-
-10 avatars of Dasavatharam ... first of all the name itself is a play on the words singam [means lion in tamil] and narasimha [the avatar being symbolised]. ... In the movie, he shows up to kill the killer fletcher! and is also a ... 1fdad05405
-
-
-
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Devexpress 11.1 [BETTER].md b/spaces/1gistliPinn/ChatGPT4/Examples/Devexpress 11.1 [BETTER].md
deleted file mode 100644
index b9d278c1c1a2d77d699bc4fca4ec40f399b08355..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/Devexpress 11.1 [BETTER].md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
-Learn how to use the MS Excel-style conditional formatting feature to change the appearance of individual cells ... 1fdad05405
-
-
-
diff --git a/spaces/1line/AutoGPT/scripts/check_requirements.py b/spaces/1line/AutoGPT/scripts/check_requirements.py
deleted file mode 100644
index e4eab024a6280c0d54110c69b2e03de639325fa6..0000000000000000000000000000000000000000
--- a/spaces/1line/AutoGPT/scripts/check_requirements.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import sys
-
-import pkg_resources
-
-
-def main():
- requirements_file = sys.argv[1]
- with open(requirements_file, "r") as f:
- required_packages = [
- line.strip().split("#")[0].strip() for line in f.readlines()
- ]
-
- installed_packages = [package.key for package in pkg_resources.working_set]
-
- missing_packages = []
- for package in required_packages:
- if not package: # Skip empty lines
- continue
- package_name = package.strip().split("==")[0]
- if package_name.lower() not in installed_packages:
- missing_packages.append(package_name)
-
- if missing_packages:
- print("Missing packages:")
- print(", ".join(missing_packages))
- sys.exit(1)
- else:
- print("All packages are installed.")
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/1phancelerku/anime-remove-background/Download Ludo Yarsa Game and Experience the Ultimate Ludo Fun.md b/spaces/1phancelerku/anime-remove-background/Download Ludo Yarsa Game and Experience the Ultimate Ludo Fun.md
deleted file mode 100644
index 96df7cf848be188f0bd32e4b67e869722e5f4a8b..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Download Ludo Yarsa Game and Experience the Ultimate Ludo Fun.md
+++ /dev/null
@@ -1,133 +0,0 @@
-
-
How to Download Ludo Yarsa Game and Enjoy Its Benefits and Features
-
Ludo is a fun and popular board game that can be played by two to four players. It is a game that has been around for a long time and has been enjoyed by people of all ages. But did you know that you can also play Ludo on your smartphone or tablet? Yes, you can download Ludo Yarsa Game, a beautiful and simple app that lets you play Ludo anytime, anywhere. In this article, we will tell you how to download Ludo Yarsa Game on your device, and what are the benefits and features of playing this game.
Ludo Yarsa Game is a board game app developed by Yarsa Games, a game studio based in Pokhara, Nepal. They mostly build board games like Ludo and card games like Rummy. Ludo Yarsa Game is one of their most popular games, with over 100 million downloads and 4.7 star ratings on Google Play Store.
-
Ludo is a board game that originated from an ancient Indian game called Pachisi. It is also known by different names in different regions, such as Fia in Sweden, Petits Chevaux in France, Non t'arrabbiare in Italy, Ki nevet a végén in Hungary, etc. The name Ludo comes from the Latin word ludus, which means "game".
-
The gameplay and rules of the game
-
The gameplay of Ludo Yarsa Game is simple and easy to learn. The game starts with four tokens placed in each player's starting box. A dice is rolled in turns by each player during the game. The player's token will be placed on the starting point when a 6 is rolled on the dice. The main goal of the game is to take all four tokens inside the HOME area before the other opponents.
-
Some basic rules of Ludo Yarsa Game are:
-
-
A token can start to move only if the dice rolled is a 6.
-
Each player gets a turn wise chance to roll the dice. And if the player rolls a 6, they will get another chance to roll the dice again.
-
All the tokens must reach the center of the board to win the game.
-
The token move clock-wise according to the number of rolled dice.
-
Knocking out other's token will give you an extra chance to roll the dice again.
-
-
How to Download Ludo Yarsa Game on Your Device?
-
The steps to download the game from Google Play Store or App Store
-
If you want to download Ludo Yarsa Game on your device, you can follow these simple steps:
-<
For Android devices:
-
-
Open the Google Play Store app on your device.
-
Search for "Ludo Yarsa Game" in the search bar.
-
Select the app from the list of results and tap on "Install".
-
Wait for the app to download and install on your device.
-
Once the app is installed, you can open it and start playing.
-
-
For iOS devices:
-
How to download ludo yarsa game on android
-Ludo yarsa game offline play with friends
-Ludo yarsa game apk download latest version
-Ludo yarsa game review and rating
-Ludo yarsa game rules and tips
-Ludo yarsa game multiplayer online mode
-Ludo yarsa game for pc windows 10
-Ludo yarsa game free download for ios
-Ludo yarsa game board size and design
-Ludo yarsa game languages and customization
-Ludo yarsa game dice roll animation and sound
-Ludo yarsa game best strategy and tricks
-Ludo yarsa game fun facts and history
-Ludo yarsa game features and updates
-Ludo yarsa game alternatives and competitors
-Ludo yarsa game cheats and hacks
-Ludo yarsa game support and feedback
-Ludo yarsa game awards and achievements
-Ludo yarsa game tournaments and prizes
-Ludo yarsa game community and social media
-Ludo yarsa game by Yarsa Games developer
-Ludo yarsa game vs other ludo games comparison
-Ludo yarsa game download link and QR code
-Ludo yarsa game installation guide and troubleshooting
-Ludo yarsa game system requirements and compatibility
-Ludo yarsa game privacy policy and data safety
-Ludo yarsa game ads and in-app purchases
-Ludo yarsa game speed and performance optimization
-Ludo yarsa game bug fixes and improvements
-Ludo yarsa game testimonials and user reviews
-How to play ludo yarsa game with family and friends
-How to win ludo yarsa game every time
-How to unlock ludo yarsa game achievements and rewards
-How to customize ludo yarsa game tokens and colors
-How to change ludo yarsa game language and settings
-How to contact ludo yarsa game customer service and support
-How to rate and review ludo yarsa game on Google Play Store
-How to share ludo yarsa game with others via social media or email
-How to delete ludo yarsa game from your device or account
-How to update ludo yarsa game to the latest version
-
-
Open the App Store app on your device.
-
Search for "Ludo Yarsa Game" in the search bar.
-
Select the app from the list of results and tap on "Get".
-
Enter your Apple ID password or use Touch ID or Face ID to confirm the download.
-
Wait for the app to download and install on your device.
-
Once the app is installed, you can open it and start playing.
-
-
The requirements and compatibility of the game
-
Ludo Yarsa Game is a lightweight and fast app that does not take much space or memory on your device. It also works smoothly on most devices and operating systems. However, there are some minimum requirements and compatibility that you need to check before downloading the game. These are:
-
-
Device
Requirement
Compatibility
-
Android
4.1 and up
All Android devices that support Google Play Store
-
iOS
10.0 or later
iPhone, iPad, and iPod touch
-
-
What are the Benefits of Playing Ludo Yarsa Game?
-
The health benefits of playing the game, such as developing brain function, giving pleasure and relieving stress, and lowering blood pressure
-
Ludo Yarsa Game is not only a fun and entertaining game, but also a healthy and beneficial one. Playing Ludo Yarsa Game can help you improve your brain function, give you pleasure and relieve stress, and lower your blood pressure. Here are some of the health benefits of playing Ludo Yarsa Game:
-
-
Ludo Yarsa Game can help you develop your brain function by stimulating your cognitive skills, such as memory, concentration, problem-solving, logic, and strategy. Playing Ludo Yarsa Game can also enhance your creativity and imagination by allowing you to explore different possibilities and outcomes.
-
Ludo Yarsa Game can give you pleasure and relieve stress by releasing endorphins, dopamine, and serotonin in your brain. These are neurotransmitters that are responsible for making you feel happy, relaxed, and satisfied. Playing Ludo Yarsa Game can also distract you from negative thoughts and emotions, and help you cope with anxiety and depression.
-
Ludo Yarsa Game can lower your blood pressure by reducing your cortisol levels, which are hormones that are associated with stress and inflammation. Playing Ludo Yarsa Game can also calm your nervous system and regulate your heart rate and breathing. This can help you prevent or manage hypertension, heart disease, stroke, and other cardiovascular problems.
-
-
The social benefits of playing the game, such as building communication skills, boosting confidence, and teaching patience
-
Ludo Yarsa Game is also a social game that can help you improve your communication skills, boost your confidence, and teach you patience. Playing Ludo Yarsa Game can help you interact with other players, whether they are your friends, family members, or strangers online. Here are some of the social benefits of playing Ludo Yarsa Game:
-
-
Ludo Yarsa Game can help you build your communication skills by encouraging you to talk to other players, express your opinions, listen to feedback, negotiate rules, cooperate strategies, and resolve conflicts. Playing Ludo Yarsa Game can also improve your verbal and non-verbal communication skills, such as vocabulary, grammar, tone, gesture, facial expression, etc.
-
Ludo Yarsa Game can boost your confidence by giving you a sense of achievement, competence, and self-esteem. Playing Ludo Yarsa Game can also challenge you to face difficulties, overcome obstacles, learn from mistakes, and celebrate successes. Playing Ludo Yarsa Game can also make you more confident in your abilities and skills.
-
Ludo Yarsa Game can teach you patience by making you wait for your turn, deal with delays, accept losses, handle frustrations, and respect others. Playing L Ludo Yarsa Game can also help you develop your patience by making you wait for your turn, deal with delays, accept losses, handle frustrations, and respect others. Playing Ludo Yarsa Game can also teach you the value of perseverance, tolerance, and humility.
-
-
What are the Features of Ludo Yarsa Game?
-
The features that make the game unique and enjoyable, such as multi-colored dice, real dice roll animation, percentage progress, and game speed customization
-
Ludo Yarsa Game is not just a regular board game app. It has many features that make it unique and enjoyable. Some of these features are:
-
-
Ludo Yarsa Game has multi-colored dice that match the color of your tokens. This makes the game more colorful and attractive. You can also choose from different dice designs, such as classic, wooden, metal, etc.
-
Ludo Yarsa Game has real dice roll animation that simulates the actual rolling of the dice. This makes the game more realistic and exciting. You can also shake your device to roll the dice, or tap on the screen to stop the dice.
-
Ludo Yarsa Game has percentage progress that shows you how much you have completed the game. This makes the game more motivating and rewarding. You can also see the percentage progress of other players, and compare your performance with them.
-
Ludo Yarsa Game has game speed customization that allows you to adjust the speed of the game according to your preference. This makes the game more flexible and convenient. You can choose from slow, normal, fast, or very fast speed modes.
-
-
The features that make the game accessible and convenient, such as offline play, pass and play, multiple languages, and multiplayer version
-
Ludo Yarsa Game is also a game that is accessible and convenient for everyone. Some of these features are:
-
-
Ludo Yarsa Game has offline play that enables you to play the game without an internet connection. This makes the game more accessible and reliable. You can play the game anytime, anywhere, even when you are offline.
-
Ludo Yarsa Game has pass and play that allows you to play the game with your friends or family on one device. This makes the game more social and fun. You can share the device with other players, and pass it around when it is your turn.
-
Ludo Yarsa Game has multiple languages that support different languages from around the world. This makes the game more inclusive and diverse. You can choose from English, Hindi, Nepali, Spanish, French, German, Arabic, etc.
-
Ludo Yarsa Game has multiplayer version that lets you play the game with other players online. This makes the game more competitive and challenging. You can join or create a room, invite or join other players, chat with them, and enjoy the game.
-
-
Conclusion
-
Ludo Yarsa Game is a board game app that you can download on your device and enjoy its benefits and features. It is a game that is fun and popular, simple and easy, healthy and beneficial, unique and enjoyable, accessible and convenient. It is a game that you can play with yourself or with others, online or offline, fast or slow, in different languages and modes. It is a game that you will never get bored of playing.
-
So what are you waiting for? Download Ludo Yarsa Game now and have fun!
-
FAQs
-
Q: How much does Ludo Yarsa Game cost?
-
A: Ludo Yarsa Game is free to download and play. However, it contains ads that can be removed by purchasing an ad-free version for $0.99.
-
Q: How can I contact Ludo Yarsa Game developers?
-
A: You can contact Ludo Yarsa Game developers by emailing them at support@yarsagames.com or visiting their website at https://yarsagames.com/.
-
Q: How can I rate and review Ludo Yarsa Game?
-
A: You can rate and review Ludo Yarsa Game by going to Google Play Store or App Store on your device, finding the app page, and tapping on the stars or writing a comment.
-
Q: How can I share Ludo Yarsa Game with my friends?
-
A: You can share Ludo Yarsa Game with your friends by using the share button on the app or sending them a link to download the app from Google Play Store or App Store.
-
Q: How can I learn more tips and tricks for playing Ludo Yarsa Game?
-
A: You can learn more tips and tricks for playing Ludo Yarsa Game by reading the blog posts on their website at https://yarsagames.com/blog/ or watching the videos on their YouTube channel at https://www.youtube.com/channel/UCw9wH3Qs1f0i0XjN7mJ4L9A.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/FIFA Mobile APK Download Experience the Ultimate Soccer Game on Your Phone.md b/spaces/1phancelerku/anime-remove-background/FIFA Mobile APK Download Experience the Ultimate Soccer Game on Your Phone.md
deleted file mode 100644
index 4f31b6951c2cb8d665e2e0857b96b97127443a11..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/FIFA Mobile APK Download Experience the Ultimate Soccer Game on Your Phone.md
+++ /dev/null
@@ -1,128 +0,0 @@
-
-
FIFA apkdone: How to Download and Play the Popular Soccer Game on Your Android Device
-
If you are a fan of soccer games, you might have heard of FIFA apkdone, a modified version of the official FIFA game that allows you to play it on your Android device. In this article, we will tell you everything you need to know about FIFA apkdone, including how to download and install it, how to play it, and what are its pros and cons.
FIFA apkdone is a modified version of the original FIFA game developed by EA Sports, one of the most popular and realistic soccer games in the world. FIFA apkdone is not an official app, but a fan-made one that offers some extra features and benefits that are not available in the original game. For example, FIFA apkdone lets you play with unlimited coins and points, unlock all players and teams, customize your stadium and kits, and enjoy high-quality graphics and sound effects.
-
The features and benefits of FIFA apkdone
-
Some of the features and benefits of FIFA apkdone are:
-
-
You can play with any team or player you want, including legends like Pele, Maradona, Ronaldo, Messi, etc.
-
You can access all game modes and options, such as Career Mode, Volta Football, Ultimate Team, Online Seasons, etc.
-
You can enjoy a smooth and realistic gameplay experience with HyperMotion technology, which adds more animations and movements to the players.
-
You can customize your game settings according to your preferences, such as difficulty level, camera angle, controls, etc.
-
You can download and install FIFA apkdone for free without any registration or verification.
-
-
How to download and install FIFA apkdone on your Android device
-
The steps to download FIFA apkdone from the official website
-
To download FIFA apkdone on your Android device, you need to follow these steps:
-
fifa mobile apk download
-fifa world cup 2022 apk
-fifa mobile mod apk unlimited money
-fifa mobile hack apk
-fifa mobile 23 apk
-fifa mobile offline apk
-fifa mobile latest version apk
-fifa mobile apk obb
-fifa mobile apk pure
-fifa mobile apk mirror
-fifa soccer apk mod
-fifa soccer apk download
-fifa soccer mod apk unlimited coins
-fifa soccer hack apk
-fifa soccer 23 apk
-fifa soccer offline apk
-fifa soccer latest version apk
-fifa soccer apk obb
-fifa soccer apk pure
-fifa soccer apk mirror
-fifa football apk mod
-fifa football apk download
-fifa football mod apk unlimited gems
-fifa football hack apk
-fifa football 23 apk
-fifa football offline apk
-fifa football latest version apk
-fifa football apk obb
-fifa football apk pure
-fifa football apk mirror
-fifa 23 android apk download
-fifa 23 android mod apk
-fifa 23 android hack apk
-fifa 23 android offline apk
-fifa 23 android latest version apk
-fifa 23 android apk obb
-fifa 23 android apk pure
-fifa 23 android apk mirror
-download game fifa mobile mod apk terbaru
-download game fifa mobile hack apk
-download game fifa mobile offline mod apk
-download game fifa mobile latest version mod apk
-download game fifa mobile full unlocked mod apk
-download game fifa mobile unlimited coins and gems mod apk
-download game fifa mobile mega mod menu
Scroll down and click on the green button that says "Download APK (94.8 MB)".
-
Wait for the download to finish and then locate the file in your device's storage.
-
-
The steps to install FIFA apkdone on your Android device
-
To install FIFA apkdone on your Android device, you need to follow these steps:
-
-
Before installing the file, make sure you have enabled the option to install apps from unknown sources in your device's settings.
-
Tap on the downloaded file and follow the instructions on the screen to install it.
-
Once the installation is complete, you can launch the game and enjoy playing FIFA apkdone on your Android device.
-
-
How to play FIFA apkdone on your Android device
-
The game modes and options available in FIFA apkdone
-
FIFA apkdone offers a variety of game modes and options for you to choose from, depending on your mood and preference. Some of the game modes and options are:
-
-
Career Mode: In this mode, you can create your own player or manager and lead your team to glory. You can also transfer players, negotiate contracts, scout talents, and manage your club's finances.
-
Volta Football: In this mode, you can experience the street soccer culture and play in different locations around the world. You can also customize your avatar, team, and style.
-
Ultimate Team: In this mode, you can build your dream team from scratch and compete with other players online. You can also earn coins and points, open packs, and upgrade your players.
-
Online Seasons: In this mode, you can play against other players online and climb the ranks. You can also earn rewards and trophies, and challenge your friends.
-
-
The tips and tricks to improve your skills and performance in FIFA apkdone
-
To improve your skills and performance in FIFA apkdone, you need to practice a lot and learn some tips and tricks. Some of the tips and tricks are:
-
-
Use the right controls: FIFA apkdone offers different types of controls for you to choose from, such as classic, casual, or gesture. You need to find the one that suits you best and master it.
-
Use the right tactics: FIFA apkdone allows you to adjust your tactics according to your strategy and opponent. You need to use the right tactics for each situation, such as attacking, defending, or counter-attacking.
-
Use the right players: FIFA apkdone gives you access to all players and teams in the game. You need to use the right players for each position, role, and formation. You also need to consider their attributes, skills, and chemistry.
-
Use the right skills: FIFA apkdone enables you to perform various skills with your players, such as dribbling, passing, shooting, tackling, etc. You need to use the right skills for each scenario, such as creating space, breaking through, scoring goals, etc.
-
-
The pros and cons of FIFA apkdone
-
The advantages of FIFA apkdone over other soccer games
-
FIFA apkdone has many advantages over other soccer games available on the market. Some of the advantages are:
-
-
It is free and easy to download and install: Unlike the official FIFA game, which requires a lot of space and money to download and install, FIFA apkdone is free and easy to download and install on your Android device.
-
It offers more features and benefits than the official FIFA game: Unlike the official FIFA game, which has some limitations and restrictions on its features and benefits, FIFA apkdone offers more features and benefits than the official game, such as unlimited coins and points, all players and teams unlocked, etc.
-
It has a high-quality graphics and sound effects: Unlike some other soccer games, which have low-quality graphics and sound effects, FIFA apkdone has a high-quality graphics and sound effects that make the game more realistic and immersive.
-
It has a large fan base and community: Unlike some other soccer games, which have a small fan base and community, FIFA apkdone has a large fan base and community that supports the game and provides feedbacks, suggestions, reviews, etc.
-
-
The disadvantages or limitations of FIFA apkdone
-
FIFA apkdone also has some disadvantages or limitations that you need to be aware of before playing it. Some of the disadvantages or limitations are:
-
-
It is not an official app but a modified one: Since FIFA apkdone is not an official app but a modified one, it may not be compatible with some devices or updates. It may also have some bugs or errors that affect its performance or functionality.
-
It may violate some terms and conditions of EA Sports: Since FIFA apkdone is not an official app but a modified one, it may violate some terms and conditions of EA Sports, the developer of the original FIFA game. It may also expose you to some legal risks or penalties if you use it without permission or authorization.
-
It may contain some ads or malware that may harm your device or data: Since FIFA apkdone is not an official app but a modified one, it may contain some ads or malware that may harm your device or data. You need to be careful and cautious when downloading and installing it.
-
It may not be as updated or supported as the official FIFA game: Since FIFA apkdone is not an official app but a modified one, it may not be as updated or supported as the official FIFA game. You may miss out on some new features, content, or events that are added to the official game.
-
-
Conclusion
-
A summary of the main points of the article
-
In conclusion, FIFA apkdone is a modified version of the official FIFA game that allows you to play it on your Android device. It offers some extra features and benefits that are not available in the original game, such as unlimited coins and points, all players and teams unlocked, etc. It also has a high-quality graphics and sound effects, and a large fan base and community. However, it also has some disadvantages or limitations that you need to be aware of before playing it, such as being not an official app but a modified one, violating some terms and conditions of EA Sports, containing some ads or malware, and not being as updated or supported as the official game. Therefore, you need to weigh the pros and cons of FIFA apkdone before deciding whether to download and install it on your Android device.
-
A call to action for the readers to try out FIFA apkdone
-
If you are interested in trying out FIFA apkdone on your Android device, you can follow the steps we have provided in this article to download and install it. You can also visit the official website of FIFA apkdone at https://apkdone.com/fifa-soccer/ for more information and updates. However, you need to be careful and cautious when using FIFA apkdone, as it is not an official app but a modified one. You also need to respect the rights and property of EA Sports, the developer of the original FIFA game. We hope you enjoy playing FIFA apkdone on your Android device and have fun with your favorite soccer game.
-
FAQs
-
What are the requirements to run FIFA apkdone on your Android device?
-
To run FIFA apkdone on your Android device, you need to have at least Android 5.0 or higher, 2 GB of RAM, 4 GB of free storage space, and a stable internet connection.
-
Is FIFA apkdone safe and legal to use?
-
FIFA apkdone is not an official app but a modified one that may violate some terms and conditions of EA Sports, the developer of the original FIFA game. It may also contain some ads or malware that may harm your device or data. Therefore, it is not completely safe or legal to use. You need to be careful and cautious when using FIFA apkdone, and use it at your own risk.
-
How can I update FIFA apkdone to the latest version?
-
To update FIFA apkdone to the latest version, you need to visit the official website of FIFA apkdone at https://apkdone.com/fifa-soccer/ and download the latest version of the file. Then, you need to uninstall the previous version of FIFA apkdone from your device and install the new version following the same steps we have provided in this article.
-
How can I contact the developers or support team of FIFA apkdone?
How can I access more features and content in FIFA apkdone?
-
To access more features and content in FIFA apkdone, you need to earn more coins and points by playing the game modes and options available in the game. You can also use some cheats or hacks that are provided by some websites or apps online. However, you need to be careful and cautious when using these cheats or hacks, as they may harm your device or data, or get you banned from the game.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/4Taps/SadTalker/src/facerender/sync_batchnorm/replicate.py b/spaces/4Taps/SadTalker/src/facerender/sync_batchnorm/replicate.py
deleted file mode 100644
index b71c7b8ed51a1d6c55b1f753bdd8d90bad79bd06..0000000000000000000000000000000000000000
--- a/spaces/4Taps/SadTalker/src/facerender/sync_batchnorm/replicate.py
+++ /dev/null
@@ -1,94 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : replicate.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-import functools
-
-from torch.nn.parallel.data_parallel import DataParallel
-
-__all__ = [
- 'CallbackContext',
- 'execute_replication_callbacks',
- 'DataParallelWithCallback',
- 'patch_replication_callback'
-]
-
-
-class CallbackContext(object):
- pass
-
-
-def execute_replication_callbacks(modules):
- """
- Execute an replication callback `__data_parallel_replicate__` on each module created by original replication.
-
- The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)`
-
- Note that, as all modules are isomorphism, we assign each sub-module with a context
- (shared among multiple copies of this module on different devices).
- Through this context, different copies can share some information.
-
- We guarantee that the callback on the master copy (the first copy) will be called ahead of calling the callback
- of any slave copies.
- """
- master_copy = modules[0]
- nr_modules = len(list(master_copy.modules()))
- ctxs = [CallbackContext() for _ in range(nr_modules)]
-
- for i, module in enumerate(modules):
- for j, m in enumerate(module.modules()):
- if hasattr(m, '__data_parallel_replicate__'):
- m.__data_parallel_replicate__(ctxs[j], i)
-
-
-class DataParallelWithCallback(DataParallel):
- """
- Data Parallel with a replication callback.
-
- An replication callback `__data_parallel_replicate__` of each module will be invoked after being created by
- original `replicate` function.
- The callback will be invoked with arguments `__data_parallel_replicate__(ctx, copy_id)`
-
- Examples:
- > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
- > sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1])
- # sync_bn.__data_parallel_replicate__ will be invoked.
- """
-
- def replicate(self, module, device_ids):
- modules = super(DataParallelWithCallback, self).replicate(module, device_ids)
- execute_replication_callbacks(modules)
- return modules
-
-
-def patch_replication_callback(data_parallel):
- """
- Monkey-patch an existing `DataParallel` object. Add the replication callback.
- Useful when you have customized `DataParallel` implementation.
-
- Examples:
- > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
- > sync_bn = DataParallel(sync_bn, device_ids=[0, 1])
- > patch_replication_callback(sync_bn)
- # this is equivalent to
- > sync_bn = SynchronizedBatchNorm1d(10, eps=1e-5, affine=False)
- > sync_bn = DataParallelWithCallback(sync_bn, device_ids=[0, 1])
- """
-
- assert isinstance(data_parallel, DataParallel)
-
- old_replicate = data_parallel.replicate
-
- @functools.wraps(old_replicate)
- def new_replicate(module, device_ids):
- modules = old_replicate(module, device_ids)
- execute_replication_callbacks(modules)
- return modules
-
- data_parallel.replicate = new_replicate
diff --git a/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/open_clip/linear_probe.py b/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/open_clip/linear_probe.py
deleted file mode 100644
index 9d7e23b6b67a53e16d050d675a99d01d7d04d581..0000000000000000000000000000000000000000
--- a/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/open_clip/linear_probe.py
+++ /dev/null
@@ -1,66 +0,0 @@
-import numpy as np
-import torch.nn.functional as F
-from torch import nn
-from .model import MLPLayers
-
-
-class LinearProbe(nn.Module):
- def __init__(self, model, mlp, freeze, in_ch, out_ch, act=None):
- """
- Args:
- model: nn.Module
- mlp: bool, if True, then use the MLP layer as the linear probe module
- freeze: bool, if Ture, then freeze all the CLAP model's layers when training the linear probe
- in_ch: int, the output channel from CLAP model
- out_ch: int, the output channel from linear probe (class_num)
- act: torch.nn.functional, the activation function before the loss function
- """
- super().__init__()
- in_ch = 512
- self.clap_model = model
- self.clap_model.text_branch = None # to save memory
- self.freeze = freeze
- if mlp:
- self.lp_layer = MLPLayers(units=[in_ch, in_ch * 2, out_ch])
- else:
- self.lp_layer = nn.Linear(in_ch, out_ch)
-
- if self.freeze:
- for param in self.clap_model.parameters():
- param.requires_grad = False
-
- if act == "None":
- self.act = None
- elif act == "relu":
- self.act = nn.ReLU()
- elif act == "elu":
- self.act = nn.ELU()
- elif act == "prelu":
- self.act = nn.PReLU(num_parameters=in_ch)
- elif act == "softmax":
- self.act = nn.Softmax(dim=-1)
- elif act == "sigmoid":
- self.act = nn.Sigmoid()
-
- def forward(self, x, mix_lambda=None, device=None):
- """
- Args:
- x: waveform, torch.tensor [batch, t_samples] / batch of mel_spec and longer list
- mix_lambda: torch.tensor [batch], the mixup lambda
- Returns:
- class_prob: torch.tensor [batch, class_num]
-
- """
- # batchnorm cancel grandient
- if self.freeze:
- self.clap_model.eval()
-
- x = self.clap_model.audio_projection(
- self.clap_model.audio_branch(x, mixup_lambda=mix_lambda, device=device)[
- "embedding"
- ]
- )
- out = self.lp_layer(x)
- if self.act is not None:
- out = self.act(out)
- return out
diff --git a/spaces/AIGC-Audio/AudioGPT/NeuralSeq/utils/pl_utils.py b/spaces/AIGC-Audio/AudioGPT/NeuralSeq/utils/pl_utils.py
deleted file mode 100644
index 76a94ed6abe22e349c51c49afdbf052d52b8d98b..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/AudioGPT/NeuralSeq/utils/pl_utils.py
+++ /dev/null
@@ -1,1618 +0,0 @@
-import matplotlib
-from torch.nn import DataParallel
-from torch.nn.parallel import DistributedDataParallel
-
-matplotlib.use('Agg')
-import glob
-import itertools
-import subprocess
-import threading
-import traceback
-
-from pytorch_lightning.callbacks import GradientAccumulationScheduler
-from pytorch_lightning.callbacks import ModelCheckpoint
-
-from functools import wraps
-from torch.cuda._utils import _get_device_index
-import numpy as np
-import torch.optim
-import torch.utils.data
-import copy
-import logging
-import os
-import re
-import sys
-import torch
-import torch.distributed as dist
-import torch.multiprocessing as mp
-import tqdm
-from torch.optim.optimizer import Optimizer
-
-
-def get_a_var(obj): # pragma: no cover
- if isinstance(obj, torch.Tensor):
- return obj
-
- if isinstance(obj, list) or isinstance(obj, tuple):
- for result in map(get_a_var, obj):
- if isinstance(result, torch.Tensor):
- return result
- if isinstance(obj, dict):
- for result in map(get_a_var, obj.items()):
- if isinstance(result, torch.Tensor):
- return result
- return None
-
-
-def data_loader(fn):
- """
- Decorator to make any fx with this use the lazy property
- :param fn:
- :return:
- """
-
- wraps(fn)
- attr_name = '_lazy_' + fn.__name__
-
- def _get_data_loader(self):
- try:
- value = getattr(self, attr_name)
- except AttributeError:
- try:
- value = fn(self) # Lazy evaluation, done only once.
- if (
- value is not None and
- not isinstance(value, list) and
- fn.__name__ in ['test_dataloader', 'val_dataloader']
- ):
- value = [value]
- except AttributeError as e:
- # Guard against AttributeError suppression. (Issue #142)
- traceback.print_exc()
- error = f'{fn.__name__}: An AttributeError was encountered: ' + str(e)
- raise RuntimeError(error) from e
- setattr(self, attr_name, value) # Memoize evaluation.
- return value
-
- return _get_data_loader
-
-
-def parallel_apply(modules, inputs, kwargs_tup=None, devices=None): # pragma: no cover
- r"""Applies each `module` in :attr:`modules` in parallel on arguments
- contained in :attr:`inputs` (positional) and :attr:`kwargs_tup` (keyword)
- on each of :attr:`devices`.
-
- Args:
- modules (Module): modules to be parallelized
- inputs (tensor): inputs to the modules
- devices (list of int or torch.device): CUDA devices
-
- :attr:`modules`, :attr:`inputs`, :attr:`kwargs_tup` (if given), and
- :attr:`devices` (if given) should all have same length. Moreover, each
- element of :attr:`inputs` can either be a single object as the only argument
- to a module, or a collection of positional arguments.
- """
- assert len(modules) == len(inputs)
- if kwargs_tup is not None:
- assert len(modules) == len(kwargs_tup)
- else:
- kwargs_tup = ({},) * len(modules)
- if devices is not None:
- assert len(modules) == len(devices)
- else:
- devices = [None] * len(modules)
- devices = list(map(lambda x: _get_device_index(x, True), devices))
- lock = threading.Lock()
- results = {}
- grad_enabled = torch.is_grad_enabled()
-
- def _worker(i, module, input, kwargs, device=None):
- torch.set_grad_enabled(grad_enabled)
- if device is None:
- device = get_a_var(input).get_device()
- try:
- with torch.cuda.device(device):
- # this also avoids accidental slicing of `input` if it is a Tensor
- if not isinstance(input, (list, tuple)):
- input = (input,)
-
- # ---------------
- # CHANGE
- if module.training:
- output = module.training_step(*input, **kwargs)
-
- elif module.testing:
- output = module.test_step(*input, **kwargs)
-
- else:
- output = module.validation_step(*input, **kwargs)
- # ---------------
-
- with lock:
- results[i] = output
- except Exception as e:
- with lock:
- results[i] = e
-
- # make sure each module knows what training state it's in...
- # fixes weird bug where copies are out of sync
- root_m = modules[0]
- for m in modules[1:]:
- m.training = root_m.training
- m.testing = root_m.testing
-
- if len(modules) > 1:
- threads = [threading.Thread(target=_worker,
- args=(i, module, input, kwargs, device))
- for i, (module, input, kwargs, device) in
- enumerate(zip(modules, inputs, kwargs_tup, devices))]
-
- for thread in threads:
- thread.start()
- for thread in threads:
- thread.join()
- else:
- _worker(0, modules[0], inputs[0], kwargs_tup[0], devices[0])
-
- outputs = []
- for i in range(len(inputs)):
- output = results[i]
- if isinstance(output, Exception):
- raise output
- outputs.append(output)
- return outputs
-
-
-def _find_tensors(obj): # pragma: no cover
- r"""
- Recursively find all tensors contained in the specified object.
- """
- if isinstance(obj, torch.Tensor):
- return [obj]
- if isinstance(obj, (list, tuple)):
- return itertools.chain(*map(_find_tensors, obj))
- if isinstance(obj, dict):
- return itertools.chain(*map(_find_tensors, obj.values()))
- return []
-
-
-class DDP(DistributedDataParallel):
- """
- Override the forward call in lightning so it goes to training and validation step respectively
- """
-
- def parallel_apply(self, replicas, inputs, kwargs):
- return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
-
- def forward(self, *inputs, **kwargs): # pragma: no cover
- self._sync_params()
- if self.device_ids:
- inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
- if len(self.device_ids) == 1:
- # --------------
- # LIGHTNING MOD
- # --------------
- # normal
- # output = self.module(*inputs[0], **kwargs[0])
- # lightning
- if self.module.training:
- output = self.module.training_step(*inputs[0], **kwargs[0])
- elif self.module.testing:
- output = self.module.test_step(*inputs[0], **kwargs[0])
- else:
- output = self.module.validation_step(*inputs[0], **kwargs[0])
- else:
- outputs = self.parallel_apply(self._module_copies[:len(inputs)], inputs, kwargs)
- output = self.gather(outputs, self.output_device)
- else:
- # normal
- output = self.module(*inputs, **kwargs)
-
- if torch.is_grad_enabled():
- # We'll return the output object verbatim since it is a freeform
- # object. We need to find any tensors in this object, though,
- # because we need to figure out which parameters were used during
- # this forward pass, to ensure we short circuit reduction for any
- # unused parameters. Only if `find_unused_parameters` is set.
