---
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
---
### UI-Venus
This repository contains the UI-Venus model from the report [UI-Venus Technical Report: Building High-performance UI Agents with RFT](https://arxiv.org/abs/2508.10833).
UI-Venus is a native UI agent based on the Qwen2.5-VL multimodal large language model, designed to perform precise GUI element grounding and effective navigation using only screenshots as input. It achieves state-of-the-art performance through Reinforcement Fine-Tuning (RFT) with high-quality training data. More inference details and usage guides are available in the GitHub repository. We will continue to update results on standard benchmarks including Screenspot-v2/Pro and AndroidWorld.
[](https://opensource.org/licenses/Apache-2.0)
[](http://arxiv.org/abs/2508.10833)
[](https://github.com/inclusionAI/UI-Venus)
[](https://huggingface.co/inclusionAI/UI-Venus-Ground-7B)
---
📈 UI-Venus Benchmark Performance
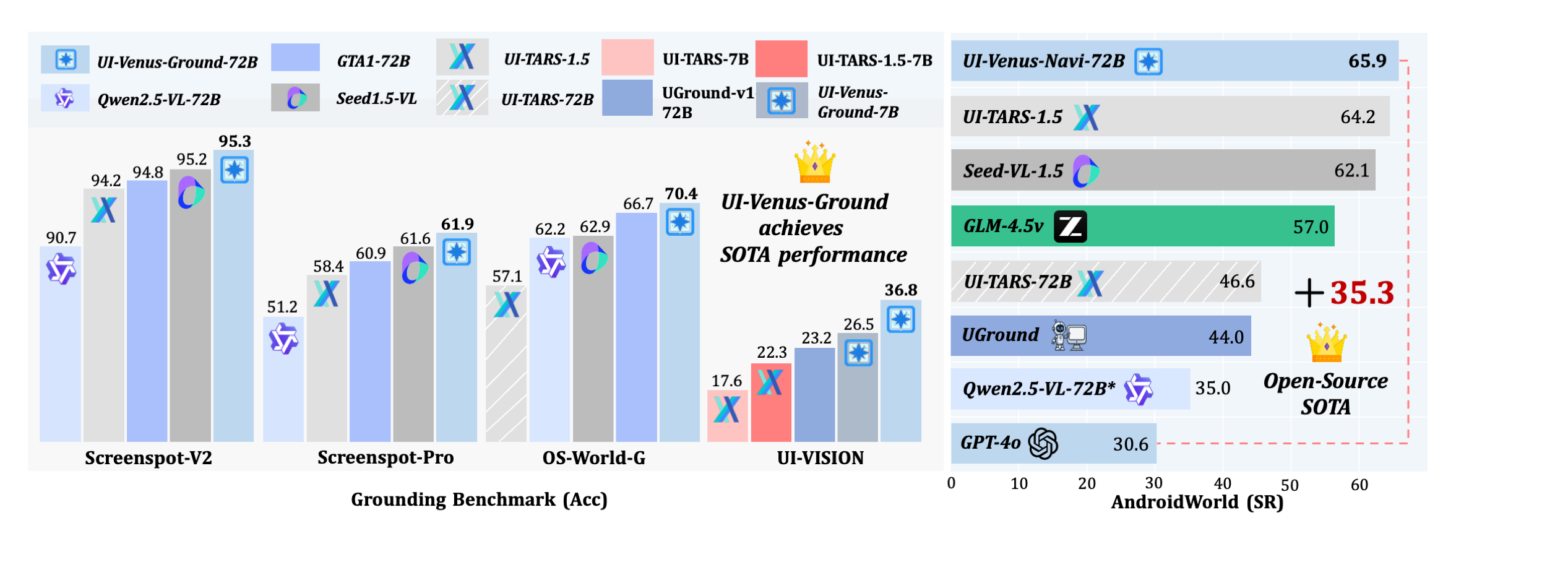
> **Figure:** Performance of UI-Venus across multiple benchmark datasets. UI-Venus achieves **State-of-the-Art (SOTA)** results on key UI understanding and interaction benchmarks, including **ScreenSpot-Pro**, **ScreenSpot-v2**, **OS-World-G**, **UI-Vision**, and **Android World**. The results demonstrate its superior capability in visual grounding, UI navigation, cross-platform generalization, and complex task reasoning.
