
File size: 15,444 Bytes
2fb7768 a78e5f2 2fb7768 a78e5f2 2fb7768 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 |
---
base_model:
- zai-org/GLM-4.5-Air-Base
language:
- zh
- en
library_name: transformers
license: mit
pipeline_tag: image-text-to-text
---
# GLM-4.5V
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-V/refs/heads/main/resources/logo.svg width="40%"/>
</div>
This model is part of the GLM-V family of models, introduced in the paper [GLM-4.1V-Thinking and GLM-4.5V: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning](https://huggingface.co/papers/2507.01006).
- **Paper**: [https://huggingface.co/papers/2507.01006](https://huggingface.co/papers/2507.01006)
- **GitHub Repository**: [https://github.com/zai-org/GLM-V/](https://github.com/zai-org/GLM-V/)
- **Online Demo**: [https://chat.z.ai/](https://chat.z.ai/)
- **API Access**: [ZhipuAI Open Platform](https://docs.z.ai/guides/vlm/glm-4.5v)
- **Desktop Assistant App**: [https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App)
- **Discord Community**: [https://discord.com/invite/8cnQKdAprg](https://discord.com/invite/8cnQKdAprg)
## Introduction & Model Overview
Vision-language models (VLMs) have become a key cornerstone of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs urgently need to enhance reasoning capabilities beyond basic multimodal perception — improving accuracy, comprehensiveness, and intelligence — to enable complex problem solving, long-context understanding, and multimodal agents.
Through our open-source work, we aim to explore the technological frontier together with the community while empowering more developers to create exciting and innovative applications.
**This Hugging Face repository hosts the `GLM-4.5V` model, part of the `GLM-V` series.**
### GLM-4.5V
GLM-4.5V is based on ZhipuAI’s next-generation flagship text foundation model GLM-4.5-Air (106B parameters, 12B active). It continues the technical approach of GLM-4.1V-Thinking, achieving SOTA performance among models of the same scale on 42 public vision-language benchmarks. It covers common tasks such as image, video, and document understanding, as well as GUI agent operations.

Beyond benchmark performance, GLM-4.5V focuses on real-world usability. Through efficient hybrid training, it can handle diverse types of visual content, enabling full-spectrum vision reasoning, including:
- **Image reasoning** (scene understanding, complex multi-image analysis, spatial recognition)
- **Video understanding** (long video segmentation and event recognition)
- **GUI tasks** (screen reading, icon recognition, desktop operation assistance)
- **Complex chart & long document parsing** (research report analysis, information extraction)
- **Grounding** (precise visual element localization)
The model also introduces a **Thinking Mode** switch, allowing users to balance between quick responses and deep reasoning. This switch works the same as in the `GLM-4.5` language model.
### GLM-4.1V-9B
*Contextual information about GLM-4.1V-9B is provided for completeness, as it is part of the GLM-V series and foundational to GLM-4.5V's development.*
Built on the [GLM-4-9B-0414](https://github.com/zai-org/GLM-4) foundation model, the **GLM-4.1V-9B-Thinking** model introduces a reasoning paradigm and uses RLCS (Reinforcement Learning with Curriculum Sampling) to comprehensively enhance model capabilities. It achieves the strongest performance among 10B-level VLMs and matches or surpasses the much larger Qwen-2.5-VL-72B in 18 benchmark tasks.
We also open-sourced the base model **GLM-4.1V-9B-Base** to support researchers in exploring the limits of vision-language model capabilities.