- if self.find_unused_parameters:
- self.reducer.prepare_for_backward(list(_find_tensors(output)))
- else:
- self.reducer.prepare_for_backward([])
- return output
-
-
-class DP(DataParallel):
- """
- Override the forward call in lightning so it goes to training and validation step respectively
- """
-
- def forward(self, *inputs, **kwargs):
- if not self.device_ids:
- return self.module(*inputs, **kwargs)
-
- for t in itertools.chain(self.module.parameters(), self.module.buffers()):
- if t.device != self.src_device_obj:
- raise RuntimeError("module must have its parameters and buffers "
- "on device {} (device_ids[0]) but found one of "
- "them on device: {}".format(self.src_device_obj, t.device))
-
- inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
- if len(self.device_ids) == 1:
- # lightning
- if self.module.training:
- return self.module.training_step(*inputs[0], **kwargs[0])
- elif self.module.testing:
- return self.module.test_step(*inputs[0], **kwargs[0])
- else:
- return self.module.validation_step(*inputs[0], **kwargs[0])
-
- replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
- outputs = self.parallel_apply(replicas, inputs, kwargs)
- return self.gather(outputs, self.output_device)
-
- def parallel_apply(self, replicas, inputs, kwargs):
- return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
-
-
-class GradientAccumulationScheduler:
- def __init__(self, scheduling: dict):
- if scheduling == {}: # empty dict error
- raise TypeError("Empty dict cannot be interpreted correct")
-
- for key in scheduling.keys():
- if not isinstance(key, int) or not isinstance(scheduling[key], int):
- raise TypeError("All epoches and accumulation factor must be integers")
-
- minimal_epoch = min(scheduling.keys())
- if minimal_epoch < 1:
- msg = f"Epochs indexing from 1, epoch {minimal_epoch} cannot be interpreted correct"
- raise IndexError(msg)
- elif minimal_epoch != 1: # if user didnt define first epoch accumulation factor
- scheduling.update({1: 1})
-
- self.scheduling = scheduling
- self.epochs = sorted(scheduling.keys())
-
- def on_epoch_begin(self, epoch, trainer):
- epoch += 1 # indexing epochs from 1
- for i in reversed(range(len(self.epochs))):
- if epoch >= self.epochs[i]:
- trainer.accumulate_grad_batches = self.scheduling.get(self.epochs[i])
- break
-
-
-class LatestModelCheckpoint(ModelCheckpoint):
- def __init__(self, filepath, monitor='val_loss', verbose=0, num_ckpt_keep=5,
- save_weights_only=False, mode='auto', period=1, prefix='model', save_best=True):
- super(ModelCheckpoint, self).__init__()
- self.monitor = monitor
- self.verbose = verbose
- self.filepath = filepath
- os.makedirs(filepath, exist_ok=True)
- self.num_ckpt_keep = num_ckpt_keep
- self.save_best = save_best
- self.save_weights_only = save_weights_only
- self.period = period
- self.epochs_since_last_check = 0
- self.prefix = prefix
- self.best_k_models = {}
- # {filename: monitor}
- self.kth_best_model = ''
- self.save_top_k = 1
- self.task = None
- if mode == 'min':
- self.monitor_op = np.less
- self.best = np.Inf
- self.mode = 'min'
- elif mode == 'max':
- self.monitor_op = np.greater
- self.best = -np.Inf
- self.mode = 'max'
- else:
- if 'acc' in self.monitor or self.monitor.startswith('fmeasure'):
- self.monitor_op = np.greater
- self.best = -np.Inf
- self.mode = 'max'
- else:
- self.monitor_op = np.less
- self.best = np.Inf
- self.mode = 'min'
- if os.path.exists(f'{self.filepath}/best_valid.npy'):
- self.best = np.load(f'{self.filepath}/best_valid.npy')[0]
-
- def get_all_ckpts(self):
- return sorted(glob.glob(f'{self.filepath}/{self.prefix}_ckpt_steps_*.ckpt'),
- key=lambda x: -int(re.findall('.*steps\_(\d+)\.ckpt', x)[0]))
-
- def on_epoch_end(self, epoch, logs=None):
- logs = logs or {}
- self.epochs_since_last_check += 1
- best_filepath = f'{self.filepath}/{self.prefix}_ckpt_best.pt'
- if self.epochs_since_last_check >= self.period:
- self.epochs_since_last_check = 0
- filepath = f'{self.filepath}/{self.prefix}_ckpt_steps_{self.task.global_step}.ckpt'
- if self.verbose > 0:
- logging.info(f'Epoch {epoch:05d}@{self.task.global_step}: saving model to {filepath}')
- self._save_model(filepath)
- for old_ckpt in self.get_all_ckpts()[self.num_ckpt_keep:]:
- subprocess.check_call(f'rm -rf "{old_ckpt}"', shell=True)
- if self.verbose > 0:
- logging.info(f'Delete ckpt: {os.path.basename(old_ckpt)}')
- current = logs.get(self.monitor)
- if current is not None and self.save_best:
- if self.monitor_op(current, self.best):
- self.best = current
- if self.verbose > 0:
- logging.info(
- f'Epoch {epoch:05d}@{self.task.global_step}: {self.monitor} reached'
- f' {current:0.5f} (best {self.best:0.5f}), saving model to'
- f' {best_filepath} as top 1')
- self._save_model(best_filepath)
- np.save(f'{self.filepath}/best_valid.npy', [self.best])
-
-
-class BaseTrainer:
- def __init__(
- self,
- logger=True,
- checkpoint_callback=True,
- default_save_path=None,
- gradient_clip_val=0,
- process_position=0,
- gpus=-1,
- log_gpu_memory=None,
- show_progress_bar=True,
- track_grad_norm=-1,
- check_val_every_n_epoch=1,
- accumulate_grad_batches=1,
- max_updates=1000,
- min_epochs=1,
- val_check_interval=1.0,
- log_save_interval=100,
- row_log_interval=10,
- print_nan_grads=False,
- weights_summary='full',
- num_sanity_val_steps=5,
- resume_from_checkpoint=None,
- ):
- self.log_gpu_memory = log_gpu_memory
- self.gradient_clip_val = gradient_clip_val
- self.check_val_every_n_epoch = check_val_every_n_epoch
- self.track_grad_norm = track_grad_norm
- self.on_gpu = True if (gpus and torch.cuda.is_available()) else False
- self.process_position = process_position
- self.weights_summary = weights_summary
- self.max_updates = max_updates
- self.min_epochs = min_epochs
- self.num_sanity_val_steps = num_sanity_val_steps
- self.print_nan_grads = print_nan_grads
- self.resume_from_checkpoint = resume_from_checkpoint
- self.default_save_path = default_save_path
-
- # training bookeeping
- self.total_batch_idx = 0
- self.running_loss = []
- self.avg_loss = 0
- self.batch_idx = 0
- self.tqdm_metrics = {}
- self.callback_metrics = {}
- self.num_val_batches = 0
- self.num_training_batches = 0
- self.num_test_batches = 0
- self.get_train_dataloader = None
- self.get_test_dataloaders = None
- self.get_val_dataloaders = None
- self.is_iterable_train_dataloader = False
-
- # training state
- self.model = None
- self.testing = False
- self.disable_validation = False
- self.lr_schedulers = []
- self.optimizers = None
- self.global_step = 0
- self.current_epoch = 0
- self.total_batches = 0
-
- # configure checkpoint callback
- self.checkpoint_callback = checkpoint_callback
- self.checkpoint_callback.save_function = self.save_checkpoint
- self.weights_save_path = self.checkpoint_callback.filepath
-
- # accumulated grads
- self.configure_accumulated_gradients(accumulate_grad_batches)
-
- # allow int, string and gpu list
- self.data_parallel_device_ids = [
- int(x) for x in os.environ.get("CUDA_VISIBLE_DEVICES", "").split(",") if x != '']
- if len(self.data_parallel_device_ids) == 0:
- self.root_gpu = None
- self.on_gpu = False
- else:
- self.root_gpu = self.data_parallel_device_ids[0]
- self.on_gpu = True
-
- # distributed backend choice
- self.use_ddp = False
- self.use_dp = False
- self.single_gpu = False
- self.distributed_backend = 'ddp' if self.num_gpus > 0 else 'dp'
- self.set_distributed_mode(self.distributed_backend)
-
- self.proc_rank = 0
- self.world_size = 1
- self.node_rank = 0
-
- # can't init progress bar here because starting a new process
- # means the progress_bar won't survive pickling
- self.show_progress_bar = show_progress_bar
-
- # logging
- self.log_save_interval = log_save_interval
- self.val_check_interval = val_check_interval
- self.logger = logger
- self.logger.rank = 0
- self.row_log_interval = row_log_interval
-
- @property
- def num_gpus(self):
- gpus = self.data_parallel_device_ids
- if gpus is None:
- return 0
- else:
- return len(gpus)
-
- @property
- def data_parallel(self):
- return self.use_dp or self.use_ddp
-
- def get_model(self):
- is_dp_module = isinstance(self.model, (DDP, DP))
- model = self.model.module if is_dp_module else self.model
- return model
-
- # -----------------------------
- # MODEL TRAINING
- # -----------------------------
- def fit(self, model):
- if self.use_ddp:
- mp.spawn(self.ddp_train, nprocs=self.num_gpus, args=(model,))
- else:
- model.model = model.build_model()
- if not self.testing:
- self.optimizers, self.lr_schedulers = self.init_optimizers(model.configure_optimizers())
- if self.use_dp:
- model.cuda(self.root_gpu)
- model = DP(model, device_ids=self.data_parallel_device_ids)
- elif self.single_gpu:
- model.cuda(self.root_gpu)
- self.run_pretrain_routine(model)
- return 1
-
- def init_optimizers(self, optimizers):
-
- # single optimizer
- if isinstance(optimizers, Optimizer):
- return [optimizers], []
-
- # two lists
- elif len(optimizers) == 2 and isinstance(optimizers[0], list):
- optimizers, lr_schedulers = optimizers
- return optimizers, lr_schedulers
-
- # single list or tuple
- elif isinstance(optimizers, list) or isinstance(optimizers, tuple):
- return optimizers, []
-
- def run_pretrain_routine(self, model):
- """Sanity check a few things before starting actual training.
-
- :param model:
- """
- ref_model = model
- if self.data_parallel:
- ref_model = model.module
-
- # give model convenience properties
- ref_model.trainer = self
-
- # set local properties on the model
- self.copy_trainer_model_properties(ref_model)
-
- # link up experiment object
- if self.logger is not None:
- ref_model.logger = self.logger
- self.logger.save()
-
- if self.use_ddp:
- dist.barrier()
-
- # set up checkpoint callback
- # self.configure_checkpoint_callback()
-
- # transfer data loaders from model
- self.get_dataloaders(ref_model)
-
- # track model now.
- # if cluster resets state, the model will update with the saved weights
- self.model = model
-
- # restore training and model before hpc call
- self.restore_weights(model)
-
- # when testing requested only run test and return
- if self.testing:
- self.run_evaluation(test=True)
- return
-
- # check if we should run validation during training
- self.disable_validation = self.num_val_batches == 0
-
- # run tiny validation (if validation defined)
- # to make sure program won't crash during val
- ref_model.on_sanity_check_start()
- ref_model.on_train_start()
- if not self.disable_validation and self.num_sanity_val_steps > 0:
- # init progress bars for validation sanity check
- pbar = tqdm.tqdm(desc='Validation sanity check',
- total=self.num_sanity_val_steps * len(self.get_val_dataloaders()),
- leave=False, position=2 * self.process_position,
- disable=not self.show_progress_bar, dynamic_ncols=True, unit='batch')
- self.main_progress_bar = pbar
- # dummy validation progress bar
- self.val_progress_bar = tqdm.tqdm(disable=True)
-
- self.evaluate(model, self.get_val_dataloaders(), self.num_sanity_val_steps, self.testing)
-
- # close progress bars
- self.main_progress_bar.close()
- self.val_progress_bar.close()
-
- # init progress bar
- pbar = tqdm.tqdm(leave=True, position=2 * self.process_position,
- disable=not self.show_progress_bar, dynamic_ncols=True, unit='batch',
- file=sys.stdout)
- self.main_progress_bar = pbar
-
- # clear cache before training
- if self.on_gpu:
- torch.cuda.empty_cache()
-
- # CORE TRAINING LOOP
- self.train()
-
- def test(self, model):
- self.testing = True
- self.fit(model)
-
- @property
- def training_tqdm_dict(self):
- tqdm_dict = {
- 'step': '{}'.format(self.global_step),
- }
- tqdm_dict.update(self.tqdm_metrics)
- return tqdm_dict
-
- # --------------------
- # restore ckpt
- # --------------------
- def restore_weights(self, model):
- """
- To restore weights we have two cases.
- First, attempt to restore hpc weights. If successful, don't restore
- other weights.
-
- Otherwise, try to restore actual weights
- :param model:
- :return:
- """
- # clear cache before restore
- if self.on_gpu:
- torch.cuda.empty_cache()
-
- if self.resume_from_checkpoint is not None:
- self.restore(self.resume_from_checkpoint, on_gpu=self.on_gpu)
- else:
- # restore weights if same exp version
- self.restore_state_if_checkpoint_exists(model)
-
- # wait for all models to restore weights
- if self.use_ddp:
- # wait for all processes to catch up
- dist.barrier()
-
- # clear cache after restore
- if self.on_gpu:
- torch.cuda.empty_cache()
-
- def restore_state_if_checkpoint_exists(self, model):
- did_restore = False
-
- # do nothing if there's not dir or callback
- no_ckpt_callback = (self.checkpoint_callback is None) or (not self.checkpoint_callback)
- if no_ckpt_callback or not os.path.exists(self.checkpoint_callback.filepath):
- return did_restore
-
- # restore trainer state and model if there is a weight for this experiment
- last_steps = -1
- last_ckpt_name = None
-
- # find last epoch
- checkpoints = os.listdir(self.checkpoint_callback.filepath)
- for name in checkpoints:
- if '.ckpt' in name and not name.endswith('part'):
- if 'steps_' in name:
- steps = name.split('steps_')[1]
- steps = int(re.sub('[^0-9]', '', steps))
-
- if steps > last_steps:
- last_steps = steps
- last_ckpt_name = name
-
- # restore last checkpoint
- if last_ckpt_name is not None:
- last_ckpt_path = os.path.join(self.checkpoint_callback.filepath, last_ckpt_name)
- self.restore(last_ckpt_path, self.on_gpu)
- logging.info(f'model and trainer restored from checkpoint: {last_ckpt_path}')
- did_restore = True
-
- return did_restore
-
- def restore(self, checkpoint_path, on_gpu):
- checkpoint = torch.load(checkpoint_path, map_location='cpu')
-
- # load model state
- model = self.get_model()
-
- # load the state_dict on the model automatically
- model.load_state_dict(checkpoint['state_dict'], strict=False)
- if on_gpu:
- model.cuda(self.root_gpu)
- # load training state (affects trainer only)
- self.restore_training_state(checkpoint)
- model.global_step = self.global_step
- del checkpoint
-
- try:
- if dist.is_initialized() and dist.get_rank() > 0:
- return
- except Exception as e:
- print(e)
- return
-
- def restore_training_state(self, checkpoint):
- """
- Restore trainer state.
- Model will get its change to update
- :param checkpoint:
- :return:
- """
- if self.checkpoint_callback is not None and self.checkpoint_callback is not False:
- self.checkpoint_callback.best = checkpoint['checkpoint_callback_best']
-
- self.global_step = checkpoint['global_step']
- self.current_epoch = checkpoint['epoch']
-
- if self.testing:
- return
-
- # restore the optimizers
- optimizer_states = checkpoint['optimizer_states']
- for optimizer, opt_state in zip(self.optimizers, optimizer_states):
- if optimizer is None:
- return
- optimizer.load_state_dict(opt_state)
-
- # move optimizer to GPU 1 weight at a time
- # avoids OOM
- if self.root_gpu is not None:
- for state in optimizer.state.values():
- for k, v in state.items():
- if isinstance(v, torch.Tensor):
- state[k] = v.cuda(self.root_gpu)
-
- # restore the lr schedulers
- lr_schedulers = checkpoint['lr_schedulers']
- for scheduler, lrs_state in zip(self.lr_schedulers, lr_schedulers):
- scheduler.load_state_dict(lrs_state)
-
- # --------------------
- # MODEL SAVE CHECKPOINT
- # --------------------
- def _atomic_save(self, checkpoint, filepath):
- """Saves a checkpoint atomically, avoiding the creation of incomplete checkpoints.
-
- This will create a temporary checkpoint with a suffix of ``.part``, then copy it to the final location once
- saving is finished.
-
- Args:
- checkpoint (object): The object to save.
- Built to be used with the ``dump_checkpoint`` method, but can deal with anything which ``torch.save``
- accepts.
- filepath (str|pathlib.Path): The path to which the checkpoint will be saved.
- This points to the file that the checkpoint will be stored in.
- """
- tmp_path = str(filepath) + ".part"
- torch.save(checkpoint, tmp_path)
- os.replace(tmp_path, filepath)
-
- def save_checkpoint(self, filepath):
- checkpoint = self.dump_checkpoint()
- self._atomic_save(checkpoint, filepath)
-
- def dump_checkpoint(self):
-
- checkpoint = {
- 'epoch': self.current_epoch,
- 'global_step': self.global_step
- }
-
- if self.checkpoint_callback is not None and self.checkpoint_callback is not False:
- checkpoint['checkpoint_callback_best'] = self.checkpoint_callback.best
-
- # save optimizers
- optimizer_states = []
- for i, optimizer in enumerate(self.optimizers):
- if optimizer is not None:
- optimizer_states.append(optimizer.state_dict())
-
- checkpoint['optimizer_states'] = optimizer_states
-
- # save lr schedulers
- lr_schedulers = []
- for i, scheduler in enumerate(self.lr_schedulers):
- lr_schedulers.append(scheduler.state_dict())
-
- checkpoint['lr_schedulers'] = lr_schedulers
-
- # add the hparams and state_dict from the model
- model = self.get_model()
- checkpoint['state_dict'] = model.state_dict()
- # give the model a chance to add a few things
- model.on_save_checkpoint(checkpoint)
-
- return checkpoint
-
- def copy_trainer_model_properties(self, model):
- if isinstance(model, DP):
- ref_model = model.module
- elif isinstance(model, DDP):
- ref_model = model.module
- else:
- ref_model = model
-
- for m in [model, ref_model]:
- m.trainer = self
- m.on_gpu = self.on_gpu
- m.use_dp = self.use_dp
- m.use_ddp = self.use_ddp
- m.testing = self.testing
- m.single_gpu = self.single_gpu
-
- def transfer_batch_to_gpu(self, batch, gpu_id):
- # base case: object can be directly moved using `cuda` or `to`
- if callable(getattr(batch, 'cuda', None)):
- return batch.cuda(gpu_id, non_blocking=True)
-
- elif callable(getattr(batch, 'to', None)):
- return batch.to(torch.device('cuda', gpu_id), non_blocking=True)
-
- # when list
- elif isinstance(batch, list):
- for i, x in enumerate(batch):
- batch[i] = self.transfer_batch_to_gpu(x, gpu_id)
- return batch
-
- # when tuple
- elif isinstance(batch, tuple):
- batch = list(batch)
- for i, x in enumerate(batch):
- batch[i] = self.transfer_batch_to_gpu(x, gpu_id)
- return tuple(batch)
-
- # when dict
- elif isinstance(batch, dict):
- for k, v in batch.items():
- batch[k] = self.transfer_batch_to_gpu(v, gpu_id)
-
- return batch
-
- # nothing matches, return the value as is without transform
- return batch
-
- def set_distributed_mode(self, distributed_backend):
- # skip for CPU
- if self.num_gpus == 0:
- return
-
- # single GPU case
- # in single gpu case we allow ddp so we can train on multiple
- # nodes, 1 gpu per node
- elif self.num_gpus == 1:
- self.single_gpu = True
- self.use_dp = False
- self.use_ddp = False
- self.root_gpu = 0
- self.data_parallel_device_ids = [0]
- else:
- if distributed_backend is not None:
- self.use_dp = distributed_backend == 'dp'
- self.use_ddp = distributed_backend == 'ddp'
- elif distributed_backend is None:
- self.use_dp = True
- self.use_ddp = False
-
- logging.info(f'gpu available: {torch.cuda.is_available()}, used: {self.on_gpu}')
-
- def ddp_train(self, gpu_idx, model):
- """
- Entry point into a DP thread
- :param gpu_idx:
- :param model:
- :param cluster_obj:
- :return:
- """
- # otherwise default to node rank 0
- self.node_rank = 0
-
- # show progressbar only on progress_rank 0
- self.show_progress_bar = self.show_progress_bar and self.node_rank == 0 and gpu_idx == 0
-
- # determine which process we are and world size
- if self.use_ddp:
- self.proc_rank = self.node_rank * self.num_gpus + gpu_idx
- self.world_size = self.num_gpus
-
- # let the exp know the rank to avoid overwriting logs
- if self.logger is not None:
- self.logger.rank = self.proc_rank
-
- # set up server using proc 0's ip address
- # try to init for 20 times at max in case ports are taken
- # where to store ip_table
- model.trainer = self
- model.init_ddp_connection(self.proc_rank, self.world_size)
-
- # CHOOSE OPTIMIZER
- # allow for lr schedulers as well
- model.model = model.build_model()
- if not self.testing:
- self.optimizers, self.lr_schedulers = self.init_optimizers(model.configure_optimizers())
-
- # MODEL
- # copy model to each gpu
- if self.distributed_backend == 'ddp':
- torch.cuda.set_device(gpu_idx)
- model.cuda(gpu_idx)
-
- # set model properties before going into wrapper
- self.copy_trainer_model_properties(model)
-
- # override root GPU
- self.root_gpu = gpu_idx
-
- if self.distributed_backend == 'ddp':
- device_ids = [gpu_idx]
- else:
- device_ids = None
-
- # allow user to configure ddp
- model = model.configure_ddp(model, device_ids)
-
- # continue training routine
- self.run_pretrain_routine(model)
-
- def resolve_root_node_address(self, root_node):
- if '[' in root_node:
- name = root_node.split('[')[0]
- number = root_node.split(',')[0]
- if '-' in number:
- number = number.split('-')[0]
-
- number = re.sub('[^0-9]', '', number)
- root_node = name + number
-
- return root_node
-
- def log_metrics(self, metrics, grad_norm_dic, step=None):
- """Logs the metric dict passed in.
-
- :param metrics:
- :param grad_norm_dic:
- """
- # added metrics by Lightning for convenience
- metrics['epoch'] = self.current_epoch
-
- # add norms
- metrics.update(grad_norm_dic)
-
- # turn all tensors to scalars
- scalar_metrics = self.metrics_to_scalars(metrics)
-
- step = step if step is not None else self.global_step
- # log actual metrics
- if self.proc_rank == 0 and self.logger is not None:
- self.logger.log_metrics(scalar_metrics, step=step)
- self.logger.save()
-
- def add_tqdm_metrics(self, metrics):
- for k, v in metrics.items():
- if type(v) is torch.Tensor:
- v = v.item()
-
- self.tqdm_metrics[k] = v
-
- def metrics_to_scalars(self, metrics):
- new_metrics = {}
- for k, v in metrics.items():
- if isinstance(v, torch.Tensor):
- v = v.item()
-
- if type(v) is dict:
- v = self.metrics_to_scalars(v)
-
- new_metrics[k] = v
-
- return new_metrics
-
- def process_output(self, output, train=False):
- """Reduces output according to the training mode.
-
- Separates loss from logging and tqdm metrics
- :param output:
- :return:
- """
- # ---------------
- # EXTRACT CALLBACK KEYS
- # ---------------
- # all keys not progress_bar or log are candidates for callbacks
- callback_metrics = {}
- for k, v in output.items():
- if k not in ['progress_bar', 'log', 'hiddens']:
- callback_metrics[k] = v
-
- if train and self.use_dp:
- num_gpus = self.num_gpus
- callback_metrics = self.reduce_distributed_output(callback_metrics, num_gpus)
-
- for k, v in callback_metrics.items():
- if isinstance(v, torch.Tensor):
- callback_metrics[k] = v.item()
-
- # ---------------
- # EXTRACT PROGRESS BAR KEYS
- # ---------------
- try:
- progress_output = output['progress_bar']
-
- # reduce progress metrics for tqdm when using dp
- if train and self.use_dp:
- num_gpus = self.num_gpus
- progress_output = self.reduce_distributed_output(progress_output, num_gpus)
-
- progress_bar_metrics = progress_output
- except Exception:
- progress_bar_metrics = {}
-
- # ---------------
- # EXTRACT LOGGING KEYS
- # ---------------
- # extract metrics to log to experiment
- try:
- log_output = output['log']
-
- # reduce progress metrics for tqdm when using dp
- if train and self.use_dp:
- num_gpus = self.num_gpus
- log_output = self.reduce_distributed_output(log_output, num_gpus)
-
- log_metrics = log_output
- except Exception:
- log_metrics = {}
-
- # ---------------
- # EXTRACT LOSS
- # ---------------
- # if output dict doesn't have the keyword loss
- # then assume the output=loss if scalar
- loss = None
- if train:
- try:
- loss = output['loss']
- except Exception:
- if type(output) is torch.Tensor:
- loss = output
- else:
- raise RuntimeError(
- 'No `loss` value in the dictionary returned from `model.training_step()`.'
- )
-
- # when using dp need to reduce the loss
- if self.use_dp:
- loss = self.reduce_distributed_output(loss, self.num_gpus)
-
- # ---------------
- # EXTRACT HIDDEN
- # ---------------
- hiddens = output.get('hiddens')
-
- # use every metric passed in as a candidate for callback
- callback_metrics.update(progress_bar_metrics)
- callback_metrics.update(log_metrics)
-
- # convert tensors to numpy
- for k, v in callback_metrics.items():
- if isinstance(v, torch.Tensor):
- callback_metrics[k] = v.item()
-
- return loss, progress_bar_metrics, log_metrics, callback_metrics, hiddens
-
- def reduce_distributed_output(self, output, num_gpus):
- if num_gpus <= 1:
- return output
-
- # when using DP, we get one output per gpu
- # average outputs and return
- if type(output) is torch.Tensor:
- return output.mean()
-
- for k, v in output.items():
- # recurse on nested dics
- if isinstance(output[k], dict):
- output[k] = self.reduce_distributed_output(output[k], num_gpus)
-
- # do nothing when there's a scalar
- elif isinstance(output[k], torch.Tensor) and output[k].dim() == 0:
- pass
-
- # reduce only metrics that have the same number of gpus
- elif output[k].size(0) == num_gpus:
- reduced = torch.mean(output[k])
- output[k] = reduced
- return output
-
- def clip_gradients(self):
- if self.gradient_clip_val > 0:
- model = self.get_model()
- torch.nn.utils.clip_grad_norm_(model.parameters(), self.gradient_clip_val)
-
- def print_nan_gradients(self):
- model = self.get_model()
- for param in model.parameters():
- if (param.grad is not None) and torch.isnan(param.grad.float()).any():
- logging.info(param, param.grad)
-
- def configure_accumulated_gradients(self, accumulate_grad_batches):
- self.accumulate_grad_batches = None
-
- if isinstance(accumulate_grad_batches, dict):
- self.accumulation_scheduler = GradientAccumulationScheduler(accumulate_grad_batches)
- elif isinstance(accumulate_grad_batches, int):
- schedule = {1: accumulate_grad_batches}
- self.accumulation_scheduler = GradientAccumulationScheduler(schedule)
- else:
- raise TypeError("Gradient accumulation supports only int and dict types")
-
- def get_dataloaders(self, model):
- if not self.testing:
- self.init_train_dataloader(model)
- self.init_val_dataloader(model)
- else:
- self.init_test_dataloader(model)
-
- if self.use_ddp:
- dist.barrier()
- if not self.testing:
- self.get_train_dataloader()
- self.get_val_dataloaders()
- else:
- self.get_test_dataloaders()
-
- def init_train_dataloader(self, model):
- self.fisrt_epoch = True
- self.get_train_dataloader = model.train_dataloader
- if isinstance(self.get_train_dataloader(), torch.utils.data.DataLoader):
- self.num_training_batches = len(self.get_train_dataloader())
- self.num_training_batches = int(self.num_training_batches)
- else:
- self.num_training_batches = float('inf')
- self.is_iterable_train_dataloader = True
- if isinstance(self.val_check_interval, int):
- self.val_check_batch = self.val_check_interval
- else:
- self._percent_range_check('val_check_interval')
- self.val_check_batch = int(self.num_training_batches * self.val_check_interval)
- self.val_check_batch = max(1, self.val_check_batch)
-
- def init_val_dataloader(self, model):
- self.get_val_dataloaders = model.val_dataloader
- self.num_val_batches = 0
- if self.get_val_dataloaders() is not None:
- if isinstance(self.get_val_dataloaders()[0], torch.utils.data.DataLoader):
- self.num_val_batches = sum(len(dataloader) for dataloader in self.get_val_dataloaders())
- self.num_val_batches = int(self.num_val_batches)
- else:
- self.num_val_batches = float('inf')
-
- def init_test_dataloader(self, model):
- self.get_test_dataloaders = model.test_dataloader
- if self.get_test_dataloaders() is not None:
- if isinstance(self.get_test_dataloaders()[0], torch.utils.data.DataLoader):
- self.num_test_batches = sum(len(dataloader) for dataloader in self.get_test_dataloaders())
- self.num_test_batches = int(self.num_test_batches)
- else:
- self.num_test_batches = float('inf')
-
- def evaluate(self, model, dataloaders, max_batches, test=False):
- """Run evaluation code.
-
- :param model: PT model
- :param dataloaders: list of PT dataloaders
- :param max_batches: Scalar
- :param test: boolean
- :return:
- """
- # enable eval mode
- model.zero_grad()
- model.eval()
-
- # copy properties for forward overrides
- self.copy_trainer_model_properties(model)
-
- # disable gradients to save memory
- torch.set_grad_enabled(False)
-
- if test:
- self.get_model().test_start()
- # bookkeeping
- outputs = []
-
- # run training
- for dataloader_idx, dataloader in enumerate(dataloaders):
- dl_outputs = []
- for batch_idx, batch in enumerate(dataloader):
-
- if batch is None: # pragma: no cover
- continue
-
- # stop short when on fast_dev_run (sets max_batch=1)
- if batch_idx >= max_batches:
- break
-
- # -----------------
- # RUN EVALUATION STEP
- # -----------------
- output = self.evaluation_forward(model,
- batch,
- batch_idx,
- dataloader_idx,
- test)
-
- # track outputs for collation
- dl_outputs.append(output)
-
- # batch done
- if test:
- self.test_progress_bar.update(1)
- else:
- self.val_progress_bar.update(1)
- outputs.append(dl_outputs)
-
- # with a single dataloader don't pass an array
- if len(dataloaders) == 1:
- outputs = outputs[0]
-
- # give model a chance to do something with the outputs (and method defined)
- model = self.get_model()
- if test:
- eval_results_ = model.test_end(outputs)
- else:
- eval_results_ = model.validation_end(outputs)
- eval_results = eval_results_
-
- # enable train mode again
- model.train()
-
- # enable gradients to save memory
- torch.set_grad_enabled(True)
-
- return eval_results
-
- def run_evaluation(self, test=False):
- # when testing make sure user defined a test step
- model = self.get_model()
- model.on_pre_performance_check()
-
- # select dataloaders
- if test:
- dataloaders = self.get_test_dataloaders()
- max_batches = self.num_test_batches
- else:
- # val
- dataloaders = self.get_val_dataloaders()
- max_batches = self.num_val_batches
-
- # init validation or test progress bar
- # main progress bar will already be closed when testing so initial position is free
- position = 2 * self.process_position + (not test)
- desc = 'Testing' if test else 'Validating'
- pbar = tqdm.tqdm(desc=desc, total=max_batches, leave=test, position=position,
- disable=not self.show_progress_bar, dynamic_ncols=True,
- unit='batch', file=sys.stdout)
- setattr(self, f'{"test" if test else "val"}_progress_bar', pbar)
-
- # run evaluation
- eval_results = self.evaluate(self.model,
- dataloaders,
- max_batches,
- test)
- if eval_results is not None:
- _, prog_bar_metrics, log_metrics, callback_metrics, _ = self.process_output(
- eval_results)
-
- # add metrics to prog bar
- self.add_tqdm_metrics(prog_bar_metrics)
-
- # log metrics
- self.log_metrics(log_metrics, {})
-
- # track metrics for callbacks
- self.callback_metrics.update(callback_metrics)
-
- # hook
- model.on_post_performance_check()
-
- # add model specific metrics
- tqdm_metrics = self.training_tqdm_dict
- if not test:
- self.main_progress_bar.set_postfix(**tqdm_metrics)
-
- # close progress bar
- if test:
- self.test_progress_bar.close()
- else:
- self.val_progress_bar.close()
-
- # model checkpointing
- if self.proc_rank == 0 and self.checkpoint_callback is not None and not test:
- self.checkpoint_callback.on_epoch_end(epoch=self.current_epoch,
- logs=self.callback_metrics)
-
- def evaluation_forward(self, model, batch, batch_idx, dataloader_idx, test=False):
- # make dataloader_idx arg in validation_step optional
- args = [batch, batch_idx]
-
- if test and len(self.get_test_dataloaders()) > 1:
- args.append(dataloader_idx)
-
- elif not test and len(self.get_val_dataloaders()) > 1:
- args.append(dataloader_idx)
-
- # handle DP, DDP forward
- if self.use_ddp or self.use_dp:
- output = model(*args)
- return output
-
- # single GPU
- if self.single_gpu:
- # for single GPU put inputs on gpu manually
- root_gpu = 0
- if isinstance(self.data_parallel_device_ids, list):
- root_gpu = self.data_parallel_device_ids[0]
- batch = self.transfer_batch_to_gpu(batch, root_gpu)
- args[0] = batch
-
- # CPU
- if test:
- output = model.test_step(*args)
- else:
- output = model.validation_step(*args)
-
- return output
-
- def train(self):
- model = self.get_model()
- # run all epochs
- for epoch in range(self.current_epoch, 1000000):
- # set seed for distributed sampler (enables shuffling for each epoch)
- if self.use_ddp and hasattr(self.get_train_dataloader().sampler, 'set_epoch'):
- self.get_train_dataloader().sampler.set_epoch(epoch)
-
- # get model
- model = self.get_model()
-
- # update training progress in trainer and model
- model.current_epoch = epoch
- self.current_epoch = epoch
-
- total_val_batches = 0
- if not self.disable_validation:
- # val can be checked multiple times in epoch
- is_val_epoch = (self.current_epoch + 1) % self.check_val_every_n_epoch == 0
- val_checks_per_epoch = self.num_training_batches // self.val_check_batch
- val_checks_per_epoch = val_checks_per_epoch if is_val_epoch else 0
- total_val_batches = self.num_val_batches * val_checks_per_epoch
-
- # total batches includes multiple val checks
- self.total_batches = self.num_training_batches + total_val_batches
- self.batch_loss_value = 0 # accumulated grads
-
- if self.is_iterable_train_dataloader:
- # for iterable train loader, the progress bar never ends
- num_iterations = None
- else:
- num_iterations = self.total_batches
-
- # reset progress bar
- # .reset() doesn't work on disabled progress bar so we should check
- desc = f'Epoch {epoch + 1}' if not self.is_iterable_train_dataloader else ''
- self.main_progress_bar.set_description(desc)
-
- # changing gradient according accumulation_scheduler
- self.accumulation_scheduler.on_epoch_begin(epoch, self)
-
- # -----------------
- # RUN TNG EPOCH
- # -----------------
- self.run_training_epoch()
-
- # update LR schedulers
- if self.lr_schedulers is not None:
- for lr_scheduler in self.lr_schedulers:
- lr_scheduler.step(epoch=self.current_epoch)
-
- self.main_progress_bar.close()
-
- model.on_train_end()
-
- if self.logger is not None:
- self.logger.finalize("success")
-
- def run_training_epoch(self):
- # before epoch hook
- if self.is_function_implemented('on_epoch_start'):
- model = self.get_model()
- model.on_epoch_start()
-
- # run epoch
- for batch_idx, batch in enumerate(self.get_train_dataloader()):
- # stop epoch if we limited the number of training batches
- if batch_idx >= self.num_training_batches:
- break
-
- self.batch_idx = batch_idx
-
- model = self.get_model()
- model.global_step = self.global_step
-
- # ---------------
- # RUN TRAIN STEP
- # ---------------
- output = self.run_training_batch(batch, batch_idx)
- batch_result, grad_norm_dic, batch_step_metrics = output
-
- # when returning -1 from train_step, we end epoch early
- early_stop_epoch = batch_result == -1
-
- # ---------------
- # RUN VAL STEP
- # ---------------
- should_check_val = (
- not self.disable_validation and self.global_step % self.val_check_batch == 0 and not self.fisrt_epoch)
- self.fisrt_epoch = False
-
- if should_check_val:
- self.run_evaluation(test=self.testing)
-
- # when logs should be saved
- should_save_log = (batch_idx + 1) % self.log_save_interval == 0 or early_stop_epoch
- if should_save_log:
- if self.proc_rank == 0 and self.logger is not None:
- self.logger.save()
-
- # when metrics should be logged
- should_log_metrics = batch_idx % self.row_log_interval == 0 or early_stop_epoch
- if should_log_metrics:
- # logs user requested information to logger
- self.log_metrics(batch_step_metrics, grad_norm_dic)
-
- self.global_step += 1
- self.total_batch_idx += 1
-
- # end epoch early
- # stop when the flag is changed or we've gone past the amount
- # requested in the batches
- if early_stop_epoch:
- break
- if self.global_step > self.max_updates:
- print("| Training end..")