### Model Description
UI-Venus is a multimodal UI agent built on Qwen2.5-VL that performs accurate UI grounding and navigation using only screenshots as input. The 7B and 72B variants achieve 94.1%/50.8% and 95.3%/61.9% on Screenspot-V2 and Screenspot-Pro benchmarks, surpassing prior SOTA models such as GTA1 and UI-TARS-1.5. On the AndroidWorld navigation benchmark, they achieve 49.1% and 65.9% success rates, respectively, demonstrating strong planning and generalization capabilities
Key innovations include:
- **SOTA Open-Source UI Agent**: Publicly released to advance research in autonomous UI interaction and agent-based systems.
- **Reinforcement Fine-Tuning (RFT)**: Utilizes carefully designed reward functions for both grounding and navigation tasks
- **Efficient Data Cleaning**: Trained on several hundred thousand high-quality samples to ensure robustness.
- **Self-Evolving Trajectory History Alignment & Sparse Action Enhancement**: Improves reasoning coherence and action distribution for better long-horizon planning.
---
## Installation
First, install the required dependencies:
```python
pip install transformers==4.49.0 qwen-vl-utils
```
---
## Quick Start
Use the shell scripts to launch the evaluation. The evaluation setup follows the same protocol as **ScreenSpot**, including data format, annotation structure, and metric calculation.
```python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
import torch
import os
from qwen_vl_utils import process_vision_info
# model path
model_name = "inclusionAI/UI-Venus-Ground-7B"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_name,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
).eval()
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_name)
generation_config = {
"max_new_tokens": 2048,
"do_sample": False,
"temperature": 0.0
}
def inference(instruction, image_path):
assert os.path.exists(image_path) and os.path.isfile(image_path), "Invalid input image path."
prompt_origin = 'Outline the position corresponding to the instruction: {}. The output should be only [x1,y1,x2,y2].'
full_prompt = prompt_origin.format(instruction)
min_pixels = 2000000
max_pixels = 4800000
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_path,
"min_pixels": min_pixels,
"max_pixels": max_pixels
},
{"type": "text", "text": full_prompt},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
model_inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**model_inputs, **generation_config)
generated_ids_trimmed = [
out_ids[len(in_ids):]
for in_ids, out_ids in zip(model_inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# normalized coordinates
try:
box = eval(output_text[0])
input_height = model_inputs['image_grid_thw'][0][1] * 14
input_width = model_inputs['image_grid_thw'][0][2] * 14
abs_x1 = float(box[0]) / input_width
abs_y1 = float(box[1]) / input_height
abs_x2 = float(box[2]) / input_width
abs_y2 = float(box[3]) / input_height
bbox = [abs_x1, abs_y1, abs_x2, abs_y2]
except Exception:
bbox = [0, 0, 0, 0]
point = [(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2]
result_dict = {
"result": "positive",
"format": "x1y1x2y2",
"raw_response": output_text,
"bbox": bbox,
"point": point
}
return result_dict
```
---
### Results on ScreenSpot-v2
| **Model** | **Mobile Text** | **Mobile Icon** | **Desktop Text** | **Desktop Icon** | **Web Text** | **Web Icon** | **Avg.** |
|--------------------------|-----------------|-----------------|------------------|------------------|--------------|--------------|----------|
| uitars-1.5 | - | - | - | - | - | - | 94.2 |
| Seed-1.5-VL | - | - | - | - | - | - | 95.2 |
| GPT-4o | 26.6 | 24.2 | 24.2 | 19.3 | 12.8 | 11.8 | 20.1 |
| Qwen2.5-VL-7B | 97.6 | 87.2 | 90.2 | 74.2 | 93.2 | 81.3 | 88.8 |
| UI-TARS-7B | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 |
| UI-TARS-72B | 94.8 | 86.3 | 91.2 | 87.9 | 91.5 | 87.7 | 90.3 |
| LPO | 97.9 | 82.9 | 95.9 | 86.4 | 95.6 | 84.2 | 90.5 |
| **UI-Venus-Ground-7B (Ours)** | **99.0** | **90.0** | **97.0** | **90.7** | **96.2** | **88.7** | **94.1** |
| **UI-Venus-Ground-72B (Ours)** | **99.7** | **93.8** | **95.9** | **90.0** | **96.2** | **92.6** | **95.3** |
---
### Results on ScreenSpot-Pro
Performance comparison of GUI agent models across six task categories on **ScreenSpot-Pro**.
Scores are in percentage (%). `T` = Text, `I` = Icon.
