
✨ Klear-Reasoner-8B
We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. We investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens.
| Resource | Link |
|---|---|
| 📝 Preprints | Paper |
| 🤗 Daily Paper | Paper |
| 🤗 Model Hub | Klear-Reasoner-8B |
| 🤗 Dataset Hub | Math RL |
| 🤗 Dataset Hub | Code RL |
| 🐛 Issues & Discussions | GitHub Issues |
| 📧 Contact | [email protected] |
📌 Overview
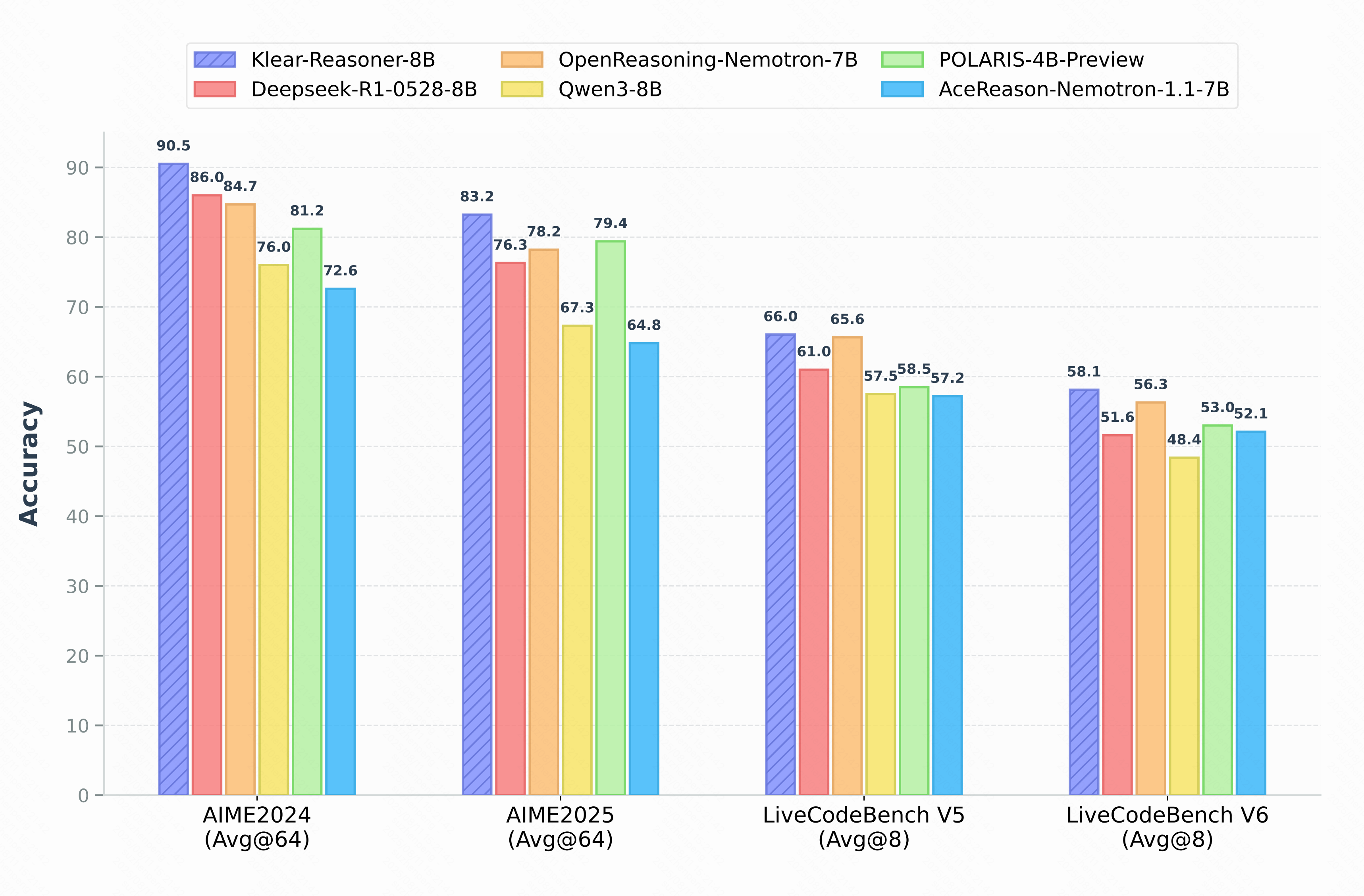
Benchmark accuracy of Klear-Reasoner-8B on AIME 2024/2025 (avg@64), LiveCodeBench V5 (2024/08/01-2025/02/01, avg@8), and v6 (2025/02/01-2025/05/01, avg@8).
