定するために外部のベンチマークライブラリを使用することをお勧めします。
</Tip>
[[open-in-colab]]
🤗 Transformersモデルをベンチマークし、ベストプラクティス、すでに利用可能なベンチマークについて見てみましょう。
🤗 Transformersモデルをベンチマークする方法について詳しく説明したノートブックは[こちら](https://github.com/huggingface/notebooks/tree/main/examples/benchmark.ipynb)で利用できます。
## How to benchmark 🤗 Transformers models
[`PyTorchBenchmark`]クラスと[`TensorFlowBenchmark`]クラスを使用すると、🤗 Transformersモデルを柔軟にベンチマークできます。
ベンチマーククラスを使用すると、_ピークメモリ使用量_ および _必要な時間_ を _推論_ および _トレーニング_ の両方について測定できます。
<Tip>
ここでの _推論_ は、単一のフォワードパスによって定義され、 _トレーニング_ は単一のフォワードパスと
バックワードパスによって定義されます。
</Tip>
ベンチマーククラス[`PyTorchBenchmark`]と[`TensorFlowBenchmark`]は、それぞれのベンチマーククラスに対する適切な設定を含む [`PyTorchBenchmarkArguments`] および [`TensorFlowBenchmarkArguments`] タイプのオブジェクトを必要とします。
[`PyTorchBenchmarkArguments`] および [`TensorFlowBenchmarkArguments`] はデータクラスであり、それぞれのベンチマーククラスに対するすべての関連する設定を含んでいます。
次の例では、タイプ _bert-base-cased_ のBERTモデルをベンチマークする方法が示されています。
<frameworkcontent>
<pt>
```py
>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments
>>> args = PyTorchBenchmarkArguments(models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512])
>>> benchmark = PyTorchBenchmark(args)
```
</pt>
<tf>
```py
>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments
>>> args = TensorFlowBenchmarkArguments(
... models=["bert-base-uncased"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
... )
>>> benchmark = TensorFlowBenchmark(args)
```
</tf>
</frameworkcontent>
ここでは、ベンチマーク引数のデータクラスに対して、`models`、`batch_sizes`
および`sequence_lengths`の3つの引数が指定されています。引数`models`は必須で、
[モデルハブ](https://huggingface.co/models)からのモデル識別子の`リスト`を期待し
ます。`batch_sizes`と`sequence_lengths`の2つの`リスト`引数は
モデルのベンチマーク対象となる`input_ids`のサイズを定義します。
ベンチマーク引数データクラスを介して設定できる他の多くのパラメータがあります。これらの詳細については、直接ファイル
`src/transformers/benchmark/benchmark_args_utils.py`、
`src/transformers/benchmark/benchmark_args.py`(PyTorch用)、および`src/transformers/benchmark/benchmark_args_tf.py`(Tensorflow用)
を参照するか、次のシェルコマンドをルートから実行すると、PyTorchとTensorflowのそれぞれに対して設定可能なすべてのパラメータの記述的なリストが表示されます。
<frameworkcontent>
<pt>
```bash
python examples/pytorch/benchmarking/run_benchmark.py --help
```
インスタンス化されたベンチマークオブジェクトは、単に `benchmark.run()` を呼び出すことで実行できます。
```py
>>> results = benchmark.run()
>>> print(results)
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base-uncased 8 8 0.006
bert-base-uncased 8 32 0.006
bert-base-uncased 8 128 0.018
bert-base-uncased 8 512 0.088
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base-uncased 8 8 1227
bert-base-uncased 8 32 1281
bert-base-uncased 8 128 1307
bert-base-uncased 8 512 1539
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.4.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 08:58:43.371351
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</pt>
<tf>
```bash
python examples/tensorflow/benchmarking/run_benchmark_tf.py --help
```
インスタンス化されたベンチマークオブジェクトは、単に `benchmark.run()` を呼び出すことで実行できます。
```py
>>> results = benchmark.run()
>>> print(results)
>>> results = benchmark.run()
>>> print(results)
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base-uncased 8 8 0.005
bert-base-uncased 8 32 0.008
bert-base-uncased 8 128 0.022
bert-base-uncased 8 512 0.105
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base-uncased 8 8 1330
bert-base-uncased 8 32 1330
bert-base-uncased 8 128 1330
bert-base-uncased 8 512 1770
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: Tensorflow
- use_xla: False
- framework_version: 2.2.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:26:35.617317
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</tf>
</frameworkcontent>
デフォルトでは、_推論時間_ と _必要なメモリ_ がベンチマークされます。
上記の例の出力では、最初の2つのセクションが _推論時間_ と _推論メモリ_
に対応する結果を示しています。さらに、計算環境に関するすべての関連情報、
例えば GPU タイプ、システム、ライブラリのバージョンなどが、_ENVIRONMENT INFORMATION_ の下に表示されます。この情報は、[`PyTorchBenchmarkArguments`]
および [`TensorFlowBenchmarkArguments`] に引数 `save_to_csv=True`
を追加することで、オプションで _.csv_ ファイルに保存することができます。この場合、各セクションは別々の _.csv_ ファイルに保存されます。_.csv_
ファイルへのパスは、データクラスの引数を使用してオプションで定義できます。
モデル識別子、例えば `bert-base-uncased` を使用して事前学習済みモデルをベンチマークする代わりに、利用可能な任意のモデルクラスの任意の設定をベンチマークすることもできます。この場合、ベンチマーク引数と共に設定の `list` を挿入する必要があります。
<frameworkcontent>
<pt>
```py
>>> from transformers import PyTorchBenchmark, PyTorchBenchmarkArguments, BertConfig
>>> args = PyTorchBenchmarkArguments(
... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
... )
>>> config_base = BertConfig()
>>> config_384_hid = BertConfig(hidden_size=384)
>>> config_6_lay = BertConfig(num_hidden_layers=6)
>>> benchmark = PyTorchBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
>>> benchmark.run()
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base 8 128 0.006
bert-base 8 512 0.006
bert-base 8 128 0.018
bert-base 8 512 0.088
bert-384-hid 8 8 0.006
bert-384-hid 8 32 0.006
bert-384-hid 8 128 0.011
bert-384-hid 8 512 0.054
bert-6-lay 8 8 0.003
bert-6-lay 8 32 0.004
bert-6-lay 8 128 0.009
bert-6-lay 8 512 0.044
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base 8 8 1277
bert-base 8 32 1281
bert-base 8 128 1307
bert-base 8 512 1539
bert-384-hid 8 8 1005
bert-384-hid 8 32 1027
bert-384-hid 8 128 1035
bert-384-hid 8 512 1255
bert-6-lay 8 8 1097
bert-6-lay 8 32 1101
bert-6-lay 8 128 1127
bert-6-lay 8 512 1359
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: PyTorch
- use_torchscript: False
- framework_version: 1.4.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:35:25.143267
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</pt>
<tf>
```py
>>> from transformers import TensorFlowBenchmark, TensorFlowBenchmarkArguments, BertConfig
>>> args = TensorFlowBenchmarkArguments(
... models=["bert-base", "bert-384-hid", "bert-6-lay"], batch_sizes=[8], sequence_lengths=[8, 32, 128, 512]
... )
>>> config_base = BertConfig()
>>> config_384_hid = BertConfig(hidden_size=384)
>>> config_6_lay = BertConfig(num_hidden_layers=6)
>>> benchmark = TensorFlowBenchmark(args, configs=[config_base, config_384_hid, config_6_lay])
>>> benchmark.run()
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
bert-base 8 8 0.005
bert-base 8 32 0.008
bert-base 8 128 0.022
bert-base 8 512 0.106
bert-384-hid 8 8 0.005
bert-384-hid 8 32 0.007
bert-384-hid 8 128 0.018
bert-384-hid 8 512 0.064
bert-6-lay 8 8 0.002
bert-6-lay 8 32 0.003
bert-6-lay 8 128 0.0011
bert-6-lay 8 512 0.074
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
bert-base 8 8 1330
bert-base 8 32 1330
bert-base 8 128 1330
bert-base 8 512 1770
bert-384-hid 8 8 1330
bert-384-hid 8 32 1330
bert-384-hid 8 128 1330
bert-384-hid 8 512 1540
bert-6-lay 8 8 1330
bert-6-lay 8 32 1330
bert-6-lay 8 128 1330
bert-6-lay 8 512 1540
--------------------------------------------------------------------------------
==================== ENVIRONMENT INFORMATION ====================
- transformers_version: 2.11.0
- framework: Tensorflow
- use_xla: False
- framework_version: 2.2.0
- python_version: 3.6.10
- system: Linux
- cpu: x86_64
- architecture: 64bit
- date: 2020-06-29
- time: 09:38:15.487125
- fp16: False
- use_multiprocessing: True
- only_pretrain_model: False
- cpu_ram_mb: 32088
- use_gpu: True
- num_gpus: 1
- gpu: TITAN RTX
- gpu_ram_mb: 24217
- gpu_power_watts: 280.0
- gpu_performance_state: 2
- use_tpu: False
```
</tf>
</frameworkcontent>
カスタマイズされたBertModelクラスの構成に対する推論時間と必要なメモリのベンチマーク
この機能は、モデルをトレーニングする際にどの構成を選択すべきかを決定する際に特に役立つことがあります。
## Benchmark best practices
このセクションでは、モデルをベンチマークする際に注意すべきいくつかのベストプラクティスをリストアップしています。
- 現在、単一デバイスのベンチマークしかサポートされていません。GPUでベンチマークを実行する場合、コードを実行するデバイスをユーザーが指定することを推奨します。
これはシェルで`CUDA_VISIBLE_DEVICES`環境変数を設定することで行えます。例:`export CUDA_VISIBLE_DEVICES=0`を実行してからコードを実行します。
- `no_multi_processing`オプションは、テストおよびデバッグ用にのみ`True`に設定すべきです。正確なメモリ計測を確保するために、各メモリベンチマークを別々のプロセスで実行することをお勧めします。これにより、`no_multi_processing`が`True`に設定されます。
- モデルのベンチマーク結果を共有する際には、常に環境情報を記述するべきです。異なるGPUデバイス、ライブラリバージョンなどでベンチマーク結果が大きく異なる可能性があるため、ベンチマーク結果単体ではコミュニティにとってあまり有用ではありません。
## Sharing your benchmark
以前、すべての利用可能なコアモデル(当時10モデル)に対して、多くの異なる設定で推論時間のベンチマークが行われました:PyTorchを使用し、TorchScriptの有無、TensorFlowを使用し、XLAの有無などです。これらのテストはすべてCPUで行われました(TensorFlow XLAを除く)。
このアプローチの詳細については、[次のブログポスト](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2)に詳しく説明されており、結果は[こちら](https://docs.google.com/spreadsheets/d/1sryqufw2D0XlUH4sq3e9Wnxu5EAQkaohzrJbd5HdQ_w/edit?usp=sharing)で利用できます。
新しいベンチマークツールを使用すると、コミュニティとベンチマーク結果を共有することがこれまで以上に簡単になります。
- [PyTorchベンチマーク結果](https://github.com/huggingface/transformers/tree/main/examples/pytorch/benchmarking/README.md)。
- [TensorFlowベンチマーク結果](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/benchmarking/README.md)。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/index.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers
[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), [JAX](https://jax.readthedocs.io/en/latest/)のための最先端機械学習。
🤗 Transformers は最先端の学習済みモデルを簡単にダウンロードして学習するAPIとツールを提供します。学習済みモデルを使用することで計算コストと二酸化炭素の排出量を削減でき、またゼロからモデルを学習するために要求される時間とリソースを節約することができます。 これらのモデルは以下のような異なるモダリティにおける一般的なタスクをサポートします:
📝 **自然言語処理**: テキスト分類、 固有表現抽出、 質問応答、 言語モデリング、 文章要約、 機械翻訳、 複数選択、テキスト生成。<br>
🖼️ **コンピュータビジョン**: 画像分類、 物体検出、 セグメンテーション。<br>
🗣️ **音声**: 自動音声認識、音声分類。<br>
🐙 **マルチモーダル**: テーブル質問応答、 光学文字認識(OCR)、 スキャンされたドキュメントからの情報抽出、 動画分類、 visual question answering(視覚的質問応答)。
🤗 Transformers はPyTorch, TensorFlow, JAX間のフレームワーク相互運用性をサポートしています。 これはモデルの各段階で異なるフレームワークを使うための柔軟性を提供します。あるフレームワークで3行のコードでモデルを学習し、別のフレームワークで推論のためにモデルをロードすることが可能です。また、本番環境のデプロイのためにモデルをONNXやTorchScriptのような形式でエクスポートすることも可能です。
[Hub](https://huggingface.co/models), [forum](https://discuss.huggingface.co/), [Discord](https://discord.com/invite/JfAtkvEtRb)で成長中のコミュニティに今日参加しましょう!
## Hugging Faceチームによるカスタムサポートをご希望の場合
<a target="_blank" href="https://huggingface.co/support">
<img alt="HuggingFace Expert Acceleration Program" src="https://cdn-media.huggingface.co/marketing/transformers/new-support-improved.png" style="width: 100%; max-width: 600px; border: 1px solid #eee; border-radius: 4px; box-shadow: 0 1px 2px 0 rgba(0, 0, 0, 0.05);">
</a>
## 目次
ドキュメントは以下の5つのセクションで構成されています:
- **はじめに** は、ライブラリのクイックツアーとライブラリを使い始めるためのインストール手順を提供しています。
- **チュートリアル** は、初心者が始めるのに最適な場所です。このセクションでは、ライブラリを使い始めるために必要な基本的なスキルを習得できます。
- **HOW-TOガイド** は、言語モデリングのために学習済みモデルをfinetuningすることやカスタムモデルの作成と共有の方法などといった特定の目標を達成するための方法を示しています。
- **コンセプトガイド** は、モデルやタスク、そして 🤗 Transformersの設計思想の背景にある基本的にコンセプトや考え方についてより深く考察し解説しています。
- **API** 全てのクラスと関数を説明します:
- **MAIN CLASSES** は、configuration, model, tokenizer, pipelineといった最も重要なクラスについて詳細に説明しています。
- **MODELS** は、ライブラリで実装されているそれぞれのモデルに関連したクラスと関数を詳細に説明しています。
- **INTERNAL HELPERS** は、内部で使用されているユーティリティクラスや関数を詳細に説明しています。
### サポートされているモデル
<!--This list is updated automatically from the README with _make fix-copies_. Do not update manually! -->
1. **[ALBERT](https://huggingface.co/docs/transformers/model_doc/albert)** (Google Research and the Toyota Technological Institute at Chicago から) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut から公開された研究論文: [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942)
1. **[AltCLIP](https://huggingface.co/docs/transformers/main/model_doc/altclip)** (BAAI から) Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell から公開された研究論文: [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679)
1. **[Audio Spectrogram Transformer](https://huggingface.co/docs/transformers/model_doc/audio-spectrogram-transformer)** (MIT から) Yuan Gong, Yu-An Chung, James Glass から公開された研究論文: [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778)
1. **[BART](https://huggingface.co/docs/transformers/model_doc/bart)** (Facebook から) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer から公開された研究論文: [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461)
1. **[BARThez](https://huggingface.co/docs/transformers/model_doc/barthez)** (École polytechnique から) Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis から公開された研究論文: [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)
1. **[BARTpho](https://huggingface.co/docs/transformers/model_doc/bartpho)** (VinAI Research から) Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen から公開された研究論文: [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)
1. **[BEiT](https://huggingface.co/docs/transformers/model_doc/beit)** (Microsoft から) Hangbo Bao, Li Dong, Furu Wei から公開された研究論文: [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254)
1. **[BERT](https://huggingface.co/docs/transformers/model_doc/bert)** (Google から) Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova から公開された研究論文: [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
1. **[BERT For Sequence Generation](https://huggingface.co/docs/transformers/model_doc/bert-generation)** (Google から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
1. **[BERTweet](https://huggingface.co/docs/transformers/model_doc/bertweet)** (VinAI Research から) Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen から公開された研究論文: [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/)
1. **[BigBird-Pegasus](https://huggingface.co/docs/transformers/model_doc/bigbird_pegasus)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
1. **[BigBird-RoBERTa](https://huggingface.co/docs/transformers/model_doc/big_bird)** (Google Research から) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed から公開された研究論文: [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062)
1. **[BioGpt](https://huggingface.co/docs/transformers/main/model_doc/biogpt)** (Microsoft Research AI4Science から) Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu から公開された研究論文: [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9)
1. **[BiT](https://huggingface.co/docs/transformers/main/model_doc/bit)** (Google AI から) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil から公開された研究論文: [Big Transfer (BiT)](https://arxiv.org/abs/1912.11370)Houlsby.
1. **[Blenderbot](https://huggingface.co/docs/transformers/model_doc/blenderbot)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
1. **[BlenderbotSmall](https://huggingface.co/docs/transformers/model_doc/blenderbot-small)** (Facebook から) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston から公開された研究論文: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637)
1. **[BLIP](https://huggingface.co/docs/transformers/main/model_doc/blip)** (Salesforce から) Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi から公開された研究論文: [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086)
1. **[BLOOM](https://huggingface.co/docs/transformers/model_doc/bloom)** (BigScience workshop から) [BigScience Workshop](https://bigscience.huggingface.co/) から公開されました.
1. **[BORT](https://huggingface.co/docs/transformers/model_doc/bort)** (Alexa から) Adrian de Wynter and Daniel J. Perry から公開された研究論文: [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499)
1. **[ByT5](https://huggingface.co/docs/transformers/model_doc/byt5)** (Google Research から) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel から公開された研究論文: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
1. **[CamemBERT](https://huggingface.co/docs/transformers/model_doc/camembert)** (Inria/Facebook/Sorbonne から) Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot から公開された研究論文: [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894)
1. **[CANINE](https://huggingface.co/docs/transformers/model_doc/canine)** (Google Research から) Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting から公開された研究論文: [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874)
1. **[Chinese-CLIP](https://huggingface.co/docs/transformers/model_doc/chinese_clip)** (OFA-Sys から) An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou から公開された研究論文: [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335)
1. **[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)** (OpenAI から) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever から公開された研究論文: [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020)
1. **[CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)** (University of Göttingen から) Timo Lüddecke and Alexander Ecker から公開された研究論文: [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003)
1. **[CodeGen](https://huggingface.co/docs/transformers/model_doc/codegen)** (Salesforce から) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong から公開された研究論文: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)
1. **[Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr)** (Microsoft Research Asia から) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang から公開された研究論文: [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152)
1. **[ConvBERT](https://huggingface.co/docs/transformers/model_doc/convbert)** (YituTech から) Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan から公開された研究論文: [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)
1. **[ConvNeXT](https://huggingface.co/docs/transformers/model_doc/convnext)** (Facebook AI から) Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie から公開された研究論文: [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545)
1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
1. **[CPM](https://huggingface.co/docs/transformers/model_doc/cpm)** (Tsinghua University から) Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun から公開された研究論文: [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413)
1. **[CTRL](https://huggingface.co/docs/transformers/model_doc/ctrl)** (Salesforce から) Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher から公開された研究論文: [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858)
1. **[CvT](https://huggingface.co/docs/transformers/model_doc/cvt)** (Microsoft から) Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang から公開された研究論文: [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808)
1. **[Data2Vec](https://huggingface.co/docs/transformers/model_doc/data2vec)** (Facebook から) Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli から公開された研究論文: [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555)
1. **[DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654)
1. **[DeBERTa-v2](https://huggingface.co/docs/transformers/model_doc/deberta-v2)** (Microsoft から) Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen から公開された研究論文: [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654)
1. **[Decision Transformer](https://huggingface.co/docs/transformers/model_doc/decision_transformer)** (Berkeley/Facebook/Google から) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch から公開された研究論文: [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
1. **[Deformable DETR](https://huggingface.co/docs/transformers/model_doc/deformable_detr)** (SenseTime Research から) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai から公開された研究論文: [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159)
1. **[DeiT](https://huggingface.co/docs/transformers/model_doc/deit)** (Facebook から) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou から公開された研究論文: [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
1. **[DETR](https://huggingface.co/docs/transformers/model_doc/detr)** (Facebook から) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko から公開された研究論文: [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
1. **[DialoGPT](https://huggingface.co/docs/transformers/model_doc/dialogpt)** (Microsoft Research から) Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan から公開された研究論文: [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536)
1. **[DiNAT](https://huggingface.co/docs/transformers/model_doc/dinat)** (SHI Labs から) Ali Hassani and Humphrey Shi から公開された研究論文: [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
1. **[DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert)** (HuggingFace から), Victor Sanh, Lysandre Debut and Thomas Wolf. 同じ手法で GPT2, RoBERTa と Multilingual BERT の圧縮を行いました.圧縮されたモデルはそれぞれ [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)、[DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) と名付けられました. 公開された研究論文: [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108)
1. **[DiT](https://huggingface.co/docs/transformers/model_doc/dit)** (Microsoft Research から) Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei から公開された研究論文: [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378)
1. **[Donut](https://huggingface.co/docs/transformers/model_doc/donut)** (NAVER から), Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park から公開された研究論文: [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664)
1. **[DPR](https://huggingface.co/docs/transformers/model_doc/dpr)** (Facebook から) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih から公開された研究論文: [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906)
1. **[DPT](https://huggingface.co/docs/transformers/master/model_doc/dpt)** (Intel Labs から) René Ranftl, Alexey Bochkovskiy, Vladlen Koltun から公開された研究論文: [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413)
1. **[EfficientNet](https://huggingface.co/docs/transformers/model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
1. **[ELECTRA](https://huggingface.co/docs/transformers/model_doc/electra)** (Google Research/Stanford University から) Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning から公開された研究論文: [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555)
1. **[EncoderDecoder](https://huggingface.co/docs/transformers/model_doc/encoder-decoder)** (Google Research から) Sascha Rothe, Shashi Narayan, Aliaksei Severyn から公開された研究論文: [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)
1. **[ERNIE](https://huggingface.co/docs/transformers/model_doc/ernie)** (Baidu から) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu から公開された研究論文: [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)
1. **[ESM](https://huggingface.co/docs/transformers/model_doc/esm)** (Meta AI から) はトランスフォーマープロテイン言語モデルです. **ESM-1b** は Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus から公開された研究論文: [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118). **ESM-1v** は Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives から公開された研究論文: [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648). **ESM-2** と **ESMFold** は Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives から公開された研究論文: [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)
1. **[FLAN-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)** (Google AI から) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V から公開されたレポジトリー [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) Le, and Jason Wei
1. **[FlauBERT](https://huggingface.co/docs/transformers/model_doc/flaubert)** (CNRS から) Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab から公開された研究論文: [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372)
1. **[FLAVA](https://huggingface.co/docs/transformers/model_doc/flava)** (Facebook AI から) Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela から公開された研究論文: [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482)
1. **[FNet](https://huggingface.co/docs/transformers/model_doc/fnet)** (Google Research から) James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon から公開された研究論文: [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824)
1. **[Funnel Transformer](https://huggingface.co/docs/transformers/model_doc/funnel)** (CMU/Google Brain から) Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le から公開された研究論文: [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236)
1. **[GIT](https://huggingface.co/docs/transformers/main/model_doc/git)** (Microsoft Research から) Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang. から公開された研究論文 [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100)
1. **[GLPN](https://huggingface.co/docs/transformers/model_doc/glpn)** (KAIST から) Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim から公開された研究論文: [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436)
1. **[GPT](https://huggingface.co/docs/transformers/model_doc/openai-gpt)** (OpenAI から) Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever から公開された研究論文: [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/)
1. **[GPT Neo](https://huggingface.co/docs/transformers/model_doc/gpt_neo)** (EleutherAI から) Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy から公開されたレポジトリー : [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo)
1. **[GPT NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)** (EleutherAI から) Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach から公開された研究論文: [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745)
1. **[GPT NeoX Japanese](https://huggingface.co/docs/transformers/model_doc/gpt_neox_japanese)** (ABEJA から) Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori からリリース.
1. **[GPT-2](https://huggingface.co/docs/transformers/model_doc/gpt2)** (OpenAI から) Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever** から公開された研究論文: [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/)
1. **[GPT-J](https://huggingface.co/docs/transformers/model_doc/gptj)** (EleutherAI から) Ben Wang and Aran Komatsuzaki から公開されたレポジトリー [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/)
1. **[GPT-Sw3](https://huggingface.co/docs/transformers/main/model_doc/gpt-sw3)** (AI-Sweden から) Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren から公開された研究論文: [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf)
1. **[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit)** (UCSD, NVIDIA から) Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang から公開された研究論文: [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094)
1. **[Hubert](https://huggingface.co/docs/transformers/model_doc/hubert)** (Facebook から) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed から公開された研究論文: [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447)
1. **[I-BERT](https://huggingface.co/docs/transformers/model_doc/ibert)** (Berkeley から) Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer から公開された研究論文: [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321)
1. **[ImageGPT](https://huggingface.co/docs/transformers/model_doc/imagegpt)** (OpenAI から) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever から公開された研究論文: [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/)
1. **[Jukebox](https://huggingface.co/docs/transformers/model_doc/jukebox)** (OpenAI から) Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever から公開された研究論文: [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf)
1. **[LayoutLM](https://huggingface.co/docs/transformers/model_doc/layoutlm)** (Microsoft Research Asia から) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou から公開された研究論文: [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318)
1. **[LayoutLMv2](https://huggingface.co/docs/transformers/model_doc/layoutlmv2)** (Microsoft Research Asia から) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou から公開された研究論文: [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740)
1. **[LayoutLMv3](https://huggingface.co/docs/transformers/model_doc/layoutlmv3)** (Microsoft Research Asia から) Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei から公開された研究論文: [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
1. **[LayoutXLM](https://huggingface.co/docs/transformers/model_doc/layoutxlm)** (Microsoft Research Asia から) Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei から公開された研究論文: [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836)
1. **[LED](https://huggingface.co/docs/transformers/model_doc/led)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
1. **[LeViT](https://huggingface.co/docs/transformers/model_doc/levit)** (Meta AI から) Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze から公開された研究論文: [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
1. **[LiLT](https://huggingface.co/docs/transformers/model_doc/lilt)** (South China University of Technology から) Jiapeng Wang, Lianwen Jin, Kai Ding から公開された研究論文: [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669)
1. **[Longformer](https://huggingface.co/docs/transformers/model_doc/longformer)** (AllenAI から) Iz Beltagy, Matthew E. Peters, Arman Cohan から公開された研究論文: [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150)
1. **[LongT5](https://huggingface.co/docs/transformers/model_doc/longt5)** (Google AI から) Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang から公開された研究論文: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916)
1. **[LUKE](https://huggingface.co/docs/transformers/model_doc/luke)** (Studio Ousia から) Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto から公開された研究論文: [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057)
1. **[LXMERT](https://huggingface.co/docs/transformers/model_doc/lxmert)** (UNC Chapel Hill から) Hao Tan and Mohit Bansal から公開された研究論文: [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490)
1. **[M-CTC-T](https://huggingface.co/docs/transformers/model_doc/mctct)** (Facebook から) Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert から公開された研究論文: [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161)
1. **[M2M100](https://huggingface.co/docs/transformers/model_doc/m2m_100)** (Facebook から) Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin から公開された研究論文: [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125)
1. **[MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)** Jörg Tiedemann から. [OPUS](http://opus.nlpl.eu/) を使いながら学習された "Machine translation" (マシントランスレーション) モデル. [Marian Framework](https://marian-nmt.github.io/) はMicrosoft Translator Team が現在開発中です.
1. **[MarkupLM](https://huggingface.co/docs/transformers/model_doc/markuplm)** (Microsoft Research Asia から) Junlong Li, Yiheng Xu, Lei Cui, Furu Wei から公開された研究論文: [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518)
1. **[Mask2Former](https://huggingface.co/docs/transformers/main/model_doc/mask2former)** (FAIR and UIUC から) Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. から公開された研究論文 [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527)
1. **[MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer)** (Meta and UIUC から) Bowen Cheng, Alexander G. Schwing, Alexander Kirillov から公開された研究論文: [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278)
1. **[mBART](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer から公開された研究論文: [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210)
1. **[mBART-50](https://huggingface.co/docs/transformers/model_doc/mbart)** (Facebook から) Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan から公開された研究論文: [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401)
1. **[Megatron-BERT](https://huggingface.co/docs/transformers/model_doc/megatron-bert)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
1. **[Megatron-GPT2](https://huggingface.co/docs/transformers/model_doc/megatron_gpt2)** (NVIDIA から) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro から公開された研究論文: [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053)
1. **[mLUKE](https://huggingface.co/docs/transformers/model_doc/mluke)** (Studio Ousia から) Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka から公開された研究論文: [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151)
1. **[MobileBERT](https://huggingface.co/docs/transformers/model_doc/mobilebert)** (CMU/Google Brain から) Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou から公開された研究論文: [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984)
1. **[MobileNetV1](https://huggingface.co/docs/transformers/model_doc/mobilenet_v1)** (Google Inc. から) Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam から公開された研究論文: [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861)
1. **[MobileNetV2](https://huggingface.co/docs/transformers/model_doc/mobilenet_v2)** (Google Inc. から) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen から公開された研究論文: [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
1. **[MobileViT](https://huggingface.co/docs/transformers/model_doc/mobilevit)** (Apple から) Sachin Mehta and Mohammad Rastegari から公開された研究論文: [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178)
1. **[MPNet](https://huggingface.co/docs/transformers/model_doc/mpnet)** (Microsoft Research から) Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu から公開された研究論文: [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297)
1. **[MT5](https://huggingface.co/docs/transformers/model_doc/mt5)** (Google AI から) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel から公開された研究論文: [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934)
1. **[MVP](https://huggingface.co/docs/transformers/model_doc/mvp)** (RUC AI Box から) Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen から公開された研究論文: [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131)
1. **[NAT](https://huggingface.co/docs/transformers/model_doc/nat)** (SHI Labs から) Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi から公開された研究論文: [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143)
1. **[Nezha](https://huggingface.co/docs/transformers/model_doc/nezha)** (Huawei Noah’s Ark Lab から) Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu から公開された研究論文: [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204)
1. **[NLLB](https://huggingface.co/docs/transformers/model_doc/nllb)** (Meta から) the NLLB team から公開された研究論文: [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672)
1. **[Nyströmformer](https://huggingface.co/docs/transformers/model_doc/nystromformer)** (the University of Wisconsin - Madison から) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh から公開された研究論文: [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902)
1. **[OneFormer](https://huggingface.co/docs/transformers/main/model_doc/oneformer)** (SHI Labs から) Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi から公開された研究論文: [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220)
1. **[OPT](https://huggingface.co/docs/transformers/master/model_doc/opt)** (Meta AI から) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al から公開された研究論文: [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068)
1. **[OWL-ViT](https://huggingface.co/docs/transformers/model_doc/owlvit)** (Google AI から) Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby から公開された研究論文: [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230)
1. **[Pegasus](https://huggingface.co/docs/transformers/model_doc/pegasus)** (Google から) Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu から公開された研究論文: [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777)
1. **[PEGASUS-X](https://huggingface.co/docs/transformers/model_doc/pegasus_x)** (Google から) Jason Phang, Yao Zhao, and Peter J. Liu から公開された研究論文: [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347)
1. **[Perceiver IO](https://huggingface.co/docs/transformers/model_doc/perceiver)** (Deepmind から) Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira から公開された研究論文: [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795)
1. **[PhoBERT](https://huggingface.co/docs/transformers/model_doc/phobert)** (VinAI Research から) Dat Quoc Nguyen and Anh Tuan Nguyen から公開された研究論文: [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/)
1. **[PLBart](https://huggingface.co/docs/transformers/model_doc/plbart)** (UCLA NLP から) Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang から公開された研究論文: [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333)
1. **[PoolFormer](https://huggingface.co/docs/transformers/model_doc/poolformer)** (Sea AI Labs から) Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng から公開された研究論文: [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418)
1. **[ProphetNet](https://huggingface.co/docs/transformers/model_doc/prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
1. **[QDQBert](https://huggingface.co/docs/transformers/model_doc/qdqbert)** (NVIDIA から) Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius から公開された研究論文: [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602)
1. **[RAG](https://huggingface.co/docs/transformers/model_doc/rag)** (Facebook から) Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela から公開された研究論文: [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
1. **[REALM](https://huggingface.co/docs/transformers/model_doc/realm.html)** (Google Research から) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang から公開された研究論文: [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909)
1. **[Reformer](https://huggingface.co/docs/transformers/model_doc/reformer)** (Google Research から) Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya から公開された研究論文: [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)
1. **[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet)** (META Platforms から) Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár から公開された研究論文: [Designing Network Design Space](https://arxiv.org/abs/2003.13678)
1. **[RemBERT](https://huggingface.co/docs/transformers/model_doc/rembert)** (Google Research から) Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder から公開された研究論文: [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821)
1. **[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)** (Microsoft Research から) Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun から公開された研究論文: [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
1. **[RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta)** (Facebook から), Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov から公開された研究論文: [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)
1. **[RoBERTa-PreLayerNorm](https://huggingface.co/docs/transformers/main/model_doc/roberta-prelayernorm)** (Facebook から) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli から公開された研究論文: [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038)
1. **[RoCBert](https://huggingface.co/docs/transformers/main/model_doc/roc_bert)** (WeChatAI から) HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou から公開された研究論文: [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf)
1. **[RoFormer](https://huggingface.co/docs/transformers/model_doc/roformer)** (ZhuiyiTechnology から), Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu から公開された研究論文: [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864)
1. **[SegFormer](https://huggingface.co/docs/transformers/model_doc/segformer)** (NVIDIA から) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo から公開された研究論文: [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203)
1. **[SEW](https://huggingface.co/docs/transformers/model_doc/sew)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
1. **[SEW-D](https://huggingface.co/docs/transformers/model_doc/sew_d)** (ASAPP から) Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi から公開された研究論文: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
1. **[SpeechToTextTransformer](https://huggingface.co/docs/transformers/model_doc/speech_to_text)** (Facebook から), Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino から公開された研究論文: [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171)
1. **[SpeechToTextTransformer2](https://huggingface.co/docs/transformers/model_doc/speech_to_text_2)** (Facebook から), Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau から公開された研究論文: [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678)
1. **[Splinter](https://huggingface.co/docs/transformers/model_doc/splinter)** (Tel Aviv University から), Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy から公開された研究論文: [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438)
1. **[SqueezeBERT](https://huggingface.co/docs/transformers/model_doc/squeezebert)** (Berkeley から) Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer から公開された研究論文: [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316)
1. **[Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)** (Microsoft から) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo から公開された研究論文: [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
1. **[Swin Transformer V2](https://huggingface.co/docs/transformers/model_doc/swinv2)** (Microsoft から) Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo から公開された研究論文: [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)
1. **[Swin2SR](https://huggingface.co/docs/transformers/main/model_doc/swin2sr)** (University of Würzburg から) Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte から公開された研究論文: [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)
1. **[SwitchTransformers](https://huggingface.co/docs/transformers/main/model_doc/switch_transformers)** (Google から) William Fedus, Barret Zoph, Noam Shazeer から公開された研究論文: [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
1. **[T5](https://huggingface.co/docs/transformers/model_doc/t5)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開された研究論文: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683)
1. **[T5v1.1](https://huggingface.co/docs/transformers/model_doc/t5v1.1)** (Google AI から) Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu から公開されたレポジトリー [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511)
1. **[Table Transformer](https://huggingface.co/docs/transformers/model_doc/table-transformer)** (Microsoft Research から) Brandon Smock, Rohith Pesala, Robin Abraham から公開された研究論文: [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061)
1. **[TAPAS](https://huggingface.co/docs/transformers/model_doc/tapas)** (Google AI から) Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos から公開された研究論文: [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349)
1. **[TAPEX](https://huggingface.co/docs/transformers/model_doc/tapex)** (Microsoft Research から) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou から公開された研究論文: [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653)
1. **[Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer)** (HuggingFace から).
1. **[TimeSformer](https://huggingface.co/docs/transformers/main/model_doc/timesformer)** (Facebook から) Gedas Bertasius, Heng Wang, Lorenzo Torresani から公開された研究論文: [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)
1. **[Trajectory Transformer](https://huggingface.co/docs/transformers/model_doc/trajectory_transformers)** (the University of California at Berkeley から) Michael Janner, Qiyang Li, Sergey Levine から公開された研究論文: [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039)
1. **[Transformer-XL](https://huggingface.co/docs/transformers/model_doc/transfo-xl)** (Google/CMU から) Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov から公開された研究論文: [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860)
1. **[TrOCR](https://huggingface.co/docs/transformers/model_doc/trocr)** (Microsoft から), Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei から公開された研究論文: [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282)
1. **[UL2](https://huggingface.co/docs/transformers/model_doc/ul2)** (Google Research から) Yi Tay, Mostafa Dehghani, Vinh Q から公開された研究論文: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (Microsoft Research から) Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang から公開された研究論文: [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (Microsoft Research から) Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu から公開された研究論文: [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
1. **[UPerNet](https://huggingface.co/docs/transformers/main/model_doc/upernet)** (Peking University から) Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun. から公開された研究論文 [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221)
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (Tsinghua University and Nankai University から) Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu から公開された研究論文: [Visual Attention Network](https://arxiv.org/abs/2202.09741)
1. **[VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)** (Multimedia Computing Group, Nanjing University から) Zhan Tong, Yibing Song, Jue Wang, Limin Wang から公開された研究論文: [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602)
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (NAVER AI Lab/Kakao Enterprise/Kakao Brain から) Wonjae Kim, Bokyung Son, Ildoo Kim から公開された研究論文: [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (UCLA NLP から) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang から公開された研究論文: [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557)
1. **[ViT Hybrid](https://huggingface.co/docs/transformers/main/model_doc/vit_hybrid)** (Google AI から) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby から公開された研究論文: [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
1. **[ViTMAE](https://huggingface.co/docs/transformers/model_doc/vit_mae)** (Meta AI から) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick から公開された研究論文: [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377)
1. **[ViTMSN](https://huggingface.co/docs/transformers/model_doc/vit_msn)** (Meta AI から) Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas から公開された研究論文: [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141)
1. **[Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/wav2vec2)** (Facebook AI から) Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477)
1. **[Wav2Vec2-Conformer](https://huggingface.co/docs/transformers/model_doc/wav2vec2-conformer)** (Facebook AI から) Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino から公開された研究論文: [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171)
1. **[Wav2Vec2Phoneme](https://huggingface.co/docs/transformers/model_doc/wav2vec2_phoneme)** (Facebook AI から) Qiantong Xu, Alexei Baevski, Michael Auli から公開された研究論文: [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
1. **[WavLM](https://huggingface.co/docs/transformers/model_doc/wavlm)** (Microsoft Research から) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei から公開された研究論文: [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
1. **[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)** (OpenAI から) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever から公開された研究論文: [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf)
1. **[X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)** (Microsoft Research から) Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling から公開された研究論文: [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816)
1. **[XGLM](https://huggingface.co/docs/transformers/model_doc/xglm)** (From Facebook AI) Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li から公開された研究論文: [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668)
1. **[XLM](https://huggingface.co/docs/transformers/model_doc/xlm)** (Facebook から) Guillaume Lample and Alexis Conneau から公開された研究論文: [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291)
1. **[XLM-ProphetNet](https://huggingface.co/docs/transformers/model_doc/xlm-prophetnet)** (Microsoft Research から) Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou から公開された研究論文: [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063)
1. **[XLM-RoBERTa](https://huggingface.co/docs/transformers/model_doc/xlm-roberta)** (Facebook AI から), Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov から公開された研究論文: [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116)
1. **[XLM-RoBERTa-XL](https://huggingface.co/docs/transformers/model_doc/xlm-roberta-xl)** (Facebook AI から), Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau から公開された研究論文: [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572)
1. **[XLNet](https://huggingface.co/docs/transformers/model_doc/xlnet)** (Google/CMU から) Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le から公開された研究論文: [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237)
1. **[XLS-R](https://huggingface.co/docs/transformers/model_doc/xls_r)** (Facebook AI から) Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli から公開された研究論文: [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296)
1. **[XLSR-Wav2Vec2](https://huggingface.co/docs/transformers/model_doc/xlsr_wav2vec2)** (Facebook AI から) Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli から公開された研究論文: [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979)
1. **[YOLOS](https://huggingface.co/docs/transformers/model_doc/yolos)** (Huazhong University of Science & Technology から) Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu から公開された研究論文: [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666)
1. **[YOSO](https://huggingface.co/docs/transformers/model_doc/yoso)** (the University of Wisconsin - Madison から) Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh から公開された研究論文: [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
### サポートされているフレームワーク
以下のテーブルはそれぞれのモデルでサポートされているライブラリを示しています。"slow"と呼ばれるPythonトークナイザー、🤗 Tokenizers ライブラリによる"fast"トークナイザー、PyTorch, TensorFlow, Flaxの5つのそれぞれがサポートされているかを示しています。
<!--This table is updated automatically from the auto modules with _make fix-copies_. Do not update manually!-->
| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
| BLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
<!-- End table-->
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/tflite.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide)は、モバイルフォン、組み込みシステム、およびモノのインターネット(IoT)デバイスなど、リソースに制約のあるデバイスに機械学習モデルを展開するための軽量なフレームワークです。TFLiteは、計算能力、メモリ、および電力消費が限られているこれらのデバイス上でモデルを効率的に最適化して実行するために設計されています。
TensorFlow Liteモデルは、`.tflite`ファイル拡張子で識別される特別な効率的なポータブル形式で表されます。
🤗 Optimumは、🤗 TransformersモデルをTFLiteにエクスポートするための機能を`exporters.tflite`モジュールを介して提供しています。サポートされているモデルアーキテクチャのリストについては、[🤗 Optimumのドキュメント](https://huggingface.co/docs/optimum/exporters/tflite/overview)をご参照ください。
モデルをTFLiteにエクスポートするには、必要な依存関係をインストールしてください:
```bash
pip install optimum[exporters-tf]
```
すべての利用可能な引数を確認するには、[🤗 Optimumドキュメント](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model)を参照するか、コマンドラインでヘルプを表示してください:
```bash
optimum-cli export tflite --help
```
🤗 Hubからモデルのチェックポイントをエクスポートするには、例えば `bert-base-uncased` を使用する場合、次のコマンドを実行します:
```bash
optimum-cli export tflite --model bert-base-uncased --sequence_length 128 bert_tflite/
```
進行状況を示すログが表示され、生成された `model.tflite` が保存された場所も表示されるはずです:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
上記の例は🤗 Hubからチェックポイントをエクスポートする方法を示しています。ローカルモデルをエクスポートする場合、まずモデルの重みファイルとトークナイザファイルを同じディレクトリ(`local_path`)に保存したことを確認してください。CLIを使用する場合、🤗 Hubのチェックポイント名の代わりに`model`引数に`local_path`を渡します。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/add_tensorflow_model.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
ライセンス:Apache License、バージョン2.0(「ライセンス」)に基づいています。このファイルは、ライセンスに準拠していない限り、使用できません。ライセンスのコピーは以下から入手できます:
http://www.apache.org/licenses/LICENSE-2.0
適用法に従って必要な場合、または書面で同意した場合を除き、ライセンスの下で配布されるソフトウェアは、「AS IS」の基盤で、明示または黙示を問わず、いかなる保証や条件も含みません。ライセンスの詳細については、ライセンス文書をご覧ください。
⚠️ このファイルはMarkdown形式ですが、弊社のドキュメントビルダー(MDXに類似した特定の構文を含む)を含むため、お使いのMarkdownビューアでは正しく表示されない場合があります。
-->
# How to convert a 🤗 Transformers model to TensorFlow?
🤗 Transformersを使用するために複数のフレームワークが利用可能であることは、アプリケーションを設計する際にそれぞれの強みを活かす柔軟性を提供しますが、
互換性をモデルごとに追加する必要があることを意味します。しかし、幸いなことに
既存のモデルにTensorFlow互換性を追加することは、[ゼロから新しいモデルを追加すること](add_new_model)よりも簡単です!
大規模なTensorFlowモデルの詳細を理解したり、主要なオープンソースの貢献を行ったり、
選択したモデルをTensorFlowで有効にするためのガイドです。
このガイドは、コミュニティのメンバーであるあなたに、TensorFlowモデルの重みおよび/または
アーキテクチャを🤗 Transformersで使用するために、Hugging Faceチームからの最小限の監視で貢献できる力を与えます。新しいモデルを書くことは小さな偉業ではありませんが、
このガイドを読むことで、それがローラーコースターのようなものから散歩のようなものになることを願っています🎢🚶。
このプロセスをますます簡単にするために、私たちの共通の経験を活用することは非常に重要ですので、
このガイドの改善を提案することを強くお勧めします!
さらに詳しく調べる前に、以下のリソースをチェックすることをお勧めします。🤗 Transformersが初めての場合:
- [🤗 Transformersの一般的な概要](add_new_model#general-overview-of-transformers)
- [Hugging FaceのTensorFlow哲学](https://huggingface.co/blog/tensorflow-philosophy)
このガイドの残りの部分では、新しいTensorFlowモデルアーキテクチャを追加するために必要なもの、
PyTorchをTensorFlowモデルの重みに変換する手順、およびMLフレームワーク間の不一致を効率的にデバッグする方法について学びます。それでは始めましょう!
<Tip>
使用したいモデルに対応するTensorFlowアーキテクチャがすでに存在するかどうかわからないですか?
選択したモデルの`config.json`の`model_type`フィールドをチェックしてみてください
([例](https://huggingface.co/bert-base-uncased/blob/main/config.json#L14))。
🤗 Transformersの該当するモデルフォルダに、名前が"modeling_tf"で始まるファイルがある場合、それは対応するTensorFlow
アーキテクチャを持っていることを意味します([例](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert))。
</Tip>
## Step-by-step guide to add TensorFlow model architecture code
大規模なモデルアーキテクチャを設計する方法はさまざまであり、その設計を実装する方法もさまざまです。
しかし、[🤗 Transformersの一般的な概要](add_new_model#general-overview-of-transformers)から
思い出していただけるかもしれませんが、私たちは意見のあるグループです - 🤗 Transformersの使いやすさは一貫性のある設計の選択肢に依存しています。経験から、TensorFlowモデルを追加する際に重要なことをいくつかお伝えできます:
- 車輪を再発明しないでください!ほとんどの場合、確認すべき少なくとも2つの参照実装があります。それは、
あなたが実装しているモデルのPyTorchバージョンと、同じ種類の問題に対する他のTensorFlowモデルです。
- 優れたモデル実装は時間の試練を乗り越えます。これは、コードがきれいだからではなく、コードが明確で、デバッグしやすく、
構築しやすいからです。TensorFlow実装でPyTorch実装と一致するパターンを複製し、PyTorch実装との不一致を最小限に抑えることで、
あなたの貢献が長期間にわたって有用であることを保証します。
- 行き詰まったら助けを求めてください! 🤗 Transformersチームはここにいますし、おそらくあなたが直面している同じ問題に対する解決策を見つけています。
TensorFlowモデルアーキテクチャを追加するために必要なステップの概要は次のとおりです:
1. 変換したいモデルを選択
2. transformersの開発環境を準備
3. (オプション)理論的な側面と既存の実装を理解
4. モデルアーキテクチャを実装
5. モデルのテストを実装
6. プルリクエストを提出
7. (オプション)デモを構築して世界と共有
### 1.-3. Prepare your model contribution
**1. 変換したいモデルを選択する**
まず、基本から始めましょう。最初に知っておく必要があることは、変換したいアーキテクチャです。
特定のアーキテクチャを決めていない場合、🤗 Transformers チームに提案を求めることは、影響を最大限にする素晴らしい方法です。
チームは、TensorFlow サイドで不足している最も注目されるアーキテクチャに向けてガイドします。
TensorFlow で使用したい特定のモデルに、🤗 Transformers に既に TensorFlow アーキテクチャの実装が存在しているが、重みが不足している場合、
このページの[重みの追加セクション](#adding-tensorflow-weights-to-hub)に直接移動してください。
簡単にするために、このガイドの残りの部分では、TensorFlow バージョンの *BrandNewBert* を貢献することを決定したと仮定しています
(これは、[新しいモデルの追加ガイド](add_new_model)での例と同じです)。
<Tip>
TensorFlow モデルのアーキテクチャに取り組む前に、それを行うための進行中の取り組みがないかを再確認してください。
GitHub ページの[プルリクエスト](https://github.com/huggingface/transformers/pulls?q=is%3Apr)で `BrandNewBert` を検索して、
TensorFlow 関連のプルリクエストがないことを確認できます。
</Tip>
**2. transformers 開発環境の準備**
モデルアーキテクチャを選択したら、意向を示すためにドラフト PR を開くための環境を設定してください。
以下の手順に従って、環境を設定し、ドラフト PR を開いてください。
1. リポジトリのページで 'Fork' ボタンをクリックして、[リポジトリ](https://github.com/huggingface/transformers)をフォークします。
これにより、コードのコピーが GitHub ユーザーアカウントの下に作成されます。
2. ローカルディスクにある 'transformers' フォークをクローンし、ベースリポジトリをリモートとして追加します:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. 開発環境を設定します。たとえば、以下のコマンドを実行してください:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
依存関係が増えているため、OSに応じて、Transformersのオプションの依存関係の数が増えるかもしれません。その場合は、TensorFlowをインストールしてから次のコマンドを実行してください。
```bash
pip install -e ".[quality]"
```
**注意:** CUDAをインストールする必要はありません。新しいモデルをCPUで動作させることが十分です。
4. メインブランチからわかりやすい名前のブランチを作成してください。
```bash
git checkout -b add_tf_brand_new_bert
```
5. 現在のmainブランチにフェッチしてリベースする
```bash
git fetch upstream
git rebase upstream/main
```
6. `transformers/src/models/brandnewbert/`に`modeling_tf_brandnewbert.py`という名前の空の`.py`ファイルを追加します。これはあなたのTensorFlowモデルファイルです。
7. 以下を使用して変更内容をアカウントにプッシュします:
```bash
git add .
git commit -m "initial commit"
git push -u origin add_tf_brand_new_bert
```
8. GitHub上でフォークしたウェブページに移動し、「プルリクエスト」をクリックします。将来の変更に備えて、Hugging Face チームのメンバーのGitHubハンドルをレビュアーとして追加してください。
9. GitHubのプルリクエストウェブページの右側にある「ドラフトに変換」をクリックして、プルリクエストをドラフトに変更します。
これで、🤗 Transformers内に*BrandNewBert*をTensorFlowに移植するための開発環境が設定されました。
**3. (任意) 理論的な側面と既存の実装を理解する**
*BrandNewBert*の論文が存在する場合、その記述的な作業を読む時間を取るべきです。論文には理解が難しい大きなセクションがあるかもしれません。その場合でも問題ありません - 心配しないでください!目標は論文の理論的な理解を深めることではなく、🤗 Transformersを使用してTensorFlowでモデルを効果的に再実装するために必要な情報を抽出することです。とは言え、理論的な側面にあまり時間をかける必要はありません。代わりに、既存のモデルのドキュメンテーションページ(たとえば、[BERTのモデルドキュメント](model_doc/bert)など)に焦点を当てるべきです。
実装するモデルの基本を把握した後、既存の実装を理解することは重要です。これは、動作する実装がモデルに対する期待と一致することを確認する絶好の機会であり、TensorFlow側での技術的な課題を予測することもできます。
情報の多さに圧倒されていると感じるのは完全に自然です。この段階ではモデルのすべての側面を理解する必要はありません。ただし、[フォーラム](https://discuss.huggingface.co/)で急な質問を解決することを強くお勧めします。
### 4. Model implementation
さあ、いよいよコーディングを始めましょう。お勧めする出発点は、PyTorchファイルそのものです。
`src/transformers/models/brand_new_bert/`内の`modeling_brand_new_bert.py`の内容を
`modeling_tf_brand_new_bert.py`にコピーします。このセクションの目標は、
🤗 Transformersのインポート構造を更新し、`TFBrandNewBert`と
`TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`を正常に読み込む動作するTensorFlow *BrandNewBert*モデルを
インポートできるようにすることです。
残念ながら、PyTorchモデルをTensorFlowに変換する明確な方法はありません。ただし、プロセスをできるだけスムーズにするためのヒントを以下に示します:
- すべてのクラスの名前の前に `TF` を付けます(例: `BrandNewBert` は `TFBrandNewBert` になります)。
- ほとんどのPyTorchの操作には、直接TensorFlowの代替があります。たとえば、`torch.nn.Linear` は `tf.keras.layers.Dense` に対応し、`torch.nn.Dropout` は `tf.keras.layers.Dropout` に対応します。特定の操作について不明確な場合は、[TensorFlowのドキュメント](https://www.tensorflow.org/api_docs/python/tf)または[PyTorchのドキュメント](https://pytorch.org/docs/stable/)を参照できます。
- 🤗 Transformersのコードベースにパターンが見つかります。特定の操作に直接的な代替がない場合、誰かがすでに同じ問題に対処している可能性が高いです。
- デフォルトでは、PyTorchと同じ変数名と構造を維持します。これにより、デバッグや問題の追跡、修正の追加が容易になります。
- 一部のレイヤーには、各フレームワークで異なるデフォルト値があります。注目すべき例は、バッチ正規化レイヤーの epsilon です(PyTorchでは`1e-5`、[TensorFlowでは](https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization) `1e-3` です)。ドキュメントを再確認してください!
- PyTorchの `nn.Parameter` 変数は通常、TF Layerの `build()` 内で初期化する必要があります。次の例を参照してください:[PyTorch](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_vit_mae.py#L212) / [TensorFlow](https://github.com/huggingface/transformers/blob/655f72a6896c0533b1bdee519ed65a059c2425ac/src/transformers/models/vit_mae/modeling_tf_vit_mae.py#L220)
- PyTorchモデルに関数の上部に `#copied from ...` がある場合、TensorFlowモデルも同じアーキテクチャからその関数を借りることができる可能性が高いです。TensorFlowアーキテクチャがある場合です。
- TensorFlow関数内で `name`属性を正しく設定することは、`from_pt=True`のウェイトのクロスロードロードを行うために重要です。通常、`name`はPyTorchコード内の対応する変数の名前です。`name`が正しく設定されていない場合、モデルウェイトのロード時にエラーメッセージで表示されます。
- ベースモデルクラス `BrandNewBertModel` のロジックは実際には `TFBrandNewBertMainLayer` にあります。これはKerasレイヤーのサブクラスです([例](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L719))。`TFBrandNewBertModel` は、単にこのレイヤーのラッパーです。
- モデルを読み込むためには、Kerasモデルをビルドする必要があります。そのため、`TFBrandNewBertPreTrainedModel` はモデルへの入力の例、`dummy_inputs` を持つ必要があります([例](https://github.com/huggingface/transformers/blob/4fd32a1f499e45f009c2c0dea4d81c321cba7e02/src/transformers/models/bert/modeling_tf_bert.py#L916))。
- 表示が止まった場合は、助けを求めてください。私たちはあなたのお手伝いにここにいます! 🤗
モデルファイル自体だけでなく、モデルクラスと関連するドキュメンテーションページへのポインターも追加する必要があります。他のPRのパターンに従ってこの部分を完了できます
([例](https://github.com/huggingface/transformers/pull/18020/files))。
以下は手動での変更が必要な一覧です:
- *BrandNewBert*のすべてのパブリッククラスを `src/transformers/__init__.py` に含める
- *BrandNewBert*クラスを `src/transformers/models/auto/modeling_tf_auto.py` の対応するAutoクラスに追加
- ドキュメンテーションテストファイルのリストにモデリングファイルを追加する `utils/documentation_tests.txt`
- `src/transformers/utils/dummy_tf_objects.py` に関連する *BrandNewBert* に関連する遅延ロードクラスを追加
- `src/transformers/models/brand_new_bert/__init__.py` でパブリッククラスのインポート構造を更新
- `docs/source/en/model_doc/brand_new_bert.md` に *BrandNewBert* のパブリックメソッドのドキュメンテーションポインターを追加
- `docs/source/en/model_doc/brand_new_bert.md` の *BrandNewBert* の貢献者リストに自分自身を追加
- 最後に、`docs/source/en/index.md` の *BrandNewBert* のTensorFlow列に緑色のチェックマーク ✅ を追加
モデルアーキテクチャが準備できていることを確認するために、以下のチェックリストを実行してください:
1. 訓練時に異なる動作をするすべてのレイヤー(例:Dropout)は、`training`引数を使用して呼び出され、それが最上位クラスから伝播されます。
2. 可能な限り `#copied from ...` を使用しました
3. `TFBrandNewBertMainLayer` およびそれを使用するすべてのクラスの `call` 関数が `@unpack_inputs` でデコレートされています
4. `TFBrandNewBertMainLayer` は `@keras_serializable` でデコレートされています
5. PyTorchウェイトからTensorFlowウェイトを使用してTensorFlowモデルをロードできます `TFBrandNewBert.from_pretrained(model_repo, from_pt=True)`
6. 予期される入力形式を使用してTensorFlowモデルを呼び出すことができます
### 5. Add model tests
やったね、TensorFlowモデルを実装しました!
今度は、モデルが期待通りに動作することを確認するためのテストを追加する時間です。
前のセクションと同様に、`tests/models/brand_new_bert/`ディレクトリ内の`test_modeling_brand_new_bert.py`ファイルを`test_modeling_tf_brand_new_bert.py`にコピーし、必要なTensorFlowの置換を行うことをお勧めします。
今の段階では、すべての`.from_pretrained()`呼び出しで、既存のPyTorchの重みをロードするために`from_pt=True`フラグを使用する必要があります。
作業が完了したら、テストを実行する準備が整いました! 😬
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
最も可能性の高い結果は、多くのエラーが表示されることです。心配しないでください、これは予想される動作です!
MLモデルのデバッグは非常に難しいとされており、成功の鍵は忍耐力(と`breakpoint()`)です。私たちの経験では、
最も難しい問題はMLフレームワーク間の微妙な不一致から発生し、これについてはこのガイドの最後にいくつかのポインタを示します。
他の場合では、一般的なテストが直接モデルに適用できない場合もあり、その場合はモデルのテストクラスレベルでオーバーライドを提案します。
問題の種類に関係なく、詰まった場合は、ドラフトのプルリクエストで助けを求めることをためらわないでください。
すべてのテストがパスしたら、おめでとうございます。あなたのモデルはほぼ🤗 Transformersライブラリに追加する準備が整いました!🎉
**6. プルリクエストを提出する**
実装とテストが完了したら、プルリクエストを提出する準備が整いました。コードをプッシュする前に、
コードフォーマットユーティリティである `make fixup` 🪄 を実行してください。
これにより、自動的なチェックに失敗する可能性のあるフォーマットの問題が自動的に修正されます。
これで、ドラフトプルリクエストを実際のプルリクエストに変換する準備が整いました。
これを行うには、「レビュー待ち」ボタンをクリックし、Joao(`@gante`)とMatt(`@Rocketknight1`)をレビュワーとして追加します。
モデルプルリクエストには少なくとも3人のレビュワーが必要ですが、モデルに適切な追加のレビュワーを見つけるのは彼らの責任です。
すべてのレビュワーがプルリクエストの状態に満足したら、最後のアクションポイントは、`.from_pretrained()` 呼び出しで `from_pt=True` フラグを削除することです。
TensorFlowのウェイトが存在しないため、それらを追加する必要があります!これを行う方法については、以下のセクションを確認してください。
最後に、TensorFlowのウェイトがマージされ、少なくとも3人のレビューアが承認し、すべてのCIチェックが
成功した場合、テストをローカルで最後にもう一度確認してください。
```bash
NVIDIA_TF32_OVERRIDE=0 RUN_SLOW=1 RUN_PT_TF_CROSS_TESTS=1 \
py.test -vv tests/models/brand_new_bert/test_modeling_tf_brand_new_bert.py
```
そして、あなたのPRをマージします!マイルストーン達成おめでとうございます 🎉
**7. (Optional) デモを作成して世界と共有**
オープンソースの最も難しい部分の1つは、発見です。あなたの素晴らしいTensorFlowの貢献が存在することを他のユーザーがどのように知ることができるでしょうか?適切なコミュニケーションです! 📣
コミュニティとモデルを共有する主要な方法は2つあります。
- デモを作成します。これにはGradioデモ、ノートブック、およびモデルを紹介するための他の楽しい方法が含まれます。[コミュニティ駆動のデモ](https://huggingface.co/docs/transformers/community)にノートブックを追加することを強くお勧めします。
- TwitterやLinkedInなどのソーシャルメディアでストーリーを共有します。あなたの仕事に誇りを持ち、コミュニティとあなたの成果を共有するべきです - あなたのモデルは今や世界中の何千人ものエンジニアや研究者によって使用される可能性があります 🌍!私たちはあなたの投稿をリツイートして共同体と共有するお手伝いを喜んでします。
## Adding TensorFlow weights to 🤗 Hub
TensorFlowモデルのアーキテクチャが🤗 Transformersで利用可能な場合、PyTorchの重みをTensorFlowの重みに変換することは簡単です!
以下がその方法です:
1. ターミナルでHugging Faceアカウントにログインしていることを確認してください。コマンド`huggingface-cli login`を使用してログインできます(アクセストークンは[こちら](https://huggingface.co/settings/tokens)で見つけることができます)。
2. `transformers-cli pt-to-tf --model-name foo/bar`というコマンドを実行します。ここで、`foo/bar`は変換したいPyTorchの重みを含むモデルリポジトリの名前です。
3. 上記のコマンドで作成された🤗 Hub PRに`@joaogante`と`@Rocketknight1`をタグ付けします。
それだけです! 🎉
## Debugging mismatches across ML frameworks 🐛
新しいアーキテクチャを追加したり、既存のアーキテクチャのTensorFlowの重みを作成したりする際、PyTorchとTensorFlow間の不一致についてのエラーに遭遇することがあります。
場合によっては、PyTorchとTensorFlowのモデルアーキテクチャがほぼ同一であるにもかかわらず、不一致を指摘するエラーが表示されることがあります。
どうしてでしょうか? 🤔
まず最初に、なぜこれらの不一致を理解することが重要かについて話しましょう。多くのコミュニティメンバーは🤗 Transformersモデルをそのまま使用し、モデルが期待どおりに動作すると信頼しています。
2つのフレームワーク間で大きな不一致があると、少なくとも1つのフレームワークのリファレンス実装に従ってモデルが動作しないことを意味します。
これにより、モデルは実行されますが性能が低下する可能性があり、静かな失敗が発生する可能性があります。これは、全く実行されないモデルよりも悪いと言えるかもしれません!そのため、モデルのすべての段階でのフレームワークの不一致が`1e-5`未満であることを目指しています。
数値計算の問題と同様に、詳細については細かいところにあります。そして、詳細指向の技術である以上、秘密の要素は忍耐です。
この種の問題に遭遇した場合のお勧めのワークフローは次のとおりです:
1. 不一致の原因を特定します。変換中のモデルにはおそらく特定の点までほぼ同一の内部変数があります。
両方のフレームワークのアーキテクチャに`breakpoint()`ステートメントを配置し、トップダウンの方法で数値変数の値を比較し、問題の原因を見つけます。
2. 問題の原因を特定したら、🤗 Transformersチームと連絡を取りましょう。同様の問題に遭遇したことがあるかもしれず、迅速に解決策を提供できるかもしれません。最終手段として、StackOverflowやGitHubの問題など、人気のあるページをスキャンします。
3. 解決策が見当たらない場合、問題を掘り下げる必要があることを意味します。良いニュースは、問題の原因を特定したことです。したがって、問題のある命令に焦点を当て、モデルの残りを抽象化できます!悪いニュースは、その命令のソース実装に進む必要があることです。一部の場合では、リファレンス実装に問題があるかもしれません - 上流リポジトリで問題を開くのを控えないでください。
🤗 Transformersチームとの話し合いで、不一致を修正することが困難であることが判明することがあります。
出力レイヤーのモデルで不一致が非常に小さい場合(ただし、隠れた状態では大きい可能性がある)、モデルを配布するためにそれを無視することにするかもしれません。
上記で言及した`pt-to-tf` CLIには、重み変換時にエラーメッセージを無視するための`--max-error`フラグがあります。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_cpu_many.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on Multiple CPUs
1つのCPUでのトレーニングが遅すぎる場合、複数のCPUを使用できます。このガイドは、PyTorchベースのDDPを使用した分散CPUトレーニングに焦点を当てています。
## Intel® oneCCL Bindings for PyTorch
[Intel® oneCCL](https://github.com/oneapi-src/oneCCL)(集合通信ライブラリ)は、allreduce、allgather、alltoallなどの収集通信を実装した効率的な分散ディープラーニングトレーニング用のライブラリです。oneCCLの詳細については、[oneCCLドキュメント](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html)と[oneCCL仕様](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html)を参照してください。
モジュール`oneccl_bindings_for_pytorch`(バージョン1.12以前は`torch_ccl`)は、PyTorch C10D ProcessGroup APIを実装し、外部のProcessGroupとして動的にロードでき、現在はLinuxプラットフォームでのみ動作します。
[torch-ccl](https://github.com/intel/torch-ccl)の詳細情報を確認してください。
### Intel® oneCCL Bindings for PyTorch installation:
Wheelファイルは、以下のPythonバージョン用に利用可能です:
| Extension Version | Python 3.6 | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 |
| :---------------: | :--------: | :--------: | :--------: | :--------: | :---------: |
| 1.13.0 | | √ | √ | √ | √ |
| 1.12.100 | | √ | √ | √ | √ |
| 1.12.0 | | √ | √ | √ | √ |
| 1.11.0 | | √ | √ | √ | √ |
| 1.10.0 | √ | √ | √ | √ | |
```
pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu
```
where `{pytorch_version}` should be your PyTorch version, for instance 1.13.0.
Check more approaches for [oneccl_bind_pt installation](https://github.com/intel/torch-ccl).
Versions of oneCCL and PyTorch must match.
<Tip warning={true}>
oneccl_bindings_for_pytorch 1.12.0 prebuilt wheel does not work with PyTorch 1.12.1 (it is for PyTorch 1.12.0)
PyTorch 1.12.1 should work with oneccl_bindings_for_pytorch 1.12.100
</Tip>
`{pytorch_version}` は、あなたのPyTorchのバージョン(例:1.13.0)に置き換える必要があります。重要なのは、oneCCLとPyTorchのバージョンが一致していることです。[oneccl_bind_ptのインストール](https://github.com/intel/torch-ccl)に関するさらなるアプローチを確認できます。
<Tip warning={true}>
`oneccl_bindings_for_pytorch`の1.12.0プリビルトホイールはPyTorch 1.12.1と互換性がありません(これはPyTorch 1.12.0用です)。PyTorch 1.12.1を使用する場合は、`oneccl_bindings_for_pytorch`バージョン1.12.100を使用する必要があります。
</Tip>
## Intel® MPI library
この基準ベースのMPI実装を使用して、Intel®アーキテクチャ上で柔軟で効率的、スケーラブルなクラスタメッセージングを提供します。このコンポーネントは、Intel® oneAPI HPC Toolkitの一部です。
oneccl_bindings_for_pytorchはMPIツールセットと一緒にインストールされます。使用する前に環境をソース化する必要があります。
for Intel® oneCCL >= 1.12.0
```
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
```
for Intel® oneCCL whose version < 1.12.0
```
torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os.path.abspath(os.path.dirname(torch_ccl.__file__)))")
source $torch_ccl_path/env/setvars.sh
```
#### IPEX installation:
IPEXは、Float32およびBFloat16の両方でCPUトレーニングのパフォーマンス最適化を提供します。詳細は[こちらのシングルCPUセクション](./perf_train_cpu)をご参照ください。
以下の「トレーナーでの使用」は、Intel® MPIライブラリでmpirunを使用する例を示しています。
## Usage in Trainer
トレーナーでのマルチCPU分散トレーニングを有効にするために、ユーザーはコマンド引数に **`--ddp_backend ccl`** を追加する必要があります。
例を見てみましょう。[質問応答の例](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
以下のコマンドは、1つのXeonノードで2つのプロセスを使用してトレーニングを有効にします。1つのプロセスが1つのソケットで実行されます。OMP_NUM_THREADS/CCL_WORKER_COUNT変数は、最適なパフォーマンスを調整するために調整できます。
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=127.0.0.1
mpirun -n 2 -genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex
```
以下のコマンドは、2つのXeonプロセッサ(node0とnode1、node0をメインプロセスとして使用)で合計4つのプロセスを使用してトレーニングを有効にします。ppn(ノードごとのプロセス数)は2に設定され、1つのソケットごとに1つのプロセスが実行されます。最適なパフォーマンスを得るために、OMP_NUM_THREADS/CCL_WORKER_COUNT変数を調整できます。
node0では、各ノードのIPアドレスを含む構成ファイルを作成し、その構成ファイルのパスを引数として渡す必要があります。
```shell script
cat hostfile
xxx.xxx.xxx.xxx #node0 ip
xxx.xxx.xxx.xxx #node1 ip
```
ノード0で次のコマンドを実行すると、ノード0とノード1で**4DDP**がBF16自動混合精度で有効になります。
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 4 -ppn 2 \
-genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex \
--bf16
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/glossary.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Glossary
この用語集は、一般的な機械学習と 🤗 トランスフォーマーの用語を定義し、ドキュメンテーションをより理解するのに役立ちます。
## A
### attention mask
アテンション マスクは、シーケンスをバッチ処理する際に使用されるオプションの引数です。
<Youtube id="M6adb1j2jPI"/>
この引数は、モデルにどのトークンを注視すべきか、どのトークンを注視しないかを示します。
例えば、次の2つのシーケンスを考えてみてください:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "This is a short sequence."
>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
```
The encoded versions have different lengths:
```python
>>> len(encoded_sequence_a), len(encoded_sequence_b)
(8, 19)
```
したがって、これらのシーケンスをそのまま同じテンソルに配置することはできません。最初のシーケンスは、
2番目のシーケンスの長さに合わせてパディングする必要があります。または、2番目のシーケンスは、最初のシーケンスの
長さに切り詰める必要があります。
最初の場合、IDのリストはパディングインデックスで拡張されます。トークナイザにリストを渡し、次のようにパディングするように
依頼できます:
```python
>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
```
0sが追加されて、最初の文が2番目の文と同じ長さになるのがわかります:
```python
>>> padded_sequences["input_ids"]
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
```
これは、PyTorchまたはTensorFlowでテンソルに変換できます。注意マスクは、モデルがそれらに注意を払わないように、埋め込まれたインデックスの位置を示すバイナリテンソルです。[`BertTokenizer`]では、`1`は注意を払う必要がある値を示し、`0`は埋め込まれた値を示します。この注意マスクは、トークナイザが返す辞書のキー「attention_mask」の下にあります。
```python
>>> padded_sequences["attention_mask"]
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
```
### autoencoding models
[エンコーダーモデル](#encoder-models) および [マスク言語モデリング](#masked-language-modeling-mlm) を参照してください。
### autoregressive models
[因果言語モデリング](#causal-language-modeling) および [デコーダーモデル](#decoder-models) を参照してください。
## B
### backbone
バックボーンは、生の隠れた状態や特徴を出力するネットワーク(埋め込みと層)です。通常、特徴を入力として受け取るために [ヘッド](#head) に接続されており、予測を行います。たとえば、[`ViTModel`] は特定のヘッドが上にないバックボーンです。他のモデルも [`VitModel`] をバックボーンとして使用できます、例えば [DPT](model_doc/dpt) です。
## C
### causal language modeling
モデルがテキストを順番に読み、次の単語を予測する事前トレーニングタスクです。通常、モデルは文全体を読み取りますが、特定のタイムステップで未来のトークンを隠すためにモデル内でマスクを使用します。
### channel
カラー画像は、赤、緑、青(RGB)の3つのチャネルの値の組み合わせから成り立っており、グレースケール画像は1つのチャネルしか持ちません。🤗 Transformers では、チャネルは画像のテンソルの最初または最後の次元になることがあります:[`n_channels`, `height`, `width`] または [`height`, `width`, `n_channels`]。
### connectionist temporal classification (CTC)
入力と出力が正確にどのように整列するかを正確に知らなくてもモデルを学習させるアルゴリズム。CTC は、特定の入力に対してすべての可能な出力の分布を計算し、その中から最も可能性の高い出力を選択します。CTC は、スピーカーの異なる発話速度など、さまざまな理由で音声がトランスクリプトと完全に整合しない場合に、音声認識タスクで一般的に使用されます。
### convolution
ニューラルネットワークの一種で、入力行列が要素ごとに小さな行列(カーネルまたはフィルター)と乗算され、値が新しい行列に合計されるレイヤーのタイプ。これは入力行列全体に対して繰り返される畳み込み操作として知られ、各操作は入力行列の異なるセグメントに適用されます。畳み込みニューラルネットワーク(CNN)は、コンピュータビジョンで一般的に使用されています。
## D
### decoder input IDs
この入力はエンコーダーデコーダーモデルに特有であり、デコーダーに供給される入力IDを含みます。これらの入力は、翻訳や要約などのシーケンスツーシーケンスタスクに使用され、通常、各モデルに固有の方法で構築されます。
ほとんどのエンコーダーデコーダーモデル(BART、T5)は、`labels` から独自に `decoder_input_ids` を作成します。このようなモデルでは、`labels` を渡すことがトレーニングを処理する優れた方法です。
シーケンスツーシーケンストレーニングにおけるこれらの入力IDの処理方法を確認するために、各モデルのドキュメントを確認してください。
### decoder models
オートリグレッションモデルとも呼ばれ、モデルがテキストを順番に読み、次の単語を予測する事前トレーニングタスク(因果言語モデリング)に関与します。通常、モデルは文全体を読み取り、特定のタイムステップで未来のトークンを隠すマスクを使用して行われます。
<Youtube id="d_ixlCubqQw"/>
### deep learning (DL)
ニューラルネットワークを使用する機械学習アルゴリズムで、複数の層を持っています。
## E
### encoder models
オートエンコーディングモデルとしても知られており、エンコーダーモデルは入力(テキストや画像など)を、埋め込みと呼ばれる簡略化された数値表現に変換します。エンコーダーモデルは、しばしば[マスクされた言語モデリング(#masked-language-modeling-mlm)](#masked-language-modeling-mlm)などの技術を使用して事前にトレーニングされ、入力シーケンスの一部をマスクし、モデルにより意味のある表現を作成することが強制されます。
<Youtube id="H39Z_720T5s"/>
## F
### feature extraction
生データをより情報豊かで機械学習アルゴリズムにとって有用な特徴のセットに選択および変換するプロセス。特徴抽出の例には、生のテキストを単語埋め込みに変換したり、画像/ビデオデータからエッジや形状などの重要な特徴を抽出したりすることが含まれます。
### feed forward chunking
トランスフォーマー内の各残差注意ブロックでは、通常、自己注意層の後に2つのフィードフォワード層が続きます。
フィードフォワード層の中間埋め込みサイズは、モデルの隠れたサイズよりも大きいことがよくあります(たとえば、`bert-base-uncased`の場合)。
入力サイズが `[batch_size、sequence_length]` の場合、中間フィードフォワード埋め込み `[batch_size、sequence_length、config.intermediate_size]` を保存するために必要なメモリは、メモリの大部分を占めることがあります。[Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451)の著者は、計算が `sequence_length` 次元に依存しないため、両方のフィードフォワード層の出力埋め込み `[batch_size、config.hidden_size]_0、...、[batch_size、config.hidden_size]_n` を個別に計算し、後で `[batch_size、sequence_length、config.hidden_size]` に連結することは数学的に等価であると気付きました。これにより、増加した計算時間とメモリ使用量のトレードオフが生じますが、数学的に等価な結果が得られます。
[`apply_chunking_to_forward`] 関数を使用するモデルの場合、`chunk_size` は並列に計算される出力埋め込みの数を定義し、メモリと時間の複雑さのトレードオフを定義します。`chunk_size` が 0 に設定されている場合、フィードフォワードのチャンキングは行われません。
### finetuned models
ファインチューニングは、事前にトレーニングされたモデルを取り、その重みを固定し、新しく追加された[model head](#head)で出力レイヤーを置き換える形式の転移学習です。モデルヘッドは対象のデータセットでトレーニングされます。
詳細については、[Fine-tune a pretrained model](https://huggingface.co/docs/transformers/training) チュートリアルを参照して、🤗 Transformersを使用したモデルのファインチューニング方法を学びましょう。
## H
### head
モデルヘッドは、ニューラルネットワークの最後のレイヤーを指し、生の隠れた状態を受け入れて異なる次元に射影します。各タスクに対して異なるモデルヘッドがあります。例えば:
* [`GPT2ForSequenceClassification`] は、ベースの[`GPT2Model`]の上にあるシーケンス分類ヘッド(線形層)です。
* [`ViTForImageClassification`] は、ベースの[`ViTModel`]の`CLS`トークンの最終隠れた状態の上にある画像分類ヘッド(線形層)です。
* [`Wav2Vec2ForCTC`] は、[CTC](#connectionist-temporal-classification-(CTC))を持つベースの[`Wav2Vec2Model`]の言語モデリングヘッドです。
## I
### image patch
ビジョンベースのトランスフォーマーモデルは、画像をより小さなパッチに分割し、それらを線形に埋め込み、モデルにシーケンスとして渡します。モデルの
### inference
推論は、トレーニングが完了した後に新しいデータでモデルを評価するプロセスです。 🤗 Transformers を使用して推論を実行する方法については、[推論のパイプライン](https://huggingface.co/docs/transformers/pipeline_tutorial) チュートリアルを参照してください。
### input IDs
入力IDは、モデルへの入力として渡す必要があるパラメーターの中で最も一般的なものです。これらはトークンのインデックスであり、モデルによって入力として使用されるシーケンスを構築するトークンの数値表現です。
<Youtube id="VFp38yj8h3A"/>
各トークナイザーは異なる方法で動作しますが、基本的なメカニズムは同じです。以下はBERTトークナイザーを使用した例です。BERTトークナイザーは[WordPiece](https://arxiv.org/pdf/1609.08144.pdf)トークナイザーです。
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence = "A Titan RTX has 24GB of VRAM"
```
トークナイザーは、シーケンスをトークナイザー語彙で使用可能なトークンに分割します。
```python
>>> tokenized_sequence = tokenizer.tokenize(sequence)
```
トークンは単語またはサブワードです。 たとえば、ここでは "VRAM" はモデルの語彙に含まれていなかったため、"V"、"RA"、"M" に分割されました。
これらのトークンが別々の単語ではなく、同じ単語の一部であることを示すために、"RA" と "M" にはダブルハッシュのプレフィックスが追加されます。
```python
>>> print(tokenized_sequence)
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
```
これらのトークンは、モデルが理解できるようにIDに変換できます。これは、文をトークナイザーに直接供給して行うことができます。トークナイザーは、パフォーマンスの向上のために[🤗 Tokenizers](https://github.com/huggingface/tokenizers)のRust実装を活用しています。
```python
>>> inputs = tokenizer(sequence)
```
トークナイザーは、対応するモデルが正しく動作するために必要なすべての引数を含む辞書を返します。トークンのインデックスは、キー `input_ids` の下にあります。
```python
>>> encoded_sequence = inputs["input_ids"]
>>> print(encoded_sequence)
[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
```
注意:トークナイザは、関連するモデルがそれらを必要とする場合に自動的に「特別なトークン」を追加します。これらは、モデルが時折使用する特別なIDです。
前のIDシーケンスをデコードする場合、
```python
>>> decoded_sequence = tokenizer.decode(encoded_sequence)
```
私たちは見ます
```python
>>> print(decoded_sequence)
[CLS] A Titan RTX has 24GB of VRAM [SEP]
```
これは[`BertModel`]がその入力を期待する方法です。
## L
### Labels
ラベルは、モデルが損失を計算するために渡すことができるオプションの引数です。これらのラベルは、モデルの予測の期待値であるべきです。モデルは、通常の損失を使用して、その予測と期待値(ラベル)との間の損失を計算します。
これらのラベルはモデルのヘッドに応じて異なります。たとえば:
- シーケンス分類モデル([`BertForSequenceClassification`])の場合、モデルは次元が `(batch_size)` のテンソルを期待し、バッチ内の各値がシーケンス全体の予測ラベルに対応します。
- トークン分類モデル([`BertForTokenClassification`])の場合、モデルは次元が `(batch_size, seq_length)` のテンソルを期待し、各値が各個々のトークンの予測ラベルに対応します。
- マスク言語モデリングの場合([`BertForMaskedLM`])、モデルは次元が `(batch_size, seq_length)` のテンソルを期待し、各値が各個々のトークンの予測ラベルに対応します。ここでのラベルはマスクされたトークンのトークンIDであり、他のトークンには通常 -100 などの値が設定されます。
- シーケンス間のタスクの場合([`BartForConditionalGeneration`]、[`MBartForConditionalGeneration`])、モデルは次元が `(batch_size, tgt_seq_length)` のテンソルを期待し、各値が各入力シーケンスに関連付けられたターゲットシーケンスに対応します。トレーニング中、BARTとT5の両方は適切な `decoder_input_ids` とデコーダーのアテンションマスクを内部で生成します。通常、これらを提供する必要はありません。これはエンコーダーデコーダーフレームワークを利用するモデルには適用されません。
- 画像分類モデルの場合([`ViTForImageClassification`])、モデルは次元が `(batch_size)` のテンソルを期待し、バッチ内の各値が各個々の画像の予測ラベルに対応します。
- セマンティックセグメンテーションモデルの場合([`SegformerForSemanticSegmentation`])、モデルは次元が `(batch_size, height, width)` のテンソルを期待し、バッチ内の各値が各個々のピクセルの予測ラベルに対応します。
- 物体検出モデルの場合([`DetrForObjectDetection`])、モデルは各個々の画像の予測ラベルと境界ボックスの数に対応する `class_labels` と `boxes` キーを持つ辞書のリストを期待します。
- 自動音声認識モデルの場合([`Wav2Vec2ForCTC`])、モデルは次元が `(batch_size, target_length)` のテンソルを期待し、各値が各個々のトークンの予測ラベルに対応します。
<Tip>
各モデルのラベルは異なる場合があるため、常に各モデルのドキュメントを確認して、それらの特定のラベルに関する詳細情報を確認してください!
</Tip>
ベースモデル([`BertModel`])はラベルを受け入れません。これらはベースのトランスフォーマーモデルであり、単に特徴を出力します。
### large language models (LLM)
大量のデータでトレーニングされた変換器言語モデル(GPT-3、BLOOM、OPT)を指す一般的な用語です。これらのモデルは通常、多くの学習可能なパラメータを持っています(たとえば、GPT-3の場合、1750億個)。
## M
### masked language modeling (MLM)
モデルはテキストの破損バージョンを見る事前トレーニングタスクで、通常はランダムに一部のトークンをマスキングして元のテキストを予測する必要があります。
### multimodal
テキストと別の種類の入力(たとえば画像)を組み合わせるタスクです。
## N
### Natural language generation (NLG)
テキストを生成する関連するすべてのタスク(たとえば、[Transformersで書く](https://transformer.huggingface.co/)、翻訳など)。
### Natural language processing (NLP)
テキストを扱う方法を一般的に表現したものです。
### Natural language understanding (NLU)
テキスト内に何があるかを理解する関連するすべてのタスク(たとえば、テキスト全体の分類、個々の単語の分類など)。
## P
### pipeline
🤗 Transformersのパイプラインは、データの前処理と変換を特定の順序で実行してデータを処理し、モデルから予測を返す一連のステップを指す抽象化です。パイプラインに見られるいくつかのステージの例には、データの前処理、特徴抽出、正規化などがあります。
詳細については、[推論のためのパイプライン](https://huggingface.co/docs/transformers/pipeline_tutorial)を参照してください。
### pixel values
モデルに渡される画像の数値表現のテンソルです。ピクセル値は、形状が [`バッチサイズ`, `チャネル数`, `高さ`, `幅`] の行列で、画像プロセッサから生成されます。
### pooling
行列を小さな行列に縮小する操作で、プール対象の次元の最大値または平均値を取ることが一般的です。プーリングレイヤーは一般的に畳み込みレイヤーの間に見られ、特徴表現をダウンサンプリングします。
### position IDs
トークンごとの位置が埋め込まれているRNNとは異なり、トランスフォーマーは各トークンの位置を把握していません。したがって、モデルはトークンの位置を識別するために位置ID(`position_ids`)を使用します。
これはオプションのパラメータです。モデルに `position_ids` が渡されない場合、IDは自動的に絶対的な位置埋め込みとして作成されます。
絶対的な位置埋め込みは範囲 `[0、config.max_position_embeddings - 1]` から選択されます。一部のモデルは、正弦波位置埋め込みや相対位置埋め込みなど、他のタイプの位置埋め込みを使用することがあります。
### preprocessing
生データを機械学習モデルで簡単に処理できる形式に準備するタスクです。例えば、テキストは通常、トークン化によって前処理されます。他の入力タイプに対する前処理の具体的な方法を知りたい場合は、[Preprocess](https://huggingface.co/docs/transformers/preprocessing) チュートリアルをご覧ください。
### pretrained model
あるデータ(たとえば、Wikipedia全体など)で事前に学習されたモデルです。事前学習の方法には、自己教師ありの目的が含まれ、テキストを読み取り、次の単語を予測しようとするもの([因果言語モデリング](#因果言語モデリング)を参照)や、一部の単語をマスクし、それらを予測しようとするもの([マスク言語モデリング](#マスク言語モデリング-mlm)を参照)があります。
音声とビジョンモデルには独自の事前学習の目的があります。たとえば、Wav2Vec2は音声モデルで、モデルに対して「真の」音声表現を偽の音声表現のセットから識別する必要がある対比的なタスクで事前学習されています。一方、BEiTはビジョンモデルで、一部の画像パッチをマスクし、モデルにマスクされたパッチを予測させるタスク(マスク言語モデリングの目的と似ています)で事前学習されています。
## R
### recurrent neural network (RNN)
テキストを処理するために層をループさせるモデルの一種です。
### representation learning
生データの意味のある表現を学習する機械学習のサブフィールドです。表現学習の技術の一部には単語埋め込み、オートエンコーダー、Generative Adversarial Networks(GANs)などがあります。
## S
### sampling rate
秒ごとに取られるサンプル(オーディオ信号など)の数をヘルツ単位で測定したものです。サンプリングレートは音声などの連続信号を離散化する結果です。
### self-attention
入力の各要素は、どの他の要素に注意を払うべきかを検出します。
### self-supervised learning
モデルがラベルのないデータから自分自身の学習目標を作成する機械学習技術のカテゴリです。これは[教師なし学習](#教師なし学習)や[教師あり学習](#教師あり学習)とは異なり、学習プロセスはユーザーからは明示的には監督されていない点が異なります。
自己教師あり学習の1つの例は[マスク言語モデリング](#マスク言語モデリング-mlm)で、モデルには一部のトークンが削除された文が与えられ、欠落したトークンを予測するように学習します。
### semi-supervised learning
ラベル付きデータの少量とラベルのないデータの大量を組み合わせてモデルの精度を向上させる広範な機械学習トレーニング技術のカテゴリです。[教師あり学習](#教師あり学習)や[教師なし学習](#教師なし学習)とは異なり、半教師あり学習のアプローチの1つは「セルフトレーニング」であり、モデルはラベル付きデータでトレーニングされ、次にラベルのないデータで予測を行います。モデルが最も自信を持って予測する部分がラベル付きデータセットに追加され、モデルの再トレーニングに使用されます。
### sequence-to-sequence (seq2seq)
入力から新しいシーケンスを生成するモデルです。翻訳モデルや要約モデル([Bart](model_doc/bart)や[T5](model_doc/t5)など)などがこれに該当します。
### stride
[畳み込み](#畳み込み)または[プーリング](#プーリング)において、ストライドはカーネルが行列上で移動する距離を指します。ストライドが1の場合、カーネルは1ピクセルずつ移動し、ストライドが2の場合、カーネルは2ピクセルずつ移動します。
### supervised learning
モデルのトレーニング方法の一つで、直接ラベル付きデータを使用してモデルの性能を修正し指導します。データがトレーニングされているモデルに供給され、その予測が既知のラベルと比較されます。モデルは予測がどれだけ誤っていたかに基づいて重みを更新し、プロセスはモデルの性能を最適化するために繰り返されます。
## T
### token
文の一部であり、通常は単語ですが、サブワード(一般的でない単語はしばしばサブワードに分割されることがあります)または句読点の記号であることもあります。
### token Type IDs
一部のモデルは、文のペアの分類や質問応答を行うことを目的としています。
<Youtube id="0u3ioSwev3s"/>
これには異なる2つのシーケンスを単一の「input_ids」エントリに結合する必要があり、通常は分類子(`[CLS]`)や区切り記号(`[SEP]`)などの特別なトークンの助けを借りて実行されます。例えば、BERTモデルは次のように2つのシーケンス入力を構築します:
日本語訳を提供していただきたいです。Markdown形式で記述してください。
```python
>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
```
我々は、前述のように、2つのシーケンスを2つの引数として `tokenizer` に渡すことで、このような文を自動的に生成することができます(以前のようにリストではなく)。以下のように:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "HuggingFace is based in NYC"
>>> sequence_b = "Where is HuggingFace based?"