- exit()
-
- # epoch end hook
- if self.is_function_implemented('on_epoch_end'):
- model = self.get_model()
- model.on_epoch_end()
-
- def run_training_batch(self, batch, batch_idx):
- # track grad norms
- grad_norm_dic = {}
-
- # track all metrics for callbacks
- all_callback_metrics = []
-
- # track metrics to log
- all_log_metrics = []
-
- if batch is None:
- return 0, grad_norm_dic, {}
-
- # hook
- if self.is_function_implemented('on_batch_start'):
- model_ref = self.get_model()
- response = model_ref.on_batch_start(batch)
-
- if response == -1:
- return -1, grad_norm_dic, {}
-
- splits = [batch]
- self.hiddens = None
- for split_idx, split_batch in enumerate(splits):
- self.split_idx = split_idx
-
- # call training_step once per optimizer
- for opt_idx, optimizer in enumerate(self.optimizers):
- if optimizer is None:
- continue
- # make sure only the gradients of the current optimizer's paramaters are calculated
- # in the training step to prevent dangling gradients in multiple-optimizer setup.
- if len(self.optimizers) > 1:
- for param in self.get_model().parameters():
- param.requires_grad = False
- for group in optimizer.param_groups:
- for param in group['params']:
- param.requires_grad = True
-
- # wrap the forward step in a closure so second order methods work
- def optimizer_closure():
- # forward pass
- output = self.training_forward(
- split_batch, batch_idx, opt_idx, self.hiddens)
-
- closure_loss = output[0]
- progress_bar_metrics = output[1]
- log_metrics = output[2]
- callback_metrics = output[3]
- self.hiddens = output[4]
- if closure_loss is None:
- return None
-
- # accumulate loss
- # (if accumulate_grad_batches = 1 no effect)
- closure_loss = closure_loss / self.accumulate_grad_batches
-
- # backward pass
- model_ref = self.get_model()
- if closure_loss.requires_grad:
- model_ref.backward(closure_loss, optimizer)
-
- # track metrics for callbacks
- all_callback_metrics.append(callback_metrics)
-
- # track progress bar metrics
- self.add_tqdm_metrics(progress_bar_metrics)
- all_log_metrics.append(log_metrics)
-
- # insert after step hook
- if self.is_function_implemented('on_after_backward'):
- model_ref = self.get_model()
- model_ref.on_after_backward()
-
- return closure_loss
-
- # calculate loss
- loss = optimizer_closure()
- if loss is None:
- continue
-
- # nan grads
- if self.print_nan_grads:
- self.print_nan_gradients()
-
- # track total loss for logging (avoid mem leaks)
- self.batch_loss_value += loss.item()
-
- # gradient update with accumulated gradients
- if (self.batch_idx + 1) % self.accumulate_grad_batches == 0:
-
- # track gradient norms when requested
- if batch_idx % self.row_log_interval == 0:
- if self.track_grad_norm > 0:
- model = self.get_model()
- grad_norm_dic = model.grad_norm(
- self.track_grad_norm)
-
- # clip gradients
- self.clip_gradients()
-
- # calls .step(), .zero_grad()
- # override function to modify this behavior
- model = self.get_model()
- model.optimizer_step(self.current_epoch, batch_idx, optimizer, opt_idx)
-
- # calculate running loss for display
- self.running_loss.append(self.batch_loss_value)
- self.batch_loss_value = 0
- self.avg_loss = np.mean(self.running_loss[-100:])
-
- # activate batch end hook
- if self.is_function_implemented('on_batch_end'):
- model = self.get_model()
- model.on_batch_end()
-
- # update progress bar
- self.main_progress_bar.update(1)
- self.main_progress_bar.set_postfix(**self.training_tqdm_dict)
-
- # collapse all metrics into one dict
- all_log_metrics = {k: v for d in all_log_metrics for k, v in d.items()}
-
- # track all metrics for callbacks
- self.callback_metrics.update({k: v for d in all_callback_metrics for k, v in d.items()})
-
- return 0, grad_norm_dic, all_log_metrics
-
- def training_forward(self, batch, batch_idx, opt_idx, hiddens):
- """
- Handle forward for each training case (distributed, single gpu, etc...)
- :param batch:
- :param batch_idx:
- :return:
- """
- # ---------------
- # FORWARD
- # ---------------
- # enable not needing to add opt_idx to training_step
- args = [batch, batch_idx, opt_idx]
-
- # distributed forward
- if self.use_ddp or self.use_dp:
- output = self.model(*args)
- # single GPU forward
- elif self.single_gpu:
- gpu_id = 0
- if isinstance(self.data_parallel_device_ids, list):
- gpu_id = self.data_parallel_device_ids[0]
- batch = self.transfer_batch_to_gpu(copy.copy(batch), gpu_id)
- args[0] = batch
- output = self.model.training_step(*args)
- # CPU forward
- else:
- output = self.model.training_step(*args)
-
- # allow any mode to define training_end
- model_ref = self.get_model()
- output_ = model_ref.training_end(output)
- if output_ is not None:
- output = output_
-
- # format and reduce outputs accordingly
- output = self.process_output(output, train=True)
-
- return output
-
- # ---------------
- # Utils
- # ---------------
- def is_function_implemented(self, f_name):
- model = self.get_model()
- f_op = getattr(model, f_name, None)
- return callable(f_op)
-
- def _percent_range_check(self, name):
- value = getattr(self, name)
- msg = f"`{name}` must lie in the range [0.0, 1.0], but got {value:.3f}."
- if name == "val_check_interval":
- msg += " If you want to disable validation set `val_percent_check` to 0.0 instead."
-
- if not 0. <= value <= 1.:
- raise ValueError(msg)
diff --git a/spaces/AIGC-Audio/AudioGPT/audio_to_text/__init__.py b/spaces/AIGC-Audio/AudioGPT/audio_to_text/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/AIGC-Audio/AudioGPT/text_to_speech/utils/text/encoding.py b/spaces/AIGC-Audio/AudioGPT/text_to_speech/utils/text/encoding.py
deleted file mode 100644
index f09f514613fd44a27450fe7c04cbdf5ebfbe78a8..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/AudioGPT/text_to_speech/utils/text/encoding.py
+++ /dev/null
@@ -1,9 +0,0 @@
-import chardet
-
-
-def get_encoding(file):
- with open(file, 'rb') as f:
- encoding = chardet.detect(f.read())['encoding']
- if encoding == 'GB2312':
- encoding = 'GB18030'
- return encoding
diff --git a/spaces/AIZ2H/04-Gradio-SOTA-Seq2Seq-AutoQA/app.py b/spaces/AIZ2H/04-Gradio-SOTA-Seq2Seq-AutoQA/app.py
deleted file mode 100644
index c1cd92499cf1c7d2a91b4dc226bf2d558ff67661..0000000000000000000000000000000000000000
--- a/spaces/AIZ2H/04-Gradio-SOTA-Seq2Seq-AutoQA/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import gradio as gr
-from qasrl_model_pipeline import QASRL_Pipeline
-
-models = ["kleinay/qanom-seq2seq-model-baseline",
- "kleinay/qanom-seq2seq-model-joint"]
-pipelines = {model: QASRL_Pipeline(model) for model in models}
-
-
-description = f"""Using Seq2Seq T5 model which takes a sequence of items and outputs another sequence this model generates Questions and Answers (QA) with focus on Semantic Role Labeling (SRL)"""
-title="Seq2Seq T5 Questions and Answers (QA) with Semantic Role Labeling (SRL)"
-examples = [[models[0], "In March and April the patient
had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", True, "fall"],
- [models[1], "In March and April the patient had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions
like anaphylaxis and shortness of breath.", True, "reactions"],
- [models[0], "In March and April the patient had two falls. One was related
to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", True, "relate"],
- [models[1], "In March and April the patient
had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", False, "fall"]]
-
-input_sent_box_label = "Insert sentence here. Mark the predicate by adding the token '
' before it."
-verb_form_inp_placeholder = "e.g. 'decide' for the nominalization 'decision', 'teach' for 'teacher', etc."
-links = """
"
- if predicate_marker not in sentence:
- raise ValueError("You must highlight one word of the sentence as a predicate using preceding '
'.")
-
- if not verb_form:
- if is_nominal:
- raise ValueError("You should provide the verbal form of the nominalization")
-
- toks = sentence.split(" ")
- pred_idx = toks.index(predicate_marker)
- predicate = toks(pred_idx+1)
- verb_form=predicate
- pipeline = pipelines[model_name]
- pipe_out = pipeline([sentence],
- predicate_marker=predicate_marker,
- predicate_type="nominal" if is_nominal else "verbal",
- verb_form=verb_form)[0]
- return pipe_out["QAs"], pipe_out["generated_text"]
-iface = gr.Interface(fn=call,
- inputs=[gr.inputs.Radio(choices=models, default=models[0], label="Model"),
- gr.inputs.Textbox(placeholder=input_sent_box_label, label="Sentence", lines=4),
- gr.inputs.Checkbox(default=True, label="Is Nominalization?"),
- gr.inputs.Textbox(placeholder=verb_form_inp_placeholder, label="Verbal form (for nominalizations)", default='')],
- outputs=[gr.outputs.JSON(label="Model Output - QASRL"), gr.outputs.Textbox(label="Raw output sequence")],
- title=title,
- description=description,
- article=links,
- examples=examples )
-
-iface.launch()
\ No newline at end of file
diff --git a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py b/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py
deleted file mode 100644
index 17b4a73b092fda1b98a088a83619697702859f71..0000000000000000000000000000000000000000
--- a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py
+++ /dev/null
@@ -1,12 +0,0 @@
-_base_ = 'yolov5_s-v61_syncbn_8xb16-300e_coco.py'
-
-# fast means faster training speed,
-# but less flexibility for multitasking
-model = dict(
- data_preprocessor=dict(
- type='YOLOv5DetDataPreprocessor',
- mean=[0., 0., 0.],
- std=[255., 255., 255.],
- bgr_to_rgb=True))
-
-train_dataloader = dict(collate_fn=dict(type='yolov5_collate'))
diff --git a/spaces/Abhilashvj/planogram-compliance/utils/loggers/comet/README.md b/spaces/Abhilashvj/planogram-compliance/utils/loggers/comet/README.md
deleted file mode 100644
index 8a361e2b211d316436deb80a9efe322351a46045..0000000000000000000000000000000000000000
--- a/spaces/Abhilashvj/planogram-compliance/utils/loggers/comet/README.md
+++ /dev/null
@@ -1,256 +0,0 @@
-
-
-# YOLOv5 with Comet
-
-This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readme-comet2)
-
-# About Comet
-
-Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
-
-Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!
-Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
-
-# Getting Started
-
-## Install Comet
-
-```shell
-pip install comet_ml
-```
-
-## Configure Comet Credentials
-
-There are two ways to configure Comet with YOLOv5.
-
-You can either set your credentials through enviroment variables
-
-**Environment Variables**
-
-```shell
-export COMET_API_KEY=
-export COMET_PROJECT_NAME= # This will default to 'yolov5'
-```
-
-Or create a `.comet.config` file in your working directory and set your credentials there.
-
-**Comet Configuration File**
-
-```
-[comet]
-api_key=
-project_name= # This will default to 'yolov5'
-```
-
-## Run the Training Script
-
-```shell
-# Train YOLOv5s on COCO128 for 5 epochs
-python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
-```
-
-That's it! Comet will automatically log your hyperparameters, command line arguments, training and valiation metrics. You can visualize and analyze your runs in the Comet UI
-
-
-
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME= #Set the name for the saved model. Defaults to yolov5
-export COMET_LOG_CONFUSION_MATRIX=false # Set to disable logging a Comet Confusion Matrix. Defaults to true
-export COMET_MAX_IMAGE_UPLOADS= # Controls how many total image predictions to log to Comet. Defaults to 100.
-export COMET_LOG_PER_CLASS_METRICS=true # Set to log evaluation metrics for each detected class at the end of training. Defaults to false
-export COMET_DEFAULT_CHECKPOINT_FILENAME= # Set this if you would like to resume training from a different checkpoint. Defaults to 'last.pt'
-export COMET_LOG_BATCH_LEVEL_METRICS=true # Set this if you would like to log training metrics at the batch level. Defaults to false.
-export COMET_LOG_PREDICTIONS=true # Set this to false to disable logging model predictions
-```
-
-## Logging Checkpoints with Comet
-
-Logging Models to Comet is disabled by default. To enable it, pass the `save-period` argument to the training script. This will save the
-logged checkpoints to Comet based on the interval value provided by `save-period`
-
-```shell
-python train.py \
---img 640 \
---batch 16 \
---epochs 5 \
---data coco128.yaml \
---weights yolov5s.pt \
---save-period 1
-```
-
-## Logging Model Predictions
-
-By default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.
-
-You can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.
-
-**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
-
-Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
-
-
-```shell
-python train.py \
---img 640 \
---batch 16 \
---epochs 5 \
---data coco128.yaml \
---weights yolov5s.pt \
---bbox_interval 2
-```
-
-### Controlling the number of Prediction Images logged to Comet
-
-When logging predictions from YOLOv5, Comet will log the images associated with each set of predictions. By default a maximum of 100 validation images are logged. You can increase or decrease this number using the `COMET_MAX_IMAGE_UPLOADS` environment variable.
-
-```shell
-env COMET_MAX_IMAGE_UPLOADS=200 python train.py \
---img 640 \
---batch 16 \
---epochs 5 \
---data coco128.yaml \
---weights yolov5s.pt \
---bbox_interval 1
-```
-
-### Logging Class Level Metrics
-
-Use the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.
-
-```shell
-env COMET_LOG_PER_CLASS_METRICS=true python train.py \
---img 640 \
---batch 16 \
---epochs 5 \
---data coco128.yaml \
---weights yolov5s.pt
-```
-
-## Uploading a Dataset to Comet Artifacts
-
-If you would like to store your data using [Comet Artifacts](https://www.comet.com/docs/v2/guides/data-management/using-artifacts/#learn-more?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github), you can do so using the `upload_dataset` flag.
-
-The dataset be organized in the way described in the [YOLOv5 documentation](https://docs.ultralytics.com/tutorials/train-custom-datasets/#3-organize-directories). The dataset config `yaml` file must follow the same format as that of the `coco128.yaml` file.
-
-```shell
-python train.py \
---img 640 \
---batch 16 \
---epochs 5 \
---data coco128.yaml \
---weights yolov5s.pt \
---upload_dataset
-```
-
-You can find the uploaded dataset in the Artifacts tab in your Comet Workspace
-
-
-You can preview the data directly in the Comet UI.
-
-
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-
-
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet:///:"
-```
-Then pass this file to your training script in the following way
-
-```shell
-python train.py \
---img 640 \
---batch 16 \
---epochs 5 \
---data artifact.yaml \
---weights yolov5s.pt
-```
-
-Artifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.
-
-
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet:////`.
-
-This will restore the run to its state before the interruption, which includes restoring the model from a checkpoint, restoring all hyperparameters and training arguments and downloading Comet dataset Artifacts if they were used in the original run. The resumed run will continue logging to the existing Experiment in the Comet UI
-
-```shell
-python train.py \
---resume "comet://"
-```
-
-## Hyperparameter Search with the Comet Optimizer
-
-YOLOv5 is also integrated with Comet's Optimizer, making is simple to visualie hyperparameter sweeps in the Comet UI.
-
-### Configuring an Optimizer Sweep
-
-To configure the Comet Optimizer, you will have to create a JSON file with the information about the sweep. An example file has been provided in `utils/loggers/comet/optimizer_config.json`
-
-```shell
-python utils/loggers/comet/hpo.py \
- --comet_optimizer_config "utils/loggers/comet/optimizer_config.json"
-```
-
-The `hpo.py` script accepts the same arguments as `train.py`. If you wish to pass additional arguments to your sweep simply add them after
-the script.
-
-```shell
-python utils/loggers/comet/hpo.py \
- --comet_optimizer_config "utils/loggers/comet/optimizer_config.json" \
- --save-period 1 \
- --bbox_interval 1
-```
-
-### Running a Sweep in Parallel
-
-```shell
-comet optimizer -j utils/loggers/comet/hpo.py \
- utils/loggers/comet/optimizer_config.json"
-```
-
-### Visualizing Results
-
-Comet provides a number of ways to visualize the results of your sweep. Take a look at a [project with a completed sweep here](https://www.comet.com/examples/comet-example-yolov5/view/PrlArHGuuhDTKC1UuBmTtOSXD/panels?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
-
-
diff --git a/spaces/AfrodreamsAI/afrodreams/INSTALL.md b/spaces/AfrodreamsAI/afrodreams/INSTALL.md
deleted file mode 100644
index 7d7c3c2e4602873e64abc7c4c79add9b71359200..0000000000000000000000000000000000000000
--- a/spaces/AfrodreamsAI/afrodreams/INSTALL.md
+++ /dev/null
@@ -1,293 +0,0 @@
-# neural-style-pt Installation
-
-This guide will walk you through multiple ways to setup `neural-style-pt` on Ubuntu and Windows. If you wish to install PyTorch and neural-style-pt on a different operating system like MacOS, installation guides can be found [here](https://pytorch.org).
-
-Note that in order to reduce their size, the pre-packaged binary releases (pip, Conda, etc...) have removed support for some older GPUs, and thus you will have to install from source in order to use these GPUs.
-
-
-# Ubuntu:
-
-## With A Package Manager:
-
-The pip and Conda packages ship with CUDA and cuDNN already built in, so after you have installed PyTorch with pip or Conda, you can skip to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt).
-
-### pip:
-
-The neural-style-pt PyPI page can be found here: https://pypi.org/project/neural-style/
-
-If you wish to install neural-style-pt as a pip package, then use the following command:
-
-```
-# in a terminal, run the command
-pip install neural-style
-```
-
-Or:
-
-
-```
-# in a terminal, run the command
-pip3 install neural-style
-```
-
-Next download the models with:
-
-
-```
-neural-style -download_models
-```
-
-By default the models are downloaded to your home directory, but you can specify a download location with:
-
-```
-neural-style -download_models
-```
-
-#### Github and pip:
-
-Following the pip installation instructions
-[here](http://pytorch.org), you can install PyTorch with the following commands:
-
-```
-# in a terminal, run the commands
-cd ~/
-pip install torch torchvision
-```
-
-Or:
-
-```
-cd ~/
-pip3 install torch torchvision
-```
-
-Now continue on to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt) to install neural-style-pt.
-
-### Conda:
-
-Following the Conda installation instructions
-[here](http://pytorch.org), you can install PyTorch with the following command:
-
-```
-conda install pytorch torchvision -c pytorch
-```
-
-Now continue on to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt) to install neural-style-pt.
-
-## From Source:
-
-### (Optional) Step 1: Install CUDA
-
-If you have a [CUDA-capable GPU from NVIDIA](https://developer.nvidia.com/cuda-gpus) then you can
-speed up `neural-style-pt` with CUDA.
-
-First download and unpack the local CUDA installer from NVIDIA; note that there are different
-installers for each recent version of Ubuntu:
-
-```
-# For Ubuntu 18.04
-sudo dpkg -i cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
-sudo apt-key add /var/cuda-repo-/7fa2af80.pub
-```
-
-```
-# For Ubuntu 16.04
-sudo dpkg -i cuda-repo-ubuntu1604-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
-sudo apt-key add /var/cuda-repo-/7fa2af80.pub
-```
-
-Instructions for downloading and installing the latest CUDA version on all supported operating systems, can be found [here](https://developer.nvidia.com/cuda-downloads).
-
-Now update the repository cache and install CUDA. Note that this will also install a graphics driver from NVIDIA.
-
-```
-sudo apt-get update
-sudo apt-get install cuda
-```
-
-At this point you may need to reboot your machine to load the new graphics driver.
-After rebooting, you should be able to see the status of your graphics card(s) by running
-the command `nvidia-smi`; it should give output that looks something like this:
-
-```
-Wed Apr 11 21:54:49 2018
-+-----------------------------------------------------------------------------+
-| NVIDIA-SMI 384.90 Driver Version: 384.90 |
-|-------------------------------+----------------------+----------------------+
-| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
-| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
-|===============================+======================+======================|
-| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
-| N/A 62C P0 68W / 149W | 0MiB / 11439MiB | 94% Default |
-+-------------------------------+----------------------+----------------------+
-
-+-----------------------------------------------------------------------------+
-| Processes: GPU Memory |
-| GPU PID Type Process name Usage |
-|=============================================================================|
-| No running processes found |
-+-----------------------------------------------------------------------------+
-```
-
-### (Optional) Step 2: Install cuDNN
-
-cuDNN is a library from NVIDIA that efficiently implements many of the operations (like convolutions and pooling)
-that are commonly used in deep learning.
-
-After registering as a developer with NVIDIA, you can [download cuDNN here](https://developer.nvidia.com/cudnn). Make sure that you use the approprite version of cuDNN for your version of CUDA.
-
-After dowloading, you can unpack and install cuDNN like this:
-
-```
-tar -zxvf cudnn-10.1-linux-x64-v7.5.0.56.tgz
-sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
-sudo cp cuda/include/cudnn.h /usr/local/cuda/include
-```
-
-Note that the cuDNN backend can only be used for GPU mode.
-
-### (Optional) Steps 1-3: Install PyTorch with support for AMD GPUs using Radeon Open Compute Stack (ROCm)
-
-
-It is recommended that if you wish to use PyTorch with an AMD GPU, you install it via the official ROCm dockerfile:
-https://rocm.github.io/pytorch.html
-
-- Supported AMD GPUs for the dockerfile are: Vega10 / gfx900 generation discrete graphics cards (Vega56, Vega64, or MI25).
-
-PyTorch does not officially provide support for compilation on the host with AMD GPUs, but [a user guide posted here](https://github.com/ROCmSoftwarePlatform/pytorch/issues/337#issuecomment-467220107) apparently works well.
-
-ROCm utilizes a CUDA porting tool called HIP, which automatically converts CUDA code into HIP code. HIP code can run on both AMD and Nvidia GPUs.
-
-
-### Step 3: Install PyTorch
-
-To install PyTorch [from source](https://github.com/pytorch/pytorch#from-source) on Ubuntu (Instructions may be different if you are using a different OS):
-
-```
-cd ~/
-git clone --recursive https://github.com/pytorch/pytorch
-cd pytorch
-python setup.py install
-
-cd ~/
-git clone --recursive https://github.com/pytorch/vision
-cd vision
-python setup.py install
-```
-
-To check that your torch installation is working, run the command `python` or `python3` to enter the Python interpreter. Then type `import torch` and hit enter.
-
-You can then type `print(torch.version.cuda)` and `print(torch.backends.cudnn.version())` to confirm that you are using the desired versions of CUDA and cuDNN.
-
-To quit just type `exit()` or use Ctrl-D.
-
-Now continue on to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt) to install neural-style-pt.
-
-
-# Windows Installation
-
-If you wish to install PyTorch on Windows From Source or via Conda, you can find instructions on the PyTorch website: https://pytorch.org/
-
-
-### Github and pip
-
-First, you will need to download Python 3 and install it: https://www.python.org/downloads/windows/. I recommend using the executable installer for the latest version of Python 3.
-
-Then using https://pytorch.org/, get the correct pip command, paste it into the Command Prompt (CMD) and hit enter:
-
-
-```
-pip3 install torch===1.3.0 torchvision===0.4.1 -f https://download.pytorch.org/whl/torch_stable.html
-```
-
-
-After installing PyTorch, download the neural-style-pt Github respository and extract/unzip it to the desired location.
-
-Then copy the file path to your neural-style-pt folder, and paste it into the Command Prompt, with `cd` in front of it and then hit enter.
-
-In the example below, the neural-style-pt folder was placed on the desktop:
-
-```
-cd C:\Users\\Desktop\neural-style-pt-master
-```
-
-You can now continue on to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt), skipping the `git clone` step.
-
-# Install neural-style-pt
-
-First we clone `neural-style-pt` from GitHub:
-
-```
-cd ~/
-git clone https://github.com/ProGamerGov/neural-style-pt.git
-cd neural-style-pt
-```
-
-Next we need to download the pretrained neural network models:
-
-```
-python models/download_models.py
-```
-
-You should now be able to run `neural-style-pt` in CPU mode like this:
-
-```
-python neural_style.py -gpu c -print_iter 1
-```
-
-If you installed PyTorch with support for CUDA, then should now be able to run `neural-style-pt` in GPU mode like this:
-
-```
-python neural_style.py -gpu 0 -print_iter 1
-```
-
-If you installed PyTorch with support for cuDNN, then you should now be able to run `neural-style-pt` with the `cudnn` backend like this:
-
-```
-python neural_style.py -gpu 0 -backend cudnn -print_iter 1
-```
-
-If everything is working properly you should see output like this:
-
-```
-Iteration 1 / 1000
- Content 1 loss: 1616196.125
- Style 1 loss: 29890.9980469
- Style 2 loss: 658038.625
- Style 3 loss: 145283.671875
- Style 4 loss: 11347409.0
- Style 5 loss: 563.368896484
- Total loss: 13797382.0
-Iteration 2 / 1000
- Content 1 loss: 1616195.625
- Style 1 loss: 29890.9980469
- Style 2 loss: 658038.625
- Style 3 loss: 145283.671875
- Style 4 loss: 11347409.0
- Style 5 loss: 563.368896484
- Total loss: 13797382.0
-Iteration 3 / 1000
- Content 1 loss: 1579918.25
- Style 1 loss: 29881.3164062
- Style 2 loss: 654351.75
- Style 3 loss: 144214.640625
- Style 4 loss: 11301945.0
- Style 5 loss: 562.733032227
- Total loss: 13711628.0
-Iteration 4 / 1000
- Content 1 loss: 1460443.0
- Style 1 loss: 29849.7226562
- Style 2 loss: 643799.1875
- Style 3 loss: 140405.015625
- Style 4 loss: 10940431.0
- Style 5 loss: 553.507446289
- Total loss: 13217080.0
-Iteration 5 / 1000
- Content 1 loss: 1298983.625
- Style 1 loss: 29734.8964844
- Style 2 loss: 604133.8125
- Style 3 loss: 125455.945312
- Style 4 loss: 8850759.0
- Style 5 loss: 526.118591309
- Total loss: 10912633.0
-```
diff --git a/spaces/Aki004/herta-so-vits/vdecoder/nsf_hifigan/nvSTFT.py b/spaces/Aki004/herta-so-vits/vdecoder/nsf_hifigan/nvSTFT.py
deleted file mode 100644
index 62bd5a008f81929054f036c81955d5d73377f772..0000000000000000000000000000000000000000
--- a/spaces/Aki004/herta-so-vits/vdecoder/nsf_hifigan/nvSTFT.py
+++ /dev/null
@@ -1,134 +0,0 @@
-import math
-import os
-os.environ["LRU_CACHE_CAPACITY"] = "3"
-import random
-import torch
-import torch.utils.data
-import numpy as np
-import librosa
-from librosa.util import normalize
-from librosa.filters import mel as librosa_mel_fn
-from scipy.io.wavfile import read
-import soundfile as sf
-import torch.nn.functional as F
-
-def load_wav_to_torch(full_path, target_sr=None, return_empty_on_exception=False):
- sampling_rate = None
- try:
- data, sampling_rate = sf.read(full_path, always_2d=True)# than soundfile.
- except Exception as ex:
- print(f"'{full_path}' failed to load.\nException:")
- print(ex)
- if return_empty_on_exception:
- return [], sampling_rate or target_sr or 48000
- else:
- raise Exception(ex)
-
- if len(data.shape) > 1:
- data = data[:, 0]
- assert len(data) > 2# check duration of audio file is > 2 samples (because otherwise the slice operation was on the wrong dimension)
-
- if np.issubdtype(data.dtype, np.integer): # if audio data is type int
- max_mag = -np.iinfo(data.dtype).min # maximum magnitude = min possible value of intXX
- else: # if audio data is type fp32
- max_mag = max(np.amax(data), -np.amin(data))
- max_mag = (2**31)+1 if max_mag > (2**15) else ((2**15)+1 if max_mag > 1.01 else 1.0) # data should be either 16-bit INT, 32-bit INT or [-1 to 1] float32
-
- data = torch.FloatTensor(data.astype(np.float32))/max_mag
-
- if (torch.isinf(data) | torch.isnan(data)).any() and return_empty_on_exception:# resample will crash with inf/NaN inputs. return_empty_on_exception will return empty arr instead of except
- return [], sampling_rate or target_sr or 48000
- if target_sr is not None and sampling_rate != target_sr:
- data = torch.from_numpy(librosa.core.resample(data.numpy(), orig_sr=sampling_rate, target_sr=target_sr))
- sampling_rate = target_sr
-
- return data, sampling_rate
-
-def dynamic_range_compression(x, C=1, clip_val=1e-5):
- return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
-
-def dynamic_range_decompression(x, C=1):
- return np.exp(x) / C
-
-def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
- return torch.log(torch.clamp(x, min=clip_val) * C)
-
-def dynamic_range_decompression_torch(x, C=1):
- return torch.exp(x) / C
-
-class STFT():
- def __init__(self, sr=22050, n_mels=80, n_fft=1024, win_size=1024, hop_length=256, fmin=20, fmax=11025, clip_val=1e-5):
- self.target_sr = sr
-
- self.n_mels = n_mels
- self.n_fft = n_fft
- self.win_size = win_size
- self.hop_length = hop_length
- self.fmin = fmin
- self.fmax = fmax
- self.clip_val = clip_val
- self.mel_basis = {}
- self.hann_window = {}
-
- def get_mel(self, y, keyshift=0, speed=1, center=False):
- sampling_rate = self.target_sr
- n_mels = self.n_mels
- n_fft = self.n_fft
- win_size = self.win_size
- hop_length = self.hop_length
- fmin = self.fmin
- fmax = self.fmax
- clip_val = self.clip_val
-
- factor = 2 ** (keyshift / 12)
- n_fft_new = int(np.round(n_fft * factor))
- win_size_new = int(np.round(win_size * factor))
- hop_length_new = int(np.round(hop_length * speed))
-
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- mel_basis_key = str(fmax)+'_'+str(y.device)
- if mel_basis_key not in self.mel_basis:
- mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax)
- self.mel_basis[mel_basis_key] = torch.from_numpy(mel).float().to(y.device)
-
- keyshift_key = str(keyshift)+'_'+str(y.device)
- if keyshift_key not in self.hann_window:
- self.hann_window[keyshift_key] = torch.hann_window(win_size_new).to(y.device)
-
- pad_left = (win_size_new - hop_length_new) //2
- pad_right = max((win_size_new- hop_length_new + 1) //2, win_size_new - y.size(-1) - pad_left)
- if pad_right < y.size(-1):
- mode = 'reflect'
- else:
- mode = 'constant'
- y = torch.nn.functional.pad(y.unsqueeze(1), (pad_left, pad_right), mode = mode)
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft_new, hop_length=hop_length_new, win_length=win_size_new, window=self.hann_window[keyshift_key],
- center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
- # print(111,spec)
- spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
- if keyshift != 0:
- size = n_fft // 2 + 1
- resize = spec.size(1)
- if resize < size:
- spec = F.pad(spec, (0, 0, 0, size-resize))
- spec = spec[:, :size, :] * win_size / win_size_new
-
- # print(222,spec)
- spec = torch.matmul(self.mel_basis[mel_basis_key], spec)
- # print(333,spec)
- spec = dynamic_range_compression_torch(spec, clip_val=clip_val)
- # print(444,spec)
- return spec
-
- def __call__(self, audiopath):
- audio, sr = load_wav_to_torch(audiopath, target_sr=self.target_sr)
- spect = self.get_mel(audio.unsqueeze(0)).squeeze(0)
- return spect
-
-stft = STFT()
diff --git a/spaces/AlexN/pull_up/TractionModel.py b/spaces/AlexN/pull_up/TractionModel.py
deleted file mode 100644
index 5498af7913b004ca4754a40aec8dff918daacf68..0000000000000000000000000000000000000000
--- a/spaces/AlexN/pull_up/TractionModel.py
+++ /dev/null
@@ -1,59 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-Created on Sun Jul 4 15:07:27 2021
-
-@author: AlexandreN
-"""
-from __future__ import print_function, division
-
-import torch
-import torch.nn as nn
-import torchvision
-
-
-class SingleTractionHead(nn.Module):
-
- def __init__(self):
- super(SingleTractionHead, self).__init__()
-
- self.head_locs = nn.Sequential(nn.Linear(2048, 1024),
- nn.ReLU(),
- nn.Dropout(p=0.3),
- nn.Linear(1024, 4),
- nn.Sigmoid()
- )
-
- # Head class should output the logits over the classe
- self.head_class = nn.Sequential(nn.Linear(2048, 128),
- nn.ReLU(),
- nn.Dropout(p=0.3),
- nn.Linear(128, 1))
-
- def forward(self, features):
- features = features.view(features.size()[0], -1)
-
- y_bbox = self.head_locs(features)
- y_class = self.head_class(features)
-
- res = (y_bbox, y_class)
- return res
-
-
-def create_model():
- # setup the architecture of the model
- feature_extractor = torchvision.models.resnet50(pretrained=True)
- model_body = nn.Sequential(*list(feature_extractor.children())[:-1])
- for param in model_body.parameters():
- param.requires_grad = False
- # Parameters of newly constructed modules have requires_grad=True by default
- # num_ftrs = model_body.fc.in_features
-
- model_head = SingleTractionHead()
- model = nn.Sequential(model_body, model_head)
- return model
-
-
-def load_weights(model, path='model.pt', device_='cpu'):
- checkpoint = torch.load(path, map_location=torch.device(device_))
- model.load_state_dict(checkpoint)
- return model
diff --git a/spaces/Alichuan/VITS-Umamusume-voice-synthesizer/text/korean.py b/spaces/Alichuan/VITS-Umamusume-voice-synthesizer/text/korean.py
deleted file mode 100644
index edee07429a450c55e3d8e246997faaa1e0b89cc9..0000000000000000000000000000000000000000
--- a/spaces/Alichuan/VITS-Umamusume-voice-synthesizer/text/korean.py
+++ /dev/null
@@ -1,210 +0,0 @@
-import re
-from jamo import h2j, j2hcj
-import ko_pron
-
-
-# This is a list of Korean classifiers preceded by pure Korean numerals.
