

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,15 +1,23 @@
|
|
| 1 |
-
---
|
| 2 |
-
base_model: scb10x/typhoon2.1-gemma3-12b
|
| 3 |
-
license: gemma
|
| 4 |
-
pipeline_tag: text-generation
|
| 5 |
-
tags:
|
| 6 |
-
- llama-cpp
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
## Use with llama.cpp
|
| 15 |
Install llama.cpp through brew (works on Mac and Linux)
|
|
@@ -22,12 +30,12 @@ Invoke the llama.cpp server or the CLI.
|
|
| 22 |
|
| 23 |
### CLI:
|
| 24 |
```bash
|
| 25 |
-
llama-cli --hf-repo
|
| 26 |
```
|
| 27 |
|
| 28 |
### Server:
|
| 29 |
```bash
|
| 30 |
-
llama-server --hf-repo
|
| 31 |
```
|
| 32 |
|
| 33 |
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
|
|
@@ -44,9 +52,9 @@ cd llama.cpp && LLAMA_CURL=1 make
|
|
| 44 |
|
| 45 |
Step 3: Run inference through the main binary.
|
| 46 |
```
|
| 47 |
-
./llama-cli --hf-repo
|
| 48 |
```
|
| 49 |
or
|
| 50 |
```
|
| 51 |
-
./llama-server --hf-repo
|
| 52 |
-
```
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: scb10x/typhoon2.1-gemma3-12b
|
| 3 |
+
license: gemma
|
| 4 |
+
pipeline_tag: text-generation
|
| 5 |
+
tags:
|
| 6 |
+
- llama-cpp
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
**Typhoon2.1-Gemma3-12B**: Thai Large Language Model (Instruct)
|
| 10 |
+
|
| 11 |
+
**Typhoon2.1-Gemma3-12B** is a instruct Thai 🇹🇭 large language model with 12 billion parameters, a 128K context length, and function-calling capabilities. It is based on Gemma3 12B.
|
| 12 |
+
|
| 13 |
+
This repo contains gguf q4_k_m quantization of the original [Typhoon2.1 12B](https://huggingface.co/scb10x/typhoon2.1-gemma3-12b).
|
| 14 |
+
|
| 15 |
+
Remark: This is text only model.
|
| 16 |
+
|
| 17 |
+
## **Performance**
|
| 18 |
+
|
| 19 |
+
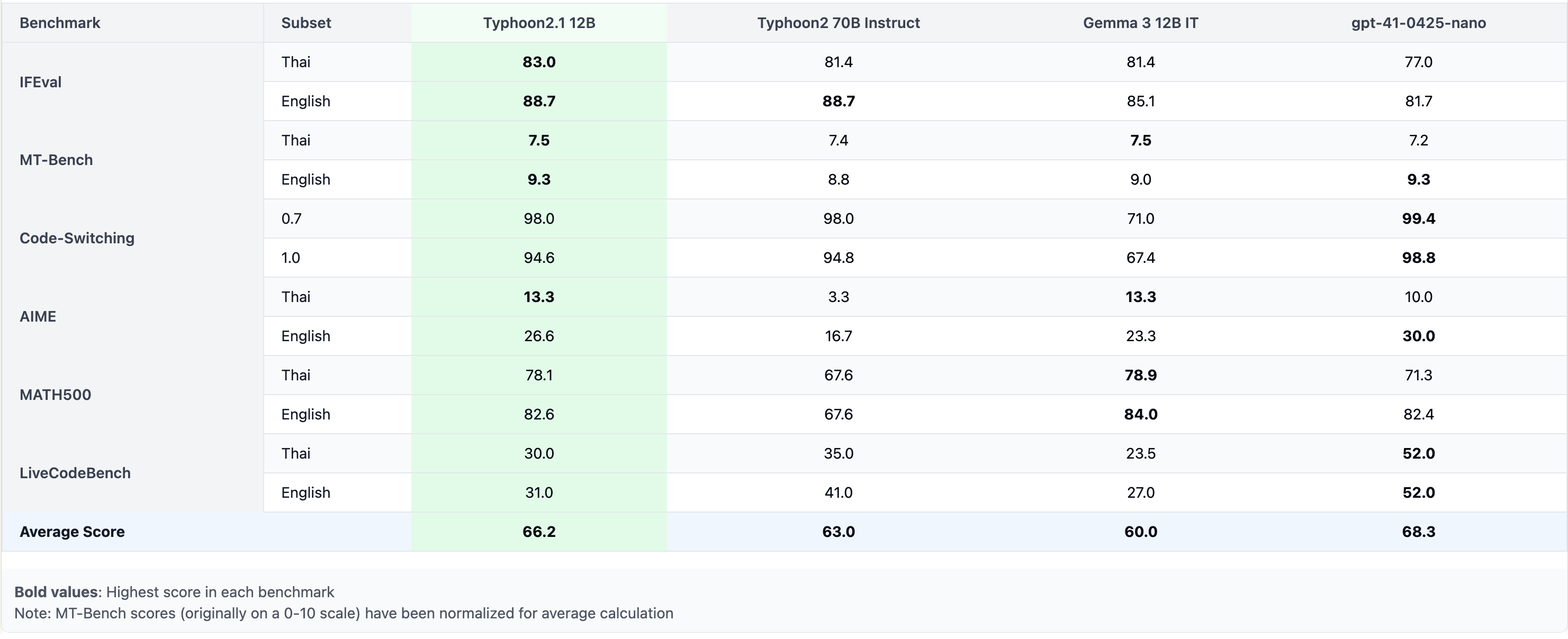
|
| 20 |
+
|
| 21 |
|
| 22 |
## Use with llama.cpp
|
| 23 |
Install llama.cpp through brew (works on Mac and Linux)
|
|
|
|
| 30 |
|
| 31 |
### CLI:
|
| 32 |
```bash
|
| 33 |
+
llama-cli --hf-repo scb10x/typhoon2.1-gemma3-12b-gguf --hf-file typhoon2.1-gemma3-12b-q4_k_m.gguf -p "The meaning to life and the universe is"
|
| 34 |
```
|
| 35 |
|
| 36 |
### Server:
|
| 37 |
```bash
|
| 38 |
+
llama-server --hf-repo scb10x/typhoon2.1-gemma3-12b-gguf --hf-file typhoon2.1-gemma3-12b-q4_k_m.gguf -c 2048
|
| 39 |
```
|
| 40 |
|
| 41 |
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
|
|
|
|
| 52 |
|
| 53 |
Step 3: Run inference through the main binary.
|
| 54 |
```
|
| 55 |
+
./llama-cli --hf-repo scb10x/typhoon2.1-gemma3-12b-gguf --hf-file typhoon2.1-gemma3-12b-q4_k_m.gguf -p "The meaning to life and the universe is"
|
| 56 |
```
|
| 57 |
or
|
| 58 |
```
|
| 59 |
+
./llama-server --hf-repo scb10x/typhoon2.1-gemma3-12b-gguf --hf-file typhoon2.1-gemma3-12b-q4_k_m.gguf -c 2048
|
| 60 |
+
```
|