`*`: reproduced; `†`: trained from UI-TARS-1.5-7B.
| Model | CAD (T/I) | Dev (T/I) | Creative (T/I) | Scientific (T/I) | Office (T/I) | OS (T/I) | Avg T | Avg I | **Overall** | Type |
|-------|-----------|-----------|----------------|------------------|--------------|---------|--------|--------|------------|------|
| GPT-4o | 2.0 / 0.0 | 1.3 / 0.0 | 1.0 / 0.0 | 2.1 / 0.0 | 1.1 / 0.0 | 0.0 / 0.0 | 1.3 | 0.0 | 0.8 | Closed |
| Claude Computer Use | 14.5 / 3.7 | 22.0 / 3.9 | 25.9 / 3.4 | 33.9 / 15.8 | 30.1 / 16.3 | 11.0 / 4.5 | 23.4 | 7.1 | 17.1 | Closed |
| UI-TARS-1.5 | – / – | – / – | – / – | – / – | – / – | – / – | – | – | **61.6** | Closed |
| Seed1.5-VL | – / – | – / – | – / – | – / – | – / – | – / – | – | – | 60.9 | Closed |
| Qwen2.5-VL-7B\* | 16.8 / 1.6 | 46.8 / 4.1 | 35.9 / 7.7 | 49.3 / 7.3 | 52.5 / 20.8 | 37.4 / 6.7 | 38.9 | 7.1 | 26.8 | SFT |
| Qwen2.5-VL-72B* | 54.8 / 15.6 | 65.6 / 16.6 | 63.1 / 19.6 | 78.5 / 34.5 | 79.1 / 47.2 | 66.4 / 29.2 | 67.3 | 25.0 | 51.2 | SFT |
| UI-TARS-7B | 20.8 / 9.4 | 58.4 / 12.4 | 50.0 / 9.1 | 63.9 / 31.8 | 63.3 / 20.8 | 30.8 / 16.9 | 47.8 | 16.2 | 35.7 | SFT |
| UI-TARS-72B | 18.8 / 12.5 | 62.9 / 17.2 | 57.1 / 15.4 | 64.6 / 20.9 | 63.3 / 26.4 | 42.1 / 15.7 | 50.9 | 17.6 | 38.1 | SFT |
| Phi-Ground-7B | 26.9 / 17.2 | 70.8 / 16.7 | 56.6 / 13.3 | 58.0 / 29.1 | 76.4 / 44.0 | 55.1 / 25.8 | 56.4 | 21.8 | 43.2 | RL |
| UI-TARS-1.5-7B | – / – | – / – | – / – | – / – | – / – | – / – | – | – | 49.6 | RL |
| GTA1-7B† | 53.3 / 17.2 | 66.9 / 20.7 | 62.6 / 18.2 | 76.4 / 31.8 | 82.5 / 50.9 | 48.6 / 25.9 | 65.5 | 25.2 | 50.1 | RL |
| GTA1-72B | 56.9 / 28.1 | 79.9 / 33.1 | 73.2 / 20.3 | 81.9 / 38.2 | 85.3 / 49.1 | 73.8 / 39.1 | 74.5 | 32.5 | 58.4 | RL |
| **UI-Venus-Ground-7B** | 60.4 / 21.9 | 74.7 / 24.1 | 63.1 / 14.7 | 76.4 / 31.8 | 75.7 / 41.5 | 49.5 / 22.5 | 67.1 | 24.3 | **50.8** | Ours (RL) |
| **UI-Venus-Ground-72B** | 66.5 / 29.7 | 84.4 / 33.1 | 73.2 / 30.8 | 84.7 / 42.7 | 83.1 / 60.4 | 75.7 / 36.0 | 77.4 | 36.8 | **61.9** | Ours (RL) |
> 🔝 **Experimental results show that UI-Venus-Ground-72B achieves state-of-the-art performance on ScreenSpot-Pro with an average score of 61.7, while also setting new benchmarks on ScreenSpot-v2(95.3), OSWorld_G(69.8), AgentCPM(84.7), and UI-Vision(38.0), highlighting its effectiveness in complex visual grounding and action prediction tasks.**
# Citation
Please consider citing if you find our work useful:
```plain
@misc{gu2025uivenustechnicalreportbuilding,
title={UI-Venus Technical Report: Building High-performance UI Agents with RFT},
author={Zhangxuan Gu and Zhengwen Zeng and Zhenyu Xu and Xingran Zhou and Shuheng Shen and Yunfei Liu and Beitong Zhou and Changhua Meng and Tianyu Xia and Weizhi Chen and Yue Wen and Jingya Dou and Fei Tang and Jinzhen Lin and Yulin Liu and Zhenlin Guo and Yichen Gong and Heng Jia and Changlong Gao and Yuan Guo and Yong Deng and Zhenyu Guo and Liang Chen and Weiqiang Wang},
year={2025},
eprint={2508.10833},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.10833},
}
```