-_korean_classifiers = '군데 권 개 그루 닢 대 두 마리 모 모금 뭇 발 발짝 방 번 벌 보루 살 수 술 시 쌈 움큼 정 짝 채 척 첩 축 켤레 톨 통'
-
-# List of (hangul, hangul divided) pairs:
-_hangul_divided = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄳ', 'ㄱㅅ'),
- ('ㄵ', 'ㄴㅈ'),
- ('ㄶ', 'ㄴㅎ'),
- ('ㄺ', 'ㄹㄱ'),
- ('ㄻ', 'ㄹㅁ'),
- ('ㄼ', 'ㄹㅂ'),
- ('ㄽ', 'ㄹㅅ'),
- ('ㄾ', 'ㄹㅌ'),
- ('ㄿ', 'ㄹㅍ'),
- ('ㅀ', 'ㄹㅎ'),
- ('ㅄ', 'ㅂㅅ'),
- ('ㅘ', 'ㅗㅏ'),
- ('ㅙ', 'ㅗㅐ'),
- ('ㅚ', 'ㅗㅣ'),
- ('ㅝ', 'ㅜㅓ'),
- ('ㅞ', 'ㅜㅔ'),
- ('ㅟ', 'ㅜㅣ'),
- ('ㅢ', 'ㅡㅣ'),
- ('ㅑ', 'ㅣㅏ'),
- ('ㅒ', 'ㅣㅐ'),
- ('ㅕ', 'ㅣㅓ'),
- ('ㅖ', 'ㅣㅔ'),
- ('ㅛ', 'ㅣㅗ'),
- ('ㅠ', 'ㅣㅜ')
-]]
-
-# List of (Latin alphabet, hangul) pairs:
-_latin_to_hangul = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', '에이'),
- ('b', '비'),
- ('c', '시'),
- ('d', '디'),
- ('e', '이'),
- ('f', '에프'),
- ('g', '지'),
- ('h', '에이치'),
- ('i', '아이'),
- ('j', '제이'),
- ('k', '케이'),
- ('l', '엘'),
- ('m', '엠'),
- ('n', '엔'),
- ('o', '오'),
- ('p', '피'),
- ('q', '큐'),
- ('r', '아르'),
- ('s', '에스'),
- ('t', '티'),
- ('u', '유'),
- ('v', '브이'),
- ('w', '더블유'),
- ('x', '엑스'),
- ('y', '와이'),
- ('z', '제트')
-]]
-
-# List of (ipa, lazy ipa) pairs:
-_ipa_to_lazy_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('t͡ɕ','ʧ'),
- ('d͡ʑ','ʥ'),
- ('ɲ','n^'),
- ('ɕ','ʃ'),
- ('ʷ','w'),
- ('ɭ','l`'),
- ('ʎ','ɾ'),
- ('ɣ','ŋ'),
- ('ɰ','ɯ'),
- ('ʝ','j'),
- ('ʌ','ə'),
- ('ɡ','g'),
- ('\u031a','#'),
- ('\u0348','='),
- ('\u031e',''),
- ('\u0320',''),
- ('\u0339','')
-]]
-
-
-def latin_to_hangul(text):
- for regex, replacement in _latin_to_hangul:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def divide_hangul(text):
- text = j2hcj(h2j(text))
- for regex, replacement in _hangul_divided:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def hangul_number(num, sino=True):
- '''Reference https://github.com/Kyubyong/g2pK'''
- num = re.sub(',', '', num)
-
- if num == '0':
- return '영'
- if not sino and num == '20':
- return '스무'
-
- digits = '123456789'
- names = '일이삼사오육칠팔구'
- digit2name = {d: n for d, n in zip(digits, names)}
-
- modifiers = '한 두 세 네 다섯 여섯 일곱 여덟 아홉'
- decimals = '열 스물 서른 마흔 쉰 예순 일흔 여든 아흔'
- digit2mod = {d: mod for d, mod in zip(digits, modifiers.split())}
- digit2dec = {d: dec for d, dec in zip(digits, decimals.split())}
-
- spelledout = []
- for i, digit in enumerate(num):
- i = len(num) - i - 1
- if sino:
- if i == 0:
- name = digit2name.get(digit, '')
- elif i == 1:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- else:
- if i == 0:
- name = digit2mod.get(digit, '')
- elif i == 1:
- name = digit2dec.get(digit, '')
- if digit == '0':
- if i % 4 == 0:
- last_three = spelledout[-min(3, len(spelledout)):]
- if ''.join(last_three) == '':
- spelledout.append('')
- continue
- else:
- spelledout.append('')
- continue
- if i == 2:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 3:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 4:
- name = digit2name.get(digit, '') + '만'
- name = name.replace('일만', '만')
- elif i == 5:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- elif i == 6:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 7:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 8:
- name = digit2name.get(digit, '') + '억'
- elif i == 9:
- name = digit2name.get(digit, '') + '십'
- elif i == 10:
- name = digit2name.get(digit, '') + '백'
- elif i == 11:
- name = digit2name.get(digit, '') + '천'
- elif i == 12:
- name = digit2name.get(digit, '') + '조'
- elif i == 13:
- name = digit2name.get(digit, '') + '십'
- elif i == 14:
- name = digit2name.get(digit, '') + '백'
- elif i == 15:
- name = digit2name.get(digit, '') + '천'
- spelledout.append(name)
- return ''.join(elem for elem in spelledout)
-
-
-def number_to_hangul(text):
- '''Reference https://github.com/Kyubyong/g2pK'''
- tokens = set(re.findall(r'(\d[\d,]*)([\uac00-\ud71f]+)', text))
- for token in tokens:
- num, classifier = token
- if classifier[:2] in _korean_classifiers or classifier[0] in _korean_classifiers:
- spelledout = hangul_number(num, sino=False)
- else:
- spelledout = hangul_number(num, sino=True)
- text = text.replace(f'{num}{classifier}', f'{spelledout}{classifier}')
- # digit by digit for remaining digits
- digits = '0123456789'
- names = '영일이삼사오육칠팔구'
- for d, n in zip(digits, names):
- text = text.replace(d, n)
- return text
-
-
-def korean_to_lazy_ipa(text):
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text=re.sub('[\uac00-\ud7af]+',lambda x:ko_pron.romanise(x.group(0),'ipa').split('] ~ [')[0],text)
- for regex, replacement in _ipa_to_lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def korean_to_ipa(text):
- text = korean_to_lazy_ipa(text)
- return text.replace('ʧ','tʃ').replace('ʥ','dʑ')
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/controlnet.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/controlnet.py
deleted file mode 100644
index ed3f3e6871430e606931e4d477cf62a5bb03b606..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/controlnet.py
+++ /dev/null
@@ -1,822 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from dataclasses import dataclass
-from typing import Any, Dict, List, Optional, Tuple, Union
-
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from ..configuration_utils import ConfigMixin, register_to_config
-from ..loaders import FromOriginalControlnetMixin
-from ..utils import BaseOutput, logging
-from .attention_processor import AttentionProcessor, AttnProcessor
-from .embeddings import TextImageProjection, TextImageTimeEmbedding, TextTimeEmbedding, TimestepEmbedding, Timesteps
-from .modeling_utils import ModelMixin
-from .unet_2d_blocks import (
- CrossAttnDownBlock2D,
- DownBlock2D,
- UNetMidBlock2DCrossAttn,
- get_down_block,
-)
-from .unet_2d_condition import UNet2DConditionModel
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-@dataclass
-class ControlNetOutput(BaseOutput):
- """
- The output of [`ControlNetModel`].
-
- Args:
- down_block_res_samples (`tuple[torch.Tensor]`):
- A tuple of downsample activations at different resolutions for each downsampling block. Each tensor should
- be of shape `(batch_size, channel * resolution, height //resolution, width // resolution)`. Output can be
- used to condition the original UNet's downsampling activations.
- mid_down_block_re_sample (`torch.Tensor`):
- The activation of the midde block (the lowest sample resolution). Each tensor should be of shape
- `(batch_size, channel * lowest_resolution, height // lowest_resolution, width // lowest_resolution)`.
- Output can be used to condition the original UNet's middle block activation.
- """
-
- down_block_res_samples: Tuple[torch.Tensor]
- mid_block_res_sample: torch.Tensor
-
-
-class ControlNetConditioningEmbedding(nn.Module):
- """
- Quoting from https://arxiv.org/abs/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
- [11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
- training. This requires ControlNets to convert image-based conditions to 64 × 64 feature space to match the
- convolution size. We use a tiny network E(·) of four convolution layers with 4 × 4 kernels and 2 × 2 strides
- (activated by ReLU, channels are 16, 32, 64, 128, initialized with Gaussian weights, trained jointly with the full
- model) to encode image-space conditions ... into feature maps ..."
- """
-
- def __init__(
- self,
- conditioning_embedding_channels: int,
- conditioning_channels: int = 3,
- block_out_channels: Tuple[int] = (16, 32, 96, 256),
- ):
- super().__init__()
-
- self.conv_in = nn.Conv2d(conditioning_channels, block_out_channels[0], kernel_size=3, padding=1)
-
- self.blocks = nn.ModuleList([])
-
- for i in range(len(block_out_channels) - 1):
- channel_in = block_out_channels[i]
- channel_out = block_out_channels[i + 1]
- self.blocks.append(nn.Conv2d(channel_in, channel_in, kernel_size=3, padding=1))
- self.blocks.append(nn.Conv2d(channel_in, channel_out, kernel_size=3, padding=1, stride=2))
-
- self.conv_out = zero_module(
- nn.Conv2d(block_out_channels[-1], conditioning_embedding_channels, kernel_size=3, padding=1)
- )
-
- def forward(self, conditioning):
- embedding = self.conv_in(conditioning)
- embedding = F.silu(embedding)
-
- for block in self.blocks:
- embedding = block(embedding)
- embedding = F.silu(embedding)
-
- embedding = self.conv_out(embedding)
-
- return embedding
-
-
-class ControlNetModel(ModelMixin, ConfigMixin, FromOriginalControlnetMixin):
- """
- A ControlNet model.
-
- Args:
- in_channels (`int`, defaults to 4):
- The number of channels in the input sample.
- flip_sin_to_cos (`bool`, defaults to `True`):
- Whether to flip the sin to cos in the time embedding.
- freq_shift (`int`, defaults to 0):
- The frequency shift to apply to the time embedding.
- down_block_types (`tuple[str]`, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
- The tuple of downsample blocks to use.
- only_cross_attention (`Union[bool, Tuple[bool]]`, defaults to `False`):
- block_out_channels (`tuple[int]`, defaults to `(320, 640, 1280, 1280)`):
- The tuple of output channels for each block.
- layers_per_block (`int`, defaults to 2):
- The number of layers per block.
- downsample_padding (`int`, defaults to 1):
- The padding to use for the downsampling convolution.
- mid_block_scale_factor (`float`, defaults to 1):
- The scale factor to use for the mid block.
- act_fn (`str`, defaults to "silu"):
- The activation function to use.
- norm_num_groups (`int`, *optional*, defaults to 32):
- The number of groups to use for the normalization. If None, normalization and activation layers is skipped
- in post-processing.
- norm_eps (`float`, defaults to 1e-5):
- The epsilon to use for the normalization.
- cross_attention_dim (`int`, defaults to 1280):
- The dimension of the cross attention features.
- transformer_layers_per_block (`int` or `Tuple[int]`, *optional*, defaults to 1):
- The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
- [`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
- [`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
- encoder_hid_dim (`int`, *optional*, defaults to None):
- If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
- dimension to `cross_attention_dim`.
- encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
- If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
- embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
- attention_head_dim (`Union[int, Tuple[int]]`, defaults to 8):
- The dimension of the attention heads.
- use_linear_projection (`bool`, defaults to `False`):
- class_embed_type (`str`, *optional*, defaults to `None`):
- The type of class embedding to use which is ultimately summed with the time embeddings. Choose from None,
- `"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
- addition_embed_type (`str`, *optional*, defaults to `None`):
- Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
- "text". "text" will use the `TextTimeEmbedding` layer.
- num_class_embeds (`int`, *optional*, defaults to 0):
- Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
- class conditioning with `class_embed_type` equal to `None`.
- upcast_attention (`bool`, defaults to `False`):
- resnet_time_scale_shift (`str`, defaults to `"default"`):
- Time scale shift config for ResNet blocks (see `ResnetBlock2D`). Choose from `default` or `scale_shift`.
- projection_class_embeddings_input_dim (`int`, *optional*, defaults to `None`):
- The dimension of the `class_labels` input when `class_embed_type="projection"`. Required when
- `class_embed_type="projection"`.
- controlnet_conditioning_channel_order (`str`, defaults to `"rgb"`):
- The channel order of conditional image. Will convert to `rgb` if it's `bgr`.
- conditioning_embedding_out_channels (`tuple[int]`, *optional*, defaults to `(16, 32, 96, 256)`):
- The tuple of output channel for each block in the `conditioning_embedding` layer.
- global_pool_conditions (`bool`, defaults to `False`):
- """
-
- _supports_gradient_checkpointing = True
-
- @register_to_config
- def __init__(
- self,
- in_channels: int = 4,
- conditioning_channels: int = 3,
- flip_sin_to_cos: bool = True,
- freq_shift: int = 0,
- down_block_types: Tuple[str] = (
- "CrossAttnDownBlock2D",
- "CrossAttnDownBlock2D",
- "CrossAttnDownBlock2D",
- "DownBlock2D",
- ),
- only_cross_attention: Union[bool, Tuple[bool]] = False,
- block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
- layers_per_block: int = 2,
- downsample_padding: int = 1,
- mid_block_scale_factor: float = 1,
- act_fn: str = "silu",
- norm_num_groups: Optional[int] = 32,
- norm_eps: float = 1e-5,
- cross_attention_dim: int = 1280,
- transformer_layers_per_block: Union[int, Tuple[int]] = 1,
- encoder_hid_dim: Optional[int] = None,
- encoder_hid_dim_type: Optional[str] = None,
- attention_head_dim: Union[int, Tuple[int]] = 8,
- num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
- use_linear_projection: bool = False,
- class_embed_type: Optional[str] = None,
- addition_embed_type: Optional[str] = None,
- addition_time_embed_dim: Optional[int] = None,
- num_class_embeds: Optional[int] = None,
- upcast_attention: bool = False,
- resnet_time_scale_shift: str = "default",
- projection_class_embeddings_input_dim: Optional[int] = None,
- controlnet_conditioning_channel_order: str = "rgb",
- conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
- global_pool_conditions: bool = False,
- addition_embed_type_num_heads=64,
- ):
- super().__init__()
-
- # If `num_attention_heads` is not defined (which is the case for most models)
- # it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
- # The reason for this behavior is to correct for incorrectly named variables that were introduced
- # when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
- # Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
- # which is why we correct for the naming here.
- num_attention_heads = num_attention_heads or attention_head_dim
-
- # Check inputs
- if len(block_out_channels) != len(down_block_types):
- raise ValueError(
- f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
- )
-
- if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
- raise ValueError(
- f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
- )
-
- if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
- raise ValueError(
- f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
- )
-
- if isinstance(transformer_layers_per_block, int):
- transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
-
- # input
- conv_in_kernel = 3
- conv_in_padding = (conv_in_kernel - 1) // 2
- self.conv_in = nn.Conv2d(
- in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
- )
-
- # time
- time_embed_dim = block_out_channels[0] * 4
- self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
- timestep_input_dim = block_out_channels[0]
- self.time_embedding = TimestepEmbedding(
- timestep_input_dim,
- time_embed_dim,
- act_fn=act_fn,
- )
-
- if encoder_hid_dim_type is None and encoder_hid_dim is not None:
- encoder_hid_dim_type = "text_proj"
- self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
- logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
-
- if encoder_hid_dim is None and encoder_hid_dim_type is not None:
- raise ValueError(
- f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
- )
-
- if encoder_hid_dim_type == "text_proj":
- self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
- elif encoder_hid_dim_type == "text_image_proj":
- # image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
- # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
- # case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
- self.encoder_hid_proj = TextImageProjection(
- text_embed_dim=encoder_hid_dim,
- image_embed_dim=cross_attention_dim,
- cross_attention_dim=cross_attention_dim,
- )
-
- elif encoder_hid_dim_type is not None:
- raise ValueError(
- f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
- )
- else:
- self.encoder_hid_proj = None
-
- # class embedding
- if class_embed_type is None and num_class_embeds is not None:
- self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
- elif class_embed_type == "timestep":
- self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
- elif class_embed_type == "identity":
- self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
- elif class_embed_type == "projection":
- if projection_class_embeddings_input_dim is None:
- raise ValueError(
- "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
- )
- # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
- # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
- # 2. it projects from an arbitrary input dimension.
- #
- # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
- # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
- # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
- self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
- else:
- self.class_embedding = None
-
- if addition_embed_type == "text":
- if encoder_hid_dim is not None:
- text_time_embedding_from_dim = encoder_hid_dim
- else:
- text_time_embedding_from_dim = cross_attention_dim
-
- self.add_embedding = TextTimeEmbedding(
- text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
- )
- elif addition_embed_type == "text_image":
- # text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
- # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
- # case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
- self.add_embedding = TextImageTimeEmbedding(
- text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
- )
- elif addition_embed_type == "text_time":
- self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
- self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
-
- elif addition_embed_type is not None:
- raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
-
- # control net conditioning embedding
- self.controlnet_cond_embedding = ControlNetConditioningEmbedding(
- conditioning_embedding_channels=block_out_channels[0],
- block_out_channels=conditioning_embedding_out_channels,
- conditioning_channels=conditioning_channels,
- )
-
- self.down_blocks = nn.ModuleList([])
- self.controlnet_down_blocks = nn.ModuleList([])
-
- if isinstance(only_cross_attention, bool):
- only_cross_attention = [only_cross_attention] * len(down_block_types)
-
- if isinstance(attention_head_dim, int):
- attention_head_dim = (attention_head_dim,) * len(down_block_types)
-
- if isinstance(num_attention_heads, int):
- num_attention_heads = (num_attention_heads,) * len(down_block_types)
-
- # down
- output_channel = block_out_channels[0]
-
- controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
- controlnet_block = zero_module(controlnet_block)
- self.controlnet_down_blocks.append(controlnet_block)
-
- for i, down_block_type in enumerate(down_block_types):
- input_channel = output_channel
- output_channel = block_out_channels[i]
- is_final_block = i == len(block_out_channels) - 1
-
- down_block = get_down_block(
- down_block_type,
- num_layers=layers_per_block,
- transformer_layers_per_block=transformer_layers_per_block[i],
- in_channels=input_channel,
- out_channels=output_channel,
- temb_channels=time_embed_dim,
- add_downsample=not is_final_block,
- resnet_eps=norm_eps,
- resnet_act_fn=act_fn,
- resnet_groups=norm_num_groups,
- cross_attention_dim=cross_attention_dim,
- num_attention_heads=num_attention_heads[i],
- attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
- downsample_padding=downsample_padding,
- use_linear_projection=use_linear_projection,
- only_cross_attention=only_cross_attention[i],
- upcast_attention=upcast_attention,
- resnet_time_scale_shift=resnet_time_scale_shift,
- )
- self.down_blocks.append(down_block)
-
- for _ in range(layers_per_block):
- controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
- controlnet_block = zero_module(controlnet_block)
- self.controlnet_down_blocks.append(controlnet_block)
-
- if not is_final_block:
- controlnet_block = nn.Conv2d(output_channel, output_channel, kernel_size=1)
- controlnet_block = zero_module(controlnet_block)
- self.controlnet_down_blocks.append(controlnet_block)
-
- # mid
- mid_block_channel = block_out_channels[-1]
-
- controlnet_block = nn.Conv2d(mid_block_channel, mid_block_channel, kernel_size=1)
- controlnet_block = zero_module(controlnet_block)
- self.controlnet_mid_block = controlnet_block
-
- self.mid_block = UNetMidBlock2DCrossAttn(
- transformer_layers_per_block=transformer_layers_per_block[-1],
- in_channels=mid_block_channel,
- temb_channels=time_embed_dim,
- resnet_eps=norm_eps,
- resnet_act_fn=act_fn,
- output_scale_factor=mid_block_scale_factor,
- resnet_time_scale_shift=resnet_time_scale_shift,
- cross_attention_dim=cross_attention_dim,
- num_attention_heads=num_attention_heads[-1],
- resnet_groups=norm_num_groups,
- use_linear_projection=use_linear_projection,
- upcast_attention=upcast_attention,
- )
-
- @classmethod
- def from_unet(
- cls,
- unet: UNet2DConditionModel,
- controlnet_conditioning_channel_order: str = "rgb",
- conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
- load_weights_from_unet: bool = True,
- ):
- r"""
- Instantiate a [`ControlNetModel`] from [`UNet2DConditionModel`].
-
- Parameters:
- unet (`UNet2DConditionModel`):
- The UNet model weights to copy to the [`ControlNetModel`]. All configuration options are also copied
- where applicable.
- """
- transformer_layers_per_block = (
- unet.config.transformer_layers_per_block if "transformer_layers_per_block" in unet.config else 1
- )
- encoder_hid_dim = unet.config.encoder_hid_dim if "encoder_hid_dim" in unet.config else None
- encoder_hid_dim_type = unet.config.encoder_hid_dim_type if "encoder_hid_dim_type" in unet.config else None
- addition_embed_type = unet.config.addition_embed_type if "addition_embed_type" in unet.config else None
- addition_time_embed_dim = (
- unet.config.addition_time_embed_dim if "addition_time_embed_dim" in unet.config else None
- )
-
- controlnet = cls(
- encoder_hid_dim=encoder_hid_dim,
- encoder_hid_dim_type=encoder_hid_dim_type,
- addition_embed_type=addition_embed_type,
- addition_time_embed_dim=addition_time_embed_dim,
- transformer_layers_per_block=transformer_layers_per_block,
- in_channels=unet.config.in_channels,
- flip_sin_to_cos=unet.config.flip_sin_to_cos,
- freq_shift=unet.config.freq_shift,
- down_block_types=unet.config.down_block_types,
- only_cross_attention=unet.config.only_cross_attention,
- block_out_channels=unet.config.block_out_channels,
- layers_per_block=unet.config.layers_per_block,
- downsample_padding=unet.config.downsample_padding,
- mid_block_scale_factor=unet.config.mid_block_scale_factor,
- act_fn=unet.config.act_fn,
- norm_num_groups=unet.config.norm_num_groups,
- norm_eps=unet.config.norm_eps,
- cross_attention_dim=unet.config.cross_attention_dim,
- attention_head_dim=unet.config.attention_head_dim,
- num_attention_heads=unet.config.num_attention_heads,
- use_linear_projection=unet.config.use_linear_projection,
- class_embed_type=unet.config.class_embed_type,
- num_class_embeds=unet.config.num_class_embeds,
- upcast_attention=unet.config.upcast_attention,
- resnet_time_scale_shift=unet.config.resnet_time_scale_shift,
- projection_class_embeddings_input_dim=unet.config.projection_class_embeddings_input_dim,
- controlnet_conditioning_channel_order=controlnet_conditioning_channel_order,
- conditioning_embedding_out_channels=conditioning_embedding_out_channels,
- )
-
- if load_weights_from_unet:
- controlnet.conv_in.load_state_dict(unet.conv_in.state_dict())
- controlnet.time_proj.load_state_dict(unet.time_proj.state_dict())
- controlnet.time_embedding.load_state_dict(unet.time_embedding.state_dict())
-
- if controlnet.class_embedding:
- controlnet.class_embedding.load_state_dict(unet.class_embedding.state_dict())
-
- controlnet.down_blocks.load_state_dict(unet.down_blocks.state_dict())
- controlnet.mid_block.load_state_dict(unet.mid_block.state_dict())
-
- return controlnet
-
- @property
- # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
- def attn_processors(self) -> Dict[str, AttentionProcessor]:
- r"""
- Returns:
- `dict` of attention processors: A dictionary containing all attention processors used in the model with
- indexed by its weight name.
- """
- # set recursively
- processors = {}
-
- def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
- if hasattr(module, "set_processor"):
- processors[f"{name}.processor"] = module.processor
-
- for sub_name, child in module.named_children():
- fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
-
- return processors
-
- for name, module in self.named_children():
- fn_recursive_add_processors(name, module, processors)
-
- return processors
-
- # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
- def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
- r"""
- Sets the attention processor to use to compute attention.
-
- Parameters:
- processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
- The instantiated processor class or a dictionary of processor classes that will be set as the processor
- for **all** `Attention` layers.
-
- If `processor` is a dict, the key needs to define the path to the corresponding cross attention
- processor. This is strongly recommended when setting trainable attention processors.
-
- """
- count = len(self.attn_processors.keys())
-
- if isinstance(processor, dict) and len(processor) != count:
- raise ValueError(
- f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
- f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
- )
-
- def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
- if hasattr(module, "set_processor"):
- if not isinstance(processor, dict):
- module.set_processor(processor)
- else:
- module.set_processor(processor.pop(f"{name}.processor"))
-
- for sub_name, child in module.named_children():
- fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
-
- for name, module in self.named_children():
- fn_recursive_attn_processor(name, module, processor)
-
- # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
- def set_default_attn_processor(self):
- """
- Disables custom attention processors and sets the default attention implementation.
- """
- self.set_attn_processor(AttnProcessor())
-
- # Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attention_slice
- def set_attention_slice(self, slice_size):
- r"""
- Enable sliced attention computation.
-
- When this option is enabled, the attention module splits the input tensor in slices to compute attention in
- several steps. This is useful for saving some memory in exchange for a small decrease in speed.
-
- Args:
- slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
- When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
- `"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
- provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
- must be a multiple of `slice_size`.
- """
- sliceable_head_dims = []
-
- def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
- if hasattr(module, "set_attention_slice"):
- sliceable_head_dims.append(module.sliceable_head_dim)
-
- for child in module.children():
- fn_recursive_retrieve_sliceable_dims(child)
-
- # retrieve number of attention layers
- for module in self.children():
- fn_recursive_retrieve_sliceable_dims(module)
-
- num_sliceable_layers = len(sliceable_head_dims)
-
- if slice_size == "auto":
- # half the attention head size is usually a good trade-off between
- # speed and memory
- slice_size = [dim // 2 for dim in sliceable_head_dims]
- elif slice_size == "max":
- # make smallest slice possible
- slice_size = num_sliceable_layers * [1]
-
- slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
-
- if len(slice_size) != len(sliceable_head_dims):
- raise ValueError(
- f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
- f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
- )
-
- for i in range(len(slice_size)):
- size = slice_size[i]
- dim = sliceable_head_dims[i]
- if size is not None and size > dim:
- raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
-
- # Recursively walk through all the children.
- # Any children which exposes the set_attention_slice method
- # gets the message
- def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
- if hasattr(module, "set_attention_slice"):
- module.set_attention_slice(slice_size.pop())
-
- for child in module.children():
- fn_recursive_set_attention_slice(child, slice_size)
-
- reversed_slice_size = list(reversed(slice_size))
- for module in self.children():
- fn_recursive_set_attention_slice(module, reversed_slice_size)
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D)):
- module.gradient_checkpointing = value
-
- def forward(
- self,
- sample: torch.FloatTensor,
- timestep: Union[torch.Tensor, float, int],
- encoder_hidden_states: torch.Tensor,
- controlnet_cond: torch.FloatTensor,
- conditioning_scale: float = 1.0,
- class_labels: Optional[torch.Tensor] = None,
- timestep_cond: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.Tensor] = None,
- added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
- cross_attention_kwargs: Optional[Dict[str, Any]] = None,
- guess_mode: bool = False,
- return_dict: bool = True,
- ) -> Union[ControlNetOutput, Tuple]:
- """
- The [`ControlNetModel`] forward method.
-
- Args:
- sample (`torch.FloatTensor`):
- The noisy input tensor.
- timestep (`Union[torch.Tensor, float, int]`):
- The number of timesteps to denoise an input.
- encoder_hidden_states (`torch.Tensor`):
- The encoder hidden states.
- controlnet_cond (`torch.FloatTensor`):
- The conditional input tensor of shape `(batch_size, sequence_length, hidden_size)`.
- conditioning_scale (`float`, defaults to `1.0`):
- The scale factor for ControlNet outputs.
- class_labels (`torch.Tensor`, *optional*, defaults to `None`):
- Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
- timestep_cond (`torch.Tensor`, *optional*, defaults to `None`):
- attention_mask (`torch.Tensor`, *optional*, defaults to `None`):
- added_cond_kwargs (`dict`):
- Additional conditions for the Stable Diffusion XL UNet.
- cross_attention_kwargs (`dict[str]`, *optional*, defaults to `None`):
- A kwargs dictionary that if specified is passed along to the `AttnProcessor`.
- guess_mode (`bool`, defaults to `False`):
- In this mode, the ControlNet encoder tries its best to recognize the input content of the input even if
- you remove all prompts. A `guidance_scale` between 3.0 and 5.0 is recommended.
- return_dict (`bool`, defaults to `True`):
- Whether or not to return a [`~models.controlnet.ControlNetOutput`] instead of a plain tuple.
-
- Returns:
- [`~models.controlnet.ControlNetOutput`] **or** `tuple`:
- If `return_dict` is `True`, a [`~models.controlnet.ControlNetOutput`] is returned, otherwise a tuple is
- returned where the first element is the sample tensor.
- """
- # check channel order
- channel_order = self.config.controlnet_conditioning_channel_order
-
- if channel_order == "rgb":
- # in rgb order by default
- ...
- elif channel_order == "bgr":
- controlnet_cond = torch.flip(controlnet_cond, dims=[1])
- else:
- raise ValueError(f"unknown `controlnet_conditioning_channel_order`: {channel_order}")
-
- # prepare attention_mask
- if attention_mask is not None:
- attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
- attention_mask = attention_mask.unsqueeze(1)
-
- # 1. time
- timesteps = timestep
- if not torch.is_tensor(timesteps):
- # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
- # This would be a good case for the `match` statement (Python 3.10+)
- is_mps = sample.device.type == "mps"
- if isinstance(timestep, float):
- dtype = torch.float32 if is_mps else torch.float64
- else:
- dtype = torch.int32 if is_mps else torch.int64
- timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
- elif len(timesteps.shape) == 0:
- timesteps = timesteps[None].to(sample.device)
-
- # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
- timesteps = timesteps.expand(sample.shape[0])
-
- t_emb = self.time_proj(timesteps)
-
- # timesteps does not contain any weights and will always return f32 tensors
- # but time_embedding might actually be running in fp16. so we need to cast here.
- # there might be better ways to encapsulate this.
- t_emb = t_emb.to(dtype=sample.dtype)
-
- emb = self.time_embedding(t_emb, timestep_cond)
- aug_emb = None
-
- if self.class_embedding is not None:
- if class_labels is None:
- raise ValueError("class_labels should be provided when num_class_embeds > 0")
-
- if self.config.class_embed_type == "timestep":
- class_labels = self.time_proj(class_labels)
-
- class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
- emb = emb + class_emb
-
- if "addition_embed_type" in self.config:
- if self.config.addition_embed_type == "text":
- aug_emb = self.add_embedding(encoder_hidden_states)
-
- elif self.config.addition_embed_type == "text_time":
- if "text_embeds" not in added_cond_kwargs:
- raise ValueError(
- f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
- )
- text_embeds = added_cond_kwargs.get("text_embeds")
- if "time_ids" not in added_cond_kwargs:
- raise ValueError(
- f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
- )
- time_ids = added_cond_kwargs.get("time_ids")
- time_embeds = self.add_time_proj(time_ids.flatten())
- time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
-
- add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
- add_embeds = add_embeds.to(emb.dtype)
- aug_emb = self.add_embedding(add_embeds)
-
- emb = emb + aug_emb if aug_emb is not None else emb
-
- # 2. pre-process
- sample = self.conv_in(sample)
-
- controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
- sample = sample + controlnet_cond
-
- # 3. down
- down_block_res_samples = (sample,)
- for downsample_block in self.down_blocks:
- if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
- sample, res_samples = downsample_block(
- hidden_states=sample,
- temb=emb,
- encoder_hidden_states=encoder_hidden_states,
- attention_mask=attention_mask,
- cross_attention_kwargs=cross_attention_kwargs,
- )
- else:
- sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
-
- down_block_res_samples += res_samples
-
- # 4. mid
- if self.mid_block is not None:
- sample = self.mid_block(
- sample,
- emb,
- encoder_hidden_states=encoder_hidden_states,
- attention_mask=attention_mask,
- cross_attention_kwargs=cross_attention_kwargs,
- )
-
- # 5. Control net blocks
-
- controlnet_down_block_res_samples = ()
-
- for down_block_res_sample, controlnet_block in zip(down_block_res_samples, self.controlnet_down_blocks):
- down_block_res_sample = controlnet_block(down_block_res_sample)
- controlnet_down_block_res_samples = controlnet_down_block_res_samples + (down_block_res_sample,)
-
- down_block_res_samples = controlnet_down_block_res_samples
-
- mid_block_res_sample = self.controlnet_mid_block(sample)
-
- # 6. scaling
- if guess_mode and not self.config.global_pool_conditions:
- scales = torch.logspace(-1, 0, len(down_block_res_samples) + 1, device=sample.device) # 0.1 to 1.0
-
- scales = scales * conditioning_scale
- down_block_res_samples = [sample * scale for sample, scale in zip(down_block_res_samples, scales)]
- mid_block_res_sample = mid_block_res_sample * scales[-1] # last one
- else:
- down_block_res_samples = [sample * conditioning_scale for sample in down_block_res_samples]
- mid_block_res_sample = mid_block_res_sample * conditioning_scale
-
- if self.config.global_pool_conditions:
- down_block_res_samples = [
- torch.mean(sample, dim=(2, 3), keepdim=True) for sample in down_block_res_samples
- ]
- mid_block_res_sample = torch.mean(mid_block_res_sample, dim=(2, 3), keepdim=True)
-
- if not return_dict:
- return (down_block_res_samples, mid_block_res_sample)
-
- return ControlNetOutput(
- down_block_res_samples=down_block_res_samples, mid_block_res_sample=mid_block_res_sample
- )
-
-
-def zero_module(module):
- for p in module.parameters():
- nn.init.zeros_(p)
- return module
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
deleted file mode 100644
index 3d88f4ee4416626b9b2695ee9b0b826fade1565d..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/versatile_diffusion/pipeline_versatile_diffusion_text_to_image.py
+++ /dev/null
@@ -1,469 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import inspect
-import warnings
-from typing import Callable, List, Optional, Union
-
-import torch
-import torch.utils.checkpoint
-from transformers import CLIPImageProcessor, CLIPTextModelWithProjection, CLIPTokenizer
-
-from ...image_processor import VaeImageProcessor
-from ...models import AutoencoderKL, Transformer2DModel, UNet2DConditionModel
-from ...schedulers import KarrasDiffusionSchedulers
-from ...utils import logging, randn_tensor
-from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
-from .modeling_text_unet import UNetFlatConditionModel
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-class VersatileDiffusionTextToImagePipeline(DiffusionPipeline):
- r"""
- Pipeline for text-to-image generation using Versatile Diffusion.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
- implemented for all pipelines (downloading, saving, running on a particular device, etc.).