>>> encoded_dict = tokenizer(sequence_a, sequence_b)
>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
```
これに対応するコードは以下です:
```python
>>> print(decoded)
[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
```
一部のモデルでは、1つのシーケンスがどこで終わり、別のシーケンスがどこで始まるかを理解するのに十分な情報が備わっています。ただし、BERTなどの他のモデルでは、トークンタイプID(セグメントIDとも呼ばれる)も使用されています。これは、モデル内の2つのシーケンスを識別するバイナリマスクとして表されます。
トークナイザは、このマスクを「token_type_ids」として返します。
```python
>>> encoded_dict["token_type_ids"]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
最初のシーケンス、つまり質問のために使用される「コンテキスト」は、すべてのトークンが「0」で表されています。一方、2番目のシーケンス、質問に対応するものは、すべてのトークンが「1」で表されています。
一部のモデル、例えば [`XLNetModel`] のように、追加のトークンが「2」で表されます。
### transfer learning
事前に学習されたモデルを取り、それをタスク固有のデータセットに適応させる技術。ゼロからモデルを訓練する代わりに、既存のモデルから得た知識を出発点として活用できます。これにより学習プロセスが加速し、必要な訓練データの量が減少します。
### transformer
自己注意ベースの深層学習モデルアーキテクチャ。
## U
### unsupervised learning
モデルに提供されるデータがラベル付けされていないモデルトレーニングの形態。教師なし学習の技術は、タスクに役立つパターンを見つけるためにデータ分布の統計情報を活用します。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_hardware.md
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Custom hardware for training
モデルのトレーニングおよび推論に使用するハードウェアは、パフォーマンスに大きな影響を与えることがあります。GPUについて詳しく知りたい場合は、Tim Dettmerの優れた[ブログ記事](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/)をチェックしてみてください。
GPUセットアップの実用的なアドバイスをいくつか見てみましょう。
## GPU
より大きなモデルをトレーニングする場合、基本的には以下の3つのオプションがあります:
- より大きなGPU
- より多くのGPU
- より多くのCPUおよびNVMe([DeepSpeed-Infinity](main_classes/deepspeed#nvme-support)によるオフロード)
まず、単一のGPUを使用する場合から始めましょう。
### Power and Cooling
高価なハイエンドGPUを購入した場合、正しい電力供給と十分な冷却を提供することが重要です。
**電力**:
一部の高級コンシューマGPUカードには、2つまたは3つのPCI-E 8ピン電源ソケットがあります。カードにあるソケットの数だけ、独立した12V PCI-E 8ピンケーブルが接続されていることを確認してください。同じケーブルの一端にある2つの分岐(またはピッグテールケーブルとしても知られています)を使用しないでください。つまり、GPUに2つのソケットがある場合、PSUからカードに向けて2つのPCI-E 8ピンケーブルを使用し、1つのケーブルの端に2つのPCI-E 8ピンコネクタがあるものは使用しないでください!そうしないと、カードからのパフォーマンスを十分に引き出すことができません。
各PCI-E 8ピン電源ケーブルは、PSU側の12Vレールに接続する必要があり、最大で150Wの電力を供給できます。
一部のカードはPCI-E 12ピンコネクタを使用することがあり、これらは最大で500-600Wの電力を供給できます。
低価格帯のカードは6ピンコネクタを使用することがあり、最大で75Wの電力を供給します。
さらに、カードが必要とする安定した電圧を提供する高品質な電源ユニット(PSU)を使用する必要があります。
もちろん、PSUにはカードを駆動するために十分な未使用の電力が必要です。
**冷却**:
GPUが過熱すると、スロットリングが開始され、フルパフォーマンスを提供しなくなり、過熱しすぎるとシャットダウンすることさえあります。
GPUが重要な負荷の下でどのような温度を目指すべきかを正確に示すことは難しいですが、おそらく+80℃未満であれば良いでしょうが、それより低い方が良いです - おそらく70-75℃が優れた範囲でしょう。スロットリングの開始温度はおそらく84-90℃のあたりからでしょう。スロットリングによるパフォーマンスの低下以外にも、長時間にわたる非常に高い温度はGPUの寿命を短縮する可能性があります。
次に、複数のGPUを持つ際に最も重要な側面の一つである接続について詳しく見てみましょう。
### Multi-GPU Connectivity
複数のGPUを使用する場合、カードの相互接続方法はトータルのトレーニング時間に大きな影響を与える可能性があります。GPUが同じ物理ノードにある場合、次のように実行できます:
```
nvidia-smi topo -m
```
もちろん、GPUがどのように相互接続されているかについて説明します。デュアルGPUを搭載し、NVLinkで接続されているマシンでは、おそらく以下のような情報が表示されるでしょう:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X NV2 0-23 N/A
GPU1 NV2 X 0-23 N/A
```
別のNVLinkなしのマシンでは、以下のような状況が発生するかもしれません:
```
GPU0 GPU1 CPU Affinity NUMA Affinity
GPU0 X PHB 0-11 N/A
GPU1 PHB X 0-11 N/A
```
こちらが伝説です:
```
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
```
最初のレポートである `NV2` では、GPUは2つのNVLinkで接続されており、2番目のレポートである `PHB` では、典型的な消費者向けのPCIe+Bridgeセットアップが行われています。
あなたのセットアップでどの種類の接続性があるかを確認してください。これらの接続方法のいくつかはカード間の通信を速くすることができます(例:NVLink)、他のものは遅くすることができます(例:PHB)。
使用されるスケーラビリティソリューションの種類に応じて、接続速度は大きな影響を与えることも、小さな影響を与えることもあります。GPUがあまり頻繁に同期する必要がない場合、DDPのように、遅い接続の影響はそれほど重要ではありません。しかし、GPUが頻繁にメッセージを送信する必要がある場合、ZeRO-DPのように、高速の接続がより高速なトレーニングを実現するために非常に重要になります。
#### NVlink
[NVLink](https://en.wikipedia.org/wiki/NVLink) は、Nvidiaによって開発された有線のシリアルマルチレーンの近距離通信リンクです。
各新世代では、より高速な帯域幅が提供されます。たとえば、[Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf) からの引用です。
> Third-Generation NVLink®
> GA102 GPUs utilize NVIDIA’s third-generation NVLink interface, which includes four x4 links,
> with each link providing 14.0625 GB/sec bandwidth in each direction between two GPUs. Four
> links provide 56.25 GB/sec bandwidth in each direction, and 112.5 GB/sec total bandwidth
> between two GPUs. Two RTX 3090 GPUs can be connected together for SLI using NVLink.
> (Note that 3-Way and 4-Way SLI configurations are not supported.)
したがって、`nvidia-smi topo -m` の出力の `NVX` レポートで取得する `X` が高いほど良いです。世代はあなたのGPUアーキテクチャに依存します。
小さなサンプルのwikitextを使用したgpt2言語モデルのトレーニングの実行を比較しましょう。
結果は次のとおりです:
(ここに結果を挿入)
上記のテキストの日本語訳を提供しました。Markdownコードとしてフォーマットしました。どんな他の質問があれば、お気軽にお知らせください!
| NVlink | Time |
| ----- | ---: |
| Y | 101s |
| N | 131s |
NVLinkを使用すると、トレーニングが約23%速く完了することがわかります。2番目のベンチマークでは、`NCCL_P2P_DISABLE=1`を使用して、GPUがNVLinkを使用しないように指示しています。
以下は、完全なベンチマークコードと出力です:
```bash
# DDP w/ NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVLink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 \
--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
Hardware: 2x TITAN RTX 24GB each + NVlink with 2 NVLinks (`NV2` in `nvidia-smi topo -m`)
Software: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/hpo_train.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Hyperparameter Search using Trainer API
🤗 Transformersは、🤗 Transformersモデルのトレーニングを最適化する[`Trainer`]クラスを提供し、独自のトレーニングループを手動で記述せずにトレーニングを開始するのが簡単になります。[`Trainer`]はハイパーパラメーター検索のAPIも提供しています。このドキュメントでは、それを例示します。
## Hyperparameter Search backend
[`Trainer`]は現在、4つのハイパーパラメーター検索バックエンドをサポートしています:
[optuna](https://optuna.org/)、[sigopt](https://sigopt.com/)、[raytune](https://docs.ray.io/en/latest/tune/index.html)、および[wandb](https://wandb.ai/site/sweeps)。
これらを使用する前に、ハイパーパラメーター検索バックエンドをインストールする必要があります。
```bash
pip install optuna/sigopt/wandb/ray[tune]
```
## How to enable Hyperparameter search in example
ハイパーパラメータの検索スペースを定義し、異なるバックエンドには異なるフォーマットが必要です。
Sigoptの場合、sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter) を参照してください。それは以下のようなものです:
```py
>>> def sigopt_hp_space(trial):
... return [
... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
... {
... "categorical_values": ["16", "32", "64", "128"],
... "name": "per_device_train_batch_size",
... "type": "categorical",
... },
... ]
```
Optunaに関しては、[object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py)をご覧ください。以下のようになります:
```py
>>> def optuna_hp_space(trial):
... return {
... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
... }
```
Optunaは、多目的のハイパーパラメータ最適化(HPO)を提供しています。 `hyperparameter_search` で `direction` を渡し、複数の目的関数値を返すための独自の `compute_objective` を定義することができます。 Pareto Front(`List[BestRun]`)は `hyperparameter_search` で返され、[test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py) のテストケース `TrainerHyperParameterMultiObjectOptunaIntegrationTest` を参照する必要があります。これは以下のようになります。
```py
>>> best_trials = trainer.hyperparameter_search(
... direction=["minimize", "maximize"],
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
Ray Tuneに関して、[object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html)を参照してください。以下のようになります:
```py
>>> def ray_hp_space(trial):
... return {
... "learning_rate": tune.loguniform(1e-6, 1e-4),
... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
... }
```
Wandbについては、[object_parameter](https://docs.wandb.ai/guides/sweeps/configuration)をご覧ください。これは以下のようになります:
```py
>>> def wandb_hp_space(trial):
... return {
... "method": "random",
... "metric": {"name": "objective", "goal": "minimize"},
... "parameters": {
... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
... },
... }
```
`model_init` 関数を定義し、それを [`Trainer`] に渡す例を示します:
```py
>>> def model_init(trial):
... return AutoModelForSequenceClassification.from_pretrained(
... model_args.model_name_or_path,
... from_tf=bool(".ckpt" in model_args.model_name_or_path),
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
... token=True if model_args.use_auth_token else None,
... )
```
[`Trainer`] を `model_init` 関数、トレーニング引数、トレーニングデータセット、テストデータセット、および評価関数と共に作成してください:
```py
>>> trainer = Trainer(
... model=None,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... tokenizer=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
```
ハイパーパラメーターの探索を呼び出し、最良のトライアル パラメーターを取得します。バックエンドは `"optuna"` / `"sigopt"` / `"wandb"` / `"ray"` である可能性があります。方向は `"minimize"` または `"maximize"` であり、目標をより大きくするか小さくするかを示します。
`compute_objective` 関数を独自に定義することもできます。定義されていない場合、デフォルトの `compute_objective` が呼び出され、F1などの評価メトリックの合計が目標値として返されます。
```py
>>> best_trial = trainer.hyperparameter_search(
... direction="maximize",
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
## Hyperparameter search For DDP finetune
現在、DDP(Distributed Data Parallel)のためのハイパーパラメーター検索は、Optuna と SigOpt に対して有効になっています。ランクゼロプロセスのみが検索トライアルを生成し、他のランクに引数を渡します。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/run_scripts.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Train with a script
🤗 Transformersの[notebooks](./notebooks/README)と一緒に、[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch)、[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow)、または[JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax)を使用してモデルをトレーニングする方法を示すサンプルスクリプトもあります。
また、私たちの[研究プロジェクト](https://github.com/huggingface/transformers/tree/main/examples/research_projects)や[レガシーの例](https://github.com/huggingface/transformers/tree/main/examples/legacy)で使用したスクリプトも見つかります。これらのスクリプトは現在メンテナンスされておらず、おそらく最新バージョンのライブラリと互換性がない特定の🤗 Transformersのバージョンが必要です。
サンプルスクリプトはすべての問題でそのまま動作することは期待されておらず、解決しようとしている問題にスクリプトを適応させる必要があるかもしれません。この点をサポートするために、ほとんどのスクリプトはデータがどのように前処理されているかを完全に公開し、必要に応じて編集できるようにしています。
サンプルスクリプトで実装したい機能がある場合は、[フォーラム](https://discuss.huggingface.co/)か[イシュートラッカー](https://github.com/huggingface/transformers/issues)で議論してからプルリクエストを提出してください。バグ修正は歓迎しますが、読みやすさのコストで機能を追加するプルリクエストはほとんどマージされない可能性が高いです。
このガイドでは、[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)と[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)で実行するサマリゼーショントレーニングスクリプトの実行方法を示します。すべての例は、明示的に指定されていない限り、両方のフレームワークともに動作することが期待されています。
## Setup
最新バージョンのサンプルスクリプトを正常に実行するには、新しい仮想環境に🤗 Transformersをソースからインストールする必要があります:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
以前のスクリプトのバージョンについては、以下のトグルをクリックしてください:
<details>
<summary>以前の🤗 Transformersのバージョンに関する例</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
次に、現在の🤗 Transformersのクローンを特定のバージョンに切り替えてください。たとえば、v3.5.1などです。
```bash
git checkout tags/v3.5.1
```
適切なライブラリバージョンを設定したら、任意の例のフォルダに移動し、例固有の要件をインストールします:
```bash
pip install -r requirements.txt
```
## Run a script
<frameworkcontent>
<pt>
この例のスクリプトは、🤗 [Datasets](https://huggingface.co/docs/datasets/) ライブラリからデータセットをダウンロードし、前処理を行います。次に、[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) を使用して要約をサポートするアーキテクチャ上でデータセットをファインチューニングします。以下の例では、[CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) データセット上で [T5-small](https://huggingface.co/t5-small) をファインチューニングする方法が示されています。T5 モデルは、そのトレーニング方法に起因して追加の `source_prefix` 引数が必要です。このプロンプトにより、T5 はこれが要約タスクであることを知ることができます。
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
この例のスクリプトは、🤗 [Datasets](https://huggingface.co/docs/datasets/) ライブラリからデータセットをダウンロードして前処理します。その後、スクリプトは要約をサポートするアーキテクチャ上で Keras を使用してデータセットをファインチューニングします。以下の例では、[T5-small](https://huggingface.co/t5-small) を [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) データセットでファインチューニングする方法を示しています。T5 モデルは、そのトレーニング方法に起因して追加の `source_prefix` 引数が必要です。このプロンプトは、T5 にこれが要約タスクであることを知らせます。
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Distributed training and mixed precision
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer)は、分散トレーニングと混合精度をサポートしています。つまり、この機能をスクリプトで使用することができます。これらの機能を有効にするには、次の手順を実行します。
- `fp16`引数を追加して混合精度を有効にします。
- `nproc_per_node`引数で使用するGPUの数を設定します。
以下は提供されたBashコードです。このコードの日本語訳をMarkdown形式で記載します。
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlowスクリプトは、分散トレーニングに[`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy)を使用し、トレーニングスクリプトに追加の引数を追加する必要はありません。TensorFlowスクリプトは、デフォルトで複数のGPUが利用可能な場合にそれらを使用します。
## Run a script on a TPU
<frameworkcontent>
<pt>
Tensor Processing Units (TPUs)は、パフォーマンスを加速させるために特別に設計されています。PyTorchは、[XLA](https://www.tensorflow.org/xla)ディープラーニングコンパイラを使用してTPUsをサポートしており、詳細については[こちら](https://github.com/pytorch/xla/blob/master/README.md)をご覧ください。TPUを使用するには、`xla_spawn.py`スクリプトを起動し、`num_cores`引数を使用して使用するTPUコアの数を設定します。
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
もちろん、Tensor Processing Units(TPUs)は性能を高速化するために特別に設計されています。TensorFlowスクリプトは、TPUsでトレーニングするために[`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy)を利用します。TPUを使用するには、TPUリソースの名前を`tpu`引数に渡します。
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Run a script with 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate)は、PyTorch専用のライブラリで、CPUのみ、複数のGPU、TPUなど、さまざまなセットアップでモデルをトレーニングするための統一された方法を提供します。PyTorchのトレーニングループを完全に可視化しながら実行できます。まだインストールしていない場合は、🤗 Accelerateをインストールしてください:
> 注意:Accelerateは急速に開発が進行しているため、スクリプトを実行するにはaccelerateのgitバージョンをインストールする必要があります
```bash
pip install git+https://github.com/huggingface/accelerate
```
代わりに、`run_summarization_no_trainer.py` スクリプトを使用する必要があります。 🤗 Accelerate がサポートするスクリプトには、フォルダ内に `task_no_trainer.py` ファイルが含まれています。まず、次のコマンドを実行して設定ファイルを作成し、保存します:
```bash
accelerate config
```
テストを行い、設定が正しく構成されているか確認してください:
```bash
accelerate test
```
Now you are ready to launch the training:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Use a custom dataset
要約スクリプトは、CSVまたはJSON Lineファイルであれば、カスタムデータセットをサポートしています。独自のデータセットを使用する場合、いくつかの追加の引数を指定する必要があります。
- `train_file`および`validation_file`は、トレーニングとバリデーションのファイルへのパスを指定します。
- `text_column`は要約するための入力テキストです。
- `summary_column`は出力する対象テキストです。
カスタムデータセットを使用した要約スクリプトは、以下のようになります:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Test a script
すべてが予想通りに動作することを確認するために、データセット全体を処理する前に、データセットの一部の例でスクリプトを実行することは良いアイデアです。以下の引数を使用して、データセットを最大サンプル数に切り詰めます:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
一部の例のスクリプトは、`max_predict_samples`引数をサポートしていないことがあります。この引数がサポートされているかどうかがわからない場合は、`-h`引数を追加して確認してください。
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Resume training from checkpoint
以前のチェックポイントからトレーニングを再開するための役立つオプションもあります。これにより、トレーニングが中断された場合でも、最初からやり直すことなく、中断したところから再開できます。チェックポイントからトレーニングを再開するための2つの方法があります。
最初の方法は、`output_dir previous_output_dir` 引数を使用して、`output_dir` に保存された最新のチェックポイントからトレーニングを再開する方法です。この場合、`overwrite_output_dir` を削除する必要があります:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
2番目の方法では、`resume_from_checkpoint path_to_specific_checkpoint` 引数を使用して、特定のチェックポイントフォルダからトレーニングを再開します。
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Share your model
すべてのスクリプトは、最終的なモデルを [Model Hub](https://huggingface.co/models) にアップロードできます。開始する前に Hugging Face にログインしていることを確認してください。
```bash
huggingface-cli login
```
次に、スクリプトに `push_to_hub` 引数を追加します。この引数は、Hugging Face のユーザー名と `output_dir` で指定したフォルダ名でリポジトリを作成します。
特定の名前をリポジトリに付けるには、`push_to_hub_model_id` 引数を使用して追加します。このリポジトリは自動的にあなたの名前空間の下にリストされます。
以下の例は、特定のリポジトリ名でモデルをアップロードする方法を示しています:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/multilingual.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 推論のための多言語モデル
[[open-in-colab]]
🤗 Transformers にはいくつかの多言語モデルがあり、それらの推論の使用方法は単一言語モデルとは異なります。ただし、多言語モデルの使用方法がすべて異なるわけではありません。 [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased) などの一部のモデルは、単一言語モデルと同様に使用できます。 このガイドでは、推論のために使用方法が異なる多言語モデルをどのように使うかを示します。
## XLM
XLM には10の異なるチェックポイントがあり、そのうちの1つだけが単一言語です。 残りの9つのモデルチェックポイントは、言語埋め込みを使用するチェックポイントと使用しないチェックポイントの2つのカテゴリに分けることができます。
### 言語の埋め込みがある XLM
次の XLM モデルは、言語の埋め込みを使用して、推論で使用される言語を指定します。
- `xlm-mlm-ende-1024` (マスク化された言語モデリング、英語-ドイツ語)
- `xlm-mlm-enfr-1024` (マスク化された言語モデリング、英語-フランス語)
- `xlm-mlm-enro-1024` (マスク化された言語モデリング、英語-ルーマニア語)
- `xlm-mlm-xnli15-1024` (マスク化された言語モデリング、XNLI 言語)
- `xlm-mlm-tlm-xnli15-1024` (マスク化された言語モデリング + 翻訳 + XNLI 言語)
- `xlm-clm-enfr-1024` (因果言語モデリング、英語-フランス語)
- `xlm-clm-ende-1024` (因果言語モデリング、英語-ドイツ語)
言語の埋め込みは、モデルに渡される `input_ids` と同じ形状のテンソルとして表されます。 これらのテンソルの値は、使用される言語に依存し、トークナイザーの `lang2id` および `id2lang` 属性によって識別されます。
この例では、`xlm-clm-enfr-1024` チェックポイントをロードします (因果言語モデリング、英語-フランス語)。
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
```
トークナイザーの `lang2id` 属性は、このモデルの言語とその ID を表示します。
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
次に、入力例を作成します。
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
言語 ID を `en` に設定し、それを使用して言語の埋め込みを定義します。 言語の埋め込みは、英語の言語 ID であるため、`0` で埋められたテンソルです。 このテンソルは `input_ids` と同じサイズにする必要があります。
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
これで、`input_ids` と言語の埋め込みをモデルに渡すことができます。
```py
>>> outputs = model(input_ids, langs=langs)
```
[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) スクリプトは、`xlm-clm` チェックポイントを使用して、言語が埋め込まれたテキストを生成できます。
### 言語の埋め込みがないXLM
次の XLM モデルは、推論中に言語の埋め込みを必要としません。
- `xlm-mlm-17-1280` (マスク化された言語モデリング、17の言語)
- `xlm-mlm-100-1280` (マスク化された言語モデリング、100の言語)
これらのモデルは、以前の XLM チェックポイントとは異なり、一般的な文の表現に使用されます。
## BERT
以下の BERT モデルは、多言語タスクに使用できます。
- `bert-base-multilingual-uncased` (マスク化された言語モデリング + 次の文の予測、102の言語)
- `bert-base-multilingual-cased` (マスク化された言語モデリング + 次の文の予測、104の言語)
これらのモデルは、推論中に言語の埋め込みを必要としません。 文脈から言語を識別し、それに応じて推測する必要があります。
## XLM-RoBERTa
次の XLM-RoBERTa モデルは、多言語タスクに使用できます。
- `xlm-roberta-base` (マスク化された言語モデリング、100の言語)
- `xlm-roberta-large` (マスク化された言語モデリング、100の言語)
XLM-RoBERTa は、100の言語で新しく作成およびクリーニングされた2.5 TB の CommonCrawl データでトレーニングされました。 これは、分類、シーケンスのラベル付け、質問応答などのダウンストリームタスクで、mBERT や XLM などの以前にリリースされた多言語モデルを大幅に改善します。
## M2M100
次の M2M100 モデルは、多言語翻訳に使用できます。
- `facebook/m2m100_418M` (翻訳)
- `facebook/m2m100_1.2B` (翻訳)
この例では、`facebook/m2m100_418M` チェックポイントをロードして、中国語から英語に翻訳します。 トークナイザーでソース言語を設定できます。
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
テキストをトークン化します。
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 は、最初に生成されたトークンとしてターゲット言語 ID を強制的にターゲット言語に翻訳します。 英語に翻訳するには、`generate` メソッドで `forced_bos_token_id` を `en` に設定します。
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
多言語翻訳には、次の MBart モデルを使用できます。
- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
- `facebook/mbart-large-cc25`
この例では、`facebook/mbart-large-50-many-to-many-mmt` チェックポイントをロードして、フィンランド語を英語に翻訳します。トークナイザーでソース言語を設定できます。
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
テキストをトークン化します。
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart は、最初に生成されたトークンとしてターゲット言語 ID を強制的にターゲット言語に翻訳します。 英語に翻訳するには、`generate` メソッドで `forced_bos_token_id` を `en` に設定します。
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
`facebook/mbart-large-50-many-to-one-mmt` チェックポイントを使用している場合、最初に生成されたトークンとしてターゲット言語 ID を強制する必要はありません。それ以外の場合、使用方法は同じです。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/chat_templating.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Templates for Chat Models
## Introduction
LLM(Language Model)のますます一般的な使用事例の1つは「チャット」です。
チャットのコンテキストでは、通常の言語モデルのように単一のテキストストリングを継続するのではなく、モデルは1つ以上の「メッセージ」からなる会話を継続します。
各メッセージには「ロール」とメッセージテキストが含まれます。
最も一般的に、これらのロールはユーザーからのメッセージには「ユーザー」、モデルからのメッセージには「アシスタント」が割り当てられます。
一部のモデルは「システム」ロールもサポートしています。
システムメッセージは通常会話の開始時に送信され、モデルの動作方法に関する指示が含まれます。
すべての言語モデル、チャット用に微調整されたモデルを含むすべてのモデルは、トークンのリニアシーケンスで動作し、ロールに特有の特別な処理を持ちません。
つまり、ロール情報は通常、メッセージ間に制御トークンを追加して注入され、メッセージの境界と関連するロールを示すことで提供されます。
残念ながら、トークンの使用方法については(まだ!)標準が存在せず、異なるモデルはチャット用のフォーマットや制御トークンが大きく異なる形式でトレーニングされています。
これはユーザーにとって実際の問題になる可能性があります。正しいフォーマットを使用しないと、モデルは入力に混乱し、パフォーマンスが本来よりも遥かに低下します。
これが「チャットテンプレート」が解決しようとする問題です。
チャット会話は通常、各辞書が「ロール」と「コンテンツ」のキーを含み、単一のチャットメッセージを表すリストとして表現されます。
チャットテンプレートは、指定されたモデルの会話を単一のトークン化可能なシーケンスにどのようにフォーマットするかを指定するJinjaテンプレートを含む文字列です。
トークナイザとこの情報を保存することにより、モデルが期待する形式の入力データを取得できるようになります。
さっそく、`BlenderBot` モデルを使用した例を示して具体的にしましょう。`BlenderBot` のデフォルトテンプレートは非常にシンプルで、ほとんどが対話のラウンド間に空白を追加するだけです。
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
```
指定された通り、チャット全体が単一の文字列にまとめられています。デフォルトの設定である「tokenize=True」を使用すると、
その文字列もトークン化されます。しかし、より複雑なテンプレートが実際にどのように機能するかを確認するために、
「meta-llama/Llama-2-7b-chat-hf」モデルを使用してみましょう。ただし、このモデルはゲート付きアクセスを持っており、
このコードを実行する場合は[リポジトリでアクセスをリクエスト](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)する必要があります。
```python
>> from transformers import AutoTokenizer
>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>> tokenizer.use_default_system_prompt = False
>> tokenizer.apply_chat_template(chat, tokenize=False)
"<s>[INST] Hello, how are you? [/INST] I'm doing great. How can I help you today? </s><s>[INST] I'd like to show off how chat templating works! [/INST]"
```
今回、トークナイザは制御トークン [INST] と [/INST] を追加しました。これらはユーザーメッセージの開始と終了を示すためのものです(ただし、アシスタントメッセージには適用されません!)
## How do chat templates work?
モデルのチャットテンプレートは、`tokenizer.chat_template`属性に格納されています。チャットテンプレートが設定されていない場合、そのモデルクラスのデフォルトテンプレートが代わりに使用されます。`BlenderBot`のテンプレートを見てみましょう:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> tokenizer.default_chat_template
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
```
これは少し抑圧的ですね。可読性を高めるために、新しい行とインデントを追加しましょう。
各ブロックの直前の空白と、ブロックの直後の最初の改行は、デフォルトでJinjaの `trim_blocks` および `lstrip_blocks` フラグを使用して削除します。
これにより、インデントと改行を含むテンプレートを書いても正常に機能することができます。
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ ' ' }}
{% endif %}
{{ message['content'] }}
{% if not loop.last %}
{{ ' ' }}
{% endif %}
{% endfor %}
{{ eos_token }}
```
これが初めて見る方へ、これは[Jinjaテンプレート](https://jinja.palletsprojects.com/en/3.1.x/templates/)です。
Jinjaはテキストを生成するためのシンプルなコードを記述できるテンプレート言語です。多くの点で、コードと
構文はPythonに似ています。純粋なPythonでは、このテンプレートは次のようになるでしょう:
```python
for idx, message in enumerate(messages):
if message['role'] == 'user':
print(' ')
print(message['content'])
if not idx == len(messages) - 1: # Check for the last message in the conversation
print(' ')
print(eos_token)
```
実際に、このテンプレートは次の3つのことを行います:
1. 各メッセージに対して、メッセージがユーザーメッセージである場合、それの前に空白を追加し、それ以外の場合は何も表示しません。
2. メッセージの内容を追加します。
3. メッセージが最後のメッセージでない場合、その後に2つのスペースを追加します。最後のメッセージの後にはEOSトークンを表示します。
これは非常にシンプルなテンプレートです。制御トークンを追加しないし、モデルに対する指示を伝える一般的な方法である「システム」メッセージをサポートしていません。
ただし、Jinjaはこれらのことを行うための多くの柔軟性を提供しています!
LLaMAがフォーマットする方法に類似した入力をフォーマットするためのJinjaテンプレートを見てみましょう
(実際のLLaMAテンプレートはデフォルトのシステムメッセージの処理や、一般的なシステムメッセージの処理が若干異なるため、
実際のコードではこのテンプレートを使用しないでください!)
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ ' ' + message['content'] + ' ' + eos_token }}
{% endif %}
{% endfor %}
```
願わくば、少し見つめていただければ、このテンプレートが何を行っているかがわかるかもしれません。
このテンプレートは、各メッセージの「役割」に基づいて特定のトークンを追加します。これらのトークンは、メッセージを送信した人を表すものです。
ユーザー、アシスタント、およびシステムメッセージは、それらが含まれるトークンによってモデルによって明確に区別されます。
## How do I create a chat template?
簡単です。単純にJinjaテンプレートを書いて、`tokenizer.chat_template`を設定します。
他のモデルから既存のテンプレートを始点にして、必要に応じて編集すると便利かもしれません!
例えば、上記のLLaMAテンプレートを取って、アシスタントメッセージに"[ASST]"と"[/ASST]"を追加できます。
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'].strip() + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
{% endif %}
{% endfor %}
```
次に、単に`tokenizer.chat_template`属性を設定してください。
次回、[`~PreTrainedTokenizer.apply_chat_template`]を使用する際に、新しいテンプレートが使用されます!
この属性は`tokenizer_config.json`ファイルに保存されるため、[`~utils.PushToHubMixin.push_to_hub`]を使用して
新しいテンプレートをHubにアップロードし、みんなが正しいテンプレートを使用していることを確認できます!
```python
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
```
[`~PreTrainedTokenizer.apply_chat_template`] メソッドは、あなたのチャットテンプレートを使用するために [`ConversationalPipeline`] クラスによって呼び出されます。
したがって、正しいチャットテンプレートを設定すると、あなたのモデルは自動的に [`ConversationalPipeline`] と互換性があるようになります。
## What are "default" templates?
チャットテンプレートの導入前に、チャットの処理はモデルクラスレベルでハードコードされていました。
後方互換性のために、このクラス固有の処理をデフォルトテンプレートとして保持し、クラスレベルで設定されています。
モデルにチャットテンプレートが設定されていない場合、ただしモデルクラスのデフォルトテンプレートがある場合、
`ConversationalPipeline`クラスや`apply_chat_template`などのメソッドはクラステンプレートを使用します。
トークナイザのデフォルトのチャットテンプレートを確認するには、`tokenizer.default_chat_template`属性をチェックしてください。
これは、後方互換性のために純粋に行っていることで、既存のワークフローを壊さないようにしています。
モデルにとってクラステンプレートが適切である場合でも、デフォルトテンプレートをオーバーライドして
`chat_template`属性を明示的に設定することを強くお勧めします。これにより、ユーザーにとって
モデルがチャット用に正しく構成されていることが明確になり、デフォルトテンプレートが変更されたり廃止された場合に備えることができます。
## What template should I use?
すでにチャットのトレーニングを受けたモデルのテンプレートを設定する場合、テンプレートがトレーニング中にモデルが見たメッセージのフォーマットとまったく一致することを確認する必要があります。
そうでない場合、性能の低下を経験する可能性が高いです。これはモデルをさらにトレーニングしている場合でも同様です - チャットトークンを一定に保つと、おそらく最高の性能が得られます。
これはトークン化と非常に類似しており、通常はトレーニング中に使用されたトークン化と正確に一致する場合に、推論またはファインチューニングの際に最良の性能が得られます。
一方、ゼロからモデルをトレーニングするか、チャットのためにベース言語モデルをファインチューニングする場合、適切なテンプレートを選択する自由度があります。
LLM(Language Model)はさまざまな入力形式を処理できるほどスマートです。クラス固有のテンプレートがないモデル用のデフォルトテンプレートは、一般的なユースケースに対して良い柔軟な選択肢です。
これは、[ChatMLフォーマット](https://github.com/openai/openai-python/blob/main/chatml.md)に従ったもので、多くのユースケースに適しています。次のようになります:
```
{% for message in messages %}
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
```
If you like this one, here it is in one-liner form, ready to copy into your code:
```
tokenizer.chat_template = "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}"
```
このテンプレートは、各メッセージを「``」トークンで囲み、役割を文字列として単純に記述します。
これにより、トレーニングで使用する役割に対する柔軟性が得られます。出力は以下のようになります:
```
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm doing great!<|im_end|>
```
「ユーザー」、「システム」、および「アシスタント」の役割は、チャットの標準です。
特に、[`ConversationalPipeline`]との連携をスムーズに行う場合には、これらの役割を使用することをお勧めします。ただし、これらの役割に制約はありません。テンプレートは非常に柔軟で、任意の文字列を役割として使用できます。
## I want to use chat templates! How should I get started?
チャットモデルを持っている場合、そのモデルの`tokenizer.chat_template`属性を設定し、[`~PreTrainedTokenizer.apply_chat_template`]を使用してテストする必要があります。
これはモデルの所有者でない場合でも適用されます。モデルのリポジトリが空のチャットテンプレートを使用している場合、またはデフォルトのクラステンプレートを使用している場合でも、
この属性を適切に設定できるように[プルリクエスト](https://huggingface.co/docs/hub/repositories-pull-requests-discussions)を開いてください。
一度属性が設定されれば、それで完了です! `tokenizer.apply_chat_template`は、そのモデルに対して正しく動作するようになります。これは、
`ConversationalPipeline`などの場所でも自動的にサポートされます。
モデルがこの属性を持つことを確認することで、オープンソースモデルの全コミュニティがそのフルパワーを使用できるようになります。
フォーマットの不一致はこの分野に悩み続け、パフォーマンスに黙って影響を与えてきました。それを終わらせる時が来ました!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/big_models.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Instantiating a big model
非常に大規模な事前学習済みモデルを使用する場合、RAMの使用量を最小限に抑えることは課題の1つです。通常のPyTorchのワークフローは次のとおりです:
1. ランダムな重みを持つモデルを作成します。
2. 事前学習済みの重みをロードします。
3. これらの事前学習済みの重みをランダムなモデルに配置します。
ステップ1と2の両方がメモリにモデルの完全なバージョンを必要とし、ほとんどの場合は問題ありませんが、モデルのサイズが数ギガバイトになると、これらの2つのコピーをRAMから排除することができなくなる可能性があります。さらに悪いことに、分散トレーニングを実行するために`torch.distributed`を使用している場合、各プロセスは事前学習済みモデルをロードし、これらの2つのコピーをRAMに保存します。
<Tip>
ランダムに作成されたモデルは、メモリ内に「空の」テンソルで初期化されます。これらのランダムな値は、メモリの特定のチャンクにあったものを使用します(したがって、ランダムな値はその時点でのメモリチャンク内の値です)。モデル/パラメータの種類に適した分布(たとえば、正規分布)に従うランダムな初期化は、ステップ3で初期化されていない重みに対して、できるだけ高速に実行されます!
</Tip>
このガイドでは、Transformersがこの問題に対処するために提供するソリューションを探ります。なお、これは現在も開発が進行中の分野であり、将来、ここで説明されているAPIがわずかに変更される可能性があることに注意してください。
## Sharded checkpoints
バージョン4.18.0から、10GBを超えるサイズのモデルチェックポイントは自動的に複数の小さな部分に分割されます。`model.save_pretrained(save_dir)`を実行する際に1つの単一のチェックポイントを持つ代わりに、いくつかの部分的なチェックポイント(それぞれのサイズが<10GB)と、パラメータ名をそれらが格納されているファイルにマップするインデックスが生成されます。
`max_shard_size`パラメータでシャーディング前の最大サイズを制御できるため、例として通常サイズのモデルと小さなシャードサイズを使用します。従来のBERTモデルを使用してみましょう。
```py
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-cased")
```
もし[`~PreTrainedModel.save_pretrained`]を使用して保存する場合、新しいフォルダが2つのファイルを含む形で作成されます: モデルの設定情報とその重み情報です。
```py
>>> import os
>>> import tempfile
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir)
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model.bin']
```
最大シャードサイズを200MBに設定します:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... print(sorted(os.listdir(tmp_dir)))
['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
```
モデルの設定の上に、3つの異なる重みファイルと、`index.json`ファイルが見られます。これは私たちのインデックスです。
このようなチェックポイントは、[`~PreTrainedModel.from_pretrained`]メソッドを使用して完全に再ロードできます:
```py
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... new_model = AutoModel.from_pretrained(tmp_dir)
```
主要な利点は、大規模なモデルの場合、上記のワークフローのステップ2において、各チェックポイントのシャードが前のシャードの後にロードされ、RAMのメモリ使用量をモデルのサイズと最大のシャードのサイズを合わせたものに制限できることです。
内部では、インデックスファイルが使用され、どのキーがチェックポイントに存在し、対応する重みがどこに格納されているかを判断します。このインデックスは通常のJSONファイルのように読み込むことができ、辞書として取得できます。
```py
>>> import json
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
... index = json.load(f)
>>> print(index.keys())
dict_keys(['metadata', 'weight_map'])
```
メタデータには現時点ではモデルの総サイズのみが含まれています。
将来的には他の情報を追加する予定です:
```py
>>> index["metadata"]
{'total_size': 433245184}
```
重みマップはこのインデックスの主要な部分であり、各パラメータ名(通常はPyTorchモデルの`state_dict`で見つかるもの)をその格納されているファイルにマップします:
```py
>>> index["weight_map"]
{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
...
```
直接モデル内で[`~PreTrainedModel.from_pretrained`]を使用せずに、
シャーディングされたチェックポイントをロードしたい場合(フルチェックポイントの場合に`model.load_state_dict()`を使用するように行う方法)、[`~modeling_utils.load_sharded_checkpoint`]を使用する必要があります:
```py
>>> from transformers.modeling_utils import load_sharded_checkpoint
>>> with tempfile.TemporaryDirectory() as tmp_dir:
... model.save_pretrained(tmp_dir, max_shard_size="200MB")
... load_sharded_checkpoint(model, tmp_dir)
```
## Low memory loading
シャードされたチェックポイントは、上記のワークフローのステップ2におけるメモリ使用量を削減しますが、
低メモリの環境でそのモデルを使用するために、Accelerateライブラリに基づいた当社のツールを活用することをお勧めします。
詳細については、以下のガイドをご覧ください:[Accelerateを使用した大規模モデルの読み込み](./main_classes/model#large-model-loading)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/transformers_agents.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformers Agents
<Tip warning={true}>
Transformers Agentsは、いつでも変更される可能性のある実験的なAPIです。エージェントが返す結果は、APIまたは基礎となるモデルが変更される可能性があるため、異なることがあります。
</Tip>
Transformersバージョンv4.29.0は、*ツール*と*エージェント*のコンセプトを基に構築されています。この[colab](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj)で試すことができます。
要するに、これはtransformersの上に自然言語APIを提供するものです:私たちは一連の厳選されたツールを定義し、自然言語を解釈し、これらのツールを使用するエージェントを設計します。これは設計上拡張可能です。私たちはいくつかの関連するツールを厳選しましたが、コミュニティによって開発された任意のツールを使用するためにシステムを簡単に拡張できる方法も示します。
この新しいAPIで何ができるかのいくつかの例から始めましょう。特に多モーダルなタスクに関して強力ですので、画像を生成したりテキストを読み上げたりするのに最適です。
上記のテキストの上に、日本語の翻訳を提供します。
```py
agent.run("Caption the following image", image=image)
```
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/beaver.png" width=200> | A beaver is swimming in the water |
---
```py
agent.run("Read the following text out loud", text=text)
```
| **Input** | **Output** |
|-------------------------------------------------------------------------------------------------------------------------|----------------------------------------------|
| A beaver is swimming in the water | <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tts_example.wav" type="audio/wav"> your browser does not support the audio element. </audio>
---
```py
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)
```
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|----------------|
| <img src="https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/0/image/image.jpg" width=200> | ballroom foyer |
## Quickstart
`agent.run`を使用する前に、エージェントをインスタンス化する必要があります。エージェントは、大規模な言語モデル(LLM)です。
OpenAIモデルとBigCode、OpenAssistantからのオープンソースの代替モデルをサポートしています。OpenAIモデルはパフォーマンスが優れていますが、OpenAIのAPIキーが必要であり、無料で使用することはできません。一方、Hugging FaceはBigCodeとOpenAssistantモデルのエンドポイントへの無料アクセスを提供しています。
まず、デフォルトの依存関係をすべてインストールするために`agents`のエクストラをインストールしてください。
```bash
pip install transformers[agents]
```
OpenAIモデルを使用するには、`openai`の依存関係をインストールした後、`OpenAiAgent`をインスタンス化します。
```bash
pip install openai
```
```py
from transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")
```
BigCodeまたはOpenAssistantを使用するには、まずログインしてInference APIにアクセスしてください。
```py
from huggingface_hub import login
login("<YOUR_TOKEN>")
```
次に、エージェントをインスタンス化してください。
```py
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
```
これは、Hugging Faceが現在無料で提供している推論APIを使用しています。このモデル(または別のモデル)の独自の推論エンドポイントをお持ちの場合は、上記のURLエンドポイントをご自分のURLエンドポイントで置き換えることができます。
<Tip>
StarCoderとOpenAssistantは無料で利用でき、シンプルなタスクには非常に優れた性能を発揮します。ただし、より複雑なプロンプトを処理する際には、チェックポイントが十分でないことがあります。そのような場合には、現時点ではオープンソースではないものの、パフォーマンスが向上する可能性のあるOpenAIモデルを試してみることをお勧めします。
</Tip>
これで準備が整いました!これから、あなたが利用できる2つのAPIについて詳しく説明します。
### Single execution (run)
単一実行メソッドは、エージェントの [`~Agent.run`] メソッドを使用する場合です。
```py
agent.run("Draw me a picture of rivers and lakes.")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
これは、実行したいタスクに適したツール(またはツール)を自動的に選択し、適切に実行します。1つまたは複数のタスクを同じ命令で実行することができます(ただし、命令が複雑であるほど、エージェントが失敗する可能性が高くなります)。
```py
agent.run("Draw me a picture of the sea then transform the picture to add an island")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sea_and_island.png" width=200>
<br/>
[`~Agent.run`] 操作は独立して実行できますので、異なるタスクで何度も実行することができます。
注意点として、あなたの `agent` は単なる大規模な言語モデルであるため、プロンプトのわずかな変更でも完全に異なる結果が得られる可能性があります。したがって、実行したいタスクをできるだけ明確に説明することが重要です。良いプロンプトの書き方については、[こちら](custom_tools#writing-good-user-inputs) で詳しく説明しています。
実行ごとに状態を保持したり、テキスト以外のオブジェクトをエージェントに渡したりする場合は、エージェントが使用する変数を指定することができます。例えば、最初の川や湖の画像を生成し、その画像に島を追加するようにモデルに指示するには、次のように行うことができます:
```python
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)
```
<Tip>
これは、モデルがあなたのリクエストを理解できない場合や、ツールを混同する場合に役立つことがあります。例えば:
```py
agent.run("Draw me the picture of a capybara swimming in the sea")
```
ここでは、モデルは2つの方法で解釈できます:
- `text-to-image`に海で泳ぐカピバラを生成させる
- または、`text-to-image`でカピバラを生成し、それを海で泳がせるために`image-transformation`ツールを使用する
最初のシナリオを強制したい場合は、プロンプトを引数として渡すことができます:
```py
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")
```
</Tip>
### Chat-based execution (チャット)
エージェントは、[`~Agent.chat`] メソッドを使用することで、チャットベースのアプローチも可能です。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
```py
agent.chat("Transform the picture so that there is a rock in there")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_and_beaver.png" width=200>
<br/>
これは、指示をまたいで状態を保持したい場合に便利なアプローチで、単一の指示に比べて複雑な指示を処理するのは難しいかもしれません(その場合は [`~Agent.run`] メソッドの方が適しています)。
このメソッドは、非テキスト型の引数や特定のプロンプトを渡したい場合にも使用できます。
### ⚠️ Remote execution
デモンストレーションの目的やすべてのセットアップで使用できるように、リリースのためにいくつかのデフォルトツール用のリモート実行ツールも作成しました。これらは [推論エンドポイント](https://huggingface.co/inference-endpoints) を使用して作成されます。
これらは現在オフになっていますが、リモート実行ツールを自分で設定する方法については、[カスタムツールガイド](./custom_tools) を読むことをお勧めします。
### What's happening here? What are tools, and what are agents?

#### Agents
ここでの「エージェント」とは、大規模な言語モデルのことであり、特定の一連のツールにアクセスできるようにプロンプトを設定しています。
LLM(大規模言語モデル)は、コードの小さなサンプルを生成するのにかなり優れており、このAPIは、エージェントに特定のツールセットを使用してタスクを実行するコードの小さなサンプルを生成させることに利用しています。このプロンプトは、エージェントにタスクとツールの説明を提供することで、エージェントが使用しているツールのドキュメントにアクセスし、関連するコードを生成できるようになります。
#### Tools
ツールは非常に単純で、名前と説明からなる単一の関数です。それから、これらのツールの説明を使用してエージェントをプロンプトします。プロンプトを通じて、エージェントに、ツールを使用してクエリで要求されたタスクをどのように実行するかを示します。特に、ツールの期待される入力と出力を示します。
これは新しいツールを使用しており、パイプラインではなくツールを使用しています。なぜなら、エージェントは非常に原子的なツールでより良いコードを生成するからです。パイプラインはよりリファクタリングされ、しばしば複数のタスクを組み合わせています。ツールは非常に単純なタスクに焦点を当てることを意図しています。
#### Code-execution?!
このコードは、ツールとツールと一緒に渡される入力のセットで、当社の小規模なPythonインタープリタで実行されます。すでに提供されたツールとprint関数しか呼び出すことができないため、実行できることはすでに制限されています。Hugging Faceのツールに制限されているため、安全だと考えても問題ありません。
さらに、属性の検索やインポートは許可しておらず(それらは渡された入力/出力を処理するためには必要ないはずです)、最も明らかな攻撃は問題ありません(エージェントにそれらを出力するようにプロンプトする必要があります)。超安全な側に立ちたい場合は、追加の引数 return_code=True を指定して run() メソッドを実行できます。その場合、エージェントは実行するコードを返すだけで、実行するかどうかはあなた次第です。
実行は、違法な操作を試みる行またはエージェントが生成したコードに通常のPythonエラーがある場合に停止します。
### A curated set of tools
私たちは、このようなエージェントを強化できるツールのセットを特定します。以下は、`transformers`に統合されたツールの更新されたリストです:
- **ドキュメント質問応答**: 画像形式のドキュメント(PDFなど)が与えられた場合、このドキュメントに関する質問に回答します([Donut](./model_doc/donut))
- **テキスト質問応答**: 長いテキストと質問が与えられた場合、テキスト内の質問に回答します([Flan-T5](./model_doc/flan-t5))
- **無条件の画像キャプション**: 画像にキャプションを付けます!([BLIP](./model_doc/blip))
- **画像質問応答**: 画像が与えられた場合、その画像に関する質問に回答します([VILT](./model_doc/vilt))
- **画像セグメンテーション**: 画像とプロンプトが与えられた場合、そのプロンプトのセグメンテーションマスクを出力します([CLIPSeg](./model_doc/clipseg))
- **音声からテキストへの変換**: 人の話し声のオーディオ録音が与えられた場合、その音声をテキストに転記します([Whisper](./model_doc/whisper))
- **テキストから音声への変換**: テキストを音声に変換します([SpeechT5](./model_doc/speecht5))
- **ゼロショットテキスト分類**: テキストとラベルのリストが与えられた場合、テキストが最も対応するラベルを識別します([BART](./model_doc/bart))
- **テキスト要約**: 長いテキストを1つまたは数文に要約します([BART](./model_doc/bart))
- **翻訳**: テキストを指定された言語に翻訳します([NLLB](./model_doc/nllb))
これらのツールはtransformersに統合されており、手動でも使用できます。たとえば、次のように使用できます:
```py
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
```
### Custom tools
私たちは、厳選されたツールのセットを特定する一方、この実装が提供する主要な価値は、カスタムツールを迅速に作成して共有できる能力だと強く信じています。
ツールのコードをHugging Face Spaceまたはモデルリポジトリにプッシュすることで、エージェントと直接連携してツールを活用できます。[`huggingface-tools` organization](https://huggingface.co/huggingface-tools)には、**transformers非依存**のいくつかのツールが追加されました:
- **テキストダウンローダー**: ウェブURLからテキストをダウンロードするためのツール
- **テキストから画像へ**: プロンプトに従って画像を生成するためのツール。安定した拡散を活用します
- **画像変換**: 初期画像とプロンプトを指定して画像を変更するためのツール。instruct pix2pixの安定した拡散を活用します
- **テキストからビデオへ**: プロンプトに従って小さなビデオを生成するためのツール。damo-vilabを活用します
最初から使用しているテキストから画像へのツールは、[*huggingface-tools/text-to-image*](https://huggingface.co/spaces/huggingface-tools/text-to-image)にあるリモートツールです!今後も、この組織および他の組織にさらにこのようなツールをリリースし、この実装をさらに強化していきます。
エージェントはデフォルトで[`huggingface-tools`](https://huggingface.co/huggingface-tools)にあるツールにアクセスできます。
ツールの作成と共有方法、またHubに存在するカスタムツールを活用する方法についての詳細は、[次のガイド](custom_tools)で説明しています。
### Code generation
これまで、エージェントを使用してあなたのためにアクションを実行する方法を示しました。ただし、エージェントはコードを生成するだけで、非常に制限されたPythonインタープリタを使用して実行します。生成されたコードを異なる環境で使用したい場合、エージェントにコードを返すように指示できます。ツールの定義と正確なインポートも含めて。
例えば、以下の命令:
```python
agent.run("Draw me a picture of rivers and lakes", return_code=True)
```
次のコードを返します
```python
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")
```
その後、自分で変更して実行できます。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/pipeline_tutorial.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdown形式ですが、当社のdoc-builder(MDXに似た構文)を含むため、Markdownビューアで正しく表示されないことがあります。
-->
# Pipelines for inference
[`pipeline`]を使用することで、[Hub](https://huggingface.co/models)からの任意のモデルを言語、コンピュータビジョン、音声、およびマルチモーダルタスクの推論に簡単に使用できます。
特定のモダリティに関する経験がない場合や、モデルの背後にあるコードに精通していない場合でも、[`pipeline`]を使用して推論できます!
このチュートリアルでは、次のことを学びます:
- 推論のための[`pipeline`]の使用方法。
- 特定のトークナイザやモデルの使用方法。
- オーディオ、ビジョン、マルチモーダルタスクのための[`pipeline`]の使用方法。
<Tip>
サポートされているタスクと利用可能なパラメータの完全な一覧については、[`pipeline`]のドキュメンテーションをご覧ください。
</Tip>
## Pipeline usage
各タスクには関連する[`pipeline`]がありますが、タスク固有の[`pipeline`]を使用する代わりに、すべてのタスク固有のパイプラインを含む一般的な[`pipeline`]の抽象化を使用すると、より簡単です。[`pipeline`]は自動的にデフォルトのモデルと、タスクの推論が可能な前処理クラスを読み込みます。
1. [`pipeline`]を作成し、推論タスクを指定して始めます:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="automatic-speech-recognition")
```
2. [`pipeline`]に入力テキストを渡します:
```python
>>> generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
```
チェックアウトできなかったか? [Hubの最もダウンロードされた自動音声認識モデル](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=downloads) のいくつかを見て、より良い転写を得ることができるかどうかを確認してみてください。
[openai/whisper-large](https://huggingface.co/openai/whisper-large) を試してみましょう:
```python
>>> generator = pipeline(model="openai/whisper-large")
>>> generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
この結果はより正確に見えますね!
異なる言語、専門分野に特化したモデル、その他のモデルについては、Hubをチェックすることを強くお勧めします。
Hubでは、ブラウザから直接モデルの結果をチェックして、他のモデルよりも適しているか、特殊なケースをよりよく処理できるかを確認できます。
そして、あなたのユースケースに適したモデルが見つからない場合、いつでも[トレーニング](training)を開始できます!
複数の入力がある場合、入力をリストとして渡すことができます:
```py
generator(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)
```
データセット全体を繰り返し処理したり、ウェブサーバーで推論に使用したい場合は、専用の部分をチェックしてください。
[データセットでパイプラインを使用する](#using-pipelines-on-a-dataset)
[ウェブサーバーでパイプラインを使用する](./pipeline_webserver)
## パラメータ
[`pipeline`]は多くのパラメータをサポートしており、一部はタスク固有であり、一部はすべてのパイプラインに共通です。
一般的には、どこでもパラメータを指定できます:
```py
generator = pipeline(model="openai/whisper-large", my_parameter=1)
out = generator(...) # これは `my_parameter=1` を使用します。
out = generator(..., my_parameter=2) # これは上書きして `my_parameter=2` を使用します。
out = generator(...) # これは再び `my_parameter=1` を使用します。
```
3つの重要なものを確認しましょう:
### Device
`device=n` を使用すると、パイプラインはモデルを指定したデバイスに自動的に配置します。
これは、PyTorchまたはTensorflowを使用しているかどうかに関係なく機能します。
```py
generator = pipeline(model="openai/whisper-large", device=0)
```
もしモデルが単一のGPUには大きすぎる場合、`device_map="auto"`を設定して、🤗 [Accelerate](https://huggingface.co/docs/accelerate) にモデルの重みをどのようにロードし、保存するかを自動的に決定させることができます。
```python
#!pip install accelerate
generator = pipeline(model="openai/whisper-large", device_map="auto")
```
注意: `device_map="auto"` が渡された場合、`pipeline` をインスタンス化する際に `device=device` 引数を追加する必要はありません。そうしないと、予期しない動作に遭遇する可能性があります!
### Batch size
デフォルトでは、パイプラインは詳細について[こちら](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching)で説明されている理由から、推論をバッチ処理しません。その理由は、バッチ処理が必ずしも速くないためであり、実際にはいくつかのケースでかなり遅くなることがあるからです。
ただし、あなたのユースケースで機能する場合は、次のように使用できます:
```py
generator = pipeline(model="openai/whisper-large", device=0, batch_size=2)
audio_filenames = [f"audio_{i}.flac" for i in range(10)]
texts = generator(audio_filenames)
```
これにより、パイプラインは提供された10個のオーディオファイルでパイプラインを実行しますが、
モデルにはバッチ処理がより効果的であるGPU上にあり、バッチ処理を行うための追加のコードは必要ありません。
出力は常にバッチ処理なしで受け取ったものと一致するはずです。これは単にパイプラインからより高速な処理を得るための方法として提供されています。
パイプラインは、バッチ処理のいくつかの複雑さを軽減することもできます。なぜなら、一部のパイプラインでは、
モデルで処理するために1つのアイテム(長いオーディオファイルのようなもの)を複数の部分に分割する必要がある場合があるからです。
パイプラインはこれをあなたのために実行します。[*チャンクバッチ処理*](./main_classes/pipelines#pipeline-chunk-batching)として知られるものを実行します。
### Task specific parameters
すべてのタスクは、タスク固有のパラメータを提供し、追加の柔軟性とオプションを提供して、作業をスムーズに進めるのに役立ちます。
たとえば、[`transformers.AutomaticSpeechRecognitionPipeline.__call__`]メソッドには、ビデオの字幕作成に有用な`return_timestamps`パラメータがあります。
```py
>>> # Not using whisper, as it cannot provide timestamps.
>>> generator = pipeline(model="facebook/wav2vec2-large-960h-lv60-self", return_timestamps="word")
>>> generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP AND LIVE OUT THE TRUE MEANING OF ITS CREED', 'chunks': [{'text': 'I', 'timestamp': (1.22, 1.24)}, {'text': 'HAVE', 'timestamp': (1.42, 1.58)}, {'text': 'A', 'timestamp': (1.66, 1.68)}, {'text': 'DREAM', 'timestamp': (1.76, 2.14)}, {'text': 'BUT', 'timestamp': (3.68, 3.8)}, {'text': 'ONE', 'timestamp': (3.94, 4.06)}, {'text': 'DAY', 'timestamp': (4.16, 4.3)}, {'text': 'THIS', 'timestamp': (6.36, 6.54)}, {'text': 'NATION', 'timestamp': (6.68, 7.1)}, {'text': 'WILL', 'timestamp': (7.32, 7.56)}, {'text': 'RISE', 'timestamp': (7.8, 8.26)}, {'text': 'UP', 'timestamp': (8.38, 8.48)}, {'text': 'AND', 'timestamp': (10.08, 10.18)}, {'text': 'LIVE', 'timestamp': (10.26, 10.48)}, {'text': 'OUT', 'timestamp': (10.58, 10.7)}, {'text': 'THE', 'timestamp': (10.82, 10.9)}, {'text': 'TRUE', 'timestamp': (10.98, 11.18)}, {'text': 'MEANING', 'timestamp': (11.26, 11.58)}, {'text': 'OF', 'timestamp': (11.66, 11.7)}, {'text': 'ITS', 'timestamp': (11.76, 11.88)}, {'text': 'CREED', 'timestamp': (12.0, 12.38)}]}
```
モデルは、テキストを推測し、文の中で各単語がいつ発音されたかを出力しました。
各タスクごとに利用可能な多くのパラメータがありますので、何を調整できるかを確認するために各タスクのAPIリファレンスを確認してください!
たとえば、[`~transformers.AutomaticSpeechRecognitionPipeline`]には、モデル単体では処理できない非常に長いオーディオファイル(たとえば、映画全体や1時間のビデオの字幕付けなど)で役立つ`chunk_length_s`パラメータがあります。
<!--役立つパラメータが見つからない場合は、[リクエスト](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)してください!-->
役立つパラメータが見つからない場合は、[リクエスト](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)してください!
## Using pipeline in a dataset
パイプラインは大規模なデータセット上で推論を実行することもできます。これを行う最も簡単な方法は、イテレータを使用することです:
```py
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])
```
イテレーター `data()` は各結果を生成し、パイプラインは自動的に入力が反復可能であることを認識し、データを取得し続けながらGPU上で処理を行います(これは[DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)を内部で使用しています)。
これは、データセット全体にメモリを割り当てる必要がなく、GPUにできるだけ速くデータを供給できるため重要です。
バッチ処理は処理を高速化できる可能性があるため、ここで`batch_size`パラメータを調整して試すことが役立つかもしれません。
データセットを反復処理する最も簡単な方法は、🤗 [Datasets](https://github.com/huggingface/datasets/)からデータセットを読み込むことです:
```py
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)
```
## Using pipelines for a webserver
<Tip>
推論エンジンを作成することは複雑なトピックで、独自のページが必要です。
</Tip>
[リンク](./pipeline_webserver)
## Vision pipeline
ビジョンタスク用の[`pipeline`]を使用する方法はほぼ同じです。
タスクを指定し、画像をクラシファイアに渡します。画像はリンク、ローカルパス、またはBase64エンコードされた画像であることができます。例えば、以下の画像はどの種類の猫ですか?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## Text pipeline
[`pipeline`]を使用することは、NLPタスクに対してほぼ同じです。
```py
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
```
## Multimodal pipeline
[`pipeline`]は、1つ以上のモダリティをサポートしています。たとえば、視覚的な質問応答(VQA)タスクはテキストと画像を組み合わせています。
好きな画像リンクと画像に関する質問を自由に使ってください。画像はURLまたは画像のローカルパスで指定できます。
例えば、この[請求書画像](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png)を使用する場合:
```py
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
[{'score': 0.42515, 'answer': 'us-001', 'start': 16, 'end': 16}]
```
<Tip>
上記の例を実行するには、🤗 Transformersに加えて [`pytesseract`](https://pypi.org/project/pytesseract/) がインストールされている必要があります。
```bash
sudo apt install -y tesseract-ocr
pip install pytesseract
```
</Tip>
## Using `pipeline` on large models with 🤗 `accelerate`:
まず、`accelerate` を`pip install accelerate` でインストールしていることを確認してください。
次に、`device_map="auto"` を使用してモデルをロードします。この例では `facebook/opt-1.3b` を使用します。
```python
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("これは素晴らしい例です!", do_sample=True, top_p=0.95)
```
もし `bitsandbytes` をインストールし、`load_in_8bit=True` 引数を追加すれば、8ビットで読み込まれたモデルを渡すこともできます。
```py
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)
```
注意: BLOOMなどの大規模モデルのロードをサポートするHugging Faceモデルのいずれかで、チェックポイントを置き換えることができます!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/quicktour.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdown形式ですが、Hugging Faceのドキュメントビルダー向けに特定の構文を含んでいるため、
通常のMarkdownビューアーで正しく表示されないことに注意してください。
-->
# Quick tour
[[open-in-colab]]
🤗 Transformersを使い始めましょう! 開発者であろうと、日常的なユーザーであろうと、このクイックツアーは
初めて始めるのを支援し、[`pipeline`]を使った推論方法、[AutoClass](./model_doc/auto)で事前学習済みモデルとプリプロセッサをロードする方法、
そしてPyTorchまたはTensorFlowで素早くモデルをトレーニングする方法を示します。 初心者の場合、ここで紹介されたコンセプトの詳細な説明を提供する
チュートリアルまたは[コース](https://huggingface.co/course/chapter1/1)を次に参照することをお勧めします。
始める前に、必要なライブラリがすべてインストールされていることを確認してください:
```bash
!pip install transformers datasets
```
あなたはまた、好きな機械学習フレームワークをインストールする必要があります:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
## Pipeline
<Youtube id="tiZFewofSLM"/>
[`pipeline`] は、事前学習済みモデルを推論に最も簡単で高速な方法です。
[`pipeline`] を使用することで、さまざまなモダリティにわたる多くのタスクに対して即座に使用できます。
いくつかのタスクは以下の表に示されています:
<Tip>
使用可能なタスクの完全な一覧については、[pipeline API リファレンス](./main_classes/pipelines)を確認してください。
</Tip>
| **タスク** | **説明** | **モダリティ** | **パイプライン識別子** |
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|-----------------------------------------------|
| テキスト分類 | テキストのシーケンスにラベルを割り当てる | NLP | pipeline(task="sentiment-analysis") |
| テキスト生成 | プロンプトを指定してテキストを生成する | NLP | pipeline(task="text-generation") |
| 要約 | テキストまたはドキュメントの要約を生成する | NLP | pipeline(task="summarization") |
| 画像分類 | 画像にラベルを割り当てる | コンピュータビジョン | pipeline(task="image-classification") |
| 画像セグメンテーション | 画像の各個別のピクセルにラベルを割り当てる(セマンティック、パノプティック、およびインスタンスセグメンテーションをサポート) | コンピュータビジョン | pipeline(task="image-segmentation") |
| オブジェクト検出 | 画像内のオブジェクトの境界ボックスとクラスを予測する | コンピュータビジョン | pipeline(task="object-detection") |
| オーディオ分類 | オーディオデータにラベルを割り当てる | オーディオ | pipeline(task="audio-classification") |
| 自動音声認識 | 音声をテキストに変換する | オーディオ | pipeline(task="automatic-speech-recognition") |
| ビジュアルクエスチョン応答 | 画像と質問が与えられた場合に、画像に関する質問に回答する | マルチモーダル | pipeline(task="vqa") |
| ドキュメントクエスチョン応答 | ドキュメントと質問が与えられた場合に、ドキュメントに関する質問に回答する | マルチモーダル | pipeline(task="document-question-answering") |
| 画像キャプショニング | 与えられた画像にキャプションを生成する | マルチモーダル | pipeline(task="image-to-text") |
まず、[`pipeline`] のインスタンスを作成し、使用したいタスクを指定します。
このガイドでは、センチメント分析のために [`pipeline`] を使用する例を示します:
```python
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
[`pipeline`]は、感情分析のためのデフォルトの[事前学習済みモデル](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)とトークナイザをダウンロードしてキャッシュし、使用できるようになります。
これで、`classifier`を対象のテキストに使用できます:
```python
>>> classifier("私たちは🤗 Transformersライブラリをお見せできてとても嬉しいです。")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
複数の入力がある場合は、[`pipeline`]に入力をリストとして渡して、辞書のリストを返します:
```py
>>> results = classifier(["🤗 Transformersライブラリをご紹介できて非常に嬉しいです。", "嫌いにならないでほしいです。"])
>>> for result in results:
... print(f"label: {result['label']}, スコア: {round(result['score'], 4)}")
label: POSITIVE, スコア: 0.9998
label: NEGATIVE, スコア: 0.5309
```
[`pipeline`]は、任意のタスクに対してデータセット全体を繰り返し処理することもできます。この例では、自動音声認識をタスクとして選びましょう:
```python
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
オーディオデータセットをロードします(詳細については🤗 Datasets [クイックスタート](https://huggingface.co/docs/datasets/quickstart#audio)を参照してください)。
たとえば、[MInDS-14](https://huggingface.co/datasets/PolyAI/minds14)データセットをロードします:
```python
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
データセットのサンプリングレートが[`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h)がトレーニングされたサンプリングレートと一致することを確認してください:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
"audio"列を呼び出すと、オーディオファイルは自動的にロードされ、リサンプリングされます。最初の4つのサンプルから生の波形配列を抽出し、それをパイプラインにリストとして渡します。
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
```
大規模なデータセットで、入力が大きい場合(音声や画像など)、すべての入力をメモリに読み込む代わりに、リストではなくジェネレータを渡すことがお勧めです。詳細については[パイプラインAPIリファレンス](./main_classes/pipelines)を参照してください。
### Use another model and tokenizer in the pipeline
[`pipeline`]は[Hub](https://huggingface.co/models)からの任意のモデルを収容でき、他のユースケースに[`pipeline`]を適応させることが容易です。たとえば、フランス語のテキストを処理できるモデルが必要な場合、Hubのタグを使用して適切なモデルをフィルタリングできます。トップのフィルタリングされた結果は、フランス語のテキストに使用できる感情分析用に調整された多言語の[BERTモデル](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)を返します:
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
[`AutoModelForSequenceClassification`]と[`AutoTokenizer`]を使用して事前学習済みモデルとそれに関連するトークナイザをロードします(次のセクションで`AutoClass`について詳しく説明します):
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
以下のコードは、[`TFAutoModelForSequenceClassification`]および[`AutoTokenizer`]を使用して、事前学習済みモデルとその関連するトークナイザをロードする方法を示しています(`TFAutoClass`については次のセクションで詳しく説明します):
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
指定したモデルとトークナイザを[`pipeline`]に設定し、今度はフランス語のテキストに`classifier`を適用できます:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
もし、あなたのユースケースに適したモデルが見つからない場合、事前学習済みモデルをあなたのデータでファインチューニングする必要があります。
ファインチューニングの方法については、[ファインチューニングのチュートリアル](./training)をご覧ください。
最後に、ファインチューニングした事前学習済みモデルを共有し、コミュニティと共有ハブで共有することを検討してください。これにより、機械学習を民主化する手助けができます! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
[`AutoModelForSequenceClassification`] および [`AutoTokenizer`] クラスは、上記で使用した [`pipeline`] を駆動するために協力して動作します。
[AutoClass](./model_doc/auto) は、事前学習済みモデルのアーキテクチャをその名前またはパスから自動的に取得するショートカットです。
適切な `AutoClass` を選択し、それに関連する前処理クラスを選択するだけで済みます。
前のセクションからの例に戻り、`AutoClass` を使用して [`pipeline`] の結果を再現する方法を見てみましょう。
### AutoTokenizer
トークナイザはテキストをモデルの入力として使用できる数値の配列に前処理する役割を果たします。
トークナイゼーションプロセスには、単語をどのように分割するかや、単語をどのレベルで分割するかといった多くのルールがあります
(トークナイゼーションについての詳細は [トークナイザサマリー](./tokenizer_summary) をご覧ください)。
最も重要なことは、モデルが事前学習済みになったときと同じトークナイゼーションルールを使用するために、同じモデル名でトークナイザをインスタンス化する必要があることです。
[`AutoTokenizer`] を使用してトークナイザをロードします:
```python
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Pass your text to the tokenizer:
```python
>>> encoding = tokenizer("私たちは🤗 Transformersライブラリをお見せできてとても嬉しいです。")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
トークナイザは、次の情報を含む辞書を返します:
- [input_ids](./glossary#input-ids): トークンの数値表現。
- [attention_mask](.glossary#attention-mask): どのトークンにアテンションを向けるかを示します。
トークナイザはまた、入力のリストを受け入れ、一様な長さのバッチを返すためにテキストをパディングおよび切り詰めることができます。
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["🤗 Transformersライブラリをお見せできて非常に嬉しいです。", "嫌いではないことを願っています。"],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
<Tip>
[前処理](./preprocessing)チュートリアルをご覧いただき、トークナイゼーションの詳細や、[`AutoImageProcessor`]、[`AutoFeatureExtractor`]、[`AutoProcessor`]を使用して画像、オーディオ、およびマルチモーダル入力を前処理する方法について詳しく説明されているページもご覧ください。
</Tip>
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformersは事前学習済みインスタンスを簡単に統一的にロードする方法を提供します。
これは、[`AutoTokenizer`]をロードするのと同じように[`AutoModel`]をロードできることを意味します。
タスクに適した[`AutoModel`]を選択する以外の違いはありません。
テキスト(またはシーケンス)分類の場合、[`AutoModelForSequenceClassification`]をロードする必要があります:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
[`AutoModel`]クラスでサポートされているタスクに関する詳細については、[タスクの概要](./task_summary)を参照してください。
</Tip>
今、前処理済みのバッチを直接モデルに渡します。辞書を展開するだけで、`**`を追加する必要があります:
```python
>>> pt_outputs = pt_model(**pt_batch)
```
モデルは、`logits`属性に最終的なアクティベーションを出力します。 `logits`にsoftmax関数を適用して確率を取得します:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformersは事前学習済みインスタンスをロードするためのシンプルで統一された方法を提供します。
これは、[`TFAutoModel`]を[`AutoTokenizer`]をロードするのと同じようにロードできることを意味します。
唯一の違いは、タスクに適した[`TFAutoModel`]を選択することです。
テキスト(またはシーケンス)分類の場合、[`TFAutoModelForSequenceClassification`]をロードする必要があります:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
詳細については、[`AutoModel`]クラスでサポートされているタスクに関する情報は、[タスクの概要](./task_summary)を参照してください。
</Tip>
次に、前処理済みのバッチを直接モデルに渡します。テンソルをそのまま渡すことができます:
```python
>>> tf_outputs = tf_model(tf_batch)
```
モデルは`logits`属性に最終的なアクティベーションを出力します。`logits`にソフトマックス関数を適用して確率を取得します:
```python
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
🤗 Transformersのすべてのモデル(PyTorchまたはTensorFlow)は、最終的な活性化関数(softmaxなど)*前*のテンソルを出力します。
最終的な活性化関数は、しばしば損失と結合されているためです。モデルの出力は特別なデータクラスであり、その属性はIDEで自動補完されます。
モデルの出力は、タプルまたは辞書のように動作します(整数、スライス、または文字列でインデックスを付けることができます)。
この場合、Noneである属性は無視されます。
</Tip>
### Save a Model
<frameworkcontent>
<pt>
モデルをファインチューニングしたら、[`PreTrainedModel.save_pretrained`]を使用してトークナイザと共に保存できます:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
再びモデルを使用する準備ができたら、[`PreTrainedModel.from_pretrained`]を使用して再度ロードします:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
モデルをファインチューニングしたら、そのトークナイザを使用してモデルを保存できます。[`TFPreTrainedModel.save_pretrained`]を使用します:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
モデルを再度使用する準備ができたら、[`TFPreTrainedModel.from_pretrained`]を使用して再度ロードします:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
🤗 Transformersの特に素晴らしい機能の一つは、モデルを保存し、それをPyTorchモデルまたはTensorFlowモデルとして再ロードできることです。 `from_pt`または`from_tf`パラメータを使用してモデルをフレームワーク間で変換できます:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent>
## Custom model builds
モデルを構築方法を変更するには、モデルの設定クラスを変更できます。設定はモデルの属性を指定します。例えば、隠れ層の数やアテンションヘッドの数などがこれに含まれます。カスタム設定クラスからモデルを初期化する際には、ゼロから始めます。モデルの属性はランダムに初期化され、有意義な結果を得るためにモデルをトレーニングする必要があります。
最初に[`AutoConfig`]をインポートし、変更したい事前学習済みモデルをロードします。[`AutoConfig.from_pretrained`]内で、変更したい属性(例:アテンションヘッドの数)を指定できます:
```python
>>> from transformers import AutoConfig
>>> my_config = AutoConfig.from_pretrained("distilbert-base-uncased", n_heads=12)
```
<frameworkcontent>
<pt>
[`AutoModel.from_config`]を使用してカスタム設定からモデルを作成します:
```python
>>> from transformers import AutoModel
>>> my_model = AutoModel.from_config(my_config)
```
</pt>
<tf>
カスタム構成からモデルを作成するには、[`TFAutoModel.from_config`]を使用します:
```py
>>> from transformers import TFAutoModel
>>> my_model = TFAutoModel.from_config(my_config)
```
</tf>
</frameworkcontent>
[カスタムアーキテクチャを作成](./create_a_model)ガイドを参照して、カスタム構成の詳細情報を確認してください。
## Trainer - PyTorch向けの最適化されたトレーニングループ
すべてのモデルは標準の[`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)であるため、通常のトレーニングループで使用できます。
独自のトレーニングループを作成できますが、🤗 TransformersはPyTorch向けに[`Trainer`]クラスを提供しており、基本的なトレーニングループに加えて、
分散トレーニング、混合精度などの機能の追加を行っています。
タスクに応じて、通常は[`Trainer`]に以下のパラメータを渡します:
1. [`PreTrainedModel`]または[`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)から始めます:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. [`TrainingArguments`]には、変更できるモデルのハイパーパラメータが含まれており、学習率、バッチサイズ、トレーニングエポック数などが変更できます。指定しない場合、デフォルト値が使用されます:
```py
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(
... output_dir="path/to/save/folder/",
... learning_rate=2e-5,
... per_device_train_batch_size=8,
... per_device_eval_batch_size=8,
... num_train_epochs=2,
... )
```
3. トークナイザ、画像プロセッサ、特徴量抽出器、またはプロセッサのような前処理クラスをロードします:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
4. データセットをロードする:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
```
5. データセットをトークン化するための関数を作成します:
```python
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"])
```
その後、[`~datasets.Dataset.map`]を使用してデータセット全体に適用します:
```python
>>> dataset = dataset.map(tokenize_dataset, batched=True)
```
6. データセットからの例のバッチを作成するための [`DataCollatorWithPadding`]:
```py
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
次に、これらのクラスを[`Trainer`]にまとめます:
```python
>>> from transformers import Trainer
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=dataset["train"],
... eval_dataset=dataset["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... ) # doctest: +SKIP
```
訓練を開始する準備ができたら、[`~Trainer.train`]を呼び出してトレーニングを開始します:
```py
>>> trainer.train() # doctest: +SKIP
```
<Tip>
翻訳や要約など、シーケンス間モデルを使用するタスクには、代わりに[`Seq2SeqTrainer`]と[`Seq2SeqTrainingArguments`]クラスを使用してください。
</Tip>
[`Trainer`]内のメソッドをサブクラス化することで、トレーニングループの動作をカスタマイズできます。これにより、損失関数、オプティマイザ、スケジューラなどの機能をカスタマイズできます。サブクラス化できるメソッドの一覧については、[`Trainer`]リファレンスをご覧ください。
トレーニングループをカスタマイズする別の方法は、[Callbacks](./main_classes/callbacks)を使用することです。コールバックを使用して他のライブラリと統合し、トレーニングループを監視して進捗状況を報告したり、トレーニングを早期に停止したりできます。コールバックはトレーニングループ自体には何も変更を加えません。損失関数などのカスタマイズを行う場合は、[`Trainer`]をサブクラス化する必要があります。
## Train with TensorFlow
すべてのモデルは標準の[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)であるため、[Keras](https://keras.io/) APIを使用してTensorFlowでトレーニングできます。
🤗 Transformersは、データセットを`tf.data.Dataset`として簡単にロードできるようにする[`~TFPreTrainedModel.prepare_tf_dataset`]メソッドを提供しており、Kerasの[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)および[`fit`](https://keras.io/api/models/model_training_apis/#fit-method)メソッドを使用してトレーニングをすぐに開始できます。
1. [`TFPreTrainedModel`]または[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)から始めます:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
2. トークナイザ、画像プロセッサ、特徴量抽出器、またはプロセッサのような前処理クラスをロードします:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
```
3. データセットをトークナイズするための関数を作成します:
```python
>>> def tokenize_dataset(dataset):
... return tokenizer(dataset["text"]) # doctest: +SKIP
```
4. [`~datasets.Dataset.map`]を使用してデータセット全体にトークナイザを適用し、データセットとトークナイザを[`~TFPreTrainedModel.prepare_tf_dataset`]に渡します。バッチサイズを変更し、データセットをシャッフルすることもできます。
```python
>>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
>>> tf_dataset = model.prepare_tf_dataset(
... dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
... ) # doctest: +SKIP
```
5. 準備ができたら、`compile`と`fit`を呼び出してトレーニングを開始できます。 Transformersモデルはすべてデフォルトのタスクに関連する損失関数を持っているため、指定しない限り、損失関数を指定する必要はありません。
```python
>>> from tensorflow.keras.optimizers import Adam
>>> model.compile(optimizer=Adam(3e-5)) # 損失関数の引数は不要です!
>>> model.fit(tf
```
## What's next?
🤗 Transformersのクイックツアーを完了したら、ガイドをチェックして、カスタムモデルの作成、タスクのためのファインチューニング、スクリプトを使用したモデルのトレーニングなど、より具体的なことを学ぶことができます。🤗 Transformersのコアコンセプトについてもっと詳しく知りたい場合は、コンセプチュアルガイドを読んでみてください!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/performance.md
|
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Performance and Scalability
大規模なトランスフォーマーモデルのトレーニングおよび本番環境への展開はさまざまな課題を提起します。
トレーニング中には、モデルが利用可能なGPUメモリよりも多くを必要としたり、トレーニング速度が遅かったりする可能性があります。
デプロイフェーズでは、モデルが本番環境で必要なスループットを処理するのに苦労することがあります。
このドキュメンテーションは、これらの課題を克服し、ユースケースに最適な設定を見つけるのに役立つことを目的としています。
ガイドはトレーニングと推論のセクションに分かれており、それぞれ異なる課題と解決策が存在します。
各セクション内には、トレーニング用のシングルGPU対マルチGPU、推論用のCPU対GPUなど、異なるハードウェア構成用の別々のガイドが用意されています。
このドキュメントを出発点として、シナリオに合った方法に進むための情報源としてご利用ください。
## Training
大規模なトランスフォーマーモデルを効率的にトレーニングするには、GPUやTPUなどのアクセラレータが必要です。
最も一般的なケースは、シングルGPUがある場合です。シングルGPUでのトレーニング効率を最適化するための一般的なアプローチを学ぶには、以下を参照してください。
* [シングルGPUでの効率的なトレーニングのための方法とツール](perf_train_gpu_one): GPUメモリの効果的な利用、トレーニングの高速化などを支援する共通のアプローチを学ぶためにここから始めてください。
* [マルチGPUトレーニングセクション](perf_train_gpu_many): マルチGPU環境に適用されるデータ、テンソル、パイプライン並列性など、さらなる最適化方法について詳細に学びます。
* [CPUトレーニングセクション](perf_train_cpu): CPU上での混合精度トレーニングについて学びます。
* [複数CPUでの効率的なトレーニング](perf_train_cpu_many): 分散CPUトレーニングについて学びます。
* [TensorFlowでTPUを使用したトレーニング](perf_train_tpu_tf): TPUに慣れていない場合は、TPUでのトレーニングとXLAの使用についてのセクションを参照してください。
* [トレーニングのためのカスタムハードウェア](perf_hardware): 独自のディープラーニング環境を構築する際のヒントやトリックを見つけます。
* [Trainer APIを使用したハイパーパラメーター検索](hpo_train)
## Inference
本番環境で大規模なモデルを効率的に推論することは、それらをトレーニングすることと同じくらい難しいことがあります。
以下のセクションでは、CPUおよびシングル/マルチGPU環境で推論を実行する手順について説明します。
* [シングルCPUでの推論](perf_infer_cpu)
* [シングルGPUでの推論](perf_infer_gpu_one)
* [マルチGPU推論](perf_infer_gpu_many)
* [TensorFlowモデルのXLA統合](tf_xla)
## Training and inference
モデルをトレーニングするか、それを使用して推論を実行するかに関係なく適用されるテクニック、ヒント、トリックがここにあります。
* [大規模モデルのインスタンス化](big_models)
* [パフォーマンスの問題のトラブルシューティング](debugging)
## Contribute
このドキュメントはまだ完全ではなく、さらに追加する必要がある項目がたくさんあります。
追加や訂正が必要な場合は、遠慮せずにPRをオープンするか、詳細を議論するためにIssueを開始してください。
AがBよりも優れているという貢献を行う際には、再現可能なベンチマークやその情報の出典へのリンクを含めてみてください(あなた自身の情報である場合を除く)。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_infer_cpu.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Inference on CPU
このガイドは、CPU上で大規模なモデルの効率的な推論に焦点を当てています。
## `BetterTransformer` for faster inference
最近、テキスト、画像、および音声モデルのCPU上での高速な推論のために`BetterTransformer`を統合しました。詳細については、この統合に関するドキュメンテーションを[こちら](https://huggingface.co/docs/optimum/bettertransformer/overview)で確認してください。
## PyTorch JITモード(TorchScript)
TorchScriptは、PyTorchコードからシリアライズ可能で最適化可能なモデルを作成する方法です。任意のTorchScriptプログラムは、Python依存性のないプロセスで保存およびロードできます。
デフォルトのイーガーモードと比較して、PyTorchのjitモードは通常、オペレーターフュージョンなどの最適化手法によりモデル推論のパフォーマンスが向上します。
TorchScriptの簡単な紹介については、[PyTorch TorchScriptチュートリアル](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html#tracing-modules)を参照してください。
### JITモードでのIPEXグラフ最適化
Intel® Extension for PyTorchは、Transformersシリーズモデルのjitモードにさらなる最適化を提供します。Intel® Extension for PyTorchをjitモードで使用することを強くお勧めします。Transformersモデルからよく使用されるオペレーターパターンのいくつかは、既にIntel® Extension for PyTorchでjitモードのフュージョンに対応しています。これらのフュージョンパターン(Multi-head-attentionフュージョン、Concat Linear、Linear+Add、Linear+Gelu、Add+LayerNormフュージョンなど)は有効でパフォーマンスが良いです。フュージョンの利点は、ユーザーに透過的に提供されます。分析によれば、最も人気のある質問応答、テキスト分類、トークン分類のNLPタスクの約70%が、これらのフュージョンパターンを使用してFloat32精度とBFloat16混合精度の両方でパフォーマンスの利点を得ることができます。
[IPEXグラフ最適化の詳細情報](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html)を確認してください。
#### IPEX installation:
IPEXのリリースはPyTorchに従っています。[IPEXのインストール方法](https://intel.github.io/intel-extension-for-pytorch/)を確認してください。
### Usage of JIT-mode
Trainerで評価または予測のためにJITモードを有効にするには、ユーザーはTrainerコマンド引数に`jit_mode_eval`を追加する必要があります。
<Tip warning={true}>
PyTorch >= 1.14.0の場合、jitモードはjit.traceでdict入力がサポートされているため、予測と評価に任意のモデルに利益をもたらす可能性があります。
PyTorch < 1.14.0の場合、jitモードはforwardパラメーターの順序がjit.traceのタプル入力の順序と一致するモデルに利益をもたらす可能性があります(質問応答モデルなど)。jit.traceがタプル入力の順序と一致しない場合、テキスト分類モデルなど、jit.traceは失敗し、これをフォールバックさせるために例外でキャッチしています。ログはユーザーに通知するために使用されます。
</Tip>
[Transformers質問応答の使用例](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)を参考にしてください。
- Inference using jit mode on CPU:
<pre>python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
<b>--jit_mode_eval </b></pre>
- Inference with IPEX using jit mode on CPU:
<pre>python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
<b>--use_ipex \</b>
<b>--jit_mode_eval</b></pre>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/custom_models.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Sharing custom models
🤗 Transformersライブラリは、簡単に拡張できるように設計されています。すべてのモデルはリポジトリの特定のサブフォルダに完全にコード化されており、抽象化はありません。したがって、モデリングファイルをコピーして調整することが簡単です。
新しいモデルを書いている場合、ゼロから始める方が簡単かもしれません。このチュートリアルでは、カスタムモデルとその設定をどのように書き、Transformers内で使用できるようにし、コードに依存する共同体と共有する方法を説明します。ライブラリに存在しない場合でも、誰でも使用できるようにします。
これを実証するために、[timmライブラリ](https://github.com/rwightman/pytorch-image-models)のResNetクラスを[`PreTrainedModel`]にラップすることによって、ResNetモデルを使用します。
## Writing a custom configuration
モデルに取り組む前に、まずその設定を書きましょう。モデルの設定は、モデルを構築するために必要なすべての情報を含むオブジェクトです。次のセクションで見るように、モデルは初期化するために`config`しか受け取ることができないため、そのオブジェクトができるだけ完全である必要があります。
この例では、ResNetクラスのいくつかの引数を取得し、調整したいかもしれないとします。異なる設定は、異なるタイプのResNetを提供します。その後、これらの引数を確認した後、それらの引数を単に格納します。
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
重要なことを3つ覚えておくべきポイントは次のとおりです:
- `PretrainedConfig` を継承する必要があります。
- あなたの `PretrainedConfig` の `__init__` は任意の kwargs を受け入れる必要があります。
- これらの `kwargs` は親クラスの `__init__` に渡す必要があります。
継承は、🤗 Transformers ライブラリのすべての機能を取得できるようにするためです。他の2つの制約は、
`PretrainedConfig` が設定しているフィールド以外にも多くのフィールドを持っていることから来ています。
`from_pretrained` メソッドで設定を再ロードする場合、これらのフィールドはあなたの設定に受け入れられ、
その後、親クラスに送信される必要があります。
設定の `model_type` を定義すること(ここでは `model_type="resnet"`)は、
自動クラスにモデルを登録したい場合を除いては必須ではありません(最後のセクションを参照)。
これで、ライブラリの他のモデル設定と同様に、設定を簡単に作成して保存できます。
以下は、resnet50d 設定を作成して保存する方法の例です:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
これにより、`custom-resnet` フォルダ内に `config.json` という名前のファイルが保存されます。その後、`from_pretrained` メソッドを使用して構成を再ロードできます。
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
また、[`PretrainedConfig`] クラスの他のメソッドを使用することもできます。たとえば、[`~PretrainedConfig.push_to_hub`] を使用して、設定を直接 Hub にアップロードできます。
## Writing a custom model
ResNet の設定ができたので、モデルを書き始めることができます。実際には2つのモデルを書きます。1つはバッチの画像から隠れた特徴を抽出するモデル([`BertModel`] のようなもの)で、もう1つは画像分類に適したモデル([`BertForSequenceClassification`] のようなもの)です。
前述したように、この例をシンプルに保つために、モデルの緩いラッパーのみを書きます。このクラスを書く前に行う必要がある唯一のことは、ブロックタイプと実際のブロッククラスの間のマップです。その後、すべてを `ResNet` クラスに渡して設定からモデルを定義します:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
画像を分類するモデルの場合、forwardメソッドを変更するだけです:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
両方の場合、`PreTrainedModel`から継承し、`config`を使用してスーパークラスの初期化を呼び出します(通常の`torch.nn.Module`を書くときのような感じです)。
`config_class`を設定する行は必須ではありませんが、(最後のセクションを参照)、モデルを自動クラスに登録したい場合に使用できます。
<Tip>
モデルがライブラリ内のモデルと非常に似ている場合、このモデルと同じ構成を再利用できます。
</Tip>
モデルが返す内容は何でも構いませんが、ラベルが渡されるときに損失を含む辞書を返す(`ResnetModelForImageClassification`のように行ったもの)と、
モデルを[`Trainer`]クラス内で直接使用できるようになります。独自のトレーニングループまたは他のライブラリを使用する予定である限り、
別の出力形式を使用することも問題ありません。
さて、モデルクラスができたので、1つ作成しましょう:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
再度、[`PreTrainedModel`]のいずれかのメソッド、例えば[`~PreTrainedModel.save_pretrained`]や
[`~PreTrainedModel.push_to_hub`]などを使用できます。次のセクションでは、モデルの重みをコードと一緒に
Hugging Face Hub にプッシュする方法を見てみます。
しかし、まずはモデル内に事前学習済みの重みをロードしましょう。
独自のユースケースでは、おそらく独自のデータでカスタムモデルをトレーニングすることになるでしょう。
このチュートリアルではスピードアップのために、resnet50dの事前学習済みバージョンを使用します。
私たちのモデルはそれをラップするだけなので、これらの重みを転送するのは簡単です:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
さて、[`~PreTrainedModel.save_pretrained`]または[`~PreTrainedModel.push_to_hub`]を実行したときに、
モデルのコードが保存されるようにする方法を見てみましょう。
## Sending the code to the Hub
<Tip warning={true}>
このAPIは実験的であり、次のリリースでわずかな変更があるかもしれません。
</Tip>
まず、モデルが`.py`ファイルに完全に定義されていることを確認してください。
ファイルは相対インポートを他のファイルに依存できますが、すべてのファイルが同じディレクトリにある限り(まだこの機能ではサブモジュールはサポートしていません)、問題ありません。
この例では、現在の作業ディレクトリ内に名前が「resnet_model」のフォルダを作成し、その中に`modeling_resnet.py`ファイルと`configuration_resnet.py`ファイルを定義します。
構成ファイルには`ResnetConfig`のコードが含まれ、モデリングファイルには`ResnetModel`と`ResnetModelForImageClassification`のコードが含まれています。
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
`__init__.py`は空であっても問題ありません。Pythonが`resnet_model`をモジュールとして検出できるようにするために存在します。
<Tip warning={true}>
ライブラリからモデリングファイルをコピーする場合、ファイルの先頭にあるすべての相対インポートを`transformers`パッケージからインポートに置き換える必要があります。
</Tip>
既存の設定やモデルを再利用(またはサブクラス化)できることに注意してください。
コミュニティとモデルを共有するために、次の手順に従ってください:まず、新しく作成したファイルからResNetモデルと設定をインポートします:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
次に、`save_pretrained`メソッドを使用してこれらのオブジェクトのコードファイルをコピーし、特定のAutoクラス(特にモデルの場合)に正しく登録するようライブラリに指示する必要があります。次のように実行します:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
注意: 設定については自動クラスを指定する必要はありません(設定用の自動クラスは1つしかなく、[`AutoConfig`]です)が、
モデルについては異なります。カスタムモデルは多くの異なるタスクに適している可能性があるため、
モデルが正確な自動クラスのうちどれに適しているかを指定する必要があります。
次に、前述のように設定とモデルを作成しましょう:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
モデルをHubに送信するには、ログインしていることを確認してください。ターミナルで次のコマンドを実行します:
```bash
huggingface-cli login
```
またはノートブックから:
```py
from huggingface_hub import notebook_login
notebook_login()
```
次に、次のようにして、独自の名前空間にプッシュできます(または、メンバーである組織にプッシュできます):
```py
resnet50d.push_to_hub("custom-resnet50d")
```
モデリングの重みとJSON形式の構成に加えて、このフォルダー「custom-resnet50d」内のモデリングおよび構成「.py」ファイルもコピーされ、結果はHubにアップロードされました。結果はこの[model repo](https://huggingface.co/sgugger/custom-resnet50d)で確認できます。
詳細については、[Hubへのプッシュ方法](model_sharing)を参照してください。
## Using a model with custom code
自動クラスと `from_pretrained` メソッドを使用して、リポジトリ内のカスタムコードファイルと共に任意の構成、モデル、またはトークナイザを使用できます。 Hubにアップロードされるすべてのファイルとコードはマルウェアのスキャンが実施されます(詳細は[Hubセキュリティ](https://huggingface.co/docs/hub/security#malware-scanning)ドキュメンテーションを参照してください)、しかし、依然として悪意のあるコードを実行しないために、モデルコードと作者を確認する必要があります。
`trust_remote_code=True` を設定してカスタムコードを持つモデルを使用できます:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
コミットハッシュを「revision」として渡すことも強く推奨されています。これにより、モデルの作者がコードを悪意のある新しい行で更新しなかったことを確認できます(モデルの作者を完全に信頼している場合を除きます)。
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
モデルリポジトリのコミット履歴をブラウジングする際には、任意のコミットのコミットハッシュを簡単にコピーできるボタンがあります。
## Registering a model with custom code to the auto classes
🤗 Transformersを拡張するライブラリを作成している場合、独自のモデルを含めるために自動クラスを拡張したい場合があります。
これはコードをHubにプッシュすることとは異なり、ユーザーはカスタムモデルを取得するためにあなたのライブラリをインポートする必要があります
(Hubからモデルコードを自動的にダウンロードするのとは対照的です)。
構成に既存のモデルタイプと異なる `model_type` 属性がある限り、またあなたのモデルクラスが適切な `config_class` 属性を持っている限り、
次のようにそれらを自動クラスに追加できます:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
注意: `AutoConfig` にカスタム設定を登録する際の最初の引数は、カスタム設定の `model_type` と一致する必要があります。
また、任意の自動モデルクラスにカスタムモデルを登録する際の最初の引数は、それらのモデルの `config_class` と一致する必要があります。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/installation.md
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# インストール
使用しているDeep Learningライブラリに対して、🤗 Transformersをインストールしてキャッシュを設定、そしてオプションでオフラインで実行できるように 🤗 Transformersを設定します。
🤗 TransformersはPython 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, Flaxで動作確認しています。 使用しているDeep Learningライブラリに合わせて、以下のインストール方法に従ってください:
* [PyTorch](https://pytorch.org/get-started/locally/)のインストール手順。
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)のインストール手順。
* [Flax](https://flax.readthedocs.io/en/latest/)のインストール手順。
## pipでのインストール
🤗 Transformersを[仮想環境](https://docs.python.org/3/library/venv.html)にインストールする必要があります。 もし、Pythonの仮想環境に馴染みがない場合は、この[ガイド](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)をご覧ください。仮想環境によって異なるプロジェクトの管理がより簡単になり、依存関係間の互換性の問題を回避できます。
まず、プロジェクトディレクトリに仮想環境を作成することから始めましょう:
```bash
python -m venv .env
```
仮想環境を起動しましょう。LinuxとMacOsの場合は以下のコマンドで起動します:
```bash
source .env/bin/activate
```
Windowsで仮想環境を起動します
```bash
.env/Scripts/activate
```
これで、次のコマンドで🤗 Transformersをインストールする準備が整いました:
```bash
pip install transformers
```
CPU対応のみ必要な場合、🤗 TransformersとDeep Learningライブラリを1行でインストールできるようになっていて便利です。例えば、🤗 TransformersとPyTorchを以下のように一緒にインストールできます:
```bash
pip install transformers[torch]
```
🤗 TransformersとTensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 TransformersとFlax:
```bash
pip install transformers[flax]
```
最後に、以下のコマンドを実行することで🤗 Transformersが正しくインストールされているかを確認します。学習済みモデルがダウンロードされます:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
その後、ラベルとスコアが出力されます:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## ソースからのインストール
以下のコマンドでソースから🤗 Transformersをインストールします:
```bash
pip install git+https://github.com/huggingface/transformers
```
このコマンドは最新の安定版ではなく、開発における最新の`main`バージョンをインストールします。`main`バージョンは最新の開発状況に対応するのに便利です。例えば、最後の公式リリース以降にバグが修正されたが、新しいリリースがまだ展開されていない場合などです。しかし、これは`main`バージョンが常に安定しているとは限らないことを意味します。私たちは`main`バージョンの運用を維持するよう努め、ほとんどの問題は通常、数時間から1日以内に解決されます。もし問題に遭遇した場合は、より早く修正できるように[Issue](https://github.com/huggingface/transformers/issues)を作成してください!
