---
license: cc-by-4.0
track_downloads: true
datasets:
- nvidia/Granary
- nvidia/nemo-asr-set-3.0
language:
- bg
- hr
- cs
- da
- nl
- en
- et
- fi
- fr
- de
- el
- hu
- it
- lv
- lt
- mt
- pl
- pt
- ro
- sk
- sl
- es
- sv
- ru
- uk
metrics:
- bleu
- wer
- comet
pipeline_tag: automatic-speech-recognition
library_name: nemo
tags:
- automatic-speech-recognition
- automatic-speech-translation
- speech
- audio
- Transformer
- FastConformer
- Conformer
- pytorch
- NeMo
- hf-asr-leaderboard
model-index:
- name: canary-1b-v2
results:
# FLEURS ASR Results
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: bg_bg
split: test
args:
language: bg
metrics:
- name: Test WER (Bg)
type: wer
value: 9.25
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: cs_cz
split: test
args:
language: cs
metrics:
- name: Test WER (Cs)
type: wer
value: 7.86
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: da_dk
split: test
args:
language: da
metrics:
- name: Test WER (Da)
type: wer
value: 11.25
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: de_de
split: test
args:
language: de
metrics:
- name: Test WER (De)
type: wer
value: 4.40
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: el_gr
split: test
args:
language: el
metrics:
- name: Test WER (El)
type: wer
value: 9.21
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en
metrics:
- name: Test WER (En)
type: wer
value: 4.50
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: es_419
split: test
args:
language: es
metrics:
- name: Test WER (Es)
type: wer
value: 2.90
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: et_ee
split: test
args:
language: et
metrics:
- name: Test WER (Et)
type: wer
value: 12.55
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: fi_fi
split: test
args:
language: fi
metrics:
- name: Test WER (Fi)
type: wer
value: 8.59
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: fr_fr
split: test
args:
language: fr
metrics:
- name: Test WER (Fr)
type: wer
value: 5.02
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: hr_hr
split: test
args:
language: hr
metrics:
- name: Test WER (Hr)
type: wer
value: 8.29
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: hu_hu
split: test
args:
language: hu
metrics:
- name: Test WER (Hu)
type: wer
value: 12.90
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: it_it
split: test
args:
language: it
metrics:
- name: Test WER (It)
type: wer
value: 3.07
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: lt_lt
split: test
args:
language: lt
metrics:
- name: Test WER (Lt)
type: wer
value: 12.36
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: lv_lv
split: test
args:
language: lv
metrics:
- name: Test WER (Lv)
type: wer
value: 9.66
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: mt_mt
split: test
args:
language: mt
metrics:
- name: Test WER (Mt)
type: wer
value: 18.31
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: nl_nl
split: test
args:
language: nl
metrics:
- name: Test WER (Nl)
type: wer
value: 6.12
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: pl_pl
split: test
args:
language: pl
metrics:
- name: Test WER (Pl)
type: wer
value: 6.64
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: pt_br
split: test
args:
language: pt
metrics:
- name: Test WER (Pt)
type: wer
value: 4.39
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: ro_ro
split: test
args:
language: ro
metrics:
- name: Test WER (Ro)
type: wer
value: 6.61
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: ru_ru
split: test
args:
language: ru
metrics:
- name: Test WER (Ru)
type: wer
value: 6.90
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: sk_sk
split: test
args:
language: sk
metrics:
- name: Test WER (Sk)
type: wer
value: 5.74
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: sl_si
split: test
args:
language: sl
metrics:
- name: Test WER (Sl)
type: wer
value: 13.32
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: sv_se
split: test
args:
language: sv
metrics:
- name: Test WER (Sv)
type: wer
value: 9.57
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: uk_ua
split: test
args:
language: uk
metrics:
- name: Test WER (Uk)
type: wer
value: 10.50
# Multilingual LibriSpeech ASR Results
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: spanish
split: test
args:
language: es
metrics:
- name: Test WER (Es)
type: wer
value: 2.94
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: french
split: test
args:
language: fr
metrics:
- name: Test WER (Fr)
type: wer
value: 3.36
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: italian
split: test
args:
language: it
metrics:
- name: Test WER (It)
type: wer
value: 9.16
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: dutch
split: test
args:
language: nl
metrics:
- name: Test WER (Nl)
type: wer
value: 11.27
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: polish
split: test
args:
language: pl
metrics:
- name: Test WER (Pl)
type: wer
value: 8.77
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: portuguese
split: test
args:
language: pt
metrics:
- name: Test WER (Pt)
type: wer
value: 8.14
# CoVoST2 ASR Results
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: de
split: test
args:
language: de
metrics:
- name: Test WER (De)
type: wer
value: 5.53
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: en
split: test
args:
language: en
metrics:
- name: Test WER (En)
type: wer
value: 6.85
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: es
split: test
args:
language: es
metrics:
- name: Test WER (Es)
type: wer
value: 3.81
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: et
split: test
args:
language: et
metrics:
- name: Test WER (Et)
type: wer
value: 18.28
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: fr
split: test
args:
language: fr
metrics:
- name: Test WER (Fr)
type: wer
value: 6.30
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: it
split: test
args:
language: it
metrics:
- name: Test WER (It)
type: wer
value: 4.80
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: lv
split: test
args:
language: lv
metrics:
- name: Test WER (Lv)
type: wer
value: 11.49
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: nl
split: test
args:
language: nl
metrics:
- name: Test WER (Nl)
type: wer
value: 6.93
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: pt
split: test
args:
language: pt
metrics:
- name: Test WER (Pt)
type: wer
value: 6.87
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: ru
split: test
args:
language: ru
metrics:
- name: Test WER (Ru)
type: wer
value: 5.14
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: sl
split: test
args:
language: sl
metrics:
