
hawei_LinkedIn
commited on
Commit
·
4dbda47
1
Parent(s):
2899c61
upload model weights and model card
Browse files- .gitattributes +3 -0
- README.md +111 -0
- benchmark_results_code_instruct.json +3 -0
- benchmark_results_original_capability_instruct.json +3 -0
- config.json +3 -0
- evaluation_results.json +3 -0
- generation_config.json +3 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +3 -0
- plots/control_llm_structure_analysis.png +3 -0
- special_tokens_map.json +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +3 -0
- train_params.yaml +96 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,114 @@
|
|
| 1 |
---
|
| 2 |
license: llama3.1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: llama3.1
|
| 3 |
+
datasets:
|
| 4 |
+
- OpenCoder-LLM/opc-sft-stage1
|
| 5 |
+
- OpenCoder-LLM/opc-sft-stage2
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
base_model:
|
| 9 |
+
- meta-llama/Llama-3.1-8B-Instruct
|
| 10 |
+
model-index:
|
| 11 |
+
- name: Control-LLM-Llama3.1-8B-OpenCoder8
|
| 12 |
+
results:
|
| 13 |
+
- task:
|
| 14 |
+
type: code-evaluation
|
| 15 |
+
dataset:
|
| 16 |
+
type: mixed
|
| 17 |
+
name: Code Evaluation Dataset
|
| 18 |
+
metrics:
|
| 19 |
+
- name: pass_at_1,n=1 (code_instruct)
|
| 20 |
+
type: pass_at_1
|
| 21 |
+
value: 0.770508826583593
|
| 22 |
+
stderr: 0.013547264970313243
|
| 23 |
+
verified: false
|
| 24 |
+
- name: pass_at_1,n=1 (humaneval_greedy_instruct)
|
| 25 |
+
type: pass_at_1
|
| 26 |
+
value: 0.823170731707317
|
| 27 |
+
stderr: 0.029883277857485988
|
| 28 |
+
verified: false
|
| 29 |
+
- name: pass_at_1,n=1 (humaneval_plus_greedy_instruct)
|
| 30 |
+
type: pass_at_1
|
| 31 |
+
value: 0.7621951219512195
|
| 32 |
+
stderr: 0.033346454086653404
|
| 33 |
+
verified: false
|
| 34 |
+
- name: pass_at_1,n=1 (mbpp_plus_0shot_instruct)
|
| 35 |
+
type: pass_at_1
|
| 36 |
+
value: 0.7751322751322751
|
| 37 |
+
stderr: 0.02150209607822914
|
| 38 |
+
verified: false
|
| 39 |
+