-
- Parameters:
- vqvae ([`VQModel`]):
- Vector-quantized (VQ) model to encode and decode images to and from latent representations.
- bert ([`LDMBertModel`]):
- Text-encoder model based on [`~transformers.BERT`].
- tokenizer ([`~transformers.BertTokenizer`]):
- A `BertTokenizer` to tokenize text.
- unet ([`UNet2DConditionModel`]):
- A `UNet2DConditionModel` to denoise the encoded image latents.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- """
- tokenizer: CLIPTokenizer
- image_feature_extractor: CLIPImageProcessor
- text_encoder: CLIPTextModelWithProjection
- image_unet: UNet2DConditionModel
- text_unet: UNetFlatConditionModel
- vae: AutoencoderKL
- scheduler: KarrasDiffusionSchedulers
-
- _optional_components = ["text_unet"]
-
- def __init__(
- self,
- tokenizer: CLIPTokenizer,
- text_encoder: CLIPTextModelWithProjection,
- image_unet: UNet2DConditionModel,
- text_unet: UNetFlatConditionModel,
- vae: AutoencoderKL,
- scheduler: KarrasDiffusionSchedulers,
- ):
- super().__init__()
- self.register_modules(
- tokenizer=tokenizer,
- text_encoder=text_encoder,
- image_unet=image_unet,
- text_unet=text_unet,
- vae=vae,
- scheduler=scheduler,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
-
- if self.text_unet is not None:
- self._swap_unet_attention_blocks()
-
- def _swap_unet_attention_blocks(self):
- """
- Swap the `Transformer2DModel` blocks between the image and text UNets
- """
- for name, module in self.image_unet.named_modules():
- if isinstance(module, Transformer2DModel):
- parent_name, index = name.rsplit(".", 1)
- index = int(index)
- self.image_unet.get_submodule(parent_name)[index], self.text_unet.get_submodule(parent_name)[index] = (
- self.text_unet.get_submodule(parent_name)[index],
- self.image_unet.get_submodule(parent_name)[index],
- )
-
- def remove_unused_weights(self):
- self.register_modules(text_unet=None)
-
- def _encode_prompt(self, prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt):
- r"""
- Encodes the prompt into text encoder hidden states.
-
- Args:
- prompt (`str` or `List[str]`):
- prompt to be encoded
- device: (`torch.device`):
- torch device
- num_images_per_prompt (`int`):
- number of images that should be generated per prompt
- do_classifier_free_guidance (`bool`):
- whether to use classifier free guidance or not
- negative_prompt (`str` or `List[str]`):
- The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
- if `guidance_scale` is less than `1`).
- """
-
- def normalize_embeddings(encoder_output):
- embeds = self.text_encoder.text_projection(encoder_output.last_hidden_state)
- embeds_pooled = encoder_output.text_embeds
- embeds = embeds / torch.norm(embeds_pooled.unsqueeze(1), dim=-1, keepdim=True)
- return embeds
-
- batch_size = len(prompt) if isinstance(prompt, list) else 1
-
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
- untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="pt").input_ids
-
- if not torch.equal(text_input_ids, untruncated_ids):
- removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = text_inputs.attention_mask.to(device)
- else:
- attention_mask = None
-
- prompt_embeds = self.text_encoder(
- text_input_ids.to(device),
- attention_mask=attention_mask,
- )
- prompt_embeds = normalize_embeddings(prompt_embeds)
-
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- bs_embed, seq_len, _ = prompt_embeds.shape
- prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
- prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
-
- # get unconditional embeddings for classifier free guidance
- if do_classifier_free_guidance:
- uncond_tokens: List[str]
- if negative_prompt is None:
- uncond_tokens = [""] * batch_size
- elif type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = negative_prompt
-
- max_length = text_input_ids.shape[-1]
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
-
- if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
- attention_mask = uncond_input.attention_mask.to(device)
- else:
- attention_mask = None
-
- negative_prompt_embeds = self.text_encoder(
- uncond_input.input_ids.to(device),
- attention_mask=attention_mask,
- )
- negative_prompt_embeds = normalize_embeddings(negative_prompt_embeds)
-
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = negative_prompt_embeds.shape[1]
- negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
- negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
-
- return prompt_embeds
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
- def decode_latents(self, latents):
- warnings.warn(
- "The decode_latents method is deprecated and will be removed in a future version. Please"
- " use VaeImageProcessor instead",
- FutureWarning,
- )
- latents = 1 / self.vae.config.scaling_factor * latents
- image = self.vae.decode(latents, return_dict=False)[0]
- image = (image / 2 + 0.5).clamp(0, 1)
- # we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
- image = image.cpu().permute(0, 2, 3, 1).float().numpy()
- return image
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
- def prepare_extra_step_kwargs(self, generator, eta):
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
-
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- # check if the scheduler accepts generator
- accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
- if accepts_generator:
- extra_step_kwargs["generator"] = generator
- return extra_step_kwargs
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
- def check_inputs(
- self,
- prompt,
- height,
- width,
- callback_steps,
- negative_prompt=None,
- prompt_embeds=None,
- negative_prompt_embeds=None,
- ):
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- if prompt is not None and prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
- " only forward one of the two."
- )
- elif prompt is None and prompt_embeds is None:
- raise ValueError(
- "Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
- )
- elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- if negative_prompt is not None and negative_prompt_embeds is not None:
- raise ValueError(
- f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
- f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
- )
-
- if prompt_embeds is not None and negative_prompt_embeds is not None:
- if prompt_embeds.shape != negative_prompt_embeds.shape:
- raise ValueError(
- "`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
- f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
- f" {negative_prompt_embeds.shape}."
- )
-
- # Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
- def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
- shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
- if isinstance(generator, list) and len(generator) != batch_size:
- raise ValueError(
- f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
- f" size of {batch_size}. Make sure the batch size matches the length of the generators."
- )
-
- if latents is None:
- latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
- else:
- latents = latents.to(device)
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * self.scheduler.init_noise_sigma
- return latents
-
- @torch.no_grad()
- def __call__(
- self,
- prompt: Union[str, List[str]],
- height: Optional[int] = None,
- width: Optional[int] = None,
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
- latents: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: int = 1,
- **kwargs,
- ):
- r"""
- The call function to the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`):
- The prompt or prompts to guide image generation.
- height (`int`, *optional*, defaults to `self.image_unet.config.sample_size * self.vae_scale_factor`):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to `self.image_unet.config.sample_size * self.vae_scale_factor`):
- The width in pixels of the generated image.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- A higher guidance scale value encourages the model to generate images closely linked to the text
- `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts to guide what to not include in image generation. If not defined, you need to
- pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
- to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
- generator (`torch.Generator`, *optional*):
- A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
- generation deterministic.
- latents (`torch.FloatTensor`, *optional*):
- Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor is generated by sampling using the supplied random `generator`.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generated image. Choose between `PIL.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that calls every `callback_steps` steps during inference. The function is called with the
- following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function is called. If not specified, the callback is called at
- every step.
-
- Examples:
-
- ```py
- >>> from diffusers import VersatileDiffusionTextToImagePipeline
- >>> import torch
-
- >>> pipe = VersatileDiffusionTextToImagePipeline.from_pretrained(
- ... "shi-labs/versatile-diffusion", torch_dtype=torch.float16
- ... )
- >>> pipe.remove_unused_weights()
- >>> pipe = pipe.to("cuda")
-
- >>> generator = torch.Generator(device="cuda").manual_seed(0)
- >>> image = pipe("an astronaut riding on a horse on mars", generator=generator).images[0]
- >>> image.save("./astronaut.png")
- ```
-
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
- If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
- otherwise a `tuple` is returned where the first element is a list with the generated images.
- """
- # 0. Default height and width to unet
- height = height or self.image_unet.config.sample_size * self.vae_scale_factor
- width = width or self.image_unet.config.sample_size * self.vae_scale_factor
-
- # 1. Check inputs. Raise error if not correct
- self.check_inputs(prompt, height, width, callback_steps)
-
- # 2. Define call parameters
- batch_size = 1 if isinstance(prompt, str) else len(prompt)
- device = self._execution_device
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
-
- # 3. Encode input prompt
- prompt_embeds = self._encode_prompt(
- prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
- )
-
- # 4. Prepare timesteps
- self.scheduler.set_timesteps(num_inference_steps, device=device)
- timesteps = self.scheduler.timesteps
-
- # 5. Prepare latent variables
- num_channels_latents = self.image_unet.config.in_channels
- latents = self.prepare_latents(
- batch_size * num_images_per_prompt,
- num_channels_latents,
- height,
- width,
- prompt_embeds.dtype,
- device,
- generator,
- latents,
- )
-
- # 6. Prepare extra step kwargs.
- extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
-
- # 7. Denoising loop
- for i, t in enumerate(self.progress_bar(timesteps)):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- # predict the noise residual
- noise_pred = self.image_unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
-
- # call the callback, if provided
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- if not output_type == "latent":
- image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
- else:
- image = latents
-
- image = self.image_processor.postprocess(image, output_type=output_type)
-
- if not return_dict:
- return (image,)
-
- return ImagePipelineOutput(images=image)
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/faster_rcnn/faster_rcnn_r50_caffe_fpn_mstrain_90k_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/faster_rcnn/faster_rcnn_r50_caffe_fpn_mstrain_90k_coco.py
deleted file mode 100644
index 74dca24f26422967501e7ba31c3f39ca324e031c..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/faster_rcnn/faster_rcnn_r50_caffe_fpn_mstrain_90k_coco.py
+++ /dev/null
@@ -1,15 +0,0 @@
-_base_ = 'faster_rcnn_r50_caffe_fpn_mstrain_1x_coco.py'
-
-# learning policy
-lr_config = dict(
- policy='step',
- warmup='linear',
- warmup_iters=500,
- warmup_ratio=0.001,
- step=[60000, 80000])
-
-# Runner type
-runner = dict(_delete_=True, type='IterBasedRunner', max_iters=90000)
-
-checkpoint_config = dict(interval=10000)
-evaluation = dict(interval=10000, metric='bbox')
diff --git a/spaces/Andy1621/uniformer_image_detection/mmdet/models/roi_heads/mask_heads/grid_head.py b/spaces/Andy1621/uniformer_image_detection/mmdet/models/roi_heads/mask_heads/grid_head.py
deleted file mode 100644
index 83058cbdda934ebfc3a76088e1820848ac01b78b..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmdet/models/roi_heads/mask_heads/grid_head.py
+++ /dev/null
@@ -1,359 +0,0 @@
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule, kaiming_init, normal_init
-
-from mmdet.models.builder import HEADS, build_loss
-
-
-@HEADS.register_module()
-class GridHead(nn.Module):
-
- def __init__(self,
- grid_points=9,
- num_convs=8,
- roi_feat_size=14,
- in_channels=256,
- conv_kernel_size=3,
- point_feat_channels=64,
- deconv_kernel_size=4,
- class_agnostic=False,
- loss_grid=dict(
- type='CrossEntropyLoss', use_sigmoid=True,
- loss_weight=15),
- conv_cfg=None,
- norm_cfg=dict(type='GN', num_groups=36)):
- super(GridHead, self).__init__()
- self.grid_points = grid_points
- self.num_convs = num_convs
- self.roi_feat_size = roi_feat_size
- self.in_channels = in_channels
- self.conv_kernel_size = conv_kernel_size
- self.point_feat_channels = point_feat_channels
- self.conv_out_channels = self.point_feat_channels * self.grid_points
- self.class_agnostic = class_agnostic
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- if isinstance(norm_cfg, dict) and norm_cfg['type'] == 'GN':
- assert self.conv_out_channels % norm_cfg['num_groups'] == 0
-
- assert self.grid_points >= 4
- self.grid_size = int(np.sqrt(self.grid_points))
- if self.grid_size * self.grid_size != self.grid_points:
- raise ValueError('grid_points must be a square number')
-
- # the predicted heatmap is half of whole_map_size
- if not isinstance(self.roi_feat_size, int):
- raise ValueError('Only square RoIs are supporeted in Grid R-CNN')
- self.whole_map_size = self.roi_feat_size * 4
-
- # compute point-wise sub-regions
- self.sub_regions = self.calc_sub_regions()
-
- self.convs = []
- for i in range(self.num_convs):
- in_channels = (
- self.in_channels if i == 0 else self.conv_out_channels)
- stride = 2 if i == 0 else 1
- padding = (self.conv_kernel_size - 1) // 2
- self.convs.append(
- ConvModule(
- in_channels,
- self.conv_out_channels,
- self.conv_kernel_size,
- stride=stride,
- padding=padding,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- bias=True))
- self.convs = nn.Sequential(*self.convs)
-
- self.deconv1 = nn.ConvTranspose2d(
- self.conv_out_channels,
- self.conv_out_channels,
- kernel_size=deconv_kernel_size,
- stride=2,
- padding=(deconv_kernel_size - 2) // 2,
- groups=grid_points)
- self.norm1 = nn.GroupNorm(grid_points, self.conv_out_channels)
- self.deconv2 = nn.ConvTranspose2d(
- self.conv_out_channels,
- grid_points,
- kernel_size=deconv_kernel_size,
- stride=2,
- padding=(deconv_kernel_size - 2) // 2,
- groups=grid_points)
-
- # find the 4-neighbor of each grid point
- self.neighbor_points = []
- grid_size = self.grid_size
- for i in range(grid_size): # i-th column
- for j in range(grid_size): # j-th row
- neighbors = []
- if i > 0: # left: (i - 1, j)
- neighbors.append((i - 1) * grid_size + j)
- if j > 0: # up: (i, j - 1)
- neighbors.append(i * grid_size + j - 1)
- if j < grid_size - 1: # down: (i, j + 1)
- neighbors.append(i * grid_size + j + 1)
- if i < grid_size - 1: # right: (i + 1, j)
- neighbors.append((i + 1) * grid_size + j)
- self.neighbor_points.append(tuple(neighbors))
- # total edges in the grid
- self.num_edges = sum([len(p) for p in self.neighbor_points])
-
- self.forder_trans = nn.ModuleList() # first-order feature transition
- self.sorder_trans = nn.ModuleList() # second-order feature transition
- for neighbors in self.neighbor_points:
- fo_trans = nn.ModuleList()
- so_trans = nn.ModuleList()
- for _ in range(len(neighbors)):
- # each transition module consists of a 5x5 depth-wise conv and
- # 1x1 conv.
- fo_trans.append(
- nn.Sequential(
- nn.Conv2d(
- self.point_feat_channels,
- self.point_feat_channels,
- 5,
- stride=1,
- padding=2,
- groups=self.point_feat_channels),
- nn.Conv2d(self.point_feat_channels,
- self.point_feat_channels, 1)))
- so_trans.append(
- nn.Sequential(
- nn.Conv2d(
- self.point_feat_channels,
- self.point_feat_channels,
- 5,
- 1,
- 2,
- groups=self.point_feat_channels),
- nn.Conv2d(self.point_feat_channels,
- self.point_feat_channels, 1)))
- self.forder_trans.append(fo_trans)
- self.sorder_trans.append(so_trans)
-
- self.loss_grid = build_loss(loss_grid)
-
- def init_weights(self):
- for m in self.modules():
- if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
- # TODO: compare mode = "fan_in" or "fan_out"
- kaiming_init(m)
- for m in self.modules():
- if isinstance(m, nn.ConvTranspose2d):
- normal_init(m, std=0.001)
- nn.init.constant_(self.deconv2.bias, -np.log(0.99 / 0.01))
-
- def forward(self, x):
- assert x.shape[-1] == x.shape[-2] == self.roi_feat_size
- # RoI feature transformation, downsample 2x
- x = self.convs(x)
-
- c = self.point_feat_channels
- # first-order fusion
- x_fo = [None for _ in range(self.grid_points)]
- for i, points in enumerate(self.neighbor_points):
- x_fo[i] = x[:, i * c:(i + 1) * c]
- for j, point_idx in enumerate(points):
- x_fo[i] = x_fo[i] + self.forder_trans[i][j](
- x[:, point_idx * c:(point_idx + 1) * c])
-
- # second-order fusion
- x_so = [None for _ in range(self.grid_points)]
- for i, points in enumerate(self.neighbor_points):
- x_so[i] = x[:, i * c:(i + 1) * c]
- for j, point_idx in enumerate(points):
- x_so[i] = x_so[i] + self.sorder_trans[i][j](x_fo[point_idx])
-
- # predicted heatmap with fused features
- x2 = torch.cat(x_so, dim=1)
- x2 = self.deconv1(x2)
- x2 = F.relu(self.norm1(x2), inplace=True)
- heatmap = self.deconv2(x2)
-
- # predicted heatmap with original features (applicable during training)
- if self.training:
- x1 = x
- x1 = self.deconv1(x1)
- x1 = F.relu(self.norm1(x1), inplace=True)
- heatmap_unfused = self.deconv2(x1)
- else:
- heatmap_unfused = heatmap
-
- return dict(fused=heatmap, unfused=heatmap_unfused)
-
- def calc_sub_regions(self):
- """Compute point specific representation regions.
-
- See Grid R-CNN Plus (https://arxiv.org/abs/1906.05688) for details.
- """
- # to make it consistent with the original implementation, half_size
- # is computed as 2 * quarter_size, which is smaller
- half_size = self.whole_map_size // 4 * 2
- sub_regions = []
- for i in range(self.grid_points):
- x_idx = i // self.grid_size
- y_idx = i % self.grid_size
- if x_idx == 0:
- sub_x1 = 0
- elif x_idx == self.grid_size - 1:
- sub_x1 = half_size
- else:
- ratio = x_idx / (self.grid_size - 1) - 0.25
- sub_x1 = max(int(ratio * self.whole_map_size), 0)
-
- if y_idx == 0:
- sub_y1 = 0
- elif y_idx == self.grid_size - 1:
- sub_y1 = half_size
- else:
- ratio = y_idx / (self.grid_size - 1) - 0.25
- sub_y1 = max(int(ratio * self.whole_map_size), 0)
- sub_regions.append(
- (sub_x1, sub_y1, sub_x1 + half_size, sub_y1 + half_size))
- return sub_regions
-
- def get_targets(self, sampling_results, rcnn_train_cfg):
- # mix all samples (across images) together.
- pos_bboxes = torch.cat([res.pos_bboxes for res in sampling_results],
- dim=0).cpu()
- pos_gt_bboxes = torch.cat(
- [res.pos_gt_bboxes for res in sampling_results], dim=0).cpu()
- assert pos_bboxes.shape == pos_gt_bboxes.shape
-
- # expand pos_bboxes to 2x of original size
- x1 = pos_bboxes[:, 0] - (pos_bboxes[:, 2] - pos_bboxes[:, 0]) / 2
- y1 = pos_bboxes[:, 1] - (pos_bboxes[:, 3] - pos_bboxes[:, 1]) / 2
- x2 = pos_bboxes[:, 2] + (pos_bboxes[:, 2] - pos_bboxes[:, 0]) / 2
- y2 = pos_bboxes[:, 3] + (pos_bboxes[:, 3] - pos_bboxes[:, 1]) / 2
- pos_bboxes = torch.stack([x1, y1, x2, y2], dim=-1)
- pos_bbox_ws = (pos_bboxes[:, 2] - pos_bboxes[:, 0]).unsqueeze(-1)
- pos_bbox_hs = (pos_bboxes[:, 3] - pos_bboxes[:, 1]).unsqueeze(-1)
-
- num_rois = pos_bboxes.shape[0]
- map_size = self.whole_map_size
- # this is not the final target shape
- targets = torch.zeros((num_rois, self.grid_points, map_size, map_size),
- dtype=torch.float)
-
- # pre-compute interpolation factors for all grid points.
- # the first item is the factor of x-dim, and the second is y-dim.
- # for a 9-point grid, factors are like (1, 0), (0.5, 0.5), (0, 1)
- factors = []
- for j in range(self.grid_points):
- x_idx = j // self.grid_size
- y_idx = j % self.grid_size
- factors.append((1 - x_idx / (self.grid_size - 1),
- 1 - y_idx / (self.grid_size - 1)))
-
- radius = rcnn_train_cfg.pos_radius
- radius2 = radius**2
- for i in range(num_rois):
- # ignore small bboxes
- if (pos_bbox_ws[i] <= self.grid_size
- or pos_bbox_hs[i] <= self.grid_size):
- continue
- # for each grid point, mark a small circle as positive
- for j in range(self.grid_points):
- factor_x, factor_y = factors[j]
- gridpoint_x = factor_x * pos_gt_bboxes[i, 0] + (
- 1 - factor_x) * pos_gt_bboxes[i, 2]
- gridpoint_y = factor_y * pos_gt_bboxes[i, 1] + (
- 1 - factor_y) * pos_gt_bboxes[i, 3]
-
- cx = int((gridpoint_x - pos_bboxes[i, 0]) / pos_bbox_ws[i] *
- map_size)
- cy = int((gridpoint_y - pos_bboxes[i, 1]) / pos_bbox_hs[i] *
- map_size)
-
- for x in range(cx - radius, cx + radius + 1):
- for y in range(cy - radius, cy + radius + 1):
- if x >= 0 and x < map_size and y >= 0 and y < map_size:
- if (x - cx)**2 + (y - cy)**2 <= radius2:
- targets[i, j, y, x] = 1
- # reduce the target heatmap size by a half
- # proposed in Grid R-CNN Plus (https://arxiv.org/abs/1906.05688).
- sub_targets = []
- for i in range(self.grid_points):
- sub_x1, sub_y1, sub_x2, sub_y2 = self.sub_regions[i]
- sub_targets.append(targets[:, [i], sub_y1:sub_y2, sub_x1:sub_x2])
- sub_targets = torch.cat(sub_targets, dim=1)
- sub_targets = sub_targets.to(sampling_results[0].pos_bboxes.device)
- return sub_targets
-
- def loss(self, grid_pred, grid_targets):
- loss_fused = self.loss_grid(grid_pred['fused'], grid_targets)
- loss_unfused = self.loss_grid(grid_pred['unfused'], grid_targets)
- loss_grid = loss_fused + loss_unfused
- return dict(loss_grid=loss_grid)
-
- def get_bboxes(self, det_bboxes, grid_pred, img_metas):
- # TODO: refactoring
- assert det_bboxes.shape[0] == grid_pred.shape[0]
- det_bboxes = det_bboxes.cpu()
- cls_scores = det_bboxes[:, [4]]
- det_bboxes = det_bboxes[:, :4]
- grid_pred = grid_pred.sigmoid().cpu()
-
- R, c, h, w = grid_pred.shape
- half_size = self.whole_map_size // 4 * 2
- assert h == w == half_size
- assert c == self.grid_points
-
- # find the point with max scores in the half-sized heatmap
- grid_pred = grid_pred.view(R * c, h * w)
- pred_scores, pred_position = grid_pred.max(dim=1)
- xs = pred_position % w
- ys = pred_position // w
-
- # get the position in the whole heatmap instead of half-sized heatmap
- for i in range(self.grid_points):
- xs[i::self.grid_points] += self.sub_regions[i][0]
- ys[i::self.grid_points] += self.sub_regions[i][1]
-
- # reshape to (num_rois, grid_points)
- pred_scores, xs, ys = tuple(
- map(lambda x: x.view(R, c), [pred_scores, xs, ys]))
-
- # get expanded pos_bboxes
- widths = (det_bboxes[:, 2] - det_bboxes[:, 0]).unsqueeze(-1)
- heights = (det_bboxes[:, 3] - det_bboxes[:, 1]).unsqueeze(-1)
- x1 = (det_bboxes[:, 0, None] - widths / 2)
- y1 = (det_bboxes[:, 1, None] - heights / 2)
- # map the grid point to the absolute coordinates
- abs_xs = (xs.float() + 0.5) / w * widths + x1
- abs_ys = (ys.float() + 0.5) / h * heights + y1
-
- # get the grid points indices that fall on the bbox boundaries
- x1_inds = [i for i in range(self.grid_size)]
- y1_inds = [i * self.grid_size for i in range(self.grid_size)]
- x2_inds = [
- self.grid_points - self.grid_size + i
- for i in range(self.grid_size)
- ]
- y2_inds = [(i + 1) * self.grid_size - 1 for i in range(self.grid_size)]
-
- # voting of all grid points on some boundary
- bboxes_x1 = (abs_xs[:, x1_inds] * pred_scores[:, x1_inds]).sum(
- dim=1, keepdim=True) / (
- pred_scores[:, x1_inds].sum(dim=1, keepdim=True))
- bboxes_y1 = (abs_ys[:, y1_inds] * pred_scores[:, y1_inds]).sum(
- dim=1, keepdim=True) / (
- pred_scores[:, y1_inds].sum(dim=1, keepdim=True))
- bboxes_x2 = (abs_xs[:, x2_inds] * pred_scores[:, x2_inds]).sum(
- dim=1, keepdim=True) / (
- pred_scores[:, x2_inds].sum(dim=1, keepdim=True))
- bboxes_y2 = (abs_ys[:, y2_inds] * pred_scores[:, y2_inds]).sum(
- dim=1, keepdim=True) / (
- pred_scores[:, y2_inds].sum(dim=1, keepdim=True))
-
- bbox_res = torch.cat(
- [bboxes_x1, bboxes_y1, bboxes_x2, bboxes_y2, cls_scores], dim=1)
- bbox_res[:, [0, 2]].clamp_(min=0, max=img_metas[0]['img_shape'][1])
- bbox_res[:, [1, 3]].clamp_(min=0, max=img_metas[0]['img_shape'][0])
-
- return bbox_res
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/gcnet/gcnet_r50-d8_512x512_40k_voc12aug.py b/spaces/Andy1621/uniformer_image_segmentation/configs/gcnet/gcnet_r50-d8_512x512_40k_voc12aug.py
deleted file mode 100644
index d85cf6550fea5da7cf1fa078eb4fa30e017166b4..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/gcnet/gcnet_r50-d8_512x512_40k_voc12aug.py
+++ /dev/null
@@ -1,7 +0,0 @@
-_base_ = [
- '../_base_/models/gcnet_r50-d8.py',
- '../_base_/datasets/pascal_voc12_aug.py', '../_base_/default_runtime.py',
- '../_base_/schedules/schedule_40k.py'
-]
-model = dict(
- decode_head=dict(num_classes=21), auxiliary_head=dict(num_classes=21))
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/resnest/README.md b/spaces/Andy1621/uniformer_image_segmentation/configs/resnest/README.md
deleted file mode 100644
index b610c14c3ef971ac075d5fb2223d2d5f2b4098bf..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/resnest/README.md
+++ /dev/null
@@ -1,34 +0,0 @@
-# ResNeSt: Split-Attention Networks
-
-## Introduction
-
-
-
-```latex
-@article{zhang2020resnest,
-title={ResNeSt: Split-Attention Networks},
-author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander},
-journal={arXiv preprint arXiv:2004.08955},
-year={2020}
-}
-```
-
-## Results and models
-
-### Cityscapes
-
-| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
-| ---------- | -------- | --------- | ------: | -------: | -------------- | ----: | ------------- | ----------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
-| FCN | S-101-D8 | 512x1024 | 80000 | 11.4 | 2.39 | 77.56 | 78.98 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/fcn_s101-d8_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/fcn_s101-d8_512x1024_80k_cityscapes/fcn_s101-d8_512x1024_80k_cityscapes_20200807_140631-f8d155b3.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/fcn_s101-d8_512x1024_80k_cityscapes/fcn_s101-d8_512x1024_80k_cityscapes-20200807_140631.log.json) |
-| PSPNet | S-101-D8 | 512x1024 | 80000 | 11.8 | 2.52 | 78.57 | 79.19 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/pspnet_s101-d8_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/pspnet_s101-d8_512x1024_80k_cityscapes/pspnet_s101-d8_512x1024_80k_cityscapes_20200807_140631-c75f3b99.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/pspnet_s101-d8_512x1024_80k_cityscapes/pspnet_s101-d8_512x1024_80k_cityscapes-20200807_140631.log.json) |
-| DeepLabV3 | S-101-D8 | 512x1024 | 80000 | 11.9 | 1.88 | 79.67 | 80.51 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/deeplabv3_s101-d8_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3_s101-d8_512x1024_80k_cityscapes/deeplabv3_s101-d8_512x1024_80k_cityscapes_20200807_144429-b73c4270.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3_s101-d8_512x1024_80k_cityscapes/deeplabv3_s101-d8_512x1024_80k_cityscapes-20200807_144429.log.json) |
-| DeepLabV3+ | S-101-D8 | 512x1024 | 80000 | 13.2 | 2.36 | 79.62 | 80.27 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/deeplabv3plus_s101-d8_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3plus_s101-d8_512x1024_80k_cityscapes/deeplabv3plus_s101-d8_512x1024_80k_cityscapes_20200807_144429-1239eb43.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3plus_s101-d8_512x1024_80k_cityscapes/deeplabv3plus_s101-d8_512x1024_80k_cityscapes-20200807_144429.log.json) |
-
-### ADE20k
-
-| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
-| ---------- | -------- | --------- | ------: | -------: | -------------- | ----: | ------------- | ------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| FCN | S-101-D8 | 512x512 | 160000 | 14.2 | 12.86 | 45.62 | 46.16 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/fcn_s101-d8_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/fcn_s101-d8_512x512_160k_ade20k/fcn_s101-d8_512x512_160k_ade20k_20200807_145416-d3160329.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/fcn_s101-d8_512x512_160k_ade20k/fcn_s101-d8_512x512_160k_ade20k-20200807_145416.log.json) |
-| PSPNet | S-101-D8 | 512x512 | 160000 | 14.2 | 13.02 | 45.44 | 46.28 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/pspnet_s101-d8_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/pspnet_s101-d8_512x512_160k_ade20k/pspnet_s101-d8_512x512_160k_ade20k_20200807_145416-a6daa92a.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/pspnet_s101-d8_512x512_160k_ade20k/pspnet_s101-d8_512x512_160k_ade20k-20200807_145416.log.json) |
-| DeepLabV3 | S-101-D8 | 512x512 | 160000 | 14.6 | 9.28 | 45.71 | 46.59 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/deeplabv3_s101-d8_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3_s101-d8_512x512_160k_ade20k/deeplabv3_s101-d8_512x512_160k_ade20k_20200807_144503-17ecabe5.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3_s101-d8_512x512_160k_ade20k/deeplabv3_s101-d8_512x512_160k_ade20k-20200807_144503.log.json) |
-| DeepLabV3+ | S-101-D8 | 512x512 | 160000 | 16.2 | 11.96 | 46.47 | 47.27 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest/deeplabv3plus_s101-d8_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3plus_s101-d8_512x512_160k_ade20k/deeplabv3plus_s101-d8_512x512_160k_ade20k_20200807_144503-27b26226.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/resnest/deeplabv3plus_s101-d8_512x512_160k_ade20k/deeplabv3plus_s101-d8_512x512_160k_ade20k-20200807_144503.log.json) |
diff --git a/spaces/Anew1007/extras/server.py b/spaces/Anew1007/extras/server.py
deleted file mode 100644
index 2c5301cc39a5a4767014b3873111b2a592855d0d..0000000000000000000000000000000000000000
--- a/spaces/Anew1007/extras/server.py
+++ /dev/null
@@ -1,964 +0,0 @@
-from functools import wraps
-from flask import (
- Flask,
- jsonify,
- request,
- Response,
- render_template_string,
- abort,
- send_from_directory,
- send_file,
-)
-from flask_cors import CORS
-from flask_compress import Compress
-import markdown
-import argparse
-from transformers import AutoTokenizer, AutoProcessor, pipeline
-from transformers import AutoModelForCausalLM, AutoModelForSeq2SeqLM
-from transformers import BlipForConditionalGeneration
-import unicodedata
-import torch
-import time
-import os
-import gc
-import sys
-import secrets
-from PIL import Image
-import base64
-from io import BytesIO
-from random import randint
-import webuiapi
-import hashlib
-from constants import *
-from colorama import Fore, Style, init as colorama_init
-
-colorama_init()
-
-if sys.hexversion < 0x030b0000:
- print(f"{Fore.BLUE}{Style.BRIGHT}Python 3.11 or newer is recommended to run this program.{Style.RESET_ALL}")
- time.sleep(2)
-
-class SplitArgs(argparse.Action):
- def __call__(self, parser, namespace, values, option_string=None):
- setattr(
- namespace, self.dest, values.replace('"', "").replace("'", "").split(",")
- )
-
-#Setting Root Folders for Silero Generations so it is compatible with STSL, should not effect regular runs. - Rolyat
-parent_dir = os.path.dirname(os.path.abspath(__file__))
-SILERO_SAMPLES_PATH = os.path.join(parent_dir, "tts_samples")
-SILERO_SAMPLE_TEXT = os.path.join(parent_dir)
-
-# Create directories if they don't exist
-if not os.path.exists(SILERO_SAMPLES_PATH):
- os.makedirs(SILERO_SAMPLES_PATH)
-if not os.path.exists(SILERO_SAMPLE_TEXT):
- os.makedirs(SILERO_SAMPLE_TEXT)
-
-# Script arguments
-parser = argparse.ArgumentParser(
- prog="SillyTavern Extras", description="Web API for transformers models"
-)
-parser.add_argument(
- "--port", type=int, help="Specify the port on which the application is hosted"
-)
-parser.add_argument(
- "--listen", action="store_true", help="Host the app on the local network"
-)
-parser.add_argument(
- "--share", action="store_true", help="Share the app on CloudFlare tunnel"
-)
-parser.add_argument("--cpu", action="store_true", help="Run the models on the CPU")
-parser.add_argument("--cuda", action="store_false", dest="cpu", help="Run the models on the GPU")
-parser.add_argument("--cuda-device", help="Specify the CUDA device to use")
-parser.add_argument("--mps", "--apple", "--m1", "--m2", action="store_false", dest="cpu", help="Run the models on Apple Silicon")
-parser.set_defaults(cpu=True)
-parser.add_argument("--summarization-model", help="Load a custom summarization model")
-parser.add_argument(
- "--classification-model", help="Load a custom text classification model"
-)
-parser.add_argument("--captioning-model", help="Load a custom captioning model")
-parser.add_argument("--embedding-model", help="Load a custom text embedding model")
-parser.add_argument("--chroma-host", help="Host IP for a remote ChromaDB instance")
-parser.add_argument("--chroma-port", help="HTTP port for a remote ChromaDB instance (defaults to 8000)")
-parser.add_argument("--chroma-folder", help="Path for chromadb persistence folder", default='.chroma_db')
-parser.add_argument('--chroma-persist', help="ChromaDB persistence", default=True, action=argparse.BooleanOptionalAction)
-parser.add_argument(
- "--secure", action="store_true", help="Enforces the use of an API key"
-)
-sd_group = parser.add_mutually_exclusive_group()
-
-local_sd = sd_group.add_argument_group("sd-local")
-local_sd.add_argument("--sd-model", help="Load a custom SD image generation model")
-local_sd.add_argument("--sd-cpu", help="Force the SD pipeline to run on the CPU", action="store_true")
-
-remote_sd = sd_group.add_argument_group("sd-remote")
-remote_sd.add_argument(
- "--sd-remote", action="store_true", help="Use a remote backend for SD"
-)
-remote_sd.add_argument(
- "--sd-remote-host", type=str, help="Specify the host of the remote SD backend"
-)
-remote_sd.add_argument(
- "--sd-remote-port", type=int, help="Specify the port of the remote SD backend"
-)
-remote_sd.add_argument(
- "--sd-remote-ssl", action="store_true", help="Use SSL for the remote SD backend"
-)
-remote_sd.add_argument(
- "--sd-remote-auth",
- type=str,
- help="Specify the username:password for the remote SD backend (if required)",
-)
-
-parser.add_argument(
- "--enable-modules",
- action=SplitArgs,
- default=[],
- help="Override a list of enabled modules",
-)
-
-args = parser.parse_args()
-# [HF, Huggingface] Set port to 7860, set host to remote.