以下のコマンドを実行して、🤗 Transformersが正しくインストールされているかどうかを確認します:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## 編集可能なインストール
必要に応じて、編集可能なインストールをします:
* ソースコードの`main`バージョンを使います。
* 🤗 Transformersにコントリビュートし、コードの変更をテストする必要があります。
以下のコマンドでレポジトリをクローンして、🤗 Transformersをインストールします:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
上記のコマンドは、レポジトリをクローンしたフォルダとPythonのライブラリをパスをリンクします。Pythonは通常のライブラリパスに加えて、あなたがクローンしたフォルダの中も見るようになります。例えば、Pythonパッケージが通常、`~/anaconda3/envs/main/lib/python3.7/site-packages/`にインストールされている場合、Pythonはクローンしたフォルダも検索するようになります: `~/transformers/`.
<Tip warning={true}>
ライブラリーを使い続けたい場合は、transformersフォルダーを保持しつづける必要があります。
</Tip>
これで、次のコマンドで簡単にクローンを🤗 Transformersの最新版に更新できます:
```bash
cd ~/transformers/
git pull
```
Python環境は次回の実行時に🤗 Transformersの`main`バージョンを見つけるようになります。
## condaでのインストール
`conda-forge`のcondaチャンネルからインストールします:
```bash
conda install conda-forge::transformers
```
## キャッシュの設定
学習済みモデルはダウンロードされ、ローカルにキャッシュされます: `~/.cache/huggingface/hub`. これはシェル環境変数`TRANSFORMERS_CACHE`で指定されるデフォルトのディレクトリです。Windowsでは、デフォルトのディレクトリは`C:\Users\username\.cache\huggingface\hub`になっています。異なるキャッシュディレクトリを指定するために、以下のシェル環境変数を変更することが可能です。優先度は以下の順番に対応します:
1. シェル環境変数 (デフォルト): `HUGGINGFACE_HUB_CACHE` または `TRANSFORMERS_CACHE`.
2. シェル環境変数: `HF_HOME`.
3. シェル環境変数: `XDG_CACHE_HOME` + `/huggingface`.
<Tip>
もし、以前のバージョンのライブラリを使用していた人で、`PYTORCH_TRANSFORMERS_CACHE`または`PYTORCH_PRETRAINED_BERT_CACHE`を設定していた場合、シェル環境変数`TRANSFORMERS_CACHE`を指定しない限り🤗 Transformersはこれらのシェル環境変数を使用します。
</Tip>
## オフラインモード
🤗 Transformersはローカルファイルのみを使用することでファイアウォールやオフラインの環境でも動作させることができます。この動作を有効にするためには、環境変数`TRANSFORMERS_OFFLINE=1`を設定します。
<Tip>
環境変数`HF_DATASETS_OFFLINE=1`を設定し、オフライントレーニングワークフローに[🤗 Datasets](https://huggingface.co/docs/datasets/)を追加します。
</Tip>
例えば、外部インスタンスに対してファイアウォールで保護された通常のネットワーク上でプログラムを実行する場合、通常以下のようなコマンドで実行することになります:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
オフラインインスタンスでこの同じプログラムを実行します:
```bash
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
このスクリプトは、ローカルファイルのみを検索することが分かっているので、ハングアップしたりタイムアウトを待ったりすることなく実行されるはずです。
### オフラインで使用するためにモデルやトークナイザーを取得する
オフラインで🤗 Transformersを使用するもう1つの方法は、前もってファイルをダウンロードしておき、オフラインで使用する必要があるときにそのローカルパスを指定することです。これには3つの方法があります:
* [Model Hub](https://huggingface.co/models)のユーザーインターフェース上から↓アイコンをクリックしてファイルをダウンロードする方法。

* [`PreTrainedModel.from_pretrained`]および[`PreTrainedModel.save_pretrained`]のワークフローを使用する方法:
1. [`PreTrainedModel.from_pretrained`]で前もってファイルをダウンロードします:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. [`PreTrainedModel.save_pretrained`]で指定されたディレクトリにファイルを保存しておきます:
```py
>>> tokenizer.save_pretrained("./your/path/bigscience_t0")
>>> model.save_pretrained("./your/path/bigscience_t0")
```
3. オフラインにある時、[`PreTrainedModel.from_pretrained`]に指定したディレクトリからファイルをリロードします:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
```
* プログラム的に[huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub)ライブラリを用いて、ファイルをダウンロードする方法:
1. 仮想環境に`huggingface_hub`ライブラリをインストールします:
```bash
python -m pip install huggingface_hub
```
2. 指定のパスにファイルをダウンロードするために、[`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub)関数を使用します。例えば、以下のコマンドで、[T0](https://huggingface.co/bigscience/T0_3B)モデルの`config.json`ファイルを指定のパスにダウンロードできます:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
```
ファイルがダウンロードされ、ローカルにキャッシュされたら、そのローカルパスを指定してファイルをロードして使用します:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
```
<Tip>
Hubに保存されているファイルをダウンロードする方法の詳細については、[How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream)セクションを参照してください。
</Tip>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_tpu_tf.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Training on TPU with TensorFlow
<Tip>
詳細な説明が不要で、単にTPUのコードサンプルを入手してトレーニングを開始したい場合は、[私たちのTPUの例のノートブックをチェックしてください!](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)
</Tip>
### What is a TPU?
TPUは**Tensor Processing Unit(テンソル処理ユニット)**の略です。これらはGoogleが設計したハードウェアで、ニューラルネットワーク内のテンソル計算を大幅に高速化するために使用されます。これはGPUのようなものです。ネットワークのトレーニングと推論の両方に使用できます。一般的にはGoogleのクラウドサービスを介してアクセスされますが、Google ColabとKaggle Kernelsを通じても無料で小規模のTPUに直接アクセスできます。
[🤗 TransformersのすべてのTensorFlowモデルはKerasモデルです](https://huggingface.co/blog/tensorflow-philosophy)ので、この文書のほとんどの方法は一般的にKerasモデル用のTPUトレーニングに適用できます!ただし、TransformersとDatasetsのHuggingFaceエコシステム(hug-o-system?)に固有のポイントもいくつかあり、それについては適用するときにそれを示します。
### What kinds of TPU are available?
新しいユーザーは、さまざまなTPUとそのアクセス方法に関する幅広い情報によく混乱します。理解するための最初の重要な違いは、**TPUノード**と**TPU VM**の違いです。
**TPUノード**を使用すると、事実上リモートのTPUに間接的にアクセスします。別個のVMが必要で、ネットワークとデータパイプラインを初期化し、それらをリモートノードに転送します。Google ColabでTPUを使用すると、**TPUノード**スタイルでアクセスしています。
TPUノードを使用すると、それに慣れていない人々にはかなり予期しない動作が発生することがあります!特に、TPUはPythonコードを実行しているマシンと物理的に異なるシステムに配置されているため、データはローカルマシンにローカルで格納されているデータパイプラインが完全に失敗します。代わりに、データはGoogle Cloud Storageに格納する必要があります。ここでデータパイプラインはリモートのTPUノードで実行されている場合でも、データにアクセスできます。
<Tip>
すべてのデータを`np.ndarray`または`tf.Tensor`としてメモリに収めることができる場合、ColabまたはTPUノードを使用している場合でも、データをGoogle Cloud Storageにアップロードせずに`fit()`でトレーニングできます。
</Tip>
<Tip>
**🤗 Hugging Face固有のヒント🤗:** TFコードの例でよく見るであろう`Dataset.to_tf_dataset()`とその高レベルのラッパーである`model.prepare_tf_dataset()`は、TPUノードで失敗します。これは、`tf.data.Dataset`を作成しているにもかかわらず、それが「純粋な」`tf.data`パイプラインではなく、`tf.numpy_function`または`Dataset.from_generator()`を使用して基盤となるHuggingFace `Dataset`からデータをストリームで読み込むことからです。このHuggingFace `Dataset`はローカルディスク上のデータをバックアップしており、リモートTPUノードが読み取ることができないためです。
</Tip>
TPUにアクセスする第二の方法は、**TPU VM**を介してです。TPU VMを使用する場合、TPUが接続されているマシンに直接接続します。これはGPU VMでトレーニングを行うのと同様です。TPU VMは一般的にデータパイプラインに関しては特に作業がしやすく、上記のすべての警告はTPU VMには適用されません!
これは主観的な文書ですので、こちらの意見です:**可能な限りTPUノードの使用を避けてください。** TPU VMよりも混乱しやすく、デバッグが難しいです。将来的にはサポートされなくなる可能性もあります - Googleの最新のTPUであるTPUv4は、TPU VMとしてのみアクセスできるため、TPUノードは将来的には「レガシー」のアクセス方法になる可能性が高いです。ただし、無料でTPUにアクセスできるのはColabとKaggle Kernelsの場合があります。その場合、どうしても使用しなければならない場合の取り扱い方法を説明しようとします!詳細は[TPUの例のノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)で詳細な説明を確認してください。
### What sizes of TPU are available?
単一のTPU(v2-8/v3-8/v4-8)は8つのレプリカを実行します。TPUは数百から数千のレプリカを同時に実行できる**ポッド**に存在します。単一のTPUよりも多くのTPUを使用するが、ポッド全体ではない場合(たとえばv3-32)、TPUフリートは**ポッドスライス**として参照されます。
Colabを介して無料のTPUにアクセスする場合、通常は単一のv2-8 TPUが提供されます。
### I keep hearing about this XLA thing. What’s XLA, and how does it relate to TPUs?
XLAは、TensorFlowとJAXの両方で使用される最適化コンパイラです。JAXでは唯一のコンパイラであり、TensorFlowではオプションですが(しかしTPUでは必須です!)、Kerasモデルをトレーニングする際に`model.compile()`に引数`jit_compile=True`を渡すことで最も簡単に有効にできます。エラーが発生せず、パフォーマンスが良好であれば、それはTPUに移行する準備が整った良い兆候です!
TPU上でのデバッグは一般的にCPU/GPUよりも少し難しいため、TPUで試す前にまずCPU/GPUでXLAを使用してコードを実行することをお勧めします。もちろん、長時間トレーニングする必要はありません。モデルとデータパイプラインが期待通りに動作するかを確認するための数ステップだけです。
<Tip>
XLAコンパイルされたコードは通常高速です。したがって、TPUで実行する予定がない場合でも、`jit_compile=True`を追加することでパフォーマンスを向上させることができます。ただし、以下のXLA互換性に関する注意事項に注意してください!
</Tip>
<Tip warning={true}>
**苦い経験から生まれたヒント:** `jit_compile=True`を使用することは、CPU/GPUコードがXLA互換であることを確認し、速度を向上させる良い方法ですが、実際にTPUでコードを実行する際には多くの問題を引き起こす可能性があります。 XLAコンパイルはTPU上で暗黙的に行われるため、実際にコードをTPUで実行する前にその行を削除することを忘れないでください!
</Tip>
### How do I make my model XLA compatible?
多くの場合、コードはすでにXLA互換かもしれません!ただし、XLAでは動作する通常のTensorFlowでも動作しないいくつかの要素があります。以下に、3つの主要なルールにまとめています:
<Tip>
**🤗 HuggingFace固有のヒント🤗:** TensorFlowモデルと損失関数をXLA互換に書き直すために多くの努力を払っています。通常、モデルと損失関数はデフォルトでルール#1と#2に従っているため、`transformers`モデルを使用している場合はこれらをスキップできます。ただし、独自のモデルと損失関数を記述する場合は、これらのルールを忘れないでください!
</Tip>
#### XLA Rule #1: Your code cannot have “data-dependent conditionals”
これは、任意の`if`ステートメントが`tf.Tensor`内の値に依存していない必要があることを意味します。例えば、次のコードブロックはXLAでコンパイルできません!
```python
if tf.reduce_sum(tensor) > 10:
tensor = tensor / 2.0
```
これは最初は非常に制限的に思えるかもしれませんが、ほとんどのニューラルネットコードはこれを行う必要はありません。通常、この制約を回避するために`tf.cond`を使用するか(ドキュメントはこちらを参照)、条件を削除して代わりに指示変数を使用したりすることができます。次のように:
```python
sum_over_10 = tf.cast(tf.reduce_sum(tensor) > 10, tf.float32)
tensor = tensor / (1.0 + sum_over_10)
```
このコードは、上記のコードとまったく同じ効果を持っていますが、条件を回避することで、XLAで問題なくコンパイルできることを確認します!
#### XLA Rule #2: Your code cannot have “data-dependent shapes”
これは、コード内のすべての `tf.Tensor` オブジェクトの形状が、その値に依存しないことを意味します。たとえば、`tf.unique` 関数はXLAでコンパイルできないので、このルールに違反します。なぜなら、これは入力 `Tensor` の一意の値の各インスタンスを含む `tensor` を返すためです。この出力の形状は、入力 `Tensor` の重複具合によって異なるため、XLAはそれを処理しないことになります!
一般的に、ほとんどのニューラルネットワークコードはデフォルトでルール#2に従います。ただし、いくつかの一般的なケースでは問題が発生することがあります。非常に一般的なケースの1つは、**ラベルマスキング**を使用する場合です。ラベルを無視して損失を計算する場所を示すために、ラベルを負の値に設定する方法です。NumPyまたはPyTorchのラベルマスキングをサポートする損失関数を見ると、次のような[ブールインデックス](https://numpy.org/doc/stable/user/basics.indexing.html#boolean-array-indexing)を使用したコードがよく見られます:
```python
label_mask = labels >= 0
masked_outputs = outputs[label_mask]
masked_labels = labels[label_mask]
loss = compute_loss(masked_outputs, masked_labels)
mean_loss = torch.mean(loss)
```
このコードはNumPyやPyTorchでは完全に機能しますが、XLAでは動作しません!なぜなら、`masked_outputs`と`masked_labels`の形状はマスクされた位置の数に依存するため、これは**データ依存の形状**になります。ただし、ルール#1と同様に、このコードを書き直して、データ依存の形状なしでまったく同じ出力を生成できることがあります。
```python
label_mask = tf.cast(labels >= 0, tf.float32)
loss = compute_loss(outputs, labels)
loss = loss * label_mask # Set negative label positions to 0
mean_loss = tf.reduce_sum(loss) / tf.reduce_sum(label_mask)
```
ここでは、データ依存の形状を避けるために、各位置で損失を計算してから、平均を計算する際に分子と分母の両方でマスクされた位置をゼロ化する方法を紹介します。これにより、最初のアプローチとまったく同じ結果が得られますが、XLA互換性を維持します。注意点として、ルール#1と同じトリックを使用します - `tf.bool`を`tf.float32`に変換して指標変数として使用します。これは非常に便利なトリックですので、自分のコードをXLAに変換する必要がある場合には覚えておいてください!
#### XLA Rule #3: XLA will need to recompile your model for every different input shape it sees
これは重要なルールです。これはつまり、入力形状が非常に変動的な場合、XLA はモデルを何度も再コンパイルする必要があるため、大きなパフォーマンスの問題が発生する可能性があるということです。これは NLP モデルで一般的に発生し、トークナイズ後の入力テキストの長さが異なる場合があります。他のモダリティでは、静的な形状が一般的であり、このルールはほとんど問題になりません。
ルール#3を回避する方法は何でしょうか?鍵は「パディング」です - すべての入力を同じ長さにパディングし、次に「attention_mask」を使用することで、可変形状と同じ結果を得ることができますが、XLA の問題は発生しません。ただし、過度のパディングも深刻な遅延を引き起こす可能性があります - データセット全体で最大の長さにすべてのサンプルをパディングすると、多くの計算とメモリを無駄にする可能性があります!
この問題には完璧な解決策はありませんが、いくつかのトリックを試すことができます。非常に便利なトリックの1つは、**バッチのサンプルを32または64トークンの倍数までパディングする**ことです。これにより、トークン数がわずかに増加するだけで、すべての入力形状が32または64の倍数である必要があるため、一意の入力形状の数が大幅に減少します。一意の入力形状が少ないと、XLA の再コンパイルが少なくなります!
<Tip>
**🤗 HuggingFace に関する具体的なヒント🤗:** 弊社のトークナイザーとデータコレクターには、ここで役立つメソッドがあります。トークナイザーを呼び出す際に `padding="max_length"` または `padding="longest"` を使用して、パディングされたデータを出力するように設定できます。トークナイザーとデータコレクターには、一意の入力形状の数を減らすのに役立つ `pad_to_multiple_of` 引数もあります!
</Tip>
### How do I actually train my model on TPU?
一度トレーニングが XLA 互換性があることを確認し、(TPU Node/Colab を使用する場合は)データセットが適切に準備されている場合、TPU 上で実行することは驚くほど簡単です!コードを変更する必要があるのは、いくつかの行を追加して TPU を初期化し、モデルとデータセットが `TPUStrategy` スコープ内で作成されるようにすることだけです。これを実際に見るには、[TPU のサンプルノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)をご覧ください!
### Summary
ここでは多くの情報が提供されましたので、TPU でモデルをトレーニングする際に以下のチェックリストを使用できます:
- コードが XLA の三つのルールに従っていることを確認します。
- CPU/GPU で `jit_compile=True` を使用してモデルをコンパイルし、XLA でトレーニングできることを確認します。
- データセットをメモリに読み込むか、TPU 互換のデータセット読み込みアプローチを使用します([ノートブックを参照](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))。
- コードを Colab(アクセラレータを「TPU」に設定)または Google Cloud の TPU VM に移行します。
- TPU 初期化コードを追加します([ノートブックを参照](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))。
- `TPUStrategy` を作成し、データセットの読み込みとモデルの作成が `strategy.scope()` 内で行われることを確認します([ノートブックを参照](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb))。
- TPU に移行する際に `jit_compile=True` を外すのを忘れないでください!
- 🙏🙏🙏🥺🥺🥺
- `model.fit()` を呼び出します。
- おめでとうございます!
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_tpu.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Training on TPUs
<Tip>
注意: [シングルGPUセクション](perf_train_gpu_one)で紹介されているほとんどの戦略(混合精度トレーニングや勾配蓄積など)および[マルチGPUセクション](perf_train_gpu_many)は一般的なモデルのトレーニングに適用できますので、このセクションに入る前にそれを確認してください。
</Tip>
このドキュメントは、TPUでのトレーニング方法に関する情報をまもなく追加いたします。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/torchscript.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TorchScript
<Tip>
これはTorchScriptを使用した実験の最初であり、可変入力サイズのモデルに対するその能力をまだ探求中です。これは私たちの関心の焦点であり、今後のリリースでは、より柔軟な実装や、PythonベースのコードとコンパイルされたTorchScriptを比較するベンチマークを含む、より多くのコード例で詳細な分析を行います。
</Tip>
[TorchScriptのドキュメント](https://pytorch.org/docs/stable/jit.html)によれば:
> TorchScriptは、PyTorchコードから直列化および最適化可能なモデルを作成する方法です。
TorchScriptを使用すると、効率志向のC++プログラムなど、他のプログラムでモデルを再利用できるようになります。PyTorchベースのPythonプログラム以外の環境で🤗 Transformersモデルをエクスポートして使用するためのインターフェースを提供しています。ここでは、TorchScriptを使用してモデルをエクスポートし、使用する方法を説明します。
モデルをエクスポートするには、次の2つの要件があります:
- `torchscript`フラグを使用したモデルのインスタンス化
- ダミーの入力を使用したフォワードパス
これらの必要条件は、以下で詳細に説明されているように、開発者が注意する必要があるいくつかのことを意味します。
## TorchScript flag and tied weights
`torchscript`フラグは、ほとんどの🤗 Transformers言語モデルにおいて、`Embedding`レイヤーと`Decoding`レイヤー間で重みが連結されているため必要です。
TorchScriptでは、重みが連結されているモデルをエクスポートすることはできませんので、事前に重みを切り離して複製する必要があります。
`torchscript`フラグを使用してインスタンス化されたモデルは、`Embedding`レイヤーと`Decoding`レイヤーが分離されており、そのため後でトレーニングしてはいけません。
トレーニングは、これらの2つのレイヤーを非同期にする可能性があり、予期しない結果をもたらす可能性があります。
言語モデルヘッドを持たないモデルには言及しませんが、これらのモデルには連結された重みが存在しないため、`torchscript`フラグなしで安全にエクスポートできます。
## Dummy inputs and standard lengths
ダミー入力はモデルのフォワードパスに使用されます。入力の値はレイヤーを通じて伝播される間、PyTorchは各テンソルに実行された異なる操作を追跡します。これらの記録された操作は、モデルの*トレース*を作成するために使用されます。
トレースは入力の寸法に対して作成されます。そのため、ダミー入力の寸法に制約され、他のシーケンス長やバッチサイズでは動作しません。異なるサイズで試すと、以下のエラーが発生します:
```
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
お勧めしますのは、モデルの推論中に供給される最大の入力と同じ大きさのダミー入力サイズでモデルをトレースすることです。パディングを使用して不足値を補完することもできます。ただし、モデルがより大きな入力サイズでトレースされるため、行列の寸法も大きくなり、より多くの計算が発生します。
異なるシーケンス長のモデルをエクスポートする際に、各入力に対して実行される演算の総数に注意して、パフォーマンスを密接にフォローすることをお勧めします。
## Using TorchScript in Python
このセクションでは、モデルの保存と読み込み、および推論にトレースを使用する方法を示します。
### Saving a model
TorchScriptで`BertModel`をエクスポートするには、`BertConfig`クラスから`BertModel`をインスタンス化し、それをファイル名`traced_bert.pt`でディスクに保存します:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### Loading a model
以前に保存した `BertModel`、`traced_bert.pt` をディスクから読み込んで、以前に初期化した `dummy_input` で使用できます。
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### Using a traced model for inference
トレースモデルを使用して推論を行うには、その `__call__` ダンダーメソッドを使用します。
```python
traced_model(tokens_tensor, segments_tensors)
```
## Deploy Hugging Face TorchScript models to AWS with the Neuron SDK
AWSはクラウドでの低コストで高性能な機械学習推論向けに [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) インスタンスファミリーを導入しました。Inf1インスタンスはAWS Inferentiaチップによって駆動され、ディープラーニング推論ワークロードに特化したカスタムビルドのハードウェアアクセラレータです。[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) はInferentia用のSDKで、トランスフォーマーモデルをトレースして最適化し、Inf1に展開するためのサポートを提供します。
Neuron SDK が提供するもの:
1. クラウドでの推論のためにTorchScriptモデルをトレースして最適化するための、1行のコード変更で使用できる簡単なAPI。
2. [改善されたコストパフォーマンス](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/) のためのボックス外のパフォーマンス最適化。
3. [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html) または [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html) で構築されたHugging Faceトランスフォーマーモデルへのサポート。
### Implications
BERT(Bidirectional Encoder Representations from Transformers)アーキテクチャやその変種([distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) や [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) など)に基づくトランスフォーマーモデルは、非生成タスク(抽出型質問応答、シーケンス分類、トークン分類など)において、Inf1上で最適に動作します。ただし、テキスト生成タスクも [AWS Neuron MarianMT チュートリアル](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html) に従ってInf1上で実行できます。Inferentiaでボックス外で変換できるモデルに関する詳細情報は、Neuronドキュメンテーションの [Model Architecture Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia) セクションにあります。
### Dependencies
モデルをAWS Neuronに変換するには、[Neuron SDK 環境](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide) が必要で、[AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html) に事前に構成されています。
### Converting a model for AWS Neuron
モデルをAWS NEURON用に変換するには、[PythonでTorchScriptを使用する](torchscript#using-torchscript-in-python) と同じコードを使用して `BertModel` をトレースします。Python APIを介してNeuron SDKのコンポーネントにアクセスするために、`torch.neuron` フレームワーク拡張をインポートします。
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
次の行を変更するだけで済みます。
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
これにより、Neuron SDKはモデルをトレースし、Inf1インスタンス向けに最適化します。
AWS Neuron SDKの機能、ツール、サンプルチュートリアル、最新のアップデートについて詳しく知りたい場合は、[AWS NeuronSDK ドキュメンテーション](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html) をご覧ください。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/generation_strategies.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Text generation strategies
テキスト生成は、オープンエンドのテキスト生成、要約、翻訳など、多くの自然言語処理タスクに不可欠です。また、テキストを出力とするさまざまな混在モダリティアプリケーションにも影響を与えており、例えば音声からテキストへの変換や画像からテキストへの変換などがあります。テキストを生成できるいくつかのモデルには、GPT2、XLNet、OpenAI GPT、CTRL、TransformerXL、XLM、Bart、T5、GIT、Whisperが含まれます。
[`~transformers.generation_utils.GenerationMixin.generate`] メソッドを使用して、異なるタスクのテキスト出力を生成するいくつかの例をご紹介します:
* [テキスト要約](./tasks/summarization#inference)
* [画像のキャプション](./model_doc/git#transformers.GitForCausalLM.forward.example)
* [音声の転記](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
generateメソッドへの入力は、モデルのモダリティに依存します。これらの入力は、AutoTokenizerやAutoProcessorなどのモデルのプリプロセッサクラスによって返されます。モデルのプリプロセッサが複数の種類の入力を生成する場合は、すべての入力をgenerate()に渡します。各モデルのプリプロセッサについての詳細は、対応するモデルのドキュメンテーションで確認できます。
テキストを生成するためのトークンの選択プロセスはデコーディングとして知られ、`generate()`メソッドが使用するデコーディング戦略をカスタマイズできます。デコーディング戦略を変更することは、訓練可能なパラメータの値を変更しませんが、生成されるテキストの品質に顕著な影響を与えることがあります。これにより、テキスト内の繰り返しを減少させ、より一貫性のあるテキストを生成するのに役立ちます。
このガイドでは以下の内容が説明されています:
* デフォルトのテキスト生成設定
* 一般的なデコーディング戦略とその主要なパラメータ
* 🤗 Hubのあなたのファインチューンモデルとカスタム生成設定の保存と共有
## Default text generation configuration
モデルのデコーディング戦略は、その生成設定で定義されています。[`pipeline`] 内で推論に事前訓練モデルを使用する際には、モデルはデフォルトの生成設定を内部で適用する `PreTrainedModel.generate()` メソッドを呼び出します。デフォルトの設定は、モデルにカスタム設定が保存されていない場合にも使用されます。
モデルを明示的に読み込む場合、それに付属する生成設定を `model.generation_config` を介して確認できます。
```python
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
```
`model.generation_config` を出力すると、デフォルトの生成設定から異なる値のみが表示され、デフォルトの値はリストされません。
デフォルトの生成設定では、出力のサイズは入力プロンプトとの組み合わせで最大20トークンに制限されており、リソース制限に達しないようにしています。デフォルトのデコーディング戦略は貪欲探索で、最も確率の高いトークンを次のトークンとして選択する最も単純なデコーディング戦略です。多くのタスクや小さな出力サイズの場合、これはうまく機能します。ただし、長い出力を生成するために使用される場合、貪欲探索は高度に繰り返される結果を生成し始めることがあります。
## Customize text generation
`generate` メソッドに直接パラメータとその値を渡すことで、`generation_config` を上書きできます。
```python
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
```
デフォルトのデコーディング戦略がほとんどのタスクでうまく機能する場合でも、いくつかの設定を微調整できます。一般的に調整されるパラメータには次のものがあります:
- `max_new_tokens`: 生成するトークンの最大数。つまり、出力シーケンスのサイズであり、プロンプト内のトークンは含まれません。
- `num_beams`: 1よりも大きなビーム数を指定することで、貪欲検索からビームサーチに切り替えることができます。この戦略では、各時間ステップでいくつかの仮説を評価し、最終的に全体のシーケンスに対する最も高い確率を持つ仮説を選択します。これにより、初期の確率が低いトークンで始まる高確率のシーケンスが貪欲検索によって無視されることがなくなります。
- `do_sample`: このパラメータを`True`に設定すると、多項分布サンプリング、ビームサーチ多項分布サンプリング、Top-Kサンプリング、Top-pサンプリングなどのデコーディング戦略が有効になります。これらの戦略は、各戦略固有の調整を含む単語彙全体の確率分布から次のトークンを選択します。
- `num_return_sequences`: 各入力に対して返すシーケンス候補の数。これは、複数のシーケンス候補をサポートするデコーディング戦略(ビームサーチやサンプリングのバリエーションなど)にのみ適用されます。貪欲検索や対照的な検索など、単一の出力シーケンスを返すデコーディング戦略では使用できません。
## Save a custom decoding strategy with your model
特定の生成構成で調整したモデルを共有したい場合、以下の手順を実行できます:
* [`GenerationConfig`] クラスのインスタンスを作成する
* デコーディング戦略のパラメータを指定する
* [`GenerationConfig.save_pretrained`] を使用して生成構成を保存し、`config_file_name` 引数を空にすることを忘れないでください
* `push_to_hub` を `True` に設定して、構成をモデルのリポジトリにアップロードします
```python
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
>>> generation_config = GenerationConfig(
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
... )
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
```
1つのディレクトリに複数の生成設定を保存することもでき、[`GenerationConfig.save_pretrained`] の `config_file_name`
引数を使用します。後で [`GenerationConfig.from_pretrained`] でこれらをインスタンス化できます。これは、1つのモデルに対して複数の生成設定を保存したい場合に便利です
(例:サンプリングを使用したクリエイティブなテキスト生成用の1つと、ビームサーチを使用した要約用の1つ)。モデルに設定ファイルを追加するには、適切な Hub 権限が必要です。
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
>>> translation_generation_config = GenerationConfig(
... num_beams=4,
... early_stopping=True,
... decoder_start_token_id=0,
... eos_token_id=model.config.eos_token_id,
... pad_token=model.config.pad_token_id,
... )
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']
```
## Streaming
`generate()` は、その `streamer` 入力を介してストリーミングをサポートしています。`streamer` 入力は、次のメソッドを持つクラスのインスタンスと互換性があります:`put()` と `end()`。内部的には、`put()` は新しいトークンをプッシュするために使用され、`end()` はテキスト生成の終了をフラグ付けするために使用されます。
<Tip warning={true}>
ストリーマークラスのAPIはまだ開発中であり、将来変更される可能性があります。
</Tip>
実際には、さまざまな目的に対して独自のストリーミングクラスを作成できます!また、使用できる基本的なストリーミングクラスも用意されています。例えば、[`TextStreamer`] クラスを使用して、`generate()` の出力を画面に単語ごとにストリームすることができます:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
```
## Decoding strategies
特定の `generate()` パラメータの組み合わせ、そして最終的に `generation_config` は、特定のデコーディング戦略を有効にするために使用できます。このコンセプトが新しい場合、[このブログポスト](https://huggingface.co/blog/how-to-generate)を読むことをお勧めします。このブログポストでは、一般的なデコーディング戦略がどのように動作するかが説明されています。
ここでは、デコーディング戦略を制御するいくつかのパラメータを示し、それらをどのように使用できるかを説明します。
### Greedy Search
[`generate`] はデフォルトで貪欲探索デコーディングを使用するため、有効にするためにパラメータを渡す必要はありません。これは、パラメータ `num_beams` が 1 に設定され、`do_sample=False` であることを意味します。
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
```
### Contrastive search
コントラスティブ検索デコーディング戦略は、2022年の論文[A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417)で提案されました。
これは、非反復的でありながら一貫性のある長い出力を生成するために優れた結果を示しています。コントラスティブ検索の動作原理を学ぶには、[このブログポスト](https://huggingface.co/blog/introducing-csearch)をご覧ください。
コントラスティブ検索の動作を有効にし、制御する2つの主要なパラメータは「penalty_alpha」と「top_k」です:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']
```
### Multinomial sampling
常に最高確率のトークンを次のトークンとして選択する貪欲検索とは異なり、多項分布サンプリング(または祖先サンプリングとも呼ばれます)はモデルによって提供される語彙全体の確率分布に基づいて次のトークンをランダムに選択します。ゼロ以外の確率を持つすべてのトークンには選択される可能性があり、これにより繰り返しのリスクが減少します。
多項分布サンプリングを有効にするには、`do_sample=True` および `num_beams=1` を設定します。
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']
```
### Beam-search decoding
貪欲探索とは異なり、ビームサーチデコーディングは各時間ステップでいくつかの仮説を保持し、最終的にシーケンス全体で最も確率が高い仮説を選択します。これにより、貪欲探索では無視されてしまう初期トークンの確率が低い高確率のシーケンスを特定する利点があります。
このデコーディング戦略を有効にするには、`num_beams`(追跡する仮説の数)を1よりも大きな値に指定します。
希望されるテキストの翻訳がお手伝いできて嬉しいです!もしさらなる質問やサポートが必要な場合は、お気軽にお知らせください。
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
```
### Beam-search multinomial sampling
その名前からもわかるように、このデコーディング戦略はビームサーチと多項サンプリングを組み合わせています。このデコーディング戦略を使用するには、`num_beams` を1より大きな値に設定し、`do_sample=True` を設定する必要があります。
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'
```
### Diverse beam search decoding
多様なビームサーチデコーディング戦略は、ビームサーチ戦略の拡張であり、選択肢からより多様なビームシーケンスを生成できるようにします。この仕組みの詳細については、[Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf) をご参照ください。このアプローチには、`num_beams`、`num_beam_groups`、および `diversity_penalty` という3つの主要なパラメータがあります。多様性ペナルティは、出力がグループごとに異なることを保証し、ビームサーチは各グループ内で使用されます。
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
... "The Permaculture Design Principles are a set of universal design principles "
... "that can be applied to any location, climate and culture, and they allow us to design "
... "the most efficient and sustainable human habitation and food production systems. "
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
... "as ecology, landscape design, environmental science and energy conservation, and the "
... "Permaculture design principles are drawn from these various disciplines. Each individual "
... "design principle itself embodies a complete conceptual framework based on sound "
... "scientific principles. When we bring all these separate principles together, we can "
... "create a design system that both looks at whole systems, the parts that these systems "
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
... "living system. Each design principle serves as a tool that allows us to integrate all "
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
... "whole system, where the elements harmoniously interact and work together in the most "
... "efficient way possible."
... )
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'
```
### Assisted Decoding
アシストデコーディングは、上記のデコーディング戦略を変更したもので、同じトークナイザー(理想的にははるかに小さなモデル)を使用して、いくつかの候補トークンを貪欲に生成するアシスタントモデルを使用します。その後、主要なモデルは候補トークンを1つの前向きパスで検証し、デコーディングプロセスを高速化します。現在、アシストデコーディングでは貪欲検索とサンプリングのみがサポートされており、バッチ入力はサポートされていません。アシストデコーディングの詳細については、[このブログ記事](https://huggingface.co/blog/assisted-generation) をご覧ください。
アシストデコーディングを有効にするには、`assistant_model` 引数をモデルで設定します。
このガイドは、さまざまなデコーディング戦略を可能にする主要なパラメーターを説明しています。さらに高度なパラメーターは [`generate`] メソッドに存在し、[`generate`] メソッドの動作をさらに制御できます。使用可能なパラメーターの完全なリストについては、[APIドキュメント](./main_classes/text_generation.md) を参照してください。
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
```
サンプリング方法を使用する場合、アシストデコーディングでは `temperature` 引数を使用して、多項サンプリングと同様にランダム性を制御できます。ただし、アシストデコーディングでは、温度を低くすることで遅延の改善に役立ちます。
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/preprocessing.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdown形式ですが、特定のMDXに類似したドキュメントビルダーの構文を含んでおり、
Markdownビューアーで正しく表示されないことがあります。
-->
# Preprocess
[[open-in-colab]]
データセットでモデルをトレーニングする前に、それをモデルの期待する入力形式に前処理する必要があります。
データがテキスト、画像、またはオーディオであるかどうかにかかわらず、それらはテンソルのバッチに変換して組み立てる必要があります。
🤗 Transformersは、データをモデル用に準備するのに役立つ前処理クラスのセットを提供しています。
このチュートリアルでは、次のことを学びます:
* テキストの場合、[Tokenizer](./main_classes/tokenizer)を使用してテキストをトークンのシーケンスに変換し、トークンの数値表現を作成し、それらをテンソルに組み立てる方法。
* 音声とオーディオの場合、[Feature extractor](./main_classes/feature_extractor)を使用してオーディオ波形から連続的な特徴を抽出し、それらをテンソルに変換する方法。
* 画像入力の場合、[ImageProcessor](./main_classes/image)を使用して画像をテンソルに変換する方法。
* マルチモーダル入力の場合、[Processor](./main_classes/processors)を使用してトークナイザと特徴抽出器または画像プロセッサを組み合わせる方法。
<Tip>
`AutoProcessor`は常に動作し、使用するモデルに適切なクラスを自動的に選択します。
トークナイザ、画像プロセッサ、特徴抽出器、またはプロセッサを使用しているかにかかわらず、動作します。
</Tip>
始める前に、🤗 Datasetsをインストールして、いくつかのデータセットを試すことができるようにしてください:
```bash
pip install datasets
```
## Natural Language Processing
<Youtube id="Yffk5aydLzg"/>
テキストデータの前処理に使用する主要なツールは、[トークナイザ](main_classes/tokenizer)です。トークナイザは、一連のルールに従ってテキストを*トークン*に分割します。トークンは数値に変換され、その後テンソルに変換され、モデルの入力となります。モデルが必要とする追加の入力は、トークナイザによって追加されます。
<Tip>
事前学習済みモデルを使用する予定の場合、関連する事前学習済みトークナイザを使用することが重要です。これにより、テキストが事前学習コーパスと同じ方法で分割され、事前学習中に通常*ボキャブ*として参照される対応するトークンインデックスを使用します。
</Tip>
[`AutoTokenizer.from_pretrained`]メソッドを使用して事前学習済みトークナイザをロードして、開始しましょう。これにより、モデルが事前学習された*ボキャブ*がダウンロードされます:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
```
次に、テキストをトークナイザに渡します:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
トークナイザは、重要な3つの項目を持つ辞書を返します:
* [input_ids](glossary#input-ids) は文中の各トークンに対応するインデックスです。
* [attention_mask](glossary#attention-mask) はトークンがアテンションを受ける必要があるかどうかを示します。
* [token_type_ids](glossary#token-type-ids) は複数のシーケンスがある場合、トークンがどのシーケンスに属しているかを識別します。
`input_ids` をデコードして入力を返します:
```python
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] 魔法使いの事に干渉するな、彼らは微妙で怒りっぽい。 [SEP]'
```
如何にお分かりいただけるかと思いますが、トークナイザはこの文章に2つの特別なトークン、`CLS`(クラシファイア)と`SEP`(セパレータ)を追加しました。
すべてのモデルが特別なトークンを必要とするわけではありませんが、必要な場合、トークナイザは自動的にそれらを追加します。
複数の文章を前処理する場合、トークナイザにリストとして渡してください:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### Pad
文章は常に同じ長さではないことがあり、これはテンソル(モデルの入力)が均一な形状を持つ必要があるため問題となります。
パディングは、短い文に特別な「パディングトークン」を追加して、テンソルを長いシーケンスに合わせるための戦略です。
バッチ内の短いシーケンスを最長のシーケンスに合わせるために、`padding`パラメータを`True`に設定します:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
1番目と3番目の文は、短いために`0`でパディングされています。
### Truncation
逆のスペクトルでは、時折、モデルが処理するのに長すぎるシーケンスがあるかもしれません。この場合、シーケンスを短縮する必要があります。
モデルが受け入れる最大の長さにシーケンスを切り詰めるには、`truncation`パラメータを`True`に設定します:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
<Tip>
異なるパディングと切り詰めの引数について詳しくは、[パディングと切り詰め](./pad_truncation)のコンセプトガイドをご覧ください。
</Tip>
### Build tensors
最後に、トークナイザがモデルに供給される実際のテンソルを返すように設定します。
`return_tensors`パラメータを`pt`(PyTorch用)または`tf`(TensorFlow用)に設定します:
<frameworkcontent>
<pt>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
</pt>
<tf>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
```
</tf>
</frameworkcontent>
## Audio
オーディオタスクの場合、データセットをモデル用に準備するために[特徴抽出器](main_classes/feature_extractor)が必要です。
特徴抽出器は生のオーディオデータから特徴を抽出し、それらをテンソルに変換するために設計されています。
[PolyAI/minds14](https://huggingface.co/datasets/PolyAI/minds14)データセットをロードして(データセットのロード方法の詳細については🤗 [Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照)、
オーディオデータセットで特徴抽出器をどのように使用できるかを確認してみましょう:
```python
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
アクセスして`audio`列の最初の要素を確認します。`audio`列を呼び出すと、自動的にオーディオファイルが読み込まれ、リサンプリングされます:
```py
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
これにより、3つのアイテムが返されます:
* `array` は読み込まれた音声信号で、1Dの配列として読み込まれます。必要に応じてリサンプリングされることもあります。
* `path` は音声ファイルの場所を指します。
* `sampling_rate` は音声信号内のデータポイントが1秒間にいくつ測定されるかを示します。
このチュートリアルでは、[Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)モデルを使用します。
モデルカードを確認すると、Wav2Vec2が16kHzのサンプリングされた音声オーディオで事前学習されていることがわかります。
モデルの事前学習に使用されたデータセットのサンプリングレートと、あなたのオーディオデータのサンプリングレートが一致することが重要です。
データのサンプリングレートが異なる場合、データをリサンプリングする必要があります。
1. 🤗 Datasetsの [`~datasets.Dataset.cast_column`] メソッドを使用して、サンプリングレートを16kHzにアップサンプリングします:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
```
2. 再び `audio` 列を呼び出してオーディオファイルをリサンプルします:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
次に、入力を正規化しパディングするために特徴抽出器をロードします。テキストデータをパディングする場合、短いシーケンスには `0` が追加されます。同じ考え方がオーディオデータにも適用されます。特徴抽出器は `array` に `0` を追加します(これは無音として解釈されます)。
[`AutoFeatureExtractor.from_pretrained`]を使用して特徴抽出器をロードします:
```python
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
オーディオ `array` を特徴抽出器に渡します。特徴抽出器で発生する可能性のある無音エラーをより良くデバッグするために、特徴抽出器に `sampling_rate` 引数を追加することをお勧めします。
```python
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
```
同様に、トークナイザと同様に、バッチ内の可変シーケンスを処理するためにパディングまたは切り詰めを適用できます。次に、これらの2つのオーディオサンプルのシーケンス長を確認してみましょう:
```python
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
```
この関数は、データセットを前処理してオーディオサンプルの長さを同じにするためのものです。最大サンプル長を指定し、特徴抽出器はシーケンスをそれに合わせてパディングまたは切り詰めます。
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
```
`preprocess_function`をデータセットの最初の数例に適用します:
```python
>>> processed_dataset = preprocess_function(dataset[:5])
```
サンプルの長さは現在同じで、指定された最大長と一致しています。これで処理されたデータセットをモデルに渡すことができます!
```py
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
```
## Computer Vision
コンピュータビジョンタスクでは、モデル用にデータセットを準備するための[画像プロセッサ](main_classes/image_processor)が必要です。
画像の前処理には、画像をモデルが期待する入力形式に変換するためのいくつかのステップが含まれています。これらのステップには、リサイズ、正規化、カラーチャネルの補正、および画像をテンソルに変換するなどが含まれます。
<Tip>
画像の前処理は、通常、画像の増強の形式に従います。画像の前処理と画像の増強の両方は画像データを変換しますが、異なる目的があります:
* 画像の増強は、過学習を防ぎ、モデルの堅牢性を向上させるのに役立つ方法で画像を変更します。データを増強する方法は無限で、明るさや色の調整、クロップ、回転、リサイズ、ズームなど、様々な方法があります。ただし、増強操作によって画像の意味が変わらないように注意する必要があります。
* 画像の前処理は、画像がモデルの期待する入力形式と一致することを保証します。コンピュータビジョンモデルをファインチューニングする場合、画像はモデルが最初にトレーニングされたときとまったく同じ方法で前処理する必要があります。
画像の増強には任意のライブラリを使用できます。画像の前処理には、モデルに関連付けられた`ImageProcessor`を使用します。
</Tip>
コンピュータビジョンのデータセットで画像プロセッサを使用する方法を示すために、[food101](https://huggingface.co/datasets/food101)データセットをロードします(データセットのロード方法の詳細については🤗[Datasetsチュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照):
<Tip>
データセットがかなり大きいため、🤗 Datasetsの`split`パラメータを使用してトレーニングデータの小さなサンプルのみをロードします!
</Tip>
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
次に、🤗 Datasetsの [`Image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image) 機能で画像を見てみましょう:
```python
>>> dataset[0]["image"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vision-preprocess-tutorial.png"/>
</div>
AutoImageProcessorを[`AutoImageProcessor.from_pretrained`]を使用してロードします:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
1. まず、画像の拡張を追加しましょう。好きなライブラリを使用できますが、このチュートリアルではtorchvisionの[`transforms`](https://pytorch.org/vision/stable/transforms.html)モジュールを使用します。別のデータ拡張ライブラリを使用したい場合は、[Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)または[Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)で詳細を学ぶことができます。
ここでは、[`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html)を使用していくつかの変換を連鎖させます - [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)と[`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html)。
サイズの変更に関しては、`image_processor`から画像サイズの要件を取得できます。
一部のモデルでは、正確な高さと幅が必要ですが、他のモデルでは`shortest_edge`のみが定義されています。
```py
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
>>> size = (
... image_processor.size["shortest_edge"]
... if "shortest_edge" in image_processor.size
... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
```
2. モデルは[`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values)を入力として受け取ります。
`ImageProcessor`は画像の正規化と適切なテンソルの生成を処理できます。
一連の画像に対する画像拡張と画像前処理を組み合わせ、`pixel_values`を生成する関数を作成します:
```python
>>> def transforms(examples):
... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
... return examples
```
<Tip>
上記の例では、画像のサイズ変更を既に画像増強変換で行っているため、`do_resize=False`を設定しました。
適切な `image_processor` からの `size` 属性を活用しています。画像増強中に画像のサイズ変更を行わない場合は、このパラメータを省略してください。
デフォルトでは、`ImageProcessor` がサイズ変更を処理します。
画像を増強変換の一部として正規化したい場合は、`image_processor.image_mean` と `image_processor.image_std` の値を使用してください。
</Tip>
3. 次に、🤗 Datasetsの[`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)を使用して、変換をリアルタイムで適用します:
```python
>>> dataset.set_transform(transforms)
```
4. 画像にアクセスすると、画像プロセッサが `pixel_values` を追加したことがわかります。これで処理済みのデータセットをモデルに渡すことができます!
```python
>>> dataset[0].keys()
```
以下は、変換が適用された後の画像の外観です。 画像はランダムに切り抜かれ、その色の特性も異なります。
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/preprocessed_image.png"/>
</div>
<Tip>
オブジェクト検出、意味セグメンテーション、インスタンスセグメンテーション、およびパノプティックセグメンテーションなどのタスクの場合、`ImageProcessor`は
ポスト処理メソッドを提供します。これらのメソッドは、モデルの生の出力を境界ボックスやセグメンテーションマップなどの意味のある予測に変換します。
</Tip>
### Pad
一部の場合、たとえば、[DETR](./model_doc/detr)をファインチューニングする場合、モデルはトレーニング時にスケールの変更を適用します。
これにより、バッチ内の画像のサイズが異なる場合があります。[`DetrImageProcessor`]から[`DetrImageProcessor.pad`]を使用し、
カスタムの`collate_fn`を定義して画像を一緒にバッチ処理できます。
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## Multi Modal
マルチモーダル入力を使用するタスクの場合、モデル用にデータセットを準備するための[プロセッサ](main_classes/processors)が必要です。プロセッサは、トークナイザや特徴量抽出器などの2つの処理オブジェクトを結合します。
自動音声認識(ASR)のためのプロセッサの使用方法を示すために、[LJ Speech](https://huggingface.co/datasets/lj_speech)データセットをロードします(データセットのロード方法の詳細については🤗 [Datasets チュートリアル](https://huggingface.co/docs/datasets/load_hub)を参照):
```python
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
ASR(自動音声認識)の場合、主に `audio` と `text` に焦点を当てているため、他の列を削除できます:
```python
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
次に、`audio`と`text`の列を見てみましょう:
```python
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
常に、オーディオデータセットのサンプリングレートを、モデルの事前学習に使用されたデータセットのサンプリングレートと一致させるように[リサンプル](preprocessing#audio)する必要があります!
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
プロセッサを [`AutoProcessor.from_pretrained`] を使用してロードします:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. `array`内に含まれるオーディオデータを`input_values`に処理し、`text`を`labels`にトークン化する関数を作成します:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. サンプルに`prepare_dataset`関数を適用します:
```py
>>> prepare_dataset(lj_speech[0])
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/model_memory_anatomy.md
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Model training anatomy
モデルトレーニングの効率を向上させるために適用できるパフォーマンス最適化テクニックを理解するには、トレーニング中にGPUがどのように利用されるか、および実行される操作に応じて計算強度がどのように変化するかを理解することが役立ちます。
まずは、GPUの利用例とモデルのトレーニング実行に関する示唆に富む例を探求することから始めましょう。デモンストレーションのために、いくつかのライブラリをインストールする必要があります:
```bash
pip install transformers datasets accelerate nvidia-ml-py3
```
`nvidia-ml-py3` ライブラリは、Python内からモデルのメモリ使用状況をモニターすることを可能にします。おそらく、ターミナルでの `nvidia-smi` コマンドについてはお聞きかもしれませんが、このライブラリを使用すると、Pythonから同じ情報にアクセスできます。
それから、いくつかのダミーデータを作成します。100から30000の間のランダムなトークンIDと、分類器のためのバイナリラベルです。合計で、512のシーケンスがあり、それぞれの長さは512で、PyTorchフォーマットの [`~datasets.Dataset`] に格納されます。
```py
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
... "labels": np.random.randint(0, 1, (dataset_size)),
... }
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")
```
[`Trainer`]を使用してGPU利用率とトレーニング実行の要約統計情報を表示するために、2つのヘルパー関数を定義します。
```py
>>> from pynvml import *
>>> def print_gpu_utilization():
... nvmlInit()
... handle = nvmlDeviceGetHandleByIndex(0)
... info = nvmlDeviceGetMemoryInfo(handle)
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
... print(f"Time: {result.metrics['train_runtime']:.2f}")
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
... print_gpu_utilization()
```
以下は、無料のGPUメモリから開始していることを確認しましょう:
```py
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.
```
GPUメモリがモデルを読み込む前のように占有されていないように見えます。これがお使いのマシンでの状況でない場合は、GPUメモリを使用しているすべてのプロセスを停止してください。ただし、すべての空きGPUメモリをユーザーが使用できるわけではありません。モデルがGPUに読み込まれると、カーネルも読み込まれ、1〜2GBのメモリを使用することがあります。それがどれくらいかを確認するために、GPUに小さなテンソルを読み込むと、カーネルも読み込まれます。
```py
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.
```
カーネルだけで1.3GBのGPUメモリを使用していることがわかります。次に、モデルがどれだけのスペースを使用しているかを見てみましょう。
## Load Model
まず、`bert-large-uncased` モデルを読み込みます。モデルの重みを直接GPUに読み込むことで、重みだけがどれだけのスペースを使用しているかを確認できます。
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.
```
モデルの重みだけで、GPUメモリを1.3 GB使用していることがわかります。正確な数値は、使用している具体的なGPUに依存します。新しいGPUでは、モデルの重みが最適化された方法で読み込まれるため、モデルの使用を高速化することがあるため、モデルがより多くのスペースを占有することがあります。さて、`nvidia-smi` CLIと同じ結果が得られるかを簡単に確認することもできます。
```bash
nvidia-smi
```
```bash
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
```
前回と同じ数値を取得し、16GBのメモリを搭載したV100 GPUを使用していることがわかります。さて、モデルのトレーニングを開始し、GPUメモリの消費がどのように変化するかを確認してみましょう。まず、いくつかの標準的なトレーニング引数を設定します:
```py
default_args = {
"output_dir": "tmp",
"evaluation_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
```
<Tip>
複数の実験を実行する予定がある場合、実験間でメモリを適切にクリアするために、実験の間に Python カーネルを再起動してください。
</Tip>
## Memory utilization at vanilla training
[`Trainer`] を使用して、GPU パフォーマンスの最適化テクニックを使用せずにバッチサイズ 4 でモデルをトレーニングしましょう:
```py
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)
```
```
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
```
既に、比較的小さいバッチサイズでも、GPUのほとんどのメモリがすでに使用されていることがわかります。しかし、より大きなバッチサイズを使用することは、しばしばモデルの収束が速くなったり、最終的な性能が向上したりすることがあります。したがって、理想的には、バッチサイズをモデルの要件に合わせて調整したいのですが、GPUの制限に合わせて調整する必要はありません。興味深いことに、モデルのサイズよりもはるかに多くのメモリを使用しています。なぜそうなるのかを少し理解するために、モデルの操作とメモリの必要性を見てみましょう。
## Anatomy of Model's Operations
Transformerアーキテクチャには、計算強度によって以下の3つの主要な操作グループが含まれています。
1. **テンソルの収縮**
線形層とMulti-Head Attentionのコンポーネントは、すべてバッチ処理された **行列-行列の乗算** を行います。これらの操作は、Transformerのトレーニングにおいて最も計算集約的な部分です。
2. **統計的正規化**
Softmaxと層正規化は、テンソルの収縮よりも計算負荷が少なく、1つまたは複数の **縮約操作** を含み、その結果がマップを介して適用されます。
3. **要素ごとの演算子**
これらは残りの演算子です:**バイアス、ドロップアウト、活性化、および残差接続** です。これらは最も計算集約的な操作ではありません。
パフォーマンスのボトルネックを分析する際に、この知識は役立つことがあります。
この要約は、[Data Movement Is All You Need: Optimizing Transformers 2020に関するケーススタディ](https://arxiv.org/abs/2007.00072)から派生しています。
## Anatomy of Model's Memory
モデルのトレーニングがGPUに配置されたモデルよりもはるかに多くのメモリを使用することを見てきました。これは、トレーニング中にGPUメモリを使用する多くのコンポーネントが存在するためです。GPUメモリ上のコンポーネントは以下の通りです:
1. モデルの重み
2. オプティマイザの状態
3. 勾配
4. 勾配計算のために保存された前向き活性化
5. 一時バッファ
6. 機能固有のメモリ
通常、AdamWを使用して混合精度でトレーニングされたモデルは、モデルパラメータごとに18バイトとアクティベーションメモリが必要です。推論ではオプティマイザの状態と勾配は不要ですので、これらを差し引くことができます。したがって、混合精度の推論においては、モデルパラメータごとに6バイトとアクティベーションメモリが必要です。
詳細を見てみましょう。
**モデルの重み:**
- fp32トレーニングのパラメーター数 * 4バイト
- ミックスプレシジョントレーニングのパラメーター数 * 6バイト(メモリ内にfp32とfp16のモデルを維持)
**オプティマイザの状態:**
- 通常のAdamWのパラメーター数 * 8バイト(2つの状態を維持)
- 8-bit AdamWオプティマイザのパラメーター数 * 2バイト([bitsandbytes](https://github.com/TimDettmers/bitsandbytes)のようなオプティマイザ)
- モーメンタムを持つSGDのようなオプティマイザのパラメーター数 * 4バイト(1つの状態を維持)
**勾配**
- fp32またはミックスプレシジョントレーニングのパラメーター数 * 4バイト(勾配は常にfp32で保持)
**フォワードアクティベーション**
- サイズは多くの要因に依存し、主要な要因はシーケンスの長さ、隠れ層のサイズ、およびバッチサイズです。
フォワードとバックワードの関数によって渡され、返される入力と出力、および勾配計算のために保存されるフォワードアクティベーションがあります。
**一時的なメモリ**
さらに、計算が完了した後に解放されるさまざまな一時変数がありますが、これらは一時的に追加のメモリを必要とし、OOMに達する可能性があります。したがって、コーディング時にはこのような一時変数に戦略的に考え、必要なくなったら明示的に解放することが非常に重要です。
**機能固有のメモリ**
次に、ソフトウェアには特別なメモリ要件がある場合があります。たとえば、ビームサーチを使用してテキストを生成する場合、ソフトウェアは複数の入力と出力のコピーを維持する必要があります。
**`forward`と`backward`の実行速度**
畳み込み層と線形層では、バックワードにフォワードと比べて2倍のFLOPSがあり、一般的には約2倍遅くなります(バックワードのサイズが不便であることがあるため、それ以上になることがあります)。 アクティベーションは通常、バンド幅制限されており、バックワードでアクティベーションがフォワードよりも多くのデータを読むことが一般的です(たとえば、アクティベーションフォワードは1回読み取り、1回書き込み、アクティベーションバックワードはフォワードのgradOutputおよび出力を2回読み取り、1回書き込みます)。
ご覧の通り、GPUメモリを節約したり操作を高速化できる可能性のあるいくつかの場所があります。 GPUの利用と計算速度に影響を与える要因を理解したので、パフォーマンス最適化の技術については、[単一GPUでの効率的なトレーニングのための方法とツール](perf_train_gpu_one)のドキュメンテーションページを参照してください。
詳細を見てみましょう。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/create_a_model.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Create a custom architecture
[`AutoClass`](model_doc/auto)は、モデルのアーキテクチャを自動的に推論し、事前学習済みの設定と重みをダウンロードします。一般的には、チェックポイントに依存しないコードを生成するために`AutoClass`を使用することをお勧めします。ただし、特定のモデルパラメータに対する制御をより詳細に行いたいユーザーは、いくつかの基本クラスからカスタム🤗 Transformersモデルを作成できます。これは、🤗 Transformersモデルを研究、トレーニング、または実験する興味があるユーザーに特に役立つかもしれません。このガイドでは、`AutoClass`を使用しないカスタムモデルの作成について詳しく説明します。次の方法を学びます:
- モデルの設定をロードおよびカスタマイズする。
- モデルアーキテクチャを作成する。
- テキスト用の遅いトークナイザと高速トークナイザを作成する。
- ビジョンタスク用の画像プロセッサを作成する。
- オーディオタスク用の特徴抽出器を作成する。
- マルチモーダルタスク用のプロセッサを作成する。
## Configuration
[設定](main_classes/configuration)は、モデルの特定の属性を指します。各モデルの設定には異なる属性があります。たとえば、すべてのNLPモデルには、`hidden_size`、`num_attention_heads`、`num_hidden_layers`、および`vocab_size`属性が共通してあります。これらの属性は、モデルを構築するための注意ヘッドの数や隠れ層の数を指定します。
[DistilBERT](model_doc/distilbert)をより詳しく調べるために、[`DistilBertConfig`]にアクセスしてその属性を調べてみましょう:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`]は、基本の[`DistilBertModel`]を構築するために使用されるすべてのデフォルト属性を表示します。
すべての属性はカスタマイズ可能で、実験のためのスペースを提供します。例えば、デフォルトのモデルをカスタマイズして以下のようなことができます:
- `activation`パラメータで異なる活性化関数を試す。
- `attention_dropout`パラメータで注意確率の高いドロップアウト率を使用する。
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
事前学習済みモデルの属性は、[`~PretrainedConfig.from_pretrained`] 関数で変更できます:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Once you are satisfied with your model configuration, you can save it with [`PretrainedConfig.save_pretrained`]. Your configuration file is stored as a JSON file in the specified save directory.
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
設定ファイルを再利用するには、[`~PretrainedConfig.from_pretrained`]を使用してそれをロードします:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
```
<Tip>
カスタム構成ファイルを辞書として保存することも、カスタム構成属性とデフォルトの構成属性の違いだけを保存することもできます!詳細については[configuration](main_classes/configuration)のドキュメンテーションをご覧ください。
</Tip>
## Model
次のステップは、[モデル](main_classes/models)を作成することです。モデル(アーキテクチャとも緩く言われることがあります)は、各レイヤーが何をしているか、どの操作が行われているかを定義します。構成からの `num_hidden_layers` のような属性はアーキテクチャを定義するために使用されます。
すべてのモデルは [`PreTrainedModel`] をベースクラスとし、入力埋め込みのリサイズやセルフアテンションヘッドのプルーニングなど、共通のメソッドがいくつかあります。
さらに、すべてのモデルは [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)、[`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)、または [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) のいずれかのサブクラスでもあります。つまり、モデルはそれぞれのフレームワークの使用法と互換性があります。
<frameworkcontent>
<pt>
モデルにカスタム構成属性をロードします:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
>>> model = DistilBertModel(my_config)
```
これにより、事前トレーニング済みの重みではなくランダムな値を持つモデルが作成されます。
これは、トレーニングが行われるまで、まだ有用なものとして使用することはできません。
トレーニングはコストと時間がかかるプロセスです。
通常、トレーニングに必要なリソースの一部しか使用せず、より速くより良い結果を得るために事前学習済みモデルを使用することが良いでしょう。
[`~PreTrainedModel.from_pretrained`]を使用して事前学習済みモデルを作成します:
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased")
```
事前学習済みの重みをロードする際、モデルが🤗 Transformersによって提供されている場合、デフォルトのモデル設定が自動的にロードされます。ただし、必要に応じてデフォルトのモデル設定属性の一部またはすべてを独自のもので置き換えることができます。
```py
>>> model = DistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
モデルにカスタム設定属性をロードしてください:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
これにより、事前学習済みの重みではなくランダムな値を持つモデルが作成されます。
このモデルを有用な目的にはまだ使用することはできません。トレーニングはコストがかかり、時間がかかるプロセスです。
一般的には、トレーニングに必要なリソースの一部しか使用せずに、より速く優れた結果を得るために事前学習済みモデルを使用することが良いでしょう。
[`~TFPreTrainedModel.from_pretrained`]を使用して事前学習済みモデルを作成します:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
```
事前学習済みの重みをロードする際、モデルが🤗 Transformersによって提供されている場合、デフォルトのモデル構成が自動的にロードされます。ただし、必要であればデフォルトのモデル構成属性の一部またはすべてを独自のもので置き換えることもできます:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Model heads
この時点で、ベースのDistilBERTモデルがあり、これは隠れた状態を出力します。隠れた状態はモデルのヘッドへの入力として渡され、最終的な出力を生成します。🤗 Transformersは、モデルがそのタスクをサポートしている限り、各タスクに対応する異なるモデルヘッドを提供します(つまり、DistilBERTを翻訳のようなシーケンス対シーケンスタスクに使用することはできません)。
<frameworkcontent>
<pt>
たとえば、[`DistilBertForSequenceClassification`]は、シーケンス分類ヘッドを持つベースのDistilBERTモデルです。シーケンス分類ヘッドは、プールされた出力の上にある線形層です。
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
新しいタスクにこのチェックポイントを簡単に再利用するには、異なるモデルヘッドに切り替えます。
質問応答タスクの場合、[`DistilBertForQuestionAnswering`] モデルヘッドを使用します。
質問応答ヘッドはシーケンス分類ヘッドと類似していますが、隠れ状態の出力の上に線形層があります。
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</pt>
<tf>
例えば、[`TFDistilBertForSequenceClassification`]は、シーケンス分類ヘッドを持つベースのDistilBERTモデルです。シーケンス分類ヘッドは、プールされた出力の上にある線形層です。
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
別のタスクにこのチェックポイントを簡単に再利用することができ、異なるモデルヘッドに切り替えるだけです。
質問応答タスクの場合、[`TFDistilBertForQuestionAnswering`]モデルヘッドを使用します。
質問応答ヘッドはシーケンス分類ヘッドと似ていますが、隠れ状態の出力の上に線形層があるだけです。
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
テキストデータをモデルで使用する前に必要な最後のベースクラスは、生のテキストをテンソルに変換するための[トークナイザ](main_classes/tokenizer)です。
🤗 Transformersで使用できる2つのタイプのトークナイザがあります:
- [`PreTrainedTokenizer`]: トークナイザのPython実装です。
- [`PreTrainedTokenizerFast`]: Rustベースの[🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/)ライブラリからのトークナイザです。
このトークナイザのタイプは、そのRust実装により、特にバッチトークナイゼーション中に高速です。
高速なトークナイザは、トークンを元の単語または文字にマッピングする*オフセットマッピング*などの追加メソッドも提供します。
両方のトークナイザは、エンコードとデコード、新しいトークンの追加、特別なトークンの管理など、共通のメソッドをサポートしています。
<Tip warning={true}>
すべてのモデルが高速なトークナイザをサポートしているわけではありません。
モデルが高速なトークナイザをサポートしているかどうかを確認するには、この[表](index#supported-frameworks)をご覧ください。
</Tip>
独自のトークナイザをトレーニングした場合、*ボキャブラリー*ファイルからトークナイザを作成できます。
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
カスタムトークナイザーから生成される語彙は、事前学習済みモデルのトークナイザーが生成する語彙とは異なることを覚えておくことは重要です。
事前学習済みモデルを使用する場合は、事前学習済みモデルの語彙を使用する必要があります。そうしないと、入力が意味をなさなくなります。
[`DistilBertTokenizer`]クラスを使用して、事前学習済みモデルの語彙を持つトークナイザーを作成します:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
```
[`DistilBertTokenizerFast`]クラスを使用して高速なトークナイザを作成します:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert-base-uncased")
```
<Tip>
デフォルトでは、[`AutoTokenizer`]は高速なトークナイザを読み込もうとします。`from_pretrained`内で`use_fast=False`を設定することで、この動作を無効にすることができます。
</Tip>
## Image Processor
画像プロセッサはビジョン入力を処理します。これは基本クラス [`~image_processing_utils.ImageProcessingMixin`] を継承しています。
使用するには、使用しているモデルに関連付けられた画像プロセッサを作成します。
たとえば、画像分類に[ViT](model_doc/vit)を使用する場合、デフォルトの [`ViTImageProcessor`] を作成します。
```py
>>> from transformers import ViTImageProcessor
>>> vit_extractor = ViTImageProcessor()
>>> print(vit_extractor)
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
カスタマイズを必要としない場合、モデルのデフォルトの画像プロセッサパラメータをロードするには、単純に`from_pretrained`メソッドを使用してください。
</Tip>
[`ViTImageProcessor`]のパラメータを変更して、カスタムの画像プロセッサを作成できます:
```py
>>> from transformers import ViTImageProcessor
>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTImageProcessor {
"do_normalize": false,
"do_resize": true,
"image_processor_type": "ViTImageProcessor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
## Feature Extractor
フィーチャー抽出器は音声入力を処理します。これは基本的な [`~feature_extraction_utils.FeatureExtractionMixin`] クラスから継承され、音声入力を処理するための [`SequenceFeatureExtractor`] クラスからも継承されることがあります。
使用するには、モデルに関連付けられたフィーチャー抽出器を作成します。たとえば、音声分類に [Wav2Vec2](model_doc/wav2vec2) を使用する場合、デフォルトの [`Wav2Vec2FeatureExtractor`] を作成します。
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
<Tip>
カスタマイズを行わない場合、モデルのデフォルトの特徴抽出器パラメーターをロードするには、単に `from_pretrained` メソッドを使用してください。
</Tip>
[`Wav2Vec2FeatureExtractor`] のパラメーターを変更して、カスタム特徴抽出器を作成できます:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": false,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 8000
}
```
## Processor
マルチモーダルタスクをサポートするモデルに対して、🤗 Transformersは便利なプロセッサクラスを提供しています。
このプロセッサクラスは、特徴量抽出器やトークナイザなどの処理クラスを便利にラップし、単一のオブジェクトに結合します。
たとえば、自動音声認識タスク(ASR)用に[`Wav2Vec2Processor`]を使用してみましょう。
ASRは音声をテキストに転写するタスクであり、音声入力を処理するために特徴量抽出器とトークナイザが必要です。
音声入力を処理する特徴量抽出器を作成します:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
テキスト入力を処理するトークナイザを作成します:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
[`Wav2Vec2Processor`]で特徴量抽出器とトークナイザを組み合わせます:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
二つの基本クラス - 設定とモデル - および追加の前処理クラス(トークナイザ、画像プロセッサ、特徴抽出器、またはプロセッサ)を使用することで、🤗 Transformers がサポートするモデルのいずれかを作成できます。これらの基本クラスは設定可能で、必要な特性を使用できます。モデルをトレーニング用に簡単にセットアップしたり、既存の事前学習済みモデルを微調整することができます。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/tasks_explained.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# How 🤗 Transformers solve tasks
[🤗 Transformersでできること](task_summary)で、自然言語処理(NLP)、音声とオーディオ、コンピュータビジョンのタスク、それらの重要なアプリケーションについて学びました。このページでは、モデルがこれらのタスクをどのように解決するかを詳しく見て、モデルの内部で何が起こっているかを説明します。特定のタスクを解決するためには多くの方法があり、一部のモデルは特定のテクニックを実装するか、または新しい観点からタスクに取り組むかもしれませんが、Transformerモデルにとって、一般的なアイデアは同じです。柔軟なアーキテクチャのおかげで、ほとんどのモデルはエンコーダ、デコーダ、またはエンコーダ-デコーダ構造の変種です。Transformerモデル以外にも、当社のライブラリにはコンピュータビジョンタスクに今でも使用されているいくつかの畳み込みニューラルネットワーク(CNN)もあります。また、現代のCNNがどのように機能するかも説明します。
タスクがどのように解決されるかを説明するために、モデル内部で有用な予測を出力するために何が起こるかについて説明します。
- [Wav2Vec2](model_doc/wav2vec2):オーディオ分類および自動音声認識(ASR)向け
- [Vision Transformer(ViT)](model_doc/vit)および[ConvNeXT](model_doc/convnext):画像分類向け
- [DETR](model_doc/detr):オブジェクト検出向け
- [Mask2Former](model_doc/mask2former):画像セグメンテーション向け
- [GLPN](model_doc/glpn):深度推定向け
- [BERT](model_doc/bert):エンコーダを使用するテキスト分類、トークン分類、および質問応答などのNLPタスク向け
- [GPT2](model_doc/gpt2):デコーダを使用するテキスト生成などのNLPタスク向け
- [BART](model_doc/bart):エンコーダ-デコーダを使用する要約および翻訳などのNLPタスク向け
<Tip>
さらに進む前に、元のTransformerアーキテクチャの基本的な知識を持つと良いです。エンコーダ、デコーダ、および注意力がどのように動作するかを知っておくと、異なるTransformerモデルがどのように動作するかを理解するのに役立ちます。始めているか、リフレッシュが必要な場合は、詳細な情報については当社の[コース](https://huggingface.co/course/chapter1/4?fw=pt)をチェックしてください!
</Tip>
## Speech and audio
[Wav2Vec2](model_doc/wav2vec2)は、未ラベルの音声データで事前トレーニングされ、オーディオ分類および自動音声認識のラベル付きデータでファインチューンされた自己教師モデルです。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/wav2vec2_architecture.png"/>
</div>
このモデルには主に次の4つのコンポーネントがあります。
1. *特徴エンコーダ*:生の音声波形を受け取り、平均値をゼロに正規化し、単位分散に変換し、それを20msごとの特徴ベクトルのシーケンスに変換します。
2. 波形は自然に連続しているため、テキストのシーケンスを単語に分割できるようにできるように、特徴ベクトルは*量子化モジュール*に渡され、離散音声ユニットを学習しようとします。音声ユニットは*コードブック*(語彙と考えることができます)として知られるコードワードのコレクションから選択されます。コードブックから、連続したオーディオ入力を最もよく表すベクトルまたは音声ユニット(ターゲットラベルと考えることができます)が選択され、モデルを介して転送されます。
3. 特徴ベクトルの約半分はランダムにマスクされ、マスクされた特徴ベクトルは*コンテキストネットワーク*に供給されます。これは、相対的な位置エンベッディングも追加するTransformerエンコーダです。
4. コンテキストネットワークの事前トレーニングの目的は*コントラスティブタスク*です。モデルはマスクされた予測の真の量子化音声表現を、偽の予測のセットから予測しなければならず、モデルは最も似たコンテキストベクトルと量子化音声ユニット(ターゲットラベル)を見つけるように促されます。
今、Wav2Vec2は事前トレーニングされているので、オーディオ分類または自動音声認識のためにデータをファインチューンできます!
### Audio classification
事前トレーニングされたモデルをオーディオ分類に使用するには、基本的なWav2Vec2モデルの上にシーケンス分類ヘッドを追加します。分類ヘッドはエンコーダの隠れた状態を受け入れる線形層で、各オーディオフレームから学習された特徴を表します。これらの隠れた状態は長さが異なる可能性があるため、最初に隠れた状態がプールされ、次にクラスラベルに対するロジットに変換されます。ロジットとターゲット間のクロスエントロピー損失が計算され、最も可能性の高いクラスを見つけるために使用されます。
オーディオ分類を試す準備はできましたか?Wav2Vec2をファインチューンして推論に使用する方法を学ぶための完全な[オーディオ分類ガイド](tasks/audio_classification)をチェックしてください!
### Automatic speech recognition
事前トレーニングされたモデルを自動音声認識に使用するには、[connectionist temporal classification(CTC)](glossary#connectionist-temporal-classification-ctc)のための基本的なWav2Vec2モデルの上に言語モデリングヘッドを追加します。言語モデリングヘッドはエンコーダの隠れた状態を受け入れ、それらをロジットに変換します。各ロジットはトークンクラスを表し(トークン数はタスクの語彙から来ます)、ロジットとターゲット間のCTC損失が計算され、次に転写に変換されます。
自動音声認識を試す準備はできましたか?Wav2Vec2をファインチューンして推論に使用する方法を学ぶための完全な[自動音声認識ガイド](tasks/asr)をチェックしてください!
## Computer vision
コンピュータビジョンのタスクをアプローチする方法は2つあります。
1. 画像をパッチのシーケンスに分割し、Transformerを使用して並列に処理します。
2. [ConvNeXT](model_doc/convnext)などのモダンなCNNを使用します。これらは畳み込み層を使用しますが、モダンなネットワーク設計を採用しています。
<Tip>
サードアプローチでは、Transformerと畳み込みを組み合わせたものもあります(例:[Convolutional Vision Transformer](model_doc/cvt)または[LeViT](model_doc/levit))。これらについては議論しませんが、これらはここで調べる2つのアプローチを組み合わせています。
</Tip>
ViTとConvNeXTは画像分類によく使用されますが、オブジェクト検出、セグメンテーション、深度推定などの他のビジョンタスクに対しては、DETR、Mask2Former、GLPNなどが適しています。
### Image classification
ViTとConvNeXTの両方を画像分類に使用できます。主な違いは、ViTが注意メカニズムを使用し、ConvNeXTが畳み込みを使用することです。
#### Transformer
[ViT](model_doc/vit)は畳み込みを完全にTransformerアーキテクチャで置き換えます。元のTransformerに精通している場合、ViTの理解は既にほとんど完了しています。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/vit_architecture.jpg"/>
</div>
ViTが導入した主な変更点は、画像をTransformerに供給する方法です。
1. 画像は正方形で重ならないパッチのシーケンスに分割され、各パッチはベクトルまたは*パッチ埋め込み*に変換されます。パッチ埋め込みは、適切な入力次元を作成するために2D畳み込み層から生成されます(基本のTransformerの場合、各パッチ埋め込みに768の値があります)。224x224ピクセルの画像がある場合、それを16x16の画像パッチに分割できます。テキストが単語にトークン化されるように、画像はパッチのシーケンスに「トークン化」されます。
2. *学習埋め込み*、つまり特別な `[CLS]` トークンが、BERTのようにパッチ埋め込みの先頭に追加されます。 `[CLS]` トークンの最終的な隠れた状態は、付属の分類ヘッドの入力として使用されます。他の出力は無視されます。このトークンは、モデルが画像の表現をエンコードする方法を学ぶのに役立ちます。
3. パッチと学習埋め込みに追加する最後の要素は*位置埋め込み*です。モデルは画像パッチがどのように並べられているかを知りませんので、位置埋め込みも学習可能で、パッチ埋め込みと同じサイズを持ちます。最後に、すべての埋め込みがTransformerエンコーダに渡されます。
4. 出力、具体的には `[CLS]` トークンの出力だけが、多層パーセプトロンヘッド(MLP)に渡されます。ViTの事前トレーニングの目的は単純に分類です。他の分類ヘッドと同様に、MLPヘッドは出力をクラスラベルに対するロジットに変換し、クロスエントロピー損失を計算して最も可能性の高いクラスを見つけます。
画像分類を試す準備はできましたか?ViTをファインチューンして推論に使用する方法を学ぶための完全な[画像分類ガイド](tasks/image_classification)をチェックしてください!
#### CNN
<Tip>
このセクションでは畳み込みについて簡単に説明していますが、画像の形状とサイズがどのように変化するかを事前に理解していると役立ちます。畳み込みに慣れていない場合は、fastaiの書籍から[Convolution Neural Networks chapter](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb)をチェックしてみてください!
</Tip>
[ConvNeXT](model_doc/convnext)は、性能を向上させるために新しいモダンなネットワーク設計を採用したCNNアーキテクチャです。ただし、畳み込みはモデルの中核にまだあります。高レベルから見た場合、[畳み込み(convolution)](glossary#convolution)は、小さな行列(*カーネル*)が画像のピクセルの小さなウィンドウに乗算される操作です。それは特定のテクスチャや線の曲率などの特徴を計算します。その後、次のピクセルのウィンドウに移動します。畳み込みが移動する距離は*ストライド*として知られています。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convolution.gif"/>
</div>
<small>[Convolution Arithmetic for Deep Learning](https://arxiv.org/abs/1603.07285) からの基本的なパディングやストライドのない畳み込み。</small>
この出力を別の畳み込み層に供給し、各連続した層ごとに、ネットワークはホットドッグやロケットのようなより複雑で抽象的なものを学習します。畳み込み層の間には、特徴の次元を削減し、特徴の位置の変動に対してモデルをより堅牢にするためにプーリング層を追加するのが一般的です。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convnext_architecture.png"/>
</div>
ConvNeXTは、以下の5つの方法でCNNをモダン化しています。
1. 各ステージのブロック数を変更し、画像をより大きなストライドと対応するカーネルサイズで*パッチ化*します。重ならないスライディングウィンドウは、これにより画像をパッチに分割するViTの戦略と似ています。
2. *ボトルネック* レイヤーはチャネル数を縮小し、それを復元します。1x1の畳み込みを実行するのは速く、深さを増やすことができます。逆ボトルネックは逆のことを行い、チャネル数を拡張し、それを縮小します。これはメモリ効率が高いです。
3. ボトルネックレイヤー内の通常の3x3の畳み込み層を、*深度方向の畳み込み*で置き換えます。これは各入力チャネルに個別に畳み込みを適用し、最後にそれらを積み重ねる畳み込みです。これにより、性能向上のためにネットワーク幅が広がります。
4. ViTはグローバル受容野を持っているため、その注意メカニズムのおかげで一度に画像の多くを見ることができます。ConvNeXTはこの効果を再現しようとし、カーネルサイズを7x7に増やします。
5. ConvNeXTはまた、Transformerモデルを模倣するいくつかのレイヤーデザイン変更を行っています。アクティベーションと正規化レイヤーが少なく、活性化関数はReLUの代わりにGELUに切り替え、BatchNormの代わりにLayerNormを使用しています。
畳み込みブロックからの出力は、分類ヘッドに渡され、出力をロジットに変換し、最も可能性の高いラベルを見つけるためにクロスエントロピー損失が計算されます。
### Object detection
[DETR](model_doc/detr)、*DEtection TRansformer*、はCNNとTransformerエンコーダーデコーダーを組み合わせたエンドツーエンドのオブジェクト検出モデルです。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/detr_architecture.png"/>
</div>
1. 事前トレーニングされたCNN *バックボーン* は、ピクセル値で表される画像を受け取り、それの低解像度の特徴マップを作成します。特徴マップには次元削減のために1x1の畳み込みが適用され、高レベルの画像表現を持つ新しい特徴マップが作成されます。Transformerは連続モデルであるため、特徴マップは特徴ベクトルのシーケンスに平坦化され、位置エンベディングと組み合わせられます。
2. 特徴ベクトルはエンコーダーに渡され、その注意レイヤーを使用して画像表現を学習します。次に、エンコーダーの隠れ状態はデコーダーの*オブジェクトクエリ*と組み合わされます。オブジェクトクエリは、画像の異なる領域に焦点を当てる学習埋め込みで、各注意レイヤーを進行するにつれて更新されます。デコーダーの隠れ状態は、各オブジェクトクエリに対してバウンディングボックスの座標とクラスラベルを予測するフィードフォワードネットワークに渡されます。または、存在しない場合は `no object` が渡されます。
DETRは各オブジェクトクエリを並行してデコードして、*N*の最終的な予測(*N*はクエリの数)を出力します。典型的な自己回帰モデルが1つの要素を1回ずつ予測するのとは異なり、オブジェクト検出はセット予測タスク(`バウンディングボックス`、`クラスラベル`)であり、1回のパスで*N*の予測を行います。
3. 訓練中、DETRは*二部マッチング損失*を使用して、固定された数の予測と固定された一連の正解ラベルを比較します。 *N*のラベルセットに正解ラベルが少ない場合、 `no object` クラスでパディングされます。この損失関数は、DETRに予測と正解ラベルとの間で1対1の割り当てを見つけるように促します。バウンディングボックスまたはクラスラベルのどちらかが正しくない場合、損失が発生します。同様に、DETRが存在しないオブジェクトを予測した場合、罰金が科せられます。これにより、DETRは1つの非常に顕著なオブジェクトに焦点を当てるのではなく、画像内の他のオブジェクトを見つけるように促されます。
DETRの上にオブジェクト検出ヘッドを追加して、クラスラベルとバウンディングボックスの座標を見つけます。オブジェクト検出ヘッドには2つのコンポーネントがあります:デコーダーの隠れ状態をクラスラベルのロジットに変換するための線形層、およびバウンディングボックスを予測するためのMLPです。
オブジェクト検出を試す準備はできましたか?DETROの完全な[オブジェクト検出ガイド](tasks/object_detection)をチェックして、DETROのファインチューニング方法と推論方法を学んでください!