- name: pass_at_1,n=1 (mbpp_sanitized_0shot_instruct)
|
| 40 |
+
type: pass_at_1
|
| 41 |
+
value: 0.7354085603112841
|
| 42 |
+
stderr: 0.027569713464529938
|
| 43 |
+
verified: false
|
| 44 |
+
- task:
|
| 45 |
+
type: original-capability
|
| 46 |
+
dataset:
|
| 47 |
+
type: meta/Llama-3.1-8B-Instruct-evals
|
| 48 |
+
name: Llama-3.1-8B-Instruct-evals Dataset
|
| 49 |
+
dataset_path: "meta-llama/llama-3.1-8_b-instruct-evals"
|
| 50 |
+
dataset_name: "Llama-3.1-8B-Instruct-evals__arc_challenge__details"
|
| 51 |
+
metrics:
|
| 52 |
+
- name: exact_match,strict-match (original_capability_instruct)
|
| 53 |
+
type: exact_match
|
| 54 |
+
value: 0.5599378769819771
|
| 55 |
+
stderr: 0.0028491774433443513
|
| 56 |
+
verified: false
|
| 57 |
+
- name: exact_match,strict-match (meta_arc_0shot_instruct)
|
| 58 |
+
type: exact_match
|
| 59 |
+
value: 0.8094420600858369
|
| 60 |
+
stderr: 0.011511446994122106
|
| 61 |
+
verified: false
|
| 62 |
+
- name: exact_match,strict-match (meta_gpqa_0shot_cot_instruct)
|
| 63 |
+
type: exact_match
|
| 64 |
+
value: 0.32589285714285715
|
| 65 |
+
stderr: 0.02216910313464341
|
| 66 |
+
verified: false
|
| 67 |
+
- name: exact_match,strict-match (meta_mmlu_0shot_instruct)
|
| 68 |
+
type: exact_match
|
| 69 |
+
value: 0.681241988320752
|
| 70 |
+
stderr: 0.003932622311434926
|
| 71 |
+
verified: false
|
| 72 |
+
- name: exact_match,strict-match (meta_mmlu_pro_5shot_instruct)
|
| 73 |
+
type: exact_match
|
| 74 |
+
value: 0.4029255319148936
|
| 75 |
+
stderr: 0.004471732136513382
|
| 76 |
+
verified: false
|
| 77 |
---
|
| 78 |
+
# Control-LLM-Llama3.1-8B-OpenCoder8
|
| 79 |
+
This is a fine-tuned model of Llama-3.1-8B-Instruct for coding tasks on OpenCoder SFT dataset.
|
| 80 |
+
|
| 81 |
+
## Evaluation Results
|
| 82 |
+
Here is an overview of the evaluation results and findings:
|
| 83 |
+
|
| 84 |
+
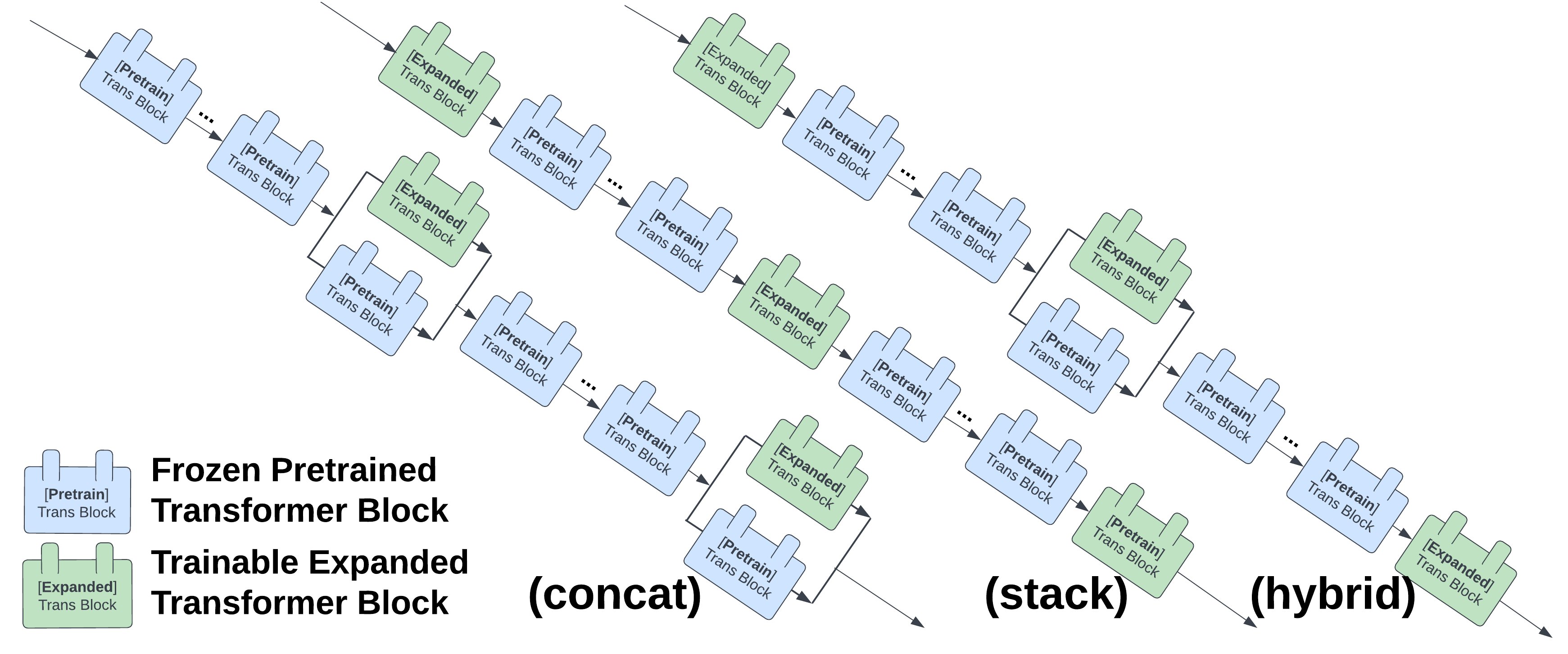
### Hybrid Expansion on OpenCoder
|
| 85 |
+
The following diagram illustrates how hybrid expansion works.