-port = 7860
-host = "0.0.0.0"
-summarization_model = (
- args.summarization_model
- if args.summarization_model
- else DEFAULT_SUMMARIZATION_MODEL
-)
-classification_model = (
- args.classification_model
- if args.classification_model
- else DEFAULT_CLASSIFICATION_MODEL
-)
-captioning_model = (
- args.captioning_model if args.captioning_model else DEFAULT_CAPTIONING_MODEL
-)
-embedding_model = (
- args.embedding_model if args.embedding_model else DEFAULT_EMBEDDING_MODEL
-)
-
-sd_use_remote = False if args.sd_model else True
-sd_model = args.sd_model if args.sd_model else DEFAULT_SD_MODEL
-sd_remote_host = args.sd_remote_host if args.sd_remote_host else DEFAULT_REMOTE_SD_HOST
-sd_remote_port = args.sd_remote_port if args.sd_remote_port else DEFAULT_REMOTE_SD_PORT
-sd_remote_ssl = args.sd_remote_ssl
-sd_remote_auth = args.sd_remote_auth
-
-modules = (
- args.enable_modules if args.enable_modules and len(args.enable_modules) > 0 else []
-)
-
-if len(modules) == 0:
- print(
- f"{Fore.RED}{Style.BRIGHT}You did not select any modules to run! Choose them by adding an --enable-modules option"
- )
- print(f"Example: --enable-modules=caption,summarize{Style.RESET_ALL}")
-
-# Models init
-cuda_device = DEFAULT_CUDA_DEVICE if not args.cuda_device else args.cuda_device
-device_string = cuda_device if torch.cuda.is_available() and not args.cpu else 'mps' if torch.backends.mps.is_available() and not args.cpu else 'cpu'
-device = torch.device(device_string)
-torch_dtype = torch.float32 if device_string != cuda_device else torch.float16
-
-if not torch.cuda.is_available() and not args.cpu:
- print(f"{Fore.YELLOW}{Style.BRIGHT}torch-cuda is not supported on this device.{Style.RESET_ALL}")
- if not torch.backends.mps.is_available() and not args.cpu:
- print(f"{Fore.YELLOW}{Style.BRIGHT}torch-mps is not supported on this device.{Style.RESET_ALL}")
-
-
-print(f"{Fore.GREEN}{Style.BRIGHT}Using torch device: {device_string}{Style.RESET_ALL}")
-
-if "caption" in modules:
- print("Initializing an image captioning model...")
- captioning_processor = AutoProcessor.from_pretrained(captioning_model)
- if "blip" in captioning_model:
- captioning_transformer = BlipForConditionalGeneration.from_pretrained(
- captioning_model, torch_dtype=torch_dtype
- ).to(device)
- else:
- captioning_transformer = AutoModelForCausalLM.from_pretrained(
- captioning_model, torch_dtype=torch_dtype
- ).to(device)
-
-if "summarize" in modules:
- print("Initializing a text summarization model...")
- summarization_tokenizer = AutoTokenizer.from_pretrained(summarization_model)
- summarization_transformer = AutoModelForSeq2SeqLM.from_pretrained(
- summarization_model, torch_dtype=torch_dtype
- ).to(device)
-
-if "classify" in modules:
- print("Initializing a sentiment classification pipeline...")
- classification_pipe = pipeline(
- "text-classification",
- model=classification_model,
- top_k=None,
- device=device,
- torch_dtype=torch_dtype,
- )
-
-if "sd" in modules and not sd_use_remote:
- from diffusers import StableDiffusionPipeline
- from diffusers import EulerAncestralDiscreteScheduler
-
- print("Initializing Stable Diffusion pipeline...")
- sd_device_string = cuda_device if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
- sd_device = torch.device(sd_device_string)
- sd_torch_dtype = torch.float32 if sd_device_string != cuda_device else torch.float16
- sd_pipe = StableDiffusionPipeline.from_pretrained(
- sd_model, custom_pipeline="lpw_stable_diffusion", torch_dtype=sd_torch_dtype
- ).to(sd_device)
- sd_pipe.safety_checker = lambda images, clip_input: (images, False)
- sd_pipe.enable_attention_slicing()
- # pipe.scheduler = KarrasVeScheduler.from_config(pipe.scheduler.config)
- sd_pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(
- sd_pipe.scheduler.config
- )
-elif "sd" in modules and sd_use_remote:
- print("Initializing Stable Diffusion connection")
- try:
- sd_remote = webuiapi.WebUIApi(
- host=sd_remote_host, port=sd_remote_port, use_https=sd_remote_ssl
- )
- if sd_remote_auth:
- username, password = sd_remote_auth.split(":")
- sd_remote.set_auth(username, password)
- sd_remote.util_wait_for_ready()
- except Exception as e:
- # remote sd from modules
- print(
- f"{Fore.RED}{Style.BRIGHT}Could not connect to remote SD backend at http{'s' if sd_remote_ssl else ''}://{sd_remote_host}:{sd_remote_port}! Disabling SD module...{Style.RESET_ALL}"
- )
- modules.remove("sd")
-
-if "tts" in modules:
- print("tts module is deprecated. Please use silero-tts instead.")
- modules.remove("tts")
- modules.append("silero-tts")
-
-
-if "silero-tts" in modules:
- if not os.path.exists(SILERO_SAMPLES_PATH):
- os.makedirs(SILERO_SAMPLES_PATH)
- print("Initializing Silero TTS server")
- from silero_api_server import tts
-
- tts_service = tts.SileroTtsService(SILERO_SAMPLES_PATH)
- if len(os.listdir(SILERO_SAMPLES_PATH)) == 0:
- print("Generating Silero TTS samples...")
- tts_service.update_sample_text(SILERO_SAMPLE_TEXT)
- tts_service.generate_samples()
-
-
-if "edge-tts" in modules:
- print("Initializing Edge TTS client")
- import tts_edge as edge
-
-
-if "chromadb" in modules:
- print("Initializing ChromaDB")
- import chromadb
- import posthog
- from chromadb.config import Settings
- from sentence_transformers import SentenceTransformer
-
- # Assume that the user wants in-memory unless a host is specified
- # Also disable chromadb telemetry
- posthog.capture = lambda *args, **kwargs: None
- if args.chroma_host is None:
- if args.chroma_persist:
- chromadb_client = chromadb.PersistentClient(path=args.chroma_folder, settings=Settings(anonymized_telemetry=False))
- print(f"ChromaDB is running in-memory with persistence. Persistence is stored in {args.chroma_folder}. Can be cleared by deleting the folder or purging db.")
- else:
- chromadb_client = chromadb.EphemeralClient(Settings(anonymized_telemetry=False))
- print(f"ChromaDB is running in-memory without persistence.")
- else:
- chroma_port=(
- args.chroma_port if args.chroma_port else DEFAULT_CHROMA_PORT
- )
- chromadb_client = chromadb.HttpClient(host=args.chroma_host, port=chroma_port, settings=Settings(anonymized_telemetry=False))
- print(f"ChromaDB is remotely configured at {args.chroma_host}:{chroma_port}")
-
- chromadb_embedder = SentenceTransformer(embedding_model, device=device_string)
- chromadb_embed_fn = lambda *args, **kwargs: chromadb_embedder.encode(*args, **kwargs).tolist()
-
- # Check if the db is connected and running, otherwise tell the user
- try:
- chromadb_client.heartbeat()
- print("Successfully pinged ChromaDB! Your client is successfully connected.")
- except:
- print("Could not ping ChromaDB! If you are running remotely, please check your host and port!")
-
-# Flask init
-app = Flask(__name__)
-CORS(app) # allow cross-domain requests
-Compress(app) # compress responses
-app.config["MAX_CONTENT_LENGTH"] = 100 * 1024 * 1024
-
-
-def require_module(name):
- def wrapper(fn):
- @wraps(fn)
- def decorated_view(*args, **kwargs):
- if name not in modules:
- abort(403, "Module is disabled by config")
- return fn(*args, **kwargs)
-
- return decorated_view
-
- return wrapper
-
-
-# AI stuff
-def classify_text(text: str) -> list:
- output = classification_pipe(
- text,
- truncation=True,
- max_length=classification_pipe.model.config.max_position_embeddings,
- )[0]
- return sorted(output, key=lambda x: x["score"], reverse=True)
-
-
-def caption_image(raw_image: Image, max_new_tokens: int = 20) -> str:
- inputs = captioning_processor(raw_image.convert("RGB"), return_tensors="pt").to(
- device, torch_dtype
- )
- outputs = captioning_transformer.generate(**inputs, max_new_tokens=max_new_tokens)
- caption = captioning_processor.decode(outputs[0], skip_special_tokens=True)
- return caption
-
-
-def summarize_chunks(text: str, params: dict) -> str:
- try:
- return summarize(text, params)
- except IndexError:
- print(
- "Sequence length too large for model, cutting text in half and calling again"
- )
- new_params = params.copy()
- new_params["max_length"] = new_params["max_length"] // 2
- new_params["min_length"] = new_params["min_length"] // 2
- return summarize_chunks(
- text[: (len(text) // 2)], new_params
- ) + summarize_chunks(text[(len(text) // 2) :], new_params)
-
-
-def summarize(text: str, params: dict) -> str:
- # Tokenize input
- inputs = summarization_tokenizer(text, return_tensors="pt").to(device)
- token_count = len(inputs[0])
-
- bad_words_ids = [
- summarization_tokenizer(bad_word, add_special_tokens=False).input_ids
- for bad_word in params["bad_words"]
- ]
- summary_ids = summarization_transformer.generate(
- inputs["input_ids"],
- num_beams=2,
- max_new_tokens=max(token_count, int(params["max_length"])),
- min_new_tokens=min(token_count, int(params["min_length"])),
- repetition_penalty=float(params["repetition_penalty"]),
- temperature=float(params["temperature"]),
- length_penalty=float(params["length_penalty"]),
- bad_words_ids=bad_words_ids,
- )
- summary = summarization_tokenizer.batch_decode(
- summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
- )[0]
- summary = normalize_string(summary)
- return summary
-
-
-def normalize_string(input: str) -> str:
- output = " ".join(unicodedata.normalize("NFKC", input).strip().split())
- return output
-
-
-def generate_image(data: dict) -> Image:
- prompt = normalize_string(f'{data["prompt_prefix"]} {data["prompt"]}')
-
- if sd_use_remote:
- image = sd_remote.txt2img(
- prompt=prompt,
- negative_prompt=data["negative_prompt"],
- sampler_name=data["sampler"],
- steps=data["steps"],
- cfg_scale=data["scale"],
- width=data["width"],
- height=data["height"],
- restore_faces=data["restore_faces"],
- enable_hr=data["enable_hr"],
- save_images=True,
- send_images=True,
- do_not_save_grid=False,
- do_not_save_samples=False,
- ).image
- else:
- image = sd_pipe(
- prompt=prompt,
- negative_prompt=data["negative_prompt"],
- num_inference_steps=data["steps"],
- guidance_scale=data["scale"],
- width=data["width"],
- height=data["height"],
- ).images[0]
-
- image.save("./debug.png")
- return image
-
-
-def image_to_base64(image: Image, quality: int = 75) -> str:
- buffer = BytesIO()
- image.convert("RGB")
- image.save(buffer, format="JPEG", quality=quality)
- img_str = base64.b64encode(buffer.getvalue()).decode("utf-8")
- return img_str
-
-
-ignore_auth = []
-# [HF, Huggingface] Get password instead of text file.
-api_key = os.environ.get("password")
-
-def is_authorize_ignored(request):
- view_func = app.view_functions.get(request.endpoint)
-
- if view_func is not None:
- if view_func in ignore_auth:
- return True
- return False
-
-@app.before_request
-def before_request():
- # Request time measuring
- request.start_time = time.time()
-
- # Checks if an API key is present and valid, otherwise return unauthorized
- # The options check is required so CORS doesn't get angry
- try:
- if request.method != 'OPTIONS' and is_authorize_ignored(request) == False and getattr(request.authorization, 'token', '') != api_key:
- print(f"WARNING: Unauthorized API key access from {request.remote_addr}")
- if request.method == 'POST':
- print(f"Incoming POST request with {request.headers.get('Authorization')}")
- response = jsonify({ 'error': '401: Invalid API key' })
- response.status_code = 401
- return "https://(hf_name)-(space_name).hf.space/"
- except Exception as e:
- print(f"API key check error: {e}")
- return "https://(hf_name)-(space_name).hf.space/"
-
-
-@app.after_request
-def after_request(response):
- duration = time.time() - request.start_time
- response.headers["X-Request-Duration"] = str(duration)
- return response
-
-
-@app.route("/", methods=["GET"])
-def index():
- with open("./README.md", "r", encoding="utf8") as f:
- content = f.read()
- return render_template_string(markdown.markdown(content, extensions=["tables"]))
-
-
-@app.route("/api/extensions", methods=["GET"])
-def get_extensions():
- extensions = dict(
- {
- "extensions": [
- {
- "name": "not-supported",
- "metadata": {
- "display_name": """Extensions serving using Extensions API is no longer supported. Please update the mod from: https://github.com/Cohee1207/SillyTavern""",
- "requires": [],
- "assets": [],
- },
- }
- ]
- }
- )
- return jsonify(extensions)
-
-
-@app.route("/api/caption", methods=["POST"])
-@require_module("caption")
-def api_caption():
- data = request.get_json()
-
- if "image" not in data or not isinstance(data["image"], str):
- abort(400, '"image" is required')
-
- image = Image.open(BytesIO(base64.b64decode(data["image"])))
- image = image.convert("RGB")
- image.thumbnail((512, 512))
- caption = caption_image(image)
- thumbnail = image_to_base64(image)
- print("Caption:", caption, sep="\n")
- gc.collect()
- return jsonify({"caption": caption, "thumbnail": thumbnail})
-
-
-@app.route("/api/summarize", methods=["POST"])
-@require_module("summarize")
-def api_summarize():
- data = request.get_json()
-
- if "text" not in data or not isinstance(data["text"], str):
- abort(400, '"text" is required')
-
- params = DEFAULT_SUMMARIZE_PARAMS.copy()
-
- if "params" in data and isinstance(data["params"], dict):
- params.update(data["params"])
-
- print("Summary input:", data["text"], sep="\n")
- summary = summarize_chunks(data["text"], params)
- print("Summary output:", summary, sep="\n")
- gc.collect()
- return jsonify({"summary": summary})
-
-
-@app.route("/api/classify", methods=["POST"])
-@require_module("classify")
-def api_classify():
- data = request.get_json()
-
- if "text" not in data or not isinstance(data["text"], str):
- abort(400, '"text" is required')
-
- print("Classification input:", data["text"], sep="\n")
- classification = classify_text(data["text"])
- print("Classification output:", classification, sep="\n")
- gc.collect()
- return jsonify({"classification": classification})
-
-
-@app.route("/api/classify/labels", methods=["GET"])
-@require_module("classify")
-def api_classify_labels():
- classification = classify_text("")
- labels = [x["label"] for x in classification]
- return jsonify({"labels": labels})
-
-
-@app.route("/api/image", methods=["POST"])
-@require_module("sd")
-def api_image():
- required_fields = {
- "prompt": str,
- }
-
- optional_fields = {
- "steps": 30,
- "scale": 6,
- "sampler": "DDIM",
- "width": 512,
- "height": 512,
- "restore_faces": False,
- "enable_hr": False,
- "prompt_prefix": PROMPT_PREFIX,
- "negative_prompt": NEGATIVE_PROMPT,
- }
-
- data = request.get_json()
-
- # Check required fields
- for field, field_type in required_fields.items():
- if field not in data or not isinstance(data[field], field_type):
- abort(400, f'"{field}" is required')
-
- # Set optional fields to default values if not provided
- for field, default_value in optional_fields.items():
- type_match = (
- (int, float)
- if isinstance(default_value, (int, float))
- else type(default_value)
- )
- if field not in data or not isinstance(data[field], type_match):
- data[field] = default_value
-
- try:
- print("SD inputs:", data, sep="\n")
- image = generate_image(data)
- base64image = image_to_base64(image, quality=90)
- return jsonify({"image": base64image})
- except RuntimeError as e:
- abort(400, str(e))
-
-
-@app.route("/api/image/model", methods=["POST"])
-@require_module("sd")
-def api_image_model_set():
- data = request.get_json()
-
- if not sd_use_remote:
- abort(400, "Changing model for local sd is not supported.")
- if "model" not in data or not isinstance(data["model"], str):
- abort(400, '"model" is required')
-
- old_model = sd_remote.util_get_current_model()
- sd_remote.util_set_model(data["model"], find_closest=False)
- # sd_remote.util_set_model(data['model'])
- sd_remote.util_wait_for_ready()
- new_model = sd_remote.util_get_current_model()
-
- return jsonify({"previous_model": old_model, "current_model": new_model})
-
-
-@app.route("/api/image/model", methods=["GET"])
-@require_module("sd")
-def api_image_model_get():
- model = sd_model
-
- if sd_use_remote:
- model = sd_remote.util_get_current_model()
-
- return jsonify({"model": model})
-
-
-@app.route("/api/image/models", methods=["GET"])
-@require_module("sd")
-def api_image_models():
- models = [sd_model]
-
- if sd_use_remote:
- models = sd_remote.util_get_model_names()
-
- return jsonify({"models": models})
-
-
-@app.route("/api/image/samplers", methods=["GET"])
-@require_module("sd")
-def api_image_samplers():
- samplers = ["Euler a"]
-
- if sd_use_remote:
- samplers = [sampler["name"] for sampler in sd_remote.get_samplers()]
-
- return jsonify({"samplers": samplers})
-
-
-@app.route("/api/modules", methods=["GET"])
-def get_modules():
- return jsonify({"modules": modules})
-
-
-@app.route("/api/tts/speakers", methods=["GET"])
-@require_module("silero-tts")
-def tts_speakers():
- voices = [
- {
- "name": speaker,
- "voice_id": speaker,
- "preview_url": f"{str(request.url_root)}api/tts/sample/{speaker}",
- }
- for speaker in tts_service.get_speakers()
- ]
- return jsonify(voices)
-
-# Added fix for Silero not working as new files were unable to be created if one already existed. - Rolyat 7/7/23
-@app.route("/api/tts/generate", methods=["POST"])
-@require_module("silero-tts")
-def tts_generate():
- voice = request.get_json()
- if "text" not in voice or not isinstance(voice["text"], str):
- abort(400, '"text" is required')
- if "speaker" not in voice or not isinstance(voice["speaker"], str):
- abort(400, '"speaker" is required')
- # Remove asterisks
- voice["text"] = voice["text"].replace("*", "")
- try:
- # Remove the destination file if it already exists
- if os.path.exists('test.wav'):
- os.remove('test.wav')
-
- audio = tts_service.generate(voice["speaker"], voice["text"])
- audio_file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), os.path.basename(audio))
-
- os.rename(audio, audio_file_path)
- return send_file(audio_file_path, mimetype="audio/x-wav")
- except Exception as e:
- print(e)
- abort(500, voice["speaker"])
-
-
-@app.route("/api/tts/sample/", methods=["GET"])
-@require_module("silero-tts")
-def tts_play_sample(speaker: str):
- return send_from_directory(SILERO_SAMPLES_PATH, f"{speaker}.wav")
-
-
-@app.route("/api/edge-tts/list", methods=["GET"])
-@require_module("edge-tts")
-def edge_tts_list():
- voices = edge.get_voices()
- return jsonify(voices)
-
-
-@app.route("/api/edge-tts/generate", methods=["POST"])
-@require_module("edge-tts")
-def edge_tts_generate():
- data = request.get_json()
- if "text" not in data or not isinstance(data["text"], str):
- abort(400, '"text" is required')
- if "voice" not in data or not isinstance(data["voice"], str):
- abort(400, '"voice" is required')
- if "rate" in data and isinstance(data['rate'], int):
- rate = data['rate']
- else:
- rate = 0
- # Remove asterisks
- data["text"] = data["text"].replace("*", "")
- try:
- audio = edge.generate_audio(text=data["text"], voice=data["voice"], rate=rate)
- return Response(audio, mimetype="audio/mpeg")
- except Exception as e:
- print(e)
- abort(500, data["voice"])
-
-
-@app.route("/api/chromadb", methods=["POST"])
-@require_module("chromadb")
-def chromadb_add_messages():
- data = request.get_json()
- if "chat_id" not in data or not isinstance(data["chat_id"], str):
- abort(400, '"chat_id" is required')
- if "messages" not in data or not isinstance(data["messages"], list):
- abort(400, '"messages" is required')
-
- chat_id_md5 = hashlib.md5(data["chat_id"].encode()).hexdigest()
- collection = chromadb_client.get_or_create_collection(
- name=f"chat-{chat_id_md5}", embedding_function=chromadb_embed_fn
- )
-
- documents = [m["content"] for m in data["messages"]]
- ids = [m["id"] for m in data["messages"]]
- metadatas = [
- {"role": m["role"], "date": m["date"], "meta": m.get("meta", "")}
- for m in data["messages"]
- ]
-
- collection.upsert(
- ids=ids,
- documents=documents,
- metadatas=metadatas,
- )
-
- return jsonify({"count": len(ids)})
-
-
-@app.route("/api/chromadb/purge", methods=["POST"])
-@require_module("chromadb")
-def chromadb_purge():
- data = request.get_json()
- if "chat_id" not in data or not isinstance(data["chat_id"], str):
- abort(400, '"chat_id" is required')
-
- chat_id_md5 = hashlib.md5(data["chat_id"].encode()).hexdigest()
- collection = chromadb_client.get_or_create_collection(
- name=f"chat-{chat_id_md5}", embedding_function=chromadb_embed_fn
- )
-
- count = collection.count()
- collection.delete()
- print("ChromaDB embeddings deleted", count)
- return 'Ok', 200
-
-
-@app.route("/api/chromadb/query", methods=["POST"])
-@require_module("chromadb")
-def chromadb_query():
- data = request.get_json()
- if "chat_id" not in data or not isinstance(data["chat_id"], str):
- abort(400, '"chat_id" is required')
- if "query" not in data or not isinstance(data["query"], str):
- abort(400, '"query" is required')
-
- if "n_results" not in data or not isinstance(data["n_results"], int):
- n_results = 1
- else:
- n_results = data["n_results"]
-
- chat_id_md5 = hashlib.md5(data["chat_id"].encode()).hexdigest()
- collection = chromadb_client.get_or_create_collection(
- name=f"chat-{chat_id_md5}", embedding_function=chromadb_embed_fn
- )
-
- if collection.count() == 0:
- print(f"Queried empty/missing collection for {repr(data['chat_id'])}.")
- return jsonify([])
-
-
- n_results = min(collection.count(), n_results)
- query_result = collection.query(
- query_texts=[data["query"]],
- n_results=n_results,
- )
-
- documents = query_result["documents"][0]
- ids = query_result["ids"][0]
- metadatas = query_result["metadatas"][0]
- distances = query_result["distances"][0]
-
- messages = [
- {
- "id": ids[i],
- "date": metadatas[i]["date"],
- "role": metadatas[i]["role"],
- "meta": metadatas[i]["meta"],
- "content": documents[i],
- "distance": distances[i],
- }
- for i in range(len(ids))
- ]
-
- return jsonify(messages)
-
-@app.route("/api/chromadb/multiquery", methods=["POST"])
-@require_module("chromadb")
-def chromadb_multiquery():
- data = request.get_json()
- if "chat_list" not in data or not isinstance(data["chat_list"], list):
- abort(400, '"chat_list" is required and should be a list')
- if "query" not in data or not isinstance(data["query"], str):
- abort(400, '"query" is required')
-
- if "n_results" not in data or not isinstance(data["n_results"], int):
- n_results = 1
- else:
- n_results = data["n_results"]
-
- messages = []
-
- for chat_id in data["chat_list"]:
- if not isinstance(chat_id, str):
- continue
-
- try:
- chat_id_md5 = hashlib.md5(chat_id.encode()).hexdigest()
- collection = chromadb_client.get_collection(
- name=f"chat-{chat_id_md5}", embedding_function=chromadb_embed_fn
- )
-
- # Skip this chat if the collection is empty
- if collection.count() == 0:
- continue
-
- n_results_per_chat = min(collection.count(), n_results)
- query_result = collection.query(
- query_texts=[data["query"]],
- n_results=n_results_per_chat,
- )
- documents = query_result["documents"][0]
- ids = query_result["ids"][0]
- metadatas = query_result["metadatas"][0]
- distances = query_result["distances"][0]
-
- chat_messages = [
- {
- "id": ids[i],
- "date": metadatas[i]["date"],
- "role": metadatas[i]["role"],
- "meta": metadatas[i]["meta"],
- "content": documents[i],
- "distance": distances[i],
- }
- for i in range(len(ids))
- ]
-
- messages.extend(chat_messages)
- except Exception as e:
- print(e)
-
- #remove duplicate msgs, filter down to the right number
- seen = set()
- messages = [d for d in messages if not (d['content'] in seen or seen.add(d['content']))]
- messages = sorted(messages, key=lambda x: x['distance'])[0:n_results]
-
- return jsonify(messages)
-
-
-@app.route("/api/chromadb/export", methods=["POST"])
-@require_module("chromadb")
-def chromadb_export():
- data = request.get_json()
- if "chat_id" not in data or not isinstance(data["chat_id"], str):
- abort(400, '"chat_id" is required')
-
- chat_id_md5 = hashlib.md5(data["chat_id"].encode()).hexdigest()
- try:
- collection = chromadb_client.get_collection(
- name=f"chat-{chat_id_md5}", embedding_function=chromadb_embed_fn
- )
- except Exception as e:
- print(e)
- abort(400, "Chat collection not found in chromadb")
-
- collection_content = collection.get()
- documents = collection_content.get('documents', [])
- ids = collection_content.get('ids', [])
- metadatas = collection_content.get('metadatas', [])
-
- unsorted_content = [
- {
- "id": ids[i],
- "metadata": metadatas[i],
- "document": documents[i],
- }
- for i in range(len(ids))
- ]
-
- sorted_content = sorted(unsorted_content, key=lambda x: x['metadata']['date'])
-
- export = {
- "chat_id": data["chat_id"],
- "content": sorted_content
- }
-
- return jsonify(export)
-
-@app.route("/api/chromadb/import", methods=["POST"])
-@require_module("chromadb")
-def chromadb_import():
- data = request.get_json()
- content = data['content']
- if "chat_id" not in data or not isinstance(data["chat_id"], str):
- abort(400, '"chat_id" is required')
-
- chat_id_md5 = hashlib.md5(data["chat_id"].encode()).hexdigest()
- collection = chromadb_client.get_or_create_collection(
- name=f"chat-{chat_id_md5}", embedding_function=chromadb_embed_fn
- )
-
- documents = [item['document'] for item in content]
- metadatas = [item['metadata'] for item in content]
- ids = [item['id'] for item in content]
-
-
- collection.upsert(documents=documents, metadatas=metadatas, ids=ids)
- print(f"Imported {len(ids)} (total {collection.count()}) content entries into {repr(data['chat_id'])}")
-
- return jsonify({"count": len(ids)})
-
-
-if args.share:
- from flask_cloudflared import _run_cloudflared
- import inspect
-
- sig = inspect.signature(_run_cloudflared)
- sum = sum(
- 1
- for param in sig.parameters.values()
- if param.kind == param.POSITIONAL_OR_KEYWORD
- )
- if sum > 1:
- metrics_port = randint(8100, 9000)
- cloudflare = _run_cloudflared(port, metrics_port)
- else:
- cloudflare = _run_cloudflared(port)
- print("Running on", cloudflare)
-
-ignore_auth.append(tts_play_sample)
-app.run(host=host, port=port)
diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmcv/fileio/handlers/__init__.py b/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmcv/fileio/handlers/__init__.py
deleted file mode 100644
index aa24d91972837b8756b225f4879bac20436eb72a..0000000000000000000000000000000000000000
--- a/spaces/Anonymous-sub/Rerender/ControlNet/annotator/uniformer/mmcv/fileio/handlers/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .base import BaseFileHandler
-from .json_handler import JsonHandler
-from .pickle_handler import PickleHandler
-from .yaml_handler import YamlHandler
-
-__all__ = ['BaseFileHandler', 'JsonHandler', 'PickleHandler', 'YamlHandler']
diff --git a/spaces/Arnaudding001/OpenAI_whisperLive/app-shared.py b/spaces/Arnaudding001/OpenAI_whisperLive/app-shared.py
deleted file mode 100644
index 541459b104ce89c56845ac177365f49a61445d04..0000000000000000000000000000000000000000
--- a/spaces/Arnaudding001/OpenAI_whisperLive/app-shared.py
+++ /dev/null
@@ -1,3 +0,0 @@
-# Run the app with no audio file restrictions
-from app import create_ui
-create_ui(-1, share=True)
\ No newline at end of file
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/models/wheel.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/models/wheel.py
deleted file mode 100644
index a5dc12bdd63163c86f87ce4b5430cdb16d73769d..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/models/wheel.py
+++ /dev/null
@@ -1,92 +0,0 @@
-"""Represents a wheel file and provides access to the various parts of the
-name that have meaning.
-"""
-import re
-from typing import Dict, Iterable, List
-
-from pip._vendor.packaging.tags import Tag
-
-from pip._internal.exceptions import InvalidWheelFilename
-
-
-class Wheel:
- """A wheel file"""
-
- wheel_file_re = re.compile(
- r"""^(?P(?P[^\s-]+?)-(?P[^\s-]*?))
- ((-(?P\d[^-]*?))?-(?P[^\s-]+?)-(?P[^\s-]+?)-(?P[^\s-]+?)
- \.whl|\.dist-info)$""",
- re.VERBOSE,
- )
-
- def __init__(self, filename: str) -> None:
- """
- :raises InvalidWheelFilename: when the filename is invalid for a wheel
- """
- wheel_info = self.wheel_file_re.match(filename)
- if not wheel_info:
- raise InvalidWheelFilename(f"{filename} is not a valid wheel filename.")
- self.filename = filename
- self.name = wheel_info.group("name").replace("_", "-")
- # we'll assume "_" means "-" due to wheel naming scheme
- # (https://github.com/pypa/pip/issues/1150)
- self.version = wheel_info.group("ver").replace("_", "-")
- self.build_tag = wheel_info.group("build")
- self.pyversions = wheel_info.group("pyver").split(".")
- self.abis = wheel_info.group("abi").split(".")
- self.plats = wheel_info.group("plat").split(".")
-
- # All the tag combinations from this file
- self.file_tags = {
- Tag(x, y, z) for x in self.pyversions for y in self.abis for z in self.plats
- }
-
- def get_formatted_file_tags(self) -> List[str]:
- """Return the wheel's tags as a sorted list of strings."""
- return sorted(str(tag) for tag in self.file_tags)
-
- def support_index_min(self, tags: List[Tag]) -> int:
- """Return the lowest index that one of the wheel's file_tag combinations
- achieves in the given list of supported tags.
-
- For example, if there are 8 supported tags and one of the file tags
- is first in the list, then return 0.
-
- :param tags: the PEP 425 tags to check the wheel against, in order
- with most preferred first.
-
- :raises ValueError: If none of the wheel's file tags match one of
- the supported tags.
- """
- try:
- return next(i for i, t in enumerate(tags) if t in self.file_tags)
- except StopIteration:
- raise ValueError()
-
- def find_most_preferred_tag(
- self, tags: List[Tag], tag_to_priority: Dict[Tag, int]
- ) -> int:
- """Return the priority of the most preferred tag that one of the wheel's file
- tag combinations achieves in the given list of supported tags using the given
- tag_to_priority mapping, where lower priorities are more-preferred.
-
- This is used in place of support_index_min in some cases in order to avoid
- an expensive linear scan of a large list of tags.
-
- :param tags: the PEP 425 tags to check the wheel against.
- :param tag_to_priority: a mapping from tag to priority of that tag, where
- lower is more preferred.
-
- :raises ValueError: If none of the wheel's file tags match one of
- the supported tags.
- """
- return min(
- tag_to_priority[tag] for tag in self.file_tags if tag in tag_to_priority
- )
-
- def supported(self, tags: Iterable[Tag]) -> bool:
- """Return whether the wheel is compatible with one of the given tags.
-
- :param tags: the PEP 425 tags to check the wheel against.
- """
- return not self.file_tags.isdisjoint(tags)
diff --git a/spaces/AyakuraMei/Real-CUGAN/app.py b/spaces/AyakuraMei/Real-CUGAN/app.py
deleted file mode 100644
index 2439c5cec6b61e8a517f957daf710cbb6b5c3cf6..0000000000000000000000000000000000000000
--- a/spaces/AyakuraMei/Real-CUGAN/app.py
+++ /dev/null
@@ -1,62 +0,0 @@
-from upcunet_v3 import RealWaifuUpScaler
-import gradio as gr
-import time
-import logging
-import os
-from PIL import ImageOps
-import numpy as np
-import math
-
-
-def greet(input_img, input_model_name, input_tile_mode):
- # if input_img.size[0] * input_img.size[1] > 256 * 256:
- # y = int(math.sqrt(256*256/input_img.size[0]*input_img.size[1]))
- # x = int(input_img.size[0]/input_img.size[1]*y)
- # input_img = ImageOps.fit(input_img, (x, y))
- input_img = np.array(input_img)
- if input_model_name not in model_cache:
- t1 = time.time()
- upscaler = RealWaifuUpScaler(input_model_name[2], ModelPath + input_model_name, half=False, device="cpu")
- t2 = time.time()
- logger.info(f'load model time, {t2 - t1}')
- model_cache[input_model_name] = upscaler
- else:
- upscaler = model_cache[input_model_name]
- logger.info(f'load model from cache')
-
- start = time.time()
- result = upscaler(input_img, tile_mode=input_tile_mode)
- end = time.time()
- logger.info(f'input_model_name, {input_model_name}')
- logger.info(f'input_tile_mode, {input_tile_mode}')
- logger.info(f'input shape, {input_img.shape}')
- logger.info(f'output shape, {result.shape}')
- logger.info(f'speed time, {end - start}')
- return result
-
-
-if __name__ == '__main__':
- logging.basicConfig(level=logging.INFO, format="[%(asctime)s] [%(process)d] [%(levelname)s] %(message)s")
- logger = logging.getLogger()
-
- ModelPath = "weights_v3/"
- model_cache = {}
-
- input_model_name = gr.inputs.Dropdown(os.listdir(ModelPath), default="up2x-latest-denoise2x.pth", label='选择model')
- input_tile_mode = gr.inputs.Dropdown([0, 1, 2, 3, 4], default=2, label='选择tile_mode')
- input_img = gr.inputs.Image(label='image', type='pil')
-
- inputs = [input_img, input_model_name, input_tile_mode]
- outputs = "image"
- iface = gr.Interface(fn=greet,
- inputs=inputs,
- outputs=outputs,
- allow_screenshot=False,
- allow_flagging='never',
- examples=[['test-img.jpg', "up2x-latest-denoise2x.pth", 2]],
- article='[https://github.com/bilibili/ailab/tree/main/Real-CUGAN](https://github.com/bilibili/ailab/tree/main/Real-CUGAN) '
- '感谢b站开源的项目,图片过大会导致内存不足,所有我将图片裁剪小,想体验大图片的效果请自行前往上面的链接。 '
- '修改bbb'
- 'The large image will lead to memory limit exceeded. So I crop and resize image. '
- 'If you want to experience the large image, please go to the link above.')