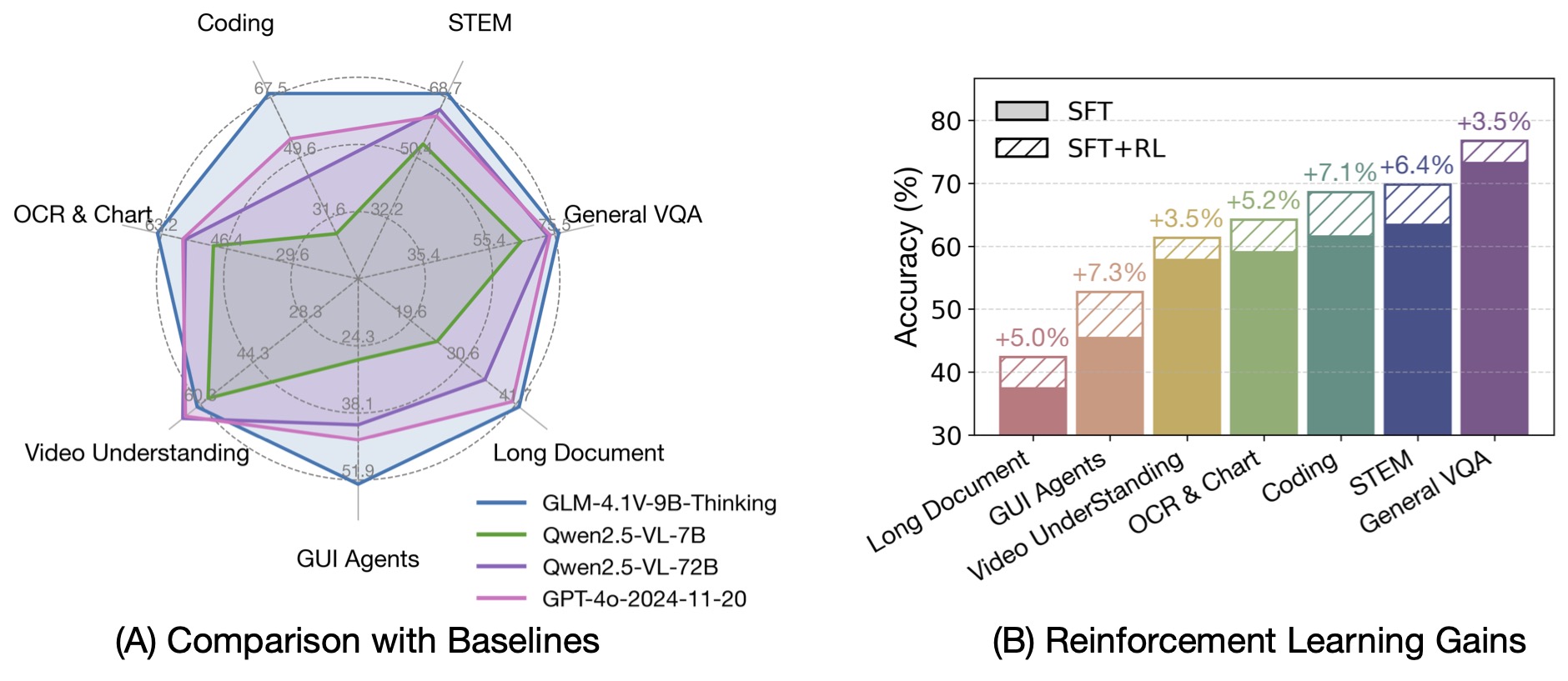
Compared with the previous generation CogVLM2 and GLM-4V series, **GLM-4.1V-Thinking** brings:
1. The series’ first reasoning-focused model, excelling in multiple domains beyond mathematics.
2. **64k** context length support.
3. Support for **any aspect ratio** and up to **4k** image resolution.
4. A bilingual (Chinese/English) open-source version.
GLM-4.1V-9B-Thinking integrates the **Chain-of-Thought** reasoning mechanism, improving accuracy, richness, and interpretability. It leads on 23 out of 28 benchmark tasks at the 10B parameter scale, and outperforms Qwen-2.5-VL-72B on 18 tasks despite its smaller size.

## Project Updates
- 🔥 **News**: `2025/08/11`: We released **GLM-4.5V** with significant improvements across multiple benchmarks. We also open-sourced our handcrafted **desktop assistant app** for debugging. Once connected to GLM-4.5V, it can capture visual information from your PC screen via screenshots or screen recordings. Feel free to try it out or customize it into your own multimodal assistant. Click [here](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App) to download the installer or [build from source](https://github.com/zai-org/GLM-V/blob/main/examples/vllm-chat-helper/README.md)!
- **News**: `2025/07/16`: We have open-sourced the **VLM Reward System** used to train GLM-4.1V-Thinking. View the [code repository](https://github.com/zai-org/GLM-V/tree/main/glmv_reward) and run locally: `python examples/reward_system_demo.py`.