- name: Test WER (Sl)
type: wer
value: 7.59
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: sv
split: test
args:
language: sv
metrics:
- name: Test WER (Sv)
type: wer
value: 13.32
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: CoVoST2
type: covost2
config: uk
split: test
args:
language: uk
metrics:
- name: Test WER (Uk)
type: wer
value: 18.15
# FLEURS Speech Translation Results (X->En)
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: bg_bg
split: test
args:
language: bg-en
metrics:
- name: Test BLEU (Bg->En)
type: bleu
value: 30.93
- name: Test COMET (Bg->En)
type: comet
value: 79.60
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: cs_cz
split: test
args:
language: cs-en
metrics:
- name: Test BLEU (Cs->En)
type: bleu
value: 29.28
- name: Test COMET (Cs->En)
type: comet
value: 78.64
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: da_dk
split: test
args:
language: da-en
metrics:
- name: Test BLEU (Da->En)
type: bleu
value: 34.80
- name: Test COMET (Da->En)
type: comet
value: 80.45
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: de_de
split: test
args:
language: de-en
metrics:
- name: Test BLEU (De->En)
type: bleu
value: 36.03
- name: Test COMET (De->En)
type: comet
value: 83.09
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: el_gr
split: test
args:
language: el-en
metrics:
- name: Test BLEU (El->En)
type: bleu
value: 24.08
- name: Test COMET (El->En)
type: comet
value: 76.73
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: es_419
split: test
args:
language: es-en
metrics:
- name: Test BLEU (Es->En)
type: bleu
value: 25.45
- name: Test COMET (Es->En)
type: comet
value: 81.19
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: et_ee
split: test
args:
language: et-en
metrics:
- name: Test BLEU (Et->En)
type: bleu
value: 28.38
- name: Test COMET (Et->En)
type: comet
value: 80.25
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: fi_fi
split: test
args:
language: fi-en
metrics:
- name: Test BLEU (Fi->En)
type: bleu
value: 24.68
- name: Test COMET (Fi->En)
type: comet
value: 80.81
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: fr_fr
split: test
args:
language: fr-en
metrics:
- name: Test BLEU (Fr->En)
type: bleu
value: 34.10
- name: Test COMET (Fr->En)
type: comet
value: 82.80
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: hr_hr
split: test
args:
language: hr-en
metrics:
- name: Test BLEU (Hr->En)
type: bleu
value: 29.09
- name: Test COMET (Hr->En)
type: comet
value: 78.48
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: hu_hu
split: test
args:
language: hu-en
metrics:
- name: Test BLEU (Hu->En)
type: bleu
value: 24.26
- name: Test COMET (Hu->En)
type: comet
value: 76.86
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: it_it
split: test
args:
language: it-en
metrics:
- name: Test BLEU (It->En)
type: bleu
value: 25.57
- name: Test COMET (It->En)
type: comet
value: 82.03
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: lt_lt
split: test
args:
language: lt-en
metrics:
- name: Test BLEU (Lt->En)
type: bleu
value: 22.86
- name: Test COMET (Lt->En)
type: comet
value: 76.30
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: lv_lv
split: test
args:
language: lv-en
metrics:
- name: Test BLEU (Lv->En)
type: bleu
value: 27.86
- name: Test COMET (Lv->En)
type: comet
value: 79.71
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: mt_mt
split: test
args:
language: mt-en
metrics:
- name: Test BLEU (Mt->En)
type: bleu
value: 34.99
- name: Test COMET (Mt->En)
type: comet
value: 70.00
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: nl_nl
split: test
args:
language: nl-en
metrics:
- name: Test BLEU (Nl->En)
type: bleu
value: 26.49
- name: Test COMET (Nl->En)
type: comet
value: 80.72
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: pl_pl
split: test
args:
language: pl-en
metrics:
- name: Test BLEU (Pl->En)
type: bleu
value: 22.30
- name: Test COMET (Pl->En)
type: comet
value: 77.05
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: pt_br
split: test
args:
language: pt-en
metrics:
- name: Test BLEU (Pt->En)
type: bleu
value: 39.43
- name: Test COMET (Pt->En)
type: comet
value: 82.91
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: ro_ro
split: test
args:
language: ro-en
metrics:
- name: Test BLEU (Ro->En)
type: bleu
value: 33.55
- name: Test COMET (Ro->En)
type: comet
value: 81.61
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: ru_ru
split: test
args:
language: ru-en
metrics:
- name: Test BLEU (Ru->En)
type: bleu
value: 27.26
- name: Test COMET (Ru->En)
type: comet
value: 79.17
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: sk_sk
split: test
args:
language: sk-en
metrics:
- name: Test BLEU (Sk->En)
type: bleu
value: 30.55
- name: Test COMET (Sk->En)
type: comet
value: 79.86
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: sl_si
split: test
args:
language: sl-en
metrics:
- name: Test BLEU (Sl->En)
type: bleu
value: 23.65
- name: Test COMET (Sl->En)
type: comet
value: 76.89
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: sv_se
split: test
args:
language: sv-en
metrics:
- name: Test BLEU (Sv->En)
type: bleu
value: 34.92
- name: Test COMET (Sv->En)
type: comet
value: 80.75
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: uk_ua
split: test
args:
language: uk-en
metrics:
- name: Test BLEU (Uk->En)
type: bleu
value: 27.50
- name: Test COMET (Uk->En)
type: comet
value: 77.23
# CoVoST2 Speech Translation Results (X->En)
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: de
split: test
args:
language: de-en
metrics:
- name: Test BLEU (De->En)
type: bleu
value: 39.22
- name: Test COMET (De->En)
type: comet
value: 78.32
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: es
split: test
args:
language: es-en
metrics:
- name: Test BLEU (Es->En)
type: bleu
value: 42.74
- name: Test COMET (Es->En)
type: comet
value: 80.82
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: et
split: test
args:
language: et-en
metrics:
- name: Test BLEU (Et->En)
type: bleu
value: 25.52
- name: Test COMET (Et->En)
type: comet
value: 75.78
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: fr
split: test
args:
language: fr-en
metrics:
- name: Test BLEU (Fr->En)
type: bleu
value: 41.43
- name: Test COMET (Fr->En)
type: comet
value: 78.52
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: it
split: test
args:
language: it-en
metrics:
- name: Test BLEU (It->En)
type: bleu
value: 40.03
- name: Test COMET (It->En)
type: comet
value: 79.45
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: lv
split: test
args:
language: lv-en
metrics:
- name: Test BLEU (Lv->En)
type: bleu
value: 31.77
- name: Test COMET (Lv->En)