|
| 86 |
+
|
| 87 |
+

|
| 88 |
+
|
| 89 |
+
### Benchmark Results Table
|
| 90 |
+
The table below summarizes evaluation results across coding tasks and original capabilities.
|
| 91 |
+
|
| 92 |
+
| **Model** | **MB+** | **MS** | **HE+** | **HE** | **C-Avg** | **ARC** | **GP** | **MLU** | **MLUP** | **O-Avg** | **Overall** |
|
| 93 |
+
|--------------------|---------|---------|---------|---------|-----------|---------|---------|---------|----------|-----------|-------------|
|
| 94 |
+
| Llama3.1-8B-Ins | 70.4 | 67.7 | 66.5 | 70.7 | 69.1 | 83.4 | 29.9 | 72.4 | 46.7 | 60.5 | 64.8 |
|
| 95 |
+
| OpenCoder-8B-Ins | 81.2 | 76.3 | 78.0 | 82.3 | 79.5 | 8.2 | 25.4 | 37.4 | 11.3 | 24.6 | 52.1 |
|
| 96 |
+
| Full Param Tune | 75.1 | 69.6 | 71.3 | 76.8 | 73.3 | 24.4 | 21.9 | 43.0 | 19.2 | 31.5 | 52.4 |
|
| 97 |
+
| Partial Param Tune | 75.7 | 71.6 | 74.4 | 79.3 | 75.0 | 70.2 | 28.1 | 60.7 | 32.4 | 48.3 | 61.7 |
|
| 98 |
+
| Stack Expansion | 77.2 | 72.8 | 73.2 | 78.7 | 75.6 | 80.0 | 26.3 | 66.6 | 38.2 | 54.2 | 64.9 |
|
| 99 |
+
| **ControlLLM-Hybrid** | 77.5 | 73.5 | **76.2**| **82.3**| 77.1 | 80.9 | **32.6**| 68.1 | 40.3 | 56.0 | 66.6 |
|
| 100 |
+
|
| 101 |
+
---
|
| 102 |
+
|
| 103 |
+
### Explanation:
|
| 104 |
+
- **MB+**: MBPP Plus
|
| 105 |
+
- **MS**: MBPP Sanitized
|
| 106 |
+
- **HE+**: HumanEval Plus
|
| 107 |
+
- **HE**: HumanEval
|
| 108 |
+
- **C-Avg**: Coding - Size Weighted Average across MB+, MS, HE+, and HE
|
| 109 |
+
- **ARC**: ARC benchmark
|
| 110 |
+
- **GP**: GPQA benchmark
|
| 111 |
+
- **MLU**: MMLU (Massive Multitask Language Understanding)
|
| 112 |
+
- **MLUP**: MMLU Pro
|
| 113 |
+
- **O-Avg**: Original Capability - Size Weighted Average across ARC, GPQA, MMLU, and MMLU Pro
|
| 114 |
+
- **Overall**: Combined average across all tasks
|
benchmark_results_code_instruct.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dd81d8a75dc67b64e07892ddef054a4f97b500a473eefef59fe9e199c2b62796
|
| 3 |
+
size 18314
|
benchmark_results_original_capability_instruct.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:88c9c5080306c367e72b0d15f4ecfb846397be12642931381f512373461bf94c
|
| 3 |
+
size 17215
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:191b75a990419ab5d7c37089f16c9a52e380e84a51a1507436e146164cb2bcdb
|
| 3 |
+
size 1868
|
evaluation_results.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b8c14f9cecfe02b33a127abf1ee2747d728353fa9b6f74c091c4397fa6b848e4
|
| 3 |