### Image segmentation
[Mask2Former](model_doc/mask2former)は、すべての種類の画像セグメンテーションタスクを解決するためのユニバーサルアーキテクチャです。従来のセグメンテーションモデルは通常、インスタンス、セマンティック、またはパノプティックセグメンテーションの特定のサブタスクに合わせて設計されています。Mask2Formerは、それらのタスクのそれぞれを*マスク分類*の問題として捉えます。マスク分類はピクセルを*N*のセグメントにグループ化し、与えられた画像に対して*N*のマスクとそれに対応するクラスラベルを予測します。このセクションでは、Mask2Formerの動作方法を説明し、最後にSegFormerのファインチューニングを試すことができます。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/mask2former_architecture.png"/>
</div>
Mask2Formerの主要なコンポーネントは次の3つです。
1. [Swin](model_doc/swin)バックボーンは画像を受け入れ、3つの連続する3x3の畳み込みから低解像度の画像特徴マップを作成します。
2. 特徴マップは*ピクセルデコーダー*に渡され、低解像度の特徴を高解像度のピクセル埋め込みに徐々にアップサンプリングします。ピクセルデコーダーは実際には解像度1/32、1/16、および1/8のオリジナル画像のマルチスケール特徴(低解像度と高解像度の特徴を含む)を生成します。
3. これらの異なるスケールの特徴マップのそれぞれは、高解像度の特徴から小さいオブジェクトをキャプチャするために1回ずつトランスフォーマーデコーダーレイヤーに渡されます。Mask2Formerの要点は、デコーダーの*マスクアテンション*メカニズムです。クロスアテンションが画像全体に注意を向けることができるのに対し、マスクアテンションは画像の特定の領域にのみ焦点を当てます。これは速く、ローカルな画像特徴だけでもモデルが学習できるため、パフォーマンスが向上します。
4. [DETR](tasks_explained#object-detection)と同様に、Mask2Formerも学習されたオブジェクトクエリを使用し、画像の特徴と組み合わせてセットの予測(`クラスラベル`、`マスク予測`)を行います。デコーダーの隠れ状態は線形層に渡され、クラスラベルに対するロジットに変換されます。ロジットと正解ラベル間のクロスエントロピー損失が最も可能性の高いものを見つけます。
マスク予測は、ピクセル埋め込みと最終的なデコーダーの隠れ状態を組み合わせて生成されます。シグモイドクロスエントロピーやダイス損失がロジットと正解マスクの間で最も可能性の高いマスクを見つけます。
セグメンテーションタスクに取り組む準備ができましたか?SegFormerのファインチューニング方法と推論方法を学ぶために、完全な[画像セグメンテーションガイド](tasks/semantic_segmentation)をチェックしてみてください!
### Depth estimation
[GLPN](model_doc/glpn)、*Global-Local Path Network*、はセグメンテーションまたは深度推定などの密な予測タスクに適しています。[SegFormer](model_doc/segformer)エンコーダーを軽量デコーダーと組み合わせたTransformerベースの深度推定モデルです。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/glpn_architecture.jpg"/>
</div>
1. ViTのように、画像はパッチのシーケンスに分割されますが、これらの画像パッチは小さいです。これはセグメンテーションや深度推定などの密な予測タスクに適しています。画像パッチはパッチ埋め込みに変換されます(パッチ埋め込みの作成方法の詳細については、[画像分類](#image-classification)セクションを参照してください)。これらのパッチ埋め込みはエンコーダーに渡されます。
2. エンコーダーはパッチ埋め込みを受け入れ、複数のエンコーダーブロックを通じてそれらを渡します。各ブロックにはアテンションとMix-FFNレイヤーが含まれています。後者の役割は位置情報を提供することです。各エンコーダーブロックの最後には、階層的表現を作成するための*パッチマージング*レイヤーがあります。隣接するパッチのグループごとの特徴が連結され、連結された特徴に対して線形層が適用され、パッチの数を1/4の解像度に削減します。これが次のエンコーダーブロックへの入力となり、ここではこのプロセス全体が繰り返され、元の画像の1/8、1/16、および1/32の解像度の画像特徴が得られます。
3. 軽量デコーダーは、エンコーダーからの最後の特徴マップ(1/32スケール)を受け取り、それを1/16スケールにアップサンプリングします。その後、特徴は各特徴に対するアテンションマップからローカルとグローバルな特徴を選択して組み合わせる*セレクティブフィーチャーフュージョン(SFF)*モジュールに渡され、1/8にアップサンプリングされます。このプロセスはデコードされた特徴が元の画像と同じサイズになるまで繰り返されます。
4. デコードされた特徴は、最終的な予測を行うためにセマンティックセグメンテーション、深度推定、またはその他の密な予測タスクに供給されます。セマンティックセグメンテーションの場合、特徴はクラス数に対するロジットに変換され、クロスエントロピー損失を使用して最適化されます。深度推定の場合、特徴は深度マップに変換され、平均絶対誤差(MAE)または平均二乗誤差(MSE)損失が使用されます。
## Natural language processing
Transformerは最初に機械翻訳のために設計され、それ以降、ほとんどのNLPタスクを解決するためのデフォルトのアーキテクチャとなっています。一部のタスクはTransformerのエンコーダー構造に適しており、他のタスクはデコーダーに適しています。さらに、一部のタスクではTransformerのエンコーダー-デコーダー構造を使用します。
### Text classification
[BERT](model_doc/bert)はエンコーダーのみのモデルであり、テキストの豊かな表現を学習するために両側の単語に注意を払うことで、深い双方向性を効果的に実装した最初のモデルです。
1. BERTは[WordPiece](tokenizer_summary#wordpiece)トークナイゼーションを使用してテキストのトークン埋め込みを生成します。単一の文と文のペアを区別するために、特別な `[SEP]` トークンが追加されます。 `[CLS]` トークンはすべてのテキストシーケンスの先頭に追加されます。 `[CLS]` トークンとともに最終出力は、分類タスクのための入力として使用されます。BERTはまた、トークンが文のペアの最初または2番目の文に属するかどうかを示すセグメント埋め込みを追加します。
2. BERTは、事前トレーニングで2つの目標を使用します:マスクされた言語モデリングと次の文の予測です。マスクされた言語モデリングでは、入力トークンの一部がランダムにマスクされ、モデルはこれらを予測する必要があります。これにより、モデルが全ての単語を見て「次の単語」を予測することができる双方向性の問題が解決されます。予測されたマスクトークンの最終的な隠れた状態は、ソフトマックスを使用した単語のマスクを予測するためのフィードフォワードネットワークに渡されます。
2番目の事前トレーニングオブジェクトは次の文の予測です。モデルは文Aの後に文Bが続くかどうかを予測する必要があります。半分の場合、文Bは次の文であり、残りの半分の場合、文Bはランダムな文です。予測(次の文かどうか)は、2つのクラス(`IsNext`および`NotNext`)に対するソフトマックスを持つフィードフォワードネットワークに渡されます。
3. 入力埋め込みは、最終的な隠れた状態を出力するために複数のエンコーダーレイヤーを介して渡されます。
事前訓練済みモデルをテキスト分類に使用するには、ベースのBERTモデルの上にシーケンス分類ヘッドを追加します。シーケンス分類ヘッドは最終的な隠れた状態を受け入れ、それらをロジットに変換するための線形層です。クロスエントロピー損失は、ロジットとターゲット間で最も可能性の高いラベルを見つけるために計算されます。
テキスト分類を試してみる準備はできましたか?DistilBERTを微調整し、推論に使用する方法を学ぶために、完全な[テキスト分類ガイド](tasks/sequence_classification)をチェックしてみてください!
### Token classification
BERTを名前エンティティ認識(NER)などのトークン分類タスクに使用するには、ベースのBERTモデルの上にトークン分類ヘッドを追加します。トークン分類ヘッドは最終的な隠れた状態を受け入れ、それらをロジットに変換するための線形層です。クロスエントロピー損失は、ロジットと各トークン間で最も可能性の高いラベルを見つけるために計算されます。
トークン分類を試してみる準備はできましたか?DistilBERTを微調整し、推論に使用する方法を学ぶために、完全な[トークン分類ガイド](tasks/token_classification)をチェックしてみてください!
### Question answering
BERTを質問応答に使用するには、ベースのBERTモデルの上にスパン分類ヘッドを追加します。この線形層は最終的な隠れた状態を受け入れ、回答に対応するテキストの「スパン」開始と終了のロジットを計算します。クロスエントロピー損失は、ロジットとラベル位置との間で最も可能性の高いテキストスパンを見つけるために計算されます。
質問応答を試してみる準備はできましたか?DistilBERTを微調整し、推論に使用する方法を学ぶために、完全な[質問応答ガイド](tasks/question_answering)をチェックしてみてください!
<Tip>
💡 注意してください。一度事前トレーニングが完了したBERTを使用してさまざまなタスクに簡単に適用できることに注目してください。必要なのは、事前トレーニング済みモデルに特定のヘッドを追加して、隠れた状態を所望の出力に変換することだけです!
</Tip>
### Text generation
[GPT-2](model_doc/gpt2)は大量のテキストで事前トレーニングされたデコーダー専用モデルです。プロンプトを与えると説得力のあるテキストを生成し、明示的にトレーニングされていないにもかかわらず、質問応答などの他のNLPタスクも完了できます。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gpt2_architecture.png"/>
</div>
1. GPT-2は[バイトペアエンコーディング(BPE)](tokenizer_summary#bytepair-encoding-bpe)を使用して単語をトークナイズし、トークン埋め込みを生成します。位置エンコーディングがトークン埋め込みに追加され、各トークンの位置を示します。入力埋め込みは複数のデコーダーブロックを介して最終的な隠れた状態を出力するために渡されます。各デコーダーブロック内で、GPT-2は「マスクされた自己注意」レイヤーを使用します。これは、GPT-2が未来のトークンに注意を払うことはできないことを意味します。GPT-2は左側のトークンにのみ注意を払うことが許可されています。これはBERTの[`mask`]トークンとは異なり、マスクされた自己注意では未来のトークンに対してスコアを`0`に設定するための注意マスクが使用されます。
2. デコーダーからの出力は、言語モデリングヘッドに渡され、最終的な隠れた状態をロジットに変換するための線形変換を実行します。ラベルはシーケンス内の次のトークンであり、これはロジットを右に1つずらして生成されます。クロスエントロピー損失は、シフトされたロジットとラベル間で計算され、次に最も可能性の高いトークンを出力します。
GPT-2の事前トレーニングの目標は完全に[因果言語モデリング](glossary#causal-language-modeling)に基づいており、シーケンス内の次の単語を予測します。これにより、GPT-2はテキスト生成を含むタスクで特に優れた性能を発揮します。
テキスト生成を試してみる準備はできましたか?DistilGPT-2を微調整し、推論に使用する方法を学ぶために、完全な[因果言語モデリングガイド](tasks/language_modeling#causal-language-modeling)をチェックしてみてください!
<Tip>
テキスト生成に関する詳細は、[テキスト生成戦略](generation_strategies)ガイドをチェックしてみてください!
</Tip>
### Summarization
[BART](model_doc/bart) や [T5](model_doc/t5) のようなエンコーダーデコーダーモデルは、要約タスクのシーケンス・トゥ・シーケンス・パターンに設計されています。このセクションでは、BARTの動作方法を説明し、最後にT5の微調整を試すことができます。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bart_architecture.png"/>
</div>
1. BARTのエンコーダーアーキテクチャは、BERTと非常に似ており、テキストのトークンと位置エンベディングを受け入れます。BARTは、入力を破壊してからデコーダーで再構築することによって事前トレーニングされます。特定の破壊戦略を持つ他のエンコーダーとは異なり、BARTは任意の種類の破壊を適用できます。ただし、*テキストインフィリング*破壊戦略が最適です。テキストインフィリングでは、いくつかのテキストスパンが**単一の** [`mask`] トークンで置き換えられます。これは重要です、なぜならモデルはマスクされたトークンを予測しなければならず、モデルに欠落トークンの数を予測させるからです。入力埋め込みとマスクされたスパンはエンコーダーを介して最終的な隠れた状態を出力しますが、BERTとは異なり、BARTは単語を予測するための最終的なフィードフォワードネットワークを最後に追加しません。
2. エンコーダーの出力はデコーダーに渡され、デコーダーはエンコーダーの出力からマスクされたトークンと非破壊トークンを予測する必要があります。これにより、デコーダーは元のテキストを復元するのに役立つ追加のコンテキストが提供されます。デコーダーからの出力は言語モデリングヘッドに渡され、隠れた状態をロジットに変換するための線形変換を実行します。クロスエントロピー損失は、ロジットとラベルの間で計算され、ラベルは単に右にシフトされたトークンです。
要約を試す準備はできましたか?T5を微調整して推論に使用する方法を学ぶために、完全な[要約ガイド](tasks/summarization)をご覧ください!
<Tip>
テキスト生成に関する詳細は、[テキスト生成戦略](generation_strategies)ガイドをチェックしてみてください!
</Tip>
### Translation
翻訳は、もう一つのシーケンス・トゥ・シーケンス・タスクの例であり、[BART](model_doc/bart) や [T5](model_doc/t5) のようなエンコーダーデコーダーモデルを使用して実行できます。このセクションでは、BARTの動作方法を説明し、最後にT5の微調整を試すことができます。
BARTは、ソース言語をターゲット言語にデコードできるようにするために、別個にランダムに初期化されたエンコーダーを追加することで翻訳に適応します。この新しいエンコーダーの埋め込みは、元の単語埋め込みの代わりに事前トレーニング済みのエンコーダーに渡されます。ソースエンコーダーは、モデルの出力からのクロスエントロピー損失を用いてソースエンコーダー、位置エンベディング、および入力エンベディングを更新することによって訓練されます。この最初のステップではモデルパラメータが固定され、すべてのモデルパラメータが2番目のステップで一緒に訓練されます。
その後、翻訳のために多言語版のmBARTが登場し、多言語で事前トレーニングされたモデルとして利用可能です。
翻訳を試す準備はできましたか?T5を微調整して推論に使用する方法を学ぶために、完全な[翻訳ガイド](tasks/summarization)をご覧ください!
<Tip>
テキスト生成に関する詳細は、[テキスト生成戦略](generation_strategies)ガイドをチェックしてみてください!
</Tip>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/philosophy.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Philosophy
🤗 Transformersは、次のような目的で構築された意見を持つライブラリです:
- 大規模なTransformersモデルを使用、研究、または拡張したい機械学習研究者および教育者。
- これらのモデルを微調整したり、本番環境で提供したり、またはその両方を行いたい実務家。
- 与えられた機械学習タスクを解決するために、事前トレーニングされたモデルをダウンロードして使用したいエンジニア。
このライブラリは、2つの強力な目標を持って設計されました:
1. できるだけ簡単かつ高速に使用できるようにすること:
- ユーザー向けの抽象化を限りなく少なくし、実際、ほとんどの場合、抽象化はありません。
各モデルを使用するために必要な3つの標準クラスだけが存在します:[構成](main_classes/configuration)、
[モデル](main_classes/model)、および前処理クラス(NLP用の[トークナイザ](main_classes/tokenizer)、ビジョン用の[イメージプロセッサ](main_classes/image_processor)、
オーディオ用の[特徴抽出器](main_classes/feature_extractor)、およびマルチモーダル入力用の[プロセッサ](main_classes/processors))。
- これらのクラスは、共通の`from_pretrained()`メソッドを使用して、事前トレーニング済みのインスタンスから簡単かつ統一された方法で初期化できます。このメソッドは、事前トレーニング済みのチェックポイントから関連するクラスのインスタンスと関連データ(構成のハイパーパラメータ、トークナイザの語彙、モデルの重み)をダウンロード(必要な場合はキャッシュ)して読み込みます。これらの基本クラスの上に、ライブラリは2つのAPIを提供しています:[パイプライン]は、特定のタスクでモデルをすばやく推論に使用するためのものであり、[`Trainer`]はPyTorchモデルを迅速にトレーニングまたは微調整するためのものです(すべてのTensorFlowモデルは`Keras.fit`と互換性があります)。
- その結果、このライブラリはニューラルネットワークのモジュラーツールボックスではありません。ライブラリを拡張または構築したい場合は、通常のPython、PyTorch、TensorFlow、Kerasモジュールを使用し、ライブラリの基本クラスから継承してモデルの読み込みと保存などの機能を再利用するだけです。モデルのコーディング哲学について詳しく知りたい場合は、[Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy)ブログ投稿をチェックしてみてください。
2. オリジナルのモデルにできるだけ近い性能を持つ最新のモデルを提供すること:
- 各アーキテクチャに対して、公式な著者から提供された結果を再現する少なくとも1つの例を提供します。
- コードは通常、可能な限り元のコードベースに近いものであり、これはPyTorchコードがTensorFlowコードに変換されることから生じ、逆もまた然りです。
その他のいくつかの目標:
- モデルの内部をできるだけ一貫して公開すること:
- フルな隠れ状態と注意の重みにアクセスできる単一のAPIを提供します。
- 前処理クラスと基本モデルのAPIは標準化され、簡単にモデル間を切り替えることができます。
- これらのモデルの微調整と調査のための有望なツールを主観的に選定すること:
- 語彙と埋め込みに新しいトークンを追加するための簡単で一貫した方法。
- Transformerヘッドをマスクおよびプルーンするための簡単な方法。
- PyTorch、TensorFlow 2.0、およびFlaxの間を簡単に切り替えて、1つのフレームワークでトレーニングし、別のフレームワークで推論を行うことを可能にすること。
## Main concepts
このライブラリは、各モデルについて次の3つのタイプのクラスを中心に構築されています:
- **モデルクラス**は、ライブラリで提供される事前トレーニング済みの重みと互換性のあるPyTorchモデル([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))、Kerasモデル([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))またはJAX/Flaxモデル([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html))を使用できます。
- **構成クラス**は、モデルを構築するために必要なハイパーパラメータを格納します(層の数や隠れ層のサイズなど)。これらを自分でインスタンス化する必要はありません。特に、変更を加えずに事前トレーニング済みモデルを使用している場合、モデルを作成すると自動的に構成がインスタンス化されるようになります(これはモデルの一部です)。
- **前処理クラス**は、生データをモデルが受け入れる形式に変換します。[トークナイザ](main_classes/tokenizer)は各モデルの語彙を保存し、文字列をトークン埋め込みのインデックスのリストにエンコードおよびデコードするためのメソッドを提供します。[イメージプロセッサ](main_classes/image_processor)はビジョン入力を前処理し、[特徴抽出器](main_classes/feature_extractor)はオーディオ入力を前処理し、[プロセッサ](main_classes/processors)はマルチモーダル入力を処理します。
これらのすべてのクラスは、事前トレーニング済みのインスタンスからインスタンス化し、ローカルに保存し、Hubで共有することができる3つのメソッドを使用しています:
- `from_pretrained()`は、ライブラリ自体によって提供される([モデルハブ](https://huggingface.co/models)でサポートされているモデルがあります)か、ユーザーによってローカルに保存された(またはサーバーに保存された)事前トレーニング済みバージョンからモデル、構成、前処理クラスをインスタンス化するためのメソッドです。
- `save_pretrained()`は、モデル、構成、前処理クラスをローカルに保存し、`from_pretrained()`を使用して再読み込みできるようにします。
- `push_to_hub()`は、モデル、構成、前処理クラスをHubに共有し、誰でも簡単にアクセスできるようにします。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/model_summary.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# The Transformer model family
2017年に導入されて以来、[元のTransformer](https://arxiv.org/abs/1706.03762)モデルは、自然言語処理(NLP)のタスクを超える多くの新しいエキサイティングなモデルをインスパイアしました。[タンパク質の折りたたまれた構造を予測](https://huggingface.co/blog/deep-learning-with-proteins)するモデル、[チーターを走らせるためのトレーニング](https://huggingface.co/blog/train-decision-transformers)するモデル、そして[時系列予測](https://huggingface.co/blog/time-series-transformers)のためのモデルなどがあります。Transformerのさまざまなバリアントが利用可能ですが、大局を見落とすことがあります。これらのすべてのモデルに共通するのは、元のTransformerアーキテクチャに基づいていることです。一部のモデルはエンコーダまたはデコーダのみを使用し、他のモデルは両方を使用します。これは、Transformerファミリー内のモデルの高レベルの違いをカテゴライズし、調査するための有用な分類法を提供し、以前に出会ったことのないTransformerを理解するのに役立ちます。
元のTransformerモデルに慣れていないか、リフレッシュが必要な場合は、Hugging Faceコースの[Transformerの動作原理](https://huggingface.co/course/chapter1/4?fw=pt)章をチェックしてください。
<div align="center">
<iframe width="560" height="315" src="https://www.youtube.com/embed/H39Z_720T5s" title="YouTubeビデオプレーヤー"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
</div>
## Computer vision
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FacQBpeFBVvrDUlzFlkejoz%2FModelscape-timeline%3Fnode-id%3D0%253A1%26t%3Dm0zJ7m2BQ9oe0WtO-1" allowfullscreen></iframe>
### Convolutional network
長い間、畳み込みネットワーク(CNN)はコンピュータビジョンのタスクにおいて支配的なパラダイムでしたが、[ビジョンTransformer](https://arxiv.org/abs/2010.11929)はそのスケーラビリティと効率性を示しました。それでも、一部のCNNの最高の特性、特に特定のタスクにとっては非常に強力な翻訳不変性など、一部のTransformerはアーキテクチャに畳み込みを組み込んでいます。[ConvNeXt](model_doc/convnext)は、畳み込みを現代化するためにTransformerから設計の選択肢を取り入れ、例えば、ConvNeXtは画像をパッチに分割するために重なり合わないスライディングウィンドウと、グローバル受容野を増加させるための大きなカーネルを使用します。ConvNeXtは、メモリ効率を向上させ、パフォーマンスを向上させるためにいくつかのレイヤーデザインの選択肢も提供し、Transformerと競合的になります!
### Encoder[[cv-encoder]]
[ビジョン トランスフォーマー(ViT)](model_doc/vit) は、畳み込みを使用しないコンピュータビジョンタスクの扉を開けました。ViT は標準のトランスフォーマーエンコーダーを使用しますが、画像を扱う方法が主要なブレークスルーでした。画像を固定サイズのパッチに分割し、それらをトークンのように使用して埋め込みを作成します。ViT は、当時のCNNと競争力のある結果を示すためにトランスフォーマーの効率的なアーキテクチャを活用しましたが、トレーニングに必要なリソースが少なくて済みました。ViT に続いて、セグメンテーションや検出などの密なビジョンタスクを処理できる他のビジョンモデルも登場しました。
これらのモデルの1つが[Swin](model_doc/swin) トランスフォーマーです。Swin トランスフォーマーは、より小さなサイズのパッチから階層的な特徴マップ(CNNのようで ViT とは異なります)を構築し、深層のパッチと隣接するパッチとマージします。注意はローカルウィンドウ内でのみ計算され、ウィンドウは注意のレイヤー間でシフトされ、モデルがより良く学習するのをサポートする接続を作成します。Swin トランスフォーマーは階層的な特徴マップを生成できるため、セグメンテーションや検出などの密な予測タスクに適しています。[SegFormer](model_doc/segformer) も階層的な特徴マップを構築するためにトランスフォーマーエンコーダーを使用しますが、すべての特徴マップを組み合わせて予測するためにシンプルなマルチレイヤーパーセプトロン(MLP)デコーダーを追加します。
BeIT および ViTMAE などの他のビジョンモデルは、BERTの事前トレーニング目標からインスピレーションを得ました。[BeIT](model_doc/beit) は *masked image modeling (MIM)* によって事前トレーニングされています。画像パッチはランダムにマスクされ、画像も視覚トークンにトークン化されます。BeIT はマスクされたパッチに対応する視覚トークンを予測するようにトレーニングされます。[ViTMAE](model_doc/vitmae) も似たような事前トレーニング目標を持っており、視覚トークンの代わりにピクセルを予測する必要があります。異例なのは画像パッチの75%がマスクされていることです!デコーダーはマスクされたトークンとエンコードされたパッチからピクセルを再構築します。事前トレーニングの後、デコーダーは捨てられ、エンコーダーはダウンストリームのタスクで使用できる状態です。
### Decoder[[cv-decoder]]
デコーダーのみのビジョンモデルは珍しいです。なぜなら、ほとんどのビジョンモデルは画像表現を学ぶためにエンコーダーを使用するからです。しかし、画像生成などのユースケースでは、デコーダーは自然な適応です。これは、GPT-2などのテキスト生成モデルから見てきたように、[ImageGPT](model_doc/imagegpt) でも同様のアーキテクチャを使用しますが、シーケンス内の次のトークンを予測する代わりに、画像内の次のピクセルを予測します。画像生成に加えて、ImageGPT は画像分類のためにもファインチューニングできます。
### Encoder-decoder[[cv-encoder-decoder]]
ビジョンモデルは一般的にエンコーダー(バックボーンとも呼ばれます)を使用して重要な画像特徴を抽出し、それをトランスフォーマーデコーダーに渡すために使用します。[DETR](model_doc/detr) は事前トレーニング済みのバックボーンを持っていますが、オブジェクト検出のために完全なトランスフォーマーエンコーダーデコーダーアーキテクチャも使用しています。エンコーダーは画像表現を学び、デコーダー内のオブジェクトクエリ(各オブジェクトクエリは画像内の領域またはオブジェクトに焦点を当てた学習された埋め込みです)と組み合わせます。DETR は各オブジェクトクエリに対する境界ボックスの座標とクラスラベルを予測します。
## Natural lanaguage processing
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FUhbQAZDlpYW5XEpdFy6GoG%2Fnlp-model-timeline%3Fnode-id%3D0%253A1%26t%3D4mZMr4r1vDEYGJ50-1" allowfullscreen></iframe>
### Encoder[[nlp-encoder]]
[BERT](model_doc/bert) はエンコーダー専用のTransformerで、入力の一部のトークンをランダムにマスクして他のトークンを見ないようにしています。これにより、トークンをマスクした文脈に基づいてマスクされたトークンを予測することが事前トレーニングの目標です。これにより、BERTは入力のより深いかつ豊かな表現を学習するのに左右の文脈を完全に活用できます。しかし、BERTの事前トレーニング戦略にはまだ改善の余地がありました。[RoBERTa](model_doc/roberta) は、トレーニングを長時間行い、より大きなバッチでトレーニングし、事前処理中に一度だけでなく各エポックでトークンをランダムにマスクし、次文予測の目標を削除する新しい事前トレーニングレシピを導入することでこれを改善しました。
性能を向上させる主要な戦略はモデルのサイズを増やすことですが、大規模なモデルのトレーニングは計算コストがかかります。計算コストを削減する方法の1つは、[DistilBERT](model_doc/distilbert) のような小さなモデルを使用することです。DistilBERTは[知識蒸留](https://arxiv.org/abs/1503.02531) - 圧縮技術 - を使用して、BERTのほぼすべての言語理解機能を保持しながら、より小さなバージョンを作成します。
しかし、ほとんどのTransformerモデルは引き続きより多くのパラメータに焦点を当て、トレーニング効率を向上させる新しいモデルが登場しています。[ALBERT](model_doc/albert) は、2つの方法でパラメータの数を減らすことによってメモリ消費量を削減します。大きな語彙埋め込みを2つの小さな行列に分割し、レイヤーがパラメータを共有できるようにします。[DeBERTa](model_doc/deberta) は、単語とその位置を2つのベクトルで別々にエンコードする解かれた注意機構を追加しました。注意はこれらの別々のベクトルから計算されます。単語と位置の埋め込みが含まれる単一のベクトルではなく、[Longformer](model_doc/longformer) は、特に長いシーケンス長のドキュメントを処理するために注意をより効率的にすることに焦点を当てました。固定されたウィンドウサイズの周りの各トークンから計算されるローカルウィンドウ付き注意(特定のタスクトークン(分類のための `[CLS]` など)のみのためのグローバルな注意を含む)の組み合わせを使用して、完全な注意行列ではなく疎な注意行列を作成します。
### Decoder[[nlp-decoder]]
[GPT-2](model_doc/gpt2)は、シーケンス内の次の単語を予測するデコーダー専用のTransformerです。モデルは先を見ることができないようにトークンを右にマスクし、"のぞき見"を防ぎます。大量のテキストを事前トレーニングしたことにより、GPT-2はテキスト生成が非常に得意で、テキストが正確であることがあるにしても、時折正確ではないことがあります。しかし、GPT-2にはBERTの事前トレーニングからの双方向コンテキストが不足しており、特定のタスクには適していませんでした。[XLNET](model_doc/xlnet)は、双方向に学習できる順列言語モデリング目標(PLM)を使用することで、BERTとGPT-2の事前トレーニング目標のベストを組み合わせています。
GPT-2の後、言語モデルはさらに大きく成長し、今では*大規模言語モデル(LLM)*として知られています。大規模なデータセットで事前トレーニングされれば、LLMはほぼゼロショット学習を示すことがあります。[GPT-J](model_doc/gptj)は、6Bのパラメータを持つLLMで、400Bのトークンでトレーニングされています。GPT-Jには[OPT](model_doc/opt)が続き、そのうち最大のモデルは175Bで、180Bのトークンでトレーニングされています。同じ時期に[BLOOM](model_doc/bloom)がリリースされ、このファミリーの最大のモデルは176Bのパラメータを持ち、46の言語と13のプログラミング言語で366Bのトークンでトレーニングされています。
### Encoder-decoder[[nlp-encoder-decoder]]
[BART](model_doc/bart)は、元のTransformerアーキテクチャを保持していますが、事前トレーニング目標を*テキスト補完*の破損に変更しています。一部のテキストスパンは単一の`mask`トークンで置換されます。デコーダーは破損していないトークンを予測し(未来のトークンはマスクされます)、エンコーダーの隠れた状態を使用して予測を補助します。[Pegasus](model_doc/pegasus)はBARTに似ていますが、Pegasusはテキストスパンの代わりに文全体をマスクします。マスクされた言語モデリングに加えて、Pegasusはギャップ文生成(GSG)によって事前トレーニングされています。GSGの目標は、文書に重要な文をマスクし、それらを`mask`トークンで置換することです。デコーダーは残りの文から出力を生成しなければなりません。[T5](model_doc/t5)は、すべてのNLPタスクを特定のプレフィックスを使用してテキスト対テキストの問題に変換するよりユニークなモデルです。たとえば、プレフィックス`Summarize:`は要約タスクを示します。T5は教師ありトレーニング(GLUEとSuperGLUE)と自己教師ありトレーニング(トークンの15%をランダムにサンプルしドロップアウト)によって事前トレーニングされています。
## Audio
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2Fvrchl8jDV9YwNVPWu2W0kK%2Fspeech-and-audio-model-timeline%3Fnode-id%3D0%253A1%26t%3DmM4H8pPMuK23rClL-1" allowfullscreen></iframe>
### Encoder[[audio-encoder]]
[Wav2Vec2](model_doc/wav2vec2) は、生のオーディオ波形から直接音声表現を学習するためのTransformerエンコーダーを使用します。これは、対照的なタスクで事前学習され、一連の偽の表現から真の音声表現を特定します。 [HuBERT](model_doc/hubert) はWav2Vec2に似ていますが、異なるトレーニングプロセスを持っています。ターゲットラベルは、類似したオーディオセグメントがクラスタに割り当てられ、これが隠れユニットになるクラスタリングステップによって作成されます。隠れユニットは埋め込みにマップされ、予測を行います。
### Encoder-decoder[[audio-encoder-decoder]]
[Speech2Text](model_doc/speech_to_text) は、自動音声認識(ASR)および音声翻訳のために設計された音声モデルです。このモデルは、オーディオ波形から抽出されたログメルフィルターバンクフィーチャーを受け入れ、事前トレーニングされた自己回帰的にトランスクリプトまたは翻訳を生成します。 [Whisper](model_doc/whisper) もASRモデルですが、他の多くの音声モデルとは異なり、✨ ラベル付き ✨ オーディオトランスクリプションデータを大量に事前に学習して、ゼロショットパフォーマンスを実現します。データセットの大部分には非英語の言語も含まれており、Whisperは低リソース言語にも使用できます。構造的には、WhisperはSpeech2Textに似ています。オーディオ信号はエンコーダーによってエンコードされたログメルスペクトログラムに変換されます。デコーダーはエンコーダーの隠れ状態と前のトークンからトランスクリプトを自己回帰的に生成します。
## Multimodal
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FcX125FQHXJS2gxeICiY93p%2Fmultimodal%3Fnode-id%3D0%253A1%26t%3DhPQwdx3HFPWJWnVf-1" allowfullscreen></iframe>
### Encoder[[mm-encoder]]
[VisualBERT](model_doc/visual_bert) は、BERTの後にリリースされたビジョン言語タスク向けのマルチモーダルモデルです。これはBERTと事前トレーニングされた物体検出システムを組み合わせ、画像特徴をビジュアル埋め込みに抽出し、テキスト埋め込みと一緒にBERTに渡します。VisualBERTは非マスクテキストを基にしたマスクテキストを予測し、テキストが画像と整合しているかどうかも予測する必要があります。ViTがリリースされた際、[ViLT](model_doc/vilt) は画像埋め込みを取得するためにこの方法を採用しました。画像埋め込みはテキスト埋め込みと共に共同で処理されます。それから、ViLTは画像テキストマッチング、マスク言語モデリング、および全単語マスキングによる事前トレーニングが行われます。
[CLIP](model_doc/clip) は異なるアプローチを取り、(`画像`、`テキスト`) のペア予測を行います。画像エンコーダー(ViT)とテキストエンコーダー(Transformer)は、(`画像`、`テキスト`) ペアデータセット上で共同トレーニングされ、(`画像`、`テキスト`) ペアの画像とテキストの埋め込みの類似性を最大化します。事前トレーニング後、CLIPを使用して画像からテキストを予測したり、その逆を行うことができます。[OWL-ViT](model_doc/owlvit) は、ゼロショット物体検出のバックボーンとしてCLIPを使用しています。事前トレーニング後、物体検出ヘッドが追加され、(`クラス`、`バウンディングボックス`) ペアに対するセット予測が行われます。
### Encoder-decoder[[mm-encoder-decoder]]
光学文字認識(OCR)は、通常、画像を理解しテキストを生成するために複数のコンポーネントが関与するテキスト認識タスクです。 [TrOCR](model_doc/trocr) は、エンドツーエンドのTransformerを使用してこのプロセスを簡略化します。エンコーダーは画像を固定サイズのパッチとして処理するためのViTスタイルのモデルであり、デコーダーはエンコーダーの隠れ状態を受け入れ、テキストを自己回帰的に生成します。[Donut](model_doc/donut) はOCRベースのアプローチに依存しないより一般的なビジュアルドキュメント理解モデルで、エンコーダーとしてSwin Transformer、デコーダーとして多言語BARTを使用します。 Donutは画像とテキストの注釈に基づいて次の単語を予測することにより、テキストを読むために事前トレーニングされます。デコーダーはプロンプトを与えられたトークンシーケンスを生成します。プロンプトは各ダウンストリームタスクごとに特別なトークンを使用して表現されます。例えば、ドキュメントの解析には`解析`トークンがあり、エンコーダーの隠れ状態と組み合わされてドキュメントを構造化された出力フォーマット(JSON)に解析します。
## Reinforcement learning
<iframe style="border: 1px solid rgba(0, 0, 0, 0.1);" width="1000" height="450" src="https://www.figma.com/embed?embed_host=share&url=https%3A%2F%2Fwww.figma.com%2Ffile%2FiB3Y6RvWYki7ZuKO6tNgZq%2Freinforcement-learning%3Fnode-id%3D0%253A1%26t%3DhPQwdx3HFPWJWnVf-1" allowfullscreen></iframe>
### Decoder[[rl-decoder]]
意思決定と軌跡トランスフォーマーは、状態、アクション、報酬をシーケンスモデリングの問題として捉えます。 [Decision Transformer](model_doc/decision_transformer) は、リターン・トゥ・ゴー、過去の状態、およびアクションに基づいて将来の希望リターンにつながるアクションの系列を生成します。最後の *K* タイムステップでは、3つのモダリティそれぞれがトークン埋め込みに変換され、将来のアクショントークンを予測するためにGPTのようなモデルによって処理されます。[Trajectory Transformer](model_doc/trajectory_transformer) も状態、アクション、報酬をトークン化し、GPTアーキテクチャで処理します。報酬調整に焦点を当てたDecision Transformerとは異なり、Trajectory Transformerはビームサーチを使用して将来のアクションを生成します。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/attention.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdown形式ですが、ドキュメンテーションビルダー用の特定の構文を含んでおり、Markdownビューアーでは正しく表示されないことに注意してください。
-->
# Attention mechanism
ほとんどのTransformerモデルは、アテンション行列が正方形であるという意味で完全なアテンションを使用します。
これは、長いテキストを扱う場合に計算のボトルネックとなることがあります。LongformerやReformerは、より効率的でトレーニングを高速化するためにアテンション行列のスパースバージョンを使用しようとするモデルです。
## LSH attention
[Reformer](#reformer)はLSH(局所的に散在ハッシュ)アテンションを使用します。
ソフトマックス(QK^t)では、行列QK^tの中で(ソフトマックス次元で)最も大きな要素のみが有用な寄与を提供します。
したがって、各クエリqについて、クエリqに近いキーkのみを考慮できます。
qとkが近いかどうかを決定するために、ハッシュ関数が使用されます。
アテンションマスクは変更され、現在のトークンをマスク化します(最初の位置を除く)。
なぜなら、それはクエリとキーが等しい(つまり非常に似ている)クエリとキーを提供するからです。
ハッシュは多少ランダムかもしれないため、実際にはいくつかのハッシュ関数が使用され(n_roundsパラメータで決定されます)、それらが平均化されます。
## Local attention
[Longformer](#longformer)はローカルアテンションを使用します。
しばしば、ローカルコンテキスト(例:左右の2つのトークンは何ですか?)は、特定のトークンに対して行動を起こすのに十分です。
また、小さなウィンドウを持つアテンションレイヤーを積み重ねることで、最後のレイヤーはウィンドウ内のトークンだけでなく、ウィンドウ内のトークンを超えて受容野を持つようになり、文全体の表現を構築できます。
一部の事前選択された入力トークンにはグローバルアテンションも与えられます。
これらの少数のトークンに対して、アテンション行列はすべてのトークンにアクセスでき、このプロセスは対称的です。
他のすべてのトークンは、これらの特定のトークンにアクセスできます(ローカルウィンドウ内のトークンに加えて)。
これは、論文の図2dに示されており、以下はサンプルのアテンションマスクです:
<div class="flex justify-center">
<img scale="50 %" align="center" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png"/>
</div>
## Other tricks
### Axial positional encodings
[Reformer](#reformer)は軸方向の位置エンコーディングを使用しています。伝統的なトランスフォーマーモデルでは、位置エンコーディングEはサイズが \\(l\\) × \\(d\\) の行列で、\\(l\\) はシーケンスの長さ、\\(d\\) は隠れ状態の次元です。非常に長いテキストを扱う場合、この行列は非常に大きく、GPU上で大量のスペースを占有します。これを緩和するために、軸方向の位置エンコーディングは、この大きな行列Eを2つの小さな行列E1とE2に分解します。それぞれの行列はサイズ \\(l_{1} \times d_{1}\\) および \\(l_{2} \times d_{2}\\) を持ち、 \\(l_{1} \times l_{2} = l\\) および \\(d_{1} + d_{2} = d\\) という条件を満たします(長さの積を考えると、これがはるかに小さくなります)。行列E内の時刻 \\(j\\) の埋め込みは、E1内の時刻 \\(j \% l1\\) の埋め込みとE2内の時刻 \\(j // l1\\) の埋め込みを連結することによって得られます。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/bertology.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERTology
大規模なトランスフォーマー、例えばBERTの内部動作を調査する研究領域が急成長しています(これを「BERTology」とも呼びます)。この分野の良い例は以下です:
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
[論文リンク](https://arxiv.org/abs/1905.05950)
- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: [論文リンク](https://arxiv.org/abs/1905.10650)
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning: [論文リンク](https://arxiv.org/abs/1906.04341)
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: [論文リンク](https://arxiv.org/abs/2210.04633)
この新しい分野の発展を支援するために、BERT/GPT/GPT-2モデルにいくつかの追加機能を組み込み、人々が内部表現にアクセスできるようにしました。これらの機能は、主にPaul Michel氏の優れた研究([論文リンク](https://arxiv.org/abs/1905.10650))に基づいています。具体的には、以下の機能が含まれています:
- BERT/GPT/GPT-2のすべての隠れ状態にアクセスすることができます。
- BERT/GPT/GPT-2の各ヘッドの注意重みにアクセスできます。
- ヘッドの出力値と勾配を取得し、ヘッドの重要性スコアを計算し、[論文リンク](https://arxiv.org/abs/1905.10650)で説明されているようにヘッドを削減できます。
これらの機能を理解し、使用するのを支援するために、特定のサンプルスクリプト「[bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py)」を追加しました。このスクリプトは、GLUEで事前トレーニングされたモデルから情報を抽出し、ヘッドを削減する役割を果たします。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perplexity.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Perplexity of fixed-length models
[[open-in-colab]]
パープレキシティ(PPL)は言語モデルの評価に最も一般的な指標の1つです。深入りする前に、この指標は特に古典的な言語モデル(時にはオートレグレッシブまたは因果言語モデルとも呼ばれる)に適用され、BERTなどのマスクされた言語モデルには適していないことに注意すべきです(モデルの概要を参照してください[モデルの概要](model_summary))。
パープレキシティは、シーケンスの指数平均負の対数尤度として定義されます。トークン化されたシーケンス \\(X = (x_0, x_1, \dots, x_t)\\) がある場合、\\(X\\) のパープレキシティは次のように表されます。
$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{<i}) } \right\}$$
ここで、\\(\log p_\theta (x_i|x_{<i})\\) はモデルによる前のトークン \\(x_{<i}\\) に対する第iトークンの対数尤度です。直感的には、これはモデルがコーパス内の指定されたトークンの集合に対して一様に予測する能力の評価と考えることができます。重要なのは、これによってトークン化手法がモデルのパープレキシティに直接影響を与えるため、異なるモデルを比較する際には常に考慮すべきであるということです。
これはまた、データとモデルの予測との間の交差エントロピーの指数化と同等です。パープレキシティおよびビット・パー・キャラクター(BPC)とデータ圧縮との関係についての詳細な情報については、この[素晴らしい The Gradient のブログ記事](https://thegradient.pub/understanding-evaluation-metrics-for-language-models/)を参照してください。
## Calculating PPL with fixed-length models
モデルのコンテキストサイズに制約がない場合、モデルのパープレキシティを評価するためには、シーケンスを自己回帰的に因子分解し、各ステップで前のサブシーケンスに条件を付けることで計算します。以下に示すように。
<img width="600" alt="完全なコンテキスト長のシーケンスの分解" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_full.gif"/>
しかし、通常、近似モデルを使用する場合、モデルが処理できるトークン数に制約があります。例えば、最大の[GPT-2](model_doc/gpt2)のバージョンは1024トークンの固定長を持っているため、1024よりも大きい \\(t\\) に対して \\(p_\theta(x_t|x_{<t})\\) を直接計算することはできません。
代わりに、通常、シーケンスはモデルの最大入力サイズに等しいサブシーケンスに分割されます。モデルの最大入力サイズが \\(k\\) の場合、トークン \\(x_t\\) の尤度を近似するには、完全なコンテキストではなく、それを先行する \\(k-1\\) トークンにのみ条件を付けることがあります。シーケンスのモデルのパープレキシティを評価する際、誘惑的ですが非効率な方法は、シーケンスを分割し、各セグメントの分解対数尤度を独立に合算することです。
<img width="600" alt="利用可能な完全なコンテキストを活用しない非最適なPPL" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_chunked.gif"/>
これは各セグメントのパープレキシティが1回のフォワードパスで計算できるため、計算が迅速ですが、通常、モデルはほとんどの予測ステップでコンテキストが少ないため、完全に因子分解されたパープレキシティの悪い近似となり、通常、より高い(悪い)PPLを返します。
代わりに、固定長モデルのPPLはスライディングウィンドウ戦略を用いて評価するべきです。これには、モデルが各予測ステップでより多くのコンテキストを持つように、コンテキストウィンドウを繰り返しスライドさせるという方法が含まれます。
<img width="600" alt="Sliding window PPL taking advantage of all available context" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/ppl_sliding.gif"/>
これはシーケンスの確率のより正確な分解に近いものであり、通常はより有利なスコアを生成します。欠点は、コーパス内の各トークンに対して別個の前方パスが必要です。実用的な妥協案は、1トークンずつスライドする代わりに、より大きなストライドでコンテキストを移動するストライド型のスライディングウィンドウを使用することです。これにより、計算がはるかに高速に進行できる一方で、モデルには各ステップで予測を行うための大きなコンテキストが提供されます。
## Example: Calculating perplexity with GPT-2 in 🤗 Transformers
GPT-2を使用してこのプロセスをデモンストレーションしてみましょう。
```python
from transformers import GPT2LMHeadModel, GPT2TokenizerFast
device = "cuda"
model_id = "gpt2-large"
model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
```
WikiText-2データセットを読み込み、異なるスライディングウィンドウ戦略を使用してパープレキシティを評価します。このデータセットは小規模で、セット全体に対して単一のフォワードパスを実行するだけなので、データセット全体をメモリに読み込んでエンコードするだけで十分です。
```python
from datasets import load_dataset
test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
```
🤗 Transformersを使用すると、単純に`input_ids`をモデルの`labels`として渡すことで、各トークンの平均負の対数尤度が損失として返されます。しかし、スライディングウィンドウのアプローチでは、各イテレーションでモデルに渡すトークンにオーバーラップがあります。私たちは、コンテキストとして扱っているトークンの対数尤度を損失に含めたくありません。そのため、これらの対象を `-100` に設定して無視されるようにします。以下は、ストライドを `512` とした場合の例です。これにより、モデルは任意のトークンの条件付けの尤度を計算する際に、少なくともコンテキストとして 512 トークンを持つことになります(512 個の前のトークンが利用可能である場合)。
```python
import torch
from tqdm import tqdm
max_length = model.config.n_positions
stride = 512
seq_len = encodings.input_ids.size(1)
nlls = []
prev_end_loc = 0
for begin_loc in tqdm(range(0, seq_len, stride)):
end_loc = min(begin_loc + max_length, seq_len)
trg_len = end_loc - prev_end_loc # may be different from stride on last loop
input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
target_ids = input_ids.clone()
target_ids[:, :-trg_len] = -100
with torch.no_grad():
outputs = model(input_ids, labels=target_ids)
# loss is calculated using CrossEntropyLoss which averages over valid labels
# N.B. the model only calculates loss over trg_len - 1 labels, because it internally shifts the labels
# to the left by 1.
neg_log_likelihood = outputs.loss
nlls.append(neg_log_likelihood)
prev_end_loc = end_loc
if end_loc == seq_len:
break
ppl = torch.exp(torch.stack(nlls).mean())
```
ストライド長が最大入力長と同じ場合、上述の最適でないスライディングウィンドウ戦略と同等です。ストライドが小さいほど、モデルは各予測を行う際により多くのコンテキストを持つため、通常、報告される困難度(perplexity)が向上します。
上記のコードを `stride = 1024` で実行すると、オーバーラップがない状態で、結果の困難度(perplexity)は `19.44` になります。これは GPT-2 の論文に報告された `19.93` とほぼ同等です。一方、`stride = 512` を使用し、このようにストライディングウィンドウ戦略を採用すると、困難度(perplexity)が `16.45` に向上します。これはより好意的なスコアだけでなく、シーケンスの尤度の真の自己回帰分解により近い方法で計算されています。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/serialization.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to ONNX
🤗 Transformersモデルを本番環境に展開する際には、モデルを特殊なランタイムおよびハードウェアで読み込み、実行できるように、モデルをシリアライズされた形式にエクスポートすることが必要であるか、その恩恵を受けることができることがあります。
🤗 Optimumは、Transformersの拡張機能であり、PyTorchまたはTensorFlowからモデルをONNXやTFLiteなどのシリアライズされた形式にエクスポートすることを可能にする「exporters」モジュールを提供しています。また、🤗 Optimumは、最大の効率でターゲットハードウェアでモデルをトレーニングおよび実行するためのパフォーマンス最適化ツールも提供しています。
このガイドでは、🤗 Transformersモデルを🤗 Optimumを使用してONNXにエクスポートする方法を示しており、モデルをTFLiteにエクスポートする方法については[Export to TFLiteページ](tflite)を参照してください。
## Export to ONNX
[ONNX(Open Neural Network eXchange)](http://onnx.ai)は、PyTorchおよびTensorFlowを含むさまざまなフレームワークで深層学習モデルを表現するための共通の一連の演算子とファイル形式を定義するオープンスタンダードです。モデルがONNX形式にエクスポートされると、これらの演算子はニューラルネットワークを介するデータの流れを表す計算グラフ(一般的には「中間表現」と呼ばれる)を構築するために使用されます。
標準化された演算子とデータ型を備えたグラフを公開することで、ONNXはフレームワーク間の切り替えを容易にします。たとえば、PyTorchでトレーニングされたモデルはONNX形式にエクスポートし、それをTensorFlowでインポートすることができます(逆も同様です)。
ONNX形式にエクスポートされたモデルは、以下のように使用できます:
- [グラフ最適化](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization)や[量子化](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization)などのテクニックを使用して推論のために最適化。
- [`ORTModelForXXX`クラス](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort)を介してONNX Runtimeで実行し、🤗 Transformersでおなじみの`AutoModel` APIに従います。
- [最適化された推論パイプライン](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines)を介して実行し、🤗 Transformersの[`pipeline`]関数と同じAPIを持っています。
🤗 Optimumは、設定オブジェクトを活用してONNXエクスポートをサポートしており、これらの設定オブジェクトは多くのモデルアーキテクチャ用に事前に作成されており、他のアーキテクチャにも簡単に拡張できるように設計されています。
事前に作成された設定のリストについては、[🤗 Optimumドキュメント](https://huggingface.co/docs/optimum/exporters/onnx/overview)を参照してください。
🤗 TransformersモデルをONNXにエクスポートする方法は2つあります。以下では両方の方法を示します:
- export with 🤗 Optimum via CLI.
- export with 🤗 Optimum with `optimum.onnxruntime`.
### Exporting a 🤗 Transformers model to ONNX with CLI
🤗 TransformersモデルをONNXにエクスポートするには、まず追加の依存関係をインストールしてください:
```bash
pip install optimum[exporters]
```
すべての利用可能な引数を確認するには、[🤗 Optimumドキュメント](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli)を参照してください。または、コマンドラインでヘルプを表示することもできます:
```bash
optimum-cli export onnx --help
```
🤗 Hubからモデルのチェックポイントをエクスポートするには、例えば `distilbert-base-uncased-distilled-squad` を使いたい場合、以下のコマンドを実行してください:
```bash
optimum-cli export onnx --model distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
```
進行状況を示し、結果の `model.onnx` が保存される場所を表示するログは、以下のように表示されるはずです:
```bash
Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
-[✓] ONNX model output names match reference model (start_logits, end_logits)
- Validating ONNX Model output "start_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "end_logits":
-[✓] (2, 16) matches (2, 16)
-[✓] all values close (atol: 0.0001)
The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
```
上記の例は🤗 Hubからのチェックポイントのエクスポートを示しています。ローカルモデルをエクスポートする場合、まずモデルの重みとトークナイザのファイルを同じディレクトリ(`local_path`)に保存してください。CLIを使用する場合、🤗 Hubのチェックポイント名の代わりに`model`引数に`local_path`を渡し、`--task`引数を指定してください。[🤗 Optimumドキュメント](https://huggingface.co/docs/optimum/exporters/task_manager)でサポートされているタスクのリストを確認できます。`task`引数が指定されていない場合、タスク固有のヘッドを持たないモデルアーキテクチャがデフォルトで選択されます。
```bash
optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
```
エクスポートされた `model.onnx` ファイルは、ONNX標準をサポートする[多くのアクセラレータ](https://onnx.ai/supported-tools.html#deployModel)の1つで実行できます。たとえば、[ONNX Runtime](https://onnxruntime.ai/)を使用してモデルを読み込み、実行する方法は以下の通りです:
```python
>>> from transformers import AutoTokenizer
>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
>>> outputs = model(**inputs)
```
🤗 HubからTensorFlowのチェックポイントをエクスポートするプロセスは、同様です。例えば、[Keras organization](https://huggingface.co/keras-io)から純粋なTensorFlowのチェックポイントをエクスポートする方法は以下の通りです:
```bash
optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
```
### Exporting a 🤗 Transformers model to ONNX with `optimum.onnxruntime`
CLIの代わりに、🤗 TransformersモデルをONNXにプログラム的にエクスポートすることもできます。以下のように行います:
```python
>>> from optimum.onnxruntime import ORTModelForSequenceClassification
>>> from transformers import AutoTokenizer
>>> model_checkpoint = "distilbert_base_uncased_squad"
>>> save_directory = "onnx/"
>>> # Load a model from transformers and export it to ONNX
>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
>>> # Save the onnx model and tokenizer
>>> ort_model.save_pretrained(save_directory)
>>> tokenizer.save_pretrained(save_directory)
```
### Exporting a model for an unsupported architecture
現在エクスポートできないモデルをサポートするために貢献したい場合、まず[`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview)でサポートされているかどうかを確認し、サポートされていない場合は[🤗 Optimumに貢献](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)してください。
### Exporting a model with `transformers.onnx`
<Tip warning={true}>
`transformers.onnx`はもはやメンテナンスされていないため、モデルを上記で説明したように🤗 Optimumでエクスポートしてください。このセクションは将来のバージョンで削除されます。
</Tip>
🤗 TransformersモデルをONNXにエクスポートするには、追加の依存関係をインストールしてください:
```bash
pip install transformers[onnx]
```
`transformers.onnx`パッケージをPythonモジュールとして使用して、事前に用意された設定を使用してチェックポイントをエクスポートする方法は以下の通りです:
```bash
python -m transformers.onnx --model=distilbert-base-uncased onnx/
```
この方法は、`--model`引数で定義されたチェックポイントのONNXグラフをエクスポートします。🤗 Hubのいずれかのチェックポイントまたはローカルに保存されたチェックポイントを渡すことができます。エクスポートされた`model.onnx`ファイルは、ONNX標準をサポートする多くのアクセラレータで実行できます。例えば、ONNX Runtimeを使用してモデルを読み込んで実行する方法は以下の通りです:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
必要な出力名(例: `["last_hidden_state"]`)は、各モデルのONNX構成を確認することで取得できます。例えば、DistilBERTの場合、次のようになります:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
ハブから純粋なTensorFlowのチェックポイントをプログラム的にエクスポートするプロセスは、以下のように同様です:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
ローカルに保存されたモデルをエクスポートする場合、モデルの重みとトークナイザのファイルを同じディレクトリに保存してください(例: `local-pt-checkpoint`)。その後、`transformers.onnx`パッケージの `--model`引数を希望するディレクトリに向けて設定して、ONNXにエクスポートします:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_gpu_one.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Methods and tools for efficient training on a single GPU
このガイドでは、メモリの利用効率を最適化し、トレーニングを高速化することで、モデルのトレーニング効率を向上させるために使用できる実用的なテクニックを紹介します。トレーニング中にGPUがどのように利用されるかを理解したい場合は、最初に「[モデルトレーニングの解剖学](model_memory_anatomy)」のコンセプトガイドを参照してください。このガイドは実用的なテクニックに焦点を当てています。
<Tip>
複数のGPUを搭載したマシンにアクセスできる場合、これらのアプローチは依然として有効です。さらに、[マルチGPUセクション](perf_train_gpu_many)で説明されている追加の方法を活用できます。
</Tip>
大規模なモデルをトレーニングする際、同時に考慮すべき2つの側面があります:
* データのスループット/トレーニング時間
* モデルのパフォーマンス
スループット(サンプル/秒)を最大化することは、トレーニングコストを低減させます。これは一般的に、GPUをできるだけ効果的に活用し、GPUメモリを限界まで埋めることによって達成されます。希望するバッチサイズがGPUメモリの制限を超える場合、勾配蓄積などのメモリ最適化テクニックが役立ちます。
しかし、好みのバッチサイズがメモリに収まる場合、メモリを最適化するテクニックを適用する理由はありません。大きなバッチサイズを使用できるからといって、それを必ずしも使用すべきではありません。ハイパーパラメータの調整の一環として、どのバッチサイズが最良の結果を生み出すかを決定し、リソースを適切に最適化する必要があります。
このガイドでカバーされている方法とツールは、トレーニングプロセスに与える影響に基づいて分類できます:
| Method/tool | Improves training speed | Optimizes memory utilization |
|:-----------------------------------------------------------|:------------------------|:-----------------------------|
| [Batch size choice](#batch-size-choice) | Yes | Yes |
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
| [Mixed precision training](#mixed-precision-training) | Yes | (No) |
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
| [Data preloading](#data-preloading) | Yes | No |
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
| [torch.compile](#using-torchcompile) | Yes | No |
<Tip>
**注意**: 小さなモデルと大きなバッチサイズを使用する場合、メモリの節約が行われますが、大きなモデルと小さなバッチサイズを使用する場合、メモリの使用量が増加します。
</Tip>
これらのテクニックは、[`Trainer`]でモデルをトレーニングしている場合や、純粋なPyTorchループを記述している場合の両方で利用できます。詳細な最適化の設定については、🤗 Accelerateを使用して[これらの最適化を設定できます](#using-accelerate)。
これらの方法が十分な利益をもたらさない場合、以下のオプションを検討できます:
* [効率的なソフトウェアプリビルドを備えたカスタムDockerコンテナの作成](#efficient-software-prebuilds)
* [Mixture of Experts(MoE)を使用するモデルを検討](#mixture-of-experts)
* [モデルをBetterTransformerに変換して、PyTorchネイティブのアテンションを活用](#using-pytorch-native-attention)
最後に、これらの方法がまだ十分でない場合、A100などのサーバーグレードGPUに切り替えても、さらなる改善が必要かもしれません。これらのアプローチは、マルチGPUセットアップでも有効であり、[マルチGPUセクション](perf_train_gpu_many)で説明されている追加の並列化技術を活用できます。
## Batch size choice
最適なパフォーマンスを実現するために、適切なバッチサイズを特定することから始めましょう。2^Nのサイズのバッチサイズと入力/出力ニューロン数を使用することが推奨されています。通常、これは8の倍数ですが、使用するハードウェアとモデルのデータ型に依存することがあります。
参考までに、NVIDIAの[入力/出力ニューロン数の推奨事項](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features)と[バッチサイズ](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size)を確認してください(これらはGEMM(一般的な行列乗算)に関与します)。
[Tensor Core要件](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)では、データ型とハードウェアに基づいて乗数が定義されています。たとえば、fp16データ型の場合、64の倍数を使用することが推奨されます(A100 GPUの場合を除く)。
小さなパラメータの場合、[次元量子化効果](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization)も考慮してください。これはタイリングが行われ、適切な乗数が大幅な高速化をもたらす場合があります。
## Gradient Accumulation
**勾配蓄積**メソッドは、GPUのメモリ容量の制約によって課せられる制限を超えた効果的なバッチサイズを実現するために、勾配を小さな増分で計算することを目的としています。このアプローチでは、モデルを順方向および逆方向に小さなバッチで反復的に計算し、その過程で勾配を蓄積します。十分な数の勾配が蓄積されたら、モデルの最適化ステップを実行します。勾配蓄積を使用することで、GPUのメモリ容量による制約を超えて**効果的なバッチサイズ**を増やすことができますが、勾配蓄積によって導入される追加の順方向および逆方向の計算はトレーニングプロセスを遅くする可能性があることに注意が必要です。
`TrainingArguments`に`gradient_accumulation_steps`引数を追加することで、勾配蓄積を有効にすることができます:
```py
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
```
上記の例では、効果的なバッチサイズは4になります。
また、トレーニングループを完全に制御するために🤗 Accelerateを使用することもできます。🤗 Accelerateの例は、[このガイドの後半にある](#using-accelerate)で見つけることができます。
できるだけGPUの使用率を最大限にすることが推奨されていますが、高い勾配蓄積ステップ数はトレーニングの遅延をより顕著にすることがあります。以下の例を考えてみましょう。`per_device_train_batch_size=4`の場合、勾配蓄積を使用しないとGPUの制限に達します。バッチサイズ64でトレーニングしたい場合、`per_device_train_batch_size`を1に設定し、`gradient_accumulation_steps`を64に設定しないでください。代わりに、`per_device_train_batch_size=4`を保持し、`gradient_accumulation_steps=16`を設定します。これにより、同じ効果的なバッチサイズが得られ、利用可能なGPUリソースが効果的に活用されます。
詳細な情報については、[RTX-3090用のバッチサイズと勾配蓄積のベンチマーク](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)および[A100用のバッチサイズと勾配蓄積のベンチマーク](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957)を参照してください。
## Gradient Checkpointing
一部の大きなモデルは、バッチサイズを1に設定し、勾配蓄積を使用している場合でもメモリの問題に直面することがあります。これは、メモリストレージが必要な他のコンポーネントも存在するためです。
前向きパスからのすべてのアクティベーションを保存して、逆向きパスで勾配を計算すると、かなりのメモリオーバーヘッドが発生します。逆向きパスで必要なときにアクティベーションを破棄して再計算する代替アプローチは、計算オーバーヘッドが大幅に増加し、トレーニングプロセスが遅くなります。
**勾配チェックポイント**は、これらの2つのアプローチの折衷案を提供し、計算グラフ全体で戦略的に選択されたアクティベーションのみを保存するため、勾配を再計算する必要があるアクティベーションの一部だけを節約します。勾配チェックポイントの詳細については、[この素晴らしい記事](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9)を参照してください。
[`Trainer`]で勾配チェックポイントを有効にするには、[`TrainingArguments`]に対応するフラグを渡します:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
```
代替手段として、🤗 Accelerateを使用することもできます - 🤗 Accelerateの例は[このガイドのさらに後ろにあります](#using-accelerate)。
<Tip>
勾配チェックポイントを使用することでメモリ効率が向上する場合がありますが、トレーニング速度は約20%遅くなることに注意してください。
</Tip>
## Mixed precision training
**混合精度トレーニング**は、モデルのトレーニングの計算効率を最適化する技術で、特定の変数に対して低精度の数値フォーマットを利用します。従来、ほとんどのモデルは変数を表現し処理するために32ビット浮動小数点精度(fp32またはfloat32)を使用しています。しかし、すべての変数が正確な結果を得るためにこの高精度のレベルを必要としない場合があります。一部の変数の精度を16ビット浮動小数点(fp16またはfloat16)などのより低い数値フォーマットに変更することで、計算を高速化できます。このアプローチでは、一部の計算は半精度で行われ、一部はまだ完全な精度で行われるため、このアプローチは混合精度トレーニングと呼ばれています。
最も一般的に混合精度トレーニングは、fp16(float16)データ型を使用して実現されますが、一部のGPUアーキテクチャ(アンペアアーキテクチャなど)ではbf16およびtf32(CUDA内部データ型)データ型も提供されています。これらのデータ型の違いについて詳しく知りたい場合は、[NVIDIAのブログ](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/)を確認してください。
### fp16
混合精度トレーニングの主な利点は、半精度(fp16)でアクティベーションを保存することから得られます。
勾配も半精度で計算されますが、最適化ステップでは再び完全精度に変換されるため、ここではメモリは保存されません。
混合精度トレーニングは計算速度を向上させる一方、特に小さなバッチサイズの場合、より多くのGPUメモリを使用することがあります。
これは、モデルがGPU上に16ビットおよび32ビット精度の両方で存在するためです(GPU上の元のモデルの1.5倍)。
混合精度トレーニングを有効にするには、`fp16`フラグを`True`に設定します:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
```
🤗 Accelerateを使用する場合、🤗 Accelerateの例は[このガイドのさらに後ろにあります](#using-accelerate)。
### BF16
Ampereまたはそれ以降のハードウェアにアクセスできる場合、混合精度トレーニングと評価にbf16を使用できます。bf16はfp16よりも精度が劣りますが、はるかに大きな動的範囲を持っています。fp16では、持つことができる最大の数は `65535` であり、それを超える数値はオーバーフローを引き起こします。一方、bf16の数値は `3.39e+38` のように大きく、これはfp32とほぼ同じです - どちらも数値範囲に8ビットを使用しているためです。
BF16を有効にするには、🤗 Trainerで以下のように設定します:
```python
training_args = TrainingArguments(bf16=True, **default_args)
```
### TF32
アンペアハードウェアは、tf32という特別なデータ型を使用します。これは、fp32と同じ数値範囲(8ビット)を持っていますが、23ビットの精度ではなく、10ビットの精度(fp16と同じ)を持ち、合計で19ビットしか使用しません。これは通常のfp32トレーニングおよび推論コードを使用し、tf32サポートを有効にすることで、最大3倍のスループットの向上が得られる点で「魔法のよう」です。行う必要があるのは、次のコードを追加するだけです:
```
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
```
使用されているGPUがアンペアシリーズであると仮定し、CUDAは可能な限りtf32を使用するように自動的に切り替えます。
[NVIDIAの研究によれば](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/)、ほとんどの機械学習トレーニングワークロードはtf32トレーニングとfp32トレーニングで同じ難解度と収束を示します。すでにfp16またはbf16混合精度を使用している場合、スループットの向上に役立つこともあります。
🤗 Trainerでこのモードを有効にすることができます:
```python
TrainingArguments(tf32=True, **default_args)
```
<Tip>
tf32は`tensor.to(dtype=torch.tf32)`を介して直接アクセスできません。これは内部のCUDAデータ型です。tf32データ型を使用するには、`torch>=1.7`が必要です。
</Tip>
tf32と他の精度に関する詳細な情報については、以下のベンチマークを参照してください:
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803)および
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189)。
## Flash Attention 2
transformersでFlash Attention 2統合を使用することで、トレーニングのスループットを向上させることができます。Flash Attention 2モジュールを含むモデルの読み込み方法については、[single GPU section](./perf_infer_gpu_one#Flash-Attention-2)の適切なセクションを確認して詳細を学びましょう。
## オプティマイザの選択
Transformerモデルをトレーニングするために最も一般的に使用されるオプティマイザはAdamまたはAdamW(重み減衰を伴うAdam)です。Adamは前回の勾配の移動平均を保存することで収束を達成しますが、モデルパラメータの数のオーダーの追加メモリフットプリントを追加します。これを解消するために、代替オプティマイザを使用できます。たとえば、[NVIDIA/apex](https://github.com/NVIDIA/apex)がインストールされている場合、`adamw_apex_fused`はすべてのサポートされているAdamWオプティマイザの中で最も高速なトレーニング体験を提供します。
[`Trainer`]は、直接使用できるさまざまなオプティマイザを統合しており、`adamw_hf`、`adamw_torch`、`adamw_torch_fused`、`adamw_apex_fused`、`adamw_anyprecision`、`adafactor`、または`adamw_bnb_8bit`が含まれています。サードパーティの実装を介してさらに多くのオプティマイザを追加できます。
AdamWオプティマイザの代替手段について詳しく見てみましょう:
1. [`Trainer`]で使用可能な`adafactor`
2. Trainerで使用可能な`adamw_bnb_8bit`は、デモンストレーション用に以下でサードパーティの統合が提供されています。
比較のため、3Bパラメータモデル(例:「t5-3b」)の場合:
* 標準のAdamWオプティマイザは、各パラメータに8バイトを使用するため、24GBのGPUメモリが必要です(8 * 3 => 24GB)。
* Adafactorオプティマイザは12GB以上必要です。各パラメータにわずか4バイト以上を使用するため、4 * 3と少し余分になります。
* 8ビットのBNB量子化オプティマイザは、すべてのオプティマイザの状態が量子化されている場合、わずか6GBしか使用しません。
### Adafactor
Adafactorは、重み行列の各要素のために前回の平均を保存しません。代わりに、(行ごとと列ごとの平均の合計など)集
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
```
他のアプローチ(勾配蓄積、勾配チェックポイント、混合精度トレーニング)と組み合わせることで、スループットを維持しながら最大3倍の向上が見られることがあります!ただし、前述のように、Adafactorの収束性はAdamよりも悪いことがあります。
### 8ビット Adam
Adafactorのようにオプティマイザの状態を集約する代わりに、8ビットのAdamは完全な状態を保持し、それを量子化します。量子化とは、状態を低い精度で保存し、最適化のためだけに非量子化することを意味します。これは混合精度トレーニングの背後にあるアイデアと似ています。
`adamw_bnb_8bit`を使用するには、単に[`TrainingArguments`]で`optim="adamw_bnb_8bit"`を設定するだけです:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
```
ただし、デモンストレーション目的で8ビットオプティマイザをサードパーティの実装を使用することもできます。これを統合する方法を確認するためです。
まず、8ビットAdamオプティマイザを実装した`bitsandbytes`ライブラリをインストールするために、GitHub [リポジトリ](https://github.com/TimDettmers/bitsandbytes)内のインストールガイドに従ってください。
次に、オプティマイザを初期化する必要があります。これには2つのステップが含まれます:
* まず、モデルのパラメータを2つのグループに分けます - 重み減衰を適用するべきグループと、適用すべきでないグループです。通常、バイアスとレイヤー正規化パラメータは重み減衰されません。
* 次に、以前に使用したAdamWオプティマイザと同じパラメータを使用するために、いくつかの引数の調整を行います。
```py
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
```
最後に、カスタムオプティマイザを`Trainer`に引数として渡します:
```py
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
```
他のアプローチ(勾配蓄積、勾配チェックポイント、混合精度トレーニング)と組み合わせることで、Adafactorの使用と同等以上の3倍のメモリ改善およびわずかに高いスループットを期待できます。
### multi_tensor
pytorch-nightlyは、多くの小さな特徴テンソルがある状況のオプティマイザを大幅に高速化するはずの`torch.optim._multi_tensor`を導入しました。これは最終的にはデフォルトになるはずですが、それを早く試してみたい場合は、このGitHub [issue](https://github.com/huggingface/transformers/issues/9965)をご覧ください。
## データの事前読み込み
優れたトレーニング速度に到達するための重要な要件の1つは、GPUが処理できる最大速度でデータを供給できる能力です。デフォルトではすべてがメインプロセスで行われ、データをディスクから十分速く読み取ることができない場合、GPUのアンダーユーティリゼーションを引き起こすボトルネックが発生する可能性があります。ボトルネックを減らすために、以下の引数を設定します:
- `DataLoader(pin_memory=True, ...)` - データをCPUのピンメモリに事前読み込みし、通常、CPUからGPUメモリへの転送がはるかに高速化されます。
- `DataLoader(num_workers=4, ...)` - データをより速く事前読み込みするために複数のワーカーを生成します。トレーニング中にGPUの利用状況の統計情報を確認し、100%から遠い場合、ワーカーの数を増やす実験を行ってください。もちろん、問題は他の場所にあるかもしれませんので、多くのワーカーが必ずしも性能向上につながるわけではありません。
[`Trainer`]を使用する場合、対応する[`TrainingArguments`]は`dataloader_pin_memory`(デフォルトでは`True`)および`dataloader_num_workers`(デフォルトは`0`)です。
## DeepSpeed ZeRO
DeepSpeedは、🤗 Transformersと🤗 Accelerateと統合されたオープンソースのディープラーニング最適化ライブラリです。
大規模なディープラーニングトレーニングの効率とスケーラビリティを向上させるために設計されたさまざまな機能と最適化を提供します。
モデルが単一のGPUに収まり、小さなバッチサイズを収めるスペースがある場合、DeepSpeedを使用する必要はありません。それはむしろ遅くなります。ただし、モデルが単一のGPUに収まらない場合、または小さなバッチを収めることができない場合、DeepSpeed ZeRO + CPU OffloadまたはNVMe Offloadを利用できます。この場合、[ライブラリを別途インストール](main_classes/deepspeed#installation)し、設定ファイルを作成し、DeepSpeedを起動するためのガイドをフォローする必要があります:
* [`Trainer`]とのDeepSpeed統合の詳細ガイドについては、[該当するドキュメンテーション](main_classes/deepspeed)を確認してください。特に、[単一GPU用のデプロイメント](main_classes/deepspeed#deployment-with-one-gpu)に関するセクションです。DeepSpeedをノートブックで使用するにはいくつかの調整が必要ですので、[該当するガイド](main_classes/deepspeed#deployment-in-notebooks)もご覧ください。
* 🤗 Accelerateを使用する場合は、[🤗 Accelerate DeepSpeedガイド](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed)を参照してください。
## torch.compileの使用
PyTorch 2.0は新しいコンパイル関数を導入しました。これは既存のPyTorchコードを変更する必要はありませんが、1行のコードを追加することでコードを最適化できます:`model = torch.compile(model)`。
[`Trainer`]を使用する場合、[`TrainingArguments`]内の`torch_compile`オプションを渡すだけです:
```python
training_args = TrainingArguments(torch_compile=True, **default_args)
```
`torch.compile`は、既存のPyTorchプログラムからグラフを自動的に作成するためにPythonのフレーム評価APIを使用します。グラフをキャプチャした後、異なるバックエンドを展開して最適化されたエンジンに変換できます。
詳細およびベンチマークについては、[PyTorchドキュメント](https://pytorch.org/get-started/pytorch-2.0/)を参照してください。
`torch.compile`には、オプションの依存関係を持つ成長中のバックエンドのリストがあり、`torchdynamo.list_backends()`を呼び出して確認できます。最も一般的に使用される一部のバックエンドは次のとおりです。
**デバッグ用バックエンド**:
* `dynamo.optimize("eager")` - 抽出されたGraphModuleを実行するためにPyTorchを使用します。これはTorchDynamoの問題をデバッグする際に非常に役立ちます。
* `dynamo.optimize("aot_eager")` - コンパイラーを使用しないAotAutogradを使用してAotAutogradの抽出されたフォワードおよびバックワードグラフに対して単にPyTorch eagerを使用します。これはデバッグに役立ち、高速化は期待できません。
**トレーニングおよび推論バックエンド**:
* `dynamo.optimize("inductor")` - TorchInductorバックエンドを使用し、AotAutogradおよびcudagraphsを活用してコード生成されたTritonカーネルを使用します [詳細はこちら](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScriptを使用します。 [詳細はこちら](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutogradを使用します。 [詳細はこちら](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_cudagraphs")` - AotAutogradを使用してcudagraphsを使用します。 [詳細はこちら](https://github.com/pytorch/torchdynamo/pull/757)
**推論専用バックエンド**:
* `dynamo.optimize("ofi")` - Torchscriptの`optimize_for_inference`を使用します。 [詳細はこちら](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
* `dynamo.optimize("fx2trt")` - Nvidia TensorRTを使用した推論の最適化にNvidia TensorRTを使用します。 [詳細はこちら](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - CPU/GPUでの推論にONNX Runtimeを使用します。 [詳細はこちら](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - CPUでの推論にIPEXを使用します。 [詳細はこちら](https://github.com/intel/intel-extension-for-pytorch)
🤗 Transformersを使用した`torch.compile`の使用例については、この[ブログ記事](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)をご覧ください。
## Using 🤗 Accelerate
[🤗 Accelerate](https://huggingface.co/docs/accelerate/index)を使用すると、上記の方法を使用しながらトレーニングループを完全に制御でき、基本的には純粋なPyTorchでループを書くことができます。
次に、[`TrainingArguments`]内で方法を組み合わせた場合を想
```py
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
```
🤗 Accelerateを使用した完全なトレーニングループの例は、ほんの数行のコードです:
```py
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
```
まず、データセットを[`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)でラップします。
次に、モデルの[`~PreTrainedModel.gradient_checkpointing_enable`]メソッドを呼び出すことで勾配チェックポイントを有効にできます。
[`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)を初期化する際に、混合精度トレーニングを使用するかどうかを[`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)の呼び出しで指定し、複数のGPUを使用する場合、`prepare`の間にデータローダーもワーカー間で分散されます。同じ[8ビットオプティマイザ](#8-bit-adam)を前の例から使用します。
最後に、主要なトレーニングループを追加できます。`backward`の呼び出しは🤗 Accelerateによって処理されることに注意してください。また、勾配の蓄積がどのように機能するかも確認できます。損失を正規化しているため、蓄積の最後に平均を得て、十分なステップがあると最適化が実行されます。
これらの最適化技術を🤗 Accelerateを使用して実装するのは、わずかなコード行で行うことができ、トレーニングループの柔軟性が向上します。すべての機能の詳細については、[Accelerateのドキュメント](https://huggingface.co/docs/accelerate/index)を参照してください。
## Efficient Software Prebuilds
PyTorchの[pipとcondaビルド](https://pytorch.org/get-started/locally/#start-locally)は、PyTorchを実行するのに十分なcudaツールキットで事前にビルドされていますが、cuda拡張をビルドする必要がある場合には不十分です。
時折、追加の努力が必要な場合があります。たとえば、事前にコンパイルされていない`apex`などのライブラリを使用している場合です。また、システム全体で適切なcudaツールキットをインストールする方法を見つけることが難しい場合もあります。
これらのシナリオに対処するために、PyTorchとNVIDIAはcuda拡張がすでに事前にビルドされているNGC dockerコンテナの新しいバージョンをリリースしました。プログラムをインストールするだけで、そのまま実行できます。
このアプローチは、PyTorchのソースを調整したり、新しいカスタマイズされたビルドを作成したりしたい場合にも役立ちます。
欲しいdockerイメージバージョンを見つけるには、まず[PyTorchのリリースノート](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/)から始め、最新の月次リリースのいずれかを選択します。希望のリリースのリリースノートに移動し、環境のコンポーネントが必要なものと一致していることを確認します(NVIDIA Driverの要件も含む!)、その文書の一番上に行き、対応するNGCページに移動します。なぜかわからない場合は、[すべてのPyTorch NGCイメージのインデックス](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch)です。
次に、dockerイメージをダウンロードして展開する手順に従います。
## Mixture of Experts
最近の論文によれば、Transformerモデルに専門家の混合(MoE)を統合することで、トレーニング速度が4〜5倍向上し、推論も高速化されることが報告されています。
より多くのパラメータがより良いパフォーマンスにつながることがわかっているため、この技術はトレーニングコストを増やすことなくパラメータの数を桁違いに増やすことを可能にします。
このアプローチでは、他のFFN層の代わりにMoE層が配置され、各専門家をトークンの位置に応じてバランスよくトレーニングするゲート関数で構成されます。

(出典: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
このアプローチの主な欠点は、GPUメモリをほぼ桁違いに多く必要とすることです。メモリ要件がはるかに大きいことがそのまま反映されます。より高いメモリ要件を克服する方法については、さまざまな蒸留およびアプローチが提案されています。
ただし、直接のトレードオフがあります。数人の専門家を使用してベースモデルを2〜3倍小さくすることで、5倍小さなモデルにし、トレーニング速度を適度に向上させ、メモリ要件を適度に増やすことができます。
関連するほとんどの論文および実装はTensorflow/TPUを中心に構築されています。
- [GShard: Conditional Computation and Automatic Shardingを活用した巨大モデルのスケーリング](https://arxiv.org/abs/2006.16668)
- [Switch Transformers: シンプルで効率的なスパース性を備えたトリリオンパラメータモデルへのスケーリング](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
PytorchにはDeepSpeedが構築したものもあります: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596)、[Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - ブログ記事: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/)、[2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/)、大規模なTransformerベースの自然言語生成モデルの具体的な展開については、[ブログ記事](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html)、[Megatron-Deepspeedブランチ](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training)を参照してください。
## PyTorchネイティブアテンションとFlash Attentionの使用
PyTorch 2.0では、ネイティブの[`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)(SDPA)がリリースされ、[メモリ効率の高いアテンション](https://arxiv.org/abs/2112.05682)や[フラッシュアテンション](https://arxiv.org/abs/2205.14135)などの融合されたGPUカーネルの使用を可能にします。
[`optimum`](https://github.com/huggingface/optimum)パッケージをインストールした後、関連する内部モジュールを置き換えて、PyTorchのネイティブアテンションを使用できます。以下のように設定します:
```python
model = model.to_bettertransformer()
```
変換後、通常通りモデルをトレーニングしてください。
<Tip warning={true}>
PyTorchネイティブの`scaled_dot_product_attention`演算子は、`attention_mask`が提供されていない場合にのみFlash Attentionにディスパッチできます。
デフォルトでは、トレーニングモードでBetterTransformer統合はマスクサポートを削除し、バッチトレーニングにパディングマスクが必要ないトレーニングにしか使用できません。これは、例えばマスク言語モデリングや因果言語モデリングのような、バッチトレーニングにパディングマスクが不要なトレーニングの場合に該当します。BetterTransformerはパディングマスクが必要なタスクに対するモデルの微調整には適していません。
</Tip>
SDPAを使用したアクセラレーションとメモリの節約について詳しく知りたい場合は、この[ブログ記事](https://pytorch.org/blog/out-of-the-box-acceleration/)をチェックしてください。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/community.md
|
<!--⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Community
このページは、コミュニティによって開発された🤗 Transformersに関するリソースをまとめたものです。
## Community resources:
| リソース | 説明 | 作者 |
|:----------|:-------------|------:|
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | [Transformers Docs Glossary](glossary)に基づいたフラッシュカードセットです。このセットは、長期の知識定着を特に考慮して設計されたオープンソースのクロスプラットフォームアプリである[Anki](https://apps.ankiweb.net/)を使用して簡単に学習/復習できる形式になっています。[フラッシュカードの使用方法に関する紹介ビデオはこちら](https://www.youtube.com/watch?v=Dji_h7PILrw)をご覧ください。 | [Darigov Research](https://www.darigovresearch.com/) |
## Community notebooks:
| ノートブック | 説明 | 著者 | |
|:----------|:-------------|:-------------|------:|
| [事前学習済みのTransformerを微調整して歌詞を生成](https://github.com/AlekseyKorshuk/huggingartists) | GPT-2モデルを微調整してお気に入りのアーティストのスタイルで歌詞を生成する方法 | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
| [Tensorflow 2でT5をトレーニング](https://github.com/snapthat/TF-T5-text-to-text) | Tensorflow 2を使用して任意のタスクに対してT5をトレーニングする方法。このノートブックはTensorflow 2を使用してSQUADで実装された質問と回答タスクを示しています。 | [Muhammad Harris](https://github.com/HarrisDePerceptron) | [](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
| [TPUでT5をトレーニング](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | TransformersとNlpを使用してSQUADでT5をトレーニングする方法 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
| [分類と多肢選択のためにT5を微調整](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | PyTorch Lightningを使用してテキスト対テキスト形式でT5を分類と多肢選択タスクに微調整する方法 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
| [新しいデータセットと言語でDialoGPTを微調整](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | DialoGPTモデルを新しいデータセットでオープンダイアログ会話用の微調整する方法 | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
| [Reformerを使用した長いシーケンスモデリング](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | Reformerを使用して500,000トークンまでのシーケンスをトレーニングする方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
| [要約のためにBARTを微調整](https://github.com/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) | Blurrを使用して要約のためにBARTを微調整する方法 | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) |
| [事前学習済みのTransformerを微調整して誰かのツイートを生成](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | GPT-2モデルを微調整してお気に入りのTwitterアカウントのスタイルでツイートを生成する方法 | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
| [🤗 Hugging FaceモデルをWeights & Biasesで最適化](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | Hugging FaceとWeights & Biasesの統合を示す完全なチュートリアル | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
| [Longformerの事前学習](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | 既存の事前学習済みモデルの「長い」バージョンを構築する方法 | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
| [QAタスクのためにLongformerを微調整](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | QAタスクのためにLongformerモデルを微調整する方法 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
| [🤗nlpを使用したモデルの評価](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | `nlp`を使用してTriviaQAでLongformerを評価する方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
| [感情スパン抽出のためにT5を微調整](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | PyTorch Lightningを使用して感情スパン抽出のためにT5を微調整する方法 | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
| [DistilBertをマルチクラス分類にファインチューニング](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | PyTorchを使用してDistilBertをマルチクラス分類にファインチューニングする方法 | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
|[BERTをマルチラベル分類にファインチューニング](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|PyTorchを使用してBERTをマルチラベル分類にファインチューニングする方法|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
|[T5を要約にファインチューニング](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|PyTorchを使用してT5を要約にファインチューニングし、WandBで実験をトラッキングする方法|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
|[ダイナミックパディング/バケッティングを使用してTransformersのファインチューニングを高速化](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|ダイナミックパディング/バケッティングを使用してファインチューニングを2倍高速化する方法|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|[マスク言語モデリングのためのReformerの事前学習](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)|双方向セルフアテンションレイヤーを備えたReformerモデルのトレーニング方法|[Patrick von Platen](https://github.com/patrickvonplaten) |[](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|[Sci-BERTを拡張してファインチューニング](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)|AllenAIのCORDデータセットで事前学習済みのSciBERTモデルの語彙を拡張し、パイプライン化する方法|[Tanmay Thakur](https://github.com/lordtt13) |[](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|[Trainer APIを使用してBlenderBotSmallを要約のためにファインチューニング](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)|カスタムデータセットでBlenderBotSmallを要約のためにファインチューニングする方法、Trainer APIを使用|[Tanmay Thakur](https://github.com/lordtt13) |[](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|[ElectraをファインチューニングしてCaptum Integrated Gradientsで解釈](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) |Electraを感情分析のためにファインチューニングし、Captum Integrated Gradientsで予測を解釈する方法|[Eliza Szczechla](https://elsanns.github.io) |[](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|[Trainerクラスを使用して非英語のGPT-2モデルをファインチューニング](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) |Trainerクラスを使用して非英語のGPT-2モデルをファインチューニングする方法|[Philipp Schmid](https://www.philschmid.de) |[](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|[DistilBERTモデルをマルチラベル分類タスクのためにファインチューニング](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) |DistilBERTモデルをマルチラベル分類タスクのためにファインチューニングする方法|[Dhaval Taunk](https://github.com/DhavalTaunk08) |[](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|[ALBERTを文ペア分類タスクのためにファインチューニング](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) |ALBERTモデルまたは他のBERTベースのモデルを文ペア分類タスクのためにファインチューニングする方法|[Nadir El Manouzi](https://github.com/NadirEM) |[](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
|[RoBERTaを感情分析のためにファインチューニング](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) |RoBERTaモデルを感情分析のためにファインチューニングする方法|[Dhaval Taunk](https://github.com/DhavalTaunk08) |[](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
|[質問生成モデルの評価](https://github.com/flexudy-pipe/qugeev) | seq2seqトランスフォーマーモデルによって生成された質問の回答の正確さを評価する方法 | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
|[DistilBERTとTensorflowを使用してテキストを分類](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | TensorFlowでテキスト分類のためにDistilBERTをファインチューニングする方法 | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
|[CNN/Dailymailでのエンコーダーデコーダー要約にBERTを活用](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | *bert-base-uncased* チェックポイントを使用してCNN/Dailymailの要約のために *EncoderDecoderModel* をウォームスタートする方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
|[BBC XSumでのエンコーダーデコーダー要約にRoBERTaを活用](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | *roberta-base* チェックポイントを使用してBBC/XSumの要約のための共有 *EncoderDecoderModel* をウォームスタートする方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
|[TAPASをシーケンシャル質問応答(SQA)でファインチューニング](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | シーケンシャル質問応答(SQA)データセットで *tapas-base* チェックポイントを使用して *TapasForQuestionAnswering* をファインチューニングする方法 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
|[TabFactでTAPASを評価](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | *tapas-base-finetuned-tabfact* チェックポイントを使用してファインチューニングされた *TapasForSequenceClassification* を評価する方法、🤗 datasets と 🤗 transformers ライブラリを組み合わせて使用 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
|[翻訳のためのmBARTをファインチューニング](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | Seq2SeqTrainerを使用してHindiからEnglishへの翻訳のためにmBARTをファインチューニングする方法 | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
|[FUNSD(フォーム理解データセット)でLayoutLMをファインチューニング](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | スキャンされたドキュメントからの情報抽出のためにFUNSDデータセットで *LayoutLMForTokenClassification* をファインチューニングする方法 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
| [DistilGPT2のファインチューニングとテキスト生成](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | DistilGPT2のファインチューニングとテキスト生成方法 | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
| [最大8KトークンでのLEDのファインチューニング](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | ロングレンジ要約のためのpubmedでLEDをファインチューニングする方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
| [ArxivでのLEDの評価](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | ロングレンジ要約のためのLEDの効果的な評価方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
| [RVL-CDIP(文書画像分類データセット)でのLayoutLMのファインチューニング](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | スキャンされた文書の分類のためのRVL-CDIPデータセットで*LayoutLMForSequenceClassification*をファインチューニングする方法 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
| [Wav2Vec2 CTCデコーディングとGPT2の調整](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | 言語モデルの調整を伴うCTCシーケンスのデコーディング方法 | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
| [Trainerクラスを使用した2言語の要約用にBARTをファインチューニング](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | トレーナークラスを使用して2つの言語での要約用にBARTをファインチューニングする方法 | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
| [PubMedデータセットでBigBirdの評価](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | Trivia QAの長いドキュメント質問応答でBigBirdの評価方法 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
| [Wav2Vec2を使用してビデオの字幕を作成する](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | Wav2Vecでオーディオを転記して任意のビデオからYouTubeの字幕を作成する方法 | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
| [PyTorch Lightningを使用したCIFAR-10でのVision Transformerのファインチューニング](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | HuggingFace Transformers、Datasets、およびPyTorch Lightningを使用してCIFAR-10でVision Transformer(ViT)をファインチューニングする方法 | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
| [🤗 Trainerを使用したCIFAR-10でのVision Transformerのファインチューニング](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | HuggingFace Transformers、Datasets、および🤗 Trainerを使用してCIFAR-10でVision Transformer(ViT)をファインチューニングする方法 | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
| [Open Entity、エンティティタイピングデータセットでLUKEの評価](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | Open Entityデータセットで*LukeForEntityClassification*の評価方法 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
| [TACRED、関係抽出データセットでLUKEの評価](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | TACREDデータセットで*LukeForEntityPairClassification*の評価方法 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
| [CoNLL-2003、重要なNERベンチマークでLUKEの評価](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | CoNLL-2003データセットで*LukeForEntitySpanClassification*の評価方法 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
| [PubMedデータセットでBigBird-Pegasusの評価](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | PubMedデータセットで*BigBirdPegasusForConditionalGeneration*の評価方法 | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
| [Wav2Vec2を使用したスピーチエモーション分類](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | MEGAデータセットでの感情分類のための事前学習済みWav2Vec2モデルの利用方法 | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
| [DETRを使用して画像内のオブジェクトを検出する](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | トレーニング済み*DetrForObjectDetection*モデルを使用して画像内のオブジェクトを検出し、注意を可視化する方法 | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/assets/colab-badge.svg)](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
| [カスタムオブジェクト検出データセットでDETRをファインチューニングする](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | カスタムオブジェクト検出データセットで*DetrForObjectDetection*をファインチューニングする方法 | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/assets/colab-badge.svg)](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
| [Named Entity RecognitionのためにT5をファインチューニング](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | Named Entity RecognitionタスクでT5をファインチューニングする方法 | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/training.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Fine-tune a pretrained model
[[open-in-colab]]
事前学習済みモデルを使用すると、計算コストを削減し、炭素排出量を減少させ、ゼロからモデルをトレーニングする必要なしに最新のモデルを使用できる利点があります。
🤗 Transformersは、さまざまなタスクに対応した数千もの事前学習済みモデルへのアクセスを提供します。
事前学習済みモデルを使用する場合、それを特定のタスクに合わせたデータセットでトレーニングします。これはファインチューニングとして知られ、非常に強力なトレーニング技術です。
このチュートリアルでは、事前学習済みモデルを選択したディープラーニングフレームワークでファインチューニングする方法について説明します:
* 🤗 Transformersの[`Trainer`]を使用して事前学習済みモデルをファインチューニングする。
* TensorFlowとKerasを使用して事前学習済みモデルをファインチューニングする。
* ネイティブのPyTorchを使用して事前学習済みモデルをファインチューニングする。
<a id='data-processing'></a>
## Prepare a dataset
<Youtube id="_BZearw7f0w"/>
事前学習済みモデルをファインチューニングする前に、データセットをダウンロードしてトレーニング用に準備する必要があります。
前のチュートリアルでは、トレーニングデータの処理方法を説明しましたが、これからはそれらのスキルを活かす機会があります!