- **News**: `2025/07/01`: We released **GLM-4.1V-9B-Thinking** and its [technical report](https://arxiv.org/abs/2507.01006).
## Model Implementation Code
* GLM-4.5V model algorithm: see the full implementation in [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v_moe).
* GLM-4.1V-9B-Thinking model algorithm: see the full implementation in [transformers](https://github.com/huggingface/transformers/tree/main/src/transformers/models/glm4v).
* Both models share identical multimodal preprocessing, but use different conversation templates — please distinguish carefully.
## Usage
### Environment Installation
For `SGLang` and `transformers`:
```bash
pip install -r https://raw.githubusercontent.com/zai-org/GLM-V/main/requirements.txt
```
For `vLLM`:
```bash
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install transformers-v4.55.0-GLM-4.5V-preview
```
### Quick Start with Transformers
```python
from transformers import AutoProcessor, Glm4vMoeForConditionalGeneration
import torch
MODEL_PATH = "zai-org/GLM-4.5V"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = Glm4vMoeForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
inputs.pop("token_type_ids", None)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
```
The special tokens `<|begin_of_box|>` and `<|end_of_box|>` in the response mark the answer’s bounding box in the image. The bounding box is given as four numbers — for example `[x1, y1, x2, y2]`, where `(x1, y1)` is the top-left corner and `(x2, y2`)` is the bottom-right corner. The bracket style may vary ([], [[]], (), <>, etc.), but the meaning is the same: it encloses the coordinates of the box. These coordinates are relative values between 0 and 1000, normalized to the image size.
For more code information, please visit our [GitHub](https://github.com/zai-org/GLM-V/).
### Grounding Example
GLM-4.5V equips precise grounding capabilities. Given a prompt that requests the location of a specific object, GLM-4.5V is able to reasoning step-by-step and identify the bounding boxes of the target object. The query prompt supports complex descriptions of the target object as well as specified output formats, for example:
> - Help me to locate <expr> in the image and give me its bounding boxes.
> - Please pinpoint the bounding box [[x1,y1,x2,y2], …] in the image as per the given description. <expr>
Here, `<expr>` is the description of the target object. The output bounding box is a quadruple $$[x_1,y_1,x_2,y_2]$$ composed of the coordinates of the top-left and bottom-right corners, where each value is normalized by the image width (for x) or height (for y) and scaled by 1000.
In the response, the special tokens `<|begin_of_box|>` and `<|end_of_box|>` are used to mark the image bounding box in the answer. The bracket style may vary ([], [[]], (), <>, etc.), but the meaning is the same: to enclose the coordinates of the box.
### GUI Agent Example
- `examples/gui-agent`: Demonstrates prompt construction and output handling for GUI Agents, including strategies for mobile, PC, and web. Prompt templates differ between GLM-4.1V and GLM-4.5V.
### Quick Demo Application
- `examples/vlm-helper`: A desktop assistant for GLM multimodal models (mainly GLM-4.5V, compatible with GLM-4.1V), supporting text, images, videos, PDFs, PPTs, and more. Connects to the GLM multimodal API for intelligent services across scenarios. Download the [installer](https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App) or [build from source](https://github.com/zai-org/GLM-V/blob/main/examples/vlm-helper/README.md).
### vLLM
```bash
vllm serve zai-org/GLM-4.5V \
--tensor-parallel-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5v \
--allowed-local-media-path / \
--media-io-kwargs '{"video": {"num_frames": -1}}'
```
### SGLang
```shell
python3 -m sglang.launch_server --model-path zai-org/GLM-4.5V \
--tp-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--served-model-name glm-4.5v \
--port 8000 \
--host 0.0.0.0
```
Notes:
- We recommend using the `FA3` attention backend in SGLang for higher inference performance and lower memory usage:
`--attention-backend fa3 --mm-attention-backend fa3 --enable-torch-compile`
Without `FA3`, large video inference may cause out-of-memory (OOM) errors.
We also recommend increasing `SGLANG_VLM_CACHE_SIZE_MB` (e.g., `1024`) to provide sufficient cache space for video understanding.