type: comet
value: 70.91
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: nl
split: test
args:
language: nl-en
metrics:
- name: Test BLEU (Nl->En)
type: bleu
value: 41.59
- name: Test COMET (Nl->En)
type: comet
value: 78.46
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: pt
split: test
args:
language: pt-en
metrics:
- name: Test BLEU (Pt->En)
type: bleu
value: 50.38
- name: Test COMET (Pt->En)
type: comet
value: 78.26
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: ru
split: test
args:
language: ru-en
metrics:
- name: Test BLEU (Ru->En)
type: bleu
value: 48.78
- name: Test COMET (Ru->En)
type: comet
value: 83.31
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: sl
split: test
args:
language: sl-en
metrics:
- name: Test BLEU (Sl->En)
type: bleu
value: 39.43
- name: Test COMET (Sl->En)
type: comet
value: 74.72
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: sv
split: test
args:
language: sv-en
metrics:
- name: Test BLEU (Sv->En)
type: bleu
value: 44.40
- name: Test COMET (Sv->En)
type: comet
value: 73.71
# FLEURS Speech Translation Results (En->X)
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-bg
metrics:
- name: Test BLEU (En->Bg)
type: bleu
value: 38.14
- name: Test COMET (En->Bg)
type: comet
value: 87.73
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-cs
metrics:
- name: Test BLEU (En->Cs)
type: bleu
value: 27.69
- name: Test COMET (En->Cs)
type: comet
value: 86.26
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-da
metrics:
- name: Test BLEU (En->Da)
type: bleu
value: 41.78
- name: Test COMET (En->Da)
type: comet
value: 86.89
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-de
metrics:
- name: Test BLEU (En->De)
type: bleu
value: 33.65
- name: Test COMET (En->De)
type: comet
value: 83.30
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-el
metrics:
- name: Test BLEU (En->El)
type: bleu
value: 23.87
- name: Test COMET (En->El)
type: comet
value: 81.49
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-es
metrics:
- name: Test BLEU (En->Es)
type: bleu
value: 25.67
- name: Test COMET (En->Es)
type: comet
value: 82.13
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-et
metrics:
- name: Test BLEU (En->Et)
type: bleu
value: 23.54
- name: Test COMET (En->Et)
type: comet
value: 87.32
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-fi
metrics:
- name: Test BLEU (En->Fi)
type: bleu
value: 21.10
- name: Test COMET (En->Fi)
type: comet
value: 87.40
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-fr
metrics:
- name: Test BLEU (En->Fr)
type: bleu
value: 43.42
- name: Test COMET (En->Fr)
type: comet
value: 83.82
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-hr
metrics:
- name: Test BLEU (En->Hr)
type: bleu
value: 24.71
- name: Test COMET (En->Hr)
type: comet
value: 85.46
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-hu
metrics:
- name: Test BLEU (En->Hu)
type: bleu
value: 20.75
- name: Test COMET (En->Hu)
type: comet
value: 83.94
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-it
metrics:
- name: Test BLEU (En->It)
type: bleu
value: 26.82
- name: Test COMET (En->It)
type: comet
value: 84.12
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-lt
metrics:
- name: Test BLEU (En->Lt)
type: bleu
value: 21.60
- name: Test COMET (En->Lt)
type: comet
value: 85.13
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-lv
metrics:
- name: Test BLEU (En->Lv)
type: bleu
value: 29.33
- name: Test COMET (En->Lv)
type: comet
value: 86.52
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-mt
metrics:
- name: Test BLEU (En->Mt)
type: bleu
value: 31.61
- name: Test COMET (En->Mt)
type: comet
value: 69.02
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-nl
metrics:
- name: Test BLEU (En->Nl)
type: bleu
value: 25.81
- name: Test COMET (En->Nl)
type: comet
value: 84.25
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-pl
metrics:
- name: Test BLEU (En->Pl)
type: bleu
value: 17.98
- name: Test COMET (En->Pl)
type: comet
value: 83.82
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-pt
metrics:
- name: Test BLEU (En->Pt)
type: bleu
value: 44.75
- name: Test COMET (En->Pt)
type: comet
value: 85.56
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-ro
metrics:
- name: Test BLEU (En->Ro)
type: bleu
value: 36.27
- name: Test COMET (En->Ro)
type: comet
value: 87.00
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-ru
metrics:
- name: Test BLEU (En->Ru)
type: bleu
value: 27.21
- name: Test COMET (En->Ru)
type: comet
value: 84.87
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-sk
metrics:
- name: Test BLEU (En->Sk)
type: bleu
value: 28.43
- name: Test COMET (En->Sk)
type: comet
value: 86.21
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-sl
metrics:
- name: Test BLEU (En->Sl)
type: bleu
value: 24.96
- name: Test COMET (En->Sl)
type: comet
value: 84.96
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-sv
metrics:
- name: Test BLEU (En->Sv)
type: bleu
value: 40.73
- name: Test COMET (En->Sv)
type: comet
value: 86.43
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: FLEURS
type: google/fleurs
config: en_us
split: test
args:
language: en-uk
metrics:
- name: Test BLEU (En->Uk)
type: bleu
value: 25.72
- name: Test COMET (En->Uk)
type: comet
value: 85.74
# CoVoST2 Speech Translation Results (En->X)
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: en
split: test
args:
language: en-de
metrics:
- name: Test BLEU (En->De)
type: bleu
value: 33.82
- name: Test COMET (En->De)
type: comet
value: 78.37
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: en
split: test
args:
language: en-et
metrics:
- name: Test BLEU (En->Et)
type: bleu
value: 28.09
- name: Test COMET (En->Et)
type: comet
value: 80.61
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: en
split: test
args:
language: en-lv
metrics:
- name: Test BLEU (En->Lv)
type: bleu
value: 27.10
- name: Test COMET (En->Lv)
type: comet
value: 81.32
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: en
split: test
args:
language: en-sl
metrics:
- name: Test BLEU (En->Sl)
type: bleu
value: 31.18
- name: Test COMET (En->Sl)
type: comet
value: 80.02
- task:
type: Automatic Speech Translation
name: automatic-speech-translation
dataset:
name: CoVoST2
type: covost2
config: en
split: test
args:
language: en-sv
metrics:
- name: Test BLEU (En->Sv)
type: bleu
value: 41.49
- name: Test COMET (En->Sv)
type: comet
value: 81.12
---
## 🐤 Canary 1B v2: Multitask Speech Transcription and Translation Model
**``Canary-1b-v2``** is a powerful 1-billion parameter model built for high-quality speech transcription and translation across 25 European languages.