まず、[Yelp Reviews](https://huggingface.co/datasets/yelp_review_full)データセットを読み込んでみましょう:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset["train"][100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
```
トークナイザがテキストを処理し、可変のシーケンス長を処理するためのパディングと切り捨て戦略を含める必要があることをご存知の通り、
データセットを1つのステップで処理するには、🤗 Datasets の [`map`](https://huggingface.co/docs/datasets/process#map) メソッドを使用して、
データセット全体に前処理関数を適用します:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
... return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
```
お好みで、実行時間を短縮するためにフルデータセットの小さなサブセットを作成することができます:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
<a id='trainer'></a>
## Train
この時点で、使用したいフレームワークに対応するセクションに従う必要があります。右側のサイドバーのリンクを使用して、ジャンプしたいフレームワークに移動できます。
そして、特定のフレームワークのすべてのコンテンツを非表示にしたい場合は、そのフレームワークのブロック右上にあるボタンを使用してください!
<frameworkcontent>
<pt>
<Youtube id="nvBXf7s7vTI"/>
## Train with Pytorch Trainer
🤗 Transformersは、🤗 Transformersモデルのトレーニングを最適化した[`Trainer`]クラスを提供し、独自のトレーニングループを手動で記述せずにトレーニングを開始しやすくしています。
[`Trainer`] APIは、ログ記録、勾配累積、混合精度など、さまざまなトレーニングオプションと機能をサポートしています。
まず、モデルをロードし、予想されるラベルの数を指定します。Yelp Review [dataset card](https://huggingface.co/datasets/yelp_review_full#data-fields)から、5つのラベルがあることがわかります:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
<Tip>
一部の事前学習済みの重みが使用されず、一部の重みがランダムに初期化された警告が表示されることがあります。心配しないでください、これは完全に正常です!
BERTモデルの事前学習済みのヘッドは破棄され、ランダムに初期化された分類ヘッドで置き換えられます。この新しいモデルヘッドをシーケンス分類タスクでファインチューニングし、事前学習モデルの知識をそれに転送します。
</Tip>
### Training Hyperparameters
次に、トレーニングオプションをアクティベートするためのすべてのハイパーパラメータと、調整できるハイパーパラメータを含む[`TrainingArguments`]クラスを作成します。
このチュートリアルでは、デフォルトのトレーニング[ハイパーパラメータ](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)を使用して開始できますが、最適な設定を見つけるためにこれらを実験しても構いません。
トレーニングのチェックポイントを保存する場所を指定します:
```python
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
```
### Evaluate
[`Trainer`]はトレーニング中に自動的にモデルのパフォーマンスを評価しません。メトリクスを計算して報告する関数を[`Trainer`]に渡す必要があります。
[🤗 Evaluate](https://huggingface.co/docs/evaluate/index)ライブラリでは、[`evaluate.load`]関数を使用して読み込むことができるシンプルな[`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy)関数が提供されています(詳細については[こちらのクイックツアー](https://huggingface.co/docs/evaluate/a_quick_tour)を参照してください):
```python
>>> import numpy as np
>>> import evaluate
>>> metric = evaluate.load("accuracy")
```
`metric`の`~evaluate.compute`を呼び出して、予測の正確度を計算します。 `compute`に予測を渡す前に、予測をロジットに変換する必要があります(すべての🤗 Transformersモデルはロジットを返すことを覚えておいてください):
```py
>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... predictions = np.argmax(logits, axis=-1)
... return metric.compute(predictions=predictions, references=labels)
```
評価メトリクスをファインチューニング中に監視したい場合、トレーニング引数で `evaluation_strategy` パラメータを指定して、各エポックの終了時に評価メトリクスを報告します:
```python
>>> from transformers import TrainingArguments, Trainer
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
```
### Trainer
モデル、トレーニング引数、トレーニングおよびテストデータセット、評価関数を使用して[`Trainer`]オブジェクトを作成します:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
その後、[`~transformers.Trainer.train`]を呼び出してモデルを微調整します:
```python
>>> trainer.train()
```
</pt>
<tf>
<a id='keras'></a>
<Youtube id="rnTGBy2ax1c"/>
## Kerasを使用してTensorFlowモデルをトレーニングする
Keras APIを使用して🤗 TransformersモデルをTensorFlowでトレーニングすることもできます!
### Loading Data from Keras
🤗 TransformersモデルをKeras APIでトレーニングする場合、データセットをKerasが理解できる形式に変換する必要があります。
データセットが小さい場合、データセット全体をNumPy配列に変換してKerasに渡すことができます。
複雑なことをする前に、まずそれを試してみましょう。
まず、データセットを読み込みます。GLUEベンチマークからCoLAデータセットを使用します
([GLUE Banchmark](https://huggingface.co/datasets/glue))、これは単純なバイナリテキスト分類タスクです。今のところトレーニング分割のみを使用します。
```py
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
dataset = dataset["train"] # 今のところトレーニング分割のみを使用します
```
次に、トークナイザをロードし、データをNumPy配列としてトークン化します。ラベルは既に`0`と`1`のリストであるため、トークン化せずに直接NumPy配列に変換できます!
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
# トークナイザはBatchEncodingを返しますが、それをKeras用に辞書に変換します
tokenized_data = dict(tokenized_data)
labels = np.array(dataset["label"]) # ラベルはすでに0と1の配列です
```
最後に、モデルをロードし、[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) と [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) メソッドを実行します。
注意点として、Transformersモデルはすべてデフォルトでタスクに関連した損失関数を持っているため、指定しなくても構いません(指定する場合を除く):
```python
from transformers import TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
# モデルをロードしてコンパイルする
model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased")
# ファインチューニングには通常、学習率を下げると良いです
model.compile(optimizer=Adam(3e-5)) # 損失関数の指定は不要です!
model.fit(tokenized_data, labels)
```
<Tip>
モデルを`compile()`する際に`loss`引数を渡す必要はありません!Hugging Faceモデルは、この引数を空白のままにしておくと、タスクとモデルアーキテクチャに適した損失を自動的に選択します。
必要に応じて自分で損失を指定してオーバーライドすることもできます!
</Tip>
このアプローチは、小規模なデータセットには適していますが、大規模なデータセットに対しては問題になることがあります。なぜなら、トークナイズされた配列とラベルはメモリに完全に読み込まれる必要があり、またNumPyは「ジャギー」な配列を処理しないため、トークナイズされた各サンプルを全体のデータセット内で最も長いサンプルの長さにパディングする必要があります。
これにより、配列がさらに大きくなり、すべてのパディングトークンがトレーニングを遅くする原因になります!
### Loading data as a tf.data.Dataset
トレーニングを遅くせずにデータを読み込むには、データを`tf.data.Dataset`として読み込むことができます。独自の`tf.data`パイプラインを作成することもできますが、これを行うための便利な方法が2つあります:
- [`~TFPreTrainedModel.prepare_tf_dataset`]: これはほとんどの場合で推奨する方法です。モデル上のメソッドなので、モデルを検査してモデル入力として使用可能な列を自動的に把握し、他の列を破棄してより単純で高性能なデータセットを作成できます。
- [`~datasets.Dataset.to_tf_dataset`]: このメソッドはより低レベルで、データセットがどのように作成されるかを正確に制御する場合に便利です。`columns`と`label_cols`を指定して、データセットに含める列を正確に指定できます。
[`~TFPreTrainedModel.prepare_tf_dataset`]を使用する前に、次のコードサンプルに示すように、トークナイザの出力をデータセットに列として追加する必要があります:
```py
def tokenize_dataset(data):
# 返された辞書のキーはデータセットに列として追加されます
return tokenizer(data["text"])
dataset = dataset.map(tokenize_dataset)
```
Hugging Faceのデータセットはデフォルトでディスクに保存されるため、これによりメモリの使用量が増えることはありません!
列が追加されたら、データセットからバッチをストリームし、各バッチにパディングを追加できます。これにより、
データセット全体にパディングを追加する場合と比べて、パディングトークンの数が大幅に削減されます。
```python
>>> tf_dataset = model.prepare_tf_dataset(dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer)
```
上記のコードサンプルでは、トークナイザを`prepare_tf_dataset`に渡して、バッチを正しく読み込む際に正しくパディングできるようにする必要があります。
データセットのすべてのサンプルが同じ長さであり、パディングが不要な場合は、この引数をスキップできます。
パディング以外の複雑な処理を行う必要がある場合(例:マスク言語モデリングのためのトークンの破損など)、
代わりに`collate_fn`引数を使用して、サンプルのリストをバッチに変換し、必要な前処理を適用する関数を渡すことができます。
このアプローチを実際に使用した例については、
[examples](https://github.com/huggingface/transformers/tree/main/examples)や
[notebooks](https://huggingface.co/docs/transformers/notebooks)をご覧ください。
`tf.data.Dataset`を作成したら、以前と同様にモデルをコンパイルし、適合させることができます:
```python
model.compile(optimizer=Adam(3e-5)) # 損失引数は不要です!
model.fit(tf_dataset)
```
</tf>
</frameworkcontent>
<a id='pytorch_native'></a>
## Train in native Pytorch
<frameworkcontent>
<pt>
<Youtube id="Dh9CL8fyG80"/>
[`Trainer`]はトレーニングループを処理し、1行のコードでモデルをファインチューニングできるようにします。
トレーニングループを独自に記述したいユーザーのために、🤗 TransformersモデルをネイティブのPyTorchでファインチューニングすることもできます。
この時点で、ノートブックを再起動するか、以下のコードを実行してメモリを解放する必要があるかもしれません:
```py
del model
del trainer
torch.cuda.empty_cache()
```
1. モデルは生のテキストを入力として受け取らないため、`text` 列を削除します:
```py
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
```
2. `label`列を`labels`に名前を変更します。モデルは引数の名前を`labels`と期待しています:
```py
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
```
3. データセットの形式をリストではなくPyTorchテンソルを返すように設定します:
```py
>>> tokenized_datasets.set_format("torch")
```
以前に示したように、ファインチューニングを高速化するためにデータセットの小さなサブセットを作成します:
```py
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
```
### DataLoader
トレーニングデータセットとテストデータセット用の`DataLoader`を作成して、データのバッチをイテレートできるようにします:
```py
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
```
ロードするモデルと期待されるラベルの数を指定してください:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
```
### Optimizer and learning rate scheduler
モデルをファインチューニングするためのオプティマイザと学習率スケジューラーを作成しましょう。
PyTorchから[`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)オプティマイザを使用します:
```python
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
```
デフォルトの学習率スケジューラを[`Trainer`]から作成する:
```py
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
... )
```
最後に、GPUを利用できる場合は `device` を指定してください。それ以外の場合、CPUでのトレーニングは数時間かかる可能性があり、数分で完了することができます。
```py
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
```
<Tip>
クラウドGPUが利用できない場合、[Colaboratory](https://colab.research.google.com/)や[SageMaker StudioLab](https://studiolab.sagemaker.aws/)などのホストされたノートブックを使用して無料でGPUにアクセスできます。
</Tip>
さて、トレーニングの準備が整いました! 🥳
### トレーニングループ
トレーニングの進捗を追跡するために、[tqdm](https://tqdm.github.io/)ライブラリを使用してトレーニングステップの数に対して進行状況バーを追加します:
```py
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... outputs = model(**batch)
... loss = outputs.loss
... loss.backward()
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
### Evaluate
[`Trainer`]に評価関数を追加したのと同様に、独自のトレーニングループを作成する際にも同様の操作を行う必要があります。
ただし、各エポックの最後にメトリックを計算および報告する代わりに、今回は[`~evaluate.add_batch`]を使用してすべてのバッチを蓄積し、最後にメトリックを計算します。
```python
>>> import evaluate
>>> metric = evaluate.load("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
... batch = {k: v.to(device) for k, v in batch.items()}
... with torch.no_grad():
... outputs = model(**batch)
... logits = outputs.logits
... predictions = torch.argmax(logits, dim=-1)
... metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
```
</pt>
</frameworkcontent>
<a id='additional-resources'></a>
## 追加リソース
さらなるファインチューニングの例については、以下を参照してください:
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) には、PyTorchとTensorFlowで一般的なNLPタスクをトレーニングするスクリプトが含まれています。
- [🤗 Transformers Notebooks](notebooks) には、特定のタスクにモデルをファインチューニングする方法に関するさまざまなノートブックが含まれています。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/pad_truncation.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Padding and truncation
バッチ入力はしばしば異なる長さであり、固定サイズのテンソルに変換できないため、変動する長さのバッチから長方形のテンソルを作成するための戦略として、パディングと切り詰めがあります。パディングは、短いシーケンスがバッチ内の最長シーケンスまたはモデルが受け入れる最大長と同じ長さになるように、特別な**パディングトークン**を追加します。切り詰めは、長いシーケンスを切り詰めることで逆方向に機能します。
ほとんどの場合、バッチを最長シーケンスの長さにパディングし、モデルが受け入れる最大長に切り詰めることで、うまく動作します。ただし、APIはそれ以上の戦略もサポートしています。必要な3つの引数は次のとおりです:`padding`、`truncation`、および `max_length`。
`padding`引数はパディングを制御します。ブール値または文字列であることができます:
- `True`または`'longest'`:バッチ内の最長シーケンスにパディングを追加します(シーケンスが1つしか提供されない場合、パディングは適用されません)。
- `max_length'`:`max_length`引数で指定された長さまでパディングを追加します。または`max_length`が提供されていない場合はモデルが受け入れる最大長(`max_length=None`)。シーケンスが1つしか提供されている場合でも、パディングは適用されます。
- `False`または`'do_not_pad'`:パディングは適用されません。これがデフォルトの動作です。
`truncation`引数は切り詰めを制御します。ブール値または文字列であることができます:
- `True`または`'longest_first'`:最大長を`max_length`引数で指定するか、モデルが受け入れる最大長(`max_length=None`)まで切り詰めます。これはトークンごとに切り詰め、適切な長さに達するまでペア内の最長シーケンスからトークンを削除します。
- `'only_second'`:最大長を`max_length`引数で指定するか、モデルが受け入れる最大長(`max_length=None`)まで切り詰めます。これはペアの2番目の文だけを切り詰めます(シーケンスのペアまたはシーケンスのバッチのペアが提供された場合)。
- `'only_first'`:最大長を`max_length`引数で指定するか、モデルが受け入れる最大長(`max_length=None`)まで切り詰めます。これはペアの最初の文だけを切り詰めます(シーケンスのペアまたはシーケンスのバッチのペアが提供された場合)。
- `False`または`'do_not_truncate'`:切り詰めは適用されません。これがデフォルトの動作です。
`max_length`引数はパディングと切り詰めの長さを制御します。整数または`None`であり、この場合、モデルが受け入れる最大入力長にデフォルトで設定されます。モデルに特定の最大入力長がない場合、`max_length`への切り詰めまたはパディングは無効になります。
以下の表は、パディングと切り詰めを設定する推奨方法を要約しています。以下の例のいずれかで入力シーケンスのペアを使用する場合、`truncation=True`を`['only_first', 'only_second', 'longest_first']`で選択した`STRATEGY`に置き換えることができます。つまり、`truncation='only_second'`または`truncation='longest_first'`を使用して、ペア内の両方のシーケンスを前述のように切り詰める方法を制御できます。
| Truncation | Padding | Instruction |
|--------------------------------------|-----------------------------------|---------------------------------------------------------------------------------------------|
| no truncation | no padding | `tokenizer(batch_sentences)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True)` or |
| | | `tokenizer(batch_sentences, padding='longest')` |
| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length')` |
| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
| | padding to a multiple of a value | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8) |
| truncation to max model input length | no padding | `tokenizer(batch_sentences, truncation=True)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True)` or |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
| | padding to max model input length | `tokenizer(batch_sentences, padding='max_length', truncation=True)` or |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
| | padding to specific length | Not possible |
| truncation to specific length | no padding | `tokenizer(batch_sentences, truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
| | padding to max sequence in batch | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
| | padding to max model input length | Not possible |
| | padding to specific length | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` or |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_infer_gpu_many.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Inference on a Multiple GPUs
この文書には、複数のGPUで効率的に推論を行う方法に関する情報が含まれています。
<Tip>
注意: 複数のGPUセットアップは、[単一のGPUセクション](./perf_infer_gpu_one)で説明されているほとんどの戦略を使用できます。ただし、より良い使用法のために使用できる簡単なテクニックについても認識しておく必要があります。
</Tip>
## Flash Attention 2
Flash Attention 2の統合は、複数のGPUセットアップでも機能します。詳細については、[単一のGPUセクション](./perf_infer_gpu_one#Flash-Attention-2)の適切なセクションをご覧ください。
## BetterTransformer
[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview)は、🤗 TransformersモデルをPyTorchネイティブの高速実行パスを使用するように変換し、その下でFlash Attentionなどの最適化されたカーネルを呼び出します。
BetterTransformerは、テキスト、画像、音声モデルの単一GPUおよび複数GPUでの高速推論もサポートしています。
<Tip>
Flash Attentionは、fp16またはbf16 dtypeを使用しているモデルにのみ使用できます。BetterTransformerを使用する前に、モデルを適切なdtypeにキャストしてください。
</Tip>
### Decoder models
テキストモデル、特にデコーダーベースのモデル(GPT、T5、Llamaなど)の場合、BetterTransformer APIはすべての注意操作を[`torch.nn.functional.scaled_dot_product_attention`オペレーター](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention)(SDPA)を使用するように変換します。これはPyTorch 2.0以降でのみ使用可能です。
モデルをBetterTransformerに変換するには:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
# convert the model to BetterTransformer
model.to_bettertransformer()
# Use it for training or inference
```
SDPAは、ハードウェアや問題のサイズなどの特定の設定で[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを呼び出すこともできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題のサイズ)で利用可能かを確認するには、[`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel)をコンテキストマネージャとして使用します。
```diff
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m").to("cuda")
# convert the model to BetterTransformer
model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
もしトレースバックで次のようなエラーメッセージが表示された場合:
```bash
RuntimeError: No available kernel. Aborting execution.
```
当日、Flash Attentionのカバレッジが広範囲である可能性があるPyTorch Nightlyバージョンを試すようにお勧めします。
```bash
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
```
[このブログ投稿](https://pytorch.org/blog/out-of-the-box-acceleration/)をチェックして、BetterTransformer + SDPA APIで可能なことについて詳しく学びましょう。
### Encoder Models
推論中のエンコーダーモデルでは、BetterTransformerはエンコーダーレイヤーのforward呼び出しを、エンコーダーレイヤーの[`torch.nn.TransformerEncoderLayer`](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html)の相当するものにディスパッチします。これにより、エンコーダーレイヤーの高速実装が実行されます。
`torch.nn.TransformerEncoderLayer`の高速実装はトレーニングをサポートしていないため、代わりに`torch.nn.functional.scaled_dot_product_attention`にディスパッチされます。これにより、ネストされたテンソルを活用しないFlash AttentionまたはMemory-Efficient Attentionの融合カーネルを使用できます。
BetterTransformerのパフォーマンスの詳細については、この[ブログ投稿](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2)をご覧いただけます。また、エンコーダーモデル用のBetterTransformerについては、この[ブログ](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/)で詳しく学ぶことができます。
## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
モデルの最良のパフォーマンスを得るために、上記で説明した異なる方法を組み合わせることができます。例えば、FP4ミックスプレシジョン推論+Flash Attentionを使用したBetterTransformerを組み合わせることができます。
```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/troubleshooting.md
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Troubleshoot
時にはエラーが発生することがありますが、私たちはここにいます!このガイドでは、私たちがよく見る最も一般的な問題と、それらを解決する方法について説明します。ただし、このガイドはすべての 🤗 Transformers の問題の包括的なコレクションではありません。問題をトラブルシューティングするための詳細なヘルプが必要な場合は、以下の方法を試してみてください:
<Youtube id="S2EEG3JIt2A"/>
1. [フォーラム](https://discuss.huggingface.co/)で助けを求める。 [初心者向け](https://discuss.huggingface.co/c/beginners/5) または [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9) など、質問を投稿できる特定のカテゴリがあります。問題が解決される可能性を最大限にするために、再現可能なコードを含む良い説明的なフォーラム投稿を書くことを確認してください!
<Youtube id="_PAli-V4wj0"/>
2. バグがライブラリに関連する場合は、🤗 Transformers リポジトリで [Issue](https://github.com/huggingface/transformers/issues/new/choose) を作成してください。バグを説明するためのできるだけ多くの情報を含めるように心がけ、何が問題で、どのように修正できるかをより良く理解できるようにしてください。
3. より古いバージョンの 🤗 Transformers を使用している場合は、[Migration](migration) ガイドを確認してください。バージョン間で重要な変更が導入されているためです。
トラブルシューティングとヘルプの詳細については、Hugging Faceコースの [第8章](https://huggingface.co/course/chapter8/1?fw=pt) を参照してください。
## Firewalled environments
一部のクラウド上のGPUインスタンスやイントラネットセットアップは、外部接続に対してファイアウォールで保護されているため、接続エラーが発生することがあります。スクリプトがモデルの重みやデータセットをダウンロードしようとすると、ダウンロードが途中で止まり、次のメッセージとタイムアウトエラーが表示されます:
```
ValueError: Connection error, and we cannot find the requested files in the cached path.
Please try again or make sure your Internet connection is on.
```
この場合、接続エラーを回避するために[オフラインモード](installation#offline-mode)で🤗 Transformersを実行してみてください。
## CUDA out of memory
数百万のパラメータを持つ大規模なモデルのトレーニングは、適切なハードウェアなしでは課題です。GPUのメモリが不足するとよくあるエラーの1つは次のとおりです:
以下はメモリ使用量を減らすために試すことができるいくつかの解決策です:
- [`TrainingArguments`]の中で [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) の値を減らす。
- [`TrainingArguments`]の中で [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps) を使用して、全体的なバッチサイズを効果的に増やすことを試す。
<Tip>
メモリ節約のテクニックについての詳細は、[ガイド](performance)を参照してください。
</Tip>
## Unable to load a saved TensorFlow model
TensorFlowの[model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model)メソッドは、モデル全体 - アーキテクチャ、重み、トレーニング設定 - を1つのファイルに保存します。しかし、モデルファイルを再度読み込む際にエラーが発生することがあります。これは、🤗 Transformersがモデルファイル内のすべてのTensorFlow関連オブジェクトを読み込まないためです。TensorFlowモデルの保存と読み込みに関する問題を回避するために、次のことをお勧めします:
- モデルの重みを`h5`ファイル拡張子で保存し、[`~TFPreTrainedModel.from_pretrained`]を使用してモデルを再読み込みする:
```py
>>> from transformers import TFPreTrainedModel
>>> from tensorflow import keras
>>> model.save_weights("some_folder/tf_model.h5")
>>> model = TFPreTrainedModel.from_pretrained("some_folder")
```
- Save the model with [`~TFPretrainedModel.save_pretrained`] and load it again with [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> from transformers import TFPreTrainedModel
>>> model.save_pretrained("path_to/model")
>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
```
## ImportError
もう一つよくあるエラーは、特に新しくリリースされたモデルの場合に遭遇することがある `ImportError` です:
```
ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
```
これらのエラータイプに関しては、最新バージョンの 🤗 Transformers がインストールされていることを確認して、最新のモデルにアクセスできるようにしてください:
```bash
pip install transformers --upgrade
```
## CUDA error: device-side assert triggered
時々、デバイスコードでエラーが発生したという一般的な CUDA エラーに遭遇することがあります。
```
RuntimeError: CUDA error: device-side assert triggered
```
より具体的なエラーメッセージを取得するために、まずはCPU上でコードを実行してみることをお勧めします。以下の環境変数をコードの冒頭に追加して、CPUに切り替えてみてください:
```py
>>> import os
>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
```
GPUからより良いトレースバックを取得する別のオプションは、次の環境変数をコードの先頭に追加することです。これにより、エラーの発生源を指すトレースバックが得られます:
```py
>>> import os
>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
```
## Incorrect output when padding tokens aren't masked
一部のケースでは、`input_ids`にパディングトークンが含まれている場合、出力の`hidden_state`が正しくないことがあります。デモンストレーションのために、モデルとトークナイザーをロードします。モデルの`pad_token_id`にアクセスして、その値を確認できます。一部のモデルでは`pad_token_id`が`None`になることもありますが、常に手動で設定することができます。
```py
>>> from transformers import AutoModelForSequenceClassification
>>> import torch
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
>>> model.config.pad_token_id
0
```
以下の例は、パディングトークンをマスクせずに出力を表示したものです:
```py
>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[ 0.1317, -0.1683]], grad_fn=<AddmmBackward0>)
```
以下は、第2のシーケンスの実際の出力です:
```py
>>> input_ids = torch.tensor([[7592]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
```
大抵の場合、モデルには `attention_mask` を提供して、パディングトークンを無視し、このような無音のエラーを回避する必要があります。これにより、2番目のシーケンスの出力が実際の出力と一致するようになります。
<Tip>
デフォルトでは、トークナイザは、トークナイザのデフォルトに基づいて `attention_mask` を自動で作成します。
</Tip>
```py
>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
>>> output = model(input_ids, attention_mask=attention_mask)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
```
🤗 Transformersは、提供されるパディングトークンをマスクするために自動的に`attention_mask`を作成しません。その理由は以下の通りです:
- 一部のモデルにはパディングトークンが存在しない場合があるためです。
- 一部のユースケースでは、ユーザーがパディングトークンにアテンションを向けることを望む場合があるためです。
## ValueError: Unrecognized configuration class XYZ for this kind of AutoModel
一般的に、事前学習済みモデルのインスタンスをロードするためには[`AutoModel`]クラスを使用することをお勧めします。このクラスは、設定に基づいて与えられたチェックポイントから正しいアーキテクチャを自動的に推測およびロードできます。モデルをロードする際にこの`ValueError`が表示される場合、Autoクラスは与えられたチェックポイントの設定から、ロードしようとしているモデルの種類へのマッピングを見つけることができなかったことを意味します。最も一般的には、特定のタスクをサポートしないチェックポイントがある場合にこのエラーが発生します。
例えば、質問応答のためのGPT2が存在しない場合、次の例でこのエラーが表示されます:
上記のテキストを日本語に翻訳し、Markdownファイルとしてフォーマットしました。
```py
>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("gpt2-medium")
>>> model = AutoModelForQuestionAnswering.from_pretrained("gpt2-medium")
ValueError: Unrecognized configuration class <class 'transformers.models.gpt2.configuration_gpt2.GPT2Config'> for this kind of AutoModel: AutoModelForQuestionAnswering.
Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig, ...
```
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/model_sharing.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdownですが、Hugging Faceのドキュメントビルダー(MDXに類似)向けの特定の構文を含んでいるため、Markdownビューアーで適切にレンダリングされないことがあります。
-->
# Share a Model
最後の2つのチュートリアルでは、PyTorch、Keras、および🤗 Accelerateを使用してモデルをファインチューニングする方法を示しました。次のステップは、モデルをコミュニティと共有することです!Hugging Faceでは、知識とリソースを公開的に共有し、人工知能を誰にでも提供することを信じています。他の人々が時間とリソースを節約できるように、モデルをコミュニティと共有することを検討することをお勧めします。
このチュートリアルでは、訓練済みまたはファインチューニングされたモデルを[Model Hub](https://huggingface.co/models)に共有する2つの方法を学びます:
- プログラムでファイルをHubにプッシュする。
- ウェブインターフェースを使用してファイルをHubにドラッグアンドドロップする。
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
コミュニティとモデルを共有するには、[huggingface.co](https://huggingface.co/join)でアカウントが必要です。既存の組織に参加したり、新しい組織を作成したりすることもできます。
</Tip>
## Repository Features
Model Hub上の各リポジトリは、通常のGitHubリポジトリのように動作します。リポジトリはバージョニング、コミット履歴、違いの視覚化の機能を提供します。
Model Hubの組み込みバージョニングはgitおよび[git-lfs](https://git-lfs.github.com/)に基づいています。言い換えれば、モデルを1つのリポジトリとして扱うことができ、より大きなアクセス制御とスケーラビリティを実現します。バージョン管理には*リビジョン*があり、コミットハッシュ、タグ、またはブランチ名で特定のモデルバージョンをピン留めする方法です。
その結果、`revision`パラメータを使用して特定のモデルバージョンをロードできます:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # タグ名、またはブランチ名、またはコミットハッシュ
... )
```
ファイルはリポジトリ内で簡単に編集でき、コミット履歴と差分を表示できます:

## Set Up
モデルをHubに共有する前に、Hugging Faceの認証情報が必要です。ターミナルへのアクセス権がある場合、🤗 Transformersがインストールされている仮想環境で以下のコマンドを実行します。これにより、アクセストークンがHugging Faceのキャッシュフォルダに保存されます(デフォルトでは `~/.cache/` に保存されます):
```bash
huggingface-cli login
```
JupyterやColaboratoryのようなノートブックを使用している場合、[`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library)ライブラリがインストールされていることを確認してください。
このライブラリを使用すると、Hubとプログラム的に対話できます。
```bash
pip install huggingface_hub
```
次に、`notebook_login`を使用してHubにサインインし、[こちらのリンク](https://huggingface.co/settings/token)にアクセスしてログインに使用するトークンを生成します:
```python
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Convert a Model for all frameworks
異なるフレームワークで作業している他のユーザーがあなたのモデルを使用できるようにするために、
PyTorchおよびTensorFlowのチェックポイントでモデルを変換してアップロードすることをお勧めします。
このステップをスキップすると、ユーザーは異なるフレームワークからモデルをロードできますが、
モデルをオンザフライで変換する必要があるため、遅くなります。
別のフレームワーク用にチェックポイントを変換することは簡単です。
PyTorchとTensorFlowがインストールされていることを確認してください(インストール手順については[こちら](installation)を参照)し、
その後、他のフレームワーク向けに特定のタスク用のモデルを見つけます。
<frameworkcontent>
<pt>
TensorFlowからPyTorchにチェックポイントを変換するには、`from_tf=True`を指定します:
```python
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
</pt>
<tf>
指定して、PyTorchからTensorFlowにチェックポイントを変換するには `from_pt=True` を使用します:
```python
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
新しいTensorFlowモデルとその新しいチェックポイントを保存できます:
```python
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
</tf>
<tf>
<jax>
Flaxでモデルが利用可能な場合、PyTorchからFlaxへのチェックポイントの変換も行うことができます:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
</jax>
</frameworkcontent>
## Push a model during traning
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
モデルをHubにプッシュすることは、追加のパラメーターまたはコールバックを追加するだけで簡単です。
[ファインチューニングチュートリアル](training)から思い出してください、[`TrainingArguments`]クラスはハイパーパラメーターと追加のトレーニングオプションを指定する場所です。
これらのトレーニングオプションの1つに、モデルを直接Hubにプッシュする機能があります。[`TrainingArguments`]で`push_to_hub=True`を設定します:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
Pass your training arguments as usual to [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
[`Trainer`]に通常通りトレーニング引数を渡します:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
ファインチューニングが完了したら、[`Trainer`]で[`~transformers.Trainer.push_to_hub`]を呼び出して、トレーニング済みモデルをHubにプッシュします。🤗 Transformersは、トレーニングのハイパーパラメータ、トレーニング結果、およびフレームワークのバージョンを自動的にモデルカードに追加します!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
[`PushToHubCallback`]を使用してモデルをHubに共有します。[`PushToHubCallback`]関数には、次のものを追加します:
- モデルの出力ディレクトリ。
- トークナイザ。
- `hub_model_id`、つまりHubのユーザー名とモデル名。
```python
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
🤗 Transformersは[`fit`](https://keras.io/api/models/model_training_apis/)にコールバックを追加し、トレーニング済みモデルをHubにプッシュします:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## `push_to_hub` 関数を使用する
また、モデルを直接Hubにアップロードするために、`push_to_hub` を呼び出すこともできます。
`push_to_hub` でモデル名を指定します:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
これにより、ユーザー名の下にモデル名 `my-awesome-model` を持つリポジトリが作成されます。
ユーザーは、`from_pretrained` 関数を使用してモデルをロードできます:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
組織に所属し、モデルを組織名のもとにプッシュしたい場合、`repo_id` にそれを追加してください:
```python
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
```
`push_to_hub`関数は、モデルリポジトリに他のファイルを追加するためにも使用できます。例えば、トークナイザをモデルリポジトリに追加します:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
あるいは、ファインチューニングされたPyTorchモデルのTensorFlowバージョンを追加したいかもしれません:
```python
>>> tf_model.push_to_hub("my-awesome-model")
```
Hugging Faceプロフィールに移動すると、新しく作成したモデルリポジトリが表示されるはずです。**Files**タブをクリックすると、リポジトリにアップロードしたすべてのファイルが表示されます。
リポジトリにファイルを作成およびアップロードする方法の詳細については、Hubドキュメンテーション[こちら](https://huggingface.co/docs/hub/how-to-upstream)を参照してください。
## Upload with the web interface
コードを書かずにモデルをアップロードしたいユーザーは、Hubのウェブインターフェースを使用してモデルをアップロードできます。[huggingface.co/new](https://huggingface.co/new)を訪れて新しいリポジトリを作成します:

ここから、モデルに関するいくつかの情報を追加します:
- リポジトリの**所有者**を選択します。これはあなた自身または所属している組織のいずれかです。
- モデルの名前を選択します。これはリポジトリの名前にもなります。
- モデルが公開か非公開かを選択します。
- モデルのライセンス使用方法を指定します。
その後、**Files**タブをクリックし、**Add file**ボタンをクリックしてリポジトリに新しいファイルをアップロードします。次に、ファイルをドラッグアンドドロップしてアップロードし、コミットメッセージを追加します。

## Add a model card
ユーザーがモデルの機能、制限、潜在的な偏り、倫理的な考慮事項を理解できるようにするために、モデルリポジトリにモデルカードを追加してください。モデルカードは`README.md`ファイルで定義されます。モデルカードを追加する方法:
* 手動で`README.md`ファイルを作成およびアップロードする。
* モデルリポジトリ内の**Edit model card**ボタンをクリックする。
モデルカードに含めるべき情報の例については、DistilBert [モデルカード](https://huggingface.co/distilbert-base-uncased)をご覧ください。`README.md`ファイルで制御できる他のオプション、例えばモデルの炭素フットプリントやウィジェットの例などについての詳細は、[こちらのドキュメンテーション](https://huggingface.co/docs/hub/models-cards)を参照してください。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/add_new_model.md
|
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ このファイルはMarkdown形式ですが、特定の文法が含まれており、通常のMarkdownビューアーでは正しく表示されない場合があります。
-->
# How to add a model to 🤗 Transformers?
🤗 Transformersライブラリは、コミュニティの貢献者のおかげで新しいモデルを提供できることがよくあります。
しかし、これは難しいプロジェクトであり、🤗 Transformersライブラリと実装するモデルについての深い知識が必要です。
Hugging Faceでは、コミュニティの多くの人々に積極的にモデルを追加する力を与えようと努力しており、
このガイドをまとめて、PyTorchモデルを追加するプロセスを説明します([PyTorchがインストールされていることを確認してください](https://pytorch.org/get-started/locally/))。
<Tip>
TensorFlowモデルを実装する興味がある場合は、[🤗 TransformersモデルをTensorFlowに変換する方法](add_tensorflow_model)ガイドを参照してみてください!
</Tip>
この過程で、以下のことを学びます:
- オープンソースのベストプラクティスに関する洞察
- 最も人気のある深層学習ライブラリの設計原則を理解する
- 大規模なモデルを効率的にテストする方法を学ぶ
- `black`、`ruff`、および`make fix-copies`などのPythonユーティリティを統合して、クリーンで読みやすいコードを確保する方法を学ぶ
Hugging Faceチームのメンバーがサポートを提供するので、一人ぼっちになることはありません。 🤗 ❤️
さあ、始めましょう!🤗 Transformersで見たいモデルについての[New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml)のイシューを開いてください。
特定のモデルを提供することに特にこだわりがない場合、[New model label](https://github.com/huggingface/transformers/labels/New%20model)で未割り当てのモデルリクエストがあるかどうかを確認して、それに取り組むことができます。
新しいモデルリクエストを開いたら、最初のステップは🤗 Transformersをよく理解することです!
## General overview of 🤗 Transformers
まず、🤗 Transformersの一般的な概要を把握する必要があります。🤗 Transformersは非常に意見が分かれるライブラリですので、
ライブラリの哲学や設計選択について同意できない可能性があります。ただし、私たちの経験から、ライブラリの基本的な設計選択と哲学は、
🤗 Transformersを効率的にスケーリングし、適切なレベルで保守コストを抑えるために不可欠です。
ライブラリの理解を深めるための良い出発点は、[哲学のドキュメント](philosophy)を読むことです。
私たちの作業方法の結果、すべてのモデルに適用しようとするいくつかの選択肢があります:
- 一般的に、抽象化よりも構成が優先されます。
- コードの重複は、読みやすさやアクセス可能性を大幅に向上させる場合、必ずしも悪いわけではありません。
- モデルファイルはできるだけ自己完結的であるべきで、特定のモデルのコードを読む際には、理想的には該当する`modeling_....py`ファイルのみを見る必要があります。
私たちの意見では、このライブラリのコードは単なる製品を提供する手段だけでなく、*例えば、推論のためにBERTを使用する能力*などの製品そのもの.
### Overview of models
モデルを正常に追加するためには、モデルとその設定、[`PreTrainedModel`]、および[`PretrainedConfig`]の相互作用を理解することが重要です。
例示的な目的で、🤗 Transformersに追加するモデルを「BrandNewBert」と呼びます。
以下をご覧ください:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers_overview.png"/>
ご覧のように、🤗 Transformersでは継承を使用していますが、抽象化のレベルを最小限に保っています。
ライブラリ内のどのモデルにも、抽象化のレベルが2つを超えることはありません。
`BrandNewBertModel` は `BrandNewBertPreTrainedModel` を継承し、さらに[`PreTrainedModel`]を継承しています。
これだけです。
一般的なルールとして、新しいモデルは[`PreTrainedModel`]にのみ依存するようにしたいと考えています。
すべての新しいモデルに自動的に提供される重要な機能は、[`~PreTrainedModel.from_pretrained`]および
[`~PreTrainedModel.save_pretrained`]です。
これらはシリアライゼーションとデシリアライゼーションに使用されます。
`BrandNewBertModel.forward`などの他の重要な機能は、新しい「modeling_brand_new_bert.py」スクリプトで完全に定義されるべきです。
次に、特定のヘッドレイヤーを持つモデル(たとえば `BrandNewBertForMaskedLM` )が `BrandNewBertModel` を継承するのではなく、
抽象化のレベルを低く保つために、そのフォワードパスで `BrandNewBertModel` を呼び出すコンポーネントとして使用されるようにしたいと考えています。
新しいモデルには常に `BrandNewBertConfig` という設定クラスが必要です。この設定は常に[`PreTrainedModel`]の属性として保存され、
したがって、`BrandNewBertPreTrainedModel`から継承するすべてのクラスで`config`属性を介してアクセスできます。
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
モデルと同様に、設定は[`PretrainedConfig`]から基本的なシリアル化および逆シリアル化の機能を継承しています。注意すべきは、設定とモデルは常に2つの異なる形式にシリアル化されることです - モデルは*pytorch_model.bin*ファイルに、設定は*config.json*ファイルにシリアル化されます。[`~PreTrainedModel.save_pretrained`]を呼び出すと、自動的に[`~PretrainedConfig.save_pretrained`]も呼び出され、モデルと設定の両方が保存されます。
### Code style
新しいモデルをコーディングする際には、Transformersは意見があるライブラリであり、コードの書き方に関していくつかの独自の考え方があります :-)
1. モデルのフォワードパスはモデリングファイルに完全に記述され、ライブラリ内の他のモデルとは完全に独立している必要があります。他のモデルからブロックを再利用したい場合、コードをコピーしてトップに`# Copied from`コメントを付けて貼り付けます(良い例は[こちら](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)、コピーに関する詳細なドキュメンテーションは[ここ](pr_checks#check-copies)を参照してください)。
2. コードは完全に理解可能でなければなりません。これは記述的な変数名を選択し、省略形を避けるべきであることを意味します。例えば、`act`ではなく`activation`が好まれます。1文字の変数名は、forループ内のインデックスでない限り、強く非推奨です。
3. より一般的に、魔法のような短いコードよりも長くて明示的なコードを好みます。
4. PyTorchでは`nn.Sequential`をサブクラス化せずに、`nn.Module`をサブクラス化し、フォワードパスを記述し、コードを使用する他の人が簡単にデバッグできるようにします。プリントステートメントやブレークポイントを追加してデバッグできるようにします。
5. 関数のシグネチャは型アノテーションを付けるべきです。その他の部分に関しては、型アノテーションよりも良い変数名が読みやすく理解しやすいことがあります。
### Overview of tokenizers
まだ完了していません :-( このセクションは近日中に追加されます!
## Step-by-step recipe to add a model to 🤗 Transformers
モデルを追加する方法は人それぞれ異なるため、他のコントリビューターが🤗 Transformersにモデルを追加する際の要約を確認することが非常に役立つ場合があります。以下は、他のコントリビューターが🤗 Transformersにモデルをポートする際のコミュニティブログ投稿のリストです。
1. [GPT2モデルのポーティング](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) by [Thomas](https://huggingface.co/thomwolf)
2. [WMT19 MTモデルのポーティング](https://huggingface.co/blog/porting-fsmt) by [Stas](https://huggingface.co/stas)
経験から言えることは、モデルを追加する際に最も重要なことは次のようになります:
- 車輪の再発明をしないでください!新しい🤗 Transformersモデルのために追加するコードのほとんどはすでに🤗 Transformers内のどこかに存在しています。類似した既存のモデルやトークナイザを見つけるために、いくつかの時間をかけて探すことが重要です。[grep](https://www.gnu.org/software/grep/)と[rg](https://github.com/BurntSushi/ripgrep)はあなたの友達です。モデルのトークナイザは1つのモデル実装に基づいているかもしれませんが、モデルのモデリングコードは別の実装に基づいていることがあることに注意してください。例えば、FSMTのモデリングコードはBARTに基づいており、FSMTのトークナイザコードはXLMに基づいています。
- これは科学的な課題よりもエンジニアリングの課題です。モデルの論文の理論的な側面をすべて理解しようとするよりも、効率的なデバッグ環境を作成するために時間を費やすべきです。
- 行き詰まった場合は助けを求めてください!モデルは🤗 Transformersのコアコンポーネントであり、Hugging Faceではモデルを追加するための各ステップでお手伝いするのを喜んでいます。進行がないことに気付いた場合は、進展していないことを気にしないでください。
以下では、🤗 Transformersにモデルをポートする際に最も役立つと考えられる一般的なレシピを提供しようとしています。
次のリストは、モデルを追加するために行う必要があるすべてのことの要約であり、To-Doリストとして使用できます:
- ☐ (オプション)モデルの理論的な側面を理解しました
- ☐ 🤗 Transformersの開発環境を準備しました
- ☐ オリジナルのリポジトリのデバッグ環境をセットアップしました
- ☐ `forward()` パスをオリジナルのリポジトリとチェックポイントで正常に実行するスクリプトを作成しました
- ☐ モデルの骨格を🤗 Transformersに正常に追加しました
- ☐ オリジナルのチェックポイントを🤗 Transformersのチェックポイントに正常に変換しました
- ☐ 🤗 Transformersで実行される `forward()` パスを正常に実行し、オリジナルのチェックポイントと同一の出力を得ました
- ☐ 🤗 Transformersでのモデルテストを完了しました
- ☐ 🤗 Transformersにトークナイザを正常に追加しました
- ☐ エンドツーエンドの統合テストを実行しました
- ☐ ドキュメントを完成させました
- ☐ モデルのウェイトをHubにアップロードしました
- ☐ プルリクエストを提出しました
- ☐ (オプション)デモノートブックを追加しました
まず、通常、`BrandNewBert`の理論的な理解を深めることをお勧めします。
ただし、もしモデルの理論的な側面を「実務中に理解する」方が好ましい場合、`BrandNewBert`のコードベースに直接アクセスするのも問題ありません。
このオプションは、エンジニアリングのスキルが理論的なスキルよりも優れている場合、
`BrandNewBert`の論文を理解するのに苦労している場合、または科学的な論文を読むよりもプログラミングを楽しんでいる場合に適しています。
### 1. (Optional) Theoretical aspects of BrandNewBert
BrandNewBertの論文がある場合、その説明を読むための時間を取るべきです。論文の中には理解が難しい部分があるかもしれません。
その場合でも心配しないでください。目標は論文の深い理論的理解を得ることではなく、
🤗 Transformersでモデルを効果的に再実装するために必要な情報を抽出することです。
ただし、理論的な側面にあまり多くの時間をかける必要はありません。代わりに、実践的な側面に焦点を当てましょう。具体的には次の点です:
- *brand_new_bert*はどの種類のモデルですか? BERTのようなエンコーダーのみのモデルですか? GPT2のようなデコーダーのみのモデルですか? BARTのようなエンコーダー-デコーダーモデルですか?
[model_summary](model_summary)を参照して、これらの違いについて詳しく知りたい場合があります。
- *brand_new_bert*の応用分野は何ですか? テキスト分類ですか? テキスト生成ですか? Seq2Seqタスク、例えば要約ですか?
- モデルをBERT/GPT-2/BARTとは異なるものにする新しい機能は何ですか?
- 既存の[🤗 Transformersモデル](https://huggingface.co/transformers/#contents)の中で*brand_new_bert*に最も似ているモデルはどれですか?
- 使用されているトークナイザの種類は何ですか? SentencePieceトークナイザですか? WordPieceトークナイザですか? BERTやBARTで使用されているトークナイザと同じですか?
モデルのアーキテクチャの良い概要を得たと感じたら、Hugging Faceチームに質問を送ることができます。
これにはモデルのアーキテクチャ、注意層などに関する質問が含まれるかもしれません。
私たちは喜んでお手伝いします。
### 2. Next prepare your environment
1. リポジトリのページで「Fork」ボタンをクリックして、[リポジトリ](https://github.com/huggingface/transformers)をフォークします。
これにより、コードのコピーがGitHubユーザーアカウントの下に作成されます。
2. ローカルディスクにある`transformers`フォークをクローンし、ベースリポジトリをリモートとして追加します:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
3. 開発環境をセットアップするために、次のコマンドを実行してください:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
お使いのOSに応じて、およびTransformersのオプションの依存関係の数が増えているため、このコマンドでエラーが発生する可能性があります。
その場合は、作業しているDeep Learningフレームワーク(PyTorch、TensorFlow、および/またはFlax)をインストールし、次の手順を実行してください:
```bash
pip install -e ".[quality]"
```
これはほとんどのユースケースには十分であるはずです。その後、親ディレクトリに戻ることができます。
```bash
cd ..
```
4. Transformersに*brand_new_bert*のPyTorchバージョンを追加することをお勧めします。PyTorchをインストールするには、
https://pytorch.org/get-started/locally/ の指示に従ってください。
**注意:** CUDAをインストールする必要はありません。新しいモデルをCPUで動作させることで十分です。
5. *brand_new_bert*を移植するには、元のリポジトリへのアクセスも必要です。
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
*brand_new_bert*を🤗 Transformersにポートするための開発環境を設定しました。
### 3.-4. Run a pretrained checkpoint using the original repository
最初に、オリジナルの*brand_new_bert*リポジトリで作業します。通常、オリジナルの実装は非常に「研究的」であり、ドキュメンテーションが不足していたり、コードが理解しにくいことがあります。しかし、これが*brand_new_bert*を再実装する動機となるべきです。Hugging Faceでは、主要な目標の1つが、動作するモデルを取り、それをできるだけ**アクセス可能でユーザーフレンドリーで美しい**ものに書き直すことです。これは、🤗 Transformersにモデルを再実装する最も重要な動機です - 複雑な新しいNLP技術を**誰にでも**アクセス可能にしようとする試みです。
まず、オリジナルのリポジトリに入り込むことから始めるべきです。
公式の事前学習済みモデルをオリジナルのリポジトリで正常に実行することは、通常、**最も困難な**ステップです。
私たちの経験から、オリジナルのコードベースに慣れるのに時間をかけることが非常に重要です。以下のことを理解する必要があります:
- 事前学習済みの重みをどこで見つけるか?
- 対応するモデルに事前学習済みの重みをロードする方法は?
- モデルから独立してトークナイザを実行する方法は?
- 1つのフォワードパスを追跡して、単純なフォワードパスに必要なクラスと関数がわかるようにします。通常、これらの関数だけを再実装する必要があります。
- モデルの重要なコンポーネントを特定できること:モデルのクラスはどこにありますか?モデルのサブクラス、*例* EncoderModel、DecoderModelがありますか?自己注意レイヤーはどこにありますか?複数の異なる注意レイヤー、*例* *自己注意*、*クロスアテンション*などが存在しますか?
- オリジナルのリポジトリの環境でモデルをデバッグする方法は?*print*ステートメントを追加する必要があるか、*ipdb*のような対話型デバッガを使用できるか、PyCharmのような効率的なIDEを使用してモデルをデバッグする必要がありますか?
重要なのは、ポーティングプロセスを開始する前に、オリジナルのリポジトリでコードを**効率的に**デバッグできることです!また、これはオープンソースライブラリで作業していることを覚えておいてください。オリジナルのリポジトリでコードを調べる誰かを歓迎するために、問題をオープンにしたり、プルリクエストを送信したりすることをためらわないでください。このリポジトリのメンテナーは、彼らのコードを調べてくれる人に対して非常に喜んでいる可能性が高いです!
この段階では、オリジナルのモデルのデバッグにどのような環境と戦略を使用するかは、あなた次第です。最初にオリジナルのリポジトリに関するコードをデバッグできることが非常に重要です。また、GPU環境をセットアップすることはお勧めしません。まず、CPU上で作業し、モデルがすでに🤗 Transformersに正常にポートされていることを確認します。最後に、モデルがGPU上でも期待通りに動作するかどうかを検証する必要があります。
一般的に、オリジナルのモデルを実行するための2つのデバッグ環境があります:
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- ローカルなPythonスクリプト。
Jupyterノートブックは、セルごとに実行できるため、論理的なコンポーネントをより分割し、中間結果を保存できるため、デバッグサイクルが速くなるという利点があります。また、ノートブックは他の共同作業者と簡単に共有できることが多く、Hugging Faceチームに助けを求める場合に非常に役立つ場合があります。Jupyterノートブックに精通している場合、それ
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
デバッグ戦略については、通常、いくつかの選択肢があります:
- 元のモデルを多くの小さなテスト可能なコンポーネントに分解し、それぞれに対して前方パスを実行して検証します
- 元のモデルを元のトークナイザと元のモデルにのみ分解し、それらに対して前方パスを実行し、検証のために中間のプリントステートメントまたはブレークポイントを使用します
再度、どの戦略を選択するかはあなた次第です。元のコードベースに依存することが多く、元のコードベースに応じて一方または他方が有利なことがあります。
元のコードベースがモデルを小さなサブコンポーネントに分解できる場合、*例えば*元のコードベースが簡単にイーガーモードで実行できる場合、それを行う価値が通常あります。最初からより難しい方法を選択することにはいくつかの重要な利点があります:
- 後で元のモデルを🤗 Transformersの実装と比較する際に、各コンポーネントが対応する🤗 Transformers実装のコンポーネントと一致することを自動的に検証できるため、視覚的な比較に依存せずに済みます
- 大きな問題を小さな問題に分解する、つまり個々のコンポーネントのみをポーティングする問題に分割するのに役立ち、作業を構造化するのに役立ちます
- モデルを論理的な意味のあるコンポーネントに分割することで、モデルの設計をよりよく理解しやすくし、モデルをよりよく理解するのに役立ちます
- 後で、コンポーネントごとのテストを行うことで、コードを変更し続ける際にリグレッションが発生しないことを確認するのに役立ちます
[Lysandreの](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) ELECTRAの統合チェックは、これがどのように行われるかの良い例です。
ただし、元のコードベースが非常に複雑で、中間コンポーネントをコンパイルモードで実行することしか許可しない場合、モデルを小さなテスト可能なサブコンポーネントに分解することが時間がかかりすぎるか、不可能であることがあります。
良い例は[T5のMeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)ライブラリであり、非常に複雑でモデルをサブコンポーネントに分解する簡単な方法を提供しないことがあります。このようなライブラリでは、通常、プリントステートメントを検証することに依存します。
どの戦略を選択しても、推奨される手順は通常同じで、最初のレイヤーからデバッグを開始し、最後のレイヤーからデバッグを行うべきです。
通常、以下の順序で次のレイヤーからの出力を取得することをお勧めします:
1. モデルに渡された入力IDを取得する
2. 単語の埋め込みを取得する
3. 最初のTransformerレイヤーの入力を取得する
4. 最初のTransformerレイヤーの出力を取得する
5. 次のn - 1つのTransformerレイヤーの出力を取得する
6. BrandNewBertモデル全体の出力を取得する
入力IDは整数の配列である必要があり、*例:* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]` のようになります。
以下のレイヤーの出力は多次元の浮動小数点配列であることが多く、次のようになることがあります:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
🤗 Transformersに追加されるすべてのモデルは、統合テストを数回合格することが期待されており、元のモデルと🤗 Transformersで再実装されたバージョンが、0.001の精度までまったく同じ出力を提供する必要があります。
異なるライブラリフレームワークで同じモデルを書いた場合、わずかに異なる出力を返すことが正常であるため、誤差許容値として1e-3(0.001)を受け入れています。モデルがほぼ同じ出力を返すだけでは不十分で、ほぼ同一である必要があります。そのため、🤗 Transformersバージョンの中間出力を元の*brand_new_bert*の実装の中間出力と複数回にわたって比較することになるでしょう。その際、元のリポジトリの**効率的な**デバッグ環境が非常に重要です。以下は、デバッグ環境をできるだけ効率的にするためのアドバイスです。
- 中間結果をデバッグする最適な方法を見つける。元のリポジトリはPyTorchで書かれていますか?その場合、元のモデルをより小さなサブコンポーネントに分解して中間値を取得する長いスクリプトを書くことがおそらく適切です。元のリポジトリがTensorflow 1で書かれている場合、[tf.print](https://www.tensorflow.org/api_docs/python/tf/print)などのTensorFlowのプリント操作を使用して中間値を出力する必要があるかもしれません。元のリポジトリがJaxで書かれている場合、フォワードパスの実行時にモデルが**jittedされていない**ことを確認してください。例:[このリンク](https://github.com/google/jax/issues/196)をチェック。
- 使用可能な最小の事前学習済みチェックポイントを使用します。チェックポイントが小さいほど、デバッグサイクルが速くなります。事前学習済みモデルがフォワードパスに10秒以上かかる場合、効率的ではありません。非常に大きなチェックポイントしか利用できない場合、新しい環境でランダムに初期化されたウェイトを持つダミーモデルを作成し、それらのウェイトを🤗 Transformersバージョンのモデルと比較する方が良いかもしれません。
- 元のリポジトリでフォワードパスを呼び出す最も簡単な方法を使用していることを確認してください。理想的には、元のリポジトリで**単一のフォワードパス**を呼び出す関数を見つけたいです。これは通常「predict」、「evaluate」、「forward」、「__call__」と呼ばれます。複数回「forward」を呼び出す関数をデバッグしたくありません。例:テキストを生成するために「autoregressive_sample」、「generate」と呼ばれる関数。
- トークナイゼーションとモデルの「フォワード」パスを分離しようとしてください。元のリポジトリが入力文字列を入力する必要がある例を示す場合、フォワードコール内で文字列入力が入力IDに変更される場所を特定し、このポイントから開始します。これは、スクリプトを自分で書くか、入力文字列ではなく入力IDを直接入力できるように元のコードを変更する必要があるかもしれません。
- デバッグセットアップ内のモデルがトレーニングモードではないことを確認してください。トレーニングモードでは、モデル内の複数のドロップアウトレイヤーのためにランダムな出力が生成されることがあります。デバッグ環境のフォワードパスが**決定論的**であることを確認し、ドロップアウトレイヤーが使用されないようにします。または、新しい実装が同じフレームワーク内にある場合、*transformers.utils.set_seed*を使用してください。
以下のセクションでは、*brand_new_bert*についてこれを具体的にどのように行うかについての詳細/ヒントを提供します。
### 5.-14. Port BrandNewBert to 🤗 Transformers
次に、ついに新しいコードを🤗 Transformersに追加できます。🤗 Transformersのフォークのクローンに移動してください:
```bash
cd transformers
```
特別なケースとして、既存のモデルと完全に一致するアーキテクチャのモデルを追加する場合、
[このセクション](#write-a-conversion-script)で説明されているように、変換スクリプトを追加するだけで済みます。
この場合、既存のモデルの完全なモデルアーキテクチャを再利用できます。
それ以外の場合、新しいモデルの生成を開始します。ここで2つの選択肢があります:
- `transformers-cli add-new-model-like`を使用して既存のモデルのような新しいモデルを追加します
- `transformers-cli add-new-model`を使用して、テンプレートから新しいモデルを追加します(モデルのタイプに応じてBERTまたはBartのように見えます)
どちらの場合でも、モデルの基本情報を入力するための質問事項が表示されます。
2番目のコマンドを実行するには、`cookiecutter`をインストールする必要があります。
詳細については[こちら](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)をご覧ください。
**主要な huggingface/transformers リポジトリでプルリクエストを開く**
自動生成されたコードを適応し始める前に、🤗 Transformers に「作業中(WIP)」プルリクエストを開くタイミングです。
例:「[WIP] *brand_new_bert* を追加」などです。
これにより、ユーザーと Hugging Face チームが🤗 Transformers にモデルを統合する作業を並行して行うことができます。
以下の手順を実行してください:
1. メインブランチから分かりやすい名前のブランチを作成します。
```bash
git checkout -b add_brand_new_bert
```
2. 自動生成されたコードをコミットしてください:
```bash
git add .
git commit
```
3. 現在の main ブランチにフェッチしてリベース
```bash
git fetch upstream
git rebase upstream/main
```
4. 変更をあなたのアカウントにプッシュするには、次のコマンドを使用します:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. 満足したら、GitHub上のフォークのウェブページに移動します。[プルリクエスト]をクリックします。将来の変更に備えて、Hugging Face チームのメンバーのGitHubハンドルをレビュアーとして追加してください。
6. GitHubのプルリクエストウェブページの右側にある「ドラフトに変換」をクリックして、PRをドラフトに変更します。
以下では、進捗があった場合は常に作業をコミットし、プッシュしてプルリクエストに表示されるようにしてください。さらに、定期的にメインからの最新の変更を取り込むために、次のように行うことを忘れないでください:
```bash
git fetch upstream
git merge upstream/main
```
一般的に、モデルや実装に関する質問はPull Request (PR) で行い、PR内で議論し、解決します。
これにより、Hugging Face チームは新しいコードをコミットする際や質問がある場合に常に通知を受けることができます。
質問や問題が解決された際に、問題や質問が理解されやすいように、Hugging Face チームにコードを指摘することが非常に役立ちます。
このためには、「Files changed」タブに移動してすべての変更を表示し、質問したい行に移動して「+」シンボルをクリックしてコメントを追加します。
質問や問題が解決された場合は、作成されたコメントの「Resolve」ボタンをクリックできます。
同様に、Hugging Face チームはコードをレビューする際にコメントを開きます。
PR上でのほとんどの質問はGitHub上で行うことをお勧めします。
一般的な質問に関しては、公にはあまり役立たない質問については、SlackやメールでHugging Face チームに連絡することもできます。
**5. 生成されたモデルコードを"brand_new_bert"に適応させる**
最初に、モデル自体に焦点を当て、トークナイザには気にしないでください。
関連するコードは、生成されたファイル`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`および`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`で見つかるはずです。
さて、ついにコーディングを始めることができます :smile:。
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`にある生成されたコードは、エンコーダーのみのモデルであればBERTと同じアーキテクチャを持っているか、エンコーダー-デコーダーモデルであればBARTと同じアーキテクチャを持っているはずです。
この段階では、モデルの理論的な側面について学んだことを思い出すべきです。つまり、「このモデルはBERTまたはBARTとどのように異なるのか?」ということです。
これらの変更を実装しますが、これは通常、セルフアテンションレイヤー、正規化レイヤーの順序などを変更することを意味します。
再び、あなたのモデルがどのように実装されるべきかをより良く理解するために、Transformers内に既存のモデルの類似アーキテクチャを見ることが役立つことがあります。
この時点では、コードが完全に正確またはクリーンである必要はありません。
むしろ、まずは必要なコードの最初の*クリーンでない*コピー&ペーストバージョンを
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`に追加し、必要なコードがすべて追加されていると感じるまで改善/修正を反復的に行うことがお勧めです。
私たちの経験から、必要なコードの最初のバージョンを迅速に追加し、次のセクションで説明する変換スクリプトを使用してコードを繰り返し改善/修正する方が効率的であることが多いです。
この時点で動作する必要があるのは、🤗 Transformersの"brand_new_bert"の実装をインスタンス化できることだけです。つまり、以下のコマンドが機能する必要があります:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
上記のコマンドは、`BrandNewBertConfig()` で定義されたデフォルトパラメータに従ってモデルを作成し、
すべてのコンポーネントの `init()` メソッドが正常に動作することを確認します。
すべてのランダムな初期化は、`BrandnewBertPreTrainedModel` クラスの `_init_weights` メソッドで行う必要があります。
このメソッドは、設定変数に依存するすべてのリーフモジュールを初期化する必要があります。以下は、BERT の `_init_weights` メソッドの例です:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
特定のモジュールに特別な初期化が必要な場合、カスタムスキームをさらに持つことができます。たとえば、
`Wav2Vec2ForPreTraining`では、最後の2つの線形層には通常のPyTorchの`nn.Linear`の初期化が必要ですが、
他のすべての層は上記のような初期化を使用する必要があります。これは以下のようにコーディングされています:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstnace(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
`_is_hf_initialized`フラグは、サブモジュールを一度だけ初期化することを確実にするために内部で使用されます。
`module.project_q`と`module.project_hid`のためにそれを`True`に設定することで、
カスタム初期化が後で上書きされないようにし、`_init_weights`関数がそれらに適用されないようにします。
**6. 変換スクリプトを書く**
次に、*brand_new_bert* の元のリポジトリでデバッグに使用したチェックポイントを、新しく作成した 🤗 Transformers 実装の *brand_new_bert* と互換性のあるチェックポイントに変換できる変換スクリプトを書く必要があります。
変換スクリプトをゼロから書くことはお勧めされませんが、代わりに 🤗 Transformers で既に存在する類似のモデルを同じフレームワークで変換したスクリプトを調べることが良いでしょう。
通常、既存の変換スクリプトをコピーして、自分のユースケースにわずかに適応させることで十分です。
Hugging Face チームに既存のモデルに類似した変換スクリプトを教えてもらうことも躊躇しないでください。
- TensorFlowからPyTorchにモデルを移植している場合、良い出発点はBERTの変換スクリプトかもしれません [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- PyTorchからPyTorchにモデルを移植している場合、良い出発点はBARTの変換スクリプトかもしれません [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
以下では、PyTorchモデルが層の重みをどのように保存し、層の名前を定義するかについて簡単に説明します。
PyTorchでは、層の名前は層に与えるクラス属性の名前によって定義されます。
PyTorchで `SimpleModel` というダミーモデルを定義しましょう:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
これで、このモデル定義のインスタンスを作成し、`dense`、`intermediate`、`layer_norm`のすべての重みをランダムな重みで埋めたモデルを作成できます。モデルのアーキテクチャを確認するために、モデルを印刷してみましょう。
```python
model = SimpleModel()
print(model)
```
これは以下を出力します:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
層の名前はPyTorchのクラス属性の名前によって定義されています。特定の層の重み値を出力することができます:
```python
print(model.dense.weight.data)
```
ランダムに初期化された重みを確認するために
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
スクリプト内の変換スクリプトでは、ランダムに初期化された重みを、対応するチェックポイント内の正確な重みで埋める必要があります。例えば、以下のように翻訳します:
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
PyTorchモデルの各ランダム初期化された重みと対応する事前学習済みチェックポイントの重みが
**形状と名前の両方**で正確に一致することを確認する必要があります。
これを行うために、形状に対するassertステートメントを追加し、チェックポイントの重みの名前を出力することが
**必要不可欠**です。例えば、次のようなステートメントを追加する必要があります:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
また、両方の重みの名前を印刷して、一致していることを確認する必要があります。例えば、次のようにします:
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
もし形状または名前のいずれかが一致しない場合、おそらく誤って🤗 Transformersの実装に初期化されたレイヤーに間違ったチェックポイントの重みを割り当ててしまった可能性があります。
誤った形状は、おそらく`BrandNewBertConfig()`での設定パラメーターが、変換したいチェックポイントで使用されたものと正確に一致しないためです。
ただし、PyTorchのレイヤーの実装によっては、重みを事前に転置する必要がある場合もあります。
最後に、**すべて**の必要な重みが初期化されていることを確認し、初期化に使用されなかったすべてのチェックポイントの重みを表示して、モデルが正しく変換されていることを確認してください。
変換トライアルが誤った形状ステートメントまたは誤った名前割り当てで失敗するのは完全に正常です。
これはおそらく、`BrandNewBertConfig()`で誤ったパラメーターを使用したか、🤗 Transformersの実装に誤ったアーキテクチャがあるか、🤗 Transformersの実装の1つのコンポーネントの`init()`関数にバグがあるか、チェックポイントの重みの1つを転置する必要があるためです。
このステップは、以前のステップと繰り返すべきです。すべてのチェックポイントの重みが正しく🤗 Transformersモデルに読み込まれるまで繰り返すべきです。
🤗 Transformers実装に正しくチェックポイントを読み込んだ後、選択したフォルダーにモデルを保存できます `/path/to/converted/checkpoint/folder`。このフォルダには`pytorch_model.bin`ファイルと`config.json`ファイルの両方が含まれるはずです。
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. 順伝播(forward pass)の実装**
🤗 Transformers実装で事前学習済みの重みを正しく読み込んだ後、順伝播が正しく実装されていることを確認する必要があります。[元のリポジトリを理解する](#34-run-a-pretrained-checkpoint-using-the-original-repository)で、元のリポジトリを使用してモデルの順伝播を実行するスクリプトをすでに作成しました。今度は、元のリポジトリの代わりに🤗 Transformers実装を使用して類似のスクリプトを作成する必要があります。以下のようになります:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
🤗 Transformersの実装と元のモデルの実装が最初の実行で完全に同じ出力を提供しないか、
フォワードパスでエラーが発生する可能性が非常に高いです。失望しないでください - これは予想されていることです!
まず、フォワードパスがエラーをスローしないことを確認する必要があります。
間違った次元が使用され、*次元の不一致*エラーや、誤ったデータ型オブジェクトが使用されることがよくあります。
例えば、`torch.long`ではなく`torch.float32`が使用されます。特定のエラーを解決できない場合は、
Hugging Faceチームに助けを求めることを躊躇しないでください。
🤗 Transformers実装が正しく機能することを確認する最終的な部分は、出力が`1e-3`の精度で同等であることを確認することです。
まず、出力の形状が同一であること、つまりスクリプトの🤗 Transformers実装と元の実装の両方で`outputs.shape`が同じ値を生成する必要があります。
次に、出力値が同一であることを確認する必要があります。
これは新しいモデルを追加する際の最も難しい部分の1つです。
出力が同一でない理由の一般的な間違いは以下の通りです。
- 一部のレイヤーが追加されていない、つまり*活性化*レイヤーが追加されていないか、リザバル接続が忘れられている
- 単語埋め込み行列が結ばれていない
- オリジナルの実装がオフセットを使用しているため、誤った位置埋め込みが使用されている
- フォワードパス中にドロップアウトが適用されています。これを修正するには、*model.trainingがFalse*であることを確認し、フォワードパス中に誤ってドロップアウトレイヤーがアクティブ化されないようにします。
*つまり* [PyTorchのfunctional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)に*model.training*を渡します。
問題を修正する最良の方法は、通常、元の実装と🤗 Transformers実装のフォワードパスを並べて表示し、違いがあるかどうかを確認することです。
理想的には、フォワードパスの両方の実装の中間出力をデバッグ/プリントアウトして、🤗 Transformers実装が元の実装と異なる出力を示すネットワーク内の正確な位置を見つけることができます。
最初に、両方のスクリプトのハードコーディングされた`input_ids`が同一であることを確認します。
次に、`input_ids`の最初の変換(通常、単語埋め込み)の出力が同一であることを確認します。
その後、ネットワークの最後のレイヤーまで作業を進めます。
いずれかの時点で、2つの実装間で違いがあることに気付くはずで、それにより🤗 Transformers実装のバグの場所が特定されます。
経験上、元の実装と🤗 Transformers実装のフォワードパスの同じ位置に多くのプリントステートメントを追加し、
中間プレゼンテーションで同じ値を示すプリントステートメントを段階的に削除するのがシンプルかつ効果的な方法です。
両方の実装が同じ出力を生成することに自信を持っている場合、`torch.allclose(original_output, output, atol=1e-3)`を使用して出力を確認すると、最も難しい部分が完了します!
おめでとうございます - 完了する作業は簡単なものになるはずです 😊。
**8. 必要なすべてのモデルテストを追加**
この時点で、新しいモデルが正常に追加されました。
ただし、モデルがまだ必要な設計に完全に準拠していない可能性が非常に高いです。
🤗 Transformersと完全に互換性があることを確認するために、すべての一般的なテストがパスする必要があります。
Cookiecutterはおそらくモデル用のテストファイルを自動的に追加しているはずで、おそらく同じディレクトリに`tests/models/brand_new_bert/test_modeling_brand_new_bert.py`として存在します。
このテストファイルを実行して、すべての一般的なテストがパスすることを確認してください:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
すべての一般的なテストを修正したら、今度は実行したすべての素晴らしい作業が適切にテストされていることを確認することが非常に重要です。これにより、
- a) コミュニティは*brand_new_bert*の特定のテストを見ることで、あなたの作業を簡単に理解できます。
- b) モデルへの将来の変更がモデルの重要な機能を壊さないようにすることができます。
まず、統合テストを追加する必要があります。これらの統合テストは、基本的にはデバッグスクリプトと同じことを行います。これらのモデルテストのテンプレートはCookiecutterによって既に追加されており、「BrandNewBertModelIntegrationTests」と呼ばれています。このテストを記入するだけです。これらのテストが合格していることを確認するには、次のコマンドを実行します。
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
<Tip>
Windowsを使用している場合、`RUN_SLOW=1`を`SET RUN_SLOW=1`に置き換えてください。
</Tip>
次に、*brand_new_bert*に特有のすべての特徴は、別個のテスト内で追加されるべきです。
`BrandNewBertModelTester`/`BrandNewBertModelTest`の下に。この部分はよく忘れられますが、2つの点で非常に役立ちます:
- モデルの追加中に獲得した知識をコミュニティに伝え、*brand_new_bert*の特別な機能がどのように動作するかを示すことによって、知識の共有を支援します。
- 将来の貢献者は、これらの特別なテストを実行することでモデルへの変更を迅速にテストできます。
**9. トークナイザの実装**
次に、*brand_new_bert*のトークナイザを追加する必要があります。通常、トークナイザは🤗 Transformersの既存のトークナイザと同等か非常に似ています。
トークナイザが正しく動作することを確認するためには、まず、元のリポジトリ内で文字列を入力し、`input_ids`を返すスクリプトを作成することをお勧めします。
このスクリプトは、次のように見えるかもしれません(疑似コードで示します):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
オリジナルのリポジトリを詳しく調査し、正しいトークナイザの関数を見つける必要があるかもしれません。
または、オリジナルのリポジトリのクローンを変更して、`input_ids`だけを出力するようにする必要があるかもしれません。
オリジナルのリポジトリを使用した機能的なトークナイゼーションスクリプトを作成した後、
🤗 Transformers向けの類似したスクリプトを作成する必要があります。
以下のように見えるべきです:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
`input_ids`が同じ値を生成した場合、最終ステップとしてトークナイザのテストファイルも追加するべきです。
*brand_new_bert*のモデルングテストファイルと同様に、*brand_new_bert*のトークナイズテストファイルには、いくつかのハードコードされた統合テストが含まれるべきです。
**10. エンドツーエンド統合テストの実行**
トークナイザを追加した後、`🤗 Transformers`内の`tests/models/brand_new_bert/test_modeling_brand_new_bert.py`に
モデルとトークナイザの両方を使用するいくつかのエンドツーエンド統合テストも追加する必要があります。
このようなテストは、🤗 Transformersの実装が期待どおりに機能することを示すべきです。
意味のあるテキスト対テキストのサンプルが含まれます。有用なテキスト対テキストのサンプルには、ソースからターゲットへの翻訳ペア、記事から要約へのペア、質問から回答へのペアなどが含まれます。
ポートされたチェックポイントがダウンストリームタスクでファインチューニングされていない場合、モデルのテストに依存するだけで十分です。
モデルが完全に機能していることを確認するために、すべてのテストをGPU上で実行することもお勧めします。
モデルの内部テンソルに`.to(self.device)`ステートメントを追加するのを忘れる可能性があるため、そのようなテストではエラーが表示されることがあります。
GPUにアクセスできない場合、Hugging Faceチームが代わりにこれらのテストを実行できます。
**11. ドキュメントの追加**
これで、*brand_new_bert*の必要なすべての機能が追加されました - ほぼ完了です!残りの追加すべきことは、良いドキュメントとドキュメントページです。
Cookiecutterが`docs/source/model_doc/brand_new_bert.md`というテンプレートファイルを追加しているはずで、これを記入する必要があります。
モデルのユーザーは通常、モデルを使用する前にまずこのページを見ます。したがって、ドキュメンテーションは理解しやすく簡潔である必要があります。
モデルの使用方法を示すためにいくつかの*Tips*を追加することはコミュニティにとって非常に役立ちます。ドキュメンテーションに関しては、Hugging Faceチームに問い合わせることをためらわないでください。
次に、`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`に追加されたドキュメンテーション文字列が正しいこと、およびすべての必要な入力および出力を含んでいることを確認してください。
ドキュメンテーションの書き方とドキュメンテーション文字列のフォーマットについて詳細なガイドが[こちら](writing-documentation)にあります。
ドキュメンテーションは通常、コミュニティとモデルの最初の接触点であるため、コードと同じくらい注意深く扱うべきであることを常に念頭に置いてください。
**コードのリファクタリング**
素晴らしい、これで*brand_new_bert*に必要なすべてのコードが追加されました。
この時点で、次のようなポテンシャルなコードスタイルの誤りを訂正するために以下を実行する必要があります:
```bash
make style
```
あなたのコーディングスタイルが品質チェックをパスすることを確認してください:
```bash
make quality
```
🤗 Transformersの非常に厳格なデザインテストには、まだ合格していない可能性があるいくつかの他のテストが存在するかもしれません。
これは、ドキュメント文字列に情報が不足しているか、名前が間違っていることが原因であることが多いです。Hugging Faceチームは、ここで詰まっている場合には必ず助けてくれるでしょう。
最後に、コードが正しく機能することを確認した後、コードをリファクタリングするのは常に良いアイデアです。
すべてのテストがパスした今、追加したコードを再度確認してリファクタリングを行うのは良いタイミングです。
これでコーディングの部分は完了しました、おめでとうございます! 🎉 あなたは素晴らしいです! 😎
**12. モデルをモデルハブにアップロード**
最後のパートでは、すべてのチェックポイントをモデルハブに変換してアップロードし、各アップロードしたモデルチェックポイントにモデルカードを追加する必要があります。
モデルハブの機能について詳しくは、[Model sharing and uploading Page](model_sharing)を読んで理解できます。
ここでは、*brand_new_bert*の著者組織の下にモデルをアップロードできるように必要なアクセス権を取得するために、Hugging Faceチームと協力する必要があります。
`transformers`のすべてのモデルに存在する`push_to_hub`メソッドは、チェックポイントをハブにプッシュする迅速かつ効率的な方法です。
以下に、少しのコードスニペットを示します:
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("<organization>/brand_new_bert")
```
各チェックポイントに適切なモデルカードを作成する価値があります。モデルカードは、この特定のチェックポイントの特性をハイライトするべきです。例えば、このチェックポイントはどのデータセットで事前学習/ファインチューニングされたか、どのような下流タスクでモデルを使用すべきかを示すべきです。また、モデルの正しい使用方法に関するコードも含めるべきです。
**13.(オプション)ノートブックの追加**
*brand_new_bert*を推論または下流タスクのファインチューニングにどのように詳細に使用できるかを示すノートブックを追加することは非常に役立ちます。これはあなたのPRをマージするために必須ではありませんが、コミュニティにとって非常に有用です。
**14. 完成したPRの提出**
プログラミングが完了したら、最後のステップに移動し、PRをメインブランチにマージしましょう。通常、Hugging Faceチームはこの時点で既にあなたをサポートしているはずですが、PRに良い説明を追加し、コードにコメントを追加して、レビュアーに特定の設計の選択肢を指摘したい場合はコメントを追加することも価値があります。
### Share your work!!
さあ、コミュニティからあなたの作業に対する評価を得る時が来ました!モデルの追加を完了することは、TransformersおよびNLPコミュニティにとって重要な貢献です。あなたのコードとポートされた事前学習済みモデルは、何百人、何千人という開発者や研究者によって確実に使用されるでしょう。あなたの仕事に誇りを持ち、コミュニティとあなたの成果を共有しましょう。
**あなたはコミュニティの誰でも簡単にアクセスできる別のモデルを作成しました! 🤯**
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/pipeline_webserver.md
|
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Webサーバー用のパイプラインの使用
<Tip>
推論エンジンの作成は複雑なトピックであり、"最適な"ソリューションはおそらく問題の領域に依存するでしょう。CPUまたはGPUを使用していますか?最低のレイテンシ、最高のスループット、多くのモデルのサポート、または特定のモデルの高度な最適化を望んでいますか?
このトピックに取り組むための多くの方法があり、私たちが紹介するのは、おそらく最適なソリューションではないかもしれないが、始めるための良いデフォルトです。
</Tip>
重要なことは、Webサーバーはリクエストを待機し、受信したように扱うシステムであるため、[データセット](pipeline_tutorial#using-pipelines-on-a-dataset)のように、イテレータを使用できることです。
通常、Webサーバーは並列処理(マルチスレッド、非同期など)されて、さまざまなリクエストを同時に処理します。一方、パイプライン(および主にその基礎となるモデル)は並列処理にはあまり適していません。それらは多くのRAMを使用するため、実行中に利用可能なリソースをすべて提供するか、計算集約型のジョブである場合に最適です。
Webサーバーは受信と送信の軽い負荷を処理し、実際の作業を1つのスレッドで処理するようにします。この例では`starlette`を使用します。実際のフレームワークはあまり重要ではありませんが、別のフレームワークを使用している場合は、同じ効果を得るためにコードを調整または変更する必要があるかもしれません。
`server.py`を作成してください:
```py
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
```
ここから始めることができます:
```bash
uvicorn server:app
```
そして、次のようにクエリできます:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
```
そして、これでウェブサーバーを作成する方法の良いアイデアを持っています!
本当に重要なのは、モデルを**一度だけ**ロードすることです。これにより、ウェブサーバー上にモデルのコピーがないため、不必要なRAMが使用されなくなります。
その後、キューイングメカニズムを使用して、動的バッチ処理を行うなど、いくつかのアイテムを蓄積してから推論を行うなど、高度な処理を行うことができます:
<Tip warning={true}>
以下のコードサンプルは、可読性のために擬似コードのように書かれています。システムリソースに合理的かどうかを確認せずに実行しないでください!