Klear-Reasoner is an 8-billion-parameter reasoning model that achieves SOTA performance on challenging math and coding benchmarks:
| Benchmark | AIME 2024 | AIME 2025 | LiveCodeBench V5 | LiveCodeBench V6 |
|---|---|---|---|---|
| Score | 90.5 % | 83.2 % | 66.0 % | 58.1 % |
The model combines:
- Quality-centric long CoT SFT – distilled from DeepSeek-R1-0528.
- Gradient-Preserving Clipping Policy Optimization (GPPO) – a novel RL method that keeps gradients from clipped tokens to boost exploration & convergence.
Evaluation
When we expand the inference budget to 64K and adopt the YaRN method with a scaling factor of 2.5. Evaluation is coming soon, stay tuned.
📊 Benchmark Results (Pass@1)
| Model | AIME2024 avg@64 |
AIME2025 avg@64 |
HMMT2025 avg@64 |
LCB V5 avg@8 |
LCB V6 avg@8 |
|---|---|---|---|---|---|
| AReal-boba-RL-7B | 61.9 | 48.3 | 29.4 | 34.3 | 31.0† |
| MiMo-7B-RL | 68.2 | 55.4 | 35.7 | 57.8 | 49.3 |
| Skywork-OR1-7B | 70.2 | 54.6 | 35.7 | 47.6 | 42.7 |
| AceReason-Nemotron-1.1-7B | 72.6 | 64.8 | 42.9 | 57.2 | 52.1 |
| POLARIS-4B-Preview | 81.2 | 79.4 | 58.7 | 58.5† | 53.0† |
| Qwen3-8B | 76.0 | 67.3 | 44.7† | 57.5 | 48.4† |
| Deepseek-R1-0528-Distill-8B | 86.0 | 76.3 | 61.5 | 61.0† | 51.6† |
| OpenReasoning-Nemotron-7B | 84.7 | 78.2 | 63.5 | _65.6_† | _56.3_† |
| Klear-Reasoner-8B-SFT | 75.6 | 70.1 | 57.6 | 58.5 | 49.6 |
| Klear-Reasoner-8B | 83.2 | 75.6 | 60.3 | 61.6 | 53.1 |
| w/ 64K Inference Budget | 90.5 | 83.2 | 70.8 | 66.0 | 58.1 |
We report the average
pass@1results (avg@n), with all other evaluation metrics following the DeepSeek-R1 assessment framework (temperature=0.6, top_p=0.95).
🧪 Training
Configure the experimental environment
git clone https://github.com/suu990901/Klear_Reasoner
cd Klear_Reasoner
pip install -r requirements.txt
For the code, we use Firejail for the sandbox environment. Additionally, we implemented multi-process control based on Pebble, enabling automatic resource reclamation upon task timeout. For mathematics, we use math_verify for judging.
Using Ray for Multi-Node Training
For multi-node training, ensure all nodes are started and connected via Ray before executing the training script. Below is a brief setup guide for Ray across multiple machines:
Step 1: Start Ray on the Head Node (node0)
On the first node (typically called node0), run:
ray start --head --dashboard-host=0.0.0.0
Get the IP address of the master node.
MASTER_IP=$(hostname -I | awk '{print $1}')
Step 2: Connect Other Nodes (e.g., node1)
On each additional worker node (e.g., node1), run the following, replacing the IP with that of your head node:
ray start --address=\"$MASTER_IP:6379\"
RL Training
Run the following script on the master node to start the training task.
bash recipe/dapo/perf_run_dapo_ours_math.sh # For Math RL
bash recipe/dapo/perf_run_dapo_ours_code.sh # For Code RL
In the startup script, you need to set the following variables:
YOUR_MODEL_PATH="<your_model_path>"
CKPTS_SAVE_DIR="<ckpts_save_path>"
YOUR_TRAIN_FILE="<train_data_path>"
YOUR_TEST_FILE="<test_data_path>"
Evaluation
When we expand the inference budget to 64K and adopt the YaRN method with a scaling factor of 2.5.
The evaluation data for AIME24, AIME25, and HMMT2025 are available in our GitHub repository under the benchmarks directory. For LiveCodeBench, please download the data from the official website.
You can run the following commands to perform inference and evaluation:
git clone https://github.com/suu990901/KlearReasoner
cd KlearReasoner/benchmarks
python inference.py --model <KlearReasoner-8B_path> --n 64 --dataset_path ./benchmarks/aime24.qs.jsonl
python judge_math.py <path_to_inference_results>
🤝 Citation
If you find this work helpful, please cite our paper:
@misc{su2025klearreasoneradvancingreasoningcapability,
title={Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization},
author={Zhenpeng Su and Leiyu Pan and Xue Bai and Dening Liu and Guanting Dong and Jiaming Huang and Wenping Hu and Fuzheng Zhang and Kun Gai and Guorui Zhou},
year={2025},
eprint={2508.07629},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07629},
}
- Downloads last month
- 74