It excels at both automatic speech recognition (ASR) and speech translation (AST), supporting:
* **Speech Transcription (ASR) for 25 languages**
* **Speech Translation (AST) from English → 24 languages**
* **Speech Translation (AST) from 24 languages → English**
**Supported Languages:**
Bulgarian (**bg**), Croatian (**hr**), Czech (**cs**), Danish (**da**), Dutch (**nl**), English (**en**), Estonian (**et**), Finnish (**fi**), French (**fr**), German (**de**), Greek (**el**), Hungarian (**hu**), Italian (**it**), Latvian (**lv**), Lithuanian (**lt**), Maltese (**mt**), Polish (**pl**), Portuguese (**pt**), Romanian (**ro**), Slovak (**sk**), Slovenian (**sl**), Spanish (**es**), Swedish (**sv**), Russian (**ru**), Ukrainian (**uk**)
🗣️ **Experience `Canary-1b-v2` in action** at [Hugging Face Demo](https://huggingface.co/spaces/nvidia/canary-1b-v2)
`Canary-1b-v2` model is ready for commercial/non-commercial use.
## License/Terms of Use
GOVERNING TERMS: Use of this model is governed by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) license.
## Key Features
**`Canary-1b-v2`** is a scaled and enhanced version of the Canary model family, offering:
* Support for **25 European languages**, expanding from the **4 languages** in [canary-1b](https://huggingface.co/nvidia/canary-1b)/[canary-1b-flash](nvidia/canary-1b-flash) to **21 additional languages**
* **State-of-the-art performance** among models of similar size
* **Comparable quality to models 3× larger**, while being up to **10× faster**
* Automatic **punctuation** and **capitalization**
* Accurate **word-level** and **segment-level** timestamps
* Segment-level timestamps also available for **translated outputs**