+
size 434
|
generation_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e3dea9cdfa4a3e0edf1b52d9b1e9609aa22efcddce630060b748284663c8e67
|
| 3 |
+
size 177
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5bd557190a8a8aeb5f1eee0ee62d69efec6d0f88a951ee259cfc918e2f6d28d1
|
| 3 |
+
size 4976715208
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:97c6393935d4d382f706f57e22089724ef6b83c77cb235c355139dedf2d5d843
|
| 3 |
+
size 4999836348
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:422f54136e61f1d2419c908bb8eb398ba87bc0c756d512ba405d6683b75e45b6
|
| 3 |
+
size 4915933074
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:27d2112bb1def37187f68c5c9cd18f6d4951a6846e2cf579ee56f22e67400e45
|
| 3 |
+
size 4657972498
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:749170718df030d8dc46588d46a1ba2d7f8a6ef945d36a3236b8fd7975924e17
|
| 3 |
+
size 31691
|
plots/control_llm_structure_analysis.png
ADDED
|
Git LFS Details
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:453db79c09538b7953c4d9846d4bc0b46b86a296f285cdecc29f739f0b98f6a9
|
| 3 |
+
size 572
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a200d62d1a1177908f4310d7e367f0194d474db0038dc1f2f2434a3ef74af7d9
|
| 3 |
+
size 17210284
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e407a45cd60fbcdad88f1a22adab70157c47e858c0c94995de05e87b06205aa
|
| 3 |
+
size 55820
|
train_params.yaml
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
batch_size_training: '4'
|
| 2 |
+
batching_strategy: padding
|
| 3 |
+
checkpoint_type: StateDictType.SHARDED_STATE_DICT
|
| 4 |
+
context_length: '8192'
|
| 5 |
+
curriculum_learning: 'False'
|
| 6 |
+
curriculum_phases: '3'
|
| 7 |
+
dataset: '[''OpenCoderSFTStage2'']'
|
| 8 |
+
ddp_timeout: '36000'
|
| 9 |
+
debug: 'False'
|
| 10 |
+
decay_steps: None
|
| 11 |
+
dist_checkpoint_folder: fine-tuned
|
| 12 |
+
drop_last: 'True'
|
| 13 |
+
dynamic_batch_size: 'False'
|
| 14 |
+
enable_deepspeed: 'False'
|
| 15 |
+
enable_fsdp: 'True'
|
| 16 |
+
enable_memory_profiling: 'False'
|
| 17 |
+
enable_memory_trace: 'False'
|
| 18 |
+
enable_mixed_precision: 'True'
|
| 19 |
+
enable_tensorboard: 'True'
|
| 20 |
+
eta_min: 1e-05
|
| 21 |
+
eval_epoch: '1'
|
| 22 |
+
eval_in_memory: 'False'
|
| 23 |
+
eval_steps: '1000'
|
| 24 |
+
evaluation_strategy: steps
|
| 25 |
+
flop_counter: 'False'
|
| 26 |
+
flop_counter_start: '3'
|
| 27 |
+
fp16: 'False'
|
| 28 |
+
freeze_layers: 'False'
|
| 29 |
+