- When using `vLLM` and `SGLang`, thinking mode is enabled by default. To disable the thinking switch, add:
`extra_body={"chat_template_kwargs": {"enable_thinking": False}}`
## Model Fine-tuning
[LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory) already supports fine-tuning for GLM-4.5V & GLM-4.1V-9B-Thinking models. Below is an example of dataset construction using two images. You should organize your dataset into `finetune.json` in the following format, This is an example for fine-tuning GLM-4.1V-9B.
```json
[
{
"messages": [
{
"content": "<image>Who are they?",
"role": "user"
},
{
"content": "<think>
User asked me to observe the image and find the answer. I know they are Kane and Goretzka from Bayern Munich.</think>
<answer>They're Kane and Goretzka from Bayern Munich.</answer>",
"role": "assistant"
},
{
"content": "<image>What are they doing?",
"role": "user"
},
{
"content": "<think>
I need to observe what these people are doing. Oh, they are celebrating on the soccer field.</think>
<answer>They are celebrating on the soccer field.</answer>",
"role": "assistant"
}
],
"images": [
"mllm_demo_data/1.jpg",
"mllm_demo_data/2.jpg"
]
}
]
```
1. The content inside `<think> ... </think>` will **not** be stored as conversation history or in fine-tuning data.
2. The `<image>` tag will be replaced with the corresponding image information.
3. For the GLM-4.5V model, the <answer> and </answer> tags should be removed.
Then, you can fine-tune following the standard LLaMA-Factory procedure.
## Fixed and Remaining Issues
Since the release of GLM-4.1V, we have addressed many community-reported issues. In GLM-4.5V, common issues such as repetitive thinking and incorrect output formatting are alleviated. However, some limitations remain:
1. In frontend code reproduction cases, the model may output raw HTML without proper markdown wrapping. There may also be character escaping issues, potentially causing rendering errors. We provide a [patch](https://github.com/zai-org/GLM-V/blob/main/inference/html_detector.py) to fix most cases.
2. Pure text Q&A capabilities still have room for improvement, as this release focused primarily on multimodal scenarios.
3. In some cases, the model may overthink or repeat content, especially for complex prompts.
4. Occasionally, the model may restate the answer at the end.
5. There are some perception issues, with room for improvement in tasks such as counting and identifying specific individuals.
We welcome feedback in the issue section and will address problems as quickly as possible.
## Citation
If you use this model, please cite the following paper:
```bibtex
@misc{vteam2025glm45vglm41vthinkingversatilemultimodal,
title={GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning},
author={V Team and Wenyi Hong and Wenmeng Yu and Xiaotao Gu and Guo Wang and Guobing Gan and Haomiao Tang and Jiale Cheng and Ji Qi and Junhui Ji and Lihang Pan and Shuaiqi Duan and Weihan Wang and Yan Wang and Yean Cheng and Zehai He and Zhe Su and Zhen Yang and Ziyang Pan and Aohan Zeng and Baoxu Wang and Bin Chen and Boyan Shi and Changyu Pang and Chenhui Zhang and Da Yin and Fan Yang and Guoqing Chen and Jiazheng Xu and Jiale Zhu and Jiali Chen and Jing Chen and Jinhao Chen and Jinghao Lin and Jinjiang Wang and Junjie Chen and Leqi Lei and Letian Gong and Leyi Pan and Mingdao Liu and Mingde Xu and Mingzhi Zhang and Qinkai Zheng and Sheng Yang and Shi Zhong and Shiyu Huang and Shuyuan Zhao and Siyan Xue and Shangqin Tu and Shengbiao Meng and Tianshu Zhang and Tianwei Luo and Tianxiang Hao and Tianyu Tong and Wenkai Li and Wei Jia and Xiao Liu and Xiaohan Zhang and Xin Lyu and Xinyue Fan and Xuancheng Huang and Yanling Wang and Yadong Xue and Yanfeng Wang and Yanzi Wang and Yifan An and Yifan Du and Yiming Shi and Yiheng Huang and Yilin Niu and Yuan Wang and Yuanchang Yue and Yuchen Li and Yutao Zhang and Yuting Wang and Yu Wang and Yuxuan Zhang and Zhao Xue and Zhenyu Hou and Zhengxiao Du and Zihan Wang and Peng Zhang and Debing Liu and Bin Xu and Juanzi Li and Minlie Huang and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2507.01006},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01006},
}
``` |