* Released under a **permissive CC BY 4.0 license**
`Canary-1b-v2` model is the first model from NeMo team that leveraged full Nvidia's Granary dataset \[1] \[2], showcasing its multitask and multilingual capabilities.
For more information, refer to the [Model Architecture](#model-architecture) section and the [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#fast-conformer).
For a deeper glimpse to Canary family models, explore this comprehensive [NeMo tutorial on multitask speech models](https://github.com/NVIDIA/NeMo/blob/main/tutorials/asr/Canary_Multitask_Speech_Model.ipynb).
We will soon release a comprehensive **Canary-1b-v2 technical report** detailing the model architecture, training methodology, datasets, and evaluation results.
### Automatic Speech Recognition (ASR)
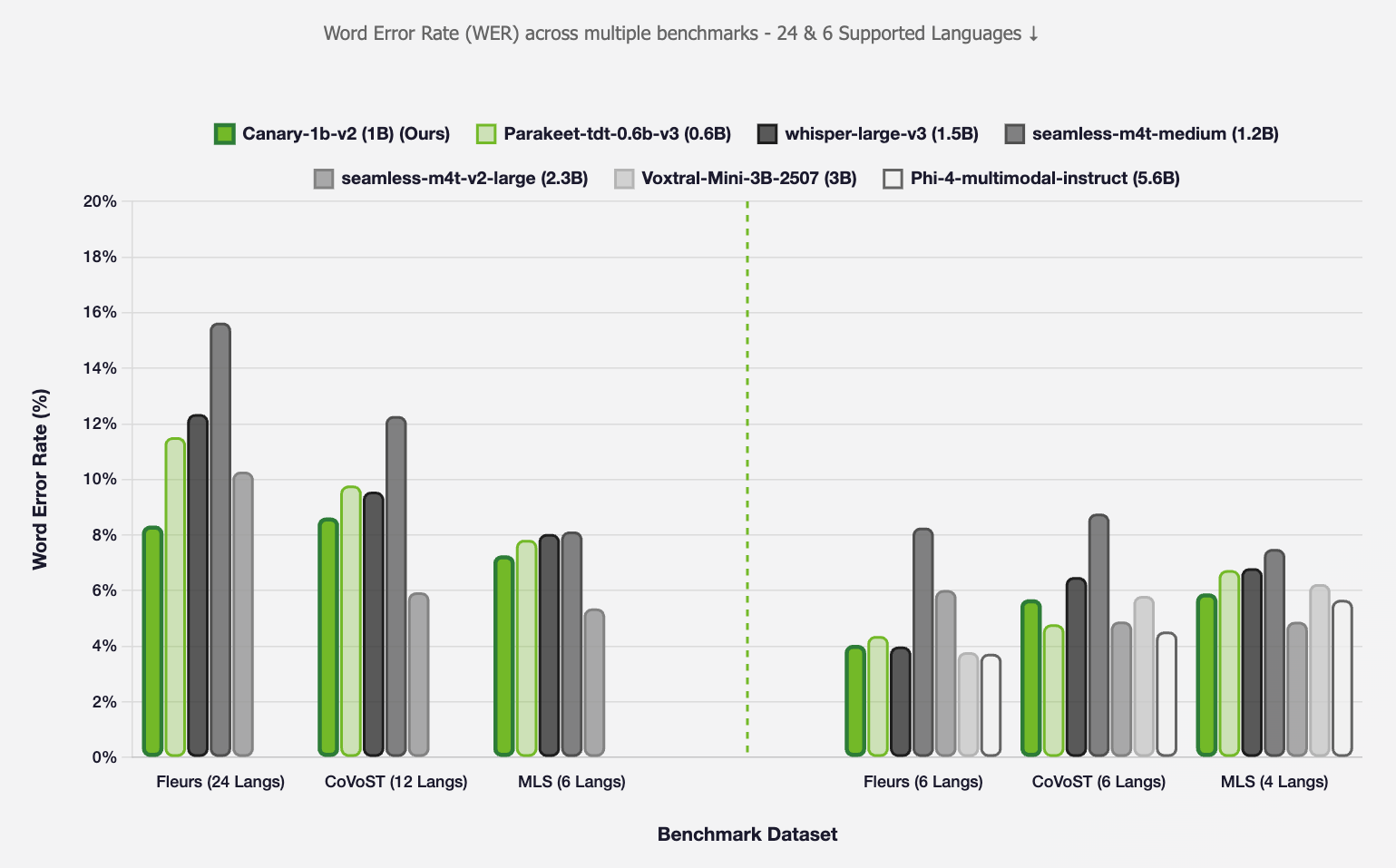
*Figure 1: ASR WER comparison across different models. This does not include Punctuation and Capitalisation errors.*
---
### Speech Translation (AST)
#### X → English
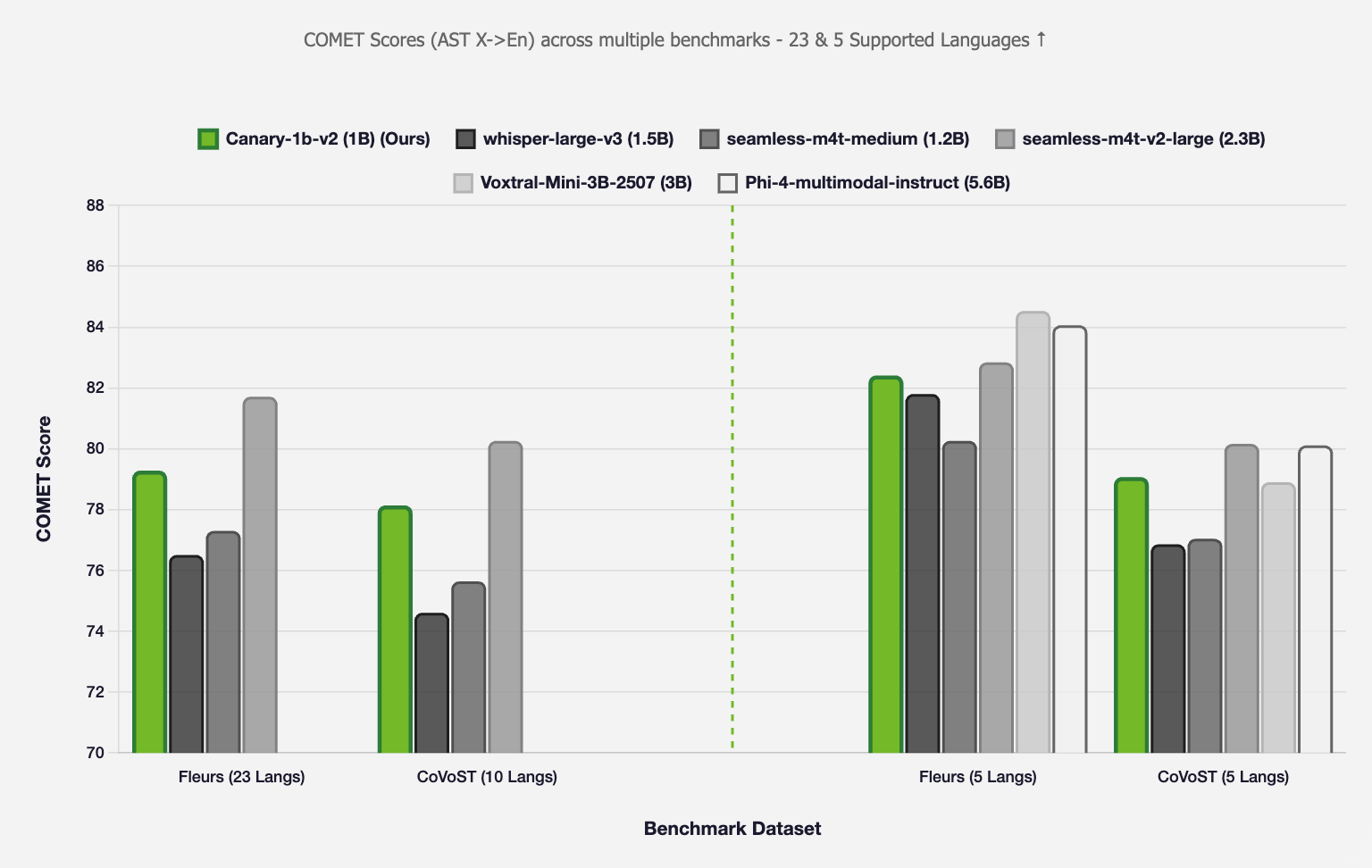
*Figure 2: AST X → En COMET scores comparison across different models*
#### English → X
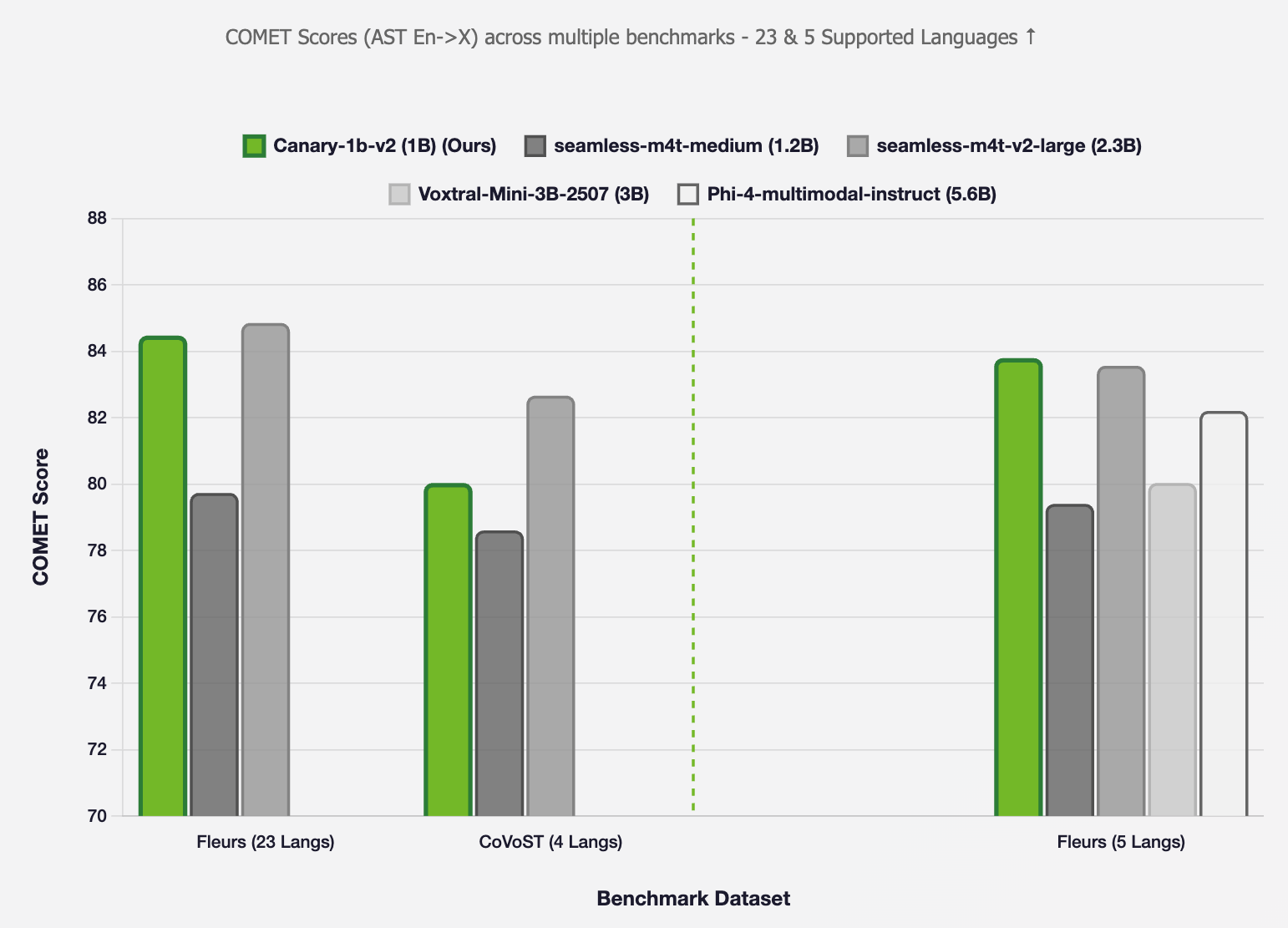
*Figure 3: AST En → X COMET scores comparison across different models*
---
### Evaluation Notes
**Note 1:** The above evaluations are conducted in two settings: (1) **All supported languages** (24 languages, excluding Latvian since `seamless-m4t-v2-large` and `seamless-m4t-medium` do not support it), and (2) **Common languages** (6 languages supported by all compared models: en, fr, de, it, pt, es).
**Note 2:** Performance differences may be partly attributed to Portuguese variant differences - our training data uses European Portuguese while most benchmarks use Brazilian Portuguese.
---