</Tip>
```py
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
```
まず第一に、通常はあまり良いアイデアではないバッチサイズの制限がありません。次に、タイムアウトはキューの取得ごとにリセットされるため、推論を実行する前に1ms以上待つ可能性があります(最初のリクエストの遅延に1ms分遅れが生じます)。
1msの締め切りを1回だけ持つのが良いでしょう。
これは、キューに何もない場合でも常に1ms待機しますが、キューに何もない場合に推論を開始したい場合は適していないかもしれません。ただし、バッチ処理が本当に重要な場合には意味があるかもしれません。再度、1つの最適な解決策は存在しません。
## Few things you might want to consider
### Error checking
本番環境では多くの問題が発生する可能性があります:メモリ不足、スペース不足、モデルの読み込みが失敗するかもしれません、クエリが誤っているかもしれません、クエリが正しい場合でもモデルの構成エラーのために実行に失敗するかもしれませんなど。
一般的には、サーバーがエラーをユーザーに出力すると良いため、これらのエラーを表示するための多くの`try..except`ステートメントを追加することは良いアイデアです。ただし、セキュリティコンテキストに応じてこれらのエラーをすべて表示することはセキュリティリスクになる可能性があることに注意してください。
### Circuit breaking
Webサーバーは通常、過負荷時に正しいエラーを返す方が良いです。クエリを無期限に待つ代わりに適切なエラーを返します。長時間待つ代わりに503エラーを返すか、長時間待ってから504エラーを返すかです。
提案されたコードでは単一のキューがあるため、キューサイズを見ることは、Webサーバーが負荷に耐える前にエラーを返すための基本的な方法です。
### Blocking the main thread
現在、PyTorchは非同期を認識していないため、計算はメインスレッドをブロックします。つまり、PyTorchが独自のスレッド/プロセスで実行されるようにすると良いでしょう。提案されたコードは、スレッドと非同期とキューがうまく連携しないため、これは行われていませんが、最終的には同じことを行います。
これは、単一のアイテムの推論が長い場合(>1秒)に重要です。この場合、推論中にすべてのクエリが1秒待たなければならないことを意味します。
### Dynamic batching
一般的に、バッチ処理は1回のアイテムを1回渡すよりも改善されることは必ずしもありません(詳細は[バッチ処理の詳細](./main_classes/pipelines#pipeline-batching)を参照)。しかし、正しい設定で使用すると非常に効果的です。APIではデフォルトで動的バッチ処理は行われません(遅延の機会が多すぎます)。しかし、非常に大規模なモデルであるBLOOM推論の場合、動的バッチ処理は**重要**です。これにより、すべてのユーザーにとってまともなエクスペリエンスを提供できます。
以上が、提供されたテキストのMarkdown形式の翻訳です。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_gpu_many.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on Multiple GPUs
単一のGPUでのトレーニングが遅すぎる場合や、モデルの重みが単一のGPUのメモリに収まらない場合、複数のGPUを使用したセットアップが必要となります。単一のGPUから複数のGPUへの切り替えには、ワークロードを分散するためのある種の並列処理が必要です。データ、テンソル、またはパイプラインの並列処理など、さまざまな並列処理技術があります。ただし、すべてに適した一つの解決策は存在せず、最適な設定は使用するハードウェアに依存します。この記事は、おそらく他のフレームワークにも適用される主要な概念に焦点を当てつつ、PyTorchベースの実装に焦点を当てています。
<Tip>
**注意**: [単一GPUセクション](perf_train_gpu_one) で紹介された多くの戦略(混合精度トレーニングや勾配蓄積など)は一般的であり、モデルのトレーニングに一般的に適用されます。したがって、マルチGPUやCPUトレーニングなどの次のセクションに入る前に、それを確認してください。
</Tip>
まず、さまざまな1D並列処理技術とその利点および欠点について詳しく説明し、それらを2Dおよび3D並列処理に組み合わせてさらに高速なトレーニングを実現し、より大きなモデルをサポートする方法を検討します。さまざまな他の強力な代替手法も紹介されます。
## Concepts
以下は、この文書で後で詳しく説明される主要な概念の簡単な説明です。
1. **DataParallel (DP)** - 同じセットアップが複数回複製され、各セットアップにデータのスライスが供給されます。処理は並行して行われ、各セットアップはトレーニングステップの最後に同期されます。
2. **TensorParallel (TP)** - 各テンソルは複数のチャンクに分割され、単一のGPUにテンソル全体が存在するのではなく、テンソルの各シャードが指定されたGPUに存在します。処理中に、各シャードは別々に並行して処理され、異なるGPUで同期され、ステップの最後に結果が同期されます。これは水平並列処理と呼ばれるもので、分割は水平レベルで行われます。
3. **PipelineParallel (PP)** - モデルは垂直(レイヤーレベル)に複数のGPUに分割され、モデルの単一または複数のレイヤーが単一のGPUに配置されます。各GPUはパイプラインの異なるステージを並行して処理し、バッチの小さなチャンクで作業します。
4. **Zero Redundancy Optimizer (ZeRO)** - TPといくらか似たようなテンソルのシャーディングを実行しますが、前向きまたは後向きの計算のためにテンソル全体が再構築されるため、モデルを変更する必要はありません。また、GPUメモリが制限されている場合に補償するためのさまざまなオフロード技術をサポートします。
5. **Sharded DDP** - Sharded DDPは、さまざまなZeRO実装で使用される基本的なZeROコンセプトの別名です。
各コンセプトの詳細に深入りする前に、大規模なインフラストラクチャで大規模なモデルをトレーニングする際の大まかな決定プロセスを見てみましょう。
## Scalability Strategy
**⇨ シングルノード / マルチGPU**
* モデルが単一のGPUに収まる場合:
1. DDP - 分散データ並列
2. ZeRO - 状況と使用される構成に応じて速いかどうかが異なります
* モデルが単一のGPUに収まらない場合:
1. PP
2. ZeRO
3. TP
非常に高速なノード内接続(NVLINKまたはNVSwitchなど)があれば、これらの3つはほぼ同じ速度になるはずで、これらがない場合、PPはTPまたはZeROよりも速くなります。TPの程度も差を生じるかもしれません。特定のセットアップでの勝者を見つけるために実験することが最善です。
TPはほとんどの場合、単一ノード内で使用されます。つまり、TPサイズ <= ノードごとのGPU数です。
* 最大のレイヤーが単一のGPUに収まらない場合:
1. ZeROを使用しない場合 - TPを使用する必要があります。PP単独では収まらないでしょう。
2. ZeROを使用する場合 - "シングルGPU"のエントリと同じものを参照してください
**⇨ マルチノード / マルチGPU**
* ノード間の高速接続がある場合:
1. ZeRO - モデルへのほとんどの変更が不要です
2. PP+TP+DP - 通信が少なく、モデルへの大規模な変更が必要です
* ノード間の接続が遅く、GPUメモリがまだ不足している場合:
1. DP+PP+TP+ZeRO-1
## Data Parallelism
2つのGPUを持つほとんどのユーザーは、`DataParallel`(DP)と`DistributedDataParallel`(DDP)によって提供されるトレーニング速度の向上をすでに享受しています。これらはほぼ自明に使用できるPyTorchの組み込み機能です。一般的に、すべてのモデルで動作するDDPを使用することをお勧めします。DPは一部のモデルで失敗する可能性があるためです。[PyTorchのドキュメンテーション](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html)自体もDDPの使用を推奨しています。
### DP vs DDP
`DistributedDataParallel`(DDP)は通常、`DataParallel`(DP)よりも高速ですが、常にそうとは限りません:
* DPはPythonスレッドベースですが、DDPはマルチプロセスベースです。そのため、GIL(Global Interpreter Lock)などのPythonスレッドの制約がないためです。
* 一方、GPUカード間の遅い相互接続性は、DDPの場合に実際には遅い結果をもたらす可能性があります。
以下は、2つのモード間のGPU間通信の主な違いです:
[DDP](https://pytorch.org/docs/master/notes/ddp.html):
- 開始時、メインプロセスはモデルをGPU 0から他のGPUに複製します。
- それから各バッチごとに:
1. 各GPUは各自のミニバッチのデータを直接消費します。
2. `backward`中、ローカル勾配が準備できると、それらはすべてのプロセスで平均化されます。
[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
各バッチごとに:
1. GPU 0はデータバッチを読み取り、それから各GPUにミニバッチを送信します。
2. GPU 0から各GPUに最新のモデルを複製します。
3. `forward`を実行し、各GPUからGPU 0に出力を送信し、損失を計算します。
4. GPU 0からすべてのGPUに損失を分散し、`backward`を実行します。
5. 各GPUからGPU 0に勾配を送信し、それらを平均化します。
DDPはバッチごとに行う通信は勾配の送信のみであり、一方、DPはバッチごとに5つの異なるデータ交換を行います。
DPはプロセス内でデータをPythonスレッドを介してコピーしますが、DDPは[torch.distributed](https://pytorch.org/docs/master/distributed.html)を介してデータをコピーします。
DPではGPU 0は他のGPUよりもはるかに多くの作業を行うため、GPUの未使用率が高くなります。
DDPは複数のマシン間で使用できますが、DPの場合はそうではありません。
DPとDDPの他にも違いがありますが、この議論には関係ありません。
これら2つのモードを深く理解したい場合、この[記事](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/)を強くお勧めします。素晴らしいダイアグラムを含み、さまざまなハードウェアでの複数のベンチマークとプロファイラの出力を示し、知っておく必要があるすべての微妙なニュアンスを説明しています。
実際のベンチマークを見てみましょう:
| Type | NVlink | Time |
| :----- | ----- | ---: |
| 2:DP | Y | 110s |
| 2:DDP | Y | 101s |
| 2:DDP | N | 131s |
解析:
ここで、DPはNVlinkを使用したDDPに比べて約10%遅く、NVlinkを使用しないDDPに比べて約15%高速であることが示されています。
実際の違いは、各GPUが他のGPUと同期する必要があるデータの量に依存します。同期するデータが多いほど、遅いリンクが合計の実行時間を遅くする可能性が高くなります。
以下は完全なベンチマークコードと出力です:
`NCCL_P2P_DISABLE=1`を使用して、対応するベンチマークでNVLink機能を無効にしました。
```
# DP
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
# DDP w/ NVlink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVlink
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
ハードウェア: 2x TITAN RTX、各24GB + 2つのNVLink(`nvidia-smi topo -m`で `NV2`)
ソフトウェア: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
## ZeRO Data Parallelism
ZeROパワードデータ並列処理(ZeRO-DP)は、次の[ブログ投稿](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)のダイアグラムで説明されています。

これは理解が難しいかもしれませんが、実際にはこの概念は非常にシンプルです。これは通常の`DataParallel`(DP)ですが、完全なモデルパラメータ、勾配、およびオプティマイザの状態を複製する代わりに、各GPUはそれぞれのスライスのみを保存します。そして、実行時に、特定のレイヤーに必要な完全なレイヤーパラメータが必要な場合、すべてのGPUが同期して、お互いに不足している部分を提供します。それがすべてです。
3つのレイヤーからなる単純なモデルを考えてみましょう。各レイヤーには3つのパラメータがあります:
```
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
```
レイヤーLaには、重みa0、a1、およびa2があります。
3つのGPUがある場合、Sharded DDP(= Zero-DP)はモデルを3つのGPUに次のように分割します:
```
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
```
これは、典型的なディープニューラルネットワーク(DNN)のダイアグラムを想像すると、テンソル並列処理と同様の水平スライスであるようなものです。垂直スライスは、異なるGPUに完全な層グループを配置する方法です。しかし、これは単なる出発点に過ぎません。
これから、各GPUは通常のデータ並列処理(DP)と同様に、通常のミニバッチを受け取ります:
```
x0 => GPU0
x1 => GPU1
x2 => GPU2
```
最初に、入力データはレイヤーLaに適用されます。
GPU0に焦点を当てましょう:x0は、その前向きパスを実行するためにa0、a1、a2のパラメータが必要ですが、GPU0にはa0しかありません。GPU1からa1を、GPU2からa2を受け取り、モデルの各部分をまとめます。
同様に、GPU1はミニバッチx1を受け取り、a1しか持っていませんが、a0とa2のパラメータが必要です。これらはGPU0とGPU2から取得します。
GPU2もx2を受け取ります。a0とa1はGPU0とGPU1から受け取り、a2とともに完全なテンソルを再構築します。
3つのGPUは完全なテンソルを再構築し、前向き計算が行われます。
計算が完了すると、不要になったデータは削除されます。計算中だけ使用され、再構築は事前にフェッチを使用して効率的に行われます。
そして、このプロセス全体がレイヤーLb、次に前向きでLc、そして逆方向でLc -> Lb -> Laに対して繰り返されます。
私にとって、これは効率的なグループでの重みの分散戦略のように聞こえます:
1. 人Aはテントを持っています。
2. 人Bはストーブを持っています。
3. 人Cは斧を持っています。
今、彼らは毎晩持っているものを共有し、他の人から持っていないものをもらい、朝には割り当てられたタイプのギアを詰めて旅を続けます。これがSharded DDP / Zero DPです。
この戦略を、各人が独自のテント、ストーブ、斧を持って運ばなければならないシンプルな戦略と比較してみてください。これがPyTorchのDataParallel(DPおよびDDP)です。
このトピックの文献を読む際に、以下の類義語に出会うかもしれません:Sharded、Partitioned。
ZeROがモデルの重みを分割する方法に注意を払うと、これはテンソルパラレリズムと非常に似ているように見えます。これは後で議論される垂直モデルパラレリズムとは異なり、各レイヤーの重みをパーティション/シャーディングします。
Implementations:
- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) ZeRO-DP stages 1+2+3
- [`transformers` integration](main_classes/trainer#trainer-integrations)
## Naive Model Parallelism (Vertical) and Pipeline Parallelism
ナイーブモデルパラレリズム(MP)は、モデルの層を複数のGPUに分散させる方法です。このメカニズムは比較的単純で、希望する層を`.to()`メソッドを使用して特定のデバイスに切り替えるだけです。これにより、データがこれらの層を通過するたびに、データも層と同じデバイスに切り替えられ、残りの部分は変更されません。
私たちはこれを「垂直MP」と呼びます。なぜなら、ほとんどのモデルがどのように描かれるかを思い出すと、層を垂直にスライスするからです。たとえば、以下の図は8層のモデルを示しています:
```
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
gpu0 gpu1
```
我々は、モデルを垂直に2つに分割し、レイヤー0から3をGPU0に配置し、レイヤー4から7をGPU1に配置しました。
データがレイヤー0から1、1から2、2から3に移動する間は通常のモデルと同じです。しかし、データがレイヤー3からレイヤー4に移動する必要がある場合、GPU0からGPU1への移動が発生し、通信のオーバーヘッドが発生します。参加しているGPUが同じコンピュートノード(例:同じ物理マシン)にある場合、このコピーは非常に高速ですが、異なるコンピュートノード(例:複数のマシン)にある場合、通信のオーバーヘッドは大幅に増加する可能性があります。
その後、レイヤー4から5、6から7までは通常のモデルと同様に動作し、7番目のレイヤーが完了すると、データをしばしばレイヤー0に戻す必要があります(またはラベルを最後のレイヤーに送信します)。これで損失を計算し、オプティマイザが作業を開始できます。
問題点:
- 主な欠点、およびなぜこれを「単純な」MPと呼ぶのかは、1つを除いてすべてのGPUがどんな瞬間でもアイドル状態であることです。したがって、4つのGPUを使用する場合、単純なMPは、1つのGPUのメモリ容量を4倍にするのとほぼ同じであり、ハードウェアの残りを無視します。さらに、データのコピーのオーバーヘッドがあることを忘れてはいけません。したがって、4枚の6GBのカードは、データのコピーのオーバーヘッドがない1枚の24GBのカードと同じサイズを収容できるでしょうが、後者はトレーニングをより迅速に完了します。ただし、たとえば40GBのカードがあり、45GBのモデルを収める必要がある場合、勾配とオプティマイザの状態のためにほとんど収めることができません。
- 共有の埋め込みは、GPU間でコピーする必要があるかもしれません。
パイプライン並列処理(PP)は、ほぼ単純なMPと同じですが、GPUがアイドル状態になる問題を解決し、入力バッチをマイクロバッチに分割し、パイプラインを人工的に作成することにより、異なるGPUが計算プロセスに同時に参加できるようにします。
以下は、[GPipe論文](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)からの図で、上部には単純なMP、下部にはPPが示されています:

この図から、PPがGPUがアイドル状態の領域である「バブル」を少なく持つことがわかります。アイドル状態の部分は「バブル」と呼ばれます。
図の両方の部分は、4つのGPUがパイプラインに参加している4の次元の並列性を示しています。つまり、4つのパイプステージF0、F1、F2、F3のフォワードパスがあり、逆順のバックワードパスB3、B2、B1、B0があります。
PPは調整する新しいハイパーパラメータを導入します。それは `chunks` で、同じパイプステージを通じて連続して送信されるデータのチャンクの数を定義します。たとえば、下の図では `chunks=4` が表示されています。GPU0はチャンク0、1、2、3(F0,0、F0,1、F0,2、F0,3)で同じフォワードパスを実行し、他のGPUが作業を開始し始めるのを待ってから、GPU0はチャンク3、2、1、0(B0,3、B0,2、B0,1、B0,0)で逆順パスを実行します。
注意すべきは、概念的にはこれが勾配蓄積ステップ(GAS)と同じコンセプトであることです。PyTorchは `chunks` を使用し、DeepSpeedは同じハイパーパラメータをGASと呼びます。
`chunks` の導入により、PPはマイクロバッチ(MBS)の概念を導入します。DPはグローバルデータバッチサイズをミニバッチに分割します。したがって、DPの次数が4で、グローバルバッチサイズが1024の場合、4つのミニバッチ(それぞれ256)に分割されます(1024/4)。そして、`chunks`(またはGAS)の数が32である場合、マイクロバッチサイズは8になります(256/32)。各パイプラインステージは1つのマイクロバッチで作業します。
DP + PPセットアップのグローバルバッチサイズを計算するには、`mbs*chunks*dp_degree`(`8*32*4=1024`)を行います。
図に戻りましょう。
`chunks=1` であれば、非効率な単純なMPになります。非常に大きな `chunks` 値を使用すると、非常に小さなマイクロバッチサイズになり、効率があまり高くないかもしれません。したがって、GPUの効率的な利用を最大化する値を見つけるために実験する必要があります。これは、バブルのサイズを最小限にすることに対応する、すべての参加GPUにわたる高い並行GPU利用を可能にするためです。
2つのソリューショングループがあります。従来のパイプラインAPIソリューションと、ユーザーのモデルを大幅に変更する必要があるより現代的なソリューションです。
従来のパイプラインAPIソリューション:
- PyTorch
- DeepSpeed
- Megatron-LM
現代的なソリューション:
- Varuna
- Sagemaker
従来のパイプラインAPIソリューションの問題点:
- モデルをかなり変更する必要があるため、Pipelineはモジュールの通常のフローを`nn.Sequential`シーケンスに再書き込む必要があり、モデルの設計を変更することが必要です。
- 現在、Pipeline APIは非常に制限的です。最初のパイプラインステージに渡されるPython変数のセットがある場合、回避策を見つける必要があります。現在、パイプラインインターフェースでは、唯一のテンソルまたはテンソルのタプルを入力と出力として要求しています。これらのテンソルはバッチサイズを最初の次元として持っている必要があります。パイプラインはミニバッチをマイクロバッチに分割します。可能な改善点については、こちらの議論が行われています:https://github.com/pytorch/pytorch/pull/50693
- パイプステージのレベルでの条件付き制御フローは不可能です。例えば、T5のようなエンコーダーデコーダーモデルは、条件付きエンコーダーステージを処理するために特別な回避策が必要です。
- 各レイヤーを配置する必要があるため、1つのモデルの出力が他のモデルの入力になるようにします。
VarunaとSageMakerとの実験はまだ行っていませんが、彼らの論文によれば、上記で述べた問題のリストを克服し、ユーザーのモデルにははるかに小さな変更しか必要としないと報告されています。
実装:
- [Pytorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - この実装は、Hugging Face Transformersに基づいています。
🤗 Transformersのステータス: この執筆時点では、いずれのモデルも完全なPP(パイプライン並列処理)をサポートしていません。GPT2モデルとT5モデルは単純なMP(モデル並列処理)サポートを持っています。主な障害は、モデルを`nn.Sequential`に変換できず、すべての入力がテンソルである必要があることです。現在のモデルには、変換を非常に複雑にする多くの機能が含まれており、これらを削除する必要があります。
他のアプローチ:
DeepSpeed、Varuna、およびSageMakerは、[交互にパイプラインを実行](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)するコンセプトを使用しています。ここでは、バックワードパスを優先させてバブル(アイドル時間)をさらに最小限に抑えます。
Varunaは、最適なスケジュールを発見するためにシミュレーションを使用してスケジュールをさらに改善しようとします。
OSLOは、`nn.Sequential`の変換なしでTransformersに基づくパイプライン並列処理を実装しています。
## Tensor Parallelism
テンソル並列処理では、各GPUがテンソルのスライスのみを処理し、全体が必要な操作のためにのみ完全なテンソルを集約します。
このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://arxiv.org/abs/2104.04473)。
どのトランスフォーマの主要な構築要素は、完全に接続された`nn.Linear`に続く非線形アクティベーション`GeLU`です。
Megatronの論文の表記法に従って、行列の乗算部分を`Y = GeLU(XA)`と書くことができます。ここで、`X`と`Y`は入力ベクトルと出力ベクトルで、`A`は重み行列です。
行列の計算を行列形式で見ると、行列乗算を複数のGPUで分割できる方法が簡単に理解できます:

重み行列`A`を`N`個のGPUに対して列ごとに分割し、並列で行列乗算`XA_1`から`XA_n`を実行すると、`N`個の出力ベクトル`Y_1、Y_2、...、Y_n`が得られ、それらを独立して`GeLU`に供給できます:

この原理を使用して、最後まで同期が必要ないまま、任意の深さのMLPを更新できます。Megatron-LMの著者はそのための有用なイラストを提供しています:

マルチヘッドアテンションレイヤーを並列化することはさらに簡単です。それらは既に複数の独立したヘッドを持っているため、本質的に並列です!

特別な考慮事項:TPには非常に高速なネットワークが必要であり、したがって1つのノードを超えてTPを実行しないことがお勧めされません。実際には、1つのノードに4つのGPUがある場合、最大のTP度数は4です。TP度数8が必要な場合は、少なくとも8つのGPUを持つノードを使用する必要があります。
このセクションは、元のより詳細な[TPの概要](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530)に基づいています。
by [@anton-l](https://github.com/anton-l)。
SageMakerは、より効率的な処理のためにTPとDPを組み合わせて使用します。
代替名:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)はこれを「テンソルスライシング」と呼びます。詳細は[DeepSpeedの特徴](https://www.deepspeed.ai/training/#model-parallelism)をご覧ください。
実装例:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)には、モデル固有の内部実装があります。
- [parallelformers](https://github.com/tunib-ai/parallelformers)(現時点では推論のみ)。
- [SageMaker](https://arxiv.org/abs/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
- [OSLO](https://github.com/tunib-ai/oslo)には、Transformersに基づいたテンソル並列実装があります。
🤗 Transformersの状況:
- コア: まだコアには実装されていません。
- ただし、推論が必要な場合、[parallelformers](https://github.com/tunib-ai/parallelformers)はほとんどのモデルに対してサポートを提供します。これがコアに実装されるまで、これを使用できます。そして、トレーニングモードもサポートされることを期待しています。
- Deepspeed-Inferenceでは、BERT、GPT-2、およびGPT-NeoモデルをCUDAカーネルベースの高速推論モードでサポートしています。詳細は[こちら](https://www.deepspeed.ai/tutorials/inference-tutorial/)をご覧ください。
## DP+PP
DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/tutorials/pipeline/)からの次の図は、DPをPPと組み合わせる方法を示しています。

ここで重要なのは、DPランク0がGPU2を見えなくし、DPランク1がGPU3を見えなくすることです。DPにとって、存在するのはGPU 0 と 1 のみで、それらの2つのGPUのようにデータを供給します。GPU0はPPを使用してGPU2に一部の負荷を「秘密裏に」オフロードし、GPU1も同様にGPU3を支援に引き入れます。
各次元には少なくとも2つのGPUが必要ですので、ここでは少なくとも4つのGPUが必要です。
実装例:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません
## DP+PP+TP
さらに効率的なトレーニングを行うために、3Dパラレリズムを使用し、PPをTPとDPと組み合わせます。これは次の図で示されています。

この図は[3Dパラレリズム:兆パラメータモデルへのスケーリング](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)というブログ投稿から取得されたもので、おすすめの読み物です。
各次元には少なくとも2つのGPUが必要ですので、ここでは少なくとも8つのGPUが必要です。
実装例:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeedには、さらに効率的なDPであるZeRO-DPと呼ばれるものも含まれています。
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
## ZeRO DP+PP+TP
DeepSpeedの主要な機能の1つはZeROで、これはDPの拡張機能です。これについてはすでに「ZeROデータ並列化」で説明されています。通常、これは単独で動作する機能で、PPやTPは必要ありません。しかし、PPとTPと組み合わせることもできます。
ZeRO-DPがPPと組み合わされる場合、通常はZeROステージ1(オプティマイザーシャーディング)のみが有効になります。
ZeROステージ2(勾配シャーディング)をパイプライン並列化と組み合わせて使用する理論的な可能性はありますが、性能に悪影響を及ぼします。各マイクロバッチごとに勾配をシャーディングする前に、勾配を集約するための追加のリダクションスキャッター集計が必要で、通信オーバーヘッドが発生する可能性があります。パイプライン並列化の性質上、小さなマイクロバッチが使用され、計算の集中度(マイクロバッチサイズ)をバランスにかけ、パイプラインバブル(マイクロバッチ数)を最小限に抑えることに焦点が当てられています。したがって、これらの通信コストは影響を及ぼすでしょう。
さらに、PPには通常よりも少ない層が含まれており、メモリの節約はそれほど大きくありません。PPは既に勾配サイズを「1/PP」に削減するため、勾配シャーディングの節約は純粋なDPよりもはるかに重要ではありません。
ZeROステージ3も同様の理由で適していません - より多くのノード間通信が必要です。
そして、ZeROを持っているので、もう一つの利点はZeRO-Offloadです。これはステージ1オプティマイザーステートをCPUにオフロードできます。
実装例:
- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed)と[BigScienceからのMegatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed)は、前者のリポジトリのフォークです。
- [OSLO](https://github.com/tunib-ai/oslo)
重要な論文:
- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://arxiv.org/abs/2201.11990)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
## FlexFlow
[FlexFlow](https://github.com/flexflow/FlexFlow)は、わずかに異なるアプローチで並列化の問題を解決します。
論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://arxiv.org/abs/1807.05358)
FlexFlowは、サンプル-オペレータ-属性-パラメータの4D並列化を行います。
1. サンプル = データ並列化(サンプル単位の並列化)
2. オペレータ = 単一の操作をいくつかのサブ操作に並列化
3. 属性 = データ並列化(長さ方向の並列化)
4. パラメータ = モデル並列化(次元に関係なく、水平または垂直)
例:
* サンプル
シーケンス長512の10バッチを考えてみましょう。これらをサンプル次元で2つのデバイスに並列化すると、10 x 512が5 x 2 x 512になります。
* オペレータ
層正規化を行う場合、まずstdを計算し、次にmeanを計算し、データを正規化できます。オペレータの並列化により、stdとmeanを並列に計算できます。したがって、オペレータ次元で2つのデバイス(cuda:0、cuda:1)に並列化すると、最初に入力データを両方のデバイスにコピーし、cuda:0でstdを計算し、cuda:1でmeanを同時に計算します。
* 属性
10バッチの512長があります。これらを属性次元で2つのデバイスに並列化すると、10 x 512が10 x 2 x 256になります。
* パラメータ
これはテンソルモデルの並列化または単純な層ごとのモデルの並列化と似ています。
このフレームワークの重要性は、(1)GPU/TPU/CPU対(2)RAM/DRAM対(3)高速内部接続/低速外部接続などのリソースを取り、これらすべてをアルゴリズムによって自動的に最適化することです。どの並列化をどこで使用するかをアルゴリズム的に決定します。
非常に重要な側面の1つは、FlexFlowは静的で固定のワークロードを持つモデルのために設計されており、動的な動作を持つモデルはイテレーションごとに異なる並列化戦略を好む場合があることです。
したがって、このフレームワークの約束は非常に魅力的です。選択したクラスタで30分間のシミュレーションを実行し、この特定の環境を最適に利用するための最良の戦略を提供します。部分を追加/削除/置換すると、それに対して実行して再最適化プランを作成します。その後、トレーニングできます。異なるセットアップには独自の最適化があります。
🤗 Transformersの現在の状況: まだ統合されていません。すでに[transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py)を使用してモデルがFXトレース可能であるため、FlexFlowを動作させるために必要な手順を誰かが見つける必要があります。
## Which Strategy To Use When
ここでは、どの並列化戦略をいつ使用するかの非常におおまかなアウトラインを示します。各リストの最初が通常よりも速いことが一般的です。
**⇨ 単一GPU**
* モデルが単一GPUに収まる場合:
1. 通常の使用
* モデルが単一GPUに収まらない場合:
1. ZeRO + CPUをオフロードし、オプションでNVMeをオフロード
2. 上記に加えて、最大のレイヤーが単一GPUに収まらない場合、[Memory Centric Tiling](https://deepspeed.readthedocs.io/en/latest/zero3.html#memory-centric-tiling)(詳細は以下参照)を有効化
* 最大のレイヤーが単一GPUに収まらない場合:
1. ZeROを使用しない場合 - TPを有効化する必要があります。なぜなら、PPだけでは収めることができないからです。
2. ZeROを使用する場合は、上記の「単一GPU」のエントリと同じものを参照してください
**⇨ 単一ノード/マルチGPU**
* モデルが単一GPUに収まる場合:
1. DDP - 分散データ並列
2. ZeRO - 状況と使用される構成に依存して速いかどうかが異なることがあります
* モデルが単一GPUに収まらない場合:
1. PP
2. ZeRO
3. TP
非常に高速なノード内接続がNVLINKまたはNVSwitchである場合、これらのすべてはほとんど同等の性能です。これらがない場合、PPはTPまたはZeROよりも速くなります。TPの度合いも違いを生じるかもしれません。特定のセットアップで勝者を見つけるために実験するのが最善です。
TPはほとんど常に単一ノード内で使用されます。つまり、TPサイズ <= ノードあたりのGPUです。
* 最大のレイヤーが単一GPUに収まらない場合:
1. ZeROを使用しない場合 - TPを使用する必要があります。なぜなら、PPだけでは収めることができないからです。
2. ZeROを使用する場合は、上記の「単一GPU」のエントリと同じものを参照してください
**⇨ マルチノード/マルチGPU**
* 高速なノード間接続がある場合:
1. ZeRO - モデルへのほとんどの変更が不要です
2. PP+TP+DP - 通信が少なく、モデルに大規模な変更が必要です
* 遅いノード間接続があり、GPUメモリが少ない場合:
1. DP+PP+TP+ZeRO-1
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/pr_checks.md
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Checks on a Pull Request
🤗 Transformersリポジトリでプルリクエストを開くと、追加しているパッチが既存のものを壊していないことを確認するために、かなりの数のチェックが実行されます。これらのチェックには、次の4つのタイプがあります:
- 通常のテスト
- ドキュメンテーションのビルド
- コードとドキュメンテーションのスタイル
- リポジトリ全体の一貫性
このドキュメントでは、これらのさまざまなチェックとその背後にある理由、そしてそれらのいずれかがあなたのプルリクエストで失敗した場合のローカルでのデバッグ方法について説明します。
なお、理想的には、開発者用のインストールが必要です:
```bash
pip install transformers[dev]
```
または編集可能なインストールの場合:
```bash
pip install -e .[dev]
```
トランスフォーマーズのリポジトリ内で作業しています。トランスフォーマーズのオプションの依存関係の数が増えたため、すべてを取得できない可能性があります。開発用インストールが失敗した場合、作業しているディープラーニングフレームワーク(PyTorch、TensorFlow、および/またはFlax)をインストールし、次の手順を実行してください。
```bash
pip install transformers[quality]
```
または編集可能なインストールの場合:
```bash
pip install -e .[quality]
```
## Tests
`ci/circleci: run_tests_` で始まるすべてのジョブは、Transformersのテストスイートの一部を実行します。これらのジョブは、特定の環境でライブラリの一部に焦点を当てて実行されます。たとえば、`ci/circleci: run_tests_pipelines_tf` は、TensorFlowのみがインストールされた環境でパイプラインのテストを実行します。
テストスイートの一部のみが実行されるように注意してください。テストスイートは、変更前と変更後のPRのライブラリの違いを決定し、その違いに影響を受けるテストを選択するためのユーティリティが実行されます。このユーティリティは、ローカルで以下のコマンドを実行して実行できます:
```bash
python utils/tests_fetcher.py
```
1. リポジトリのルートからスクリプトを実行します。これは次のステップを実行します:
1. 差分内の各ファイルをチェックし、変更がコード内にあるか、コメントやドキュメンテーション文字列のみにあるかを確認します。実際のコード変更があるファイルのみを保持します。
2. 内部のマップを構築します。このマップは、ライブラリのソースコードの各ファイルが再帰的に影響を与えるすべてのファイルを提供します。モジュールAがモジュールBに影響を与えるとは、モジュールBがモジュールAをインポートする場合を指します。再帰的な影響を得るには、モジュールAからモジュールBへのモジュールのチェーンが必要で、各モジュールは前のモジュールをインポートする必要があります。
3. このマップをステップ1で収集したファイルに適用します。これにより、PRに影響を受けるモデルファイルのリストが得られます。
4. これらのファイルをそれに対応するテストファイルにマップし、実行するテストのリストを取得します。
2. スクリプトをローカルで実行する場合、ステップ1、3、および4の結果が表示され、実行するテストがわかります。スクリプトはまた、`test_list.txt` という名前のファイルを作成します。このファイルには実行するテストのリストが含まれており、次のコマンドでローカルで実行できます:
```bash
python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
```
## Documentation build
`build_pr_documentation` ジョブは、ドキュメンテーションのビルドを行い、あなたのPRがマージされた後にすべてが正常に表示されることを確認します。ボットがプレビューのドキュメンテーションへのリンクをPRに追加します。PRに対する変更は、プレビューに自動的に反映されます。ドキュメンテーションのビルドに失敗した場合、失敗したジョブの隣にある「詳細」をクリックして、何が問題になっているかを確認できます。多くの場合、問題は`toctree`内のファイルが不足しているなど、単純なものです。
ドキュメンテーションをローカルでビルドまたはプレビューしたい場合は、[docsフォルダ内の`README.md`](https://github.com/huggingface/transformers/tree/main/docs)をご覧ください。
## Code and documentation style
すべてのソースファイル、例、テストには、`black`と`ruff`を使用してコードのフォーマットが適用されます。また、ドックストリングと`rst`ファイルのフォーマット、Transformersの`__init__.py`ファイルで実行される遅延インポートの順序についてもカスタムツールが存在します(`utils/style_doc.py`と`utils/custom_init_isort.py`)。これらすべては、以下を実行することで起動できます。
```bash
make style
```
CIは、`ci/circleci: check_code_quality` チェック内でこれらのチェックが適用されていることを確認します。また、`ruff` を実行し、未定義の変数や使用されていない変数がある場合にエラーを報告します。このチェックをローカルで実行するには、以下のコマンドを使用してください。
```bash
make quality
```
時間がかかることがあります。したがって、現在のブランチで変更したファイルのみで同じことを実行するには、次のコマンドを実行します。
```bash
make fixup
```
この最後のコマンドは、リポジトリの整合性のためのすべての追加のチェックも実行します。それらを詳しく見てみましょう。
## Repository consistency
これには、あなたのPRがリポジトリを適切な状態に保ったままであることを確認するためのすべてのテストが含まれており、ci/`circleci: check_repository_consistency` チェックによって実行されます。ローカルでこのチェックを実行するには、以下を実行します。
```bash
make repo-consistency
```
これを確認します:
- `utils/check_repo.py` によって実行される、init に追加されたすべてのオブジェクトが文書化されています。
- `utils/check_inits.py` によって実行される、すべての `__init__.py` ファイルがその2つのセクションで同じ内容を持っています。
- `utils/check_copies.py` によって実行される、他のモジュールからのコピーとして識別されたすべてのコードが元のコードと一致しています。
- `utils/check_config_docstrings.py` によって実行される、すべての設定クラスには少なくとも1つの有効なチェックポイントがドキュメント文字列に記載されています。
- `utils/check_config_attributes.py` によって実行される、すべての設定クラスには、対応するモデリングファイルで使用されている属性のみが含まれています。
- `utils/check_copies.py` によって実行される、README とドキュメントのインデックスの翻訳が、メインのREADME と同じモデルリストを持っています。
- `utils/check_table.py` によって実行される、ドキュメンテーションの自動生成テーブルが最新であることを確認します。
- `utils/check_dummies.py` によって実行される、すべてのオブジェクトが利用可能であり、オプションの依存関係がすべてインストールされていなくても問題ありません。
このチェックが失敗する場合、最初の2つの項目は手動で修正する必要があり、最後の4つはコマンドを実行して自動的に修正できます。
```bash
make fix-copies
```
追加のチェックポイントは、新しいモデルを追加するPull Request(PR)に関連しています。主に次の点を確認します:
- すべての追加されたモデルは、Auto-mapping(`utils/check_repo.py`で実行)に含まれています。
<!-- TODO Sylvain、共通のテストが実装されていることを確認するチェックを追加してください。-->
- すべてのモデルが適切にテストされています(`utils/check_repo.py`で実行)。
<!-- TODO Sylvain、以下を追加してください
- すべてのモデルがメインのREADMEおよびメインのドキュメント内に追加されています。
- 使用されているすべてのチェックポイントが実際にHubに存在しています
-->
### Check copies
Transformersライブラリは、モデルコードに関して非常に意見があるため、各モデルは他のモデルに依存せずに完全に1つのファイルに実装する必要があります。したがって、特定のモデルのコードのコピーが元のコードと一貫しているかどうかを確認する仕組みを追加しました。これにより、バグ修正がある場合、他の影響を受けるモデルをすべて確認し、変更を伝達するかコピーを破棄するかを選択できます。
<Tip>
ファイルが別のファイルの完全なコピーである場合、それを`utils/check_copies.py`の`FULL_COPIES`定数に登録する必要があります。
</Tip>
この仕組みは、`# Copied from xxx`という形式のコメントに依存しています。`xxx`は、コピーされているクラスまたは関数の完全なパスを含む必要があります。例えば、`RobertaSelfOutput`は`BertSelfOutput`クラスの直接のコピーですので、[こちら](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L289)にコメントがあります。
```py
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
```
注意点として、これをクラス全体に適用する代わりに、コピー元の関連メソッドに適用できます。たとえば、[こちら](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L598)では、`RobertaPreTrainedModel._init_weights` が `BertPreTrainedModel` からコピーされており、以下のコメントがあります:
```py
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
```
注:矢印の周りにはスペースが含まれていてはいけません(もちろん、そのスペースが置換パターンの一部である場合を除きます)。
カンマで区切られた複数のパターンを追加できます。例えば、ここでは `CamemberForMaskedLM` は `RobertaForMaskedLM` の直接のコピーで、2つの置換があります: `Roberta` から `Camembert` へ、そして `ROBERTA` から `CAMEMBERT` へと置換されます。[こちら](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929)で、この作業はコメント付きで行われています。
```py
# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
```
もし順序が重要な場合(以前の置換と競合する可能性があるため)、置換は左から右に実行されます。
<Tip>
もし置換がフォーマットを変更する場合(たとえば、短い名前を非常に長い名前に置き換える場合など)、自動フォーマッタを適用した後にコピーが確認されます。
</Tip>
パターンが同じ置換の異なるケース(大文字と小文字のバリアントがある)の場合、オプションとして `all-casing` を追加するだけの別の方法もあります。[こちら](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237)は、`MobileBertForSequenceClassification` 内の例で、コメントがついています。
```py
# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
```
この場合、コードは「BertForSequenceClassification」からコピーされ、次のように置換されます:
- `Bert` を `MobileBert` に置き換える(例:`init`で `MobileBertModel` を使用する場合)
- `bert` を `mobilebert` に置き換える(例:`self.mobilebert` を定義する場合)
- `BERT` を `MOBILEBERT` に置き換える(定数 `MOBILEBERT_INPUTS_DOCSTRING` 内で)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/autoclass_tutorial.md
|
<!--
著作権 2023 The HuggingFace Team。全著作権所有。
Apache License、Version 2.0(以下「ライセンス」と呼びます)に基づくライセンスで、
ライセンスに従わない限り、このファイルを使用できません。
ライセンスのコピーは以下から入手できます:
http://www.apache.org/licenses/LICENSE-2.0
適用法に従うか、書面による同意がある限り、ライセンスの下でソフトウェアは配布されます。
ライセンスに基づく特定の言語での条件を確認するか、ライセンスを参照してください。
このファイルはMarkdown形式ですが、doc-builder(MDXに類似したもの)の特定の構文を含んでおり、
お使いのMarkdownビューアで正しくレンダリングされない場合があります。
-->
# AutoClassを使用して事前学習済みインスタンスをロードする
さまざまなTransformerアーキテクチャが存在するため、自分のタスクに合ったモデルを作成するのは難しいことがあります。
🤗 Transformersのコア哲学の一環として、ライブラリを使用しやすく、シンプルで柔軟にするために、
`AutoClass`は与えられたチェックポイントから正しいアーキテクチャを自動的に推論してロードします。
`from_pretrained()`メソッドを使用すると、事前学習済みモデルを素早くロードできるため、モデルをゼロからトレーニングするために時間とリソースを費やす必要がありません。
この種のチェックポイントに依存しないコードを生成することは、
コードが1つのチェックポイントで動作すれば、アーキテクチャが異なっていても、同じタスクに向けてトレーニングされた場合は別のチェックポイントでも動作することを意味します。
<Tip>
アーキテクチャはモデルの骨格を指し、チェックポイントは特定のアーキテクチャの重みです。
たとえば、[BERT](https://huggingface.co/bert-base-uncased)はアーキテクチャであり、`bert-base-uncased`はチェックポイントです。
モデルはアーキテクチャまたはチェックポイントのどちらを指す一般的な用語です。
</Tip>
このチュートリアルでは、以下を学習します:
* 事前学習済みトークナイザをロードする。
* 事前学習済み画像プロセッサをロードする。
* 事前学習済み特徴量抽出器をロードする。
* 事前学習済みプロセッサをロードする。
* 事前学習済みモデルをロードする。
## AutoTokenizer
ほとんどのNLPタスクはトークナイザで始まります。トークナイザは入力をモデルで処理できる形式に変換します。
[`AutoTokenizer.from_pretrained`]を使用してトークナイザをロードします:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
```
次に、以下のように入力をトークナイズします:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoImageProcessor
ビジョンタスクの場合、画像プロセッサが画像を正しい入力形式に変換します。
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
## AutoFeatureExtractor
オーディオタスクの場合、特徴量抽出器がオーディオ信号を正しい入力形式に変換します。
[`AutoFeatureExtractor.from_pretrained`]を使用して特徴量抽出器をロードします.
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
マルチモーダルタスクの場合、2つの前処理ツールを組み合わせるプロセッサが必要です。たとえば、
[LayoutLMV2](model_doc/layoutlmv2)モデルは画像を処理するための画像プロセッサとテキストを処理するためのトークナイザが必要です。
プロセッサはこれらの両方を組み合わせます。
[`AutoProcessor.from_pretrained`]を使用してプロセッサをロードします:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
最後に、`AutoModelFor`クラスは特定のタスクに対して事前学習済みモデルをロードできます(使用可能なタスクの完全な一覧については[こちら](model_doc/auto)を参照)。
たとえば、[`AutoModelForSequenceClassification.from_pretrained`]を使用してシーケンス分類用のモデルをロードできます:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
同じチェックポイントを再利用して異なるタスクのアーキテクチャをロードできます:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
<Tip warning={true}>
PyTorchモデルの場合、 `from_pretrained()`メソッドは内部で`torch.load()`を使用し、内部的には`pickle`を使用しており、セキュリティの問題が知られています。
一般的には、信頼性のないソースから取得した可能性があるモデルや改ざんされた可能性のあるモデルをロードしないでください。
このセキュリティリスクは、`Hugging Face Hub`でホストされている公開モデルに対して部分的に緩和されており、各コミットでマルウェアのスキャンが行われています。
GPGを使用した署名済みコミットの検証などのベストプラクティスについては、Hubのドキュメンテーションを参照してください。
TensorFlowおよびFlaxのチェックポイントには影響がなく、`from_pretrained`メソッドの`from_tf`および`from_flax`引数を使用してPyTorchアーキテクチャ内でロードできます。
</Tip>
一般的に、事前学習済みモデルのインスタンスをロードするために`AutoTokenizer`クラスと`AutoModelFor`クラスの使用をお勧めします。
これにより、常に正しいアーキテクチャをロードできます。
次の[tutorial](preprocessing)では、新しくロードしたトークナイザ、画像プロセッサ、特徴量抽出器、およびプロセッサを使用して、ファインチューニング用にデータセットを前処理する方法を学びます。
</pt>
<tf>
最後に、`TFAutoModelFor`クラスは特定のタスクに対して事前学習済みモデルをロードできます(使用可能なタスクの完全な一覧についてはこちらを参照)。
たとえば、[`TFAutoModelForSequenceClassification.from_pretrained`]を使用してシーケンス分類用のモデルをロードできます:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
```
同じチェックポイントを再利用して異なるタスクのアーキテクチャをロードできます:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert-base-uncased")
```
一般的には、事前学習済みモデルのインスタンスをロードするために`AutoTokenizer`クラスと`TFAutoModelFor`クラスの使用をお勧めします。
これにより、常に正しいアーキテクチャをロードできます。
次の[tutorial](preproccesing)では、新しくロードしたトークナイザ、画像プロセッサ、特徴量抽出器、およびプロセッサを使用して、ファインチューニング用にデータセットを前処理する方法を学びます。
</tf>
</frameworkcontent>
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/_toctree.yml
|
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: クイックツアー
- local: installation
title: インストール
title: Get started
- sections:
- local: pipeline_tutorial
title: パイプラインを使用して推論を実行する
- local: autoclass_tutorial
title: AutoClass を使用して移植可能なコードを作成する
- local: preprocessing
title: データの前処理
- local: training
title: 事前トレーニングされたモデルを微調整する
- local: run_scripts
title: スクリプトを使用してトレーニングする
- local: accelerate
title: 🤗 Accelerate を使用して分散トレーニングをセットアップする
- local: peft
title: 🤗 PEFT を使用してアダプターをロードしてトレーニングする
- local: model_sharing
title: モデルを共有する
- local: transformers_agents
title: エージェント
- local: llm_tutorial
title: LLM を使用した生成
title: Tutorials
- sections:
- isExpanded: false
sections:
- local: tasks/sequence_classification
title: テキストの分類
- local: tasks/token_classification
title: トークンの分類
- local: tasks/question_answering
title: 質疑応答
- local: tasks/language_modeling
title: 因果言語モデリング
- local: tasks/masked_language_modeling
title: マスクされた言語モデリング
- local: tasks/translation
title: 翻訳
- local: tasks/summarization
title: 要約
- local: tasks/multiple_choice
title: 複数の選択肢
title: 自然言語処理
- isExpanded: false
sections:
- local: tasks/audio_classification
title: 音声の分類
- local: tasks/asr
title: 自動音声認識
title: オーディオ
- isExpanded: false
sections:
- local: tasks/image_classification
title: 画像分類
- local: tasks/semantic_segmentation
title: セマンティックセグメンテーション
- local: tasks/video_classification
title: ビデオの分類
- local: tasks/object_detection
title: 物体検出
- local: tasks/zero_shot_object_detection
title: ゼロショット物体検出
- local: tasks/zero_shot_image_classification
title: ゼロショット画像分類
- local: tasks/monocular_depth_estimation
title: 深さの推定
- local: tasks/image_to_image
title: 画像から画像へ
- local: tasks/knowledge_distillation_for_image_classification
title: コンピュータビジョンのための知識の蒸留
title: コンピュータビジョン
- isExpanded: false
sections:
- local: tasks/image_captioning
title: 画像のキャプション
- local: tasks/document_question_answering
title: 文書の質問への回答
- local: tasks/visual_question_answering
title: 視覚的な質問への回答
- local: tasks/text-to-speech
title: テキスト読み上げ
title: マルチモーダル
- isExpanded: false
sections:
- local: generation_strategies
title: 生成戦略をカスタマイズする
title: 世代
- isExpanded: false
sections:
- local: tasks/idefics
title: IDEFICS を使用したイメージ タスク
- local: tasks/prompting
title: LLM プロンプト ガイド
title: プロンプト
title: Task Guides
- sections:
- local: fast_tokenizers
title: 🤗 トークナイザーの高速トークナイザーを使用する
- local: multilingual
title: 多言語モデルで推論を実行する
- local: create_a_model
title: モデル固有の API を使用する
- local: custom_models
title: カスタムモデルを共有する
- local: chat_templating
title: チャットモデルのテンプレート
- local: serialization
title: ONNX へのエクスポート
- local: tflite
title: TFLite へのエクスポート
- local: torchscript
title: トーチスクリプトへのエクスポート
- local: benchmarks
title: ベンチマーク
- local: community
title: コミュニティリソース
- local: custom_tools
title: カスタムツールとプロンプト
- local: troubleshooting
title: トラブルシューティング
title: 開発者ガイド
- sections:
- local: performance
title: 概要
- sections:
- local: perf_train_gpu_one
title: 単一の GPU で効率的にトレーニングするための方法とツール
- local: perf_train_gpu_many
title: 複数の GPU と並列処理
- local: perf_train_cpu
title: CPU での効率的なトレーニング
- local: perf_train_cpu_many
title: 分散CPUトレーニング
- local: perf_train_tpu
title: TPU に関するトレーニング
- local: perf_train_tpu_tf
title: TensorFlow を使用した TPU のトレーニング
- local: perf_train_special
title: 特殊なハードウェアに関するトレーニング
- local: perf_hardware
title: トレーニング用のカスタム ハードウェア
- local: hpo_train
title: Trainer API を使用したハイパーパラメータ検索
title: 効率的なトレーニングテクニック
- sections:
- local: perf_infer_cpu
title: CPUでの推論
- local: perf_infer_gpu_one
title: 1 つの GPU での推論
- local: perf_infer_gpu_many
title: 多くの GPU での推論
- local: perf_infer_special
title: 特殊なハードウェアでの推論
title: 推論の最適化
- local: big_models
title: 大きなモデルのインスタンス化
- local: tf_xla
title: TensorFlowモデルのXLA統合
- local: perf_torch_compile
title: torch.compile()を使用した推論の最適化
title: パフォーマンスとスケーラビリティ
- sections:
- local: add_new_model
title: 🤗 Transformersにモデルを追加する方法
- local: add_tensorflow_model
title: 🤗 TransformersモデルをTensorFlowに変換する方法
- local: testing
title: テスト
- local: pr_checks
title: プルリクエストのチェック
title: 貢献する
- sections:
- local: philosophy
title: フィロソフィー
- local: glossary
title: 用語集
- local: task_summary
title: 🤗 Transformersの機能
- local: tasks_explained
title: 🤗 Transformersがタスクを解決する方法
- local: model_summary
title: Transformerモデルファミリー
- local: tokenizer_summary
title: トークナイザーの概要
- local: attention
title: 注意機構
- local: pad_truncation
title: パディングと切り詰め
- local: bertology
title: BERTology
- local: perplexity
title: 固定長モデルのパープレキシティ
- local: pipeline_webserver
title: Webサーバー推論用パイプライン
- local: model_memory_anatomy
title: モデルトレーニングの解剖学
title: コンセプチュアルガイド
- sections:
- sections:
- local: main_classes/agent
title: エージェントとツール
- local: model_doc/auto
title: Auto Classes
- local: main_classes/callback
title: コールバック
- local: main_classes/configuration
title: 構成
- local: main_classes/data_collator
title: データ照合者
- local: main_classes/keras_callbacks
title: Keras コールバック
- local: main_classes/logging
title: ロギング
- local: main_classes/model
title: モデル
- local: main_classes/text_generation
title: テキストの生成
- local: main_classes/onnx
title: ONNX
- local: main_classes/optimizer_schedules
title: 最適化
- local: main_classes/output
title: モデルの出力
- local: main_classes/pipelines
title: パイプライン
- local: main_classes/processors
title: プロセッサー
- local: main_classes/quantization
title: 量子化
- local: main_classes/tokenizer
title: トークナイザー
- local: main_classes/trainer
title: トレーナー
- local: main_classes/deepspeed
title: ディープスピードの統合
- local: main_classes/feature_extractor
title: 特徴抽出器
- local: main_classes/image_processor
title: 画像処理プロセッサ
title: 主要なクラス
- sections:
- isExpanded: false
sections:
- local: model_doc/albert
title: ALBERT
- local: model_doc/bart
title: BART
- local: model_doc/barthez
title: BARThez
- local: model_doc/bartpho
title: BARTpho
- local: model_doc/bert
title: BERT
- local: model_doc/bert-generation
title: BertGeneration
- local: model_doc/bert-japanese
title: BertJapanese
- local: model_doc/bertweet
title: Bertweet
- local: model_doc/big_bird
title: BigBird
- local: model_doc/bigbird_pegasus
title: BigBirdPegasus
- local: model_doc/biogpt
title: BioGpt
- local: model_doc/blenderbot
title: Blenderbot
- local: model_doc/blenderbot-small
title: Blenderbot Small
- local: model_doc/bloom
title: BLOOM
- local: model_doc/bort
title: BORT
- local: model_doc/byt5
title: ByT5
- local: model_doc/camembert
title: CamemBERT
- local: model_doc/canine
title: CANINE
- local: model_doc/codegen
title: CodeGen
- local: model_doc/code_llama
title: CodeLlama
- local: model_doc/convbert
title: ConvBERT
- local: model_doc/cpm
title: CPM
- local: model_doc/cpmant
title: CPMANT
- local: model_doc/ctrl
title: CTRL
- local: model_doc/deberta
title: DeBERTa
- local: model_doc/deberta-v2
title: DeBERTa-v2
title: 文章モデル
- isExpanded: false
sections:
- local: model_doc/beit
title: BEiT
- local: model_doc/bit
title: BiT
- local: model_doc/conditional_detr
title: Conditional DETR
- local: model_doc/convnext
title: ConvNeXT
- local: model_doc/convnextv2
title: ConvNeXTV2
- local: model_doc/cvt
title: CvT
- local: model_doc/deformable_detr
title: Deformable DETR
title: ビジョンモデル
- isExpanded: false
sections:
- local: model_doc/audio-spectrogram-transformer
title: Audio Spectrogram Transformer
- local: model_doc/bark
title: Bark
- local: model_doc/clap
title: CLAP
title: 音声モデル
- isExpanded: false
sections:
- local: model_doc/align
title: ALIGN
- local: model_doc/altclip
title: AltCLIP
- local: model_doc/blip
title: BLIP
- local: model_doc/blip-2
title: BLIP-2
- local: model_doc/bridgetower
title: BridgeTower
- local: model_doc/bros
title: BROS
- local: model_doc/chinese_clip
title: Chinese-CLIP
- local: model_doc/clip
title: CLIP
- local: model_doc/clipseg
title: CLIPSeg
- local: model_doc/clvp
title: CLVP
- local: model_doc/data2vec
title: Data2Vec
title: マルチモーダルモデル
- isExpanded: false
sections:
- local: model_doc/decision_transformer
title: Decision Transformer
title: 強化学習モデル
- isExpanded: false
sections:
- local: model_doc/autoformer
title: Autoformer
title: 時系列モデル
title: モデル
- sections:
- local: internal/modeling_utils
title: カスタムレイヤーとユーティリティ
- local: internal/pipelines_utils
title: パイプライン用のユーティリティ
- local: internal/tokenization_utils
title: ト=ークナイザー用のユーティリティ
- local: internal/trainer_utils
title: トレーナー用ユーティリティ
- local: internal/generation_utils
title: 発電用ユーティリティ
- local: internal/image_processing_utils
title: 画像プロセッサ用ユーティリティ
- local: internal/audio_utils
title: オーディオ処理用のユーティリティ
- local: internal/file_utils
title: 一般公共事業
- local: internal/time_series_utils
title: 時系列用のユーティリティ
title: 内部ヘルパー
title: API
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_infer_special.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Inference on Specialized Hardware
こちらのドキュメントは、専用のハードウェアでの推論方法についての情報がまもなく提供されます。その間に、CPUでの推論に関するガイドをご覧いただけます。[the guide for inference on CPUs](perf_infer_cpu).
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_cpu.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on CPU
このガイドは、CPU上で大規模なモデルを効率的にトレーニングする方法に焦点を当てています。
## Mixed precision with IPEX
IPEXはAVX-512以上のCPUに最適化されており、AVX2のみのCPUでも機能的に動作します。そのため、AVX-512以上のIntel CPU世代ではパフォーマンスの向上が期待されますが、AVX2のみのCPU(例:AMD CPUまたは古いIntel CPU)ではIPEXの下でより良いパフォーマンスが得られるかもしれませんが、保証されません。IPEXは、Float32とBFloat16の両方でCPUトレーニングのパフォーマンスを最適化します。以下のセクションでは、BFloat16の使用に重点を置いて説明します。
低精度データ型であるBFloat16は、AVX512命令セットを備えた第3世代Xeon® Scalable Processors(別名Cooper Lake)でネイティブサポートされており、さらに高性能なIntel® Advanced Matrix Extensions(Intel® AMX)命令セットを備えた次世代のIntel® Xeon® Scalable Processorsでもサポートされます。CPUバックエンド用の自動混合精度がPyTorch-1.10以降で有効になっています。同時に、Intel® Extension for PyTorchでのCPU用BFloat16の自動混合精度サポートと、オペレーターのBFloat16最適化のサポートが大幅に向上し、一部がPyTorchのメインブランチにアップストリームされています。ユーザーはIPEX Auto Mixed Precisionを使用することで、より優れたパフォーマンスとユーザーエクスペリエンスを得ることができます。
詳細な情報については、[Auto Mixed Precision](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html)を確認してください。
### IPEX installation:
IPEXのリリースはPyTorchに従っており、pipを使用してインストールできます:
| PyTorch Version | IPEX version |
| :---------------: | :----------: |
| 1.13 | 1.13.0+cpu |
| 1.12 | 1.12.300+cpu |
| 1.11 | 1.11.200+cpu |
| 1.10 | 1.10.100+cpu |
```
pip install intel_extension_for_pytorch==<version_name> -f https://developer.intel.com/ipex-whl-stable-cpu
```
[IPEXのインストール方法](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html)について、さらなるアプローチを確認してください。
### Trainerでの使用方法
TrainerでIPEXの自動混合精度を有効にするには、ユーザーはトレーニングコマンド引数に `use_ipex`、`bf16`、および `no_cuda` を追加する必要があります。
[Transformersの質問応答](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)のユースケースを例に説明します。
- CPU上でBF16自動混合精度を使用してIPEXでトレーニングを行う場合:
<pre> python run_qa.py \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
<b>--use_ipex \</b>
<b>--bf16 --no_cuda</b></pre>
### Practice example
Blog: [Accelerating PyTorch Transformers with Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/accelerate.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Accelerate を用いた分散学習
モデルが大きくなるにつれて、限られたハードウェアでより大きなモデルを訓練し、訓練速度を大幅に上昇させるための方法として並列処理が浮上してきました。1台のマシンに複数のGPUがあっても、複数のマシンにまたがる複数のGPUがあっても、あらゆるタイプの分散処理セットアップ上でユーザーが簡単に 🤗 Transformers モデルを訓練できるように、 Hugging Face では [🤗 Accelerate](https://huggingface.co/docs/accelerate) ライブラリを作成しました。このチュートリアルでは、PyTorch の訓練ループをカスタマイズして、分散処理環境での訓練を可能にする方法について学びます。
## セットアップ
はじめに 🤗 Accelerate をインストールしましょう:
```bash
pip install accelerate
```
そしたらインポートして [`~accelerate.Accelerator`] オブジェクトを作成しましょう。[`~accelerate.Accelerator`] は分散処理セットアップを自動的に検出し、訓練のために必要な全てのコンポーネントを初期化します。モデルをデバイスに明示的に配置する必要はありません。
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## Accelerate する準備をしましょう
次に、関連する全ての訓練オブジェクトを [`~accelerate.Accelerator.prepare`] メソッドに渡します。これには、訓練と評価それぞれのDataloader、モデル、optimizer が含まれます:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## Backward
最後に訓練ループ内の `loss.backward()` を 🤗 Accelerate の [`~accelerate.Accelerator.backward`] メソッドで置き換えます:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
以下のコードで確認できる通り、訓練ループに4行のコードを追加するだけで分散学習が可能です!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## 訓練する
関連するコードを追加したら、スクリプトまたは Colaboratory などのノートブックで訓練を開始します。
### スクリプトで訓練する
スクリプトから訓練をしている場合は、設定ファイルを作成・保存するために以下のコマンドを実行してください:
```bash
accelerate config
```
そして次のようにして訓練を開始します:
```bash
accelerate launch train.py
```
### ノートブックで訓練する
Colaboratory の TPU の利用をお考えの場合、🤗 Accelerate はノートブック上で実行することもできます。訓練に必要な全てのコードを関数に含め、[`~accelerate.notebook_launcher`] に渡してください:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
🤗 Accelerate と豊富な機能についてもっと知りたい方は[ドキュメント](https://huggingface.co/docs/accelerate)を参照してください。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/tf_xla.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# XLA Integration for TensorFlow Models
[[open-in-colab]]
加速線形代数(Accelerated Linear Algebra)、通称XLAは、TensorFlowモデルのランタイムを高速化するためのコンパイラです。[公式ドキュメント](https://www.tensorflow.org/xla)によれば、XLA(Accelerated Linear Algebra)は線形代数のためのドメイン固有のコンパイラで、TensorFlowモデルを潜在的にソースコードの変更なしで高速化できます。
TensorFlowでXLAを使用するのは簡単です。XLAは`tensorflow`ライブラリ内にパッケージ化されており、[`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs)などのグラフを作成する関数内で`jit_compile`引数を使用してトリガーできます。`fit()`や`predict()`などのKerasメソッドを使用する場合、`model.compile()`に`jit_compile`引数を渡すだけでXLAを有効にできます。ただし、XLAはこれらのメソッドに限定されているわけではありません。任意の`tf.function`を高速化するためにも使用できます。
🤗 Transformers内のいくつかのTensorFlowメソッドは、XLAと互換性があるように書き直されています。これには、[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)、[T5](https://huggingface.co/docs/transformers/model_doc/t5)、[OPT](https://huggingface.co/docs/transformers/model_doc/opt)などのテキスト生成モデルや、[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)などの音声処理モデルも含まれます。
速度向上の具体的な量はモデルに非常に依存しますが、🤗 Transformers内のTensorFlowテキスト生成モデルでは、約100倍の速度向上を確認しています。このドキュメントでは、これらのモデルにXLAを使用して最大のパフォーマンスを得る方法を説明します。また、ベンチマークとXLA統合のデザイン哲学について詳しく学びたい場合の追加リソースへのリンクも提供します。
## Running TF functions with XLA
以下のTensorFlowモデルを考えてみましょう:
```py
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
```
上記のモデルは、次元が`(10, )`の入力を受け入れます。このモデルをフォワードパスで実行するには、次のようにします:
```py
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
```
XLAでコンパイルされた関数を使用してフォワードパスを実行するには、以下のようにします:
```py
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
```
`model`のデフォルトの `call()` 関数はXLAグラフをコンパイルするために使用されます。ただし、XLAにコンパイルしたい他のモデル関数がある場合、それも可能です。以下はその方法です:
```py
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
```
## Running a TF text generation model with XLA from 🤗 Transformers
🤗 Transformers内でXLAでの高速化された生成を有効にするには、最新バージョンの`transformers`がインストールされている必要があります。次のコマンドを実行してインストールできます:
```bash
pip install transformers --upgrade
```
次に、次のコードを実行できます:
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
```
`generate()`でXLAを有効にするのは、たった一行のコードです。コードの残り部分は変更されていません。ただし、XLA固有のいくつかの注意点が上記のコードスニペットにあります。これらに注意する必要があり、XLAがもたらす速度向上を実現するためにそれらを把握することが重要です。次のセクションでこれらについて詳しく説明します。
## Gotchas to be aware of
XLAを有効にした関数(上記の`xla_generate()`など)を初めて実行すると、内部で計算グラフを推論しようとしますが、これは時間がかかります。このプロセスは["トレーシング"(tracing)](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing)として知られています。
生成時間が高速ではないことに気付くかもしれません。`xla_generate()`(または他のXLA対応関数)の連続呼び出しでは、関数への入力が最初に計算グラフが構築されたときと同じ形状に従っている場合、計算グラフを推論する必要はありません。これは、入力形状が固定されているモダリティ(例:画像)には問題ありませんが、変数の入力形状モダリティ(例:テキスト)を扱う場合には注意が必要です。
`xla_generate()`が常に同じ入力形状で動作するようにするには、トークナイザを呼び出す際に`padding`引数を指定できます。
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
```
これにより、`xla_generate()`への入力が常にトレースされた形状の入力を受け取ることを確認し、生成時間の高速化を実現できます。以下のコードでこれを確認できます:
```py
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
```
Tesla T4 GPUを使用すると、次のような出力が期待されます:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
```
最初の`xla_generate()`呼び出しはトレーシングのために時間がかかりますが、連続する呼び出しは桁違いに高速です。生成オプションのいかなる変更も、再トレーシングを引き起こし、生成時間の遅延を引き起こすことに注意してください。
このドキュメントでは、🤗 Transformersが提供するテキスト生成オプションをすべて網羅していません。高度なユースケースについてはドキュメンテーションを参照することをお勧めします。
## Additional Resources
ここでは、🤗 Transformersと一般的なXLAについてさらに詳しく学びたい場合のいくつかの追加リソースを提供します。
* [このColab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb)では、XLA対応のエンコーダーデコーダー([T5](https://huggingface.co/docs/transformers/model_doc/t5)など)およびデコーダー専用([GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)など)テキスト生成モデルを試すための対話型デモが提供されています。
* [このブログ記事](https://huggingface.co/blog/tf-xla-generate)では、XLA対応モデルの比較ベンチマークの概要と、TensorFlowでのXLAについての友好的な紹介が提供されています。
* [このブログ記事](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html)では、🤗 TransformersのTensorFlowモデルにXLAサポートを追加する際の設計哲学について説明しています。
* 一般的なXLAとTensorFlowグラフについて詳しく学ぶためのおすすめの投稿:
* [XLA: 機械学習用の最適化コンパイラ](https://www.tensorflow.org/xla)
* [グラフと`tf.function`の紹介](https://www.tensorflow.org/guide/intro_to_graphs)
* [`tf.function`を使用したパフォーマンス向上](https://www.tensorflow.org/guide/function)
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_train_special.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Training on Specialized Hardware
<Tip>
注意: [単一GPUセクション](perf_train_gpu_one)で紹介されたほとんどの戦略(混合精度トレーニングや勾配蓄積など)および[マルチGPUセクション](perf_train_gpu_many)は一般的なトレーニングモデルに適用される汎用的なものですので、このセクションに入る前にそれを確認してください。
</Tip>
このドキュメントは、専用ハードウェアでトレーニングする方法に関する情報を近日中に追加予定です。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/llm_tutorial.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation with LLMs
[[open-in-colab]]
LLM、またはLarge Language Models(大規模言語モデル)は、テキスト生成の鍵となる要素です。要するに、これらは大規模な事前訓練済みトランスフォーマーモデルで、与えられた入力テキストに基づいて次の単語(または、より正確にはトークン)を予測するように訓練されています。トークンを1つずつ予測するため、モデルを呼び出すだけでは新しい文を生成するために何かより精巧なことをする必要があります。自己回帰生成を行う必要があります。
自己回帰生成は、推論時の手続きで、いくつかの初期入力を与えた状態で、モデルを反復的に呼び出す手法です。🤗 Transformersでは、これは[`~generation.GenerationMixin.generate`]メソッドによって処理され、これは生成能力を持つすべてのモデルで利用可能です。
このチュートリアルでは、以下のことを示します:
* LLMを使用してテキストを生成する方法
* 一般的な落とし穴を回避する方法
* LLMを最大限に活用するための次のステップ
始める前に、必要なライブラリがすべてインストールされていることを確認してください:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## Generate text
[因果言語モデリング](tasks/language_modeling)のためにトレーニングされた言語モデルは、テキストトークンのシーケンスを入力として受け取り、次のトークンの確率分布を返します。
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"Forward pass of an LLM"</figcaption>
</figure>
LLM(Language Model)による自己回帰生成の重要な側面の1つは、この確率分布から次のトークンを選択する方法です。このステップでは、次のイテレーションのためのトークンが得られる限り、何でも可能です。これは、確率分布から最も可能性の高いトークンを選択するだけのシンプルな方法から、結果の分布からサンプリングする前に数々の変換を適用するほど複雑な方法まで、あらゆる方法が考えられます。
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"Autoregressive generation iteratively selects the next token from a probability distribution to generate text"</figcaption>
</figure>
上記のプロセスは、ある停止条件が満たされるまで反復的に繰り返されます。理想的には、停止条件はモデルによって指示され、モデルは終了シーケンス(`EOS`)トークンを出力するタイミングを学習すべきです。これがそうでない場合、生成はあらかじめ定義された最大長に達したときに停止します。
トークン選択ステップと停止条件を適切に設定することは、モデルがタスクで期待どおりに振る舞うために重要です。それが、各モデルに関連付けられた [`~generation.GenerationConfig`] ファイルがある理由であり、これには優れたデフォルトの生成パラメータ化が含まれ、モデルと一緒に読み込まれます。
コードについて話しましょう!
<Tip>
基本的なLLMの使用に興味がある場合、高レベルの [`Pipeline`](pipeline_tutorial) インターフェースが良い出発点です。ただし、LLMはしばしば量子化やトークン選択ステップの細かい制御などの高度な機能が必要であり、これは [`~generation.GenerationMixin.generate`] を介して最良に行われます。LLMとの自己回帰生成はリソースが多く必要であり、適切なスループットのためにGPUで実行する必要があります。
</Tip>
<!-- TODO: llama 2(またはより新しい一般的なベースライン)が利用可能になったら、例を更新する -->
まず、モデルを読み込む必要があります。
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
... )
```
`from_pretrained` 呼び出しで2つのフラグがあることに注意してください:
- `device_map` はモデルをあなたのGPUに移動させます
- `load_in_4bit` は[4ビットの動的量子化](main_classes/quantization)を適用してリソース要件を大幅に削減します
モデルを初期化する他の方法もありますが、これはLLMを始めるための良い基準です。
次に、[トークナイザ](tokenizer_summary)を使用してテキスト入力を前処理する必要があります。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
```
`model_inputs` 変数は、トークン化されたテキスト入力とアテンションマスクを保持しています。 [`~generation.GenerationMixin.generate`] は、アテンションマスクが渡されていない場合でも、最善の努力をしてそれを推測しようとしますが、できる限り渡すことをお勧めします。最適な結果を得るためです。
最後に、[`~generation.GenerationMixin.generate`] メソッドを呼び出して生成されたトークンを取得し、それを表示する前にテキストに変換する必要があります。
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, black, white, and brown'
```
これで完了です!わずかなコード行数で、LLM(Large Language Model)のパワーを活用できます。
## Common pitfalls
[生成戦略](generation_strategies)はたくさんあり、デフォルトの値があなたのユースケースに適していないことがあります。出力が期待通りでない場合、最も一般的な落とし穴とその回避方法のリストを作成しました。
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "openlm-research/open_llama_7b", device_map="auto", load_in_4bit=True
... )
```
### Generated output is too short/long
[`~generation.GenerationConfig`] ファイルで指定されていない場合、`generate` はデフォルトで最大で 20 トークンまで返します。我々は `generate` コールで `max_new_tokens` を手動で設定することを強くお勧めします。これにより、返される新しいトークンの最大数を制御できます。LLM(正確には、[デコーダー専用モデル](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt))も出力の一部として入力プロンプトを返すことに注意してください。
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### Incorrect generation mode
デフォルトでは、 [`~generation.GenerationConfig`] ファイルで指定されていない限り、`generate` は各イテレーションで最も可能性の高いトークンを選択します(貪欲デコーディング)。タスクに応じて、これは望ましくないことがあります。チャットボットやエッセイのような創造的なタスクでは、サンプリングが有益です。一方、音声の転写や翻訳のような入力に基づくタスクでは、貪欲デコーディングが有益です。`do_sample=True` でサンプリングを有効にできます。このトピックについての詳細は、この[ブログポスト](https://huggingface.co/blog/how-to-generate)で学ぶことができます。
```py
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(0)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat.\nI just need to be. I am always.\nEvery time'
```
### Wrong padding side
LLM(Large Language Models)は[デコーダー専用](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)のアーキテクチャであり、入力プロンプトを繰り返し処理することを意味します。入力が同じ長さでない場合、それらをパディングする必要があります。LLMはパッドトークンからの続きを学習していないため、入力は左パディングする必要があります。また、生成に対して注目マスクを渡し忘れないようにしてください!
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)[0]
''
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
## Further resources
オートリグレッシブ生成プロセスは比較的簡単ですが、LLMを最大限に活用することは多くの要素が絡むため、挑戦的な試みとなります。LLMの使用と理解をさらに深めるための次のステップについては以下のリソースをご覧ください。
<!-- TODO: 新しいガイドで完了 -->
### Advanced generate usage
1. [ガイド](generation_strategies):異なる生成方法を制御する方法、生成構成ファイルの設定方法、出力のストリーミング方法についてのガイド;
2. [`~generation.GenerationConfig`]、[`~generation.GenerationMixin.generate`]、および[生成関連クラス](internal/generation_utils)に関するAPIリファレンス。
### LLM leaderboards
1. [Open LLM リーダーボード](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard):オープンソースモデルの品質に焦点を当てたリーダーボード;
2. [Open LLM-Perf リーダーボード](https://huggingface.co/spaces/optimum/llm-perf-leaderboard):LLMのスループットに焦点を当てたリーダーボード。
### Latency and throughput
1. [ガイド](main_classes/quantization):ダイナミッククオンタイズに関するガイド。これによりメモリ要件を劇的に削減する方法が示されています。
### Related libraries
1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference):LLM用の本番向けサーバー;
2. [`optimum`](https://github.com/huggingface/optimum):特定のハードウェアデバイス向けに最適化された🤗 Transformersの拡張。
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_torch_compile.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimize inference using torch.compile()
このガイドは、[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) を使用した推論速度の向上に関するベンチマークを提供することを目的としています。これは、[🤗 Transformers のコンピュータビジョンモデル](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)向けのものです。
## Benefits of torch.compile
`torch.compile()`の利点
モデルとGPUによっては、torch.compile()は推論時に最大30%の高速化を実現します。 `torch.compile()`を使用するには、バージョン2.0以上のtorchをインストールするだけです。
モデルのコンパイルには時間がかかるため、毎回推論するのではなく、モデルを1度だけコンパイルする場合に役立ちます。
任意のコンピュータビジョンモデルをコンパイルするには、以下のようにモデルに`torch.compile()`を呼び出します:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` は、コンパイルに関する異なるモードを備えており、基本的にはコンパイル時間と推論のオーバーヘッドが異なります。`max-autotune` は `reduce-overhead` よりも時間がかかりますが、推論速度が速くなります。デフォルトモードはコンパイルにおいては最速ですが、推論時間においては `reduce-overhead` に比べて効率が良くありません。このガイドでは、デフォルトモードを使用しました。詳細については、[こちら](https://pytorch.org/get-started/pytorch-2.0/#user-experience) を参照してください。
`torch` バージョン 2.0.1 で異なるコンピュータビジョンモデル、タスク、ハードウェアの種類、およびバッチサイズを使用して `torch.compile` をベンチマークしました。
## Benchmarking code
以下に、各タスクのベンチマークコードを示します。推論前にGPUをウォームアップし、毎回同じ画像を使用して300回の推論の平均時間を取得します。
### Image Classification with ViT
```
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### Object Detection with DETR
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### Image Segmentation with Segformer
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
以下は、私たちがベンチマークを行ったモデルのリストです。
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
以下は、`torch.compile()`を使用した場合と使用しない場合の推論時間の可視化と、異なるハードウェアとバッチサイズの各モデルに対するパフォーマンス向上の割合です。
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
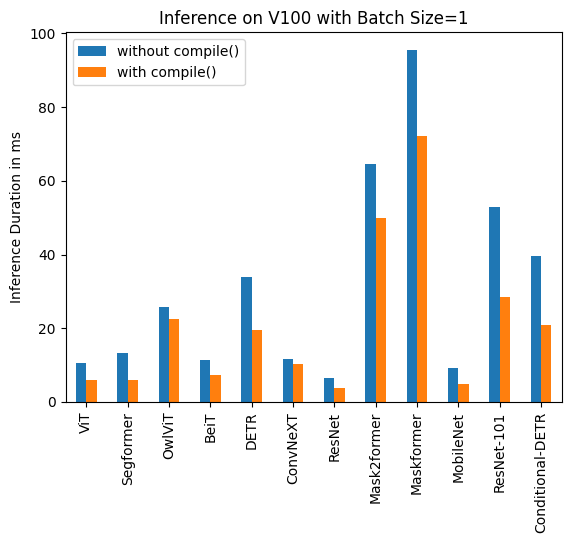
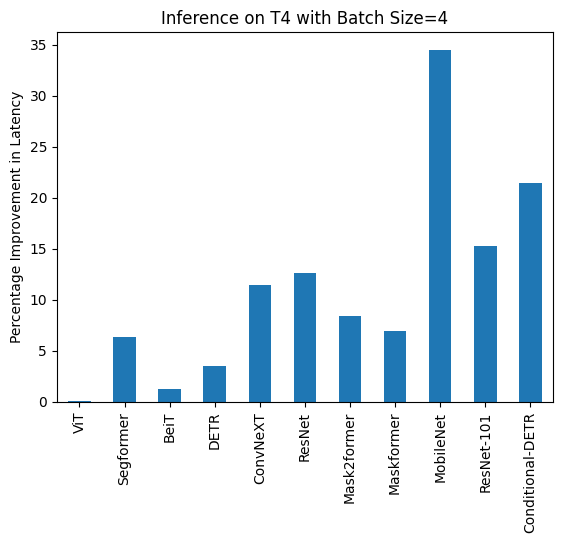
下記は、各モデルについて`compile()`を使用した場合と使用しなかった場合の推論時間(ミリ秒単位)です。なお、OwlViTは大きなバッチサイズでの使用時にメモリ不足(OOM)が発生することに注意してください。
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
また、PyTorchのナイトリーバージョン(2.1.0dev)でのベンチマークを行い、コンパイルされていないモデルとコンパイル済みモデルの両方でレイテンシーの向上を観察しました。ホイールは[こちら](https://download.pytorch.org/whl/nightly/cu118)から入手できます。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
NightlyビルドでA100およびT4向けの `reduce-overhead` コンパイルモードをベンチマークしました。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
| 0 |
hf_public_repos/transformers/docs/source
|
hf_public_repos/transformers/docs/source/ja/perf_infer_gpu_one.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Inference on a Single GPU
このガイドに加えて、[1つのGPUでのトレーニングガイド](perf_train_gpu_one)と[CPUでの推論ガイド](perf_infer_cpu)に関連する情報があります。
## Flash Attention 2
<Tip>
この機能は実験的であり、将来のバージョンで大幅に変更される可能性があります。たとえば、Flash Attention 2 APIは近い将来`BetterTransformer` APIに移行するかもしれません。
</Tip>
Flash Attention 2は、トランスフォーマーベースのモデルのトレーニングと推論速度を大幅に高速化できます。Flash Attention 2は、Tri Dao氏によって[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)で導入されました。Flash Attentionに関する科学論文は[こちら](https://arxiv.org/abs/2205.14135)で見ることができます。
Flash Attention 2を正しくインストールするには、上記のリポジトリに記載されているインストールガイドに従ってください。
以下のモデルに対してFlash Attention 2をネイティブサポートしています:
- Llama
- Falcon
さらに多くのモデルにFlash Attention 2のサポートを追加することをGitHubで提案することもでき、変更を統合するためにプルリクエストを開くこともできます。サポートされているモデルは、パディングトークンを使用してトレーニングを含む、推論とトレーニングに使用できます(現在の`BetterTransformer` APIではサポートされていない)。
<Tip>
Flash Attention 2は、モデルのdtypeが`fp16`または`bf16`の場合にのみ使用でき、NVIDIA-GPUデバイスでのみ実行されます。この機能を使用する前に、モデルを適切なdtypeにキャストし、サポートされているデバイスにロードしてください。
</Tip>
### Quick usage
モデルでFlash Attention 2を有効にするには、`from_pretrained`の引数に`attn_implementation="flash_attention_2"`を追加します。
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
こちらは、生成または微調整のために使用するテキストです。
### Expected speedups
特に長いシーケンスに対して、微調整と推論の際には、かなりの高速化が期待できます。ただし、Flash Attentionはパディングトークンを使用してアテンションスコアを計算しないため、シーケンスにパディングトークンが含まれる場合、バッチ推論においてアテンションスコアを手動でパッド/アンパッドする必要があり、パディングトークンを含むバッチ生成の大幅な遅延が発生します。
これを克服するために、トレーニング中にシーケンスにパディングトークンを使用せずにFlash Attentionを使用する必要があります(たとえば、データセットをパックすることにより、シーケンスを最大シーケンス長に達するまで連結することなど)。ここに[例](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516)が提供されています。
以下は、パディングトークンのない場合に、シーケンス長が4096の[tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b)に対する単純なフォワードパスの予想される高速化です。さまざまなバッチサイズが示されています:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/falcon-7b-inference-large-seqlen.png">
</div>
以下は、パディングトークンのない場合に、シーケンス長が4096の[`meta-llama/Llama-7b-hf`](https://hf.co/meta-llama/Llama-7b-hf)に対する単純なフォワードパスの予想される高速化です。さまざまなバッチサイズが示されています:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/llama-7b-inference-large-seqlen.png">
</div>
パディングトークンを含むシーケンス(パディングトークンを使用してトレーニングまたは生成する)の場合、アテンションスコアを正しく計算するために入力シーケンスをアンパッド/パッドする必要があります。比較的小さいシーケンス長の場合、純粋なフォワードパスではパディングトークンが30%未満しか埋められていないため、これはわずかな高速化をもたらします。
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/llama-2-small-seqlen-padding.png">
</div>
しかし、大きなシーケンス長の場合、純粋な推論(トレーニングも含む)には興味深い高速化が得られます。
Flash Attentionは、アテンション計算をよりメモリ効率の良いものにし、大きなシーケンス長でのCUDA OOMの問題を回避できるようにします。大きなシーケンス長に対して最大20のメモリ削減をもたらすことがあります。詳細については、[公式のFlash Attentionリポジトリ](https://github.com/Dao-AILab/flash-attention)をご覧ください。
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/llama-2-large-seqlen-padding.png">
</div>
### Advanced usage
この機能をモデルの最適化に多くの既存の機能と組み合わせることができます。以下にいくつかの例を示します:
### Combining Flash Attention 2 and 8-bit models
この機能を8ビットの量子化と組み合わせることができます:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
```
### Combining Flash Attention 2 and 4-bit models
この機能を 4 ビットの量子化と組み合わせることができます:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
```
### Combining Flash Attention 2 and PEFT
この機能を使用して、Flash Attention 2をベースにアダプターをトレーニングする際にPEFTを組み合わせることができます。
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
from peft import LoraConfig
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
lora_config = LoraConfig(
r=8,
task_type="CAUSAL_LM"
)
model.add_adapter(lora_config)
... # train your model
```
## BetterTransformer
[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview)は、🤗 TransformersモデルをPyTorchネイティブの高速パス実行に変換します。これにより、Flash Attentionなどの最適化されたカーネルが内部で呼び出されます。
BetterTransformerは、テキスト、画像、およびオーディオモデルの単一およびマルチGPUでの高速な推論をサポートしています。
<Tip>
Flash Attentionは、fp16またはbf16のdtypeを使用するモデルにのみ使用できます。BetterTransformerを使用する前に、モデルを適切なdtypeにキャストしてください。
</Tip>
### Encoder models
PyTorchネイティブの[`nn.MultiHeadAttention`](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/)アテンション高速パス、BetterTransformerと呼ばれるものは、[🤗 Optimumライブラリ](https://huggingface.co/docs/optimum/bettertransformer/overview)の統合を通じてTransformersと一緒に使用できます。
PyTorchのアテンション高速パスを使用すると、カーネルフュージョンと[ネストされたテンソル](https://pytorch.org/docs/stable/nested.html)の使用により、推論を高速化できます。詳細なベンチマーク情報は[このブログ記事](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2)にあります。
[`optimum`](https://github.com/huggingface/optimum)パッケージをインストールした後、推論中にBetter Transformerを使用するには、関連する内部モジュールを呼び出すことで置き換える必要があります[`~PreTrainedModel.to_bettertransformer`]:
```python
model = model.to_bettertransformer()
```
メソッド [`~PreTrainedModel.reverse_bettertransformer`] は、モデルを保存する前に使用すべきで、標準のトランスフォーマーモデリングを使用するためのものです:
```python
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")
```
BetterTransformer APIを使ったエンコーダーモデルの可能性について詳しく知るには、[このブログポスト](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2)をご覧ください。
### Decoder models
テキストモデル、特にデコーダーベースのモデル(GPT、T5、Llamaなど)にとって、BetterTransformer APIはすべての注意操作を[`torch.nn.functional.scaled_dot_product_attention`オペレーター](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention)(SDPA)を使用するように変換します。このオペレーターはPyTorch 2.0以降でのみ利用可能です。
モデルをBetterTransformerに変換するには、以下の手順を実行してください:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
# convert the model to BetterTransformer
model.to_bettertransformer()
# Use it for training or inference
```
SDPAは、ハードウェアや問題のサイズに応じて[Flash Attention](https://arxiv.org/abs/2205.14135)カーネルを使用することもできます。Flash Attentionを有効にするか、特定の設定(ハードウェア、問題サイズ)で使用可能かどうかを確認するには、[`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel)をコンテキストマネージャとして使用します。
```diff
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
# convert the model to BetterTransformer
model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
もしトレースバックにバグが表示された場合
```bash
RuntimeError: No available kernel. Aborting execution.
```
Flash Attention の広範なカバレッジを持つかもしれない PyTorch のナイトリーバージョンを試してみることをお勧めします。
```bash
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
```
Or make sure your model is correctly casted in float16 or bfloat16
モデルが正しくfloat16またはbfloat16にキャストされていることを確認してください。
Have a look at [this detailed blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to read more about what is possible to do with `BetterTransformer` + SDPA API.
`BetterTransformer` + SDPA APIを使用して何が可能かについて詳しく読むには、[この詳細なブログポスト](https://pytorch.org/blog/out-of-the-box-acceleration/)をご覧ください。
## `bitsandbytes` integration for FP4 mixed-precision inference
FP4混合精度推論のための`bitsandbytes`統合
You can install `bitsandbytes` and benefit from easy model compression on GPUs. Using FP4 quantization you can expect to reduce up to 8x the model size compared to its native full precision version. Check out below how to get started.
`bitsandbytes`をインストールし、GPUで簡単なモデルの圧縮を利用できます。FP4量子化を使用すると、ネイティブのフルプレシジョンバージョンと比較してモデルサイズを最大8倍削減できることが期待できます。以下を確認して、どのように始めるかをご覧ください。
<Tip>
Note that this feature can also be used in a multi GPU setup.
この機能は、マルチGPUセットアップでも使用できることに注意してください。
</Tip>
### Requirements [[requirements-for-fp4-mixedprecision-inference]]
- Latest `bitsandbytes` library
`pip install bitsandbytes>=0.39.0`
- Install latest `accelerate` from source
`pip install git+https://github.com/huggingface/accelerate.git`
- Install latest `transformers` from source
`pip install git+https://github.com/huggingface/transformers.git`
### Running FP4 models - single GPU setup - Quickstart
以下のコードを実行することで、簡単に単一のGPUでFP4モデルを実行できます:
```py
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
```
注意: `device_map`はオプションですが、推論時に `device_map = 'auto'` を設定することが推奨されています。これにより、利用可能なリソースに効率的にモデルがディスパッチされます。
### Running FP4 models - multi GPU setup
混合4ビットモデルを複数のGPUにロードする方法は、単一GPUセットアップと同じです(単一GPUセットアップと同じコマンドです):
```py
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
```
しかし、`accelerate`を使用して、各GPUに割り当てるGPU RAMを制御することができます。以下のように、`max_memory`引数を使用します:
```py
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
```
この例では、最初のGPUは600MBのメモリを使用し、2番目のGPUは1GBを使用します。
### Advanced usage
このメソッドのさらなる高度な使用法については、[量子化](main_classes/quantization)のドキュメンテーションページをご覧ください。
## `bitsandbytes` integration for Int8 mixed-precision matrix decomposition
<Tip>
この機能は、マルチGPU環境でも使用できます。
</Tip>
論文[`LLM.int8():スケーラブルなTransformer向けの8ビット行列乗算`](https://arxiv.org/abs/2208.07339)によれば、Hugging Face統合がHub内のすべてのモデルでわずか数行のコードでサポートされています。このメソッドは、半精度(`float16`および`bfloat16`)の重みの場合に`nn.Linear`サイズを2倍、単精度(`float32`)の重みの場合は4倍に縮小し、外れ値に対してほとんど影響を与えません。

Int8混合精度行列分解は、行列乗算を2つのストリームに分割することによって動作します:(1) システマティックな特徴外れ値ストリームがfp16で行列乗算(0.01%)、(2) int8行列乗算の通常のストリーム(99.9%)。この方法を使用すると、非常に大きなモデルに対して予測の劣化なしにint8推論が可能です。
このメソッドの詳細については、[論文](https://arxiv.org/abs/2208.07339)または[この統合に関するブログ記事](https://huggingface.co/blog/hf-bitsandbytes-integration)をご確認ください。

なお、この機能を使用するにはGPUが必要であり、カーネルはGPU専用にコンパイルされている必要があります。この機能を使用する前に、モデルの1/4(またはハーフ精度の重みの場合は1/2)を保存するのに十分なGPUメモリがあることを確認してください。
このモジュールを使用する際のヘルプに関する詳細は、以下のノートをご覧いただくか、[Google Colabのデモ](#colab-demos)をご覧ください。
### Requirements [[requirements-for-int8-mixedprecision-matrix-decomposition]]
- `bitsandbytes<0.37.0`を使用する場合、NVIDIA GPUを使用していることを確認し、8ビットテンソルコアをサポートしていることを確認してください(Turing、Ampere、またはそれ以降のアーキテクチャー、例:T4、RTX20s RTX30s、A40-A100など)。`bitsandbytes>=0.37.0`の場合、すべてのGPUがサポートされるはずです。
- 正しいバージョンの`bitsandbytes`をインストールするには、次のコマンドを実行してください:
`pip install bitsandbytes>=0.31.5`
- `accelerate`をインストールします:
`pip install accelerate>=0.12.0`
### Running mixed-Int8 models - single GPU setup
必要なライブラリをインストールした後、ミックス 8 ビットモデルを読み込む方法は次の通りです:
```py
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
```
以下はシンプルな例です:
* `pipeline()` 関数の代わりに、モデルの `generate()` メソッドを使用することをお勧めします。`pipeline()` 関数を使用して推論することは可能ですが、混合8ビットモデルに最適化されておらず、`generate()` メソッドを使用するよりも遅くなります。また、一部のサンプリング戦略(例:ヌクレウスサンプリング)は、`pipeline()` 関数では混合8ビットモデルではサポートされていません。
* すべての入力をモデルと同じデバイスに配置してください。
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
```
### Running mixed-int8 models - multi GPU setup
複数のGPUに混合8ビットモデルをロードする方法は、次の通りです(シングルGPUセットアップと同じコマンドです):
```py
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True)
```
`accelerate`を使用して各GPUに割り当てるGPU RAMを制御する際には、以下のように`max_memory`引数を使用します:
```py
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
```
In this example, the first GPU will use 1GB of memory and the second 2GB.