from_peft_checkpoint: ''
|
| 30 |
+
fsdp_activation_checkpointing: 'True'
|
| 31 |
+
fsdp_cpu_offload: 'False'
|
| 32 |
+
fsdp_cpu_ram_efficient_loading: 'False'
|
| 33 |
+
gamma: '0.85'
|
| 34 |
+
gradient_accumulation_steps: '8'
|
| 35 |
+
gradient_checkpointing: 'True'
|
| 36 |
+
gradient_checkpointing_kwargs: '{''use_reentrant'': False}'
|
| 37 |
+
gradient_clipping: 'False'
|
| 38 |
+
gradient_clipping_threshold: '1.0'
|
| 39 |
+
handle_long_sequences: 'True'
|
| 40 |
+
hf_hub_metrics_cache_dir: /shared/public/data/controlllm/metrics/
|
| 41 |
+
hsdp: 'True'
|
| 42 |
+
learning_rate: 5e-05
|
| 43 |
+
load_best_model_at_end: 'False'
|
| 44 |
+
logging_steps: '500'
|
| 45 |
+
long_sequence_threshold: '16384'
|
| 46 |
+
low_cpu_fsdp: 'False'
|
| 47 |
+
lr: '0.0001'
|
| 48 |
+
lr_scheduler_per_iter: 'True'
|
| 49 |
+
max_eval_step: '500'
|
| 50 |
+
max_grad_norm: '1.0'
|
| 51 |
+
max_step: '0'
|
| 52 |
+
max_tokens_per_batch: '-1'
|
| 53 |
+
max_train_step: '-1'
|
| 54 |
+
memory_per_token: '-1'
|
| 55 |
+
mixed_precision: 'True'
|
| 56 |
+
model_name: PATH/to/Model
|
| 57 |
+
no_cuda: 'False'
|
| 58 |
+
num_epochs: '3'
|
| 59 |
+
num_freeze_layers: '1'
|
| 60 |
+
num_train_epochs: '20'
|
| 61 |
+
num_unfrozen_layers: '8'
|
| 62 |
+
num_workers_dataloader: '0'
|
| 63 |
+
one_gpu: 'False'
|
| 64 |
+
optimizer: AdamW
|
| 65 |
+
overwrite_output_dir: 'False'
|
| 66 |
+
peft_method: lora
|
| 67 |
+
per_device_eval_batch_size: '1'
|
| 68 |
+
per_device_train_batch_size: '12'
|
| 69 |
+
precompute_batches: None
|
| 70 |
+
pure_bf16: 'False'
|
| 71 |
+
quantization: 'False'
|
| 72 |
+
replica_group_size: '1'
|
| 73 |
+
resume_checkpoint_folder: None
|
| 74 |
+
resume_from_latest: 'True'
|
| 75 |
+
run_validation: 'True'
|
| 76 |
+
save_epoch: '1'
|
| 77 |
+
save_metrics: 'False'
|
| 78 |
+
save_model: 'True'
|
| 79 |
+
save_optimizer: 'False'
|
| 80 |
+
save_steps: '1000'
|
| 81 |
+
seed: '42'
|
| 82 |
+
sharding_group_size: '8'
|
| 83 |
+
sharding_strategy: ShardingStrategy.HYBRID_SHARD
|
| 84 |
+
step_size: '1'
|
| 85 |
+
tokenizer_name: None
|
| 86 |
+
trainer: native
|
| 87 |
+
unfrozen_strategy: interweave
|
| 88 |
+
use_fast_kernels: 'False'
|
| 89 |
+
use_fp16: 'False'
|
| 90 |
+
use_peft: 'False'
|
| 91 |
+
use_profiler: 'False'
|
| 92 |
+
use_wandb: 'False'
|
| 93 |
+
val_batch_size: '1'
|
| 94 |
+
warmup_steps: '1000'
|
| 95 |
+
weight_decay: '0.01'
|
| 96 |
+
weight_decay_ratio: '0.1'
|