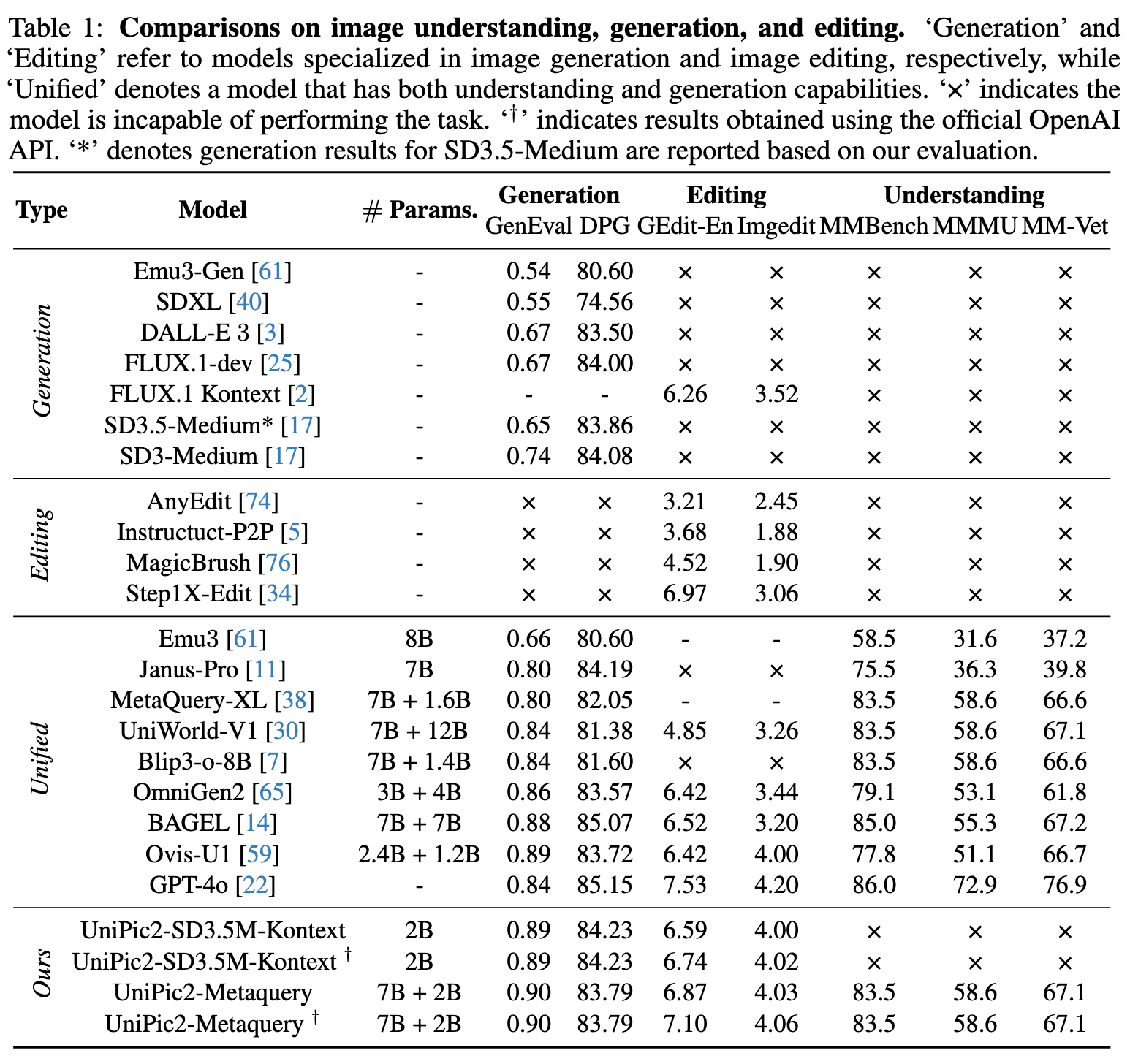
---
pipeline_tag: any-to-any
library_name: transformers
tags:
- text-to-image
- image-editing
- image-understanding
- vision-language
- multimodal
- autoregressive
- unified-model
license: mit
---
## 🌌 UniPic2-Metaquery-GRPO-9B



## 📖 Introduction
**UniPic2-Metaquery-GRPO-9B** is an unified multimodal model trained on UniPic2-Metaquery-9B with enhanced text rendering. It delivers end-to-end image understanding, text-to-image (T2I) generation, and image editing. Requires approximately 40 GB VRAM. For NVIDIA RTX 40-series GPUs, we recommend using the [Skywork/UniPic2-Metaquery-GRPO-Flash](https://huggingface.co/Skywork/UniPic2-Metaquery-GRPO-Flash)
## 📊 Benchmarks
## 🧠 Usage
### 1. Clone the Repository
```bash
git clone https://github.com/SkyworkAI/UniPic
cd UniPic-2
```
### 2. Set Up the Environment
```bash
# Requires ~40GB VRAM; for NVIDIA RTX 40-series GPUs, please use the Flash version
conda create -n unipic python=3.10
conda activate unipic
pip install -r requirements.txt
```
### 3.Text-to-Image Generation
```bash
import torch
from PIL import Image
from unipicv2.pipeline_stable_diffusion_3_kontext import StableDiffusion3KontextPipeline
from unipicv2.transformer_sd3_kontext import SD3Transformer2DKontextModel
from unipicv2.stable_diffusion_3_conditioner import StableDiffusion3Conditioner
from transformers import Qwen2_5_VLForConditionalGeneration, Qwen2_5_VLProcessor
from diffusers import FlowMatchEulerDiscreteScheduler, AutoencoderKL
# Load model components
pretrained_model_name_or_path = "Skywork/UniPic2-Metaquery-GRPO-9B"