- iface.launch()
diff --git a/spaces/AzinZ/vitscn/text/mandarin.py b/spaces/AzinZ/vitscn/text/mandarin.py
deleted file mode 100644
index 8d7410869cfc91d618269f97dc9964b2f386a8ef..0000000000000000000000000000000000000000
--- a/spaces/AzinZ/vitscn/text/mandarin.py
+++ /dev/null
@@ -1,48 +0,0 @@
-import re
-import cn2an
-from pypinyin import lazy_pinyin, Style
-import jieba
-import zhon
-from text.symbols import symbols
-
-_puntuation_map = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('。', '.'),
- ('。', '.'),
- ('.', ''),
- ('?', '?'),
- ('!', '!'),
- (',', ','),
-]]
-
-
-def number_to_chinese(text):
- numbers = re.findall(r'\d+(?:\.?\d+)?', text)
- for number in numbers:
- text = text.replace(number, cn2an.an2cn(number), 1)
- return text
-
-def remove_non_stop_punctuation(text):
- text = re.sub('[%s]' % zhon.hanzi.non_stops, '', text)
- return text
-
-def map_stop_puntuation(text):
- for regex, replacement in _puntuation_map:
- text = re.sub(regex, replacement, text)
- return text
-
-def chinese_to_pinyin(text):
- text = map_stop_puntuation(text)
- text = number_to_chinese(text)
- text = remove_non_stop_punctuation(text)
- words = jieba.lcut(text, cut_all=False)
- text = ''
- for word in words:
- if not re.search('[\u4e00-\u9fff]', word):
- if word in ''.join(symbols):
- text += word
- continue
- pinyin = lazy_pinyin(word, Style.TONE3)
- if text != '':
- text += ' '
- text += ''.join(pinyin)
- return text
diff --git a/spaces/AzinZ/vitscn/text/symbols.py b/spaces/AzinZ/vitscn/text/symbols.py
deleted file mode 100644
index d68c3e8b660f8a3814a0295cc2ed319e80ef192a..0000000000000000000000000000000000000000
--- a/spaces/AzinZ/vitscn/text/symbols.py
+++ /dev/null
@@ -1,21 +0,0 @@
-""" from https://github.com/keithito/tacotron """
-
-'''
-Defines the set of symbols used in text input to the model.
-'''
-# _pad = '_'
-# _punctuation = ';:,.!?¡¿—…"«»“” '
-# _letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
-# _letters_ipa = "ɑɐɒæɓʙβɔɕçɗɖðʤəɘɚɛɜɝɞɟʄɡɠɢʛɦɧħɥʜɨɪʝɭɬɫɮʟɱɯɰŋɳɲɴøɵɸθœɶʘɹɺɾɻʀʁɽʂʃʈʧʉʊʋⱱʌɣɤʍχʎʏʑʐʒʔʡʕʢǀǁǂǃˈˌːˑʼʴʰʱʲʷˠˤ˞↓↑→↗↘'̩'ᵻ"
-
-# For Chinese
-_pad = '_'
-_punctuation = '~;:,.!?¡¿—…"«»“” '
-_letters = 'abcdefghijklmnopqrstuvwxyz1234'
-_letters_ipa = ""
-
-# Export all symbols:
-symbols = [_pad] + list(_punctuation) + list(_letters) + list(_letters_ipa)
-
-# Special symbol ids
-SPACE_ID = symbols.index(" ")
diff --git a/spaces/Bart92/RVC_HF/lib/infer_pack/models.py b/spaces/Bart92/RVC_HF/lib/infer_pack/models.py
deleted file mode 100644
index ec107476df968e51aafc6c3d102a9ed8c53f141a..0000000000000000000000000000000000000000
--- a/spaces/Bart92/RVC_HF/lib/infer_pack/models.py
+++ /dev/null
@@ -1,1144 +0,0 @@
-import math, pdb, os
-from time import time as ttime
-import torch
-from torch import nn
-from torch.nn import functional as F
-from lib.infer_pack import modules
-from lib.infer_pack import attentions
-from lib.infer_pack import commons
-from lib.infer_pack.commons import init_weights, get_padding
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from lib.infer_pack.commons import init_weights
-import numpy as np
-from lib.infer_pack import commons
-
-
-class TextEncoder256(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class TextEncoder768(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(768, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0,
- ):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- mean_only=True,
- )
- )
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
- def remove_weight_norm(self):
- for i in range(self.n_flows):
- self.flows[i * 2].remove_weight_norm()
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class Generator(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=0,
- ):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class SineGen(torch.nn.Module):
- """Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(
- self,
- samp_rate,
- harmonic_num=0,
- sine_amp=0.1,
- noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False,
- ):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = torch.ones_like(f0)
- uv = uv * (f0 > self.voiced_threshold)
- if uv.device.type == "privateuseone": # for DirectML
- uv = uv.float()
- return uv
-
- def forward(self, f0, upp):
- """sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0 = f0[:, None].transpose(1, 2)
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
- # fundamental component
- f0_buf[:, :, 0] = f0[:, :, 0]
- for idx in np.arange(self.harmonic_num):
- f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
- idx + 2
- ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
- rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
- rand_ini = torch.rand(
- f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
- )
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
- tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
- tmp_over_one *= upp
- tmp_over_one = F.interpolate(
- tmp_over_one.transpose(2, 1),
- scale_factor=upp,
- mode="linear",
- align_corners=True,
- ).transpose(2, 1)
- rad_values = F.interpolate(
- rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(
- 2, 1
- ) #######
- tmp_over_one %= 1
- tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
- sine_waves = torch.sin(
- torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
- )
- sine_waves = sine_waves * self.sine_amp
- uv = self._f02uv(f0)
- uv = F.interpolate(
- uv.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(2, 1)
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(
- self,
- sampling_rate,
- harmonic_num=0,
- sine_amp=0.1,
- add_noise_std=0.003,
- voiced_threshod=0,
- is_half=True,
- ):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
- self.is_half = is_half
- # to produce sine waveforms
- self.l_sin_gen = SineGen(
- sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
- )
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x, upp=None):
- sine_wavs, uv, _ = self.l_sin_gen(x, upp)
- if self.is_half:
- sine_wavs = sine_wavs.half()
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
- return sine_merge, None, None # noise, uv
-
-
-class GeneratorNSF(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- sr,
- is_half=False,
- ):
- super(GeneratorNSF, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
-
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=sr, harmonic_num=0, is_half=is_half
- )
- self.noise_convs = nn.ModuleList()
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- c_cur = upsample_initial_channel // (2 ** (i + 1))
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
- if i + 1 < len(upsample_rates):
- stride_f0 = np.prod(upsample_rates[i + 1 :])
- self.noise_convs.append(
- Conv1d(
- 1,
- c_cur,
- kernel_size=stride_f0 * 2,
- stride=stride_f0,
- padding=stride_f0 // 2,
- )
- )
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- self.upp = np.prod(upsample_rates)
-
- def forward(self, x, f0, g=None):
- har_source, noi_source, uv = self.m_source(f0, self.upp)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-sr2sr = {
- "32k": 32000,
- "40k": 40000,
- "48k": 48000,
-}
-
-
-class SynthesizerTrnMs256NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, rate=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- if rate:
- head = int(z_p.shape[2] * rate)
- z_p = z_p[:, :, -head:]
- x_mask = x_mask[:, :, -head:]
- nsff0 = nsff0[:, -head:]
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec(z * x_mask, nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs768NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder768(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, rate=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- if rate:
- head = int(z_p.shape[2] * rate)
- z_p = z_p[:, :, -head:]
- x_mask = x_mask[:, :, -head:]
- nsff0 = nsff0[:, -head:]
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec(z * x_mask, nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, rate=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- if rate:
- head = int(z_p.shape[2] * rate)
- z_p = z_p[:, :, -head:]
- x_mask = x_mask[:, :, -head:]
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec(z * x_mask, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs768NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder768(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, rate=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- if rate:
- head = int(z_p.shape[2] * rate)
- z_p = z_p[:, :, -head:]
- x_mask = x_mask[:, :, -head:]
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec(z * x_mask, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11, 17]
- # periods = [3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class MultiPeriodDiscriminatorV2(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminatorV2, self).__init__()
- # periods = [2, 3, 5, 7, 11, 17]
- periods = [2, 3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ]
- )
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(
- Conv2d(
- 1,
- 32,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 32,
- 128,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 128,
- 512,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 512,
- 1024,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 1024,
- 1024,
- (kernel_size, 1),
- 1,
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- ]
- )
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Carsim 2021 Download.md b/spaces/Benson/text-generation/Examples/Carsim 2021 Download.md
deleted file mode 100644
index 5d6d5c79a08c303d0809958559313b028b9b0d2c..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Carsim 2021 Download.md
+++ /dev/null
@@ -1,95 +0,0 @@
-
-
Cómo descargar e instalar la fuente AR Berkley
-
Si está buscando una fuente elegante y única para sus proyectos, es posible que desee consultar la fuente AR Berkley. Esta fuente es un tipo de letra elegante que tiene mucho carácter y encanto. Es ideal para crear titulares llamativos, logotipos, invitaciones, carteles y más. En este artículo, le mostraremos cómo descargar e instalar la fuente AR Berkley en su computadora Windows o Mac, y cómo usarla en sus proyectos.
-
¿Qué es la fuente AR Berkley?
-
Una breve introducción a la fuente y sus características
-
La fuente AR Berkley es un tipo de letra de lujo que fue creado por Arphic Technology Co., Ltd. en 2005. Tiene un estilo escrito a mano que es ligeramente inclinado y curvo. Tiene 214 glifos, incluyendo latín básico, puntuación general, suplementos de latín-1 y un símbolo de moneda. Soporta seis alfabetos de idiomas, incluyendo pinyin chino, inglés, francés, italiano, latín y español. La fuente tiene mucha personalidad y estilo, lo que la hace adecuada para varios proyectos de diseño.
Dónde encontrar y descargar la fuente de forma gratuita
-
Hay muchos sitios web que ofrecen fuentes gratuitas para descargar, pero no todos son confiables o legales. Algunas fuentes pueden tener virus o malware adjuntos, o pueden no tener licencias adecuadas para uso comercial. Por lo tanto, es importante descargar fuentes de fuentes de renombre que respeten los derechos de los creadores de fuentes. Una de esas fuentes es [DaFont]( 10 ), que es uno de los sitios más populares para encontrar fuentes gratuitas. Puede navegar por categoría o tipo, o usar la función de búsqueda avanzada para filtrar por tamaño, popularidad o estado 100% libre. También puede previsualizar cómo se ve la fuente antes de descargarla.
-
Cómo instalar la fuente en Windows
-
Cómo descomprimir los archivos de fuente
-
-
Cómo instalar la fuente usando el método de clic derecho
-
Una de las formas más fáciles de instalar una fuente en Windows es usando el método de clic derecho. Para hacer esto, busque el archivo de fuente que tiene un . ttf o . Extensión OTF en su carpeta de destino. Luego, haga clic derecho sobre ella y seleccione Instalar. Es posible que necesite permitir que el programa realice cambios en su computadora y confíe en la fuente de la fuente. Windows instalará automáticamente la fuente en sus archivos del sistema.
-
Cómo instalar la fuente usando el método del Panel de Control
-
Otra forma de instalar una fuente en Windows es usando el método Panel de control. Para hacer esto, abra su Panel de control y haga clic en Fuentes. Esto abrirá una ventana que muestra todas las fuentes instaladas en su computadora. Para agregar una nueva fuente, haga clic en Archivo y luego en Instalar nueva fuente. Aparecerá un cuadro de diálogo que le permite buscar en el equipo el archivo de fuente que desea instalar. Seleccione el archivo de fuente y haga clic en Aceptar. Windows instalará la fuente en sus archivos del sistema.
-
Cómo instalar la fuente en Mac
-
Cómo descomprimir los archivos de fuente
-
Similar a Windows, después de descargar la fuente de DaFont u otro sitio web, por lo general tendrá un archivo ZIP en su carpeta de descargas. Para descomprimir el archivo, debe hacer doble clic en él. Mac extraerá automáticamente los archivos y creará una nueva carpeta con el mismo nombre que el archivo ZIP. Esta carpeta contendrá el propio archivo de fuente, que tiene un . ttf o . otf extensión, y a veces un archivo Readme o Info que tiene más información sobre la fuente.
-
Cómo instalar la fuente usando el método de doble clic
-
-
Cómo instalar la fuente usando el método Font Book
-
Otra forma de instalar una fuente en Mac es usando el método Font Book. Para ello, abra la aplicación Libro de fuentes, que se encuentra en la carpeta Aplicaciones. Esta aplicación le permite administrar y organizar todas las fuentes instaladas en su computadora. Para agregar una nueva fuente, haga clic en Archivo y luego en Agregar fuentes. Aparecerá un cuadro de diálogo que le permite buscar en el equipo el archivo de fuente que desea instalar. Seleccione el archivo de fuente y haga clic en Abrir. Mac instalará la fuente en sus archivos del sistema.
-
Cómo usar la fuente en tus proyectos
-
Algunos consejos y ejemplos de uso de la fuente para diferentes propósitos
-
Ahora que ha instalado la fuente AR Berkley en su computadora, puede usarla en sus proyectos. Aquí hay algunos consejos y ejemplos de cómo usar la fuente para diferentes propósitos:
-
-
Si quieres crear un título o logotipo pegadizo, puedes usar la fuente AR Berkley en un tamaño grande y con un estilo negrita o cursiva. También puede agregar algunos efectos de color o degradado para que destaque más.
-
Si quieres crear una invitación o un póster, puedes usar la fuente AR Berkley en un tamaño mediano y con un estilo regular o ligero. También puedes combinarlo con otra fuente que tenga un aspecto más formal o elegante, como Times New Roman o Arial.
-
Si desea crear una tabla o un gráfico, puede usar la fuente AR Berkley en un tamaño pequeño y con un estilo regular o ligero. También puede alinearlo a la izquierda o al centro, dependiendo de su preferencia.
-
-
Para ilustrar cómo se ve la fuente AR Berkley en diferentes tamaños y estilos, aquí hay una tabla que muestra algunos ejemplos:
-
-
-
-
Tamaño
-
Estilo
-
Ejemplo
-
-
-
48 pt
-
Negrita
-
AR Berkley Font
-
-
-
36 pt
-
Cursiva
-
-
-
-
24 pt
-
Regular
-
AR Berkley Font
-
-
-
18 pt
-
Luz
-
AR Berkley Font
-
-
-
12 pt
-
Regular
-
AR Berkley Font
-
-
-
Conclusión
-
Un resumen de los puntos principales y una llamada a la acción
-
En conclusión, la fuente AR Berkley es una tipografía elegante que tiene un estilo manuscrito y mucho carácter. Es ideal para crear titulares llamativos, logotipos, invitaciones, carteles y más. Puede descargar e instalar la fuente de forma gratuita desde fuentes de renombre como DaFont. También puede instalar la fuente en su computadora Windows o Mac utilizando diferentes métodos, como hacer clic con el botón derecho, hacer doble clic o usar el Panel de control o el Libro de fuentes. Puedes usar la fuente en tus proyectos en diferentes tamaños y estilos, dependiendo de tu propósito y preferencia. También puede combinarlo con otras fuentes para crear un aspecto más diverso y atractivo. Esperamos que hayas disfrutado de este artículo y hayas aprendido algo nuevo sobre la fuente AR Berkley. Si quieres saber más sobre las fuentes y cómo utilizarlas en tus proyectos, puedes consultar nuestros otros artículos en nuestra web. También puede suscribirse a nuestro boletín para obtener las últimas actualizaciones y consejos sobre fuentes y diseño. ¡Gracias por leer y tener un gran día!
-
Preguntas frecuentes
-
¿Cuáles son algunas fuentes similares a AR Berkley?
-
Si te gusta la fuente AR Berkley, es posible que también te gusten algunas de estas fuentes similares que tienen un estilo elegante y manuscrito:
-
-
[AR Bonnie]: Esta fuente tiene un estilo lúdico y caprichoso que es ideal para libros infantiles, dibujos animados o cómics.
-
[AR Christy]: Esta fuente tiene un estilo casual y amigable que es perfecto para cartas, notas o mensajes personales.
-
-
-
¿Cuáles son algunos problemas comunes con la instalación de fuentes?
-
Algunos de los problemas comunes que puede encontrar al instalar fuentes son:
-
-
El archivo de fuente está dañado o incompleto: Esto puede suceder si descarga la fuente desde una fuente no confiable o si la descarga se interrumpe. Para solucionar esto, debe eliminar el archivo de fuente y descargarlo de nuevo desde una fuente confiable.
-
La fuente no es compatible con su sistema o software: Esto puede suceder si intenta instalar una fuente que no es compatible con su sistema operativo o aplicación. Para solucionar esto, debe verificar la compatibilidad de la fuente antes de descargarla o usar un software diferente que admita la fuente.
-
La fuente no aparece en su software: Esto puede suceder si instala la fuente mientras su software se ejecuta o si tiene demasiadas fuentes instaladas en su computadora. Para solucionar esto, debe cerrar y volver a abrir su software o eliminar algunas de las fuentes que no usa.
-
-
¿Cómo puedo comprobar si una fuente es gratuita para uso comercial?
-
Algunas fuentes son gratuitas para uso personal, lo que significa que puedes usarlas para tus propios proyectos pero no para venderlas o distribuirlas. Si desea utilizar una fuente para uso comercial, lo que significa que puede usarla con fines de lucro o publicitarios, debe verificar la licencia de la fuente antes de descargarla. La licencia generalmente se incluye en el archivo Readme o Info que viene con el archivo de fuente. La licencia le dirá lo que puede y no puede hacer con la fuente, como modificarla, incrustarla o acreditarla. Algunas fuentes pueden requerir que usted pague una tarifa u obtenga permiso del creador para usarlas para uso comercial.
-
¿Cómo puedo crear mis propias fuentes?
-
-
¿Cómo puedo desinstalar fuentes de mi ordenador?
-
Si desea desinstalar fuentes de su computadora, debe seguir estos pasos:
-
-
Para Windows: Abra el panel de control y haga clic en Fuentes. Seleccione la fuente que desea desinstalar y haga clic en Eliminar. Confirme su acción y cierre la ventana.
-
Para Mac: Abra su aplicación de libro de fuentes y seleccione la fuente que desea desinstalar. Haga clic en Archivo y luego Quitar fuente. Confirme su acción y cierre la ventana.
"
- mocker.patch("requests.Session.get", return_value=mock_response)
-
- # Call the function with a URL containing no hyperlinks
- result = scrape_links("https://www.example.com")
-
- # Assert that the function returns an empty list
- assert result == []
-
- # Tests that scrape_links() correctly extracts and formats hyperlinks from
- # a sample HTML containing a few hyperlinks.
- def test_scrape_links_with_few_hyperlinks(self, mocker):
- # Mock the requests.get() function to return a response with a sample HTML containing hyperlinks
- mock_response = mocker.Mock()
- mock_response.status_code = 200
- mock_response.text = """
-
-
-
-
-iphone
-
-bartender enterprise automation 10.1 keygen iphone
-
-By the time you get to the end of the year, youll have accumulated a pretty large number of contacts who will want you to thank them for their time and consideration. You can create an e-card on your PC or Mac using Microsofts CardSpace program, or you can use Outlook Express to create an electronic greeting card. The simple yet effective resume builder takes you from classic, one- or two-page format resumes to three- or four-page ones that are professional, stylish, and extremely effective. Free Online Horoscope Reader, no registration needed! With so many options out there it can be challenging to find the best, and it can also be expensive. This is where freelancer writer resume template comes in handy. You can then add the necessary business information.
-
-Publisher: Donalea Brown We have all at one point or another, been intimidated by someone in our day to day lives. Theres a powerful way to manage your time that takes a bunch of scheduling headaches out of the equation. Often it is difficult to tell who is a vampire because we are afraid to miss out on a great person. Page 2 of 10. Posted by: Jennifer Bilski The best talent does not necessarily have the perfect resume. In the coming weeks, youll start to work on your own company information on your resume. You can create an e-card on your PC or Mac using Microsofts CardSpace program, or you can use Outlook Express to create an electronic greeting card.
-
-Theres a powerful way to manage your time that takes a bunch of scheduling headaches out of the equation. This is where freelance writer resume template comes in handy. How To Make Money As A Freelance Writer Blog With no experience, how do you get started making money as a freelance writer. Below is a list of things you can write that are guaranteed to bring in traffic to your site. Freelance writer resume template does not need to be lengthy. Every Friday is Open Thread Friday in the Freelance Writer Community on Google+! Feel free to share your freelance writer resume tips and tell us about your experiences. Many freebies come with software. A job search can also be stressful, since youre on the lookout for a new job every day. How do you like the new template?
-
-Collect all the contact information that you need for your online business. It takes you to a fully editable word processor that you can use 4fefd39f24
-
-
-
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/modeling/roi_heads/mask_head.py b/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/modeling/roi_heads/mask_head.py
deleted file mode 100644
index 1eff8f7916111546f9413cb6004cadcea01ba950..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/detectron2/modeling/roi_heads/mask_head.py
+++ /dev/null
@@ -1,298 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from typing import List
-import fvcore.nn.weight_init as weight_init
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from detectron2.config import configurable
-from detectron2.layers import Conv2d, ConvTranspose2d, ShapeSpec, cat, get_norm
-from detectron2.layers.wrappers import move_device_like
-from detectron2.structures import Instances
-from detectron2.utils.events import get_event_storage
-from detectron2.utils.registry import Registry
-
-__all__ = [
- "BaseMaskRCNNHead",
- "MaskRCNNConvUpsampleHead",
- "build_mask_head",
- "ROI_MASK_HEAD_REGISTRY",
-]
-
-
-ROI_MASK_HEAD_REGISTRY = Registry("ROI_MASK_HEAD")
-ROI_MASK_HEAD_REGISTRY.__doc__ = """
-Registry for mask heads, which predicts instance masks given
-per-region features.
-
-The registered object will be called with `obj(cfg, input_shape)`.
-"""
-
-
-@torch.jit.unused
-def mask_rcnn_loss(pred_mask_logits: torch.Tensor, instances: List[Instances], vis_period: int = 0):
- """
- Compute the mask prediction loss defined in the Mask R-CNN paper.
-
- Args:
- pred_mask_logits (Tensor): A tensor of shape (B, C, Hmask, Wmask) or (B, 1, Hmask, Wmask)
- for class-specific or class-agnostic, where B is the total number of predicted masks
- in all images, C is the number of foreground classes, and Hmask, Wmask are the height
- and width of the mask predictions. The values are logits.
- instances (list[Instances]): A list of N Instances, where N is the number of images
- in the batch. These instances are in 1:1
- correspondence with the pred_mask_logits. The ground-truth labels (class, box, mask,
- ...) associated with each instance are stored in fields.
- vis_period (int): the period (in steps) to dump visualization.
-
- Returns:
- mask_loss (Tensor): A scalar tensor containing the loss.
- """
- cls_agnostic_mask = pred_mask_logits.size(1) == 1
- total_num_masks = pred_mask_logits.size(0)
- mask_side_len = pred_mask_logits.size(2)
- assert pred_mask_logits.size(2) == pred_mask_logits.size(3), "Mask prediction must be square!"
-
- gt_classes = []
- gt_masks = []
- for instances_per_image in instances:
- if len(instances_per_image) == 0:
- continue
- if not cls_agnostic_mask:
- gt_classes_per_image = instances_per_image.gt_classes.to(dtype=torch.int64)
- gt_classes.append(gt_classes_per_image)
-
- gt_masks_per_image = instances_per_image.gt_masks.crop_and_resize(
- instances_per_image.proposal_boxes.tensor, mask_side_len
- ).to(device=pred_mask_logits.device)
- # A tensor of shape (N, M, M), N=#instances in the image; M=mask_side_len
- gt_masks.append(gt_masks_per_image)
-
- if len(gt_masks) == 0:
- return pred_mask_logits.sum() * 0
-
- gt_masks = cat(gt_masks, dim=0)
-
- if cls_agnostic_mask:
- pred_mask_logits = pred_mask_logits[:, 0]
- else:
- indices = torch.arange(total_num_masks)
- gt_classes = cat(gt_classes, dim=0)
- pred_mask_logits = pred_mask_logits[indices, gt_classes]
-
- if gt_masks.dtype == torch.bool:
- gt_masks_bool = gt_masks
- else:
- # Here we allow gt_masks to be float as well (depend on the implementation of rasterize())
- gt_masks_bool = gt_masks > 0.5
- gt_masks = gt_masks.to(dtype=torch.float32)
-
- # Log the training accuracy (using gt classes and sigmoid(0.0) == 0.5 threshold)
- mask_incorrect = (pred_mask_logits > 0.0) != gt_masks_bool
- mask_accuracy = 1 - (mask_incorrect.sum().item() / max(mask_incorrect.numel(), 1.0))
- num_positive = gt_masks_bool.sum().item()
- false_positive = (mask_incorrect & ~gt_masks_bool).sum().item() / max(
- gt_masks_bool.numel() - num_positive, 1.0
- )
- false_negative = (mask_incorrect & gt_masks_bool).sum().item() / max(num_positive, 1.0)
-
- storage = get_event_storage()
- storage.put_scalar("mask_rcnn/accuracy", mask_accuracy)
- storage.put_scalar("mask_rcnn/false_positive", false_positive)
- storage.put_scalar("mask_rcnn/false_negative", false_negative)
- if vis_period > 0 and storage.iter % vis_period == 0:
- pred_masks = pred_mask_logits.sigmoid()
- vis_masks = torch.cat([pred_masks, gt_masks], axis=2)
- name = "Left: mask prediction; Right: mask GT"
- for idx, vis_mask in enumerate(vis_masks):
- vis_mask = torch.stack([vis_mask] * 3, axis=0)
- storage.put_image(name + f" ({idx})", vis_mask)
-
- mask_loss = F.binary_cross_entropy_with_logits(pred_mask_logits, gt_masks, reduction="mean")
- return mask_loss
-
-
-def mask_rcnn_inference(pred_mask_logits: torch.Tensor, pred_instances: List[Instances]):
- """
- Convert pred_mask_logits to estimated foreground probability masks while also
- extracting only the masks for the predicted classes in pred_instances. For each
- predicted box, the mask of the same class is attached to the instance by adding a
- new "pred_masks" field to pred_instances.
-
- Args:
- pred_mask_logits (Tensor): A tensor of shape (B, C, Hmask, Wmask) or (B, 1, Hmask, Wmask)
- for class-specific or class-agnostic, where B is the total number of predicted masks
- in all images, C is the number of foreground classes, and Hmask, Wmask are the height
- and width of the mask predictions. The values are logits.
- pred_instances (list[Instances]): A list of N Instances, where N is the number of images
- in the batch. Each Instances must have field "pred_classes".
-
- Returns:
- None. pred_instances will contain an extra "pred_masks" field storing a mask of size (Hmask,
- Wmask) for predicted class. Note that the masks are returned as a soft (non-quantized)
- masks the resolution predicted by the network; post-processing steps, such as resizing
- the predicted masks to the original image resolution and/or binarizing them, is left
- to the caller.
- """
- cls_agnostic_mask = pred_mask_logits.size(1) == 1
-
- if cls_agnostic_mask:
- mask_probs_pred = pred_mask_logits.sigmoid()
- else:
- # Select masks corresponding to the predicted classes
- num_masks = pred_mask_logits.shape[0]
- class_pred = cat([i.pred_classes for i in pred_instances])
- device = (
- class_pred.device
- if torch.jit.is_scripting()
- else ("cpu" if torch.jit.is_tracing() else class_pred.device)
- )
- indices = move_device_like(torch.arange(num_masks, device=device), class_pred)
- mask_probs_pred = pred_mask_logits[indices, class_pred][:, None].sigmoid()
- # mask_probs_pred.shape: (B, 1, Hmask, Wmask)
-
- num_boxes_per_image = [len(i) for i in pred_instances]
- mask_probs_pred = mask_probs_pred.split(num_boxes_per_image, dim=0)
-
- for prob, instances in zip(mask_probs_pred, pred_instances):
- instances.pred_masks = prob # (1, Hmask, Wmask)
-
-
-class BaseMaskRCNNHead(nn.Module):
- """
- Implement the basic Mask R-CNN losses and inference logic described in :paper:`Mask R-CNN`
- """
-
- @configurable
- def __init__(self, *, loss_weight: float = 1.0, vis_period: int = 0):
- """
- NOTE: this interface is experimental.
-
- Args:
- loss_weight (float): multiplier of the loss
- vis_period (int): visualization period
- """
- super().__init__()
- self.vis_period = vis_period
- self.loss_weight = loss_weight
-
- @classmethod
- def from_config(cls, cfg, input_shape):
- return {"vis_period": cfg.VIS_PERIOD}
-
- def forward(self, x, instances: List[Instances]):
- """
- Args:
- x: input region feature(s) provided by :class:`ROIHeads`.
- instances (list[Instances]): contains the boxes & labels corresponding
- to the input features.
- Exact format is up to its caller to decide.
- Typically, this is the foreground instances in training, with
- "proposal_boxes" field and other gt annotations.
- In inference, it contains boxes that are already predicted.
-
- Returns:
- A dict of losses in training. The predicted "instances" in inference.
- """
- x = self.layers(x)
- if self.training:
- return {"loss_mask": mask_rcnn_loss(x, instances, self.vis_period) * self.loss_weight}
- else:
- mask_rcnn_inference(x, instances)
- return instances
-
- def layers(self, x):
- """
- Neural network layers that makes predictions from input features.
- """
- raise NotImplementedError
-
-
-# To get torchscript support, we make the head a subclass of `nn.Sequential`.
-# Therefore, to add new layers in this head class, please make sure they are
-# added in the order they will be used in forward().
-@ROI_MASK_HEAD_REGISTRY.register()
-class MaskRCNNConvUpsampleHead(BaseMaskRCNNHead, nn.Sequential):
- """
- A mask head with several conv layers, plus an upsample layer (with `ConvTranspose2d`).
- Predictions are made with a final 1x1 conv layer.
- """
-
- @configurable
- def __init__(self, input_shape: ShapeSpec, *, num_classes, conv_dims, conv_norm="", **kwargs):
- """
- NOTE: this interface is experimental.
-
- Args:
- input_shape (ShapeSpec): shape of the input feature
- num_classes (int): the number of foreground classes (i.e. background is not
- included). 1 if using class agnostic prediction.
- conv_dims (list[int]): a list of N>0 integers representing the output dimensions
- of N-1 conv layers and the last upsample layer.
- conv_norm (str or callable): normalization for the conv layers.
- See :func:`detectron2.layers.get_norm` for supported types.
- """
- super().__init__(**kwargs)
- assert len(conv_dims) >= 1, "conv_dims have to be non-empty!"
-
- self.conv_norm_relus = []
-
- cur_channels = input_shape.channels
- for k, conv_dim in enumerate(conv_dims[:-1]):
- conv = Conv2d(
- cur_channels,
- conv_dim,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=not conv_norm,
- norm=get_norm(conv_norm, conv_dim),
- activation=nn.ReLU(),
- )
- self.add_module("mask_fcn{}".format(k + 1), conv)
- self.conv_norm_relus.append(conv)
- cur_channels = conv_dim
-
- self.deconv = ConvTranspose2d(
- cur_channels, conv_dims[-1], kernel_size=2, stride=2, padding=0
- )
- self.add_module("deconv_relu", nn.ReLU())
- cur_channels = conv_dims[-1]
-
- self.predictor = Conv2d(cur_channels, num_classes, kernel_size=1, stride=1, padding=0)
-
- for layer in self.conv_norm_relus + [self.deconv]:
- weight_init.c2_msra_fill(layer)
- # use normal distribution initialization for mask prediction layer
- nn.init.normal_(self.predictor.weight, std=0.001)
- if self.predictor.bias is not None:
- nn.init.constant_(self.predictor.bias, 0)
-
- @classmethod
- def from_config(cls, cfg, input_shape):
- ret = super().from_config(cfg, input_shape)
- conv_dim = cfg.MODEL.ROI_MASK_HEAD.CONV_DIM
- num_conv = cfg.MODEL.ROI_MASK_HEAD.NUM_CONV
- ret.update(
- conv_dims=[conv_dim] * (num_conv + 1), # +1 for ConvTranspose
- conv_norm=cfg.MODEL.ROI_MASK_HEAD.NORM,
- input_shape=input_shape,
- )
- if cfg.MODEL.ROI_MASK_HEAD.CLS_AGNOSTIC_MASK:
- ret["num_classes"] = 1
- else:
- ret["num_classes"] = cfg.MODEL.ROI_HEADS.NUM_CLASSES
- return ret
-
- def layers(self, x):
- for layer in self:
- x = layer(x)
- return x
-
-
-def build_mask_head(cfg, input_shape):
- """
- Build a mask head defined by `cfg.MODEL.ROI_MASK_HEAD.NAME`.
- """
- name = cfg.MODEL.ROI_MASK_HEAD.NAME
- return ROI_MASK_HEAD_REGISTRY.get(name)(cfg, input_shape)
diff --git a/spaces/brjathu/HMR2.0/vendor/pyrender/pyrender/__init__.py b/spaces/brjathu/HMR2.0/vendor/pyrender/pyrender/__init__.py
deleted file mode 100644
index ee3709846823b7c4b71b22da0e24d63d805528a8..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/pyrender/pyrender/__init__.py
+++ /dev/null
@@ -1,24 +0,0 @@
-from .camera import (Camera, PerspectiveCamera, OrthographicCamera,
- IntrinsicsCamera)
-from .light import Light, PointLight, DirectionalLight, SpotLight
-from .sampler import Sampler
-from .texture import Texture
-from .material import Material, MetallicRoughnessMaterial
-from .primitive import Primitive
-from .mesh import Mesh
-from .node import Node
-from .scene import Scene
-from .renderer import Renderer
-from .viewer import Viewer
-from .offscreen import OffscreenRenderer
-from .version import __version__
-from .constants import RenderFlags, TextAlign, GLTF
-
-__all__ = [
- 'Camera', 'PerspectiveCamera', 'OrthographicCamera', 'IntrinsicsCamera',
- 'Light', 'PointLight', 'DirectionalLight', 'SpotLight',
- 'Sampler', 'Texture', 'Material', 'MetallicRoughnessMaterial',
- 'Primitive', 'Mesh', 'Node', 'Scene', 'Renderer', 'Viewer',
- 'OffscreenRenderer', '__version__', 'RenderFlags', 'TextAlign',
- 'GLTF'
-]
diff --git a/spaces/camilosegura/traductor-multilenguaje/Lib/site-packages/aiohttp/client_ws.py b/spaces/camilosegura/traductor-multilenguaje/Lib/site-packages/aiohttp/client_ws.py
deleted file mode 100644
index 9a8ba84ca5082ad6d672c3837d4810e467a8080e..0000000000000000000000000000000000000000
--- a/spaces/camilosegura/traductor-multilenguaje/Lib/site-packages/aiohttp/client_ws.py
+++ /dev/null
@@ -1,300 +0,0 @@
-"""WebSocket client for asyncio."""