### Colab demos
この方法を使用すると、以前のGoogle Colabでは推論できなかったモデルに対して推論を行うことができます。以下は、Google Colabで8ビット量子化を使用してT5-11b(fp32で42GB)を実行するデモのリンクです:
[](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing)
また、BLOOM-3Bのデモもご覧いただけます:
[](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing)
## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
異なる方法を組み合わせて、モデルの最適なパフォーマンスを得ることができます。例えば、BetterTransformerを使用してFP4ミックスプレシジョン推論とフラッシュアテンションを組み合わせることができます。
```py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/pipelines_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# パイプライン用のユーティリティ
このページには、ライブラリがパイプラインに提供するすべてのユーティリティ関数がリストされます。
これらのほとんどは、ライブラリ内のモデルのコードを研究する場合にのみ役に立ちます。
## Argument handling
[[autodoc]] pipelines.ArgumentHandler
[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
## Data format
[[autodoc]] pipelines.PipelineDataFormat
[[autodoc]] pipelines.CsvPipelineDataFormat
[[autodoc]] pipelines.JsonPipelineDataFormat
[[autodoc]] pipelines.PipedPipelineDataFormat
## Utilities
[[autodoc]] pipelines.PipelineException
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/image_processing_utils.md
|
!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 画像プロセッサ用ユーティリティ
このページには、画像プロセッサーで使用されるすべてのユーティリティー関数がリストされています。主に機能的なものです。
画像を処理するために使用される変換。
これらのほとんどは、ライブラリ内の画像プロセッサのコードを学習する場合にのみ役に立ちます。
## Image Transformations
[[autodoc]] image_transforms.center_crop
[[autodoc]] image_transforms.center_to_corners_format
[[autodoc]] image_transforms.corners_to_center_format
[[autodoc]] image_transforms.id_to_rgb
[[autodoc]] image_transforms.normalize
[[autodoc]] image_transforms.pad
[[autodoc]] image_transforms.rgb_to_id
[[autodoc]] image_transforms.rescale
[[autodoc]] image_transforms.resize
[[autodoc]] image_transforms.to_pil_image
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/time_series_utils.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 時系列ユーティリティ
このページには、時系列ベースのモデルに使用できるすべてのユーティリティ関数とクラスがリストされます。
これらのほとんどは、時系列モデルのコードを研究している場合、または分散出力クラスのコレクションに追加したい場合にのみ役立ちます。
## Distributional Output
[[autodoc]] time_series_utils.NormalOutput
[[autodoc]] time_series_utils.StudentTOutput
[[autodoc]] time_series_utils.NegativeBinomialOutput
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/audio_utils.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# `FeatureExtractor` 用のユーティリティ
このページには、*短時間フーリエ変換* や *ログ メル スペクトログラム* などの一般的なアルゴリズムを使用して生のオーディオから特別な特徴を計算するために、オーディオ [`FeatureExtractor`] で使用できるすべてのユーティリティ関数がリストされています。
これらのほとんどは、ライブラリ内のオーディオ プロセッサのコードを学習する場合にのみ役に立ちます。
## オーディオ変換
[[autodoc]] audio_utils.hertz_to_mel
[[autodoc]] audio_utils.mel_to_hertz
[[autodoc]] audio_utils.mel_filter_bank
[[autodoc]] audio_utils.optimal_fft_length
[[autodoc]] audio_utils.window_function
[[autodoc]] audio_utils.spectrogram
[[autodoc]] audio_utils.power_to_db
[[autodoc]] audio_utils.amplitude_to_db
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/file_utils.md
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 一般的なユーティリティ
このページには、ファイル `utils.py` にある Transformers の一般的なユーティリティ関数がすべてリストされています。
これらのほとんどは、ライブラリで一般的なコードを学習する場合にのみ役に立ちます。
## 列挙型と名前付きタプル
[[autodoc]] utils.ExplicitEnum
[[autodoc]] utils.PaddingStrategy
[[autodoc]] utils.TensorType
## 特別なデコレーター
[[autodoc]] utils.add_start_docstrings
[[autodoc]] utils.add_start_docstrings_to_model_forward
[[autodoc]] utils.add_end_docstrings
[[autodoc]] utils.add_code_sample_docstrings
[[autodoc]] utils.replace_return_docstrings
## 特殊なプロパティ
[[autodoc]] utils.cached_property
## その他のユーティリティ
[[autodoc]] utils._LazyModule
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/modeling_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# カスタムレイヤーとユーティリティ
このページには、ライブラリで使用されるすべてのカスタム レイヤーと、モデリングに提供されるユーティリティ関数がリストされます。
これらのほとんどは、ライブラリ内のモデルのコードを研究する場合にのみ役に立ちます。
## Pytorch custom modules
[[autodoc]] pytorch_utils.Conv1D
[[autodoc]] modeling_utils.PoolerStartLogits
- forward
[[autodoc]] modeling_utils.PoolerEndLogits
- forward
[[autodoc]] modeling_utils.PoolerAnswerClass
- forward
[[autodoc]] modeling_utils.SquadHeadOutput
[[autodoc]] modeling_utils.SQuADHead
- forward
[[autodoc]] modeling_utils.SequenceSummary
- forward
## PyTorch Helper Functions
[[autodoc]] pytorch_utils.apply_chunking_to_forward
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
[[autodoc]] pytorch_utils.prune_layer
[[autodoc]] pytorch_utils.prune_conv1d_layer
[[autodoc]] pytorch_utils.prune_linear_layer
## TensorFlow custom layers
[[autodoc]] modeling_tf_utils.TFConv1D
[[autodoc]] modeling_tf_utils.TFSequenceSummary
## TensorFlow loss functions
[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
## TensorFlow Helper Functions
[[autodoc]] modeling_tf_utils.get_initializer
[[autodoc]] modeling_tf_utils.keras_serializable
[[autodoc]] modeling_tf_utils.shape_list
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/generation_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 発電用ユーティリティ
このページには、[`~generation.GenerationMixin.generate`] で使用されるすべてのユーティリティ関数がリストされています。
[`~generation.GenerationMixin.greedy_search`],
[`~generation.GenerationMixin.contrastive_search`],
[`~generation.GenerationMixin.sample`],
[`~generation.GenerationMixin.beam_search`],
[`~generation.GenerationMixin.beam_sample`],
[`~generation.GenerationMixin.group_beam_search`]、および
[`~generation.GenerationMixin.constrained_beam_search`]。
これらのほとんどは、ライブラリ内の生成メソッドのコードを学習する場合にのみ役に立ちます。
## 出力を生成する
[`~generation.GenerationMixin.generate`] の出力は、次のサブクラスのインスタンスです。
[`~utils.ModelOutput`]。この出力は、返されたすべての情報を含むデータ構造です。
[`~generation.GenerationMixin.generate`] によって作成されますが、タプルまたは辞書としても使用できます。
以下に例を示します。
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
```
`generation_output` オブジェクトは、できる限り [`~generation.GenerateDecoderOnlyOutput`] です。
以下のそのクラスのドキュメントを参照してください。これは、次の属性があることを意味します。
- `sequences`: 生成されたトークンのシーケンス
- `scores` (オプション): 各生成ステップの言語モデリング ヘッドの予測スコア
- `hidden_states` (オプション): 生成ステップごとのモデルの隠れた状態
- `attentions` (オプション): 生成ステップごとのモデルのアテンションの重み
ここでは、`output_scores=True`を渡したので `scores` がありますが、`hidden_states` はありません。
`attentions` は、`output_hidden_states=True`または`output_attentions=True`を渡さなかったためです。
通常と同じように各属性にアクセスできます。その属性がモデルから返されなかった場合は、
は「なし」を取得します。ここで、たとえば`generation_output.scores`は、生成されたすべての予測スコアです。
言語モデリングのヘッドであり、`generation_output.attentions`は`None`です。
`generation_output` オブジェクトをタプルとして使用する場合、`None` 値を持たない属性のみが保持されます。
たとえば、ここには 2 つの要素、`loss`、次に`logits`があります。
```python
generation_output[:2]
```
たとえば、タプル `(generation_output.sequences,generation_output.scores)` を返します。
`generation_output` オブジェクトを辞書として使用する場合、`None` を持たない属性のみが保持されます。
ここでは、たとえば、`sequences`と`scores`という 2 つのキーがあります。
ここではすべての出力タイプを文書化します。
### PyTorch
[[autodoc]] generation.GenerateDecoderOnlyOutput
[[autodoc]] generation.GenerateEncoderDecoderOutput
[[autodoc]] generation.GenerateBeamDecoderOnlyOutput
[[autodoc]] generation.GenerateBeamEncoderDecoderOutput
### TensorFlow
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
[[autodoc]] generation.TFSampleEncoderDecoderOutput
[[autodoc]] generation.TFSampleDecoderOnlyOutput
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
### FLAX
[[autodoc]] generation.FlaxSampleOutput
[[autodoc]] generation.FlaxGreedySearchOutput
[[autodoc]] generation.FlaxBeamSearchOutput
## LogitsProcessor
[`LogitsProcessor`] を使用して、言語モデルのヘッドの予測スコアを変更できます。
世代。
### PyTorch
[[autodoc]] AlternatingCodebooksLogitsProcessor
- __call__
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] EpsilonLogitsWarper
- __call__
[[autodoc]] EtaLogitsWarper
- __call__
[[autodoc]] ExponentialDecayLengthPenalty
- __call__
[[autodoc]] ForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] ForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] ForceTokensLogitsProcessor
- __call__
[[autodoc]] HammingDiversityLogitsProcessor
- __call__
[[autodoc]] InfNanRemoveLogitsProcessor
- __call__
[[autodoc]] LogitNormalization
- __call__
[[autodoc]] LogitsProcessor
- __call__
[[autodoc]] LogitsProcessorList
- __call__
[[autodoc]] LogitsWarper
- __call__
[[autodoc]] MinLengthLogitsProcessor
- __call__
[[autodoc]] MinNewTokensLengthLogitsProcessor
- __call__
[[autodoc]] NoBadWordsLogitsProcessor
- __call__
[[autodoc]] NoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] PrefixConstrainedLogitsProcessor
- __call__
[[autodoc]] RepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] SequenceBiasLogitsProcessor
- __call__
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] SuppressTokensLogitsProcessor
- __call__
[[autodoc]] TemperatureLogitsWarper
- __call__
[[autodoc]] TopKLogitsWarper
- __call__
[[autodoc]] TopPLogitsWarper
- __call__
[[autodoc]] TypicalLogitsWarper
- __call__
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] WhisperTimeStampLogitsProcessor
- __call__
### TensorFlow
[[autodoc]] TFForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForceTokensLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessorList
- __call__
[[autodoc]] TFLogitsWarper
- __call__
[[autodoc]] TFMinLengthLogitsProcessor
- __call__
[[autodoc]] TFNoBadWordsLogitsProcessor
- __call__
[[autodoc]] TFNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensLogitsProcessor
- __call__
[[autodoc]] TFTemperatureLogitsWarper
- __call__
[[autodoc]] TFTopKLogitsWarper
- __call__
[[autodoc]] TFTopPLogitsWarper
- __call__
### FLAX
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForceTokensLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessorList
- __call__
[[autodoc]] FlaxLogitsWarper
- __call__
[[autodoc]] FlaxMinLengthLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensLogitsProcessor
- __call__
[[autodoc]] FlaxTemperatureLogitsWarper
- __call__
[[autodoc]] FlaxTopKLogitsWarper
- __call__
[[autodoc]] FlaxTopPLogitsWarper
- __call__
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
- __call__
## StoppingCriteria
[`StoppingCriteria`] を使用して、(EOS トークン以外の) 生成を停止するタイミングを変更できます。これは PyTorch 実装でのみ利用可能であることに注意してください。
[[autodoc]] StoppingCriteria
- __call__
[[autodoc]] StoppingCriteriaList
- __call__
[[autodoc]] MaxLengthCriteria
- __call__
[[autodoc]] MaxTimeCriteria
- __call__
## Constraints
[`Constraint`] を使用すると、生成時に出力に特定のトークンまたはシーケンスが含まれるように強制できます。これは PyTorch 実装でのみ利用可能であることに注意してください。
[[autodoc]] Constraint
[[autodoc]] PhrasalConstraint
[[autodoc]] DisjunctiveConstraint
[[autodoc]] ConstraintListState
## BeamSearch
[[autodoc]] BeamScorer
- process
- finalize
[[autodoc]] BeamSearchScorer
- process
- finalize
[[autodoc]] ConstrainedBeamSearchScorer
- process
- finalize
## Utilities
[[autodoc]] top_k_top_p_filtering
[[autodoc]] tf_top_k_top_p_filtering
## Streamers
[[autodoc]] TextStreamer
[[autodoc]] TextIteratorStreamer
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/tokenization_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for Tokenizers
このページには、トークナイザーによって使用されるすべてのユーティリティ関数 (主にクラス) がリストされます。
[`~tokenization_utils_base.PreTrainedTokenizerBase`] 間の共通メソッドを実装します。
[`PreTrainedTokenizer`] と [`PreTrainedTokenizerFast`] およびミックスイン
[`~tokenization_utils_base.SpecialTokensMixin`]。
これらのほとんどは、ライブラリ内のトークナイザーのコードを学習する場合にのみ役に立ちます。
## PreTrainedTokenizerBase
[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
- __call__
- all
## SpecialTokensMixin
[[autodoc]] tokenization_utils_base.SpecialTokensMixin
## Enums and namedtuples
[[autodoc]] tokenization_utils_base.TruncationStrategy
[[autodoc]] tokenization_utils_base.CharSpan
[[autodoc]] tokenization_utils_base.TokenSpan
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/internal/trainer_utils.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# トレーナー用ユーティリティ
このページには、[`Trainer`] で使用されるすべてのユーティリティ関数がリストされています。
これらのほとんどは、ライブラリ内のトレーナーのコードを学習する場合にのみ役に立ちます。
## Utilities
[[autodoc]] EvalPrediction
[[autodoc]] IntervalStrategy
[[autodoc]] enable_full_determinism
[[autodoc]] set_seed
[[autodoc]] torch_distributed_zero_first
## Callbacks internals
[[autodoc]] trainer_callback.CallbackHandler
## Distributed Evaluation
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
## Distributed Evaluation
[[autodoc]] HfArgumentParser
## Debug Utilities
[[autodoc]] debug_utils.DebugUnderflowOverflow
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/feature_extractor.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Feature Extractor
フィーチャーエクストラクタは、オーディオまたはビジョンモデルのための入力フィーチャーの準備を担当しています。これには、シーケンスからのフィーチャー抽出(例:オーディオファイルの前処理からLog-Melスペクトログラムフィーチャーへの変換)、画像からのフィーチャー抽出(例:画像ファイルのクロッピング)、またパディング、正規化、そしてNumpy、PyTorch、TensorFlowテンソルへの変換も含まれます。
## FeatureExtractionMixin
[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
- from_pretrained
- save_pretrained
## SequenceFeatureExtractor
[[autodoc]] SequenceFeatureExtractor
- pad
## BatchFeature
[[autodoc]] BatchFeature
## ImageFeatureExtractionMixin
[[autodoc]] image_utils.ImageFeatureExtractionMixin
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/output.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Model outputs
すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
辞書。
これがどのようになるかを例で見てみましょう。
```python
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
```
`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
`output_attentions=True`を渡さなかったからだ。
<Tip>
`output_hidden_states=True`を渡すと、`outputs.hidden_states[-1]`が `outputs.last_hidden_states` と正確に一致することを期待するかもしれない。
しかし、必ずしもそうなるとは限りません。モデルによっては、最後に隠された状態が返されたときに、正規化やその後の処理を適用するものもあります。
</Tip>
通常と同じように各属性にアクセスできます。その属性がモデルから返されなかった場合は、
は `None`を取得します。ここで、たとえば`outputs.loss`はモデルによって計算された損失であり、`outputs.attentions`は
`None`。
`outputs`オブジェクトをタプルとして考える場合、`None`値を持たない属性のみが考慮されます。
たとえば、ここには 2 つの要素、`loss`、次に`logits`があります。
```python
outputs[:2]
```
たとえば、タプル `(outputs.loss, Outputs.logits)` を返します。
`outputs`オブジェクトを辞書として考慮する場合、「None」を持たない属性のみが考慮されます。
価値観。たとえば、ここには`loss` と `logits`という 2 つのキーがあります。
ここでは、複数のモデル タイプで使用される汎用モデルの出力を文書化します。具体的な出力タイプは次のとおりです。
対応するモデルのページに記載されています。
## ModelOutput
[[autodoc]] utils.ModelOutput
- to_tuple
## BaseModelOutput
[[autodoc]] modeling_outputs.BaseModelOutput
## BaseModelOutputWithPooling
[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
## BaseModelOutputWithCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
## BaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
## BaseModelOutputWithPast
[[autodoc]] modeling_outputs.BaseModelOutputWithPast
## BaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
## Seq2SeqModelOutput
[[autodoc]] modeling_outputs.Seq2SeqModelOutput
## CausalLMOutput
[[autodoc]] modeling_outputs.CausalLMOutput
## CausalLMOutputWithCrossAttentions
[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
## CausalLMOutputWithPast
[[autodoc]] modeling_outputs.CausalLMOutputWithPast
## MaskedLMOutput
[[autodoc]] modeling_outputs.MaskedLMOutput
## Seq2SeqLMOutput
[[autodoc]] modeling_outputs.Seq2SeqLMOutput
## NextSentencePredictorOutput
[[autodoc]] modeling_outputs.NextSentencePredictorOutput
## SequenceClassifierOutput
[[autodoc]] modeling_outputs.SequenceClassifierOutput
## Seq2SeqSequenceClassifierOutput
[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
## MultipleChoiceModelOutput
[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
## TokenClassifierOutput
[[autodoc]] modeling_outputs.TokenClassifierOutput
## QuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
## Seq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
## Seq2SeqSpectrogramOutput
[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
## SemanticSegmenterOutput
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
## ImageClassifierOutput
[[autodoc]] modeling_outputs.ImageClassifierOutput
## ImageClassifierOutputWithNoAttention
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
## DepthEstimatorOutput
[[autodoc]] modeling_outputs.DepthEstimatorOutput
## Wav2Vec2BaseModelOutput
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
## XVectorOutput
[[autodoc]] modeling_outputs.XVectorOutput
## Seq2SeqTSModelOutput
[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
## Seq2SeqTSPredictionOutput
[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
## SampleTSPredictionOutput
[[autodoc]] modeling_outputs.SampleTSPredictionOutput
## TFBaseModelOutput
[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
## TFBaseModelOutputWithPooling
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
## TFBaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
## TFBaseModelOutputWithPast
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
## TFBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
## TFSeq2SeqModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
## TFCausalLMOutput
[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
## TFCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
## TFCausalLMOutputWithPast
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
## TFMaskedLMOutput
[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
## TFSeq2SeqLMOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
## TFNextSentencePredictorOutput
[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
## TFSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
## TFSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
## TFMultipleChoiceModelOutput
[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
## TFTokenClassifierOutput
[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
## TFQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
## TFSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
## FlaxBaseModelOutput
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
## FlaxBaseModelOutputWithPast
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
## FlaxBaseModelOutputWithPooling
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
## FlaxBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
## FlaxSeq2SeqModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
## FlaxCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
## FlaxMaskedLMOutput
[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
## FlaxSeq2SeqLMOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
## FlaxNextSentencePredictorOutput
[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
## FlaxSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
## FlaxSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
## FlaxMultipleChoiceModelOutput
[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
## FlaxTokenClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
## FlaxQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
## FlaxSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/text_generation.md
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation
各フレームワークには、それぞれの `GenerationMixin` クラスに実装されたテキスト生成のための Generate メソッドがあります。
- PyTorch [`~generation.GenerationMixin.generate`] は [`~generation.GenerationMixin`] に実装されています。
- TensorFlow [`~generation.TFGenerationMixin.generate`] は [`~generation.TFGenerationMixin`] に実装されています。
- Flax/JAX [`~generation.FlaxGenerationMixin.generate`] は [`~generation.FlaxGenerationMixin`] に実装されています。
選択したフレームワークに関係なく、[`~generation.GenerationConfig`] を使用して生成メソッドをパラメータ化できます。
クラスインスタンス。動作を制御する生成パラメータの完全なリストについては、このクラスを参照してください。
生成方法のこと。
モデルの生成構成を検査する方法、デフォルトとは何か、パラメーターをアドホックに変更する方法を学習するには、
カスタマイズされた生成構成を作成して保存する方法については、「
[テキスト生成戦略ガイド](../generation_strategies)。このガイドでは、関連機能の使用方法についても説明しています。
トークンストリーミングのような。
## GenerationConfig
[[autodoc]] generation.GenerationConfig
- from_pretrained
- from_model_config
- save_pretrained
## GenerationMixin
[[autodoc]] generation.GenerationMixin
- generate
- compute_transition_scores
- greedy_search
- sample
- beam_search
- beam_sample
- contrastive_search
- group_beam_search
- constrained_beam_search
## TFGenerationMixin
[[autodoc]] generation.TFGenerationMixin
- generate
- compute_transition_scores
## FlaxGenerationMixin
[[autodoc]] generation.FlaxGenerationMixin
- generate
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/logging.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Logging
🤗 Transformersには、ライブラリの詳細度を簡単に設定できる中央集中型のロギングシステムがあります。
現在、ライブラリのデフォルトの詳細度は「WARNING」です。
詳細度を変更するには、直接設定メソッドの1つを使用するだけです。例えば、詳細度をINFOレベルに変更する方法は以下の通りです。
```python
import transformers
transformers.logging.set_verbosity_info()
```
環境変数 `TRANSFORMERS_VERBOSITY` を使用して、デフォルトの冗長性をオーバーライドすることもできます。設定できます
`debug`、`info`、`warning`、`error`、`critical` のいずれかに変更します。例えば:
```bash
TRANSFORMERS_VERBOSITY=error ./myprogram.py
```
さらに、一部の「警告」は環境変数を設定することで無効にできます。
`TRANSFORMERS_NO_ADVISORY_WARNINGS` を *1* などの true 値に設定します。これにより、次を使用してログに記録される警告が無効になります。
[`logger.warning_advice`]。例えば:
```bash
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
```
以下は、独自のモジュールまたはスクリプトでライブラリと同じロガーを使用する方法の例です。
```python
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
logger.info("INFO")
logger.warning("WARN")
```
このロギング モジュールのすべてのメソッドは以下に文書化されています。主なメソッドは次のとおりです。
[`logging.get_verbosity`] ロガーの現在の冗長レベルを取得します。
[`logging.set_verbosity`] を使用して、冗長性を選択したレベルに設定します。順番に(少ないものから)
冗長から最も冗長まで)、それらのレベル (括弧内は対応する int 値) は次のとおりです。
- `transformers.logging.CRITICAL` または `transformers.logging.FATAL` (int 値、50): 最も多いもののみをレポートします。
重大なエラー。
- `transformers.logging.ERROR` (int 値、40): エラーのみを報告します。
- `transformers.logging.WARNING` または `transformers.logging.WARN` (int 値、30): エラーと
警告。これはライブラリで使用されるデフォルトのレベルです。
- `transformers.logging.INFO` (int 値、20): エラー、警告、および基本情報をレポートします。
- `transformers.logging.DEBUG` (int 値、10): すべての情報をレポートします。
デフォルトでは、モデルのダウンロード中に「tqdm」進行状況バーが表示されます。 [`logging.disable_progress_bar`] および [`logging.enable_progress_bar`] を使用して、この動作を抑制または抑制解除できます。
## `logging` vs `warnings`
Python には、よく組み合わせて使用される 2 つのロギング システムがあります。上で説明した `logging` と `warnings` です。
これにより、特定のバケット内の警告をさらに分類できます (例: 機能またはパスの`FutureWarning`)
これはすでに非推奨になっており、`DeprecationWarning`は今後の非推奨を示します。
両方とも`transformers`ライブラリで使用します。 `logging`の`captureWarning`メソッドを活用して適応させて、
これらの警告メッセージは、上記の冗長設定ツールによって管理されます。
それはライブラリの開発者にとって何を意味しますか?次のヒューリスティックを尊重する必要があります。
- `warnings`は、ライブラリおよび`transformers`に依存するライブラリの開発者に優先されるべきです。
- `logging`は、日常のプロジェクトでライブラリを使用するライブラリのエンドユーザーに使用する必要があります。
以下の`captureWarnings`メソッドのリファレンスを参照してください。
[[autodoc]] logging.captureWarnings
## Base setters
[[autodoc]] logging.set_verbosity_error
[[autodoc]] logging.set_verbosity_warning
[[autodoc]] logging.set_verbosity_info
[[autodoc]] logging.set_verbosity_debug
## Other functions
[[autodoc]] logging.get_verbosity
[[autodoc]] logging.set_verbosity
[[autodoc]] logging.get_logger
[[autodoc]] logging.enable_default_handler
[[autodoc]] logging.disable_default_handler
[[autodoc]] logging.enable_explicit_format
[[autodoc]] logging.reset_format
[[autodoc]] logging.enable_progress_bar
[[autodoc]] logging.disable_progress_bar
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/configuration.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 構成
基本クラス [`PretrainedConfig`] は、設定をロード/保存するための一般的なメソッドを実装します。
ローカル ファイルまたはディレクトリから、またはライブラリ (ダウンロードされた) によって提供される事前トレーニング済みモデル構成から
HuggingFace の AWS S3 リポジトリから)。
各派生構成クラスはモデル固有の属性を実装します。すべての構成クラスに存在する共通の属性は次のとおりです。
`hidden_size`、`num_attention_heads`、および `num_hidden_layers`。テキスト モデルはさらに以下を実装します。
`vocab_size`。
## PretrainedConfig
[[autodoc]] PretrainedConfig
- push_to_hub
- all
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/processors.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Processors
Transformers ライブラリでは、プロセッサは 2 つの異なる意味を持ちます。
- [Wav2Vec2](../model_doc/wav2vec2) などのマルチモーダル モデルの入力を前処理するオブジェクト (音声とテキスト)
または [CLIP](../model_doc/clip) (テキストとビジョン)
- 古いバージョンのライブラリで GLUE または SQUAD のデータを前処理するために使用されていたオブジェクトは非推奨になりました。
## Multi-modal processors
マルチモーダル モデルでは、オブジェクトが複数のモダリティ (テキスト、
視覚と音声)。これは、2 つ以上の処理オブジェクトをグループ化するプロセッサーと呼ばれるオブジェクトによって処理されます。
トークナイザー (テキスト モダリティ用)、画像プロセッサー (視覚用)、特徴抽出器 (オーディオ用) など。
これらのプロセッサは、保存およびロード機能を実装する次の基本クラスを継承します。
[[autodoc]] ProcessorMixin
## Deprecated processors
すべてのプロセッサは、同じアーキテクチャに従っています。
[`~data.processors.utils.DataProcessor`]。プロセッサは次のリストを返します。
[`~data.processors.utils.InputExample`]。これら
[`~data.processors.utils.InputExample`] は次のように変換できます。
[`~data.processors.utils.Input features`] をモデルにフィードします。
[[autodoc]] data.processors.utils.DataProcessor
[[autodoc]] data.processors.utils.InputExample
[[autodoc]] data.processors.utils.InputFeatures
## GLUE
[一般言語理解評価 (GLUE)](https://gluebenchmark.com/) は、
既存の NLU タスクの多様なセットにわたるモデルのパフォーマンス。紙と同時発売された [GLUE: A
自然言語理解のためのマルチタスクベンチマークおよび分析プラットフォーム](https://openreview.net/pdf?id=rJ4km2R5t7)
このライブラリは、MRPC、MNLI、MNLI (不一致)、CoLA、SST2、STSB、
QQP、QNLI、RTE、WNLI。
それらのプロセッサは次のとおりです。
- [`~data.processors.utils.MrpcProcessor`]
- [`~data.processors.utils.MnliProcessor`]
- [`~data.processors.utils.MnliMismatchedProcessor`]
- [`~data.processors.utils.Sst2Processor`]
- [`~data.processors.utils.StsbProcessor`]
- [`~data.processors.utils.QqpProcessor`]
- [`~data.processors.utils.QnliProcessor`]
- [`~data.processors.utils.RteProcessor`]
- [`~data.processors.utils.WnliProcessor`]
さらに、次のメソッドを使用して、データ ファイルから値をロードし、それらをリストに変換することができます。
[`~data.processors.utils.InputExample`]。
[[autodoc]] data.processors.glue.glue_convert_examples_to_features
## XNLI
[クロスリンガル NLI コーパス (XNLI)](https://www.nyu.edu/projects/bowman/xnli/) は、
言語を超えたテキスト表現の品質。 XNLI は、[*MultiNLI*](http://www.nyu.edu/projects/bowman/multinli/) に基づくクラウドソースのデータセットです。テキストのペアには、15 個のテキスト含意アノテーションがラベル付けされています。
さまざまな言語 (英語などの高リソース言語とスワヒリ語などの低リソース言語の両方を含む)。
論文 [XNLI: Evaluating Cross-lingual Sentence Representations](https://arxiv.org/abs/1809.05053) と同時にリリースされました。
このライブラリは、XNLI データをロードするプロセッサをホストします。
- [`~data.processors.utils.XnliProcessor`]
テストセットにはゴールドラベルが付いているため、評価はテストセットで行われますのでご了承ください。
これらのプロセッサを使用する例は、[run_xnli.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_xnli.py) スクリプトに示されています。
## SQuAD
[The Stanford Question Answering Dataset (SQuAD)](https://rajpurkar.github.io/SQuAD-explorer//) は、次のベンチマークです。
質問応答に関するモデルのパフォーマンスを評価します。 v1.1 と v2.0 の 2 つのバージョンが利用可能です。最初のバージョン
(v1.1) は、論文 [SQuAD: 100,000+ question for Machine Comprehension of Text](https://arxiv.org/abs/1606.05250) とともにリリースされました。 2 番目のバージョン (v2.0) は、論文 [Know What You Don't と同時にリリースされました。
知っておくべき: SQuAD の答えられない質問](https://arxiv.org/abs/1806.03822)。
このライブラリは、次の 2 つのバージョンのそれぞれのプロセッサをホストします。
### Processors
それらのプロセッサは次のとおりです。
- [`~data.processors.utils.SquadV1Processor`]
- [`~data.processors.utils.SquadV2Processor`]
どちらも抽象クラス [`~data.processors.utils.SquadProcessor`] を継承しています。
[[autodoc]] data.processors.squad.SquadProcessor
- all
さらに、次のメソッドを使用して、SQuAD の例を次の形式に変換できます。
モデルの入力として使用できる [`~data.processors.utils.SquadFeatures`]。
[[autodoc]] data.processors.squad.squad_convert_examples_to_features
これらのプロセッサと前述の方法は、データを含むファイルだけでなく、
*tensorflow_datasets* パッケージ。以下に例を示します。
### Example usage
以下にプロセッサを使用した例と、データ ファイルを使用した変換方法を示します。
```python
# Loading a V2 processor
processor = SquadV2Processor()
examples = processor.get_dev_examples(squad_v2_data_dir)
# Loading a V1 processor
processor = SquadV1Processor()
examples = processor.get_dev_examples(squad_v1_data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
*tensorflow_datasets* の使用は、データ ファイルを使用するのと同じくらい簡単です。
```python
# tensorflow_datasets only handle Squad V1.
tfds_examples = tfds.load("squad")
examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=args.doc_stride,
max_query_length=max_query_length,
is_training=not evaluate,
)
```
これらのプロセッサを使用する別の例は、[run_squad.py](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering/run_squad.py) スクリプトに示されています。
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/pipelines.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines
パイプラインは、推論にモデルを使うための簡単で優れた方法である。パイプラインは、複雑なコードのほとんどを抽象化したオブジェクトです。
パイプラインは、ライブラリから複雑なコードのほとんどを抽象化したオブジェクトで、名前付き固有表現認識、マスク言語モデリング、感情分析、特徴抽出、質問応答などのタスクに特化したシンプルなAPIを提供します。
Recognition、Masked Language Modeling、Sentiment Analysis、Feature Extraction、Question Answeringなどのタスクに特化したシンプルなAPIを提供します。以下を参照のこと。
[タスク概要](../task_summary)を参照してください。
パイプラインの抽象化には2つのカテゴリーがある:
- [`pipeline`] は、他のすべてのパイプラインをカプセル化する最も強力なオブジェクトです。
- タスク固有のパイプラインは、[オーディオ](#audio)、[コンピューター ビジョン](#computer-vision)、[自然言語処理](#natural-language-processing)、および [マルチモーダル](#multimodal) タスクで使用できます。
## The pipeline abstraction
*パイプライン* 抽象化は、他のすべての利用可能なパイプラインのラッパーです。他のものと同様にインスタンス化されます
パイプラインですが、さらなる生活の質を提供できます。
1 つの項目に対する単純な呼び出し:
```python
>>> pipe = pipeline("text-classification")
>>> pipe("This restaurant is awesome")
[{'label': 'POSITIVE', 'score': 0.9998743534088135}]
```
[ハブ](https://huggingface.co) の特定のモデルを使用したい場合は、モデルがオンになっている場合はタスクを無視できます。
ハブはすでにそれを定義しています。
```python
>>> pipe = pipeline(model="roberta-large-mnli")
>>> pipe("This restaurant is awesome")
[{'label': 'NEUTRAL', 'score': 0.7313136458396912}]
```
多くの項目に対してパイプラインを呼び出すには、*list* を使用してパイプラインを呼び出すことができます。
```python
>>> pipe = pipeline("text-classification")
>>> pipe(["This restaurant is awesome", "This restaurant is awful"])
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9996669292449951}]
```
完全なデータセットを反復するには、`Dataset`を直接使用することをお勧めします。これは、割り当てる必要がないことを意味します
データセット全体を一度に処理することも、自分でバッチ処理を行う必要もありません。これはカスタムループと同じくらい速く動作するはずです。
GPU。それが問題でない場合は、ためらわずに問題を作成してください。
```python
import datasets
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
from tqdm.auto import tqdm
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h", device=0)
dataset = datasets.load_dataset("superb", name="asr", split="test")
# KeyDataset (only *pt*) will simply return the item in the dict returned by the dataset item
# as we're not interested in the *target* part of the dataset. For sentence pair use KeyPairDataset
for out in tqdm(pipe(KeyDataset(dataset, "file"))):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
使いやすくするために、ジェネレーターを使用することもできます。
```python
from transformers import pipeline
pipe = pipeline("text-classification")
def data():
while True:
# This could come from a dataset, a database, a queue or HTTP request
# in a server
# Caveat: because this is iterative, you cannot use `num_workers > 1` variable
# to use multiple threads to preprocess data. You can still have 1 thread that
# does the preprocessing while the main runs the big inference
yield "This is a test"
for out in pipe(data()):
print(out)
# {"text": "NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND"}
# {"text": ....}
# ....
```
[[autodoc]] pipeline
## Pipeline batching
すべてのパイプラインでバッチ処理を使用できます。これはうまくいきます
パイプラインがストリーミング機能を使用するときは常に (つまり、リスト、`dataset`、または `generator`を渡すとき)。
```python
from transformers import pipeline
from transformers.pipelines.pt_utils import KeyDataset
import datasets
dataset = datasets.load_dataset("imdb", name="plain_text", split="unsupervised")
pipe = pipeline("text-classification", device=0)
for out in pipe(KeyDataset(dataset, "text"), batch_size=8, truncation="only_first"):
print(out)
# [{'label': 'POSITIVE', 'score': 0.9998743534088135}]
# Exactly the same output as before, but the content are passed
# as batches to the model
```
<Tip warning={true}>
ただし、これによってパフォーマンスが自動的に向上するわけではありません。状況に応じて、10 倍の高速化または 5 倍の低速化のいずれかになります。
ハードウェア、データ、使用されている実際のモデルについて。
主に高速化である例:
</Tip>
```python
from transformers import pipeline
from torch.utils.data import Dataset
from tqdm.auto import tqdm
pipe = pipeline("text-classification", device=0)
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
return "This is a test"
dataset = MyDataset()
for batch_size in [1, 8, 64, 256]:
print("-" * 30)
print(f"Streaming batch_size={batch_size}")
for out in tqdm(pipe(dataset, batch_size=batch_size), total=len(dataset)):
pass
```
```
# On GTX 970
------------------------------
Streaming no batching
100%|██████████████████████████████████████████████████████████████████████| 5000/5000 [00:26<00:00, 187.52it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:04<00:00, 1205.95it/s]
------------------------------
Streaming batch_size=64
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:02<00:00, 2478.24it/s]
------------------------------
Streaming batch_size=256
100%|█████████████████████████████████████████████████████████████████████| 5000/5000 [00:01<00:00, 2554.43it/s]
(diminishing returns, saturated the GPU)
```
最も速度が低下する例:
```python
class MyDataset(Dataset):
def __len__(self):
return 5000
def __getitem__(self, i):
if i % 64 == 0:
n = 100
else:
n = 1
return "This is a test" * n
```
これは、他の文に比べて非常に長い文が時折あります。その場合、**全体**のバッチは 400 である必要があります。
トークンが長いため、バッチ全体が [64, 4] ではなく [64, 400] になり、速度が大幅に低下します。さらに悪いことに、
バッチが大きくなると、プログラムは単純にクラッシュします。
```
------------------------------
Streaming no batching
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 183.69it/s]
------------------------------
Streaming batch_size=8
100%|█████████████████████████████████████████████████████████████████████| 1000/1000 [00:03<00:00, 265.74it/s]
------------------------------
Streaming batch_size=64
100%|██████████████████████████████████████████████████████████████████████| 1000/1000 [00:26<00:00, 37.80it/s]
------------------------------
Streaming batch_size=256
0%| | 0/1000 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/nicolas/src/transformers/test.py", line 42, in <module>
for out in tqdm(pipe(dataset, batch_size=256), total=len(dataset)):
....
q = q / math.sqrt(dim_per_head) # (bs, n_heads, q_length, dim_per_head)
RuntimeError: CUDA out of memory. Tried to allocate 376.00 MiB (GPU 0; 3.95 GiB total capacity; 1.72 GiB already allocated; 354.88 MiB free; 2.46 GiB reserved in total by PyTorch)
```
この問題に対する適切な (一般的な) 解決策はなく、使用できる距離はユースケースによって異なる場合があります。のルール
親指:
ユーザーにとっての経験則は次のとおりです。
- **ハードウェアを使用して、負荷に対するパフォーマンスを測定します。測って、測って、測り続ける。実数というのは、
進むべき唯一の方法。**
- レイテンシに制約がある場合 (実際の製品が推論を実行している場合)、バッチ処理を行わないでください。
- CPU を使用している場合は、バッチ処理を行わないでください。
- GPU でスループットを使用している場合 (大量の静的データでモデルを実行したい場合)、次のようにします。
- sequence_length (「自然な」データ) のサイズについてまったくわからない場合は、デフォルトではバッチ処理や測定を行わず、
暫定的に追加してみます。失敗した場合に回復するために OOM チェックを追加します (失敗した場合は、ある時点で回復します)。
sequence_length を制御します。)
- sequence_length が非常に規則的である場合、バッチ処理は非常に興味深いものとなる可能性が高く、測定してプッシュしてください。
OOM が発生するまで続けます。
- GPU が大きいほど、バッチ処理がより興味深いものになる可能性が高くなります。
- バッチ処理を有効にしたらすぐに、OOM を適切に処理できることを確認してください。
## Pipeline chunk batching
`zero-shot-classification` と `question-answering` は、単一の入力で結果が得られる可能性があるという意味で、少し特殊です。
モデルの複数の前方パス。通常の状況では、これにより `batch_size` 引数に関する問題が発生します。
この問題を回避するために、これらのパイプラインはどちらも少し特殊になっており、代わりに `ChunkPipeline` になっています。
通常の `Pipeline`。要するに:
```python
preprocessed = pipe.preprocess(inputs)
model_outputs = pipe.forward(preprocessed)
outputs = pipe.postprocess(model_outputs)
```
今は次のようになります:
```python
all_model_outputs = []
for preprocessed in pipe.preprocess(inputs):
model_outputs = pipe.forward(preprocessed)
all_model_outputs.append(model_outputs)
outputs = pipe.postprocess(all_model_outputs)
```
パイプラインは以下で使用されるため、これはコードに対して非常に透過的である必要があります。
同じ方法。
パイプラインはバッチを自動的に処理できるため、これは簡略化されたビューです。気にする必要はないという意味です
入力が実際にトリガーする前方パスの数については、`batch_size` を最適化できます。
入力とは独立して。前のセクションの注意事項が引き続き適用されます。
## Pipeline custom code
特定のパイプラインをオーバーライドする場合。
目の前のタスクに関する問題を作成することを躊躇しないでください。パイプラインの目標は、使いやすく、ほとんどのユーザーをサポートすることです。
したがって、`transformers`があなたのユースケースをサポートする可能性があります。
単純に試してみたい場合は、次のことができます。
- 選択したパイプラインをサブクラス化します
```python
class MyPipeline(TextClassificationPipeline):
def postprocess():
# Your code goes here
scores = scores * 100
# And here
my_pipeline = MyPipeline(model=model, tokenizer=tokenizer, ...)
# or if you use *pipeline* function, then:
my_pipeline = pipeline(model="xxxx", pipeline_class=MyPipeline)
```
これにより、必要なカスタム コードをすべて実行できるようになります。
## Implementing a pipeline
[Implementing a new pipeline](../add_new_pipeline)
## Audio
オーディオ タスクに使用できるパイプラインには次のものがあります。
### AudioClassificationPipeline
[[autodoc]] AudioClassificationPipeline
- __call__
- all
### AutomaticSpeechRecognitionPipeline
[[autodoc]] AutomaticSpeechRecognitionPipeline
- __call__
- all
### TextToAudioPipeline
[[autodoc]] TextToAudioPipeline
- __call__
- all
### ZeroShotAudioClassificationPipeline
[[autodoc]] ZeroShotAudioClassificationPipeline
- __call__
- all
## Computer vision
コンピューター ビジョン タスクに使用できるパイプラインには次のものがあります。
### DepthEstimationPipeline
[[autodoc]] DepthEstimationPipeline
- __call__
- all
### ImageClassificationPipeline
[[autodoc]] ImageClassificationPipeline
- __call__
- all
### ImageSegmentationPipeline
[[autodoc]] ImageSegmentationPipeline
- __call__
- all
### ImageToImagePipeline
[[autodoc]] ImageToImagePipeline
- __call__
- all
### ObjectDetectionPipeline
[[autodoc]] ObjectDetectionPipeline
- __call__
- all
### VideoClassificationPipeline
[[autodoc]] VideoClassificationPipeline
- __call__
- all
### ZeroShotImageClassificationPipeline
[[autodoc]] ZeroShotImageClassificationPipeline
- __call__
- all
### ZeroShotObjectDetectionPipeline
[[autodoc]] ZeroShotObjectDetectionPipeline
- __call__
- all
## Natural Language Processing
自然言語処理タスクに使用できるパイプラインには次のものがあります。
### ConversationalPipeline
[[autodoc]] Conversation
[[autodoc]] ConversationalPipeline
- __call__
- all
### FillMaskPipeline
[[autodoc]] FillMaskPipeline
- __call__
- all
### NerPipeline
[[autodoc]] NerPipeline
詳細については、[`TokenClassificationPipeline`] を参照してください。
### QuestionAnsweringPipeline
[[autodoc]] QuestionAnsweringPipeline
- __call__
- all
### SummarizationPipeline
[[autodoc]] SummarizationPipeline
- __call__
- all
### TableQuestionAnsweringPipeline
[[autodoc]] TableQuestionAnsweringPipeline
- __call__
### TextClassificationPipeline
[[autodoc]] TextClassificationPipeline
- __call__
- all
### TextGenerationPipeline
[[autodoc]] TextGenerationPipeline
- __call__
- all
### Text2TextGenerationPipeline
[[autodoc]] Text2TextGenerationPipeline
- __call__
- all
### TokenClassificationPipeline
[[autodoc]] TokenClassificationPipeline
- __call__
- all
### TranslationPipeline
[[autodoc]] TranslationPipeline
- __call__
- all
### ZeroShotClassificationPipeline
[[autodoc]] ZeroShotClassificationPipeline
- __call__
- all
## Multimodal
マルチモーダル タスクに使用できるパイプラインには次のものがあります。
### DocumentQuestionAnsweringPipeline
[[autodoc]] DocumentQuestionAnsweringPipeline
- __call__
- all
### FeatureExtractionPipeline
[[autodoc]] FeatureExtractionPipeline
- __call__
- all
### ImageToTextPipeline
[[autodoc]] ImageToTextPipeline
- __call__
- all
### VisualQuestionAnsweringPipeline
[[autodoc]] VisualQuestionAnsweringPipeline
- __call__
- all
## Parent class: `Pipeline`
[[autodoc]] Pipeline
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/image_processor.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image Processor
画像プロセッサは、ビジョン モデルの入力特徴の準備とその出力の後処理を担当します。これには、サイズ変更、正規化、PyTorch、TensorFlow、Flax、Numpy テンソルへの変換などの変換が含まれます。ロジットをセグメンテーション マスクに変換するなど、モデル固有の後処理も含まれる場合があります。
## ImageProcessingMixin
[[autodoc]] image_processing_utils.ImageProcessingMixin
- from_pretrained
- save_pretrained
## BatchFeature
[[autodoc]] BatchFeature
## BaseImageProcessor
[[autodoc]] image_processing_utils.BaseImageProcessor
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/optimizer_schedules.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimization
`.optimization` モジュールは以下を提供します。
- モデルの微調整に使用できる重み減衰が修正されたオプティマイザー、および
- `_LRSchedule` から継承するスケジュール オブジェクトの形式のいくつかのスケジュール:
- 複数のバッチの勾配を累積するための勾配累積クラス
## AdamW (PyTorch)
[[autodoc]] AdamW
## AdaFactor (PyTorch)
[[autodoc]] Adafactor
## AdamWeightDecay (TensorFlow)
[[autodoc]] AdamWeightDecay
[[autodoc]] create_optimizer
## Schedules
### Learning Rate Schedules (Pytorch)
[[autodoc]] SchedulerType
[[autodoc]] get_scheduler
[[autodoc]] get_constant_schedule
[[autodoc]] get_constant_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_constant_schedule.png"/>
[[autodoc]] get_cosine_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_schedule.png"/>
[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_cosine_hard_restarts_schedule.png"/>
[[autodoc]] get_linear_schedule_with_warmup
<img alt="" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/warmup_linear_schedule.png"/>
[[autodoc]] get_polynomial_decay_schedule_with_warmup
[[autodoc]] get_inverse_sqrt_schedule
### Warmup (TensorFlow)
[[autodoc]] WarmUp
## Gradient Strategies
### GradientAccumulator (TensorFlow)
[[autodoc]] GradientAccumulator
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/quantization.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Quantize 🤗 Transformers models
## `AutoGPTQ` Integration
🤗 Transformers には、言語モデルで GPTQ 量子化を実行するための `optimum` API が統合されています。パフォーマンスを大幅に低下させることなく、推論速度を高速化することなく、モデルを 8、4、3、さらには 2 ビットでロードおよび量子化できます。これは、ほとんどの GPU ハードウェアでサポートされています。
量子化モデルの詳細については、以下を確認してください。
- [GPTQ](https://arxiv.org/pdf/2210.17323.pdf) 論文
- GPTQ 量子化に関する `optimum` [ガイド](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- バックエンドとして使用される [`AutoGPTQ`](https://github.com/PanQiWei/AutoGPTQ) ライブラリ
### Requirements
以下のコードを実行するには、以下の要件がインストールされている必要があります:
- 最新の `AutoGPTQ` ライブラリをインストールする。
`pip install auto-gptq` をインストールする。
- 最新の `optimum` をソースからインストールする。
`git+https://github.com/huggingface/optimum.git` をインストールする。
- 最新の `transformers` をソースからインストールする。
最新の `transformers` をソースからインストールする `pip install git+https://github.com/huggingface/transformers.git`
- 最新の `accelerate` ライブラリをインストールする。
`pip install --upgrade accelerate` を実行する。
GPTQ統合は今のところテキストモデルのみをサポートしているので、視覚、音声、マルチモーダルモデルでは予期せぬ挙動に遭遇するかもしれないことに注意してください。
### Load and quantize a model
GPTQ は、量子化モデルを使用する前に重みのキャリブレーションを必要とする量子化方法です。トランスフォーマー モデルを最初から量子化する場合は、量子化モデルを作成するまでに時間がかかることがあります (`facebook/opt-350m`モデルの Google colab では約 5 分)。
したがって、GPTQ 量子化モデルを使用するシナリオは 2 つあります。最初の使用例は、ハブで利用可能な他のユーザーによってすでに量子化されたモデルをロードすることです。2 番目の使用例は、モデルを最初から量子化し、保存するかハブにプッシュして、他のユーザーが使用できるようにすることです。それも使ってください。
#### GPTQ Configuration
モデルをロードして量子化するには、[`GPTQConfig`] を作成する必要があります。データセットを準備するには、`bits`の数、量子化を調整するための`dataset`、およびモデルの`Tokenizer`を渡す必要があります。
```python
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
```
独自のデータセットを文字列のリストとして渡すことができることに注意してください。ただし、GPTQ 論文のデータセットを使用することを強くお勧めします。
```python
dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
quantization = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
```
#### Quantization
`from_pretrained` を使用し、`quantization_config` を設定することでモデルを量子化できます。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
```
モデルを量子化するには GPU が必要であることに注意してください。モデルを CPU に配置し、量子化するためにモジュールを GPU に前後に移動させます。
CPU オフロードの使用中に GPU の使用量を最大化したい場合は、`device_map = "auto"` を設定できます。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
```
ディスク オフロードはサポートされていないことに注意してください。さらに、データセットが原因でメモリが不足している場合は、`from_pretained` で `max_memory` を渡す必要がある場合があります。 `device_map`と`max_memory`の詳細については、この [ガイド](https://huggingface.co/docs/accelerate/usage_guides/big_modeling#designing-a-device-map) を参照してください。
<Tip warning={true}>
GPTQ 量子化は、現時点ではテキスト モデルでのみ機能します。さらに、量子化プロセスはハードウェアによっては長時間かかる場合があります (NVIDIA A100 を使用した場合、175B モデル = 4 gpu 時間)。モデルの GPTQ 量子化バージョンが存在しない場合は、ハブで確認してください。そうでない場合は、github で要求を送信できます。
</Tip>
### Push quantized model to 🤗 Hub
他の 🤗 モデルと同様に、`push_to_hub` を使用して量子化モデルをハブにプッシュできます。量子化構成は保存され、モデルに沿ってプッシュされます。
```python
quantized_model.push_to_hub("opt-125m-gptq")
tokenizer.push_to_hub("opt-125m-gptq")
```
量子化されたモデルをローカル マシンに保存したい場合は、`save_pretrained` を使用して行うこともできます。
```python
quantized_model.save_pretrained("opt-125m-gptq")
tokenizer.save_pretrained("opt-125m-gptq")
```
`device_map` を使用してモデルを量子化した場合は、保存する前にモデル全体を GPU または `cpu` のいずれかに移動してください。
```python
quantized_model.to("cpu")
quantized_model.save_pretrained("opt-125m-gptq")
```
### Load a quantized model from the 🤗 Hub
`from_pretrained`を使用して、量子化されたモデルをハブからロードできます。
属性 `quantization_config` がモデル設定オブジェクトに存在することを確認して、プッシュされた重みが量子化されていることを確認します。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq")
```
必要以上のメモリを割り当てずにモデルをより速くロードしたい場合は、`device_map` 引数は量子化モデルでも機能します。 `accelerate`ライブラリがインストールされていることを確認してください。
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
```
### Exllama kernels for faster inference
4 ビット モデルの場合、推論速度を高めるために exllama カーネルを使用できます。デフォルトで有効になっています。 [`GPTQConfig`] で `disable_exllama` を渡すことで、その動作を変更できます。これにより、設定に保存されている量子化設定が上書きされます。カーネルに関連する属性のみを上書きできることに注意してください。さらに、exllama カーネルを使用したい場合は、モデル全体を GPU 上に置く必要があります。
```py
import torch
gptq_config = GPTQConfig(bits=4, disable_exllama=False)
model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config = gptq_config)
```
現時点では 4 ビット モデルのみがサポートされていることに注意してください。さらに、peft を使用して量子化モデルを微調整している場合は、exllama カーネルを非アクティブ化することをお勧めします。
#### Fine-tune a quantized model
Hugging Face エコシステムのアダプターの公式サポートにより、GPTQ で量子化されたモデルを微調整できます。
詳細については、[`peft`](https://github.com/huggingface/peft) ライブラリをご覧ください。
### Example demo
GPTQ を使用してモデルを量子化する方法と、peft を使用して量子化されたモデルを微調整する方法については、Google Colab [ノートブック](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) を参照してください。
### GPTQConfig
[[autodoc]] GPTQConfig
## `bitsandbytes` Integration
🤗 Transformers は、`bitsandbytes` で最もよく使用されるモジュールと緊密に統合されています。数行のコードでモデルを 8 ビット精度でロードできます。
これは、`bitsandbytes`の `0.37.0`リリース以降、ほとんどの GPU ハードウェアでサポートされています。
量子化方法の詳細については、[LLM.int8()](https://arxiv.org/abs/2208.07339) 論文、または [ブログ投稿](https://huggingface.co/blog/hf-bitsandbytes-) をご覧ください。統合)コラボレーションについて。
`0.39.0`リリース以降、FP4 データ型を活用し、4 ビット量子化を使用して`device_map`をサポートする任意のモデルをロードできます。
独自の pytorch モデルを量子化したい場合は、🤗 Accelerate ライブラリの [ドキュメント](https://huggingface.co/docs/accelerate/main/en/usage_guides/quantization) をチェックしてください。
`bitsandbytes`統合を使用してできることは次のとおりです
### General usage
モデルが 🤗 Accelerate による読み込みをサポートし、`torch.nn.Linear` レイヤーが含まれている限り、 [`~PreTrainedModel.from_pretrained`] メソッドを呼び出すときに `load_in_8bit` または `load_in_4bit` 引数を使用してモデルを量子化できます。これはどのようなモダリティでも同様に機能するはずです。
```python
from transformers import AutoModelForCausalLM
model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
model_4bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True)
```
デフォルトでは、他のすべてのモジュール (例: `torch.nn.LayerNorm`) は `torch.float16` に変換されますが、その `dtype` を変更したい場合は、`torch_dtype` 引数を上書きできます。
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM
>>> model_8bit = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True, torch_dtype=torch.float32)
>>> model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
torch.float32
```
### FP4 quantization
#### Requirements
以下のコード スニペットを実行する前に、以下の要件がインストールされていることを確認してください。
- 最新の`bitsandbytes`ライブラリ
`pip install bitsandbytes>=0.39.0`
- 最新の`accelerate`をインストールする
`pip install --upgrade accelerate`
- 最新の `transformers` をインストールする
`pip install --upgrade transformers`
#### Tips and best practices
- **高度な使用法:** 可能なすべてのオプションを使用した 4 ビット量子化の高度な使用法については、[この Google Colab ノートブック](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf) を参照してください。
- **`batch_size=1` による高速推論 :** bitsandbytes の `0.40.0` リリース以降、`batch_size=1` では高速推論の恩恵を受けることができます。 [これらのリリース ノート](https://github.com/TimDettmers/bitsandbytes/releases/tag/0.40.0) を確認し、この機能を活用するには`0.40.0`以降のバージョンを使用していることを確認してください。箱の。
- **トレーニング:** [QLoRA 論文](https://arxiv.org/abs/2305.14314) によると、4 ビット基本モデルをトレーニングする場合 (例: LoRA アダプターを使用)、`bnb_4bit_quant_type='nf4'` を使用する必要があります。 。
- **推論:** 推論の場合、`bnb_4bit_quant_type` はパフォーマンスに大きな影響を与えません。ただし、モデルの重みとの一貫性を保つために、必ず同じ `bnb_4bit_compute_dtype` および `torch_dtype` 引数を使用してください。
#### Load a large model in 4bit
`.from_pretrained` メソッドを呼び出すときに `load_in_4bit=True` を使用すると、メモリ使用量を (おおよそ) 4 で割ることができます。
```python
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_4bit=True)
```
<Tip warning={true}>
モデルが 4 ビットでロードされると、現時点では量子化された重みをハブにプッシュすることはできないことに注意してください。 4 ビットの重みはまだサポートされていないため、トレーニングできないことにも注意してください。ただし、4 ビット モデルを使用して追加のパラメーターをトレーニングすることもできます。これについては次のセクションで説明します。
</Tip>
### Load a large model in 8bit
`.from_pretrained` メソッドを呼び出すときに `load_in_8bit=True` 引数を使用すると、メモリ要件をおよそ半分にしてモデルをロードできます。
```python
# pip install transformers accelerate bitsandbytes
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "bigscience/bloom-1b7"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", load_in_8bit=True)
```
次に、通常 [`PreTrainedModel`] を使用するのと同じようにモデルを使用します。
`get_memory_footprint` メソッドを使用して、モデルのメモリ フットプリントを確認できます。
```python
print(model.get_memory_footprint())
```
この統合により、大きなモデルを小さなデバイスにロードし、問題なく実行できるようになりました。
<Tip warning={true}>
モデルが 8 ビットでロードされると、最新の `transformers`と`bitsandbytes`を使用する場合を除き、量子化された重みをハブにプッシュすることは現在不可能であることに注意してください。 8 ビットの重みはまだサポートされていないため、トレーニングできないことにも注意してください。ただし、8 ビット モデルを使用して追加のパラメーターをトレーニングすることもできます。これについては次のセクションで説明します。
また、`device_map` はオプションですが、利用可能なリソース上でモデルを効率的にディスパッチするため、推論には `device_map = 'auto'` を設定することが推奨されます。
</Tip>
#### Advanced use cases
ここでは、FP4 量子化を使用して実行できるいくつかの高度な使用例について説明します。
##### Change the compute dtype
compute dtype は、計算中に使用される dtype を変更するために使用されます。たとえば、隠し状態は`float32`にありますが、高速化のために計算を bf16 に設定できます。デフォルトでは、compute dtype は `float32` に設定されます。
```python
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
```
##### Using NF4 (Normal Float 4) data type
NF4 データ型を使用することもできます。これは、正規分布を使用して初期化された重みに適合した新しい 4 ビット データ型です。その実行のために:
```python
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
```
##### Use nested quantization for more memory efficient inference
また、ネストされた量子化手法を使用することをお勧めします。これにより、パフォーマンスを追加することなく、より多くのメモリが節約されます。経験的な観察から、これにより、NVIDIA-T4 16GB 上でシーケンス長 1024、バッチ サイズ 1、勾配累積ステップ 4 の llama-13b モデルを微調整することが可能になります。
```python
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
```
### Push quantized models on the 🤗 Hub
`push_to_hub`メソッドを単純に使用することで、量子化されたモデルをハブにプッシュできます。これにより、最初に量子化構成ファイルがプッシュされ、次に量子化されたモデルの重みがプッシュされます。
この機能を使用できるようにするには、必ず `bitsandbytes>0.37.2` を使用してください (この記事の執筆時点では、`bitsandbytes==0.38.0.post1` でテストしました)。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom-560m", device_map="auto", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
model.push_to_hub("bloom-560m-8bit")
```
<Tip warning={true}>
大規模なモデルでは、ハブ上で 8 ビット モデルをプッシュすることが強く推奨されます。これにより、コミュニティはメモリ フットプリントの削減と、たとえば Google Colab での大規模なモデルの読み込みによる恩恵を受けることができます。
</Tip>
### Load a quantized model from the 🤗 Hub
`from_pretrained`メソッドを使用して、ハブから量子化モデルをロードできます。属性 `quantization_config` がモデル設定オブジェクトに存在することを確認して、プッシュされた重みが量子化されていることを確認します。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
```
この場合、引数 `load_in_8bit=True` を指定する必要はありませんが、`bitsandbytes` と `accelerate` がインストールされていることを確認する必要があることに注意してください。
また、`device_map` はオプションですが、利用可能なリソース上でモデルを効率的にディスパッチするため、推論には `device_map = 'auto'` を設定することが推奨されます。
### Advanced use cases
このセクションは、8 ビット モデルのロードと実行以外に何ができるかを探求したい上級ユーザーを対象としています。
#### Offload between `cpu` and `gpu`
この高度な使用例の 1 つは、モデルをロードし、`CPU`と`GPU`の間で重みをディスパッチできることです。 CPU 上でディスパッチされる重みは **8 ビットに変換されない**ため、`float32`に保持されることに注意してください。この機能は、非常に大規模なモデルを適合させ、そのモデルを GPU と CPU の間でディスパッチしたいユーザーを対象としています。
まず、`transformers` から [`BitsAndBytesConfig`] をロードし、属性 `llm_int8_enable_fp32_cpu_offload` を `True` に設定します。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
```
`bigscience/bloom-1b7`モデルをロードする必要があり、`lm_head`を除くモデル全体に適合するのに十分な GPU RAM があるとします。したがって、次のようにカスタム device_map を作成します。
```python
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 0,
}
```
そして、次のようにモデルをロードします。
```python
model_8bit = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-1b7",
device_map=device_map,
quantization_config=quantization_config,
)
```
以上です!モデルを楽しんでください!
#### Play with `llm_int8_threshold`
`llm_int8_threshold` 引数を操作して、外れ値のしきい値を変更できます。 外れ値 とは、特定のしきい値より大きい隠れた状態の値です。
これは、`LLM.int8()`論文で説明されている外れ値検出の外れ値しきい値に対応します。このしきい値を超える隠し状態の値は外れ値とみなされ、それらの値に対する操作は fp16 で実行されます。通常、値は正規分布します。つまり、ほとんどの値は [-3.5, 3.5] の範囲内にありますが、大規模なモデルでは大きく異なる分布を示す例外的な系統的外れ値がいくつかあります。これらの外れ値は、多くの場合 [-60, -6] または [6, 60] の範囲内にあります。 Int8 量子化は、大きさが 5 程度までの値ではうまく機能しますが、それを超えると、パフォーマンスが大幅に低下します。適切なデフォルトのしきい値は 6 ですが、より不安定なモデル (小規模なモデル、微調整) では、より低いしきい値が必要になる場合があります。
この引数は、モデルの推論速度に影響を与える可能性があります。このパラメータを試してみて、ユースケースに最適なパラメータを見つけることをお勧めします。
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_threshold=10,
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```
#### Skip the conversion of some modules
一部のモデルには、安定性を確保するために 8 ビットに変換する必要がないモジュールがいくつかあります。たとえば、ジュークボックス モデルには、スキップする必要があるいくつかの `lm_head` モジュールがあります。 `llm_int8_skip_modules` で遊んでみる
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "bigscience/bloom-1b7"
quantization_config = BitsAndBytesConfig(
llm_int8_skip_modules=["lm_head"],
)
model_8bit = AutoModelForCausalLM.from_pretrained(
model_id,
device_map=device_map,
quantization_config=quantization_config,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
```
#### Fine-tune a model that has been loaded in 8-bit
Hugging Face エコシステムのアダプターの公式サポートにより、8 ビットでロードされたモデルを微調整できます。
これにより、単一の Google Colab で`flan-t5-large`や`facebook/opt-6.7b`などの大規模モデルを微調整することができます。詳細については、[`peft`](https://github.com/huggingface/peft) ライブラリをご覧ください。
トレーニング用のモデルをロードするときに `device_map` を渡す必要がないことに注意してください。モデルが GPU に自動的にロードされます。必要に応じて、デバイス マップを特定のデバイスに設定することもできます (例: `cuda:0`、`0`、`torch.device('cuda:0')`)。 `device_map=auto`は推論のみに使用する必要があることに注意してください。
### BitsAndBytesConfig
[[autodoc]] BitsAndBytesConfig
## Quantization with 🤗 `optimum`
`optimum`でサポートされている量子化方法の詳細については、[Optimum ドキュメント](https://huggingface.co/docs/optimum/index) を参照し、これらが自分のユースケースに適用できるかどうかを確認してください。
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/agent.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# エージェントとツール
<Tip warning={true}>
Transformers Agents は実験的な API であり、いつでも変更される可能性があります。エージェントから返される結果
API または基礎となるモデルは変更される傾向があるため、変更される可能性があります。
</Tip>
エージェントとツールの詳細については、[入門ガイド](../transformers_agents) を必ずお読みください。このページ
基礎となるクラスの API ドキュメントが含まれています。
## エージェント
私たちは 3 種類のエージェントを提供します。[`HfAgent`] はオープンソース モデルの推論エンドポイントを使用し、[`LocalAgent`] は選択したモデルをローカルで使用し、[`OpenAiAgent`] は OpenAI クローズド モデルを使用します。
### HfAgent
[[autodoc]] HfAgent
### LocalAgent
[[autodoc]] LocalAgent
### OpenAiAgent
[[autodoc]] OpenAiAgent
### AzureOpenAiAgent
[[autodoc]] AzureOpenAiAgent
### Agent
[[autodoc]] Agent
- chat
- run
- prepare_for_new_chat
## Tools
### load_tool
[[autodoc]] load_tool
### Tool
[[autodoc]] Tool
### PipelineTool
[[autodoc]] PipelineTool
### RemoteTool
[[autodoc]] RemoteTool
### launch_gradio_demo
[[autodoc]] launch_gradio_demo
## エージェントの種類
エージェントはツール間であらゆる種類のオブジェクトを処理できます。ツールは完全にマルチモーダルであるため、受け取りと返品が可能です
テキスト、画像、オーディオ、ビデオなどのタイプ。ツール間の互換性を高めるためだけでなく、
これらの戻り値を ipython (jupyter、colab、ipython ノートブックなど) で正しくレンダリングするには、ラッパー クラスを実装します。
このタイプの周り。
ラップされたオブジェクトは最初と同じように動作し続けるはずです。テキストオブジェクトは依然として文字列または画像として動作する必要があります
オブジェクトは依然として `PIL.Image` として動作するはずです。
これらのタイプには、次の 3 つの特定の目的があります。
- 型に対して `to_raw` を呼び出すと、基になるオブジェクトが返されるはずです
- 型に対して `to_string` を呼び出すと、オブジェクトを文字列として返す必要があります。`AgentText` の場合は文字列になる可能性があります。
ただし、他のインスタンスのオブジェクトのシリアル化されたバージョンのパスになります。
- ipython カーネルで表示すると、オブジェクトが正しく表示されるはずです
### AgentText
[[autodoc]] transformers.tools.agent_types.AgentText
### AgentImage
[[autodoc]] transformers.tools.agent_types.AgentImage
### AgentAudio
[[autodoc]] transformers.tools.agent_types.AgentAudio
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/trainer.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer
[`Trainer`] クラスは、ほとんどの標準的なユースケースに対して、PyTorch で機能を完全にトレーニングするための API を提供します。これは、[サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples) のほとんどで使用されています。
[`Trainer`] をインスタンス化する前に、トレーニング中にカスタマイズのすべてのポイントにアクセスするために [`TrainingArguments`] を作成します。
この API は、複数の GPU/TPU での分散トレーニング、[NVIDIA Apex](https://github.com/NVIDIA/apex) および PyTorch のネイティブ AMP による混合精度をサポートします。
[`Trainer`] には、上記の機能をサポートする基本的なトレーニング ループが含まれています。カスタム動作を挿入するには、それらをサブクラス化し、次のメソッドをオーバーライドします。
- **get_train_dataloader** -- トレーニング データローダーを作成します。
- **get_eval_dataloader** -- 評価用データローダーを作成します。
- **get_test_dataloader** -- テスト データローダーを作成します。
- **log** -- トレーニングを監視しているさまざまなオブジェクトに関する情報をログに記録します。
- **create_optimizer_and_scheduler** -- オプティマイザと学習率スケジューラが渡されなかった場合にセットアップします。
初期化。 `create_optimizer`メソッドと`create_scheduler`メソッドをサブクラス化またはオーバーライドすることもできることに注意してください。
別々に。
- **create_optimizer** -- init で渡されなかった場合にオプティマイザーをセットアップします。
- **create_scheduler** -- init で渡されなかった場合、学習率スケジューラを設定します。
- **compute_loss** - トレーニング入力のバッチの損失を計算します。
- **training_step** -- トレーニング ステップを実行します。
- **prediction_step** -- 評価/テスト ステップを実行します。
- **evaluate** -- 評価ループを実行し、メトリクスを返します。
- **predict** -- テスト セットの予測 (ラベルが使用可能な場合はメトリクスも含む) を返します。
<Tip warning={true}>
[`Trainer`] クラスは 🤗 Transformers モデル用に最適化されており、驚くべき動作をする可能性があります
他の機種で使用する場合。独自のモデルで使用する場合は、次の点を確認してください。
- モデルは常に [`~utils.ModelOutput`] のタプルまたはサブクラスを返します。
- `labels` 引数が指定され、その損失が最初の値として返される場合、モデルは損失を計算できます。
タプルの要素 (モデルがタプルを返す場合)
- モデルは複数のラベル引数を受け入れることができます ([`TrainingArguments`] で `label_names` を使用して、その名前を [`Trainer`] に示します) が、それらのいずれにも `"label"` という名前を付ける必要はありません。
</Tip>
以下は、加重損失を使用するように [`Trainer`] をカスタマイズする方法の例です (不均衡なトレーニング セットがある場合に役立ちます)。
```python
from torch import nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss (suppose one has 3 labels with different weights)
loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
```
PyTorch [`Trainer`] のトレーニング ループの動作をカスタマイズするもう 1 つの方法は、トレーニング ループの状態を検査できる [callbacks](コールバック) を使用することです (進行状況レポート、TensorBoard または他の ML プラットフォームでのログ記録など)。決定(早期停止など)。
## Trainer
[[autodoc]] Trainer
- all
## Seq2SeqTrainer
[[autodoc]] Seq2SeqTrainer
- evaluate
- predict
## TrainingArguments
[[autodoc]] TrainingArguments
- all
## Seq2SeqTrainingArguments
[[autodoc]] Seq2SeqTrainingArguments
- all
## Checkpoints
デフォルトでは、[`Trainer`] はすべてのチェックポイントを、
[`TrainingArguments`] を使用しています。これらは、xxx を含む`checkpoint-xxx`という名前のサブフォルダーに保存されます。
それはトレーニングの段階でした。
チェックポイントからトレーニングを再開するには、次のいずれかを使用して [`Trainer.train`] を呼び出します。
- `resume_from_checkpoint=True` は最新のチェックポイントからトレーニングを再開します
- `resume_from_checkpoint=checkpoint_dir` ディレクトリ内の特定のチェックポイントからトレーニングを再開します
合格した。
さらに、`push_to_hub=True` を使用すると、モデル ハブにチェックポイントを簡単に保存できます。デフォルトでは、すべて
中間チェックポイントに保存されたモデルは別のコミットに保存されますが、オプティマイザーの状態は保存されません。適応できます
[`TrainingArguments`] の `hub-strategy` 値を次のいずれかにします。
- `"checkpoint"`: 最新のチェックポイントも last-checkpoint という名前のサブフォルダーにプッシュされます。
`trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")` を使用してトレーニングを簡単に再開します。
- `"all_checkpoints"`: すべてのチェックポイントは、出力フォルダーに表示されるようにプッシュされます (したがって、1 つのチェックポイントが得られます)
最終リポジトリ内のフォルダーごとのチェックポイント フォルダー)
## Logging
デフォルトでは、[`Trainer`] はメインプロセスに `logging.INFO` を使用し、レプリカがある場合には `logging.WARNING` を使用します。
これらのデフォルトは、[`TrainingArguments`] の 5 つの `logging` レベルのいずれかを使用するようにオーバーライドできます。
引数:
- `log_level` - メインプロセス用
- `log_level_replica` - レプリカ用
さらに、[`TrainingArguments`] の `log_on_each_node` が `False` に設定されている場合、メイン ノードのみが
メイン プロセスのログ レベル設定を使用すると、他のすべてのノードはレプリカのログ レベル設定を使用します。
[`Trainer`] は、`transformers` のログ レベルをノードごとに個別に設定することに注意してください。
[`Trainer.__init__`]。したがって、他の機能を利用する場合は、これをより早く設定することをお勧めします (次の例を参照)。
[`Trainer`] オブジェクトを作成する前の `transformers` 機能。
これをアプリケーションで使用する方法の例を次に示します。
```python
[...]
logger = logging.getLogger(__name__)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
# set the main code and the modules it uses to the same log-level according to the node
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
trainer = Trainer(...)
```
そして、メイン ノードと他のすべてのノードで重複する可能性が高いものを出力しないように警告するだけを表示したい場合は、
警告: 次のように実行できます。
```bash
my_app.py ... --log_level warning --log_level_replica error
```
マルチノード環境で、各ノードのメインプロセスのログを繰り返したくない場合は、次のようにします。
上記を次のように変更します。
```bash
my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
```
その後、最初のノードのメイン プロセスのみが「警告」レベルでログに記録され、メイン ノード上の他のすべてのプロセスはログに記録されます。
ノードと他のノード上のすべてのプロセスは「エラー」レベルでログに記録されます。
アプリケーションをできるだけ静かにする必要がある場合は、次のようにします。
```bash
my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
```
(マルチノード環境の場合は `--log_on_each_node 0` を追加します)
## Randomness
[`Trainer`] によって生成されたチェックポイントから再開する場合、すべての努力がその状態を復元するために行われます。
_python_、_numpy_、および _pytorch_ の RNG 状態は、そのチェックポイントを保存した時点と同じ状態になります。
これにより、「停止して再開」というスタイルのトレーニングが、ノンストップトレーニングに可能な限り近づけられるはずです。
ただし、さまざまなデフォルトの非決定的な pytorch 設定により、これは完全に機能しない可能性があります。フルをご希望の場合は
決定論については、[ランダム性のソースの制御](https://pytorch.org/docs/stable/notes/randomness) を参照してください。ドキュメントで説明されているように、これらの設定の一部は
物事を決定論的にするもの (例: `torch.backends.cudnn.deterministic`) は物事を遅くする可能性があるため、これは
デフォルトでは実行できませんが、必要に応じて自分で有効にすることができます。
## Specific GPUs Selection
どの GPU をどのような順序で使用するかをプログラムに指示する方法について説明します。
[`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.Parallel.DistributedDataParallel.html) を使用して GPU のサブセットのみを使用する場合、使用する GPU の数を指定するだけです。 。たとえば、GPU が 4 つあるが、最初の 2 つを使用したい場合は、次のようにします。
```bash
torchrun --nproc_per_node=2 trainer-program.py ...
```
[`accelerate`](https://github.com/huggingface/accelerate) または [`deepspeed`](https://github.com/microsoft/DeepSpeed) がインストールされている場合は、次を使用して同じことを達成することもできます。の一つ:
```bash
accelerate launch --num_processes 2 trainer-program.py ...
```
```bash
deepspeed --num_gpus 2 trainer-program.py ...
```
これらのランチャーを使用するために、Accelerate または [Deepspeed 統合](deepspeed) 機能を使用する必要はありません。
これまでは、プログラムに使用する GPU の数を指示できました。次に、特定の GPU を選択し、その順序を制御する方法について説明します。
次の環境変数は、使用する GPU とその順序を制御するのに役立ちます。
**`CUDA_VISIBLE_DEVICES`**
複数の GPU があり、そのうちの 1 つまたはいくつかの GPU だけを使用したい場合は、環境変数 `CUDA_VISIBLE_DEVICES` を使用する GPU のリストに設定します。
たとえば、4 つの GPU (0、1、2、3) があるとします。物理 GPU 0 と 2 のみで実行するには、次のようにします。
```bash
CUDA_VISIBLE_DEVICES=0,2 torchrun trainer-program.py ...
```
したがって、pytorch は 2 つの GPU のみを認識し、物理 GPU 0 と 2 はそれぞれ `cuda:0` と `cuda:1` にマッピングされます。
順序を変更することもできます。
```bash
CUDA_VISIBLE_DEVICES=2,0 torchrun trainer-program.py ...
```
ここでは、物理 GPU 0 と 2 がそれぞれ`cuda:1`と`cuda:0`にマッピングされています。
上記の例はすべて `DistributedDataParallel` 使用パターンのものですが、同じ方法が [`DataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.DataParallel.html) でも機能します。
```bash
CUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...
```
GPU のない環境をエミュレートするには、次のようにこの環境変数を空の値に設定するだけです。
```bash
CUDA_VISIBLE_DEVICES= python trainer-program.py ...
```
他の環境変数と同様に、これらをコマンド ラインに追加する代わりに、次のようにエクスポートすることもできます。
```bash
export CUDA_VISIBLE_DEVICES=0,2
torchrun trainer-program.py ...