## Deployment Geography
Global
## Use case
This model serves developers, researchers, academics, and industries building applications that require speech-to-text capabilities, including but not limited to: conversational AI, voice assistants, transcription services, subtitle generation, and voice analytics platforms.
## Release Date
Huggingface [08/14/2025](https://huggingface.co/nvidia/canary-1b-v2)
## Model Architecture
`Canary-1b-v2` is an encoder-decoder architecture featuring a FastConformer Encoder \[3] and a Transformer Decoder \[4]. The model extracts audio features through the encoder and uses task-specific tokens—such as `` and ``—to guide the Transformer Decoder in generating text output.
It uses a unified SentencePiece Tokenizer \[5] with a vocabulary of **16,384 tokens**, optimized across all 25 supported languages. The architecture includes **32 encoder layers** and **8 decoder layers**, totaling **978 million parameters**.
For implementation details, see the [NeMo repository](https://github.com/NVIDIA/NeMo).
## Input
- **Input Type(s):** 16kHz Audio
- **Input Format(s):** `.wav` and `.flac` audio formats
- **Input Parameters:** 1D (audio signal)
- **Other Properties Related to Input:** Monochannel audio
## Output
- **Output Type(s):** Text
- **Output Format:** String
- **Output Parameters:** 1D (text)
- **Other Properties Related to Output:** Punctuation and Capitalization included.
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA's hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## How to Use This Model
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo) \[6]. We recommend you install it after you've installed latest PyTorch version.