transformer = SD3Transformer2DKontextModel.from_pretrained(
pretrained_model_name_or_path, subfolder="transformer", torch_dtype=torch.bfloat16).cuda()
vae = AutoencoderKL.from_pretrained(
pretrained_model_name_or_path, subfolder="vae", torch_dtype=torch.bfloat16).cuda()
# Load Qwen2.5-VL model
lmm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2").cuda()
processor = Qwen2_5_VLProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct")
processor.chat_template = processor.chat_template.replace(
"{% if loop.first and message['role'] != 'system' %}<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n{% endif %}",
"")
conditioner = StableDiffusion3Conditioner.from_pretrained(
pretrained_model_name_or_path, subfolder="conditioner", torch_dtype=torch.bfloat16).cuda()
scheduler = FlowMatchEulerDiscreteScheduler.from_pretrained(pretrained_model_name_or_path, subfolder="scheduler")
# Create pipeline (note: text encoders set to None)
pipeline = StableDiffusion3KontextPipeline(
transformer=transformer, vae=vae,
text_encoder=None, tokenizer=None,
text_encoder_2=None, tokenizer_2=None,
text_encoder_3=None, tokenizer_3=None,
scheduler=scheduler)
# Prepare prompts
prompt = 'a pig with wings and a top hat flying over a happy futuristic scifi city'
negative_prompt = 'blurry, low quality, low resolution, distorted, deformed, broken content, missing parts, damaged details, artifacts, glitch, noise, pixelated, grainy, compression artifacts, bad composition, wrong proportion, incomplete editing, unfinished, unedited areas.'