```
ただし、この方法では、以前に環境変数を設定したことを忘れて、なぜ間違った GPU が使用されているのか理解できない可能性があるため、混乱を招く可能性があります。したがって、このセクションのほとんどの例で示されているように、同じコマンド ラインで特定の実行に対してのみ環境変数を設定するのが一般的です。
**`CUDA_DEVICE_ORDER`**
物理デバイスの順序を制御する追加の環境変数 `CUDA_DEVICE_ORDER` があります。選択肢は次の 2 つです。
1. PCIe バス ID 順 (`nvidia-smi` の順序と一致) - これがデフォルトです。
```bash
export CUDA_DEVICE_ORDER=PCI_BUS_ID
```
2. GPU コンピューティング能力順に並べる
```bash
export CUDA_DEVICE_ORDER=FASTEST_FIRST
```
ほとんどの場合、この環境変数を気にする必要はありませんが、古い GPU と新しい GPU が物理的に挿入されているため、遅い古いカードが遅くなっているように見えるような偏ったセットアップを行っている場合には、非常に役立ちます。初め。これを解決する 1 つの方法は、カードを交換することです。ただし、カードを交換できない場合 (デバイスの冷却が影響を受けた場合など)、`CUDA_DEVICE_ORDER=FASTEST_FIRST`を設定すると、常に新しい高速カードが最初に配置されます。ただし、`nvidia-smi`は依然として PCIe の順序でレポートするため、多少混乱するでしょう。
順序を入れ替えるもう 1 つの解決策は、以下を使用することです。
```bash
export CUDA_VISIBLE_DEVICES=1,0
```
この例では 2 つの GPU だけを使用していますが、もちろん、コンピューターに搭載されている数の GPU にも同じことが当てはまります。
また、この環境変数を設定する場合は、`~/.bashrc` ファイルまたはその他の起動設定ファイルに設定して、忘れるのが最善です。
## Trainer Integrations
[`Trainer`] は、トレーニングを劇的に改善する可能性のあるライブラリをサポートするように拡張されました。
時間とはるかに大きなモデルに適合します。
現在、サードパーティのソリューション [DeepSpeed](https://github.com/microsoft/DeepSpeed) および [PyTorch FSDP](https://pytorch.org/docs/stable/fsdp.html) をサポートしています。論文 [ZeRO: メモリの最適化]
兆パラメータ モデルのトレーニングに向けて、Samyam Rajbhandari、Jeff Rasley、Olatunji Ruwase、Yuxiong He 著](https://arxiv.org/abs/1910.02054)。
この提供されるサポートは、この記事の執筆時点では新しくて実験的なものです。 DeepSpeed と PyTorch FSDP のサポートはアクティブであり、それに関する問題は歓迎しますが、FairScale 統合は PyTorch メインに統合されているため、もうサポートしていません ([PyTorch FSDP 統合](#pytorch-fully-sharded-data-parallel))
<a id='zero-install-notes'></a>
### CUDA Extension Installation Notes
この記事の執筆時点では、Deepspeed を使用するには、CUDA C++ コードをコンパイルする必要があります。
すべてのインストールの問題は、[Deepspeed](https://github.com/microsoft/DeepSpeed/issues) の対応する GitHub の問題を通じて対処する必要がありますが、ビルド中に発生する可能性のある一般的な問題がいくつかあります。
CUDA 拡張機能を構築する必要がある PyTorch 拡張機能。
したがって、次の操作を実行中に CUDA 関連のビルドの問題が発生した場合は、次のとおりです。
```bash
pip install deepspeed
```
まず次の注意事項をお読みください。
これらのノートでは、`pytorch` が CUDA `10.2` でビルドされた場合に何をすべきかの例を示します。あなたの状況が次のような場合
異なる場合は、バージョン番号を目的のバージョンに調整することを忘れないでください。
#### Possible problem #1
Pytorch には独自の CUDA ツールキットが付属していますが、これら 2 つのプロジェクトをビルドするには、同一バージョンの CUDA が必要です。
システム全体にインストールされます。
たとえば、Python 環境に `cudatoolkit==10.2` を指定して `pytorch` をインストールした場合は、次のものも必要です。
CUDA `10.2` がシステム全体にインストールされました。
正確な場所はシステムによって異なる場合がありますが、多くのシステムでは`/usr/local/cuda-10.2`が最も一般的な場所です。
Unix システム。 CUDA が正しく設定され、`PATH`環境変数に追加されると、
次のようにしてインストール場所を指定します。
```bash
which nvcc
```
CUDA がシステム全体にインストールされていない場合は、最初にインストールしてください。お気に入りを使用して手順を見つけることができます
検索エンジン。たとえば、Ubuntu を使用している場合は、[ubuntu cuda 10.2 install](https://www.google.com/search?q=ubuntu+cuda+10.2+install) を検索するとよいでしょう。
#### Possible problem #2
もう 1 つの考えられる一般的な問題は、システム全体に複数の CUDA ツールキットがインストールされている可能性があることです。たとえばあなた
がある可能性があり:
```bash
/usr/local/cuda-10.2
/usr/local/cuda-11.0
```
この状況では、`PATH` および `LD_LIBRARY_PATH` 環境変数に以下が含まれていることを確認する必要があります。
目的の CUDA バージョンへの正しいパス。通常、パッケージ インストーラーは、これらに、
最後のバージョンがインストールされました。適切なパッケージが見つからないためにパッケージのビルドが失敗するという問題が発生した場合は、
CUDA バージョンがシステム全体にインストールされているにもかかわらず、前述の 2 つを調整する必要があることを意味します
環境変数。
まず、その内容を見てみましょう。
```bash
echo $PATH
echo $LD_LIBRARY_PATH
```
それで、中に何が入っているかがわかります。
`LD_LIBRARY_PATH` が空である可能性があります。
`PATH` は実行可能ファイルが存在する場所をリストし、`LD_LIBRARY_PATH` は共有ライブラリの場所を示します。
探すことです。どちらの場合も、前のエントリが後のエントリより優先されます。 `:` は複数を区切るために使用されます
エントリ。
ここで、ビルド プログラムに特定の CUDA ツールキットの場所を指示するには、最初にリストされる希望のパスを挿入します。
やっていること:
```bash
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
```
既存の値を上書きするのではなく、先頭に追加することに注意してください。
もちろん、必要に応じてバージョン番号やフルパスを調整します。割り当てたディレクトリが実際に機能することを確認してください
存在する。 `lib64` サブディレクトリは、`libcudart.so` などのさまざまな CUDA `.so` オブジェクトが存在する場所です。
システムでは別の名前が付けられますが、現実を反映するように調整してください。
#### Possible problem #3
一部の古い CUDA バージョンは、新しいコンパイラでのビルドを拒否する場合があります。たとえば、あなたは`gcc-9`を持っていますが、それが必要です
`gcc-7`。
それにはさまざまな方法があります。
最新の CUDA ツールキットをインストールできる場合は、通常、新しいコンパイラがサポートされているはずです。
あるいは、既に所有しているコンパイラに加えて、下位バージョンのコンパイラをインストールすることもできます。
すでに存在しますが、デフォルトではないため、ビルドシステムはそれを認識できません。 「gcc-7」がインストールされているが、
ビルドシステムが見つからないというメッセージを表示する場合は、次の方法で解決できる可能性があります。
```bash
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++
```
ここでは、`/usr/local/cuda-10.2/bin/gcc` から `gcc-7` へのシンボリックリンクを作成しています。
`/usr/local/cuda-10.2/bin/` は `PATH` 環境変数内にある必要があります (前の問題の解決策を参照)。
`gcc-7` (および `g++7`) が見つかるはずで、ビルドは成功します。
いつものように、状況に合わせて例のパスを編集してください。
### PyTorch Fully Sharded Data parallel
より大きなバッチ サイズで巨大なモデルのトレーニングを高速化するには、完全にシャード化されたデータ並列モデルを使用できます。
このタイプのデータ並列パラダイムでは、オプティマイザーの状態、勾配、パラメーターをシャーディングすることで、より多くのデータと大規模なモデルをフィッティングできます。
この機能とその利点の詳細については、[完全シャーディング データ並列ブログ](https://pytorch.org/blog/introducing-pytorch-full-sharded-data-Parallel-api/) をご覧ください。
最新の PyTorch の Fully Sharded Data Parallel (FSDP) トレーニング機能を統合しました。
必要なのは、設定を通じて有効にすることだけです。
**FSDP サポートに必要な PyTorch バージョン**: PyTorch Nightly (リリース後にこれを読んだ場合は 1.12.0)
FSDP を有効にしたモデルの保存は、最近の修正でのみ利用できるためです。
**使用法**:
- 配布されたランチャーが追加されていることを確認してください
まだ使用していない場合は、`-m torch.distributed.launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE`を使用します。
- **シャーディング戦略**:
- FULL_SHARD : データ並列ワーカー/GPU にわたるシャード オプティマイザーの状態 + 勾配 + モデル パラメーター。
このためには、コマンドライン引数に`--fsdp full_shard`を追加します。
- SHARD_GRAD_OP : シャード オプティマイザーの状態 + データ並列ワーカー/GPU 全体の勾配。
このためには、コマンドライン引数に`--fsdp shard_grad_op`を追加します。
- NO_SHARD : シャーディングなし。このためには、コマンドライン引数に`--fsdp no_shard`を追加します。
- パラメータと勾配を CPU にオフロードするには、
コマンドライン引数に`--fsdp "full_shard offload"`または`--fsdp "shard_grad_op offload"`を追加します。
- `default_auto_wrap_policy` を使用して FSDP でレイヤーを自動的に再帰的にラップするには、
コマンドライン引数に`--fsdp "full_shard auto_wrap"`または`--fsdp "shard_grad_op auto_wrap"`を追加します。
- CPU オフロードと自動ラッピングの両方を有効にするには、
コマンドライン引数に`--fsdp "full_shard offload auto_wrap"`または`--fsdp "shard_grad_op offload auto_wrap"`を追加します。
- 残りの FSDP 構成は、`--fsdp_config <path_to_fsdp_config.json>`を介して渡されます。それは、次のいずれかの場所です。
FSDP json 構成ファイル (例: `fsdp_config.json`)、またはすでにロードされている json ファイルを `dict` として使用します。
- 自動ラッピングが有効な場合は、トランスベースの自動ラップ ポリシーまたはサイズ ベースの自動ラップ ポリシーを使用できます。
- トランスフォーマーベースの自動ラップポリシーの場合、構成ファイルで `fsdp_transformer_layer_cls_to_wrap` を指定することをお勧めします。指定しない場合、使用可能な場合、デフォルト値は `model._no_split_modules` になります。
これは、ラップするトランスフォーマー層クラス名のリスト (大文字と小文字を区別) を指定します (例: [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] ...)。
重みを共有するサブモジュール (埋め込み層など) が異なる FSDP ラップされたユニットにならないようにする必要があるため、これは重要です。
このポリシーを使用すると、マルチヘッド アテンションとそれに続くいくつかの MLP レイヤーを含むブロックごとにラッピングが発生します。
共有埋め込みを含む残りの層は、同じ最も外側の FSDP ユニットにラップされるのが便利です。
したがって、トランスベースのモデルにはこれを使用してください。
- サイズベースの自動ラップポリシーの場合は、設定ファイルに`fsdp_min_num_params`を追加してください。
自動ラッピングのための FSDP のパラメータの最小数を指定します。
- 設定ファイルで `fsdp_backward_prefetch` を指定できるようになりました。次のパラメータのセットをいつプリフェッチするかを制御します。
`backward_pre` と `backward_pos` が利用可能なオプションです。
詳細については、`torch.distributed.fsdp.full_sharded_data_Parallel.BackwardPrefetch`を参照してください。
- 設定ファイルで `fsdp_forward_prefetch` を指定できるようになりました。次のパラメータのセットをいつプリフェッチするかを制御します。
`True`の場合、FSDP はフォワード パスでの実行中に、次に来るオールギャザーを明示的にプリフェッチします。
- 設定ファイルで `limit_all_gathers` を指定できるようになりました。
`True`の場合、FSDP は CPU スレッドを明示的に同期して、実行中のオールギャザが多すぎるのを防ぎます。
- `activation_checkpointing`を設定ファイルで指定できるようになりました。
`True`の場合、FSDP アクティベーション チェックポイントは、FSDP のアクティベーションをクリアすることでメモリ使用量を削減する手法です。
特定のレイヤーを処理し、バックワード パス中にそれらを再計算します。事実上、これは余分な計算時間を犠牲にします
メモリ使用量を削減します。
**注意すべき注意点がいくつかあります**
- これは `generate` と互換性がないため、 `--predict_with_generate` とも互換性がありません
すべての seq2seq/clm スクリプト (翻訳/要約/clm など)。
問題 [#21667](https://github.com/huggingface/transformers/issues/21667) を参照してください。
### PyTorch/XLA Fully Sharded Data parallel
TPU ユーザーの皆様に朗報です。 PyTorch/XLA は FSDP をサポートするようになりました。
最新の Fully Sharded Data Parallel (FSDP) トレーニングがすべてサポートされています。
詳細については、[FSDP を使用した Cloud TPU での PyTorch モデルのスケーリング](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) および [PyTorch/XLA 実装 を参照してください。 FSDP の](https://github.com/pytorch/xla/tree/master/torch_xla/distributed/fsdp)
必要なのは、設定を通じて有効にすることだけです。
**FSDP サポートに必要な PyTorch/XLA バージョン**: >=2.0
**使用法**:
`--fsdp "full shard"` を、`--fsdp_config <path_to_fsdp_config.json>` に加えられる次の変更とともに渡します。
- PyTorch/XLA FSDP を有効にするには、`xla`を`True`に設定する必要があります。
- `xla_fsdp_settings` 値は、XLA FSDP ラッピング パラメータを格納する辞書です。
オプションの完全なリストについては、[こちら](
https://github.com/pytorch/xla/blob/master/torch_xla/distributed/fsdp/xla_full_sharded_data_Parallel.py)。
- `xla_fsdp_grad_ckpt`。 `True`の場合、ネストされた XLA FSDP でラップされた各レイヤー上で勾配チェックポイントを使用します。
この設定は、xla フラグが true に設定されており、自動ラッピング ポリシーが指定されている場合にのみ使用できます。
`fsdp_min_num_params` または `fsdp_transformer_layer_cls_to_wrap`。
- トランスフォーマー ベースの自動ラップ ポリシーまたはサイズ ベースの自動ラップ ポリシーのいずれかを使用できます。
- トランスフォーマーベースの自動ラップポリシーの場合、構成ファイルで `fsdp_transformer_layer_cls_to_wrap` を指定することをお勧めします。指定しない場合、使用可能な場合、デフォルト値は `model._no_split_modules` になります。
これは、ラップするトランスフォーマー層クラス名のリスト (大文字と小文字を区別) を指定します (例: [`BertLayer`]、[`GPTJBlock`]、[`T5Block`] ...)。
重みを共有するサブモジュール (埋め込み層など) が異なる FSDP ラップされたユニットにならないようにする必要があるため、これは重要です。
このポリシーを使用すると、マルチヘッド アテンションとそれに続くいくつかの MLP レイヤーを含むブロックごとにラッピングが発生します。
共有埋め込みを含む残りの層は、同じ最も外側の FSDP ユニットにラップされるのが便利です。
したがって、トランスベースのモデルにはこれを使用してください。
- サイズベースの自動ラップポリシーの場合は、設定ファイルに`fsdp_min_num_params`を追加してください。
自動ラッピングのための FSDP のパラメータの最小数を指定します。
### Using Trainer for accelerated PyTorch Training on Mac
PyTorch v1.12 リリースにより、開発者と研究者は Apple シリコン GPU を利用してモデル トレーニングを大幅に高速化できます。
これにより、プロトタイピングや微調整などの機械学習ワークフローを Mac 上でローカルで実行できるようになります。
PyTorch のバックエンドとしての Apple の Metal Performance Shaders (MPS) はこれを可能にし、新しい `"mps"` デバイス経由で使用できます。
これにより、計算グラフとプリミティブが MPS Graph フレームワークと MPS によって提供される調整されたカーネルにマッピングされます。
詳細については、公式ドキュメント [Mac での Accelerated PyTorch Training の紹介](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) を参照してください。
および [MPS バックエンド](https://pytorch.org/docs/stable/notes/mps.html)。
<Tip warning={false}>
MacOS マシンに PyTorch >= 1.13 (執筆時点ではナイトリー バージョン) をインストールすることを強くお勧めします。
トランスベースのモデルのモデルの正確性とパフォーマンスの向上に関連する主要な修正が行われています。
詳細については、https://github.com/pytorch/pytorch/issues/82707 を参照してください。
</Tip>
**Apple Silicon チップを使用したトレーニングと推論の利点**
1. ユーザーがローカルで大規模なネットワークやバッチ サイズをトレーニングできるようにします
2. ユニファイド メモリ アーキテクチャにより、データ取得の遅延が短縮され、GPU がメモリ ストア全体に直接アクセスできるようになります。
したがって、エンドツーエンドのパフォーマンスが向上します。
3. クラウドベースの開発に関連するコストや追加のローカル GPU の必要性を削減します。
**前提条件**: mps サポートを備えたトーチをインストールするには、
この素晴らしいメディア記事 [GPU アクセラレーションが M1 Mac の PyTorch に登場](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1) に従ってください。 。
**使用法**:
`mps` デバイスは、`cuda` デバイスが使用される方法と同様に利用可能な場合、デフォルトで使用されます。
したがって、ユーザーによるアクションは必要ありません。
たとえば、以下のコマンドを使用して、Apple Silicon GPU を使用して公式の Glue テキスト分類タスクを (ルート フォルダーから) 実行できます。
```bash
export TASK_NAME=mrpc
python examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
**注意すべきいくつかの注意事項**
1. 一部の PyTorch 操作は mps に実装されていないため、エラーがスローされます。
これを回避する 1 つの方法は、環境変数 `PYTORCH_ENABLE_MPS_FALLBACK=1` を設定することです。
これらの操作では CPU にフォールバックします。ただし、それでも UserWarning がスローされます。
2. 分散セットアップ`gloo`および`nccl`は、`mps`デバイスでは動作しません。
これは、現在「mps」デバイス タイプの単一 GPU のみを使用できることを意味します。
最後に、覚えておいてください。 🤗 `Trainer` は MPS バックエンドのみを統合するため、
MPS バックエンドの使用に関して問題や質問がある場合は、
[PyTorch GitHub](https://github.com/pytorch/pytorch/issues) に問題を提出してください。
## Using Accelerate Launcher with Trainer
加速してトレーナーにパワーを与えましょう。ユーザーが期待することに関しては、次のとおりです。
- トレーナー引数に対して FSDP、DeepSpeed などのトレーナー インテレーションを変更せずに使用し続けることができます。
- トレーナーで Accelerate Launcher を使用できるようになりました (推奨)。
トレーナーで Accelerate Launcher を使用する手順:
1. 🤗 Accelerate がインストールされていることを確認してください。Accelerate がないと `Trainer` を使用することはできません。そうでない場合は、`pip install accelerate`してください。 Accelerate のバージョンを更新する必要がある場合もあります: `pip install activate --upgrade`
2. `accelerate config`を実行し、アンケートに記入します。以下は加速設定の例です。
a. DDP マルチノード マルチ GPU 構成:
```yaml
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0 #change rank as per the node
main_process_ip: 192.168.20.1
main_process_port: 9898
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
b. FSDP config:
```yaml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: FULL_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
c.ファイルを指す DeepSpeed 構成:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /home/user/configs/ds_zero3_config.json
zero3_init_flag: true
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
d.加速プラグインを使用した DeepSpeed 構成:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 0.7
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: true
zero_stage: 2
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
3. 加速設定またはランチャー引数によって上記で処理された引数以外の引数を使用して、トレーナー スクリプトを実行します。
以下は、上記の FSDP 構成で`accelerate launcher`を使用して`run_glue.py`を実行する例です。
```bash
cd transformers
accelerate launch \
./examples/pytorch/text-classification/run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
4. `accelerate launch`するための cmd 引数を直接使用することもできます。上の例は次のようにマッピングされます。
```bash
cd transformers
accelerate launch --num_processes=2 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="BertLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
./examples/pytorch/text-classification/run_glue.py
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 16 \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$TASK_NAME/ \
--overwrite_output_dir
```
詳細については、🤗 Accelerate CLI ガイドを参照してください: [🤗 Accelerate スクリプトの起動](https://huggingface.co/docs/accelerate/basic_tutorials/launch)。
移動されたセクション:
[ <a href="./deepspeed#deepspeed-trainer-integration">DeepSpeed</a><a id="deepspeed"></a>
| <a href="./deepspeed#deepspeed-installation">Installation</a><a id="installation"></a>
| <a href="./deepspeed#deepspeed-multi-gpu">Deployment with multiple GPUs</a><a id="deployment-with-multiple-gpus"></a>
| <a href="./deepspeed#deepspeed-one-gpu">Deployment with one GPU</a><a id="deployment-with-one-gpu"></a>
| <a href="./deepspeed#deepspeed-notebook">Deployment in Notebooks</a><a id="deployment-in-notebooks"></a>
| <a href="./deepspeed#deepspeed-config">Configuration</a><a id="configuration"></a>
| <a href="./deepspeed#deepspeed-config-passing">Passing Configuration</a><a id="passing-configuration"></a>
| <a href="./deepspeed#deepspeed-config-shared">Shared Configuration</a><a id="shared-configuration"></a>
| <a href="./deepspeed#deepspeed-zero">ZeRO</a><a id="zero"></a>
| <a href="./deepspeed#deepspeed-zero2-config">ZeRO-2 Config</a><a id="zero-2-config"></a>
| <a href="./deepspeed#deepspeed-zero3-config">ZeRO-3 Config</a><a id="zero-3-config"></a>
| <a href="./deepspeed#deepspeed-nvme">NVMe Support</a><a id="nvme-support"></a>
| <a href="./deepspeed#deepspeed-zero2-zero3-performance">ZeRO-2 vs ZeRO-3 Performance</a><a id="zero-2-vs-zero-3-performance"></a>
| <a href="./deepspeed#deepspeed-zero2-example">ZeRO-2 Example</a><a id="zero-2-example"></a>
| <a href="./deepspeed#deepspeed-zero3-example">ZeRO-3 Example</a><a id="zero-3-example"></a>
| <a href="./deepspeed#deepspeed-optimizer">Optimizer</a><a id="optimizer"></a>
| <a href="./deepspeed#deepspeed-scheduler">Scheduler</a><a id="scheduler"></a>
| <a href="./deepspeed#deepspeed-fp32">fp32 Precision</a><a id="fp32-precision"></a>
| <a href="./deepspeed#deepspeed-amp">Automatic Mixed Precision</a><a id="automatic-mixed-precision"></a>
| <a href="./deepspeed#deepspeed-bs">Batch Size</a><a id="batch-size"></a>
| <a href="./deepspeed#deepspeed-grad-acc">Gradient Accumulation</a><a id="gradient-accumulation"></a>
| <a href="./deepspeed#deepspeed-grad-clip">Gradient Clipping</a><a id="gradient-clipping"></a>
| <a href="./deepspeed#deepspeed-weight-extraction">Getting The Model Weights Out</a><a id="getting-the-model-weights-out"></a>
]
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/model.md
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Models
ベースクラスである [`PreTrainedModel`]、[`TFPreTrainedModel`]、[`FlaxPreTrainedModel`] は、モデルの読み込みと保存に関する共通のメソッドを実装しており、これはローカルのファイルやディレクトリから、またはライブラリが提供する事前学習モデル構成(HuggingFaceのAWS S3リポジトリからダウンロード)からモデルを読み込むために使用できます。
[`PreTrainedModel`] と [`TFPreTrainedModel`] は、次の共通のメソッドも実装しています:
- 語彙に新しいトークンが追加された場合に、入力トークン埋め込みのリサイズを行う
- モデルのアテンションヘッドを刈り込む
各モデルに共通するその他のメソッドは、[`~modeling_utils.ModuleUtilsMixin`](PyTorchモデル用)および[`~modeling_tf_utils.TFModuleUtilsMixin`](TensorFlowモデル用)で定義されており、テキスト生成の場合、[`~generation.GenerationMixin`](PyTorchモデル用)、[`~generation.TFGenerationMixin`](TensorFlowモデル用)、および[`~generation.FlaxGenerationMixin`](Flax/JAXモデル用)もあります。
## PreTrainedModel
[[autodoc]] PreTrainedModel
- push_to_hub
- all
<a id='from_pretrained-torch-dtype'></a>
### 大規模モデルの読み込み
Transformers 4.20.0では、[`~PreTrainedModel.from_pretrained`] メソッドが再設計され、[Accelerate](https://huggingface.co/docs/accelerate/big_modeling) を使用して大規模モデルを扱うことが可能になりました。これには Accelerate >= 0.9.0 と PyTorch >= 1.9.0 が必要です。以前の方法でフルモデルを作成し、その後事前学習の重みを読み込む代わりに(これにはメモリ内のモデルサイズが2倍必要で、ランダムに初期化されたモデル用と重み用の2つが必要でした)、モデルを空の外殻として作成し、事前学習の重みが読み込まれるときにパラメーターを実体化するオプションが追加されました。
このオプションは `low_cpu_mem_usage=True` で有効にできます。モデルはまず空の重みを持つメタデバイス上に作成され、その後状態辞書が内部に読み込まれます(シャードされたチェックポイントの場合、シャードごとに読み込まれます)。この方法で使用される最大RAMは、モデルの完全なサイズだけです。
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
```
さらに、モデルが完全にRAMに収まらない場合(現時点では推論のみ有効)、異なるデバイスにモデルを直接配置できます。`device_map="auto"` を使用すると、Accelerateは各レイヤーをどのデバイスに配置するかを決定し、最速のデバイス(GPU)を最大限に活用し、残りの部分をCPU、あるいはGPU RAMが不足している場合はハードドライブにオフロードします。モデルが複数のデバイスに分割されていても、通常どおり実行されます。
`device_map` を渡す際、`low_cpu_mem_usage` は自動的に `True` に設定されるため、それを指定する必要はありません。
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
```
モデルがデバイス間でどのように分割されたかは、その `hf_device_map` 属性を見ることで確認できます:
```py
t0pp.hf_device_map
```
```python out
{'shared': 0,
'decoder.embed_tokens': 0,
'encoder': 0,
'decoder.block.0': 0,
'decoder.block.1': 1,
'decoder.block.2': 1,
'decoder.block.3': 1,
'decoder.block.4': 1,
'decoder.block.5': 1,
'decoder.block.6': 1,
'decoder.block.7': 1,
'decoder.block.8': 1,
'decoder.block.9': 1,
'decoder.block.10': 1,
'decoder.block.11': 1,
'decoder.block.12': 1,
'decoder.block.13': 1,
'decoder.block.14': 1,
'decoder.block.15': 1,
'decoder.block.16': 1,
'decoder.block.17': 1,
'decoder.block.18': 1,
'decoder.block.19': 1,
'decoder.block.20': 1,
'decoder.block.21': 1,
'decoder.block.22': 'cpu',
'decoder.block.23': 'cpu',
'decoder.final_layer_norm': 'cpu',
'decoder.dropout': 'cpu',
'lm_head': 'cpu'}
```
同じフォーマットに従って、独自のデバイスマップを作成することもできます(レイヤー名からデバイスへの辞書です)。モデルのすべてのパラメータを指定されたデバイスにマップする必要がありますが、1つのレイヤーが完全に同じデバイスにある場合、そのレイヤーのサブモジュールのすべてがどこに行くかの詳細を示す必要はありません。例えば、次のデバイスマップはT0ppに適しています(GPUメモリがある場合):
```python
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
```
モデルのメモリへの影響を最小限に抑えるもう 1 つの方法は、低精度の dtype (`torch.float16` など) でモデルをインスタンス化するか、以下で説明する直接量子化手法を使用することです。
### Model Instantiation dtype
Pytorch では、モデルは通常 `torch.float32` 形式でインスタンス化されます。これは、しようとすると問題になる可能性があります
重みが fp16 にあるモデルをロードすると、2 倍のメモリが必要になるためです。この制限を克服するには、次のことができます。
`torch_dtype` 引数を使用して、目的の `dtype` を明示的に渡します。
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
```
または、モデルを常に最適なメモリ パターンでロードしたい場合は、特別な値 `"auto"` を使用できます。
そして、`dtype` はモデルの重みから自動的に導出されます。
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
```
スクラッチからインスタンス化されたモデルには、どの `dtype` を使用するかを指示することもできます。
```python
config = T5Config.from_pretrained("t5")
model = AutoModel.from_config(config)
```
Pytorch の設計により、この機能は浮動小数点 dtype でのみ使用できます。
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
## TFPreTrainedModel
[[autodoc]] TFPreTrainedModel
- push_to_hub
- all
## TFModelUtilsMixin
[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
## FlaxPreTrainedModel
[[autodoc]] FlaxPreTrainedModel
- push_to_hub
- all
## Pushing to the Hub
[[autodoc]] utils.PushToHubMixin
## Sharded checkpoints
[[autodoc]] modeling_utils.load_sharded_checkpoint
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/tokenizer.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tokenizer
トークナイザーは、モデルの入力の準備を担当します。ライブラリには、すべてのモデルのトークナイザーが含まれています。ほとんど
トークナイザーの一部は、完全な Python 実装と、
Rust ライブラリ [🤗 Tokenizers](https://github.com/huggingface/tokenizers)。 「高速」実装では次のことが可能になります。
1. 特にバッチトークン化を行う場合の大幅なスピードアップと
2. 元の文字列 (文字と単語) とトークン空間の間でマッピングする追加のメソッド (例:
特定の文字を含むトークンのインデックス、または特定のトークンに対応する文字の範囲)。
基本クラス [`PreTrainedTokenizer`] および [`PreTrainedTokenizerFast`]
モデル入力の文字列入力をエンコードし (以下を参照)、Python をインスタンス化/保存するための一般的なメソッドを実装します。
ローカル ファイルまたはディレクトリ、またはライブラリによって提供される事前トレーニング済みトークナイザーからの「高速」トークナイザー
(HuggingFace の AWS S3 リポジトリからダウンロード)。二人とも頼りにしているのは、
共通メソッドを含む [`~tokenization_utils_base.PreTrainedTokenizerBase`]
[`~tokenization_utils_base.SpecialTokensMixin`]。
したがって、[`PreTrainedTokenizer`] と [`PreTrainedTokenizerFast`] はメインを実装します。
すべてのトークナイザーを使用するためのメソッド:
- トークン化 (文字列をサブワード トークン文字列に分割)、トークン文字列を ID に変換したり、その逆の変換を行ったりします。
エンコード/デコード (つまり、トークン化と整数への変換)。
- 基礎となる構造 (BPE、SentencePiece...) から独立した方法で、語彙に新しいトークンを追加します。
- 特別なトークン (マスク、文の始まりなど) の管理: トークンの追加、属性への割り当て。
トークナイザーにより、簡単にアクセスでき、トークン化中に分割されないようにすることができます。
[`BatchEncoding`] は、
[`~tokenization_utils_base.PreTrainedTokenizerBase`] のエンコード メソッド (`__call__`、
`encode_plus` および `batch_encode_plus`) であり、Python 辞書から派生しています。トークナイザーが純粋な Python の場合
tokenizer の場合、このクラスは標準の Python 辞書と同じように動作し、によって計算されたさまざまなモデル入力を保持します。
これらのメソッド (`input_ids`、`attention_mask`...)。トークナイザーが「高速」トークナイザーである場合 (つまり、
HuggingFace [トークナイザー ライブラリ](https://github.com/huggingface/tokenizers))、このクラスはさらに提供します
元の文字列 (文字と単語) と
トークンスペース (例: 指定された文字または対応する文字の範囲を構成するトークンのインデックスの取得)
与えられたトークンに)。
## PreTrainedTokenizer
[[autodoc]] PreTrainedTokenizer
- __call__
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## PreTrainedTokenizerFast
[`PreTrainedTokenizerFast`] は [tokenizers](https://huggingface.co/docs/tokenizers) ライブラリに依存します。 🤗 トークナイザー ライブラリから取得したトークナイザーは、
🤗 トランスに非常に簡単にロードされます。これがどのように行われるかを理解するには、[🤗 tokenizers からの tokenizers を使用する](../fast_tokenizers) ページを参照してください。
[[autodoc]] PreTrainedTokenizerFast
- __call__
- apply_chat_template
- batch_decode
- decode
- encode
- push_to_hub
- all
## BatchEncoding
[[autodoc]] BatchEncoding
| 0 |
hf_public_repos/transformers/docs/source/ja
|
hf_public_repos/transformers/docs/source/ja/main_classes/deepspeed.md
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeepSpeed Integration
[DeepSpeed](https://github.com/microsoft/DeepSpeed) は、[ZeRO 論文](https://arxiv.org/abs/1910.02054) で説明されているすべてを実装します。現在、次のものを完全にサポートしています。
1. オプティマイザーの状態分割 (ZeRO ステージ 1)
2. 勾配分割 (ZeRO ステージ 2)
3. パラメーターの分割 (ZeRO ステージ 3)
4. カスタム混合精度トレーニング処理
5. 一連の高速 CUDA 拡張ベースのオプティマイザー
6. CPU および NVMe への ZeRO オフロード
ZeRO-Offload には独自の専用ペーパーがあります: [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)。 NVMe サポートについては、論文 [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)。
DeepSpeed ZeRO-2 は、その機能が推論には役に立たないため、主にトレーニングのみに使用されます。
DeepSpeed ZeRO-3 は、巨大なモデルを複数の GPU にロードできるため、推論にも使用できます。
単一の GPU では不可能です。
🤗 Transformers は、2 つのオプションを介して [DeepSpeed](https://github.com/microsoft/DeepSpeed) を統合します。
1. [`Trainer`] によるコア DeepSpeed 機能の統合。何でもやってくれるタイプです
統合の場合 - カスタム構成ファイルを指定するか、テンプレートを使用するだけで、他に何もする必要はありません。たいていの
このドキュメントではこの機能に焦点を当てています。
2. [`Trainer`] を使用せず、DeepSpeed を統合した独自のトレーナーを使用したい場合
`from_pretrained` や `from_config` などのコア機能には、重要な機能の統合が含まれています。
ZeRO ステージ 3 以降の `zero.Init`などの DeepSpeed の部分。この機能を活用するには、次のドキュメントをお読みください。
[非トレーナー DeepSpeed 統合](#nontrainer-deepspeed-integration)。
統合されているもの:
トレーニング:
1. DeepSpeed ZeRO トレーニングは、ZeRO-Infinity (CPU および NVME オフロード) を使用して完全な ZeRO ステージ 1、2、および 3 をサポートします。
推論:
1. DeepSpeed ZeRO Inference は、ZeRO-Infinity による ZeRO ステージ 3 をサポートします。トレーニングと同じ ZeRO プロトコルを使用しますが、
オプティマイザと lr スケジューラは使用せず、ステージ 3 のみが関連します。詳細については、以下を参照してください。
[ゼロ推論](#zero-inference)。
DeepSpeed Inference もあります。これは、Tensor Parallelism の代わりに Tensor Parallelism を使用するまったく異なるテクノロジーです。
ZeRO (近日公開)。
<a id='deepspeed-trainer-integration'></a>
## Trainer Deepspeed Integration
<a id='deepspeed-installation'></a>
### Installation
pypi 経由でライブラリをインストールします。
```bash
pip install deepspeed
```
または`tansformers`, `extras`経由:
```bash
pip install transformers[deepspeed]
```
または、[DeepSpeed の GitHub ページ](https://github.com/microsoft/deepspeed#installation) で詳細を確認してください。
[高度なインストール](https://www.deepspeed.ai/tutorials/advanced-install/)。
それでもビルドに苦労する場合は、まず [CUDA 拡張機能のインストール ノート](trainer#cuda-extension-installation-notes) を必ず読んでください。
拡張機能を事前ビルドせず、実行時に拡張機能がビルドされることに依存しており、上記の解決策をすべて試した場合
それが役に立たなかった場合、次に試すべきことは、モジュールをインストールする前にモジュールを事前にビルドすることです。
DeepSpeed のローカル ビルドを作成するには:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
```
NVMe オフロードを使用する場合は、上記の手順に`DS_BUILD_AIO=1`を含める必要があります (また、
*libaio-dev* システム全体にインストールします)。
`TORCH_CUDA_ARCH_LIST` を編集して、使用する GPU カードのアーキテクチャのコードを挿入します。すべてを仮定すると
あなたのカードは同じで、次の方法でアーチを取得できます。
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
```
したがって、`8, 6`を取得した場合は、`TORCH_CUDA_ARCH_LIST="8.6"`を使用します。複数の異なるカードをお持ちの場合は、すべてをリストすることができます
それらのうち、`TORCH_CUDA_ARCH_LIST="6.1;8.6"`が好きです
複数のマシンで同じセットアップを使用する必要がある場合は、バイナリ ホイールを作成します。
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 \
python setup.py build_ext -j8 bdist_wheel
```
`dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`のようなものが生成されるので、これをインストールできます
`pip install deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`としてローカルまたは他のマシンにインストールします。
繰り返しますが、`TORCH_CUDA_ARCH_LIST`をターゲット アーキテクチャに合わせて調整することを忘れないでください。
NVIDIA GPU の完全なリストと、それに対応する **コンピューティング機能** (この記事の Arch と同じ) を見つけることができます。
コンテキスト) [ここ](https://developer.nvidia.com/cuda-gpus)。
以下を使用して、pytorch が構築されたアーチを確認できます。
```bash
python -c "import torch; print(torch.cuda.get_arch_list())"
```
ここでは、インストールされている GPU の 1 つのアーチを見つける方法を説明します。たとえば、GPU 0 の場合:
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; \
print(torch.cuda.get_device_properties(torch.device('cuda')))"
```
出力が次の場合:
```bash
_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)
```
そうすれば、このカードのアーチが`8.6`であることがわかります。
`TORCH_CUDA_ARCH_LIST` を完全に省略することもできます。そうすれば、ビルド プログラムが自動的にクエリを実行します。
ビルドが行われる GPU のアーキテクチャ。これは、ターゲット マシンの GPU と一致する場合もあれば、一致しない場合もあります。
目的のアーチを明示的に指定することをお勧めします。
提案されたことをすべて試してもまだビルドの問題が発生する場合は、GitHub の問題に進んでください。
[ディープスピード](https://github.com/microsoft/DeepSpeed/issues)、
<a id='deepspeed-multi-gpu'></a>
### Deployment with multiple GPUs
DeepSpeed 統合をデプロイするには、[`Trainer`] コマンド ライン引数を調整して新しい引数 `--deepspeed ds_config.json` を含めます。ここで、`ds_config.json` は DeepSpeed 構成ファイルです。
[こちら](https://www.deepspeed.ai/docs/config-json/)に記載されています。ファイル名はあなた次第です。
DeepSpeed の`add_config_arguments`ユーティリティを使用して、必要なコマンド ライン引数をコードに追加することをお勧めします。
詳細については、[DeepSpeed の引数解析](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) ドキュメントを参照してください。
ここで選択したランチャーを使用できます。 pytorch ランチャーを引き続き使用できます。
```bash
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json
```
または、`deepspeed`によって提供されるランチャーを使用します。
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
```
ご覧のとおり、引数は同じではありませんが、ほとんどのニーズではどちらでも機能します。の
さまざまなノードと GPU を構成する方法の詳細については、[こちら](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) を参照してください。
`deepspeed`ランチャーを使用し、利用可能なすべての GPU を使用したい場合は、`--num_gpus`フラグを省略するだけです。
以下は、利用可能なすべての GPU をデプロイする DeepSpeed で`run_translation.py`を実行する例です。
```bash
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
DeepSpeed のドキュメントには、`--deepspeed --deepspeed_config ds_config.json`が表示される可能性が高いことに注意してください。
DeepSpeed 関連の引数が 2 つありますが、簡単にするためであり、処理すべき引数がすでに非常に多いためです。
この 2 つを 1 つの引数に結合しました。
実際の使用例については、この [投稿](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400) を参照してください。
<a id='deepspeed-one-gpu'></a>
### Deployment with one GPU
1 つの GPU で DeepSpeed をデプロイするには、[`Trainer`] コマンド ライン引数を次のように調整します。
```bash
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
これは複数の GPU の場合とほぼ同じですが、ここでは、DeepSpeed に 1 つの GPU だけを使用するように明示的に指示します。
`--num_gpus=1`。デフォルトでは、DeepSpeed は指定されたノード上で認識できるすべての GPU をデプロイします。起動する GPU が 1 つだけの場合
の場合、この引数は必要ありません。次の [ドキュメント](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) では、ランチャー オプションについて説明しています。
1 つの GPU だけで DeepSpeed を使用したいのはなぜですか?
1. 一部の計算とメモリをホストの CPU と RAM に委任できる ZeRO オフロード機能を備えているため、
モデルのニーズに合わせてより多くの GPU リソースを残しておきます。より大きなバッチ サイズ、または非常に大きなモデルのフィッティングを可能にする
普通は合わないでしょう。
2. スマートな GPU メモリ管理システムを提供し、メモリの断片化を最小限に抑えます。
より大きなモデルとデータ バッチ。
次に構成について詳しく説明しますが、単一の GPU で大幅な改善を実現するための鍵は次のとおりです。
DeepSpeed を使用するには、構成ファイルに少なくとも次の構成が必要です。
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true
}
}
```
これにより、オプティマイザーのオフロードやその他の重要な機能が有効になります。バッファ サイズを試してみるとよいでしょう。
詳細については、以下のディスカッションを参照してください。
このタイプのデプロイメントの実際的な使用例については、この [投稿](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685) を参照してください。
このドキュメントで詳しく説明されているように、CPU および NVMe オフロードを備えた ZeRO-3 を試すこともできます。
ノート:
- GPU 0 とは異なる特定の GPU で実行する必要がある場合、`CUDA_VISIBLE_DEVICES` を使用して制限することはできません。
利用可能な GPU の表示範囲。代わりに、次の構文を使用する必要があります。
```bash
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
```
この例では、DeepSpeed に GPU 1 (2 番目の GPU) を使用するように指示します。
<a id='deepspeed-multi-node'></a>
### 複数のノードを使用したデプロイメント
このセクションの情報は DeepSpeed 統合に固有のものではなく、あらゆるマルチノード プログラムに適用できます。ただし、DeepSpeed は、SLURM 環境でない限り、他のランチャーよりも使いやすい`deepspeed`ランチャーを提供します。
このセクションでは、それぞれ 8 GPU を備えた 2 つのノードがあると仮定します。また、最初のノードには `ssh hostname1` を使用して、2 番目のノードには `ssh hostname2` を使用して接続できます。両方ともパスワードなしでローカルの ssh 経由で相互に接続できる必要があります。もちろん、これらのホスト (ノード) 名を、作業している実際のホスト名に変更する必要があります。
#### The torch.distributed.run launcher
たとえば、`torch.distributed.run` を使用するには、次のようにします。
```bash
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
```
各ノードに SSH で接続し、それぞれのノードで同じコマンドを実行する必要があります。急ぐ必要はありません。ランチャーは両方のノードが同期するまで待機します。
詳細については、[torchrun](https://pytorch.org/docs/stable/elastic/run.html) を参照してください。ちなみに、これは pytorch の数バージョン前の`torch.distributed.launch`を置き換えたランチャーでもあります。
#### ディープスピード ランチャー
代わりに`deepspeed`ランチャーを使用するには、まず`hostfile`ファイルを作成する必要があります。
```
hostname1 slots=8
hostname2 slots=8
```
そして、次のように起動できます。
```bash
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
```
`torch.distributed.run`ランチャーとは異なり、`deepspeed`は両方のノードでこのコマンドを自動的に起動します。
詳細については、[リソース構成 (マルチノード)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) を参照してください。
#### Launching in a SLURM environment
SLURM 環境では、次のアプローチを使用できます。以下は、特定の SLURM 環境に適合させるために必要な slurm スクリプト `launch.slurm` です。
```bash
#SBATCH --job-name=test-nodes # name
#SBATCH --nodes=2 # nodes
#SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
#SBATCH --cpus-per-task=10 # number of cores per tasks
#SBATCH --gres=gpu:8 # number of gpus
#SBATCH --time 20:00:00 # maximum execution time (HH:MM:SS)
#SBATCH --output=%x-%j.out # output file name
export GPUS_PER_NODE=8
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
export MASTER_PORT=9901
srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
--nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
--master_addr $MASTER_ADDR --master_port $MASTER_PORT \
your_program.py <normal cl args> --deepspeed ds_config.json'
```
あとは実行をスケジュールするだけです。
```bash
sbatch launch.slurm
```
#### Use of Non-shared filesystem
デフォルトでは、DeepSpeed はマルチノード環境が共有ストレージを使用することを想定しています。これが当てはまらず、各ノードがローカル ファイルシステムしか参照できない場合は、設定ファイルを調整して [`checkpoint`_section](https://www.deepspeed.ai/docs/config-json/#) を含める必要があります。チェックポイント オプション) を次の設定で指定します。
```json
{
"checkpoint": {
"use_node_local_storage": true
}
}
```
あるいは、[`Trainer`] の `--save_on_each_node` 引数を使用することもでき、上記の設定は自動的に追加されます。
<a id='deepspeed-notebook'></a>
### Deployment in Notebooks
ノートブックのセルをスクリプトとして実行する場合の問題は、依存する通常の`deepspeed`ランチャーがないことです。
特定の設定では、それをエミュレートする必要があります。
GPU を 1 つだけ使用している場合、DeepSpeed を使用するためにノートブック内のトレーニング コードを調整する必要がある方法は次のとおりです。
```python
# DeepSpeed requires a distributed environment even when only one process is used.
# This emulates a launcher in the notebook
import os
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
# Now proceed as normal, plus pass the deepspeed config file
training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
trainer = Trainer(...)
trainer.train()
```
注: `...` は、関数に渡す通常の引数を表します。
複数の GPU を使用する場合、DeepSpeed が動作するにはマルチプロセス環境を使用する必要があります。つまり、あなたは持っています
その目的でランチャーを使用することはできませんが、これは、提示された分散環境をエミュレートすることによっては実現できません。
このセクションの冒頭で。
現在のディレクトリのノートブックにその場で構成ファイルを作成したい場合は、専用の
セルの内容:
```python no-style
%%bash
cat <<'EOT' > ds_config_zero3.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
EOT
```
トレーニング スクリプトがノートブックのセルではなく通常のファイルにある場合は、次のようにして`deepspeed`を通常どおり起動できます。
細胞からのシェル。たとえば、`run_translation.py` を使用するには、次のように起動します。
```python no-style
!git clone https://github.com/huggingface/transformers
!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
```
または、`%%bash` マジックを使用すると、シェル プログラムを実行するための複数行のコードを記述することができます。
```python no-style
%%bash
git clone https://github.com/huggingface/transformers
cd transformers
deepspeed examples/pytorch/translation/run_translation.py ...
```
そのような場合、このセクションの最初に示したコードは必要ありません。
注: `%%bash` マジックは優れていますが、現時点では出力をバッファリングするため、プロセスが終了するまでログは表示されません。
完了します。
<a id='deepspeed-config'></a>
### Configuration
設定ファイルで使用できる DeepSpeed 設定オプションの完全なガイドについては、次を参照してください。
[次のドキュメント](https://www.deepspeed.ai/docs/config-json/) にアクセスしてください。
さまざまな実際のニーズに対応する数十の DeepSpeed 構成例を [DeepSpeedExamples] (https://github.com/microsoft/DeepSpeedExamples)で見つけることができます。
リポジトリ:
```bash
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find . -name '*json'
```
上記のコードを続けて、Lamb オプティマイザーを構成しようとしているとします。したがって、次の中から検索できます
`.json` ファイルの例:
```bash
grep -i Lamb $(find . -name '*json')
```
さらにいくつかの例が [メイン リポジトリ](https://github.com/microsoft/DeepSpeed) にもあります。
DeepSpeed を使用する場合は、常に DeepSpeed 構成ファイルを指定する必要がありますが、一部の構成パラメータには
コマンドライン経由で設定します。微妙な違いについては、このガイドの残りの部分で説明します。
DeepSpeed 構成ファイルがどのようなものかを理解するために、ZeRO ステージ 2 機能を有効にする構成ファイルを次に示します。
オプティマイザー状態の CPU オフロードを含み、`AdamW`オプティマイザーと`WarmupLR`スケジューラーを使用し、混合を有効にします。
`--fp16` が渡された場合の精度トレーニング:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
}
```
プログラムを実行すると、DeepSpeed は [`Trainer`] から受け取った設定をログに記録します。
コンソールに渡されるため、最終的にどのような設定が渡されたのかを正確に確認できます。
<a id='deepspeed-config-passing'></a>
### Passing Configuration
このドキュメントで説明したように、通常、DeepSpeed 設定は json ファイルへのパスとして渡されますが、
トレーニングの設定にコマンド ライン インターフェイスを使用せず、代わりにインスタンスを作成します。
[`Trainer`] via [`TrainingArguments`] その後、`deepspeed` 引数については次のことができます
ネストされた `dict` を渡します。これにより、その場で構成を作成でき、それを書き込む必要がありません。
[`TrainingArguments`] に渡す前にファイル システムを変更します。
要約すると、次のことができます。
```python
TrainingArguments(..., deepspeed="/path/to/ds_config.json")
```
または:
```python
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
TrainingArguments(..., deepspeed=ds_config_dict)
```
<a id='deepspeed-config-shared'></a>
### Shared Configuration
<Tip warning={true}>
このセクションは必読です
</Tip>
[`Trainer`] と DeepSpeed の両方が正しく機能するには、いくつかの設定値が必要です。
したがって、検出が困難なエラーにつながる可能性のある定義の競合を防ぐために、それらを構成することにしました。
[`Trainer`] コマンドライン引数経由。
さらに、一部の構成値はモデルの構成に基づいて自動的に導出されます。
複数の値を手動で調整することを忘れないでください。[`Trainer`] に大部分を任せるのが最善です
の設定を行います。
したがって、このガイドの残りの部分では、特別な設定値 `auto` が表示されます。これを設定すると、
正しい値または最も効率的な値に自動的に置き換えられます。これを無視することを自由に選択してください
推奨事項を参照し、値を明示的に設定します。この場合、次の点に十分注意してください。
[`Trainer`] 引数と DeepSpeed 設定は一致します。たとえば、同じものを使用していますか
学習率、バッチサイズ、または勾配累積設定?これらが一致しない場合、トレーニングは非常に失敗する可能性があります
方法を検出するのが難しい。あなたは警告を受けました。
DeepSpeed のみに固有の値や、それに合わせて手動で設定する必要がある値が他にも複数あります。
あなたの要望。
独自のプログラムで、DeepSpeed 構成をマスターとして変更したい場合は、次のアプローチを使用することもできます。
それに基づいて [`TrainingArguments`] を設定します。手順は次のとおりです。
1. マスター構成として使用する DeepSpeed 構成を作成またはロードします
2. これらの値に基づいて [`TrainingArguments`] オブジェクトを作成します
`scheduler.params.total_num_steps`などの一部の値は次のように計算されることに注意してください。
`train` 中に [`Trainer`] を実行しますが、もちろん自分で計算することもできます。
<a id='deepspeed-zero'></a>
### ZeRO
[Zero Redundancy Optimizer (ZeRO)](https://www.deepspeed.ai/tutorials/zero/) は、DeepSpeed の主力製品です。それ
3 つの異なるレベル (段階) の最適化をサポートします。最初のものは、スケーラビリティの観点からはあまり興味深いものではありません。
したがって、このドキュメントではステージ 2 と 3 に焦点を当てます。ステージ 3 は、最新の ZeRO-Infinity の追加によってさらに改善されています。
詳細については、DeepSpeed のドキュメントを参照してください。
構成ファイルの `zero_optimization` セクションは最も重要な部分です ([docs](https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training))。ここで定義します
どの ZeRO ステージを有効にするか、そしてそれらをどのように構成するか。各パラメータの説明は、
DeepSpeed のドキュメント。
このセクションは、DeepSpeed 設定を介してのみ設定する必要があります - [`Trainer`] が提供します
同等のコマンドライン引数はありません。
注: 現在、DeepSpeed はパラメーター名を検証しないため、スペルを間違えると、デフォルト設定が使用されます。
スペルが間違っているパラメータ。 DeepSpeed エンジンの起動ログ メッセージを見て、その値を確認できます。
使用するつもりです。
<a id='deepspeed-zero2-config'></a>
#### ZeRO-2 Config
以下は、ZeRO ステージ 2 の構成例です。
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
}
}
```
**性能調整:**
- `offload_optimizer` を有効にすると、GPU RAM の使用量が削減されます (`"stage": 2` が必要です)
- `"overlap_comm": true` は、GPU RAM 使用量の増加とトレードオフして、遅延をすべて削減します。 `overlap_comm`は 4.5x を使用します
`allgather_bucket_size`と`reduce_bucket_size`の値。したがって、5e8 に設定されている場合、9GB が必要になります。
フットプリント (`5e8 x 2Bytes x 2 x 4.5`)。したがって、8GB 以下の RAM を搭載した GPU を使用している場合、
OOM エラーが発生した場合は、これらのパラメータを`2e8`程度に減らす必要があり、それには 3.6GB が必要になります。やりたくなるでしょう
OOM に達し始めている場合は、より大容量の GPU でも同様です。
- これらのバッファを減らすと、より多くの GPU RAM を利用するために通信速度を犠牲にすることになります。バッファサイズが小さいほど、
通信が遅くなり、他のタスクで使用できる GPU RAM が増えます。したがって、バッチサイズが大きい場合は、
重要なのは、トレーニング時間を少し遅らせることは良いトレードになる可能性があります。
さらに、`deepspeed==0.4.4`には、次のコマンドで有効にできる新しいオプション`round_robin_gradients`が追加されました。
```json
{
"zero_optimization": {
"round_robin_gradients": true
}
}
```
これは、きめ細かい勾配パーティショニングによってランク間の CPU メモリへの勾配コピーを並列化する、CPU オフロードのステージ 2 最適化です。パフォーマンスの利点は、勾配累積ステップ (オプティマイザー ステップ間のコピーの増加) または GPU 数 (並列処理の増加) に応じて増加します。
<a id='deepspeed-zero3-config'></a>
#### ZeRO-3 Config
以下は、ZeRO ステージ 3 の構成例です。
```json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
モデルまたはアクティベーションが GPU メモリに適合せず、CPU が未使用であるために OOM が発生している場合
`"device": "cpu"` を使用してオプティマイザの状態とパラメータを CPU メモリにメモリオフロードすると、この制限が解決される可能性があります。
CPU メモリにオフロードしたくない場合は、`device`エントリに`cpu`の代わりに`none`を使用します。オフロード先
NVMe については後ほど説明します。
固定メモリは、`pin_memory`を`true`に設定すると有効になります。この機能により、次のようなコストをかけてスループットを向上させることができます。
他のプロセスが使用できるメモリが少なくなります。ピン留めされたメモリは、それを要求した特定のプロセスのために確保されます。
通常、通常の CPU メモリよりもはるかに高速にアクセスされます。
**性能調整:**
- `stage3_max_live_parameters`: `1e9`
- `stage3_max_reuse_distance`: `1e9`
OOM に達した場合は、「stage3_max_live_parameters」と「stage3_max_reuse_ distance」を減らします。影響は最小限に抑えられるはずです
アクティブ化チェックポイントを実行しない限り、パフォーマンスに影響します。 `1e9`は約 2GB を消費します。記憶を共有しているのは、
`stage3_max_live_parameters` と `stage3_max_reuse_distance` なので、加算されるものではなく、合計で 2GB になります。
`stage3_max_live_parameters` は、特定の時点で GPU 上に保持する完全なパラメータの数の上限です。
時間。 「再利用距離」は、パラメータが将来いつ再び使用されるかを判断するために使用する指標です。
`stage3_max_reuse_ distance`を使用して、パラメータを破棄するか保持するかを決定します。パラメータが
近い将来に再び使用される予定 (`stage3_max_reuse_distance`未満) なので、通信を減らすために保持します。
オーバーヘッド。これは、アクティベーション チェックポイントを有効にしている場合に非常に役立ちます。フォワード再計算が行われ、
backward は単一レイヤー粒度を渡し、後方再計算までパラメータを前方再計算に保持したいと考えています。
次の構成値は、モデルの非表示サイズによって異なります。
- `reduce_bucket_size`: `hidden_size*hidden_size`
- `stage3_prefetch_bucket_size`: `0.9 * hidden_size * hidden_size`
- `stage3_param_persistence_threshold`: `10 * hidden_size`
したがって、これらの値を `auto` に設定すると、[`Trainer`] が推奨される値を自動的に割り当てます。
価値観。ただし、もちろん、これらを明示的に設定することもできます。
`stage3_gather_16bit_weights_on_model_save` は、モデルの保存時にモデル fp16 の重み統合を有効にします。大きい
モデルと複数の GPU の場合、これはメモリと速度の両方の点で高価な操作です。現在必須となっているのは、
トレーニングを再開する予定です。この制限を取り除き、より便利にする今後のアップデートに注目してください。
フレキシブル。
ZeRO-2 構成から移行している場合は、`allgather_partitions`、`allgather_bucket_size`、および
`reduce_scatter`設定パラメータは ZeRO-3 では使用されません。これらを設定ファイルに保存しておくと、
無視される。
- `sub_group_size`: `1e9`
`sub_group_size` は、オプティマイザーのステップ中にパラメーターが更新される粒度を制御します。パラメータは次のとおりです。
`sub_group_size` のバケットにグループ化され、各バケットは一度に 1 つずつ更新されます。 NVMeオフロードで使用する場合
したがって、ZeRO-Infinity の `sub_group_size`は、モデルの状態が CPU に出入りする粒度を制御します。
オプティマイザステップ中に NVMe からメモリを取得します。これにより、非常に大規模なモデルの CPU メモリ不足が防止されます。
NVMe オフロードを使用しない場合は、`sub_group_size`をデフォルト値の *1e9* のままにすることができます。変更することもできます
次の場合のデフォルト値:
1. オプティマイザー ステップ中に OOM が発生する: `sub_group_size` を減らして、一時バッファーのメモリ使用量を削減します。
2. オプティマイザー ステップに時間がかかります。`sub_group_size`を増やして、帯域幅の使用率を向上させます。
データバッファの増加。
#### ZeRO-0 Config
ステージ 0 と 1 はめったに使用されないため、最後にリストしていることに注意してください。
ステージ 0 では、すべてのタイプのシャーディングを無効にし、DDP として DeepSpeed のみを使用します。次のコマンドでオンにできます。
```json
{
"zero_optimization": {
"stage": 0
}
}
```
これにより、他に何も変更する必要がなく、基本的に ZeRO が無効になります。
#### ZeRO-1 Config
ステージ 1 は、ステージ 2 からグラデーション シャーディングを除いたものです。オプティマイザーの状態をシャード化するだけで、処理を少し高速化するためにいつでも試すことができます。
```json
{
"zero_optimization": {
"stage": 1
}
}
```
<a id='deepspeed-nvme'></a>
### NVMe Support
ZeRO-Infinity は、GPU と CPU メモリを NVMe メモリで拡張することで、非常に大規模なモデルのトレーニングを可能にします。おかげで
スマート パーティショニングおよびタイリング アルゴリズムでは、各 GPU が非常に少量のデータを送受信する必要があります。
オフロードにより、最新の NVMe がトレーニングに利用できる合計メモリ プールをさらに大きくするのに適していることが判明しました。
プロセス。 ZeRO-Infinity には、ZeRO-3 が有効になっている必要があります。
次の設定例では、NVMe がオプティマイザの状態とパラメータの両方をオフロードできるようにします。
```json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
}
```
オプティマイザの状態とパラメータの両方を NVMe にオフロードするか、どちらか 1 つだけをオフロードするか、まったくオフロードしないかを選択できます。たとえば、次の場合
利用可能な CPU メモリが大量にある場合は、高速になるため、必ず CPU メモリのみにオフロードしてください (ヒント:
*"device": "CPU"*)。
[オプティマイザーの状態](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) と [パラメーター](https://www.deepspeed.ai/docs/config-json/#parameter-offloading)。
`nvme_path`が実際に NVMe であることを確認してください。NVMe は通常のハードドライブまたは SSD で動作しますが、
はるかに遅くなります。高速スケーラブルなトレーニングは、最新の NVMe 転送速度を念頭に置いて設計されました (この時点では
書き込みでは、読み取り最大 3.5 GB/秒、書き込み最大 3 GB/秒のピーク速度が得られます)。
最適な`aio`構成ブロックを見つけるには、ターゲット設定でベンチマークを実行する必要があります。
[ここで説明](https://github.com/microsoft/DeepSpeed/issues/998)。
<a id='deepspeed-zero2-zero3-performance'></a>
#### ZeRO-2 vs ZeRO-3 Performance
ZeRO-3 は、他のすべてが同じように構成されている場合、ZeRO-2 よりも遅くなる可能性があります。前者は収集する必要があるためです。
ZeRO-2 の機能に加えてモデルの重み付けを行います。 ZeRO-2 がニーズを満たし、数個の GPU を超えて拡張する必要がない場合
そうすれば、それに固執することを選択することもできます。 ZeRO-3 により、はるかに高いスケーラビリティ容量が可能になることを理解することが重要です
スピードを犠牲にして。
ZeRO-3 の構成を調整して、ZeRO-2 に近づけることができます。
- `stage3_param_persistence_threshold` を非常に大きな数値に設定します。たとえば、`6 * hidden_size * hidden_size` のように、最大パラメータよりも大きくなります。これにより、パラメータが GPU に保持されます。
- ZeRO-2 にはそのオプションがないため、`offload_params` をオフにします。
変更しなくても、`offload_params`をオフにするだけでパフォーマンスが大幅に向上する可能性があります。
`stage3_param_persistence_threshold`。もちろん、これらの変更はトレーニングできるモデルのサイズに影響します。それで
これらは、ニーズに応じて、スケーラビリティと引き換えに速度を向上させるのに役立ちます。
<a id='deepspeed-zero2-example'></a>
#### ZeRO-2 Example
以下は、完全な ZeRO-2 自動構成ファイル `ds_config_zero2.json` です。
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
以下は、手動で設定された完全な ZeRO-2 のすべてが有効な構成ファイルです。ここでは主に、典型的なものを確認するためのものです。
値は次のようになりますが、複数の`auto`設定が含まれる値を使用することを強くお勧めします。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
<a id='deepspeed-zero3-example'></a>
#### ZeRO-3 Example
以下は、完全な ZeRO-3 自動構成ファイル`ds_config_zero3.json`です。
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
以下は、手動で設定された完全な ZeRO-3 のすべてが有効な構成ファイルです。ここでは主に、典型的なものを確認するためのものです。
値は次のようになりますが、複数の`auto`設定が含まれる値を使用することを強くお勧めします。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e6,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
#### How to Choose Which ZeRO Stage and Offloads To Use For Best Performance
これで、さまざまな段階があることがわかりました。どちらを使用するかをどのように決定すればよいでしょうか?このセクションでは、この質問に答えていきます。
一般に、次のことが当てはまります。
- 速度の点(左の方が右より速い)
ステージ 0 (DDP) > ステージ 1 > ステージ 2 > ステージ 2 + オフロード > ステージ 3 > ステージ 3 + オフロード
- GPU メモリの使用状況 (右は左よりも GPU メモリ効率が高い)
ステージ 0 (DDP) < ステージ 1 < ステージ 2 < ステージ 2 + オフロード < ステージ 3 < ステージ 3 + オフロード
したがって、最小限の数の GPU に収まりながら最速の実行を実現したい場合は、次のプロセスに従うことができます。最も速いアプローチから開始し、GPU OOM に陥った場合は、次に遅いアプローチに進みますが、これにより使用される GPU メモリが少なくなります。などなど。
まず、バッチ サイズを 1 に設定します (必要な有効バッチ サイズに対して、いつでも勾配累積を使用できます)。
1. `--gradient_checkpointing 1` (HF Trainer) または直接 `model.gradient_checkpointing_enable()` を有効にします - OOM の場合
2. 最初に ZeRO ステージ 2 を試してください。 OOMの場合
3. ZeRO ステージ 2 + `offload_optimizer` を試します - OOM の場合
4. ZeRO ステージ 3 に切り替える - OOM の場合
5. `cpu` に対して `offload_param` を有効にします - OOM の場合
6. OOM の場合は、`cpu`に対して`offload_optimizer`を有効にします。
7. それでもバッチ サイズ 1 に適合しない場合は、まずさまざまなデフォルト値を確認し、可能であれば値を下げます。たとえば、`generate`を使用し、広い検索ビームを使用しない場合は、大量のメモリを消費するため、検索ビームを狭くします。
8. fp32 では必ず混合半精度を使用します。つまり、Ampere 以上の GPU では bf16、古い GPU アーキテクチャでは fp16 を使用します。
9. それでも OOM を行う場合は、ハードウェアを追加するか、ZeRO-Infinity を有効にすることができます。つまり、オフロード `offload_param` と `offload_optimizer` を `nvme` に切り替えます。非常に高速な nvme であることを確認する必要があります。逸話として、ZeRO-Infinity を使用して小さな GPU で BLOOM-176B を推論することができましたが、非常に遅かったです。でも、うまくいきました!
もちろん、最も GPU メモリ効率の高い構成から始めて、後から逆に進むことで、これらの手順を逆に実行することもできます。あるいは二等分してみてください。
OOM を引き起こさないバッチ サイズ 1 を取得したら、実効スループットを測定します。
次に、バッチ サイズをできるだけ大きくしてみます。バッチ サイズが大きいほど、乗算する行列が巨大な場合に GPU のパフォーマンスが最高になるため、GPU の効率が向上します。
ここで、パフォーマンス最適化ゲームが始まります。一部のオフロード機能をオフにするか、ZeRO 段階でステップダウンしてバッチ サイズを増減して、実効スループットを再度測定することができます。満足するまで洗い流し、繰り返します。
永遠にこれに費やす必要はありませんが、3 か月のトレーニングを開始しようとしている場合は、スループットに関して最も効果的な設定を見つけるために数日かけてください。そのため、トレーニングのコストが最小限になり、トレーニングをより早く完了できます。現在の目まぐるしく変化する ML の世界では、何かをトレーニングするのにさらに 1 か月かかる場合、絶好の機会を逃す可能性があります。もちろん、これは私が意見を共有しているだけであり、決してあなたを急かそうとしているわけではありません。 BLOOM-176B のトレーニングを開始する前に、このプロセスに 2 日間費やし、スループットを 90 TFLOP から 150 TFLOP に向上させることができました。この取り組みにより、トレーニング時間を 1 か月以上節約できました。
これらのメモは主にトレーニング モード用に書かれたものですが、ほとんどの場合は推論にも適用されるはずです。たとえば、勾配チェックポイントはトレーニング中にのみ役立つため、推論中は何も行われません。さらに、マルチ GPU 推論を実行していて、[DeepSpeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/)、[Accelerate](https://ハグフェイス.co/blog/bloom-inference-pytorch-scripts) は優れたパフォーマンスを提供するはずです。
その他のパフォーマンス関連の簡単なメモ:
- 何かを最初からトレーニングしている場合は、常に 16 で割り切れる形状のテンソル (隠れたサイズなど) を使用するようにしてください。バッチ サイズについては、少なくとも 2 で割り切れるようにしてください。 GPU からさらに高いパフォーマンスを引き出したい場合は、ハードウェア固有の [波とタイルの量子化](https://developer.nvidia.com/blog/optimizing-gpu-performance-tensor-cores/) の可分性があります。
### Activation Checkpointing or Gradient Checkpointing
アクティベーション チェックポイントと勾配チェックポイントは、同じ方法論を指す 2 つの異なる用語です。とてもややこしいですが、こんな感じです。
勾配チェックポイントを使用すると、速度を GPU メモリと引き換えにできます。これにより、GPU OOM を克服したり、バッチ サイズを増やすことができ、多くの場合、パフォーマンスの向上につながります。
HF Transformers モデルは、DeepSpeed のアクティベーション チェックポイントについて何も知らないため、DeepSpeed 構成ファイルでその機能を有効にしようとしても、何も起こりません。
したがって、この非常に有益な機能を活用するには 2 つの方法があります。
1. HF Transformers モデルを使用したい場合は、`model.gradient_checkpointing_enable()` を実行するか、HF トレーナーで `--gradient_checkpointing` を使用します。これにより、これが自動的に有効になります。そこで使われるのが `torch.utils.checkpoint` です。
2. 独自のモデルを作成し、DeepSpeed のアクティベーション チェックポイントを使用したい場合は、[そこで規定されている API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html) を使用できます。 HF Transformers モデリング コードを使用して、`torch.utils.checkpoint` を DeepSpeed の API に置き換えることもできます。後者は、順方向アクティベーションを再計算する代わりに CPU メモリにオフロードできるため、より柔軟です。
### Optimizer and Scheduler
`offload_optimizer`を有効にしない限り、DeepSpeed スケジューラーと HuggingFace スケジューラーを組み合わせて使用できます。
オプティマイザー (HuggingFace スケジューラーと DeepSpeed オプティマイザーの組み合わせを除く):
| Combos | HF Scheduler | DS Scheduler |
|:-------------|:-------------|:-------------|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
`offload_optimizer`が有効な場合、CPU と
GPU 実装 (LAMB を除く)。
<a id='deepspeed-optimizer'></a>
#### Optimizer
DeepSpeed の主なオプティマイザーは、Adam、AdamW、OneBitAdam、Lamb です。これらは ZeRO で徹底的にテストされており、
したがって、使用することをお勧めします。ただし、他のオプティマイザを「torch」からインポートすることはできます。完全なドキュメントは [こちら](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters) にあります。
設定ファイルで `optimizer` エントリを設定しない場合、[`Trainer`] は
自動的に`AdamW`に設定され、指定された値または次のコマンドラインのデフォルトが使用されます。
引数: `--learning_rate`、`--adam_beta1`、`--adam_beta2`、`--adam_epsilon`、および `--weight_decay`。
以下は、`AdamW`の自動構成された`optimizer`エントリの例です。
```json
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
```
コマンドライン引数によって構成ファイル内の値が設定されることに注意してください。これは 1 つあるためです
値の決定的なソースを提供し、たとえば学習率が次のように設定されている場合に、見つけにくいエラーを回避します。
さまざまな場所でさまざまな価値観。コマンドラインのルール。オーバーライドされる値は次のとおりです。
- `lr` と `--learning_rate` の値
- `betas` と `--adam_beta1 --adam_beta2` の値
- `eps` と `--adam_epsilon` の値
- `weight_decay` と `--weight_decay` の値
したがって、コマンドラインで共有ハイパーパラメータを調整することを忘れないでください。
値を明示的に設定することもできます。
```json
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.001,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
}
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
上記にリストされていない別のオプティマイザーを使用する場合は、トップレベルの構成に追加する必要があります。
```json
{
"zero_allow_untested_optimizer": true
}
```
`AdamW`と同様に、公式にサポートされている他のオプティマイザーを構成できます。これらは異なる設定値を持つ可能性があることに注意してください。例えばAdam の場合は、`weight_decay`を`0.01`付近にする必要があります。
さらに、オフロードは、Deepspeed の CPU Adam オプティマイザーと併用すると最も効果的に機能します。 `deepspeed==0.8.3` なので、オフロードで別のオプティマイザーを使用したい場合は、以下も追加する必要があります。
```json
{
"zero_force_ds_cpu_optimizer": false
}
```
最上位の構成に移行します。
<a id='deepspeed-scheduler'></a>
#### Scheduler
DeepSpeed は、`LRRangeTest`、`OneCycle`、`WarmupLR`、および`WarmupDecayLR`学習率スケジューラーをサポートしています。完全な
ドキュメントは[ここ](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters)です。
ここでは、🤗 Transformers と DeepSpeed の間でスケジューラーが重複する場所を示します。
- `--lr_scheduler_type constant_with_warmup` 経由の `WarmupLR`
- `--lr_scheduler_type Linear` を介した `WarmupDecayLR`。これは `--lr_scheduler_type` のデフォルト値でもあります。
したがって、スケジューラを設定しない場合、これがデフォルトで設定されるスケジューラになります。
設定ファイルで `scheduler` エントリを設定しない場合、[`Trainer`] は
`--lr_scheduler_type`、`--learning_rate`、および `--warmup_steps` または `--warmup_ratio` の値を設定します。
🤗 それのトランスフォーマーバージョン。
以下は、`WarmupLR`の自動構成された`scheduler`エントリの例です。
```json
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
*"auto"* が使用されているため、[`Trainer`] 引数は設定に正しい値を設定します。
ファイル。これは、値の決定的なソースが 1 つあることと、たとえば次のような場合に見つけにくいエラーを避けるためです。
学習率は、場所ごとに異なる値に設定されます。コマンドラインのルール。設定される値は次のとおりです。
- `warmup_min_lr` の値は `0` です。
- `warmup_max_lr` と `--learning_rate` の値。
- `warmup_num_steps` と `--warmup_steps` の値 (指定されている場合)。それ以外の場合は `--warmup_ratio` を使用します
トレーニング ステップの数を乗算し、切り上げます。
- `total_num_steps` には `--max_steps` の値を指定するか、指定されていない場合は実行時に自動的に導出されます。
環境、データセットのサイズ、およびその他のコマンド ライン引数 (
`WarmupDecayLR`)。
もちろん、構成値の一部またはすべてを引き継いで、自分で設定することもできます。
```json
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
}
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
たとえば、`WarmupDecayLR`の場合は、次のエントリを使用できます。
```json
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"last_batch_iteration": -1,
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
`total_num_steps`、`warmup_max_lr`、`warmup_num_steps`、および `total_num_steps` はロード時に設定されます。
<a id='deepspeed-fp32'></a>
### fp32 Precision
Deepspeed は、完全な fp32 と fp16 の混合精度をサポートします。
fp16 混合精度を使用すると、必要なメモリが大幅に削減され、速度が向上するため、
使用しているモデルがこのトレーニング モードで適切に動作しない場合は、使用しない方がよいでしょう。通常これ
モデルが fp16 混合精度で事前トレーニングされていない場合に発生します (たとえば、これは bf16 で事前トレーニングされた場合によく発生します)
モデル)。このようなモデルでは、オーバーフローまたはアンダーフローが発生し、`NaN`損失が発生する可能性があります。これがあなたの場合は、使用したいと思うでしょう
完全な fp32 モード。デフォルトの fp16 混合精度モードを次のように明示的に無効にします。
```json
{
"fp16": {
"enabled": false,
}
}
```
Ampere アーキテクチャ ベースの GPU を使用している場合、pytorch バージョン 1.7 以降は自動的に を使用するように切り替わります。
一部の操作でははるかに効率的な tf32 形式を使用しますが、結果は依然として fp32 になります。詳細と
ベンチマークについては、[Ampere デバイス上の TensorFloat-32(TF32)](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices) を参照してください。文書には以下が含まれます
何らかの理由でこの自動変換を使用したくない場合は、この自動変換を無効にする方法について説明します。
🤗 トレーナーでは、`--tf32` を使用して有効にするか、`--tf32 0` または `--no_tf32` を使用して無効にすることができます。デフォルトでは、PyTorch のデフォルトが使用されます。
<a id='deepspeed-amp'></a>
### Automatic Mixed Precision
pytorch のような AMP の方法または apex のような方法で自動混合精度を使用できます。
### fp16
fp16 (float16) を設定して pytorch AMP のようなモードを設定するには:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
[`Trainer`] は、の値に基づいてそれを自動的に有効または無効にします。
`args.fp16_backend`。残りの設定値はあなた次第です。
このモードは、`--fp16 --fp16_backend amp`または`--fp16_full_eval`コマンドライン引数が渡されると有効になります。
このモードを明示的に有効/無効にすることもできます。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
これが[ドキュメント](https://www.deepspeed.ai/docs/config-json/#fp16-training-options)です。
### BF16
fp16 の代わりに bf16 (bfloat16) が必要な場合は、次の構成セクションが使用されます。
```json
{
"bf16": {
"enabled": "auto"
}
}
```
bf16 は fp32 と同じダイナミック レンジを備えているため、損失スケーリングは必要ありません。
このモードは、`--bf16` または `--bf16_full_eval` コマンドライン引数が渡されると有効になります。
このモードを明示的に有効/無効にすることもできます。
```json
{
"bf16": {
"enabled": true
}
}
```
<Tip>
`deepspeed==0.6.0`の時点では、bf16 サポートは新しく実験的なものです。
bf16 が有効な状態で [勾配累積](#gradient-accumulation) を使用する場合は、bf16 で勾配が累積されることに注意する必要があります。この形式の精度が低いため、これは希望どおりではない可能性があります。損失のある蓄積につながります。
この問題を修正し、より高精度の `dtype` (fp16 または fp32) を使用するオプションを提供するための作業が行われています。
</Tip>
### NCCL Collectives
訓練体制の`dtype`があり、さまざまな削減や収集/分散操作などのコミュニケーション集合体に使用される別の`dtype`があります。
すべての収集/分散操作は、データが含まれているのと同じ `dtype` で実行されるため、bf16 トレーニング体制を使用している場合、データは bf16 で収集されます。収集は損失のない操作です。
さまざまなリデュース操作は非常に損失が大きい可能性があります。たとえば、複数の GPU 間で勾配が平均化される場合、通信が fp16 または bf16 で行われる場合、結果は損失が多くなる可能性があります。複数の数値を低精度でアドバタイズすると結果は正確ではないためです。 。 bf16 では fp16 よりも精度が低いため、さらにそうです。通常は非常に小さい grad を平均する際の損失が最小限に抑えられるため、fp16 で十分であることがよくあります。したがって、デフォルトでは、半精度トレーニングでは fp16 がリダクション演算のデフォルトとして使用されます。ただし、この機能を完全に制御でき、必要に応じて小さなオーバーヘッドを追加して、リダクションが累積 dtype として fp32 を使用し、結果の準備ができた場合にのみ半精度 `dtype` にダウンキャストするようにすることもできます。でトレーニング中です。
デフォルトをオーバーライドするには、新しい構成エントリを追加するだけです。
```json
{
"communication_data_type": "fp32"
}
```
この記事の執筆時点での有効な値は、"fp16"、"bfp16"、"fp32"です。
注: ステージ ゼロ 3 には、bf16 通信タイプに関するバグがあり、`deepspeed==0.8.1`で修正されました。
### apex
apex AMP のようなモード セットを設定するには:
```json
"amp": {
"enabled": "auto",
"opt_level": "auto"
}
```
[`Trainer`] は `args.fp16_backend` の値に基づいて自動的に設定します。
`args.fp16_opt_level`。
このモードは、`--fp16 --fp16_backend apex --fp16_opt_level 01`コマンド ライン引数が渡されると有効になります。
このモードを明示的に構成することもできます。
```json
{
"amp": {
"enabled": true,
"opt_level": "O1"
}
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
これは[ドキュメント](https://www.deepspeed.ai/docs/config-json/#automatic-mixed-precision-amp-training-options)です。
<a id='deepspeed-bs'></a>
### Batch Size
バッチサイズを設定するには、次を使用します。
```json
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto"
}
```
[`Trainer`] は自動的に `train_micro_batch_size_per_gpu` を次の値に設定します。
`args.per_device_train_batch_size`と`train_batch_size`を`args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`に変更します。
値を明示的に設定することもできます。
```json
{
"train_batch_size": 12,
"train_micro_batch_size_per_gpu": 4
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
<a id='deepspeed-grad-acc'></a>
### Gradient Accumulation
勾配累積セットを構成するには:
```json
{
"gradient_accumulation_steps": "auto"
}
```
[`Trainer`] は自動的にそれを `args.gradient_accumulation_steps` の値に設定します。
値を明示的に設定することもできます。
```json
{
"gradient_accumulation_steps": 3
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
<a id='deepspeed-grad-clip'></a>
### Gradient Clipping
グラデーション グラデーション クリッピング セットを構成するには:
```json
{
"gradient_clipping": "auto"
}
```
[`Trainer`] は自動的にそれを `args.max_grad_norm` の値に設定します。
値を明示的に設定することもできます。
```json
{
"gradient_clipping": 1.0
}
```
ただし、[`Trainer`] コマンドライン引数と DeepSpeed を自分で同期することになります。
構成。
<a id='deepspeed-weight-extraction'></a>
### Getting The Model Weights Out
トレーニングを継続し、DeepSpeed の使用を再開する限り、何も心配する必要はありません。 DeepSpeed ストア
fp32 のカスタム チェックポイント オプティマイザー ファイル内のマスターの重み。これは `global_step*/*optim_states.pt` (これは glob
パターン)、通常のチェックポイントの下に保存されます。
**FP16 ウェイト:**
モデルを ZeRO-2 で保存すると、モデルの重みを含む通常の `pytorch_model.bin` ファイルが作成されますが、
これらは重みの fp16 バージョンにすぎません。
ZeRO-3 では、モデルの重みが複数の GPU に分割されるため、状況はさらに複雑になります。
したがって、fp16 を保存するための `Trainer` を取得するには、`"stage3_gather_16bit_weights_on_model_save": true` が必要です。
重みのバージョン。この設定が`False`の場合、`pytorch_model.bin`は作成されません。これは、デフォルトで DeepSpeed の `state_dict` に実際の重みではなくプレースホルダーが含まれるためです。この `state_dict` を保存した場合、ロードし直すことはできません。
```json
{
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
**FP32 重量:**
fp16 ウェイトはトレーニングを再開するのに適していますが、モデルの微調整が完了し、それを
[モデル ハブ](https://huggingface.co/models) にアクセスするか、fp32 を入手したいと思われる他の人に渡します。
重み。これは大量のメモリを必要とするプロセスであるため、トレーニング中に行うべきではないのが理想的です。
したがって、トレーニングの完了後にオフラインで実行するのが最適です。ただし、必要に応じて、空き CPU が十分にある場合は、
同じトレーニング スクリプトで実行できることを思い出してください。次のセクションでは、両方のアプローチについて説明します。
**ライブ FP32 ウェイト リカバリ:**
モデルが大きく、トレーニングの終了時に空き CPU メモリがほとんど残っていない場合、このアプローチは機能しない可能性があります。
少なくとも 1 つのチェックポイントを保存していて、最新のチェックポイントを使用したい場合は、次の手順を実行できます。
```python
from transformers.trainer_utils import get_last_checkpoint
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
`--load_best_model_at_end` class:*~transformers.TrainingArguments* 引数を使用している場合 (最適なモデルを追跡するため)
チェックポイント)、最初に最終モデルを明示的に保存してから、上記と同じことを行うことでトレーニングを終了できます。
```python
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
<Tip>
`load_state_dict_from_zero_checkpoint` が実行されると、`model` はもはや使用できなくなることに注意してください。
同じアプリケーションの DeepSpeed コンテキスト。つまり、deepspeed エンジンを再初期化する必要があります。
`model.load_state_dict(state_dict)` はそこからすべての DeepSpeed マジックを削除します。したがって、これは最後にのみ実行してください
トレーニングの様子。
</Tip>
もちろん、class:*~transformers.Trainer* を使用する必要はなく、上記の例を独自のものに調整することができます。
トレーナー。
何らかの理由でさらに改良したい場合は、重みの fp32 `state_dict` を抽出して適用することもできます。
次の例に示すように、これらは自分で作成します。
```python
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
model = model.cpu()
model.load_state_dict(state_dict)
```
**オフライン FP32 ウェイト リカバリ:**
DeepSpeed は特別な変換スクリプト`zero_to_fp32.py`を作成し、チェックポイントの最上位に配置します。
フォルダ。このスクリプトを使用すると、いつでも重みを抽出できます。スクリプトはスタンドアロンなので、もう必要ありません。
抽出を行うための設定ファイルまたは `Trainer` が必要です。
チェックポイント フォルダーが次のようになっているとします。
```bash
$ ls -l output_dir/checkpoint-1/
-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
```
この例では、DeepSpeed チェックポイント サブフォルダー *global_step1* が 1 つだけあります。したがって、FP32を再構築するには
重みを実行するだけです:
```bash
python zero_to_fp32.py . pytorch_model.bin
```
これだよ。 `pytorch_model.bin`には、複数の GPU から統合された完全な fp32 モデルの重みが含まれるようになります。
スクリプトは、ZeRO-2 または ZeRO-3 チェックポイントを自動的に処理できるようになります。
`python zero_to_fp32.py -h` を実行すると、使用方法の詳細が表示されます。
スクリプトは、ファイル`latest`の内容を使用して deepspeed サブフォルダーを自動検出します。
例には`global_step1`が含まれます。
注: 現在、スクリプトには最終的な fp32 モデルの重みの 2 倍の一般 RAM が必要です。
### ZeRO-3 と Infinity Nuances
ZeRO-3 は、パラメータ シャーディング機能の点で ZeRO-2 とは大きく異なります。
ZeRO-Infinity は ZeRO-3 をさらに拡張し、NVMe メモリやその他の複数の速度とスケーラビリティの向上をサポートします。
モデルに特別な変更を加える必要がなくても正常に動作するようにあらゆる努力が払われてきましたが、特定の点では
状況によっては、次の情報が必要になる場合があります。
#### Constructing Massive Models
DeepSpeed/ZeRO-3 は、既存の RAM に収まらない可能性のある数兆のパラメータを持つモデルを処理できます。そのような場合、
また、初期化をより高速に実行したい場合は、*deepspeed.zero.Init()* を使用してモデルを初期化します。
コンテキスト マネージャー (関数デコレーターでもあります)。次のようになります。
```python
from transformers import T5ForConditionalGeneration, T5Config
import deepspeed
with deepspeed.zero.Init():
config = T5Config.from_pretrained("t5-small")
model = T5ForConditionalGeneration(config)
```
ご覧のとおり、これによりランダムに初期化されたモデルが得られます。
事前トレーニングされたモデルを使用したい場合、`model_class.from_pretrained` は次の条件を満たす限りこの機能を有効にします。
`is_deepspeed_zero3_enabled()` は `True` を返します。これは現在、
[`TrainingArguments`] オブジェクト (渡された DeepSpeed 構成ファイルに ZeRO-3 構成が含まれている場合)
セクション。したがって、呼び出しの前に** [`TrainingArguments`] オブジェクトを作成する必要があります。
`from_pretrained`。考えられるシーケンスの例を次に示します。
```python
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("t5-small")
trainer = Trainer(model=model, args=training_args, ...)
```
公式のサンプル スクリプトを使用していて、コマンド ライン引数に `--deepspeed ds_config.json` が含まれている場合
ZeRO-3 設定を有効にすると、これがサンプル スクリプトの記述方法であるため、すべてがすでに完了しています。
注: モデルの fp16 重みが単一の GPU のメモリに収まらない場合は、この機能を使用する必要があります。
この方法とその他の関連機能の詳細については、[大規模モデルの構築](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models) を参照してください。
また、fp16 で事前訓練されたモデルをロードするときは、`from_pretrained` に使用するように指示する必要があります。
`torch_dtype=torch.float16`。詳細については、[from_pretrained-torch-dtype](#from_pretrained-torch-dtype) を参照してください。
#### Gathering Parameters
複数の GPU 上の ZeRO-3 では、現在の GPU のパラメータでない限り、単一の GPU がすべてのパラメータを持つことはありません。
実行層。したがって、すべてのレイヤーのすべてのパラメーターに一度にアクセスする必要がある場合は、それを行うための特定の方法があります。
ほとんどの場合は必要ありませんが、必要な場合は、[パラメータの収集](https://deepspeed.readthedocs.io/en/latest/zero3.html#manual-parameter-coordination) を参照してください。
ただし、いくつかの場所で内部的に使用しています。その例の 1 つは、事前トレーニングされたモデルの重みをロードするときです。
`from_pretrained`。一度に 1 つのレイヤーをロードし、参加しているすべての GPU に即座に分割します。
大規模なモデルでは、メモリの関係で、1 つの GPU にロードしてから複数の GPU に分散することはできません。
制限。
また、ZeRO-3 では、独自のコードを作成し、次のようなモデル パラメーターの重みが発生するとします。
```python
tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
```
`tensor([1.])` にストレスを感じた場合、またはパラメータのサイズが `1` であるというエラーが発生した場合
より大きな多次元形状。これは、パラメーターが分割されており、表示されるのは ZeRO-3 プレースホルダーであることを意味します。
<a id='deepspeed-zero-inference'></a>
### ZeRO Inference
ZeRO Inference は、ZeRO-3 Training と同じ構成を使用します。オプティマイザーとスケジューラーのセクションは必要ありません。で
実際、同じものをトレーニングと共有したい場合は、これらを設定ファイルに残すことができます。彼らはただそうなるだろう
無視されました。
それ以外の場合は、通常の [`TrainingArguments`] 引数を渡すだけです。例えば:
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json
```
唯一重要なことは、ZeRO-2 には何の利点もないため、ZeRO-3 構成を使用する必要があるということです。
ZeRO-3 のみがパラメーターのシャーディングを実行するのに対し、ZeRO-1 は勾配とオプティマイザーの状態をシャーディングするため、推論に役立ちます。
以下は、利用可能なすべての GPU をデプロイする DeepSpeed で`run_translation.py`を実行する例です。
```bash
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --output_dir output_dir \
--do_eval --max_eval_samples 50 --warmup_steps 50 \
--max_source_length 128 --val_max_target_length 128 \
--overwrite_output_dir --per_device_eval_batch_size 4 \
--predict_with_generate --dataset_config "ro-en" --fp16 \
--source_lang en --target_lang ro --dataset_name wmt16 \
--source_prefix "translate English to Romanian: "
```
推論のために、オプティマイザーの状態と勾配によって使用される追加の大きなメモリは必要ないため、
はるかに大きなバッチやシーケンス長を同じハードウェアに適合できる必要があります。
さらに、DeepSpeed は現在、Deepspeed-Inference と呼ばれる関連製品を開発していますが、これとは何の関係もありません。
ZeRO テクノロジーに準拠していますが、代わりにテンソル並列処理を使用して、単一の GPU に収まらないモデルをスケーリングします。これは
現在開発中です。製品が完成したら統合を提供する予定です。
### Memory Requirements
Deepspeed ZeRO はメモリを CPU (および NVMe) にオフロードできるため、フレームワークは、使用されている GPU の数に応じて必要な CPU および GPU メモリの量を知ることができるユーティリティを提供します。
単一の GPU で `bigscience/T0_3B`を微調整するために必要なメモリの量を見積もってみましょう。
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 1 GPU per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
```
したがって、単一の 80 GB GPU で CPU オフロードなしで搭載することも、小さな 8 GB GPU でも最大 60 GB の CPU メモリが必要になることも可能です。 (これはパラメータ、オプティマイザの状態、および勾配のためのメモリであることに注意してください。cuda カーネル、アクティベーション、および一時メモリにはもう少し多くのメモリが必要です。)
次に、コストと速度のトレードオフになります。より小さい GPU を購入またはレンタルした方が安くなります (Deepspeed ZeRO では複数の GPU を使用できるため、GPU の数を減らすこともできます)。しかし、その場合は遅くなります。そのため、何かを実行する速度を気にしなくても、速度の低下は GPU の使用時間に直接影響し、コストが増大するため、どれが最も効果的かを実験して比較してください。
十分な GPU メモリがある場合は、すべてが高速になるため、CPU/NVMe オフロードを必ず無効にしてください。
たとえば、2 つの GPU に対して同じことを繰り返してみましょう。
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=2, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 2 GPUs per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.74GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=1
31.11GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=0
```
したがって、ここでは、CPU にオフロードせずに 2x 32GB 以上の GPU が必要になります。
詳細については、[メモリ推定ツール](https://deepspeed.readthedocs.io/en/latest/memory.html) を参照してください。
### Filing Issues
ここでは、問題の真相をすぐに解明し、作業のブロックを解除できるよう、問題を報告する方法を説明します。
レポートには必ず次の内容を含めてください。
1. レポート内の完全な Deepspeed 構成ファイル
2. [`Trainer`] を使用している場合はコマンドライン引数、または
トレーナーのセットアップを自分でスクリプト作成している場合は、[`TrainingArguments`] 引数。しないでください
[`TrainingArguments`] には無関係なエントリが多数含まれているため、ダンプします。
3. 次の出力:
```bash
python -c 'import torch; print(f"torch: {torch.__version__}")'
python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
```
4. 可能であれば、問題を再現できる Google Colab ノートブックへのリンクを含めてください。これを使えます
[ノートブック](https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb) として
出発点。
5. 不可能でない限り、カスタムデータセットではなく、常に使用できる標準データセットを使用してください。
6. 可能であれば、既存の [サンプル](https://github.com/huggingface/transformers/tree/main/examples/pytorch) のいずれかを使用して問題を再現してみてください。
- Deepspeed が問題の原因ではないことがよくあります。
提出された問題の一部は、Deepspeed とは無関係であることが判明しました。それは、Deepspeed がセットアップから削除された後です。
問題はまだ残っていた。
したがって、完全に明白でない場合は、DeepSpeed 関連の問題です。
例外が発生し、DeepSpeed モジュールが関係していることがわかります。まず、DeepSpeed を含まないセットアップを再テストしてください。
問題が解決しない場合にのみ、Deepspeed について言及し、必要な詳細をすべて提供してください。
- 問題が統合部分ではなく DeepSpeed コアにあることが明らかな場合は、問題を提出してください。
[Deepspeed](https://github.com/microsoft/DeepSpeed/) を直接使用します。よくわからない場合でも、ご安心ください。
どちらの問題トラッカーでも問題ありません。投稿されたらそれを判断し、次の場合は別の問題トラッカーにリダイレクトします。
そうである必要がある。
### Troubleshooting
#### the `deepspeed` process gets killed at startup without a traceback
`deepspeed`プロセスが起動時にトレースバックなしで強制終了された場合、それは通常、プログラムが試行したことを意味します。
システムが持っているよりも多くの CPU メモリを割り当てるか、プロセスが割り当てを許可されているため、OS カーネルがそれを強制終了します。
プロセス。これは、設定ファイルに `offload_optimizer` または `offload_param` が含まれている可能性が高いためです。
どちらも`cpu`にオフロードするように設定されています。 NVMe を使用している場合は、次の環境で実行している場合は NVMe へのオフロードを試してください。
ゼロ-3。 [特定のモデルに必要なメモリ量を見積もる]方法は次のとおりです(https://deepspeed.readthedocs.io/en/latest/memory.html)。
#### training and/or eval/predict loss is `NaN`
これは、bf16 混合精度モードで事前トレーニングされたモデルを取得し、それを fp16 (混合精度の有無にかかわらず) で使用しようとした場合によく発生します。 TPU でトレーニングされたほとんどのモデル、および多くの場合、Google によってリリースされたモデルは、このカテゴリに分類されます (たとえば、ほぼすべての t5 ベースのモデル)。ここでの解決策は、ハードウェアがサポートしている場合 (TPU、Ampere GPU 以降)、fp32 または bf16 を使用することです。
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
ログには、Deepspeed が次のように`OVERFLOW!`を報告していることがわかります。
```
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
```
これは、Deepspeed 損失スケーラーが損失オーバーフローを克服するスケーリング係数を見つけられないことを意味します。
(ログはここで読みやすくするためにマッサージされています。)
この場合、通常は `initial_scale_power` の値を上げる必要があります。通常、`initial_scale_power: 32` に設定すると問題が解決します。
### Notes
- DeepSpeed には pip でインストール可能な PyPI パッケージがありますが、ハードウェアに最も適合するように、また有効にする必要がある場合は、[ソース](https://github.com/microsoft/deepspeed#installation) からインストールすることを強くお勧めします。
1 ビット Adam などの特定の機能は、pypi ディストリビューションでは利用できません。
- 🤗 Transformers で DeepSpeed を使用するために [`Trainer`] を使用する必要はありません - 任意のモデルを使用できます
後者は [DeepSpeed 統合手順](https://www.deepspeed.ai/getting-started/#writing-deepspeed-models) に従って調整する必要があります。
## Non-Trainer Deepspeed Integration
[`~integrations.HfDeepSpeedConfig`] は、Deepspeed を 🤗 Transformers コアに統合するために使用されます
[`Trainer`] を使用しない場合の機能。実行する唯一のことは、Deepspeed ZeRO-3 パラメータ収集を処理し、`from_pretrained`呼び出し中にモデルを複数の GPU に自動的に分割することです。それ以外はすべて自分で行う必要があります。
[`Trainer`] を使用すると、すべてが自動的に処理されます。
[`Trainer`] を使用しない場合、DeepSpeed ZeRO-3 を効率的に導入するには、
モデルをインスタンス化する前に [`~integrations.HfDeepSpeedConfig`] オブジェクトを削除し、そのオブジェクトを生きたままにします。
Deepspeed ZeRO-1 または ZeRO-2 を使用している場合は、`HfDeepSpeedConfig`を使用する必要はまったくありません。
たとえば、事前トレーニングされたモデルの場合は次のようになります。
```python
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
model = AutoModel.from_pretrained("gpt2")
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
または、事前トレーニングされていないモデルの場合:
```python
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel, AutoConfig
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
config = AutoConfig.from_pretrained("gpt2")
model = AutoModel.from_config(config)
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
[`Trainer`] 統合を使用していない場合は、完全に独力で行うことになることに注意してください。基本的には、[Deepspeed](https://www.deepspeed.ai/) Web サイトのドキュメントに従ってください。また、設定ファイルを明示的に設定する必要があります。`"auto"`値は使用できず、代わりに実際の値を入力する必要があります。
## HfDeepSpeedConfig
[[autodoc]] integrations.HfDeepSpeedConfig
- all
### Custom DeepSpeed ZeRO Inference
以下は、単一の GPU にモデルを適合できない場合に、[`Trainer`] を使用せずに DeepSpeed ZeRO 推論を実行する方法の例です。解決策には、追加の GPU の使用、または GPU メモリを CPU メモリにオフロードすることが含まれます。
ここで理解すべき重要なニュアンスは、ZeRO の設計方法により、異なる GPU で異なる入力を並行して処理できるということです。
この例には大量のメモがあり、自己文書化されています。
必ず次のことを行ってください。
1. 十分な GPU メモリがある場合は、CPU オフロードを無効にします (速度が低下するため)。
2. Ampere または新しい GPU を所有している場合は、処理を高速化するために bf16 を有効にします。そのハードウェアがない場合は、bf16 混合精度で事前トレーニングされたモデル (ほとんどの t5 モデルなど) を使用しない限り、fp16 を有効にすることができます。これらは通常、fp16 でオーバーフローし、出力としてガベージが表示されます。
```python
#!/usr/bin/env python
# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
# into a single GPU
#
# 1. Use 1 GPU with CPU offload
# 2. Or use multiple GPUs instead
#
# First you need to install deepspeed: pip install deepspeed
#
# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
#
# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
# process multiple inputs at once.
#
# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
# run faster if you don't want offload to CPU - so disable that section then.
#
# To deploy on 1 gpu:
#
# deepspeed --num_gpus 1 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=1 t0.py
#
# To deploy on 2 gpus:
#
# deepspeed --num_gpus 2 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=2 t0.py
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
from transformers.integrations import HfDeepSpeedConfig
import deepspeed
import os
import torch
os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
# distributed setup
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
torch.cuda.set_device(local_rank)
deepspeed.init_distributed()
model_name = "bigscience/T0_3B"
config = AutoConfig.from_pretrained(model_name)
model_hidden_size = config.d_model
# batch size has to be divisible by world_size, but can be bigger than world_size
train_batch_size = 1 * world_size
# ds_config notes
#
# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
# faster.
#
# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
# all official t5 models are bf16-pretrained
#
# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
# - want CPU offload
#
# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
# - which params should remain on gpus - the larger the value the smaller the offload size
#
# For indepth info on Deepspeed config see
# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
# keeping the same format as json for consistency, except it uses lower case for true/false
# fmt: off
ds_config = {
"fp16": {
"enabled": False
},
"bf16": {
"enabled": False
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": train_batch_size,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
# fmt: on
# next line instructs transformers to partition the model directly over multiple gpus using
# deepspeed.zero.Init when model's `from_pretrained` method is called.
#
# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
#
# otherwise the model will first be loaded normally and only partitioned at forward time which is
# less efficient and when there is little CPU RAM may fail
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
# now a model can be loaded.
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# initialise Deepspeed ZeRO and store only the engine object
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
ds_engine.module.eval() # inference
# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
# If you use more GPUs adjust for more.
# And of course if you have just one input to process you then need to pass the same string to both gpus
# If you use only one GPU, then you will have only rank 0.
rank = torch.distributed.get_rank()
if rank == 0:
text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
elif rank == 1:
text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
with torch.no_grad():
outputs = ds_engine.module.generate(inputs, synced_gpus=True)
text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"rank{rank}:\n in={text_in}\n out={text_out}")
```
それを`t0.py`として保存して実行しましょう。
```
$ deepspeed --num_gpus 2 t0.py
rank0:
in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
out=Positive
rank1:
in=Is this review positive or negative? Review: this is the worst restaurant ever
out=negative
```
これは非常に基本的な例であり、ニーズに合わせて調整してください。
### `generate` nuances
ZeRO Stage-3 で複数の GPU を使用する場合、`generate(..., synced_gpus=True)`を呼び出して GPU を同期する必要があります。これを行わないと、1 つの GPU が他の GPU より先に生成を終了した場合、残りの GPU が生成を停止した GPU からウェイトのシャードを受信できなくなるため、システム全体がハングします。
`transformers>=4.28` 以降、`synced_gpus` が明示的に指定されていない場合、これらの条件が検出されると自動的に `True` に設定されます。ただし、必要に応じて `synced_gpus` の値をオーバーライドすることもできます。
## Deepspeed 統合のテスト
DeepSpeed 統合を含む PR を送信する場合は、CircleCI PR CI セットアップには GPU がないことに注意してください。そのため、GPU を必要とするテストは別の CI で毎晩のみ実行されます。したがって、PR で緑色の CI レポートが表示されても、DeepSpeed テストが合格したことを意味するわけではありません。
DeepSpeed テストを実行するには、少なくとも以下を実行してください。
```
RUN_SLOW=1 pytest tests/deepspeed/test_deepspeed.py
```
モデリングまたは pytorch サンプル コードのいずれかを変更した場合は、Model Zoo テストも実行します。以下はすべての DeepSpeed テストを実行します。
```
RUN_SLOW=1 pytest tests/deepspeed
```
## Main DeepSpeed Resources
- [プロジェクトの github](https://github.com/microsoft/deepspeed)
- [使用方法ドキュメント](https://www.deepspeed.ai/getting-started/)
- [API ドキュメント](https://deepspeed.readthedocs.io/en/latest/index.html)
- [ブログ投稿](https://www.microsoft.com/en-us/research/search/?q=deepspeed)
論文:
- [ZeRO: 兆パラメータ モデルのトレーニングに向けたメモリの最適化](https://arxiv.org/abs/1910.02054)
- [ZeRO-Offload: 10 億規模のモデル トレーニングの民主化](https://arxiv.org/abs/2101.06840)
- [ZeRO-Infinity: 極限スケールの深層学習のための GPU メモリの壁を打ち破る](https://arxiv.org/abs/2104.07857)
最後に、HuggingFace [`Trainer`] は DeepSpeed のみを統合していることを覚えておいてください。
DeepSpeed の使用に関して問題や質問がある場合は、[DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues) に問題を提出してください。
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.