```bash
pip install -U nemo_toolkit['asr']
```
The model is available for use in the NeMo toolkit [6], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
#### Automatically instantiate the model
```python
from nemo.collections.asr.models import ASRModel
asr_ast_model = ASRModel.from_pretrained(model_name="nvidia/canary-1b-v2")
```
#### Transcribing using Python
First, let's get a sample:
```bash
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```python
output = asr_ast_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='en')
print(output[0].text)
```
#### Translating using Python
Be sure to specify necessary `target_lang` for proper translation:
```python
output = asr_ast_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='fr')
print(output[0].text)
```
#### Transcribing with timestamps
> **Note:** Use [main branch of NeMo](https://github.com/NVIDIA/NeMo/) to get timestamps until it is released in NeMo 2.5.
To transcribe with timestamps:
```python
output = asr_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='en', timestamps=True)
# by default, timestamps are enabled for word and segment level
word_timestamps = output[0].timestamp['word'] # word level timestamps for first sample
segment_timestamps = output[0].timestamp['segment'] # segment level timestamps
for stamp in segment_timestamps:
print(f"{stamp['start']}s - {stamp['end']}s : {stamp['segment']}")
```
#### Translating with timestamps
To translate with timestamps:
```python
output = asr_model.transcribe(['2086-149220-0033.wav'], source_lang='en', target_lang='fr', timestamps=True)
segment_timestamps = output[0].timestamp['segment'] # only supports segment level timestamps for translation
for stamp in segment_timestamps:
print(f"{stamp['start']}s - {stamp['end']}s : {stamp['segment']}")
```
For translation task, please, refer to segment-level timestamps for getting intuitive and accurate alignment.
## Software Integration
**Runtime Engine(s):**
* NeMo main branch (until it is released in NeMo 2.5)
**Supported Hardware Microarchitecture Compatibility:**
* NVIDIA Ampere
* NVIDIA Blackwell
* NVIDIA Hopper
**\[Preferred/Supported] Operating System(s):**
* Linux
**Hardware Specific Requirements:**
At least 6GB RAM for model to load.
#### Model Version
Current version: `Canary-1b-v2`. Previous versions can be [accessed](https://huggingface.co/collections/nvidia/canary-65c3b83ff19b126a3ca62926) here.
## Training and Evaluation Datasets
### Training
The model was trained using the NeMo toolkit \[4], following a 3-stage training procedure:
* Initialized from a 4-language ASR model
* Stage 1: Trained for 150,000 steps on X→En and English ASR tasks using 64 A100 GPUs
* Stage 2: Trained for 115,000 additional steps on the full dataset (ASR, X→En, En→X)
* Stage 3: Fine-tuned for 10,000 steps on a language-balanced high-quality subset of Granary and NeMo ASR Set 3.0
For all the stages of training, both languages and corpora are weighted using temperature sampling (τ = 0.5).
Training script: [speech\_to\_text\_aed.py](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/speech_multitask/speech_to_text_aed.py)
Tokenizer script: [process\_asr\_text\_tokenizer.py](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py)
---
### Training Dataset
`Canary-1b-v2` was trained on a massive multilingual speech recognition and translation dataset combining Nvidia's newly published [Granary](https://huggingface.co/datasets/nvidia/Granary) and in-house dataset NeMo ASR Set 3.0.
**Granary Dataset \[5] \[6] with improved pseudo-labels and efficiently filtered versions of the following corpora:**
* [YTC](https://huggingface.co/datasets/FBK-MT/mosel) \[7]
* [MOSEL](https://huggingface.co/datasets/FBK-MT/mosel) \[8]
* [YODAS](https://huggingface.co/datasets/espnet/yodas-granary) \[9]
Granary is now available on [Hugging Face](https://huggingface.co/datasets/nvidia/Granary).
To read more about the pseudo-labeling technique and [pipeline](https://github.com/NVIDIA/NeMo-speech-data-processor/tree/main/dataset_configs/multilingual/granary), please refer to the [Granary Paper](https://arxiv.org/abs/2505.13404).
**NeMo ASR Set 3.0 including human-labeled transcriptions from the following corpora:**
* Multilingual LibriSpeech (MLS)
* Mozilla Common Voice (v7.0)
* AMI (70 hrs)
* Fleurs
* LibriSpeech (960 hours)
* Fisher Corpus
* National Speech Corpus Part 1
* VCTK
* Europarl-ASR
**Total training hours:** 1.7M
* ASR: 660,000 hrs
* X→En: 360,000 hrs
* En→X: 690,000 hrs
* Non-speech: 36,000 hrs
All transcripts include punctuation and capitalization.
**Data Collection Method by dataset**
* Hybrid: Automated, Human
**Labeling Method by dataset**
* Hybrid: Synthetic, Human
---
### Evaluation Dataset
* Fleurs \[10], MLS \[11], CoVoST \[12]
* Hugging Face Open ASR Leaderboard \[13]
* Earnings-22 \[14], This American Life \[15] (long-form)
* MUSAN \[16]
**Data Collection Method by dataset**
* Human
**Labeling Method by dataset**
* Human
## Benchmark Results
This section reports the evaluation results of the ``Canary-1b-v2`` model across multiple tasks, including Automatic Speech Recognition (ASR), Speech Translation (AST), robustness to noise, and long-form transcription.