messages = [[{"role": "user", "content": [{"type": "text", "text": f'Generate an image: {txt}'}]}]
for txt in [prompt, negative_prompt]]
texts = [processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True) for msg in messages]
inputs = processor(text=texts, images=None, videos=None, padding=True, return_tensors="pt").to("cuda")
# Process with Qwen2.5-VL
input_ids, attention_mask = inputs.input_ids, inputs.attention_mask
input_ids = torch.cat([input_ids, input_ids.new_zeros(2, conditioner.config.num_queries)], dim=1)
attention_mask = torch.cat([attention_mask, attention_mask.new_ones(2, conditioner.config.num_queries)], dim=1)
inputs_embeds = lmm.get_input_embeddings()(input_ids)
inputs_embeds[:, -conditioner.config.num_queries:] = conditioner.meta_queries[None].expand(2, -1, -1)
outputs = lmm.model(inputs_embeds=inputs_embeds, attention_mask=attention_mask, use_cache=False)
hidden_states = outputs.last_hidden_state[:, -conditioner.config.num_queries:]
prompt_embeds, pooled_prompt_embeds = conditioner(hidden_states)
# Generate image
image = pipeline(
prompt_embeds=prompt_embeds[:1],
pooled_prompt_embeds=pooled_prompt_embeds[:1],
negative_prompt_embeds=prompt_embeds[1:],
negative_pooled_prompt_embeds=pooled_prompt_embeds[1:],
height=512, width=384,
num_inference_steps=50,
guidance_scale=3.5,
generator=torch.Generator(device=transformer.device).manual_seed(42)
).images[0]
image.save("text2image.png")
```
### 4. Image Editing
```bash
# Load image for editing
image = Image.open("text2image.png")
image = fix_longer_edge(image, image_size=512)
prompt = "remove the pig's hat"
negative_prompt = "blurry, low quality, low resolution, distorted, deformed, broken content, missing parts, damaged details, artifacts, glitch, noise, pixelated, grainy, compression artifacts, bad composition, wrong proportion, incomplete editing, unfinished, unedited areas."
# Prepare messages with image input
messages = [[{"role": "user", "content": [{"type": "image", "image": image}, {"type": "text", "text": txt}]}]
for txt in [prompt, negative_prompt]]
texts = [processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True) for msg in messages]
min_pixels = max_pixels = int(image.height * 28 / 32 * image.width * 28 / 32)
inputs = processor(
text=texts, images=[image]*2,
min_pixels=min_pixels, max_pixels=max_pixels,
videos=None, padding=True, return_tensors="pt").to("cuda")
# Process with vision understanding
input_ids, attention_mask, pixel_values, image_grid_thw = \
inputs.input_ids, inputs.attention_mask, inputs.pixel_values, inputs.image_grid_thw
input_ids = torch.cat([input_ids, input_ids.new_zeros(2, conditioner.config.num_queries)], dim=1)
attention_mask = torch.cat([attention_mask, attention_mask.new_ones(2, conditioner.config.num_queries)], dim=1)
inputs_embeds = lmm.get_input_embeddings()(input_ids)
inputs_embeds[:, -conditioner.config.num_queries:] = conditioner.meta_queries[None].expand(2, -1, -1)
image_embeds = lmm.visual(pixel_values, grid_thw=image_grid_thw)
image_token_id = processor.tokenizer.convert_tokens_to_ids('<|image_pad|>')
inputs_embeds[input_ids == image_token_id] = image_embeds
lmm.model.rope_deltas = None
outputs = lmm.model(inputs_embeds=inputs_embeds, attention_mask=attention_mask,
image_grid_thw=image_grid_thw, use_cache=False)
hidden_states = outputs.last_hidden_state[:, -conditioner.config.num_queries:]
prompt_embeds, pooled_prompt_embeds = conditioner(hidden_states)
# Generate edited image
edited_image = pipeline(
image=image,
prompt_embeds=prompt_embeds[:1],
pooled_prompt_embeds=pooled_prompt_embeds[:1],
negative_prompt_embeds=prompt_embeds[1:],
negative_pooled_prompt_embeds=pooled_prompt_embeds[1:],
height=image.height, width=image.width,
num_inference_steps=50,
guidance_scale=3.5,
generator=torch.Generator(device=transformer.device).manual_seed(42)
).images[0]
edited_image.save("image_editing.png")
```
## 📄 License
This model is released under the MIT License.
## Citation
If you use Skywork-UniPic in your research, please cite:
```
@misc{wang2025skyworkunipicunifiedautoregressive,
title={Skywork UniPic: Unified Autoregressive Modeling for Visual Understanding and Generation},
author={Peiyu Wang and Yi Peng and Yimeng Gan and Liang Hu and Tianyidan Xie and Xiaokun Wang and Yichen Wei and Chuanxin Tang and Bo Zhu and Changshi Li and Hongyang Wei and Eric Li and Xuchen Song and Yang Liu and Yahui Zhou},
year={2025},
eprint={2508.03320},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.03320},
}
```