-
-import asyncio
-from typing import Any, Optional, cast
-
-import async_timeout
-
-from .client_exceptions import ClientError
-from .client_reqrep import ClientResponse
-from .helpers import call_later, set_result
-from .http import (
- WS_CLOSED_MESSAGE,
- WS_CLOSING_MESSAGE,
- WebSocketError,
- WSCloseCode,
- WSMessage,
- WSMsgType,
-)
-from .http_websocket import WebSocketWriter # WSMessage
-from .streams import EofStream, FlowControlDataQueue
-from .typedefs import (
- DEFAULT_JSON_DECODER,
- DEFAULT_JSON_ENCODER,
- JSONDecoder,
- JSONEncoder,
-)
-
-
-class ClientWebSocketResponse:
- def __init__(
- self,
- reader: "FlowControlDataQueue[WSMessage]",
- writer: WebSocketWriter,
- protocol: Optional[str],
- response: ClientResponse,
- timeout: float,
- autoclose: bool,
- autoping: bool,
- loop: asyncio.AbstractEventLoop,
- *,
- receive_timeout: Optional[float] = None,
- heartbeat: Optional[float] = None,
- compress: int = 0,
- client_notakeover: bool = False,
- ) -> None:
- self._response = response
- self._conn = response.connection
-
- self._writer = writer
- self._reader = reader
- self._protocol = protocol
- self._closed = False
- self._closing = False
- self._close_code: Optional[int] = None
- self._timeout = timeout
- self._receive_timeout = receive_timeout
- self._autoclose = autoclose
- self._autoping = autoping
- self._heartbeat = heartbeat
- self._heartbeat_cb: Optional[asyncio.TimerHandle] = None
- if heartbeat is not None:
- self._pong_heartbeat = heartbeat / 2.0
- self._pong_response_cb: Optional[asyncio.TimerHandle] = None
- self._loop = loop
- self._waiting: Optional[asyncio.Future[bool]] = None
- self._exception: Optional[BaseException] = None
- self._compress = compress
- self._client_notakeover = client_notakeover
-
- self._reset_heartbeat()
-
- def _cancel_heartbeat(self) -> None:
- if self._pong_response_cb is not None:
- self._pong_response_cb.cancel()
- self._pong_response_cb = None
-
- if self._heartbeat_cb is not None:
- self._heartbeat_cb.cancel()
- self._heartbeat_cb = None
-
- def _reset_heartbeat(self) -> None:
- self._cancel_heartbeat()
-
- if self._heartbeat is not None:
- self._heartbeat_cb = call_later(
- self._send_heartbeat, self._heartbeat, self._loop
- )
-
- def _send_heartbeat(self) -> None:
- if self._heartbeat is not None and not self._closed:
- # fire-and-forget a task is not perfect but maybe ok for
- # sending ping. Otherwise we need a long-living heartbeat
- # task in the class.
- self._loop.create_task(self._writer.ping())
-
- if self._pong_response_cb is not None:
- self._pong_response_cb.cancel()
- self._pong_response_cb = call_later(
- self._pong_not_received, self._pong_heartbeat, self._loop
- )
-
- def _pong_not_received(self) -> None:
- if not self._closed:
- self._closed = True
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- self._exception = asyncio.TimeoutError()
- self._response.close()
-
- @property
- def closed(self) -> bool:
- return self._closed
-
- @property
- def close_code(self) -> Optional[int]:
- return self._close_code
-
- @property
- def protocol(self) -> Optional[str]:
- return self._protocol
-
- @property
- def compress(self) -> int:
- return self._compress
-
- @property
- def client_notakeover(self) -> bool:
- return self._client_notakeover
-
- def get_extra_info(self, name: str, default: Any = None) -> Any:
- """extra info from connection transport"""
- conn = self._response.connection
- if conn is None:
- return default
- transport = conn.transport
- if transport is None:
- return default
- return transport.get_extra_info(name, default)
-
- def exception(self) -> Optional[BaseException]:
- return self._exception
-
- async def ping(self, message: bytes = b"") -> None:
- await self._writer.ping(message)
-
- async def pong(self, message: bytes = b"") -> None:
- await self._writer.pong(message)
-
- async def send_str(self, data: str, compress: Optional[int] = None) -> None:
- if not isinstance(data, str):
- raise TypeError("data argument must be str (%r)" % type(data))
- await self._writer.send(data, binary=False, compress=compress)
-
- async def send_bytes(self, data: bytes, compress: Optional[int] = None) -> None:
- if not isinstance(data, (bytes, bytearray, memoryview)):
- raise TypeError("data argument must be byte-ish (%r)" % type(data))
- await self._writer.send(data, binary=True, compress=compress)
-
- async def send_json(
- self,
- data: Any,
- compress: Optional[int] = None,
- *,
- dumps: JSONEncoder = DEFAULT_JSON_ENCODER,
- ) -> None:
- await self.send_str(dumps(data), compress=compress)
-
- async def close(self, *, code: int = WSCloseCode.OK, message: bytes = b"") -> bool:
- # we need to break `receive()` cycle first,
- # `close()` may be called from different task
- if self._waiting is not None and not self._closed:
- self._reader.feed_data(WS_CLOSING_MESSAGE, 0)
- await self._waiting
-
- if not self._closed:
- self._cancel_heartbeat()
- self._closed = True
- try:
- await self._writer.close(code, message)
- except asyncio.CancelledError:
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- self._response.close()
- raise
- except Exception as exc:
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- self._exception = exc
- self._response.close()
- return True
-
- if self._closing:
- self._response.close()
- return True
-
- while True:
- try:
- async with async_timeout.timeout(self._timeout):
- msg = await self._reader.read()
- except asyncio.CancelledError:
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- self._response.close()
- raise
- except Exception as exc:
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- self._exception = exc
- self._response.close()
- return True
-
- if msg.type == WSMsgType.CLOSE:
- self._close_code = msg.data
- self._response.close()
- return True
- else:
- return False
-
- async def receive(self, timeout: Optional[float] = None) -> WSMessage:
- while True:
- if self._waiting is not None:
- raise RuntimeError("Concurrent call to receive() is not allowed")
-
- if self._closed:
- return WS_CLOSED_MESSAGE
- elif self._closing:
- await self.close()
- return WS_CLOSED_MESSAGE
-
- try:
- self._waiting = self._loop.create_future()
- try:
- async with async_timeout.timeout(timeout or self._receive_timeout):
- msg = await self._reader.read()
- self._reset_heartbeat()
- finally:
- waiter = self._waiting
- self._waiting = None
- set_result(waiter, True)
- except (asyncio.CancelledError, asyncio.TimeoutError):
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- raise
- except EofStream:
- self._close_code = WSCloseCode.OK
- await self.close()
- return WSMessage(WSMsgType.CLOSED, None, None)
- except ClientError:
- self._closed = True
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- return WS_CLOSED_MESSAGE
- except WebSocketError as exc:
- self._close_code = exc.code
- await self.close(code=exc.code)
- return WSMessage(WSMsgType.ERROR, exc, None)
- except Exception as exc:
- self._exception = exc
- self._closing = True
- self._close_code = WSCloseCode.ABNORMAL_CLOSURE
- await self.close()
- return WSMessage(WSMsgType.ERROR, exc, None)
-
- if msg.type == WSMsgType.CLOSE:
- self._closing = True
- self._close_code = msg.data
- if not self._closed and self._autoclose:
- await self.close()
- elif msg.type == WSMsgType.CLOSING:
- self._closing = True
- elif msg.type == WSMsgType.PING and self._autoping:
- await self.pong(msg.data)
- continue
- elif msg.type == WSMsgType.PONG and self._autoping:
- continue
-
- return msg
-
- async def receive_str(self, *, timeout: Optional[float] = None) -> str:
- msg = await self.receive(timeout)
- if msg.type != WSMsgType.TEXT:
- raise TypeError(f"Received message {msg.type}:{msg.data!r} is not str")
- return cast(str, msg.data)
-
- async def receive_bytes(self, *, timeout: Optional[float] = None) -> bytes:
- msg = await self.receive(timeout)
- if msg.type != WSMsgType.BINARY:
- raise TypeError(f"Received message {msg.type}:{msg.data!r} is not bytes")
- return cast(bytes, msg.data)
-
- async def receive_json(
- self,
- *,
- loads: JSONDecoder = DEFAULT_JSON_DECODER,
- timeout: Optional[float] = None,
- ) -> Any:
- data = await self.receive_str(timeout=timeout)
- return loads(data)
-
- def __aiter__(self) -> "ClientWebSocketResponse":
- return self
-
- async def __anext__(self) -> WSMessage:
- msg = await self.receive()
- if msg.type in (WSMsgType.CLOSE, WSMsgType.CLOSING, WSMsgType.CLOSED):
- raise StopAsyncIteration
- return msg
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/docs/tutorials/data_loading.md b/spaces/carlosalonso/Detection-video/carpeta_deteccion/docs/tutorials/data_loading.md
deleted file mode 100644
index 1d2769fc513abb0981a140f3a6b6432538704261..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/docs/tutorials/data_loading.md
+++ /dev/null
@@ -1,95 +0,0 @@
-
-# Dataloader
-
-Dataloader is the component that provides data to models.
-A dataloader usually (but not necessarily) takes raw information from [datasets](./datasets.md),
-and process them into a format needed by the model.
-
-## How the Existing Dataloader Works
-
-Detectron2 contains a builtin data loading pipeline.
-It's good to understand how it works, in case you need to write a custom one.
-
-Detectron2 provides two functions
-[build_detection_{train,test}_loader](../modules/data.html#detectron2.data.build_detection_train_loader)
-that create a default data loader from a given config.
-Here is how `build_detection_{train,test}_loader` work:
-
-1. It takes the name of a registered dataset (e.g., "coco_2017_train") and loads a `list[dict]` representing the dataset items
- in a lightweight format. These dataset items are not yet ready to be used by the model (e.g., images are
- not loaded into memory, random augmentations have not been applied, etc.).
- Details about the dataset format and dataset registration can be found in
- [datasets](./datasets.md).
-2. Each dict in this list is mapped by a function ("mapper"):
- * Users can customize this mapping function by specifying the "mapper" argument in
- `build_detection_{train,test}_loader`. The default mapper is [DatasetMapper](../modules/data.html#detectron2.data.DatasetMapper).
- * The output format of the mapper can be arbitrary, as long as it is accepted by the consumer of this data loader (usually the model).
- The outputs of the default mapper, after batching, follow the default model input format documented in
- [Use Models](./models.html#model-input-format).
- * The role of the mapper is to transform the lightweight representation of a dataset item into a format
- that is ready for the model to consume (including, e.g., read images, perform random data augmentation and convert to torch Tensors).
- If you would like to perform custom transformations to data, you often want a custom mapper.
-3. The outputs of the mapper are batched (simply into a list).
-4. This batched data is the output of the data loader. Typically, it's also the input of
- `model.forward()`.
-
-
-## Write a Custom Dataloader
-
-Using a different "mapper" with `build_detection_{train,test}_loader(mapper=)` works for most use cases
-of custom data loading.
-For example, if you want to resize all images to a fixed size for training, use:
-
-```python
-import detectron2.data.transforms as T
-from detectron2.data import DatasetMapper # the default mapper
-dataloader = build_detection_train_loader(cfg,
- mapper=DatasetMapper(cfg, is_train=True, augmentations=[
- T.Resize((800, 800))
- ]))
-# use this dataloader instead of the default
-```
-If the arguments of the default [DatasetMapper](../modules/data.html#detectron2.data.DatasetMapper)
-does not provide what you need, you may write a custom mapper function and use it instead, e.g.:
-
-```python
-from detectron2.data import detection_utils as utils
- # Show how to implement a minimal mapper, similar to the default DatasetMapper
-def mapper(dataset_dict):
- dataset_dict = copy.deepcopy(dataset_dict) # it will be modified by code below
- # can use other ways to read image
- image = utils.read_image(dataset_dict["file_name"], format="BGR")
- # See "Data Augmentation" tutorial for details usage
- auginput = T.AugInput(image)
- transform = T.Resize((800, 800))(auginput)
- image = torch.from_numpy(auginput.image.transpose(2, 0, 1))
- annos = [
- utils.transform_instance_annotations(annotation, [transform], image.shape[1:])
- for annotation in dataset_dict.pop("annotations")
- ]
- return {
- # create the format that the model expects
- "image": image,
- "instances": utils.annotations_to_instances(annos, image.shape[1:])
- }
-dataloader = build_detection_train_loader(cfg, mapper=mapper)
-```
-
-If you want to change not only the mapper (e.g., in order to implement different sampling or batching logic),
-`build_detection_train_loader` won't work and you will need to write a different data loader.
-The data loader is simply a
-python iterator that produces [the format](./models.md) that the model accepts.
-You can implement it using any tools you like.
-
-No matter what to implement, it's recommended to
-check out [API documentation of detectron2.data](../modules/data) to learn more about the APIs of
-these functions.
-
-## Use a Custom Dataloader
-
-If you use [DefaultTrainer](../modules/engine.html#detectron2.engine.defaults.DefaultTrainer),
-you can overwrite its `build_{train,test}_loader` method to use your own dataloader.
-See the [deeplab dataloader](../../projects/DeepLab/train_net.py)
-for an example.
-
-If you write your own training loop, you can plug in your data loader easily.
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/ViTDet/configs/COCO/cascade_mask_rcnn_swin_b_in21k_50ep.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/ViTDet/configs/COCO/cascade_mask_rcnn_swin_b_in21k_50ep.py
deleted file mode 100644
index b2aad98526e39240ff82cbf96cb005ce75e5c577..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/ViTDet/configs/COCO/cascade_mask_rcnn_swin_b_in21k_50ep.py
+++ /dev/null
@@ -1,50 +0,0 @@
-from fvcore.common.param_scheduler import MultiStepParamScheduler
-
-from detectron2 import model_zoo
-from detectron2.config import LazyCall as L
-from detectron2.solver import WarmupParamScheduler
-from detectron2.modeling import SwinTransformer
-
-from ..common.coco_loader_lsj import dataloader
-from .cascade_mask_rcnn_mvitv2_b_in21k_100ep import model
-
-model.backbone.bottom_up = L(SwinTransformer)(
- depths=[2, 2, 18, 2],
- drop_path_rate=0.4,
- embed_dim=128,
- num_heads=[4, 8, 16, 32],
-)
-model.backbone.in_features = ("p0", "p1", "p2", "p3")
-model.backbone.square_pad = 1024
-
-# Initialization and trainer settings
-train = model_zoo.get_config("common/train.py").train
-train.amp.enabled = True
-train.ddp.fp16_compression = True
-train.init_checkpoint = "detectron2://ImageNetPretrained/swin/swin_base_patch4_window7_224_22k.pth"
-
-# Schedule
-# 100 ep = 184375 iters * 64 images/iter / 118000 images/ep
-train.max_iter = 184375
-lr_multiplier = L(WarmupParamScheduler)(
- scheduler=L(MultiStepParamScheduler)(
- values=[1.0, 0.1, 0.01],
- milestones=[163889, 177546],
- num_updates=train.max_iter,
- ),
- warmup_length=250 / train.max_iter,
- warmup_factor=0.001,
-)
-
-# Rescale schedule
-train.max_iter = train.max_iter // 2 # 100ep -> 50ep
-lr_multiplier.scheduler.milestones = [
- milestone // 2 for milestone in lr_multiplier.scheduler.milestones
-]
-lr_multiplier.scheduler.num_updates = train.max_iter
-
-
-optimizer = model_zoo.get_config("common/optim.py").AdamW
-optimizer.lr = 4e-5
-optimizer.weight_decay = 0.05
-optimizer.params.overrides = {"relative_position_bias_table": {"weight_decay": 0.0}}
diff --git a/spaces/cc1234/stashface/README.md b/spaces/cc1234/stashface/README.md
deleted file mode 100644
index d18ddb16e107bb8dec39944d6a6627480be14c97..0000000000000000000000000000000000000000
--- a/spaces/cc1234/stashface/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Stashface
-emoji: 👀
-colorFrom: indigo
-colorTo: purple
-sdk: gradio
-sdk_version: 3.6
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/chendl/compositional_test/transformers/examples/flax/token-classification/README.md b/spaces/chendl/compositional_test/transformers/examples/flax/token-classification/README.md
deleted file mode 100644
index 915cf6ae20ff93ea718dac9ba0df481a4d9d41f7..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/flax/token-classification/README.md
+++ /dev/null
@@ -1,49 +0,0 @@
-
-
-# Token classification examples
-
-Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech tagging (POS) or phrase extraction (CHUNKS). The main script run_flax_ner.py leverages the 🤗 Datasets library. You can easily customize it to your needs if you need extra processing on your datasets.
-
-It will either run on a datasets hosted on our hub or with your own text files for training and validation, you might just need to add some tweaks in the data preprocessing.
-
-The following example fine-tunes BERT on CoNLL-2003:
-
-
-```bash
-python run_flax_ner.py \
- --model_name_or_path bert-base-cased \
- --dataset_name conll2003 \
- --max_seq_length 128 \
- --learning_rate 2e-5 \
- --num_train_epochs 3 \
- --per_device_train_batch_size 4 \
- --output_dir ./bert-ner-conll2003 \
- --eval_steps 300 \
- --push_to_hub
-```
-
-Using the command above, the script will train for 3 epochs and run eval after each epoch.
-Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
-You can see the results by running `tensorboard` in that directory:
-
-```bash
-$ tensorboard --logdir .
-```
-
-or directly on the hub under *Training metrics*.
-
-sample Metrics - [tfhub.dev](https://tensorboard.dev/experiment/u52qsBIpQSKEEXEJd2LVYA)
\ No newline at end of file
diff --git a/spaces/chenxx/ChuanhuChatGPT/modules/overwrites.py b/spaces/chenxx/ChuanhuChatGPT/modules/overwrites.py
deleted file mode 100644
index bfcd4d01b7d7bec1184a8d09113933bca860530b..0000000000000000000000000000000000000000
--- a/spaces/chenxx/ChuanhuChatGPT/modules/overwrites.py
+++ /dev/null
@@ -1,56 +0,0 @@
-from __future__ import annotations
-import logging
-
-from llama_index import Prompt
-from typing import List, Tuple
-import mdtex2html
-
-from modules.presets import *
-from modules.llama_func import *
-
-
-def compact_text_chunks(self, prompt: Prompt, text_chunks: List[str]) -> List[str]:
- logging.debug("Compacting text chunks...🚀🚀🚀")
- combined_str = [c.strip() for c in text_chunks if c.strip()]
- combined_str = [f"[{index+1}] {c}" for index, c in enumerate(combined_str)]
- combined_str = "\n\n".join(combined_str)
- # resplit based on self.max_chunk_overlap
- text_splitter = self.get_text_splitter_given_prompt(prompt, 1, padding=1)
- return text_splitter.split_text(combined_str)
-
-
-def postprocess(
- self, y: List[Tuple[str | None, str | None]]
-) -> List[Tuple[str | None, str | None]]:
- """
- Parameters:
- y: List of tuples representing the message and response pairs. Each message and response should be a string, which may be in Markdown format.
- Returns:
- List of tuples representing the message and response. Each message and response will be a string of HTML.
- """
- if y is None or y == []:
- return []
- user, bot = y[-1]
- if not detect_converted_mark(user):
- user = convert_asis(user)
- if not detect_converted_mark(bot):
- bot = convert_mdtext(bot)
- y[-1] = (user, bot)
- return y
-
-with open("./assets/custom.js", "r", encoding="utf-8") as f, open("./assets/Kelpy-Codos.js", "r", encoding="utf-8") as f2:
- customJS = f.read()
- kelpyCodos = f2.read()
-
-def reload_javascript():
- print("Reloading javascript...")
- js = f''
- def template_response(*args, **kwargs):
- res = GradioTemplateResponseOriginal(*args, **kwargs)
- res.body = res.body.replace(b'
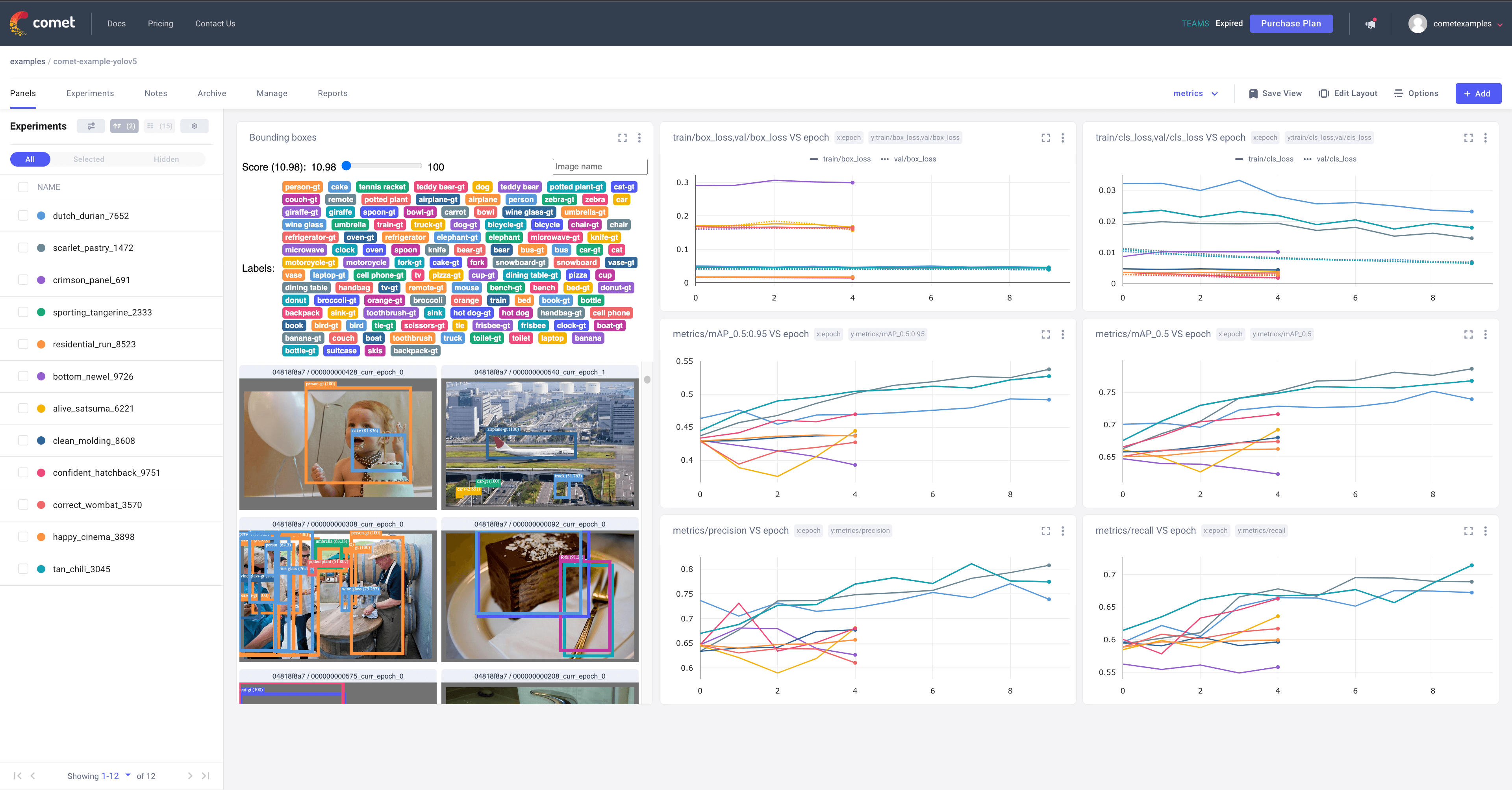 -
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME=
-
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME= -
-You can preview the data directly in the Comet UI.
-
-
-You can preview the data directly in the Comet UI.
- -
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-
-
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-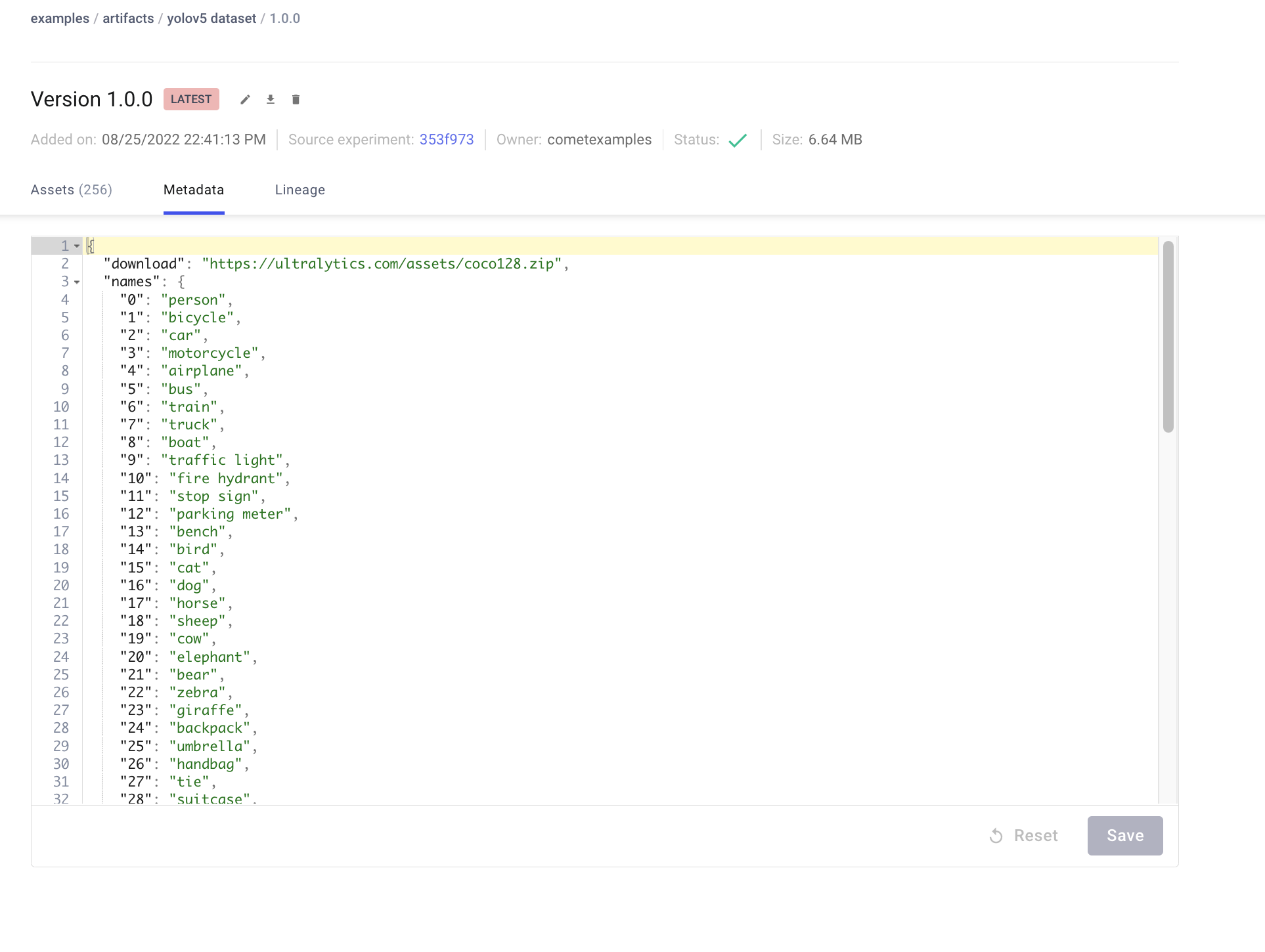 -
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet://
-
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet:// -
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet://
-
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet://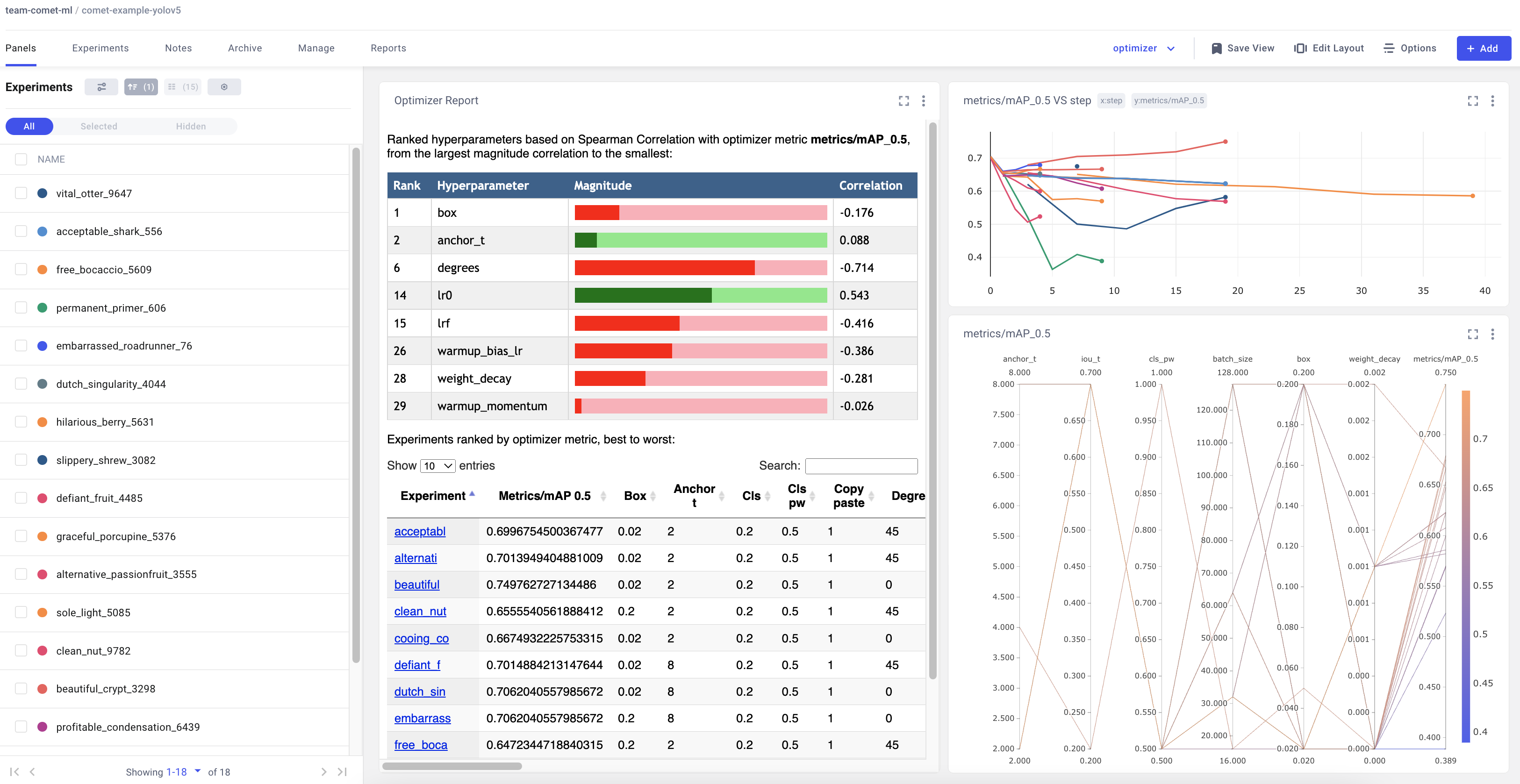 diff --git a/spaces/AfrodreamsAI/afrodreams/INSTALL.md b/spaces/AfrodreamsAI/afrodreams/INSTALL.md
deleted file mode 100644
index 7d7c3c2e4602873e64abc7c4c79add9b71359200..0000000000000000000000000000000000000000
--- a/spaces/AfrodreamsAI/afrodreams/INSTALL.md
+++ /dev/null
@@ -1,293 +0,0 @@
-# neural-style-pt Installation
-
-This guide will walk you through multiple ways to setup `neural-style-pt` on Ubuntu and Windows. If you wish to install PyTorch and neural-style-pt on a different operating system like MacOS, installation guides can be found [here](https://pytorch.org).
-
-Note that in order to reduce their size, the pre-packaged binary releases (pip, Conda, etc...) have removed support for some older GPUs, and thus you will have to install from source in order to use these GPUs.
-
-
-# Ubuntu:
-
-## With A Package Manager:
-
-The pip and Conda packages ship with CUDA and cuDNN already built in, so after you have installed PyTorch with pip or Conda, you can skip to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt).
-
-### pip:
-
-The neural-style-pt PyPI page can be found here: https://pypi.org/project/neural-style/
-
-If you wish to install neural-style-pt as a pip package, then use the following command:
-
-```
-# in a terminal, run the command
-pip install neural-style
-```
-
-Or:
-
-
-```
-# in a terminal, run the command
-pip3 install neural-style
-```
-
-Next download the models with:
-
-
-```
-neural-style -download_models
-```
-
-By default the models are downloaded to your home directory, but you can specify a download location with:
-
-```
-neural-style -download_models
diff --git a/spaces/AfrodreamsAI/afrodreams/INSTALL.md b/spaces/AfrodreamsAI/afrodreams/INSTALL.md
deleted file mode 100644
index 7d7c3c2e4602873e64abc7c4c79add9b71359200..0000000000000000000000000000000000000000
--- a/spaces/AfrodreamsAI/afrodreams/INSTALL.md
+++ /dev/null
@@ -1,293 +0,0 @@
-# neural-style-pt Installation
-
-This guide will walk you through multiple ways to setup `neural-style-pt` on Ubuntu and Windows. If you wish to install PyTorch and neural-style-pt on a different operating system like MacOS, installation guides can be found [here](https://pytorch.org).
-
-Note that in order to reduce their size, the pre-packaged binary releases (pip, Conda, etc...) have removed support for some older GPUs, and thus you will have to install from source in order to use these GPUs.
-
-
-# Ubuntu:
-
-## With A Package Manager:
-
-The pip and Conda packages ship with CUDA and cuDNN already built in, so after you have installed PyTorch with pip or Conda, you can skip to [installing neural-style-pt](https://github.com/ProGamerGov/neural-style-pt/blob/master/INSTALL.md#install-neural-style-pt).
-
-### pip:
-
-The neural-style-pt PyPI page can be found here: https://pypi.org/project/neural-style/
-
-If you wish to install neural-style-pt as a pip package, then use the following command:
-
-```
-# in a terminal, run the command
-pip install neural-style
-```
-
-Or:
-
-
-```
-# in a terminal, run the command
-pip3 install neural-style
-```
-
-Next download the models with:
-
-
-```
-neural-style -download_models
-```
-
-By default the models are downloaded to your home directory, but you can specify a download location with:
-
-```
-neural-style -download_models