---
### Automatic Speech Recognition (ASR)
| **WER ↓** | Fleurs-25 Langs | CoVoST-13 Langs | MLS - 6 Langs |
| --------------- | -------------------- | -------------------- | ------------------ |
| **`Canary-1b-v2`** | 8.40% | 8.85% | 7.27% |
**Note:** Presented WERs do not include Punctuation and Capitalization errors.
---
#### Hugging Face Open ASR Leaderboard
| **WER ↓** | **RTFx** | **Mean** | **AMI** | **GigaSpeech** | **LS Clean** | **LS Other** | **Earnings22** | **SPGISpech** | **Tedlium** | **Voxpopuli** |
|:-----------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|:------:|
| `Canary-1b-v2` | 749 | 7.15 | 16.01 | 10.82 | 2.18 | 3.56 | 11.79 | 2.28 | 4.29 | 6.25 |
More details on evaluation can be found at [HuggingFace ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
---
### Speech Translation (AST)
#### X → English
| | **COMET ↑** | | **BLEU ↑** | |
| --------------- | --------------- | --------------- | --------------- | -------------- |
| | Fleurs-24 Langs | CoVoST-13 Langs | Fleurs-24 Langs | CoVoST-13 Langs|
| **`Canary-1b-v2`** | 79.30 | 77.48 | 29.08 | 40.48 |
#### English → X
| | **COMET ↑** | | **BLEU ↑** | |
| --------------- | ------------- | --------------- | --------------- | -------------- |
| | Fleurs-24 Langs | CoVoST-5 Langs | Fleurs-24 Langs | CoVoST-5 Langs |
| **`Canary-1b-v2`** | 84.56 | 80.29 | 29.4 | 32.33 |
---
### Noise Robustness
Performance across different Signal-to-Noise Ratios (SNR) using MUSAN music and noise samples \[16] on the [LibriSpeech Clean test set](https://www.openslr.org/12).
**Metric**: Word Error Rate (**WER**)
| **SNR (dB)** | 100 | 10 | 5 | 0 | -5 |
| --------------- | ----- | ----- | ----- | ----- | ----- |
| **`Canary-1b-v2`** | 2.18% | 2.29% | 2.80% | 5.08% | 19.38% |
### Hallucination Robustness
Number of characters per minute on [MUSAN](https://www.openslr.org/17) \[16] 48 hrs eval set:
| | **# of character per minute ↓** |
|:---------:|:----------:|
| **`Canary-1b-v2`** | 134.7 |
---
### Long-form Inference
`Canary-1b-v2` achieves strong performance on long-form transcription by using dynamic chunking with 1-second overlap between chunks, allowing for efficient parallel processing. This dynamic chunking feature is automatically enabled when calling `.transcribe()` on a single audio file, or when using `batch_size=1` with multiple audio files that are longer than 40 seconds.
| **Dataset** | **WER ↓** |
| ----------------------- | --------- |
| Earnings-22 | 13.78% |
| This American Life | 9.87% |
**Note:** Presented WERs do not include Punctuation and Capitalization errors.
---
## Inference
**Engine**:
* NVIDIA NeMo
**Test Hardware**:
* NVIDIA A10
* NVIDIA A100
* NVIDIA A30
* NVIDIA A5000
* NVIDIA H100
* NVIDIA L4
* NVIDIA L40
---
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards [here](https://developer.nvidia.com/blog/enhancing-ai-transparency-and-ethical-considerations-with-model-card/).
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Bias:
Field | Response
:---------------------------------------------------------------------------------------------------|:---------------:
Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing | None
Measures taken to mitigate against unwanted bias | None
## Explainability:
Field | Response
:------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------:
Intended Domain | Speech to Text Transcription and Translation
Model Type | Attention Encoder-Decoder
Intended Users | This model is intended for developers, researchers, academics, and industries building conversational based applications.
Output | Text
Describe how the model works | Speech input is encoded into embeddings and passed into conformer-based model and output a text response.
Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of | Not Applicable
Technical Limitations & Mitigation | Transcripts and translations may be not 100% accurate. Accuracy varies based on source and target language and characteristics of input audio (Domain, Use Case, Accent, Noise, Speech Type, Context of speech, etc.)
Verified to have met prescribed NVIDIA quality standards | Yes
Performance Metrics | Word Error Rate (Speech Transcription) / BLEU score (Speech Translation) / COMET score (Speech Translation)
Potential Known Risks | If a word is not trained in the language model and not presented in vocabulary, the word is not likely to be recognized. Not recommended for word-for-word/incomplete sentences as accuracy varies based on the context of input text
Licensing | GOVERNING TERMS: Use of this model is governed by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) license.
## Privacy:
Field | Response
:----------------------------------------------------------------------------------------------------------------------------------:|:-----------------------------------------------:
Generatable or reverse engineerable personal data? | None
Personal data used to create this model? | None
Is there provenance for all datasets used in training? | Yes
Does data labeling (annotation, metadata) comply with privacy laws? | Yes
Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data.
Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/
## Safety:
Field | Response
:---------------------------------------------------:|:----------------------------------
Model Application(s) | Speech to Text Transcription
Describe the life critical impact | None
Use Case Restrictions | Abide by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en) License
Model and dataset restrictions | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to.
## References
\[1] [Granary: Speech Recognition and Translation Dataset in 25 European Languages](https://arxiv.org/abs/2505.13404)
\[2] [NVIDIA Granary Dataset Card](https://huggingface.co/datasets/nvidia/Granary)
\[3] [Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition](https://arxiv.org/abs/2305.05084)
\[4] [Attention is All You Need](https://arxiv.org/abs/1706.03762)
\[5] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
\[6] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
\[7] [Youtube-Commons](https://huggingface.co/datasets/PleIAs/YouTube-Commons)
\[8] [MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages](https://arxiv.org/abs/2410.01036)
\[9] [YODAS: Youtube-Oriented Dataset for Audio and Speech](https://arxiv.org/pdf/2406.00899)
\[10] [FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech](https://arxiv.org/abs/2205.12446)
\[11] [MLS: A Large-Scale Multilingual Dataset for Speech Research](https://arxiv.org/abs/2012.03411)
\[12] [CoVoST 2 and Massively Multilingual Speech-to-Text Translation](https://arxiv.org/abs/2007.10310)
\[13] [HuggingFace Open ASR Leaderboard](https://huggingface.co/spaces/hf-audio/open_asr_leaderboard)
\[14] [Earnings-22 Benchmark](https://github.com/revdotcom/speech-datasets/tree/main/earnings22)
\[15] [Speech Recognition and Multi-Speaker Diarization of Long Conversations](https://arxiv.org/abs/2005.08072)
\[16] [MUSAN: A Music, Speech, and Noise Corpus](https://arxiv.org/abs/1510.08484)